Post Syndicated from Ravikiran Rao original https://aws.amazon.com/blogs/big-data/batch-data-ingestion-into-amazon-opensearch-service-using-aws-glue/
Organizations constantly work to process and analyze vast volumes of data to derive actionable insights. Effective data ingestion and search capabilities have become essential for use cases like log analytics, application search, and enterprise search. These use cases demand a robust pipeline that can handle high data volumes and enable efficient data exploration.
Apache Spark, an open source powerhouse for large-scale data processing, is widely recognized for its speed, scalability, and ease of use. Its ability to process and transform massive datasets has made it an indispensable tool in modern data engineering. Amazon OpenSearch Service—a community-driven search and analytics solution—empowers organizations to search, aggregate, visualize, and analyze data seamlessly. Together, Spark and OpenSearch Service offer a compelling solution for building powerful data pipelines. However, ingesting data from Spark into OpenSearch Service can present challenges, especially with diverse data sources.
This post showcases how to use Spark on AWS Glue to seamlessly ingest data into OpenSearch Service. We cover batch ingestion methods, share practical examples, and discuss best practices to help you build optimized and scalable data pipelines on AWS.
Overview of solution
AWS Glue is a serverless data integration service that simplifies data preparation and integration tasks for analytics, machine learning, and application development. In this post, we focus on batch data ingestion into OpenSearch Service using Spark on AWS Glue.
AWS Glue offers multiple integration options with OpenSearch Service using various open source and AWS managed libraries, including:
In the following sections, we explore each integration method in detail, guiding you through the setup and implementation. As we progress, we incrementally build the architecture diagram shown in the following figure, providing a clear path for creating robust data pipelines on AWS. Each implementation is independent of the others. We chose to showcase them separately, because in a real-world scenario, only one of the three integration methods is likely to be used.

You can find the code base in the accompanying GitHub repo. In the following sections, we walk through the steps to implement the solution.
Prerequisites
Before you deploy this solution, make sure the following prerequisites are in place:
- Access to a valid AWS account
- The latest AWS Command Line Interface (AWS CLI) installed on your local machine
- git, awk, curl, and bash installed on your local machine
- Permission to create AWS resources
- Familiarity with Apache Spark, AWS Glue, and Amazon OpenSearch Service
Clone the repository to your local machine
Clone the repository to your local machine and set the BLOG_DIR environment variable. All the relative paths assume BLOG_DIR is set to the repository location in your machine. If BLOG_DIR is not being used, adjust the path accordingly.
Deploy the AWS CloudFormation template to create the necessary infrastructure
The main focus of this post is to demonstrate how to use the mentioned libraries in Spark on AWS Glue to ingest data into OpenSearch Service. Though we center on this core topic, several key AWS components will need to be pre-provisioned for the integration examples, such as a Amazon Virtual Private Cloud (Amazon VPC), multiple Subnets, an AWS Key Management Service (AWS KMS) key, an Amazon Simple Storage Service (Amazon S3) bucket, an AWS Glue role, and an OpenSearch Service cluster with domains for OpenSearch Service and Elasticsearch. To simplify the setup, we’ve automated the provisioning of this core infrastructure using the cloudformation/opensearch-glue-infrastructure.yaml AWS CloudFormation template.
- Run the following commands
The CloudFormation template will deploy the necessary networking components (such as VPC and subnets), Amazon CloudWatch logging, AWS Glue role, and OpenSearch Service and Elasticsearch domains required to implement the proposed architecture. Use a strong password (8–128 characters, three of which are lowercase, uppercase, numbers, or special characters, and no /, “, or spaces) and adhere to your organization’s security standards for ESMasterUserPassword and OSMasterUserPassword in the following command:
You should see a success message such as "Successfully created/updated stack – GlueOpenSearchStack" after the resources have been provisioned successfully. Provisioning this CloudFormation stack typically takes approximately 30 minutes to complete.
- On the AWS CloudFormation console, locate the
GlueOpenSearchStackstack, and confirm that its status is CREATE_COMPLETE.

You can review the deployed resources on the Resources tab, as shown in the following screenshot.The screenshot does not display all the created resources.

Additional setup steps
In this section, we collect essential information, including the S3 bucket name and the OpenSearch Service and Elasticsearch domain endpoints. These details are required for executing the code in subsequent sections.
Capture the details of the provisioned resources
Use the following AWS CLI command to extract and save the output values from the CloudFormation stack to a file named GlueOpenSearchStack_outputs.txt. We refer to the values in this file in upcoming steps.
Download NY Green Taxi December 2022 dataset and copy to S3 bucket
The purpose of this post is to demonstrate the technical implementation of ingesting data into OpenSearch Service using AWS Glue. Understanding the dataset itself is not essential, aside from its data format, which we discuss in AWS Glue notebooks in later sections. To learn more about the dataset, you can find additional information on the NYC Taxi and Limousine Commission website.
We specifically request that you download the December 2022 dataset, because we have tested the solution using this particular dataset:
Download the required JARs from the Maven repository and copy to S3 bucket
We’ve specified a particular JAR file version to ensure stable deployment experience. However, we recommend adhering to your organization’s security best practices and reviewing any known vulnerabilities in the version of the JAR files before deployment. AWS does not guarantee the security of any open-source code used here. Additionally, please verify the downloaded JAR file’s checksum against the published value to confirm its integrity and authenticity.
In the following sections, we implement the individual data ingestion methods as outlined in the architecture diagram.
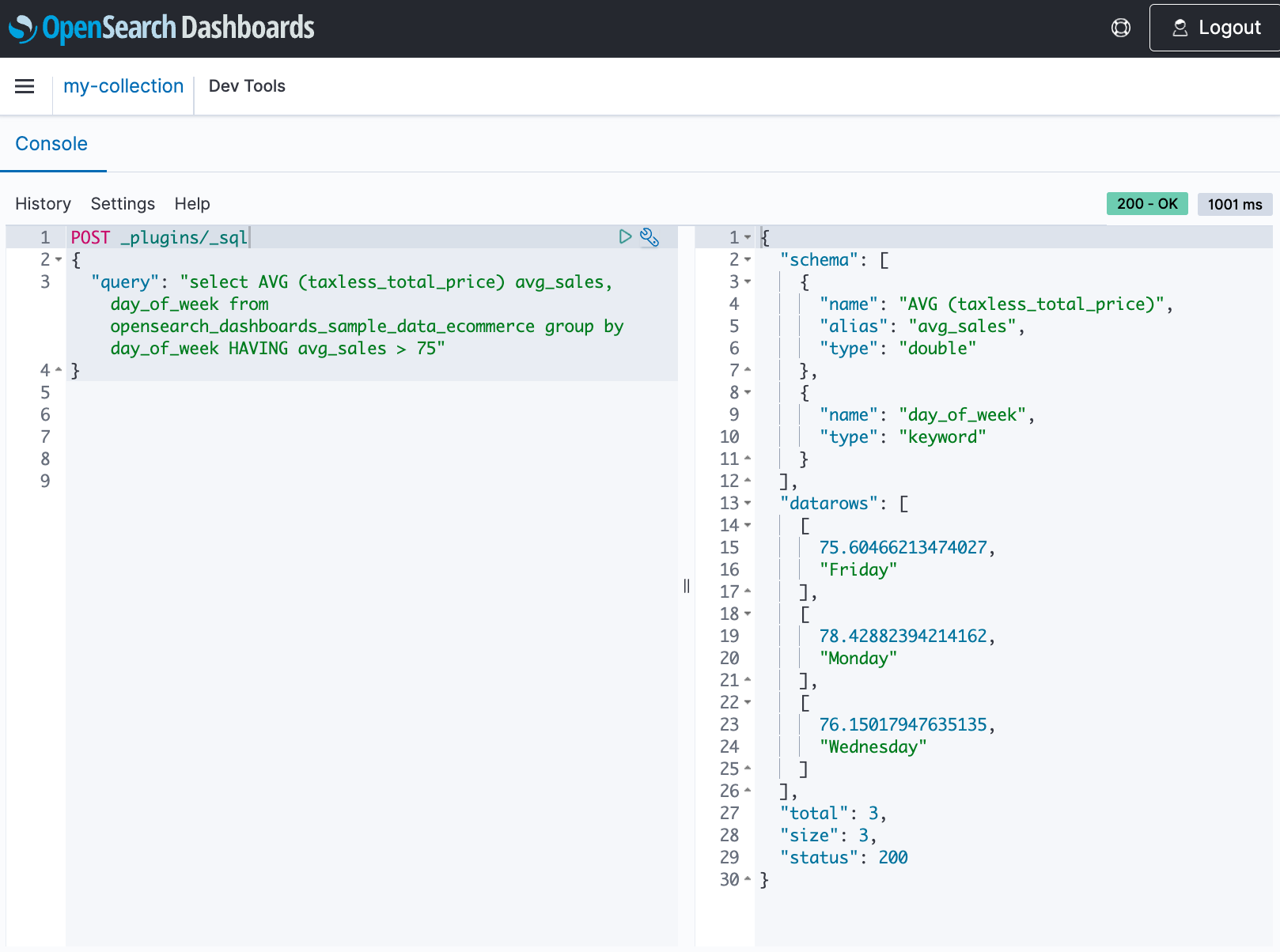
Ingest data into OpenSearch Service using the OpenSearch Spark library
In this section, we load an OpenSearch Service index using Spark and the OpenSearch Spark library. We demonstrate this implementation by using AWS Glue notebooks, employing basic authentication using user name and password.
To demonstrate the ingestion mechanisms, we have provided the Spark-and-OpenSearch-Code-Steps.ipynb notebook with detailed instructions. Follow the steps in this section in conjunction with the instructions in the notebook.
Set up the AWS Glue Studio notebook
Complete the following steps:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- Under Create job, choose Notebook.

- Upload the notebook file located at
${BLOG_DIR}/glue_jobs/Spark-and-OpenSearch-Code-Steps.ipynb. - For IAM role, choose the AWS Glue job IAM role that begins with
GlueOpenSearchStack-GlueRole-*.

- Enter a name for the notebook (for example,
Spark-and-OpenSearch-Code-Steps) and choose Save.

Replace the placeholder values in the notebook
Complete the following steps to update the placeholders in the notebook:
- In Step 1 in the notebook, replace the placeholder <GLUE-INTERACTIVE-SESSION-CONNECTION-NAME> with the AWS Glue interactive session connection name. You can get the name of the interactive session by executing the following command:
- In Step 1 in the notebook, replace the placeholder <S3-BUCKET-NAME> and populate the variable
s3_bucketwith the bucket name. You can get the name of the S3 bucket by executing the following command:
- In Step 4 in the notebook, replace <OPEN-SEARCH-DOMAIN-WITHOUT-HTTPS> with the OpenSearch Service domain name. You can get the domain name by executing the following command:
Run the notebook
Run each cell of the notebook to load data into the OpenSearch Service domain and read it back to verify the successful load. Refer to the detailed instructions within the notebook for execution-specific guidance.
Spark write modes (append vs. overwrite)
It is recommended to write data incrementally into OpenSearch Service indexes using the append mode, as demonstrated in Step 8 in the notebook. However, in certain cases, you may need to refresh the entire dataset in the OpenSearch Service index. In these scenarios, you can use the overwrite mode, though it is not advised for large indexes. When using overwrite mode, the Spark library deletes rows from the OpenSearch Service index one by one and then rewrites the data, which can be inefficient for large datasets. To avoid this, you can implement a preprocessing step in Spark to identify insertions and updates, and then write the data into OpenSearch Service using append mode.
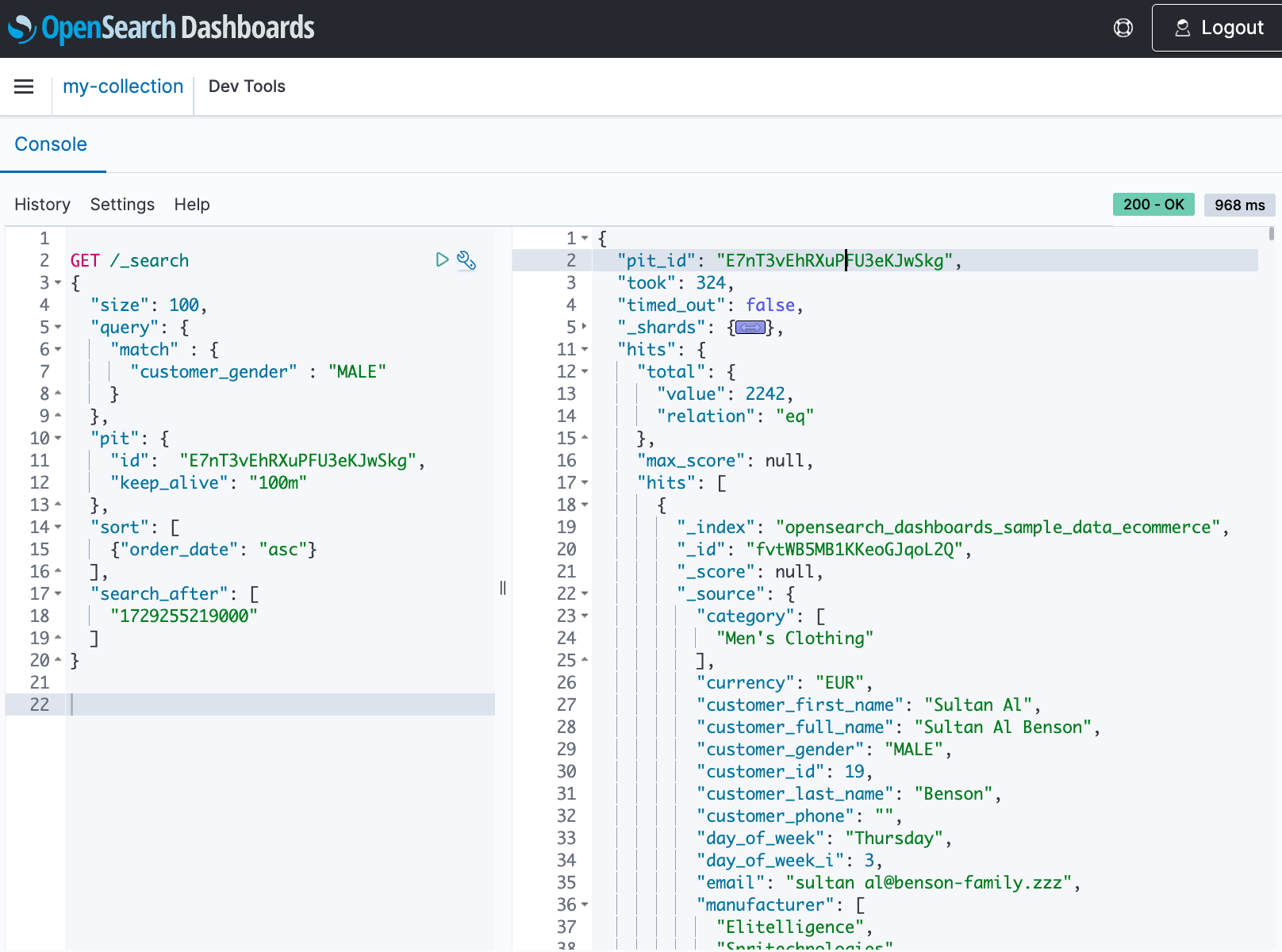
Ingest data into Elasticsearch using the Elasticsearch Hadoop library
In this section, we load an Elasticsearch index using Spark and the Elasticsearch Hadoop Library. We demonstrate this implementation by using AWS Glue as the engine for Spark.
Set up the AWS Glue Studio notebook
Complete the following steps to set up the notebook:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- Under Create job, choose Notebook.

- Upload the notebook file located at
${BLOG_DIR}/glue_jobs/Spark-and-Elasticsearch-Code-Steps.ipynb. - For IAM role, choose the AWS Glue job IAM role that begins with
GlueOpenSearchStack-GlueRole-*.

- Enter a name for the notebook (for example,
Spark-and-ElasticSearch-Code-Steps) and choose Save.

Replace the placeholder values in the notebook
Complete the following steps:
- In Step 1 in the notebook, replace the placeholder <GLUE-INTERACTIVE-SESSION-CONNECTION-NAME> with the AWS Glue interactive session connection name. You can get the name of the interactive session by executing the following command:
- In Step 1 in the notebook, replace the placeholder <S3-BUCKET-NAME> and populate the variable
s3_bucketwith the bucket name. You can get the name of the S3 bucket by executing the following command:
- In Step 4 in the notebook, replace <ELASTIC-SEARCH-DOMAIN-WITHOUT-HTTPS> with the Elasticsearch domain name. You can get the domain name by executing the following command:
Run the notebook
Run each cell in the notebook to load data to the Elasticsearch domain and read it back to verify the successful load. Refer to the detailed instructions within the notebook for execution-specific guidance.
Ingest data into OpenSearch Service using the AWS Glue OpenSearch Service connection
In this section, we load an OpenSearch Service index using Spark and the AWS Glue OpenSearch Service connection.
Create the AWS Glue job
Complete the following steps to create an AWS Glue Visual ETL job:
- On the AWS Glue console, choose ETL jobs in the navigation pane.
- Under Create job, choose Visual ETL
This will open the AWS Glue job visual editor.
- Choose the plus sign, and under Sources, choose Amazon S3.

- In the visual editor, choose the Data Source – S3 bucket node.
- In the Data source properties – S3 pane, configure the data source as follows:
-
- For S3 source type, select S3 location.
- For S3 URL, choose Browse S3, and choose the
green_tripdata_2022-12.parquetfile from the designated S3 bucket. - For Data format, choose Parquet.
- Choose Infer schema to let AWS Glue detect the schema of the data.
This will set up your data source from the specified S3 bucket.

- Choose the plus sign again to add a new node.
- For Transforms, choose Drop Fields to include this transformation step.
This will allow you to remove any unnecessary fields from your dataset before loading it into OpenSearch Service.

- Choose the Drop Fields transform node, then select the following fields to drop from the dataset:
-
payment_typetrip_typecongestion_surcharge
This will remove these fields from the data before it is loaded into OpenSearch Service.

- Choose the plus sign again to add a new node.
- For Targets, choose Amazon OpenSearch Service.
This will configure OpenSearch Service as the destination for the data being processed.

- Choose the Data target – Amazon OpenSearch Service node and configure it as follows:
-
- For Amazon OpenSearch Service connection, choose the connection
GlueOpenSearchServiceConnec-*from the drop down. - For Index, enter
green_taxi. Thegreen_taxiindex was created earlier in the “Ingest data into OpenSearch Service using the OpenSearch Spark library” section.
- For Amazon OpenSearch Service connection, choose the connection
This configures the OpenSearch Service to write the processed data to the specified index.

- On the Job details tab, update the job details as follows:
-
- For Name, enter a name (for example,
Spark-and-Glue-OpenSearch-Connection). - For Description, enter an optional description (for example,
AWS Glue job using Glue OpenSearch Connection to load data into Amazon OpenSearch Service). - For IAM role, choose the role starting with
GlueOpenSearchStack-GlueRole-*. - For the Glue version, choose
Glue 4.0 – Supports spark 3.3, Scala 2, Python 3 - Leave the rest of the fields as default.
- Choose Save to save the changes.
- For Name, enter a name (for example,

- To run the AWS Glue job Spark-and-Glue-OpenSearch-Connector, choose Run.
This will initiate the job execution.

- Choose the Runs tab and wait for the AWS Glue job to complete successfully.
You will see the status change to Succeeded when the job is complete.

Clean up
To clean up your resources, complete the following steps:
- Delete the CloudFormation stack:
- Delete the AWS Glue jobs:
-
- On the AWS Glue console, under ETL jobs in the navigation pane, choose Visual ETL.
- Select the jobs you created (
Spark-and-Glue-OpenSearch-Connector,Spark-and-ElasticSearch-Code-Steps, andSpark-and-OpenSearch-Code-Steps) and on the Actions menu, choose Delete.
Conclusion
In this post, we explored several ways to ingest data into OpenSearch Service using Spark on AWS Glue. We demonstrated the use of three key libraries: the AWS Glue OpenSearch Service connection, the OpenSearch Spark Library, and the Elasticsearch Hadoop Library. The methods outlined in this post can help you streamline your data ingestion into OpenSearch Service.
If you’re interested in learning more and getting hands-on experience, we’ve created a workshop that walks you through the entire process in detail. You can explore the full setup for ingesting data into OpenSearch Service, handling both batch and real-time streams, and building dashboards. Check out the workshop Unified Real-Time Data Processing and Analytics Using Amazon OpenSearch and Apache Spark to deepen your understanding and apply these techniques step by step.
About the Authors
 Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
 Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
 Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.This post showcases how to use Spark on AWS Glue to seamlessly ingest data into OpenSearch Service. We cover batch ingestion methods, share practical examples, and discuss best practices to help you build optimized and scalable data pipelines on AWS.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.This post showcases how to use Spark on AWS Glue to seamlessly ingest data into OpenSearch Service. We cover batch ingestion methods, share practical examples, and discuss best practices to help you build optimized and scalable data pipelines on AWS.
 Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open-source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience. Vamshi Vijay Nakkirtha is a software engineering manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various OpenSearch projects such as k-NN, Geospatial, and dashboard-maps.
Vamshi Vijay Nakkirtha is a software engineering manager working on the OpenSearch Project and Amazon OpenSearch Service. His primary interests include distributed systems. He is an active contributor to various OpenSearch projects such as k-NN, Geospatial, and dashboard-maps.








 Camille Birbes is a Senior Solutions Architect with AWS and is based in Hong Kong. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Camille enjoys any form of gaming, from board games to the latest video game.
Camille Birbes is a Senior Solutions Architect with AWS and is based in Hong Kong. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Camille enjoys any form of gaming, from board games to the latest video game. Sriharsha Subramanya Begolli works as a Senior Solutions Architect with AWS, based in Bengaluru, India. His primary focus is assisting large enterprise customers in modernizing their applications and developing cloud-based systems to meet their business objectives. His expertise lies in the domains of data and analytics.
Sriharsha Subramanya Begolli works as a Senior Solutions Architect with AWS, based in Bengaluru, India. His primary focus is assisting large enterprise customers in modernizing their applications and developing cloud-based systems to meet their business objectives. His expertise lies in the domains of data and analytics.







































 Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence.
Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence. Chris Helma is a Senior Engineer at Amazon Web Services based in Austin, Texas. He is currently developing tools and techniques to enable users to shift petabyte-scale data workloads into OpenSearch. He has extensive experience building highly-scalable technologies in diverse areas such as search, security analytics, cryptography, and developer productivity. He has functional domain expertise in distributed systems, AI/ML, cloud-native design, and optimizing DevOps workflows. In his free time, he loves to explore specialty coffee and run through the West Austin hills.
Chris Helma is a Senior Engineer at Amazon Web Services based in Austin, Texas. He is currently developing tools and techniques to enable users to shift petabyte-scale data workloads into OpenSearch. He has extensive experience building highly-scalable technologies in diverse areas such as search, security analytics, cryptography, and developer productivity. He has functional domain expertise in distributed systems, AI/ML, cloud-native design, and optimizing DevOps workflows. In his free time, he loves to explore specialty coffee and run through the West Austin hills. Andre Kurait is a Software Development Engineer II at Amazon Web Services, based in Austin, Texas. He is currently working on Migration Assistant for Amazon OpenSearch Service. Prior to joining Amazon OpenSearch, Andre worked within Amazon Health Services. In his free time, Andre enjoys traveling, cooking, and playing in his church sport leagues. Andre holds Bachelor of the Science degrees from the University of Kansas in Computer Science and Mathematics.
Andre Kurait is a Software Development Engineer II at Amazon Web Services, based in Austin, Texas. He is currently working on Migration Assistant for Amazon OpenSearch Service. Prior to joining Amazon OpenSearch, Andre worked within Amazon Health Services. In his free time, Andre enjoys traveling, cooking, and playing in his church sport leagues. Andre holds Bachelor of the Science degrees from the University of Kansas in Computer Science and Mathematics. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.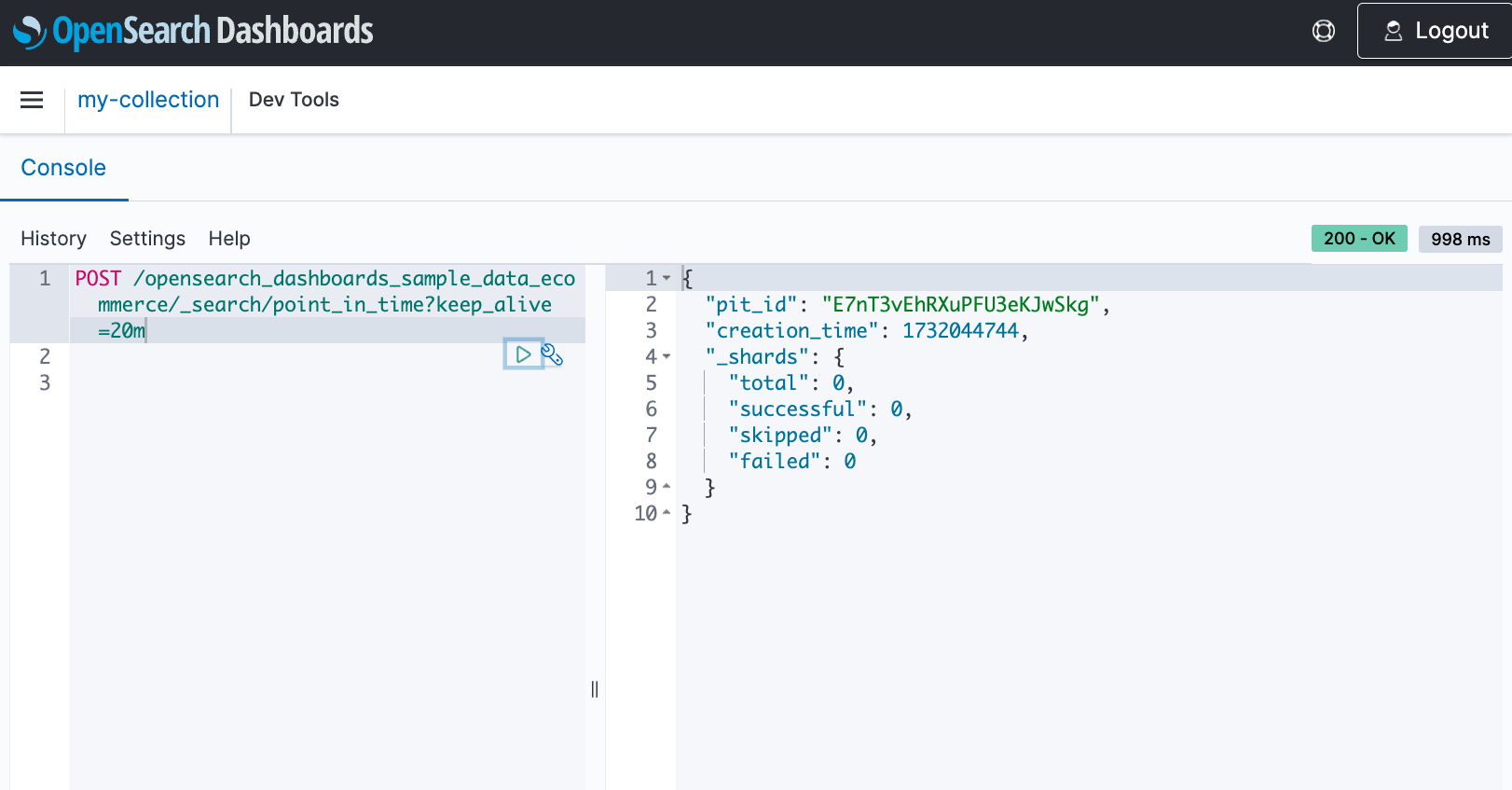
 Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS. Frank Dattalo is a Software Engineer with Amazon OpenSearch Service. He focuses on the search and plugin experience in Amazon OpenSearch Serverless. He has an extensive background in search, data ingestion, and AI/ML. In his free time, he likes to explore Seattle’s coffee landscape.
Frank Dattalo is a Software Engineer with Amazon OpenSearch Service. He focuses on the search and plugin experience in Amazon OpenSearch Serverless. He has an extensive background in search, data ingestion, and AI/ML. In his free time, he likes to explore Seattle’s coffee landscape. Milav Shah is an Engineering Leader with Amazon OpenSearch Service. He focuses on the search experience for OpenSearch customers. He has extensive experience building highly scalable solutions in databases, real-time streaming, and distributed computing. He also possesses functional domain expertise in verticals like Internet of Things, fraud protection, gaming, and ML/AI. In his free time, he likes to ride his bicycle, hike, and play chess.
Milav Shah is an Engineering Leader with Amazon OpenSearch Service. He focuses on the search experience for OpenSearch customers. He has extensive experience building highly scalable solutions in databases, real-time streaming, and distributed computing. He also possesses functional domain expertise in verticals like Internet of Things, fraud protection, gaming, and ML/AI. In his free time, he likes to ride his bicycle, hike, and play chess.




















 M Mehrtens has been working in distributed systems engineering throughout their career, working as a Software Engineer, Architect, and Data Engineer. In the past, M has supported and built systems to process terrabytes of streaming data at low latency, run enterprise Machine Learning pipelines, and created systems to share data across teams seamlessly with varying data toolsets and software stacks. At AWS, they are a Sr. Solutions Architect supporting US Federal Financial customers.
M Mehrtens has been working in distributed systems engineering throughout their career, working as a Software Engineer, Architect, and Data Engineer. In the past, M has supported and built systems to process terrabytes of streaming data at low latency, run enterprise Machine Learning pipelines, and created systems to share data across teams seamlessly with varying data toolsets and software stacks. At AWS, they are a Sr. Solutions Architect supporting US Federal Financial customers. Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington.
Arjun Nambiar is a Product Manager with Amazon OpenSearch Service. He focuses on ingestion technologies that enable ingesting data from a wide variety of sources into Amazon OpenSearch Service at scale. Arjun is interested in large-scale distributed systems and cloud-centered technologies, and is based out of Seattle, Washington. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.










 Samir Patel is a Senior Data Architect at Amazon Web Services, where he specializes in OpenSearch, data analytics, and cutting-edge generative AI technologies. Samir works directly with enterprise customers to design and build customized solutions catered to their data analytics and cybersecurity needs. When not immersed in technical work, Samir pursues his passion for outdoor activities, including hiking, pickleball, and grilling with family and friends.
Samir Patel is a Senior Data Architect at Amazon Web Services, where he specializes in OpenSearch, data analytics, and cutting-edge generative AI technologies. Samir works directly with enterprise customers to design and build customized solutions catered to their data analytics and cybersecurity needs. When not immersed in technical work, Samir pursues his passion for outdoor activities, including hiking, pickleball, and grilling with family and friends. Sesha Sanjana Mylavarapu is an Associate Data Lake Consultant at AWS Professional Services. She specializes in cloud-based data management and collaborates with enterprise clients to design and implement scalable data lakes. She has a strong interest in data analytics and enjoys assisting customers solve their business and technical challenges. Beyond her professional pursuits, Sanjana enjoys hiking, playing guitar, and is passionate about teaching yoga.
Sesha Sanjana Mylavarapu is an Associate Data Lake Consultant at AWS Professional Services. She specializes in cloud-based data management and collaborates with enterprise clients to design and implement scalable data lakes. She has a strong interest in data analytics and enjoys assisting customers solve their business and technical challenges. Beyond her professional pursuits, Sanjana enjoys hiking, playing guitar, and is passionate about teaching yoga. Vivek Gautam is a Senior Data Architect with specialization in data analytics at AWS Professional Services. He works with enterprise customers building data products, analytics platforms, streaming, and search solutions on AWS. When not building and designing data products, Vivek is a food enthusiast who also likes to explore new travel destinations and go on hikes.
Vivek Gautam is a Senior Data Architect with specialization in data analytics at AWS Professional Services. He works with enterprise customers building data products, analytics platforms, streaming, and search solutions on AWS. When not building and designing data products, Vivek is a food enthusiast who also likes to explore new travel destinations and go on hikes.

 On November 9, 2004, Jeff Barr published
On November 9, 2004, Jeff Barr published 



 AWS re:Invent – You can still
AWS re:Invent – You can still  Arvind Mahesh is a Senior Manager-Product at Amazon Web Services for Amazon OpenSearch Service. He has close to two decades of technology experience across a variety of domains such as Analytics, Search, Cloud, Network Security, and Telecom.
Arvind Mahesh is a Senior Manager-Product at Amazon Web Services for Amazon OpenSearch Service. He has close to two decades of technology experience across a variety of domains such as Analytics, Search, Cloud, Network Security, and Telecom. Kuldeep Yadav is a Senior Technical Program Manager at Amazon Web Services who is passionate about driving innovation and complex problem solving. He works closely with teams and customers in ensuring operational excellence and achieving more with less. Outside of work he enjoys trekking and all sports
Kuldeep Yadav is a Senior Technical Program Manager at Amazon Web Services who is passionate about driving innovation and complex problem solving. He works closely with teams and customers in ensuring operational excellence and achieving more with less. Outside of work he enjoys trekking and all sports Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.













 Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence.
Hang (Arthur) Zuo is a Senior Product Manager with Amazon OpenSearch Service. Arthur leads the core experience in the next-gen OpenSearch UI and data migration to Amazon OpenSearch Service. Arthur is passionate about cloud technologies and building data products that help users and businesses gain actionable insights and achieve operational excellence. Rushabh Vora is a Principal Product Manager for the OpenSearch project of Amazon Web Services. Rushabh leads core experiences in data exploration, dashboards, visualizations, reporting, and data management to help organizations unlock insights at scale. Rushabh is passionate about cloud technologies and building products that enable businesses to make data-driven decisions and achieve operational excellence.
Rushabh Vora is a Principal Product Manager for the OpenSearch project of Amazon Web Services. Rushabh leads core experiences in data exploration, dashboards, visualizations, reporting, and data management to help organizations unlock insights at scale. Rushabh is passionate about cloud technologies and building products that enable businesses to make data-driven decisions and achieve operational excellence. Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges.
Sohaib Katariwala is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service based out of Chicago, IL. His interests are in all things data and analytics. More specifically he loves to help customers use AI in their data strategy to solve modern day challenges. Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He works closely with customers on their OpenSearch journey across various use cases including vector search, observability, and security analytics.
Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He works closely with customers on their OpenSearch journey across various use cases including vector search, observability, and security analytics. Xenia Tupitsyna is a UX Designer at OpenSearch. She is working on user experiences across security analytics solutions, anomaly detection, alerting, and core dashboards.
Xenia Tupitsyna is a UX Designer at OpenSearch. She is working on user experiences across security analytics solutions, anomaly detection, alerting, and core dashboards.

 Akshay Zade is a Senior SDE working for Amazon OpenSearch Service, passionate about solving real-world problems with the power of large-scale distributed systems. Outside of work, he enjoys drawing, painting, and diving into fantasy books.
Akshay Zade is a Senior SDE working for Amazon OpenSearch Service, passionate about solving real-world problems with the power of large-scale distributed systems. Outside of work, he enjoys drawing, painting, and diving into fantasy books.


























 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.” He can be reached via
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled “Data Wrangling on AWS.” He can be reached via  Mike Mosher is s Senior Principal Cloud Platform Network Architect at a multi-national financial credit reporting company. He has more than 16 years of experience in on-premises and cloud networking and is passionate about building new architectures on the cloud that serve customers and solve problems. Outside of work, he enjoys time with his family and traveling back home to the mountains of Colorado.
Mike Mosher is s Senior Principal Cloud Platform Network Architect at a multi-national financial credit reporting company. He has more than 16 years of experience in on-premises and cloud networking and is passionate about building new architectures on the cloud that serve customers and solve problems. Outside of work, he enjoys time with his family and traveling back home to the mountains of Colorado.