Seems that there is a deliberate backdoor in the twenty-year-old TErrestrial Trunked RAdio (TETRA) standard used by police forces around the world.
The European Telecommunications Standards Institute (ETSI), an organization that standardizes technologies across the industry, first created TETRA in 1995. Since then, TETRA has been used in products, including radios, sold by Motorola, Airbus, and more. Crucially, TETRA is not open-source. Instead, it relies on what the researchers describe in their presentation slides as “secret, proprietary cryptography,” meaning it is typically difficult for outside experts to verify how secure the standard really is.
The researchers said they worked around this limitation by purchasing a TETRA-powered radio from eBay. In order to then access the cryptographic component of the radio itself, Wetzels said the team found a vulnerability in an interface of the radio.
[…]
Most interestingly is the researchers’ findings of what they describe as the backdoor in TEA1. Ordinarily, radios using TEA1 used a key of 80-bits. But Wetzels said the team found a “secret reduction step” which dramatically lowers the amount of entropy the initial key offered. An attacker who followed this step would then be able to decrypt intercepted traffic with consumer-level hardware and a cheap software defined radio dongle.
Looks like the encryption algorithm was intentionally weakened by intelligence agencies to facilitate easy eavesdropping.
Specifically on the researchers’ claims of a backdoor in TEA1, Boyer added “At this time, we would like to point out that the research findings do not relate to any backdoors. The TETRA security standards have been specified together with national security agencies and are designed for and subject to export control regulations which determine the strength of the encryption.”
And I would like to point out that that’s the very definition of a backdoor.
Why aren’t we done with secret, proprietary cryptography? It’s just not a good idea.
New research suggests that AIs can produce perfectly secure steganographic images:
Abstract: Steganography is the practice of encoding secret information into innocuous content in such a manner that an adversarial third party would not realize that there is hidden meaning. While this problem has classically been studied in security literature, recent advances in generative models have led to a shared interest among security and machine learning researchers in developing scalable steganography techniques. In this work, we show that a steganography procedure is perfectly secure under Cachin (1998)’s information theoretic-model of steganography if and only if it is induced by a coupling. Furthermore, we show that, among perfectly secure procedures, a procedure is maximally efficient if and only if it is induced by a minimum entropy coupling. These insights yield what are, to the best of our knowledge, the first steganography algorithms to achieve perfect security guarantees with non-trivial efficiency; additionally, these algorithms are highly scalable. To provide empirical validation, we compare a minimum entropy coupling-based approach to three modern baselines—arithmetic coding, Meteor, and adaptive dynamic grouping—using GPT-2, WaveRNN, and Image Transformer as communication channels. We find that the minimum entropy coupling-based approach achieves superior encoding efficiency, despite its stronger security constraints. In aggregate, these results suggest that it may be natural to view information-theoretic steganography through the lens of minimum entropy coupling.
AWS is excited to announce a new eBook, 5 Keys to Secure Enterprise Messaging. The new eBook includes best practices for addressing the security and compliance risks associated with messaging apps.
An estimated 3.09 billion mobile phone users access messaging apps to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
Legal and regulatory requirements for data protection, privacy, and data retention have made protecting business communications a priority for organizations across the globe. Although consumer messaging apps are convenient and support real-time communication with colleagues, customers, and partners, they often lack the robust security and administrative controls many businesses require.
The eBook details five keys to secure enterprise messaging that balance people, process, and technology.
We encourage you to read the eBook, and learn about:
Establishing messaging policies and guidelines that are effective for your workforce
Training employees to use messaging apps in a way that doesn’t increase organizational risk
Building a security-first culture
Using true end-to-end encryption (E2EE) to secure communications
Retaining data to help meet requirements, without exposing it to outside parties
In an open letter, seven secure messaging apps—including Signal and WhatsApp—point out that the UK’s Online Safety Bill could destroy end-to-end encryption:
As currently drafted, the Bill could break end-to-end encryption,opening the door to routine, general and indiscriminate surveillance of personal messages of friends, family members, employees, executives, journalists, human rights activists and even politicians themselves, which would fundamentally undermine everyone’s ability to communicate securely.
The Bill provides no explicit protection for encryption, and if implemented as written, could empower OFCOM to try to force the proactive scanning of private messages on end-to-end encrypted communication services—nullifying the purpose of end-to-end encryption as a result and compromising the privacy of all users.
In short, the Bill poses an unprecedented threat to the privacy, safety and security of every UK citizen and the people with whom they communicate around the world, while emboldening hostile governments who may seek to draft copy-cat laws.
Both Signal and WhatsApp have said that they will cease services in the UK rather than compromise the security of their users worldwide.
Researchers have just published a side-channel attack—using power consumption—against an implementation of the algorithm that was supposed to be resistant against that sort of attack.
The algorithm is not “broken” or “cracked”—despite headlines to the contrary—this is just a side-channel attack. What makes this work really interesting is that the researchers used a machine-learning model to train the system to exploit the side channel.
Given the pace of Amazon Web Services (AWS) innovation, it can be challenging to stay up to date on the latest AWS service and feature launches. AWS provides services and tools to help you protect your data, accounts, and workloads from unauthorized access. AWS data protection services provide encryption capabilities, key management, and sensitive data discovery. Last year, we saw growth and evolution in AWS data protection services as we continue to give customers features and controls to help meet their needs. Protecting data in the AWS Cloud is a top priority because we know you trust us to help protect your most critical and sensitive asset: your data. This post will highlight some of the key AWS data protection launches in the last year that security professionals should be aware of.
AWS Key Management Service Create and control keys to encrypt or digitally sign your data
In April, AWS Key Management Service (AWS KMS) launched hash-based message authentication code (HMAC) APIs. This feature introduced the ability to create AWS KMS keys that can be used to generate and verify HMACs. HMACs are a powerful cryptographic building block that incorporate symmetric key material within a hash function to create a unique keyed message authentication code. HMACs provide a fast way to tokenize or sign data such as web API requests, credit card numbers, bank routing information, or personally identifiable information (PII). This technology is used to verify the integrity and authenticity of data and communications. HMACs are often a higher performing alternative to asymmetric cryptographic methods like RSA or elliptic curve cryptography (ECC) and should be used when both message senders and recipients can use AWS KMS.
At AWS re:Invent in November, AWS KMS introduced the External Key Store (XKS), a new feature for customers who want to protect their data with encryption keys that are stored in an external key management system under their control. This capability brings new flexibility for customers to encrypt or decrypt data with cryptographic keys, independent authorization, and audit in an external key management system outside of AWS. XKS can help you address your compliance needs where encryption keys for regulated workloads must be outside AWS and solely under your control. To provide customers with a broad range of external key manager options, AWS KMS developed the XKS specification with feedback from leading key management and hardware security module (HSM) manufacturers as well as service providers that can help customers deploy and integrate XKS into their AWS projects.
AWS Nitro System A combination of dedicated hardware and a lightweight hypervisor enabling faster innovation and enhanced security
In November, we published The Security Design of the AWS Nitro System whitepaper. The AWS Nitro System is a combination of purpose-built server designs, data processors, system management components, and specialized firmware that serves as the underlying virtualization technology that powers all Amazon Elastic Compute Cloud (Amazon EC2) instances launched since early 2018. This new whitepaper provides you with a detailed design document that covers the inner workings of the AWS Nitro System and how it is used to help secure your most critical workloads. The whitepaper discusses the security properties of the Nitro System, provides a deeper look into how it is designed to eliminate the possibility of AWS operator access to a customer’s EC2 instances, and describes its passive communications design and its change management process. Finally, the paper surveys important aspects of the overall system design of Amazon EC2 that provide mitigations against potential side-channel vulnerabilities that can exist in generic compute environments.
AWS Secrets Manager Centrally manage the lifecycle of secrets
In February, AWS Secrets Manager added the ability to schedule secret rotations within specific time windows. Previously, Secrets Manager supported automated rotation of secrets within the last 24 hours of a specified rotation interval. This new feature added the ability to limit a given secret rotation to specific hours on specific days of a rotation interval. This helps you avoid having to choose between the convenience of managed rotations and the operational safety of application maintenance windows. In November, Secrets Manager also added the capability to rotate secrets as often as every four hours, while providing the same managed rotation experience.
In May, Secrets Manager started publishing secrets usage metrics to Amazon CloudWatch. With this feature, you have a streamlined way to view how many secrets you are using in Secrets Manager over time. You can also set alarms for an unexpected increase or decrease in number of secrets.
At the end of December, Secrets Manager added support for managed credential rotation for service-linked secrets. This feature helps eliminate the need for you to manage rotation Lambda functions and enables you to set up rotation without additional configuration. Amazon Relational Database Service (Amazon RDS) has integrated with this feature to streamline how you manage your master user password for your RDS database instances. Using this feature can improve your database’s security by preventing the RDS master user password from being visible during the database creation workflow. Amazon RDS fully manages the master user password’s lifecycle and stores it in Secrets Manager whenever your RDS database instances are created, modified, or restored. To learn more about how to use this feature, see Improve security of Amazon RDS master database credentials using AWS Secrets Manager.
AWS Private Certificate Authority Create private certificates to identify resources and protect data
In September, AWS Private Certificate Authority (AWS Private CA) launched as a standalone service. AWS Private CA was previously a feature of AWS Certificate Manager (ACM). One goal of this launch was to help customers differentiate between ACM and AWS Private CA. ACM and AWS Private CA have distinct roles in the process of creating and managing the digital certificates used to identify resources and secure network communications over the internet, in the cloud, and on private networks. This launch coincided with the launch of an updated console for AWS Private CA, which includes accessibility improvements to enhance screen reader support and additional tab key navigation for people with motor impairment.
In October, AWS Private CA introduced a short-lived certificate mode, a lower-cost mode of AWS Private CA that is designed for issuing short-lived certificates. With this new mode, public key infrastructure (PKI) administrators, builders, and developers can save money when issuing certificates where a validity period of 7 days or fewer is desired. To learn more about how to use this feature, see How to use AWS Private Certificate Authority short-lived certificate mode.
Additionally, AWS Private CA supported the launches of certificate-based authentication with Amazon AppStream 2.0 and Amazon WorkSpaces to remove the logon prompt for the Active Directory domain password. AppStream 2.0 and WorkSpaces certificate-based authentication integrates with AWS Private CA to automatically issue short-lived certificates when users sign in to their sessions. When you configure your private CA as a third-party root CA in Active Directory or as a subordinate to your Active Directory Certificate Services enterprise CA, AppStream 2.0 or WorkSpaces with AWS Private CA can enable rapid deployment of end-user certificates to seamlessly authenticate users. To learn more about how to use this feature, see How to use AWS Private Certificate Authority short-lived certificate mode.
AWS Certificate Manager Provision and manage SSL/TLS certificates with AWS services and connected resources
In early November, ACM launched the ability to request and use Elliptic Curve Digital Signature Algorithm (ECDSA) P-256 and P-384 TLS certificates to help secure your network traffic. You can use ACM to request ECDSA certificates and associate the certificates with AWS services like Application Load Balancer or Amazon CloudFront. Previously, you could only request certificates with an RSA 2048 key algorithm from ACM. Now, AWS customers who need to use TLS certificates with at least 120-bit security strength can use these ECDSA certificates to help meet their compliance needs. The ECDSA certificates have a higher security strength—128 bits for P-256 certificates and 192 bits for P-384 certificates—when compared to 112-bit RSA 2048 certificates that you can also issue from ACM. The smaller file footprint of ECDSA certificates makes them ideal for use cases with limited processing capacity, such as small Internet of Things (IoT) devices.
Amazon Macie Discover and protect your sensitive data at scale
Amazon Macie introduced two major features at AWS re:Invent. The first is a new capability that allows for one-click, temporary retrieval of up to 10 samples of sensitive data found in Amazon Simple Storage Service (Amazon S3). With this new capability, you can more readily view and understand which contents of an S3 object were identified as sensitive, so you can review, validate, and quickly take action as needed without having to review every object that a Macie job returned. Sensitive data samples captured with this new capability are encrypted by using customer-managed AWS KMS keys and are temporarily viewable within the Amazon Macie console after retrieval.
Additionally, Amazon Macie introduced automated sensitive data discovery, a new feature that provides continual, cost-efficient, organization-wide visibility into where sensitive data resides across your Amazon S3 estate. With this capability, Macie automatically samples and analyzes objects across your S3 buckets, inspecting them for sensitive data such as personally identifiable information (PII) and financial data; builds an interactive data map of where your sensitive data in S3 resides across accounts; and provides a sensitivity score for each bucket. Macie uses multiple automated techniques, including resource clustering by attributes such as bucket name, file types, and prefixes, to minimize the data scanning needed to uncover sensitive data in your S3 buckets. This helps you continuously identify and remediate data security risks without manual configuration and lowers the cost to monitor for and respond to data security risks.
Support for new open source encryption libraries
In February, we announced the availability of s2n-quic, an open source Rust implementation of the QUIC protocol, in our AWS encryption open source libraries. QUIC is a transport layer network protocol used by many web services to provide lower latencies than classic TCP. AWS has long supported open source encryption libraries for network protocols; in 2015 we introduced s2n-tls as a library for implementing TLS over HTTP. The name s2n is short for signal to noise and is a nod to the act of encryption—disguising meaningful signals, like your critical data, as seemingly random noise. Similar to s2n-tls, s2n-quic is designed to be small and fast, with simplicity as a priority. It is written in Rust, so it has some of the benefits of that programming language, such as performance, threads, and memory safety.
Cryptographic computing for AWS Clean Rooms (preview)
At re:Invent, we also announced AWS Clean Rooms, currently in preview, which includes a cryptographic computing feature that allows you to run a subset of queries on encrypted data. Clean rooms help customers and their partners to match, analyze, and collaborate on their combined datasets—without sharing or revealing underlying data. If you have data handling policies that require encryption of sensitive data, you can pre-encrypt your data by using a common collaboration-specific encryption key so that data is encrypted even when queries are run. With cryptographic computing, data that is used in collaborative computations remains encrypted at rest, in transit, and in use (while being processed).
With AWS, you control your data by using powerful AWS services and tools to determine where your data is stored, how it is secured, and who has access to it. In 2023, we will further the AWS Digital Sovereignty Pledge, our commitment to offering AWS customers the most advanced set of sovereignty controls and features available in the cloud.
You can join us at our security learning conference, AWS re:Inforce 2023, in Anaheim, CA, June 13–14, for the latest advancements in AWS security, compliance, identity, and privacy solutions.
The team of computer scientist George Lasry, pianist Norbert Biermann and astrophysicist Satoshi Tomokiyo—all keen cryptographers—initially thought the batch of encoded documents related to Italy, because that was how they were filed at the Bibliothèque Nationale de France.
However, they quickly realised the letters were in French. Many verb and adjectival forms being feminine, regular mention of captivity, and recurring names—such as Walsingham—all put them on the trail of Mary. Sir Francis Walsingham was Queen Elizabeth’s spymaster.
The code was a simple replacement system in which symbols stand either for letters, or for common words and names. But it would still have taken centuries to crunch all the possibilities, so the team used an algorithm that homed in on likely solutions.
Over the last few years, there has been a rise in the number of attacks that affect how a computer boots. Most modern computers use a specification called Unified Extensible Firmware Interface (UEFI) that defines a software interface between an operating system (e.g. Windows) and platform firmware (e.g. disk drives, video cards). There are security mechanisms built into UEFI that ensure that platform firmware can be cryptographically validated and boot securely through an application called a bootloader. This firmware is stored in non-volatile SPI flash memory on the motherboard, so it persists on the system even if the operating system is reinstalled and drives are replaced.
This creates a ‘trust anchor’ used to validate each stage of the boot process, but, unfortunately, this trust anchor is also a target for attack. In these UEFI attacks, malicious actions are loaded onto a compromised device early in the boot process. This means that malware can change configuration data, establish persistence by ‘implanting’ itself, and can bypass security measures that are only loaded at the operating system stage. So, while UEFI-anchored secure boot protects the bootloader from bootloader attacks, it does not protect the UEFI firmware itself.
Because of this growing trend of attacks, we began the process of cryptographically signing our UEFI firmware as a mitigation step. While our existing solution is platform specific to our x86 AMD server fleet, we did not have a similar solution to UEFI firmware signing for Arm. To determine what was missing, we had to take a deep dive into the Arm secure boot process.
Read on to learn about the world of Arm Trusted Firmware Secure Boot.
Arm Trusted Firmware Secure Boot
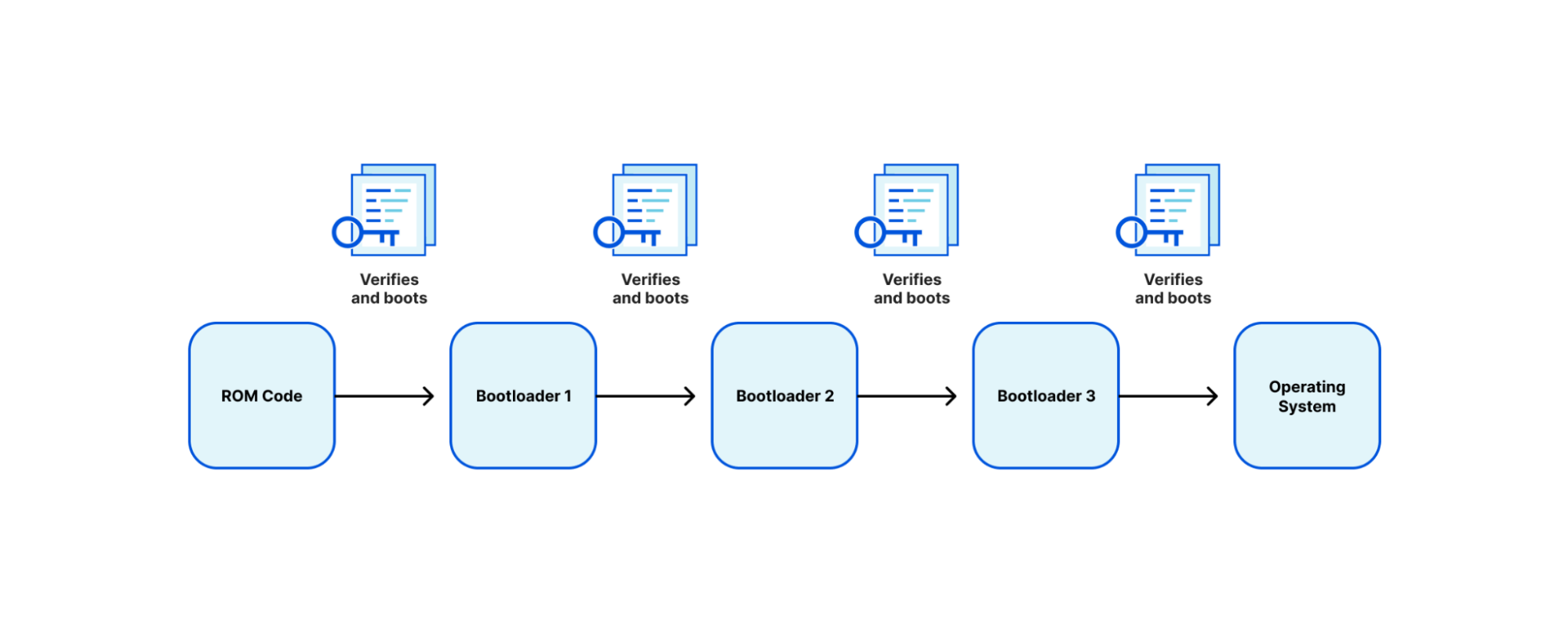
Arm defines a trusted boot process through an architecture called Trusted Board Boot Requirements (TBBR), or Arm Trusted Firmware (ATF) Secure Boot. TBBR works by authenticating a series of cryptographically signed binary images each containing a different stage or element in the system boot process to be loaded and executed. Every bootloader (BL) stage accomplishes a different stage in the initialization process:
BL1
BL1 defines the boot path (is this a cold boot or warm boot), initializes the architectures (exception vectors, CPU initialization, and control register setup), and initializes the platform (enables watchdog processes, MMU, and DDR initialization).
BL2
BL2 prepares initialization of the Arm Trusted Firmware (ATF), the stack responsible for setting up the secure boot process. After ATF setup, the console is initialized, memory is mapped for the MMU, and message buffers are set for the next bootloader.
BL3
The BL3 stage has multiple parts, the first being initialization of runtime services that are used in detecting system topology. After initialization, there is a handoff between the ATF ‘secure world’ boot stage to the ‘normal world’ boot stage that includes setup of UEFI firmware. Context is set up to ensure that no secure state information finds its way into the normal world execution state.
Each image is authenticated by a public key, which is stored in a signed certificate and can be traced back to a root key stored on the SoC in one time programmable (OTP) memory or ROM.
TBBR was originally designed for cell phones. This established a reference architecture on how to build a “Chain of Trust” from the first ROM executed (BL1) to the handoff to “normal world” firmware (BL3). While this creates a validated firmware signing chain, it has caveats:
SoC manufacturers are heavily involved in the secure boot chain, while the customer has little involvement.
A unique SoC SKU is required per customer. With one customer this could be easy, but most manufacturers have thousands of SKUs
The SoC manufacturer is primarily responsible for end-to-end signing and maintenance of the PKI chain. This adds complexity to the process requiring USB key fobs for signing.
Doesn’t scale outside the manufacturer.
What this tells us is what was built for cell phones doesn’t scale for servers.
If we were involved 100% in the manufacturing process, then this wouldn’t be as much of an issue, but we are a customer and consumer. As a customer, we have a lot of control of our server and block design, so we looked at design partners that would take some of the concepts we were able to implement with AMD Platform Secure Boot and refine them to fit Arm CPUs.
Amping it up
We partnered with Ampere and tested their Altra Max single socket rack server CPU (code named Mystique) that provides high performance with incredible power efficiency per core, much of what we were looking for in reducing power consumption. These are only a small subset of specs, but Ampere backported various features into the Altra Max notably, speculative attack mitigations that include Meltdown and Spectre (variants 1 and 2) from the Armv8.5 instruction set architecture, giving Altra the “+” designation in their ISA.
Ampere does implement a signed boot process similar to the ATF signing process mentioned above, but with some slight variations. We’ll explain it a bit to help set context for the modifications that we made.
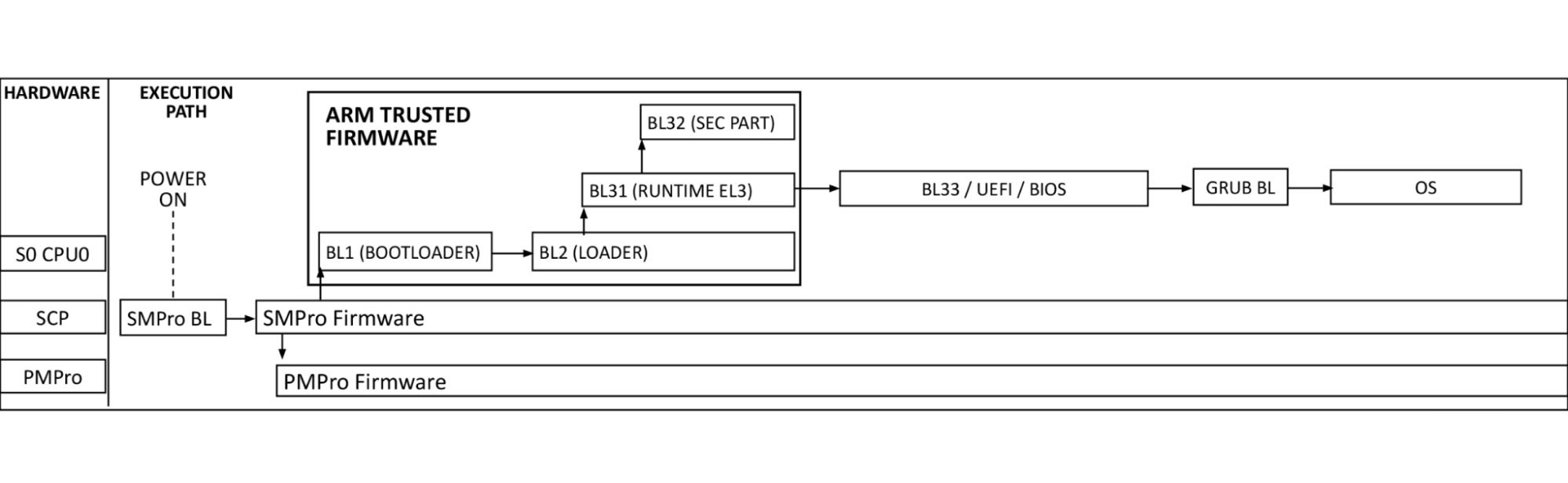
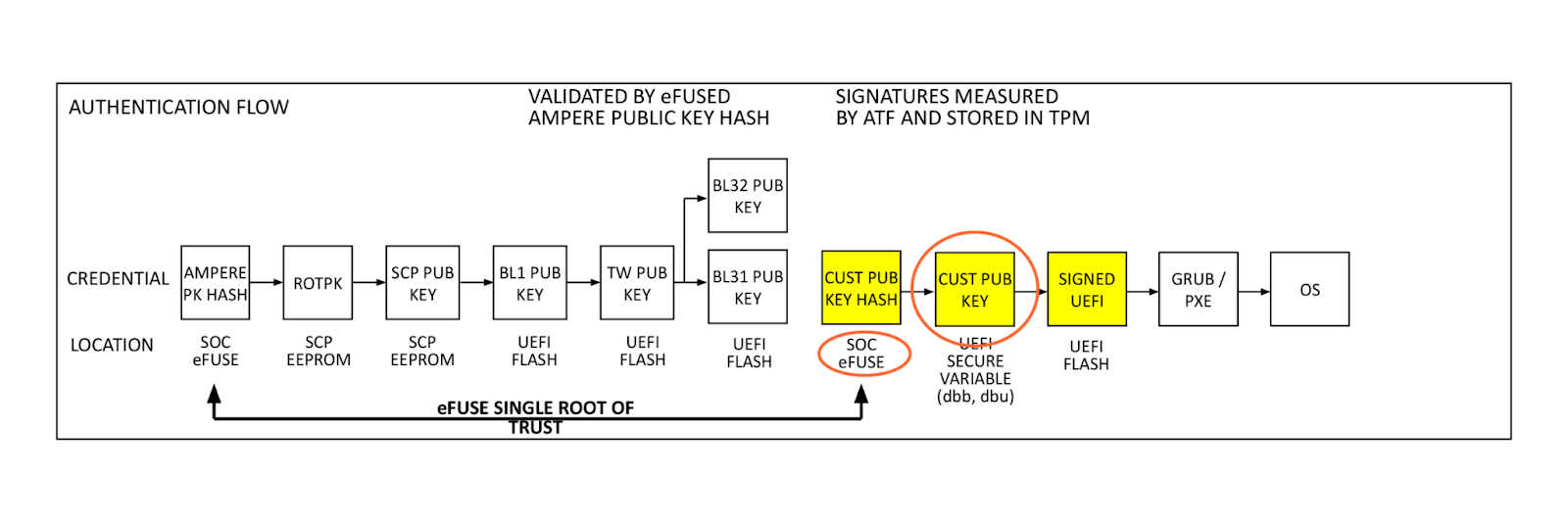
Ampere Secure Boot
The diagram above shows the Arm processor boot sequence as implemented by Ampere. System Control Processors (SCP) are comprised of the System Management Processor (SMpro) and the Power Management Processor (PMpro). The SMpro is responsible for features such as secure boot and bmc communication while the PMpro is responsible for power features such as Dynamic Frequency Scaling and on-die thermal monitoring.
At power-on-reset, the SCP runs the system management bootloader from ROM and loads the SMpro firmware. After initialization, the SMpro spawns the power management stack on the PMpro and ATF threads. The ATF BL2 and BL31 bring up processor resources such as DRAM, and PCIe. After this, control is passed to BL33 BIOS.
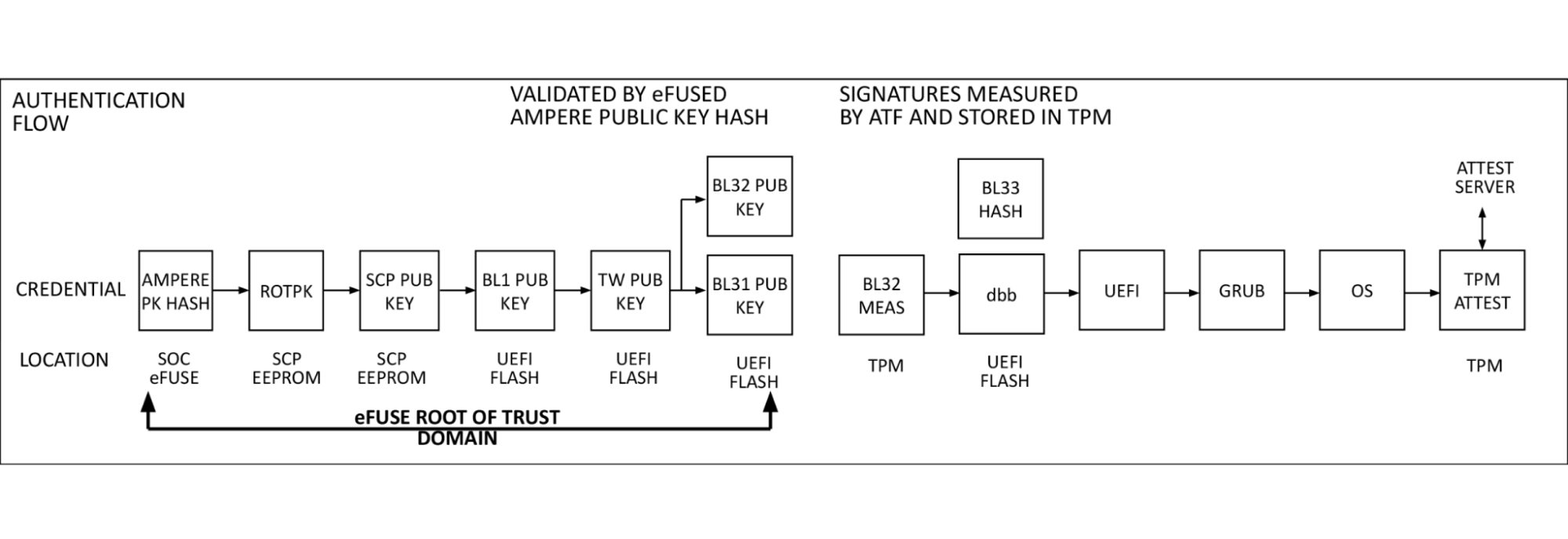
Authentication flow
At power on, the SMpro firmware reads Ampere’s public key (ROTPK) from the SMpro key certificate in SCP EEPROM, computes a hash and compares this to Ampere’s public key hash stored in eFuse. Once authenticated, Ampere’s public key is used to decrypt key and content certificates for SMpro, PMpro, and ATF firmware, which are launched in the order described above.
The SMpro public key will be used to authenticate the SMpro and PMpro images and ATF keys which in turn will authenticate ATF images. This cascading set of authentication that originates with the Ampere root key and stored in chip called an electronic fuse, or eFuse. An eFuse can be programmed only once, setting the content to be read-only and can not be tampered with nor modified.
This is the original hardware root of trust used for signing system, secure world firmware. When we looked at this, after referencing the signing process we had with AMD PSB and knowing there was a large enough one-time-programmable (OTP) region within the SoC, we thought: why can’t we insert our key hash in here?
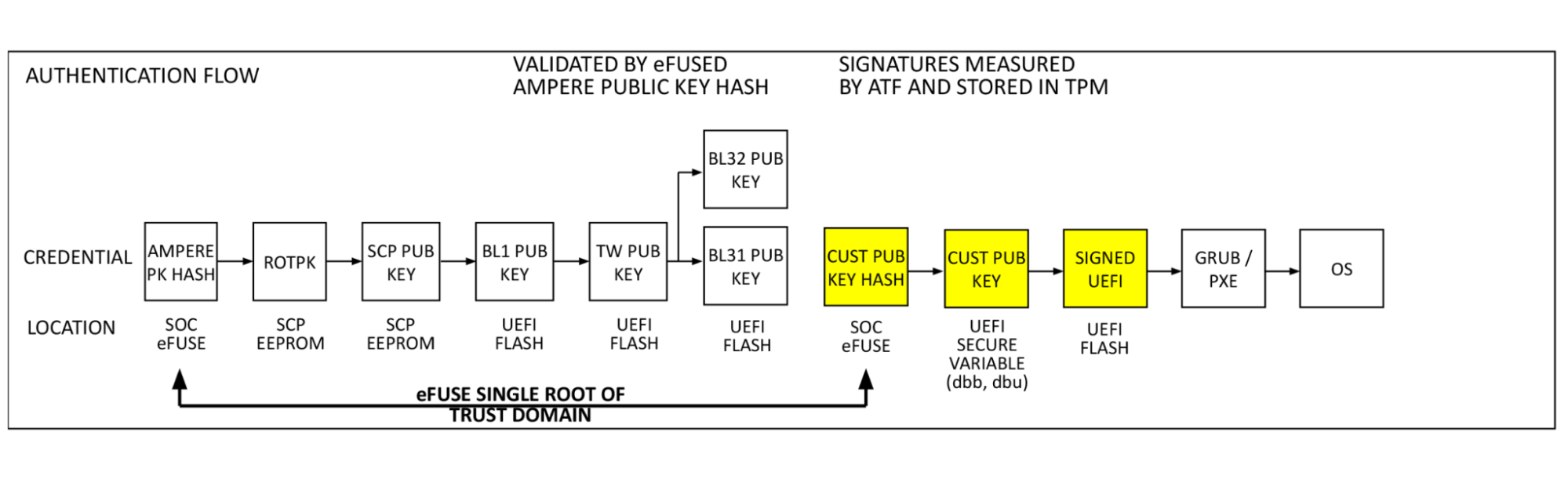
Single Domain Secure Boot
Single Domain Secure Boot takes the same authentication flow and adds a hash of the customer public key (Cloudflare firmware signing key in this case) to the eFuse domain. This enables the verification of UEFI firmware by a hardware root of trust. This process is performed in the already validated ATF firmware by BL2. Our public key (dbb) is read from UEFI secure variable storage, a hash is computed and compared to the public key hash stored in eFuse. If they match, the validated public key is used to decrypt the BL33 content certificate, validating and launching the BIOS, and remaining boot items. This is the key feature added by SDSB. It validates the entire software boot chain with a single eFuse root of trust on the processor.
Building blocks
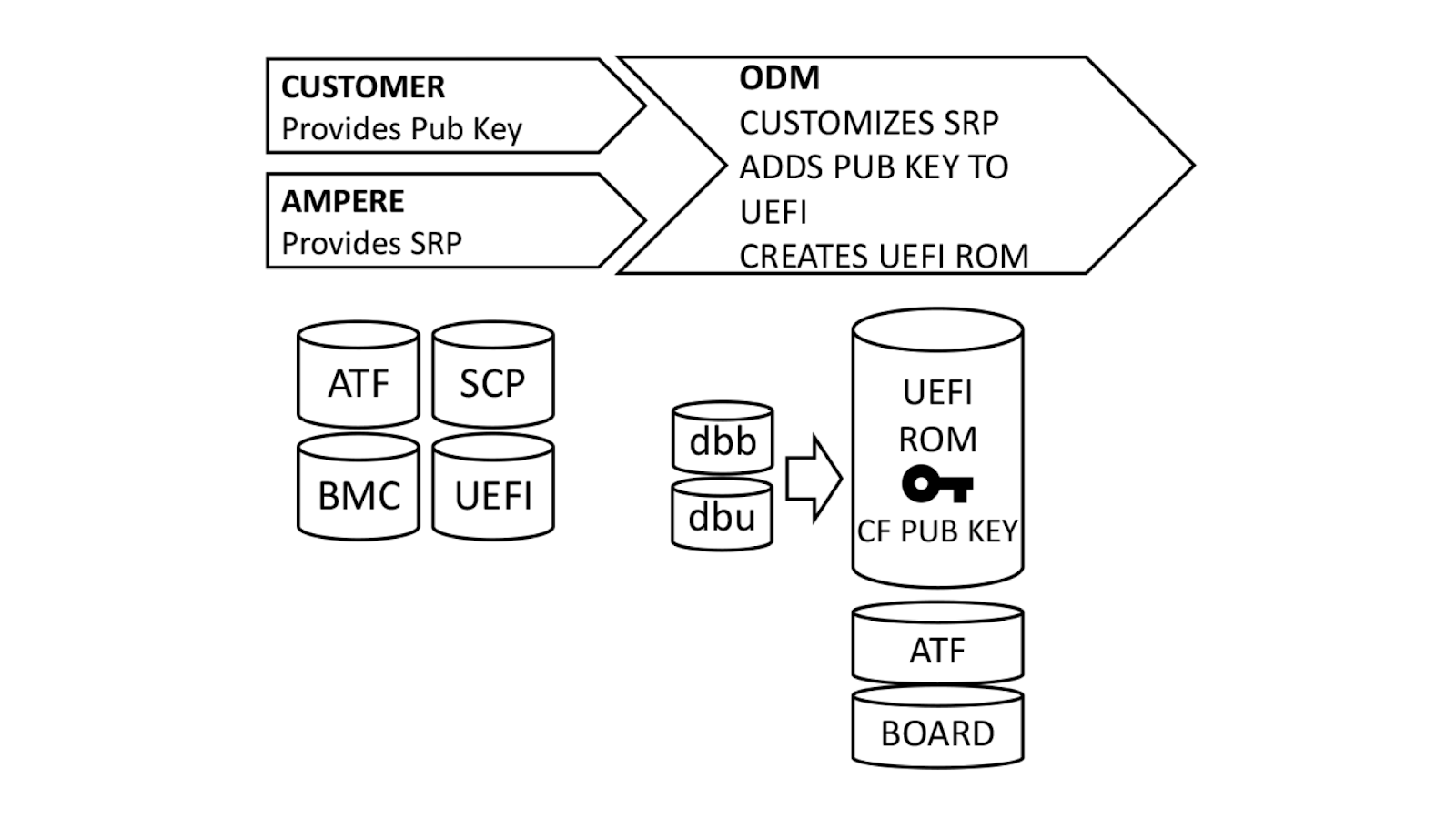
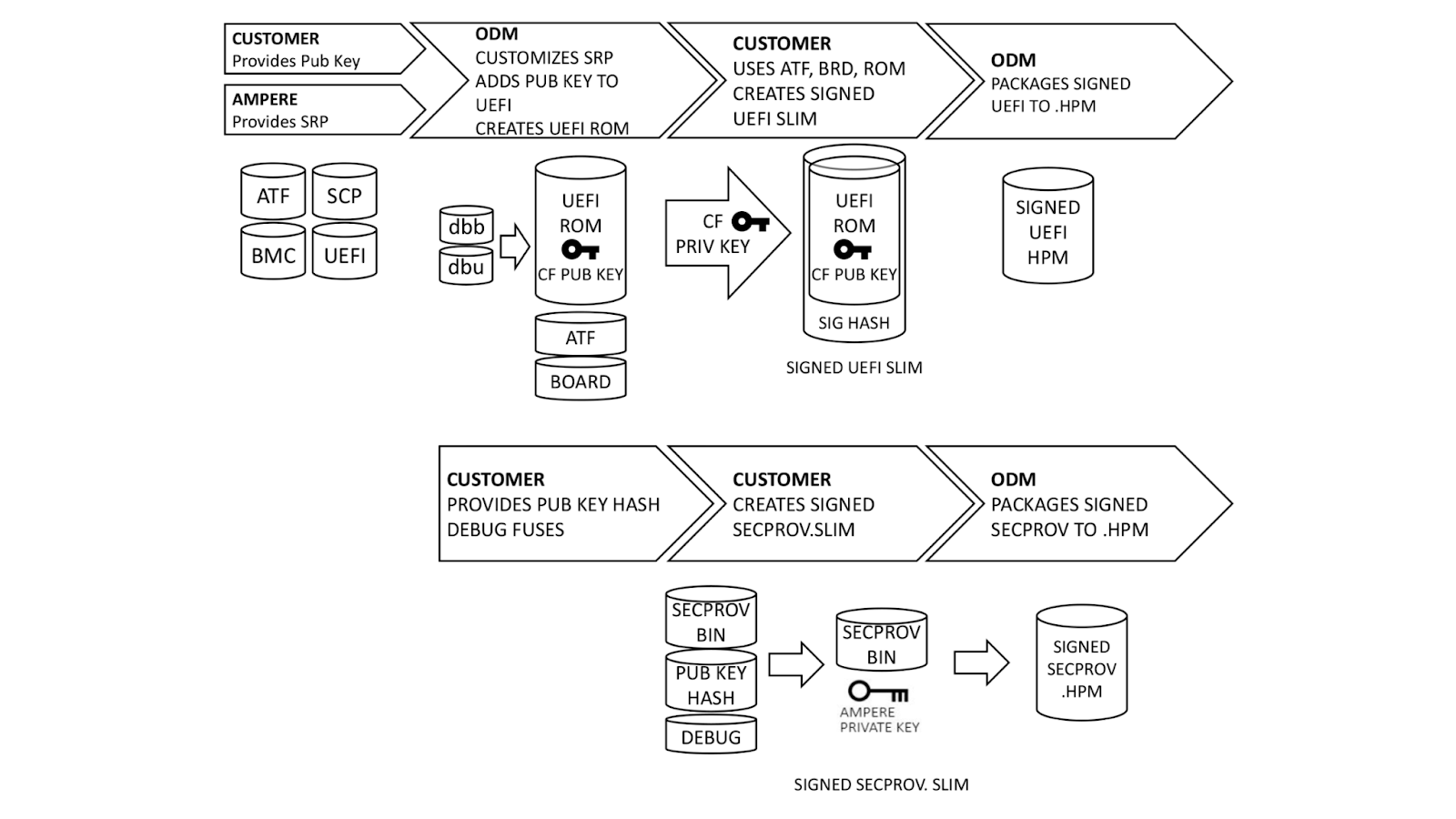
With a basic understanding of how Single Domain Secure Boot works, the next logical question is “How does it get implemented?”. We ensure that all UEFI firmware is signed at build time, but this process can be better understood if broken down into steps.
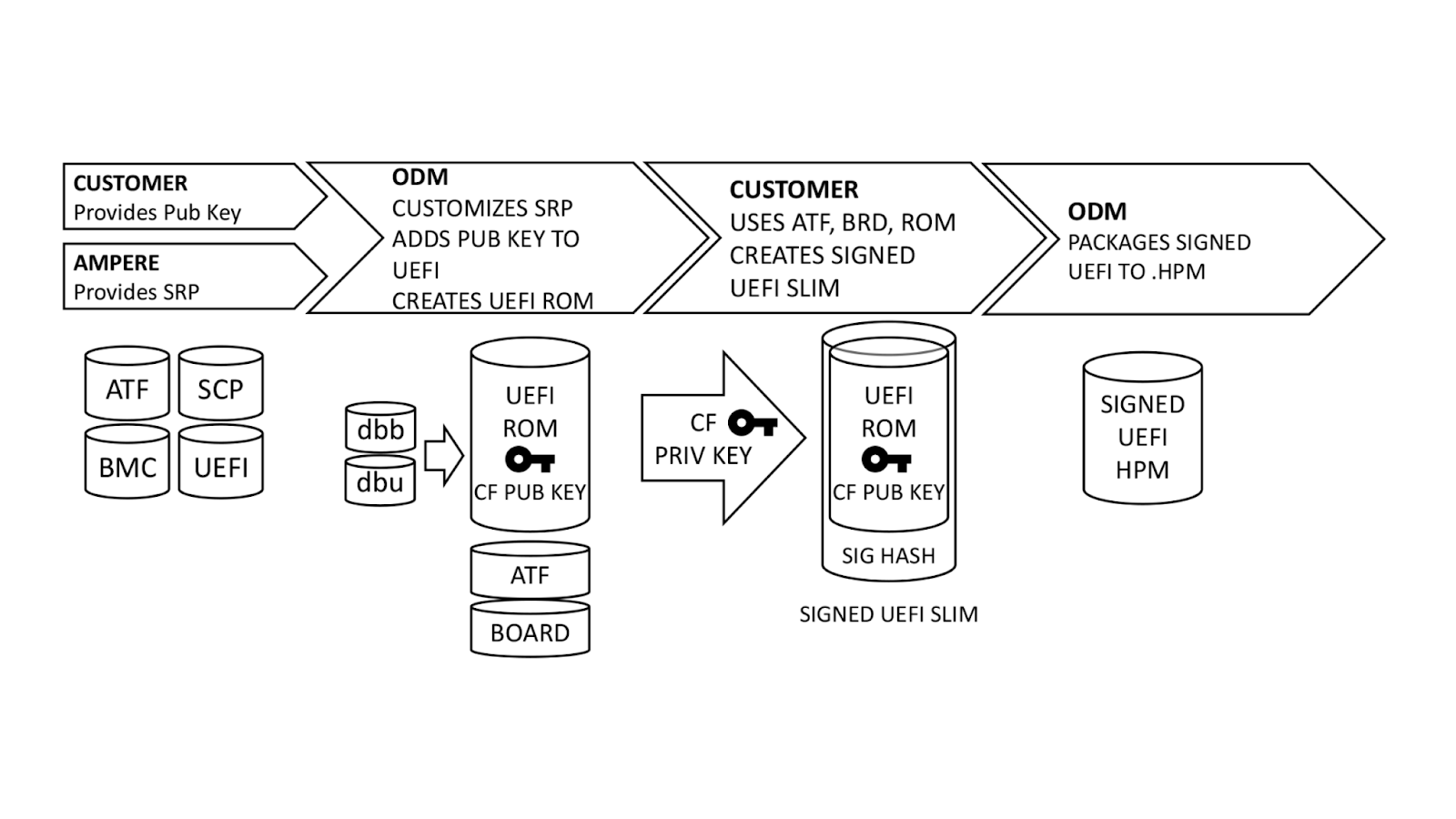
Ampere, our original device manufacturer (ODM), and we play a role in execution of SDSB. First, we generate certificates for a public-private key pair using our internal, secure PKI. The public key side is provided to the ODM as dbb.auth and dbu.auth in UEFI secure variable format. Ampere provides a reference Software Release Package (SRP) including the baseboard management controller, system control processor, UEFI, and complex programmable logic device (CPLD) firmware to the ODM, who customizes it for their platform. The ODM generates a board file describing the hardware configuration, and also customizes the UEFI to enroll dbb and dbu to secure variable storage on first boot.
Once this is done, we generate a UEFI.slim file using the ODM’s UEFI ROM image, Arm Trusted Firmware (ATF) and Board File. (Note: This differs from AMD PSB insofar as the entire image and ATF files are signed; with AMD PSB, only the first block of boot code is signed.) The entire .SLIM file is signed with our private key, producing a signature hash in the file. This can only be authenticated by the correct public key. Finally, the ODM packages the UEFI into .HPM format compatible with their platform BMC.
In parallel, we provide the debug fuse selection and hash of our DER-formatted public key. Ampere uses this information to create a special version of the SCP firmware known as Security Provisioning (SECPROV) .slim format. This firmware is run one time only, to program the debug fuse settings and public key hash into the SoC eFuses. Ampere delivers the SECPROV .slim file to the ODM, who packages it into a .hpm file compatible with the BMC firmware update tooling.
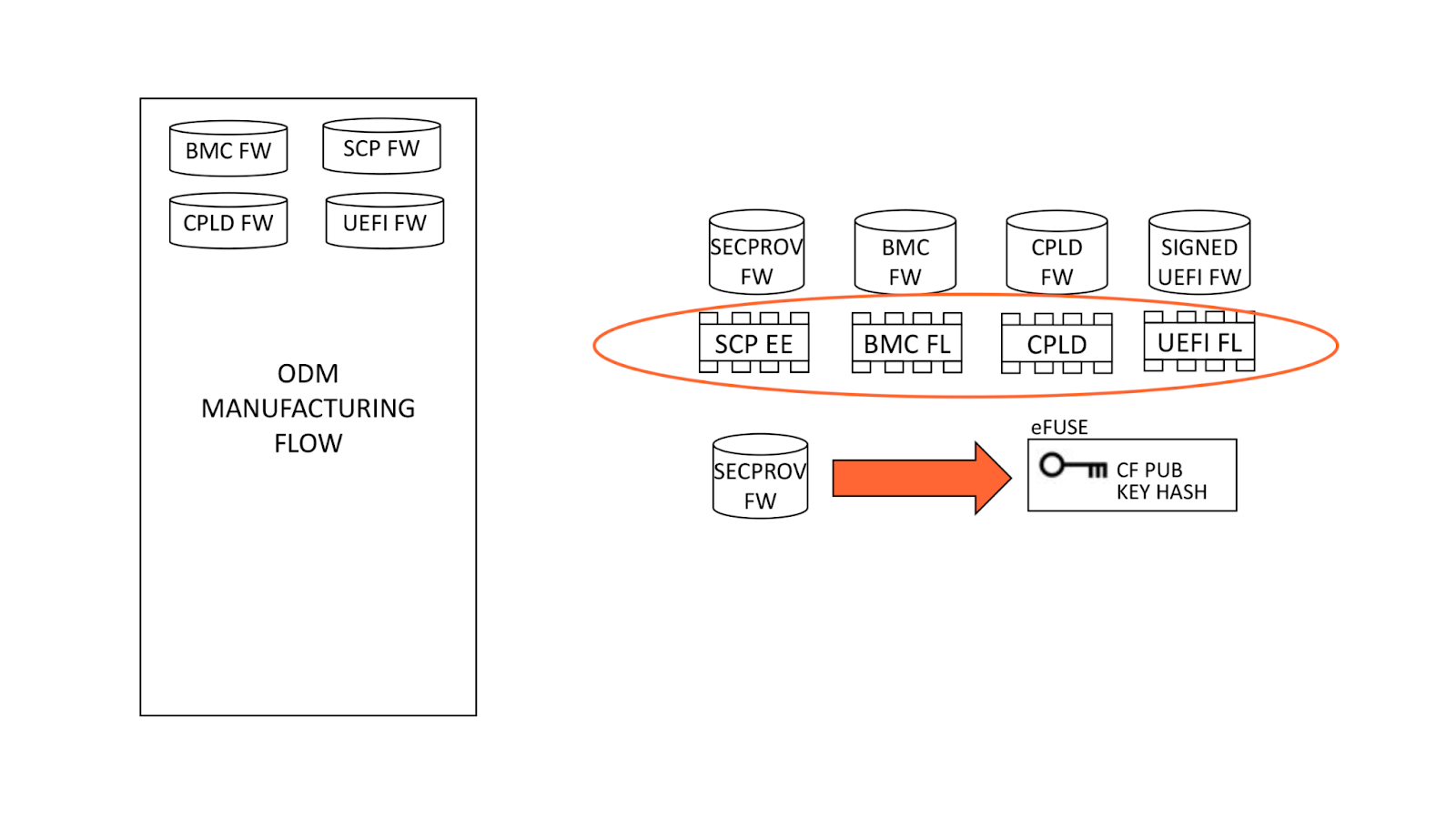
Fusing the keys
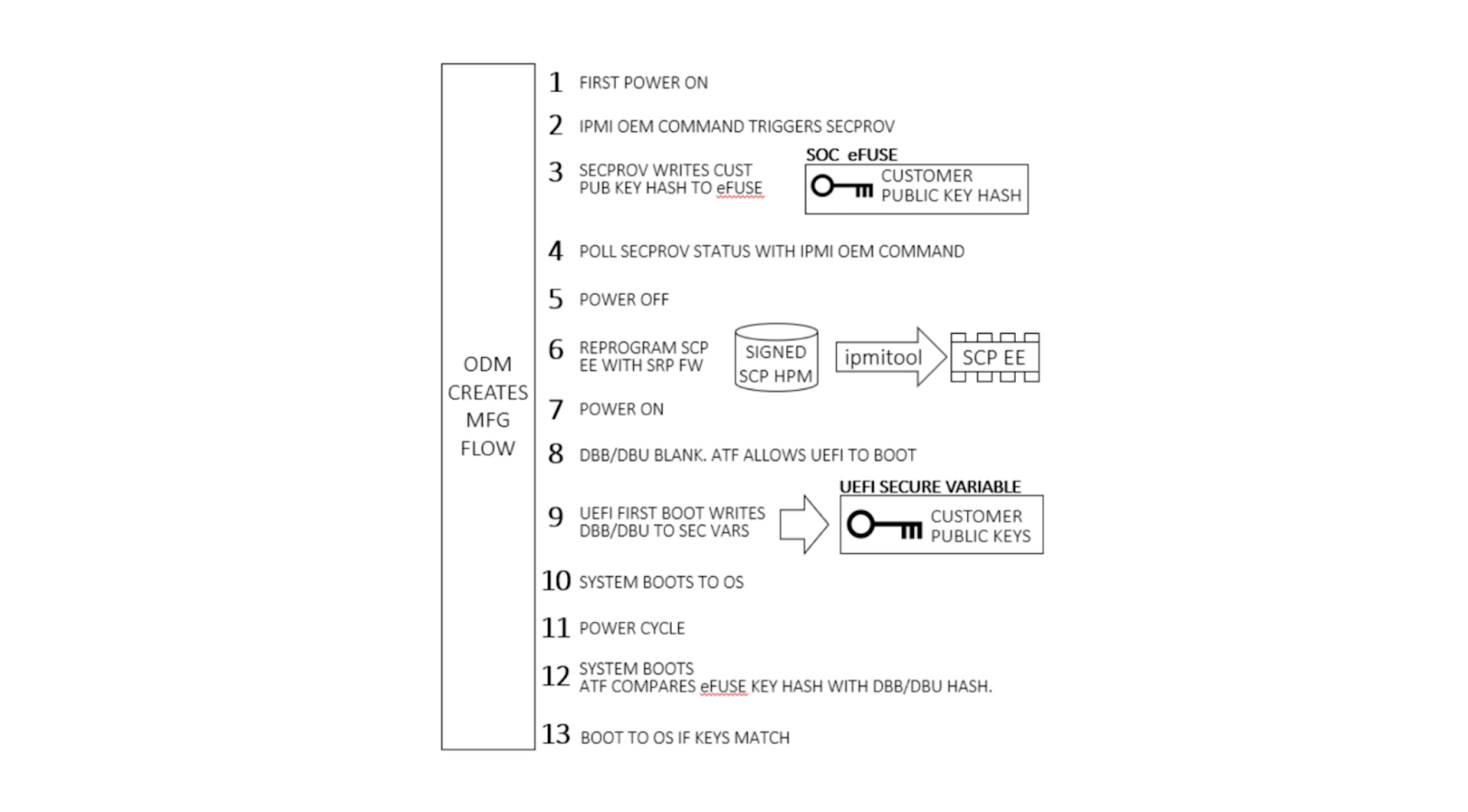
During system manufacturing, firmware is pre-programmed into storage ICs before placement on the motherboard. Note that the SCP EEPROM contains the SECPROV image, not standard SCP firmware. After a system is first powered on, an IPMI command is sent to the BMC which releases the Ampere processor from reset. This allows SECPROV firmware to run, burning the SoC eFuse with our public key hash and debug fuse settings.
Final manufacturing flow
Once our public key has been provisioned, manufacturing proceeds by re-programming the SCP EEPROM with its regular firmware. Once the system powers on, ATF detects there are no keys present in secure variable storage and allows UEFI firmware to boot, regardless of signature. Since this is the first UEFI boot, it programs our public key into secure variable storage and reboots. ATF is validated by Ampere’s public key hash as usual. Since our public key is present in dbb, it is validated against our public key hash in eFuse and allows UEFI to boot.
Validation
The first part of validation requires observing successful destruction of the eFuses. This imprints our public key hash into a dedicated, immutable memory region, not allowing the hash to be overwritten. Upon automatic or manual issue of an IPMI OEM command to the BMC, the BMC observes a signal from the SECPROV firmware, denoting eFuse programming completion. This can be probed with BMC commands.
When the eFuses have been blown, validation continues by observing the boot chain of the other firmware. Corruption of the SCP, ATF, or UEFI firmware obstructs boot flow and boot authentication and will cause the machine to fail booting to the OS. Once firmware is in place, happy path validation begins with booting the machine.
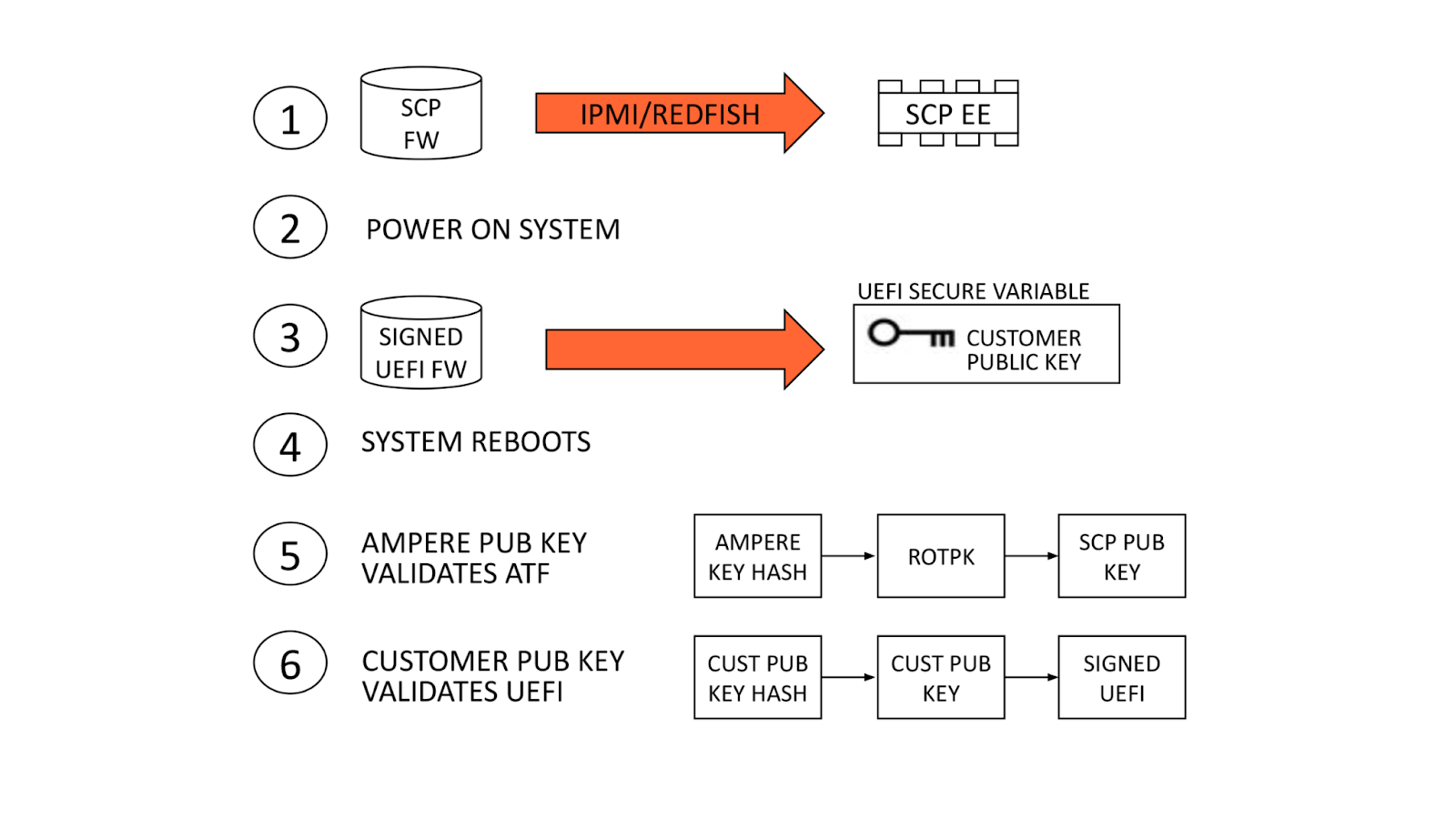
Upon first boot, firmware boots in the following order: BMC, SCP, ATF, and UEFI. The BMC, SCP, and ATF firmware can be observed via their respective serial consoles. The UEFI will automatically enroll the dbb and dbu files to the secure variable storage and trigger a reset of the system.
After observing the reset, the machine should successfully boot to the OS if the feature is executed correctly. For further validation, we can use the UEFI shell environment to extract the dbb file and compare the hash against the hash submitted to Ampere. After successfully validating the keys, we flash an unsigned UEFI image. An unsigned UEFI image causes authentication failure at bootloader stage BL3-2. The ATF firmware undergoes a boot loop as a result. Similar results will occur for a UEFI image signed with incorrect keys.
Updated authentication flow
On all subsequent boot cycles, the ATF will read secure variable dbb (our public key), compute a hash of the key, and compare it to the read-only Cloudflare public key hash in eFuse. If the computed and eFuse hashes match, our public key variable can be trusted and is used to authenticate the signed UEFI. After this, the system boots to the OS.
Let’s boot!
We were unable to get a machine without the feature enabled to demonstrate the set-up of the feature since we have the eFuse set at build time, but we can demonstrate what it looks like to go between an unsigned BIOS and a signed BIOS. What we would have observed with the set-up of the feature is a custom BMC command to instruct the SCP to burn the ROTPK into the SOC’s OTP fuses. From there, we would observe feedback to the BMC detailing whether burning the fuses was successful. Upon booting the UEFI image for the first time, the UEFI will write the dbb and dbu into secure storage.
As you can see, after flashing the unsigned BIOS, the machine fails to boot.
Despite the lack of visibility in failure to boot, there are a few things going on underneath the hood. The SCP (System Control Processor) still boots.
The SCP image holds a key certificate with Ampere’s generated ROTPK and the SCP key hash. SCP will calculate the ROTPK hash and compare it against the burned OTP fuses. In the failure case, where the hash does not match, you will observe a failure as you saw earlier. If successful, the SCP firmware will proceed to boot the PMpro and SMpro. Both the PMpro and SMpro firmware will be verified and proceed with the ATF authentication flow.
The conclusion of the SCP authentication is the passing of the BL1 key to the first stage bootloader via the SCP HOB(hand-off-block) to proceed with the standard three stage bootloader ATF authentication mentioned previously.
At BL2, the dbb is read out of the secure variable storage and used to authenticate the BL33 certificate and complete the boot process by booting the BL33 UEFI image.
Still more to do
In recent years, management interfaces on servers, like the BMC, have been the target of cyber attacks including ransomware, implants, and disruptive operations. Access to the BMC can be local or remote. With remote vectors open, there is potential for malware to be installed on the BMC via network interfaces. With compromised software on the BMC, malware or spyware could maintain persistence on the server. An attacker might be able to update the BMC directly using flashing tools such as flashrom or socflash without the same level of firmware resilience established at the UEFI level.
The future state involves using host CPU-agnostic infrastructure to enable a cryptographically secure host prior to boot time. We will look to incorporate a modular approach that has been proposed by the Open Compute Project’s Data Center Secure Control
Module Specification (DC-SCM) 2.0 specification. This will allow us to standardize our Root of Trust, sign our BMC, and assign physically unclonable function (PUF) based identity keys to components and peripherals to limit the use of OTP fusing. OTP fusing creates a problem with trying to “e-cycle” or reuse machines as you cannot truly remove a machine identity.
A group of Swiss researchers have published an impressive security analysis of Threema.
We provide an extensive cryptographic analysis of Threema, a Swiss-based encrypted messaging application with more than 10 million users and 7000 corporate customers. We present seven different attacks against the protocol in three different threat models. As one example, we present a cross-protocol attack which breaks authentication in Threema and which exploits the lack of proper key separation between different sub-protocols. As another, we demonstrate a compression-based side-channel attack that recovers users’ long-term private keys through observation of the size of Threema encrypted back-ups. We discuss remediations for our attacks and draw three wider lessons for developers of secure protocols.
Threema has more than 10 million users, which include the Swiss government, the Swiss army, German Chancellor Olaf Scholz, and other politicians in that country. Threema developers advertise it as a more secure alternative to Meta’s WhatsApp messenger. It’s among the top Android apps for a fee-based category in Switzerland, Germany, Austria, Canada, and Australia. The app uses a custom-designed encryption protocol in contravention of established cryptographic norms.
The company is performing the usual denials and deflections:
In a web post, Threema officials said the vulnerabilities applied to an old protocol that’s no longer in use. It also said the researchers were overselling their findings.
“While some of the findings presented in the paper may be interesting from a theoretical standpoint, none of them ever had any considerable real-world impact,” the post stated. “Most assume extensive and unrealistic prerequisites that would have far greater consequences than the respective finding itself.”
Left out of the statement is that the protocol the researchers analyzed is old because they disclosed the vulnerabilities to Threema, and Threema updated it.
AWS re:Invent returned to Las Vegas, Nevada, November 28 to December 2, 2022. After a virtual event in 2020 and a hybrid 2021 edition, spirits were high as over 51,000 in-person attendees returned to network and learn about the latest AWS innovations.
Now in its 11th year, the conference featured 5 keynotes, 22 leadership sessions, and more than 2,200 breakout sessions and hands-on labs at 6 venues over 5 days.
With well over 100 service and feature announcements—and innumerable best practices shared by AWS executives, customers, and partners—distilling highlights is a challenge. From a security perspective, three key themes emerged.
Turn data into actionable insights
Security teams are always looking for ways to increase visibility into their security posture and uncover patterns to make more informed decisions. However, as AWS Vice President of Data and Machine Learning, Swami Sivasubramanian, pointed out during his keynote, data often exists in silos; it isn’t always easy to analyze or visualize, which can make it hard to identify correlations that spark new ideas.
“Data is the genesis for modern invention.” – Swami Sivasubramanian, AWS VP of Data and Machine Learning
At AWS re:Invent, we launched new features and services that make it simpler for security teams to store and act on data. One such service is Amazon Security Lake, which brings together security data from cloud, on-premises, and custom sources in a purpose-built data lake stored in your account. The service, which is now in preview, automates the sourcing, aggregation, normalization, enrichment, and management of security-related data across an entire organization for more efficient storage and query performance. It empowers you to use the security analytics solutions of your choice, while retaining control and ownership of your security data.
Amazon Security Lake has adopted the Open Cybersecurity Schema Framework (OCSF), which AWS cofounded with a number of organizations in the cybersecurity industry. The OCSF helps standardize and combine security data from a wide range of security products and services, so that it can be shared and ingested by analytics tools. More than 37 AWS security partners have announced integrations with Amazon Security Lake, enhancing its ability to transform security data into a powerful engine that helps drive business decisions and reduce risk. With Amazon Security Lake, analysts and engineers can gain actionable insights from a broad range of security data and improve threat detection, investigation, and incident response processes.
Strengthen security programs
According to Gartner, by 2026, at least 50% of C-Level executives will have performance requirements related to cybersecurity risk built into their employment contracts. Security is top of mind for organizations across the globe, and as AWS CISO CJ Moses emphasized during his leadership session, we are continuously building new capabilities to help our customers meet security, risk, and compliance goals.
In addition to Amazon Security Lake, several new AWS services announced during the conference are designed to make it simpler for builders and security teams to improve their security posture in multiple areas.
Identity and networking
Authorization is a key component of applications. Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for custom applications that simplifies policy-based access for developers and centralizes access governance. The new service gives developers a simple-to-use policy and schema management system to define and manage authorization models. The policy-based authorization system that Amazon Verified Permissions offers can shorten development cycles by months, provide a consistent user experience across applications, and facilitate integrated auditing to support stringent compliance and regulatory requirements.
Additional services that make it simpler to define authorization and service communication include Amazon VPC Lattice, an application-layer service that consistently connects, monitors, and secures communications between your services, and AWS Verified Access, which provides secure access to corporate applications without a virtual private network (VPN).
Threat detection and monitoring
Monitoring for malicious activity and anomalous behavior just got simpler. Amazon GuardDuty RDS Protection expands the threat detection capabilities of GuardDuty by using tailored machine learning (ML) models to detect suspicious logins to Amazon Aurora databases. You can enable the feature with a single click in the GuardDuty console, with no agents to manually deploy, no data sources to enable, and no permissions to configure. When RDS Protection detects a potentially suspicious or anomalous login attempt that indicates a threat to your database instance, GuardDuty generates a new finding with details about the potentially compromised database instance. You can view GuardDuty findings in AWS Security Hub, Amazon Detective (if enabled), and Amazon EventBridge, allowing for integration with existing security event management or workflow systems.
To bolster vulnerability management processes, Amazon Inspector now supports AWS Lambda functions, adding automated vulnerability assessments for serverless compute workloads. With this expanded capability, Amazon Inspector automatically discovers eligible Lambda functions and identifies software vulnerabilities in application package dependencies used in the Lambda function code. Actionable security findings are aggregated in the Amazon Inspector console, and pushed to Security Hub and EventBridge to automate workflows.
Data protection and privacy
The first step to protecting data is to find it. Amazon Macie now automatically discovers sensitive data, providing continual, cost-effective, organization-wide visibility into where sensitive data resides across your Amazon Simple Storage Service (Amazon S3) estate. With this new capability, Macie automatically and intelligently samples and analyzes objects across your S3 buckets, inspecting them for sensitive data such as personally identifiable information (PII), financial data, and AWS credentials. Macie then builds and maintains an interactive data map of your sensitive data in S3 across your accounts and Regions, and provides a sensitivity score for each bucket. This helps you identify and remediate data security risks without manual configuration and reduce monitoring and remediation costs.
Encryption is a critical tool for protecting data and building customer trust. The launch of the end-to-end encrypted enterprise communication service AWS Wickr offers advanced security and administrative controls that can help you protect sensitive messages and files from unauthorized access, while working to meet data retention requirements.
Management and governance
Maintaining compliance with regulatory, security, and operational best practices as you provision cloud resources is key. AWS Config rules, which evaluate the configuration of your resources, have now been extended to support proactive mode, so that they can be incorporated into infrastructure-as-code continuous integration and continuous delivery (CI/CD) pipelines to help identify noncompliant resources prior to provisioning. This can significantly reduce time spent on remediation.
Managing the controls needed to meet your security objectives and comply with frameworks and standards can be challenging. To make it simpler, we launched comprehensive controls management with AWS Control Tower. You can use it to apply managed preventative, detective, and proactive controls to accounts and organizational units (OUs) by service, control objective, or compliance framework. You can also use AWS Control Tower to turn on Security Hub detective controls across accounts in an OU. This new set of features reduces the time that it takes to define and manage the controls required to meet specific objectives, such as supporting the principle of least privilege, restricting network access, and enforcing data encryption.
Do more with less
As we work through macroeconomic conditions, security leaders are facing increased budgetary pressures. In his opening keynote, AWS CEO Adam Selipsky emphasized the effects of the pandemic, inflation, supply chain disruption, energy prices, and geopolitical events that continue to impact organizations.
Now more than ever, it is important to maintain your security posture despite resource constraints. Citing specific customer examples, Selipsky underscored how the AWS Cloud can help organizations move faster and more securely. By moving to the cloud, agricultural machinery manufacturer Agco reduced costs by 78% while increasing data retrieval speed, and multinational HVAC provider Carrier Global experienced a 40% reduction in the cost of running mission-critical ERP systems.
“If you’re looking to tighten your belt, the cloud is the place to do it.” – Adam Selipsky, AWS CEO
Security teams can do more with less by maximizing the value of existing controls, and bolstering security monitoring and analytics capabilities. Services and features announced during AWS re:Invent—including Amazon Security Lake, sensitive data discovery with Amazon Macie, support for Lambda functions in Amazon Inspector, Amazon GuardDuty RDS Protection, and more—can help you get more out of the cloud and address evolving challenges, no matter the economic climate.
Security is our top priority
AWS re:Invent featured many more highlights on a variety of topics, such as Amazon EventBridge Pipes and the pre-announcement of GuardDuty EKS Runtime protection, as well as Amazon CTO Dr. Werner Vogels’ keynote, and the security partnerships showcased on the Expo floor. It was a whirlwind week, but one thing is clear: AWS is working harder than ever to make our services better and to collaborate on solutions that ease the path to proactive security, so that you can focus on what matters most—your business.
I don’t know how much of a thing this will end up being, but we are seeing ChatGPT-written malware in the wild.
…within a few weeks of ChatGPT going live, participants in cybercrime forums—some with little or no coding experience—were using it to write software and emails that could be used for espionage, ransomware, malicious spam, and other malicious tasks.
“It’s still too early to decide whether or not ChatGPT capabilities will become the new favorite tool for participants in the Dark Web,” company researchers wrote. “However, the cybercriminal community has already shown significant interest and are jumping into this latest trend to generate malicious code.”
Last month, one forum participant posted what they claimed was the first script they had written and credited the AI chatbot with providing a “nice [helping] hand to finish the script with a nice scope.”
The Python code combined various cryptographic functions, including code signing, encryption, and decryption. One part of the script generated a key using elliptic curve cryptography and the curve ed25519 for signing files. Another part used a hard-coded password to encrypt system files using the Blowfish and Twofish algorithms. A third used RSA keys and digital signatures, message signing, and the blake2 hash function to compare various files.
ChatGPT-generated code isn’t that good, but it’s a start. And the technology will only get better. Where it matters here is that it gives less skilled hackers—script kiddies—new capabilities.
Based on a screenshot from Apple, these categories are covered when you flip on Advanced Data Protection: device backups, messages backups, iCloud Drive, Notes, Photos, Reminders, Safari bookmarks, Siri Shortcuts, Voice Memos, and Wallet Passes. Apple says the only “major” categories not covered by Advanced Data Protection are iCloud Mail, Contacts, and Calendar because “of the need to interoperate with the global email, contacts, and calendar systems,” according to its press release.
You can see the full list of data categories and what is protected under standard data protection, which is the default for your account, and Advanced Data Protection on Apple’s website.
With standard data protection, Apple holds the encryption keys for things that aren’t end-to-end encrypted, which means the company can help you recover that data if needed. Data that’s end-to-end encrypted can only be encrypted on “your trusted devices where you’re signed in with your Apple ID,” according to Apple, meaning that the company—or law enforcement or hackers—cannot access your data from Apple’s databases.
Note that this system doesn’t have the backdoor that was in Apple’s previous proposal, the one put there under the guise of detecting CSAM.
Apple says that it will roll out worldwide by the end of next year. I wonder how China will react to this.
If you’re a SaaS vendor, you may need to store and process personal and sensitive data for large numbers of customers across different geographies. When processing sensitive data at scale, you have an increased responsibility to secure this data end-to-end. Client-side encryption of data, such as your customers’ contact information, provides an additional mechanism that can help you protect your customers and earn their trust.
Amazon DynamoDB supports data encryption at rest using encryption keys stored in AWS KMS. This functionality helps reduce operational burden and complexity involved in protecting sensitive data. In this post, you’ll learn about the benefits of adding client-side encryption to achieve end-to-end encryption in transit and at rest for your data, from its source to storage in DynamoDB. Client-side encryption helps ensure that your plaintext data isn’t available to any third party, including AWS.
You can use the Amazon DynamoDB Encryption Client to implement client-side encryption with DynamoDB. In the solution in this post, client-side encryption refers to the cryptographic operations that are performed on the application-side in the application’s Lambda function, before the data is sent to or retrieved from DynamoDB. The solution in this post uses the DynamoDB Encryption Client with the Direct KMS Materials Provider so that your data is encrypted by using AWS KMS. However, the underlying concept of the solution is not limited to the use of the DynamoDB Encryption Client, you can apply it to any client-side use of AWS KMS, for example using the AWS Encryption SDK.
For detailed information about using the DynamoDB Encryption Client, see the blog post How to encrypt and sign DynamoDB data in your application. This is a great place to start if you are not yet familiar with DynamoDB Encryption Client. If you are unsure about whether you should use client-side encryption, see Client-side and server-side encryption in the Amazon DynamoDB Encryption Client Developer Guide to help you with the decision.
AWS KMS encryption context
AWS KMS gives you the ability to add an additional layer of authentication for your AWS KMS API decrypt operations by using encryption context. The encryption context is one or more key-value pairs of additional data that you want associated with AWS KMS protected information.
Encryption context helps you defend against the risks of ciphertexts being tampered with, modified, or replaced — whether intentionally or unintentionally. Encryption context helps defend against both an unauthorized user replacing one ciphertext with another, as well as problems like operational events. To use encryption context, you specify associated key-value pairs on encrypt. You must provide the exact same key-value pairs in the encryption context on decrypt, or the operation will fail. Encryption context is not secret, and is not an access-control mechanism. The encryption context is a means of authenticating the data, not the caller.
The Direct KMS Materials Provider used in this blog post transparently generates a unique data key by using AWS KMS for each item stored in the DynamoDB table. It automatically sets the item’s partition key and sort key (if any) as AWS KMS encryption context key-value pairs.
The solution in this blog post relies on the partition key of each table item being defined in the encryption context. If you encrypt data with your own implementation, make sure to add your tenant ID to the encryption context in all your AWS KMS API calls.
Attribute-based access control (ABAC) is an authorization strategy that defines permissions based on attributes. In AWS, these attributes are called tags. In the solution in this post, ABAC helps you create tenant-isolated access policies for your application, without the need to provision tenant specific AWS IAM roles.
If you are a SaaS vendor expecting large numbers of tenants, it is important that your underlying architecture can cost effectively scale with minimal complexity to support the required number of tenants, without compromising on security. One way to meet these criteria is to store your tenant data in a single pooled DynamoDB table, and to encrypt the data using a single AWS KMS key.
Using a single shared KMS key to read and write encrypted data in DynamoDB for multiple tenants reduces your per-tenant costs. This may be especially relevant to manage your costs if you have users on your organization’s free tier, with no direct revenue to offset your costs.
When you use shared resources such as a single pooled DynamoDB table encrypted by using a single KMS key, you need a mechanism to help prevent cross-tenant access to the sensitive data. This is where you can use ABAC for AWS. By using ABAC, you can build an application with strong tenant isolation capabilities, while still using shared and pooled underlying resources for storing your sensitive tenant data.
You can find the solution described in this blog post in the aws-dynamodb-encrypt-with-abac GitHub repository. This solution uses ABAC combined with KMS encryption context to provide isolation of tenant data, both at rest and at run time. By using a single KMS key, the application encrypts tenant data on the client-side, and stores it in a pooled DynamoDB table, which is partitioned by a tenant ID.
Solution Architecture
Figure 1: Components of solution architecture
The presented solution implements an API with a single AWS Lambda function behind an Amazon API Gateway, and implements processing for two types of requests:
GET request: fetch any key-value pairs stored in the tenant data store for the given tenant ID.
POST request: store the provided key-value pairs in the tenant data store for the given tenant ID, overwriting any existing data for the same tenant ID.
It also uses the DynamoDB Encryption Client for Python, which includes several helper classes that mirror the AWS SDK for Python (Boto3) classes for DynamoDB. This solution uses the EncryptedResource helper class which provides Boto3 compatible get_item and put_item methods. The helper class is used together with the KMS Materials Provider to handle encryption and decryption with AWS KMS transparently for the application.
Note: This example solution provides no authentication of the caller identity. See chapter “Considerations for authentication and authorization” for further guidance.
How it works
Figure 2: Detailed architecture for storing new or updated tenant data
As requests are made into the application’s API, they are routed by API Gateway to the application’s Lambda function (1). The Lambda function begins to run with the IAM permissions that its IAM execution role (DefaultExecutionRole) has been granted. These permissions do not grant any access to the DynamoDB table or the KMS key. In order to access these resources, the Lambda function first needs to assume the ResourceAccessRole, which does have the necessary permissions. To implement ABAC more securely in this use case, it is important that the application maintains clear separation of IAM permissions between the assumed ResourceAccessRole and the DefaultExecutionRole.
As the application assumes the ResourceAccessRole using the AssumeRole API call (2), it also sets a TenantID session tag. Session tags are key-value pairs that can be passed when you assume an IAM role in AWS Simple Token Service (AWS STS), and are a fundamental core building block of ABAC on AWS. When the session credentials (3) are used to make a subsequent request, the request context includes the aws:PrincipalTag context key, which can be used to access the session’s tags. The chapter “The ResourceAccessRole policy” describes how the aws:PrincipalTag context key is used in IAM policy condition statements to implement ABAC for this solution. Note that for demonstration purposes, this solution receives the value for the TenantID tag directly from the request URL, and it is not authenticated.
The trust policy of the ResourceAccessRole defines the principals that are allowed to assume the role, and to tag the assumed role session. Make sure to limit the principals to the least needed for your application to function. In this solution, the application Lambda function is the only trusted principal defined in the trust policy.
Next, the Lambda function prepares to encrypt or decrypt the data (4). To do so, it uses the DynamoDB Encryption Client. The KMS Materials Provider and the EncryptedResource helper class are both initialized with sessions by using the temporary credentials from the AssumeRole API call. This allows the Lambda function to access the KMS key and DynamoDB table resources, with access restricted to operations on data belonging only to the specific tenant ID.
Finally, using the EncryptedResource helper class provided by the DynamoDB Encryption Library, the data is written to and read from the DynamoDB table (5).
Considerations for authentication and authorization
The solution in this blog post intentionally does not implement authentication or authorization of the client requests. Instead, the requested tenant ID from the request URL is passed as the tenant identity. Your own applications should always authenticate and authorize tenant requests. There are multiple ways you can achieve this.
Modern web applications commonly use OpenID Connect (OIDC) for authentication, and OAuth for authorization. JSON Web Tokens (JWTs) can be used to pass the resulting authorization data from client to the application. You can validate a JWT when using AWS API Gateway with one of the following methods:
Regardless of the chosen method, you must be able to map a suitable claim from the user’s JWT, such as the subject, to the tenant ID, so that it can be used as the session tag in this solution.
The ResourceAccessRole policy
A critical part of the correct operation of ABAC in this solution is with the definition of the IAM access policy for the ResourceAccessRole. In the following policy, be sure to replace <region>, <account-id>, <table-name>, and <key-id> with your own values.
The policy defines two access statements, both of which apply separate ABAC conditions:
The first statement grants access to the DynamoDB table with the condition that the partition key of the item matches the TenantID session tag in the caller’s session.
The second statement grants access to the KMS key with the condition that one of the key-value pairs in the encryption context of the API call has a key called tenant_id with a value that matches the TenantID session tag in the caller’s session.
Warning: Do not use a ForAnyValue or ForAllValues set operator with the kms:EncryptionContext single-valued condition key. These set operators can create a policy condition that does not require values you intend to require, and allows values you intend to forbid.
Deploying and testing the solution
Prerequisites
To deploy and test the solution, you need the following:
After you have the prerequisites installed, run the following steps in a command line environment to deploy the solution. Make sure that your AWS CLI is configured with your AWS account credentials. Note that standard AWS service charges apply to this solution. For more information about pricing, see the AWS Pricing page.
To deploy the solution into your AWS account
Use the following command to download the source code:
git clone https://github.com/aws-samples/aws-dynamodb-encrypt-with-abac
cd aws-dynamodb-encrypt-with-abac
(Optional) You will need an AWS CDK version compatible with the application (2.37.0) to deploy. The simplest way is to install a local copy with npm, but you can also use a globally installed version if you already have one. To install locally, use the following command to use npm to install the AWS CDK:
With the application deployed, you can test the solution by making API calls against the API URL that you captured from the deployment output. You can start with a simple HTTP POST request to insert data for a tenant. The API expects a JSON string as the data to store, so make sure to post properly formatted JSON in the body of the request.
An example request using curl -command looks like:
curl https://<api url>/prod/tenant/<tenant-name> -X POST --data '{"email":"<[email protected]>"}'
You can then read the same data back with an HTTP GET request:
curl https://<api url>/prod/tenant/<tenant-name>
You can store and retrieve data for any number of tenants, and can store as many attributes as you like. Each time you store data for a tenant, any previously stored data is overwritten.
Additional considerations
A tenant ID is used as the DynamoDB table’s partition key in the example application in this solution. You can replace the tenant ID with another unique partition key, such as a product ID, as long as the ID is consistently used in the IAM access policy, the IAM session tag, and the KMS encryption context. In addition, while this solution does not use a sort key in the table, you can modify the application to support a sort key with only a few changes. For more information, see Working with tables and data in DynamoDB.
Clean up
To clean up the application resources that you deployed while testing the solution, in the solution’s home directory, run the command cdk destroy.
In this post, you learned a method for simple and cost-efficient client-side encryption for your tenant data. By using the DynamoDB Encryption Client, you were able to implement the encryption with less effort, all while using a standard Boto3 DynamoDB Table resource compatible interface.
Adding to the client-side encryption, you also learned how to apply attribute-based access control (ABAC) to your IAM access policies. You used ABAC for tenant isolation by applying conditions for both the DynamoDB table access, as well as access to the KMS key that is used for encryption of the tenant data in the DynamoDB table. By combining client-side encryption with ABAC, you have increased your data protection with multiple layers of security.
You can start experimenting today on your own by using the provided solution. If you have feedback about this post, submit comments in the Comments section below. If you have questions on the content, consider submitting them to AWS re:Post
Want more AWS Security news? Follow us on Twitter.
In painstaking work backed by computers, Pierrot found “distinct families” of about 120 symbols used by Charles V. “Whole words are encrypted with a single symbol” and the emperor replaced vowels coming after consonants with marks, she said, an inspiration probably coming from Arabic.
In another obstacle, he used meaningless symbols to mislead any adversary trying to decipher the message.
The breakthrough came in June when Pierrot managed to make out a phrase in the letter, and the team then cracked the code with the help of Camille Desenclos, a historian. “It was painstaking and long work but there was really a breakthrough that happened in one day, where all of a sudden we had the right hypothesis,” she said.
Brian Krebs writes about how the Zeppelin ransomware encryption scheme was broken:
The researchers said their break came when they understood that while Zeppelin used three different types of encryption keys to encrypt files, they could undo the whole scheme by factoring or computing just one of them: An ephemeral RSA-512 public key that is randomly generated on each machine it infects.
“If we can recover the RSA-512 Public Key from the registry, we can crack it and get the 256-bit AES Key that encrypts the files!” they wrote. “The challenge was that they delete the [public key] once the files are fully encrypted. Memory analysis gave us about a 5-minute window after files were encrypted to retrieve this public key.”
Unit 221B ultimately built a “Live CD” version of Linux that victims could run on infected systems to extract that RSA-512 key. From there, they would load the keys into a cluster of 800 CPUs donated by hosting giant Digital Ocean that would then start cracking them. The company also used that same donated infrastructure to help victims decrypt their data using the recovered keys.
A company offered recovery services based on this break, but was reluctant to advertise because it didn’t want Zeppelin’s creators to fix their encryption flaw.
A developer says it was possible to run their own software on the car infotainment hardware after discovering the vehicle’s manufacturer had secured its system using keys that were not only publicly known but had been lifted from programming examples.
[…]
“Turns out the [AES] encryption key in that script is the first AES 128-bit CBC example key listed in the NIST document SP800-38A [PDF]”.
[…]
Luck held out, in a way. “Greenluigi1” found within the firmware image the RSA public key used by the updater, and searched online for a portion of that key. The search results pointed to a common public key that shows up in online tutorials like “RSA Encryption & Decryption Example with OpenSSL in C.“
AWS is excited to announce the launch of the AWS Wickr ATAK Plugin, which makes it easier for ATAK users to maintain secure communications.
The Android Team Awareness Kit (ATAK)—also known as Android Tactical Assault Kit (ATAK) for military use—is a smartphone geospatial infrastructure and situational awareness application. It provides mapping, messaging, and geofencing capabilities to enable safe collaboration over geography.
ATAK users, referred to as operators, can view the location of other operators and potential hazards—a major advantage over relying on hand-held radio transmissions. While ATAK was initially designed for use in combat zones, the technology has been adapted to fit the missions of local, state, and federal agencies.
ATAK is currently in use by over 40,000 US Department of Defense (DoD) users—including the Air Force, Army, Special Operations, and National Guard—along with the Department of Justice (DOJ), the Department of Homeland Security (DHS), and 32,000 nonfederal users.
Using AWS Wickr with ATAK
AWS Wickr is a secure collaboration service that provides enterprises and government agencies with advanced security and administrative controls to help them meet security and compliance requirements. The AWS Wickr service is now in preview.
With AWS Wickr, communication mechanisms such as one-to-one and group messaging, audio and video calling, screen sharing, and file sharing are protected with 256-bit end-to-end encryption (E2EE). Encryption takes place locally, on the endpoint. Every message, call, and file is encrypted with a new random key, and no one but the intended recipients can decrypt them. Flexible administrative features enable organizations to deploy at scale, and facilitate information governance.
AWS Wickr supports many agencies that use ATAK. However, until now, ATAK operators have had to leave the ATAK application in order to use AWS Wickr, which creates operational risk.
AWS Wickr ATAK Plugin
AWS Wickr has developed a plugin that enhances ATAK with secure communications features. ATAK operators are provided with a Wickr Enterprise or Wickr Pro account, so they can use AWS Wickr within ATAK for secure messaging, calling, and file transfer. This helps reduce interruptions, and the complexity of configuration with ATAK chat features.
Use cases
The AWS Wickr ATAK Plugin has multiple use cases.
Military
The military uses ATAK for blue force tracking to locate team members, red force tracking to locate enemies, terrain and weather analysis, and to visually communicate their movements to friendly forces.
The AWS Wickr ATAK Plugin enhances the ability of military personnel to maintain the situational awareness ATAK provides, while quickly receiving and reacting to Wickr communications. Ephemeral messaging options allow unit leaders to send mission plans, GPS points of interest, and set burn-on-read and expiration timers. Information can be deleted from the device, while being retained on the AWS Wickr service to help meet compliance requirements, and facilitate the creation of after-action reports.
Law enforcement
ATAK is a powerful tool for team tracking and mission planning that promotes a safer and better response to critical law enforcement and public-safety events.
The AWS Wickr ATAK Plugin adds to the capabilities of ATAK by supporting secure communications between tactical, negotiation, and investigative teams.
First responders
ATAK aids in search-and-rescue and multi-jurisdictional natural disaster responses, such as hurricane relief efforts.
The AWS Wickr ATAK Plugin provides secure, uninterrupted communication between all levels of first responders to help them get oriented quickly, and support complex coordination needs.
We present an efficient key recovery attack on the Supersingular Isogeny Diffie-Hellman protocol (SIDH), based on a “glue-and-split” theorem due to Kani. Our attack exploits the existence of a small non-scalar endomorphism on the starting curve, and it also relies on the auxiliary torsion point information that Alice and Bob share during the protocol. Our Magma implementation breaks the instantiation SIKEp434, which aims at security level 1 of the Post-Quantum Cryptography standardization process currently ran by NIST, in about one hour on a single core.
At Amazon Web Services (AWS) we prioritize security, performance, and strong encryption in our cloud services. In order to be prepared for quantum computer advancements, we’ve been investigating the use of quantum-safe algorithms for key exchange in the TLS protocol. In this blog post, we’ll first bring you up to speed on what we’ve been doing on the TLS front. Then, we’ll focus on the QUIC transport protocol and show how you can enable and experiment with the newly released post-quantum (PQ) key exchange by using our s2n-quic library. The s2n-quic library is an open-source implementation of the QUIC protocol.
Why use PQ-hybrid key establishment in s2n-quic?
A large-scale quantum computer could break the current public key cryptography that is used to establish keys for secure communication connections. Although a large-scale quantum computer isn’t available today, traffic that is recorded now could be decrypted by one in the future. With such concerns in mind, the recent US Congress Quantum Computing Cybersecurity Preparedness Act and the White House National Security Memorandum set a goal of a timely and equitable transition of cryptographic systems to quantum-resistant cryptography.
PQ-hybrid key establishment in TLS is a feature that introduces post-quantum KEMs used in conjunction with classical Elliptic Curve Diffie-Hellman (ECDH) key exchange. The client and server still do an ECDH key exchange. Additionally, the server encapsulates a post-quantum shared secret to the client’s post-quantum KEM public key, which is advertised in the ClientHello message. This strategy combines the high assurance of a classical key exchange with the security of the proposed post-quantum key exchanges, to ensure that the handshakes are protected as long as the ECDH or the post-quantum shared secret cannot be broken.
After decapsulating the secret, the client and server have an ECDH and a post-quantum shared secret, which they concatenate and use to derive the symmetric keys that are used in the Authenticated Encryption with Additional Data (AEAD) cipher in TLS. These symmetric keys used by the AEAD cipher for data encryption will be secure against a quantum computer, which means that the TLS communication is secure against a quantum computer. The AWS implementation of TLS is s2n-tls, a streamlined open source implementation of TLS. The s2n-tls implementation already supports PQ-hybrid key exchange with ECDH and three NIST PQC Project KEMs (Kyber, BIKE, and SIKE) for TLS 1.2 and 1.3. The use of KEMs for TLS 1.2 is described in the draft-campagna-tls-bike-sike-hybrid IETF draft, and the use of KEMs for TLS 1.3 is described in the draft-ietf-tls-hybrid-design IETF draft.
Note: The Kyber, BIKE, and SIKE implementations follow the algorithm specifications described in NIST PQ Project Round 3, which are expected to be updated as standardization proceeds.
How PQ-hybrid key exchange works in s2n-quic
AWS recently announceds2n-quic, an open-source Rust implementation of the QUIC protocol. QUIC is an encrypted transport protocol that is designed for performance and is the foundation of HTTP/3. For tunnel establishment, QUIC uses TLS 1.3 carried over QUIC transport. To alleviate the harvest-now-decrypt-later concerns for customers that use s2n-quic, in the next section we show you how to enable PQ-hybrid key establishment in s2n-quic. AWS services and software that use s2n-quic will automatically inherit the ability to support quantum-safe key exchanges in the future when post-quantum algorithms are standardized and are officially supported in s2n-quic.
The s2n-quic implementation is written in the Rust programming language. It can use either s2n-tls (the TLS library for AWS) or rustls (the TLS library in Rust) to perform the TLS handshake. If you build s2n-quic with s2n-tls, then s2n-quic inherits the post-quantum support that is offered in s2n-tls. In turn, s2n-tls is built over other crypto libraries such as the AWS libcrypto (AWS-LC) or alternatively OpenSSL crypto library (libcrypto). AWS-LC is a general-purpose cryptographic library that is maintained by AWS, which will incorporate standardized post-quantum algorithms. Therefore, building s2n-tls with AWS-LC will provide s2n-tls with the post-quantum cryptographic algorithms for use in s2n-quic.
Such a model allows for AWS services and software that use s2n-quic to automatically inherit the standardized post-quantum options as they are implemented in s2n-tls and its underlying crypto libraries. There will be no need to tweak s2n-quic to support post-quantum TLS 1.3 handshakes. The whole stack of protocol implementations is architected in an agile manner without duplication of work.
The public s2n-quic GitHub repository includes an example that demonstrates how to build the library with PQ-hybrid key exchange support, along with a server and client to test. The PQ-hybrid key exchange feature test requires CMake in Linux or macOS. The experiments below were run in an Amazon Linux 2 instance with rustc, Cargo, Clang, and CMake installed. Connections that you establish with this experimental build of s2n-quic will support PQ-hybrid key exchange.
To test PQ-hybrid key establishment
Clone s2n-quic by using the following commands:
git clone https://github.com/aws/s2n-quic cd s2n-quic
Run the example post-quantum s2n-quic client and server in the post-quantum directory to confirm that they negotiate a PQ-hybrid key by using the following commands:
cd examples/post-quantum cargo run –bin pq_server cargo run –bin pq_client
Note: Although these examples with the PQ-hybrid feature experimental build of s2n-quic are self-contained, if you want to manually change and build s2n-quic and s2n-tls to enable PQ-hybrid key exchange, you have to update the default_tls13 policy in s2n-tls to point to security_policy_pq_tls_1_0_2021_05_26 in tls/s2n_security_policies.c. Then you rebuild s2n-tls and override the location that s2n-quic links to by setting the S2N_TLS_DIR, S2N_TLS_LIB_DIR, and S2N_TLS_INCLUDE_DIR environment variables at build time.
To confirm the PQ-hybrid key establishment, you capture the QUIC negotiation by using the following tcpdump command:
sudo tcpdump -i lo port 4433 -w test.pcap
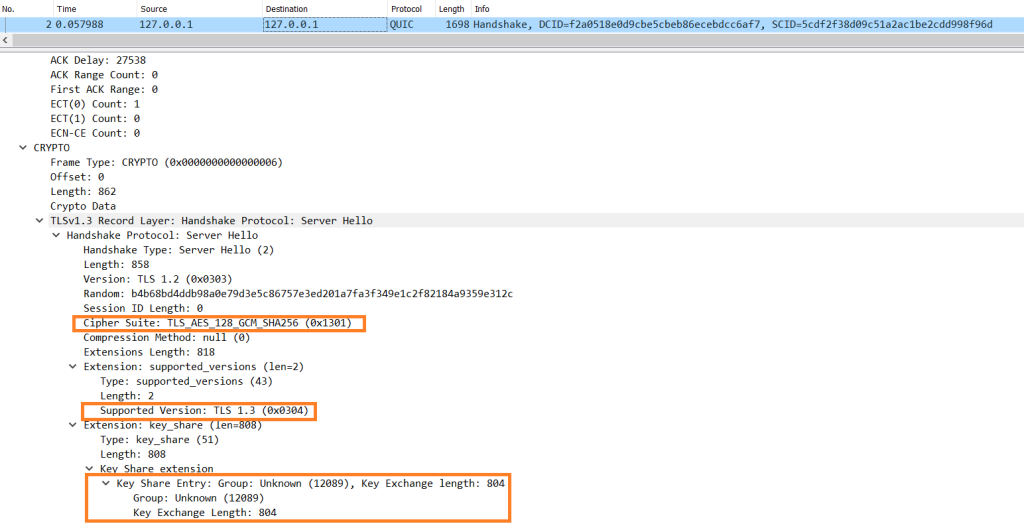
Open the capture by using a packet capture visualization application. First you look at the ClientHello message, as shown in the capture in Figure 1 taken from Wireshark.
Figure 1: pq_client ClientHello in QUIC
In the QUIC CRYPTO frame, you can see the TLS 1.3 cipher suites, and that the TLS version is 1.3 while the supported key exchange groups are classical ECDH (with identifiers 0x0017, 0x0018, 0x001d) and 0x2f39, 0x2f3a, 0x2f37…. 0x2f1f. The 0x2f… groups are the agreed upon identifiers (not standardized yet) for PQ-hybrid key exchange. You also see the PQ-hybrid X25519+Kyber512 (with identifier 12089 or 0x2f39) key share that is offered by the client. That key share includes 32 bytes for the Curve25519 ephemeral ECDH client public key, 800 bytes for the ephemeral Kyber512 public key, and 4 bytes for the identifier and the key share length.
Note: The post-quantum KEMs implementations at the time of this writing follow the NIST Round 3 Kyber, BIKE, and SIKE specifications. We expect these specifications to change as the NIST PQC Project proceeds with standardization. Post-quantum support in s2n-tls and s2n-quic will be experimental until NIST has selected and published standardized algorithms and identifiers. Pushing the change to the main branch now would mean that s2n-quic clients would be sending a PQ-hybrid key share that won’t be used until the servers on the internet start supporting it. The actual algorithms and their identifiers will still be integrated in future releases of s2n-tls and AWS-LC. Therefore, s2n-quic will still be able to negotiate the NIST and IETF standardized options. Meanwhile, we will continue to experiment with post-quantum QUIC and its potential challenges.
Next, take a look at the server-negotiated keys in the ServerHello message, as shown in Figure 2.
Figure 2: pq_server ServerHello in QUIC
You can again see the TLS 1.3 cipher suite, the TLS version being 1.3, and the picked PQ-hybrid X25519+Kyber512 key share. The key share includes 4 bytes for the identifier and the key share length, 32 bytes for the Curve25519 ephemeral ECDH server public key, and 768 bytes for the Kyber512 ciphertext that encapsulates a post-quantum shared secret to the client’s ephemeral Kyber512 public key (included in its ClientHello message).
The rest of the handshake completes successfully by deriving symmetric keys from the X25519 and Kyber512 post-quantum shared secrets (as defined in the draft-ietf-tls-hybrid-design IETF draft) and encrypting the rest of the messages with Advanced Encryption Standard with Galois/Counter Mode (AES-GCM) by using these symmetric keys over QUIC.
Benchmark
Now you can benchmark the post-quantum QUIC client and server by using netbench, a transport protocol benchmarking tool that is available in the s2n-quic repository.
To benchmark the post-quantum QUIC client and server
Go in the netbench directory and build it with the correct flags for the experimental post-quantum QUIC examples, by using the following commands:
cd s2n-quic/netbench RUSTFLAGS=”–cfg s2n_quic_unstable –cfg s2n_quic_enable_pq_tls” cargo build –release
Generate the netbench scenario by using the following commands:
In this example, you’re trying to create 10,000 sequential QUIC connections. The scenario opens a connection, sends a single byte, receives a single byte, closes it, and repeats 10,000 times.
The drivers read the request_response.json to run the scenario. Then the driver is wrapped in a collector that outputs statistics to another JSON file. At the end of all of the 10,000 runs, the cli feature is used to generate the report.
Figure 3 shows the performance results for X25519, X25519+Kyber512, X25519+BIKE-1, and X25519+SIKEp434 key exchange. All connections used an ECDSA P256 server certificate for authentication.
Figure 3: PQ-hybrid key exchange impact on QUIC connection rates
The x-axis is time in seconds. The y-axis is the number of times send is called—which, for 1 byte per connection, practically means that the diagram shows the connection establishment rate (per second). The absolute performance numbers in these benchmarks are not important, because the results could change based on the netbench scenario parameters. The performance difference between PQ-hybrid key exchange algorithms is what this graph is highlighting.
You can see that the classical X25519 achieves higher connection rates, because it is the most efficient option (that offers no post-quantum protection). The performance of Kyber is competitive and achieves 8% fewer connections per second when used with X25519 in a PQ-hybrid key exchange. BIKE-1 is relatively efficient, but adds some extra latency and introduces two frames for the ClientHello, which leads to 37% fewer connections per second. SIKEp434, although it offers much smaller public keys and ciphertexts, is orders of magnitude slower, which means it offers 95% fewer connections per second. These results match previous results we have shared before and other research works, where the most efficient signature algorithms ended up with higher connection rates and lower connection failure probabilities due to overload.
Conclusion
In this post, we showed how you can use s2n-quic in conjunction with s2n-tls to enable QUIC connections to negotiate encryption keys in a quantum-resistant manner. If you’re interested in learning more about s2n-quic, join us at AWS re:Inforce in July for the breakout session entitled NIS304: Using s2n-quic: Bringing QUIC, the secure transport protocol, to AWS.
As always, if you’re interested in using or contributing to s2n-quic, the source code and documentation are publicly available under the terms of the Apache Software License 2.0 from our s2n-quic GitHub repository. If you package or distribute s2n-quic or s2n-tls, or use it as part of a large multi-user service, you might be eligible for pre-notification of security issues. Contact [email protected] for more information. If you discover a potential security issue in s2n-quic or s2n-tls, we ask that you notify AWS Security by using our vulnerability reporting page.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Some sites, including Facebook, add parameters to the web address for tracking purposes. These parameters have no functionality that is relevant to the user, but sites rely on them to track users across pages and properties.
Mozilla introduced support for URL stripping in Firefox 102, which it launched in June 2022. Firefox removes tracking parameters from web addresses automatically, but only in private browsing mode or when the browser’s Tracking Protection feature is set to strict. Firefox users may enable URL stripping in all Firefox modes, but this requires manual configuration. Brave Browser strips known tracking parameters from web addresses as well.
Facebook has responded by encrypting the entire URL into a single ciphertext blob.
Since it is no longer possible to identify the tracking part of the web address, it is no longer possible to remove it from the address automatically. In other words: Facebook has the upper hand in regards to URL-based tracking at the time, and there is little that can be done about it short of finding a way to decrypt the information.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.