QsrSoft is a software as a service (SaaS) company that develops solutions for clients in the restaurant, hospitality, and retail industries to help them achieve operational excellence. QsrSoft has provided these services for more than two decades and now services over 14,000 locations. QsrSoft started using AWS in 2015 and fully migrated all their workloads to AWS by 2016. QsrSoft can innovate rapidly with AWS and use best-in class technologies for cloud-native solutions for their customers.
In QsrSoft’s target industries, it is important to have a way to focus and motivate employees on common objectives. It can be hard to stay on top of ongoing activities and inspire a team towards operational goals. Through client engagement and data collection, QsrSoft identified this as a pressing business challenge that could be solved with technology. After attending an AWS Digital Innovation Program workshop, QsrSoft conceptualized a digital huddle board that connects teams through gamification, communication, recognition, and excellence in shift management. To bring QsrSoft TV to market in the shortest possible time, QsrSoft decided to build using the AWS serverless suite of services.
QsrSoft successfully lowered the barrier of entry when installing a digital huddle board. Using commodity hardware from Amazon devices such as Fire TV Sticks and Fire Smart TVs, QsrSoft released the product as an app in the Amazon App store. Clients can use existing TV screens when rolling out QsrSoft TV, and only have to plug in a Fire TV Stick and pair it with a five-digit code. This blog post describes QsrSoft TV’s architecture and the AWS services employed in building it.
QsrSoft TV architecture
Building on top of their existing microservices architecture and AWS Amplify, a team of three developers brought QsrSoft TV to market in three months. The solution relies heavily on serverless technologies on AWS. Traditionally, in developing a new product, QsrSoft would need to engage several specialized technical resources. Using the fully managed experience of serverless technologies, QsrSoft can focus on delivering business value for the use case. AWS takes care of managing the technology’s hosting and implementation. With serverless, you only pay for what you use, which makes it possible to correlate your costs with the success of your solution.
Figure 1 illustrates the architecture of this solution:
Figure 1. Architecture diagram of QsrSoft TV solution
Digital huddle board app
The customer-facing component of the solution is the application, which runs on Fire devices in restaurants. AWS Amplify is a service that streamlines development of both web applications and native apps. The app is derived from a single-page application (SPA) developed with Vue.js. AWS Amplify provides features such as integrated authentication, CI/CD, and Web Preview. It also provides GraphQL-based endpoints to access Amazon DynamoDB using AWS AppSync. This enables the QsrSoft development team to function autonomously without dependency on the operations or data integration teams. You can connect to the different Amplify backends from the AWS Management Console or with command line interface (CLI) commands. With the Amplify CLI, you can use default categories for the backends or use the AWS Cloud Development Kit (CDK) to customize them.
GraphQL based API layer
The heart of QsrSoft TV is the API that provides the application with its core functionality. QsrSoft built an AWS AppSync endpoint to power QsrSoft TV’s business logic. AWS Amplify provides an easy way to create a secure AWS AppSync API endpoint through integrated authentication and transport layer security (TLS) for in-transit encryption. The development team can first model the data visually in Amplify Studio. Amplify then creates the queries, subscriptions, and mutations. With a single click from the Studio, you can deploy this model to an AWS AppSync API endpoint. The use of annotations permitted the dev team to customize the model further for the application’s needs, such as indexing by key attributes, authorization, and model relationships. This feature of Amplify Studio saved the development team up to 50% of the total API development effort.
Continuous automated deployments and releases
AWS Amplify abstracts the need for a dedicated operations team. This is enabled by AWS Amplify’s fully managed deployment and hosting for full-stack web applications. The development team connected Amplify to the GitHub repository, and in minutes had a complete CI/CD pipeline in place. There was no need to configure any pipelines or handcraft any YAML files. QsrSoft uses Amplify Web Previews, which enabled the product team and beta testers to preview multiple changes and experiments without releasing code to production. While Amplify deployed the Vue.js application, QsrSoft used fastlane to automate the deployment of the Fire TV application into the Amazon App Store. fastlane is an open-source tool that automates tasks like code signing and releasing the Fire TV binary to the Amazon App Store. This enabled QsrSoft to stay true to its automated deployments and infrastructure as code (IaC) practices.
Simplified password-less authentication
With this command line statement, amplify add auth, QsrSoft laid the groundwork for securing their TV application. Behind the scenes, Amplify uses Amazon Cognito to set up a user pool for the app users. QsrSoft TV provides a password-less login experience to the users, by abstracting the need to log in using a username and password. Instead, you use a five-digit code to pair the Fire TV app with a specific location. Amazon Cognito enables this by securing the app with JSON web tokens (JWT).
Automatic data synchronization
The development team focused on data modeling using the visual tools built into Amplify Studio. Amplify provided an AWS AppSync endpoint, so the developers could use GraphQL to interact with Amplify DataStore. Since the data models in the Amplify Studio support DataStore, the development team can now support an app that works offline. Offline mode is vital to any enterprise application, and it engages QsrSoft TV’s users even during an internet outage. Amplify is used to create an AWS AppSync backend with Amazon DynamoDB tables that match the schema created at the application. As the app interacts with the local DataStore, it starts an instance of its Sync Engine, which publishes the data changes by the application to the DynamoDB backend. An additional AWS Lambda-based backend called QORM, aggregates information from QsrSoft’s custom data warehouse implementation based on Amazon S3 and Amazon Aurora.
The scaling and performance provided by DynamoDB and Lambda allowed QsrSoft to scale without extensive planning, as the number of installs increased. This fully serverless application stack is cost-effective and enables QsrSoft to innovate freely. QsrSoft TV onboarded 100 locations in the first week. QsrSoft projects 7,000+ installs in the first year.
Conclusion
AWS is constantly innovating on behalf of our customers like QsrSoft. By leveraging serverless technologies on AWS, QsrSoft accelerated the go-to-market time for QsrSoft TV. Serverless on AWS provides a low barrier to entry for innovation-focused organizations who want to bring an idea to life quickly to provide business value to their customers.
Amazon Fire devices enable software vendors to make their applications available for large-scale distribution. Fire devices are today being used by several thousand households and workplaces worldwide. Many industries can benefit from developing apps for Amazon Fire devices that can be used on large displays and television screens.
Data is at the center of many applications. In this post, Part 2, we will look at AWS data services that offer native features to help get your data where it needs to be.
In Part 3, we’ll look at AWS application management and monitoring services to help you build, monitor, and maintain a multi-Region application.
Considerations with replicating data
Data replication across the AWS network can happen quickly, but we are still limited by the speed of light. For this reason, data consistency must be considered when building a multi-Region application. Generally speaking, the longer a physical distance is, the longer it will take the data to get there.
When building a distributed system, consider the consistency, availability, partition tolerance (CAP) theorem. This theorem states that an application can only pick 2 out of the 3, and tradeoffs should be considered.
Consistency – all clients always have the same view of data
Availability – all clients can always read and write data
Partition Tolerance – the system will continue to work despite physical partitions
Achieving consistency and availability is common for single-Region applications. For example, when an application connects to a single in-Region database. However, this becomes more difficult with multi-Region applications due to the latency added by transferring data over long distances. For this reason, highly distributed systems will typically follow an eventual consistency approach, favoring availability and partition tolerance.
Traditionally, each S3 bucket has its own single, Regional endpoint. To simplify connecting to and managing multiple endpoints, S3 Multi-Region Access Points create a single global endpoint spanning multiple S3 buckets in different Regions. When applications connect to this endpoint, it will route over the AWS network using AWS Global Accelerator to the bucket with the lowest latency. Failover routing is also automatically handled if the connectivity or availability to a bucket changes.
File and object replication should be expected to be eventually consistent. The rate at which a given dataset can transfer is a function of the amount of data, I/O bandwidth, network bandwidth, and network conditions.
Figure 1 shows how these data transfer services can be combined for each resource.
Figure 1. Storage replication services
Spanning non-relational databases across Regions
Amazon DynamoDBglobal tables provide multi-Region and multi-writer features to help you build global applications at scale. A DynamoDB global table is the only AWS managed offering that allows for multiple active writers in a multi-Region topology (active-active and multi-Region). This allows for applications to read and write in the Region closest to them, with changes automatically replicated to other Regions.
Global reads and fast recovery for Amazon DocumentDB (with MongoDB compatibility) can be achieved with global clusters. These clusters have a primary Region that handles write operations. Dedicated storage-based replication infrastructure enables low-latency global reads with a lag of typically less than one second.
Keeping in-memory caches warm with the same data across Regions can be critical to maintain application performance. Amazon ElastiCache for Redis offers global datastore to create a fully managed, fast, reliable, and secure cross-Region replica for Redis caches and databases. With global datastore, writes occurring in one Region can be read from up to two other cross-Region replica clusters – eliminating the need to write to multiple caches to keep them warm.
Spanning relational databases across Regions
For applications that require a relational data model, Amazon Auroraglobal database provides for scaling of database reads across Regions in Aurora PostgreSQL-compatible and MySQL-compatible editions. Dedicated replication infrastructure utilizes physical replication to achieve consistently low replication lag that outperforms the built-in logical replication database engines offer, as shown in Figure 2.
Figure 2. SysBench OLTP (write-only) stepped every 600 seconds on R4.16xlarge
With Aurora global database, one primary Region is designated as the writer, and secondary Regions are dedicated to reads. Aurora MySQL supports write forwarding, which forwards write requests from a secondary Region to the primary Region to simplify logic in application code. Failover testing can happen by utilizing managed planned failover, which will change the active write cluster to another Region while keeping the replication topology intact. All databases discussed in this post employ eventual consistency when used across Regions, but Aurora PostgreSQL has an option to set the maximum a replica lag allowed with managed recovery point objective (managed RPO).
Logical replication, which utilizes a database engine’s built-in replication technology, can be set up for Amazon Relational Database Service (Amazon RDS) for MariaDB, MySQL, Oracle, PostgreSQL, and Aurora databases. A cross-Region read replica will receive these changes from the writer in the primary Region. For applications built on RDS for Microsoft SQL Server, cross-Region replication can be achieved by utilizing the AWS Database Migration Service. Cross-Region replicas allow for quicker local reads and can reduce data loss and recovery times in the case of a disaster by being promoted to a standalone instance.
For situations where a longer RPO and recovery time objective (RTO) are acceptable, backups can be copied across Regions. This is true for all of the relational and non-relational databases mentioned in this post, except for ElastiCache for Redis. Amazon Redshift can also automatically do this for your data warehouse. Backup copy times will vary depending on size and change rates.
Figure 3. Purpose-built global database architecture
Summary
Data is at the center of almost every application. In this post, we reviewed AWS services that offer cross-Region data replication to get your data where it needs to be quickly. Whether you need faster local reads, an active-active database, or simply need your data durably stored in a second Region, we have a solution for you. In the 3rd and final post of this series, we’ll cover application management and monitoring features.
Deploying global applications has many challenges, especially when accessing a database to build custom pages for end users. One example is an application using AWS Lambda@Edge. Two main challenges include performance and availability.
This blog explains how you can optimally deploy a global application with fast response times and without application changes.
The Amazon Aurora Global Database enables a single database cluster to span multiple AWS Regions by asynchronously replicating your data within subsecond timing. This provides fast, low-latency local reads in each Region. It also enables disaster recovery from Region-wide outages using multi-Region writer failover. These capabilities minimize the recovery time objective (RTO) of cluster failure, thus reducing data loss during failure. You will then be able to achieve your recovery point objective (RPO).
However, there are some implementation challenges. Most applications are designed to connect to a single hostname with atomic, consistent, isolated, and durable (ACID) consistency. But Global Aurora clusters provide reader hostname endpoints in each Region. In the primary Region, there are two endpoints, one for writes, and one for reads. To achieve strong data consistency, a global application requires the ability to:
Choose the optimal reader endpoints
Change writer endpoints on a database failover
Intelligently select the reader with the most up-to-date, freshest data
These capabilities typically require additional development.
The architecture in Figure 1 shows Aurora Global Databases primary Region in AP-SOUTHEAST-2, and secondary Regions in AP-SOUTH-1 and US-WEST-2. The Heimdall Proxy uses latency-based routing to determine the closest Reader Instance for read traffic, and redirects all write traffic to the Writer Instance. The Heimdall Configuration stores the Amazon Resource Name (ARN) of the global cluster. It automatically detects failover and cross-Region on the cluster, and directs traffic accordingly.
With an Aurora Global Database, there are two approaches to failover:
Managed planned failover. To relocate your primary database cluster to one of the secondary Regions in your Aurora global database, see Managed planned failovers with Amazon Aurora Global Database. With this feature, RPO is 0 (no data loss) and it synchronizes secondary DB clusters with the primary before making any other changes. RTO for this automated process is typically less than that of the manual failover.
Manual unplanned failover. To recover from an unplanned outage, you can manually perform a cross-Region failover to one of the secondaries in your Aurora Global Database. The RTO for this manual process depends on how quickly you can manually recover an Aurora global database from an unplanned outage. The RPO is typically measured in seconds, but this is dependent on the Aurora storage replication lag across the network at the time of the failure.
The Heimdall Proxy automatically detects Amazon Relational Database Service (RDS) / Amazon Aurora configuration changes based on the ARN of the Aurora Global cluster. Therefore, both managed planned and manual unplanned failovers are supported.
Solution benefits for global applications
Implementing the Heimdall Proxy has many benefits for global applications:
An Aurora Global Database has a primary DB cluster in one Region and up to five secondary DB clusters in different Regions. But the Heimdall Proxy deployment does not have this limitation. This allows for a larger number of endpoints to be globally deployed. Combined with Amazon Route 53 latency-based routing, new connections have a shorter establishment time. They can use connection pooling to connect to the database, which reduces overall connection latency.
SQL results are cached to the application for faster response times.
The proxy intelligently routes non-cached queries. When safe to do so, the closest (lowest latency) reader will be used. When not safe to access the reader, the query will be routed to the global writer. Proxy nodes globally synchronize their state to ensure that volatile tables are locked to provide ACID compliance.
Heimdall Data, based in the San Francisco Bay Area, is an AWS Advanced ISV partner. They have AWS Service Ready designations for Amazon RDS and Amazon Redshift. Heimdall Data offers a database proxy that offloads SQL improving database scale. Deployment does not require code changes.
Amazon DevOps Guru is an ML powered service that makes it easy to improve an application’s operational performance and availability. By analyzing application metrics, logs, events and traces, DevOps Guru identifies behaviors that deviate from normal operating patterns and creates insights that you can use to improve your application.
At re:Invent 2021, we announced a new tagging feature in DevOps Guru. This feature allows you to organize resources into logical applications, using AWS resources tags so that you can have more control over how applications are defined. Well-defined applications enable DevOps Guru to group related anomalies together to better identify problems and to provide more meaningful recommendations. A tag is a label consisting of a user-defined key and a value. Previously, the coverage boundary consisted of an entire AWS account or specific resources defined by AWS CloudFormation stacks.
Getting Started
Define Resources to analyze using AWS resources tags
An AWS resource tag is a label that consists of a key and a value. A key-value pair can create useful grouping of resources into different applications. For DevOps Guru, you specify one tag key across all your applications. Resources with the same tag value are grouped together into a logical application. The tag key needs to be prefixed with the string “devops-guru-”. Note that the prefix string is not case sensitive. The tag value can be any value you define. The next section describes how you can use tag values to define coverage boundary for your applications.
You can add tags to your resources using the AWS service to which each resource belongs, or use the Tag Editor. To manage tags using your resource’s service, you can use the console, AWS CLI or SDK of the service.
Define Application boundary using AWS resources tag values
For DevOps Guru, we define an application as a group of instantiated AWS resources (Amazon EC2, AWS Lambda, Amazon RDS, etc.) that your workload is running on. You assign the same tag value to all resources that make up your application. DevOps Guru will analyze each resource separately, and will also look at metrics and events across all resources in your application to detect anomalies and generate insights. For example, see the diagram below.
App 1 consists of 2 different resources for a database application – an EC2 instance and a database instance. Assigning the same tag value of RDS to both of the resources. I have another serverless application in App 2, which has a Lambda function and a DynamoDB instance. I assign a different tag value of serverless-app-1 to both of the App 2 resources.
Example Test Scenario
I am going to create a test scenario with an application server running in an EC2 instance. The application server is connected to an Aurora MySQL-Compatible database instance. I will instrument my application to introduce a misbehaving SQL query to create a performance anomaly.
In my example below, I tagged my EC2 instance and database instance with the tag value of RDS. I am interested in detecting performance issues in my Database instance and I want DevOps Guru to provide recommendations to fix those issues.
Manage DevOpsGuru Analysis Coverage
Next, I define the coverage boundary in DevOps Guru Console. In the Settings options in navigation pane, I select Analyzed resources and choose Edit.
Next, I select the “devops-guru-applications” as tag key from the dropdown menu. I am going to select RDS as the tag value, since I am interested in looking at performance issues in my Amazon Aurora database instance.
Filter insights by tags
Next, I created my test scenario. Once DevOps Guru generated an insight, I am able to filter the insights by tag key or tag values. To display insights for my database instance, I select “Affected applications” from the search menu bar on insights page as shown below:
Next, I select “Affected applications” as RDS in the above dropdown menu. Below is the Insight overview screen that gets displayed.
The insights generated by DevOps Guru for my Amazon Aurora instances are enabled by Amazon DevOps Guru for RDS, a new feature we announced at re:Invent 2021. It allows developers to easily detect, diagnose, and resolve performance and operational issues in Amazon Aurora. For more information on Amazon DevOps Guru for RDS, see a related news blog written by my colleague, Marcia Villalba.
The insight summary indicates that there is high DB load, ten times above baseline. DevOps Guru for RDS uses anomaly detection on the database load (DB load) performance metric to detect issues. DB load is measured in units of Average Active Sessions (AAS). DB load measures the level of activity in your database, making it a great metric to understand the health of your database.
If you continue scrolling on the DevOps Guru for RDS analysis page, you can discover the cause for the problem and some recommendations to fix it. DevOps Guru for RDS detected there was a high load of wait events, and one SQL query was found to require further investigation. You can even see the exact SQL query if you click on the SQL digest IDs. The insight’s analysis and recommendation section is full of information on how to investigate further and fix the issue.
The easy-to-understand recommendations made by DevOps Guru for RDS means that as a DevOps engineer, you do not need to rely on a database administrator (DBA) or use any third party tools.
Conclusion
AWS resources tags give you one more way to specify the resource analysis coverage boundary, in addition to existing methods of an entire AWS account or specific AWS CloudFormation stacks. AWS tags allows you to better isolate the applications you want DevOps Guru to analyze. In this post, we used AWS tags to define the coverage boundary for a database application. We reduced unrelated and unnecessary resource coverage from our analysis, thereby controlling our resource analysis costs. Visit the DevOps Guru documentation to learn more about how to use tags to identify resources in your DevOps Guru applications.
When selecting managed database services in AWS, it’s important to understand how data transfer charges are calculated – whether it’s relational, key-value, document, in-memory, graph, time series, wide column, or ledger.
This blog will outline the data transfer charges for several AWS managed database offerings to help you choose the most cost-effective setup for your workload.
This blog illustrates pricing at the time of publication and assumes no volume discounts or applicable taxes and duties. For demonstration purposes, we list the primary AWS Region as US East (Northern Virginia) and the secondary Region is US West (Oregon). Always refer to the individual service pricing pages for the most up-to-date pricing.
Data transfer between AWS and internet
There is no charge for inbound data transfer across all services in all Regions. When you transfer data from AWS resources to the internet, you’re charged per service, with rates specific to the originating Region. Figure 1 illustrates data transfer charges that accrue from AWS services discussed in this blog out to the public internet in the US East (Northern Virginia) Region.
Figure 1. Data transfer to the internet
The remainder of this blog will focus on data transfer within AWS.
Figure 2 illustrates where data transfer charges apply. For clarity, we have left out connection points to the replica servers – this is addressed in Figure 3.
Figure 2. Amazon RDS data transfer
In this setup, you will not incur charges for:
Data transfer to or from Amazon EC2 in the same Region, Availability Zone, and virtual private cloud (VPC)
You will accrue charges for data transfer between:
Amazon EC2 and Amazon RDS across Availability Zones within the same VPC, charged at Amazon EC2 and Amazon RDS ($0.01/GB in and $0.01/GB out)
Amazon EC2 and Amazon RDS across Availability Zones and across VPCs, charged at Amazon EC2 only ($0.01/GB in and $0.01/GB out). For Aurora, this is charged at Amazon EC2 and Aurora ($0.01/GB in and $0.01/GB out)
Amazon EC2 and Amazon RDS across Regions, charged on both sides of the transfer ($0.02/GB out)
Figure 3 illustrates several features that are available within Amazon RDS to show where data transfer charges apply. These include multi-Availability Zone deployment, read replicas, and cross-Region automated backups. Not all database engines support all features, consult the product documentation to learn more.
Figure 3. Amazon RDS features
In this setup, you will not incur data transfer charges for:
Data replication in a multi-Availability Zone deployment or to read replicas within the same Region
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. Figures 4 and 5 illustrate an application hosted on Amazon EC2 that uses DynamoDB as a data store and includes DynamoDB global tables and DynamoDB Accelerator (DAX).
Figure 4. DynamoDB with global tables
Figure 5. DynamoDB without global tables
You will not incur data transfer charges for:
Inbound data transfer to DynamoDB
Data transfer between DynamoDB and Amazon EC2 in the same Region
Data transfer between Amazon EC2 and DAX in the same Availability Zone
In addition to the charges you will incur when you transfer data to the internet, you will accrue charges for data transfer between:
Amazon EC2 and DAX across Availability Zones, charged at the EC2 instance ($0.01/GB in and $0.01/GB out)
Global tables for cross-Region replication or adding replicas to tables that contain data in DynamoDB, charged at the source Region, as shown in Figure 4 ($0.02/GB out)
Amazon EC2 and DynamoDB across Regions, charged on both sides of the transfer, as shown in Figure 5 ($0.02/GB out)
Amazon Redshift is a cloud data warehouse that makes it fast and cost-effective to analyze your data using standard SQL and your existing business intelligence tools. There are many integrations and services available to query and visualize data within Amazon Redshift. To illustrate data transfer costs, Figure 6 shows an EC2 instance running a consumer application connecting to Amazon Redshift over JDBC/ODBC.
Figure 6. Amazon Redshift data transfer
You will not incur data transfer charges for:
Data transfer within the same Availability Zone
Data transfer to Amazon S3 for backup, restore, load, and unload operations in the same Region
In addition to the charges you will incur when you transfer data to the internet, you will accrue charges for the following:
Across Availability Zones, charged on both sides of the transfer ($0.01/GB in and $0.01/GB out)
Across Regions, charged on both sides of the transfer ($0.02/GB out)
Amazon DocumentDB (with MongoDB compatibility) is a database service that is purpose-built for JSON data management at scale. Figure 7 illustrates an application hosted on Amazon EC2 that uses Amazon DocumentDB as a data store, with read replicas in multiple Availability Zones and cross-Region replication for Amazon DocumentDB Global Clusters.
Figure 7. Amazon DocumentDB data transfer
You will not incur data transfer charges for:
Data transfer between Amazon DocumentDB and EC2 instances in the same Availability Zone
Data transferred for replicating multi-Availability Zone deployments of Amazon DocumentDB between Availability Zones in the same Region
In addition to the charges you will incur when you transfer data to the internet, you will accrue charges for the following:
Between Amazon EC2 and Amazon DocumentDB in different Availability Zones within a Region, charged at Amazon EC2 and Amazon DocumentDB ($0.01/GB in and $0.01/GB out)
Across Regions between Amazon DocumentDB instances, charged at the source Region ($0.02/GB out)
Tips to save on data transfer costs to your databases
Review potential data transfer charges on both sides of your communication channel. Remember that “Data Transfer In” to a destination is also “Data Transfer Out” from a source.
Use Regional and global readers or replicas where available. This can reduce the amount of cross-Availability Zone or cross-Region traffic.
Consider data transfer tiered pricing when estimating workload pricing. Rate tiers aggregate usage for data transferred out to the Internet across Amazon EC2, Amazon RDS, Amazon Redshift, DynamoDB, Amazon S3, and several other services. See the Amazon EC2 On-Demand pricing page for more details.
Understand backup or snapshots requirements and how data transfer charges apply.
AWS offers various purpose-built, managed database offerings. Selecting the right one for your workload can optimize performance and cost.
Review your application and query design. Look for ways to reduce the amount of data transferred between your application and data store. Consider designing your application or queries to use read replicas.
Conclusion/next steps
AWS offers purpose-built databases to support your applications and data models, including relational, key-value, document, in-memory, graph, time series, wide column, and ledger databases. Each database has different deployment options, and understanding different data transfer charges can help you design a cost-efficient architecture.
This blog post is intended to help you make informed decisions for designing your workload using managed databases in AWS. Note that service charges and charges related to network topology, such as AWS Transit Gateway, VPC Peering, and AWS Direct Connect, are out of scope for this blog but should be carefully considered when designing any architecture.
Many of our customers are telling us they want to move away from commercial database vendors to avoid expensive costs and burdensome licensing terms. But migrating away from commercial and legacy databases can be time-consuming and resource-intensive. When migrating your databases, you can automate the migration of your database schema and data using the AWS Schema Conversation Tool and AWS Database Migration Service. But there is always more work to do to migrate the application itself, including rewriting application code that interacts with the database. Motivation is there, but costs and risks are often limiting factors.
Today, we are making Babelfish for Aurora PostgreSQL available. Babelfish allows Amazon Aurora PostgreSQL-Compatible Edition to understand the SQL Server wire protocol. It allows you to migrate your SQL Server applications to PostgreSQL cheaper, faster, and with less risks involved with such change.
You can migrate your application in a fraction of the time that a traditional migration would require. You continue to use the existing queries and drivers your application uses today. Just point the application to an Amazon Aurora PostgreSQL database with Babelfish activated. Babelfish adds the capability to Amazon Aurora PostgreSQL to understand the SQL Server wire protocol Tabular Data Stream (TDS), as well as extending PostgreSQL to understand commonly used T-SQL commands used by SQL Server. Support for T-SQL includes elements such as the SQL dialect, static cursors, data types, triggers, stored procedures, and functions. Babelfish reduces the risk associated with database migration projects by significantly reducing the number of changes required to the application. When adopting Babelfish, you save on licensing costs of using SQL Server. Amazon Aurora provides the security, availability, and reliability of commercial databases at 1/10th the cost.
SQL Server has evolved over more than 30 years, and we do not expect to support all functionalities right away. Instead, we focused on the most common T-SQL commands and returning the correct response or an error message. For example, the MONEY datatype has different characteristics in SQL Server (with four decimals precision) and PostgreSQL (with two decimals precision). Such a subtle difference might lead to rounding errors and have a significant impact on downstream processes, such as financial reporting. In this case, and many others, Babelfish ensures the semantics of SQL Server data types and T-SQL functionality are preserved: we created a MONEY datatype that behaves as SQL Server apps would expect. When you create a table with this datatype through the Babelfish connection, you get this compatible datatype and behaviors that a SQL Server app would expect.
Create a Babelfish Cluster Using the Console To show you how Babelfish works, let’s first connect to the console and create a new Amazon Aurora PostgreSQL cluster. The procedure is no different than for the regular Amazon Aurora database. In the RDS launch wizard, I first make sure I select an Aurora version compatible with PostgreSQL 13.4, or more recent. The updated console has additional filters to help you select the versions that are compatible with Babelfish.
Then, lower on the page, I select the option Turn on Babelfish.
After a couple of minutes, my cluster is created, it has two instances, one writer and one reader.
Create a Babelfish Cluster Using the CLI Alternatively, I may use the CLI to create a cluster. I first create a parameter group to activate Babelfish (the console does it automatically):
Connect to the Babelfish Cluster Once the cluster and instances are ready, I connect to the writer instance to create the database itself. I may connect to the instance using SQL Server Management Studio (SSMS) or other SQL client such as sqlcmd. The Windows client must be able to connect to the Babelfish cluster, I made sure the RDS security group authorizes connections from the Windows host.
Using SSMS on Windows, I select New Query in the toolbar, I enter the database DNS name as Servername. I select SQL Server Authentication and I enter the database Login and Password. I click on Connect.
Important: Do not connect via the SSMS Object Explorer. Be sure to connect using the query editor via the New Query button. At this time, Babelfish supports the query editor, but not the Object Explorer.
Once connected, I check the version with select @@version statement and click the green Execute button in the toolbar. I can read the statement result on the bottom part of the screen.
Finally, I create the database on the instance with the create database demo statement.
By default, Babelfish runs in single-db mode. Using this mode, you can have maximum one user database per instance. It allows to have a close mapping of schema names between SQL Server and PostgreSQL. Alternatively, you may turn on multi-db mode at cluster creation time. This allows you to create multiple user databases per instance. In PostgreSQL, user databases will be mapped to multiple schemas with the database name as a prefix.
In SQL Server Management Studio, I open the create_objects.sql script and I choose the green execute icon on the top toolbar. A confirmation message tells me the database schema is created.
I repeat the operation with the load_data.sql script to load data in the newly created tables. Data loading takes a few minutes to run.
line 12 : I type the DNS name of the Babelfish cluster I created earlier. Note that I use the DNS name of a “write” node from my cluster.
line 15 : I type the password I entered when I created the database cluster.
And that’s it! No other modification is required on this app. This code written to query and interact with SQL Server is just working “as-is” on Aurora PostgreSQL with Babelfish.
Open Source Transparency We decided to open-source the technology behind Babelfish to create the Babelfish for PostgreSQL open source project. It uses the permissive Apache 2.0 and PostgreSQL licenses, meaning you can modify or tweak or distribute Babelfish in whatever fashion you see fit. Over time, we are shifting Babelfish to fully open development on GitHub, so there is transparency from the start. Now, anyone, whether you are an AWS customer or not, can use Babelfish to leave behind SQL Server and quickly, easily, and cost-effectively migrate your applications to open source PostgreSQL. We believe Babelfish is going to make PostgreSQL accessible to a much wider group of customers and developers than ever before, particularly those with large numbers of complex applications originally written for SQL Server.
Getting the maximum scale from your database often requires fine-tuning the application. This can increase time and incur cost – effort that could be used towards other strategic initiatives. The Heimdall Proxy was designed to intelligently manage SQL connections to help you get the most out of your database.
In this blog post, we demonstrate two SQL offload features offered by this proxy:
Automated query caching
Read/Write split for improved database scale
By leveraging the solution shown in Figure 1, you can save on development costs and accelerate the onboarding of applications into production.
For ecommerce websites with high read calls and infrequent data changes, query caching can drastically improve your Amazon Relational Database Sevice (RDS) scale. You can use Amazon ElastiCache to serve results. Retrieving data from cache has a shorter access time, which reduces latency and improves I/O operations.
It can take developers considerable effort to create, maintain, and adjust TTLs for cache subsystems. The proxy technology covered in this article has features that allow for automated results caching in grid-caching chosen by the user, without code changes. What makes this solution unique is the distributed, scalable architecture. As your traffic grows, scaling is supported by simply adding proxies. Multiple proxies work together as a cohesive unit for caching and invalidation.
It can be fairly straightforward to configure a primary and read replica instance on the AWS Management Console. But it may be challenging for the developer to implement such a scale-out architecture.
Some of the issues they might encounter include:
Replication lag. A query read-after-write may result in data inconsistency due to replication lag. Many applications require strong consistency.
DNS dependencies. Due to the DNS cache, many connections can be routed to a single replica, creating uneven load distribution across replicas.
Network latency. When deploying Amazon RDS globally using the Amazon Aurora Global Database, it’s difficult to determine how the application intelligently chooses the optimal reader.
The Heimdall Proxy streamlines the ability to elastically scale out read-heavy database workloads. The Read/Write splitting supports:
ACID compliance. Determines the replication lag and know when it is safe to access a database table, ensuring data consistency.
Database load balancing. Tracks the status of each DB instance for its health and evenly distribute connections without relying on DNS.
Intelligent routing. Chooses the optimal reader to access based on the lowest latency to create local-like response times. Check out our Aurora Global Database blog.
Tornado is a modern web and mobile brokerage that empowers anyone who aspires to become a better investor.
Our engineering team was tasked to upgrade our backend such that it could handle a massive surge in traffic. With a 3-month timeline, we decided to use read replicas to reduce the load on the main database instance.
First, we migrated from Amazon RDS for PostgreSQL to Aurora for Postgres since it provided better data replication speed. But we still faced a problem – the amount of time it would take to update server code to use the read replicas would be significant. We wanted the team to stay focused on user-facing enhancements rather than server refactoring.
Enter the Heimdall Proxy: We evaluated a handful of options for a database proxy that could automatically do Read/Write splits for us with no code changes, and it became clear that Heimdall was our best option. It had the Read/Write splitting “out of the box” with zero application changes required. And it also came with database query caching built-in (integrated with Amazon ElastiCache), which promised to take additional load off the database.
Before the Tornado launch date, our load testing showed the new system handling several times more load than we were able to previously. We were using a primary Aurora Postgres instance and read replicas behind the Heimdall proxy. When the Tornado launch date arrived, the system performed well, with some background jobs averaging around a 50% hit rate on the Heimdall cache. This has really helped reduce the database load and improve the runtime of those jobs.
Using this solution, we now have a data architecture with additional room to scale. This allows us to continue to focus on enhancing the product for all our customers.
Heimdall Data, based in the San Francisco Bay Area, is an AWS Advanced Tier ISV partner. They have Amazon Service Ready designations for Amazon RDS and Amazon Redshift. Heimdall Data offers a database proxy that offloads SQL improving database scale. Deployment does not require code changes. For other proxy options, consider the Amazon RDS Proxy, PgBouncer, PgPool-II, or ProxySQL.
Many organizations are modernizing their applications to reduce costs and become more efficient. They must adapt to modern application requirements that provide 24×7 global access. The ability to scale up or down quickly to meet demand and process a large volume of data is critical. This is challenging while maintaining strict performance and availability. For many companies, modernization includes decomposing a monolith application into a set of independently developed, deployed, and managed microservices. The decoupled nature of a microservices environment allows each service to evolve agilely and independently. While there are many benefits for moving to a microservices-based architecture, there can be some tradeoffs. As your application monolith evolves into independent microservices, you must consider the implications to your data architecture.
In this blog post we will provide example use cases, and show how Lake House Architecture on AWS can streamline your microservices architecture. A Lake house architecture embraces the decentralized nature of microservices by facilitating data movement. These transfers can be between data stores, from data stores to data lake, and from data lake to data stores (Figure 1).
Figure 1. Integrating data lake, data warehouse, and all purpose-built stores into a coherent whole
Health and wellness application challenges
Our fictitious health and wellness customer has an application architecture comprised of several microservices backed by purpose-built data stores. User profiles, assessments, surveys, fitness plans, health preferences, and insurance claims are maintained in an Amazon Aurora MySQL-Compatible relational database. The event service monitors the number of steps walked, sleep pattern, pulse rate, and other behavioral data in Amazon DynamoDB, a NoSQL database (Figure 2).
Figure 2. Microservices architecture for health and wellness company
With this microservices architecture, it’s common to have data spread across various data stores. This is because each microservice uses a purpose-built data store suited to its usage patterns and performance requirements. While this provides agility, it also presents challenges to deriving needed insights.
Here are four challenges that different users might face:
As a health practitioner, how do I efficiently combine the data from multiple data stores to give personalized recommendations that improve patient outcomes?
As a sales and marketing professional, how do I get a 360 view of my customer, when data lives in multiple data stores? Profile and fitness data are in a relational data store, but important behavioral and clickstream data are in NoSQL data stores. It’s hard for me to run targeted marketing campaigns, which can lead to revenue loss.
As a product owner, how do I optimize healthcare costs when designing wellbeing programs for patients?
As a health coach, how do I find patients and help them with their wellness goals?
Our remaining subsections highlight AWS Lake House Architecture capabilities and features that allow data movement and the integration of purpose-built data stores.
1. Patient care use case
In this scenario, a health practitioner is interested in historical patient data to estimate the likelihood of a future outcome. To get the necessary insights and identify patterns, the health practitioner needs event data from Amazon DynamoDB and patient profile data from Aurora MySQL-Compatible. Our health practitioner will use Amazon Athena to run an ad-hoc analysis across these data stores.
Amazon Athena provides an interactive query service for both structured and unstructured data. The federated query functionality in Amazon Athena helps with running SQL queries across data stored in relational, NoSQL, and custom data sources. Amazon Athena uses Lambda-based data source connectors to run federated queries. Figure 3 illustrates the federated query architecture.
Figure 3. Amazon Athena federated query
The patient care team could use an Amazon Athena federated query to find out if a patient needs urgent care. It is able to detect anomalies in the combined datasets from claims processing, device data, and electronic health record (HER) as show in Figure 4.
Figure 4. Federated query result by combining data from claim, device, and EHR stores
Healthcare data from various sources, including EHRs and genetic data, helps improve personalized care. Machine learning (ML) is able to harness big data and perform predictive analytics. This creates opportunities for researchers to develop personalized treatments for various diseases, including cancer and depression.
To achieve this, you must move all the related data into a centralized repository such as an Amazon S3 data lake. For specific use cases, you also must move the data between the purpose-built data stores. Finally, you must build an ML solution that can predict the outcome. Amazon Redshift ML, combined with its federated query processing capabilities enables data analysts and database developers to create a platform to detect patterns (Figure 5). With this platform, health practitioners are able to make more accurate, data-driven decisions.
Figure 5. Amazon Redshift federated query with Amazon Redshift ML
2. Sales and marketing use case
To run marketing campaigns, the sales and marketing team must search customer data from a relational database, with event data in a non-relational data store. We will move the data from Aurora MySQL-Compatible and Amazon DynamoDB to Amazon Elasticsearch Service (ES) to meet this requirement.
AWS Database Migration Service (DMS) helps move the change data from Aurora MySQL-Compatible to Amazon ES using Change Data Capture (CDC). AWS Lambda could be used to move the change data from DynamoDB streams to Amazon ES, as shown in Figure 6.
Figure 6. Moving and combining data from Aurora MySQL-Compatible and Amazon DynamoDB to Amazon Elasticsearch Service
The sales and marketing team can now run targeted marketing campaigns by querying data from Amazon Elasticsearch Service, see Figure 7. They can improve sales operations by visualizing data with Amazon QuickSight.
Figure 7. Personalized search experience for ad-tech marketing team
3. Healthcare product owner use case
In this scenario, the product owner must define the care delivery value chain. They must develop process maps for patient activity and estimate the cost of patient care. They must analyze these datasets by building business intelligence (BI) reporting and dashboards with a tool like Amazon QuickSight. Amazon Redshift, a cloud scale data warehousing platform, is a good choice for this. Figure 8 illustrates this pattern.
Figure 8. Moving data from Amazon Aurora and Amazon DynamoDB to Amazon Redshift
The product owners can use integrated business intelligence reports with Amazon Redshift to analyze their data. This way they can make more accurate and appropriate decisions, see Figure 9.
Figure 9. Business intelligence for patient care processes
4. Health coach use case
In this scenario, the health coach must find a patient based on certain criteria. They would then send personalized communication to connect with the patient to ensure they are following the proposed health plan. This proactive approach contributes to a positive patient outcome. It can also reduce healthcare costs incurred by insurance companies.
To be able to search patient records with multiple data points, it is important to move data from Amazon DynamoDB to Amazon ES. This also will provide a fast and personalized search experience. The health coaches can be notified and will have the information they need to provide guidance to their patients. Figure 10 illustrates this pattern.
Figure 10. Moving Data from Amazon DynamoDB to Amazon ES
The health coaches can use Elasticsearch to search users based on specific criteria. This helps them with counseling and other health plans, as shown in Figure 11.
Figure 11. Simplified personalized search using patient device data
Summary
In this post, we highlight how Lake House Architecture on AWS helps with the challenges and tradeoffs of modernization. A Lake House architecture on AWS can help streamline the movement of data between the microservices data stores. This offers new capabilities for various analytics use cases.
For further reading on architectural patterns, and walkthroughs for building Lake House Architecture, see the following resources:
“Everything fails all the time” Werner Vogels, AWS CTO
In 2010, Netflix introduced a tool called “Chaos Monkey”, that was used for introducing faults in a production environment. Chaos Monkey led to the birth of Chaos engineering where teams test their live applications by purposefully injecting faults. Observations are then used to take corrective action and increase resiliency of applications.
In this blog, you will learn about the fault injection capabilities available in Amazon Aurora for simulating various database faults.
Chaos Experiments
Chaos experiments consist of:
Understanding the application baseline: The application’s steady-state behavior
Designing an experiment: Ask “What can go wrong?” to identify failure scenarios
Run the experiment: Introduce faults in the application environment
Observe and correct: Redesign apps or infrastructure for fault tolerance
Chaos experiments require fault simulation across distributed components of the application. Amazon Aurora provides a set of fault simulation capabilities that may be used by teams to exercise chaos experiments against their applications.
Amazon Aurora fault injection
Amazon Aurora is a fully managed database service that is compatible with MySQL and PostgreSQL. Aurora is highly fault tolerant due to its six-way replicated storage architecture. In order to test the resiliency of an application built with Aurora, developers can leverage the native fault injection features to design chaos experiments. The outcome of the experiments gives a better understanding of the blast radius, depth of monitoring required, and the need to evaluate event response playbooks.
In this section, we will describe the various fault injection scenarios that you can use for designing your own experiments. We’ll show you how to conduct the experiment and use the results. This will make your application more resilient and prepared for an actual event.
Note that availability of the fault injection feature is dependent on the version of MySQL and PostgreSQL.
Figure 1. Fault injection overview
1. Testing an instance crash
An Aurora cluster can have one primary and up to 15 read replicas. If the primary instance fails, one of the replicas becomes the primary. Applications must be designed to recover from these instance failures as soon as possible to have minimal impact on the end-user experience.
The instance crash fault injection simulates failure of the instance/dispatcher/node in the Aurora database cluster. Fault injection may be carried out on the primary or replicas by running the API against the target instance.
The query following will simulate a database instance crash:
SELECT aurora_inject_crash ('instance' );
Since this is a simulation, it does not lead to a failover to the replica. As an alternative to using this API, you can carry out an actual failover by using the AWS Management Console or AWS CLI.
The team should observe the change in the application’s behavior to understand the impact of the instance failure. Take corrective actions to reduce the impact of such failures on the application.
A long recovery time on the application would require the team to reduce the Domain Name Service (DNS) time-to-live (TTL) for the DB connections. As a general best practice, the Aurora Database cluster should have at least one replica.
2. Testing the replica failure
Aurora manages asynchronous replication between cluster nodes within a cluster. The typical replication lag is under 100 milliseconds. Network slowness or issues on the nodes may lead to an increase in replication lag between writer and replica nodes.
The replica failure fault injection allows you to simulate replication failure across one or more replicas. Note that this type of fault injection applies only to a DB cluster that has at least one read replica.
Replica failure manifests itself as stale data read by the application that is connecting to the replicas. The specific functional impact on the application depends on the sensitivity to the freshness of data. Note that this fault injection mechanism does not apply to the native replication supported mechanisms in PostgreSQL and MySQL databases.
The team must observe the behavior of the application from the data sensitivity perspective. If the observed lag is unacceptable, the team must evaluate corrective actions such as vertical scaling of database instances and query optimization. As a best practice, the team should monitor the replication lag and take proactive actions to address it.
3. Testing the disk failure
Aurora’s storage volume consists of six copies of data across three Availability Zones (refer the diagram preceding). Aurora has an inherent ability to repair itself for failures in the storage components. This high reliability is achieved by way of a quorum model. Reads require only 3/6 nodes and writes require 4/6 nodes to be available. However, there may still be transient impact on application depending on how widespread the issue.
The disk failure injection capability allows you to simulate failures of storage nodes and partial failure of disks. The severity of failure can be set as a percentage value. The simulation continues only for the specified amount of time. There is no impact on the actual data on the storage nodes and the disk.
Applications may experience temporary failures due to this fault injection and should be able to gracefully recover from it. If the recovery time is higher than a threshold, or the application has a complete failure, the team can redesign their application.
4. Disk congestion fault
Disk congestion usually happens because of heavy I/O traffic against the storage devices. The impact may range from degraded application performance, to complete application failures.
Aurora provides the capability to simulate disk congestion without synthetic SQL load against the database. With this fault injection mechanism, you can gain a better understanding of the performance characteristics of the application under heavy I/O spikes.
You may get the number of disks (for index) on your cluster using the query:
SELECT disks FROM aurora_show_volume_status()
The query following will simulate a 100% disk failure for 20 seconds. The failure will be simulated on disk with index 15. Simulated delay will be between 30 and 40 milliseconds.
If the observed behavior is unacceptable, then the team must carefully consider the load characteristics of their application. Depending on the observations, corrective action may include query optimization, indexing, vertical scaling of the database instances, and adding more replicas.
Conclusion
A chaos experiment involves injecting a fault in a production environment and then observing the application behavior. The outcome of the experiment helps the team identify application weaknesses and evaluate event response processes. Amazon Aurora natively provides fault-injection capabilities that can be used by teams to conduct chaos experiments for database failure scenarios. Aurora can be used for simulating instance failure, replication failure, disk failures, and disk congestion. Try out these capabilities in Aurora to make your applications more robust and resilient from database failures.
In software as a service (SaaS) systems, which are designed to be used by multiple customers, isolating tenant data is a fundamental responsibility for SaaS providers. The practice of isolation of data in a multi-tenant application platform is called tenant isolation. In this post, we describe an approach you can use to achieve tenant isolation in Amazon Simple Storage Service (Amazon S3) and Amazon Aurora PostgreSQL-Compatible Edition databases by implementing attribute-based access control (ABAC). You can also adapt the same approach to achieve tenant isolation in other AWS services.
ABAC in Amazon Web Services (AWS), which uses tags to store attributes, offers advantages over the traditional role-based access control (RBAC) model. You can use fewer permissions policies, update your access control more efficiently as you grow, and last but not least, apply granular permissions for various AWS services. These granular permissions help you to implement an effective and coherent tenant isolation strategy for your customers and clients. Using the ABAC model helps you scale your permissions and simplify the management of granular policies. The ABAC model reduces the time and effort it takes to maintain policies that allow access to only the required resources.
The solution we present here uses the pool model of data partitioning. The pool model helps you avoid the higher costs of duplicated resources for each tenant and the specialized infrastructure code required to set up and maintain those copies.
Solution overview
In a typical customer environment where this solution is implemented, the tenant request for access might land at Amazon API Gateway, together with the tenant identifier, which in turn calls an AWS Lambda function. The Lambda function is envisaged to be operating with a basic Lambda execution role. This Lambda role should also have permissions to assume the tenant roles. As the request progresses, the Lambda function assumes the tenant role and makes the necessary calls to Amazon S3 or to an Aurora PostgreSQL-Compatible database. This solution helps you to achieve tenant isolation for objects stored in Amazon S3 and data elements stored in an Aurora PostgreSQL-Compatible database cluster.
Figure 1 shows the tenant isolation architecture for both Amazon S3 and Amazon Aurora PostgreSQL-Compatible databases.
Figure 1: Tenant isolation architecture diagram
As shown in the numbered diagram steps, the workflow for Amazon S3 tenant isolation is as follows:
An Aurora PostgreSQL-Compatible cluster with a database created.
Note: Make sure to note down the default master database user and password, and make sure that you can connect to the database from your desktop or from another server (for example, from Amazon Elastic Compute Cloud (Amazon EC2) instances).
A security group and inbound rules that are set up to allow an inbound PostgreSQL TCP connection (Port 5432) from Lambda functions. This solution uses regular non-VPC Lambda functions, and therefore the security group of the Aurora PostgreSQL-Compatible database cluster should allow an inbound PostgreSQL TCP connection (Port 5432) from anywhere (0.0.0.0/0).
Make sure that you’ve completed the prerequisites before proceeding with the next steps.
Deploy the solution
The following sections describe how to create the IAM roles, IAM policies, and Lambda functions that are required for the solution. These steps also include guidelines on the changes that you’ll need to make to the prerequisite components Amazon S3 and the Aurora PostgreSQL-Compatible database cluster.
Step 1: Create the IAM policies
In this step, you create two IAM policies with the required permissions for Amazon S3 and the Aurora PostgreSQL database.
Choose IAM, choose Policies, and then choose Create policy.
Use the following JSON policy document to create a second policy. This policy grants an IAM role permission to connect to an Aurora PostgreSQL-Compatible database through a database user that is IAM authenticated. Replace the placeholders with the appropriate Region, account number, and cluster resource ID of the Aurora PostgreSQL-Compatible database cluster, respectively.
Save the policy with the name sts-ti-demo-dbuser-policy.
Figure 3: Create the IAM policy for Aurora PostgreSQL database (sts-ti-demo-dbuser-policy)
Note: Make sure that you use the cluster resource ID for the clustered database. However, if you intend to adapt this solution for your Aurora PostgreSQL-Compatible non-clustered database, you should use the instance resource ID instead.
Step 2: Create the IAM roles
In this step, you create two IAM roles for the two different tenants, and also apply the necessary permissions and tags.
To create the IAM roles
In the IAM console, choose Roles, and then choose Create role.
On the Trusted entities page, choose the EC2 service as the trusted entity.
On the Permissions policies page, select sts-ti-demo-s3-access-policy and sts-ti-demo-dbuser-policy.
On the Tags page, add two tags with the following keys and values.
Tag key
Tag value
s3_home
tenant1_home
dbuser
tenant1_dbuser
On the Review screen, name the role assumeRole-tenant1, and then choose Save.
In the IAM console, choose Roles, and then choose Create role.
On the Trusted entities page, choose the EC2 service as the trusted entity.
On the Permissions policies page, select sts-ti-demo-s3-access-policy and sts-ti-demo-dbuser-policy.
On the Tags page, add two tags with the following keys and values.
Tag key
Tag value
s3_home
tenant2_home
dbuser
tenant2_dbuser
On the Review screen, name the role assumeRole-tenant2, and then choose Save.
Step 3: Create and apply the IAM policies for the tenants
In this step, you create a policy and a role for the Lambda functions. You also create two separate tenant roles, and establish a trust relationship with the role that you created for the Lambda functions.
To create and apply the IAM policies for tenant1
In the IAM console, choose Policies, and then choose Create policy.
Use the following JSON policy document to create the policy. Replace the placeholder <111122223333> with your AWS account number.
Save the policy with the name sts-ti-demo-assumerole-policy.
In the IAM console, choose Roles, and then choose Create role.
On the Trusted entities page, select the Lambda service as the trusted entity.
On the Permissions policies page, select sts-ti-demo-assumerole-policy and AWSLambdaBasicExecutionRole.
On the review screen, name the role sts-ti-demo-lambda-role, and then choose Save.
In the IAM console, go to Roles, and enter assumeRole-tenant1 in the search box.
Select the assumeRole-tenant1 role and go to the Trust relationship tab.
Choose Edit the trust relationship, and replace the existing value with the following JSON document. Replace the placeholder <111122223333> with your AWS account number, and choose Update trust policy to save the policy.
To verify that the policies are applied correctly for tenant1
In the IAM console, go to Roles, and enter assumeRole-tenant1 in the search box. Select the assumeRole-tenant1 role and on the Permissions tab, verify that sts-ti-demo-dbuser-policy and sts-ti-demo-s3-access-policy appear in the list of policies, as shown in Figure 4.
Figure 4: The assumeRole-tenant1 Permissions tab
On the Trust relationships tab, verify that sts-ti-demo-lambda-role appears under Trusted entities, as shown in Figure 5.
Figure 5: The assumeRole-tenant1 Trust relationships tab
On the Tags tab, verify that the following tags appear, as shown in Figure 6.
Tag key
Tag value
dbuser
tenant1_dbuser
s3_home
tenant1_home
Figure 6: The assumeRole-tenant1 Tags tab
To create and apply the IAM policies for tenant2
In the IAM console, go to Roles, and enter assumeRole-tenant2 in the search box.
Select the assumeRole-tenant2 role and go to the Trust relationship tab.
Edit the trust relationship, replacing the existing value with the following JSON document. Replace the placeholder <111122223333> with your AWS account number.
To verify that the policies are applied correctly for tenant2
In the IAM console, go to Roles, and enter assumeRole-tenant2 in the search box. Select the assumeRole-tenant2 role and on the Permissions tab, verify that sts-ti-demo-dbuser-policy and sts-ti-demo-s3-access-policy appear in the list of policies, you did for tenant1. On the Trust relationships tab, verify that sts-ti-demo-lambda-role appears under Trusted entities.
On the Tags tab, verify that the following tags appear, as shown in Figure 7.
Tag key
Tag value
dbuser
tenant2_dbuser
s3_home
tenant2_home
Figure 7: The assumeRole-tenant2 Tags tab
Step 4: Set up an Amazon S3 bucket
Next, you’ll set up an S3 bucket that you’ll use as part of this solution. You can either create a new S3 bucket or re-purpose an existing one. The following steps show you how to create two user homes (that is, S3 prefixes, which are also known as folders) in the S3 bucket.
In the AWS Management Console, go to Amazon S3 and select the S3 bucket you want to use.
Create two prefixes (folders) with the names tenant1_home and tenant2_home.
Place two test objects with the names tenant.info-tenant1_home and tenant.info-tenant2_home in the prefixes that you just created, respectively.
Step 5: Set up test objects in Aurora PostgreSQL-Compatible database
In this step, you create a table in Aurora PostgreSQL-Compatible Edition, insert tenant metadata, create a row level security (RLS) policy, create tenant users, and grant permission for testing purposes.
To set up Aurora PostgreSQL-Compatible
Connect to Aurora PostgreSQL-Compatible through a client of your choice, using the master database user and password that you obtained at the time of cluster creation.
Run the following commands to create a table for testing purposes and to insert a couple of testing records.
CREATE TABLE tenant_metadata (
tenant_id VARCHAR(30) PRIMARY KEY,
email VARCHAR(50) UNIQUE,
status VARCHAR(10) CHECK (status IN ('active', 'suspended', 'disabled')),
tier VARCHAR(10) CHECK (tier IN ('gold', 'silver', 'bronze')));
INSERT INTO tenant_metadata (tenant_id, email, status, tier)
VALUES ('tenant1_dbuser','[email protected]','active','gold');
INSERT INTO tenant_metadata (tenant_id, email, status, tier)
VALUES ('tenant2_dbuser','[email protected]','suspended','silver');
ALTER TABLE tenant_metadata ENABLE ROW LEVEL SECURITY;
Run the following command to query the newly created database table.
SELECT * FROM tenant_metadata;
Figure 8: The tenant_metadata table content
Run the following command to create the row level security policy.
CREATE POLICY tenant_isolation_policy ON tenant_metadata
USING (tenant_id = current_user);
Run the following commands to establish two tenant users and grant them the necessary permissions.
CREATE USER tenant1_dbuser WITH LOGIN;
CREATE USER tenant2_dbuser WITH LOGIN;
GRANT rds_iam TO tenant1_dbuser;
GRANT rds_iam TO tenant2_dbuser;
GRANT select, insert, update, delete ON tenant_metadata to tenant1_dbuser, tenant2_dbuser;
Run the following commands to verify the newly created tenant users.
SELECT usename AS role_name,
CASE
WHEN usesuper AND usecreatedb THEN
CAST('superuser, create database' AS pg_catalog.text)
WHEN usesuper THEN
CAST('superuser' AS pg_catalog.text)
WHEN usecreatedb THEN
CAST('create database' AS pg_catalog.text)
ELSE
CAST('' AS pg_catalog.text)
END role_attributes
FROM pg_catalog.pg_user
WHERE usename LIKE (‘tenant%’)
ORDER BY role_name desc;
Figure 9: Verify the newly created tenant users output
Step 6: Set up the AWS Lambda functions
Next, you’ll create two Lambda functions for Amazon S3 and Aurora PostgreSQL-Compatible. You also need to create a Lambda layer for the Python package PG8000.
To set up the Lambda function for Amazon S3
Navigate to the Lambda console, and choose Create function.
Choose Author from scratch. For Function name, enter sts-ti-demo-s3-lambda.
For Runtime, choose Python 3.7.
Change the default execution role to Use an existing role, and then select sts-ti-demo-lambda-role from the drop-down list.
Keep Advanced settings as the default value, and then choose Create function.
Copy the following Python code into the lambda_function.py file that is created in your Lambda function.
import json
import os
import time
def lambda_handler(event, context):
import boto3
bucket_name = os.environ['s3_bucket_name']
try:
login_tenant_id = event['login_tenant_id']
data_tenant_id = event['s3_tenant_home']
except:
return {
'statusCode': 400,
'body': 'Error in reading parameters'
}
prefix_of_role = 'assumeRole'
file_name = 'tenant.info' + '-' + data_tenant_id
# create an STS client object that represents a live connection to the STS service
sts_client = boto3.client('sts')
account_of_role = sts_client.get_caller_identity()['Account']
role_to_assume = 'arn:aws:iam::' + account_of_role + ':role/' + prefix_of_role + '-' + login_tenant_id
# Call the assume_role method of the STSConnection object and pass the role
# ARN and a role session name.
RoleSessionName = 'AssumeRoleSession' + str(time.time()).split(".")[0] + str(time.time()).split(".")[1]
try:
assumed_role_object = sts_client.assume_role(
RoleArn = role_to_assume,
RoleSessionName = RoleSessionName,
DurationSeconds = 900) #15 minutes
except:
return {
'statusCode': 400,
'body': 'Error in assuming the role ' + role_to_assume + ' in account ' + account_of_role
}
# From the response that contains the assumed role, get the temporary
# credentials that can be used to make subsequent API calls
credentials=assumed_role_object['Credentials']
# Use the temporary credentials that AssumeRole returns to make a connection to Amazon S3
s3_resource=boto3.resource(
's3',
aws_access_key_id=credentials['AccessKeyId'],
aws_secret_access_key=credentials['SecretAccessKey'],
aws_session_token=credentials['SessionToken']
)
try:
obj = s3_resource.Object(bucket_name, data_tenant_id + "/" + file_name)
return {
'statusCode': 200,
'body': obj.get()['Body'].read()
}
except:
return {
'statusCode': 400,
'body': 'error in reading s3://' + bucket_name + '/' + data_tenant_id + '/' + file_name
}
Under Basic settings, edit Timeout to increase the timeout to 29 seconds.
Edit Environment variables to add a key called s3_bucket_name, with the value set to the name of your S3 bucket.
Configure a new test event with the following JSON document, and save it as testEvent.
Choose Test to test the Lambda function with the newly created test event testEvent. You should see status code 200, and the body of the results should contain the data for tenant1.
Figure 10: The result of running the sts-ti-demo-s3-lambda function
Next, create another Lambda function for Aurora PostgreSQL-Compatible. To do this, you first need to create a new Lambda layer.
To set up the Lambda layer
Use the following commands to create a .zip file for Python package pg8000.
Note: This example is created by using an Amazon EC2 instance running the Amazon Linux 2 Amazon Machine Image (AMI). If you’re using another version of Linux or don’t have the Python 3 or pip3 packages installed, install them by using the following commands.
Choose Test to test the Lambda function with the newly created test event testEvent. You should see status code 200, and the body of the results should contain the data for tenant1.
Figure 12: The result of running the sts-ti-demo-pgdb-lambda function
Step 7: Perform negative testing of tenant isolation
You already performed positive tests of tenant isolation during the Lambda function creation steps. However, it’s also important to perform some negative tests to verify the robustness of the tenant isolation controls.
To perform negative tests of tenant isolation
In the Lambda console, navigate to the sts-ti-demo-s3-lambda function. Update the test event to the following, to mimic a scenario where tenant1 attempts to access other tenants’ objects.
Choose Test to test the Lambda function with the updated test event. You should see status code 400, and the body of the results should contain an error message.
Figure 13: The results of running the sts-ti-demo-s3-lambda function (negative test)
Navigate to the sts-ti-demo-pgdb-lambda function and update the test event to the following, to mimic a scenario where tenant1 attempts to access other tenants’ data elements.
Choose Test to test the Lambda function with the updated test event. You should see status code 400, and the body of the results should contain an error message.
Figure 14: The results of running the sts-ti-demo-pgdb-lambda function (negative test)
Cleaning up
To de-clutter your environment, remove the roles, policies, Lambda functions, Lambda layers, Amazon S3 prefixes, database users, and the database table that you created as part of this exercise. You can choose to delete the S3 bucket, as well as the Aurora PostgreSQL-Compatible database cluster that we mentioned in the Prerequisites section, to avoid incurring future charges.
Update the security group of the Aurora PostgreSQL-Compatible database cluster to remove the inbound rule that you added to allow a PostgreSQL TCP connection (Port 5432) from anywhere (0.0.0.0/0).
Conclusion
By taking advantage of attribute-based access control (ABAC) in IAM, you can more efficiently implement tenant isolation in SaaS applications. The solution we presented here helps to achieve tenant isolation in Amazon S3 and Aurora PostgreSQL-Compatible databases by using ABAC with the pool model of data partitioning.
If you run into any issues, you can use Amazon CloudWatch and AWS CloudTrail to troubleshoot. If you have feedback about this post, submit comments in the Comments section below.
To learn more, see these AWS Blog and AWS Support articles:
This post was co-written by Ashutosh Pateriya, Solution Architect at AWS and Nirmal Tomar, Principal Consultant at Infosys Technologies Ltd.
Various organizations have stringent regulatory compliance obligations or business requirements that require an effective cross-account and cross-region database setup. We recommend to establish a Disaster Recovery (DR) environment in different AWS accounts and Regions for a system design that can handle AWS Region failures.
Account-level separation is important for isolating production environments from other environments, that is, development, test, UAT and DR environments. These are defined by external compliance requirements, such as PCI-DSS or HIPAA. Cross-account replication helps an organization recover data from a replicated account, when the primary AWS account is compromised, and access to the account is lost. Using multiple Regions gives you greater control over the recovery time, if there is a hard dependency failure on a Regional AWS service.
You can use Amazon Aurora Global Database to replicate your RDS database across Regions, within the same AWS Account. In this blog, we show how to build a custom solution for Cross-Account, Cross-Region database replication with configurable Recovery Time Objective (RTO)/ Recovery Point Objective (RPO).
Solution Overview
Figure 1 – Architecture of a Cross-Account, Cross-Region database replication with configurable Recovery Time Objective (RTO)/ Recovery Point Objective (RPO)
Step 1: Automated Amazon Aurora snapshots cannot be shared with other AWS accounts. Hence, create a manual version of the snapshot for the same.
Step 2: Amazon Aurora cannot be restored from the snapshot created in different AWS Regions. To overcome this, you must copy the snapshot in the target AWS Region after AWS KMS encryption.
Step 3: Share the DB cluster snapshot with the target account, in order to restore the cluster.
Step 4: Restore Aurora Cluster from the shared snapshot.
Step 5: Restore the required Aurora Instances.
Step 6: Swap the cluster and instance names, to make it accessible from the previous Reader/Writer endpoint.
Step 7: Perform a sanity test and shut down the old cluster.
Prerequisites
Two AWS accounts with permission to spin up required resources.
A running Aurora instance in the source AWS account.
Launch a one-time set up of the AWS KMS in the AWS source account to share the key with destination account. This key will be used by the destination account to restore the Aurora cluster from a KMS encrypted snapshot.
Set up the step function workflow in the AWS source account and source Region. On a scheduled interval, this workflow creates a snapshot in the source account and source Region. Copy it to the target Region and push a notification to the SNS topic and setup a Lambda function as a target for the SNS topic. Refer to the documentation to learn more about Using Lambda with Amazon SNS.
Set up the step function workflow in the AWS target account and in the target Region. This workflow is initiated from the previous workflow after sharing the snapshot. It restores the Aurora cluster from the shared snapshot in the target account and in the target Region.
Provide access to the Lambda function in the target account and target Region. Set it up to listen to the SNS topic in the source account and source Region.
Figure 2 – Architecture showing AWS Step Function in Source Account and Source Region
We can implement a Lambda function with different supported programming languages. For this solution, we selected Python to implement various Lambda functions used in both step function workflows.
Note: We are using us-west-2 as the source Region and us-west-1 as the target Region for this demo. You can choose Regions as per your design need.
Part 1: One Time AWS KMS key setup in the Source Account and Target Region for cross-account access of the Encrypted Snapshot
We can share a Customer Master Key (CMK) across multiple AWS accounts using different ways, such as using AWS CloudFormation templates, CLI, and AWS console.
Following are one-time steps that allow you to create an AWS KMS key in the source AWS account. You can then provide cross-account usage access of the same key to the destination account for restoring the Aurora cluster. You can achieve this with the AWS Console and AWS CloudFormation Template.
Note: Several AWS services being used do not fall under the AWS Free Tier. To avoid extra charges, make sure to delete resources once the demo is completed.
This workflow first creates a snapshot in the AWS source account and source Region> The snapshot copies it in target Region after KMS encryption, shares the snapshot with the target account and sends a notification to SNS Topic. A Lambda function is subscribed to the topic in the target account.
Figure 3 – Architecture showing the AWS Step Functions Workflow
The Import Lambda functions involved in this workflow:
a. CreateRDSSnapshotInSourceRegion: This Lambda function creates a snapshot in the source Account and Region for an existing Aurora cluster.
b. FetchSourceRDSSnapshotStatus: This Lambda function fetches the snapshot status and waits for its availability before moving to the next step.
c. EncrytAndCopySnapshotInTargetRegion: This Lambda function copies the source snapshot in the target AWS Region after encryption with AWS KMS keys.
d. FetchTargetRDSSnapshotStatus: This Lambda function fetch the snapshot status in the target Region and will wait to move to the next step once snapshot status changed to available.
e. ShareSnapshotStateWithTargetAccount: This Lambda function shares the snapshot with the target account and target Region.
f. SendSNSNotificationToTargetAccount: This option sends the notification to the SNS topic. An AWS Lambda function is subscribed to this topic for the destination AWS Account.
Using the following AWS CloudFormation Template, we set up the required services/workflow in the source account and source Region:
a. Launch the template in the source account and source Region:
b. Fill out the preceding form with the following details and select next.
Stack name: Stack Name which you want to create.
DestinationAccountNumber: Destination AWS Account number where you want to restore the Aurora cluster.
KMSKey: KMS key ARN number setup in previous steps.
ScheduleExpression: Schedule a cron expression when you want to run this workflow. Sample expressions are available in this guide, Schedule expressions using rate or cron.
SourceDBClusterIdentifier: The identifier of the DB cluster, for which a snapshot is created. It must match the identifier of an existing DBCluster. This parameter isn’t case-sensitive.
SourceDBSnapshotName: Snapshot name which we will use in this flow.
TargetAWSRegion: Destination AWS Account Region where you want to restore the Aurora cluster.
c. Select IAM role to launch this template per best practices.
d. Acknowledge to create various resources including IAM roles/policies and select Create Stack.
Part 3: Workflow to Restore the Aurora Cluster in the AWS Target Account and Target Region
Once AWS Lambda receives a cross-account sns notification for the shared snapshot, this workflow begins:
The Lambda function starts the AWS Step Function workflow in an asynchronous mode.
The workflow checks for the snapshot availability and starts restoring the Aurora cluster based on the configured engine, version, and other parameters.
Depending on the availability of the cluster, it adds instances based on a predefined configuration.
Once the instances are available, it swaps cluster names so that the updated database is available at the same reader and writer endpoints.
Once the databases are restored, the old Aurora cluster is shut down.
Note:
a) The database is restored in the default VPC, Availability Zone, and option group, with the default cluster version and option group. If you want to restore with the specific configurations, you can edit the restore cluster function with details available in the same section.
b) Database credentials will be the same as source account. If you want to override credential or change the authentication mechanism, you can edit the restore cluster function with details available in the same section.
Figure 4 – Architecture showing the AWS Step Functions Workflow
Import Lambda functions involved in this workflow:
a) FetchRDSSnapshotStatus: This Lambda function fetches the snapshot status and moves to RestoreCluster functionality once the snapshot is available.
b) RestoreRDSCluster: This Lambda function restores the cluster from the shared snapshot with the mandatory attribute only.
– You can edit the Lambda function as described following to add specific parameters like specific VPC, Subnets, AvailabilityZones, DBSubnetGroupName, Autoscaling for reader capacity, DBClusterParameterGroupName, BacktrackWindow and many more.
c) RestoreInstance: This Lambda function creates an instance for the restored cluster.
d) SwapClusterName: This Lambda function swaps the cluster name, so that the updated database is available at previous endpoints. Then the cluster url is swapped.
e) TerminateOldCluster: This Lambda function will shut down the previous cluster.
Using the following AWS CloudFormation Template, we can set up the required services/workflow in the target account and target Region:
a) Launch the template in target account and target Region:
b) Fill out the preceding form with the following details and click the next button.
Stack name: Stack name which you want to create.
Engine: The database engine to be used for the new DB cluster, such as aurora-mysql. It must be compatible with the engine of the source.
DBInstanceClass: The compute and memory capacity of the Amazon RDS DB instance, for example, db.t3.medium.
Not all DB instance classes are available in all AWS Regions, or for all database engines. For the full list of DB instance classes, and availability for your engine, see DB Instance Class in the Amazon RDS User Guide.
ExistingDBClusterIdentifier: Name of the existing DB cluster. In the final step, if the old cluster is available with this name, it will be deleted and a new cluster will be available with this name, so the reader/writer endpoint will not change. This parameter isn’t case-sensitive. It must contain from 1 to 63 letters, numbers, or hyphens. The first character must be a letter. DBClusterIdentifier can’t end with a hyphen or contain two consecutive hyphens.
TempDBClusterIdentifier: Temporary name of the DB cluster created from the DB snapshot or DB cluster snapshot. In the final step, this cluster name will be swapped with the original cluster and the previous cluster will be deleted. This parameter isn’t case-sensitive. Must contain from 1 to 63 letters, numbers, or hyphens. The first character must be a letter. DBClusterIdentifier can’t end with a hyphen or contain two consecutive hyphens.
ExistingDBInstanceIdentifier: Name of the existing DB instance identifier. In the final step, if an previous instance is available with this name, it will be deleted and a new instance will be available with this name. This parameter is stored as a lowercase string. Must contain from 1 to 63 letters, numbers, or hyphens. The first character must be a letter, can’t end with a hyphen or contain two consecutive hyphens.
TempDBInstanceIdentifier: Temporary name of the existing DB instance. In the final step, if a previous instance is available with this name, it will be deleted and a new instance will be available. This parameter is stored as a lowercase string. Must contain from 1 to 63 letters, numbers, or hyphens. The first character must be a letter, can’t end with a hyphen or contain two consecutive hyphens.
c) Select IAM role to launch this template as per best practices and select Next.
d) Acknowledge to create various resources including IAM roles/policies and select Create Stack.
After launching the CloudFormation steps, all resources like IAM roles, step function workflow and Lambda functions will be set up in the target account.
Part 4: Cross Account Role for Lambda Invocation to restore the Aurora Cluster
In this step, we provide access to Lambda function setup in the target account and target Region to listen to the SNS topic setup in the source account and source Region. An SNS notification is initiated by the first workflow after the snapshot sharing steps. The Lambda function initiates a workflow to restore the Aurora cluster in the target account and target Region.
Replace << targetAccountID >> with target AWS account number and <<snsTopicinSourceAccount>> with sns topic created as an output of part 2 CloudFormation template in the source account.
b) Configure the InvokeStepFunction Lambda function in target account to allow invocation from the SNS topic in source account by using following AWS CLI command in the target account. This policy allows the specific SNS topic in the source account to invoke the Lambda function.
Replace <<snsTopicinSourceAccount>> with sns topic created as an output of part 2 CloudFormation template.
c) Subscribe the Lambda function in the target account to the SNS topic in the source account by using the following AWS CLI command in the target account.
Initiate the CLI command in the source Region as sns topic is created there. Replace <<snsTopicinSourceAccount>> with sns topic created as an output of part 2 CloudFormation template execution and << InvokeStepFunctionArninTargetAccount >>with InvokeStepFunction Lambda in the target account created as an output of part 3 CloudFormation template launch.
Security Consideration:
1. We can share the snapshots with different accounts using public and private mode.
Public mode permits all AWS accounts to restore a DB instance from the shared snapshot.
Private mode permits only AWS accounts that you specify to restore a DB instance from the shared snapshot. We recommend sharing the snapshot with the destination account in private mode, as we are using the same in our solution.
2. Sharing a manual DB cluster snapshot (whether encrypted or unencrypted) enables authorized AWS accounts to directly restore a DB cluster from the snapshot. This is instead of taking a copy and restoring from that. We recommend sharing an encrypted snapshot with the destination account, as we are using the same in our solution.
Cleaning up
Delete the resources to avoid future incurring charges.
Conclusion
In this blog, you learned how to replicate databases across the Region and across different accounts. This helps in designing your DR environment and fulfilling compliance requirements. This solution can be customized for any RDS-based databases or Aurora Serverless, and you can achieve the desired level of RTO and RPO.
Field Notes provides hands-on technical guidance from AWS Solutions Architects, consultants, and technical account managers, based on their experiences in the field solving real-world business problems for customers.
Search engines provide the means to retrieve relevant content from a collection of content. However, this can be challenging if certain exact words aren’t entered. You need to find the right item from a catalog of products, or the correct provider from a list of service providers, for example. The most common method of specifying your query is through a text box. If you enter the wrong terms, you won’t match the right items, and won’t get the best results.
Synonyms enable better search results by matching words that all match to a single indexable term. In Amazon Elasticsearch Service (Amazon ES), you can provide synonyms for keywords that your application’s users may look for. For example, your website may provide medical practitioner searches, and your users may search for “child’s doctor” instead of “pediatrician.” Mapping the two words together enables either search term to match documents that contain the term “pediatrician.” You can achieve similar search results by using synonym files. Amazon ES custom packages allow you to upload synonym files that define the synonyms in your catalog. One best practice is to manage the synonyms in Amazon Relational Database Service (Amazon RDS). You then need to deploy the synonyms to your Amazon ES domain. You can do this with AWS Lambda and Amazon Simple Storage Service (Amazon S3).
In this post, we discuss an approach using Amazon Aurora and Lambda functions to automate updating synonym files for improved search results.
Overview of solution
Amazon ES is a fully managed service that makes it easy to deploy, secure, and run Elasticsearch cost-effectively and at scale. You can build, monitor, and troubleshoot your applications using the tools you love, at the scale you need. The service supports open-source Elasticsearch API operations, managed Kibana, integration with Logstash, and many AWS services with built-in alerting and SQL querying.
The following diagram shows the solution architecture. One Lambda function pushes files to Amazon S3, and another function distributes the updates to Amazon ES.
Walkthrough overview
For search engineers, the synonym file’s content is usually stored within a database or in a data lake. You may have data in tabular format in Amazon RDS (in this case, we use Amazon Aurora MySQL). When updates to the synonym data table occur, the change triggers a Lambda function that pushes data to Amazon S3. The S3 event triggers a second function, which pushes the synonym file from Amazon S3 to Amazon ES. This architecture automates the entire synonym file update process.
To achieve this architecture, we complete the following high-level steps:
Create a stored procedure to trigger the Lambda function.
Write a Lambda function to verify data changes and push them to Amazon S3.
Write a Lambda function to update the synonym file in Amazon ES.
Test the data flow.
We discuss each step in detail in the next sections.
Prerequisites
Make sure you complete the following prerequisites:
Configure an Amazon ES domain. We use a domain running Elasticsearch version 7.9 for this architecture.
Create a stored procedure to trigger a Lambda function
You can invoke a Lambda function from an Aurora MySQL database cluster using a native function or a stored procedure.
The following script creates an example synonym data table:
CREATE TABLE SynonymsTable (
SynID int NOT NULL AUTO_INCREMENT,
Base_Term varchar(255),
Synonym_1 varchar(255),
Synonym_2 varchar(255),
PRIMARY KEY (SynID)
)
You can now populate the table with sample data. To generate sample data in your table, run the following script:
INSERT INTO SynonymsTable(Base_Term, Synonym_1, Synonym_2)
VALUES ( 'danish', 'croissant', 'pastry')
Create a Lambda function
You can use two different methods to send data from Aurora to Amazon S3: a Lambda function or SELECT INTO OUTFILE S3.
To demonstrate the ease of setting up integration between multiple AWS services, we use a Lambda function that is called every time a change occurs that must be tracked in the database table. This function passes the data to Amazon S3. First create an S3 bucket where you store the synonym file using the Lambda function.
When you create your function, make sure you give the right permissions using an AWS Identity and Access Management (IAM) role for the S3 bucket. These permissions are for the Lambda execution role and S3 bucket where you store the synonyms.txt file. By default, Lambda creates an execution role with minimal permissions when you create a function on the Lambda console. The following is the Python code to create the synonyms.txt file in S3:
import boto3
import json
import botocore
from botocore.exceptions import ClientError
s3_resource = boto3.resource('s3')
filename = 'synonyms.txt'
BucketName = '<<provide your bucket name>>
local_file = '/tmp/test.txt'
def lambda_handler(event, context):
S3_data = (("%s,%s,%s \n") %(event['Base_Term'], event['Synonym_1'], event['Synonym_2']))
# open a file and append new line
try:
obj=s3_resource.Bucket(BucketName).download_file(local_file,filename)
except ClientError as e:
if e.response['Error']['Code'] == "404":
# create a new file if file does not exits
s3_resource.meta.client.put_object(Body=S3_data, Bucket= BucketName,Key=filename)
else:
# append file
raise
with open('/tmp/test.txt', 'a') as fd:
fd.write(S3_data)
s3_resource.meta.client.upload_file('/tmp/test.txt', BucketName, filename)
Note the Amazon Resource Name (ARN) of this Lambda function to use in a later step.
Give Aurora permissions to invoke a Lambda function
When you’re finished, the Aurora database has access to invoke a Lambda function.
Create a stored procedure and a trigger in Aurora
To create a new stored procedure, return to MySQL Workbench. Change the ARN in the following code to your Lambda function’s ARN before running the procedure:
DROP PROCEDURE IF EXISTS Syn_TO_S3;
DELIMITER ;;
CREATE PROCEDURE Syn_TO_S3 (IN SysID INT,IN Base_Term varchar(255),IN Synonym_1 varchar(255),IN Synonym_2 varchar(255)) LANGUAGE SQL
BEGIN
CALL mysql.lambda_async('<<Lambda-Funtion-ARN>>,
CONCAT('{ "SysID ": "', SysID,
'", "Base_Term" : "', Base_Term,
'", "Synonym_1" : "', Synonym_1,
'", "Synonym_2" : "', Synonym_2,'"}')
);
END
;;
DELIMITER
When this stored procedure is called, it invokes the Lambda function you created.
Create a trigger TR_SynonymTable_CDC on the table SynonymTable. When a new record is inserted, this trigger calls the Syn_TO_S3 stored procedure. See the following code:
DROP TRIGGER IF EXISTS TR_Synonym_CDC;
DELIMITER ;;
CREATE TRIGGER TR_Synonym_CDC
AFTER INSERT ON SynonymsTable
FOR EACH ROW
BEGIN
SELECT NEW.SynID, NEW.Base_Term, New.Synonym_1, New.Synonym_2
INTO @SynID, @Base_Term, @Synonym_1, @Synonym_2;
CALL Syn_TO_S3(@SynID, @Base_Term, @Synonym_1, @Synonym_2);
END
;;
DELIMITER ;
If a new row is inserted in SynonymsTable, the Lambda function that is mentioned in the stored procedure is invoked.
Verify that data is being sent from the function to Amazon S3 successfully. You may have to insert a few records, depending on the size of your data, before new records appear in Amazon S3.
Update synonyms in Amazon ES when a new synonym file becomes available
Amazon ES lets you upload custom dictionary files (for example, stopwords and synonyms) for use with your cluster. The generic term for these types of files is packages. Before you can associate a package with your domain, you must upload it to an S3 bucket. For instructions on uploading a synonym file for the first time and associating it to an Amazon ES domain, see Uploading packages to Amazon S3 and Importing and Associating packages.
To update the synonyms (package) when a new version of the synonym file becomes available, we complete the following steps:
Create a Lambda function to update the existing package.
Set up an S3 event notification to trigger the function.
Create a Lambda function to update the existing package
We use a Python-based Lambda function that uses the Boto3 AWS SDK for updating the Elasticsearch package. For more information about how to create a Python-based Lambda function, see Building Lambda functions with Python. You need the following information before we start coding for the function:
The S3 bucket ARN where the new synonym file is written
The Amazon ES domain name (available on the Amazon ES console)
The package ID of the Elasticsearch package we’re updating (available on the Amazon ES console)
You can use the following code for the Lambda function:
import logging
import boto3
import os
# Elasticsearch client
client = boto3.client('es')
# set up logging
logger = logging.getLogger('boto3')
logger.setLevel(logging.INFO)
# fetch from Environment Variable
package_id = os.environ['PACKAGE_ID']
es_domain_nm = os.environ['ES_DOMAIN_NAME']
def lambda_handler(event, context):
s3_bucket = event["Records"][0]["s3"]["bucket"]["name"]
s3_key = event["Records"][0]["s3"]["object"]["key"]
logger.info("bucket: {}, key: {}".format(s3_bucket, s3_key))
# update package with the new Synonym file.
up_response = client.update_package(
PackageID=package_id,
PackageSource={
'S3BucketName': s3_bucket,
'S3Key': s3_key
},
CommitMessage='New Version: ' + s3_key
)
logger.info('Response from Update_Package: {}'.format(up_response))
# check if the package update is completed
finished = False
while finished == False:
# describe the package by ID
desc_response = client.describe_packages(
Filters=[{
'Name': 'PackageID',
'Value': [package_id]
}],
MaxResults=1
)
status = desc_response['PackageDetailsList'][0]['PackageStatus']
logger.info('Package Status: {}'.format(status))
# check if the Package status is back to available or not.
if status == 'AVAILABLE':
finished = True
logger.info('Package status is now Available. Exiting loop.')
else:
finished = False
logger.info('Package: {} update is now Complete. Proceed to Associating to ES Domain'.format(package_id))
# once the package update is completed, re-associate with the ES domain
# so that the new version is applied to the nodes.
ap_response = client.associate_package(
PackageID=package_id,
DomainName=es_domain_nm
)
logger.info('Response from Associate_Package: {}'.format(ap_response))
return {
'statusCode': 200,
'body': 'Custom Package Updated.'
}
The preceding code requires environment variables to be set to the appropriate values and the IAM execution role assigned to the Lambda function.
Set up an S3 event notification to trigger the Lambda function
Now we set up event notification (all object create events) for the S3 bucket in which the updated synonym file is uploaded. For more information about how to set up S3 event notifications with Lambda, see Using AWS Lambda with Amazon S3.
Test the solution
To test our solution, let’s consider an Elasticsearch index (es-blog-index-01) that consists of the following documents:
tennis shoe
hightop
croissant
ice cream
A synonym file is already associated with the Amazon ES domain via Amazon ES custom packages and the index (es-blog-index-01) has the synonym file in the settings (analyzer, filter, mappings). For more information about how to associate a file to an Amazon ES domain and use it with the index settings, see Importing and associating packages and Using custom packages with Elasticsearch. The synonym file contains the following data:
danish, croissant, pastry
Test 1: Search with a word present in the synonym file
For our first search, we use a word that is present in the synonym file. The following screenshot shows that searching for “danish” brings up the document croissant based on a synonym match.
Test 2: Search with a synonym not present in the synonym file
Next, we search using a synonym that’s not in the synonym file. In the following screenshot, our search for “gelato” yields no result. The word “gelato” doesn’t match with the document ice cream because no synonym mapping is present for it.
In the next test, we add synonyms for “ice cream” and perform the search again.
Test 3: Add synonyms for “ice cream” and redo the search
To add the synonyms, let’s insert a new record into our database. We can use the following SQL statement:
In this post, we implemented a solution using Aurora, Lambda, Amazon S3, and Amazon ES that enables you to update synonyms automatically in Amazon ES. This provides central management for synonyms and ensures your users can obtain accurate search results when synonyms are changed in your source database.
About the Authors
Ashwini Rudra is a Solutions Architect at AWS. He has more than 10 years of experience architecting Windows workloads in on-premises and cloud environments. He is also an AI/ML enthusiast. He helps AWS customers, namely major sports leagues, define their cloud-first digital innovation strategy.
Arnab Ghosh is a Solutions Architect for AWS in North America helping enterprise customers build resilient and cost-efficient architectures. He has over 13 years of experience in architecting, designing, and developing enterprise applications solving complex business problems.
Jennifer Ng is an AWS Solutions Architect working with enterprise customers to understand their business requirements and provide solutions that align with their objectives. Her background is in enterprise architecture and web infrastructure, where she has held various implementation and architect roles in the financial services industry.
In this post, you’ll learn how to implement an active/active strategy to run your workload and serve requests in two or more distinct sites. Like other DR strategies, this enables your workload to remain available despite disaster events such as natural disasters, technical failures, or human actions.
DR strategies: Multi-site active/active
As we know from our now familiar DR strategies diagram (Figure 1), the multi-site active/active strategy will give you the lowest RTO (recovery time objective) and RPO (recovery point objective). However, this must be weighed against the potential cost and complexity of operating active stacks in multiple sites.
Figure 1. DR strategies
Implementing multi-site active/active
The architecture in Figure 2 shows you how to use AWS Regions as your active sites, creating a multi-Region active/active architecture. Only two Regions are shown, which is common, but more may be used. Each Region hosts a highly available, multi-Availability Zone (AZ) workload stack. In each Region, data is replicated live between the data stores and also backed up. This protects against disasters that include data deletion or corruption, since the data backup can be restored to the last known good state.
Figure 2. Multi-site active/active DR strategy
Traffic routing
Each regional stack serves production traffic. How you implement traffic routing determines which Region will receive a given request. Figure 2 shows Amazon Route 53, a highly available and scalable cloud Domain Name System (DNS), used for routing. Route 53 offers multiple routing policies. For example, the geolocation or latency routing policies are good choices for active/active deployments. For geolocation routing, you configure which Region a request goes to based on the origin location of the request. For latency routing, AWS automatically sends requests to the Region that provides the shortest round-trip time.
Your data governance strategy helps inform which routing policy to use. Geolocation routing lets you distribute requests in a deterministic way. This allows you to keep data for certain users within a specific Region, or you can control where write operations are routed to prevent contention. If optimizing for performance is your top priority, then latency routing is a good choice.
Read/write patterns
Read local/write local pattern
The Region to which a request is routed is called the “local Region” for that request. To maintain low latencies and reduce the potential for network error, serve all read and write requests from the local Region of your multi-Region active/active architecture.
I use Amazon DynamoDB for the example architecture in Figure 2. DynamoDB global tables replicate a table to multiple Regions. Writes to the table in any Region are replicated to other Regions within a second. This makes it a good choice when using the read local/write local pattern. However, there is the possibility of write contention if updates are made to the same item in different Regions at about the same time. To help ensure eventual consistency, DynamoDB global tables use a last writer wins reconciliation between concurrent updates. In this case, the data written by the first writer is lost. If your application cannot handle this and you require strong consistency, use another write pattern to avoid write contention.
Read local/write global pattern
With a write global pattern, you choose a Region to be the global write Region and only accept writes in that Region. DynamoDB global tables are still an excellent choice for replicating data globally; however, you must ensure that locally received write requests are re-directed to the global write Region.
Amazon Aurora is another good choice. When deployed as an Aurora global database, a primary cluster is deployed to your global write Region, and read-only instances (Aurora Replicas) are deployed to other AWS Regions. Data is replicated to these read-only instances with typical latency of under a second. Aurora global database write forwarding (available using Aurora MySQL-Compatible Edition) allows Aurora Replicas in the secondary cluster to forward write operations to the primary cluster in the global write Region. This way, you can treat the read-only replicas in all your Regions as if they were read/write capable. Using write forwarding, the request travels over the AWS network and not the public internet, reducing latency.
Amazon ElastiCache for Redis also can replicate data across Regions. For example, to store session data, you write to your global write Region and use Global Datastore to ensure that this data is available to be read from other Regions.
Read local/write partitioned pattern
For write-heavy workloads with users located around the world, your application may not be suited to incur the round trip to the global write Region with every write. Consider using a write partitioned pattern to mitigate this. With this pattern, each item or record is assigned a home Region. This can be done based on the Region it was first written to. Or it can be based on a partition key in the record (such as user ID) by pre-assigning a home Region for each value of this key. As shown in Figure 3, records for this user are assigned to the left AWS Region as their home Region. The goal is to try to map records to a home Region close to where most write requests will originate.
Figure 3. Read local/write partitioned pattern for multi-site active/active DR strategy
When the user in Figure 3 travels away from home, they will read local, but writes will be routed back to their home Region. Usually writes will not incur long round trips as they are expected to typically come from near the home Region. Since writes are accepted in all Regions (for records homed to that respective Region), DynamoDB global tables, which accept writes in all Regions, are a good choice here also.
Failover
With a multi-Region active/active strategy, if your workload cannot operate in a Region, failover will route traffic away from the impacted Region to healthy Region(s). You can accomplish this with Route 53 by updating the DNS records. Make sure you set TTL (time to live) on these records low enough so that DNS resolvers will reflect your changes quickly enough to meet your RTO targets. Alternatively, you can use AWS Global Accelerator for routing and failover. It does not rely on DNS. Global Accelerator gives you two static IP addresses. You then configure which Regions user traffic goes to based on traffic dials and weights you set.
If you’re using a write global pattern and the impacted Region is the global write Region, then a new Region needs to be promoted to be the new global write Region. If you’re using a write partitioned pattern, your workload must repartition so that the records homed in the impacted Region are assigned to one of the remaining Regions. Using write local, all Regions can accept writes. With no changes needed to the data storage layer, this pattern can have the fastest (near zero) RTO.
Conclusion
Consider the multi-site active/active strategy for your workload if you need DR with the quickest recovery time (lowest RTO) and least data loss (lowest RPO). Implementing it across Regions (multi-Region) is a good option if you are looking for the most separation and complete independence of your sites, or if you need to provide low latency access to the workload from users in globally diverse locations.
Also consider the trade-offs. Implementing and operating this strategy, particularly using multi-Region, can be more complicated and more expensive, than other DR strategies. When implementing multi-Region active/active in AWS, you have access to resources to choose the routing policy and the read/write pattern that is right for your workload.
The standard workflow for setting up Amazon Redshift federated query involves six steps. For more information, see Querying data with federated queries in Amazon Redshift. With a CloudFormation template, you can condense these manual procedures into a few steps listed in a text file. The declarative code in the file captures the intended state of the resources that you want to create and allows you to automate the setup of AWS resources to support Amazon Redshift federated query. You can further enhance this template to become the single source of truth for your infrastructure.
A CloudFormation template acts as an accelerator. It helps you automate the deployment of technology and infrastructure in a safe and repeatable manner across multiple Regions and accounts with the least amount of effort and time.
Architecture overview
The following diagram illustrates the solution architecture.
The CloudFormation template provisions the following components in the architecture:
Aurora for MySQL cluster with TPC-DS dataset preloaded
Amazon Redshift cluster with TPC-DS dataset preloaded
Amazon Redshift IAM role with required permissions
Prerequisites
Before you create your resources in AWS CloudFormation, you must complete the following prerequisites:
Have an AWS Identity and Access Management (IAM) user with sufficient permissions to interact with the AWS Management Console and related AWS services. Your IAM permissions must also include access to create IAM roles and policies via the CloudFormation template.
Create an Amazon Elastic Compute Cloud (Amazon EC2) key pair in the us-east-1 Region. For instructions, see Create a key pair using Amazon EC2. Make sure that you save the private key; this is the only time you can do so. You use this key pair as an input parameter when you set up the CloudFormation stack.
Setting up resources with AWS CloudFormation
This post provides a CloudFormation template as a general guide. You can review and customize it to suit your needs. Some of the resources that this stack deploys incur costs when in use.
To create your resources, complete the following steps:
Sign in to the console.
Choose the us-east-1 Region in which to create the stack.
Choose Launch Stack:
Choose Next.
This automatically launches AWS CloudFormation in your AWS account with a template. It prompts you to sign in as needed. You can view the CloudFormation template from within the console.
For Stack name, enter a stack name.
For Session, leave as the default.
For ec2KeyPair, choose the key pair you created earlier.
Choose Next.
On the next screen, choose Next.
Review the details on the final screen and select I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create.
Stack creation can take up to 45 minutes.
After the stack creation is complete, on the Outputs tab of the stack, record the value of the key for the following components, which you use in a later step:
AuroraClusterEndpoint
AuroraSecretArn
RedshiftClusterEndpoint
RedshiftClusterRoleArn
As of this writing, this feature is in public preview. You can create a snapshot of your Amazon Redshift cluster created by the stack and restore the snapshot as a new cluster in the sql_preview maintenance track with the same configuration.
You’re now ready to log in to both the Aurora MySQL and Amazon Redshift cluster and run some basic commands to test them.
Logging in to the clusters using the Amazon Linux bastion host
The following steps assume that you use a computer with an SSH client to connect to the bastion host. For more information about connecting using various clients, see Connect to your Linux instance.
Move the private key of the EC2 key pair (that you saved previously) to a location on your SSH client, where you are connecting to the Amazon Linux bastion host.
Change the permission of the private key using the following code, so that it’s not publicly viewable:
chmod 400 <private key file name; for example, bastion-key.pem>
On the Amazon EC2 console, choose Instances.
Choose the Amazon Linux bastion host that the CloudFormation stack created.
Choose Connect.
Copy the value for SSHCommand.
On the SSH client, change the directory to the location where you saved the EC2 private key, and enter the SSHCommand value.
The CloudFormation template has already set up MySQL Command-Line Client binaries on the Amazon Linux bastion host.
On the Amazon Redshift console, choose Editor.
Choose Query editor.
For Connection, choose Create new connection.
For Cluster, choose the Amazon Redshift cluster.
For Database name, enter your database.
Enter the database user and password recorded earlier.
Choose Connect to database.
Enter the following SQL command:
select "table" from svv_table_info where schema='public';
You should see 25 tables as the output.
Launch a command prompt session of the bastion host and enter the following code (substitute <AuroraClusterEndpoint> with the value from the AWS CloudFormation output):
mysql --host=<AuroraClusterEndpoint> --user=awsuser --password=<database user password recorded earlier>
Enter the following SQL command:
use tpc;
show tables;
You should see the following eight tables as the output:
mysql> use tpc;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+------------------------+
| Tables_in_tpc |
+------------------------+
| customer |
| customer_address |
| household_demographics |
| income_band |
| item |
| promotion |
| web_page |
| web_sales |
+------------------------+
8 rows in set (0.01 sec)
Completing federated query setup
The final step is to create an external schema to connect to the Aurora MySQL instance. The following example code creates an external schema statement that you need to run on your Amazon Redshift cluster to complete this step:
CREATE EXTERNAL SCHEMA IF NOT EXISTS mysqlfq
FROM MYSQL
DATABASE 'tpc'
URI '<AuroraClusterEndpoint>'
PORT 3306
IAM_ROLE '<IAMRole>'
SECRET_ARN '<SecretARN>'
Use the following parameters:
URI – The AuroraClusterEndpoint value from the CloudFormation stack outputs. The value is in the format <stackname>-cluster.<randomcharacter>.us-east-1.rds.amazonaws.com.
IAM_Role – The RedshiftClusterRoleArn value from the CloudFormation stack outputs. The value is in the format arn:aws:iam::<accountnumber>:role/<stackname>-RedshiftClusterRole-<randomcharacter>.
Secret_ARN – The AuroraSecretArn value from the CloudFormation stack outputs. The value is in the format arn:aws:secretsmanager:us-east-1:<accountnumber>: secret:secretAuroraMasterUser-<randomcharacter>.
Federated query test
Now that you have set up federated query, you can start testing the feature using the TPC-DS dataset that was preloaded into both Aurora MySQL and Amazon Redshift.
For example, the following query aggregates the total net sales by product category and class from the web_sales fact table and date and item dimension tables. Tables web_sales and date are stored in Amazon Redshift, and the item table is stored in Aurora MySQL:
select
sum(ws_net_paid
) as total_sum, i_category, i_class, 0 as g_category, 0 as g_class
from
web_sales ,date_dim d1 ,mysqlfq.item
where
d1.d_month_seq between 1205
and 1205+11
and d1.d_date_sk = ws_sold_date_sk
and i_item_sk = ws_item_sk
group
by i_category,i_class ;
You can continue to experiment with the dataset and explore the three main use cases in the post [exact name of post title with embedded link].
Cleaning up
When you’re finished, delete the CloudFormation stack, because some of the AWS resources in this walkthrough incur a cost if you continue to use them. Complete the following steps:
On the AWS CloudFormation console, choose Stacks.
Choose the stack you launched in this walkthrough. The stack must be currently running.
In the stack details pane, choose Delete.
Choose Delete stack.
Summary
This post showed you how to automate the creation of an Aurora MySQL and Amazon Redshift cluster preloaded with the TPC-DS dataset, the prerequisites for the new Amazon Redshift federated query feature using AWS CloudFormation, and a single manual step to complete the setup. It also provided an example federated query using the TPC-DS dataset, which you can use to accelerate your learning and adoption of the new feature. You can continue to modify the CloudFormation templates from this post to support your business needs.
If you have any questions or suggestions, please leave a comment.
About the Authors
BP Yau is an Analytics Specialist Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
Srikanth Sopirala is a Sr. Specialist Solutions Architect, Analytics at AWS. He is passionate about helping customers build scalable data and analytics solutions in the cloud.
Zhouyi Yang is a Software Development Engineer for Amazon Redshift Query Processing team. He’s passionate about gaining new knowledge about large databases and has worked on SQL language features such as federated query and IAM role privilege control. In his spare time, he enjoys swimming, tennis, and reading.
Entong Shen is a Senior Software Development Engineer for Amazon Redshift. He has been working on MPP databases for over 8 years and has focused on query optimization, statistics, and SQL language features such as stored procedures and federated query. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Today, we’re launching a new feature of Amazon Redshift federated query to Amazon Aurora MySQL and Amazon RDS for MySQL to help you expand your operational databases in the MySQL family. With this lake house architecture expansion to support more operational data stores, you can query and combine data more easily in real time and store data in open file formats in your Amazon Simple Storage Service (Amazon S3) data lake. Your data can then be more available to other analytics and machine learning (ML) tools, rather than siloed in disparate data stores.
In this post, we share information about how to get started with this new federated query feature to MySQL.
Prerequisites
To try this new feature, create a new Amazon Redshift cluster in a sql_preview maintenance track and Aurora MySQL instance and load sample TPC data into both data stores. To make sure both Aurora MySQL DB instances can accept connections from the Amazon Redshift cluster, you should make sure that both your Amazon Redshift cluster and Aurora MySQL instances are in the same Amazon Virtual Private Cloud (Amazon VPC) and subnet group. This way, you can add the security group for the Amazon Redshift cluster to the inbound rules of the security group for the Aurora MySQL DB instance.
If your Amazon Redshift cluster and Aurora MySQL instances are in the different VPC, you can set up VPC peering or other networking to allow Amazon Redshift to make connections to your Aurora MySQL instances. For more information about VPC networking, see Working with a DB instance in a VPC.
Configuring AWS Secrets Manager for remote database credentials
Amazon Redshift needs database credentials to issue a federated query to a MySQL database. AWS Secrets Manager provides a centralized service to manage secrets and can be used to store your MySQL database credentials. Because Amazon Redshift retrieves and uses these credentials, they are transient, not stored in any generated code, and discarded after the query runs.
Storing credentials in Secrets Manager takes only a few minutes. To store a new secret, complete the following steps:
On the Secrets Manager console, choose Secrets.
Choose Store a new secret.
For Select secret type, select Credentials for RDS database.
For User name, enter a name.
For Password, enter a password.
For Select the encryption key, choose DefaultEncryptionkey.
For Select which RDS database this secret will access, choose your database.
Optionally, copy programmatic code for accessing your secret using your preferred programming languages (which is not needed for this post).
Choose Next.
After you create the secret, you can retrieve the secret ARN by choosing the secret on the Secrets Manager console. The secret ARN is needed in the subsequent step.
Setting up IAM role
You can now pull everything together by embedding the secret ARN into an AWS Identity and Access Management (IAM) policy, naming the policy, and attaching it to an IAM role. See the following code:
Finally, attach the same IAM role to your Amazon Redshift cluster.
On the Amazon Redshift console, choose Clusters.
Choose your cluster.
On the Actions drop-down menu, choose Manage IAM roles.
Choose and add the IAM role you just created.
Setting up external schema
The final step is to create an external schema to connect to your Aurora MySQL instance. The following example code creates the external schema statement that you need to run on your Amazon Redshift cluster to complete this step:
CREATE EXTERNAL SCHEMA IF NOT EXISTS mysqlfq
FROM MYSQL
DATABASE 'tpc'
URI '<AuroraClusterEndpoint>'
PORT 3306
IAM_ROLE '<IAMRole>'
SECRET_ARN '<SecretARN>'
Use the following parameters:
URI – Aurora MySQL cluster endpoint
IAM_Role – IAM role created from the previous step
Secret_ARN – Secret ARN
After you set up the external schema, you’re ready to run some queries to test different use cases.
Querying live operational data
You can now query real-time operational data in your Aurora MySQL instance from Amazon Redshift. Note that isolation level is read committed for MySQL. See the following code:
Querying mysqlfq.web_sales in Amazon Redshift routes the request to MySQL tpc database and web_sales table. If you examine the query plan, you can see the query runs at the MySQL instance as shown by the step Remote MySQL Seq Scan:
dev=# explain select top 10 ws_order_number from mysqlfq.web_sales;
QUERY PLAN
-----------------------------------------------------------------------------------------------
XN Limit (cost=0.00..0.20 rows=10 width=8)
-> XN MySQL Query Scan web_sales (cost=0.00..6869.28 rows=343464 width=8)
-> Remote MySQL Seq Scan mysqlfq.web_sales (cost=0.00..3434.64 rows=343464 width=8)
(3 rows)
Simplifying ELT and ETL
You can also extract operational data directly from your Aurora MySQL instance and load it into Amazon Redshift. See the following code:
dev=# create table staging_customer as select c_customer_id from mysqlfq.customer where c_customer_id not in (select c_customer_id from customer);
SELECT
dev=# select count(*) from staging_customer;
count
--------
350000
(1 row)
The preceding code uses CTAS to create and load incremental data from your operational MySQL instance into a staging table in Amazon Redshift. You can then perform transformation and merge operations from the staging table to the target table. For more information, see Updating and inserting new data.
Combining operational data with data from your data warehouse and data lake
You can combine live operational data from your Aurora MySQL instance with data from your Amazon Redshift data warehouse and S3 data lake by creating a late binding view.
To access your S3 data lake historical data via Amazon Redshift Spectrum, create an external table:
create external schema mysqlspectrum
from data catalog
database 'spectrumdb'
iam_role '<IAMRole>'
create external database if not exists;
create external table mysqlspectrum.customer
stored as parquet
location 's3://<yourS3bucket>/customer/'
as select * from customer where c_customer_sk <= 100000;
You can then run queries on the view to gain insight on data across the three sources:
drop view vwCustomer;
create view vwCustomer as
select c_customer_sk, 'redshift' as source from public.customer where c_customer_sk > 100000
union all
select c_customer_sk, 'mysql' as source from mysqlfq.customer
union all
select c_customer_sk, 's3' as source from mysqlspectrum.customer
with no schema binding;
select * from vwCustomer where c_customer_sk in (1, 149712,29033279);
You should the following three records as output:
dev=# select * from vwCustomer where c_customer_sk in (1, 149712,29033279);
c_customer_sk | source
---------------+----------
29033279 | mysql
1 | s3
149712 | redshift
(3 rows)
If you examine the query plan, you can see that the predicates are pushed down to your MySQL instance to run:
Amazon Redshift federated querying to Aurora MySQL and Amazon RDS for MySQL is now available for public preview with Amazon Redshift release version 1.0.21591 or later. Refer to the AWS Region Table for Amazon Redshift availability and to check the version of your clusters.
About the Authors
BP Yau is an Analytics Specialist Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next-generation big data analytics platform using AWS technologies.
Zhouyi Yang is a Software Development Engineer for the Amazon Redshift Query Processing team. He’s passionate about gaining new knowledge about large databases and has worked on SQL language features such as federated query and IAM role privilege control. In his spare time, he enjoys swimming, tennis, and reading.
Entong Shen is a Senior Software Development Engineer for Amazon Redshift. He has been working on MPP databases for over 8 years and has focused on query optimization, statistics, and SQL language features such as stored procedures and federated query. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Machine learning (ML) is becoming more mainstream, but even with the increasing adoption, it’s still in its infancy. For ML to have the broad impact that we think it can have, it has to get easier to do and easier to apply. We launched Amazon SageMaker in 2017 to remove the challenges from each stage of the ML process, making it radically easier and faster for everyday developers and data scientists to build, train, and deploy ML models. SageMaker has made ML model building and scaling more accessible to more people, but there’s a large group of database developers, data analysts, and business analysts who work with databases and data lakes where much of the data used for ML resides. These users still find it too difficult and involved to extract meaningful insights from that data using ML.
This group is typically proficient in SQL but not Python, and must rely on data scientists to build the models needed to add intelligence to applications or derive predictive insights from data. And even when you have the model in hand, there’s a long and involved process to prepare and move data to use the model. The result is that ML isn’t being used as much as it can be.
To meet the needs of this large and growing group of builders, we’re integrating ML into AWS databases, analytics, and business intelligence (BI) services.
AWS customers generate, process, and collect more data than ever to better understand their business landscape, market, and customers. And you don’t just use one type of data store for all your needs. You typically use several types of databases, data warehouses, and data lakes, to fit your use case. Because all these use cases could benefit from ML, we’re adding ML capabilities to our purpose-built databases and analytics services so that database developers, data analysts, and business analysts can train models on their data or add inference results right from their database, without having to export and process their data or write large amounts of ETL code.
Machine Learning for database developers
At re:Invent last year, we announced ML integrated inside Amazon Aurora for developers working with relational databases. Previously, adding ML using data from Aurora to an application was a very complicated process. First, a data scientist had to build and train a model, then write the code to read data from the database. Next, you had to prepare the data so it can be used by the ML model. Then, you called an ML service to run the model, reformat the output for your application, and finally load it into the application.
Now, with a simple SQL query in Aurora, you can add ML to an enterprise application. When you run an ML query in Aurora using SQL, it can directly access a wide variety of ML models from Amazon SageMaker and Amazon Comprehend. The integration between Aurora and each AWS ML service is optimized, delivering up to 100 times better throughput when compared to moving data between Aurora and SageMaker or Amazon Comprehend without this integration. Because the ML model is deployed separately from the database and the application, each can scale up or scale out independently of the other.
In addition to making ML available in relational databases, combining ML with certain types of non-relational database models can also lead to better predictions. For example, database developers use Amazon Neptune, a purpose-built, high-performance graph database, to store complex relationships between data in a graph data model. You can query these graphs for insights and patterns and apply the results to implement capabilities such as product recommendations or fraud detection.
However, human intuition and analyzing individual queries is not enough to discover the full breadth of insights available from large graphs. ML can help, but as was the case with relational databases it requires you to do a significant amount of heavy lifting upfront to prepare the graph data and then select the best ML model to run against that data. The entire process can take weeks.
To help with this, today we announced the general availability of Amazon Neptune ML to provide database developers access to ML purpose-built for graph data. This integration is powered by SageMaker and uses the Deep Graph Library (DGL), a framework for applying deep learning to graph data. It does the hard work of selecting the graph data needed for ML training, automatically choosing the best model for the selected data, exposing ML capabilities via simple graph queries, and providing templates to allow you to customize ML models for advanced scenarios. The following diagram illustrates this workflow.
And because the DGL is purpose-built to run deep learning on graph data, you can improve accuracy of most predictions by over 50% compared to that of traditional ML techniques.
Machine Learning for data analysts
At re:Invent last year, we announced ML integrated inside Amazon Athena for data analysts. With this integration, you can access more than a dozen built-in ML models or use your own models in SageMaker directly from ad-hoc queries in Athena. As a result, you can easily run ad-hoc queries in Athena that use ML to forecast sales, detect suspicious logins, or sort users into customer cohorts.
Similarly, data analysts also want to apply ML to the data in their Amazon Redshift data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day. These Amazon Redshift users want to run ML on their data in Amazon Redshift without having to write a single line of Python. Today we announced the preview of Amazon Redshift ML to do just that.
Amazon Redshift now enables you to run ML algorithms on Amazon Redshift data without manually selecting, building, or training an ML model. Amazon Redshift ML works with Amazon SageMaker Autopilot, a service that automatically trains and tunes the best ML models for classification or regression based on your data while allowing full control and visibility.
When you run an ML query in Amazon Redshift, the selected data is securely exported from Amazon Redshift to Amazon Simple Storage Service (Amazon S3). SageMaker Autopilot then performs data cleaning and preprocessing of the training data, automatically creates a model, and applies the best model. All the interactions between Amazon Redshift, Amazon S3, and SageMaker are abstracted away and automatically occur. When the model is trained, it becomes available as a SQL function for you to use. The following diagram illustrates this workflow.
Rackspace Technology – a leading end-to-end multicloud technology services company, and Slalom – a modern consulting firm focused on strategy, technology, and business transformation are both users of Redshift ML in preview.
Nihar Gupta, General Manager for Data Solutions at Rackspace Technology says “At Rackspace Technology, we help companies elevate their AI/ML operationsthe seamless integration with Amazon SageMaker will empower data analysts to use data in new ways, and provide even more insight back to the wider organization.”
And Marcus Bearden, Practice Director at Slalom shared “We hear from our customers that they want to have the skills and tools to get more insight from their data, and Amazon Redshift is a popular cloud data warehouse that many of our customers depend on to power their analytics, the new Amazon Redshift ML feature will make it easier for SQL users to get new types of insight from their data with machine learning, without learning new skills.”
Machine Learning for business analysts
To bring ML to business analysts, we launched new ML capabilities in Amazon QuickSight earlier this year called ML Insights. ML Insights uses SageMaker Autopilot to enable business analysts to perform ML inference on their data and visualize it in BI dashboards with just a few clicks. You can get results for different use cases that require ML, such as anomaly detection to uncover hidden insights by continuously analyzing billions of data points, to do forecasting, to predict growth, and other business trends. In addition, QuickSight can also give you an automatically generated summary in plain language (a capability we call auto-narratives), which interprets and describes what the data in your dashboard means. See the following screenshot for an example.
Customers like Expedia Group, Tata Consultancy Services, and Ricoh Company are already benefiting from ML out of the box with QuickSight. These human-readable narratives enable you to quickly interpret the data in a shared dashboard and focus on the insights that matter most.
In addition, customers have also been interested in asking questions of their business data in plain language and receiving answers in near-real time. Although some BI tools and vendors have attempted to solve this challenge with Natural Language Query (NLQ), the existing approaches require that you first spend months in advance preparing and building a model on a pre-defined set of data, and even then, you still have no way of asking ad hoc questions when those questions require a new calculation that wasn’t pre-defined in the data model. For example, the question “What is our year-over-year growth rate?” requires that “growth rate” be pre-defined as a calculation in the model. With today’s BI tools, you need to work with your BI teams to create and update the model to account for any new calculation or data, which can take days or weeks of effort.
Last week, we announced Amazon QuickSight Q. ‘Q’ gives business analysts the ability to ask any question of all their data and receive an accurate answer in seconds. To ask a question, you simply type it into the QuickSight Q search bar using natural language and business terminology that you’re familiar with. Q uses ML (natural language processing, schema understanding, and semantic parsing for SQL code generation) to automatically generate a data model that understands the meaning of and relationships between business data, so you can get answers to your business questions without waiting weeks for a data model to be built. Because Q eliminates the need to build a data model, you’re also not limited to asking only a specific set of questions. See the following screenshot for an example.
Best Western Hotels & Resorts is a privately-held hotel brand with a global network of approximately 4,700 hotels in over 100 countries and territories worldwide. “With Amazon QuickSight Q, we look forward to enabling our business partners to self-serve their ad hoc questions while reducing the operational overhead on our team for ad hoc requests,” said Joseph Landucci, Senior Manager of Database and Enterprise Analytics at Best Western Hotels & Resorts. “This will allow our partners to get answers to their critical business questions quickly by simply typing and searching their questions in plain language.”
Summary
For ML to have a broad impact, we believe it has to get easier to do and easier to apply. Database developers, data analysts, and business analysts who work with databases and data lakes have found it too difficult and involved to extract meaningful insights from their data using ML. To meet the needs of this large and growing group of builders, we’ve added ML capabilities to our purpose-built databases and analytics services so that database developers, data analysts, and business analysts can all use ML more easily without the need to be an ML expert. These capabilities put ML in the hands of every data professional so that they can get the most value from their data.
About the Authors
Swami Sivasubramanian is Vice President at AWS in charge of all Amazon AI and Machine Learning services. His team’s mission is “to put machine learning capabilities in the hands on every developer and data scientist.” Swami and the AWS AI and ML organization work on all aspects of machine learning, from ML frameworks (Tensorflow, Apache MXNet and PyTorch) and infrastructure, to Amazon SageMaker (an end-to-end service for building, training and deploying ML models in the cloud and at the edge), and finally AI services (Transcribe, Translate, Personalize, Forecast, Rekognition, Textract, Lex, Comprehend, Kendra, etc.) that make it easier for app developers to incorporate ML into their apps with no ML experience required.
Previously, Swami managed AWS’s NoSQL and big data services. He managed the engineering, product management, and operations for AWS database services that are the foundational building blocks for AWS: DynamoDB, Amazon ElastiCache (in-memory engines), Amazon QuickSight, and a few other big data services in the works. Swami has been awarded more than 250 patents, authored 40 referred scientific papers and journals, and participates in several academic circles and conferences.
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
Founded in 2008, Dream11 is India’s leading sports-tech startup with a growing base of more than 45 million users playing multiple sports such as fantasy cricket, football, kabaddi, and basketball.
Dream11 uses Amazon Aurora with Amazon ElastiCache to serve 1 million concurrent users within 50ms response time, serving at an average 3 million requests per minute (rpm), which can surge to 3X in a 30-second time span. In this video, we’ll be shedding some light on our architecture, along with our battle plan to handle transactions without locking. We’ll also talk about the features of Aurora and ElastiCache that helped Dream11 to handle 5 million daily active users with 4X growth YoY.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

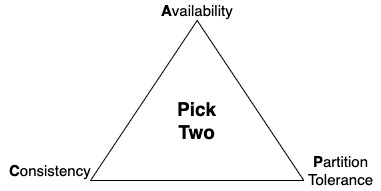


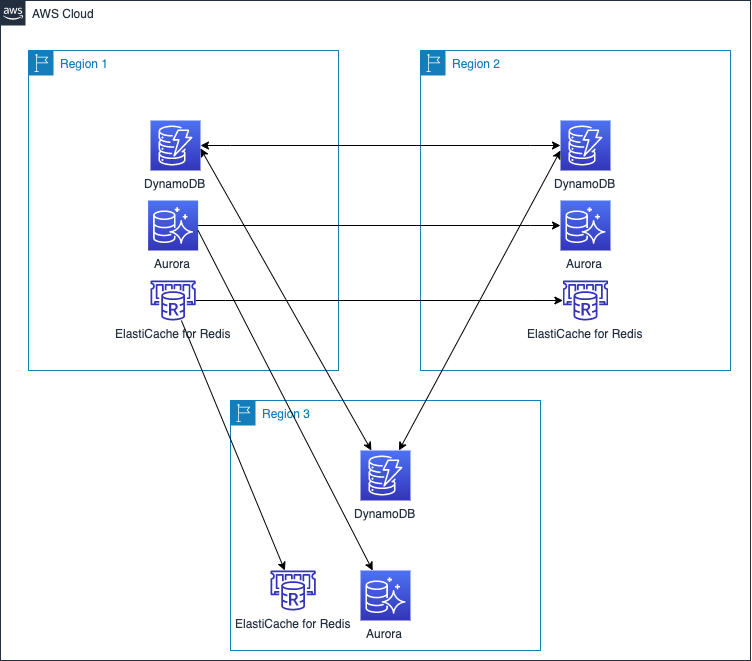


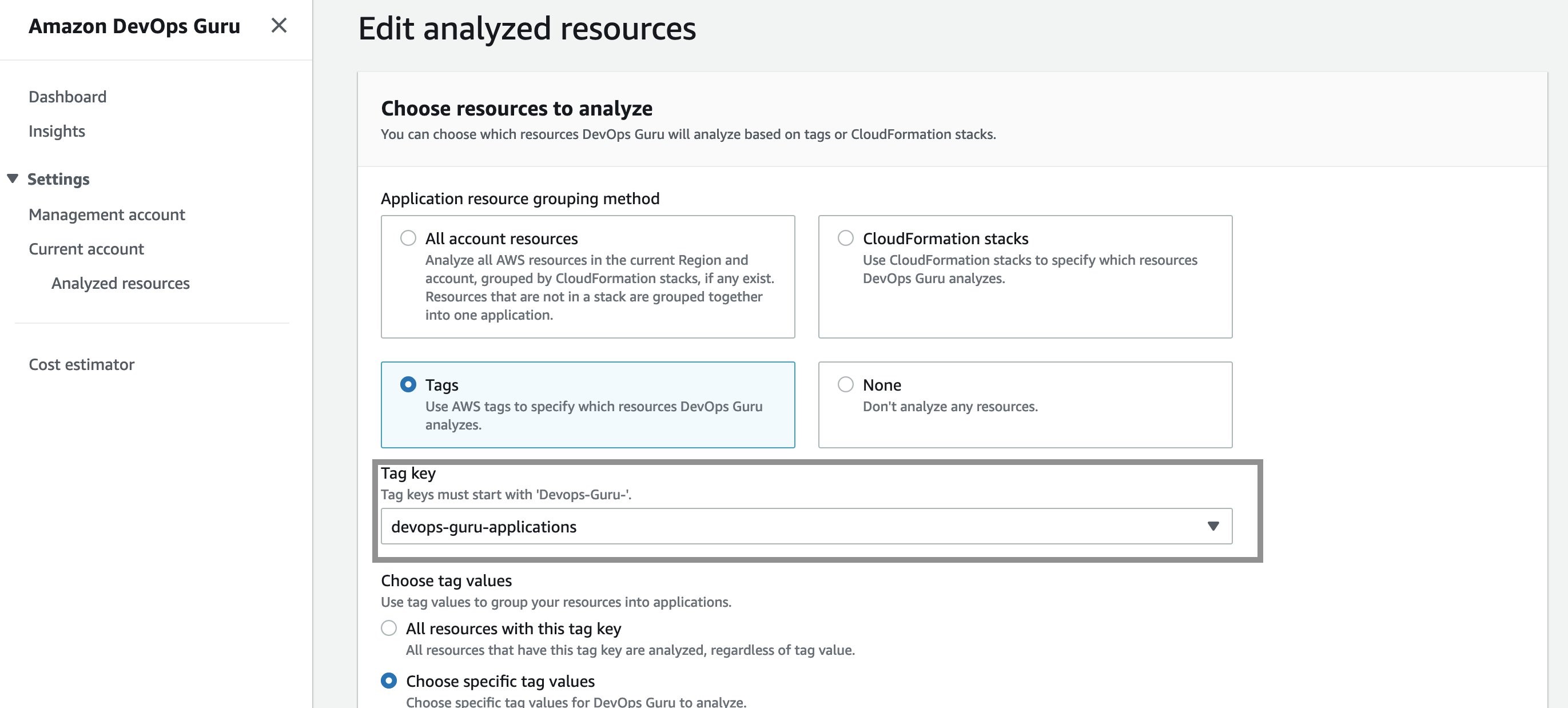

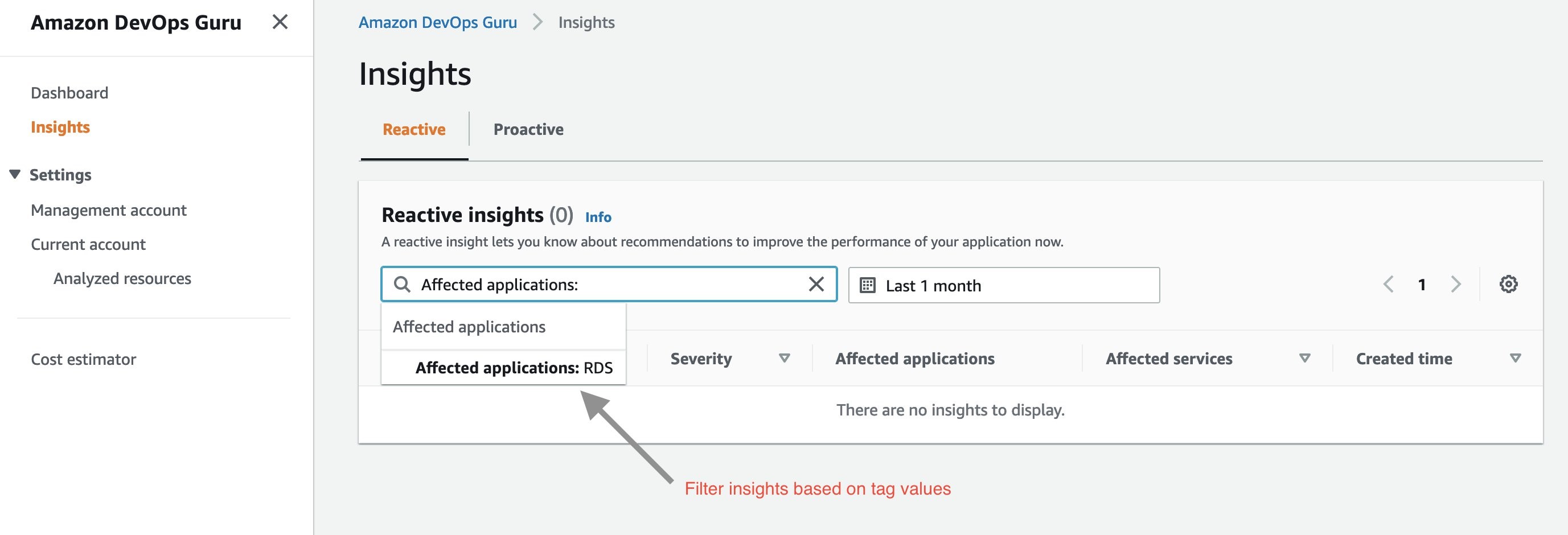

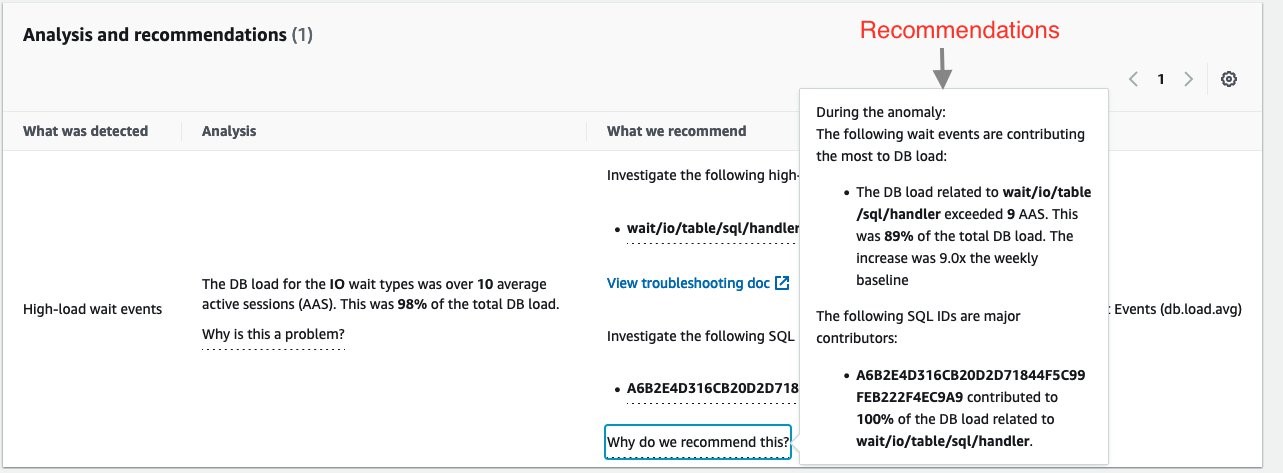






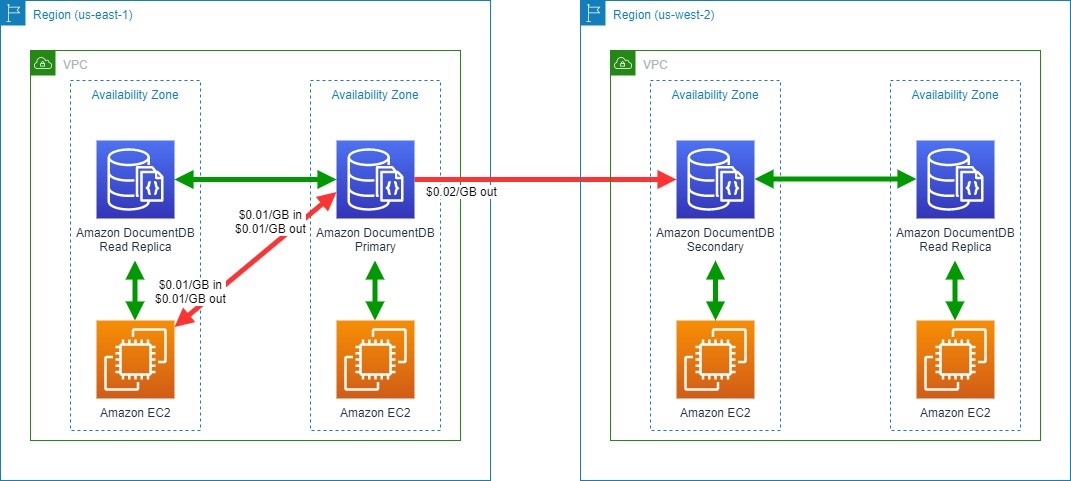

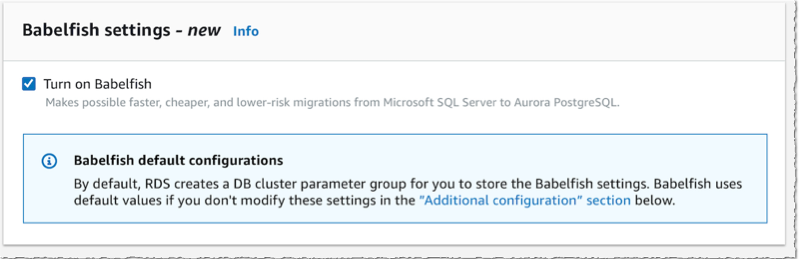

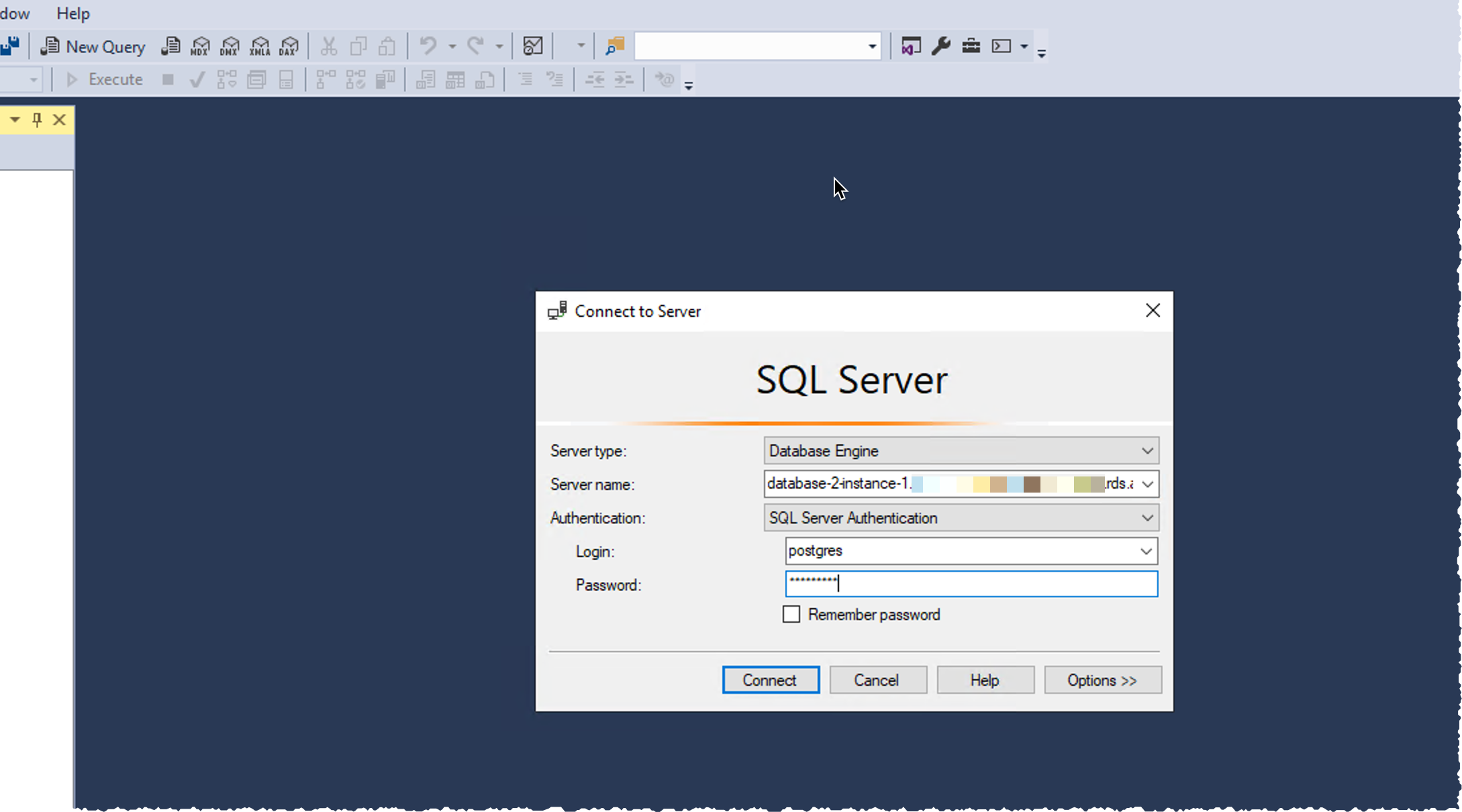

















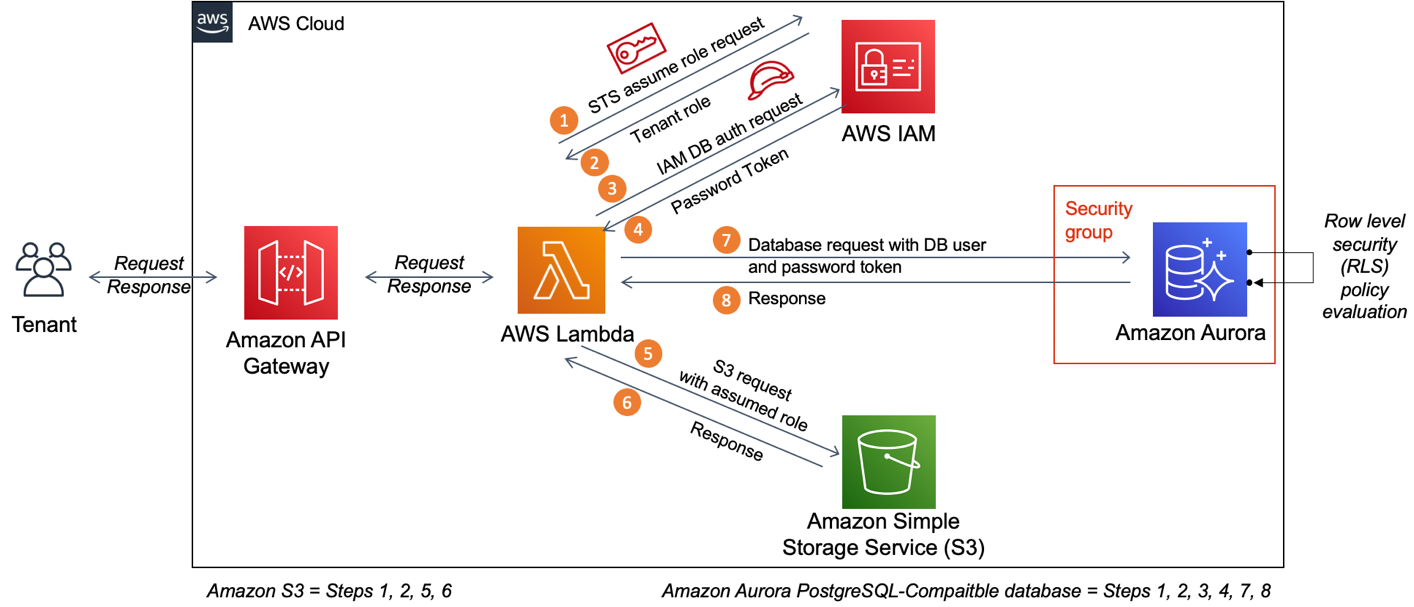


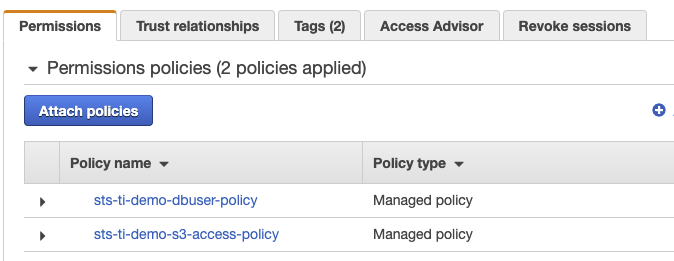
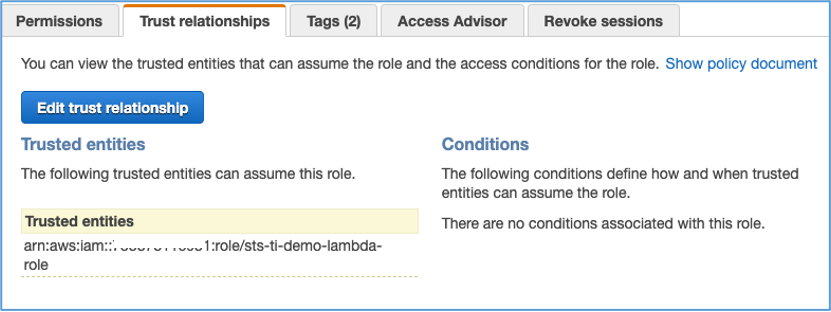
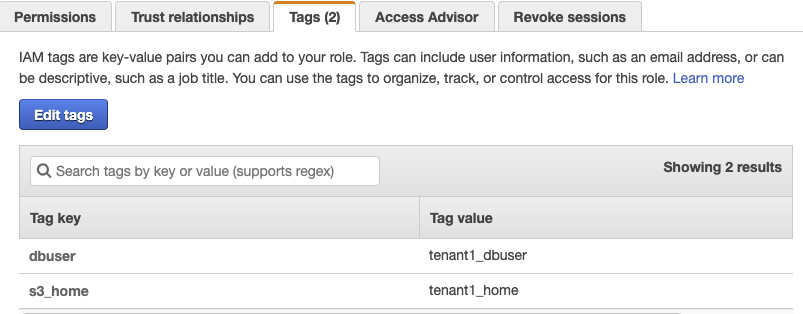
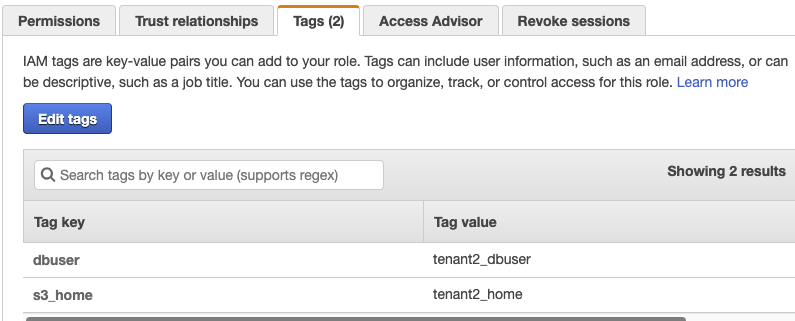







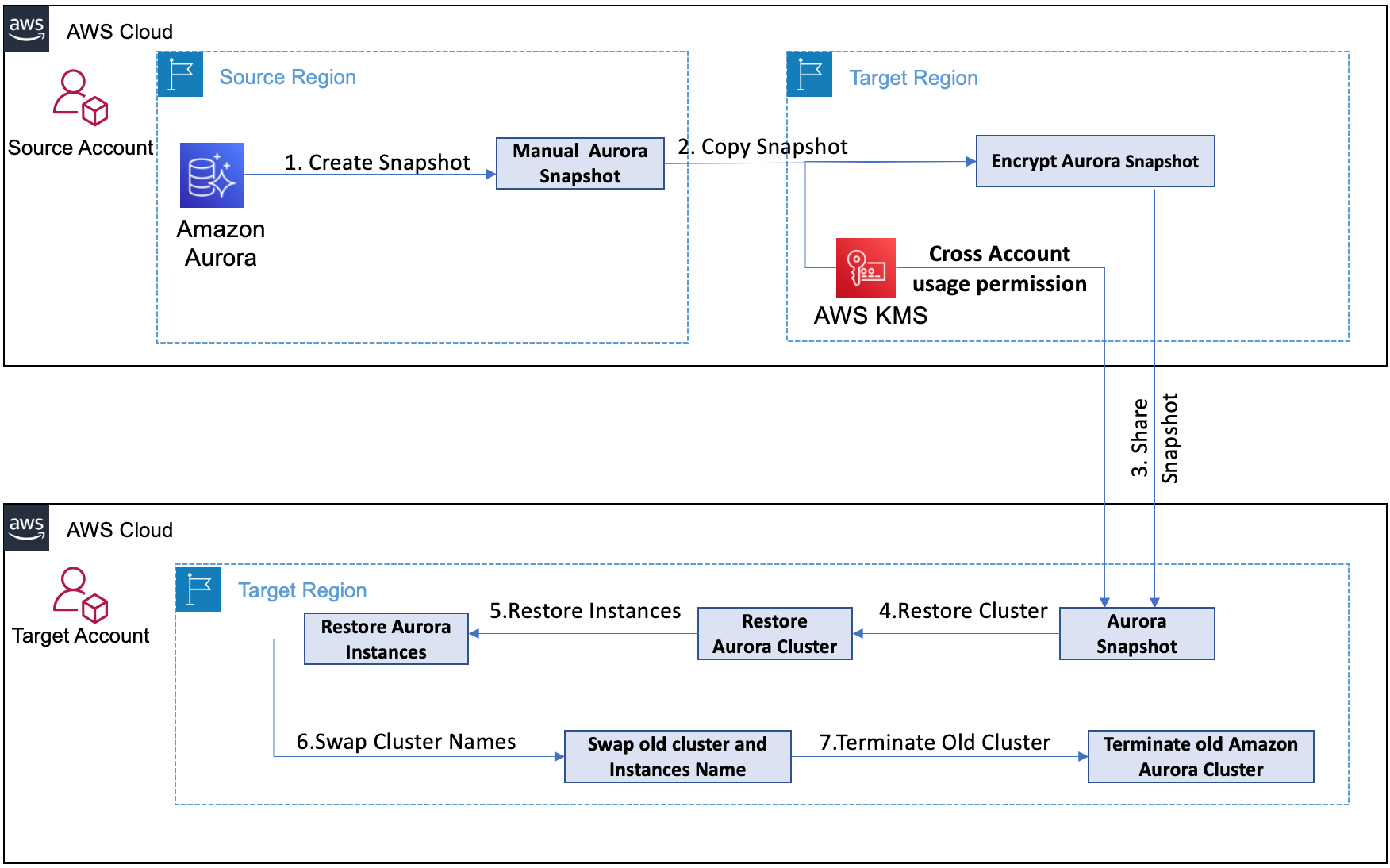
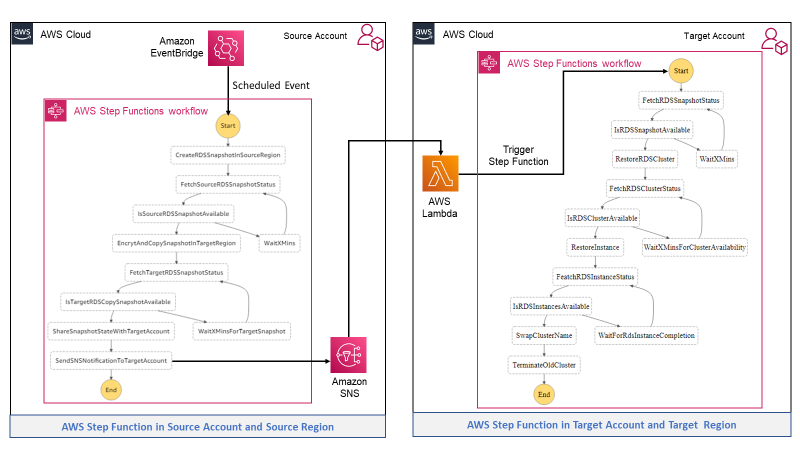



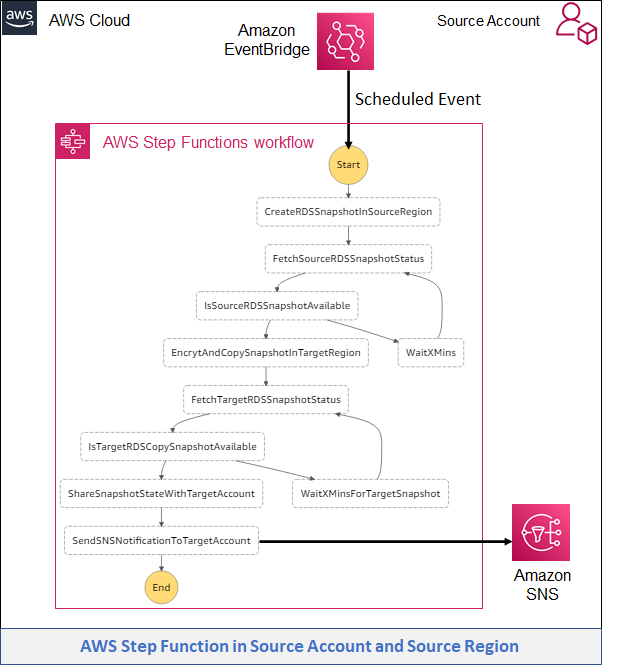



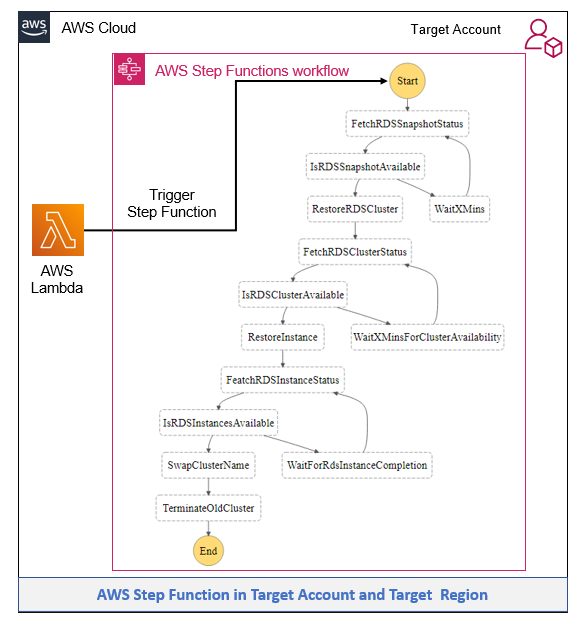




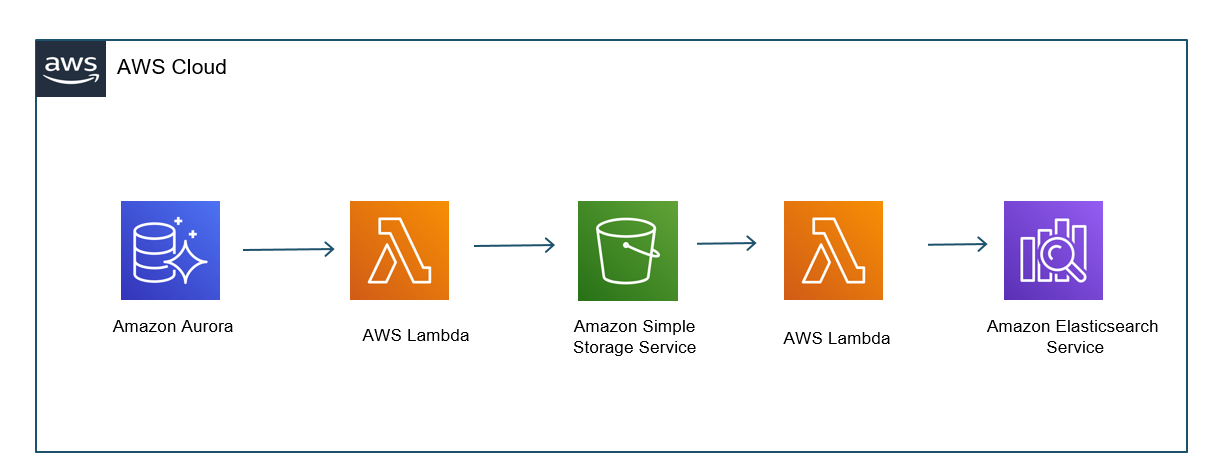
















 BP Yau is an Analytics Specialist Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
BP Yau is an Analytics Specialist Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies. Srikanth Sopirala is a Sr. Specialist Solutions Architect, Analytics at AWS. He is passionate about helping customers build scalable data and analytics solutions in the cloud.
Srikanth Sopirala is a Sr. Specialist Solutions Architect, Analytics at AWS. He is passionate about helping customers build scalable data and analytics solutions in the cloud. Zhouyi Yang is a Software Development Engineer for Amazon Redshift Query Processing team. He’s passionate about gaining new knowledge about large databases and has worked on SQL language features such as federated query and IAM role privilege control. In his spare time, he enjoys swimming, tennis, and reading.
Zhouyi Yang is a Software Development Engineer for Amazon Redshift Query Processing team. He’s passionate about gaining new knowledge about large databases and has worked on SQL language features such as federated query and IAM role privilege control. In his spare time, he enjoys swimming, tennis, and reading. Entong Shen is a Senior Software Development Engineer for Amazon Redshift. He has been working on MPP databases for over 8 years and has focused on query optimization, statistics, and SQL language features such as stored procedures and federated query. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.
Entong Shen is a Senior Software Development Engineer for Amazon Redshift. He has been working on MPP databases for over 8 years and has focused on query optimization, statistics, and SQL language features such as stored procedures and federated query. In his spare time, he enjoys listening to music of all genres and working in his succulent garden.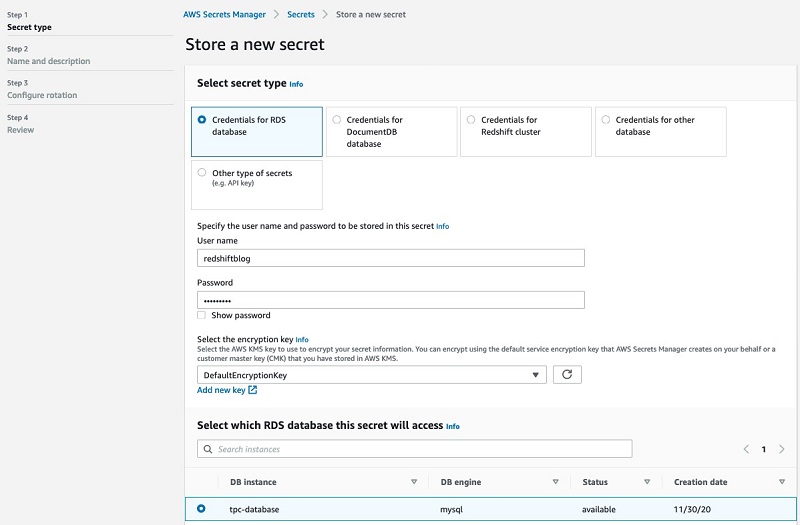
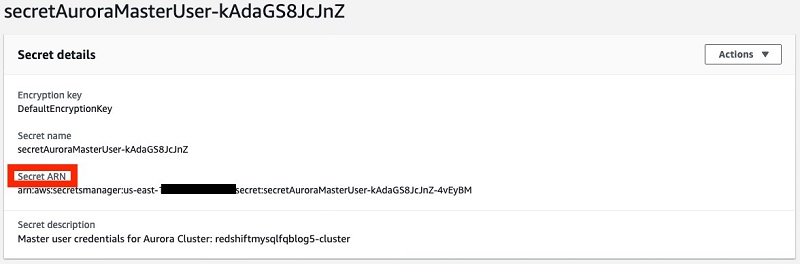




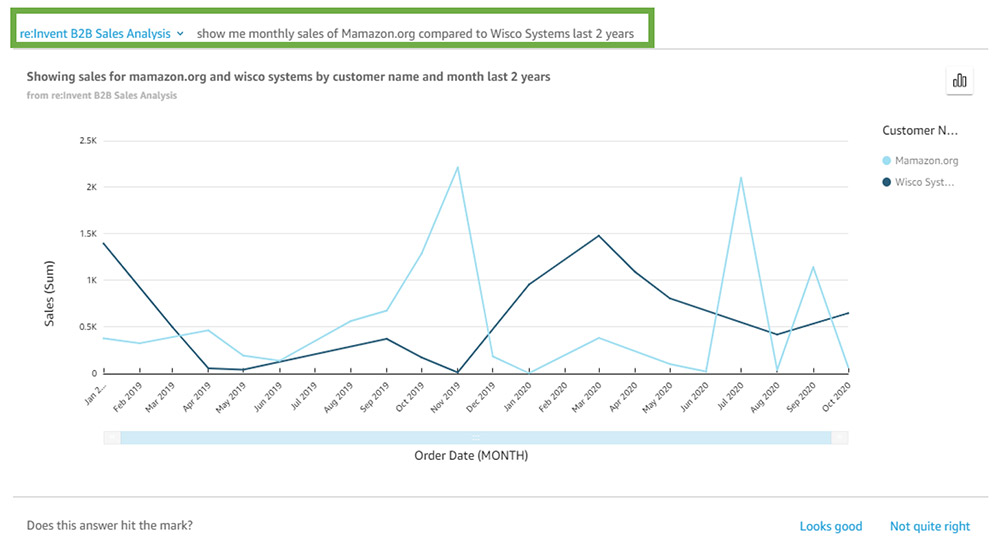

 Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.