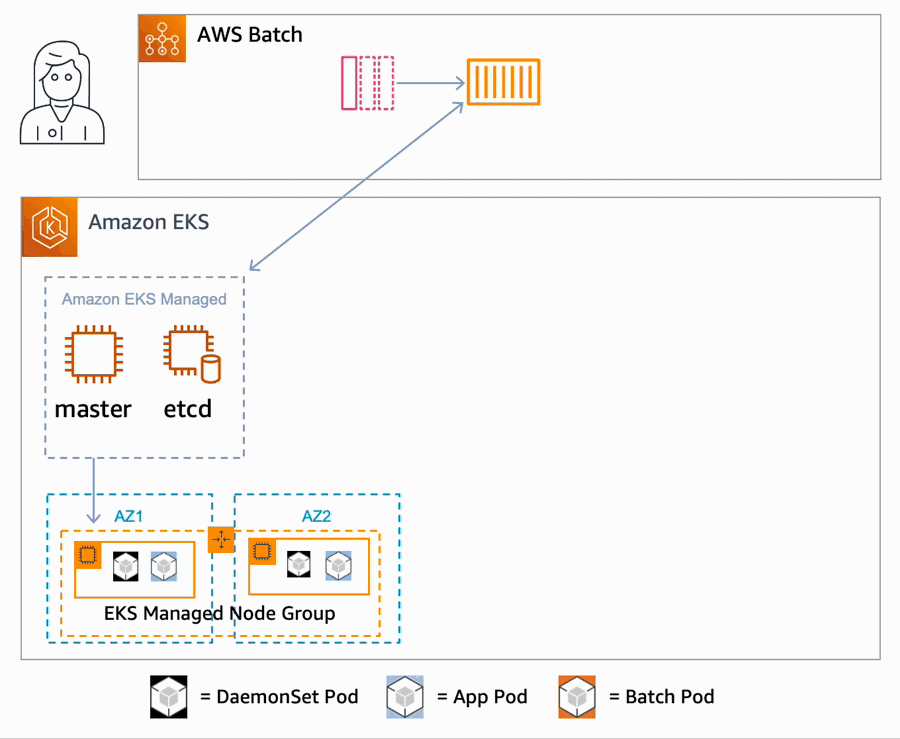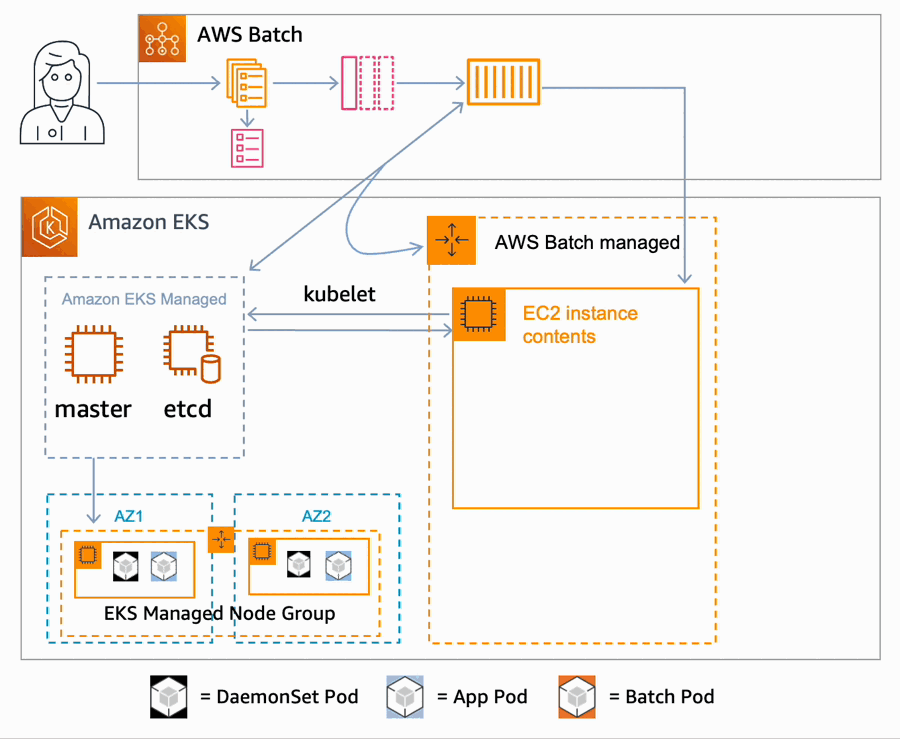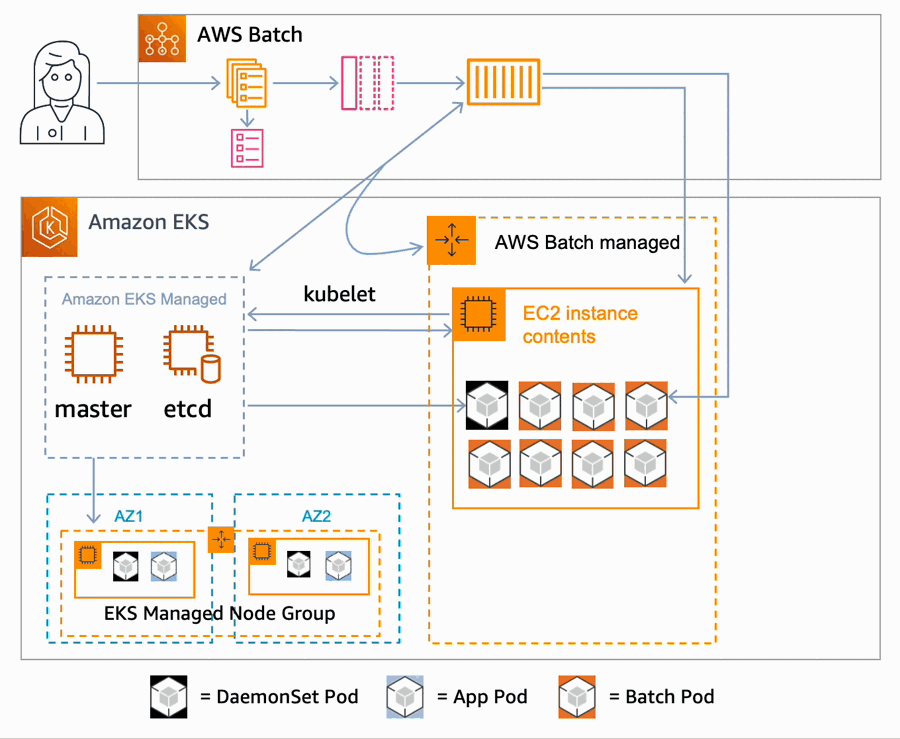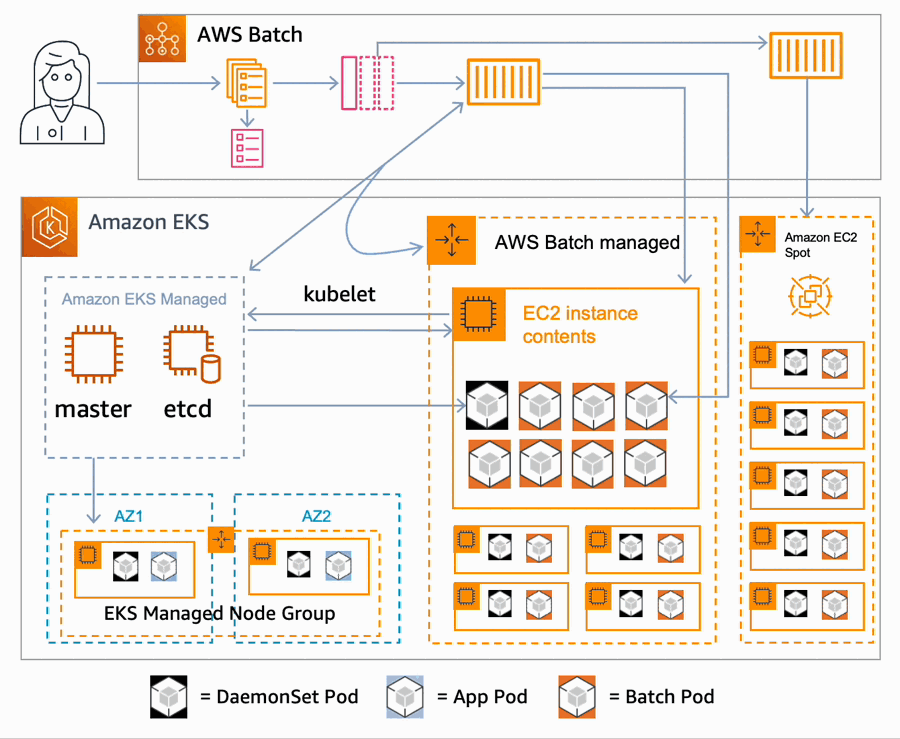
Your privacy considerations are at the core of our compliance work at Amazon Web Services (AWS), and we are focused on the protection of your content while using AWS services.
We are happy to announce that our Fall 2022 SOC 2 Type 2 Privacy report is now available. The report provides a third-party attestation of our system and the suitability of the design of our privacy controls. The SOC 2 Privacy Trust Service Criteria (TSC), developed by the American Institute of Certified Public Accountants (AICPA), establishes the criteria for evaluating controls that relate to how personal information is collected, used, retained, disclosed, and disposed of. For more information about our privacy commitments supporting the SOC 2 Type 2 report, see the AWS Customer Agreement.
The scope of the Fall 2022 SOC 2 Type 2 Privacy report includes information about how we handle the content that you upload to AWS, and how that content is protected across the services and locations that are in scope for the latest AWS SOC reports. AWS customers can download the SOC 2 Type 2 Privacy report through AWS Artifact in the AWS Management Console.
As always, we value your feedback and questions. Feel free to reach out to the compliance team through the AWS Compliance Contact Us page. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to-content, news, and feature announcements? Follow us on Twitter.
As we head into 2023, it’s time to think about lessons from this year and incorporate them into planning for the next year and beyond. At AWS, we continually learn from our customers, who influence the best practices that we share and the security services that we offer.
We heard that you’re looking for more prescriptive guidance, patterns, and trends that AWS Security is seeing in the industry, so I’m happy to share an ebook that I recently authored called Security Predictions in 2023 and Beyond. In this ebook, you’ll learn about what we think is next for the security industry and some high-level pointers on how you can stay ahead.
The last few years has brought rapid acceleration of digital transformation in a short time and forced organizations to manage disruptions to their business, such as the impact of remote work. As security and risk management leaders handle the recovery and renewal phases from the past two years, they must consider forward-looking strategic planning assumptions when allocating budget, selecting services, and prioritizing employee effort. We are now at an interesting point in time where it will take the right mix of technology and humans to shape the future of cybersecurity.
I encourage you to read through the ebook and consider how these predictions could influence strategic planning for your security program. Drop us your feedback in the comments or reach out to your account team with questions. You can also follow @AWSSecurityInfo for the latest from AWS Security, and you can find me at @mosescj58.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
The AWS Region in Aragón, Spain, is now open. The official name is Europe (Spain), and the API name is eu-south-2. You can start using it today to deploy workloads and store your data in Spain.
The AWS Europe (Spain) Region has three Availability Zones (AZ) that you can use to reliably spread your applications across multiple data centers. Each Availability Zone is a fully isolated partition of AWS infrastructure that contains one or more data centers.
Availability Zones are separate and distinct geographic locations with enough distance to reduce the risk of a single event affecting the availability of the Region but near enough for business continuity for applications that require rapid failover and synchronous replication. This gives you the ability to operate production applications that are more highly available, fault-tolerant, and scalable than would be possible from a single data center.
AWS in Spain The new AWS Europe (Spain) Region is a natural progression for AWS to support the tens of thousands of customers on the Iberian Peninsula. The Region will support our customers’ most mission-critical workloads by providing lower latency to end users across Iberia and meeting data residency needs (now customers can store their data in Spain).
In addition to the new Region in Spain, AWS currently has four Amazon CloudFront edge locations available in Madrid, Spain. And since 2016, customers can benefit from AWS Direct Connect locations to establish private connectivity between AWS and their data centers and offices. The Region in Spain also offers low-latency connections to other AWS Regions in the area, as shown in the following chart:
AWS also has had offices in Madrid since 2014 and in Barcelona since 2018 and has a broad network of local partners. In addition to expanding infrastructure, AWS continues to make investments in education initiatives, training, and start-up enablement to support Spain’s digital transformation and economic development plans.
AWS Activate – Since 2013, this program has given Spanish start-ups access to guidance and one-on-one time with AWS experts, along with web-based training, self-paced labs, customer support, offers from third parties, and up to $100,000 in credits to use AWS services.
AWS Educate and AWS Academy – AWS has trained over one hundred thousand individuals in Spain in cloud skills since 2017. These programs provide higher-education institutions, educators, and students with cloud computing courses and certifications. AWS Academy has delivered courses for institutions such as ESADE, IE, UNIR, and others.
AWS re/Start – AWS re/Start is a skills development and job training program that aims to build local talent by providing AWS Cloud skills development and job opportunities at no cost to learners who are unemployed or are members of under-represented communities in Spain. In November 2020, AWS launched this program in Spain in collaboration with Cámara de Comercio de Madrid and in 2021 in collaboration with Universidad of Granada.
AWS GetIT – AWS knows that having a diverse workforce gives organizations a better understanding of customers’ needs and is key to unlocking ideas and speeding up innovation. AWS supports many programs focused on diversity and launched AWS GetIT in Spain across 11 schools to introduce young students (ESO—Educación Secundaria Obligatoria—students) to cloud computing and inspire them to consider a career in technology.
Sustainability is also very important for AWS. In 2019, Amazon and Global Optimism co-founded The Climate Pledge, a commitment to reach net-zero carbon emissions by 2040—10 years ahead of the Paris Agreement. That is why in Spain, Amazon and AWS currently have two operational renewable energy projects delivering clean energy into the Spanish grid to support the AWS Europe (Spain) Region and Amazon’s logistics network in the country.
Amazon and AWS have announced 14 more projects, currently in development, that will come online from 2022 to 2024. The 16 projects in Spain will add 1.5 gigawatts of renewable energy to the Spanish grid. This is enough to power over 850,000 average Spanish homes. Learn more about AWS sustainability in Spain.
AWS Customers in Spain We have many amazing customers in Spain that are doing incredible things with AWS, for example:
LactApp is a Spanish start-up that was created out of the vision that every mother should have a breastfeeding and motherhood expert in their pocket. LactApp uses AWS services to build their video-on-demand capability that allows experts to upload their content and process the videos, and they make it available for their over 4,000 end users automatically.
Glovo is one of the biggest companies in the food delivery industry, born in Barcelona, Spain. The Glovo app is available in 25 countries with over 150,000 restaurants. Glovo receives over 2 TB of data daily from all the usage of their customers. Using AWS, Glovo built a data lake that allows them to store data securely and access it when they need it.
Madrid-based Savana helps healthcare providers unlock the value of their electronic medical records (EMRs) for research. They operate one of the largest artificial intelligence–enabled, multicentric research networks in the world, with over 180 hospitals across 15 countries. They use AWS to process billions of EMRs and data points to run machine learning algorithms to investigate disease prediction and treatment.
Available Now The new Region in Spain is ready to support your business. You can find a detailed list of the services available in this Region on the AWS Regional Service List.
With this launch, AWS now spans 93 Availability Zones within 29 geographic Regions around the world. We have also announced plans for 18 more Availability Zones and six more AWS Regions in Australia, Canada, India, Israel, New Zealand, and Thailand.
For more information on our global infrastructure, upcoming Regions, and the custom hardware we use, visit the Global Infrastructure page.
The AWS Heroes program celebrates and recognizes builders who are making an impact within the global AWS community. As we come to the end of 2022, the program is recognizing seven individuals who are passionate about AWS, and focused on organizing and speaking at community events, mentoring, authoring content, and even preserving wildlife. Please meet the newest AWS Heroes!
Ed Miller – San Jose, USA
Machine Learning Hero Ed Miller is a Senior Principal Engineer at Arm where he leads technical engagements with strategic partners around machine learning and IoT. He also volunteers with the BearID Project, developing open source, machine learning solutions for non-invasive wildlife monitoring. Ed is working on a human-in-the-loop machine learning application for identifying the famous fat bears on Explore.org’s Brooks Falls Brown Bears webcam. The serverless application, Bearcam Companion, is built using AWS Amplify and various AWS AI services. You can read about it and other projects on Ed’s blogs at dev.to, Hashnode, and the BearID Project.
Jones Zachariah Noel N – Karnataka, India
Serverless Hero Jones Zachariah Noel N is a Senior Developer Advocate in the Developer Relations ecospace at Freshworks, and has previously worked as a Cloud Architect – Serverless where he was focused on designing and architecting solutions built with the AWS Serverless tech stack. Jones is a tech enthusiast who loves to interact with the community, which has helped him learn and share his knowledge, as he also co-organizes AWS User Group Bengaluru. He writes regularly about AWS Serverless and talks about new features and different Serverless services, which can help you level up your Serverless applications’ architecture on dev.to. Additionally, Jones co-runs a YouTube podcast called The Zacs’ Show Talking AWS about DevOps and Serverless practices along with another Zack whom he met through the AWS Community Builder program.
Luciano Mammino – Dublin, Ireland
Serverless Hero Luciano Mammino is a full-stack web developer and a senior cloud architect at fourTheorem. He is a co-author of the book Node.js Design Patterns and co-host of the podcast AWS Bites. Luciano is one of the creators of Middy, one of the most adopted middleware-based Node.js frameworks for AWS Lambda. Through fourTheorem, he also contributes to several other open-source projects in the serverless space, such as SLIC Watch for automated observability. Finally, he is also an eager tech speaker who has evangelized the adoption of serverless from the very early days.
Madhu Kumar – Budapest, Hungary
Container Hero Madhu Kumar is a Principal Cloud Architect and Product Owner (Container Services) working for T-Systems International with over 22 years of IT experience working across multiple regions, including Asia, the Middle East, the US, Europe, and the UK. He is an AWS User Group Leader, DevSecCon Chapter Leader for Hungary, DevOps Institute Brand Ambassador and Chapter Leader, HashiCorp User Group Leader for Hungary, and formally an AWS Community Builder. Madhu is passionate about organizing meetups, driving and assisting global and local communities to come together, and sharing knowledge. He is also a regular speaker at container conferences and AWS events.
Paweł Zubkiewicz – Wroclaw, Poland
Serverless Hero Paweł Zubkiewicz works as a Cloud Architect and Consultant who helps companies build products on AWS. In 2018, Paweł started Serverless Polska, an online community for serverless enthusiasts where he shares his technical knowledge and introduces serverless to a broader audience. Shortly after, he began publishing a newsletter about serverless and AWS cloud. He continuously shares his expertise and insights with the Polish-speaking community to this day, both online and as a conference speaker. Before becoming an AWS Hero, he was an AWS Community Builder since 2020, and shares serverless tutorials on dev.to. He lives in Wroclaw, Poland with his wife and his dog named Pixel. He’s an avid mountain biker and a traveler.
Rossana Suarez – Resistencia, Argentina
Container Hero Rossana Suarez is a DevOps consultant and trainer. She started the ‘295devops’ channel to share her expertise about various DevOps topics, and to help enthusiasts get into the field more easily and with more motivation. She consults with teams of developers and DevOps engineers to help them improve their existing processes for automations, CI/CD, containerization, and orchestration. Rossana presents at Women in Technology’s local meetups to encourage more women to pursue careers in DevOps, is a volunteer with AWS Girls Argentina, and is a frequent speaker about container technologies at AWS Community Days, ContainersDays, and more.
TaeSeong Park – Seoul, Korea
Community Hero TaeSeong Park is a front-end engineer and Unity mobile developer working at IDEASAM. He’s spoken at major AWSKRUG community events, and has led hands-on labs specific to a front-end and mobile app on AWS Amplify. For the past 5 years, TaeSeong has been an organizer of the AWSKRUG Group and was an AWS Community Builder for 2-years. Not only he did he organize the AWSKRUG Gudi meetup, but he’s been a speaker and supporter of other AWSKRUG meetups.
It’s now just two weeks to AWS re:Invent in Las Vegas, and the pace is picking up, both here on the News Blog, and throughout AWS as everyone get ready for the big event! I hope you get the chance to join us, and have shared links and other information at the bottom of this post. First, though, let’s dive straight in to this week’s review of news and announcements from AWS.
Last Week’s Launches As usual, let’s start with a summary of some launches from the last week that I want to remind you of:
New Switzerland Region – First and foremost, AWS has opened a new Region, this time in Switzerland. Check out Seb’s post here on the News Blog announcing the launch.
New AWS Resource Explorer – if you’ve ever spent time searching for specific resources in your AWS account, especially across Regions, be sure to take a look at the new AWS Resource Explorer, described in this post by Danilo. Once enabled, indexes of the resources in your account are built and maintained (you have control over which resources are indexed). Once the indexes are built, you can issue queries to more quickly arrive at the required resource without jumping between different Regions and service dashboards in the Management Console.
New models for Amazon SageMaker JumpStart – Two new state-of-the-art models have been released for Amazon SageMaker JumpStart. SageMaker JumpStart provides pretrained, open-source models covering a wide variety of problem types that help you get started with machine learning. The first new model, Bloom, can be used to complete sentences or generate long paragraphs of text in 46 different languages. The second model, Stable Diffusion, generates realistic images from given text. Find out more about the new models in this What’s New post.
Other AWS News Some other news items you may want to explore:
AWS Open Source News and Updates – This blog is published each week, and Installment 135 is now available, highlighting new open-source projects, tools, and demos from the AWS community.
Upcoming AWS Events AWS re:Invent 2022 – As I noted at the top of this post, we’re now just two weeks away from the event! Join us live in Las Vegas November 28–December 2 for keynotes, opportunities for training and certification, and over 1,500 technical sessions. If you are joining us, be sure to check out the re:Invent 2022 Attendee Guides, each curated by an AWS Hero, AWS industry team, or AWS partner.
If you can’t join us live in Las Vegas, be sure to join us online to watch the keynotes and leadership sessions. My cohosts and I on the AWS on Air show will also be livestreaming daily from the event, chatting with service teams and special guests about all the launches and other announcements. You can find us on Twitch.tv (we’ll be on the front page throughout the event), the AWS channel on LinkedIn Live, Twitter.com/awsonair, and YouTube Live.
And one final update for the event – if you’re a .NET developer, be sure to check out the XNT track in the session catalog to find details on the seven breakouts, three chalk talks, and the workshop we have available for you at the conference!
Check back next Monday for our last week in review before the start of re:Invent!
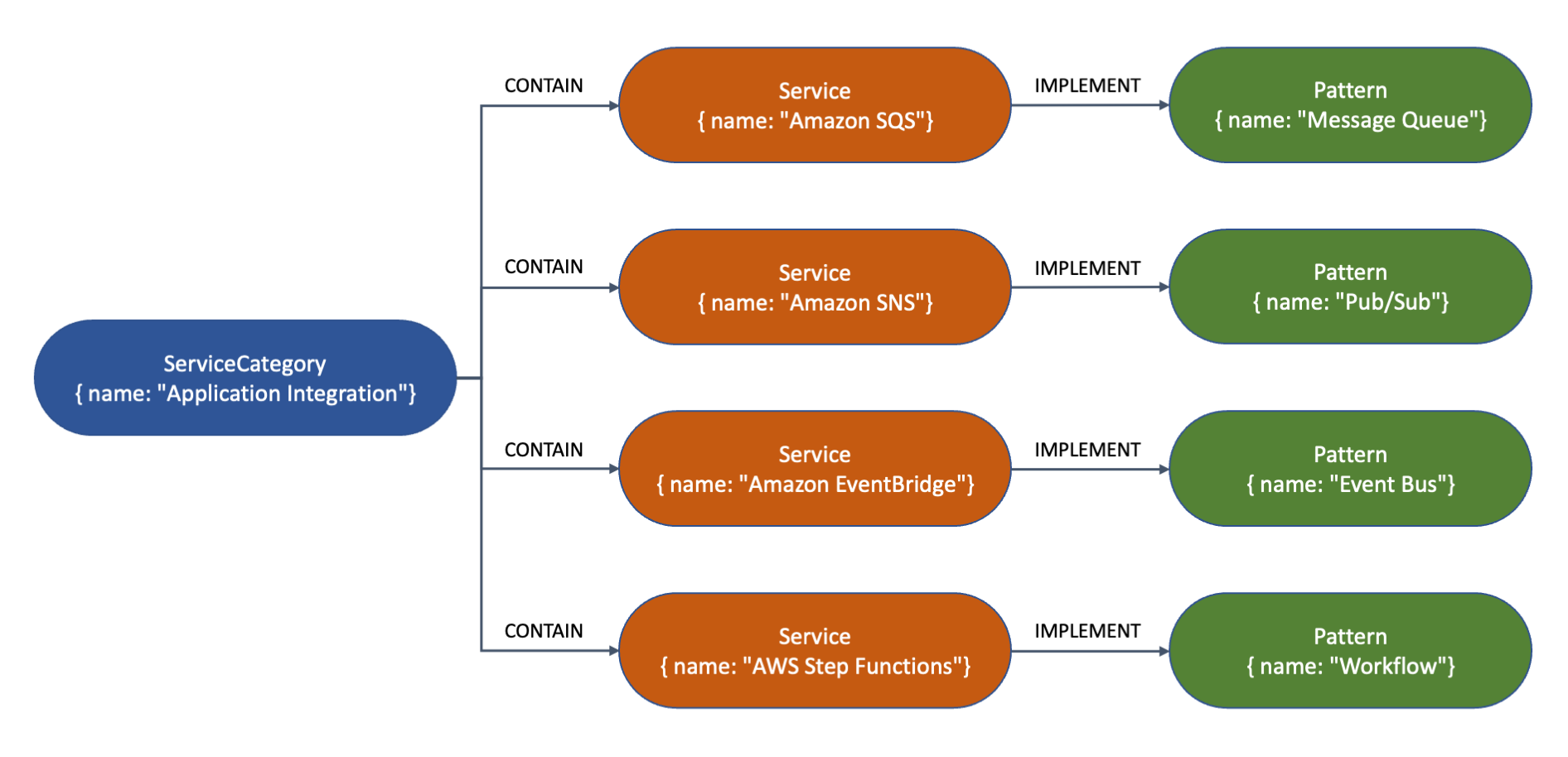
Today, we are announcing Amazon EventBridge Scheduler. This is a new capability from Amazon EventBridge that allows you to create, run, and manage scheduled tasks at scale. With EventBridge Scheduler, you can schedule one-time or recurrently tens of millions of tasks across many AWS services without provisioning or managing underlying infrastructure.
Previously, many customers used commercial off-the-shelf tools or built their own scheduling capabilities. This can increase application complexity, slow application development, and increase costs, which are magnified at scale. Most of these solutions are limited in what services they can trigger and create complexity in managing concurrency limitations of invoked targets that can affect application performance.
When to use EventBridge Scheduler?
For example, consider a company that develops a task management system. One feature that the application provides is that users can add a reminder for a task and be reminded by email one week before, two days before, or on the day of the task due date. You can automate the creation of all the schedules with EventBridge Scheduler, create the task for each of the reminders, and send it to Amazon SNS to send the notifications.
Or consider a large organization, like a supermarket, with thousands of AWS accounts and tens of thousands of Amazon EC2 instances. These instances are used in different parts of the world during business hours. You want to make sure that all the instances are started before the stores open and terminated after the business hours to reduce costs as much as possible. You can use EventBridge Scheduler to start and stop all the thousands of instances and also respect time zones.
SaaS providers can also benefit from EventBridge Scheduler, as now they can more easily manage all the different scheduled tasks that their customers have. For example, consider a SaaS provider with a subscription model for your customers paying a monthly or annual fee. You want to ensure that their license key is valid until the end of their current billing period. With Scheduler, you can create a schedule that removes the access to the service when the billing period is over, or when the user cancels their subscription. Also, you can create a series of emails that let your customer knows that their license is expiring so they can purchase a renewal.
Use cases for EventBridge Scheduler are diverse, from simplifying new feature development to improving your infrastructure operations.
How does EventBridge Scheduler work?
With EventBridge Scheduler, you can now create single or recurrent schedules that trigger over 200 services with more than 6,000 APIs. EventBridge Scheduler allows you to configure schedules with a minimum granularity of one minute.
EventBridge Scheduler provides at-least-once event delivery to targets, and you can create schedules that adjust to different delivery patterns by setting the window of delivery, the number of retries, the time for the event to be retained, and the dead letter queue (DLQ). You can learn more about each configuration from the Scheduler User Guide.
Time window allows you to start a schedule within a window of time. This means that the scheduled tasks are dispersed across the time window to reduce the impact of multiple requests on downstream services.
Maximum retention time of the event is the maximum time to keep an unprocessed event in the scheduler. If the target is not responding during this time, the event is dropped or sent to a DLQ.
Retries with exponential backoff help to retry a failed task with delayed attempts. This improves the success of the task when the target is available.
A dead letter queue is an Amazon SQS queue where events that failed to get delivered to the target are routed.
By default, EventBridge Scheduler tries to send the event for 24 hours and a maximum of 185 times. You can configure these values. If that fails, the message is dropped, since by default there is not a DLQ configured.
In addition, by default, all events in Scheduler are encrypted with a key that AWS owns and manages. You can also use your own AWS KMS encryption keys.
You can also schedule tasks using Amazon EventBridge rules. But to schedule tasks at scale, EventBridge Scheduler is better suited for this task. The following table shows the main differences between EventBridge Scheduler and EventBridge rules:
Amazon EventBridge Scheduler
Amazon EventBridge rules
Quota on schedules
1 million per account
300 rule limit per account per Region
Event invocation throughput
Able to support throughput in 1,000s of TPS
Because of the schedule limit, you can only have 300 1-minute schedules for max throughput of 5 TPS
Targets
Over 270 services and over 6,000 API Actions with AWS SDK targets
20+ targets supported by EventBridge
Time expression and time-zones
at(), cron(), rate()
All time-zones and DST
cron(), rate(), UTC
No support for DST
One-time schedules
Yes
No
Time window schedules
Yes
No
Event bus support
No event bus is needed
Default bus only
Rule quota consumption
No. 1 million schedules soft limit
Yes, consumes from 2,000 rules per bus
Getting started with EventBridge Scheduler
This walkthrough builds a series of schedules to get started with EventBridge Scheduler. For that, you use the AWS Command Line (AWS CLI) to configure the schedules that send notifications using Amazon SNS.
Prerequisites
Update your AWS CLI to the latest version (v1.27.7).
As a prerequisite, you must create an SNS topic with an email subscription and an AWS IAM role that EventBridge Scheduler can assume to publish messages on your behalf. You can deploy these AWS resources using AWS SAM. Follow the instructions in the README file.
Scheduling a one-time schedule
Once configured, create your first schedule. This is a one-time schedule that publishes an event for the SNS topic you created.
For creating the schedule, run this command in your terminal and replace the schedule expression and time zone with values for your task:
Let’s analyze the different parts of this command. The first parameter is the name of the schedule.
In the scheduleexpression attribute, you can define if the event is a one-time schedule or a recurrent schedule. Because this is a one-time schedule, it uses the at() expression with the date and time you want this schedule to run. Also, you must configure the schedule expression time zone in which this schedule run:
Another setting that you can configure is the flexible time window. It’s not used for this example, but if you choose a time window, EventBridge Scheduler invokes the task within that timeframe. This setting helps to distribute the invocations across time and manage the downstream service limits.
--flexible-time-window "{\"Mode\": \"OFF\"}"
Finally, pass the IAMroleARN. This is the role previously created with the AWS SAM template. This role is the one that EventBridge Scheduler assumes when publishing events to SNS and it has permissions to publish messages on that topic.
Finally, you must configure the target. Scheduler comes with predefined targets with simpler APIs, that include actions like putting events for Amazon EventBridge, invoke a Lambda function, send a message to an Amazon SQS queue. For this example, use the universal target, which allows you to invoke almost any AWS services. Learn more about the targets from the User Guide.
Scheduling groups help you organize your schedules. Scheduling groups support tags that you can use for cost allocation, access control, and resource organization. When creating a new schedule, you can add it to a scheduling group.
Now let’s create a recurrent schedule for that scheduling group. This schedule runs every five minutes and publishes a message to the SNS topic you created during the prerequisites.
Recurrent schedules can be configured with a cron expression or rate expression, to define the frequency that this schedule should be triggered. For scheduling this to run every five minutes, you can use an expression like this one:
--schedule-expression "rate(5minutes)"
Because you have selected the recurring schedule, you can define the timeframe in which this schedule runs. You can optionally choose a start and end date and time for your schedule. If you don’t do it, the schedule starts as soon as you create the task. These times are formatted in the same way as other AWS CLI timestamps.
If you run the previous recurrent schedule for some time, and then check Amazon CloudWatch metrics, you find a metric called InvocationAttemptCount, for the schedule invocations that happened within the scheduling group you just created.
You can graph that metric in a dashboard and see how many times this schedule run. Also, you can create alarms to get notified if the number of invocations exceeds a threshold. For example, you can set this threshold to be close to the limits of your downstream service, to prevent reaching those limits.
Cleaning up
Make sure that you delete all the recurrent schedules that you created without an end time.
To check all the schedules that you have configured:
Also delete the CloudFormation stack with the prerequisite infrastructure when you complete this demo, as is defined in the README file of that project.
Conclusion
This blog post introduces the new Amazon EventBridge Scheduler, its use cases and its differences with existing scheduling options. It shows you how to create a new schedule using Amazon EventBridge Scheduler to simplify the creation, execution, and managing of scheduled tasks at scale.
You can get started today with EventBridge Scheduler from the AWS Management Console, AWS CLI, AWS CloudFormation, AWS SDK, and AWS SAM.
For more serverless learning resources, visit Serverless Land.
This blog post is written by Anton Aleksandrov, Principal Solution Architect and Shridhar Pandey, Senior Product Manager
Today AWS is announcing the AWS Lambda Telemetry API. This provides an easier way to receive enhanced function telemetry directly from the Lambda service and send it to custom destinations. Developers and operators can now more easily monitor and observe their Lambda functions using Lambda extensions from their preferred observability tool providers.
Extensions can use the Lambda Logs API to collect logs generated by the Lambda service and code running in their Lambda function. While the Logs API provides extensions with access to logs, it does not provide a way to collect additional telemetry, such as traces and metrics, which the Lambda service generates during initialization and invocation of your Lambda function.
Previously, observability tools retrieved traces from AWS X-Ray using the AWS X-Ray API or built their own custom tracing libraries to generate traces during Lambda function invocation. Tools required customers to modify AWS Identity and Access Management (IAM) policies to grant access to the traces from X-Ray. This caused additional complexity for tools to collect traces and metrics from multiple sources and introduced latency in seeing Lambda function traces in observability tool dashboards.
The Lambda Telemetry API is a new API that enhances the existing Lambda Logs API functionality. With the new Telemetry API, observability tools can receive function and extension logs, and also events, traces, and metrics directly from within the Lambda service. You do not need to install additional tracing libraries. This reduces latency and simplifies access permissions, as the extension does not require additional access to X-Ray.
Today you can use Telemetry API-enabled extensions to send telemetry data to Coralogix, Datadog, Dynatrace, Lumigo, New Relic, Sedai, Site24x7, Serverless.com, Sumo Logic, Sysdig, Thundra, or your own custom destinations.
The Lambda service then streams the telemetry events directly to the extension. The events include platform events, trace spans, function and extension logs, and additional Lambda platform metrics. The extension can then process, filter, and route them to any preferred destination.
Lambda Extensions from the AWS Partner Network (APN) available at launch
Today, you can use Lambda extensions that use Telemetry API from the following Lambda partners:
The Coralogix AWS Lambda Telemetry Exporter extension now offers improved monitoring and alerting for Lambda functions by further streamlining collection and correlation of logs, metrics, and traces.
The Datadog extension further simplifies how you visualize the impact of cold starts, and monitor and alert on latency, duration, and payload size of your Lambda functions by collecting logs, traces, and real-time metrics from your function in a simple and cost-effective way.
Dynatrace now provides a simplified observability configuration for AWS Lambda through a seamless integration. The new solution delivers low-latency telemetry, enables monitoring at scale, and helps reduce monitoring costs for your serverless workloads.
The Lumigo lambda-log-shipper extension simplifies aggregating and forwarding Lambda logs to third-party tools. It now also makes it easy for you to detect Lambda function timeouts.
The New Relic extension now provides a unified observability view for your Lambda functions with insights that help you better understand and optimize the performance of your functions.
Sedai now uses the Telemetry API to help you improve the performance and availability of your Lambda functions by gathering insights about your function and providing recommendations for manual and autonomous remediation in a cost-effective manner.
The Site24x7 extension now offers new metrics, which enable you to get deeper insights into the different phases of the Lambda function lifecycle, such as initialization and invocation.
Serverless.com now uses the Telemetry API to provide real-time performance details for your Lambda function through the Dev Mode feature of their new Serverless Console V.2 offering, which simplifies debugging in the AWS Cloud.
Sumo Logic now makes it easier, faster, and more cost-effective for you to get your mission-critical Lambda function telemetry sent directly to Sumo Logic so you could quickly analyze and remediate errors and exceptions.
The Sysdig Monitor extension generates and collects real-time metrics directly from the Lambda platform. The simplified instrumentation offers lower latency, reduced MTTR (mean time to resolution) for critical issues, and cost benefits while monitoring your serverless applications.
The Thundra extension enables you to export logs, metrics, and events for Lambda execution environment lifecycle events emitted by the Telemetry API to a destination of your choice such as an S3 bucket, a database, or a monitoring backend.
Seeing example Telemetry API extensions in action
This demo shows an example of using a telemetry extension to receive telemetry, batch, and send it to a desired destination.
To set up the example, visit the GitHub repo for the extension implemented in the language of your choice and follow the instructions in the README.md file.
To configure the batching behavior, which controls when the extension sends the data, set the Lambda environment variable DISPATCH_MIN_BATCH_SIZE. When the extension receives the batch threshold, it POSTs the telemetry events batch to the destination specified in the DISPATCH_POST_URI environment variable.
You can configure an example DISPATCH_POST_URL for the extension to deliver the telemetry data using https://webhook.site/.
Lambda environment variables
Telemetry events for one invoke may be received and processed during the next invocation. Events for the last invoke may be processed during the SHUTDOWN event.
Test and invoke the function from the Lambda console, or AWS CLI. You can see that the webhook receives the telemetry data.
Webhook receiving telemetry data
You can also view the function and extension logs in CloudWatch Logs. The example extension includes verbose logging to understand the extension lifecycle.
Sample Telemetry API events
When the extension receives telemetry data, each event contains a JSON dictionary with additional information, such as related metrics or trace spans. The following example shows a function initialization event. You can see that the function initializes with on-demand concurrency. The runtime version is Node.js 14, the initialization is successful, and the initialization duration is 123 milliseconds.
Function invocation events include the associated requestId and tracing information connecting this invocation with the X-Ray tracing context, and platform spans showing response latency and response duration as well as invocation metrics such as duration in milliseconds.
Lambda extensions run as independent processes in the execution environment and continue to run after the function invocation is fully processed. Because extensions run as separate processes, you can write them in a language different from the function code. We recommend implementing extensions using a compiled language as a self-contained binary. This makes the extension compatible with all the supported runtimes.
Extensions that use the Telemetry API have the following lifecycle.
Telemetry API lifecycle
The extension registers itself using the Lambda Extension API and subscribes to receive INVOKE and SHUTDOWN events. With the Telemetry API, the registration response body contains additional information, such as function name, function version, and account ID.
The extensions start a telemetry listener. This is a local HTTP or TCP endpoint. We recommend using HTTP rather than TCP.
The extensions use the Telemetry API to subscribe to desired telemetry event streams.
The Lambda service POSTs telemetry stream data to your telemetry listener. We recommend batching the telemetry data as it arrives to the listener. You can perform any custom processing on this data and send it on to an S3 bucket, other custom destination, or an external observability service.
The Lambda Telemetry API supersedes the Lambda Logs API. While the Logs API remains fully functional, AWS recommends using the Telemetry API. New functionality is only available with the Extensions API. Extensions can only subscribe to either the Logs or Telemetry API. After subscribing to one of them, any attempt to subscribe to the other returns an error.
Mapping Telemetry API schema to OpenTelemetry spans
The Lambda Telemetry API schema is semantically compatible with OpenTelemetry (OTEL). You can use events received from the Telemetry API to build and report OTEL spans. Three Telemetry API lifecycle events represent a single function invocation: start, runtimeDone, and runtimeReport. You should represent this as a single OTEL span. You can add additional details to your spans using information available in runtimeDone events under the event.spans property.
The Telemetry API introduces new per-invoke metrics to help you understand the impact of extensions on your function’s performance. The metrics are available within the report.runtimeDone event.
platform.runtime measures the time taken by the Lambda Runtime to run your function handler code.
producedBytes measures the number of bytes returned during the invoke phase.
There are also two new trace spans available within the report.runtimeDone event:
responseLatencyMs measures the time taken by the Runtime to send a response.
responseDurationMs measures the time taken by the Runtime to finish sending the response from when it starts streaming it.
Extensions using Telemetry API, like other extensions, share the same billing model as Lambda functions. When using Lambda functions with extensions, you pay for requests served, and the combined compute time used to run your code and all extensions, in 1-ms increments. To learn more about the billing for extensions, visit the Lambda pricing page.
The Lambda Telemetry API allows you to receive enhanced telemetry data more easily using your preferred monitoring and observability tools. The Telemetry API enhances the functionality of the Logs API to receive logs, metrics, and traces directly from the Lambda service. Developers and operators can send telemetry to destinations without custom libraries, with reduced latency, and simplified permissions.
To see how the Telemetry API works, try the demos in the GitHub repository.
Build your own extensions using the Telemetry API today, or use extensions provided by the Lambda observability partners.
For more serverless learning resources, visit Serverless Land.
I am pleased to announce today the opening of our 28th AWS Region: Europe (Zurich), also known by its API name: eu-central-2.
An AWS Region allows you to deploy your most demanding workloads and replicate your applications and data across distinct groups of data centers called Availability Zones. This new Region has three fully redundant Availability Zones located in the vicinity of Zurich. It offers your customers low-latency access to your applications while meeting your data residency requirements.
Regions and Availability Zones AWS has the concept of a Region. Each Region is fully isolated from all other Regions. Within each Region, we have built Availability Zones. These Availability Zones are fully isolated partitions of our infrastructure that contain a cluster of data centers. Availability Zones are typically separated by multiple kilometers to mitigate the impact of disasters that could affect data centers. The distance between Availability Zones varies between Regions. The distance is large enough to avoid having data centers impacted by the same event at the same time but close enough to allow workloads with synchronous data replication. Availability Zones are linked by redundant, high-bandwidth, and low-latency network connections. Regions are linked by our custom-built, global, low-latency, private network with exabits per second of capacity in Europe.
Unlike other cloud providers, who often define a region as a single data center, the multiple Availability Zone design of every AWS Region offers advantages such as security, availability, performance, and scalability.
Continuous Investments in Switzerland AWS has a long history of presence in Switzerland. We have worked with Swiss customers and partners since the launch of AWS 16 years ago. The first Swiss office was opened in Zurich in April 2016 to host the growing local team of technical and business professionals dedicated to supporting Swiss customers. In 2017, the AWS network was expanded into Switzerland with the launch of an Amazon CloudFront edge location and an AWS Direct Connect location. To support this growth, a second AWS office was opened in Geneva.
AWS plans to invest up to 5.9 billion Swiss francs (approximately $5.9 billion) in the Europe (Zurich) Region from 2022–2036 as we build, maintain, operate, and develop data centers to support the projected growth in demand for AWS technologies by our customers.
According to an AWS Economic Impact Study (EIS), this investment will contribute 16.3 billion Swiss francs (approximately $16.3 billion) to the GDP of Switzerland during the same period. This includes the value added by AWS services to the IT sector in Switzerland, as well as the direct, indirect, and induced effects of AWS purchases from the Swiss data center supply chain. The study estimates that this investment will support an average of 2,500 full-time jobs annually at external businesses in the Swiss data supply chain from 2022–2036.
Global luxury group Richemont, owners of prestigious brands like Cartier, Montblanc, IWC Schaffhausen, and Van Cleef & Arpels, moved its entire enterprise IT infrastructure, including 120 SAP instances, to AWS. AWS, with its depth and breadth of services, enables Richemont to provide their customers with new digital experiences faster, including personalized storefronts and styling services, video chat consultations featuring fashion shows customized to the shoppers’ tastes, and tailored offers for early access to new items before they hit stores.
Swisscom, Switzerland’s leading telecoms company and one of its leading IT companies, is using AWS’s proven and broad infrastructure and cloud capabilities to power its 5G network, increase operational efficiency, and fuel innovation. Swisscom is pursuing a cloud-first strategy and will use AWS to increase IT agility, drive operational efficiencies, and accelerate time to market for new information and communications technology (ICT) features and services.
With AWS infrastructure, Swiss startups have been able to quickly scale their businesses and compete globally. Ava, a digital women’s health startup (acquired by FemTec Health) with offices in Zurich, San Francisco, Makati, and Belgrade, is all in on AWS. They created the Ava Fertility Tracker as a daily companion for women, which provides women with real-time, personalized information about fertility, pregnancy, and general health. The Ava bracelet is now sold in 36 countries worldwide and has been running on AWS since the first sales day.
Extending Reach through AWS Partner Network Switzerland-based AWS Partner Network (APN) Partners also welcomed the news of the launch of the Europe (Zurich) Region.
The APN includes tens of thousands of independent software vendors (ISVs) and systems integrators (SIs) around the world. AWS SIs, consulting partners, and ISVs help enterprise and public sector customers migrate to AWS, deploy mission-critical applications, and provide a full range of services for your cloud environments. We have more than 150 partners ready to help you in Switzerland, one third of them have their headquarters in the country.
Promoting a Diverse Community of Professionals In December 2020, Amazon announced that it will help 29 million people around the world grow their technological skills with free cloud computing skills training by 2025. Switzerland is part of this global effort. Since 2019, AWS and our AWS training partnerDigicomp have delivered training and certification programs to individual learners, customers, and AWS Partners to rapidly build cloud skills and close the skills gap.
Several universities in Switzerland have delivered AWS Academy courses as part of their curriculum, including FHNW (Fachhochschule Nordwestschweiz), Fachhochschule Luzern, and Technische Berufsschule Zürich. To date, 32 Swiss institutions participated in the AWS Academy program, and 16 of them offered classes in 2022.
In March 2022, AWS launched AWS re/Start in Switzerland in collaboration with Powerhouse Lausanne, a training provider that promotes digital equality and diversity in Switzerland. A second cohort of AWS re/Start began in October 2022 in collaboration with the non profit Powercoders, which is focused on teaching IT skills specifically to refugees and helping them transition into the Swiss labor market.
Available Today With the launch of the Europe (Zurich) Region, AWS is further expanding its infrastructure offering, empowering you with the flexibility to run applications on the most secure and reliable cloud infrastructure while maintaining local data residency and providing the lowest possible latency for Swiss end-users. The new Region is available today on the AWS Management Console and for your API calls.
Go and deploy your workloads on eu-central-2 today!
Today, we’re making that easier. Using the new AWS Resource Explorer, you can search through the AWS resources in your account across Regions using metadata such as names, tags, and IDs. When you find a resource in the AWS Management Console, you can quickly go from the search results to the corresponding service console and Region to start working on that resource. In a similar way, you can use the AWS Command Line Interface (CLI) or any of the AWS SDKs to find resources in your automation tools.
Let’s see how this works in practice.
Using AWS Resource Explorer To start using Resource Explorer, I need to turn it on so that it creates and maintains the indexes that will provide fast responses to my search queries. Usually, the administrator of the account is the one taking these steps so that authorized users in that account can start searching.
To run a query, I need a view that gives access to an index. If the view is using an aggregator index, then the query can search across all indexed Regions.
If the view is using a local index, then the query has access only to the resources in that Region.
I can control the visibility of resources in my account by creating views that define what resource information is available for search and discovery. These controls are not based only on resources but also on the information that resources bring. For example, I can give access to the Amazon Resource Names (ARNs) of all resources but not to their tags which might contain information that I want to keep confidential.
In the Resource Explorer console, I choose Enable Resource Explorer. Then, I select the Quick setup option to have visibility for all supported resources within my account. This option creates local indexes in all Regions and an aggregator index in the selected Region. A default view with a filter that includes all supported resources in the account is also created in the same Region as the aggregator index.
With the Advanced setup option, I have access to more granular controls that are useful when there are specific governance requirements. For example, I can select in which Regions to create indexes. I can choose not to replicate resource information to any other Region so that resources from each AWS Region are searchable only from within the same Region. I can also control what information is available in the default view or avoid the creation of the default view.
With the Quick setup option selected, I choose Go to Resource Explorer. A quick overview shows the progress of enabling Resource Explorer across Regions. After the indexes have been created, it can take up to 36 hours to index all supported resources, and search results might be incomplete until then. When resources are created or deleted, your indexes are automatically updated. These updates are asynchronous, so it can take some time (usually a few minutes) to see the changes.
Searching With AWS Resource Explorer After resources have been indexed, I choose Proceed to resource search. In the Search criteria, I choose which View to use. Currently, I have the default view selected. Then, I start typing in the Query field to search through the resources in my AWS account across all Regions. For example, I have an application where I used the convention to start resource names with my-app. For the resources I created manually, I also added the Project tag with value MyApp.
To find the resource of this application, I start by searching for my-app.
The results include resources from multiple services and Regions and global resources from AWS Identity and Access Management (IAM). I have a service, tasks, and a task definition from Amazon ECS, roles and policies from AWS IAM, log groups from CloudWatch. Optionally, I can filter results by Region or resource type. If I choose any of the listed resources, the link will bring me to the corresponding service console and Region with the resource selected.
To look for something in a specific Region, such as Europe (Ireland), I can restrict the results by adding region:eu-west-1 to the query.
I can further restrict results to Amazon ECS resources by adding service:ecs to the query. Now I only see the ECS cluster, service, tasks, and task definition in Europe (Ireland). That’s the task definition I was looking for!
I can also search using tags. For example, I can see the resources where I added the MyApp tag by including tag.value:MyApp in a query. To specify the actual key-value pair of the tag, I can use tag:Project=MyApp.
Creating a Custom View Sometimes you need to control the visibility of the resources in your account. For example, all the EC2 instances used for development in my account are in US West (Oregon). I create a view for the development team by choosing a specific Region (us-west-2) and filtering the results with service:ec2 in the query. Optionally, I could further filter results based on resource names or tags. For example, I could add tag:Environment=Dev to only see resources that have been tagged to be in a development environment.
Now I allow access to this view to users and roles used by the development team. To do so, I can attach an identity-based policy to the users and roles of the development team. In this way, they can only explore and search resources using this view.
Unified Search in the AWS Management Console After I turn Resource Explorer on, I can also search through my AWS resources in the search bar at the top of the Management Console. We call this capability unified search as it gives results that include AWS services, features, blogs, documentation, tutorial, events, and more.
To focus my search on AWS resources, I add /Resources at the beginning of my search.
Note that unified search automatically inserts a wildcard character (*) at the end of the first keyword in the string. This means that unified search results include resources that match any string that starts with the specified keyword.
The search performed by the Query text box on the Resource search page in the Resource Explorer console does not automatically append a wildcard character but I can do it manually after any term in the search string to have similar results.
Unified search works when I have the default view in the same Region that contains the aggregator index. To check if unified search works for me, I look at the top of the Settings page.
Availability and Pricing You can start using AWS Resource Explorer today with a global console and via the AWS Command Line Interface (CLI) and the AWS SDKs. AWS Resource Explorer is available at no additional charge. Using Resource Explorer makes it much faster to find the resources you need and use them in your automation processes and in their service console.
In the weeks leading up to AWS re:Invent 2022, I’m interviewing some of the humans who work in AWS Security, help keep our customers safe and secure, and also happen to be speaking at re:Invent. This interview is with Param Sharma, principal software engineer for AWS Private Certificate Authority (AWS Private CA). AWS Private CA enables you to create private certificate authority (CA) hierarchies, including root and subordinate CAs, without the investment and maintenance costs of operating an on-premises CA.
How long have you been at AWS and what do you do in your current role?
I’ve been here for more than eight years—I joined AWS in July 2014, working in AWS Security. These days, I work on public key infrastructure (PKI) and cryptography, focusing on products like AWS Certificate Manager (ACM) and AWS Private CA.
How did you get started in the world of security, specifically cryptography?
I had a very short stint with crypto during my university days—I presented a paper on steganography and cryptography back in 2002 or 2003. Security has been an integral part of developing and deploying large-scale web applications, which I’ve done throughout my career. But security took center stage in 2014 when I heard from an AWS recruiter about a new service being built that would make certificates easier. I had no clue what that service was, since it was confidential and hadn’t been launched yet, but it brought cryptography back into my life. I started working on this brand-new service, AWS Certificate Manager. I designed the operational security aspect of it and worked to make sure it could be used by millions of our customers and could be available and secure at the same time. I was the second person hired on the ACM team, and since then the team has grown significantly.
What was the most surprising or interesting thing you’ve worked on in your time at AWS?
It might not be surprising, but certainly interesting to me: I was the first engineer to be hired on the AWS Private CA team and I started studying the problem of how certificate authorities would work in the cloud. I had to think about how the customer experience would look, the service architecture design, the operational side of things like availability and security of customer data. Doing a 360-degree review of the service and writing the design document for a service that was eventually deployed in a multitude of AWS Regions was one of the most interesting things I have worked on at AWS. It continues to be an interesting challenge as we add new features—which tend to be like smaller AWS services in their own right even though they are features of AWS Private CA.
How do you explain to customers how to use AWS Private CA?
I start by explaining what a private certificate is. A private certificate provides a flexible way to identify almost anything in an organization without disclosing the name publicly. With AWS Private CA, AWS takes care of the undifferentiated heavy lifting involved in operating a private CA. We provide security configuration, management, and monitoring of highly available private CAs. The service also helps organizations avoid spending money on servers, hardware security modules (HSMs), operations, personnel, infrastructure, software training, and maintenance. Maintaining PKI administrators, for example, can cost hundreds or thousands of dollars per year. AWS Private CA simplifies the process of creating and managing these private CAs and certificates that are used to identify resources and provide a basis for trusted identity in communications.
In your opinion, what is the coolest feature of AWS Private CA?
That’s going to be really hard to pick! To me, the coolest feature is root CA, which gives customers the ability to create and manage root CAs in the cloud. Root CAs are used to create subordinate CAs for issuing identity certificates. And these private CAs can be used to identify resources in a private network within an organization. You can use these private certs on application services, devices, or even for identifying users for identity certificates.
AWS Private CA has evolved since its launch in 2018. What are some of the new ways you see customers using the service?
When AWS Private CA was launched in 2018, the primary feature was to create and manage subordinate CAs, which were signed offline outside of AWS Private CA. The secondary feature was to issue certificates for identifying endpoints for TLS/SSL communication. Over the last four or five years, I’ve seen use cases become more diversified, and the service has evolved as the customers’ needs have evolved. The biggest paradigm shift that I’ve seen is that customers are customizing certificates and using them to identify IoT devices or customer-managed Kubernetes clusters. The certificates can even be used on-premises for your Amazon Elastic Compute Cloud (Amazon EC2) instances or your on-premises servers, where you can use these services to encrypt the traffic in transit or at rest in certain cases. The other more recent use case I’ve started to see is customers using AWS Private CA with AWS Identity and Access Management Roles Anywhere, which launched in July 2022. Customers are using this combination to issue certificates for identity, which is tied to the credentials themselves.
I understand you’ll be speaking at re:Invent 2022. Can you tell us about your session there? What do you hope customers take away from your session?
I am doing two sessions at re:Invent this year. The first one, Understanding the evolution of cloud-based PKI use cases, is a chalk talk about how cloud-based PKI use cases have evolved over the last 5–10 years. This talk is mainly for PKI administrators, information security engineers, developers, managers, directors, and IoT security professionals who want to learn more about how X.509 digital certificates are used in the cloud. We will dive deep into how these certs are being used for normal TLS communication, device certificates, containers, or even certificates used for identity like in IAM Roles Anywhere. The second session is a breakout session called AWS data protection: Using locks, keys, signatures, and certificates. It puts a spotlight on what AWS offers in terms of cryptographic tools and PKI platforms that help our customers navigate their data protection and digital signing needs. This session will provide a ground-floor understanding of how to get this protection by default or when needed, and how can you build your own logs, keys, and signatures for you own cloud application.
What’s the thing you’re most proud of in your career?
I’m proud to work with some of the smartest people who, at the same time, are very humble and genuinely believe in making this world a better place for everyone.
Outside of your work in tech, what is something you’re interested in that might surprise people?
I have a five-year-old and a three-year-old, so whenever I get some time to myself between those two, I love to read and take long strolls. I’m a passionate advocate that every voice is unique and has value to share. I’m a diversity and inclusion ambassador at Amazon and as part of this program, I mentor underrepresented groups and help build a community with integrity and a willingness to listen to others, which provides a space for us to be ourselves without fear of judgement. I try to do volunteer work whenever possible, being involved in community service programs organized through my children’s school activities, or even participating in local community kitchens by cooking and serving food that is distributed through a local non-profit organization.
If you had to pick an industry outside of security, what would you want to do?
I would’ve been a teacher or worked with a non-profit organization mentoring and volunteering. I think volunteering gives me a sense of peace.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run on datasets at petabyte scale. You can use Athena to query your S3 data lake for use cases such as data exploration for machine learning (ML) and AI, business intelligence (BI) reporting, and ad hoc querying.
It’s not uncommon for datasets in data lakes to update only daily, or at most a few times per day, yet queries running on these datasets may be repeated more frequently. Previously, all queries resulted in a data scan, even if the same query was repeated again. When the source data hasn’t changed, repeat queries run needlessly, leading to the same results with higher data scan costs and query latency. Wouldn’t it be better if the results of a recent query could be reused instead?
Query Result Reuse is a new feature available in Athena engine version 3 that makes it possible to reuse the results of a previous query. This can improve performance and reduce cost for frequently run queries, by skipping scanning the source data and instead returning a previously calculated result directly. With Query Result Reuse, you can tell Athena that you want to reuse results of a previous query run, with a maximum age setting that controls how recent a previous result has to be.
Athena automatically reuses any previous results that match your query and maximum age setting, or transparently runs the query again if no match is found. If you know that a dataset changes a few times per day, you can, for example, tell Athena to reuse results that are up to an hour old to avoid rerunning most queries, but still get new results when you run a query soon after new data has become available.
In this post, we demonstrate how to reduce cost and improve query performance with the new Query Result Reuse feature.
When should you use Query Result Reuse?
We recommend using Query Result Reuse for every query where the source data doesn’t change frequently. You can configure the maximum age of results to reuse per query, or use the default, which is 60 minutes. In certain cases where queries include non-deterministic functions such as RAND(), the query fetches fresh data from the input source even if the Query Result Reuse feature is enabled.
Query Result Reuse allows results to be shared among users in a workgroup, as long as they have access to the tables and data. This means Query Result Reuse can benefit not only a single user, but also other users in the workgroup who might be running the same queries. One example where this may be especially beneficial is when you have dashboards that are viewed by many users. The dashboard widgets run the same queries for all users, and are therefore accelerated by Query Result Reuse, when enabled.
Another example is if you have a dataset that is updated daily, and many users who all query the most recent data to create reports. Different people might run the same queries as part of their work; with Query Result Reuse, they can collectively avoid running the same query more than once, making everyone more productive and lowering overall cost by avoiding repeated scans of the same data.
Finally, if you have a historical dataset that is frequently queried, but never or very rarely updated, you can configure queries to reuse results that are up to 7 days old to maximize the chances of reusing results and avoid unnecessary costs.
How does Query Result Reuse work?
Query Result Reuse takes advantage of the fact that Athena writes query results to Amazon S3 as a CSV file. Before the introduction of Query Result Reuse, it was possible to reuse query results by reading these files directly. You could also use the ClientRequestToken parameter of the StartQueryExecution API to ensure queries are run only once, and subsequent runs return the same results. With Query Result Reuse, the process of reusing query results is easier and more versatile.
When Athena receives a query with Query Result Reuse enabled, it looks for a result for a query with the same query string that was run in the same workgroup. The query string has to be identical in order to match.
Query Result Reuse is enabled on a per query basis. When you run a query, you specify how old a result can be for it to be reused, from 1 minute up to 7 days. If the query has been run before, and a result exists that matches the request, it’s returned, otherwise the query is run and a new result is calculated. This new result is then available to be reused by subsequent queries.
You can run the query multiple times with different settings for how old a result you can accept. Results can be reused within the same workgroup, even if a different user ran the query previously.
Before a query result is reused, Athena does a few checks to make sure that the user is still allowed to see the results. It checks that the user has access to the tables involved in the query and permission to read the result file on Amazon S3.
There are some situations where query results can’t be reused, for example if the query uses non-deterministic functions, or has AWS Lake Form ation fine-grained access controls enabled. These limitations are described in more detail later in this post.
Run queries with Query Result Reuse
In this section, we demonstrate how to run queries with the Query Result Reuse feature via the Athena API, the Athena console, and the JDBC and ODBC drivers.
Run queries using the Athena API
For applications that use the Athena API through the AWS Command Line Interface (AWS CLI) or the AWS SDKs, the StartQueryExecution API call now has the additional parameter ResultReuseConfiguration, where you can enable Query Result Reuse and specify the maximum age of results. For example, when using the AWS CLI, you can run a query with Query Result Reuse enabled as follows:
These examples assume that my_work_group uses Athena engine v3, that the workgroup has an output location configured, and that the AWS Region has been set in the AWS CLI configuration.
When a query result is reused, you can see in the statistics section of the response from the GetQueryExecution API call that no data was scanned and that results were reused:
When you run queries on the Athena console, Query Result Reuse is now enabled by default. You can enable and disable Query Result Reuse in the query editor. You can also choose the pen icon to change the maximum age of results. This setting applies to all queries run on the Athena console.
The following screenshot shows an example query run against AWS CloudTrail logs with Query Result Reuse enabled.
When we ran the query again, the results showed up immediately, and we could see the message “using reused query results” in the Query results pane as a confirmation that the results of our first query had been reused. The Data scanned statistic also showed “-” to indicate that no data was scanned.
Run queries using the JDBC and ODBC drivers
If you use the JDBC or ODBC driver to query Athena, you can now add enableResultReuse=1 to your connection parameters to enable Query Result Reuse, and use ageforResultReuse=60 to set the maximum age to 60 minutes. The drivers automatically apply the setting to all queries running in the context of the connection.
Query Result Reuse is supported for most Athena queries, but there are some limitations. We want to ensure that reusing results doesn’t create surprising situations, or expose results that a user shouldn’t have access to. For that reason, Athena always runs a fresh query in the following situations:
Non-deterministic functions – Some functions and expressions produce different results from query to query, such as CURRENT_TIME and RAND(). Results for queries that use temporal and non-deterministic expressions and functions aren’t reusable because that could create surprising and inconsistent results.
Fine-grained access controls – Row-level and column-level permissions are configured in Lake Formation, and Athena can’t know if these have changed since a previous query result was created. Users using the same workgroup can also have different permissions, and checking all permissions would undo many of the cost and performance savings you get from Query Result Reuse.
Federated queries, user-defined functions (UDFs), and external Hive metastores – Users using the same workgroup can have different permissions to invoke the AWS Lambda functions that these features rely on. Athena isn’t able to check that a user that wants to reuse a result has permission to invoke these Lambda functions without running the query, which would negate the cost and performance savings.
Athena detects these conditions automatically and runs the query as if Query Result Reuse wasn’t enabled. You won’t get errors, but you can determine that Query Result Reuse wasn’t in effect by inspecting the query status (see our earlier examples).
Query Result Reuse is available in Athena engine version 3 only.
Conclusion
Query Result Reuse is a new feature in Athena that aims to reduce cost and query response times for datasets that change less frequently than they are queried. For teams that often run the same query, or have dashboards that are used more often than the data changes, Query Result Reuse can result in lower costs and faster results. It’s easy to get started with Query Result Reuse via the Athena console, API, and JDBC/ODBC; all you have to do is set the maximum age of results, and run your queries as usual.
We hope that you will like this new feature, and that it will save cost and improve performance for you and your team!
About the authors
Theo Tolv is a Senior Big Data Architect in the Athena team. He’s worked with small and big data for most of his career and often hangs out on Stack Overflow answering questions about Athena.
Vijay Jain is a Senior Product Manager in Amazon Web Services (AWS) Athena team. He is passionate about building scalable analytics technologies and products working closely with enterprise customers. Outside of work, Vijay likes running and spending time with his family.
With three weeks to go until AWS re:Invent opens in Las Vegas, the AWS News Blog Team is hard at work creating blog posts to share the latest launches and previews with you. As usual, we have a strong mix of new services, new features, and a surprise or two.
Last Week’s Launches Here are some launches that caught my eye last week:
Amazon SNS Data Protection and Masking – After a quick public preview, this cool feature is now generally available. It uses pattern matching, machine learning models, and content policies to help protect data at scale. You can find many different kinds of personally identifiable information (PII) and protected health information (PHI) in message bodies and either block message delivery or mask (de-identify) the sensitive data, all in real-time and on a per-topic basis. To learn more, read the blog post or the message data protection documentation.
Amazon Textract Updates – This service extracts text, handwriting, and data from any document or image. This past week we updated the AnalyzeID function so that it can now extract the machine readable zone (MRZ) on passports issued by the United States, and we added the entire OCR output to the API response. We also updated the machine learning models that power the AnalyzeDocument function, with a focus on single-character boxed forms commonly found on tax and immigration documents. Finally, we updated the AnalyzeExpense function with support for new fields and higher accuracy for existing fields, bringing the total field count to more than 40.
Another Amazon Braket Processor – Our quantum computing service now supports Aquila, a new 256-qubit quantum computer from QuEra that is based on a programmable array of neutral Rubidium atoms. According to the What’s New, Aquila supports the Analog Hamiltonian Simulation (AHS) paradigm, allowing it to solve for the static and dynamic properties of quantum systems composed of many interacting particles.
Amazon S3 on Outposts – This service now lets you use additional S3 Lifecycle rules to optimize capacity management. You can expire objects as they age or are replaced with newer versions, with control at the bucket level, or for subsets defined by prefixes, object tags, or object sizes. There’s more info in the What’s New and in the S3 documentation.
Amazon MemoryDB for Redis – You can now use data tiering as a lower cost way to to scale your clusters up to hundreds of terabytes of capacity. This new option uses a combination of instance memory and SSD storage in each cluster node, with all data stored durably in a multi-AZ transaction log. There’s more information in the What’s New and the blog post.
Amazon EC2 – You can now remove launch permissions for Amazon Machine Images (AMIs) that are directly shared with your AWS account.
X in Y – We launched existing AWS services and instance types in additional Regions:
Other AWS News Here are some additional news items that you may find interesting:
AWS Open Source News and Updates – My colleague Ricardo Sueiras highlights new open source projects, tools, and demos from the AWS Community. Read Installment 134 to see what’s going on!
New Case Study – A new AWS case study describes how Taggle (a company focused on smart water solutions in Australia) created an IoT platform that runs on AWS and uses Amazon Kinesis Data Streams to store & ingest data in real time. Using AWS allowed them to scale to accommodate 80,000 additional sensors that will roll out in 2022.
Upcoming AWS Events re:Invent 2022 – AWS re:Invent is just three weeks away! Join us live from November 28th to December 2nd for keynotes, training and certification opportunities, and over 1,500 technical sessions. If you cannot make it to Las Vegas you can also join us online to watch the keynotes and leadership sessions live. Be sure to check out the re:Invent 2022 Attendee Guides, each curated by an AWS Hero, AWS industry team, or AWS partner.
PeerTalk – If you will be attending re:Invent in person and are interested in meeting with me or any of our featured experts, be sure to check out PeerTalk, our new onsite networking program.
As Cybersecurity Awareness Month comes to a close, we want to share some of the work we’ve done and made available to you throughout October. Over the last four weeks, we have shared insights and resources aligned with this year’s theme—”See Yourself in Cyber”—to help advance awareness training, and inspire people to join the rapidly growing security industry. Here are a few highlights.
Roundtable with the Cybersecurity and Infrastructure Security Agency (CISA): Amazon Chief Security Officer Steve Schmidt hosted CISA director Jen Easterly in Seattle for a roundtable with leaders across higher education, state and local government, and private industry to discuss ways to develop the cybersecurity workforce through skills training, partnerships between government and industry, and creating pathways to cybersecurity careers.
How AWS, Cisco, Netflix & SAP Are Approaching Cybersecurity Awareness Month. I joined Cisco Chief Security and Trust Officer Brad Arkin, Netflix Head of Cloud Security Srinath Kuruvardi, and SAP Chief Trust Officer Elena Kvochko to describe how AWS, Cisco, Netflix, and SAP are instilling strong cybersecurity training and practices within our organizations, with the goal of inspiring other organizations to do the same.
Cybersecurity Awareness Month 2022 Briefing. Amazon Security Director Jenny Brinkley—who leads Amazon’s internal and external awareness training activities—participated in a Cybersecurity Awareness Month panel discussion hosted by the National Cybersecurity Alliance. Jenny met with executives from KnowBe4, Google, NortonLifeLock, and Dell and chatted about how the cybersecurity landscape has changed over the past few years, and how those changes have impacted the perception of security as a part of daily life.
Making Cybersecurity Relevant for Consumers: The Case for Personal Agency. In addition to the briefing, Jenny spoke to the National Cybersecurity Alliance about staying safe online. She highlighted simple steps that everyone can take to be safer online, including staying consistent on software updates for connected devices, using strong passwords, activating multi-factor authentication (MFA) on accounts when possible, and being on the lookout for phishing attempts.
National Cybersecurity Alliance and Nasdaq Cybersecurity Summit. Jenny and Amazon Head of Global Security Training Jyllian Clarke also joined the National Cybersecurity Alliance, Nasdaq, and public and private sector security leaders in New York City for a cybersecurity summit and got to ring the opening bell.
Resources
AWS offers free Cybersecurity Awareness Training to individuals and businesses around the world, and we’re providing complimentary MFA security keys to AWS account owners in the United States. More than 40 security-focused courses are available through AWS Skill Builder, ranging from foundational to advanced content. By subscribing to AWS Skill Builder, you gain access to security-related interactive challenges with AWS Jam, which guides you through solving real-world problems.
Additionally, Amazon and the National Cybersecurity Alliance launched a cybersecurity awareness campaign called Protect & Connect. The campaign includes a public service announcement featuring Prime Video actor Michael B. Jordan and actress-producer Tessa Thompson as “internet bodyguards,” as well as a Protect & Connect microsite for consumers, featuring additional videos on topics such as MFA and how to identify and avoid phishing attempts.
Humanizing security
Cybersecurity can seem like a complex subject but ultimately, it’s all about people. Most of today’s threats need people to activate them, so you need to train people to develop intuition, which is something that can’t be automated. By meeting employees where they are with an engaging approach to awareness training that moves security to the forefront of everything they do, you can promote positive behavioral change, and start building a security-first culture.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Email remains the core of any company’s communication stack, but emails cannot deliver maximum ROI unless they land in recipients’ inboxes. Email deliverability, or ensuring emails land in the inbox instead of spam, challenges senders because deliverability can be impacted by a number of variables, like sending identity, campaign setup, or email configuration. Today, email senders rely on dashboard metrics or deliverability consultants to optimize the inbox placement of their messages. However, the deliverability dashboards available today do not provide specific recommendations to improve deliverability. Consultants provide bespoke solutions, but can cost hundreds of dollars per hour and are not scalable.
That’s why, today, we’re proud to announce virtual deliverability manager, a suite of new deliverability features in Amazon Simple Email Service (SES) that improve deliverability insights and recommendations. A new deliverability dashboard gives email senders more insights through a detailed dashboard of metrics on email deliverability. The “advisor” feature provides configuration recommendations to help improve inbox placement. SES’ “Guardian” can implement changes to email sending to help increase the percent of messages that land in the inbox. Deliverability metrics and recommendations are generated in real-time through Amazon SES, without the need for a human consultant or agency.
The new SES feature reports email insights at-a-glance with metrics like open and click rate, but can also give deeper insights into individual ISP and configuration performance. SES will deliver specific configuration recommendations to improve deliverability based on a specific campaign’s setup, like DMARC (Domain-based Message Authentication Reporting and Conformance) or DKIM (DomainKeys Identified Mail) for a specific domain. Senders can turn on automatic implementation, which allows SES to intelligently adjust email sending configuration to maximize inbox placement.
Applying new deliverability features is simple in the AWS console. Senders can log into their SES account dashboard to enable the virtual deliverability manager features. The features are billed as monthly subscription and can be turned on or off at any time. Once the features are activated, SES provides deliverability insights and recommendations in real time, allowing senders to improve performance of future sending batches or campaigns. Senders using Simple Email Service (SES) get reliable, scalable email at the lowest industry prices. SES is backed by AWS’ data security, and email through SES supports compliance with HIPAA-eligible, FedRAMP-, GDPR-, and ISO-certified options.
To learn more about virtual deliverability manager, visit https://aws.amazon.com/ses
No tricks, just treats in this weekly roundup of news and announcements. Let’s switch our AWS Management Console into dark mode and dive right into it.
Last Week’s Launches Here are some launches that got my attention during the previous week:
AWS Local Zones in Hamburg and Warsaw now generally available – AWS Local Zones help you run latency-sensitive applications closer to end users. The AWS Local Zones in Hamburg, Germany, and Warsaw, Poland, are the first Local Zones in Europe. AWS Local Zones are now generally available in 20 metro areas globally, with announced plans to launch 33 additional Local Zones in metro areas around the world. See the full list of available and announced AWS Local Zones, and learn how to get started.
Amazon SageMaker multi-model endpoint (MME) now supports GPU instances – MME is a managed capability of SageMaker Inference that lets you deploy thousands of models on a single endpoint. MMEs can now run multiple models on a GPU core, share GPU instances behind an endpoint across multiple models, and dynamically load and unload models based on the incoming traffic. This can help you reduce costs and achieve better price performance. Learn how to run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints.
Amazon EC2 now lets you replace the root Amazon EBS volume for a running instance – You can now use the Replace Root Volume for patching features in Amazon EC2 to replace your instance root volume using an updated AMI without needing to stop the instance. This makes patching of the guest operating system and applications easier, while retraining the instance store data, networking, and IAM configuration. Check out the documentation to learn more.
AWS Fault Injection Simulator now supports network connectivity disruption – AWS Fault Injection Simulator (FIS) is a managed service for running controlled fault injection experiments on AWS. AWS FIS now has a new action type to disrupt network connectivity and validate that your applications are resilient to a total or partial loss of connectivity. To learn more, visit Network Actions in the AWS FIS user guide.
Amazon SageMaker Automatic Model Tuning now supports Grid Search – SageMaker Automatic Model Tuning helps you find the hyperparameter values that result in the best-performing model for a chosen metric. Until now, you could choose between random, Bayesian, and hyperband search strategies. Grid search now lets you cover every combination of the specified hyperparameter values for use cases in which you need reproducible tuning results. Learn how Amazon SageMaker Automatic Model Tuning now supports grid search.
Other AWS News Here are some additional news items that you may find interesting:
Celebrating over 20 years of AI/ML innovation – On October 25, we hosted the AWS AI/ML Innovation Day. Bratin Saha and other leaders in the field shared the great strides we have made in the past and discussed what’s next in the world of ML. You can watch the recording here.
AWS open-source news and updates – My colleague Ricardo Sueiras writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community. Read edition #133 here.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
AWS re:Invent is only 4 weeks away! Join us live in Las Vegas from November 28–December 2 for keynote announcements, training and certification opportunities, access to 1,500+ technical sessions, and much more. Seats are still available to reserve, and walk-ups are available onsite. You can also join us online to watch live keynotes and leadership sessions.
On November 2, there is a virtual event for building modern .NET applications on AWS. You can register for free.
On November 11–12, AWS User Groups in India are hosting the AWS Community Day India 2022, with success stories, use cases, and much more from industry leaders. Sign up for free to join this virtual event.
That’s all for this week. Check back next Monday for another Week in Review!
This year, and for the twelfth consecutive year, AWS has been named as a Leader in the 2022 Magic Quadrant for Cloud Infrastructure and Platform Services (CIPS). Per Gartner, AWS is the longest-running CIPS Magic Quadrant Leader.
As Jeff Bezos wrote in his first letter to shareholders in 1997 (reprinted at the end of each annual letter since then), Amazon makes decisions and weighs trade-offs differently than some companies. We focus on the long-term value rather than short-term profits, we make bold rather than timid investment decisions, and most importantly, we relentlessly focus on you: our customers. As a matter of fact, 90 percent of AWS’s roadmap for new services and capabilities is directly driven by your feedback and requests.
I work with AWS service teams every day. These teams work hard to innovate on your behalf. They make bold investments to invent, build, and operate services that help you innovate and build amazing experiences for your customers. The entire team is proud to see these efforts recognized by Gartner.
Our teams closely work with the vibrant AWS Partner Network. AWS has the largest and most dynamic community, with millions of active customers every month and more than 100,000 partners from over 150 countries—with almost 70% headquartered outside the United States. There is a real network effect when you use AWS.
The full Gartner report has details about the features and factors they reviewed. It explains the methodology used and the results. This report can serve as a guide when choosing a cloud provider that helps you innovate on behalf of your customers.
The Magic Quadrant graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from AWS. Gartner does not endorse any vendor, product or service depicted in our research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. Gartner and Magic Quadrant are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Amazon Neptune is a fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. With Neptune, you can use open and popular graph query languages to execute powerful queries that are easy to write and perform well on connected data. You can use Neptune for graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.
Neptune has always been fully managed and handles time-consuming tasks such as provisioning, patching, backup, recovery, failure detection and repair. However, managing database capacity for optimal cost and performance requires you to monitor and reconfigure capacity as workload characteristics change. Also, many applications have variable or unpredictable workloads where the volume and complexity of database queries can change significantly. For example, a knowledge graph application for social media may see a sudden spike in queries due to sudden popularity.
Introducing Amazon Neptune Serverless Today, we’re making that easier with the launch of Amazon Neptune Serverless. Neptune Serverless scales automatically as your queries and your workloads change, adjusting capacity in fine-grained increments to provide just the right amount of database resources that your application needs. In this way, you pay only for the capacity you use. You can use Neptune Serverless for development, test, and production workloads and optimize your database costs compared to provisioning for peak capacity.
With Neptune Serverless you can quickly and cost-effectively deploy graphs for your modern applications. You can start with a small graph, and as your workload grows, Neptune Serverless will automatically and seamlessly scale your graph databases to provide the performance you need. You no longer need to manage database capacity and you can now run graph applications without the risk of higher costs from over-provisioning or insufficient capacity from under-provisioning.
With Neptune Serverless, you can continue to use the same query languages (Apache TinkerPop Gremlin, openCypher, and RDF/SPARQL) and features (such as snapshots, streams, high availability, and database cloning) already available in Neptune.
Let’s see how this works in practice.
Creating an Amazon Neptune Serverless Database In the Neptune console, I choose Databases in the navigation pane and then Create database. For Engine type, I select Serverless and enter my-database as the DB cluster identifier.
I can now configure the range of capacity, expressed in Neptune capacity units (NCUs), that Neptune Serverless can use based on my workload. I can now choose a template that will configure some of the next options for me. I choose the Production template that by default creates a read replica in a different Availability Zone. The Development and Testing template would optimize my costs by not having a read replica and giving access to DB instances that provide burstable capacity.
Finally, I choose Create database. After a few minutes, the database is ready to use. In the list of databases, I choose the DB identifier to get the Writer and Reader endpoints that I am going to use later to access the database.
Using Amazon Neptune Serverless There is no difference in the way you use Neptune Serverless compared to a provisioned Neptune database. I can use any of the query languages supported by Neptune. For this walkthrough, I choose to use openCypher, a declarative query language for property graphs originally developed by Neo4j that was open-sourced in 2015 and contributed to the openCypher project.
With a property graph I can represent connected data. In this case, I want to create a simple graph that shows how some AWS services are part of a service category and implement common enterprise integration patterns.
I use curl to access the WriteropenCypher HTTPS endpoint and create a few nodes that represent patterns, services, and service categories. The following commands are split into multiple lines in order to improve readability.
This is a visual representation of the nodes and their relationships for the graph created by the previous command. The type (such as Service or Pattern) and properties (such as name) are shown inside each node. The arrows represent the relationships (such as CONTAIN or IMPLEMENT) between the nodes.
Now, I query the database to get some insights. To query the database, I can use either a Writer or a Reader endpoint. First, I want to know the name of the service implementing the “Message Queue” pattern. Note how the syntax of openCypher resembles that of SQL with MATCH instead of SELECT.
There are many options now that I have this graph database up and running. I can add more data (services, categories, patterns) and more relationships between the nodes. I can focus on my application and let Neptune Serverless manage capacity and infrastructure for me.
Availability and Pricing Amazon Neptune Serverless is available today in the following AWS Regions: US East (Ohio, N. Virginia), US West (N. California, Oregon), Asia Pacific (Tokyo), and Europe (Ireland, London).
With Neptune Serverless, you only pay for what you use. The database capacity is adjusted to provide the right amount of resources you need in terms of Neptune capacity units (NCUs). Each NCU is a combination of approximately 2 gibibytes (GiB) of memory with corresponding CPU and networking. The use of NCUs is billed per second. For more information, see the Neptune pricing page.
Having a serverless graph database opens many new possibilities. To learn more, see the Neptune Serverless documentation. Let us know what you build with this new capability!
Today I’m pleased to announce AWS Batch for Amazon Elastic Kubernetes Service (Amazon EKS). AWS Batch for Amazon EKS is ideal for customers who no longer want to shoulder the burden of configuring, fine-tuning, and managing Kubernetes clusters and pods to use with their batch processing workflows. Furthermore, there is no charge for this service. You only pay for the resources that your batch jobs launch.
When I’ve previously considered Kubernetes, it appeared to be focused on the management and hosting of microservice workloads. I was therefore surprised to discover that Kubernetes is also used by some customers to run large-scale, compute-intensive batch workloads. The differences between batch and microservice workloads mean that using Kubernetes for batch processing can be difficult and requires you to invest significant time in custom configuration and management to fine-tune a suitable solution.
Microservice and batch workloads on Kubernetes Before we look further at AWS Batch for Amazon EKS, let’s consider some of the important differences between batch and microservice workloads to help set some context on why running batch workloads on Kubernetes can be difficult:
Microservice workloads are assumed to start and not stop—we expect them to be continuously available. In contrast, batch workloads run to completion and then exit—regardless of success or failure.
The results from a batch workload might not be available for several minutes—and sometimes hours or even days. Microservice workloads are expected to respond to requests within milliseconds.
We usually deploy microservice workloads across several Availability Zones to ensure high availability. This isn’t a requirement for batch workloads. Although we might distribute a batch job to allow it to process different input data in a distributed analysis, we more typically want to prioritize fast and optimal access to resources the job needs within the Availability Zone in which it is running.
Microservice and batch workloads scale differently. For microservices, scaling is generally predictable and usually linear as load increases (or decreases). With batch workloads, you might first perform an initial, or infrequently repeated, proof-of-concept run to analyze performance and discover the correct tuning needed for a full production run. The difference in size between the two can be exponential. Furthermore, with batch workloads, we might scale to an extreme level for a run, then scale back to zero instances for long periods of time, sometimes months.
Although third-party frameworks can help with running batch workloads on Kubernetes, you can also roll your own. Whichever approach you take, significant gaps and challenges can remain in handling the undifferentiated heavy lifting of building, configuring, and maintaining custom batch solutions. Then you also need to consider the scheduling, placing, and scaling of batch workloads on Kubernetes in a cost-effective manner. So how does AWS Batch on Amazon EKS help?
AWS Batch for Amazon EKS AWS Batch for Amazon EKS offers a fully managed service to run batch workloads using clusters hosted on Amazon Elastic Compute Cloud (Amazon EC2) with no need to install and manage complex, custom batch solutions to address the differences highlighted earlier. AWS Batch provides a scheduler that controls and runs high-volume batch jobs, together with an orchestration component that evaluates when, where, and how to place jobs submitted to a queue. There’s no need for you, as the user, to coordinate any of this work—you just submit a job request into the queue.
Job queueing, dependency tracking, retries, prioritization, compute resource provisioning for Amazon Elastic Compute Cloud (EC2) and Amazon Elastic Compute Cloud (EC2) Spot, and pod submission are all handled using a serverless queue. As a managed service, AWS Batch for Amazon EKS enables you to reduce your operational and management overhead and focus instead on your business requirements. It provides integration with other services such as AWS Identity and Access Management (IAM), Amazon EventBridge, and AWS Step Functions and allows you to take advantage of other partners and tools in the Kubernetes ecosystem.
When running batch jobs on Amazon EKS clusters, AWS Batch is the main entry point to submit workload requests. Based on the queued jobs, AWS Batch then launches worker nodes in your cluster to process the jobs. These nodes are kept separate in a distinct namespace from your other node groups in Amazon EKS. Similarly, nodes in other pods are isolated from those used with AWS Batch.
How it works AWS Batch uses managed Amazon EKS clusters, which need to be registered with AWS Batch, and permissions set so that AWS Batch can launch and manage compute environments in those clusters to process jobs submitted to the queue. You can find instructions on how to launch a managed cluster that AWS Batch can use in this topic in the Amazon EKS User Guide. Instructions for configuring permissions can be found in the AWS Batch User Guide.
Once one or more clusters have been registered, and permissions set, users can submit jobs to the queue. When a job is submitted, the following actions take place to process the request:
On receiving a job request, the queue dispatches a request to the configured compute environment for resources. If an AWS Batch managed scaling group does not yet exist, one is created, and AWS Batch then starts launching Amazon Elastic Compute Cloud (EC2) instances in the group. These new instances are added to the AWS Batch Kubernetes namespace of the cluster.
The Kubernetes scheduler places any configured DaemonSet on the node.
Once the node is ready, AWS Batch starts sending pod placement requests to your cluster, using labels and taints to make the placement choices for the pods, bypassing much of the logic of the k8s scheduler.
This process is repeated, scaling as needed across more EC2 instances in the scaling group until the maximum configured capacity is reached.
If the job queue has another compute environment defined, such as one configured to use Spot instances, it will launch additional nodes in that compute environment.
Once all work is complete, AWS Batch removes the nodes from the cluster, and terminates the instances.
These steps are illustrated in the animation below.
Last week, we announced plans to launch the AWS Asia Pacific (Bangkok) Region, which will become our third AWS Region in Southeast Asia. This Region will have three Availability Zones and will give AWS customers in Thailand the ability to run workloads and store data that must remain in-country.
In the Works – AWS Region in Thailand With this big news, AWS announced a 190 billion baht (US 5 billion dollars) investment to drive Thailand’s digital future over the next 15 years. It includes capital expenditures on the construction of data centers, operational expenses related to ongoing utilities and facility costs, and the purchase of goods and services from Regional businesses.
Since we first opened an office in Bangkok in 2015, AWS has launched 10 Amazon CloudFront edge locations, a highly secure and programmable content delivery network (CDN) in Bangkok. In 2020, we launched AWS Outposts, a family of fully managed solutions delivering AWS infrastructure and services to virtually any on-premises or edge location for a truly consistent hybrid experience in Thailand. This year, we also plan the upcoming launch of an AWS Local Zone in Bangkok, which will enable customers to deliver applications that require single-digit millisecond latency to end users in Thailand.
Photo courtesy of Conor McNamara, Managing Director, ASEAN at AWS
The new AWS Region in Thailand is also part of our broader, multifaceted investment in the country, covering our local team, partners, skills, and the localization of services, including Amazon Transcribe, Amazon Translate, and Amazon Connect.
Many Thailand customers have chosen AWS to run their workloads to accelerate innovation, increase agility, and drive cost savings, such as 2C2P, CP All Plc., Digital Economy Promotion Agency, Energy Response Co. Ltd. (ENRES), PTT Global Public Company Limited (PTT), Siam Cement Group (SCG), Sukhothai Thammathirat Open University, The Stock Exchange of Thailand, Papyrus Studio, and more.
For example, Dr. Werner Vogels, CTO of Amazon.com, introduced the story of Papyrus Studio, a large film studio and one of the first customers in Thailand.
“Customer stories like Papyrus Studio inspire us at AWS. The cloud can allow a small company to rapidly scale and compete globally. It also provides new opportunities to create, innovate, and identify business opportunities that just aren’t possible with conventional infrastructure.”
For more information on how to enable AWS and get support in Thailand, contact our AWS Thailand team.
Last Week’s Launches My favorite news of last week was to launch dark mode as a beta feature in the AWS Management Console. In Unified Settings, you can choose between three settings for visual mode: Browser default, Light, and Dark. Browser default applies the default dark or light setting of the browser, dark applies the new built-in dark mode, and light maintains the current look and feel of the AWS console. Choose your favorite!
Here are some launches that caught my eye for web, mobile, and IoT application developers:
New AWS Amplify Library for Swift – We announce the general availability of Amplify Library for Swift (previously Amplify iOS). Developers can use Amplify Library for Swift via the Swift Package Manager to build apps for iOS and macOS (currently in beta) platforms with Auth, Storage, Geo, and more features.
New Amazon IVS Chat SDKs – Amazon Interactive Video Service (Amazon IVS) now provides SDKs for stream chat with support for web, Android, and iOS. The Amazon IVS stream chat SDKs support common functions for chat room resource management, sending and receiving messages, and managing chat room participants.
Amazon IVS is a managed, live-video streaming service using the broadcast SDKs or standard streaming software such as Open Broadcaster Software (OBS). The service provides cross-platform player SDKs for playback of Amazon IVS streams you need to make low-latency live video available to any viewer around the world. Also, it offers Chat Client Messaging SDK. For more information, see Getting Started with Amazon IVS Chat in the AWS documentation.
New AWS Parameters and Secrets Lambda Extension – This is new extension for AWS Lambda developers to retrieve parameters from AWS Systems Manager Parameter Store and secrets from AWS Secrets Manager. Lambda function developers can leverage this extension to improve their application performance as it decreases the latency and the cost of retrieving parameters and secrets.
New FreeRTOS Long Term Support Version – We announce the second release of FreeRTOS Long Term Support (LTS) – FreeRTOS 202210.00 LTS. FreeRTOS LTS offers a more stable foundation than standard releases as manufacturers deploy and later update devices in the field. This release includes new and upgraded libraries such as AWS IoT Fleet Provisioning, Cellular LTE-M Interface, coreMQTT, and FreeRTOS-Plus-TCP.
All libraries included in this FreeRTOS LTS version will receive security and critical bug fixes until October 2024. With an LTS release, you can continue to maintain your existing FreeRTOS code base and avoid any potential disruptions resulting from FreeRTOS version upgrades. To learn more, see the FreeRTOS announcement.
Here is some news on performance improvement and increasing capacity:
Up to 10X Improving Amazon Aurora Snapshot Exporting Speed – Amazon Aurora MySQL-Compatible Edition for MySQL 5.7 and 8.0 now speed up to 10x faster snapshot exports to Amazon S3. The performance improvement is automatically applied to all types of database snapshot exports, including manual snapshots, automated system snapshots, and snapshots created by the AWS Backup service. For more information, see Exporting DB cluster snapshot data to Amazon S3 in the Amazon Aurora documentation.
3X Increasing Amazon RDS Read Capacity – Amazon Relational Database Service (RDS) for MySQL, MariaDB, and PostgreSQL now supports 15 read replicas per instance, including up to 5 cross-Region read replicas, delivering up to 3x the previous read capacity. For more information, see Working with read replicas in the Amazon RDS documentation.
2X Increasing AWS Snowball Edge Compute Capacity – The AWS Snowball Edge Compute Optimized device doubled the compute capacity up to 104 vCPUs, doubled the memory capacity up to 416GB RAM, and is now fully SSD with 28TB NVMe storage. The updated device is ideal when you need dense compute resources to run complex workloads such as machine learning inference or video analytics at the rugged, mobile edge such as trucks, aircraft or ships. You can get started by ordering a Snowball Edge device on the AWS Snow Family console.
2X Increasing Amazon SQS FIFO Default Quota – Amazon Simple Queue Service (SQS) announces the increase of default quota up to 6,000 transactions per second per API action. It is double the previous 3,000 throughput quota for a high throughput mode for FIFO (first in, first out) queues in all AWS Regions where Amazon SQS FIFO queue is available. For a detailed breakdown of default throughput quotas per Region, see Quotas related to messages in the Amazon SQS documentation.
Sustainability with AWS Partners (ft. AWS On Air) – This episode covers a broad discipline of environmental, social, and governance (ESG) issues across all regions, organization types, and industries. AWS Sustainability & Climate Tech provides a comprehensive portfolio of AWS Partner solutions built on AWS that address climate change events and the United Nation’s Sustainable Development Goals (SDG).
Upcoming AWS Events Check your calendars and sign up for these AWS events:
AWS re:Invent 2022 Attendee Guide – Browse re:Invent 2022 attendee guides, curated by AWS Heroes, AWS industry teams, and AWS Partners. Each guide contains recommended sessions, tips and tricks for building your agenda, and other useful resources. Also, seat reservations for all sessions are now open for all re:Invent attendees. You can still register for AWS re:Invent either offline or online.
AWS AI/ML Innovation Day on October 25 – Join us for this year’s AWS AI/ML Innovation Day, where you’ll hear from Bratin Saha and other leaders in the field about the great strides AI/ML has made in the past and the promises awaiting us in the future.
AWS Container Day at Kubecon 2022 on October 25–28– Come join us at KubeCon + CloudNativeCon North America 2022, where we’ll be hosting AWS Container Day Featuring Kubernetes on October 25 and educational sessions at our booth on October 26–28. Throughout the event, our sessions focus on security, cost optimization, GitOps/multi-cluster management, hybrid and edge compute, and more.
AWS re:Invent 2022 is fast approaching, and this post can help you plan your agenda with a look at the sessions in the security track. AWS re:Invent, your opportunity to catch up on the latest technologies in cloud computing, will take place in person in Las Vegas, NV, from November 28 – December 2, 2022.
This post provides abbreviated abstracts for all of the security, identity, and compliance sessions. For the full description, visit the AWS re:Invent session catalog. If you plan to attend AWS re:Invent 2022, and you’re interested in connecting with a security, identity, or compliance product team, reach out to your AWS Account Team. Don’t have a ticket yet? Join us in Las Vegas by registering for re:Invent 2022.
Leadership session
SEC214-L: What we can learn from customers: Accelerating innovation at AWS Security CJ Moses, CISO at AWS, showcases part of the peculiar AWS culture of innovation—the working backwards process—and how new security products, services, and features are built with the customer in mind. AWS Security continuously innovates based directly on customer feedback so that organizations can accelerate their pace of innovation while integrating powerful security architecture into the heart of their business and operations.
Breakout sessions
Lecture-style presentations that cover topics at all levels (200-400) and are delivered by AWS experts, builders, customers, and partners.
SEC201: Proactive security: Considerations and approaches Security is our top priority at AWS. Discover how the partnership between builder experience and security helps everyone ship securely. Hear about the tools, mechanisms, and programs that help AWS builders and security teams.
SEC203: Revitalize your security with the AWS Security Reference Architecture As your team continually evolves its use of AWS services and features, it’s important to understand how AWS security services work together to improve your security posture. In this session, learn about the recently updated AWS Security Reference Architecture (AWS SRA), which provides prescriptive guidance for deploying the full complement of AWS security services in a multi-account environment.
SEC207: Simplify your existing workforce access with IAM Identity Center In this session, learn how to simplify operations and improve efficiencies by scaling and securing your workforce access. You can easily connect AWS IAM Identity Center (successor to AWS Single Sign-On) to your existing identity source. IAM Identity Center integrated with AWS Managed Microsoft Active Directory provides a centralized and scalable access management solution for your workplace users across multiple AWS accounts while improving the overall security posture of your organization.
SEC210: AWS and privacy engineering: Explore the possibilities Learn about the intersection of technology and governance, with an emphasis on solution building. With the privacy regulation landscape continuously changing, organizations need innovative technical solutions to help solve privacy compliance challenges. This session covers a series of unique customer challenges and explores how AWS services can be used as building blocks for privacy-enhancing solutions.
SEC212: AWS data protection: Using locks, keys, signatures, and certificates AWS offers a broad array of cryptographic tools and PKI platforms to help you navigate your data protection and digital signing needs. Discover how to get this by default and how to build your own locks, keys, signatures, and certificates when needed for your next cloud application. Learn best practices for data protection, data residency, digital sovereignty, and scalable certificate management, and get a peek into future considerations around crypto agility and encryption by default.
SEC309: Threat detection and incident response using cloud-native services Threat detection and incident response processes in the cloud have many similarities to on premises, but there are some fundamental differences. In this session, explore how cloud-native services can be used to support threat detection and incident response processes in AWS environments.
SEC310: Security alchemy: How AWS uses math to prove security AWS helps you strengthen the power of your security by using mathematical logic to answer questions about your security controls. This is known as provable security. In this session, explore the math that proves security systems of the cloud.
SEC312: Deploying egress traffic controls in production environments Private workloads that require access to resources outside of the VPC should be well monitored and managed. There are solutions that can make this easier, but selecting one requires evaluation of your security, reliability, and cost requirements. Learn how Robinhood evaluated, selected, and implemented AWS Network Firewall to shape network traffic, block threats, and detect anomalous activity on workloads that process sensitive financial data.
SEC313: Harness the power of IAM policies & rein in permissions with Access Analyzer Explore the power of IAM policies and discover how to use IAM Access Analyzer to set, verify, and refine permissions. Learn advanced skills that empower builders to apply fine-grained permissions across AWS. This session dives deep into IAM policies and explains IAM policy evaluation, policy types and their use cases, and critical access controls.
SEC327: Zero-privilege operations: Running services without access to data AWS works with organizations and regulators to host some of the most sensitive workloads in industry and government. Learn how AWS secures data, even from trusted AWS operators and services. Explore the AWS Nitro System and how it provides confidential computing and a trusted runtime environment, and dive deep into the cryptographic chains of custody that are built into AWS Identity and Access Management (IAM).
SEC329: AWS security services for container threat detection Containers are a cornerstone of many AWS customers’ application modernization strategies. The increased dependence on containers in production environments requires threat detection that is designed for container workloads. To help meet the container security and visibility needs of security and DevOps teams, new container-specific security capabilities have recently been added to Amazon GuardDuty, Amazon Inspector, and Amazon Detective. The head of cloud security at HBO Max will share container security monitoring best practices.
SEC332: Build Securely on AWS: Insights from the C-Suite Security shouldn’t be top of mind only when it’s a headline in the news. A strong security posture is a proactive one. In this panel session, hear how CISOs and CIOs are taking a proactive approach to security by building securely on AWS.
SEC403: Protecting secrets, keys, and data: Cryptography for the long term This session covers the range of AWS cryptography services and solutions, including AWS KMS, AWS CloudHSM, the AWS Encryption SDK, AWS libcrypto (AWS-LC), post-quantum hybrid algorithms, AWS FIPS accreditations, configurable security policies for Application Load Balancer and Amazon CloudFront, and more.
SEC404: A day in the life of a billion requests Every day, sites around the world authenticate their callers. That is, they verify cryptographically that the requests are actually coming from who they claim to come from. In this session, learn about unique AWS requirements for scale and security that have led to some interesting and innovative solutions to this need.
SEC405: Zero Trust: Enough talk, let’s build better security Zero Trust is a powerful new security model that produces superior security outcomes compared to the traditional network perimeter model. However, endless competing definitions and debates about what, Zero Trust is have kept many organizations’ Zero Trust efforts at or near the starting line. Hear from Delphix about how they put Zero Trust into production and the results and benefits they’ve achieved.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
SEC202: Vulnerability management with Amazon Inspector and AWS Systems Manager Join this builders’ session to learn how to use Amazon Inspector and AWS Systems Manager Patch Manager to scan and patch software vulnerabilities on Amazon EC2 instances. Walk through how to understand, prioritize, suppress, and patch vulnerabilities using AWS security services.
SEC204: Analyze your network using Amazon VPC Network Access Analyzer In this builders’ session, review how the new Amazon VPC Network Access Analyzer can help you identify network configurations that might lead to unintended network access. Learn ways that you can improve your security posture while still allowing you and your organization to be agile and flexible.
SEC211: Disaster recovery and resiliency for AWS data protection services Resiliency is a core consideration when architecting cloud workloads. Preparing and implementing disaster recovery (DR) strategies is an important step for ensuring the resiliency of your solution in the face of regional disasters. Gain hands-on experience with implementing backup-restore and active-active DR strategies when working with AWS database services like Amazon DynamoDB and Amazon Aurora and data protection services like AWS KMS, AWS Secrets Manager, and AWS Backup.
SEC303: AWS CIRT toolkit for automating incident response preparedness When it comes to life in the cloud, there’s nothing more important than security. At AWS, the Customer Incident Response Team (CIRT) creates tools to support customers during active security events and to help them anticipate and respond to events using simulations. CIRT members demonstrate best practices for using these tools to enable service logs with Assisted Log Enabler for AWS, run a security event simulation using AWS CloudSaga, and analyze logs to respond to a security event with Amazon Athena.
SEC304: Machine-to-machine authentication on AWS This session offers hands-on learning around the pros and cons of several methods of machine-to-machine authentication. Examine how to implement and use Amazon Cognito, AWS Identity and Access Management (IAM), and Amazon API Gateway to authenticate services to each other with various types of keys and certificates.
SEC305: Kubernetes threat detection and incident response automation In this hands-on session, learn how to use Amazon GuardDuty and Amazon Detective to effectively analyze Kubernetes audit logs from Amazon EKS and alert on suspicious events or malicious access such as an increase in “403 Forbidden” or “401 Unauthorized” logs.
SEC308: Deploying repeatable, secure, and compliant Amazon EKS clusters Learn how to deploy, manage, and scale containerized applications that run Kubernetes on AWS with AWS Service Catalog. Walk through how to deploy the Kubernetes control plane into a virtual private cloud, connect worker nodes to the cluster, and configure a bastion host for cluster administrative operations.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
SEC206: Security operations metrics that matter Security tooling can produce thousands of security findings to act on. But what are the most important items and metrics to focus on? Learn about a framework you can use to develop and implement security operations metrics in order to prioritize the highest-risk issues across your AWS environment.
SEC209: Continuous innovation in AWS threat detection & monitoring services AWS threat detection teams continue to innovate and improve foundational security services for proactive and early detection of security events and posture management. Learn about recent launches that address use cases like container threat detection, protection from malware, and sensitive data identification. Services covered in this session include Amazon GuardDuty, Amazon Detective, Amazon Inspector, Amazon Macie, and centralized cloud security posture assessment with AWS Security Hub.
SEC311: Securing serverless workloads on AWS Walk through design patterns for building secure serverless applications on AWS. Learn how to handle secrets with AWS Lambda extensions and AWS Secrets Manager, detect vulnerabilities in code with Amazon CodeGuru, ensure security-approved libraries are used in the code with AWS CodeArtifact, provide security assurance in code with AWS Signer, and secure APIs on Amazon API Gateway.
SEC314: Automate security analysis and code reviews with machine learning Join this chalk talk to learn how developers can use machine learning to embed security during the development phase and build guardrails to automatically flag common issues that deviate from best practices. This session is tailored to developers and security professionals who are involved in improving the security of applications during the development lifecycle.
SEC315: Security best practices for Amazon Cognito applications Customer identity and access management (CIAM) is critical when building and deploying web and mobile applications for your business. To mitigate the risks of unauthorized access, you need to implement strong identity protections by using the right security measures, such as multi-factor authentication, activity monitoring and alerts, adaptive authentication, and web firewall integration.
SEC316: Establishing trust with cryptographically attested identity Cryptographic attestation is a mechanism for systems to make provable claims of their identity and state. Dive deep on the use of cryptographic attestation on AWS, powered by technologies such as NitroTPM and AWS Nitro Enclaves to assure system integrity and establish trust between systems. Come prepared for a lively discussion as you explore various use cases, architectures, and approaches for utilizing attestation to raise the security bar for workloads on AWS.
SEC317: Implementing traffic inspection capabilities at scale on AWS Learn about a broad range of security offerings that can help you integrate firewall services into your network, including AWS WAF, AWS Network Firewall, and partner appliances used in conjunction with a Gateway Load Balancer. Learn how to choose network architectures for these firewall options to protect inbound traffic to your internet-facing applications.
SEC318: Scaling the possible: Digitizing the audit experience Do you want to increase the speed and scale of your audits? As companies expand to new industries and markets, so does the scale of regulatory compliance. AWS undergoes hundreds of audits in a year. In this chalk talk, AWS experts discuss how they digitize and automate the regulator and auditor experience. Learn about pre-audit educational training, self-service of control evidence and walkthrough information, live chats with audit control owners, and virtual data center tours.
SEC319: Prevent unintended access with AWS IAM Access Analyzer policy validation In this chalk talk, walk through several approaches to building automated AWS Identity and Access Management (IAM) policy validation into your CI/CD pipeline. Consider some tools that can be used for policy validation, including AWS IAM Access Analyzer, and learn how mechanisms like AWS CloudFormation hooks and CI/CD pipeline controls can be used to incorporate these tools into your DevSecOps workflow.
SEC320: To Europe and beyond: Architecting for EU data protection regulation Companies innovating on AWS are expanding to geographies with new data transfer and privacy challenges. Explore how to navigate compliance with EU data transfer requirements and discuss how the GDPR certification initiative can simplify GDPR compliance. Dive deep in a collaborative whiteboarding session to learn how to build GDPR-certifiable architectures.
SEC321: Building your forensics capabilities on AWS You have a compromised resource on AWS. How do you acquire evidence and artifacts? Where do you transfer the data, and how do you store it? How do you analyze it safely within an isolated environment? Walk through building a forensics lab on AWS, methods for implementing effective data acquisition and analysis, and how to make sure you are getting the most out of your investigations.
SEC322: Transform builder velocity with security Learn how AWS Support uses data to measure security and make informed decisions to grow the people side of security culture while embedding security expertise within development teams. This is empowering developers to deliver production-quality code with the highest security standards at the speed of business.
SEC324: Reimagine the security perimeter with Zero Trust Zero Trust encompasses everything from the client to the cloud, so where do you start on your journey? In this chalk talk, learn how to look at your environment through a Zero Trust lens and consider architectural patterns that you can use to redefine your security perimeter.
SEC325: Beyond database password management: 5 use cases for AWS Secrets Manager AWS Secrets Manager is integrated with AWS managed databases to make it easy for you to create, rotate, consume, and monitor database user names and passwords. This chalk talk explores how client applications use Secrets Manager to manage private keys, API keys, and generic credentials.
SEC326: Establishing a data perimeter on AWS, featuring Goldman Sachs Organizations are storing an unprecedented and increasing amount of data on AWS for a range of use cases including data lakes, analytics, machine learning, and enterprise applications. They want to prevent intentional or unintentional transfers of sensitive non-public data for unauthorized use. Hear from Goldman Sachs about how they use data perimeter controls in their AWS environment to meet their security control objectives.
SEC328: Learn to create continuous detective security controls using AWS services A risk owner needs to ensure that no matter what your organization is building in the cloud, certain security invariants are in place. While preventive controls are great, they are not always sufficient. Deploying detective controls to enable early identification of configuration issues or availability problems not only adds defense in depth, but can also help detect changes in security posture as your workloads evolve. Learn how to use services like AWS Security Hub, AWS Config, and Amazon CloudWatch Synthetics to deploy canaries and perform continuous checks.
SEC330: Harness the power of temporary credentials with IAM Roles Anywhere Get an introduction to AWS Identity and Access Management (IAM) Roles Anywhere, and dive deep into how you can use IAM Roles Anywhere to access AWS services from outside of AWS. Learn how IAM Roles Anywhere securely delivers temporary AWS credentials to your workloads.
SEC331: Security at the industrial edge Industrial organizations want to process data and take actions closer to their machines at the edge, and they need innovative and highly distributed patterns for keeping their critical information and cyber-physical systems safe. In modern industrial environments, the exponential growth of IoT and edge devices brings enormous benefits but also introduces new risks.
SEC333: Designing compliance as a code with AWS security services Supporting regulatory compliance and mitigating security risks is imperative for most organizations. Addressing these challenges at scale requires automated solutions to identify compliance gaps and take continuous proactive measures. Hear about the architecture of compliance monitoring and remediation solutions, based on the example of the CPS 234 Information Security guidelines of the Australian Prudential Regulatory Authority (APRA), which are mandated for the financial services industry in Australia and New Zealand.
SEC334: Understanding the evolution of cloud-based PKI use cases Since AWS Private Certificate Authority (CA) launched in 2018, the service has evolved based on user needs. This chalk talk starts with a primer on certificate use for securing network connections and information. Learn about the predominant ways AWS customers are using ACM Private CA, and explore new use cases, including identifying IoT devices, customer-managed Kubernetes, and on premises.
SEC402: The anatomy of a ransomware event targeting data residing in Amazon S3 Ransomware events can cost governments, nonprofits, and businesses billions of dollars and interrupt operations. Early detection and automated responses are important steps that can limit your organization’s exposure. Walk through the anatomy of a ransomware event that targets data residing in Amazon S3 and hear detailed best practices for detection, response, recovery, and protection.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
SEC208: Executive security simulation This workshop features an executive security simulation, designed to take senior security management and IT or business executive teams through an experiential exercise that illuminates key decision points for a successful and secure cloud journey. During this team-based, game-like simulation, use an industry case study to make strategic security, risk, and compliance decisions and investments.
SEC301: Threat detection and response workshop This workshop takes you through threat detection and response using Amazon GuardDuty, AWS Security Hub, and Amazon Inspector. The workshop simulates different threats to Amazon S3, AWS Identity and Access Management (IAM), Amazon EKS, and Amazon EC2 and illustrates both manual and automated responses with AWS Lambda. Learn how to operationalize security findings.
SEC302: AWS Network Firewall and DNS Firewall security in multi-VPC architectures This workshop guides participants through configuring AWS Network Firewall and Amazon Route 53 Resolver DNS Firewall in an AWS multi-VPC environment. It demonstrates how VPCs can be interconnected with a centralized AWS Network Firewall and DNS Firewall configuration to ease the governance requirements of network security.
SEC306: Building a data perimeter to allow access to authorized users In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different AWS Identity and Access Management (IAM) principle or network control.
SEC307: Ship securely: Automated security testing for developers Learn how to build automated security testing into your CI/CD pipelines using AWS services and open-source tools. The workshop highlights how to identify and mitigate common risks early in the development cycle and also covers how to incorporate code review steps.
SEC323: Data discovery and classification on AWS Learn how to use Amazon Macie to discover and classify data in your Amazon S3 buckets. Dive deep into best practices as you follow the process of setting up Macie. Also use AWS Security Hub custom actions to set up a manual remediation, and investigate how to perform automated remediation using Amazon EventBridge and AWS Lambda.
SEC401: AWS Identity and Access Management (IAM) policy evaluation in action Dive deep into the logic of AWS Identity and Access Management (IAM) policy evaluation. Gain experience with hands-on labs that walk through IAM use cases and learn how different policies interact with each other.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


























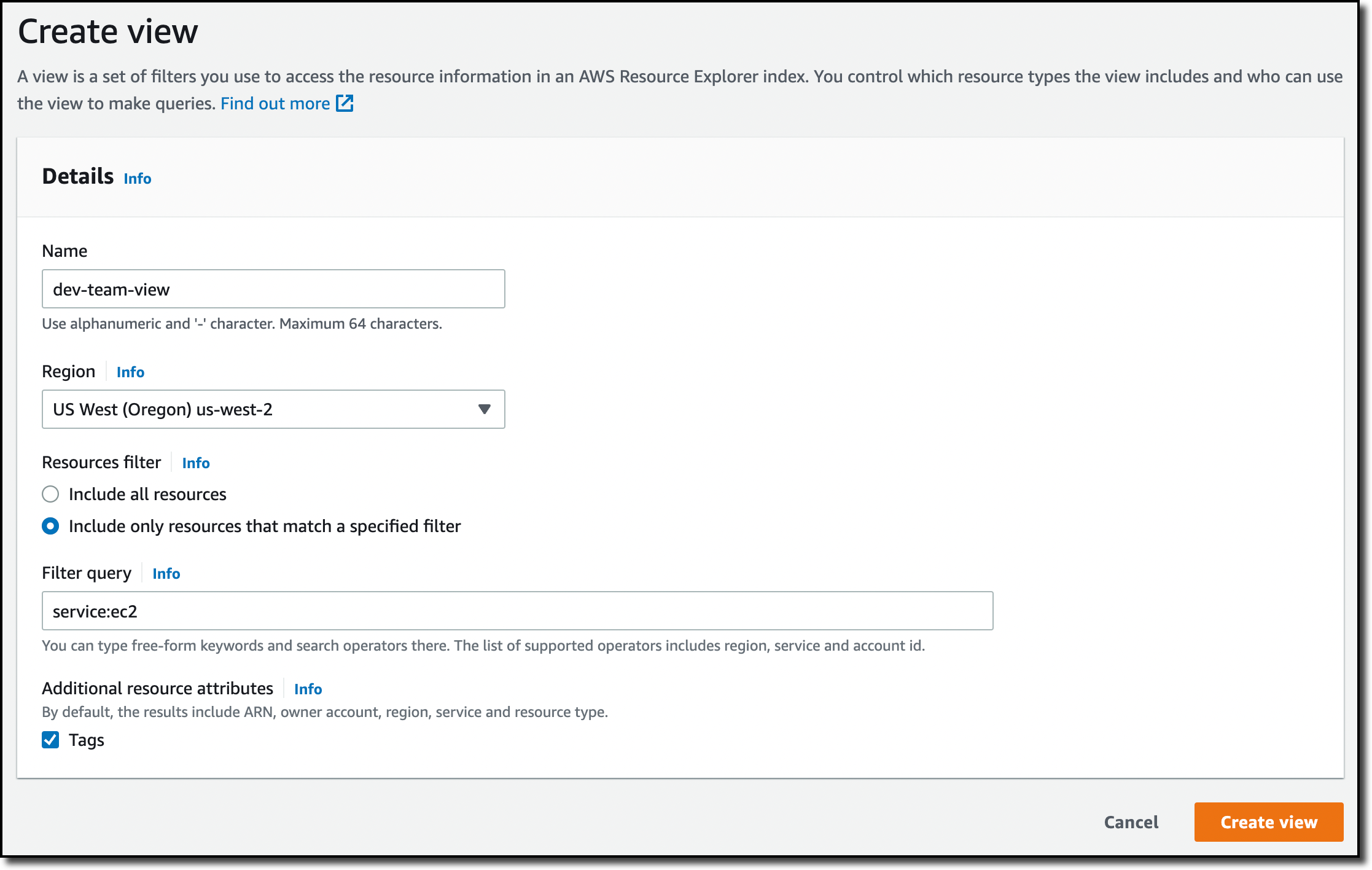
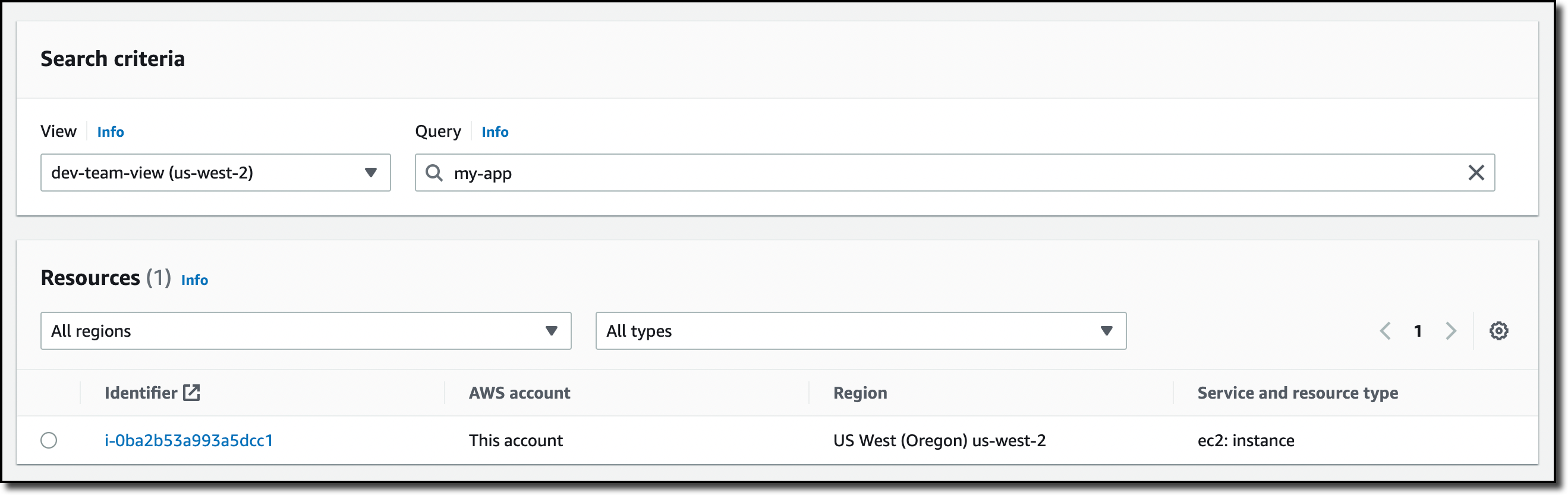




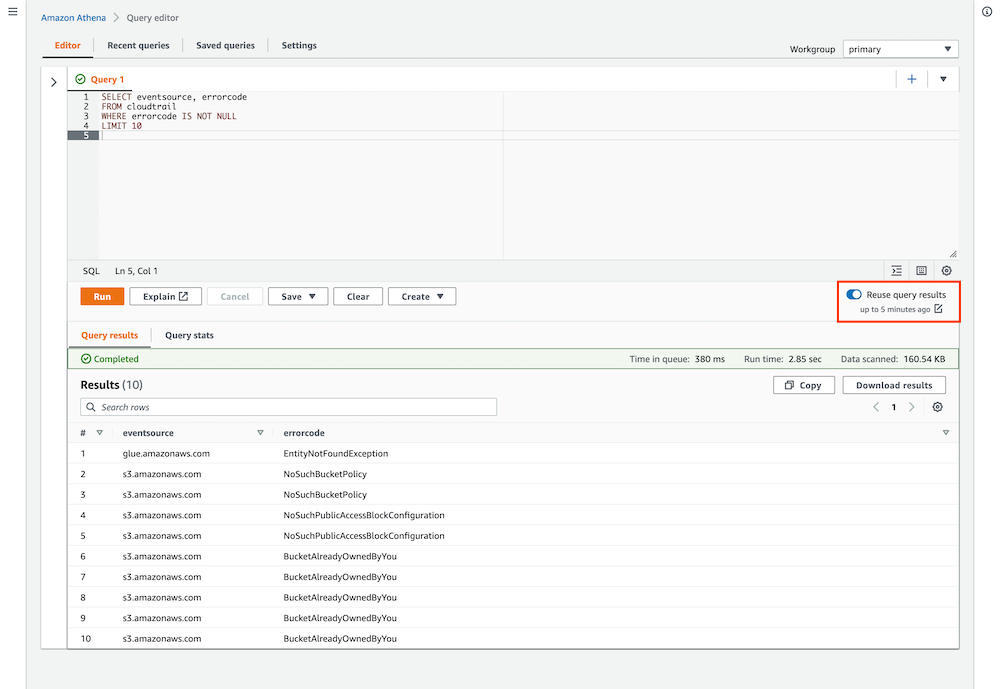


 Applying new deliverability features is simple in the AWS console. Senders can log into their SES account dashboard to enable the virtual deliverability manager features. The features are billed as monthly subscription and can be turned on or off at any time. Once the features are activated, SES provides deliverability insights and recommendations in real time, allowing senders to improve performance of future sending batches or campaigns. Senders using Simple Email Service (SES) get reliable, scalable email at the lowest industry prices. SES is backed by AWS’ data security, and email through SES supports compliance with HIPAA-eligible, FedRAMP-, GDPR-, and ISO-certified options.
Applying new deliverability features is simple in the AWS console. Senders can log into their SES account dashboard to enable the virtual deliverability manager features. The features are billed as monthly subscription and can be turned on or off at any time. Once the features are activated, SES provides deliverability insights and recommendations in real time, allowing senders to improve performance of future sending batches or campaigns. Senders using Simple Email Service (SES) get reliable, scalable email at the lowest industry prices. SES is backed by AWS’ data security, and email through SES supports compliance with HIPAA-eligible, FedRAMP-, GDPR-, and ISO-certified options.