Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/icymi-serverless-preinvent-2020/
During the last few weeks, the AWS serverless team has been releasing a wave of new features in the build-up to AWS re:Invent 2020. This post recaps some of the most important releases for serverless developers.
re:Invent is virtual and free to all attendees in 2020 – register here. See the complete list of serverless sessions planned and join the serverless DA team live on Twitch. Also, follow your DAs on Twitter for live recaps and Q&A during the event.

AWS Lambda
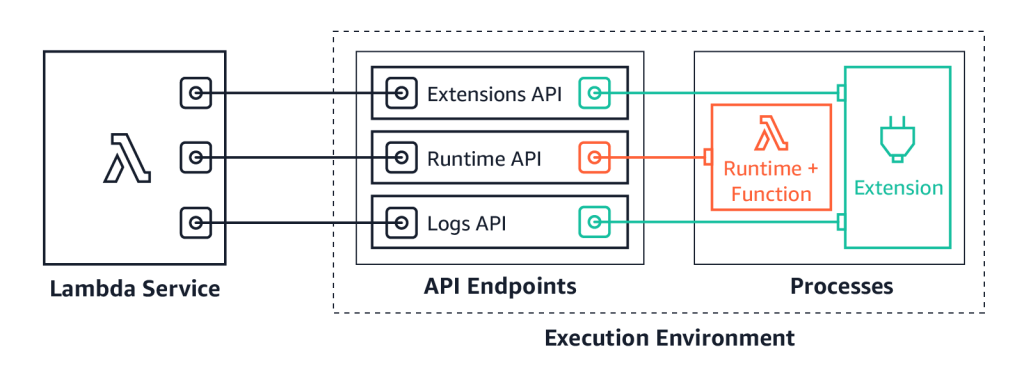
We launched Lambda Extensions in preview, enabling you to more easily integrate monitoring, security, and governance tools into Lambda functions. You can also build your own extensions that run code during Lambda lifecycle events, and there is an example extensions repo for starting development.
You can now send logs from Lambda functions to custom destinations by using Lambda Extensions and the new Lambda Logs API. Previously, you could only forward logs after they were written to Amazon CloudWatch Logs. Now, logging tools can receive log streams directly from the Lambda execution environment. This makes it easier to use your preferred tools for log management and analysis, including Datadog, Lumigo, New Relic, Coralogix, Honeycomb, or Sumo Logic.
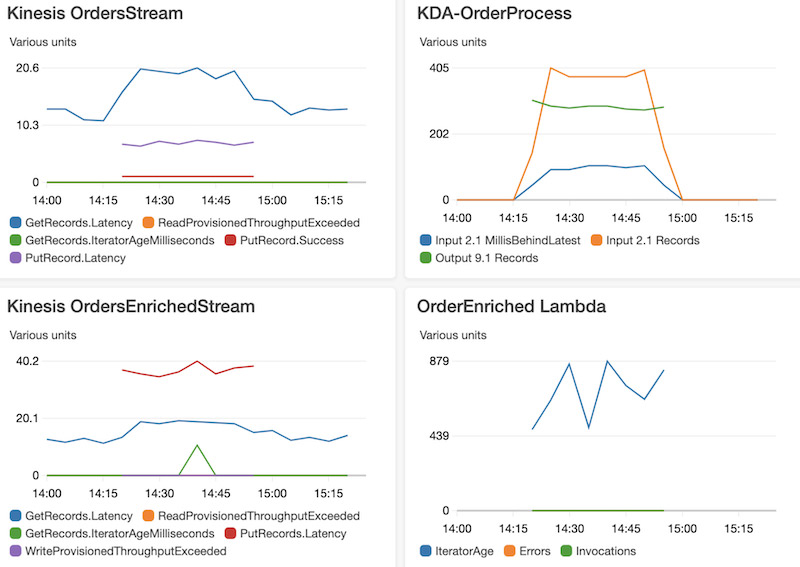
Lambda launched support for Amazon MQ as an event source. Amazon MQ is a managed broker service for Apache ActiveMQ that simplifies deploying and scaling queues. This integration increases the range of messaging services that customers can use to build serverless applications. The event source operates in a similar way to using Amazon SQS or Amazon Kinesis. In all cases, the Lambda service manages an internal poller to invoke the target Lambda function.
We also released a new layer to make it simpler to integrate Amazon CodeGuru Profiler. This service helps identify the most expensive lines of code in a function and provides recommendations to help reduce cost. With this update, you can enable the profiler by adding the new layer and setting environment variables. There are no changes needed to the custom code in the Lambda function.
Lambda announced support for AWS PrivateLink. This allows you to invoke Lambda functions from a VPC without traversing the public internet. It provides private connectivity between your VPCs and AWS services. By using VPC endpoints to access the Lambda API from your VPC, this can replace the need for an Internet Gateway or NAT Gateway.
For developers building machine learning inferencing, media processing, high performance computing (HPC), scientific simulations, and financial modeling in Lambda, you can now use AVX2 support to help reduce duration and lower cost. By using packages compiled for AVX2 or compiling libraries with the appropriate flags, your code can then benefit from using AVX2 instructions to accelerate computation. In the blog post’s example, enabling AVX2 for an image-processing function increased performance by 32-43%.
Lambda now supports batch windows of up to 5 minutes when using SQS as an event source. This is useful for workloads that are not time-sensitive, allowing developers to reduce the number of Lambda invocations from queues. Additionally, the batch size has been increased from 10 to 10,000. This is now the same as the batch size for Kinesis as an event source, helping Lambda-based applications process more data per invocation.
Code signing is now available for Lambda, using AWS Signer. This allows account administrators to ensure that Lambda functions only accept signed code for deployment. Using signing profiles for functions, this provides granular control over code execution within the Lambda service. You can learn more about using this new feature in the developer documentation.
Amazon EventBridge
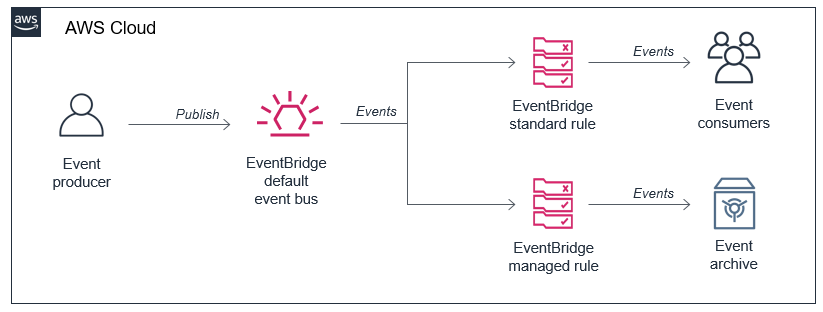
You can now use event replay to archive and replay events with Amazon EventBridge. After configuring an archive, EventBridge automatically stores all events or filtered events, based upon event pattern matching logic. You can configure a retention policy for archives to delete events automatically after a specified number of days. Event replay can help with testing new features or changes in your code, or hydrating development or test environments.
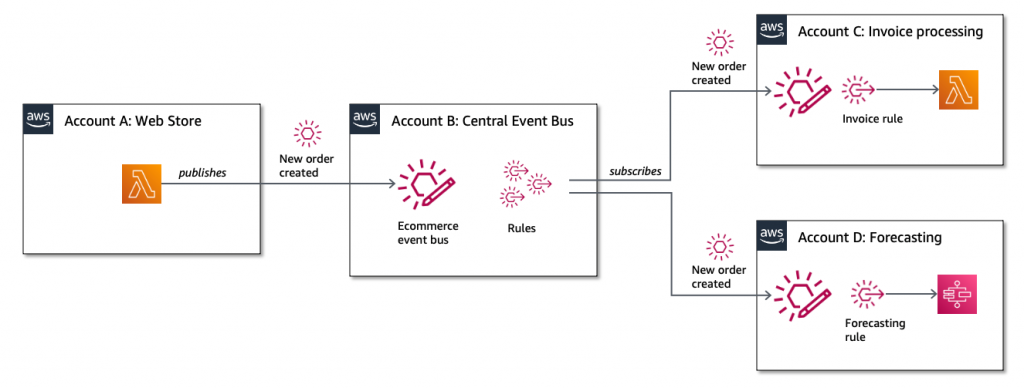
EventBridge also launched resource policies that simplify managing access to events across multiple AWS accounts. This expands the use of a policy associated with event buses to authorize API calls. Resource policies provide a powerful mechanism for modeling event buses across multiple account and providing fine-grained access control to EventBridge API actions.
EventBridge announced support for Server-Side Encryption (SSE). Events are encrypted using AES-256 at no additional cost for customers. EventBridge also increased PutEvent quotas to 10,000 transactions per second in US East (N. Virginia), US West (Oregon), and Europe (Ireland). This helps support workloads with high throughput.
AWS Step Functions
Synchronous Express Workflows have been launched for AWS Step Functions, providing a new way to run high-throughput Express Workflows. This feature allows developers to receive workflow responses without needing to poll services or build custom solutions. This is useful for high-volume microservice orchestration and fast compute tasks communicating via HTTPS.
The Step Functions service recently added support for other AWS services in workflows. You can now integrate API Gateway REST and HTTP APIs. This enables you to call API Gateway directly from a state machine as an asynchronous service integration.
Step Functions now also supports Amazon EKS service integration. This allows you to build workflows with steps that synchronously launch tasks in EKS and wait for a response. In October, the service also announced support for Amazon Athena, so workflows can now query data in your S3 data lakes.
These new integrations help minimize custom code and provide built-in error handling, parameter passing, and applying recommended security settings.
AWS SAM CLI
The AWS Serverless Application Model (AWS SAM) is an AWS CloudFormation extension that makes it easier to build, manage, and maintains serverless applications. On November 10, the AWS SAM CLI tool released version 1.9.0 with support for cached and parallel builds.
By using sam build --cached, AWS SAM no longer rebuilds functions and layers that have not changed since the last build. Additionally, you can use sam build --parallel to build functions in parallel, instead of sequentially. Both of these new features can substantially reduce the build time of larger applications defined with AWS SAM.
Amazon SNS
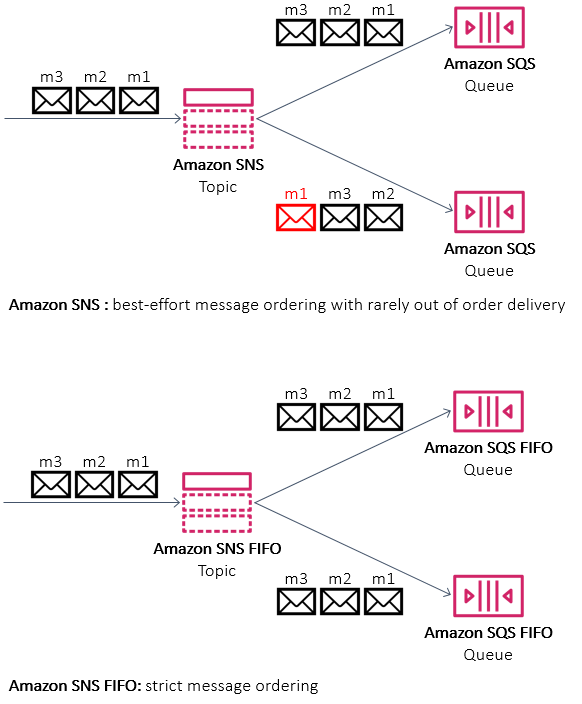
Amazon SNS announced support for First-In-First-Out (FIFO) topics. These are used with SQS FIFO queues for applications that require strict message ordering with exactly once processing and message deduplication. This is designed for workloads that perform tasks like bank transaction logging or inventory management. You can also use message filtering in FIFO topics to publish updates selectively.
AWS X-Ray
X-Ray now integrates with Amazon S3 to trace upstream requests. If a Lambda function uses the X-Ray SDK, S3 sends tracing headers to downstream event subscribers. With this, you can use the X-Ray service map to view connections between S3 and other services used to process an application request.
AWS CloudFormation
AWS CloudFormation announced support for nested stacks in change sets. This allows you to preview changes in your application and infrastructure across the entire nested stack hierarchy. You can then review those changes before confirming a deployment. This is available in all Regions supporting CloudFormation at no extra charge.
The new CloudFormation modules feature was released on November 24. This helps you develop building blocks with embedded best practices and common patterns that you can reuse in CloudFormation templates. Modules are available in the CloudFormation registry and can be used in the same way as any native resource.
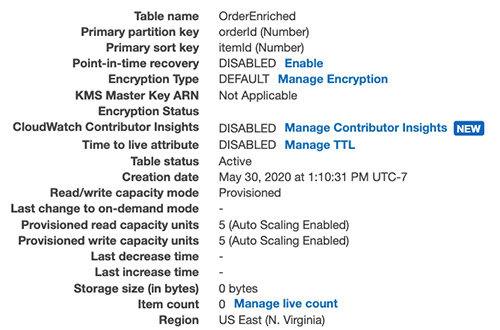
Amazon DynamoDB
For customers using DynamoDB global tables, you can now use your own encryption keys. While all data in DynamoDB is encrypted by default, this feature enables you to use customer managed keys (CMKs). DynamoDB also announced support for global tables in the Europe (Milan) and Europe (Stockholm) Regions. This feature enables you to scale global applications for local access in workloads running in different Regions and replicate tables for higher availability and disaster recovery (DR).
The DynamoDB service announced the ability to export table data to data lakes in Amazon S3. This enables you to use services like Amazon Athena and AWS Lake Formation to analyze DynamoDB data with no custom code required. This feature does not consume table capacity and does not impact performance and availability. To learn how to use this feature, see this documentation.
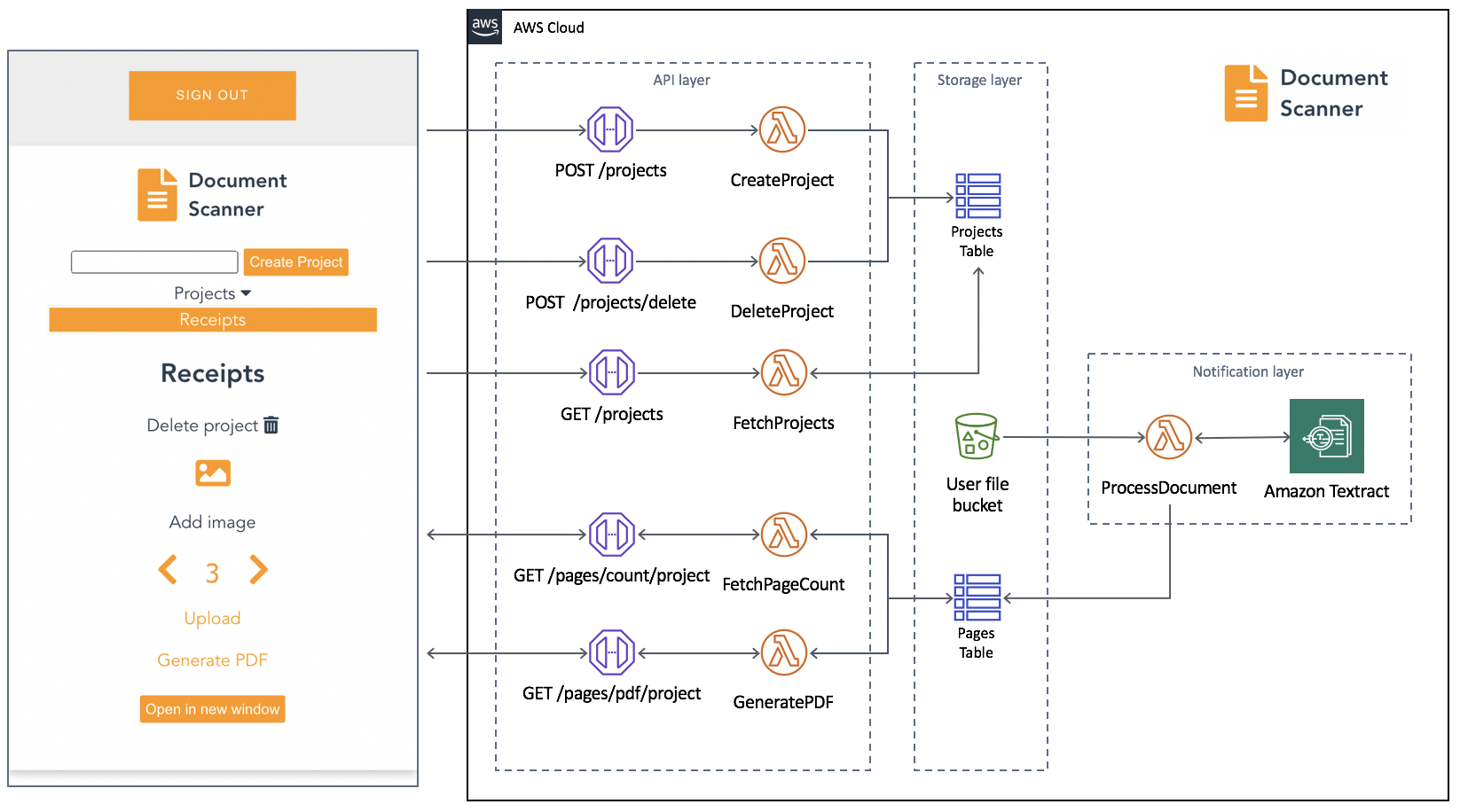
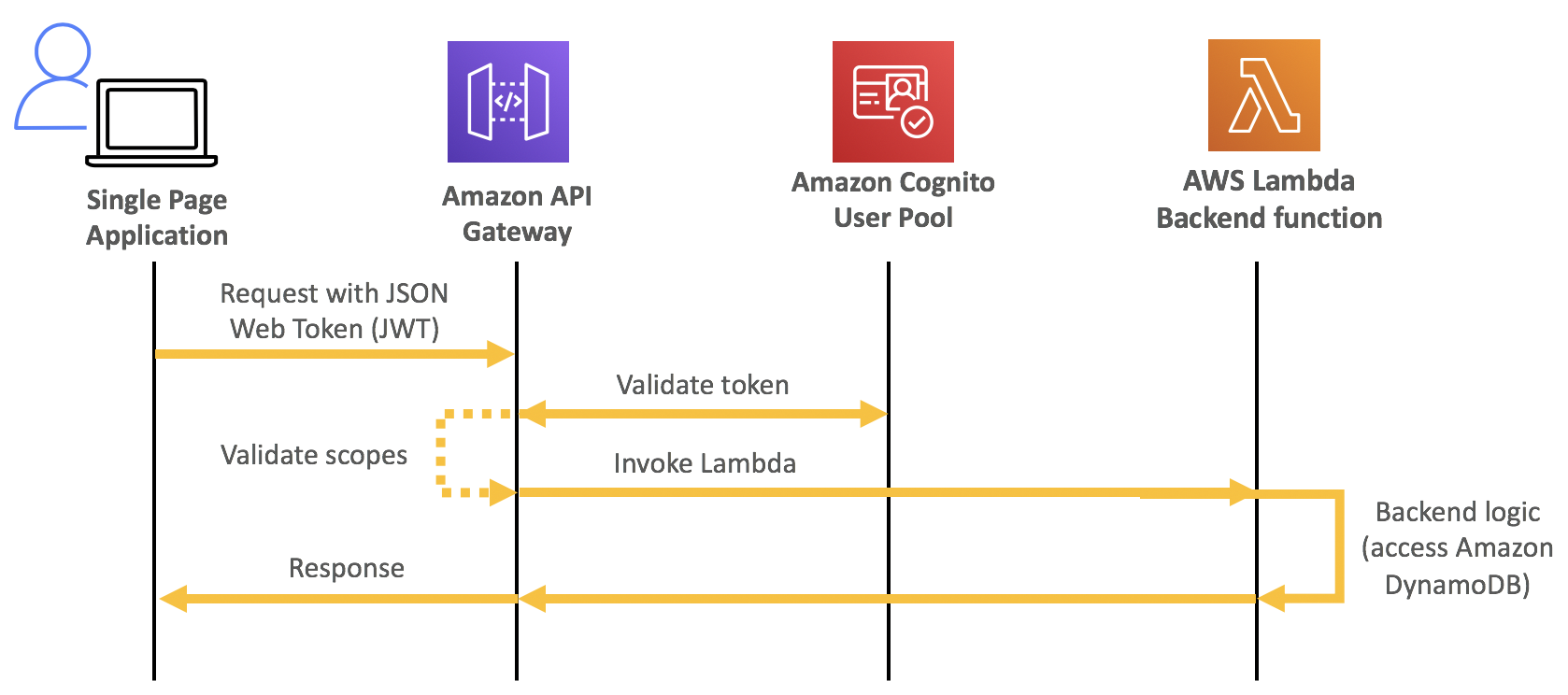
AWS Amplify and AWS AppSync
You can now use existing Amazon Cognito user pools and identity pools for Amplify projects, making it easier to build new applications for an existing user base. AWS Amplify Console, which provides a fully managed static web hosting service, is now available in the Europe (Milan), Middle East (Bahrain), and Asia Pacific (Hong Kong) Regions. This service makes it simpler to bring automation to deploying and hosting single-page applications and static sites.
AWS AppSync enabled AWS WAF integration, making it easier to protect GraphQL APIs against common web exploits. You can also implement rate-based rules to help slow down brute force attacks. Using AWS Managed Rules for AWS WAF provides a faster way to configure application protection without creating the rules directly. AWS AppSync also recently expanded service availability to the Asia Pacific (Hong Kong), Middle East (Bahrain), and China (Ningxia) Regions, making the service now available in 21 Regions globally.
Still looking for more?
Join the AWS Serverless Developer Advocates on Twitch throughout re:Invent for live Q&A, session recaps, and more! See this page for the full schedule.
For more serverless learning resources, visit Serverless Land.

 Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey.
Marco Guerriero, PhD, is a Practice Manager for Emergent Technologies and Intelligence Platform for AWS Professional Services. I love working on ways for emergent technologies such as AI/ML, Big Data, IoT, and Quantum to help businesses across different industry vertical succeed within their innovation journey. Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.
Veronika Megler, PhD, is Principal Data Scientist for Amazon.com Customer Packaging Experience. Until recently, she was the Principal Data Scientist for AWS Professional Services. She enjoys adapting innovative big data, AI, and ML technologies to help companies solve new problems, and to solve old problems more efficiently and effectively. Her work has lately been focused more heavily on economic impacts of ML models and exploring causality.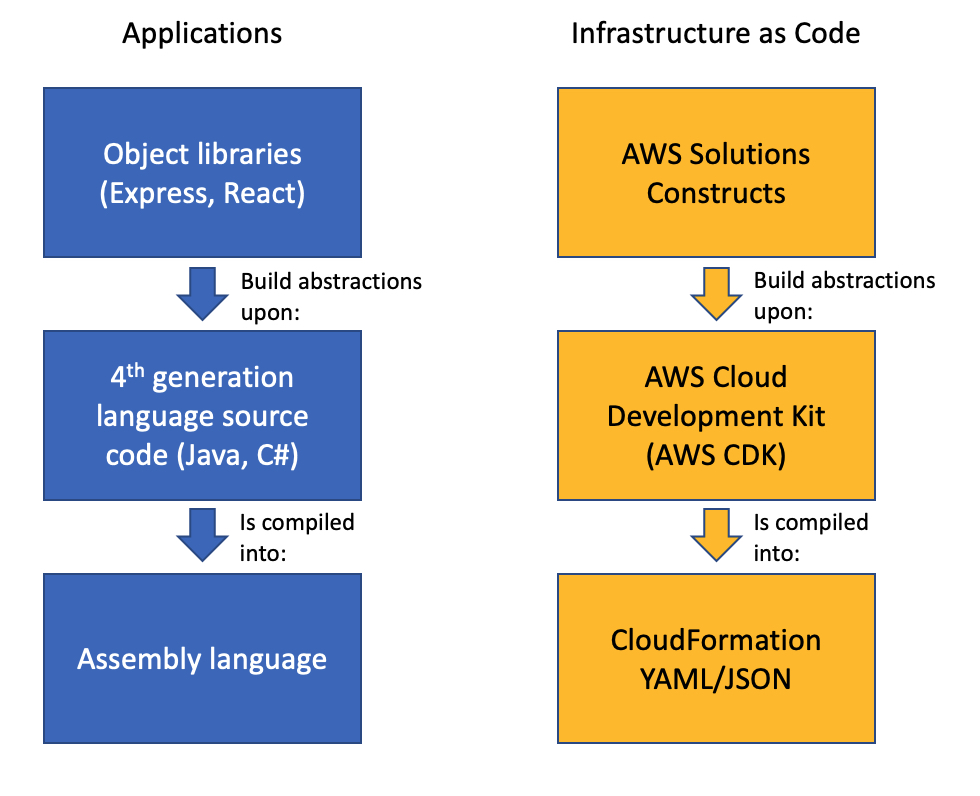



 Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.
Biff Gaut has been shipping software since 1983, from small startups to large IT shops. Along the way he has contributed to 2 books, spoken at several conferences and written many blog posts. He is now a Principal Solutions Architect at AWS working on the AWS Solutions Constructs team, helping customers deploy better architectures more quickly.






 Ram Vittal is an enterprise solutions architect at AWS. His current focus is to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys tennis, photography, and movies.
Ram Vittal is an enterprise solutions architect at AWS. His current focus is to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys tennis, photography, and movies. Akash Bhatia is a Sr. solutions architect at AWS. His current focus is helping customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale.
Akash Bhatia is a Sr. solutions architect at AWS. His current focus is helping customers achieve their business outcomes through architecting and implementing innovative and resilient solutions at scale.
 George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus. Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.
Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.