Security updates have been issued by AlmaLinux (kernel and kernel-rt), Debian (node-sha.js and python-django), Fedora (chromium, cups, exiv2, perl-Catalyst-Authentication-Credential-HTTP, perl-Catalyst-Plugin-Session, perl-Plack-Middleware-Session, and qemu), Red Hat (container-tools:rhel8, podman, and udisks2), SUSE (cargo-audit, cargo-c, cargo-packaging, and kernel-devel), and Ubuntu (libcpanel-json-xs-perl, libjson-xs-perl, rubygems, sqlite3, and vim).
Senator Ron Wyden has asked the Federal Trade Commission to investigate Microsoft over its continued use of the RC4 encryption algorithm. The letter talks about a hacker technique called Kerberoasting, that exploits the Kerberos authentication system.
Running a monitoring platform like Zabbix in a production environment demands reliability and resilience. When your monitoring solution is down, you’re flying blind – and for many organizations, that simply isn’t acceptable. This post introduces a robust high-availability (HA) architecture for Zabbix, using PostgreSQL, Patroni, etcd, HAProxy, keepalived and PgBackRest. Built on RHEL 9 or derrivates, this solution combines modern open-source tools to provide automatic failover, load balancing, and seamless monitoring, all while maintaining consistency and performance.
Architecture overview
The HA design consists of multiple layers working in tandem to maintain continuity even during node or service failures:
Database Cluster Layer
2 or more nodes form the PostgreSQL cluster, managed by Patroni and coordinated using etcd. At any given time, one node is the primary (read/write), and the others are hot standbys ready to take over automatically.
Consensus layer
etcd runs on the same nodes and acts as the distributed configuration store and coordination layer for Patroni. It ensures a consistent cluster state and enables safe failover decisions.
Load balancing layer
Two HAProxy nodes provide a single point of entry for all clients (including Zabbix), routing requests to the current PostgreSQL primary. These nodes are monitored and coordinated via Keepalived to maintain a floating Virtual IP (VIP), ensuring seamless failover at the connection layer.
Backup layer
A separate backup server is responsible for running PgBackRest, which handles full and incremental backups, WAL archiving, and Point-In-Time Recovery (PITR). This server communicates securely with all database nodes over SSH.
Monitoring layer
Two Zabbix servers, running in active-passive mode, continuously monitor all layers of this stack including the HAProxy health, Patroni cluster role, and etcd status by accessing the PostgreSQL VIP for backend connectivity.
This multi-tiered setup ensures that no single failure be it a database, load balancer, or monitoring server brings down the monitoring platform.
Why HA matters for Zabbix
Zabbix depends heavily on its PostgreSQL database backend. Every metric, trigger, event, and alert is stored there. If PostgreSQL becomes unavailable, even briefly, data loss or monitoring blind spots can occur. That’s why introducing HA at the database layer is a crucial step when scaling Zabbix for enterprise environments.
While Zabbix itself supports HA at the application level, this architecture ensures that the database backend is also fully fault-tolerant, using modern consensus-based clustering with automatic failover.
Component overview
To achieve HA, we bring together several specialized components, each fulfilling a critical role in the system:
PostgreSQL
The relational database engine used by Zabbix. In this example setup, it runs on three nodes, forming a cluster managed by Patroni.
Patroni
Patroni is the orchestrator for the PostgreSQL cluster. It monitors node health, manages replication, promotes standbys when needed, and ensures only one writable leader exists at any time. Patroni leverages a distributed consensus store in this case, etcd but other DCS’s are possible to coordinate decisions across the cluster.
etcd
etcd is a lightweight and highly available key-value store used by Patroni to maintain the cluster’s state. It stores leader election data, health statuses, and locks. We deploy it as a three-node cluster, co-located with the PostgreSQL nodes for convenience, though this setup can be scaled independently if needed as etcd is very latency prone.
HAProxy
To simplify application connectivity, HAProxy acts as a load balancer in front of the database cluster. It monitors the role of each node using Patroni’s REST API and routes connections to the active primary server. If the leader fails, HAProxy automatically reroutes traffic to the new primary.
Keepalived
Keepalived provides a floating virtual IP address (VIP) across the HAProxy nodes. This VIP allows client systems, such as the Zabbix frontend, to connect to a single stable IP even if one HAProxy node fails.
PgBackRest
To protect the data itself, we use PgBackRest for full and incremental backups, as well as Point-In-Time Recovery (PITR). A dedicated backup server is included to pull and store archive logs and backups securely via SSH.
Zabbix server
Finally, we run two Zabbix servers in active-passive mode. Both are configured to connect to the PostgreSQL cluster through the VIP exposed by HAProxy. The Zabbix frontend is deployed on both nodes as well, ensuring continued accessibility through the load-balanced setup.
Topology at a glance
Here’s a simplified view of the architecture:
2 or more database nodes (PostgreSQL + Patroni + etcd)
Two HAProxy nodes, each configured with Keepalived to manage a floating virtual IP
One backup node for PgBackRest
Two Zabbix servers pointing to the PostgreSQL VIP
All systems are tied together with consistent hostname mappings, time synchronization (Chrony), and service monitoring.
Notes:
PgBackRest is directly connected to all three PostgreSQL nodes, allowing it to archive WAL segments and pull backups regardless of which node is primary.
This design enables full standby backups and supports Point-In-Time Recovery (PITR).
HAProxy ensures Zabbix always talks to the current primary node, while Patroni and etcd handle automatic failover and cluster state management.
Design rationale
This setup prioritizes resilience and self-healing. If any single component fails a database node, a load balancer, or even a monitoring server the system continues to function.
Using Patroni with etcd ensures that failovers are handled automatically, without human intervention. HAProxy ensures client traffic is always routed to the current primary, while Keepalived ensures that this routing layer itself is highly available.
We opted for PgBackRest over simple scripts or base backups because it provides not just efficient incremental backups, but also full WAL archiving and point-in-time recovery, which are invaluable for both disaster recovery and debugging.
Lastly, we chose to integrate Zabbix itself into this HA design, treating it not just as a application but as a fully resilient service able to monitor itself, so to speak.
Real-world considerations
Resource planning: While our nodes run comfortably, scaling this setup to heavy workloads requires careful tuning of memory, I/O, and PostgreSQL parameters.
etcd placement: Although we run etcd co-located with the database nodes in this example, separating etcd onto dedicated infrastructure is ideal for large-scale environments. This avoids resource contention and preserves quorum in extreme failure scenarios.
Monitoring the monitors: Zabbix itself must be monitored. In our setup, each component including etcd, Patroni, and PostgreSQL exposes health endpoints that can be used by Zabbix agents or scripts to generate alerts on replication lag, cluster health, and failover events.
Conclusion
This architecture provides a solid foundation for running Zabbix in a fault-tolerant, production-ready environment. It not only ensures high availability for the database layer but also offers flexibility, observability, and operational safety.
Whether you’re running internal infrastructure monitoring or offering Zabbix as a managed service, adopting this type of HA setup removes single points of failure and gives you peace of mind — all using open-source technologies that are battle-tested and widely supported.
If you need assistance with the migration or want to ensure best practices for scaling and optimizing Zabbix, don’t hesitate to reach out to OICTS. We are a Zabbix Premium Partner operating globally, with offices in the USA, UK, Netherlands, and Belgium, and we’re ready to help you every step of the way.
At Grab, our engineering teams rely on a massive Go monorepo that serves as the backbone for a large portion of our backend services. This repository has been our development foundation for over a decade, but age brought complexity, and size brought sluggishness. What was once a source of unified code became a bottleneck that was slowing down our developers and straining our infrastructure.
A primer on GitLab, Gitaly, and replication
To understand our core problem, it’s helpful to know how GitLab handles repositories at scale. GitLab uses Gitaly, its Git RPC service, to manage all Git operations. In a high-availability setup like ours, we use a Gitaly Cluster with multiple nodes.
Here’s how it works:
Write operations: A primary Gitaly node handles all write operations.
Replication: Data is replicated to secondary nodes.
Read operations: Secondary nodes handle read operations, such as clones and fetches, effectively distributing the load across the cluster.
Failover: If the primary node fails, a secondary node can take over.
For the system to function effectively, replication must be nearly instantaneous. When secondary nodes experience significant delays syncing with the primary—a condition called replication lag—GitLab stops routing read requests to the secondary nodes to ensure data consistency. This forces all traffic back to the primary node, eliminating the benefits of our distributed setup. Figure 1 illustrates the replication architecture of Gitaly nodes.
Figure 1: The replication architecture of Gitaly nodes in a high-availability setup.
The scale of our problem
Our Go monorepo started as a simple repository 11 years ago but ballooned as Grab grew. A Git analysis using the git-sizer utility in early 2025 revealed the shocking scale:
12.7 million commits accumulated over a decade.
22.1 million Git trees consuming 73GB of metadata.
5.16 million blob objects totaling 176GB.
12 million references, mostly leftovers from automated processes.
429,000 commits deep on some branches.
444,000 files in the latest checkout.
This massive size wasn’t just a number—it was crippling our daily operations.
Infrastructure problems
Figure 2: Replication delays of up to four minutes during peak working hours.
In high-availability setups, replication is critical for distributing workloads and ensuring system reliability. However, when replication delays occur, they can severely impact infrastructure performance and create bottlenecks. Figure 2 illustrates replication delays of up to four minutes which caused both secondary nodes, Gitaly S1 (orange) and Gitaly S2 (blue), to lag behind the primary node, Gitaly P (green). As a result, all requests were routed exclusively to the primary node, creating significant performance challenges.
The key issues here are:
Single point of failure: Only one of our three Gitaly nodes could handle the load, creating a bottleneck.
Throttled throughput: The system limits the read capacity to just one-third of the cluster’s potential.
Developer experience issues
The growing size of the monorepo directly impacted developer workflows:
Slow clones: 8+ minutes even on fast networks.
Painful Git operations: Every commit, diff, and blame had to process millions of objects.
CI pipeline overhead: Repository cloning added up 5-8 minutes to every CI job.
Frustrated developers: “Why is this repo so slow?” became a common question.
Operational challenges
The repository’s scale introduced significant operational hurdles:
Storage issues: 250GB of Git data made backups and maintenance cumbersome.
GitLab UI timeouts: The web interface struggled to handle millions of commits and refs, frequently timing out.
Limited CI scalability: Adding more CI runners overloaded the single working node.
All these factors were dragging down developer productivity. It was clear that continuing to let the monorepo grow unchecked wasn’t sustainable. We needed to make the repository leaner and faster, without losing the important history that teams relied on.
Our solution journey
Proof of concept: Validating the theory
Before making any changes, we needed to answer a critical question: “Would trimming repository history solve our replication issues?” Without proof, committing to such a major change felt risky. So we set out to test the idea.
The test setup:
We designed a simple experiment. In our staging environment, we created two repositories:
Full history repository: This repository mirrored the original repository with full history.
Shallow history repository: This repository contained only a single commit history.
Both repositories contained the same number of files and directories. We then simulated production-like load on both of the repositories.
The results:
Full history repository: 160-240 seconds replication delay.
Shallow history repository: 1-2.5 seconds replication delay.
This was nearly a 100x improvement in replication performance.
This proof of concept gave us confidence that history trimming was the right approach and provided baseline performance expectations.
Content preservation strategies: What to keep
Initial strategy: Time-based approach (1-2 years)
Initially, we wanted to keep commits from the last 1-2 years and archive everything else, as this seemed like a reasonable balance between recent history and size reduction. However, when we developed our custom migration script, we discovered it could only process 100 commits per hour, approximately 2,400 commits per day. With millions of commits in the original repository, even keeping 1-2 years of history would take months.
We can only process ~100 commits per hour in batches of 20 to avoid memory limits on GitLab runners.
Each batch takes 2 minutes to process, but requires 10 minutes of cleanup (git gc, git reflog expire) to prevent local disk and memory exhaustion.
This means each batch takes 12 minutes, allowing only 5 batches per hour (60 ÷ 12 = 5), totaling to 100 commits per hour (5 × 20 = 100).
Larger batches increased cleanup time and skipping cleanup caused jobs to crash after 200-300 commits.
The bottleneck wasn’t just the number of commits, it was the 10-minute cleanup process.
Additional constraints discovered:
As we dug deeper, we discovered more obstacles.
Critical dependencies extended beyond two years. Some Go module tags from six years ago were still actively used.
A pure time-based cut would break existing build pipelines.
Development teams needed some recent history for troubleshooting and daily operations.
Revised strategy: Tag-based + recent history
Given the processing speed constraint of 100 commits per hour, we needed to drastically reduce the number of commits while preserving essential functionality. After careful evaluation, we settled on a tag-based approach combined with recent history.
What we decided to keep:
Critical tags: All commits reachable by 2,000+ identified tags, ensuring semantic importance for releases and dependencies.
Recent history: Complete commit history for the last month only addressing stakeholder needs within processing constraints.
Simplified merge commits: Converted complex merge commits into single commits to further reduce processing time.
Why this approach worked:
Time-feasible: Reduced processing time from months to weeks.
Functionally complete: Preserved all tagged releases and recent development context.
Stakeholder satisfaction: Met development teams’ need for recent history.
Massive size reduction: Achieved 99.9% fewer commits while keeping what matters.
The trade-off:
We sacrificed deep historical browsing of 1 to 2 years for practical migration feasibility, while ensuring no critical functionality was lost.
The approach: Use Git’s filter-repo tool with git replace --graft to remove commits older than a specified criteria.
Why it failed:
Complex history: Our repository’s highly non-linear history, with multiple branches and merges, made this approach impractical.
Workflow complexity: The process required numerous git replace --graft commands to account for various branches and dependencies, significantly complicating the workflow.
Risk of inconsistencies: The complexity introduced a high risk of errors and inconsistencies, making this method unsuitable.
History integrity: Resulted in linear sequence instead of preserving original merge structure.
Missing commits: Important merge commits were lost or incorrectly applied.
Method 4: Custom migration script (Success!)
The breakthrough: A sophisticated custom script that could handle our specific requirements and processing constraints. Unlike traditional Git history rewriting tools, our script implements a two-phase chronological processing approach that efficiently handles large-scale repositories.
Phase 1: Bulk migration
In this phase, the script focuses on reconstructing history based on critical tags.
Fetch tags chronologically: Retrieve all tags in the order they were created.
Pre-fetch Large File Storage (LFS) objects: Collect LFS objects for tag-related commits before processing.
Batch processing: Process tags in batches of 20 to optimize memory and network usage. For each tag:
Check for associated LFS objects.
Perform selective LFS fetch if required.
Create a new commit using the original tree hash and metadata.
Embed the original commit hash in the commit message for traceability.
Gracefully handle LFS checkout failures.
Then, push the processed batch of 20 commits to the destination repository, with LFS tolerance.
Cleanup and continue: Perform cleanup operations after each batch and proceed to the next.
Phase 2: Delta migration
This phase integrates recent commits after the cutoff date.
Fetch recent commits: Retrieve all commits created after the cutoff date in chronological order.
Batch processing: Process commits in batches of 20 for efficiency. For each commit:
Check for associated LFS objects.
Perform selective LFS fetch if required.
Recreate the commit with its original metadata.
Embed the original commit hash for resumption tracking in case of interruptions.
Gracefully handle LFS checkout failures.
Then, push the processed batch of commits to the destination repository, with LFS tolerance.
Tag mapping: Map tags to their corresponding new commit hashes.
Push tags: Push related tags pointing to the correct new commits.
Final validation: Validate all LFS objects to ensure completeness.
LFS handling
The script incorporates robust mechanisms to handle Git LFS efficiently.
Configure LFS for incomplete pushes.
Skip LFS download errors when possible.
Retry checkout with LFS smudge skip.
Perform selective LFS object fetching.
Gracefully degrade processing for missing LFS objects.
Key features:
Sequential processing of tags and commits in chronological order.
Resumable operations that could restart from the last processed item if interrupted.
Batch processing to manage memory and network resources efficiently.
Robust error handling for network issues and Git complications.
Maintains repository integrity while simplifying complex merge structures.
Optimized for our specific preservation strategy (tags + recent history).
Implementation: Executing the migration
With our strategy defined (tags + last month), we executed the migration using our custom script. This process involved careful planning, smart processing techniques, and overcoming technical challenges.
Smart processing approach
Our custom script employed several key strategies to ensure efficient and reliable migration:
Sequential tag processing: Replay tags chronologically to maintain logical history.
Resumable operations: The migration could restart from the last processed item if interrupted.
Batch processing: Handle items in manageable groups to prevent resource exhaustion.
Progress tracking: Monitor processing rate and estimated completion time.
Technical challenges solved
The migration addressed several critical technical hurdles.
Large file support: Handled Git LFS objects with incomplete push allowances.
Error handling: Robust retry logic for network issues and Git errors.
Merge commit simplification: Converted complex merge structures to linear commits.
Two-phase migration strategy
The migration was executed in two carefully planned phases.
Phase 1 – Bulk migration: Migrated 95% of tags while keeping the old repo live.
Phase 2 – Delta migration: Performed final synchronization during a maintenance window to migrate recent changes.
Results and impact
Infrastructure transformation
Replication delay, or the time required to sync across all Gitaly nodes, improved by 99.4% following the pruning process. As illustrated in Figures 3 and 4, the new pruned monorepo achieves replication in under ~1.5 seconds on average, compared to ~240 seconds for the old repository. This transformation eliminated the previous single-node bottleneck, enabling read requests to be distributed evenly across all three storage nodes, significantly enhancing system reliability and performance.
Figure 3: In the new pruned monorepo, replication delay ranges from 200 – 2,000 ms.
Figure 4: In the old monorepo, replication delay ranged from 16,000 – 28,000 ms.
The migration significantly improved load distribution across Gitaly nodes. As shown in Figure 5, the new monorepo leverages all three Gitaly nodes to serve requests, effectively tripling read capacity. Additionally, the migration eliminated the single point of failure that existed in the old monorepo, ensuring greater reliability and scalability.
Figure 5: In the new monorepo, requests are evenly distributed across all three servers, demonstrating improved performance and replication across nodes.
Figure 6: In the old monorepo, requests were served only by a single server during working hours, creating a single point of failure.
Performance improvements
The migration resulted in significant improvements across multiple areas.
Clone time: Reduced from 7.9 minutes to 5.1 minutes, achieving a 36% improvement, making repository cloning faster and more efficient.
Commit count: Achieved a 99.9% reduction, trimming the repository from 13 million commits to just 15.8 thousand commits, drastically simplifying its structure.
References: Reduced by 99.9%, going from 12 million to 9.8 thousand refs, streamlining repository metadata.
Storage: Reduced by 59%, shrinking storage requirements from 214GB to 87GB, optimizing resource usage.
Developer experience
The migration also transformed the developer experience.
Faster Git operations: Commits, diffs, and history commands are noticeably snappier.
Responsive GitLab UI: Web interface no longer times out.
Scalable CI: The system can now safely run 3x more concurrent jobs.
The following table summarizes the key repository metrics, comparing the state of the repository before and after the migration:
Metric
Old Monorepo
New Monorepo
Reduction
Commits
~13,000,000
~15,800
−99.9% (histories squashed)
Git trees
~23,600,000
~2,080,000
−91% (pruned)
Git references
~12,200,000
9,860
−99.9% (cleaned)
Blob storage
214 GiB
86.8 GiB
−59% (smaller packs)
Files in checkout
~444,000
~444,000
~0% (no change)
Latest code size
~9.9 GiB
~8.4 GiB
~−15% (slightly leaner)
Key challenges and lessons learned
Such a large-scale migration wasn’t without its hiccups and lessons. Here are some challenges we faced and what we learned:
Git LFS woes
Initially, GitLab rejected some commits due to missing LFS objects, even old commits that we weren’t keeping. This happened because GitLab’s push hook expected the content of LFS pointers, even if the files weren’t required. To fix this, we had to allow incomplete pushes and skip LFS download errors. We also wrote logic to selectively fetch LFS objects for commits we were keeping. This ensured that any binary assets needed by tagged commits were present in the new repo. The takeaway is that LFS adds complexity to history rewrites – plan for it by adjusting Git LFS settings (e.g., lfs.allowincompletepush) and verifying important large files are carried over.
Pipeline token scoping
Right after the cutover, some CI pipelines failed to access resources. We discovered a GitLab CI/CD pipeline token issue – our new repo’s ID wasn’t in the allowed list for certain secure token scopes. We quickly updated the settings to include the new project, resolving the authorization error. If your CI jobs interact with other projects or use project-scoped tokens, remember to update those references when you migrate repositories.
Commit hash references broke
One of our internal tools was using commit SHA-1 hashes to track deployed versions. Since rewriting history means changing all commit hashes, the tool couldn’t find the expected commits. The solution was to map old hashes to new ones for the tagged releases, or better, to modify the tool to use tag names instead of raw hashes going forward. We learned to communicate early with teams that have any dependency on Git commit IDs or history assumptions. In our case, providing a mapping of old tag→new tag (which were mostly 1-to-1 except for the commit SHA) helped them adjust. In hindsight, using stable identifiers like semantic version tags, is much more robust than relying on commit hashes, which are ephemeral in a rewritten history.
Developer concerns: “Where’s my history?”
A few engineers were concerned when they noticed that the git log in the new repo only showed two years of history. From their perspective, useful historical context seemed gone. We addressed this by pointing them to the archived full-history repo. In fact, we kept the old repository read-only in our GitLab, so anyone can still search the old history if needed (just not in the main repo). Additionally, we received suggestions on making the archive easily accessible or even automate a way to query old commits on demand. From this we learned, if you prune history, ensure there’s a plan to access legacy information for those rare times it’s needed – whether that’s an archive repo, a Git bundle, or a read-only mirror.
Office network bottleneck
Interestingly, after the migration, a few developers in certain offices didn’t feel a huge speed improvement in clones. It turned out their corporate network/VPN was the limiting factor – cloning 8 GiB vs 10 GiB over a slow link is not a night and day difference. This highlighted that we should continue to work with the IT team on improving network performance. The repo is faster, but the environment matters too. We’re using this as an opportunity to improve our office VPN throughput so that the 36% clone improvement is realized by everyone, not just CI machines.
Automation and hardcoded IDs
We had a lot of automation around the monorepo (scripts, webhooks, integrations). Most of these referenced the project by name, which remained the same, so they were fine. However, a few used the project’s numeric ID in the GitLab API, which changed when we created a new repo. Those broke. We had to scan and update some configs to use the new project ID. Our learning here is to audit all external references such as CI configs, deploy scripts, and monitor jobs when migrating repositories. Ideally, use identifiable names instead of IDs, or ensure you’re prepared to update them during the cutover.
Adjusting to new boundaries
Some teams had to adjust their workflows after the prune. For instance, one team was in the habit of digging into 3 to 5 year old commit logs to debug issues. Post-migration, git log doesn’t go back that far in the main repo; they have to consult the archive for that. It’s a cultural shift to not have all history at your fingertips. We held a short information session to explain how to access the archived repo and emphasized the benefits (faster operations) that come with the lean history. After a while, teams embraced the new normal, appreciating the speed and rarely needing the older commits anyway.
In the end, we had zero data loss – all actual code and tags were preserved – and only some minor inconveniences that were resolved within a day or two. The challenges reinforced the importance of thorough testing (our staging dry-runs caught many issues) and cross-team communication when making such a change.
Impact and next steps
This migration transformed our development infrastructure from a bottleneck into a performance enabler. We eliminated the single point of failure, restored confidence in our Git operations, and created a foundation that can support our growing engineering team.
As the next step, we plan to generalize our pruning script to apply the same optimization techniques to other repositories, ensuring consistency and scalability across our infrastructure. Additionally, we will implement continuous performance monitoring to track repository health and proactively address any emerging issues. To prevent future repository bloat, we aim to establish clear best practices and guidelines, empowering teams to maintain efficiency while supporting the growth of our engineering operations.
Conclusion
What started as a performance crisis became one of our most successful infrastructure projects. By focusing on the right problems—infrastructure reliability and performance rather than just size—we achieved dramatic improvements that benefit every developer daily.
The key takeaway is that sometimes the biggest technical challenges require custom solutions, careful planning, and willingness to iterate until you find what works. Our 99% improvement in replication performance is just the beginning of what’s possible when you tackle infrastructure problems systematically.
This migration was completed by Grab Tech Infra DevTools team, involving months of analysis, custom tooling development, and careful production migration of critical infrastructure serving thousands of developers across multiple time zones.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Let’s Encrypt has been proud to work with the IETF to maintain ACME as an open standard since we first developed the technology a decade ago. We’re happy to announce that IETF has published our latest addition to the ACME protocol, ACME Renewal Information (ARI), as RFC 9773. ARI helps keep the renewal process reliable during unexpected events affecting certificate validity.
Since the ACME protocol was first published as RFC 8555, the IETF ACME working group has remained active, defining various extensions to the original ACME protocol, initiated either by Let’s Encrypt or by colleagues from other organizations. For example, ACME WG documents have specified how to validate kinds of identifiers other than domain names, making it possible to use ACME to issue certificates for IP addresses, or even in PKIs other than the web PKI.
The publication of RFC 9773 is the culmination of a process that began in September 2021 with the first ARI draft. Along the way, numerous colleagues from Let’s Encrypt and elsewhere (thanked individually at the end of this post) contributed to the ARI specification and helped improve it.
Why implement ARI?
This is a good opportunity to remind our community about ARI and how implementing it can help users. If you’re an ACME client user, you may want to check the documentation for your client to see if it has implemented ARI yet. New functionality like this is a great reason to make sure you’re using up-to-date ACME client software. If you’re a client developer, questions about ARI implementation are welcome in the Community Forum’s Client Dev category.
Sometimes certificate authorities, including Let’s Encrypt, may perform mass revocations of an entire group or category of certificates. This most often happens when someone discovers that a certificate authority has made a mistake in how it validates or issues certificates, or has made a misstatement in how it describes its policies and procedures. In this case, the CA is required to revoke the affected certificates. This may happen through absolutely no fault of the subscribers. For example, in January 2022, we had to revoke approximately two million certificates due to a technical error in our validation processes.
When we have to revoke certificates, we want to make sure that the websites using those certificates don’t experience issues. That means those websites need to re-request issuance and install new certificates. Since CAs are sometimes required to revoke certificates on a 24 hour timeline or a 5 day timeline (depending on the nature of the incident), a process that relies on manual intervention from system administrators won’t reach most websites in time.
ARI allows a certificate authority to advise a client to perform an early renewal of a certificate that the client would have anticipated did not need to be renewed yet, broadly because the CA knows that an early renewal is helpful, or necessary, in particular circumstances. In the mass revocation scenario, this allows ARI-aware clients to avoid outages due to certificate invalidity, because they can replace their certificates even before the revocation occurs.
Of course, we and other certificate authorities work diligently to prevent mass revocation events. We’re encouraging ARI implementation as a form of emergency preparedness that can significantly mitigate the impact of this kind of problem, if and when it happens.
ARI also provides features to reduce the impact of load spikes where too many clients request certificates in a short period of time. Let’s Encrypt doesn’t need to use ARI for this today, because other improvements in popular clients’ renewal practices have already sufficiently smoothed out our load spikes. Even so, this will be a valuable ability for all ACME CAs to have available in the long term to better manage emergencies and disruptions.
On the server side, we added support for the ARI draft specification to our Boulder CA software in late 2021, so the Let’s Encrypt CA has supported ARI for some time. If you are implementing ARI in your own client, the Pebble ACME test-bed also supports ARI so you can test against that implementation.
Thanks
Thanks to all of the people who contributed to this process at the ACME WG and elsewhere, including: Roland Shoemaker and Jacob Hoffman-Andrews for coming up with the initial idea of ARI and for helping me learn the IETF process; Samantha Frank, Matt Holt, Ilari Liusvaara, and Wouter Tinus for contributing client implementations; Freddy Zhang for contributing an independent server implementation; and Rob Stradling, Andrew Ayer, and J.C. Jones for providing meaningful feedback and suggestions that significantly improved this specification.
Finally, our congratulations also to Q Misell for the recent publication of RFC 9799, another ACME WG document that went through the standards process alongside ARI.
Registration for the 2025 Linux Plumbers Conference (Tokyo,
December 11 to 13) is
now open. LPC tickets often sell out quickly, so it would be best not
to delay if you intend to attend.
Organizations often struggle to unify their data ecosystems across multiple platforms and services. The connectivity between Amazon SageMaker and Snowflake’s AI Data Cloud offers a powerful solution to this challenge, so businesses can take advantage of the strengths of both environments while maintaining a cohesive data strategy.
In this post, we demonstrate how you can break down data silos and enhance your analytical capabilities by querying Apache Iceberg tables in the lakehouse architecture of SageMaker directly from Snowflake. With this capability, you can access and analyze data stored in Amazon Simple Storage Service (Amazon S3) through AWS Glue Data Catalog using an AWS Glue Iceberg REST endpoint, all secured by AWS Lake Formation, without the need for complex extract, transform, and load (ETL) processes or data duplication. You can also automate table discovery and refresh using Snowflake catalog-linked databases for Iceberg. In the following sections, we show how to set up this integration so Snowflake users can seamlessly query and analyze data stored in AWS, thereby improving data accessibility, reducing redundancy, and enabling more comprehensive analytics across your entire data ecosystem.
Business use cases and key benefits
The capability to query Iceberg tables in SageMaker from Snowflake delivers significant value across multiple industries:
Financial services – Enhance fraud detection through unified analysis of transaction data and customer behavior patterns
Healthcare – Improve patient outcomes through integrated access to clinical, claims, and research data
Retail – Increase customer retention rates by connecting sales, inventory, and customer behavior data for personalized experiences
Manufacturing – Boost production efficiency through unified sensor and operational data analytics
Telecommunications – Reduce customer churn with comprehensive analysis of network performance and customer usage data
Key benefits of this capability include:
Accelerated decision-making – Reduce time to insight through integrated data access across platforms
Cost optimization – Accelerate time to insight by querying data directly in storage without the need for ingestion
Improved data fidelity – Reduce data inconsistencies by establishing a single source of truth
Enhanced collaboration – Increase cross-functional productivity through simplified data sharing between data scientists and analysts
By using the lakehouse architecture of SageMaker with Snowflake’s serverless and zero-tuning computational power, you can break down data silos, enabling comprehensive analytics and democratizing data access. This integration supports a modern data architecture that prioritizes flexibility, security, and analytical performance, ultimately driving faster, more informed decision-making across the enterprise.
Solution overview
The following diagram shows the architecture for catalog integration between Snowflake and Iceberg tables in the lakehouse.
The workflow consists of the following components:
Data storage and management:
Amazon S3 serves as the primary storage layer, hosting the Iceberg table data
The Data Catalog maintains the metadata for these tables
Lake Formation provides credential vending
Authentication flow:
Snowflake initiates queries using a catalog integration configuration
These credentials are automatically refreshed based on the configured refresh interval
Query flow:
Snowflake users submit queries against the mounted Iceberg tables
The AWS Glue Iceberg REST endpoint processes these requests
Query execution uses Snowflake’s compute resources while reading directly from Amazon S3
Results are returned to Snowflake users while maintaining all security controls
There are four patterns to query Iceberg tables in SageMaker from Snowflake:
Iceberg tables in an S3 bucket using an AWS Glue Iceberg REST endpoint and Snowflake Iceberg REST catalog integration, with credential vending from Lake Formation
Iceberg tables in an S3 bucket using an AWS Glue Iceberg REST endpoint and Snowflake Iceberg REST catalog integration, using Snowflake external volumes to Amazon S3 data storage
Iceberg tables in an S3 bucket using AWS Glue API catalog integration, also using Snowflake external volumes to Amazon S3
In this post, we implement the first of these four access patterns using catalog integration for the AWS Glue Iceberg REST endpoint with Signature Version 4 (SigV4) authentication in Snowflake.
An AWS Identity and Access Management (IAM) role that is a Lake Formation data lake administrator in your AWS account. A data lake administrator is an IAM principal that can register Amazon S3 locations, access the Data Catalog, grant Lake Formation permissions to other users, and view AWS CloudTrail. See Create a data lake administrator for more information.
An existing AWS Glue database named iceberg_db and Iceberg table named customer with data stored in an S3 general purpose bucket with a unique name. To create the table, refer to the table schema and dataset.
A user-defined IAM role that Lake Formation assumes when accessing the data in the aforementioned S3 location to vend scoped credentials (see Requirements for roles used to register locations). For this post, we use the IAM role LakeFormationLocationRegistrationRole.
The solution takes approximately 30–45 minutes to set up. Cost varies based on data volume and query frequency. Use the AWS Pricing Calculator for specific estimates.
Create an IAM role for Snowflake
To create an IAM role for Snowflake, you first create a policy for the role:
On the IAM console, choose Policies in the navigation pane.
Choose Create policy.
Choose the JSON editor and enter the following policy (provide your AWS Region and account ID), then choose Next.
To test the configuration, log in to Snowflake as an admin user and run the following sample query:SELECT * FROM s3iceberg_customer LIMIT 10;
Clean up
To clean up your resources, complete the following steps:
Delete the database and table in AWS Glue.
Drop the Iceberg table, catalog integration, and database in Snowflake:
DROP ICEBERG TABLE iceberg_customer;
DROP CATALOG INTEGRATION glue_irc_catalog_int;
Make sure all resources are properly cleaned up to avoid unexpected charges.
Conclusion
In this post, we demonstrated how to establish a secure and efficient connection between your Snowflake environment and SageMaker to query Iceberg tables in Amazon S3. This capability can help your organization maintain a single source of truth while also letting teams use their preferred analytics tools, ultimately breaking down data silos and enhancing collaborative analysis capabilities.
To further explore and implement this solution in your environment, consider the following resources:
These resources can help you to implement and optimize this integration pattern for your specific use case. As you begin this journey, remember to start small, validate your architecture with test data, and gradually scale your implementation based on your organization’s needs.
Organizations are innovating and growing their cloud presence to deliver better customer experiences and drive business value. To support and protect this growth, organizations can use Amazon GuardDuty, a threat detection service that continuously monitors for malicious activity and unauthorized behavior across your AWS environment. GuardDuty uses artificial intelligence (AI), machine learning (ML), and anomaly detection using both AWS and industry-leading threat intelligence to help protect your AWS accounts, workloads, and data. Building on these foundational capabilities, GuardDuty offers a comprehensive suite of protection plans and the Extended Threat Detection feature.
In this post, we explore how to use these features to provide robust security coverage for your AWS workloads, helping you detect sophisticated threats across your AWS environment.
Understanding GuardDuty protection plans
GuardDuty starts with foundational security monitoring, which analyzes AWS CloudTrail management events, Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, and DNS logs. Building on this foundation, GuardDuty offers several protection plans that extend its threat detection capabilities to additional AWS services and data sources. These protection plans are optional features that analyze data from specific AWS services in your environment to provide enhanced security coverage. GuardDuty offers the flexibility to customize how new accounts inherit protection plans, so you can add coverage for your accounts or select specific accounts based on your security needs. You can enable or disable these protection plans at any time to align with your evolving workload requirements.
Here are the available GuardDuty protection plans and their capabilities:
Detects the potential presence of malware by scanning the Amazon Elastic Block Store (Amazon EBS) volumes associated with your EC2 instances. There is an option to use this feature on-demand.
Monitors AWS Lambda network activity logs, starting with VPC Flow Logs, to detect threats to your Lambda functions. Examples of these potential threats include crypto mining and communicating with malicious servers.
Let’s explore how these protection plans help secure different aspects of your AWS environment.
S3 Protection
S3 Protection extends threat detection capabilities of GuardDuty to your S3 buckets by monitoring object-level API operations. Beyond basic monitoring, it analyzes patterns of behavior to detect sophisticated threats. When a threat actor attempts to exfiltrate data, GuardDuty can detect unusual sequences of API calls, such as ListBucket operations followed by suspicious GetObject requests from unusual locations. It also identifies potential security risks like attempts to disable S3 server access logging or unauthorized changes to bucket policies that could indicate an attempt to make buckets public. For instance, GuardDuty would generate an UnauthorizedAccess finding if it detects these suspicious API calls originating from known malicious IP addresses.
EKS Protection
For containerized workloads, EKS Protection monitors your Amazon EKS clusters’ control plane audit logs for security threats. It’s specifically designed to detect container-based exploits by analyzing Kubernetes audit logs from your EKS clusters. GuardDuty detects scenarios such as containers deployed with suspicious characteristics (like known malicious images), attempted privilege escalation through role binding modifications, and suspicious service account activities that could indicate compromise of your Kubernetes environment. When detecting such activities, GuardDuty would generate a PrivilegeEscalation finding, alerting you to potential unauthorized access attempts within your clusters. For a comprehensive understanding of the tactics, techniques, and procedures (TTPs), see the AWS Threat Technique Catalog.
Runtime Monitoring
Runtime Monitoring provides deeper visibility into potential threats by analyzing runtime behavior in EC2 instances, EKS clusters, and container workloads. This capability detects threats that manifest at the operating system level by monitoring process executions, file system changes, and network connections. GuardDuty can identify defense evasion tactics, execution of suspicious processes, and file access patterns indicating potential malware activity. For example, if a compromised instance attempts to disable security monitoring or creates unusual processes, GuardDuty would generate a Runtime finding indicating potential malicious activity at the OS level.
Malware Protection
Malware Protection offers two distinct capabilities: scanning EBS volumes attached to EC2 instances and scanning objects uploaded to S3 buckets. For EC2 instances, GuardDuty can perform both agentless scan-on-demand and continuous scanning of EBS volumes, detecting both known malware and potentially malicious files using advanced heuristics. For S3, it automatically scans newly uploaded objects, helping protect against malware distribution through your S3 buckets. When malware is detected, GuardDuty generates a Malware finding, specifying whether the threat was found in an EC2 instance or S3 bucket, helping you quickly identify and respond to the threat.
RDS Protection
RDS Protection focuses on database security by analyzing login activity for supported Amazon Aurora databases. It creates behavioral baselines of normal database access patterns and can detect anomalous sign-in attempts that might indicate unauthorized access attempts. This includes detecting unusual sign-in patterns, access from unexpected locations, and potential database compromise attempts. When suspicious database access is detected, GuardDuty generates an RDS finding, alerting you to potential unauthorized access or credential compromise.
Lambda Protection
Lambda Protection monitors your serverless applications by analyzing Lambda function activity through VPC Flow Logs. It can detect threats specific to serverless environments, such as when Lambda functions exhibit signs of compromise through unexpected network connections or potential cryptocurrency mining activity. If a Lambda function attempts to communicate with known malicious IP addresses or shows signs of cryptojacking, GuardDuty will generate a Lambda finding, so you can quickly identify and remediate compromised functions.
Each protection plan adds specialized detection capabilities designed for specific workload types, working together to provide comprehensive threat detection across your AWS environment. By enabling the protection plans relevant to your workloads, you can help make sure that GuardDuty provides targeted security monitoring for your specific use cases
Tailoring GuardDuty protection plans to your workload types
To maximize threat detection coverage, consider enabling all applicable GuardDuty protection plans across your AWS environment. This approach helps provide comprehensive coverage while maintaining cost efficiency, because you’re only charged for active protections on resources that exist in your account. For example, if you don’t use Amazon EKS, you won’t incur charges for EKS Protection even if it’s enabled. This strategy also helps facilitate automatic security coverage if teams deploy new services, without requiring immediate security team intervention. You retain the flexibility to adjust your protection plans at any time as your workload requirements evolve.
Based on AWS security best practices, we offer recommendations for different protection plan combinations aligned with common workload profiles. These recommendations help you understand how different protection plans work together to secure your specific architectures. For Amazon EC2 and Amazon S3 workloads, GuardDuty recommends Foundational, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon EC2 to detect threats to compute instances, data storage, and AWS Identity and Access Management (IAM) misuse.
Container-heavy environments using Amazon EKS and Amazon ECS benefit from Foundational, Amazon EKS Protection, Amazon GuardDuty Runtime Monitoring, and Amazon GuardDuty Malware Protection for Amazon EC2. These plans work together to monitor container control-plane and runtime for threats and malware.
For serverless-first architectures built on Lambda, GuardDuty suggests Foundational, AWS Lambda Protection, and Amazon S3 Protection (if using Amazon S3 triggers) to identify anomalous function behavior and suspicious traffic patterns.
Data systems using Amazon Aurora or Amazon RDS should consider Foundational, Amazon RDS Protection, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon S3. This combination helps detect anomalous database sign-ins and potential S3 bucket misuse.
For regulated environments or those implementing zero-trust architectures, enabling all GuardDuty protection plans helps provide comprehensive threat detection coverage that can support your broader security monitoring and compliance program requirements.
For quick reference, here’s what protection plans you should use to actively monitor your different workload types:
Workload profile
Expected security outcomes
Recommended GuardDuty plans
Amazon EC2 and Amazon S3
Detect threats to compute instances, data storage, and IAM misuse
Foundational, Amazon S3 Protection, and Amazon GuardDuty Malware Protection for Amazon EC2
Container-heavy (Amazon EKS, Amazon ECS)
Monitor container control-plane and runtime for threats and malware
Foundational, Amazon EKS Protection, Amazon GuardDuty Runtime Monitoring, and Amazon GuardDuty Malware Protection for Amazon EC2
Serverless-first (AWS Lambda)
Identify anomalous function behavior and suspicious traffic patterns
Foundational, GuardDuty Lambda Protection, GuardDuty S3 Protection (if using Amazon S3 triggers), and GuardDuty Runtime Monitoring for ECS on Fargate
Data system (Amazon Aurora or Amazon RDS)
Detect anomalous database logins and potential S3 bucket misuse
Foundational, Amazon RDS Protection, GuardDuty S3 Protection, and Amazon GuardDuty Malware Protection for Amazon S3
Regulated and Zero-Trust
Comprehensive threat detection to support compliance requirements
All Amazon GuardDuty protection plans
The power of GuardDuty Extended Threat Detection
Building upon these protection plans, GuardDuty offers Extended Threat Detection by default at no additional cost, using AI/ML capabilities to provide improved threat detection for your applications, workloads, and data. This capability correlates security signals to identify active threat sequences, offering a more comprehensive approach to cloud security.
Extended Threat Detection includes a Critical severity level for the most urgent and high-confidence threats based on correlating multiple steps taken by adversaries, such as privilege discovery, API manipulation, persistence activities, and data exfiltration. Integration with the MITRE ATT&CK® framework allows GuardDuty to map observed activities to tactics and techniques, providing context for security teams. To help teams respond quickly, GuardDuty provides specific remediation recommendations based on AWS best practices for each identified threat.
Real-world protection: Extended Threat Detection in action
To understand how GuardDuty protection plans and Extended Threat Detection work together in practice, let’s examine two sophisticated threat scenarios that security teams commonly face: data compromise and container cluster compromise.
Data compromise detection
GuardDuty Extended Threat Detection continuously analyzes and correlates events across multiple protection plans, providing comprehensive visibility when data compromise attempts occur in Amazon S3. For example, in a recent incident, GuardDuty identified a critical severity attack sequence spanning 24 hours. The sequence began with discovery actions through unusual S3 API calls, progressed to defense evasion through CloudTrail modifications, and culminated in potential data exfiltration attempts.
During the discovery phase, S3 Protection detected an IAM role making unusual ListBuckets and GetObject API calls across multiple buckets—a significant deviation from their normal pattern of accessing only specific assigned buckets. Extended Threat Detection then correlated this suspicious activity with subsequent actions from the same IAM role: attempts to disable CloudTrail logging and modify bucket policies (classic signs of defense evasion), followed by the creation of new access keys. This connected sequence of events, all from the same identity, indicated a progressing exploit moving from initial discovery to establishing persistence through credential creation.
Container environment compromise
Protecting containerized environments requires visibility across multiple layers of your Amazon EKS infrastructure. GuardDuty combines signals from EKS control plane (through EKS Protection), container runtime behavior (through Runtime Monitoring), and foundational infrastructure logs to provide comprehensive threat detection for your Kubernetes clusters. For example, EKS Protection detects suspicious activities at the Kubernetes control plane level, such as unusual kubernetes API server authentication attempts or the creation of service accounts with elevated permissions. Runtime Monitoring provides visibility into container behavior, identifying unexpected privileged commands or suspicious file system access. Together with foundational logs, these components provide multi-layer threat detection for your container workloads.
Here’s how these components worked together in detecting an attack sequence: The exploit began when EKS Protection detected unusual Kubernetes API server authentication attempts from a container within the cluster. Runtime Monitoring simultaneously observed commands that deviated from the container’s baseline behavior, such as privilege escalation attempts and unauthorized system calls. As the exploit progressed, GuardDuty detected the creation of a Kubernetes service account with elevated permissions, followed by attempts to mount sensitive host paths to containers.
The scenario then escalated when the compromised Kubernetes Pod established connections to other Pods across namespaces, suggesting lateral movement. GuardDuty Extended Threat Detection correlated these events with the Pod accessing sensitive Kubernetes secrets and AWS credentials stored in Kubernetes ConfigMaps. The final stage revealed the compromised Pod making AWS API calls using stolen credentials, targeting resources outside the cluster’s normal operational scope.
The detection of this multi-stage attack, spanning container exploitation, privilege escalation, and credential theft, demonstrates the power of the correlation capabilities of Extended Threat Detection. Security teams received a single critical finding that mapped the entire exploit sequence to MITRE ATT&CK® tactics, providing clear visibility into the exploit progression and specific remediation steps.
These real-world scenarios illustrate how GuardDuty protection plans work in concert with Extended Threat Detection to provide deep security insights. The combination of targeted protection plans and AI-powered correlation helps security teams identify and respond to sophisticated threats that might otherwise go unnoticed or be difficult to piece together manually.
Conclusion
GuardDuty protection plans, coupled with its built-in Extended Threat Detection feature, offer a powerful suite of managed detections to secure your AWS environment. By tailoring your security strategy to your specific workload types and using AI-powered insights, you can significantly enhance your ability to detect and respond to sophisticated threats. To get started with GuardDuty protection plans and Extended Threat Detection, visit the GuardDuty console. Each protection plan includes a 30-day trial at no additional cost per AWS account and AWS Region, allowing you to evaluate the security coverage for your specific needs. Remember, you can adjust your enabled plans at any time to align with your evolving security requirements and workload changes. By using these capabilities, you can strengthen your organization’s threat detection and response in the face of evolving security risks.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Brooke Deuson is the developer behind
Trafficking Free Tomorrow, a nonprofit organization that
produces free software to help law enforcement combat human trafficking. She is
a survivor of human trafficking herself.
She spoke at RustConf 2025 about her
mission, and why she chose to write her anti-trafficking software in Rust.
Interestingly, it has nothing to do with Rust’s lifetime-analysis-based memory-safety —
instead, her choice was motivated by the difficulty she faces getting police
departments to actually use her software. The fact that Rust is statically
linked and capable of cross compilation by default makes deploying Rust software
in those environments easier.
Today, I’m happy to share recent Magic Quadrant reports that named AWS as a Leader in more cloud technology markets: Cloud-Native Application Platforms (aka Cloud Application Platforms) and Container Management.
2025 Gartner Magic Quadrant for Cloud-Native Application Platforms AWS has been named a Leader in the Gartner Magic Quadrant for Cloud-Native Application Platforms for 2 consecutive years. AWS was positioned highest on “Ability to Execute”. Gartner defines cloud-native application platforms as those that provide managed application runtime environments for applications and integrated capabilities to manage the lifecycle of an application or application component in the cloud environment.
The following image is the graphical representation of the 2025 Magic Quadrant for Cloud-Native Application Platforms.
Our comprehensive cloud-native application portfolio—AWS Lambda, AWS App Runner, AWS Amplify, and AWS Elastic Beanstalk—offers flexible options for building modern applications with strong AI capabilities, demonstrated through continued innovation and deep integration across our broader AWS service portfolio.
You can simplify the service selection through comprehensive documentation, reference architectures, and prescriptive guidance available in the AWS Solutions Library, along with AI-powered, contextual recommendations from Amazon Q based on your specific requirements. While AWS Lambda is optimized for AWS to provide the best possible serverless experience, it follows industry standards for serverless computing and supports common programming languages and frameworks. You can find all necessary capabilities within AWS, including advanced features for AI/ML, edge computing, and enterprise integration.
2025 Gartner Magic Quadrant for Container Management In the 2025 Gartner Magic Quadrant for Container Management, AWS has been named as a Leader for three years and was positioned furthest for “Completeness of Vision”. Gartner defines container management as offerings that support the deployment and operation of containerized workloads. This process involves orchestrating and overseeing the entire lifecycle of containers, covering deployment, scaling, and operations, to ensure their efficient and consistent performance across different environments.
The following image is the graphical representation of the 2025 Magic Quadrant for Container Management.
AWS container services offer fully managed container orchestration with AWS native solutions and open-source technologies to focus on providing a wide range of deployment options, from Kubernetes to our native orchestrator.
You can connect on-premises and edge infrastructure back to AWS container services with EKS Hybrid Nodes and ECS Anywhere, or use EKS Anywhere for a fully disconnected Kubernetes experience supported by AWS. With flexible compute and deployment options, you can reduce operational overhead and focus on innovation and drive business value faster.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Version
8.0.0 of Varnish Cache
has been released. In addition to a number
of changes to varnishd parameters, the ability to access some
runtime parameters using the Varnish Configuration Language, and other
improvements, 8.0.0 comes with big news; the project is forming an
organization called a forening
that will set out formal governance for the project.
The move also comes with a name change due to legal difficulties in
securing the Varnish Cache name:
The new association and the new project will be named “The Vinyl
Cache Project”, and this release 8.0.0, will be the last under the
“Varnish Cache” name. The next release, in March will be under the new
name, and will include compatility scripts, to make the transition as
smooth as possible for everybody.
I want to make it absolutely clear that this is 100% a mess of my
making: I should have insisted on a firm written agreement about the
name sharing, but I did not.
I will also state for the record, that there are no hard feelings
between Varnish Software and the FOSS project.
Varnish Software has always been, and still is, an important and
valued contributor to the FOSS project, but sometimes even friends can
make a mess of a situation.
Many enterprises are adopting Apache Spark for scalable data processing tasks such as extract, transform, and load (ETL), batch analytics, and data enrichment. As data pipelines evolve, the need for flexible and cost-efficient execution environments that support automation, governance, and performance at scale also evolve in parallel. Amazon EMR provides a powerful environment to run Spark workloads, and depending on workload characteristics and compliance requirements, teams can choose between fully managed options like Amazon EMR Serverless or more customizable configurations using Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2).
In use cases where infrastructure control, data locality, or strict security postures are essential, such as in financial services, healthcare, or government, running transient EMR on EC2 clusters becomes a preferred choice. However, orchestrating the full lifecycle of these clusters, from provisioning to job submission and eventual teardown, can introduce operational overhead and risk if done manually.
To streamline this process, the AWS Cloud offers built-in orchestration capabilities using AWS Step Functions and Amazon EventBridge. Together, these services help you automate and schedule the entire EMR job lifecycle, reducing manual intervention while optimizing cost and compliance. Step Functions provides the workflow logic to manage cluster creation, Spark job execution, and cluster termination, and EventBridge schedules these workflows based on business or operational needs.
In this post, we discuss how to build a fully automated, scheduled Spark processing pipeline using Amazon EMR on EC2, orchestrated with Step Functions and triggered by EventBridge. We walk through how to deploy this solution using AWS CloudFormation, processes COVID-19 public dataset data in Amazon Simple Storage Service (Amazon S3), and store the aggregated results in Amazon S3. This architecture is ideal for periodic or scheduled batch processing scenarios where infrastructure control, auditability, and cost-efficiency are critical.
Solution overview
This solution uses the publicly available COVID-19 dataset to illustrate how to build a modular, scheduled architecture for scalable and cost-efficient batch processing for time-bound data workloads.The solution follows these steps:
Raw COVID-19 data in CSV format is stored in an S3 input bucket.
A scheduled rule in EventBridge triggers a Step Functions workflow.
The Step Functions workflow provisions a transient Amazon EMR cluster using EC2 instances.
A PySpark job is submitted to the cluster to calculate COVID-19 hospital utilization data to compute monthly state-level averages of inpatient and ICU bed utilization, and COVID-19 patient percentages.
The processed results are written back to an S3 output bucket.
After successful job completion, the EMR cluster is automatically deleted.
Logs are persisted to Amazon S3 for observability and troubleshooting.
By automating this workflow, you alleviate the need to manually manage EMR clusters while gaining cost-efficiency by running compute only when needed. This architecture is ideal for periodic Spark jobs such as ETL pipelines, regulatory reporting, and batch analytics, especially when control, compliance, and customization are required.The following diagram illustrates the architecture for this use case.
The infrastructure is deployed using AWS CloudFormation to provide consistency and repeatability. AWS Identity and Access Management (IAM) roles grant least‑privilege access to Step Functions, Amazon EMR, EC2 instances, and S3 buckets, and optional AWS Key Management Service (AWS KMS) encryption can secure data at rest in Amazon S3 and Amazon CloudWatch Logs. By combining a scheduled trigger, stateful orchestration, and centralized logging, this solution delivers a fully automated, cost‑optimized, and secure way to run transient Spark workloads in production.
Prerequisites
Before you get started, make sure you have the following prerequisites:
An AWS account. If you don’t have one, you can sign up for one.
Clone the sample repository to your local machine or AWS CloudShell and navigate into the project directory.
git clone https://github.com/aws-samples/sample-emr-transient-cluster-step-functions-eventbridge.git
cd sample-emr-transient-cluster-step-functions-eventbridge
Set an environment variable for the AWS Region where you plan to deploy the resources. Replace the placeholder with your Region code, for example, us-east-1.
export AWS_REGION=<YOUR AWS REGION>
Deploy the stack using the following command. Update the stack name if needed. In this example, the stack is created with the name covid19-analysis.
You can monitor the stack creation progress on the AWS CloudFormation console on the Events tab. The deployment typically completes in under 5 minutes.
After the stack is successfully created, go to the Outputs tab on the AWS CloudFormation console and note the following values for use in later steps:
InputBucketName
OutputBucketName
LogBucketName
Set up the COVID-19 dataset
With your infrastructure in place, complete the following steps to set up the input data:
Download the COVID-19 data CSV file from HealthData.gov to your local machine.
Rename the downloaded file to covid19-dataset.csv.
Upload the renamed file to your S3 input bucket under the raw/ folder path.
Set up the PySpark Script
Complete the following steps to set up the PySpark script:
This script processes COVID-19 hospital utilization data stored as CSV files in your S3 input bucket. When running the job, provide the following command-line arguments:
--input – The S3 path to the input CSV files
--output – The S3 path to store the processed results
The script reads the raw dataset, standardizes various date formats, and filters out records with invalid or missing dates. It then extracts key utilization metrics such as inpatient bed usage, ICU bed usage, and the percentage of beds occupied by COVID-19 patients and calculates monthly averages grouped by state. The aggregated output is saved as timestamped CSV files in the specified S3 location.
This example demonstrates how you can use PySpark to efficiently clean, transform, and analyze large-scale healthcare data to gain actionable insights on hospital capacity trends during the pandemic.
Configure a schedule in EventBridge
The Step Functions state machine is by default scheduled to run on December 31, 2025, as a one-time execution. You can update the schedule for recurring or one-time execution as needed. Complete the following steps:
On the EventBridge console, choose Schedules under Scheduler in the navigation pane.
Select the schedule named <StackName>-covid19-analysis and choose Edit.
Set your preferred schedule pattern.
If you want to run the schedule one time, select One-time schedule for Occurrence and enter a date and time.
If you want to run this on a recurring basis, select Recurring schedule. Specify the schedule type as either Cron-based schedule or Rate-based schedule as needed.
Choose Next twice and choose Save schedule.
Start the workflow in Step Functions
Based on your EventBridge schedule, the Step Functions workflow will run automatically. For this walkthrough, complete the following steps to trigger it manually:
On the Step Functions console, choose State machines in the navigation pane.
Choose the state machine that begins with Covid19AnalysisStateMachine-*.
Choose Start execution.
In the Input section, provide the following JSON (provide the log bucket and output bucket names with the appropriate values captured earlier):
After you start the workflow, you can track both the Step Functions state transitions and the EMR job progress in real time on the console.
Monitor the Step Functions state machine
Complete the following steps to monitor the Step Functions state machine:
On the Step Functions console, choose State machines in the navigation pane.
Choose the state machine that begins with Covid19AnalysisStateMachine-*.
Choose the running execution to view the visual workflow.
Each state node will update as it progresses—green for success, red for failure.
To explore a step, choose its node and inspect the input, output, and error details in the side pane.
The following screenshot shows an example of a successfully executed workflow.
Monitor the EMR cluster and EMR step
Complete the following steps to monitor the EMR cluster and EMR step status:
While the cluster is active, open the Amazon EMR console and choose Clusters in the navigation pane.
Locate the Covid19Cluster transient EMR cluster. Initially, it will be in Starting status.
On the Steps tab, you can see your Spark submit step listed. As the job progresses, the step status changes from Pending to Running to finally Completed or Failed.
Choose the Applications tab to view the application UIs, in which you can access the Spark History Server and YARN Timeline Server for monitoring and troubleshooting.
Monitor CloudWatch logs
To enable CloudWatch logging and enhanced monitoring for your EMR on EC2 cluster, refer to Amazon EMR on EC2 – Enhanced Monitoring with CloudWatch using custom metrics and logs. This guide explains how to install and configure the CloudWatch agent using a bootstrap action, so you can stream system-level metrics (such as CPU, memory, and disk usage) and application logs from EMR nodes directly to CloudWatch. With this setup, you can gain real-time visibility into cluster health and performance, simplify troubleshooting, and retain critical logs even after the cluster is terminated.
For this walkthrough, check the logs in the S3 log output location.
Confirm cluster deletion
When the Spark step is complete, Step Functions will automatically delete the Amazon EMR cluster. Refresh the Clusters page on the Amazon EMR console. You should see your cluster status change from Terminating to Terminated within a minute.
By following these steps, you gain full end-to-end visibility into your workflow from the moment the Step Functions state machine is triggered to the automatic shutdown of the EMR cluster. You can monitor execution progress, troubleshoot issues, confirm job success, and continuously optimize your transient Spark workloads.
Verify job output in Amazon S3
When the job is complete, complete the following steps to check the processed results in the S3 output bucket:
On the Amazon S3 console, choose Buckets in the navigation pane.
Open the output S3 bucket you noted earlier.
Open the processed folder.
Navigate into the timestamped subfolder to view the CSV output file.
Download the CSV file to view the processed results, as shown in the following screenshot.
Monitoring and troubleshooting
To monitor the progress of your Spark job running on a transient EMR on EC2 cluster, use the Step Functions console. It provides real-time visibility into each state transition in your workflow, from cluster creation and job submission to cluster deletion. This makes it straightforward to track execution flow and identify where issues might occur.During job execution, you can use the Amazon EMR console to access cluster-level monitoring. This includes YARN application statuses, step-level logs, and overall cluster health. If CloudWatch logging is enabled in your job configuration, driver and executor logs stream in near real time, so you can quickly detect and diagnose errors, resource constraints, or data skew within your Spark application.
After the workflow is complete, regardless of whether it succeeds or fails, you can perform a detailed post-execution analysis by reviewing the logs stored in the S3 bucket specified in the LogUri parameter. This log directory includes standard output and error logs, along with Spark history files, offering insights into execution behavior and performance metrics.
For continued access to the Spark UI during job execution, you can use persistent application UIs on the EMR console. These links remain accessible even after the cluster is stopped, enabling deeper root-cause analysis and performance tuning for future runs.
This visibility into both workflow orchestration and job execution can help teams optimize their Spark workloads, reduce troubleshooting time, and build confidence in their EMR automation pipelines.
Clean up
To avoid incurring ongoing charges, clean up the resources provisioned during this walkthrough:
Empty the S3 buckets:
On the Amazon S3 console, choose Buckets in the navigation pane.
Select the input, output, and log buckets used in this tutorial.
Choose Empty to remove all objects before deleting the buckets (optional).
Delete the CloudFormation stack:
On the AWS CloudFormation console, choose Stacks in the navigation pane.
Select the stack you created for this solution and choose Delete.
Confirm the deletion to remove associated resources.
Conclusion
In this post, we showed how to build a fully automated and cost-effective Spark processing pipeline using Step Functions, EventBridge, and Amazon EMR on EC2. The workflow provisions a transient EMR cluster, runs a Spark job to process data, and stops the cluster after the job completes. This approach helps reduce costs while giving you full control over the process. This solution is ideal for scheduled data processing tasks such as ETL jobs, log analytics, or batch reporting, especially when you need detailed control over infrastructure, security, and compliance settings.
To get started, deploy the solution in your environment using the CloudFormation stack provided and adjust it to fit your data processing needs. Check out the Step Functions Developer Guide and Amazon EMR Management Guide to explore further.
Share your feedback and ideas in the comments or connect with your AWS Solutions Architect to fine-tune this pattern for your use case.
Today, organizations are heavily using Apache Spark for their big data processing needs. However, managing the entire development lifecycle of Spark applications—from local development to production deployment—can be complex and time-consuming. Managing the entire code base—including application code, infrastructure provisioning, and continuous integration and delivery (CI/CD) pipelines—is sometimes not fully automated and a shared responsibility across multiple teams, which slows down release cycles. This undifferentiated heavy lifting diverts valuable resources away from core business objectives: deriving value from data.
In this post, we explore how to use Amazon EMR, the AWS Cloud Development Kit (AWS CDK), and the Data Solutions Framework (DSF) on AWS to streamline the development process, from setting up a local development environment to deploying serverless Spark infrastructure, and implementing a CI/CD pipeline for automated testing and deployment.
By adopting this approach, developers gain full control over their code and the infrastructure responsible for running it, alleviating the need for cross-team dependency. Developers can customize the infrastructure to meet specific business needs and optimize performance. Additionally, they can customize CI/CD stages to facilitate comprehensive testing, using the self-mutation capability of AWS CDK Pipelines to automatically update and refine the deployment process. This level of control not only accelerates development cycles but also enhances the reliability and efficiency of the entire application lifecycle, so developers can focus more on innovation and less on manual infrastructure management.
Solution overview
The solution consists of the following key components:
The local development environment to develop and test your Spark code locally
The infrastructure as code (IaC) that will run your Spark application in AWS environments
The CI/CD pipeline running end-to-end tests and deploying into the different AWS environments
In the following sections, we discuss how to set up these components.
Prerequisites
To set up this solution, you must have an AWS account with appropriate permissions, Docker and the AWS CDK CLI.
Set up the local development environment
Developing Spark applications locally can be a challenging task due to the need for a consistent and efficient environment that mirrors your production setup. With Amazon EMR, Docker, and the Amazon EMR toolkit extension for Visual Studio Code, you can quickly set up a local development environment for Spark applications, developing and testing Spark code locally, and seamlessly port it to the cloud.
The Amazon EMR toolkit for VS Code includes an “EMR: Create Local Spark Environment” command that generates a development container. This container is based on an Amazon EMR on Amazon EKS image corresponding to the Amazon EMR version you select. You can develop Spark and PySpark code locally, with full compatibility with your remote Amazon EMR environment. Additionally, the toolkit provides helpers to make it straightforward to connect to the AWS Cloud, including an Amazon EMR explorer, an AWS Glue Data Catalog explorer, and commands to run Amazon EMR Serverless jobs from VS Code.
To set up your local environment, complete the following steps:
Now you can launch your dev container using the VS Code command Dev Containers: Rebuild and Reopen in container.
The container will install the latest operating system packages and run a local Spark history server on port 18080.
The container provides spark-shell, spark-sql, and pyspark from the terminal and a Jupyter Python kernel for connecting a Jupyter notebook to execute interactive Spark code.
Using the Amazon EMR Toolkit, you can develop your Spark application and test it locally using Pytest—for example, to validate the business logic. You can also connect to other AWS accounts where you have your development environment.
Build the AWS CDK application with DSF on AWS
After you validate the business logic into your local Spark application, you can implement the infrastructure responsible for running your application. DSF provides AWS CDK L3 Constructs that simplify the creation of Spark-based data pipelines on EMR Serverless or Amazon EMR on EKS.
DSF provides the capability to package your local PySpark application, including the Python dependencies, into artifacts that can consumed by EMR Serverless jobs. The PySparkApplicationPackage is a construct that uses a Dockerfile to perform the packaging of dependencies into a Python virtual environment archive and then upload the archive and the PySpark entrypoint file into a secured Amazon Simple Storage Service (Amazon S3) bucket. The following diagram illustrates this architecture.
See the following example code:
spark_app = dsf.processing.PySparkApplicationPackage(
self,
"SparkApp",
entrypoint_path="./../spark/src/agg_trip_distance.py",
application_name="TaxiAggregation",
# Path of the Dockerfile used to package the dependencies as a Python venv
dependencies_folder='./../spark',
# Path of the venv archive in the docker image
venv_archive_path="/venv-package/pyspark-env.tar.gz",
removal_policy=RemovalPolicy.DESTROY)
You just need to provide the paths for the following:
The PySpark entrypoint. This is the main Python script of your Spark application.
The Dockerfile containing the logic for packaging a virtual environment into an archive.
The path of the resulting archive in the container file system.
DSF provides helpers to connect the application package to the EMR Serverless job. The PySparkApplicationPackage construct exposes properties that can directly be used into the SparkEmrServerlessJob construct parameters. This construct simplifies the configuration of a batch job using an AWS Step Functions state machine. The following diagram illustrates this architecture.
The following code is an example of an EMR Serverless job:
spark_job = dsf.processing.SparkEmrServerlessJob(
self,
"SparkProcessingJob",
dsf.processing.SparkEmrServerlessJobProps(
name=f"taxi-agg-job-{Names.unique_resource_name(self)}",
# ID of the previously created EMR Serverless runtime
application_id=spark_runtime.application.attr_application_id,
# The IAM role used by the EMR Job with permissions required by the application
execution_role=processing_exec_role,
spark_submit_entry_point=spark_app.entrypoint_uri,
# Add the Spark parameters from the PySpark package to configure the dependencies (using venv)
spark_submit_parameters=spark_app.spark_venv_conf + spark_params,
removal_policy=RemovalPolicy.DESTROY,
schedule=schedule))
Note the two parameters of SparkEmrServerlessJob that are provided by PySparkApplicationPackage:
entrypoint_uri, which is the S3 URI of the entrypoint file
spark_venv_conf, which contains the Spark submit parameters for using the Python virtual environment
DSF also provides a SparkEmrServerlessRuntime to simplify the creation of the EMR Serverless application responsible for running the job.
Deploy the Spark application using CI/CD
The final step is to implement a CI/CD pipeline that can test your Spark code and promote from dev/test/stage and then to production. DSF provides a L3 Construct that simplifies the creation of the CI/CD pipeline for your Spark applications. DSF’s implementation of the Spark CI/CD pipeline construct uses the AWS CDK built-in pipeline functionality. One of the key capabilities when using an AWS CDK pipeline is its self-mutating capability. It can update itself whenever you change its definition, avoiding the traditional chicken-and-egg problem of pipeline updates and helping developers fully control their CI/CD pipeline.
When the pipeline runs, it follows a carefully orchestrated sequence. First, it retrieves your code from your repository and synthesizes it into AWS CloudFormation templates. Before doing anything else, it examines these templates to see if you’ve made any changes to the pipeline’s own structure. If the pipeline detects that its definition has changed, it will pause its normal operation and update itself first. After the pipeline has updated itself, it will continue with its regular stages, such as deploying your application.
DSF provides an opinionated implementation of CDK Pipelines for Spark applications, where the PySpark code is automatically unit tested using Pytest and where the configuration is simplified. You only need to configure four components:
The CI/CD stages (testing, staging, production, and so on). This includes the AWS account ID and Region where these environments reside in.
The AWS CDK stack that is deployed in each environment.
(Optional) The integration test script that you want to run against the deployed stack.
The SparkEmrCICDPipeline AWS CDK construct.
The following diagram illustrates how everything works together.
Let’s dive into each of these components.
Define cross-account deployment and CI/CD stages
With the SparkEmrCICDPipeline construct, you can deploy your Spark application stack across different AWS accounts. For example, you can have a separate account for your CI/CD processes and different accounts for your staging and production environments.To set this up, first bootstrap the various AWS accounts (staging, production, and so on):
This step sets up the necessary resources in the environment accounts and creates a trust relationship between those accounts and the CI/CD account where the pipeline will run.Next, choose between two options to define the environments (both options require the relevant configuration in the cdk.context.json file.The first option is to use pre-defined environments, which is defined as follows:
Now that the environments have been bootstrapped and configured, let’s look at the actual stack that contains the resources that will be deployed in the various environments. Two classes must be implemented:
A class that extends the stack – This is where the resources that are going to be deployed in each of the environments are defined. This can be a normal AWS CDK stack, but it can be deployed in another AWS account depending on the environment configuration defined in the previous section.
A class that extends ApplicationStackFactory – This is DSF specific, and makes it possible to configure and then return the stack that is created.
ApplicationStackFactory supports customization of the stack before returning the initialized object to be deployed by the CI/CD pipeline. You can customize your stack behavior by passing the current stage to your stack. For example, you can skip scheduling the Spark application in the integration tests stage because the integration tests trigger it manually as part of the CI/CD pipeline. For the production stage, the scheduling facilitates automatic execution of the Spark application.
Write the integration test script
The integration test script is a bash script that is triggered after the main application stack has been deployed. Inputs to the bash script can come from the AWS CloudFormation outputs of the main application stack. These outputs are mapped into environment variables that the bash script can access directly.
In the Spark CI/CD example, the application stack uses the SparkEMRServerlessJob CDK construct. This construct uses a Step Functions state machine to manage the execution and monitoring of the Spark job. The following is an example integration test bash script that we use to test that the deployed stack can run the associated Spark job successfully:
#!/bin/bash
EXECUTION_ARN=$(aws stepfunctions start-execution --state-machine-arn $STEP_FUNCTION_ARN | jq -r '.executionArn')
while true
do
STATUS=$(aws stepfunctions describe-execution --execution-arn $EXECUTION_ARN | jq -r '.status')
if [ $STATUS = "SUCCEEDED" ]; then
exit 0
elif [ $STATUS = "FAILED" ] || [ $STATUS = "TIMED_OUT" ] || [ $STATUS = "ABORTED" ]; then
exit 1
else
sleep 10
continue
fi
done
The integration test scripts are executed within an AWS CodeBuild project. As part of the IntegrationTestStack, we’ve included a custom resource that periodically checks the status of the integration test script as it runs. Failure of the CodeBuild execution causes the parent pipeline (residing in the pipeline account) to fail. This helps teams only promote changes that pass all the required testing.
Bring all the components together
When you have your components ready, you can use the SparkEmrCICDPipeline to bring them together. See the following example code:
dsf.processing.SparkEmrCICDPipeline(
self,
"SparkCICDPipeline",
spark_application_name="SparkTest",
# The Spark image to use in the CICD unit tests
spark_image=dsf.processing.SparkImage.EMR_7_5,
# The factory class to dynamically pass the Application Stack
application_stack_factory=SparkApplicationStackFactory(),
# Path of the CDK python application to be used by the CICD build and deploy phases
cdk_application_path="infra",
# Path of the Spark application to be built and unit tested in the CICD
spark_application_path="spark",
# Path of the bash script responsible to run integration tests
integ_test_script='./infra/resources/integ-test.sh',
# Environment variables used by the integration test script, value is the CFN output name
integ_test_env={
"STEP_FUNCTION_ARN": "ProcessingStateMachineArn"
},
# Additional permissions to give to the CICD to run the integration tests
integ_test_permissions=[
PolicyStatement(
actions=["states:StartExecution", "states:DescribeExecution"
],
resources=["*"]
)
],
source= CodePipelineSource.connection("your/repo", "branch",
connection_arn="arn:aws:codeconnections:us-east-1:222222222222:connection/7d2469ff-514a-4e4f-9003-5ca4a43cdc41"
),
removal_policy=RemovalPolicy.DESTROY,
)
The following elements of the code are worth highlighting:
With the integ_test_env parameter, you can define the environment variable mapping with the output of your application stack that’s defined in the application_stack_factory parameter
The integ_test_permissions parameter specifies the AWS Identity and Access Management (IAM) permissions that are attached to the CodeBuild project where the integration test script runs in
CDK Pipelines needs an AWS code connection Amazon Resource Name (ARN) to connect to your Git repository when you host your code
Now you can deploy the stack containing the CI/CD pipeline. This is a one-time operation because the CI/CD pipeline will dynamically be updated based on code changes that impact the CI/CD pipeline itself:
cd infra
cdk deploy CICDPipeline
Then you can commit and push the code into the source code repository defined in the source parameter. This step triggers the pipeline and deploys the application in the configured environments. You can check the pipeline definition and status on the AWS CodePipeline console.
Follow the readme guide to delete the resources created by the solution.
Conclusion
By using Amazon EMR, the AWS CDK, DSF on AWS, and the Amazon EMR toolkit, developers can now streamline their Spark application development process. The solution described in this post helps developers gain full control over their code and infrastructure, making it possible to set up local development environments, implement automated CI/CD pipelines, and deploy serverless Spark infrastructure across multiple environments.
Last week, Strands Agents, AWS open source for agentic AI SDK just hit 1 million downloads and earned 3,000+ GitHub Stars less than 4 months since launching as a preview in May 2025. With Strands Agents, you can build production-ready, multi-agent AI systems in a few lines of code.
We’ve continuously improved features including support for multi-agent patterns, A2A protocol, and Amazon Bedrock AgentCore. You can use a collection of sample implementations to help you get started with building intelligent agents using Strands Agents. We always welcome your contribution and feedback to our project including bug reports, new features, corrections, or additional documentation.
Here is the latest research article of Amazon Science about the future of agentic AI and questions that scientists are asking about agent-to-agent communications, contextual understanding, common sense reasoning, and more. You can understand the technical topic of agentic AI with with relatable examples, including one about our personal behaviors about leaving doors open or closed, locked or unlocked.
Last week’s launches Here are some launches that got my attention:
Amazon EC2 M4 and M4 Pro Mac instances – New M4 Mac instances offer up to 20% better application build performance compared to M2 Mac instances, while M4 Pro Mac instances deliver up to 15% better application build performance compared to M2 Pro Mac instances. These instances are ideal for building and testing applications for Apple platforms such as iOS, macOS, iPadOS, tvOS, watchOS, visionOS, and Safari.
LocalStack integration in Visual Studio Code (VS Code) – You can use LocalStack to locally emulate and test your serverless applications using the familiar VS Code interface without switching between tools or managing complex setup, thus simplifying your local serverless development process.
AWS CloudTrail MCP Server – New AWS CloudTrail MCP server allows AI assistants to analyze API calls, track user activities, and perform advanced security analysis across your AWS environment through natural language interactions. You can explore more AWS MCP servers for working with AWS service resources.
Amazon CloudFront support for IPv6 origins – Your applications can send IPv6 traffic all the way to their origins, allowing them to meet their architectural and regulatory requirements for IPv6 adoption. End-to-end IPv6 support improves network performance for end users connecting over IPv6 networks, and also removes concerns for IPv4 address exhaustion for origin infrastructure.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS? page.
Other AWS news Here are some additional news items that you might find interesting:
A city in the palm of your hand – Check out this interactive feature that explains how our AWS Trainium chip designers think like city planners, optimizing every nanometer to move data at near light speed.
Measuring the effectiveness of software development tools and practices – Read how Amazon developers that identified specific challenges before adopting AI tools cut costs by 15.9% year-over-year using our cost-to-serve-software framework (CTS-SW). They deployed more frequently and reduced manual interventions by 30.4% by focusing on the right problems first.
Become an AWS Cloud Club Captain – Join a growing network of student cloud enthusiasts by becoming an AWS Cloud Club Captain! As a Captain, you’ll get to organize events and building cloud communities while developing leadership skills. Application window is open September 1-28, 2025.
Upcoming AWS events Check your calendars and sign up for these upcoming AWS events as well as AWS re:Invent and AWS Summits:
AWS AI Agent Global Hackathon – This is your chance to dive deep into our powerful generative AI stack and create something truly awesome. From September 8 to October 20, you have the opportunity to create AI agents using AWS suite of AI services, competing for over $45,000 in prizes and exclusive go-to-market opportunities.
AWS Gen AI Lofts – You can learn AWS AI products and services with exclusive sessions and meet industry-leading experts, and have valuable networking opportunities with investors and peers. Register in your nearest city: Mexico City (September 30–October 2), Paris (October 7–21), London (Oct 13–21), and Tel Aviv (November 11–19).
AWS Community Days – Join community-led conferences that feature technical discussions, workshops, and hands-on labs led by expert AWS users and industry leaders from around the world: Aotearoa and Poland (September 18), South Africa (September 20), Bolivia (September 20), Portugal (September 27), Germany (October 7), and Hungary (October 16).
Security teams know all too well the grind of manual investigations and remediation. With the mass adoption of AI and increasingly automated attacks, defenders cannot afford to rely on overly manual, low priority, and complex workflows.
Heavily burdensome manual response introduces delays as analysts bounce between consoles and high alert volumes, contributing to alert fatigue. Even worse, it prevents security teams from dedicating time to high-priority threats and strategic, innovative work. To keep pace, SOCs need automated responses that contain and remediate common threats at machine speed before they become business-impacting incidents.
Expanding our capabilities with CrowdStrike Falcon® Fusion’ SOAR
That’s why today, we’re excited to announce a new integration between the Cloudflare One platform and CrowdStrike’s Falcon® Fusion SOAR.
As part of our ongoing partnership with CrowdStrike, this integration introduces two out-of-the-box integrations for Zero Trust and Email Security designed for organizations already leveraging CrowdStrike Falcon® Insight XDR or CrowdStrike Falcon® Next-Gen SIEM.
This allows SOC teams to gain powerful new capabilities to stop phishing, malware, and suspicious behavior faster, with less manual effort.
Out-of-the-box integrations
Although teams can always create custom automations, we’ve made it simple to get started with two pre-built integrations focused on Zero Trust Access and Email Security. Both follow the same general structure and are available directly in the CrowdStrike Content Library.
Cloudflare within CrowdStrike Content Library
The actions you can take within CrowdStrike from these integrations are the following:
Email Security
– Update Allow Policy
– Search Email Messages
– List Trusted Domains
– List Protected Domains
– List Blocked Senders
– List Allow Policies
– Get Trusted Domain
– Get Message Details
– Get Detection Details
– Get Allow Policy
– Delete Trusted Domain
– Delete Allow Policy
Delete Blocked Sender
Create Trusted Domain
Create Blocked Sender
Create Allow Policy
Get Blocked Sender
Zero Trust Access
– Update Reusable Policy
– Update Access Group
– Revoke Application Tokens
– Read Metadata For A Key
– List Reusable Policies
– List Access Groups
– List Access Applications
– List Access App Policies
– Get Access Reusable Policy
– Get Access Group
– Get Access Application
– Get Access App Policy
– Delete Reusable Policy
– Delete Access Group
– Delete Access Application
– Delete Access App Policy
– Create Reusable Policy
– Create Access Group
– Create Access App Policy
Using these signals, customers can create automated workflows that run with minimal to no human intervention. Falcon Fusion SOAR’s drag-and-drop editor makes it easy to chain together Cloudflare actions with other signals (from CrowdStrike or even third-party vendors) to automate large portions of the SOC workflow.
An example flow that you could create is:
A phishing email is detected by Cloudflare Email Security.
Falcon Fusion SOAR automatically retrieves detection details, blocks the sender, and updates allow/deny lists.
Cloudflare Zero Trust revokes active session tokens for the impacted account.
If Falcon confirms the endpoint is compromised, the device is automatically isolated.
Another example of how a workflow like above would show in the UI is the following:
An example automated flow using Cloudflare
From the Cloudflare UI, customers can navigate to the Logpush section where they can set up a job with CrowdStrike. To do this customers need to create a job with “HTTP destination”:
From here, customers can input the HTTP endpoint provided by CrowdStrike in the data connector setup to start sending logs over to Falcon Fusion SOAR. This URL will show up in the following way: ingest.us-2.crowdstrike.com/api/ingest/hec/<CRWDconnectionID>/v1/services/collector/raw
CrowdStrike URL Location
Working Logpush to CrowdStrike
This end-to-end automation allows teams to reduce mean time-to-response from minutes to seconds.
How detection and remediation are made possible
At a technical level, the integration relies on webhook and API integrations between Cloudflare’s SASE platform and CrowdStrike Falcon Fusion SOAR. For example:
From endpoint to network: When the CrowdStrike Falcon® platform detects an endpoint compromise, it triggers a workflow to Cloudflare’s API, which enforces step-up authentication or session revocation across SaaS, private apps, or email access. This is done via Cloudflare’s Access product.
From network to endpoint: When Cloudflare flags suspicious behavior (e.g., abnormal login patterns, anomalous traffic, or unsafe email activity), it notifies CrowdStrike Falcon Fusion SOAR, which then isolates the device and launches remediation playbooks.
This bidirectional exchange makes sure threats are contained from both sides, endpoint and network, without requiring manual intervention from analysts.
How to get started
If your organization already uses CrowdStrike Falcon Fusion SOAR with Cloudflare’s SASE platform, you can enable these workflows today directly from the Cloudflare Dashboard and CrowdStrike Falcon console (Zero Trust, Email Security). You can also search for Cloudflare within the content library in CrowdStrike to find the integrations.
For organizations looking to customize further, both platforms allow extensibility through APIs and custom playbooks so SOC teams can tailor response actions to their unique risk posture.
To learn more about our integrations, feel free to reach out to us to get started with a consultation.
Today, we’re announcing some changes that will improve the security of accessing Git data over SSH.
What’s changing?
We’re adding a new post-quantum secure SSH key exchange algorithm, known alternately as sntrup761x25519-sha512 and [email protected], to our SSH endpoints for accessing Git data.
This only affects SSH access and doesn’t impact HTTPS access at all.
It also does not affect GitHub Enterprise Cloud with data residency in the United States region.
Why are we making these changes?
These changes will keep your data secure both now and far into the future by ensuring they are protected against future decryption attacks carried out on quantum computers.
When you make an SSH connection, a key exchange algorithm is used for both sides to agree on a secret. The secret is then used to generate encryption and integrity keys. While today’s key exchange algorithms are secure, new ones are being introduced that are secure against cryptanalytic attacks carried out by quantum computers.
We don’t know if it will ever be possible to produce a quantum computer powerful enough to break traditional key exchange algorithms. Nevertheless, an attacker could save encrypted sessions now and, if a suitable quantum computer is built in the future, decrypt them later. This is known as a “store now, decrypt later” attack.
To protect your traffic to GitHub when using SSH, we’re rolling out a hybrid post-quantum key exchange algorithm: sntrup761x25519-sha512 (also known by the older name [email protected]). This provides security against quantum computers by combining a new post-quantum-secure algorithm, Streamlined NTRU Prime, with the classical Elliptic Curve Diffie-Hellman algorithm using the X25519 curve. Even though these post-quantum algorithms are newer and thus have received less testing, combining them with the classical algorithm ensures that security won’t be weaker than what the classical algorithm provides.
These changes are rolling out to github.com and non-US resident GitHub Enterprise Cloud regions. Only FIPS-approved cryptography may be used within the US region, and this post-quantum algorithm isn’t approved by FIPS.
When are these changes effective?
We’ll enable the new algorithm on September 17, 2025 for GitHub.com and GitHub Enterprise Cloud with data residency (with the exception of the US region).
This will also be included in GitHub Enterprise Server 3.19.
How do I prepare?
This change only affects connections with a Git client over SSH. If your Git remotes start with https://, you won’t be impacted by this change.
For most uses, the new key exchange algorithm won’t result in any noticeable change. If your SSH client supports [email protected] or sntrup761x25519-sha512 (for example, OpenSSH 9.0 or newer), it will automatically choose the new algorithm by default if your client prefers it. No configuration change should be necessary unless you modified your client’s defaults.
If you use an older SSH client, your client should fall back to an older key exchange algorithm. That means you won’t experience the security benefits of using a post-quantum algorithm until you upgrade, but your SSH experience should continue to work as normal, since the SSH protocol automatically picks an algorithm that both sides support.
If you want to test whether your version of OpenSSH supports this algorithm, you can run the following command: ssh -Q kex. That lists all of the key exchange algorithms supported, so if you see sntrup761x25519-sha512 or [email protected], then it’s supported.
To check which key exchange algorithm OpenSSH uses when you connect to GitHub.com, run the following command on Linux, macOS, Git Bash, or other Unix-like environments:
For other implementations of SSH, please see the documentation for that implementation.
What’s next?
We’ll keep an eye on the latest developments in security. As the SSH libraries we use begin to support additional post-quantum algorithms, including ones that comply with FIPS, we’ll update you on our offerings.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.


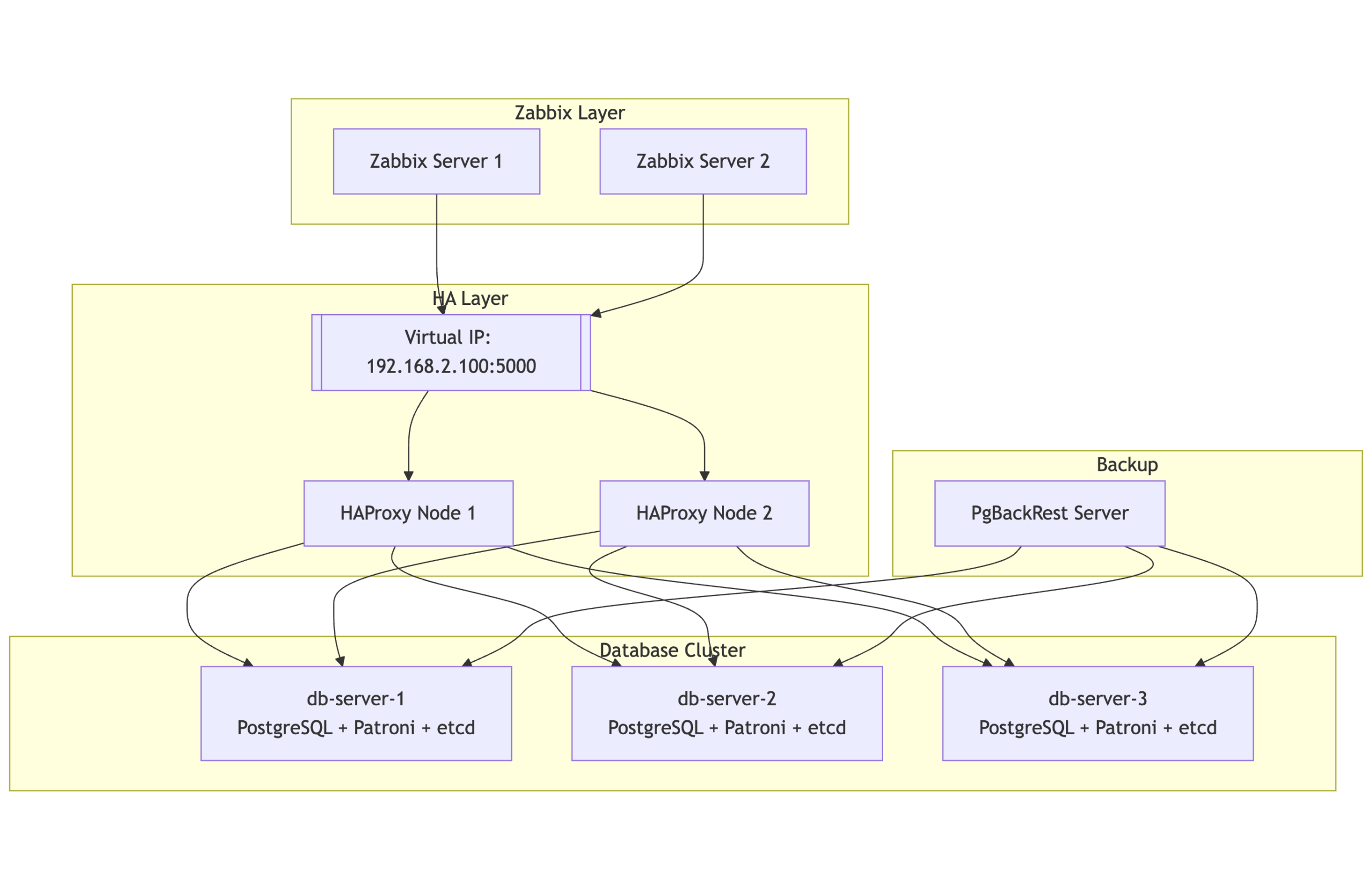
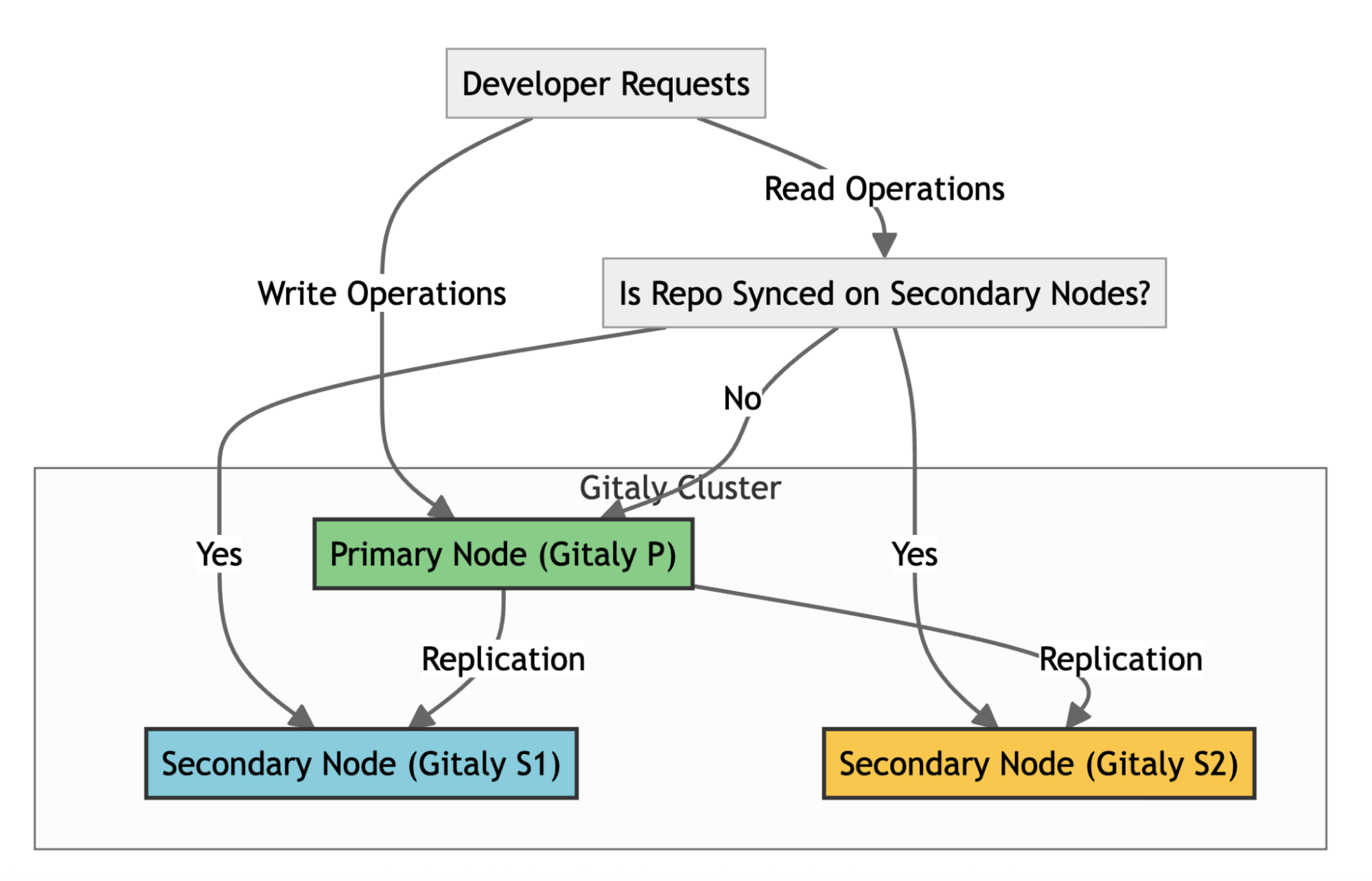
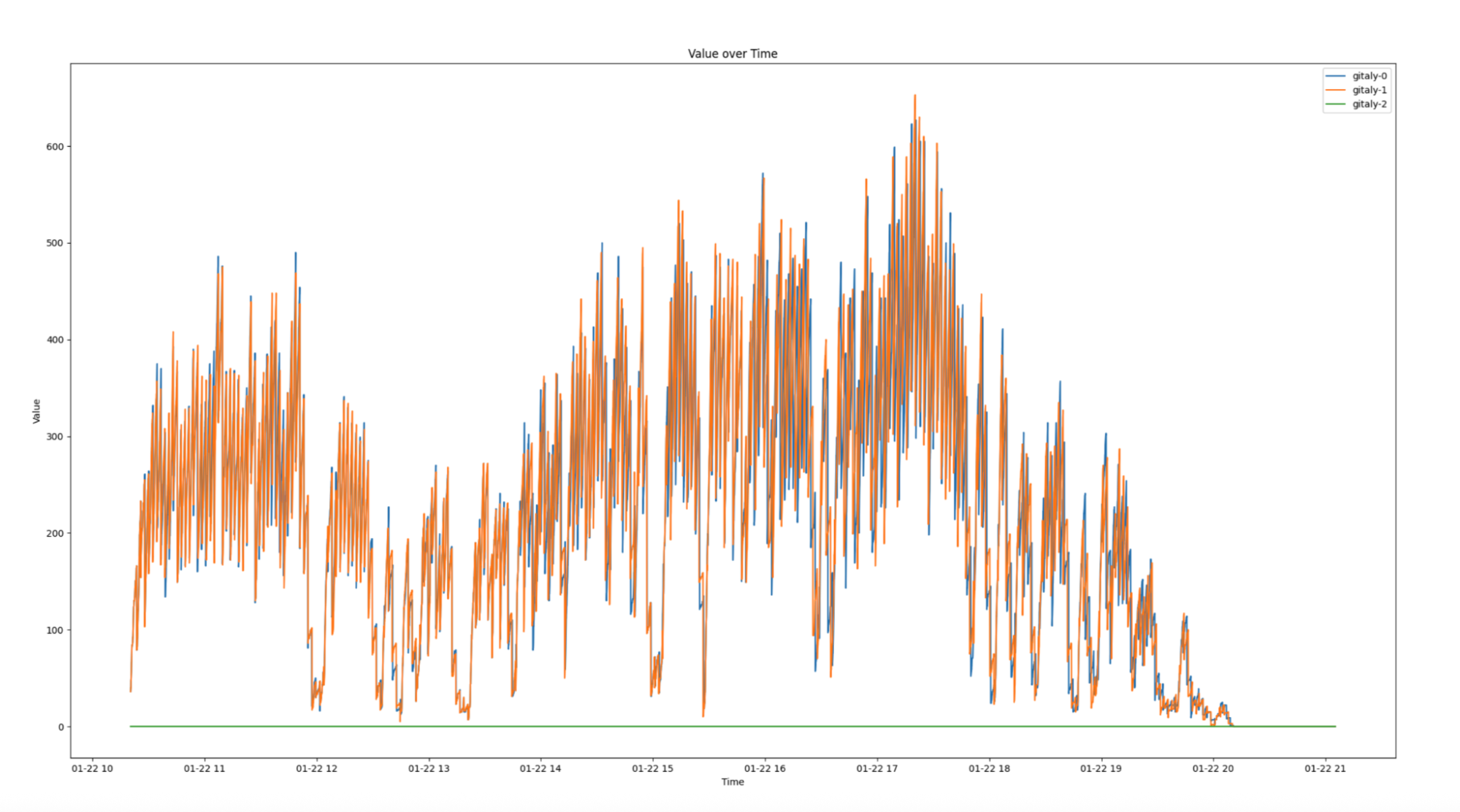
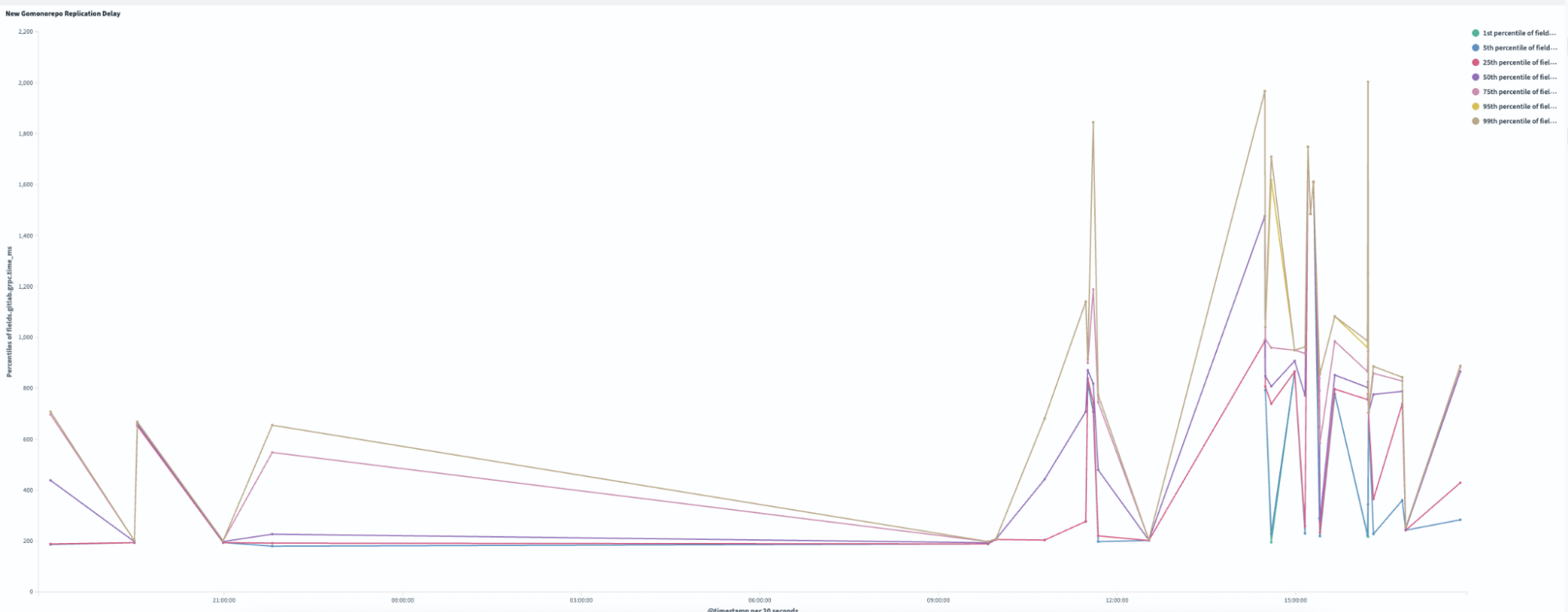
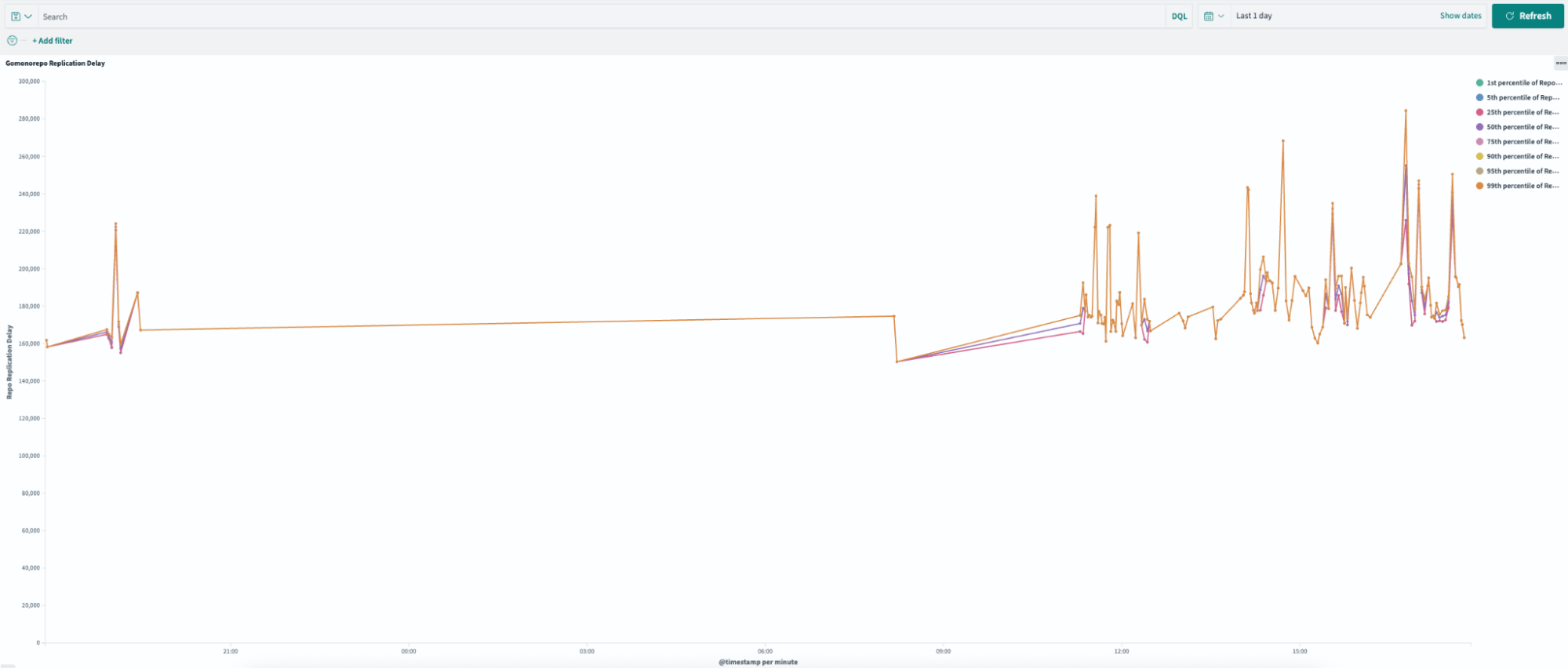
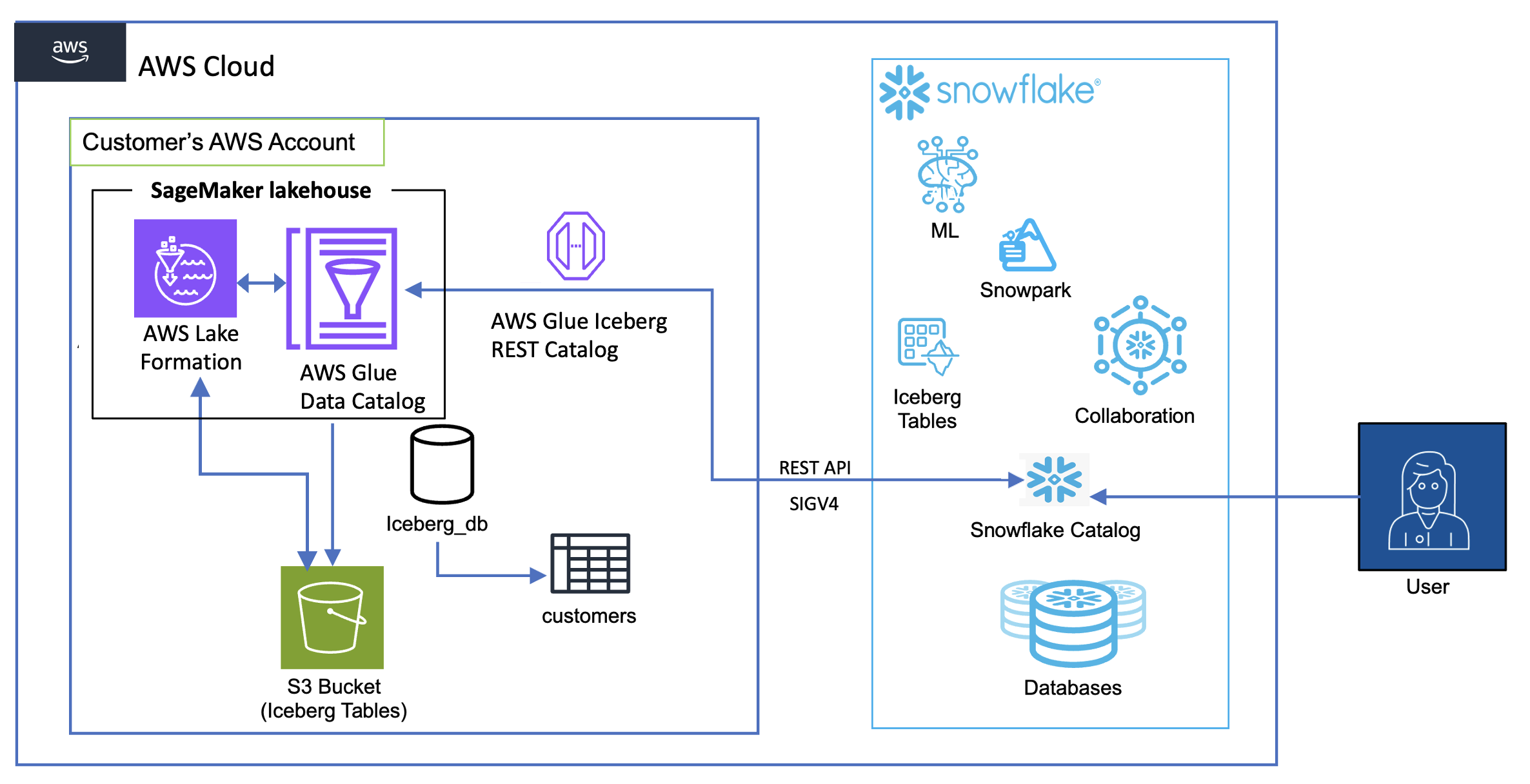

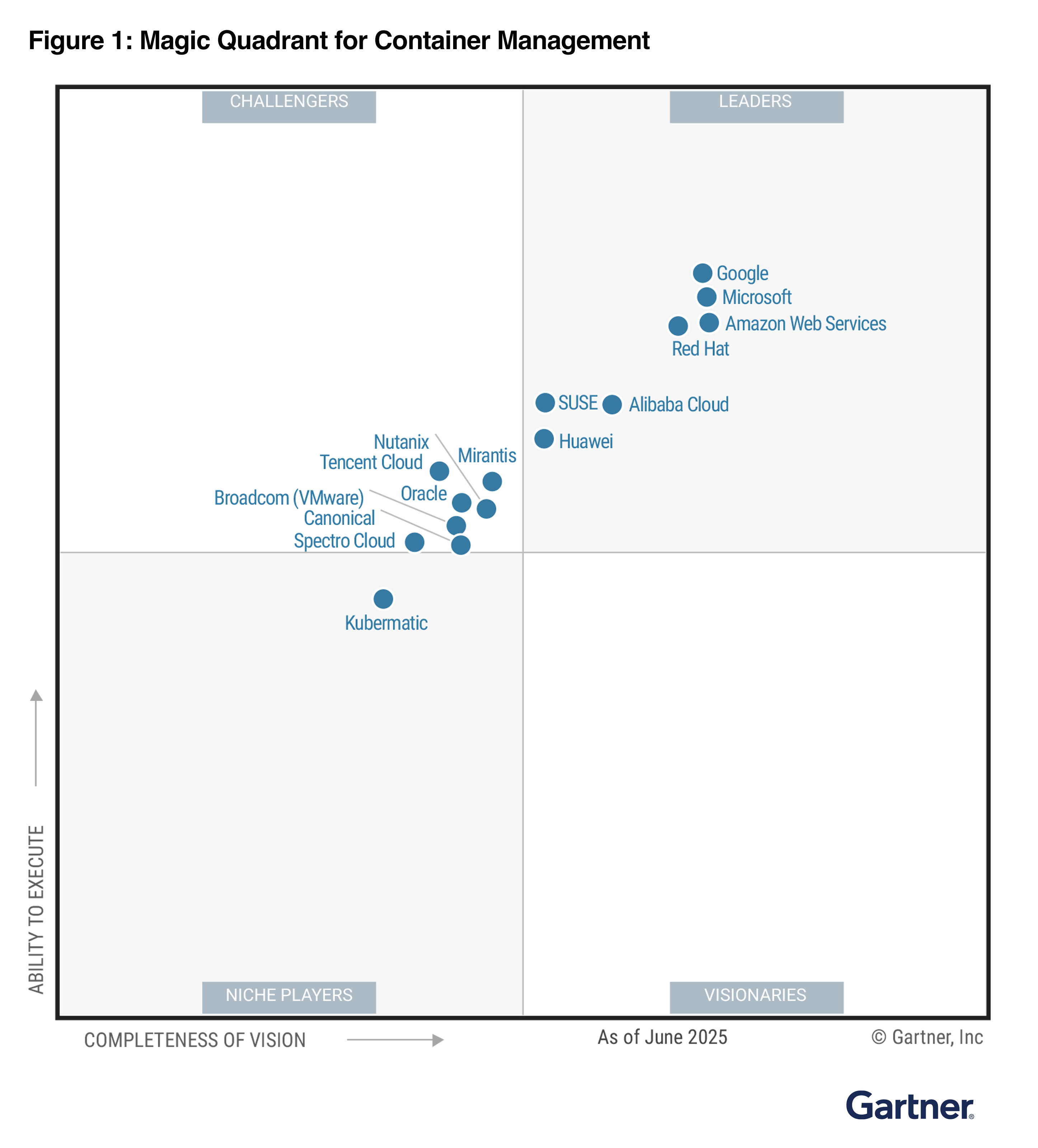
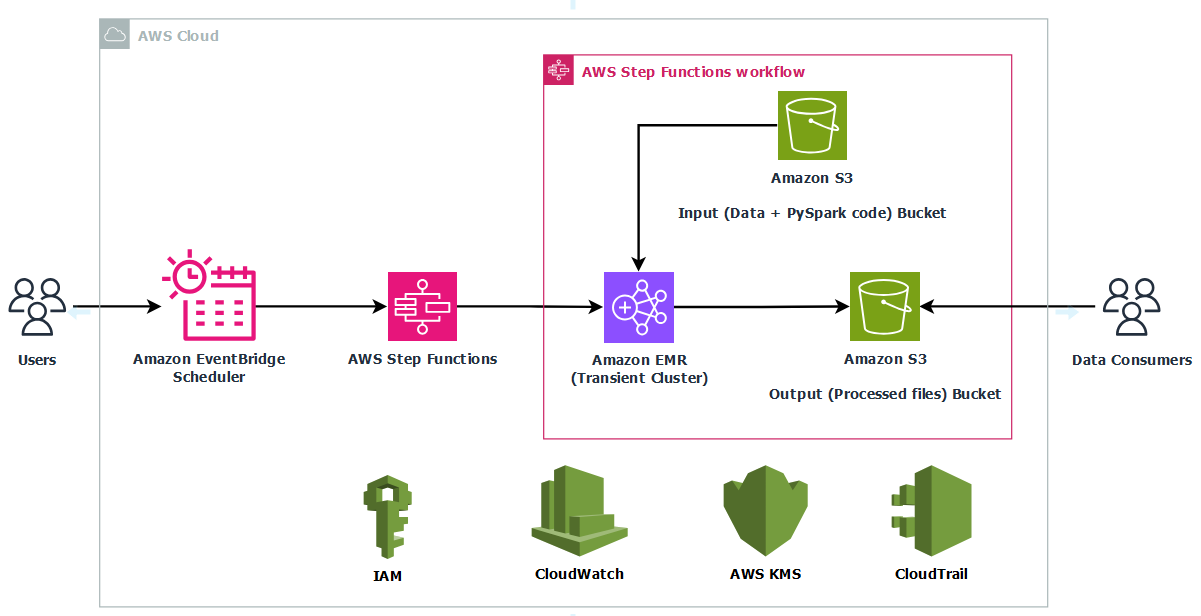
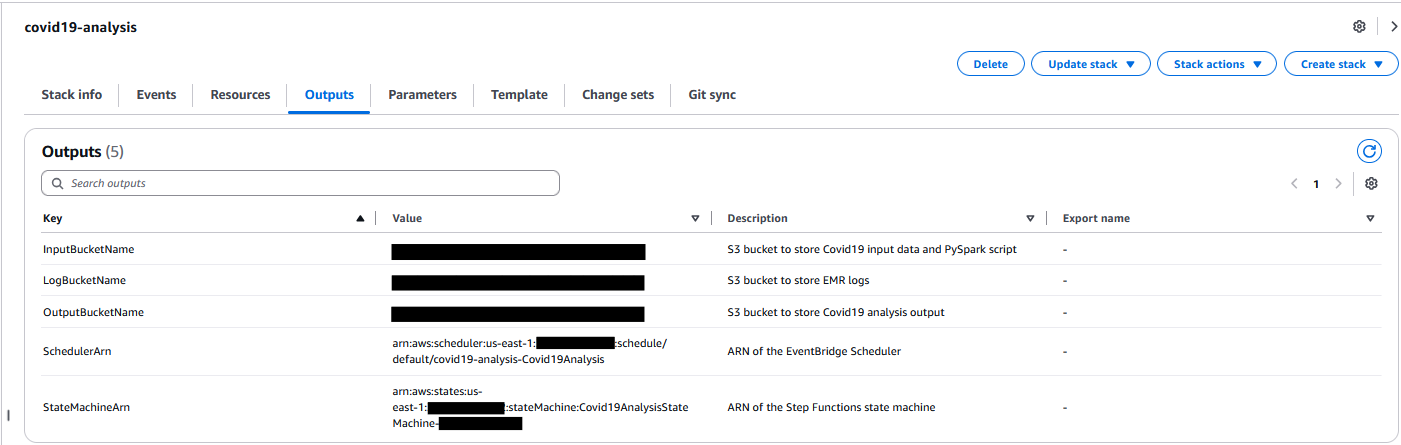
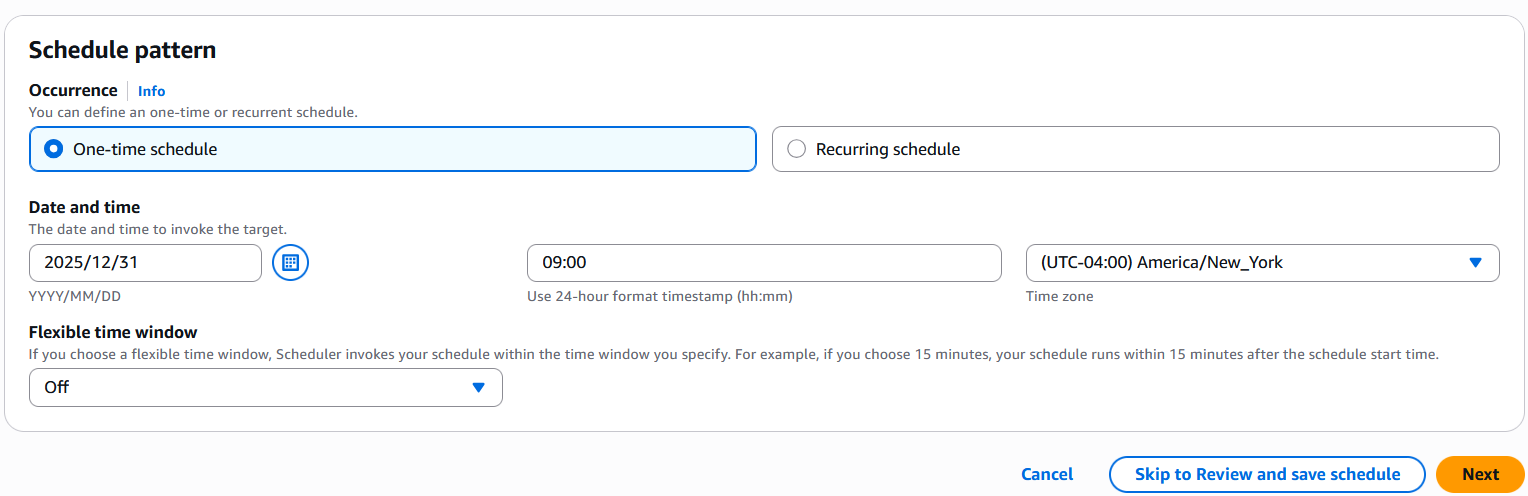
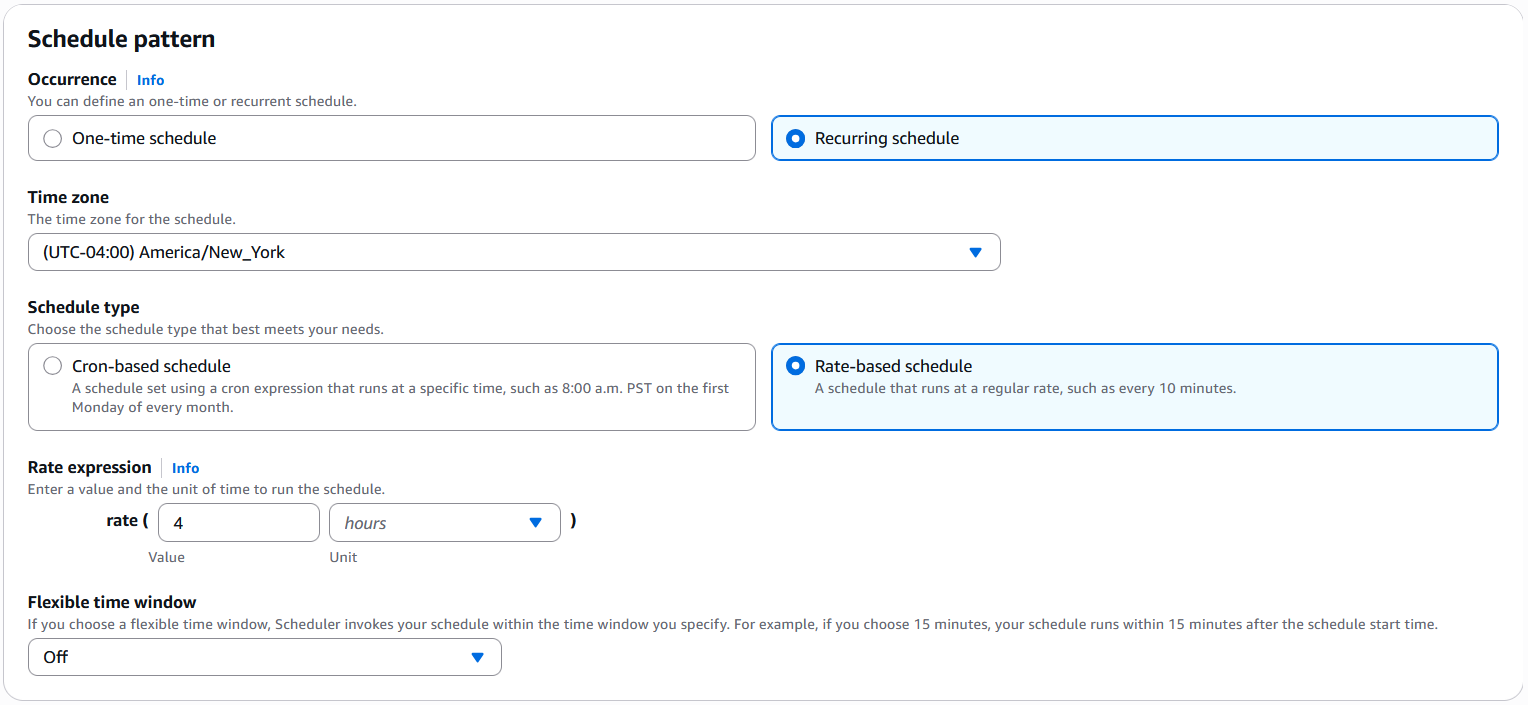
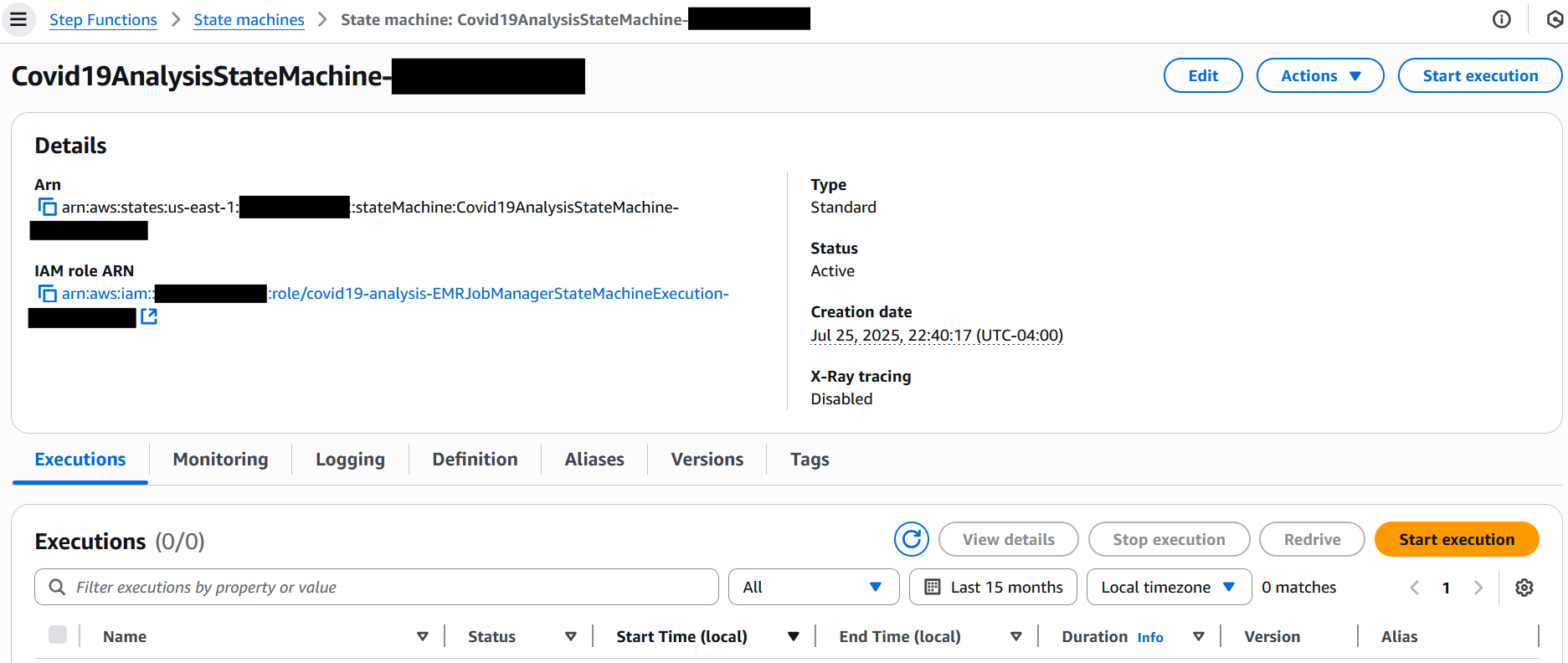
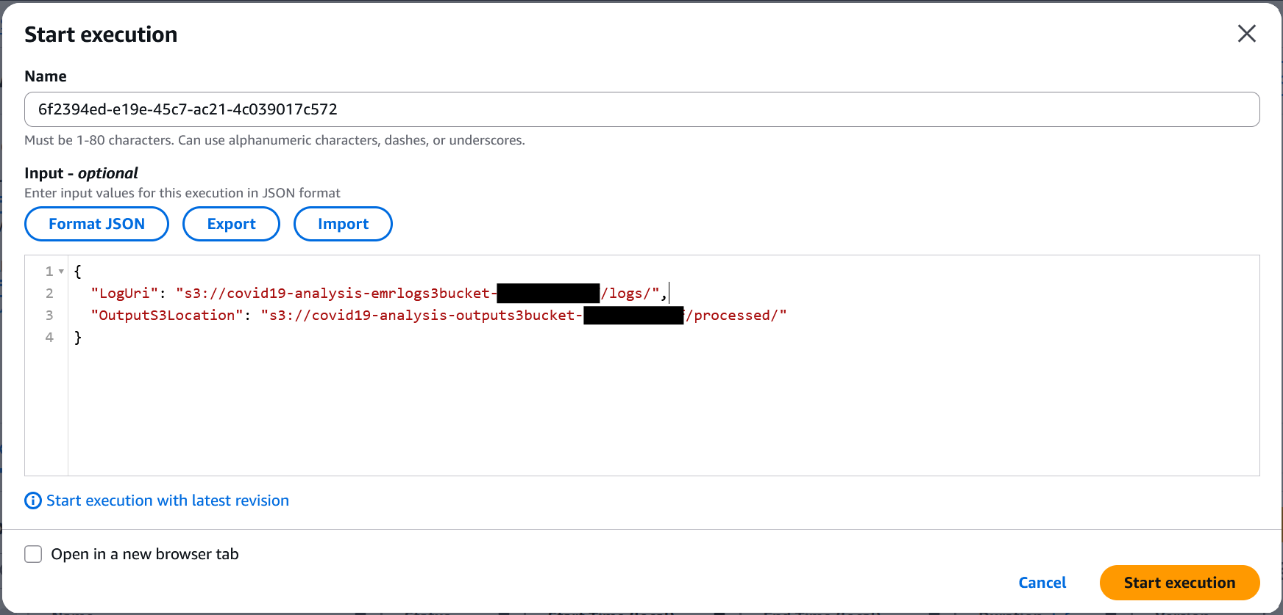
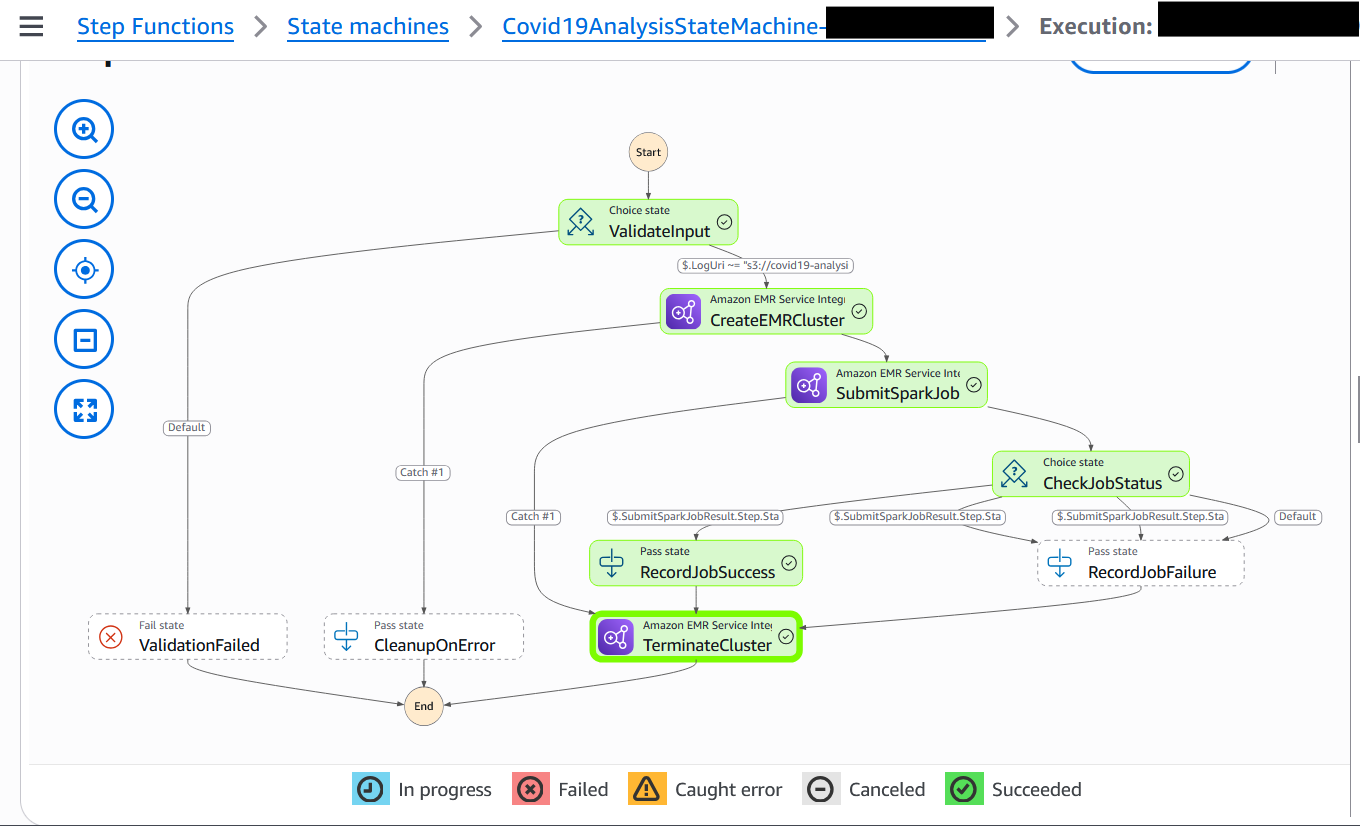

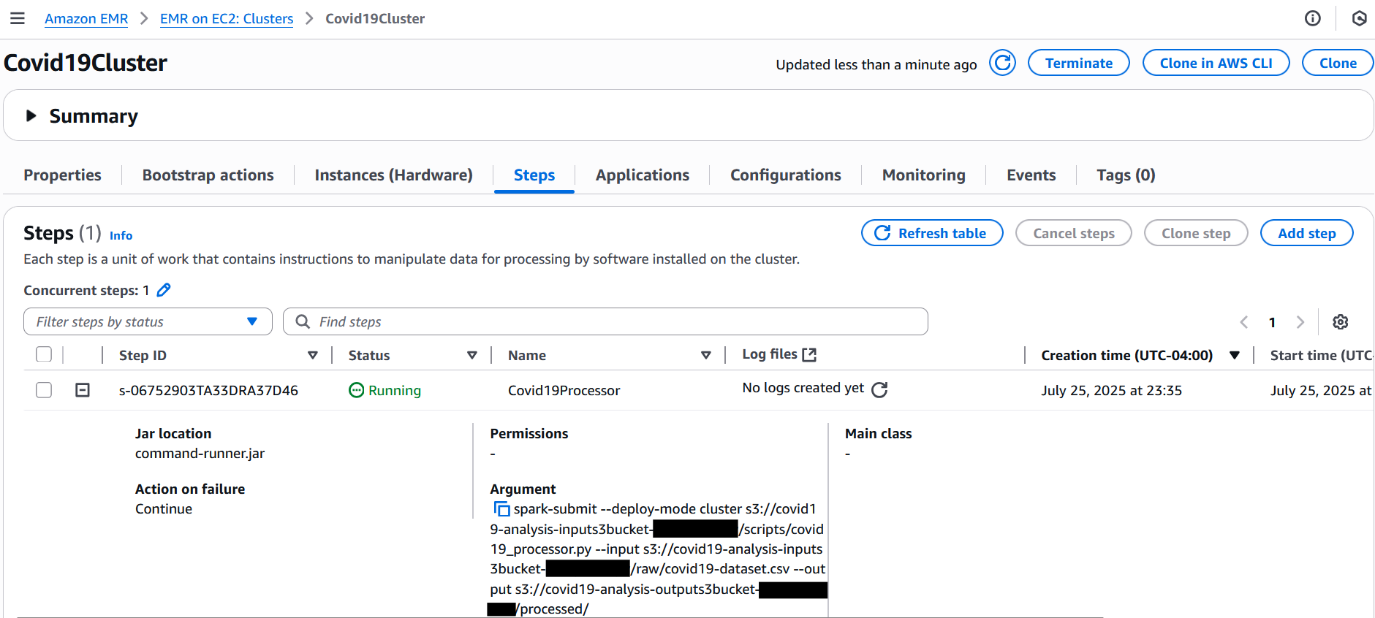
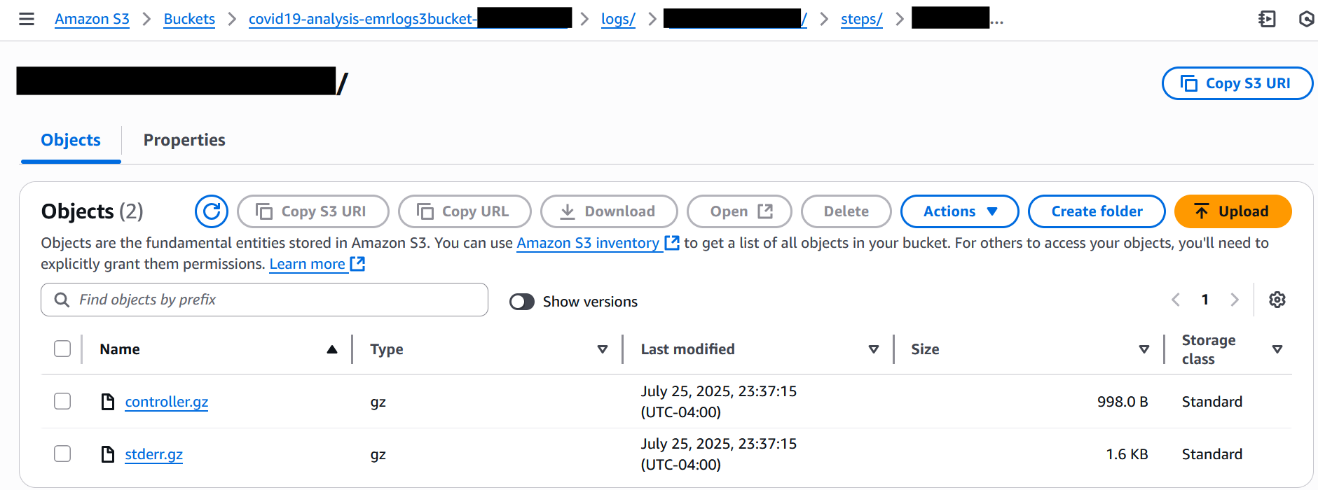
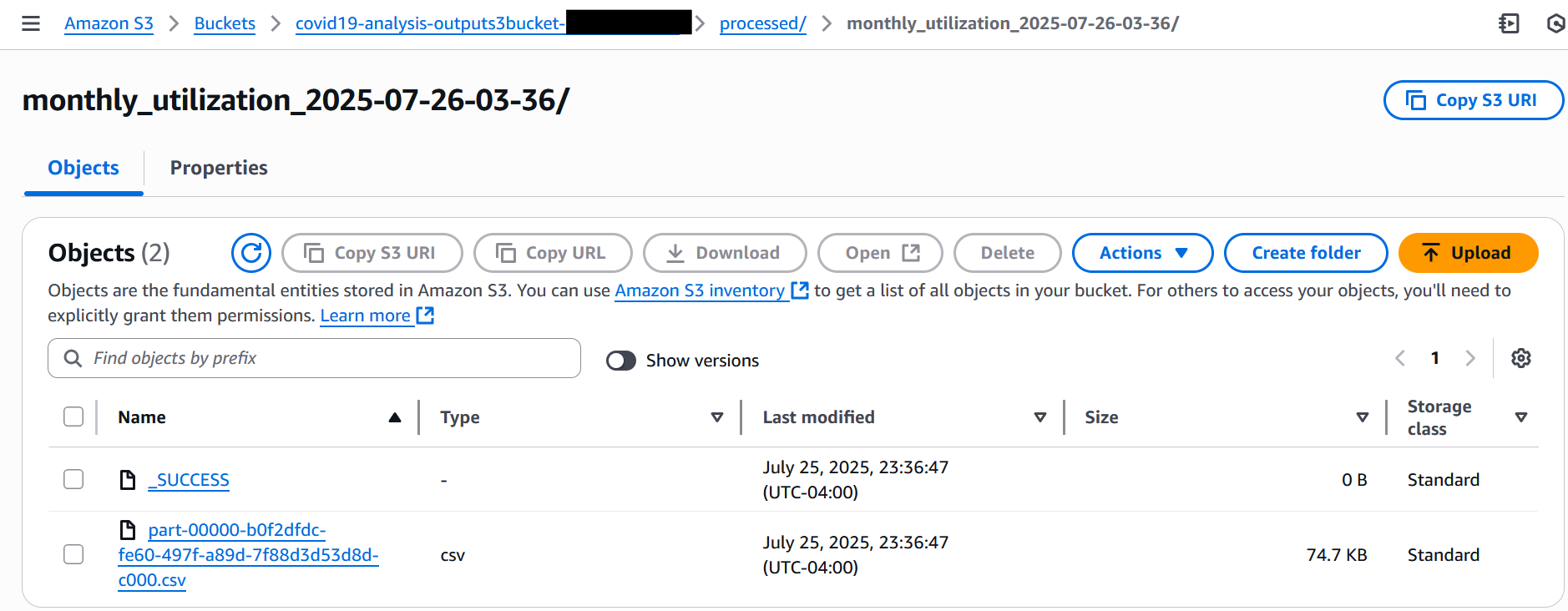
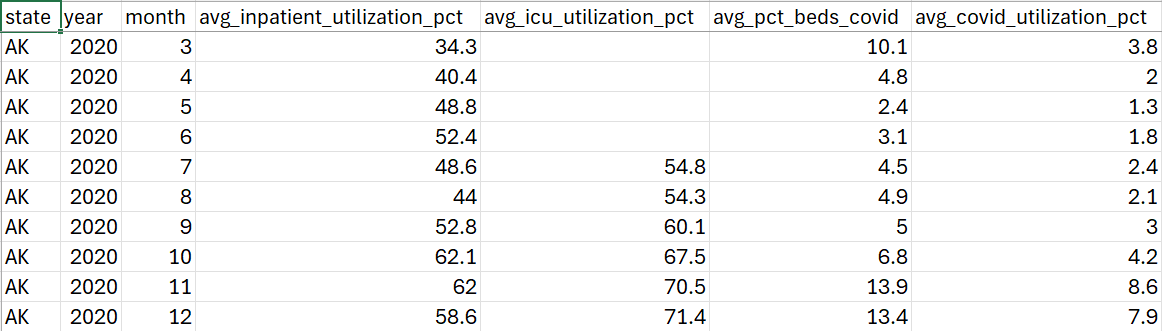
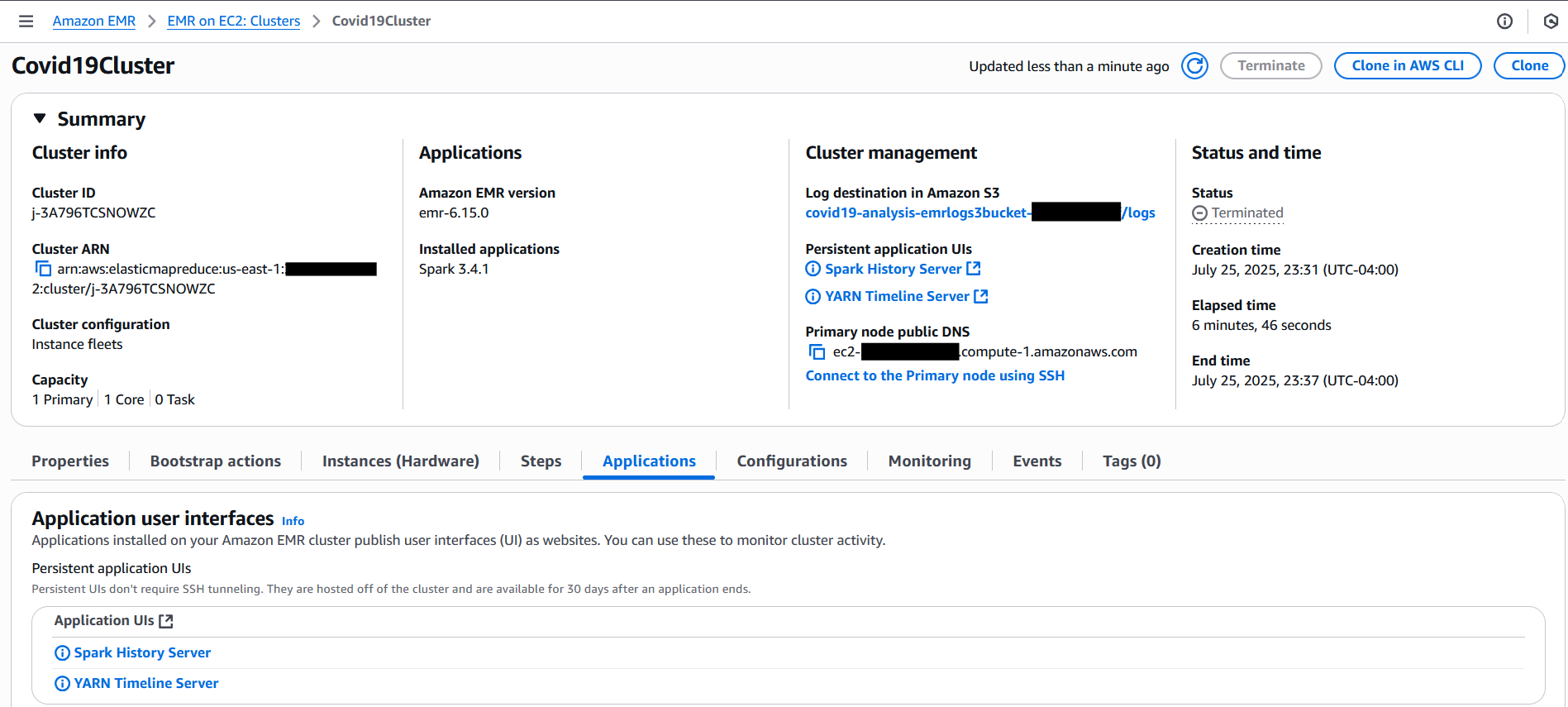
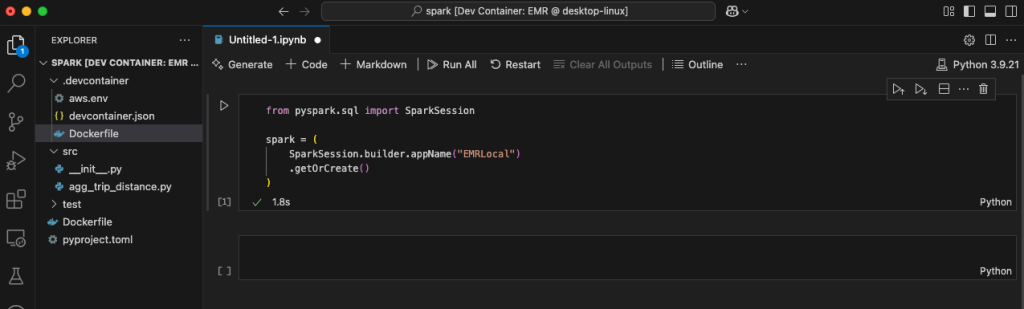
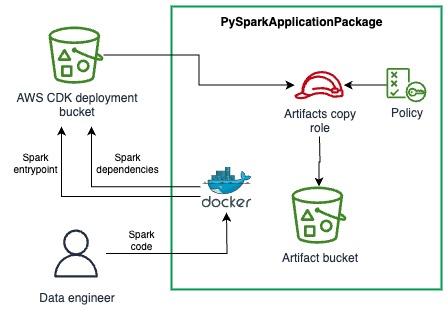
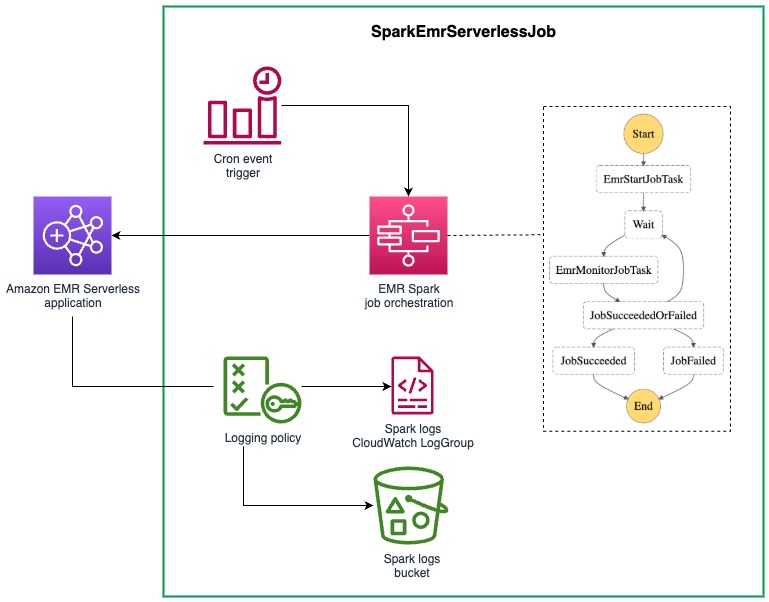
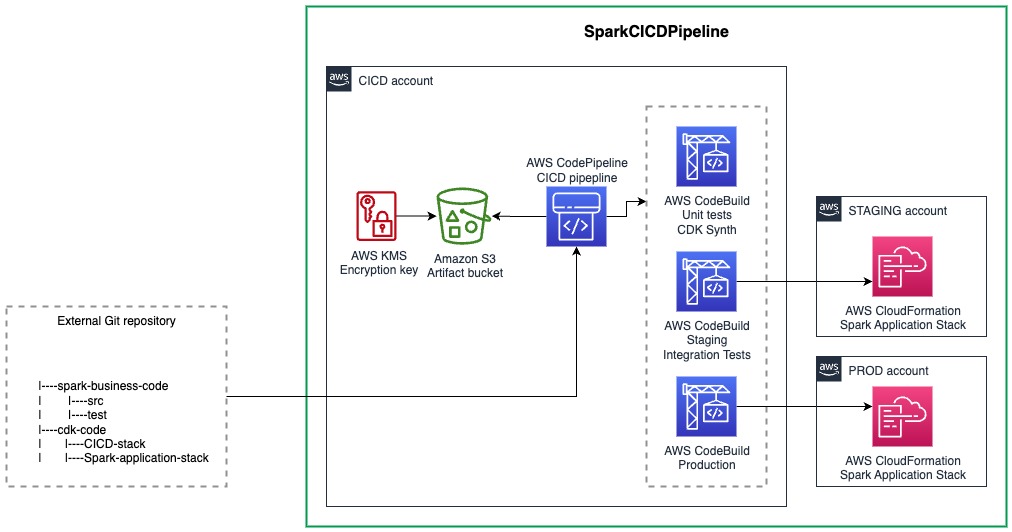
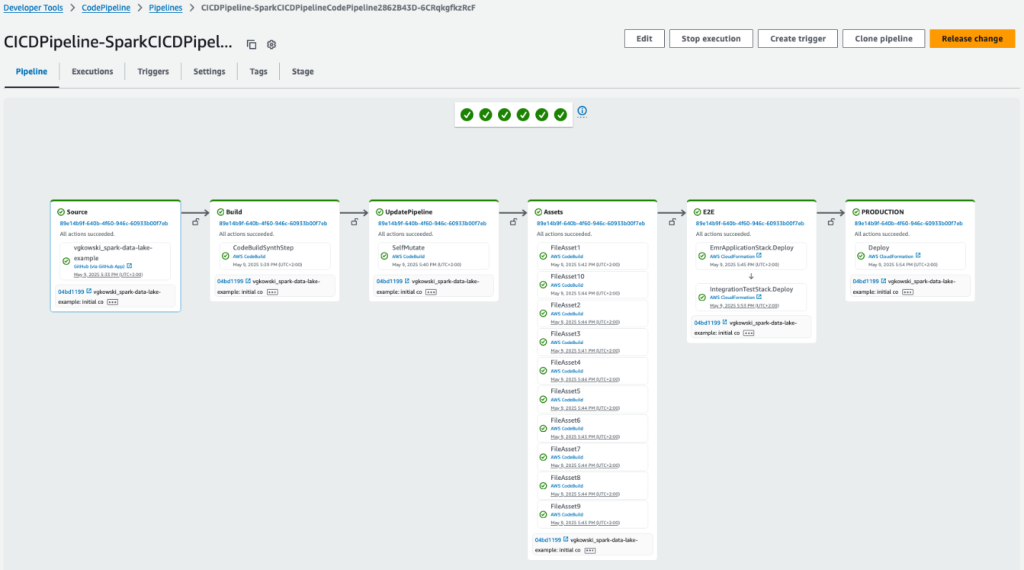
 Last week,
Last week, 



