Post Syndicated from Itay Meller original https://aws.amazon.com/blogs/security/remote-access-to-aws-a-guide-for-hybrid-workforces/
Amazon Web Services (AWS) customers can enable secure remote access to their cloud resources, supporting business operations with both speed and agility. As organizations embrace flexible work environments, employees can safely connect to AWS resources from various locations using different devices. AWS provides comprehensive security solutions that help organizations maintain strong protection of corporate resources, manage appropriate access controls, and meet compliance requirements while enabling productive remote work environments.
Because there are different types of workloads—from Amazon Elastic Compute Cloud (Amazon EC2) instances to web applications—running in the AWS Cloud, there are correspondingly multiple remote access use cases for using or operating these workloads. For example, access to an EC2 instance and its operating system to perform operations such as troubleshooting, log analysis, and data retrieval. Other use cases require access to web applications such as Jenkins, Salesforce, or the Kubernetes UI deployed on AWS.
To support these use cases, AWS provides multiple services and features that help you address access patterns using different approaches. One of the key challenges that you might face when implementing remote access solutions is understanding the tradeoffs of the different approaches and solutions. This post is designed to help you decide which remote access approach is best for your use-case.
Use cases
In this post, we address the following use cases:
- User access to internal web applications deployed in a virtual private cloud (VPC).
- Internal operator access to EC2 and Amazon Relational Database Service (Amazon RDS) instances deployed in a VPC.
- Analyst access to sensitive data residing on Amazon Simple Storage Service (Amazon S3).
- User access to SAML 2.0 and OAuth 2.0 applications.
Challenges associated with remote access
- Cost: The cost of a remote access solution is a key factor for businesses.
- Increased exposure surface: Securing a VPC with several EC2 instances, S3 buckets, and a database is a different task than securing the identities, devices, and communications channels used for remote access to the infrastructure.
- Increased risk: Susceptibility to social engineering threats. Humans accessing workloads are the weakest link in any security program, introducing risks to data and infrastructure that otherwise wouldn’t have existed.
- User experience (UX): The UX is a key factor in remote access. Lacking a well-designed UX can introduce risks by making it difficult to conduct day-to-day operations or respond quickly to incidents that affect users at scale.
A solution to mitigate the risks associated with remote access is to not provide it at certain levels, and you might sometimes choose this approach. In these cases, access to workloads that must be secure is only possible from trusted locations (such as company offices) and managed devices (such as company-issued laptops). For the remainder of this post, we talk about approaches and solutions available for you when you need to provide remote access from various locations and devices.
The different approaches
Before diving deeper into the services and features, let’s explore the different approaches for providing remote access to your users (shown in Figure 1). The main differentiator among them is where the trust boundary lies.

Figure 1: The different approaches along with the corresponding solutions
- Network-based approach: Users are given access to your network through VPCs and are granted broad access to the actual target resource, web application, or EC2 instances. The trust boundary in this case is the VPC.
- Host-based approach: Users have access to the host running the application. This is commonly used for operator access. The trust boundary is the host.
- Application-based approach: Users access the application using their corporate credentials. This is commonly the case for software as a service (SaaS) applications. The trust boundary is the application.
- End-user computing approach: End-user computing (EUC) is a combination of technologies, policies, and processes that gives users secure, remote access to applications, desktops, and data that they need to get their work done. Desktops are operated centrally in the cloud and interacted with using streamed pixels to users’ devices. This approach shifts the trust boundary from the user device to desktops and data residing in the cloud.
These approaches aren’t mutually exclusive and occasionally overlap or can be combined in a zero trust model. Zero trust is centered on the idea that access to resources shouldn’t be based solely on the network location but on authentication and authorization of each request using multiple factors; including the user identity, device, and location, among others.
The trust boundary primarily depends on the criticality of the target resource, the risk tolerance of the organization, and the complexity of the implementation. Wider trust boundaries (such as in a network-based approach) increase the exposed surface area—because the whole network is exposed to trusted users and access to the network grants access to all the resources inside it—but are the simplest to implement. Tighter trust boundaries (such as a zero trust model) considerably reduce the exposed surface area but require implementing multiple factors that feed into the authorization context.
For example, organizations might provide network-based access from trusted devices to operators for a VPC with web-servers and databases, but only allow end-user computing based access for contractors or third-party users using non-corporate devices, also known as bring your own device (BYOD).
When selecting your remote access solution, you need to consider the desired trust boundary, authentication, authorization, user experience, access visibility and cost, which we explore in the following sections.
Network-based approach
The network-based approach is popular when users need access to multiple resources residing in specific networks in a straightforward manner, while keeping the networks disconnected from the public internet. When providing access at the network level, managing security configurations such as authorization, authentication, and auditing happens at the resource (application or machine) and client device, introducing challenges at scale.
AWS Client VPN is a fully managed service that you can use to securely connect users to VPCs from virtually any location using OpenVPN-based clients. Users can authenticate using your organization’s identity provider (IdP) in combination with certificate-based authentication. The service supports authorization rules that act as firewall rules to grant users access to specific CIDR blocks based on membership in an Active Directory group or a group defined in a SAML-based IdP. Additionally, you can use client connect handlers to run custom authorization logic based on device, user, and connection attributes.
After the required infrastructure is set up, users can connect to the target VPC and access EC2 instances or web applications at the network level inside their authorization scope. The UX is as straightforward as connecting using client software installed on the user’s device and authenticating using corporate authentication policies. A client VPN provides visibility into users’ connections to the VPN through connection logs, which are streamed to an Amazon CloudWatch log group. Connection logging provides visibility into each user’s initial VPN connection; getting visibility into what happened during the connection requires gathering the data from the target resource, network, or the user’s device.
After the user is authenticated and authorized, their device gains network access to the relevant VPC—and potentially other VPCs that are peered—or is connected through AWS Transit Gateway to that VPC. This can potentially provide network access to resources and networks outside the scope of the user.
A client VPN-based solution should be implemented when the network is the intended trust boundary around resources (for example, at the subnet or security group level) and group-level access control is sufficient. See Get started with AWS Client VPN.
Host-based approach
Providing access to hosts isn’t always necessary. One way to mitigate risks related to unauthorized host access is to not allow it and rely on fully automated operations instead. In practice, operators and developers still require access to hosts for visibility, tuning the operating system settings, applying patches, or manually restarting a service.
For access to EC2 instances, you can use features such as AWS Systems Manager Session Manager or EC2 Instance Connect Endpoint. Both of these features provide access to a host without exposing it to the internet, and because they use AWS Identity and Access Management (IAM), they authenticate, authorize, and log every session request made to AWS CloudTrail, and provide capabilities such as IAM Conditions (for example, aws:SourceIp) to apply conditional access, often minimizing the need for a network-based approach.
These two features mainly differ in the way they operate. Session Manager requires an agent, which is installed by default on several Amazon Machine Images (AMIs). The agent establishes an outbound connection—through the internet or a VPC endpoint—to the service endpoints, so you don’t have to modify the host’s inbound security group rules. It allows SSH connections tunneled over a proxy connection and provides in-session logging providing visibility into users’ commands within a session.
EC2 Instance Connect doesn’t require that you install an agent; it allows a secure native SSH connection, using short-lived SSH keys. As such, it requires that inbound connections from the EC2 Instance Connect service on port 22 be allowed on the host’s security group.
Most customers use Session Manager unless they don’t want to have an agent installed on the virtual machine or require a native SSH experience.
End-user computing approach
End-user computing services like the Amazon WorkSpaces Family or Amazon AppStream 2.0 stream desktops and applications as encrypted pixels to remote users while keeping data safely within your Amazon Virtual Private Cloud (Amazon VPC) and connected private networks. Unauthorized access to the client device is exposed only to encrypted pixels, which essentially moves the trust boundary from the device accessing the resources to the virtual desktop running in the cloud.
You can dive deeper into the differences between these different services in Unified access to AWS End User Computing services.
These services are particularly popular among customers who want to minimize the user’s device as the trust boundary. This can improve operational efficiency, especially when dealing with untrusted devices or highly sensitive data, because you significantly narrow the scope of what needs to be protected. This can also reduce the use (and costs) of expensive hardware.
The idea is that a user first authenticates using credentials provided by the corporate Active Directory or a SAML federation to the corporate identity provider. After the user is authenticated and authorized, an encrypted streaming session begins and the client is remotely operating a desktop or application that’s deployed in an Amazon VPC, with an elastic network interface (ENI) deployed to the customer’s managed VPC.
When adopting end-user computing for remote access, you can choose the UX and the cost structure that best fit your use case (for example, persistent access to a desktop or on-demand access to specific applications). You can also select different compute and storage options depending on the desired performance.
AWS End User Computing provides different machine types to accommodate different UX requirements and with different pricing models depending on the consumption model being used.
For more information, see Getting Started with Amazon Workspaces and Getting Started with AppStream 2.0.
Application-based approach
IAM Identity Center is primarily known for simplifying user access to AWS accounts within an organization at scale. It also provides single sign-on (SSO) access to supported web applications, giving users seamless access to these applications after they sign in using their directory credentials. Identity Center supports two application types:
- AWS managed applications, such as Amazon Q Developer and Amazon QuickSight.
- Customer managed applications, such as Salesforce, Microsoft365, and other commonly used applications.
If you use customer managed applications that support SAML 2.0 and OAuth 2.0, you can federate your IdP to IAM Identity Center through SAML 2.0 and use Identity Center to manage user access to those applications.
For organizations operating AWS environments at scale with multiple accounts, using IAM Identity Center is the recommended service to provide access to web applications and is provided at no additional cost.
Combining multiple approaches in a zero trust model
The zero trust model combines multiple factors including the user identity, device, location, and others, to evaluate and grant access requests. One way that you can implement this model to provide remote access to workloads deployed in a VPC is to use AWS Verified Access. With Verified Access, you can provide secure access to corporate applications without a client VPN and support TCP-based connections to a VPC, be it to web applications or EC2 or RDS instances. Authentication can be done using an existing IdP or AWS IAM Identity Center and a device management service that can provide additional information to improve authorization decisions based on context from the device. Those authorization decisions are expressed as Cedar policies that you author based on your access requirements. The service provides extensive logging for each web request, so you can investigate anomalies and view information about the access that was granted. For more information, see Get Started with Amazon Verified Access.
Understanding the tradeoffs
To select the right solution for your workforce, work backwards from the use case. Start by identifying and classifying the asset inventory and mapping the users accessing it and their access patterns.
Things to consider based on the classification:
- Visibility: Determine the level of visibility into remote access activities and the type of information that you’ll need to detect and recover from a security event or to comply with regulatory and compliance requirements.
- Authentication and authorization: Determine if your existing IAM mechanisms are sufficient. You might need to identify a temporary access management system or include information coming from user devices to address risks of compromised employees.
- Network access: Know your users and what type of network access, if any, they need. When considering network access, include the potential risks of overly permissive access.
- Cost: To determine costs, you need to know how many users and resources will be supported by remote access. Also, how many connections you expect and for how much time. Use that information to help determine the total cost of ownership of your solution.
- Endpoint security: For each resource, understand risks associated with providing access to it from a user’s device. Know what mechanisms you have (or can implement) to detect threats and unauthorized access or provide additional context for the authorization decision granting access to a resource.
- User experience: Compare the cost of a streamed user experience to one that’s locally installed to see if any additional cost is balanced by the improved security of the streamed UX.
The following provides an overview of the different solutions and the factors that can help you make an informed decision.
| Solution | Use cases | Trust Boundary | Provides access to | Protocol | User experience | Authentication | Authorization | Visibility | Cost |
| Client VPN |
|
Network | VPCs, subnets, security groups | IP | Client based,native |
|
|
Connection logging (CloudWatch) | Connection time and endpoint association |
| AWS Session Manager |
|
Host | EC2 Instances: Linux, Windows, or MacOS (EC2 only) | SSH or RDP | Native |
|
|
CloudTrail, or in-session logging using CloudWatch and Amazon S3) | No additional cost for accessing EC2 instances |
| EC2 Instance Connect Endpoint |
|
Host | EC2 Instances: Linux or Windows | SSH or RDP | Native |
|
|
CloudTrail | No additional cost |
| IAM Identity Center |
|
Application | Web applications | HTTP(S) | Native |
|
|
CloudTrail | No additional cost |
| Amazon Verified Access |
|
Amazon Verified Access |
|
HTTP(S) or TCP | Native |
|
|
Per request logging | Per application or bandwidth |
| Amazon Workspaces |
|
Cloud desktop | Persistent virtual desktop | WSP or PCoIP | Client based, or non-native |
|
|
CloudTrail | Per instance |
| Amazon AppStream 2.0 |
|
Cloud desktop | Non persistent virtual desktops and applications | NICE DCV | Client based or non-native |
|
|
CloudTrail | Per instance |
Conclusion
In this post, you learned about different approaches and solutions for providing remote access for your organization’s workforce. This included tactical recommendations on how to find the remote access solution that suits your needs best based on factors such as costs, user experience, and risk. By understanding those tradeoffs, you can now map out the different use-cases based on your infrastructure and threat model and build a remote access strategy to meet your needs. As you experiment and adopt the different tools, careful planning is required when designing and deploying the services. For example, which account to deploy the service to or how to provision access to the services. Use resources such as the AWS Security Reference Architecture (AWS SRA) and the individual service documentation pages to help guide your journey.
If you have feedback about this post, submit comments in the Comments section below.




 Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends.
Raghu Kuppala is an Analytics Specialist Solutions Architect experienced working in the databases, data warehousing, and analytics space. Outside of work, he enjoys trying different cuisines and spending time with his family and friends. Sumant Nemmani is a Senior Technical Product Manager at AWS. He is focused on helping customers of Amazon Redshift benefit from features that use machine learning and intelligent mechanisms to enable the service to self-tune and optimize itself, ensuring Redshift remains price-performant as they scale their usage.
Sumant Nemmani is a Senior Technical Product Manager at AWS. He is focused on helping customers of Amazon Redshift benefit from features that use machine learning and intelligent mechanisms to enable the service to self-tune and optimize itself, ensuring Redshift remains price-performant as they scale their usage. Gagan Goel is a Software Development Manager at AWS. He ensures that Amazon Redshift features meet customer needs by prioritising and guiding the team in delivering customer-centric solutions, monitor and enhance query performance for customer workloads.
Gagan Goel is a Software Development Manager at AWS. He ensures that Amazon Redshift features meet customer needs by prioritising and guiding the team in delivering customer-centric solutions, monitor and enhance query performance for customer workloads. Kshitij Batra is a Software Development Engineer at Amazon, specializing in building resilient, scalable, and high-performing software solutions.
Kshitij Batra is a Software Development Engineer at Amazon, specializing in building resilient, scalable, and high-performing software solutions. Sanuj Basu is a Principal Engineer at AWS, driving the evolution of Amazon Redshift into a next-generation, exabyte-scale cloud data warehouse. He leads engineering for Redshift’s core data platform — including managed storage, transactions, and data sharing — enabling customers to power seamless multi-cluster analytics and modern data mesh architectures. Sanuj’s work helps Redshift customers break through th
Sanuj Basu is a Principal Engineer at AWS, driving the evolution of Amazon Redshift into a next-generation, exabyte-scale cloud data warehouse. He leads engineering for Redshift’s core data platform — including managed storage, transactions, and data sharing — enabling customers to power seamless multi-cluster analytics and modern data mesh architectures. Sanuj’s work helps Redshift customers break through th







 Xiaoxue Xu is a Solutions Architect for AWS based in Toronto. She primarily works with financial services customers to help secure their workload and design scalable solutions on the AWS Cloud.
Xiaoxue Xu is a Solutions Architect for AWS based in Toronto. She primarily works with financial services customers to help secure their workload and design scalable solutions on the AWS Cloud. Simran Singh is a Senior Solutions Architect at AWS. In this role, he assists our large enterprise customers in meeting their key business objectives using AWS. His areas of expertise include artificial intelligence and machine learning, security, and improving the experience of developers building on AWS.
Simran Singh is a Senior Solutions Architect at AWS. In this role, he assists our large enterprise customers in meeting their key business objectives using AWS. His areas of expertise include artificial intelligence and machine learning, security, and improving the experience of developers building on AWS.





 Venkata Sai Mahesh Swargam is a Cloud Engineer at AWS in Hyderabad. He specializes in Amazon MSK and Amazon Kinesis services. Mahesh is dedicated to helping customers by providing technical guidance and solving issues related to their Amazon MSK architectures. In his free time, he enjoys being with family and traveling around the world.
Venkata Sai Mahesh Swargam is a Cloud Engineer at AWS in Hyderabad. He specializes in Amazon MSK and Amazon Kinesis services. Mahesh is dedicated to helping customers by providing technical guidance and solving issues related to their Amazon MSK architectures. In his free time, he enjoys being with family and traveling around the world.


 Donatas Kuchalskis is a Cloud Operations Architect at AWS, based in London, focusing on Financial Services customers in the UK. He helps customers optimize their AWS environments for cost, security, and resiliency while providing strategic cloud guidance. Prior to this role, he served as a Prototyping Architect specializing in Big Data and as a Specialist Solutions Architect for Retail. Before joining AWS, Donatas spent 6 years as a technical consultant in the retail sector.
Donatas Kuchalskis is a Cloud Operations Architect at AWS, based in London, focusing on Financial Services customers in the UK. He helps customers optimize their AWS environments for cost, security, and resiliency while providing strategic cloud guidance. Prior to this role, he served as a Prototyping Architect specializing in Big Data and as a Specialist Solutions Architect for Retail. Before joining AWS, Donatas spent 6 years as a technical consultant in the retail sector. Jumana Nagaria is a Prototyping Architect at AWS. She builds innovative prototypes with customers to solve their business challenges. She is passionate about cloud computing and data analytics. Outside of work, Jumana enjoys travelling, reading, painting, and spending quality time with friends and family.
Jumana Nagaria is a Prototyping Architect at AWS. She builds innovative prototypes with customers to solve their business challenges. She is passionate about cloud computing and data analytics. Outside of work, Jumana enjoys travelling, reading, painting, and spending quality time with friends and family.

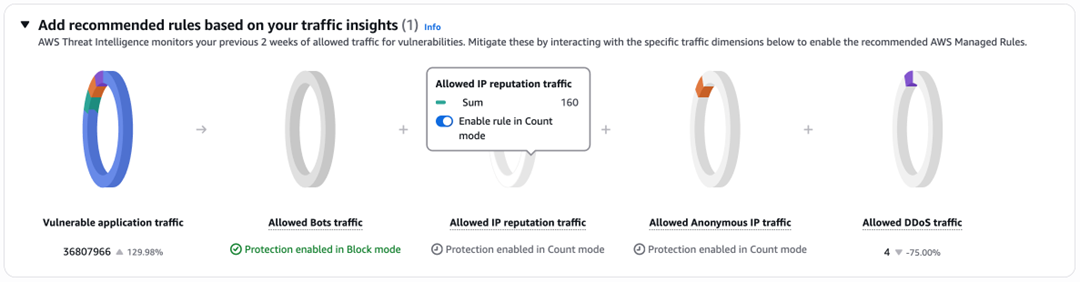
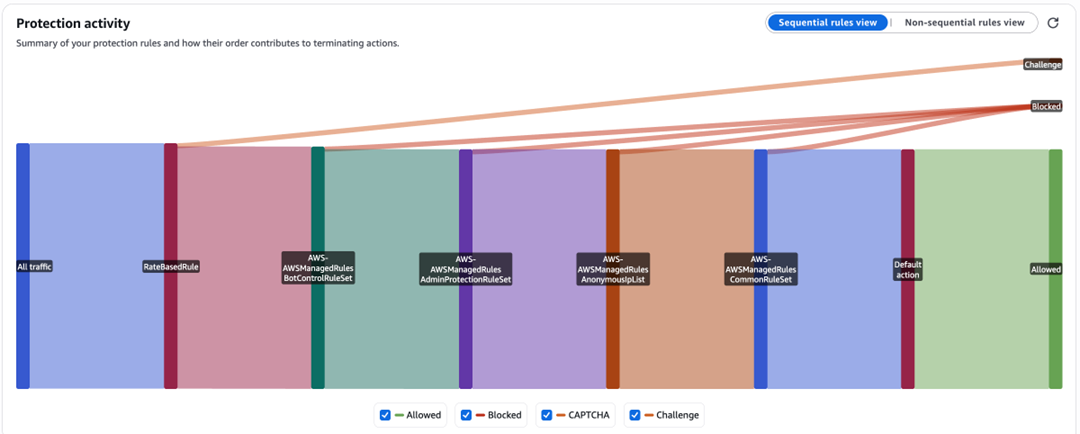
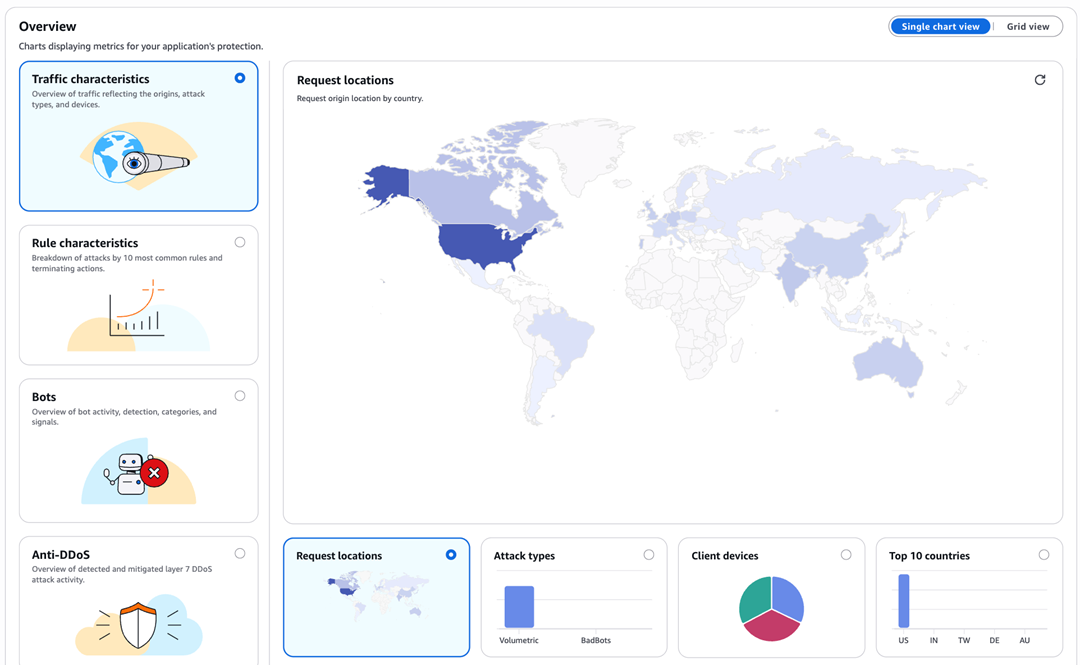


















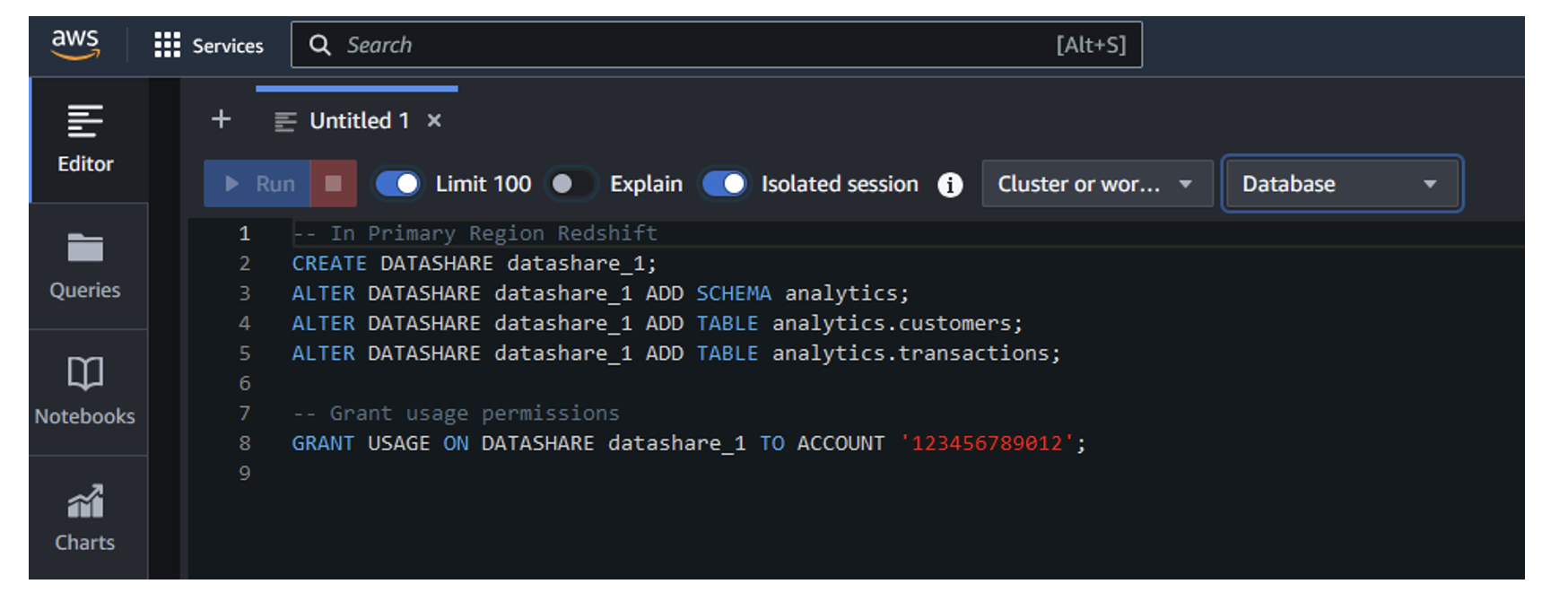
 If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
If you select Redshift, you will be transferred to the Query editor where you can execute the SQL and see the results as shown in the following figure.
 Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
Avijit Goswami is a Principal Data Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music. Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies.
Saman Irfan is a Senior Specialist Solutions Architect focusing on Data Analytics at Amazon Web Services. She focuses on helping customers across various industries build scalable and high-performant analytics solutions. Outside of work, she enjoys spending time with her family, watching TV series, and learning new technologies. Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.
Sudarshan Narasimhan is a Principal Solutions Architect at AWS specialized in data, analytics and databases. With over 19 years of experience in Data roles, he is currently helping AWS Partners & customers build modern data architectures. As a specialist & trusted advisor he helps partners build & GTM with scalable, secure and high performing data solutions on AWS. In his spare time, he enjoys spending time with his family, travelling, avidly consuming podcasts and being heartbroken about Man United’s current state.



























 Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data governance, and artificial intelligence at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure cloud solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.
Dhrubajyoti Mukherjee is a Cloud Infrastructure Architect with a strong focus on data strategy, data governance, and artificial intelligence at Amazon Web Services (AWS). He uses his deep expertise to provide guidance to global enterprise customers across industries, helping them build scalable and secure cloud solutions that drive meaningful business outcomes. Dhrubajyoti is passionate about creating innovative, customer-centric solutions that enable digital transformation, business agility, and performance improvement. Outside of work, Dhrubajyoti enjoys spending quality time with his family and exploring nature through his love of hiking mountains.




















