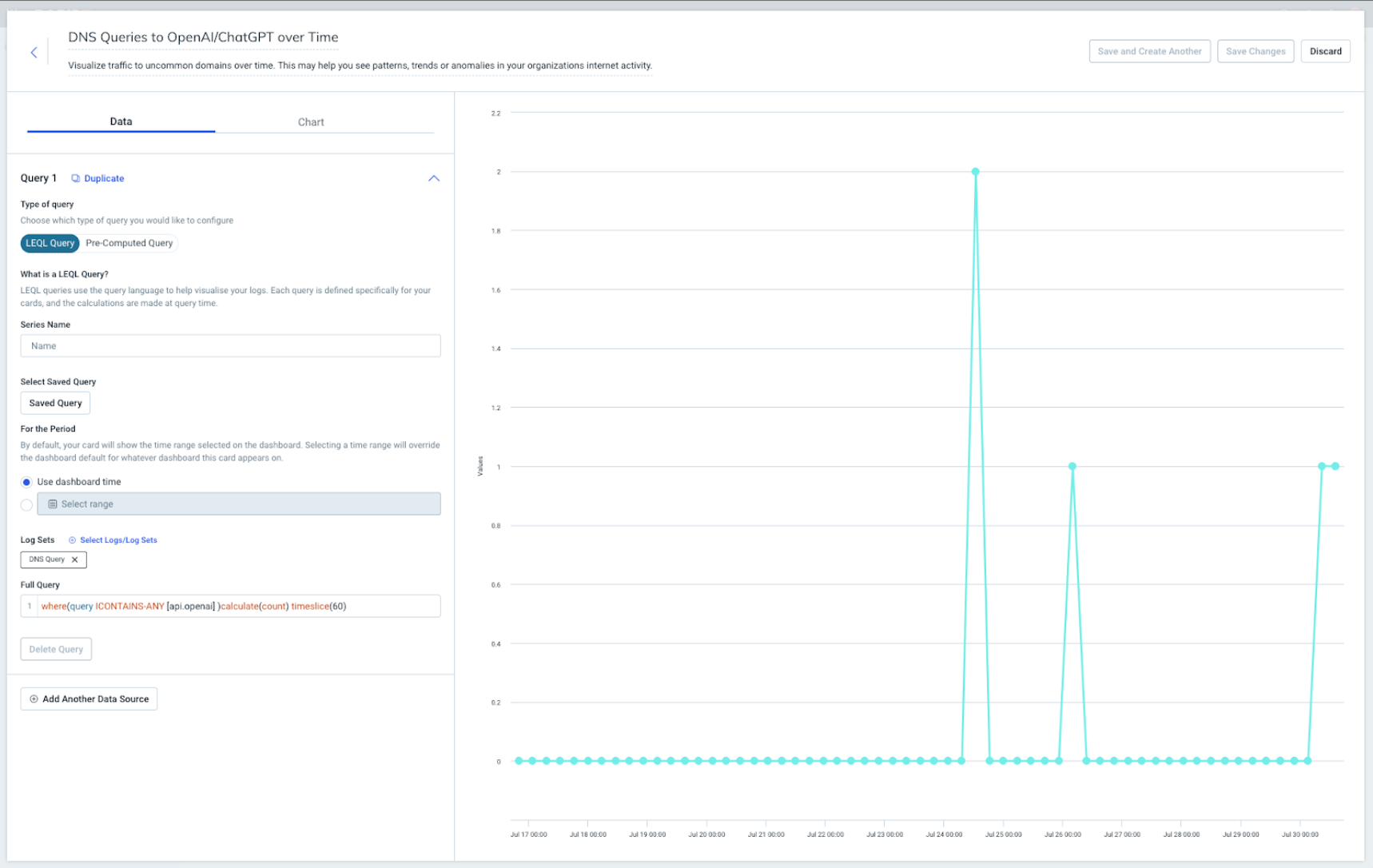
This vulnerability hacks a feature that allows ChatGPT to have long-term memory, where it uses information from past conversations to inform future conversations with that same user. A researcher found that he could use that feature to plant “false memories” into that context window that could subvert the model.
A month later, the researcher submitted a new disclosure statement. This time, he included a PoC that caused the ChatGPT app for macOS to send a verbatim copy of all user input and ChatGPT output to a server of his choice. All a target needed to do was instruct the LLM to view a web link that hosted a malicious image. From then on, all input and output to and from ChatGPT was sent to the attacker’s website.
AWS Lambda now supports Amazon Linux 2023 runtimes in AWS GovCloud (US) Regions – These runtimes offer the latest language features, including Python 3.12, Node.js 20, Java 21, .NET 8, Ruby 3.3, and Amazon Linux 2023. They have smaller deployment footprints, updated libraries, and a new package manager. Additionally, you can also use the container base images to build and deploy functions as a container image.
Amazon SageMaker Studio now supports automatic shutdown of idle applications– You can now enable automatic shutdown of inactive JupyterLab and CodeEditor applications using Amazon SageMaker Distribution image v2.0 or newer. Administrators can set idle shutdown times at domain or user profile levels, with optional user customization. This cost control mechanism helps avoid charges for unused instances and is available across all AWS Regions where SageMaker Studio is offered.
Llama 3.2 generative AI models now available in Amazon Bedrock – The collection includes 90B and 11B parameter multimodal models for sophisticated reasoning tasks, and 3B and 1B text-only models for edge devices. These models support vision tasks, offer improved performance, and are designed for responsible AI innovation across various applications. These models support a 128K context length and multilingual capabilities in eight languages. Learn more about it in Introducing Llama 3.2 models from Meta in Amazon Bedrock.
How to migrate 3DES keys from a FIPS to a non-FIPS AWS CloudHSM cluster – Learn how to securely transfer Triple Data Encryption Algorithm (3DES) keys from Federal Information Processing Standard (FIPS) hsm1 to non-FIPS hsm2 clusters using RSA-AES wrapping, without backups. This enables using new hsm2.medium instances with FIPS 140-3 Level 3 support, non-FIPS mode, increased key capacity, and mutual TLS (mTLS).
Upcoming AWS events Check your calendars and sign up for upcoming AWS events:
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. These events offer technical sessions, demonstrations, and workshops delivered by experts. There is only one event left that you can still register for: Ottawa (October 9).
AWS Community Days – Join community-led conferences featuring technical discussions, workshops, and hands-on labs driven by expert AWS users and industry leaders from around the world. Upcoming AWS Community Days are scheduled for October 3 in the Netherlands and Romania, and on October 5 in Jaipur, Mexico, Bolivia, Ecuador, and Panama. I’m happy to share with you that I will be joining the Panama community on October 5.
AWS GenAI Lofts – Collaborative spaces and immersive experiences that showcase AWS’s expertise with the cloud and AI, while providing startups and developers with hands-on access to AI products and services, exclusive sessions with industry leaders, and valuable networking opportunities with investors and peers. Find a GenAI Loft location near you and don’t forget to register. I’ll be in the San Francisco lounge with some demos on October 15 at the Gen AI Developer Day. If you’re attending, feel free to stop by and say hello!
For years now, AI has undermined the public’s ability to trust what it sees, hears, and reads. The Republican National Committee released a provocative ad offering an “AI-generated look into the country’s possible future if Joe Biden is re-elected,” showing apocalyptic, machine-made images of ruined cityscapes and chaos at the border. Fake robocalls purporting to be from Biden urged New Hampshire residents not to vote in the 2024 primary election. This summer, the Department of Justice cracked down on a Russian bot farm that was using AI to impersonate Americans on social media, and OpenAI disrupted an Iranian group using ChatGPT to generate fake social-media comments.
It’s not altogether clear what damage AI itself may cause, though the reasons for concern are obvious—the technology makes it easier for bad actors to construct highly persuasive and misleading content. With that risk in mind, there has been some movement toward constraining the use of AI, yet progress has been painstakingly slow in the area where it may count most: the 2024 election.
Two years ago, the Biden administration issued a blueprint for an AI Bill of Rights aiming to address “unsafe or ineffective systems,” “algorithmic discrimination,” and “abusive data practices,” among other things. Then, last year, Biden built on that document when he issued his executive order on AI. Also in 2023, Senate Majority Leader Chuck Schumer held an AI summit in Washington that included the centibillionaires Bill Gates, Mark Zuckerberg, and Elon Musk. Several weeks later, the United Kingdom hosted an international AI Safety Summit that led to the serious-sounding “Bletchley Declaration,” which urged international cooperation on AI regulation. The risks of AI fakery in elections have not sneaked up on anybody.
Yet none of this has resulted in changes that would resolve the use of AI in U.S. political campaigns. Even worse, the two federal agencies with a chance to do something about it have punted the ball, very likely until after the election.
On July 25, the Federal Communications Commission issued a proposal that would require political advertisements on TV and radio to disclose if they used AI. (The FCC has no jurisdiction over streaming, social media, or web ads.) That seems like a step forward, but there are two big problems. First, the proposed rules, even if enacted, are unlikely to take effect before early voting starts in this year’s election. Second, the proposal immediately devolved into a partisan slugfest. A Republican FCC commissioner alleged that the Democratic National Committee was orchestrating the rule change because Democrats are falling behind the GOP in using AI in elections. Plus, he argued, this was the Federal Election Commission’s job to do.
Yet last month, the FEC announced that it won’t even try making new rules against using AI to impersonate candidates in campaign ads through deepfaked audio or video. The FEC also said that it lacks the statutory authority to make rules about misrepresentations using deepfaked audio or video. And it lamented that it lacks the technical expertise to do so, anyway. Then, last week, the FEC compromised, announcing that it intends to enforce its existing rules against fraudulent misrepresentation regardless of what technology it is conducted with. Advocates for stronger rules on AI in campaign ads, such as Public Citizen, did not find this nearly sufficient, characterizing it as a “wait-and-see approach” to handling “electoral chaos.”
Perhaps this is to be expected: The freedom of speech guaranteed by the First Amendment generally permits lying in political ads. But the American public has signaled that it would like some rules governing AI’s use in campaigns. In 2023, more than half of Americans polled responded that the federal government should outlaw all uses of AI-generated content in political ads. Going further, in 2024, about half of surveyed Americans said they thought that political candidates who intentionally manipulated audio, images, or video should be prevented from holding office or removed if they had won an election. Only 4 percent thought there should be no penalty at all.
The underlying problem is that Congress has not clearly given any agency the responsibility to keep political advertisements grounded in reality, whether in response to AI or old-fashioned forms of disinformation. The Federal Trade Commission has jurisdiction over truth in advertising, but political ads are largely exempt—again, part of our First Amendment tradition. The FEC’s remit is campaign finance, but the Supreme Court has progressively stripped its authorities. Even where it could act, the commission is often stymied by political deadlock. The FCC has more evident responsibility for regulating political advertising, but only in certain media: broadcast, robocalls, text messages. Worse yet, the FCC’s rules are not exactly robust. It has actually loosened rules on political spam over time, leading to the barrage of messages many receive today. (That said, in February, the FCC did unanimously rule that robocalls using AI voice-cloning technology, like the Biden ad in New Hampshire, are already illegal under a 30-year-old law.)
It’s a fragmented system, with many important activities falling victim to gaps in statutory authority and a turf war between federal agencies. And as political campaigning has gone digital, it has entered an online space with even fewer disclosure requirements or other regulations. No one seems to agree where, or whether, AI is under any of these agencies’ jurisdictions. In the absence of broad regulation, some states have made their own decisions. In 2019, California was the first state in the nation to prohibit the use of deceptively manipulated media in elections, and has strengthened these protections with a raft of newly passed laws this fall. Nineteen states have now passed laws regulating the use of deepfakes in elections.
One problem that regulators have to contend with is the wide applicability of AI: The technology can simply be used for many different things, each one demanding its own intervention. People might accept a candidate digitally airbrushing their photo to look better, but not doing the same thing to make their opponent look worse. We’re used to getting personalized campaign messages and letters signed by the candidate; is it okay to get a robocall with a voice clone of the same politician speaking our name? And what should we make of the AI-generated campaign memes now shared by figures such as Musk and Donald Trump?
Despite the gridlock in Congress, these are issues with bipartisan interest. This makes it conceivable that something might be done, but probably not until after the 2024 election and only if legislators overcome major roadblocks. One bill under consideration, the AI Transparency in Elections Act, would instruct the FEC to require disclosure when political advertising uses media generated substantially by AI. Critics say, implausibly, that the disclosure is onerous and would increase the cost of political advertising. The Honest Ads Act would modernize campaign-finance law, extending FEC authority to definitively encompass digital advertising. However, it has languished for years because of reported opposition from the tech industry. The Protect Elections From Deceptive AI Act would ban materially deceptive AI-generated content from federal elections, as in California and other states. These are promising proposals, but libertarian and civil-liberties groups are already signaling challenges to all of these on First Amendment grounds. And, vexingly, at least one FEC commissioner has directly cited congressional consideration of some of these bills as a reason for his agency not to act on AI in the meantime.
One group that benefits from all this confusion: tech platforms. When few or no evident rules govern political expenditures online and uses of new technologies like AI, tech companies have maximum latitude to sell ads, services, and personal data to campaigns. This is reflected in theirlobbyingefforts, as well as the voluntary policy restraints they occasionally trumpet to convince the public they don’t need greater regulation.
Big Tech has demonstrated that it will uphold these voluntary pledges only if they benefit the industry. Facebook once, briefly, banned political advertising on its platform. No longer; now it even allows ads that baselessly deny the outcome of the 2020 presidential election. OpenAI’s policies have long prohibited political campaigns from using ChatGPT, but those restrictions are trivial to evade. Several companies have volunteered to add watermarks to AI-generated content, but they are easily circumvented. Watermarks might even make disinformation worse by giving the false impression that non-watermarked images are legitimate.
This important public policy should not be left to corporations, yet Congress seems resigned not to act before the election. Schumer hinted to NBC News in August that Congress may try to attach deepfake regulations to must-pass funding or defense bills this month to ensure that they become law before the election. More recently, he has pointed to the need for action “beyond the 2024 election.”
The three bills listed above are worthwhile, but they are just a start. The FEC and FCC should not be left to snipe with each other about what territory belongs to which agency. And the FEC needs more significant, structural reform to reduce partisan gridlock and enable it to get more done. We also need transparency into and governance of the algorithmic amplification of misinformation on social-media platforms. That requires that the pervasive influence of tech companies and their billionaire investors should be limited through stronger lobbying and campaign-finance protections.
Our regulation of electioneering never caught up to AOL, let alone social media and AI. And deceiving videos harm our democratic process, whether they are created by AI or actors on a soundstage. But the urgent concern over AI should be harnessed to advance legislative reform. Congress needs to do more than stick a few fingers in the dike to control the coming tide of election disinformation. It needs to act more boldly to reshape the landscape of regulation for political campaigning.
This essay was written with Nathan Sanders, and originally appeared in The Atlantic.
Llama 3.2 offers multimodal vision and lightweight models representing Meta’s latest advancement in large language models (LLMs) and providing enhanced capabilities and broader applicability across various use cases. With a focus on responsible innovation and system-level safety, these new models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features that help you build a new generation of AI experiences.
These models are designed to inspire builders with image reasoning and are more accessible for edge applications, unlocking more possibilities with AI.
The Llama 3.2 collection of models are offered in various sizes, from lightweight text-only 1B and 3B parameter models suitable for edge devices to small and medium-sized 11B and 90B parameter models capable of sophisticated reasoning tasks including multimodal support for high resolution images. Llama 3.2 11B and 90B are the first Llama models to support vision tasks, with a new model architecture that integrates image encoder representations into the language model. The new models are designed to be more efficient for AI workloads, with reduced latency and improved performance, making them suitable for a wide range of applications.
All Llama 3.2 models support a 128K context length, maintaining the expanded token capacity introduced in Llama 3.1. Additionally, the models offer improved multilingual support for eight languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
In addition to the existing text capable Llama 3.1 8B, 70B, and 405B models, Llama 3.2 supports multimodal use cases. You can now use four new Llama 3.2 models — 90B, 11B, 3B, and 1B — from Meta in Amazon Bedrock to build, experiment, and scale your creative ideas:
Llama 3.2 90B Vision (text + image input) – Meta’s most advanced model, ideal for enterprise-level applications. This model excels at general knowledge, long-form text generation, multilingual translation, coding, math, and advanced reasoning. It also introduces image reasoning capabilities, allowing for image understanding and visual reasoning tasks. This model is ideal for the following use cases: image captioning, image-text retrieval, visual grounding, visual question answering and visual reasoning, and document visual question answering.
Llama 3.2 11B Vision (text + image input) – Well-suited for content creation, conversational AI, language understanding, and enterprise applications requiring visual reasoning. The model demonstrates strong performance in text summarization, sentiment analysis, code generation, and following instructions, with the added ability to reason about images. This model use cases are similar to the 90B version: image captioning, image-text-retrieval, visual grounding, visual question answering and visual reasoning, and document visual question answering.
Llama 3.2 3B (text input) – Designed for applications requiring low-latency inferencing and limited computational resources. It excels at text summarization, classification, and language translation tasks. This model is ideal for the following use cases: mobile AI-powered writing assistants and customer service applications.
Llama 3.2 1B (text input) – The most lightweight model in the Llama 3.2 collection of models, perfect for retrieval and summarization for edge devices and mobile applications. This model is ideal for the following use cases: personal information management and multilingual knowledge retrieval.
In addition, Llama 3.2 is built on top of the Llama Stack, a standardized interface for building canonical toolchain components and agentic applications, making building and deploying easier than ever. Llama Stack API adapters and distributions are designed to most effectively leverage the Llama model capabilities and it gives customers the ability to benchmark Llama models across different vendors.
Meta has tested Llama 3.2 on over 150 benchmark datasets spanning multiple languages and conducted extensive human evaluations, demonstrating competitive performance with other leading foundation models. Let’s see how these models work in practice.
Using Llama 3.2 models in Amazon Bedrock To get started with Llama 3.2 models, I navigate to the Amazon Bedrock console and choose Model access on the navigation pane. There, I request access for the new Llama 3.2 models: Llama 3.2 1B, 3B, 11B Vision, and 90B Vision.
Back in the Amazon Bedrock console, I choose Chat under Playgrounds in the navigation pane, select Meta as the category, and choose the Llama 3.2 90B Vision model.
I use Choose files to select the resized chart image and use this prompt:
Based on this chart, which countries in Europe have the highest share?
I choose Run and the model analyzes the image and returns its results:
Here’s a sample AWS CLI command using the Amazon Bedrock Converse API. I use the --query parameter of the CLI to filter the result and only show the text content of the output message:
aws bedrock-runtime converse --messages '[{ "role": "user", "content": [ { "text": "Tell me the three largest cities in Italy." } ] }]' --model-id us.meta.llama3-2-90b-instruct-v1:0 --query 'output.message.content[*].text' --output text
In output, I get the response message from the "assistant".
The three largest cities in Italy are:
1. Rome (Roma) - population: approximately 2.8 million
2. Milan (Milano) - population: approximately 1.4 million
3. Naples (Napoli) - population: approximately 970,000
It’s not much different if you use one of the AWS SDKs. For example, here’s how you can use Python with the AWS SDK for Python (Boto3) to analyze the same image as in the console example:
import boto3
MODEL_ID = "us.meta.llama3-2-90b-instruct-v1:0"
# MODEL_ID = "eu.meta.llama3-2-90b-instruct-v1:0"
IMAGE_NAME = "share-electricity-renewable-small.png"
bedrock_runtime = boto3.client("bedrock-runtime")
with open(IMAGE_NAME, "rb") as f:
image = f.read()
user_message = "Based on this chart, which countries in Europe have the highest share?"
messages = [
{
"role": "user",
"content": [
{"image": {"format": "png", "source": {"bytes": image}}},
{"text": user_message},
],
}
]
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=messages,
)
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
Llama 3.2 models are also available in Amazon SageMaker JumpStart, a machine learning (ML) hub that makes it easy to deploy pre-trained models using the console or programmatically through the SageMaker Python SDK. From SageMaker JumpStart, you can also access and deploy new safeguard models that can help classify the safety level of model inputs (prompts) and outputs (responses), including Llama Guard 3 11B Vision, which are designed to support responsible innovation and system-level safety.
In addition, you can easily fine-tune Llama 3.2 1B and 3B models with SageMaker JumpStart today. Fine-tuned models can then be imported as custom models into Amazon Bedrock. Fine-tuning for the full collection of Llama 3.2 models in Amazon Bedrock and Amazon SageMaker JumpStart is coming soon.
The publicly available weights of Llama 3.2 models make it easier to deliver tailored solutions for custom needs. For example, you can fine-tune a Llama 3.2 model for a specific use case and bring it into Amazon Bedrock as a custom model, potentially outperforming other models in domain-specific tasks. Whether you’re fine-tuning for enhanced performance in areas like content creation, language understanding, or visual reasoning, Llama 3.2’s availability in Amazon Bedrock and SageMaker empowers you to create unique, high-performing AI capabilities that can set your solutions apart.
More on Llama 3.2 model architecture Llama 3.2 builds upon the success of its predecessors with an advanced architecture designed for optimal performance and versatility:
Auto-regressive language model – At its core, Llama 3.2 uses an optimized transformer architecture, allowing it to generate text by predicting the next token based on the previous context.
Fine-tuning techniques – The instruction-tuned versions of Llama 3.2 employ two key techniques:
Supervised fine-tuning (SFT) – This process adapts the model to follow specific instructions and generate more relevant responses.
Multimodal capabilities – For the 11B and 90B Vision models, Llama 3.2 introduces a novel approach to image understanding:
Separately trained image reasoning adaptor weights are integrated with the core LLM weights.
These adaptors are connected to the main model through cross-attention mechanisms. Cross-attention allows one section of the model to focus on relevant parts of another component’s output, enabling information flow between different sections of the model.
When an image is input, the model treats the image reasoning process as a “tool use” operation, allowing for sophisticated visual analysis alongside text processing. In this context, tool use is the generic term used when a model uses external resources or functions to augment its capabilities and complete tasks more effectively.
Optimized inference – All models support grouped-query attention (GQA), which enhances inference speed and efficiency, particularly beneficial for the larger 90B model.
This architecture enables Llama 3.2 to handle a wide range of tasks, from text generation and understanding to complex reasoning and image analysis, all while maintaining high performance and adaptability across different model sizes.
Llama 3.2 1B and 3B models are available in the US West (Oregon) and Europe (Frankfurt) Regions, and are available in the US East (Ohio, N. Virginia) and Europe (Ireland, Paris) Regions via cross-region inference.
Llama 3.2 11B Vision and 90B Vision models are available in the US West (Oregon) Region, and are available in the US East (Ohio, N. Virginia) Regions via cross-region inference.
You can find deep-dive technical content and discover how our Builder communities are using Amazon Bedrock at community.aws. Let us know what you build with Llama 3.2 in Amazon Bedrock!
Today, we are announcing the availability of AI21 Labs’ powerful new Jamba 1.5 family of large language models (LLMs) in Amazon Bedrock. These models represent a significant advancement in long-context language capabilities, delivering speed, efficiency, and performance across a wide range of applications. The Jamba 1.5 family of models includes Jamba 1.5 Mini and Jamba 1.5 Large. Both models support a 256K token context window, structured JSON output, function calling, and are capable of digesting document objects.
AI21 Labs is a leader in building foundation models and artificial intelligence (AI) systems for the enterprise. Together, AI21 Labs and AWS are empowering customers across industries to build, deploy, and scale generative AI applications that solve real-world challenges and spark innovation through a strategic collaboration. With AI21 Labs’ advanced, production-ready models together with Amazon’s dedicated services and powerful infrastructure, customers can leverage LLMs in a secure environment to shape the future of how we process information, communicate, and learn.
What is Jamba 1.5? Jamba 1.5 models leverage a unique hybrid architecture that combines the transformer model architecture with Structured State Space model (SSM) technology. This innovative approach allows Jamba 1.5 models to handle long context windows up to 256K tokens, while maintaining the high-performance characteristics of traditional transformer models. You can learn more about this hybrid SSM/transformer architecture in the Jamba: A Hybrid Transformer-Mamba Language Model whitepaper.
You can now use two new Jamba 1.5 models from AI21 in Amazon Bedrock:
Jamba 1.5 Large excels at complex reasoning tasks across all prompt lengths, making it ideal for applications that require high quality outputs on both long and short inputs.
Jamba 1.5 Mini is optimized for low-latency processing of long prompts, enabling fast analysis of lengthy documents and data.
Key strengths of the Jamba 1.5 models include:
Long context handling – With 256K token context length, Jamba 1.5 models can improve the quality of enterprise applications, such as lengthy document summarization and analysis, as well as agentic and RAG workflows.
Multilingual – Support for English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew.
Developer-friendly – Native support for structured JSON output, function calling, and capable of digesting document objects.
Speed and efficiency – AI21 measured the performance of Jamba 1.5 models and shared that the models demonstrate up to 2.5X faster inference on long contexts than other models of comparable sizes. For detailed performance results, visit the Jamba model family announcement on the AI21 website.
Get started with Jamba 1.5 models in Amazon Bedrock To get started with the new Jamba 1.5 models, go to the Amazon Bedrock console, choose Model access on the bottom left pane, and request access to Jamba 1.5 Mini or Jamba 1.5 Large.
To test the Jamba 1.5 models in the Amazon Bedrock console, choose the Text or Chat playground in the left menu pane. Then, choose Select model and select AI21 as the category and Jamba 1.5 Mini or Jamba 1.5 Large as the model.
By choosing View API request, you can get a code example of how to invoke the model using the AWS Command Line Interface (AWS CLI) with the current example prompt.
The following Python code example shows how to send a text message to Jamba 1.5 models using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client.
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID.
# modelId = "ai21.jamba-1-5-mini-v1:0"
model_id = "ai21.jamba-1-5-large-v1:0"
# Start a conversation with the user message.
user_message = "What are 3 fun facts about mambas?"
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = bedrock_runtime.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 256, "temperature": 0.7, "topP": 0.8},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
The Jamba 1.5 models are perfect for use cases like paired document analysis, compliance analysis, and question answering for long documents. They can easily compare information across multiple sources, check if passages meet specific guidelines, and handle very long or complex documents. You can find example code in the AI21-on-AWS GitHub repo. To learn more about how to prompt Jamba models effectively, check out AI21’s documentation.
Now available AI21 Labs’ Jamba 1.5 family of models is generally available today in Amazon Bedrock in the US East (N. Virginia) AWS Region. Check the full Region list for future updates. To learn more, check out the AI21 Labs in Amazon Bedrock product page and pricing page.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
Since they became publicly available at the end of 2022, generative AI tools have been hotly discussed by educators: what role should these tools for generating human-seeming text, images, and other media play in teaching and learning?
Two years later, the one thing most people agree on is that, like it or not, generative AI is here to stay. And as a computing educator, you probably have your learners and colleagues looking to you for guidance about this technology. We’re sharing how educators like you are approaching generative AI in issue 25 of Hello World, out today for free.
Generative AI and teaching
Since our ‘Teaching and AI’ issue a year ago, educators have been making strides grappling with generative AI’s place in their classroom, and with the potential risks to young people. In this issue, you’ll hear from a wide range of educators who are approaching this technology in different ways.
For example:
Laura Ventura from Gwinnett County Public Schools (GCPS) in Georgia, USA shares how the GCPS team has integrated AI throughout their K–12 curriculum
Mark Calleja from our team guides you through using the OCEAN prompt process to reliably get the results you want from an LLM
Kip Glazer, principal at Mountain View High School in California, USA shares a framework for AI implementation aimed at school leaders
Stefan Seegerer, a researcher and educator in Germany, discusses why unplugged activities help us focus on what’s really important in teaching about AI
This issue also includes practical solutions to problems that are unique to computer science educators:
Graham Hastings in the UK shares his solution to tricky crocodile clips when working with micro:bits
Riyad Dhuny shares his case study of home-hosting a learning management system with his students in Mauritius
And there is lots more for you to discover in issue 25.
Whether or not you use generative AI as part of your teaching practice, it’s important for you to be aware of AI technologies and how your young people may be interacting with it. In his article “A problem-first approach to the development of AI systems”, Ben Garside from our team affirms that:
“A big part of our job as educators is to help young people navigate the changing world and prepare them for their futures, and education has an essential role to play in helping people understand AI technologies so that they can avoid the dangers.
Our approach at the Raspberry Pi Foundation is not to focus purely on the threats and dangers, but to teach young people to be critical users of technologies and not passive consumers. […]
Our call to action to educators, carers, and parents is to have conversations with your young people about generative AI. Get to know their opinions on it and how they view its role in their lives, and help them to become critical thinkers when interacting with technology.”
Share your thoughts & subscribe to Hello World
Computing teachers are being asked again to teach something that they didn’t study. With generative AI as with all things computing, we want to support your teaching and share your successes. We hope you enjoy this issue of Hello World, and please get in touch with your article ideas or what you would like to see in the magazine.
Share your thoughts and ideas about Hello World and the new issue with us on social media by tagging the Hello World Twitter/X or Facebook accounts
“I’ve enjoyed actually learning about what AI is and how it works, because before I thought it was just a scary computer that thinks like a human,” a student learning with Experience AI at King Edward’s School, Bath, UK, told us.
This is the essence of what we aim to do with our Experience AI lessons, which demystify artificial intelligence (AI) and machine learning (ML). Through Experience AI, teachers worldwide are empowered to confidently deliver engaging lessons with a suite of resources that inspire and educate 11- to 14-year-olds about AI and the role it could play in their lives.
“I learned new things and it changed my mindset that AI is going to take over the world.” – Student, Malaysia
Experience AI students in Malaysia
Developed by us with Google DeepMind, our first set of Experience AI lesson resources was aimed at a UK audience and launched in April 2023. Next we released tailored versions of the resources for 5 other countries, working in close partnership with organisations in Malaysia, Kenya, Canada, Romania, and India. Thanks to new funding from Google.org, we’re now expanding Experience AI for 16 more countries and creating new resources on AI safety, with the aim of providing leading-edge AI education for more than 2 million young people across Europe, the Middle East, and Africa.
In this blog post, you’ll hear directly from students and teachers about the impact the Experience AI lessons have had so far.
Case study: Experience AI in Malaysia
Penang Science Cluster in Malaysia is among the first organisations we’ve partnered with for Experience AI. Speaking to Malaysian students learning with Experience AI, we found that the lessons were often very different from what they had expected.
Launch of Experience AI in Malaysia
“I actually thought it was going to be about boring lectures and not much about AI but more on coding, but we actually got to do a lot of hands-on activities, which are pretty fun. I thought AI was just about robots, but after joining this, I found it could be made into chatbots or could be made into personal helpers.” – Student, Malaysia
“Actually, I thought AI was mostly related to robots, so I was expecting to learn more about robots when I came to this programme. It widened my perception on AI.” – Student, Malaysia.
The Malaysian government actively promotes AI literacy among its citizens, and working with local education authorities, Penang Science Cluster is using Experience AI to train teachers and equip thousands of young people in the state of Penang with the understanding and skills to use AI effectively.
“We envision a future where AI education is as fundamental as mathematics education, providing students with the tools they need to thrive in an AI-driven world”, says Aimy Lee, Chief Operating Officer at Penang Science Cluster. “The journey of AI exploration in Malaysia has only just begun, and we’re thrilled to play a part in shaping its trajectory.”
Giving non-specialist teachers the confidence to introduce AI to students
“Our Key Stage 3 Computing students now feel immensely more knowledgeable about the importance and place that AI has in their wider lives. These lessons and activities are engaging and accessible to students and educators alike, whatever their specialism may be.” – Dave Cross, North Liverpool Academy, UK
“The feedback we’ve received from both teachers and learners has been overwhelmingly positive. They consistently rave about how accessible, fun, and hands-on these resources are. What’s more, the materials are so comprehensive that even non-specialists can deliver them with confidence.” – Storm Rae, The National Museum of Computing, UK
Experience AI teacher training in Kenya
“[The lessons] go above and beyond to ensure that students not only grasp the material but also develop a genuine interest and enthusiasm for the subject.” – Teacher, Changamwe Junior School, Mombasa, Kenya
Sparking debates on bias and the limitations of AI
When learners gain an understanding of how AI works, it gives them the confidence to discuss areas where the technology doesn’t work well or its output is incorrect. These classroom debates deepen and consolidate their knowledge, and help them to use AI more critically.
“Students enjoyed the practical aspects of the lessons, like categorising apples and tomatoes. They found it intriguing how AI could sometimes misidentify objects, sparking discussions on its limitations. They also expressed concerns about AI bias, which these lessons helped raise awareness about. I didn’t always have all the answers, but it was clear they were curious about AI’s implications for their future.” – Tracey Mayhead, Arthur Mellows Village College, Peterborough, UK
Experience AI students in UK
“The lessons that we trialled took some of the ‘magic’ out of AI and started to give the students an understanding that AI is only as good as the data that is used to build it.” – Jacky Green, Waldegrave School, UK
“I have enjoyed learning about how AI is actually programmed, rather than just hearing about how impactful and great it could be.” – Student, King Edward’s School, Bath, UK
“It has changed my outlook on AI because now I’ve realised how much AI actually needs human intelligence to be able to do anything.” – Student, Arthur Mellows Village College, Peterborough, UK
“I didn’t really know what I wanted to do before this but now knowing more about AI, I probably would consider a future career in AI as I find it really interesting and I really liked learning about it.” – Student, Arthur Mellows Village College, Peterborough, UK
If you’d like to get involved with Experience AI as an educator and use our free lesson resources with your class, you can start by visiting experience-ai.org.
New research evaluating the effectiveness of reward modeling during Reinforcement Learning from Human Feedback (RLHF): “SEAL: Systematic Error Analysis for Value ALignment.” The paper introduces quantitative metrics for evaluating the effectiveness of modeling and aligning human values:
Abstract: Reinforcement Learning from Human Feedback (RLHF) aims to align language models (LMs) with human values by training reward models (RMs) on binary preferences and using these RMs to fine-tune the base LMs. Despite its importance, the internal mechanisms of RLHF remain poorly understood. This paper introduces new metrics to evaluate the effectiveness of modeling and aligning human values, namely feature imprint, alignment resistance and alignment robustness. We categorize alignment datasets into target features (desired values) and spoiler features (undesired concepts). By regressing RM scores against these features, we quantify the extent to which RMs reward them a metric we term feature imprint. We define alignment resistance as the proportion of the preference dataset where RMs fail to match human preferences, and we assess alignment robustness by analyzing RM responses to perturbed inputs. Our experiments, utilizing open-source components like the Anthropic preference dataset and OpenAssistant RMs, reveal significant imprints of target features and a notable sensitivity to spoiler features. We observed a 26% incidence of alignment resistance in portions of the dataset where LM-labelers disagreed with human preferences. Furthermore, we find that misalignment often arises from ambiguous entries within the alignment dataset. These findings underscore the importance of scrutinizing both RMs and alignment datasets for a deeper understanding of value alignment.
Starting today, you can use three new text-to-image models from Stability AI in Amazon Bedrock: Stable Image Ultra, Stable Diffusion 3 Large, and Stable Image Core. These models greatly improve performance in multi-subject prompts, image quality, and typography and can be used to rapidly generate high-quality visuals for a wide range of use cases across marketing, advertising, media, entertainment, retail, and more.
These models excel in producing images with stunning photorealism, boasting exceptional detail, color, and lighting, addressing common challenges like rendering realistic hands and faces. The models’ advanced prompt understanding allows it to interpret complex instructions involving spatial reasoning, composition, and style.
The three new Stability AI models available in Amazon Bedrock cover different use cases:
Stable Image Ultra – Produces the highest quality, photorealistic outputs perfect for professional print media and large format applications. Stable Image Ultra excels at rendering exceptional detail and realism.
Stable Diffusion 3 Large – Strikes a balance between generation speed and output quality. Ideal for creating high-volume, high-quality digital assets like websites, newsletters, and marketing materials.
Stable Image Core – Optimized for fast and affordable image generation, great for rapidly iterating on concepts during ideation.
This table summarizes the model’s key features:
Features
Stable Image Ultra
Stable Diffusion 3 Large
Stable Image Core
Parameters
16 billion
8 billion
2.6 billion
Input
Text
Text or image
Text
Typography
Tailored for large-scale display
Tailored for large-scale display
Versatility and readability across different sizes and applications
Visual aesthetics
Photorealistic image output
Highly realistic with finer attention to detail
Good rendering; not as detail-oriented
One of the key improvements of Stable Image Ultra and Stable Diffusion 3 Large compared to Stable Diffusion XL (SDXL) is text quality in generated images, with fewer errors in spelling and typography thanks to its innovative Diffusion Transformer architecture, which implements two separate sets of weights for image and text but enables information flow between the two modalities.
Here are a few images created with these models.
Stable Image Ultra – Prompt: photo, realistic, a woman sitting in a field watching a kite fly in the sky, stormy sky, highly detailed, concept art, intricate, professional composition.
Stable Diffusion 3 Large – Prompt: comic-style illustration, male detective standing under a streetlamp, noir city, wearing a trench coat, fedora, dark and rainy, neon signs, reflections on wet pavement, detailed, moody lighting.
Stable Image Core – Prompt: professional 3d render of a white and orange sneaker, floating in center, hovering, floating, high quality, photorealistic.
Use cases for the new Stability AI models in Amazon Bedrock Text-to-image models offer transformative potential for businesses across various industries and can significantly streamline creative workflows in marketing and advertising departments, enabling rapid generation of high-quality visuals for campaigns, social media content, and product mockups. By expediting the creative process, companies can respond more quickly to market trends and reduce time-to-market for new initiatives. Additionally, these models can enhance brainstorming sessions, providing instant visual representations of concepts that can spark further innovation.
For e-commerce businesses, AI-generated images can help create diverse product showcases and personalized marketing materials at scale. In the realm of user experience and interface design, these tools can quickly produce wireframes and prototypes, accelerating the design iteration process. The adoption of text-to-image models can lead to significant cost savings, increased productivity, and a competitive edge in visual communication across various business functions.
Here are some example use cases across different industries:
Advertising and Marketing
Stable Image Ultra for luxury brand advertising and photorealistic product showcases
Stable Diffusion 3 Large for high-quality product marketing images and print campaigns
Use Stable Image Core for rapid A/B testing of visual concepts for social media ads
E-commerce
Stable Image Ultra for high-end product customization and made-to-order items
Stable Diffusion 3 Large for most product visuals across an e-commerce site
Stable Image Core to quickly generate product images and keep listings up-to-date
Media and Entertainment
Stable Image Ultra for ultra-realistic key art, marketing materials, and game visuals
Stable Diffusion 3 Large for environment textures, character art, and in-game assets
Stable Image Core for rapid prototyping and concept art exploration
Using the new Stability AI models in the Amazon Bedrock console In the Amazon Bedrock console, I choose Model access from the navigation pane to enable access the three new models in the Stability AI section.
Now that I have access, I choose Image in the Playgrounds section of the navigation pane. For the model, I choose Stability AI and Stable Image Ultra.
As prompt, I type:
A stylized picture of a cute old steampunk robot with in its hands a sign written in chalk that says "Stable Image Ultra in Amazon Bedrock".
I leave all other options to their default values and choose Run. After a few seconds, I get what I asked. Here’s the image:
Using Stable Image Ultra with the AWS CLI While I am still in the console Image playground, I choose the three small dots in the corner of the playground window and then View API request. In this way, I can see the AWS Command Line Interface (AWS CLI) command equivalent to what I just did in the console:
aws bedrock-runtime invoke-model \
--model-id stability.stable-image-ultra-v1:0 \
--body "{\"prompt\":\"A stylized picture of a cute old steampunk robot with in its hands a sign written in chalk that says \\\"Stable Image Ultra in Amazon Bedrock\\\".\",\"mode\":\"text-to-image\",\"aspect_ratio\":\"1:1\",\"output_format\":\"jpeg\"}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
invoke-model-output.txt
To use Stable Image Core or Stable Diffusion 3 Large, I can replace the model ID.
The previous command outputs the image in Base64 format inside a JSON object in a text file.
To get the image with a single command, I write the output JSON file to standard output and use the jq tool to extract the encoded image so that it can be decoded on the fly. The output is written in the img.png file. Here’s the full command:
aws bedrock-runtime invoke-model \
--model-id stability.stable-image-ultra-v1:0 \
--body "{\"prompt\":\"A stylized picture of a cute old steampunk robot with in its hands a sign written in chalk that says \\\"Stable Image Ultra in Amazon Bedrock\\\".\",\"mode\":\"text-to-image\",\"aspect_ratio\":\"1:1\",\"output_format\":\"jpeg\"}" \
--cli-binary-format raw-in-base64-out \
--region us-west-2 \
/dev/stdout | jq -r '.images[0]' | base64 --decode > img.png
Using Stable Image Ultra with AWS SDKs Here’s how you can use Stable Image Ultra with the AWS SDK for Python (Boto3). This simple application interactively asks for a text-to-image prompt and then calls Amazon Bedrock to generate the image.
import base64
import boto3
import json
import os
MODEL_ID = "stability.stable-image-ultra-v1:0"
bedrock_runtime = boto3.client("bedrock-runtime", region_name="us-west-2")
print("Enter a prompt for the text-to-image model:")
prompt = input()
body = {
"prompt": prompt,
"mode": "text-to-image"
}
response = bedrock_runtime.invoke_model(modelId=MODEL_ID, body=json.dumps(body))
model_response = json.loads(response["body"].read())
base64_image_data = model_response["images"][0]
i, output_dir = 1, "output"
if not os.path.exists(output_dir):
os.makedirs(output_dir)
while os.path.exists(os.path.join(output_dir, f"img_{i}.png")):
i += 1
image_data = base64.b64decode(base64_image_data)
image_path = os.path.join(output_dir, f"img_{i}.png")
with open(image_path, "wb") as file:
file.write(image_data)
print(f"The generated image has been saved to {image_path}")
The application writes the resulting image in an output directory that is created if not present. To not overwrite existing files, the code checks for existing files to find the first file name available with the img_<number>.png format.
Customer voices Learn from Ken Hoge, Global Alliance Director, Stability AI, how Stable Diffusion models are reshaping the industry from text-to-image to video, audio, and 3D, and how Amazon Bedrock empowers customers with an all-in-one, secure, and scalable solution.
Step into a world where reading comes alive with Nicolette Han, Product Owner, Stride Learning. With support from Amazon Bedrock and AWS, Stride Learning’s Legend Library is transforming how young minds engage with and comprehend literature using AI to create stunning, safe illustrations for children stories.
In the rapidly evolving landscape of Generative AI, the ability to deploy and iterate on features quickly and reliably is paramount. We, the Amazon Q Developer service team, relied on several offline and online testing methods, such as evaluating models on datasets, to gauge improvements. Once positive results are observed, features were rolled out to production, introducing a delay until the change affected 100% of customers.
This blog post delves into the impact of A/B testing and Multi-Model hosting on deploying Generative AI features. By leveraging these powerful techniques, our team has been able to significantly accelerate the pace of experimentation, iteration, and deployment. We have not only streamlined our development process but also gained valuable insights into model performance, user preferences, and the potential impact of new features. This data-driven approach has allowed us to make informed decisions, continuously refine our models, and provide a user experience that resonates with our customers
What is A/B Testing?
A/B testing is a controlled experiment, and a widely adopted practice in the tech industry. It involves simultaneously deploying multiple variants of a product or feature to distinct user segments. In the context of Amazon Q Developer, the service team leverages A/B testing to evaluate the impact of new model variants on the developer experience. This helps in gathering real-world feedback from a subset of users before rolling out changes to the entire user base.
Control group: Developers in the control group continue to receive the base Amazon Q Developer experience, serving as the benchmark against which changes are measured.
Treatment group: Developers in the treatment group are exposed to the new model variant or feature, providing a contrasting experience to the control group.
To run an experiment, we take a random subset of developers and evenly split it into two groups: The control group continues to receive the base Amazon Q Developer experience, while the treatment group receives a different experience.
By carefully analyzing user interactions and telemetry metrics of the control group and comparing them to those from the treatment group, we can make informed decisions about which variant performs better, ultimately shaping the direction of future releases.
How do we split the users?
Whenever a user request is received, we perform consistent hashing on the user identity and assign the user to a cohort. Irrespective on which machine the algorithm runs, the user will be assigned the same cohort. This means that we can scale horizontally – user A’s request can be served by any machine and user A will always be assigned to group A from the beginning to the end of the experiment.
Individuals in the two groups are, on average, balanced on all dimensions that will be meaningful to the test. This means that we do not expose a cohort to have more than one experiment at any given time. This enables us to conduct multivariate experiments where one experiment does not impact the result of another.
The above diagram illustrates the process of user assignment to cohorts in a system conducting multiple parallel A/B experiments.
How do we enable segmentation?
For some A/B experiments, we want to perform A/B experiments for users matching certain criteria. Assume we want to exclusively target Amazon Q Developer customers using the Visual Studio Code Integrated Development Environment (IDE). For such scenarios, we perform cohort allocation only for users who meet the criteria. In this example, we would divide a subset of Visual Studio Code IDE users into control and treatment cohorts.
How do we route the traffic between different models ?
The above diagram depicts how Application Load Balancer redirects traffic to various models based on path-based routing. Where path1 is routing to control model and path2 is routing to treatment model 1 etc.
How do we enable different IDE experiences for different groups?
The IDE plugin polls the service endpoint asking if the developer belongs to the control or treatment group. Based on the response the user will be served the control or treatment experience.
The above diagram depicts how the IDE plugin provides different experience based on control or treatment group.
How do we ingest data?
From the plugin, we publish telemetry metrics to our data plane. We honor opt-out settings of our users. If the user is opted-out, we do not store their data. In the data plane, we check the cohort of the caller. We publish telemetry metrics with cohort metadata to Amazon Data Firehose, which delivers the data to an Amazon OpenSearch Serverless destination.
The above diagram depicts how metrics are captured via the data plane into Amazon OpenSearch Serverless.
How do we analyze the data?
We publish the aggregated metrics to OpenSearch Serverless. We leverage OpenSearch Serverless to ingest and index various metrics to compare and contrast between control and treatment cohorts. We enable filtering based on metadata such as programming language and IDE.
Additionally, we publish data and metadata to a data lake to view, query and analyze the data securely using Jupyter Notebooks and dashboards. This enables our scientists and engineers to perform deeper analysis.
Conclusion
This post has focused on challenges Generative AI services face when it comes to fast experimentation cycles, the basics of A/B testing and the A/B testing capabilities built by the Amazon Q Developer service team to enable multi-variate service and client-side experimentation. We can gain valuable insights into the effectiveness of the new model variants on the developer experience within Amazon Q Developer. Through rigorous experimentation and data-driven decision-making, we can empower teams to iterate, innovate, and deliver optimal solutions that resonate with the developer community.
We hope you are as excited as us about the opportunities with Generative AI! Give Amazon Q Developer and Amazon Q Developer Customization a try today:
The current scaling approach of Amazon Redshift Serverless increases your compute capacity based on the query queue time and scales down when the queuing reduces on the data warehouse. However, you might need to automatically scale compute resources based on factors like query complexity and data volume to meet price-performance targets, irrespective of query queuing. To address this requirement, Redshift Serverless launched the artificial intelligence (AI)-driven scaling and optimization feature, which scales the compute not only based on the queuing, but also factoring data volume and query complexity.
In this post, we describe how Redshift Serverless utilizes the new AI-driven scaling and optimization capabilities to address common use cases. This post also includes example SQLs, which you can run on your own Redshift Serverless data warehouse to experience the benefits of this feature.
Solution overview
The AI-powered scaling and optimization feature in Redshift Serverless provides a user-friendly visual slider to set your desired balance between price and performance. By moving the slider, you can choose between optimized for cost, balanced performance and cost, or optimized for performance. Based on where you position the slider, Amazon Redshift will automatically add or remove resources to ensure better behavior and perform other AI-driven optimizations like automatic materialized views and automatic table design optimization to meet your selected price-performance target.
The slider offers the following options:
Optimized for cost – Prioritizes cost savings. Redshift attempts to automatically scale up compute capacity when doing so and doesn’t incur additional charges. And it will also attempt to scale down compute for lower cost, despite longer runtime.
Balanced – Offers balance between performance and cost. Redshift scales for performance with a moderate cost increase.
Optimized for performance – Prioritizes performance. Redshift scales aggressively for maximum performance, potentially incurring higher costs.
In the following sections, we illustrate how the AI-driven scaling and optimization feature can intelligently predict your workload compute needs and scale proactively for three scenarios:
Use case 1 – A long-running complex query. Compute scales based on query complexity.
Use case 2 – A sudden spike in ingestion volume (a three-fold increase, from 720 million to 2.1 billion). Compute scales based on data volume.
Use case 3 – A data lake query scanning large datasets (TBs). Compute scales based on the expected data to be scanned from the data lake. The expected data scan is predicted by machine learning (ML) models based on prior historical run statistics.
In the existing auto scaling mechanism, the use cases don’t increase compute capacity automatically unless queuing is identified across the instance.
Prerequisites
To follow along, complete the following prerequisites:
We use TPC-DS 1TB Cloud Data Warehouse Benchmark data to demonstrate this feature. Run the SQL statements to create tables and load the TPC-DS 1TB data.
Use case 1: Scale compute based on query complexity
The following query analyzes product sales across multiple channels such as websites, wholesale, and retail stores. This complex query typically takes about 25 minutes to run with the default 128 RPUs. Let’s run this workload on the preview workgroup created as part of prerequisites.
When a query is run for the first time, the AI scaling system may make a suboptimal decision regarding resource allocation or scaling as the system is still learning the query and data characteristics. However, the system learns from this experience, and when the same query is run again, it can make a more optimal scaling decision. Therefore, if the query didn’t scale during the first run, it is recommended to rerun the query. You can monitor the RPU capacity used on the Redshift Serverless console or by querying the SYS_SERVERLSS_USAGE system view.
The results cache is turned off in the following queries to avoid fetching results from the cache.
SET enable_result_cache_for_session TO off;
with /* TPC-DS demo query */
ws as
(select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk
ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp from web_sales left join web_returns on
wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join date_dim
on ws_sold_date_sk = d_date_sk where wr_order_number is null group by
d_year, ws_item_sk, ws_bill_customer_sk ),
cs as
(select d_year AS cs_sold_year,
cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from catalog_sales
left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join date_dim on cs_sold_date_sk = d_date_sk where cr_order_number is
null group by d_year, cs_item_sk, cs_bill_customer_sk ),
ss as
(select
d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity)
ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_sp
from store_sales left join store_returns on sr_ticket_number=ss_ticket_number
and ss_item_sk=sr_item_sk join date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null group by d_year, ss_item_sk, ss_customer_sk
)
select
ss_customer_sk,round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2)
ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0)
other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
from ss left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk
and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year
and cs_item_sk=cs_item_sk and cs_customer_sk=ss_customer_sk)where coalesce(ws_qty,0)>0
and coalesce(cs_qty, 0)>0 order by ss_customer_sk, ss_qty desc, ss_wc
desc, ss_sp desc, other_chan_qty, other_chan_wholesale_cost, other_chan_sales_price,
round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2);
When the query is complete, run the following SQL to capture the start and end times of the query, which will be used in the next query:
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds
from sys_query_history
where query_text like '%TPC-DS demo query%'
and query_text not like '%sys_query_history%'
order by start_time desc
Let’s assess the compute scaled during the preceding start_time and end_time period. Replace start_time and end_time in the following query with the output of the preceding query:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
-- Example
--select * from sys_serverless_usage
--where end_time >= '2024-06-03 00:17:12.322353'
--and end_time <= DATEADD(minute,1,'2024-06-03 00:19:11.553218')
--order by end_time asc
The following screenshot shows an example output.
You can notice the increase in compute over the duration of this query. This demonstrates how Redshift Serverless scales based on query complexity.
Use case 2: Scale compute based on data volume
Let’s consider the web_sales ingestion job. For this example, your daily ingestion job processes 720 million records and completes in an average of 2 minutes. This is what you ingested in the prerequisite steps.
Due to some event (such as month end processing), your volumes increased by three times and now your ingestion job needs to process 2.1 billion records. In an existing scaling approach, this would increase your ingestion job runtime unless the queue time is enough to invoke additional compute resources. But with AI-driven scaling, in performance optimized mode, Amazon Redshift automatically scales compute to complete your ingestion job within usual runtimes. This helps protect your ingestion SLAs.
Run the following job to ingest 2.1 billion records into the web_sales table:
copy web_sales from 's3://redshift-downloads/TPC-DS/2.13/3TB/web_sales/' iam_role default gzip delimiter '|' EMPTYASNULL region 'us-east-1';
Run the following query to compare the duration of ingesting 2.1 billion records and 720 million records. Both ingestion jobs completed in approximately a similar time, despite the three-fold increase in volume.
select query_id,table_name,data_source,loaded_rows,duration/1000000.0 duration_in_seconds , start_time,end_time
from sys_load_history
where
table_name='web_sales'
order by start_time desc
Run the following query with the start times and end times from the previous output:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
The following is an example output. You can notice the increase in compute capacity for the ingestion job that processes 2.1 billion records. This illustrates how Redshift Serverless scaled based on data volume.
Use case 3: Scale data lake queries
In this use case, you create external tables pointing to TPC-DS 3TB data in an Amazon Simple Storage Service (Amazon S3) location. Then you run a query that scans a large volume of data to demonstrate how Redshift Serverless can automatically scale compute capacity as needed.
In the following SQL, provide the ARN of the default IAM role you attached in the prerequisites:
-- Create external schema
create external schema ext_tpcds_3t
from data catalog
database ext_tpcds_db
iam_role '<ARN of the default IAM role attached>'
create external database if not exists;
Create external tables by running DDL statements in the following SQL file. You should see seven external tables in the query editor under the ext_tpcds_3t schema, as shown in the following screenshot.
Run the following query using external tables. As mentioned in the first use case, if the query didn’t scale during the first run, it is recommended to rerun the query, because the system will have learned from the previous experience and can potentially provide better scaling and performance for the subsequent run.
The results cache is turned off in the following queries to avoid fetching results from the cache.
SET enable_result_cache_for_session TO off;
with /* TPC-DS demo data lake query */
ws as
(select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk
ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc,
sum(ws_sales_price) ws_sp from ext_tpcds_3t.web_sales left join ext_tpcds_3t.web_returns on
wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join ext_tpcds_3t.date_dim
on ws_sold_date_sk = d_date_sk where wr_order_number is null group by
d_year, ws_item_sk, ws_bill_customer_sk ),
cs as
(select d_year AS cs_sold_year,
cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty,
sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from ext_tpcds_3t.catalog_sales
left join ext_tpcds_3t.catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk
join ext_tpcds_3t.date_dim on cs_sold_date_sk = d_date_sk where cr_order_number is
null group by d_year, cs_item_sk, cs_bill_customer_sk ),
ss as
(select
d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity)
ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_sp
from ext_tpcds_3t.store_sales left join ext_tpcds_3t.store_returns on sr_ticket_number=ss_ticket_number
and ss_item_sk=sr_item_sk join ext_tpcds_3t.date_dim on ss_sold_date_sk = d_date_sk
where sr_ticket_number is null group by d_year, ss_item_sk, ss_customer_sk)
SELECT ss_customer_sk,round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2)
ratio,ss_qty store_qty, ss_wc store_wholesale_cost, ss_sp store_sales_price,
coalesce(ws_qty,0)+coalesce(cs_qty,0) other_chan_qty,coalesce(ws_wc,0)+coalesce(cs_wc,0) other_chan_wholesale_cost,coalesce(ws_sp,0)+coalesce(cs_sp,0) other_chan_sales_price
FROM ss left join ws on (ws_sold_year=ss_sold_year and ws_item_sk=ss_item_sk and ws_customer_sk=ss_customer_sk)left join cs on (cs_sold_year=ss_sold_year and cs_item_sk=cs_item_sk and cs_customer_sk=ss_customer_sk)
where coalesce(ws_qty,0)>0
and coalesce(cs_qty, 0)>0
order by ss_customer_sk, ss_qty desc, ss_wc desc, ss_sp desc, other_chan_qty, other_chan_wholesale_cost, other_chan_sales_price, round(ss_qty/(coalesce(ws_qty+cs_qty,1)),2);
Review the total elapsed time of the query. You need the start_time and end_time from the results to feed into the next query.
select query_id,query_text,start_time,end_time, elapsed_time/1000000.0 duration_in_seconds
from sys_query_history
where query_text like '%TPC-DS demo data lake query%'
and query_text not like '%sys_query_history%'
order by start_time desc
Run the following query to see how compute scaled during the preceding start_time and end_time period. Replace start_time and end_time in the following query from the output of the preceding query:
select * from sys_serverless_usage
where end_time >= 'start_time'
and end_time <= DATEADD(minute,1,'end_time')
order by end_time asc
The following screenshot shows an example output.
The increased compute capacity for this data lake query shows that Redshift Serverless can scale to match the data being scanned. This demonstrates how Redshift Serverless can dynamically allocate resources based on query needs.
Considerations when choosing your price-performance target
You can use the price-performance slider to choose your desired price-performance target for your workload. The AI-driven scaling and optimizations provide holistic optimizations using the following models:
Query prediction models – These determine the actual resource needs (memory, CPU consumption, and so on) for each individual query
Scaling prediction models – These predict how the query would behave on different capacity sizes
Let’s consider a query that takes 7 minutes and costs $7. The following figure shows the query runtimes and cost with no scaling.
A given query might scale in a few different ways, as shown below. Based on the price-performance target you chose on the slider, AI-driven scaling predicts how the query trades off performance and cost, and scales it accordingly.
The slider options yield the following results:
Optimized for cost – When you choose Optimized for cost, the warehouse scales up if there is no additional cost or lesser costs to the user. In the preceding example, the superlinear scaling approach demonstrates this behavior. Scaling will only occur if it can be done in a cost-effective manner according to the scaling model predictions. If the scaling models predict that cost-optimized scaling isn’t possible for the given workload, then the warehouse won’t scale.
Balanced – With the Balanced option, the system will scale in favor of performance and there will be a cost increase, but it will be a limited increase in cost. In the preceding example, the linear scaling approach demonstrates this behavior.
Optimized for performance – With the Optimized for performance option, the system will scale in favor of performance even though the costs are higher and non-linear. In the preceding example, the sublinear scaling approach demonstrates this behavior. The closer the slider position is to the Optimized for performance position, the more sublinear scaling is permitted.
The following are additional points to note:
The price-performance slider options are dynamic and they can be changed anytime. However, the impact of these changes will not be realized immediately. The impact of this is effective as the system learns how to scale the current workload and any additional workloads better.
The price-performance slider options, Max capacity and Max RPU-hours are designed to work together. Max capacity and Max RPU-hours are the controls to limit maximum RPUs the data warehouse allowed to scale and maximum RPU hours allowed to consume respectively. These controls are always honored and enforced regardless of the settings on the price-performance target slider.
The AI-driven scaling and optimization feature dynamically adjusts compute resources to optimize query runtime speed while adhering to your price-performance requirements. It considers factors such as query queueing, concurrency, volume, and complexity. The system can either run queries on a compute resource with lower concurrent queries or spin up additional compute resources to avoid queueing. The goal is to provide the best price-performance balance based on your choices.
Monitoring
You can monitor the RPU scaling in the following ways:
Review the RPU capacity used graph on the Amazon Redshift console.
Monitor the ComputeCapacity metric under AWS/Redshift-Serverless and Workgroup in Amazon CloudWatch.
Query the SYS_QUERY_HISTORY view, providing the specific query ID or query text to identify the time period. Use this time period to query the SYS_SERVERLSS_USAGE system view to find the compute_capacity The compute_capacity field will show the RPUs scaled during the query runtime.
Delete the Redshift Serverless associated namespace.
Conclusion
In this post, we discussed how to optimize your workloads to scale based on the changes in data volume and query complexity. We demonstrated an approach to implement more responsive, proactive scaling with the AI-driven scaling feature in Redshift Serverless. Try this feature in your environment, conduct a proof of concept on your specific workloads, and share your feedback with us.
About the Authors
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences.
Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.
Generative, multimodal artificial intelligence (GenAI) offers transformative potential across industries, but its misuse poses significant risks. Prior research has shed light on the potential of advanced AI systems to be exploited for malicious purposes. However, we still lack a concrete understanding of how GenAI models are specifically exploited or abused in practice, including the tactics employed to inflict harm. In this paper, we present a taxonomy of GenAI misuse tactics, informed by existing academic literature and a qualitative analysis of approximately 200 observed incidents of misuse reported between January 2023 and March 2024. Through this analysis, we illuminate key and novel patterns in misuse during this time period, including potential motivations, strategies, and how attackers leverage and abuse system capabilities across modalities (e.g. image, text, audio, video) in the wild.
Blog post. Note the graphic mapping goals with strategies.
SQUID, short for Surrogate Quantitative Interpretability for Deepnets, is a computational tool created by Cold Spring Harbor Laboratory (CSHL) scientists. It’s designed to help interpret how AI models analyze the genome. Compared with other analysis tools, SQUID is more consistent, reduces background noise, and can lead to more accurate predictions about the effects of genetic mutations.
“All code will become legacy”. This saying, widely recognized amongst software developers, highlights the reality of their day-to-day activities. While writing new code is an integral part of a developer’s role, a significant portion of their time is dedicated to refactoring and maintaining existing codebases.
Developers typically encounter numerous challenges when attempting to understand and work with existing codebases. One of the primary obstacles is the lack of proper code documentation. As projects evolve and developers come and go, the rationale behind design decisions and implementation details can become obscured, making it challenging for new team members to understand the intricacies of the codebase.
Another hurdle is the need to work with unfamiliar or legacy programming languages and frameworks. The rapid pace of technology advancements means that developers must constantly adapt to new tools and libraries, while also maintaining an understanding of older technologies that may still be in use.
Compounding these challenges is the inherent difficulty of understanding code written by others. Even with comprehensive documentation and adherence to best coding practices, the nuances of another developer’s thought process and design decisions can be challenging to decipher. This lack of familiarity can lead to increased risk of introducing bugs or breaking existing functionality during code modifications.
In a bid to address these challenges, organizations must explore innovative solutions that enhance code understanding and improve developer efficiency. By empowering developers with tools that streamline code maintenance and refactoring processes, organizations can unlock their potential for innovation and accelerate their ability to deliver high-quality software products to the market.
In this blog post, we explore how developers in organizations can leverage Amazon Q Developer to simplify the process of understanding and explaining code in order to boost productivity and efficiency.
Prerequisites
The following prerequisites are required to make use of Amazon Q Developer in your IDE:
Introduction to Amazon Q Developer as a solution for simplifying code comprehension
Amazon Q Developer is a generative AI-powered service that helps developers and IT professionals with all of their tasks across the software development lifecycle—from coding, testing, and upgrading, to troubleshooting, performing security scanning and fixes, optimizing AWS resources, and creating data engineering pipelines. Amazon Q Developer aims to simplify code comprehension for developers, making it easier to understand and navigate complex codebases. It leverages advanced machine learning and natural language processing techniques to provide intelligent code analysis and exploration capabilities.
Developers can ask questions about their codebase in natural language and receive concise, relevant answers. Amazon Q Developer can explain the purpose and functionality of code elements, identify dependencies, and provide insights into code structure and architecture. This can significantly reduce the time and effort required to onboard new team members, maintain legacy systems, or refactor existing code. This result in not just better code quality and consistency across teams and projects; Amazon Q Developer also helps developers unlock a new level of productivity and efficiency by allowing them to focus more on innovation.
Understanding Amazon Q Developer’s ability to provide natural language explanations of code
One of the most powerful uses of Amazon Q Developer is getting natural language explanations of code directly within your integrated development environment (IDE). This can be an invaluable tool when trying to understand legacy code, review code you haven’t touched in a while, or learn how certain programming patterns or algorithms work. Rather than spending so much time reviewing code line-by-line or searching for tutorials, you can leverage Amazon Q Developer to provide insightful explanations.
The process is simple – highlight the section of code you need explained in your IDE, then right-click and select “Explain” from the Amazon Q Developer menu. Amazon Q Developer’s advanced language model will analyze the highlighted code and generate a plain English explanation breaking down what the code is doing line-by-line.
Figure 1 – Selecting the relevant code by highlighting or right-clicking on it.
Figure 2 – Selecting “Explain” to get natural language explanation from Amazon Q Developer
Let’s take a look at an example. If you highlight a few lines of code that creates a reference to an S3 bucket, Amazon Q Developer generates a natural language explanation such as:
Figure 3 – Amazon Q Developer analyzes the selected code and provides an explanation of what the code does in natural language.
Amazon Q Developer continues providing clear explanations of how the code implementation works. This natural language explanation can provide much-needed context and clarity, especially for complex coding patterns. This allows you to quickly catch up on code you haven’t looked at in a while. It can also be an excellent learning tool when researching how certain algorithms or coding techniques work under the hood.
If any part of the explanation is unclear, you can ask Amazon Q Developer follow-up questions using natural language in the chat interface. Amazon Q Developer will use the conversation context and the code to provide clarifying responses to follow-up questions. You can continue the back-and-forth conversation until you fully comprehend the code functionality. Optionally, you can provide feedback to Amazon Q Developer on the quality of its code explanations to help improve the service.
The “Explain” functionality is just one of the ways Amazon Q Developer augments your coding workflow by providing generative AI-powered insights into your code on-demand, right within your familiar IDE environment.
Now let’s dive into more examples.
Example demonstrating how Amazon Q Developer breaks down complex code algorithms
In this example, let’s assume a developer is working on a coding project that involves path-finding, network optimization and latency. We will use Amazon Q Developer to review code that should find the shortest path tree from a single source node, by building a set of nodes that have minimum distance from the source. This is the popular Djikstra’s algorithm and can be complex for developers that are new to graph theory and its implementation.
The developer can use Amazon Q Developer to understand what the block of code is doing in simple terms.
Here’s the code implementing the algorithm:
Figure 4 – Python code in IDE implementing Djikstra’s Algorithm for path-finding.
Figure 5 – With Amazon Q Developer, you can Explain, Refactor, Fix or Optimize your code.
You can Right-click the highlighted code to open a context window. Choose Send to Amazon Q, then select Explain. Selecting the “Explain” option will prompt Amazon Q Developer to analyze the code and provide a natural language explanation of what the code does.
Figure 6 – Amazon Q Developer will analyze the selected code and provide an explanation of what the code does in natural language.
Amazon Q Developer opens a chat panel on the right within the IDE, where you see the result of choosing the “Explain” option. Amazon Q Developer has analyzed the highlighted code and provided a detailed, step-by-step explanation in the chat panel. This explanation breaks down the complex algorithm in plain, easy-to-understand language, helping the developer better comprehend the purpose and functionality of the code. You can follow-up by asking clarifying questions within the chat panel.
You can also Refactor your code with Amazon Q Developer in order to improve code readability or efficiency, among other improvements.
Here’s how:
Figure 7 – Using Amazon Q Developer to Refactor code.
Highlight the code in the IDE and Refactor the code by first right clicking and selecting “send to Amazon Q”. This allows Amazon Q Developer to analyze the code and suggest ways to improve its readability, efficiency, or other aspects of the implementation. The chat panel provides the developer with the recommended refactoring steps.
Figure 8 – Amazon Q Developer analyzes the selected code and provides an explanation of steps you can take to refactor your code in the chat panel.
In the image above, Amazon Q Developer has carefully reviewed the code and provided a step-by-step plan for the developer to follow in order to refactor the code, making it more concise, maintainable, and aligned with best practices. This collaborative approach between the developer and Amazon Q Developer enables the efficient creation of high-quality, optimized code.
Conclusion
Amazon Q Developer is a game-changer for developers looking to streamline their understanding of complex code segments. By offering natural language explanations within the IDE, Amazon Q Developer eliminates the need for time-consuming manual research or reliance on outdated documentation. Amazon Q Developer’s ability to break down intricate algorithms and unfamiliar syntax, as shown in the preceding examples, empowers developers to tackle even the most challenging codebases with confidence.
Whether you’re a seasoned developer or just starting, Amazon Q Developer is an invaluable tool that simplifies the coding process and makes the coding environment more accessible and easier to navigate. With its seamless integration and user-friendly interface, Amazon Q Developer is poised to become an essential companion for developers worldwide, enabling them to write better code, learn more efficiently, and ultimately, deliver superior software solutions.
Shadow AI – a dramatic term for a new problem. With the rise of widely available consumer level AI services with easy-to-use chat interfaces, anyone from the summer intern to the CEO can easily use these shiny and new AI products. However, anyone who’s ever used a chatbot can understand the challenges and risks that tools like this can pose. They are very open-ended, sometimes not very useful unless implemented properly (remember SmarterChild??) and the quality and content of responses heavily depend on the person using them.
Many companies today are unsure how to regulate their employees’ use of these tools, particularly because of the open-ended nature of interaction and the lightweight browser-based interface. There is the risk that employees enter confidential or sensitive information, and an InfoSec team would have no visibility into it. Currently, there is almost no regulation around what can be used as training data for AI models, so one should assume anything put into a chatbot is not just between you and the bot.
As there is nothing running locally on machines, InfoSec teams then have to get creative in managing use, and a majority of teams are unsure how widespread the issue actually is.
Mitigating the risks
As these services are so lightweight, companies are left with few options to mitigate their usage. Of course one could use firewalls to block any network traffic to OpenAI and the like, but as companies look to take advantage of the benefits of this technology, no InfoSec or security team wants to be the department of ‘no’. So how can one weed out the potential harmful situations where employees may be putting sensitive information in places they shouldn’t from the beneficial and safe uses of AI?
The short answer is that you can’t truly block all employee usage of AI services, and so a holistic governance and security policy is the best way to achieve a good level of security. Internally at Rapid7, we have developed a comprehensive system of controls based on AI TRiSM (Trust, Risk, Security Management) to engage all employees in the security practices needed to keep our resources safe. This ebook outlines some of the ongoing projects to develop secure AI at Rapid7. But in addition to developing secure code, all employees at a company must be invested in keeping their infrastructure secure.
Implementing trust and verification
Even with all employees on board with these security measures, trusting but verifying is still important. Rapid7’s InsightIDR technology helps organizations pinpoint unacceptable uses of AI technology. Using SIEM technology such as InsightIDR’s Log Search and Dashboarding capabilities, users can easily build out views to track this behavior. InsightIDR also has behavioral analytics injected into each log – using host-to-IP observations and authentication patterns to identify which user is performing actions.
In this blog, we’ll outline how to use InsightIDR to detect shadow AI use at your organization.
Detecting Shadow AI with InsightIDR
The use cases outlined here primarily use DNS logs to search for domains affiliated with the most popular AI services like XYZ. We’ve put together a list of common AI technologies to get started, and you can utilize this method to extend to additional technologies that are applicable for your company.
Starting with a list of domains known to be associated with AI services:
AWS SageMaker
sagemaker.amazonaws.com
api.sagemaker.amazonaws.com
runtime.sagemaker.amazonaws.com
s3.amazonaws.com (for storing datasets and models)
Google AI Platform (Vertex AI)
ml.googleapis.com
aiplatform.googleapis.com
storage.googleapis.com (for storing datasets and models)
Azure Machine Learning
management.azure.com
ml.azure.com
westus2.api.azureml.ms
blob.core.windows.net (for storing datasets and models)
IBM Watson
watsonplatform.net
api.us-south.watson.cloud.ibm.com
api.eu-gb.watson.cloud.ibm.com
cloud.ibm.com
Other Common AI Service Domains
OpenAI: api.openai.com
Hugging Face: api-inference.huggingface.co
Clarifai: api.clarifai.com
Dialogflow (Google): dialogflow.googleapis.com
Algorithmia: algorithmia.com
DataRobot: app.datarobot.com
The easiest way to build dashboards and queries to find instances of network activity to these services is to first create a variable to track this activity, and then to use that variable in your queries.
Here my variable name is “Consumer_AI”. Note: variables are case sensitive when referenced in Log Search. I added all domains as a CSV list. Again, this list can be edited per an individual organization’s needs.
2. Navigate to Log Search, select any relevant DNS event sources, and use the query where(query ICONTAINS-ANY [${Consumer_AI}]).
This LEQL query will filter on anytime the “query” key matches a specified value. The “ICONTAINS-ANY” operator is a streamlined way to return log events where the values contain specified text values, particularly where there is a list of possible values. The “i” at the beginning of the phrase indicates that the search is case-insensitive. So the LEQL query reads that it is searching for any log events where the query contains any one of the CSV values listed in the variable named Consumer_AI, regardless of upper or lower case.
It is useful to use “CONTAINS-ANY” as opposed to “=”, as then the DNS query will still match even if there are appended domain prefixes or suffixes (for example, the value in the variable is “watson.cloud.ibm”. If the “=” was used, it would need to be an exact match. With the “CONTAINS” operator, a partial match is still valid, and so the result where “query”: “api.us-south.watson.cloud.ibm.com” is returned.
Now that we have a working query, this can be more easily digested by human eyes via a dashboard.
3. Navigating to Dashboards and Reports → New Dashboard will create a new dashboard that can be populated with relevant cards.
Next, using Add Card → From Card Library, we can use existing DNS Query templates to build our custom cards. I added all 5 DNS Query cards.
4. Edit the cards to query for AI usage instead of uncommon domains.
Plugging in the query that we built above but keeping the calculate(count) timeslice(60) syntax will allow the query to create a visual representation of DNS activity to those domains over time, with a time division of 60 seconds. This means that in a 1-hour time period, time is sliced into 60 intervals (so each timeslice is 1 minute each).
Enhancing user accountability
Now, you can go through the rest of the dashboard cards and edit them to accommodate the correct titles and descriptions of the cards. If you are worried about a particular website, this card is an example of how individual domains can be tracked:
InsightIDR event source parsing does much more than just breaking a log entry into JSON. It uses UEBA to tie assets to users, and allows you to then understand exactly which users are responsible for network activity. Once you have that sort of visibility, you can drive accountability for those who choose to use AI services. This is pivotal for analysts – without this sort of correlation, analysts are left to decipher who owns which asset, a time-consuming process that can eat into precious response time. By injecting users’ names and information into logs searchable with InsightIDR’s Log Search, analysts can now create queries, dashboards, and alerts to track this activity directly back to individual users.
Here at Rapid7, we have used automation via InsightConnect to close the loop and keep our employees accountable for their browser-based activity. Once a user is identified as having navigated to an AI tool for the first time, they will get a Slack notification to remind them about our AI policy. This will continue to ping them until they review the policy.
Developing an AI policy
The Rapid7 AI policy was created in conjunction with our AI Center of Excellence and Legal teams. As with all acceptable use policies we develop here, it is meant to be an easy read – taking time to define potentially ambiguous or colloquially used phrases, so that employees have no excuse not to read and internalize it. One of the core values at Rapid7 is “Challenge Convention”. This does not mean that we are throwing caution to the wind when adopting new technologies, but rather to challenge old ways of thinking and forge new paths with foresight, discipline, and determination.
AI technology holds huge capabilities for teams to boost efficiency and supercharge their ability to make fast impacts across the organization. Security teams, tasked with ensuring that sensitive information isn’t exposed to a publicly facing LLM, can enable the safe use of AI technology by shining a light on the use of shadow AI.
Today, we are announcing the general availability of the Amazon Titan Image Generator v2 model with new capabilities in Amazon Bedrock. With Amazon Titan Image Generator v2, you can guide image creation using reference images, edit existing visuals, remove backgrounds, generate image variations, and securely customize the model to maintain brand style and subject consistency. This powerful tool streamlines workflows, boosts productivity, and brings creative visions to life.
Amazon Titan Image Generator v2 brings a number of new features in addition to all features of Amazon Titan Image Generator v1, including:
Image conditioning – Provide a reference image along with a text prompt, resulting in outputs that follow the layout and structure of the user-supplied reference.
Image guidance with color palette – Control precisely the color palette of generated images by providing a list of hex codes along with the text prompt.
Subject consistency – Fine-tune the model to preserve a specific subject (for example, a particular dog, shoe, or handbag) in the generated images.
New features in Amazon Titan Image Generator v2 Before getting started, if you are new to using Amazon Titan models, go to the Amazon Bedrock console and choose Model access on the bottom left pane. To access the latest Amazon Titan models from Amazon, request access separately for Amazon Titan Image Generator G1 v2.
Here are details of the Amazon Titan Image Generator v2 in Amazon Bedrock:
Image conditioning You can use the image conditioning feature to shape your creations with precision and intention. By providing a reference image (that is, a conditioning image), you can instruct the model to focus on specific visual characteristics, such as edges, object outlines, and structural elements, or segmentation maps that define distinct regions and objects within the reference image.
We support two types of image conditioning: Canny edge and segmentation.
The Canny edge algorithm is used to extract the prominent edges within the reference image, creating a map that the Amazon Titan Image Generator can then use to guide the generation process. You can “draw” the foundations of your desired image, and the model will then fill in the details, textures, and final aesthetic based on your guidance.
Segmentation provides an even more granular level of control. By supplying the reference image, you can define specific areas or objects within the image and instruct the Amazon Titan Image Generator to generate content that aligns with those defined regions. You can precisely control the placement and rendering of characters, objects, and other key elements.
Here are generation examples that use image conditioning.
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "a cartoon deer in a fairy world.",
"conditionImage": input_image, # Optional
"controlMode": "CANNY_EDGE" # Optional: CANNY_EDGE | SEGMENTATION
"controlStrength": 0.7 # Optional: weight given to the condition image. Default: 0.7
}
The following a Python code example using AWS SDK for Python (Boto3) shows how to invoke Amazon Titan Image Generator v2 on Amazon Bedrock to use image conditioning.
import base64
import io
import json
import logging
import boto3
from PIL import Image
from botocore.exceptions import ClientError
def main():
"""
Entrypoint for Amazon Titan Image Generator V2 example.
"""
try:
logging.basicConfig(level=logging.INFO,
format="%(levelname)s: %(message)s")
model_id = 'amazon.titan-image-generator-v2:0'
# Read image from file and encode it as base64 string.
with open("/path/to/image", "rb") as image_file:
input_image = base64.b64encode(image_file.read()).decode('utf8')
body = json.dumps({
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "a cartoon deer in a fairy world",
"conditionImage": input_image,
"controlMode": "CANNY_EDGE",
"controlStrength": 0.7
},
"imageGenerationConfig": {
"numberOfImages": 1,
"height": 512,
"width": 512,
"cfgScale": 8.0
}
})
image_bytes = generate_image(model_id=model_id,
body=body)
image = Image.open(io.BytesIO(image_bytes))
image.show()
except ClientError as err:
message = err.response["Error"]["Message"]
logger.error("A client error occurred: %s", message)
print("A client error occured: " +
format(message))
except ImageError as err:
logger.error(err.message)
print(err.message)
else:
print(
f"Finished generating image with Amazon Titan Image Generator V2 model {model_id}.")
def generate_image(model_id, body):
"""
Generate an image using Amazon Titan Image Generator V2 model on demand.
Args:
model_id (str): The model ID to use.
body (str) : The request body to use.
Returns:
image_bytes (bytes): The image generated by the model.
"""
logger.info(
"Generating image with Amazon Titan Image Generator V2 model %s", model_id)
bedrock = boto3.client(service_name='bedrock-runtime')
accept = "application/json"
content_type = "application/json"
response = bedrock.invoke_model(
body=body, modelId=model_id, accept=accept, contentType=content_type
)
response_body = json.loads(response.get("body").read())
base64_image = response_body.get("images")[0]
base64_bytes = base64_image.encode('ascii')
image_bytes = base64.b64decode(base64_bytes)
finish_reason = response_body.get("error")
if finish_reason is not None:
raise ImageError(f"Image generation error. Error is {finish_reason}")
logger.info(
"Successfully generated image with Amazon Titan Image Generator V2 model %s", model_id)
return image_bytes
class ImageError(Exception):
"Custom exception for errors returned by Amazon Titan Image Generator V2"
def __init__(self, message):
self.message = message
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
if __name__ == "__main__":
main()
Color conditioning Most designers want to generate images adhering to color branding guidelines so they seek control over color palette in the generated images.
With the Amazon Titan Image Generator v2, you can generate color-conditioned images based on a color palette—a list of hex colors provided as part of the inputs adhering to color branding guidelines. You can also provide a reference image as input (optional) to generate an image with provided hex colors while inheriting style from the reference image.
In this example, the prompt describes: a jar of salad dressing in a rustic kitchen surrounded by fresh vegetables with studio lighting
The generated image reflects both the content of the text prompt and the specified color scheme to align with the brand’s color guidelines.
To use color conditioning feature, you can set taskType to COLOR_GUIDED_GENERATION with your prompt and hex codes.
"taskType": "COLOR_GUIDED_GENERATION",
"colorGuidedGenerationParam": {
"text": "a jar of salad dressing in a rustic kitchen surrounded by fresh vegetables with studio lighting",
"colors": ['#ff8080', '#ffb280', '#ffe680', '#e5ff80'], # Optional: list of color hex codes
"referenceImage": input_image, #Optional
}
Background removal Whether you’re looking to composite an image onto a solid color backdrop or layer it over another scene, the ability to cleanly and accurately remove the background is an essential tool in the creative workflow. You can instantly remove the background from your images with a single step. Amazon Titan Image Generator v2 can intelligently detect and segment multiple foreground objects, ensuring that even complex scenes with overlapping elements are cleanly isolated.
The example shows an image of an iguana sitting on a tree in a forest. The model was able to identify the iguana as the main object and remove the forest background, replacing it with a transparent background. This lets the iguana stand out clearly without the distracting forest around it.
To use background removal feature, you can set taskType to BACKGROUND_REMOVAL with your input image.
Subject consistency with fine-tuning You can now seamlessly incorporate specific subjects into visually captivating scenes. Whether it’s a brand’s product, a company logo, or a beloved family pet, you can fine-tune the Amazon Titan model using reference images to learn the unique characteristics of the chosen subject.
Once the model is fine-tuned, you can simply provide a text prompt, and the Amazon Titan Generator will generate images that maintain a consistent depiction of the subject, placing it naturally within diverse, imaginative contexts. This opens up a world of possibilities for marketing, advertising, and visual storytelling.
For example, you could use an image with the caption Ron the dog during fine-tuning, give the prompt as Ron the dog wearing a superhero cape during inference with the fine-tuned model, and get a unique image in response.
Now available The Amazon Titan Generator v2 model is available today in Amazon Bedrock in the US East (N. Virginia) and US West (Oregon) Regions. Check the full Region list for future updates. To learn more, check out the Amazon Titan product page and the Amazon Bedrock pricing page.
Visit our community.aws site to find deep-dive technical content and to discover how our Builder communities are using Amazon Bedrock in their solutions.
This blog post demonstrates how to use Amazon Bedrock with a detailed security plan to deploy a safe and responsible chatbot application. In this post, we identify common security risks and anti-patterns that can arise when exposing a large language model (LLM) in an application. Amazon Bedrock is built with features you can use to mitigate vulnerabilities and incorporate secure design principles. This post highlights architectural considerations and best practice strategies to enhance the reliability of your LLM-based application.
Amazon Bedrock unleashes the fusion of generative artificial intelligence (AI) and LLMs, empowering you to craft impactful chatbot applications. As with technologies handling sensitive data and intellectual property, it’s crucial that you prioritize security and adopt a robust security posture. Without proper measures, these applications can be susceptible to risks such as prompt injection, information disclosure, model exploitation, and regulatory violations. By proactively addressing these security considerations, you can responsibly use Amazon Bedrock foundation models and generative AI capabilities.
The chatbot application use case represents a common pattern in enterprise environments, where businesses want to use the power of generative AI foundation models (FMs) to build their own applications. This falls under the Pre-trained models category of the Generative AI Security Scoping Matrix. In this scope, businesses directly integrate with FMs like Anthropic’s Claude through Amazon Bedrock APIs to create custom applications, such as customer support Retrieval Augmented Generation (RAG) chatbots, content generation tools, and decision support systems.
This post provides a comprehensive security blueprint for deploying chatbot applications that integrate with Amazon Bedrock, enabling the responsible adoption of LLMs and generative AI in enterprise environments. We outline mitigation strategies through secure design principles, architectural considerations, and best practices tailored to the challenges of integrating LLMs and generative AI capabilities.
By following the guidance in this post, you can proactively identify and mitigate risks associated with deploying and operating chatbot applications that integrate with Amazon Bedrock and use generative AI models. The guidance can help you strengthen the security posture, protect sensitive data and intellectual property, maintain regulatory compliance, and responsibly deploy generative AI capabilities within your enterprise environments.
This post contains the following high-level sections:
The chatbot application architecture described in this post represents an example implementation that uses various AWS services and integrates with Amazon Bedrock and Anthropic’s Claude 3 Sonnet LLM. This baseline architecture serves as a foundation to understand the core components and their interactions. However, it’s important to note that there can be multiple ways for customers to design and implement a chatbot architecture that integrates with Amazon Bedrock, depending on their specific requirements and constraints. Regardless of the implementation approach, it’s crucial to incorporate appropriate security controls and follow best practices for secure design and deployment of generative AI applications.
The chatbot application allows users to interact through a frontend interface and submit prompts or queries. These prompts are processed by integrating with Amazon Bedrock, which uses the Anthropic Claude 3 Sonnet LLM and a knowledge base built from ingested data. The LLM generates relevant responses based on the prompts and retrieved context from the knowledge base. While this baseline implementation outlines the core functionality, it requires incorporating security controls and following best practices to mitigate potential risks associated with deploying generative AI applications. In the subsequent sections, we discuss security anti-patterns that can arise in such applications, along with their corresponding mitigation strategies. Additionally, we present a secure and responsible architecture blueprint for the chatbot application powered by Amazon Bedrock.
Figure 1: Baseline chatbot application architecture using AWS services and Amazon Bedrock
Components in the chatbot application baseline architecture
The chatbot application architecture uses various AWS services and integrates with the Amazon Bedrock service and Anthropic’s Claude 3 Sonnet LLM to deliver an interactive and intelligent chatbot experience. The main components of the architecture (as shown in Figure 1) are:
User interaction layer: Users interact with the chatbot application through the Streamlit frontend (3), a Python-based open-source library, used to build the user-friendly and interactive interface.
Amazon Elastic Container Service (Amazon ECS) on AWS Fargate: A fully managed and scalable container orchestration service that eliminates the need to provision and manage servers, allowing you to run containerized applications without having to manage the underlying compute infrastructure.
Application hosting and deployment: The Streamlit application (3) components are hosted and deployed on Amazon ECS on AWS Fargate (2), maintaining scalability and high availability. This architecture represents the application and hosting environment in an independent virtual private cloud (VPC) to promote a loosely-coupled architecture. The Streamlit frontend can be replaced with your organization’s specific frontend and quickly integrated with the backend Amazon API Gateway in the VPC. An application load balancer is used to distribute traffic to the Streamlit application instances.
API Gateway driven Lambda Integration: In this example architecture, instead of directly invoking the Amazon Bedrock service from the frontend, an API Gateway backed by an AWS Lambda function (5) is used as an intermediary layer. This approach promotes better separation of concerns, scalability, and secure access to Amazon Bedrock by limiting direct exposure from the frontend.
Lambda: Lambda provides highly scalable, short-term serverless compute. Here, the requests from Streamlit are processed. First, the history of the user’s session is retrieved from Amazon DynamoDB (6). Second, the user’s question, history, and the context are formatted into a prompt template and queried against Amazon Bedrock with the knowledge base, employing retrieval augmented generation (RAG).
DynamoDB: DynamoDB is responsible for storing and retrieving chat history, conversation history, recommendations, and other relevant data using the Lambda function.
Amazon Bedrock: Amazon Bedrock plays a central role in the architecture. It handles the questions posed by the user using Anthropic Claude 3 Sonnet LLM (9) combined with a previously generated knowledge base (10) of the customer’s organization-specific data.
Anthropic Claude 3 Sonnet: Anthropic Claude 3 Sonnet is the LLM used to generate tailored recommendations and responses based on user inputs and the context retrieved from the knowledge base. It’s part of the text analysis and generation module in Amazon Bedrock.
Knowledge base and data ingestion: Relevant documents classified as public are ingested from Amazon S3 (9) into in an Amazon Bedrock knowledge base. Knowledge bases are backed by Amazon OpenSearch Service. Amazon Titan Embeddings (10) are used to generate the vector embeddings database of the documents. Storing the data as vector embeddings allows for semantic similarity searching of the documents to retrieve the context of the question posed by the user (RAG). By providing the LLM with context in addition to the question, there’s a much higher chance of getting a useful answer from the LLM.
Comprehensive logging and monitoring strategy
This section outlines a comprehensive logging and monitoring strategy for the Amazon Bedrock-powered chatbot application, using various AWS services to enable centralized logging, auditing, and proactive monitoring of security events, performance metrics, and potential threats.
Logging and auditing:
AWS CloudTrail: Logs API calls made to Amazon Bedrock, including InvokeModel requests, as well as information about the user or service that made the request.
AWS CloudWatch Logs: Captures and analyzes Amazon Bedrock invocation logs, user prompts, generated responses, and errors or warnings encountered during the invocation process.
Amazon OpenSearch Service: Logs and indexes data related to the OpenSearch integration, context data retrievals, and knowledge base operations.
AWS Config: Monitors and audits the configuration of resources related to the chatbot application and Amazon Bedrock service, including IAM policies, VPC settings, encryption key management, and other resource configurations.
Monitoring and alerting:
AWS CloudWatch: Monitors metrics specific to Amazon Bedrock, such as the number of model invocations, latency of invocations, and error metrics (client-side errors, server-side errors, and throttling). Configures targeted CloudWatch alarms to proactively detect and respond to anomalies or issues related to Bedrock invocations and performance.
AWS GuardDuty: Continuously monitors CloudTrail logs for potential threats and unauthorized activity within the AWS environment.
Amazon Security Lake: Provides a centralized data lake for log analysis; is integrated with CloudTrail and SecurityHub.
Security information and event management integration:
Integrate with security information and event management (SIEM) solutions for centralized log management, real-time monitoring of security events, and correlation of logging data from multiple sources (CloudTrail, CloudWatch Logs, OpenSearch Service, and so on).
Continuous improvement:
Regularly review and update logging and monitoring configurations, alerting thresholds, and integration with security solutions to address emerging threats, changes in application requirements, or evolving best practices.
Security anti-patterns and mitigation strategies
This section identifies and explores common security anti-patterns associated with the Amazon Bedrock chatbot application architecture. By recognizing these anti-patterns early in the development and deployment phases, you can implement effective mitigation strategies and fortify your security posture.
Addressing security anti-patterns in the Amazon Bedrock chatbot application architecture is crucial for several reasons:
Data protection and privacy: The chatbot application processes and generates sensitive data, including personal information, intellectual property, and confidential business data. Failing to address security anti-patterns can lead to data breaches, unauthorized access, and potential regulatory violations.
Model integrity and reliability: Vulnerabilities in the chatbot application can enable bad actors to manipulate or exploit the underlying generative AI models, compromising the integrity and reliability of the generated outputs. This can have severe consequences, particularly in decision-support or critical applications.
Responsible AI deployment: As the adoption of generative AI models continues to grow, it’s essential to maintain responsible and ethical deployment practices. Addressing security anti-patterns is crucial for maintaining trust, transparency, and accountability in the chatbot application powered by AI models.
Compliance and regulatory requirements: Many industries and regions have specific regulations and guidelines governing the use of AI technologies, data privacy, and information security. Addressing security anti-patterns is a critical step towards adhering to and maintaining compliance for the chatbot application.
The security anti-patterns that are covered in this post include:
Lack of secure authentication and access controls
Insufficient input validation and sanitization
Insecure communication channels
Inadequate prompt and response logging, auditing, and non-repudiation
Insecure data storage and access controls
Failure to secure FMs and generative AI components
Lack of responsible AI governance and ethics
Lack of comprehensive testing and validation
Anti-pattern 1: Lack of secure authentication and access controls
In a generative AI chatbot application using Amazon Bedrock, a lack of secure authentication and access controls poses significant risks to the confidentiality, integrity, and availability of the system. Identity spoofing and unauthorized access can enable threat actors to impersonate legitimate users or systems, gain unauthorized access to sensitive data processed by the chatbot application, and potentially compromise the integrity and confidentiality of the customer’s data and intellectual property used by the application.
Identity spoofing and unauthorized access are important areas to address in this architecture, as the chatbot application handles user prompts and responses, which may contain sensitive information or intellectual property. If a threat actor can impersonate a legitimate user or system, they can potentially inject malicious prompts, retrieve confidential data from the knowledge base, or even manipulate the responses generated by the Anthropic Claude 3 LLM integrated with Amazon Bedrock.
Anti-pattern examples
Exposing the Streamlit frontend interface or the API Gateway endpoint without proper authentication mechanisms, potentially allowing unauthenticated users to interact with the chatbot application and inject malicious prompts.
Storing or hardcoding AWS access keys or API credentials in the application code or configuration files, increasing the risk of credential exposure and unauthorized access to AWS services like Amazon Bedrock or DynamoDB.
Implementing weak or easily guessable passwords for administrative or service accounts with elevated privileges to access the Amazon Bedrock service or other critical components.
Lacking multi-factor authentication (MFA) for AWS Identity and Access Management (IAM) users or roles with privileged access, increasing the risk of unauthorized access to AWS resources, including the Amazon Bedrock service, if credentials are compromised.
Mitigation strategies
To mitigate the risks associated with a lack of secure authentication and access controls, implement robust IAM controls, as well as continuous logging, monitoring, and threat detection mechanisms.
IAM controls:
Use industry-standard protocols like OAuth 2.0 or OpenID Connect, and integrate with AWS IAM Identity Center or other identity providers for centralized authentication and authorization for the Streamlit frontend interface and AWS API Gateway endpoints.
Implement fine-grained access controls using AWS IAM policies and resource-based policies to restrict access to only the necessary Amazon Bedrock resources, Lambda functions, and other components required for the chatbot application.
Enforce the use of MFA for all IAM users, roles, and service accounts with access to critical components like Amazon Bedrock, DynamoDB, or the Streamlit application.
Continuous logging and monitoring and threat detection:
See the Comprehensive logging and monitoring strategy section for guidance on implementing centralized logging and monitoring solutions to track and audit authentication events, access attempts, and potential unauthorized access or credential misuse across the chatbot application components and Amazon Bedrock service, as well as using CloudWatch, Lambda, and GuardDuty to detect and respond to anomalous behavior and potential threats.
Anti-pattern 2: Insufficient input sanitization and validation
Insufficient input validation and sanitization in a generative AI chatbot application can expose the system to various threats, including injection events, data tampering, adversarial events, and data poisoning events. These vulnerabilities can lead to unauthorized access, data manipulation, and compromised model outputs.
Injection events: If user prompts or inputs aren’t properly sanitized and validated, a threat actor can potentially inject malicious code, such as SQL code, leading to unauthorized access or manipulation of the DynamoDB chat history data. Additionally, if the chatbot application or components process user input without proper validation, a threat actor can potentially inject and run arbitrary code on the backend systems, compromising the entire application.
Data tampering: A threat actor can potentially modify user prompts or payloads in transit between the chatbot interface and Amazon Bedrock service, leading to unintended model responses or actions. Lack of data integrity checks can allow a threat actor to tamper with the context data exchanged between Amazon Bedrock and OpenSearch, potentially leading to incorrect or malicious search results influencing the LLM responses.
Data poisoning events: If the training data or context data used by the LLM or chatbot application isn’t properly validated and sanitized, bad actors can potentially introduce malicious or misleading data, leading to biased or compromised model outputs.
Anti-pattern examples
Failure to validate and sanitize user prompts before sending them to Amazon Bedrock, potentially leading to injection events or unintended data exposure.
Lack of input validation and sanitization for context data retrieved from OpenSearch, allowing malformed or malicious data to influence the LLM’s responses.
Insufficient sanitization of LLM-generated responses before displaying them to users, enabling potential code injection or rendering of harmful content.
Inadequate sanitization of user input in the Streamlit application or Lambda functions, failing to remove or escape special characters, code snippets, or potentially malicious patterns, enabling code injection events.
Insufficient validation and sanitization of training data or other data sources used by the LLM or chatbot application, allowing data poisoning events that can introduce malicious or misleading data, leading to biased or compromised model outputs.
Allowing unrestricted character sets, input lengths, or special characters in user prompts or data inputs, enabling adversaries to craft inputs that bypass input validation and sanitization mechanisms, potentially causing undesirable or malicious outputs.
Relying solely on deny lists for input validation, which can be quickly bypassed by adversaries, potentially leading to injection events, data tampering, or other exploit scenarios.
Mitigation strategies
To mitigate the risks associated with insufficient input validation and sanitization, implement robust input validation and sanitization mechanisms throughout the chatbot application and its components.
Input validation and sanitization:
Implement strict input validation rules for user prompts at the chatbot interface and Amazon Bedrock service boundaries, defining allowed character sets, maximum input lengths, and disallowing special characters or code snippets. Use Amazon Bedrock’s Guardrails feature, which allows defining denied topics and content filters to remove undesirable and harmful content from user interactions with your applications.
Use allow lists instead of deny lists for input validation to maintain a more robust and comprehensive approach.
Sanitize user input by removing or escaping special characters, code snippets, or potentially malicious patterns.
Data flow validation:
Validate and sanitize data flows between components, including:
User prompts sent to the FM and responses generated by the FM and returned to the chatbot interface.
Training data, context data, and other data sources used by the FM or chatbot application.
Use AWS Shield for protection against distributed denial of service (DDoS) events.
Use CloudTrail to monitor API calls to Amazon Bedrock, including InvokeModel requests.
See the Comprehensive logging and monitoring strategy section for guidance on implementing Lambda functions, Amazon EventBridge rules, and CloudWatch Logs to analyze CloudTrail logs, ingest application logs, user prompts, and responses, and integrate with incident response and SIEM solutions for detecting, investigating, and mitigating security incidents related to input validation and sanitization, including jailbreaking attempts and anomalous behavior.
Anti-pattern 3: Insecure communication channels
Insecure communication channels between chatbot application components can expose sensitive data to interception, tampering, and unauthorized access risks. Unsecured channels enable man-in-the-middle events where threat actors intercept, modify data in transit such as user prompts, responses, and context data, leading to data tampering, malicious payload injection, and unauthorized information access.
Anti-pattern examples
Failure to use AWS PrivateLink for secure service-to-service communication within the VPC, exposing communications between Amazon Bedrock and other AWS services to potential risks over the public internet, even when using HTTPS.
Absence of data integrity checks or mechanisms to detect and prevent data tampering during transmission between components.
Failure to regularly review and update communication channel configurations, protocols, and encryption mechanisms to address emerging threats and ensure compliance with security best practices.
Mitigation strategies
To mitigate the risks associated with insecure communication channels, implement secure communication mechanisms and enforce data integrity throughout the chatbot application’s components and their interactions. Proper encryption, authentication, and integrity checks should be employed to protect sensitive data in transit and help prevent unauthorized access, data tampering, and man-in-the-middle events.
Secure communication channels:
Use PrivateLink for secure service-to-service communication between Amazon Bedrock and other AWS services used in the chatbot application architecture. PrivateLink provides a private, isolated communication channel within the Amazon VPC, eliminating the need to traverse the public internet. This mitigates the risk of potential interception, tampering, or unauthorized access to sensitive data transmitted between services, even when using HTTPS.
Use AWS Certificate Manager (ACM) to manage and automate the deployment of SSL/TLS certificates used for secure communication between the chatbot frontend interface (the Streamlit application) and the API Gateway endpoint. ACM simplifies the provisioning, renewal, and deployment of SSL/TLS certificates, making sure that communication channels between the user-facing components and the backend API are securely encrypted using industry-standard protocols and up-to-date certificates.
Continuous logging and monitoring:
See the Comprehensive Logging and Monitoring Strategy section for guidance on implementing centralized logging and monitoring mechanisms to detect and respond to potential communication channel anomalies or security incidents, including monitoring communication channel metrics, API call patterns, request payloads, and response data, using AWS services like CloudWatch, CloudTrail, and AWS WAF.
Network segmentation and isolation controls
Implement network segmentation by deploying the Amazon ECS cluster within a dedicated VPC and subnets, isolating it from other components and restricting communication based on the principle of least privilege.
Create separate subnets within the VPC for the public-facing frontend tier and the backend application tier, further isolating the components.
Use AWS security groups and network access control lists (NACLs) to control inbound and outbound traffic at the instance and subnet levels, respectively, for the ECS cluster and the frontend instances.
Anti-pattern 4: Inadequate logging, auditing, and non-repudiation
Inadequate logging, auditing, and non-repudiation mechanisms in a generative AI chatbot application can lead to several risks, including a lack of accountability, challenges in forensic analysis, and compliance concerns. Without proper logging and auditing, it’s challenging to track user activities, diagnose issues, perform forensic analysis in case of security incidents, and demonstrate compliance with regulations or internal policies.
Anti-pattern examples
Lack of logging for data flows between components, such as user prompts sent to Amazon Bedrock, context data exchanged with OpenSearch, and responses from the LLM, hindering investigative efforts in case of security incidents or data breaches.
Insufficient logging of user activities within the chatbot application—such as sign in attempts, session duration, and actions performed—limiting the ability to track and attribute actions to specific users.
Absence of mechanisms to ensure the integrity and authenticity of logged data, allowing potential tampering or repudiation of logged events.
Failure to securely store and protect log data from unauthorized access or modification, compromising the reliability and confidentiality of log information.
Mitigation strategies
To mitigate the risks associated with inadequate logging, auditing, and non-repudiation, implement comprehensive logging and auditing mechanisms to capture critical events, user activities, and data flows across the chatbot application components. Additionally, measures must be taken to maintain the integrity and authenticity of log data, help prevent tampering or repudiation, and securely store and protect log information from unauthorized access.
Comprehensive logging and auditing:
See the Comprehensive logging and monitoring strategy section for detailed guidance on implementing logging mechanisms using CloudTrail, CloudWatch Logs, and OpenSearch Service, as well as using CloudTrail for logging and monitoring API calls, especially Amazon Bedrock API calls and other API activities within the AWS environment, using CloudWatch for monitoring Amazon Bedrock-specific metrics, and ensuring log data integrity and non-repudiation through the CloudTrail log file integrity validation feature and implementing S3 Object Lock and S3 Versioning for log data stored in Amazon S3.
Make sure that log data is securely stored and protected from unauthorized access by using AWS Key Management Service (AWS KMS) for encryption at rest and implementing restrictive IAM policies and resource-based policies to control access to log data.
Retain log data for an appropriate period based on compliance requirements, using CloudTrail log file integrity validation and CloudWatch Logs retention periods and data archiving capabilities.
User activity monitoring and tracking:
Use CloudTrail for logging and monitoring API calls, especially Amazon Bedrock API calls and other API activities within the AWS environment, such as API Gateway, Lambda, and DynamoDB. Additionally, use CloudWatch for monitoring metrics specific to Amazon Bedrock, including the number of model invocations, latency, and error metrics (client-side errors, server-side errors, and throttling).
Integrate with security information and event management (SIEM) solutions for centralized log management and real-time monitoring of security events.
Data integrity and non-repudiation:
Implement digital signatures or non-repudiation mechanisms to verify the integrity and authenticity of logged data, minimizing tampering or repudiation of logged events. Use the CloudTrail log file integrity validation feature, which uses industry-standard algorithms (SHA-256 for hashing and SHA-256 with RSA for digital signing) to provide non-repudiation and verify log data integrity. For log data stored in Amazon S3, enable S3 Object Lock and S3 Versioning to provide an immutable, write once, read many (WORM) data storage model, helping to prevent object deletions or modifications, and maintaining data integrity and non-repudiation. Additionally, implement S3 bucket policies and IAM policies to restrict access to log data stored in S3, further enhancing the security and non-repudiation of logged events.
Anti-pattern 5: Insecure data storage and access controls
Insecure data storage and access controls in a generative AI chatbot application can lead to significant risks, including information disclosure, data tampering, and unauthorized access. Storing sensitive data, such as chat history, in an unencrypted or insecure manner can result in information disclosure if the data store is compromised or accessed by unauthorized entities. Additionally, a lack of proper access controls can allow unauthorized parties to access, modify, or delete data, leading to data tampering or unauthorized access.
Anti-pattern examples
Storing chat history data in DynamoDB without encryption at rest using AWS KMS customer-managed keys (CMKs).
Lack of encryption at rest using CMKs from AWS KMS for data in OpenSearch, Amazon S3, or other components that handle sensitive data.
Overly permissive access controls or lack of fine-grained access control mechanisms for the DynamoDB chat history, OpenSearch, Amazon S3, or other data stores, increasing the risk of unauthorized access or data breaches.
Storing sensitive data in clear text, or using insecure encryption algorithms or key management practices.
Failure to regularly review and rotate encryption keys or update access control policies to address potential security vulnerabilities or changes in access requirements.
Mitigation strategies
To mitigate the risks associated with insecure data storage and access controls, implement robust encryption mechanisms, secure key management practices, and fine-grained access control policies. Encrypting sensitive data at rest and in transit, using customer-managed encryption keys from AWS KMS, and implementing least- privilege access controls based on IAM policies and resource-based policies can significantly enhance the security and protection of data within the chatbot application architecture.
Key management and encryption at rest:
Implement AWS KMS to manage and control access to CMKs for data encryption across components like DynamoDB, OpenSearch, and Amazon S3.
Use CMKs to configure DynamoDB to automatically encrypt chat history data at rest.
Configure OpenSearch and Amazon S3 to use encryption at rest with AWS KMS CMKs for data stored in these services.
CMKs provide enhanced security and control, allowing you to create, rotate, disable, and revoke encryption keys, enabling better key isolation and separation of duties.
CMKs enable you to enforce key policies, audit key usage, and adhere to regulatory requirements or organizational policies that mandate customer-managed encryption keys.
CMKs offer portability and independence from specific services, allowing you to migrate or integrate data across multiple services while maintaining control over the encryption keys.
AWS KMS provides a centralized and secure key management solution, simplifying the management and auditing of encryption keys across various components and services.
Regular key rotation to maintain the security of your encrypted data.
Separation of duties to make sure that no single individual has complete control over key management operations.
Strict access controls for key management operations, using IAM policies and roles to enforce the principle of least privilege.
Fine-grained access controls:
Implement fine-grained access controls for the DynamoDB chat history data store, OpenSearch, Amazon S3, and other data stores using IAM policies and roles.
Implement fine-grained access controls and define least-privilege access policies for all resources handling sensitive data, such as the DynamoDB chat history data store, OpenSearch, Amazon S3, and other data stores or services. For example, use IAM policies and resource-based policies to restrict access to specific DynamoDB tables, OpenSearch domains, and S3 buckets, limiting access to only the necessary actions (for example, read, write, and list) based on the principle of least privilege. Extend this approach to all resources handling sensitive data within the chatbot application architecture, making sure that access is granted only to the minimum required resources and actions necessary for each component or user role.
Continuous improvement:
Regularly review and update encryption configurations, access control policies, and key management practices to address potential security vulnerabilities or changes in access requirements.
Anti-pattern 6: Failure to secure FM and generative AI components
Inadequate security measures for FMs and generative AI components in a chatbot application can lead to severe risks, including model tampering, unintended information disclosure, and denial of service. Threat actors can manipulate unsecured FMs and generative AI models to generate biased, harmful, or malicious responses, potentially causing significant harm or reputational damage.
Lack of proper access controls or input validation can result in unintended information disclosure, where sensitive data is inadvertently included in model responses. Additionally, insecure FM or generative AI components can be vulnerable to denial-of-service events, disrupting the availability of the chatbot application and impacting its functionality.
Anti-pattern examples
Insecure model fine tuning practices, such as using untrusted or compromised data sources, can lead to biased or malicious models.
Lack of continuous monitoring for FM and generative AI components, leaving them vulnerable to emerging threats or known vulnerabilities.
Lack of guardrails or safety measures to control and filter the outputs of FMs and generative AI components, potentially leading to the generation of harmful, biased, or undesirable content.
Inadequate access controls or input validation for prompts and context data sent to the FM components, increasing the risk of injection events or unintended information disclosure.
Failure to implement secure deployment practices for FM and generative AI components, including secure communication channels, encryption of model artifacts, and access controls.
Mitigation strategies
To mitigate the risks associated with inadequately secured foundational models (FMs) and generative AI components, implement secure integration mechanisms, robust model fine-tuning and deployment practices, continuous monitoring, and effective guardrails and safety measures. These mitigation strategies help prevent model tampering, unintended information disclosure, denial-of-service events, and the generation of harmful or undesirable content, while ensuring the security, reliability, and ethical alignment of the chatbot application’s generative AI capabilities.
Secure integration with LLMs and knowledge bases:
Implement secure communication channels (for example HTTPS or PrivateLink) between Amazon Bedrock, OpenSearch, and the FM components to help prevent unauthorized access or data tampering.
Implement strict input validation and sanitization for prompts and context data sent to the FM components to help prevent injection events or unintended information disclosure.
Implement access controls and least-privilege principles for the OpenSearch integration to limit the data accessible to the LLM components.
Secure model fine tuning, deployment, and monitoring:
Establish secure and auditable fine-tuning pipelines, using trusted and vetted data sources, to help prevent tampering or the introduction of biases.
Implement secure deployment practices for FM and generative AI components, including access controls, secure communication channels, and encryption of model artifacts.
Continuously monitor FM and generative AI components for security vulnerabilities, performance issues, and unintended behavior.
Implement rate-limiting, throttling, and load-balancing mechanisms to help prevent denial-of-service events on FM and generative AI components.
Regularly review and audit FM and generative AI components for compliance with security policies, industry best practices, and regulatory requirements.
Guardrails and safety measures
Implement guardrails, which are safety measures designed to reduce harmful outputs and align the behavior of FMs and generative AI components with human values.
Use keyword-based filtering, metric-based thresholds, human oversight, and customized guardrails tailored to the specific risks and cultural and ethical norms of each application domain.
Monitor the effectiveness of guardrails through performance benchmarking and adversarial testing.
Jailbreak robustness testing
Conduct jailbreak robustness testing by prompting the FMs and generative AI components with a diverse set of jailbreak attempts across different prohibited scenarios to identify weaknesses and improve model robustness.
Anti-pattern 7: Lack of responsible AI governance and ethics
While the previous anti-patterns focused on technical security aspects, it is equally important to address the ethical and responsible governance of generative AI systems. Without strong governance frameworks, ethical guidelines, and accountability measures, chatbot applications can result in unintended consequences, biased outcomes, and a lack of transparency and trust.
Anti-pattern examples
Lack of an established ethical AI governance framework, including principles, policies, and processes to guide the responsible development and deployment of the generative AI chatbot application.
Insufficient measures to ensure transparency, explainability, and interpretability of the LLM and generative AI components, making it difficult to understand and audit their decision-making processes.
Absence of mechanisms for stakeholder engagement, public consultation, and consideration of societal impacts, potentially leading to a lack of trust and acceptance of the chatbot application.
Failure to address potential biases, discrimination, or unfairness in the training data, models, or outputs of the generative AI system.
Inadequate processes for testing, validation, and ongoing monitoring of the chatbot application’s ethical behavior and alignment with organizational values and societal norms.
Mitigation strategies
To minimize a lack of responsible AI governance and ethics, establish a comprehensive ethical AI governance framework, promote transparency and interpretability, engage stakeholders and consider societal impacts, address potential biases and fairness issues, implement continuous improvement and monitoring processes, and use guardrails and safety measures. These mitigation strategies help to foster trust, accountability, and ethical alignment in the development and deployment of the generative AI chatbot application, mitigating the risks of unintended consequences, biased outcomes, and a lack of transparency.
Ethical AI governance framework:
Establish an ethical AI governance framework, including principles, policies, and processes to guide the responsible development and deployment of the generative AI chatbot application.
Define clear ethical guidelines and decision-making frameworks to address potential ethical dilemmas, biases, or unintended consequences.
Implement accountability measures, such as designated ethics boards, ethics officers, or external advisory committees, to oversee the ethical development and deployment of the chatbot application.
Transparency and interpretability:
Implement measures to promote transparency and interpretability of the LLM and generative AI components, allowing for auditing and understanding of their decision-making processes.
Provide clear and accessible information to stakeholders and users about the chatbot application’s capabilities, limitations, and potential biases or ethical considerations.
Stakeholder engagement and societal impact:
Establish mechanisms for stakeholder engagement, public consultation, and consideration of societal impacts, fostering trust and acceptance of the chatbot application.
Conduct impact assessments to identify and mitigate potential negative consequences or risks to individuals, communities, or society.
Bias and fairness:
Address potential biases, discrimination, or unfairness in the training data, models, or outputs of the generative AI system through rigorous testing, bias mitigation techniques, and ongoing monitoring.
Promote diverse and inclusive representation in the development, testing, and governance processes to reduce potential biases and blind spots.
Continuous improvement and monitoring:
Implement processes for ongoing testing, validation, and monitoring of the chatbot application’s behavior and alignment with organizational values and societal norms.
Regularly review and update the AI governance framework, policies, and processes to address emerging ethical challenges, societal expectations, and regulatory developments.
Guardrails and safety measures:
Implement guardrails, such as Guardrails for Amazon Bedrock, which are safety measures designed to reduce harmful outputs and align the behavior of LLMs and generative AI components with human values and responsible AI policies.
Use Guardrails for Amazon Bedrock to define denied topics and content filters to remove undesirable and harmful content from interactions between users and your applications.
Define denied topics using natural language descriptions to specify topics or subject areas that are undesirable in the context of your application.
Configure content filters to set thresholds for filtering harmful content across categories such as hate, insults, sexuality, and violence based on your use cases and responsible AI policies.
Use the personally identifiable information (PII) redaction feature to redact information such as names, email addresses, and phone numbers from LLM-generated responses or block user inputs that contain PII.
Integrate Guardrails for Amazon Bedrock with CloudWatch to monitor and analyze user inputs and LLM responses that violate defined policies, enabling proactive detection and response to potential issues.
Monitor the effectiveness of guardrails through performance benchmarking and adversarial testing, continuously refining and updating the guardrails based on real-world usage and emerging ethical considerations.
Jailbreak robustness testing:
Conduct jailbreak robustness testing by prompting the LLMs and generative AI components with a diverse set of jailbreak attempts across different prohibited scenarios to identify weaknesses and improve model robustness.
Anti-pattern 8: Lack of comprehensive testing and validation
Inadequate testing and validation processes for the LLM system and the generative AI chatbot application can lead to unidentified vulnerabilities, performance bottlenecks, and availability issues. Without comprehensive testing and validation, organizations might fail to detect potential security risks, functionality gaps, or scalability and performance limitations before deploying the application in a production environment.
Anti-pattern examples
Lack of functional testing to validate the correctness and completeness of the LLM’s responses and the chatbot application’s features and functionalities.
Insufficient performance testing to identify bottlenecks, resource constraints, or scalability limitations under various load conditions.
Absence of security testing, such as penetration testing, vulnerability scanning, and adversarial testing to uncover potential security vulnerabilities or model exploits.
Failure to incorporate automated testing and validation processes into a continuous integration and continuous deployment (CI/CD) pipeline, leading to manual and one-time testing efforts that might overlook critical issues.
Inadequate testing of the chatbot application’s integration with external services and components, such as Amazon Bedrock, OpenSearch, and DynamoDB, potentially leading to compatibility issues or data integrity problems.
Mitigation strategies
To address the lack of comprehensive testing and validation, implement a robust testing strategy encompassing functional, performance, security, and integration testing. Integrate automated testing into a CI/CD pipeline, conduct security testing like threat modeling and penetration testing, and use adversarial validation techniques. Continuously improve testing processes to verify the reliability, security, and scalability of the generative AI chatbot application.
Comprehensive testing strategy:
Establish a comprehensive testing strategy that includes functional testing, performance testing, load testing, security testing, and integration testing for the LLM system and the overall chatbot application.
Define clear testing requirements, test cases, and acceptance criteria based on the application’s functional and non-functional requirements, as well as security and compliance standards.
Automated testing and CI/CD integration:
Incorporate automated testing and validation processes into a CI/CD pipeline, enabling continuous monitoring and assessment of the LLM’s performance, security, and reliability throughout its lifecycle.
Use automated testing tools and frameworks to streamline the testing process, improve test coverage, and facilitate regression testing.
Security testing and adversarial validation:
Conduct threat modeling exercises early in the design process and as soon as the design is finalized for the chatbot application architecture to proactively identify potential security risks and vulnerabilities. Subsequently, conduct regular security testing—including penetration testing, vulnerability scanning, and adversarial testing—to uncover and validate identified security vulnerabilities or model exploits.
Implement adversarial validation techniques, such as prompting the LLM with carefully crafted inputs designed to expose weaknesses or vulnerabilities, to improve the model’s robustness and security.
Performance and load testing:
Perform comprehensive performance and load testing to identify potential bottlenecks, resource constraints, or scalability limitations under various load conditions.
Use tools and techniques for load generation, stress testing, and capacity planning to ensure the chatbot application can handle anticipated user traffic and workloads.
Integration testing:
Conduct thorough integration testing to validate the chatbot application’s integration with external services and components, such as Amazon Bedrock, OpenSearch, and DynamoDB, maintaining seamless communication and data integrity.
Continuous improvement:
Regularly review and update the testing and validation processes to address emerging threats, new vulnerabilities, or changes in application requirements.
Use testing insights and results to continuously improve the LLM system, the chatbot application, and the overall security posture.
Common mitigation strategies for all anti-patterns
Regularly review and update security measures, access controls, monitoring mechanisms, and guardrails for LLM and generative AI components to address emerging threats, vulnerabilities, and evolving responsible AI best practices.
Conduct regular security assessments, penetration testing, and code reviews to identify and remediate vulnerabilities or misconfigurations related to logging, auditing, and non-repudiation mechanisms.
Stay current with security best practices, guidance, and updates from AWS and industry organizations regarding logging, auditing, and non-repudiation for generative AI applications.
Secure and responsible architecture blueprint
After discussing the baseline chatbot application architecture and identifying critical security anti-patterns associated with generative AI applications built using Amazon Bedrock, we now present the secure and responsible architecture blueprint. This blueprint (Figure 2) incorporates the recommended mitigation strategies and security controls discussed throughout the anti-pattern analysis.
Figure 2: Secure and responsible generative AI chatbot architecture blueprint
In this target state architecture, unauthenticated users interact with the chatbot application through the frontend interface (1), where it’s crucial to mitigate the anti-pattern of insufficient input validation and sanitization by implementing secure coding practices and input validation. The user inputs are then processed through AWS Shield, AWS WAF, and CloudFront (2), which provide DDoS protection, web application firewall capabilities, and a content delivery network, respectively. These services help mitigate insufficient input validation, web exploits, and lack of comprehensive testing by using AWS WAF for input validation and conducting regular security testing.
The user requests are then routed through API Gateway (3), which acts as the entry point for the chatbot application, facilitating API connections to the Streamlit frontend. To address anti-patterns related to authentication, insecure communication, and LLM security, it’s essential to implement secure authentication protocols, HTTPS/TLS, access controls, and input validation within API Gateway. Communication between the VPC resources and API Gateway is secured through VPC endpoints (4), using PrivateLink for secure private communication and attaching endpoint policies to control which AWS principals can access the API Gateway service (8), mitigating the insecure communication channels anti-pattern.
The Streamlit application (5) is hosted on Amazon ECS in a private subnet within the VPC. It hosts the frontend interface and must implement secure coding practices and input validation to mitigate insufficient input validation and sanitization. User inputs are then processed by Lambda (6), a serverless compute service hosted within the VPC, which connects to Amazon Bedrock, OpenSearch, and DynamoDB through VPC endpoints (7). These VPC endpoints have endpoint policies attached to control access, enabling secure private communication between the Lambda function and the services, mitigating the insecure communication channels anti-pattern. Within Lambda, strict input validation rules, allow-lists, and user input sanitization are implemented to address the input validation anti-pattern.
User requests from the chatbot application are sent to Amazon Bedrock (12), a generative AI solution that powers the LLM capabilities. To mitigate the failure to secure FM and generative AI components anti-pattern, secure communication channels, input validation, and sanitization for prompts and context data must be implemented when interacting with Amazon Bedrock.
Amazon Bedrock interacts with OpenSearch Service (9) using Amazon Bedrock knowledge bases to retrieve relevant context data for the user’s question. The knowledge base is created by ingesting public documents from Amazon S3 (10). To mitigate the anti-pattern of insecure data storage and access controls, implement encryption at rest using AWS KMS and fine-grained IAM policies and roles for access control within OpenSearch Service. Titan Embeddings (11) are the format of the vector embeddings, which represent the documents stored in Amazon S3. The vector format enables similarity calculation and retrieval of relevant information (12). To address the failure to secure FM and generative AI components anti-pattern, secure integration with Titan Embeddings and input data validation should be implemented.
The knowledge base data, user prompts, and context data are processed by Amazon Bedrock (13) with the Claude 3 LLM (14). To address the anti-patterns of failure to secure FM and generative AI components, as well as lack of responsible AI governance and ethics, secure communication channels, input validation, ethical AI governance frameworks, transparency and interpretability measures, stakeholder engagement, bias mitigation, and guardrails like Guardrails for Amazon Bedrock should be implemented.
The generated responses and recommendations are then stored and retrieved in Amazon DynamoDB (15) by the Lambda function. To mitigate insecure data storage and access, encrypting data at rest with AWS KMS (16) and implement fine-grained access controls through IAM policies and roles.
Comprehensive logging, auditing, and monitoring mechanisms are provided by CloudTrail (17), CloudWatch (18), and AWS Config (19) to address the inadequate logging, auditing, and non-repudiation anti-pattern. See the Comprehensive logging and monitoring strategy section for detailed guidance on implementing comprehensive logging, auditing, and monitoring mechanisms using CloudTrail, CloudWatch, CloudWatch Logs, and AWS Config to address the inadequate logging, auditing, and non-repudiation anti-pattern; including logging API calls made to Amazon Bedrock service, monitoring Amazon Bedrock-specific metrics, capturing and analyzing Bedrock invocation logs, and monitoring and auditing the configuration of resources related to the chatbot application and Amazon Bedrock service.
IAM (20) plays a crucial role in the overall architecture and in mitigating anti-patterns related to authentication and insecure data storage and access. IAM roles and permissions are critical in enforcing secure authentication mechanisms, least privilege access, multi-factor authentication, and robust credential management across the various components of the chatbot application. Additionally, service control policies (SCPs) can be configured to restrict access to specific models or knowledge bases within Amazon Bedrock, preventing unauthorized access or use of sensitive intellectual property.
Finally, GuardDuty (21), Amazon Inspector (22), Security Hub (23), and Security Lake (24) have been included as additional recommended services to further enhance the security posture of the chatbot application. GuardDuty (21) provides threat detection across the control and data planes, Amazon Inspector (22) enables vulnerability assessments and continuous monitoring of Amazon ECS and Lambda workloads. Security Hub (23) offers centralized security posture management and compliance checks, while Security Lake (24) acts as a centralized data lake for log analysis, integrated with CloudTrail and SecurityHub.
Conclusion
By identifying critical anti-patterns and providing comprehensive mitigation strategies, you now have a solid foundation for a secure and responsible deployment of generative AI technologies in enterprise environments.
The secure and responsible architecture blueprint presented in this post serves as a comprehensive guide for organizations that want to use the power of generative AI while ensuring robust security, data protection, and ethical governance. By incorporating industry-leading security controls—such as secure authentication mechanisms, encrypted data storage, fine-grained access controls, secure communication channels, input validation and sanitization, comprehensive logging and auditing, secure FM integration and monitoring, and responsible AI guardrails—this blueprint addresses the unique challenges and vulnerabilities associated with generative AI applications.
Moreover, the emphasis on comprehensive testing and validation processes, as well as the incorporation of ethical AI governance principles, makes sure that you can not only mitigate potential risks, but also promote transparency, explainability, and interpretability of the LLM components, while addressing potential biases and ensuring alignment with organizational values and societal norms.
By following the guidance outlined in this post and depicted in the architectural blueprint, you can proactively identify and mitigate potential risks, enhance the security posture of your generative AI-based chatbot solutions, protect sensitive data and intellectual property, maintain regulatory compliance, and responsibly deploy LLMs and generative AI technologies in your enterprise environments.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
If you are into tech, keeping up with the latest updates can be tough, particularly when it comes to artificial intelligence (AI) and generative AI (GenAI). Sometimes I admit to feeling this way myself, however, there was one update recently that really caught my attention. OpenAI launched their latest iteration of ChatGPT, this time adding a female-sounding voice. Their launch video demonstrated the model supporting the presenters with a maths problem and giving advice around presentation techniques, sounding friendly and jovial along the way.
Adding a voice to these AI models was perhaps inevitable as big tech companies try to compete for market share in this space, but it got me thinking, why would they add a voice? Why does the model have to flirt with the presenter?
Working in the field of AI, I’ve always seen AI as a really powerful problem-solving tool. But with GenAI, I often wonder what problems the creators are trying to solve and how we can help young people understand the tech.
What problem are we trying to solve with GenAI?
The fact is that I’m really not sure. That’s not to suggest that I think that GenAI hasn’t got its benefits — it does. I’ve seen so many great examples in education alone: teachers using large language models (LLMs) to generate ideas for lessons, to help differentiate work for students with additional needs, to create example answers to exam questions for their students to assess against the mark scheme. Educators are creative people and whilst it is cool to see so many good uses of these tools, I wonder if the developers had solving specific problems in mind while creating them, or did they simply hope that society would find a good use somewhere down the line?
Whilst there are good uses of GenAI, you don’t need to dig very deeply before you start unearthing some major problems.
Anthropomorphism
Anthropomorphism relates to assigning human characteristics to things that aren’t human. This is something that we all do, all of the time, without it having consequences. The problem with doing this with GenAI is that, unlike an inanimate object you’ve named (I call my vacuum cleaner Henry, for example), chatbots are designed to be human-like in their responses, so it’s easy for people to forget they’re not speaking to a human.
As feared, since my last blog post on the topic, evidence has started to emerge that some young people are showing a desire to befriend these chatbots, going to them for advice and emotional support. It’s easy to see why. Here is an extract from an exchange between the presenters at the ChatGPT-4o launch and the model:
ChatGPT (presented with a live image of the presenter): “It looks like you’re feeling pretty happy and cheerful with a big smile and even maybe a touch of excitement. Whatever is going on? It seems like you’re in a great mood. Care to share the source of those good vibes?” Presenter: “The reason I’m in a good mood is we are doing a presentation showcasing how useful and amazing you are.” ChatGPT: “Oh stop it, you’re making me blush.”
“Some people just want to talk to somebody. Just because it’s not a real person, doesn’t mean it can’t make a person feel — because words are powerful. At the end of the day, it can always help in an emotional and mental way.”
The prospect of teenagers seeking solace and emotional support from a generative AI tool is a concerning development. While these AI tools can mimic human-like conversations, their outputs are based on patterns and data, not genuine empathy or understanding. The ultimate concern is that this exposes vulnerable young people to be manipulated in ways we can’t predict. Relying on AI for emotional support could lead to a sense of isolation and detachment, hindering the development of healthy coping mechanisms and interpersonal relationships.
Arguably worse is the recent news of the world’s first AI beauty pageant. The very thought of this probably elicits some kind of emotional response depending on your view of beauty pageants. There are valid concerns around misogyny and reinforcing misguided views on body norms, but it’s also important to note that the winner of “Miss AI” is being described as a lifestyle influencer. The questions we should be asking are, who are the creators trying to have influence over? What influence are they trying to gain that they couldn’t get before they created a virtual woman?
DeepFake tools
Another use of GenAI is the ability to create DeepFakes. If you’ve watched the most recent Indiana Jones movie, you’ll have seen the technology in play, making Harrison Ford appear as a younger version of himself. This is not in itself a bad use of GenAI technology, but the application of DeepFake technology can easily become problematic. For example, recently a teacher was arrested for creating a DeepFake audio clip of the school principal making racist remarks. The recording went viral before anyone realised that AI had been used to generate the audio clip.
Easy-to-use DeepFake tools are freely available and, as with many tools, they can be used inappropriately to cause damage or even break the law. One such instance is the rise in using the technology for pornography. This is particularly dangerous for young women, who are the more likely victims, and can cause severe and long-lasting emotional distress and harm to the individuals depicted, as well as reinforce harmful stereotypes and the objectification of women.
Why we should focus on using AI as a problem-solving tool
Technological developments causing unforeseen negative consequences is nothing new. A lot of our job as educators is about helping young people navigate the changing world and preparing them for their futures and education has an essential role in helping people understand AI technologies to avoid the dangers.
Our approach at the Raspberry Pi Foundation is not to focus purely on the threats and dangers, but to teach young people to be critical users of technologies and not passive consumers. Having an understanding of how these technologies work goes a long way towards achieving sufficient AI literacy skills to make informed choices and this is where our Experience AI program comes in.
Experience AI is a set of lessons developed in collaboration with Google DeepMind and, before we wrote any lessons, our team thought long and hard about what we believe are the important principles that should underpin teaching and learning about artificial intelligence. One such principle is taking a problem-first approach and emphasising that computers are tools that help us solve problems. In the Experience AI fundamentals unit, we teach students to think about the problem they want to solve before thinking about whether or not AI is the appropriate tool to use to solve it.
Taking a problem-first approach doesn’t by default avoid an AI system causing harm — there’s still the chance it will increase bias and societal inequities — but it does focus the development on the end user and the data needed to train the models. I worry that focusing on market share and opportunity rather than the problem to be solved is more likely to lead to harm.
Another set of principles that underpins our resources is teaching about fairness, accountability, transparency, privacy, and security (Fairness, Accountability, Transparency, and Ethics (FATE) in Artificial Intelligence (AI) and higher education, Understanding Artificial Intelligence Ethics and Safety) in relation to the development of AI systems. These principles are aimed at making sure that creators of AI models develop models ethically and responsibly. The principles also apply to consumers, as we need to get to a place in society where we expect these principles to be adhered to and consumer power means that any models that don’t, simply won’t succeed.
Furthermore, once students have created their models in the Experience AI fundamentals unit, we teach them about model cards, an approach that promotes transparency about their models. Much like how nutritional information on food labels allows the consumer to make an informed choice about whether or not to buy the food, model cards give information about an AI model such as the purpose of the model, its accuracy, and known limitations such as what bias might be in the data. Students write their own model cards based on the AI solutions they have created.
What else can we do?
At the Raspberry Pi Foundation, we have set up an AI literacy team with the aim to embed principles around AI safety, security, and responsibility into our resources and align them with the Foundations’ mission to help young people to:
Be critical consumers of AI technology
Understand the limitations of AI
Expect fairness, accountability, transparency, privacy, and security and work toward reducing inequities caused by technology
See AI as a problem-solving tool that can augment human capabilities, but not replace or narrow their futures
Our call to action to educators, carers, and parents is to have conversations with your young people about GenAI. Get to know their opinions on GenAI and how they view its role in their lives, and help them to become critical thinkers when interacting with technology.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
























 Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe. Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences.
Ashish Agrawal is a Principal Product Manager with Amazon Redshift, building cloud-based data warehouses and analytics cloud services. Ashish has over 25 years of experience in IT. Ashish has expertise in data warehouses, data lakes, and platform as a service. Ashish has been a speaker at worldwide technical conferences. Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.
Davide Pagano is a Software Development Manager with Amazon Redshift based out of Palo Alto, specialized in building cloud-based data warehouses and analytics cloud services solutions. He has over 10 years of experience with databases, out of which 6 years of experience tailored to Amazon Redshift.