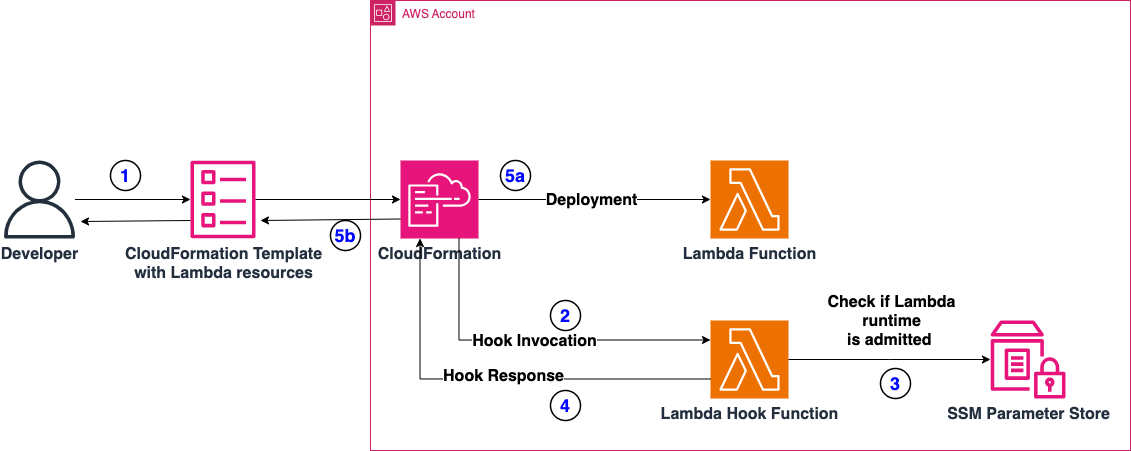
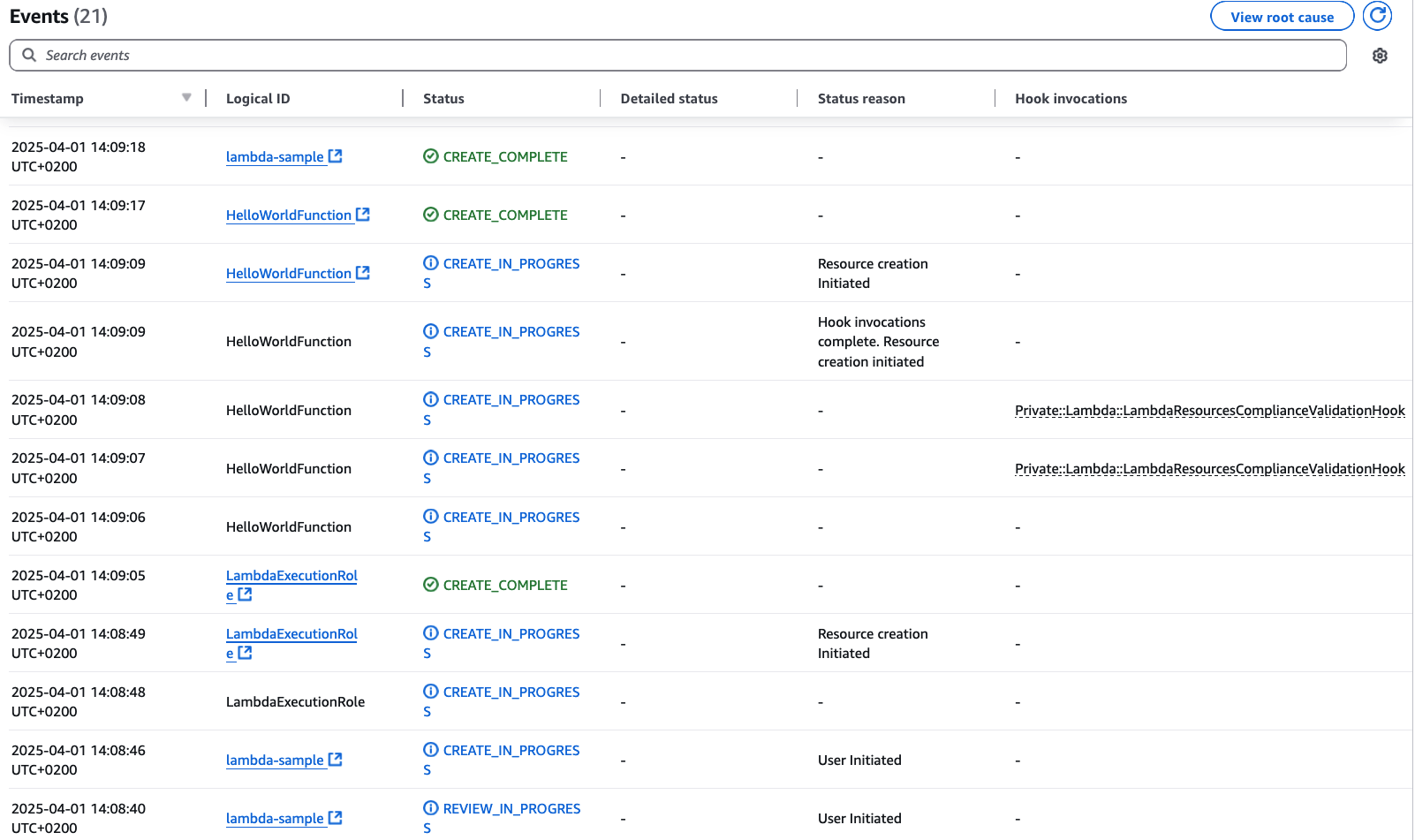
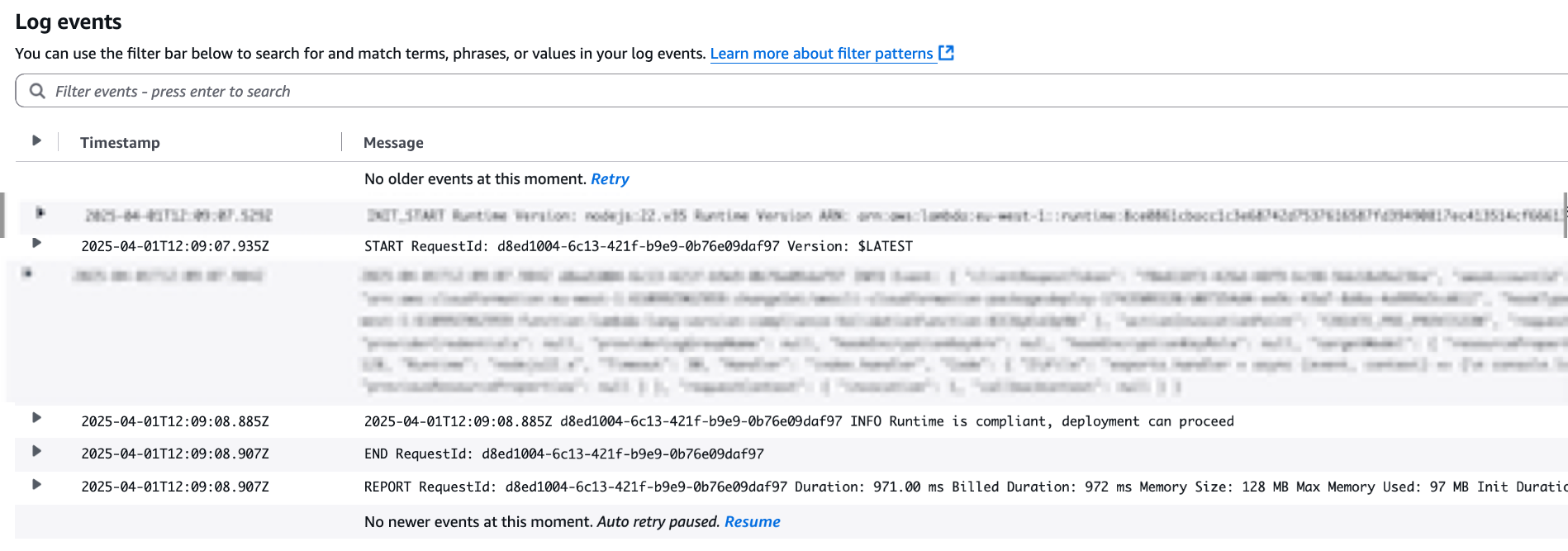
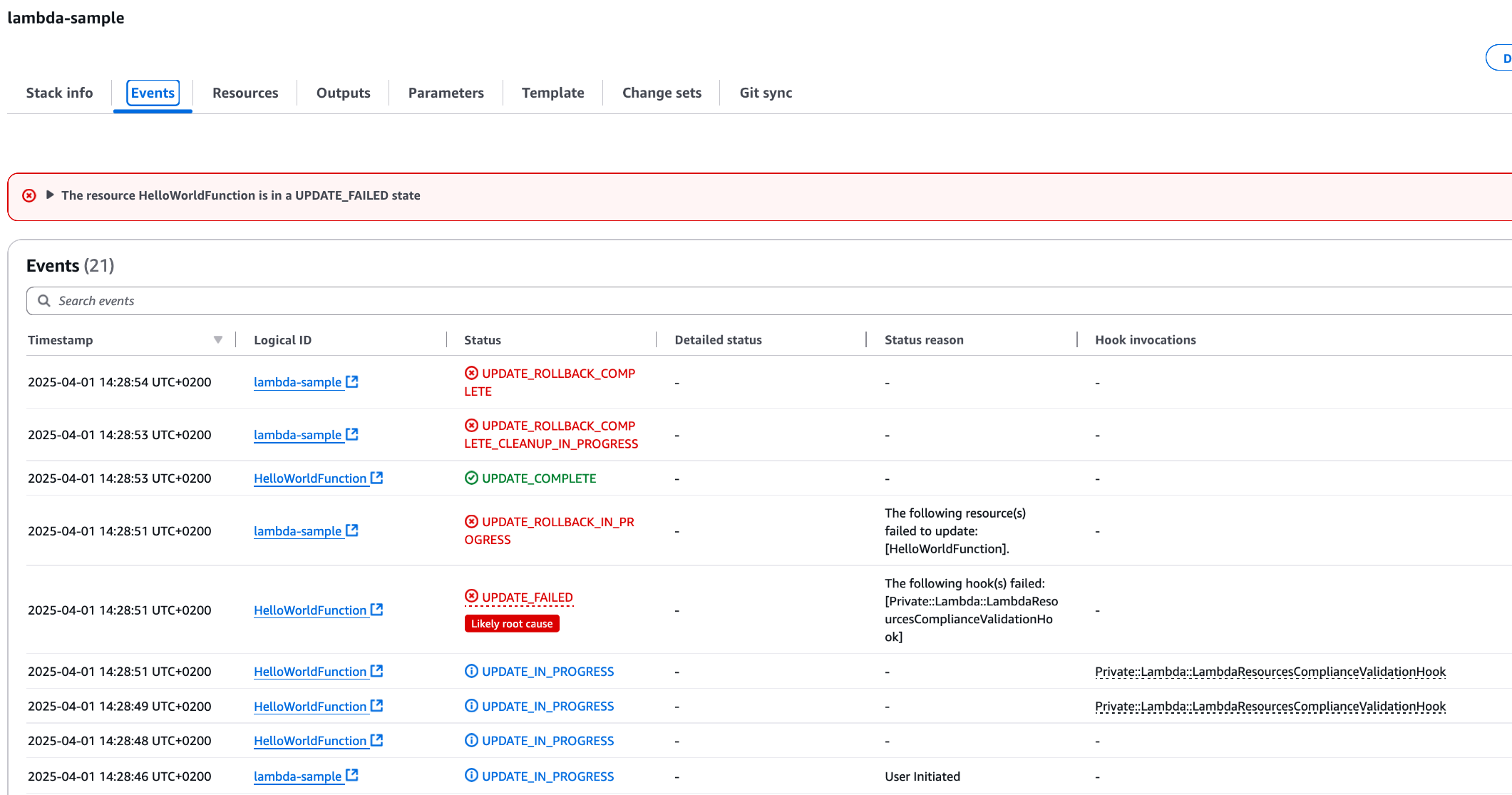
Post Syndicated from Satesh Sonti original https://aws.amazon.com/blogs/big-data/scalable-analytics-and-centralized-governance-for-apache-iceberg-tables-using-amazon-s3-tables-and-amazon-redshift/
Amazon Redshift supports querying data stored in Apache Iceberg tables managed by Amazon S3 Tables, which we previously covered as part of getting started blog post. While this blog post helps you to get started using Amazon Redshift with Amazon S3 Tables, there are additional steps you need to consider when working with your data in production environments, including who has access to your data and with what level of permissions.
In this post, we’ll build on the first post in this series to show you how to set up an Apache Iceberg data lake catalog using Amazon S3 Tables and provide different levels of access control to your data. Through this example, you’ll set up fine-grained access controls for multiple users and see how this works using Amazon Redshift. We’ll also review an example with simultaneously using data that resides both in Amazon Redshift and Amazon S3 Tables, enabling a unified analytics experience.
Solution overview
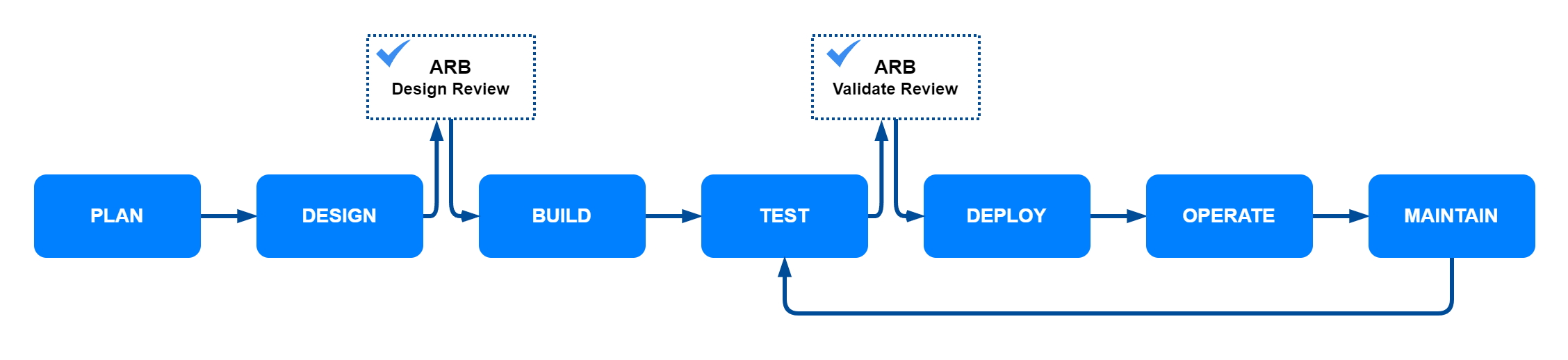
In this solution, we show how to query a dataset stored in Amazon S3 Tables for further analysis using data managed in Amazon Redshift. Specifically, we go through the steps shown in the following figure to load a dataset into Amazon S3 Tables, grant appropriate permissions, and finally execute queries to analyze our dataset for trends and insights.

In this post, you walk through the following steps:
- Creating an Amazon S3 Table bucket: In AWS Management Console for Amazon S3, create an Amazon S3 Table bucket and integrate with other AWS analytics services
- Creating an S3 Table and loading data: Run spark SQL in Amazon EMR to create a namespace and an S3 Table and load diabetic patients’ visit data
- Granting permissions: Granting fine-grained access controls in AWS Lake Formation
- Running SQL analytics: Querying S3 Tables using the auto mounted S3 Table catalog.
This post uses data from a healthcare use case to analyze information about diabetic patients and identify the frequency of age groups admitted to the hospital. You’ll use the preceding steps to perform this analysis.
Prerequisites
To begin, you need to add an Amazon Redshift service-linked role—AWSServiceRoleForRedshift—as a read-only administrator in Lake Formation. You can run following AWS Command Line Interface (AWS CLI) command to add the role.
Replace <account_number> with your account number and replace <region> with the AWS Region that you are using. You can run this command from AWS CloudShell or through AWS CLI configured in your environment.
You also need to create or use an existing Amazon Elastic Compute Cloud (Amazon EC2) key pair that will be used for SSH connections to cluster instances. For more information, see Amazon EC2 key pairs.
The examples in this post require the following AWS services and features:
- Amazon Redshift Serverless
- Amazon S3 Tables
- AWS Glue Data Catalog
- AWS Lake Formation
- Apache Spark with Amazon EMR
- AWS CloudFormation
The CloudFormation template that follows creates the following resources:
- An Amazon EMR 7.6.0 cluster with Apache Iceberg packages
- An Amazon Redshift Serverless instance
- An AWS Identity and Access Management (IAM) instance profile, service role, and security groups
- IAM roles with required policies
- Two IAM users: nurse and analyst
Download the CloudFormation template, or you can use the Launch Stack button to automatically download it to your AWS environment. Note that network routes are directed to 255.255.255.255/32 for security reasons. Replace the routes with your organization’s IP addresses. Also enter your IP or VPN range for Jupyter Notebook access in the SourceCidrForNotebook parameter in CloudFormation.
![]()
Download the diabetic encounters and patient datasets and upload it into your S3 bucket. These files are from a publicly available open dataset.
This sample dataset is used to highlight this use case, the techniques covered can be adapted to your workflows. The following are more details about this dataset:
diabetic_encounters_s3.csv: Contains information about patient visits for diabetic treatment.
encounter_id: Unique number to refer to an encounter with a patient who has diabetes.patient_nbr: Unique number to identify a patient.num_procedures: Number of medical procedures administered.num_medications: Number of medications provided during the visitinsulin: Insulin level observed. Valid values are steady, up, and no.time_in_hospital: Duration of time in hospital in days.readmitted: Readmitted to hospital within 30 days or after 30 days.
diabetic_patients_rs.csv: Contains patient information such as age group, gender, race, and number of visits.
patient_nbr: Unique number to identify a patientrace: Patient’s racegender: Patient’s genderage_grp: Patient’s age group. Valid values are 0-10, 10-20, 20-30, and so onnumber_outpatient: Number of outpatient visitsnumber_emergency: Number of emergency room visitsnumber_inpatient: Number of inpatient visits
Now that you’ve set up the prerequisites, you’re ready to connect Amazon Redshift to query Apache Iceberg data stored in Amazon S3 Tables.
Create an S3 Table bucket
Before you can use Amazon Redshift to query the data in an Amazon S3 Table, you must create an Amazon S3 Table.
- Sign in to the AWS Management Console and go to Amazon S3.
- Go to Amazon S3 Table buckets. This is an option in the Amazon S3 console.
- In the Table buckets view, there’s a section that describes Integration with AWS analytics services. Choose Enable Integration if you haven’t previously set this up. This sets up the integration with AWS analytics services, including Amazon Redshift, Amazon EMR, and Amazon Athena.

- Wait a few seconds for the status to change to Enabled.

- Choose Create table bucket and enter a bucket name. You can use any name that follows the naming conventions. In this example, we used the bucket name patient-encounter. When you’re finished, choose Create table bucket.

- After the S3 Table bucket is created, you’ll be redirected to the Table buckets list. Copy the Amazon Resource Name (ARN) of the table bucket you just created to use in the next section.





Now that your S3 Table bucket is set up, you can load data.
Create S3 Table and load data
The CloudFormation template in the prerequisites created an Apache Spark cluster using Amazon EMR. You’ll use the Amazon EMR cluster to load data into Amazon S3 Tables.
- Connect to the Apache Spark primary node using SSH or through Jupyter Notebooks. Note that an Amazon EMR cluster was launched when you deployed the CloudFormation template.
- Enter the following command to launch the Spark shell and initialize a Spark session for Iceberg that connects to your S3 Table bucket. Replace
<Region>,<accountID>and<bucketname><bucket arn>with the information your region, account and bucket name.
See Accessing Amazon S3 Tables with Amazon EMR for upgrades to software.amazon.s3tables package versions.
- Next, create a namespace that will link your S3 Table bucket with your Amazon Redshift Serverless workgroup. We chose encounters as the namespace for this example, but you can use a different name. Use the following SparkSQL command:
- Create an Apache Iceberg table with name
diabetic_encounters. - Load csv into the S3 Table
encounters.diabetic_encounters. Replace<diabetic_encounters_s3.csv file location>with the Amazon S3 file path of thediabetic_encounters_s3.csvfile you uploaded earlier. - Query the data to validate it using Spark shell.
Grant permissions
In this section, you grant fine-grained access control to the two IAM users created as part of the prerequisites.
- nurse: Grant access to all columns in the
diabetic_encounterstable - analyst: Grant access to only
{encounter_id, patient_nbr, readmitted}columns
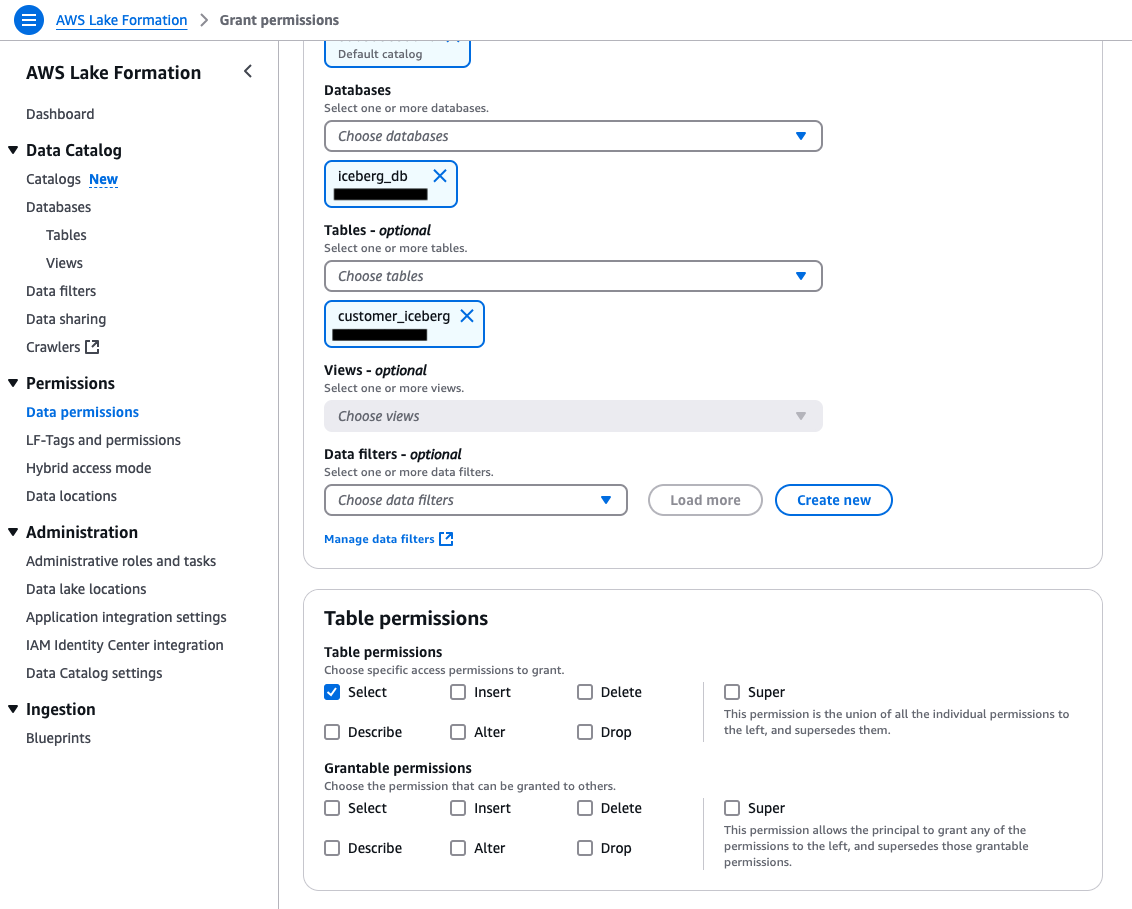
First, grant access to the diabetic_encounters table for nurse user.
- In AWS Lake Formation, Choose Data Permissions.
- On the Grant Permissions page, under Principals, select IAM users and roles.
- Select the IAM user nurse.
- For Catalogs, select
<accoundID>:s3tablescatalog/patient-encounter. - For Databases, select encounter

- Scroll down. For Tables, select diabetic_encounters.
- For Table permissions, select Select.
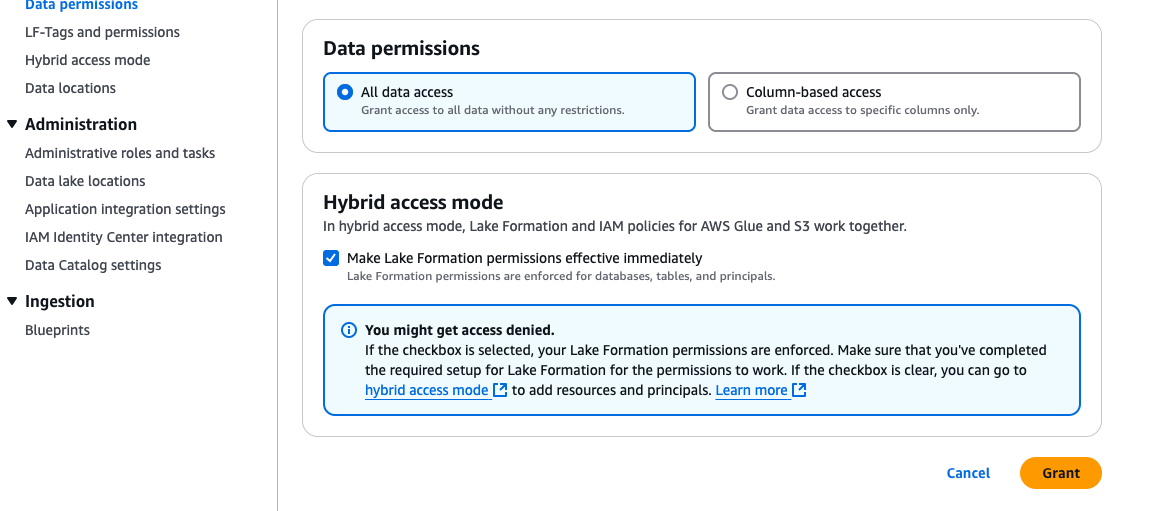
- For Data permissions, select All data access.

- Choose Grant. This will grant select access on all the columns in
diabetic_encountersto the nurse


Now grant access to the diabetic_encounters table for the analyst user.
- Repeat the same steps that you followed for nurse user up to step 7 in the previous section.
- For Data permissions, select Column-based access. Select Include columns and select the
encounter_id,patient_nbr, andreadmittedcolumns

- Choose Grant. This will grant select access on the
encounter_id,patient_nbr, andreadmittedcolumns indiabetic_encountersto the analyst

Run SQL analytics
In this section, you will access the data in the diabetic_encounters S3 Table using nurse and analyst to learn how fine-grain access control works. You will also combine data from the S3 Table data with a local table in Amazon Redshift using a single query.
- In the Amazon Redshift Query Editor V2, connect to
serverless:rs-demo-wg, an Amazon Redshift Serverless instance created by the CloudFormation template. - Select Database user name and password as the connection method and connect using super user
awsuser. Provide the password you gave as an input parameter to the CloudFormation stack.
- Run the following commands to create the IAM users nurse and analyst in Amazon Redshift.
- Amazon Redshift automatically mounts the Data Catalog as an external database named
awsdatacatalogto simplify accessing your tables in Data Catalog. You can grant usage access to this database for the IAM users:

For the next steps, you must first sign in to the AWS Console as the nurse IAM user. You can find the IAM user’s password in the AWS Secrets Manager console and retrieving the value from the secret ending with iam-users-credentials. See Get a secret value using the AWS console for more information.
- After you’ve signed in to the console, navigate to the Amazon Redshift Query Editor V2.
- Sign in to your Amazon Redshift cluster using the IAM:nurse. You can do this by connecting to serverless:rs-demo-wg as Federated user. This applies the permission provided in Lake Formation for accessing your data in Amazon S3 Tables:

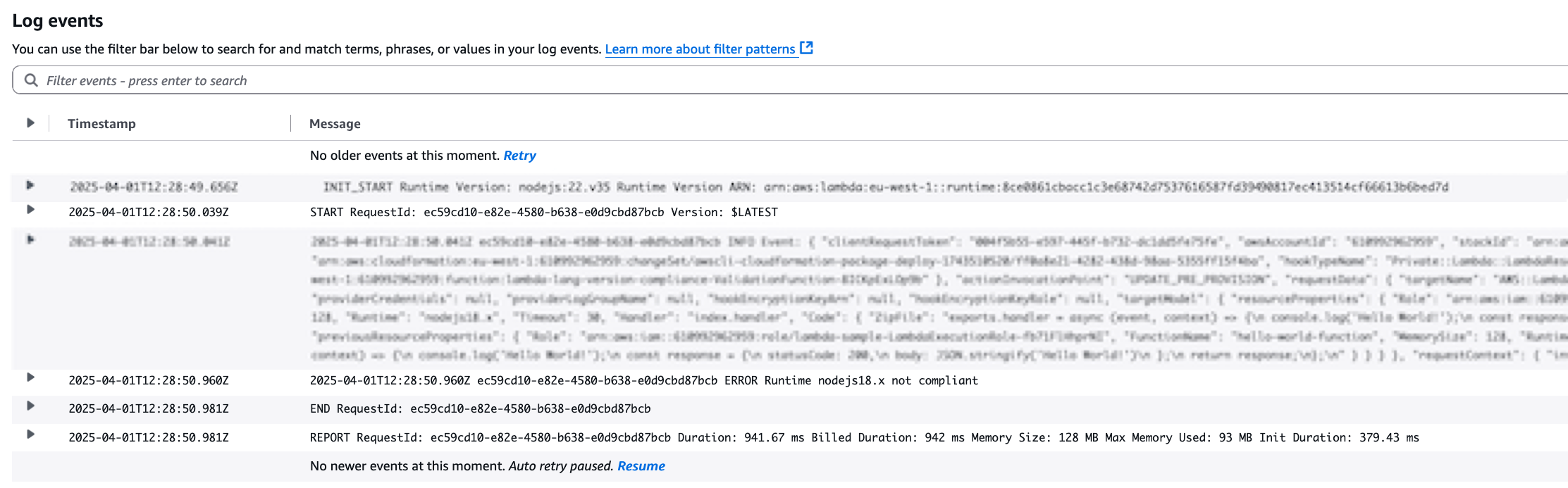
- Run following SQL to query S3 Table diabetic_encounters.

This returns all the data in the S3 Table for diabetic_encounters across every column in the table, as shown in the following figure:

Recall that you also created an IAM user called analyst that only has access to the encounter_id, patient_nbr, and readmitted columns. Let’s verify that analyst user can only access those columns.
- Sign in to the AWS console as the analyst IAM user and open the Amazon Redshift Query Editor v2 using the same steps as above. Run the same query as before:
This time, you should only the encounter_id, patient_nbr, and readmitted columns:

Now that you’ve seen how you can access data in Amazon S3 Tables from Amazon Redshift while setting the levels of access required for your users, let’s see how we can join data in S3 Tables to tables that already exist in Amazon Redshift.
Combine data from an S3 Table and a local table in Amazon Redshift
For this section, you’ll load data into your local Amazon Redshift cluster. After this is complete, you can analyze the datasets in both Amazon Redshift and S3 Tables.
- First, as the analytics federated user, sign in to your Amazon Redshift cluster using Amazon Redshift Query Editor v2.
- Use the following SQL command to create a table that contains patient information.:
- Copy patient information from the file csv that’s stored in your Amazon S3 object bucket. Replace
<diabetic_patients_rs.csv file S3 location>with the location of the file in your S3 bucket. - Use the following query to review the sample data to verify that the command was successful. This will show information from 10 patients, as shown in the following figure.

- Now combine data from the Amazon S3 Table
diabetic_encountersand the Amazon Redshiftpatient_info. In this example, the query fetches information about what age group was most frequently readmitted to the hospital within 30 days of an initial hospital visit:

This query returns results showing an age group and the number of re-admissions, as shown in the following figure.

Cleanup
To clean up your resources, delete the stack you deployed using AWS CloudFormation. For instructions, see Deleting a stack on the AWS CloudFormation console.
Conclusion
In this post, you walked through an end-to-end process for setting up security and governance controls for Apache Iceberg data stored in Amazon S3 Tables and accessing it from Amazon Redshift. This includes creating S3 Tables, loading data into them, registering the tables in a data lake catalog, setting up access controls, and querying the data using Amazon Redshift. You also learned how to combine data from Amazon S3 Tables and local Amazon Redshift tables stored in Redshift Managed Storage in a single query, enabling a seamless, unified analytics experience. Try out these features and see Working with Amazon S3 Tables and table buckets for more details. We welcome your feedback in the comments section.
About the Authors
 Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specializing in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specializing in building enterprise data platforms, data warehousing, and analytics solutions. He has over 19 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
 Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project.
Jonathan Katz is a Principal Product Manager – Technical on the Amazon Redshift team and is based in New York. He is a Core Team member of the open source PostgreSQL project and an active open source contributor, including PostgreSQL and the pgvector project.

 Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate.
Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate. Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing.
Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing. Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
















 Sachin Kale is a senior software development engineer at AWS working on OpenSearch.
Sachin Kale is a senior software development engineer at AWS working on OpenSearch. Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch. Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.




















 Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions.
Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions. Ismael Murillo is a Solutions Architect for Amazon QuickSight. Before joining AWS, Ismael worked in Amazon Logistics (AMZL) with delivery station management, delivery service providers, and our customer actively in the field. Ismael focused on last mile delivery and delivery success. He designed and implemented many innovative solutions to help reduce cost, influence delivery success. He is also a United States Army Veteran, where he served for eleven years.
Ismael Murillo is a Solutions Architect for Amazon QuickSight. Before joining AWS, Ismael worked in Amazon Logistics (AMZL) with delivery station management, delivery service providers, and our customer actively in the field. Ismael focused on last mile delivery and delivery success. He designed and implemented many innovative solutions to help reduce cost, influence delivery success. He is also a United States Army Veteran, where he served for eleven years.











































 Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She collaborates with the service team to enhance product features, works with AWS customers and partners to architect lake house solutions, and establishes best practices.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She collaborates with the service team to enhance product features, works with AWS customers and partners to architect lake house solutions, and establishes best practices. Parul Saxena is a Senior Big Data Specialist Solutions Architect in AWS. She helps customers and partners build highly optimized, scalable, and secure solutions. She specializes in Amazon EMR, Amazon Athena, and AWS Lake Formation, providing architectural guidance for complex big data workloads and assisting organizations in modernizing their architectures and migrating analytics workloads to AWS.
Parul Saxena is a Senior Big Data Specialist Solutions Architect in AWS. She helps customers and partners build highly optimized, scalable, and secure solutions. She specializes in Amazon EMR, Amazon Athena, and AWS Lake Formation, providing architectural guidance for complex big data workloads and assisting organizations in modernizing their architectures and migrating analytics workloads to AWS.























 BP Yau is a Sr Partner Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
BP Yau is a Sr Partner Solutions Architect at AWS. His role is to help customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies. Ali Alladin is the Senior Director of Product Management and Partner Solutions at ThoughtSpot. In this role, Ali oversees Cloud Engineering and Operations, ensuring seamless integration and optimal performance of ThoughtSpot’s cloud-based services. Additionally, Ali spearheads the development of AI-powered solutions in augmented and embedded analytics, collaborating closely with technology partners to drive innovation and deliver cutting-edge analytics capabilities. With a robust background in product management and a keen understanding of AI technologies, Ali is dedicated to pushing the boundaries of what’s possible in the analytics space, helping organizations harness the full potential of their data.
Ali Alladin is the Senior Director of Product Management and Partner Solutions at ThoughtSpot. In this role, Ali oversees Cloud Engineering and Operations, ensuring seamless integration and optimal performance of ThoughtSpot’s cloud-based services. Additionally, Ali spearheads the development of AI-powered solutions in augmented and embedded analytics, collaborating closely with technology partners to drive innovation and deliver cutting-edge analytics capabilities. With a robust background in product management and a keen understanding of AI technologies, Ali is dedicated to pushing the boundaries of what’s possible in the analytics space, helping organizations harness the full potential of their data.
 Figure 1: AWS KMS GenerateDataKey requests per second without TLS connection reuse
Figure 1: AWS KMS GenerateDataKey requests per second without TLS connection reuse
 Figure 2: AWS KMS GenerateDataKey requests per second with TLS connection reuse
Figure 2: AWS KMS GenerateDataKey requests per second with TLS connection reuse










 Balaji Mohan is a Senior Delivery Consultant specializing in application and data modernization to the cloud. His business-first approach provides seamless transitions, aligning technology with organizational goals. Using cloud-centered architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth.
Balaji Mohan is a Senior Delivery Consultant specializing in application and data modernization to the cloud. His business-first approach provides seamless transitions, aligning technology with organizational goals. Using cloud-centered architectures, he delivers scalable, agile, and cost-effective solutions, driving innovation and growth. Senthil Ramasamy is a Senior Database Consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database services, helping them with database migrations to the AWS Cloud and improving the value of their solutions when using AWS.
Senthil Ramasamy is a Senior Database Consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database services, helping them with database migrations to the AWS Cloud and improving the value of their solutions when using AWS. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.