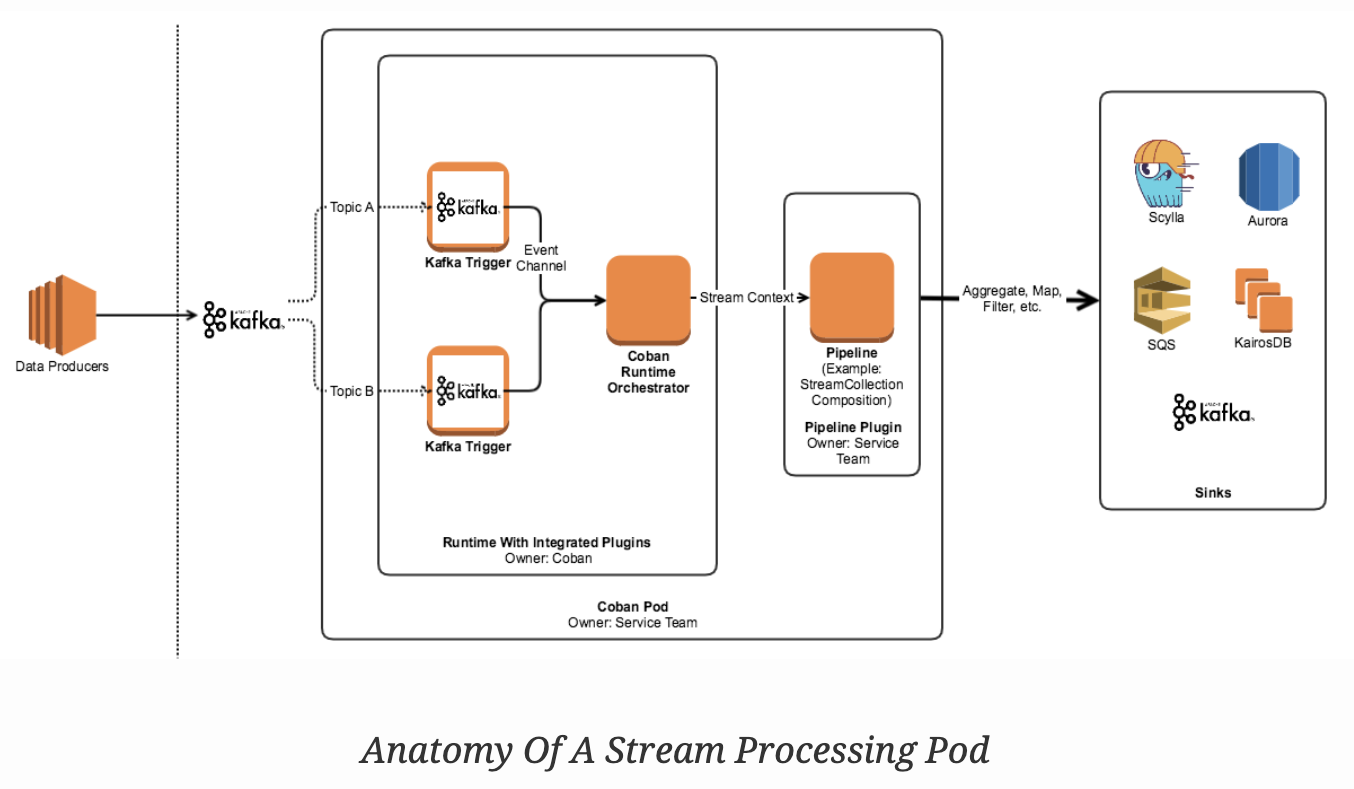
Security for Kubernetes might not be quite the same as what you’re used to. In our previous article, we covered why security is so important in both Linux on-premises servers and cloud Kubernetes clusters. We also talked about 3 major aspects of Linux server security — processes, network, and file system — and how they correspond to Kubernetes. So today, we’ll talk more about the security concerns unique to Kubernetes.
Configurations
When trying to secure your infrastructure, you have to start by configuring it well. For example, this might mean disabling all unused features or using allow-policies wherever you can to keep your files, executables, or network available only to the intended entity. Both Linux servers and Kubernetes clusters have known vulnerabilities and recommendations.
The Kubernetes API server is the admin panel, so to speak, of your cluster. In most deployments, this HTTP server is exposed to the internet. This means that a hacker that finds their way to the API server can have full control over your cluster.
Using the most strict authentication and authorization settings is highly recommended to prevent this. If you can set your cluster to private, with access only allowed from an internal network, you can sleep well at night. And just as with with configurations, you should be aware at all times of who (and what) can have access to which resources and operations in your cluster.
Audit log and other Kubernetes logs
In Kubernetes, there are additional attack vectors using the Kubernetes control plane itself that don’t exist in Linux server security. For example, an attack could call the Kubernetes API to load a new pod you didn’t want.
Kubernetes and cloud providers invest a lot of effort in preventing unauthorized users and machines from doing this. But there is always a chance that one of your employees gets hacked or a badly configured service account has too much power. Kubernetes logs all requests to its audit log so they can be investigated later in case of a breach. Additional logs include the kube-API log or etcd (resources DB) log.
Container runtime
Container runtime is also a unique aspect of Kubernetes security. In Kubernetes, each node is actually a virtual Linux server running a container runtime daemon. A container runtime is responsible for managing the images and running and monitoring the containers, their storage and network provisioning, and more. You might be familiar with Docker as a container runtime. In reality, Docker is a company developing multiple container tools, and their container runtime is named containerd. Other container runtimes for Kubernetes include CRI-O, Rocket, and more.
Apart from a whole Linux server or virtual machine that uses its own single operating system, multiple containers are usually running over multiple operating systems that share the same host kernel. Although the operating systems of the containers are minimal, they may still have security holes. And the more holes the merrier for the attacker! Monitoring the container runtime activity can also yield a lot of information about what is going on in the node — what processes are running inside the container, any internal communication that might escape from network monitoring, the data being collected and created, and so on.
Right tools, lower risks
The unique interfaces and engines of Kubernetes can be an additional exposed surface in terms of security, especially when considering the complexity of the system. However, don’t forget that distribution and containerization add to security and help isolate potential malware.
Kubernetes may come with a few new risks to watch out for, but that’s no reason to be scared off. As long as you know what to look for, security for your Kubernetes clusters doesn’t have to be any harder than it was for your Linux servers. And there’s no need to go it alone — not when you can have handy tools like InsightCloudSec, Rapid7’s cloud-native security platform, at your side.
Kubernetes was first presented in 2014, and it almost entirely changed the way technological and even non-tech companies use infrastructure for running their applications. The Kubernetes platform still feels new and exciting — it has awesome features and can fit most use cases.
But hackers find the combination of new technology and user inexperience that’s just right for their malicious activity. Deploying your product on a Kubernetes cluster has a different security cost than on a traditional Linux server.
What are the risks of using Kubernetes?
The risks of a Kubernetes (K8s) deployment are actually the same as in traditional Linux servers. Most of them can be summed up to these 3 targets:
Denial of Service (DoS): These kinds of attacks want your service down. They can be caused in many different ways, including distributed denial of service (DDoS) attacks or SQL injections that erase your databases. As there is no direct profit to the attacker, these attacks are of most interest to malicious groups who disagree with your company values or products, or to your competitors.
Information exfiltration: Another type of attack targets the information you hold. These attacks can collect your information, like your profits, source codes, names of employees, and so on. Or they can collect private data about your customers and users — who they are, their credit card numbers, health state, financial assets, and everything you know about them. None of this is data you want to be known outside the company.
Hardware hijack: A hardware hijack is any type of attack that runs a malicious code on your compute resources and causes them to operate in a way that you did not program or intend them to run. Most of these attacks are related to cryptocurrency. They typically either turn your CPU/GPU to Bitcoin miner or conduct a ransomware attack by encrypting your file system and requesting you to pay ransom (usually in Bitcoin) to unencrypt it. As the important point here for attackers is profit, not the identity of the victim, these attacks usually originate from bots or automatic scripts, rather than with dedicated special operations of malicious groups or individuals.
How can you defend yourself?
Securing deployments and identifying malicious activity on Kubernetes clusters is similar to how it’s done on traditional Linux servers. Most of the differences are in the implementation itself. But there are some distinctions worth mentioning. Let’s focus in on the operating system aspects of security.
Processes and system calls
“The system call is the fundamental interface between an application and the Linux kernel.” —Linux manual page
Linux has over 400 different system calls. These can be used for requesting to read a file, executing another program, sending a network message, and more. As you’ve probably guessed, these operations can be risky when used by unwanted programs.
The Linux Kernel has security mechanisms against malware, but it isn’t fully protected. So system calls may seem legitimate even when they aren’t. Tracking these system calls can give good insight on what a process does. In native Linux, it can be easy to track these down from a single point on the server. However, in K8s Linux nodes, the distribution, dynamics, and containerization makes this mission a very complex task.
Network security
The internet connection is your face for the customers, but it’s also the entry point for various malicious software into your infrastructure. Luckily, the big cloud providers and most of the internet-facing frameworks are well-protected against these attacks. But nothing is 100% safe. Moreover, some of the images you are using may contain security holes themselves. These can cause a malicious program to initiate from inside your cluster.
Tracking the network from the inside out can give you a lot of information on malicious activity. But you also have to consider the “east-to-west” traffic inside your infrastructure — the internal communication. In traditional Linux servers and VMs, you know exactly which microservices exist and define firewall services accordingly. However, in Kubernetes, the dynamic nature of the pods and resources makes it hard to track this traffic, so it can be difficult to find the network holes.
File system
It may seem easy to detect new files and file changes in order to determine unwanted changes, but tracking and analyzing your whole file system can be a large, complex task in Linux servers. They can have terabytes of storage, and reading them — especially from a magnetic hard disk — isn’t fast enough to detect malicious activity when it happens. However, the containerization concept of Kubernetes can be to our advantage here, as container images are usually small, lightweight, and repetitive. Looking inside the containers files should have highly expected results.
More to come
This is one of two articles covering the detective resources that can help us identify unwanted activity in your Kubernetes clusters. In this first part, we saw that both Kubernetes and traditional Linux servers have vulnerabilities that originate in the processes, network, or file system. However, there are differences in how to monitor malicious activity in Kubernetes versus Linux. Some vulnerabilities may seem harder to defend in Kubernetes, but most of them are actually easier.
InsightCloudSec, Rapid7’s cloud-native security platform, covers these differences and ensures your on-premises server farm is secured.
The next article will explain further about the unique aspects of Kubernetes security that do not exist in traditional Linux servers. Stay tuned!
This post is written by Carlos Manzanedo Rueda, WW SA Leader for EC2 Spot, and Brandon Wagner, Senior Software Development Engineer for EC2.
This post focuses on how you can leverage recently released tools to optimize your usage of Amazon EC2 Spot Instances on Kubernetes Operations (kOps) clusters. Spot Instances let you utilize unused capacity in the AWS cloud for up to 90% off compared to On-Demand prices, and they are a great fit for fault-tolerant, containerized applications. kOps is an open source project providing a cohesive toolset for provisioning, operating, and deleting Kubernetes clusters in the cloud.
Even with customers such as Snap Inc., Babylon Health, and Fidelity Investments telling us how Amazon Elastic Kubernetes Service (EKS) is essential for running their containerized workloads, we appreciate that there are scenarios where using Amazon EC2 instances and kOps are a viable alternative. At AWS, we understand “one size does not fit all.” While we encourage Kubernetes users to contribute their feedback to the AWS container roadmap so that we can improve our services, we also would like to reduce heavy lifting and simplify Spot best practices integration in kOps clusters.
To simplify the integration of Spot Instances in kOps clusters, in January of 2021 we introduced a new kops toolbox command: kops toolbox instance-selector. The utility is distributed as part of the standard kOps distribution. Moreover, it simplifies the creation of kOps Instance Groups by configuring them with full adherence to Spot Instances best practices.
Handling Spot interruption notifications in Kubernetes
Let’s quickly recap Spot best practices. Spot Instances perform exactly like any other EC2 Instances, except that in exchange for their discounted price, they can be interrupted with a two-minute warning when EC2 must reclaim capacity. Applications running on Spot can typically recover from transient interruptions by simply starting a new instance. Spot best practices involve measures such as diversifying into as many Spot capacity pools as possible, choosing the right Spot allocation strategy, and utilizing Spot integrated services. These handle the Spot Instances lifecycles for you. This blog post on handling Spot interruptions dives deeper into AWS’s EC2 Spot best practices.
The kOps managed addon will let you configure the Node Termination Handler within your kOps cluster spec and, more importantly, manage provisioning the necessary infrastructure for you.
To deploy the AWS Node Termination Handler, we start by editing our cluster spec:
kops edit cluster --name ${KOPS_CLUSTER_NAME}
We append the nodeTerminationHandler configuration to the spec node:
${KOPS_CLUSTER_NAME} refers to the environment variable containing the cluster name, and ${KOPS_STATE_STORE} indicates the Amazon Simple Storage Service (S3) bucket – or kOps State Store – where kOps configuration is stored.
To check that your Node Termination Handler deployment was successful, you can execute:
kops get deployment aws-node-termination-handler -n kube-system
Instance Flexibility and Diversification
Diversification and selection of multiple instances types is essential to acquire and maintain Spot capacity, as well as to successfully replace interrupted instances with others from different pools. When running kOps on AWS, this is implemented by utilizing Amazon EC2 Auto Scaling. Amazon Auto Scaling group’s capacity-optimized allocation strategy ensures that Spot capacity is provisioned from the optimal pools, thereby reducing the chances of Spot terminations.
Simplifying adoption of Spot Best practices on kOps
Before the kops toolbox instance-selector, you would have to setup Spot best practices on kOps manually. This involved writing a stub file following the InstanceGroup specification and examples, and then implementing every best practice, including finding every pool that qualifies for our workload.
The new functionality in kops toolbox instance-selector simplifies InstanceGroup creation by moving the focus of kOps users and administrators from this manual configuration over to simply selecting the vCPUs and Memory requirements for their application (or a base instance type), and then letting kops toolbox instance-selector define the right configuration. Behind the scenes, it utilizes a library allowing it to plug into the feature-set of Amazon EC2 instance selector. At its core, ec2 instance selector helps you select compatible instance types for your application to run on. Utilize ec2 instance selector CLI or library when automating your configurations. In the case of kOps, the integration already comes in the kops toolbox.
For example, let’s say your cluster runs stateless, fault tolerant applications that are CPU/Memory bound and have a ratio of vCPU to Memory requiring at least 1vCPU : 4GB of RAM. You can run the following command in order to acquire cluster spot capacity:
Let’s focus first on the command, and later cover its output. You can get a list of parameters and default values by running: kops toolbox instance-selector –help. A few default parameters weren’t passed in the command above, but they will be set to sane defaults, such as the maximum and minimum number of instances in the Instance Group. The parameter –flexible refers to our request to provide a group of flexible instance types spanning multiple generations.
Once you’ve defined the InstanceGroups, start them up by using the command:
The two commands above define and create a request for spot capacity from a flexible and diversified pool set, which meet the criteria to provide at least 4GB of RAM for each vCPU. The command creates not just one, but two node groups named “spot-group-1” and “spot-group-2” (–ig-count 2).
Now, let’s check the contents of the configuration file generated by kops toolbox instance-selector. To preview a configuration without making changes, add –dry-run –output yaml.
The configuration above lists one of the groups created by kops toolbox instance-selector in the previous example. The second group will have a very similar make-up and format, except that it will refer to instances such as: r3.xlarge, r4.xlarge, r5.xlarge, and r5a.xlarge in the mixedInstancesPolicy section. By defining the parameter –usage-class to Spot, the configuration created by kops toolbox instance-selector will add the tags identifying this Auto Scaling group as a Spot group. When the nodes are initialized, kOps controller will identify the nodes as Spot and add the label node-role.kubernetes.io/spot-worker=true. Therefore, at a later stage, we can apply placement logic to our cluster by using nodeSelector and affinity. The configuration above adheres to the definition of kOps support for mixed Instance Groups in AWS, and adds all of the right cloudLabels in order to integrate and implement not only with Spot best practices, but also with Cluster Autoscaler Auto-Discovery configuration best practices.
Kubernetes Cluster Autoscaler is a Kubernetes controller that dynamically adjusts the cluster size. According to a 2020 survey by Cloud Native Computing Foundation (CNCF), 70% of Kubernetes workloads plan to autoscale their stateless applications. Dynamically scaling applications and clusters is also a great practice for optimizing your system costs in situations where capacity is unnecessary, as well as for scaling out accordingly in order to meet business demands. If there are Pods that can’t be scheduled due to insufficient resources, then Cluster Autoscaler will issue a Scale-out action. When there are nodes in the cluster that have been under-utilized for a configurable period of time, Cluster Autoscaler will Scale-in the cluster, and even down-scale to 0 instances when applications don’t need to be run.
On Scale-out operations, Cluster Autoscaler evaluates a set of node groups. When Cluster Autoscaler runs on AWS, node groups are implemented by using Auto Scaling groups (referring to the same instance group as a kOps Instance Group). Therefore, to calculate the number of nodes to scale-out, Cluster Autoscaler assumes that every instance in a node group has the same number of vCPUs and memory size.
By creating two node groups, you apply two diversification levels. You diversify within each node group by using an Auto Scaling group with Mixed Instance Policies and capacity-optimized allocation strategy. Then, to increase the pool range you can leverage, you add more than one node group, while still adhering to the best practices required by Cluster Autoscaler.
While we’ve been focusing on Spot Instances, the parameter –usage-class can be utilized to get OnDemand instances instead of Spot. In the next example, let’s say we would like to get On-Demand capacity in order to train complex deep learning models that will take hours to run. To train our models, we need instances that have at least one GPU with 16GB of RAM on instances that have at least 32GB Ram and 8 vCPUs.
The command above, followed by kops update cluster –state=${KOPS_STATE_STORE} –name=${KOPS_CLUSTER_NAME} –yes can be utilized to produce a configuration and create a nodegroup with the right requirements. This could be created at the start of the training procedure, and then – once the training is done and the capacity is no longer needed – you could automate the nodegroup removal with the following command:
We believe the best way to run Kubernetes on AWS is by using Amazon EKS. However, scenarios may exist where kOps is utilized in AWS. By using the kOps managed add-on to install aws-node-termination-handler and kops toolbox instance-selector, it is easier than ever to apply Spot best practices to Kubernetes workloads on kOps, and cost-optimize fault-tolerant, stateless applications. These tools let kOps workloads gracefully terminate applications, as well as proactively handle the replacement of instances that are at an elevated risk of termination. kops toolbox instance-selector leverages Amazon ec2-instance-selector in order to simplify the creation of Instance Group configurations adhering to Spot Instances best practices, implementing instance type flexibility, and utilizing capacity-optimized allocation strategy.
By adhering to these best practices to reduce the frequency of Spot interruptions, we will optimize not only the cost, but also our Spot Instances selection. This will enable us to acquire capacity at a massive scale if necessary.
To start using the tools we have described, follow along this step-by-step tutorial. Also, head over to the kops toolbox documentation to learn more about the ways in which you can use it.
Customers want a single and comprehensive view of the security posture of their workloads. Runtime security event monitoring is important to building secure, operationally excellent, and reliable workloads, especially in environments that run containers and container orchestration platforms. In this blog post, we show you how to use services such as AWS Security Hub and Falco, a Cloud Native Computing Foundation project, to build a continuous runtime security monitoring solution.
With the solution in place, you can collect runtime security findings from multiple AWS accounts running one or more workloads on AWS container orchestration platforms, such as Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Container Service (Amazon ECS). The solution collates the findings across those accounts into a designated account where you can view the security posture across accounts and workloads.
Solution overview
Security Hub collects security findings from other AWS services using a standardized AWS Security Findings Format (ASFF). Falco provides the ability to detect security events at runtime for containers. Partner integrations like Falco are also available on Security Hub and use ASFF. Security Hub provides a custom integrations feature using ASFF to enable collection and aggregation of findings that are generated by custom security products.
Figure 1: Architecture diagram of continuous runtime security monitoring
Here’s how the solution works, as shown in Figure 1:
An AWS account is running a workload on Amazon EKS.
Runtime security events detected by Falco for that workload are sent to CloudWatch logs using AWS FireLens.
CloudWatch logs act as the source for FireLens and a trigger for the Lambda function in the next step.
The Lambda function transforms the logs into the ASFF. These findings can now be imported into Security Hub.
The Security Hub instance that is running in the same account as the workload running on Amazon EKS stores and processes the findings provided by Lambda and provides the security posture to users of the account. This instance also acts as a member account for Security Hub.
Another AWS account is running a workload on Amazon ECS.
Runtime security events detected by Falco for that workload are sent to CloudWatch logs using AWS FireLens.
CloudWatch logs acts as the source for FireLens and a trigger for the Lambda function in the next step.
The Lambda function transforms the logs into the ASFF. These findings can now be imported into Security Hub.
The Security Hub instance that is running in the same account as the workload running on Amazon ECS stores and processes the findings provided by Lambda and provides the security posture to users of the account. This instance also acts as another member account for Security Hub.
The designated Security Hub administrator account combines the findings generated by the two member accounts, and then provides a comprehensive view of security alerts and security posture across AWS accounts. If your workloads span multiple regions, Security Hub supports aggregating findings across Regions.
Prerequisites
For this walkthrough, you should have the following in place:
Three AWS accounts.
Note: We recommend three accounts so you can experience Security Hub’s support for a multi-account setup. However, you can use a single AWS account instead to host the Amazon ECS and Amazon EKS workloads, and send findings to Security Hub in the same account. If you are using a single account, skip the following account specific-guidance. If you are integrated with AWS Organizations, the designated Security Hub administrator account will automatically have access to the member accounts.
Security Hub set up with an administrator account on one account.
Security Hub set up with member accounts on two accounts: one account to host the Amazon EKS workload, and one account to host the Amazon ECS workload.
Falco set up on the Amazon EKS and Amazon ECS clusters, with logs routed to CloudWatch Logs using FireLens. For instructions on how to do this, see:
Important: Take note of the names of the CloudWatch Logs groups, as you will need them in the next section.
AWS Cloud Development Kit (CDK) installed on the member accounts to deploy the solution that provides the custom integration between Falco and Security Hub.
Deploying the solution
In this section, you will learn how to deploy the solution and enable the CloudWatch Logs group. Enabling the CloudWatch Logs group is the trigger for running the Lambda function in both member accounts.
To deploy this solution in your own account
Clone the aws-securityhub-falco-ecs-eks-integration GitHub repository by running the following command. $git clone https://github.com/aws-samples/aws-securityhub-falco-ecs-eks-integration
Follow the instructions in the README file provided on GitHub to build and deploy the solution. Make sure that you deploy the solution to the accounts hosting the Amazon EKS and Amazon ECS clusters.
Navigate to the AWS Lambda console and confirm that you see the newly created Lambda function. You will use this function in the next section.
Figure 2: Lambda function for Falco integration with Security Hub
To enable the CloudWatch Logs group
In the AWS Management Console, select the Lambda function shown in Figure 2—AwsSecurityhubFalcoEcsEksln-lambdafunction—and then, on the Function overview screen, select + Add trigger.
On the Add trigger screen, provide the following information and then select Add, as shown in Figure 3.
Trigger configuration – From the drop-down, select CloudWatch logs.
Log group – Choose the Log group you noted in Step 4 of the Prerequisites. In our setup, the log group for the Amazon ECS and Amazon EKS clusters, deployed in separate AWS accounts, was set with the same value (falco).
Filter name – Provide a name for the filter. In our example, we used the name falco.
Filter pattern – optional – Leave this field blank.
Figure 3: Lambda function trigger – CloudWatch Log group
Repeat these steps (as applicable) to set up the trigger for the Lambda function deployed in other accounts.
Testing the deployment
Now that you’ve deployed the solution, you will verify that it’s working.
With the default rules, Falco generates alerts for activities such as:
An attempt to write to a file below the /etc folder. The /etc folder contains important system configuration files.
An attempt to open a sensitive file (such as /etc/shadow) for reading.
To test your deployment, you will attempt to perform these activities to generate Falco alerts that are reported as Security Hub findings in the same account. Then you will review the findings.
To test the deployment in member account 1
Run the following commands to trigger an alert in member account 1, which is running an Amazon EKS cluster. Replace <container_name> with your own value. kubectl exec -it <container_name> /bin/bash touch /etc/5 cat /etc/shadow > /dev/null
To see the list of findings, log in to your Security Hub admin account and navigate to Security Hub > Findings. As shown in Figure 4, you will see the alerts generated by Falco, including the Falco-generated title, and the instance where the alert was triggered.
Figure 4: Findings in Security Hub
To see more detail about a finding, check the box next to the finding. Figure 5 shows some of the details for the finding Read sensitive file untrusted.
Figure 6 shows the Resources section of this finding, that includes the instance ID of the Amazon EKS cluster node. In our example this is the Amazon Elastic Compute Cloud (Amazon EC2) instance.
To test the deployment in member account 2
Run the following commands to trigger a Falco alert in member account 2, which is running an Amazon ECS cluster. Replace <<container_id> with your own value. docker exec -it <container_id> bash touch /etc/5 cat /etc/shadow > /dev/null
As in the preceding example with member account 1, to view the findings related to this alert, navigate to your Security Hub admin account and select Findings.
To view the collated findings from both member accounts in Security Hub
In the designated Security Hub administrator account, navigate to Security Hub> Findings. The findings from both member accounts are collated in the designated Security Hub administrator account. You can use this centralized account to view the security posture across accounts and workloads. Figure 7 shows two findings, one from each member account, viewable in the Single Pane of Glass administrator account.
Figure 7: Write below /etc findings in a single view
To see more information and a link to the corresponding member account where the finding was generated, check the box next to the finding. Figure 8 shows the account detail associated with a specific finding in member account 1.
Figure 8: Write under /etc detail view in Security Hub admin account
By centralizing and enriching the findings from Falco, you can take action more quickly or perform automated remediation on the impacted resources.
Delete the Amazon EKS and Amazon ECS clusters created as part of the Prerequisites.
Conclusion
In this post, you learned how to achieve multi-account continuous runtime security monitoring for container-based workloads running on Amazon EKS and Amazon ECS. This is achieved by creating a custom integration between Falco and Security Hub.
You can extend this solution in a number of ways. For example:
You can forward findings across accounts using a single source to security information and event management (SIEM) tools such as Splunk.
You can perform automated remediation activities based on the findings generated, using Lambda.
When it comes to cloud-native applications, optimal security requires a modern, integrated, and automated approach that starts in development and extends to runtime protection. Cloud workload protection (CWP) helps make that goal possible by bringing major structural changes to software development and enhancing security across all processes.
Assessing workload risk in the cloud
Both the rise of cloud proliferation and the high speed of deployments can make distilling down the necessary cloud security controls an overwhelming challenge. Add to the mix the ever-evolving threat landscape, and the measures you take can literally make or break your cloud deployments, including the security of your workloads.
The increasing distribution and complexity of cloud-native applications across VMs, hosts, Kubernetes, and multiple vendors requires an end-to-end, consistent workload protection platform that unifies both CSPM and CWPP functionalities, thus enabling a holistic approach for protecting valuable assets in the cloud.
How Rapid7 is changing cloud workload protection
In order to get unmanaged risk under control, Rapid7 is on a mission to help drive cloud security forward, both within individual organizations and as an entire industry.
This is why Rapid7 recently introduced InsightCloudSec, an entire division dedicated solely to cloud security and all it encompasses.
In its most recent launch, InsightCloudSec brings forward a series of functionalities that bolsters our ability to help our customers protect their cloud workloads and deployments by providing a fully integrated, cloud-native security solution at scale. These improvements include:
Enhancing risk assessment of Kubernetes and containers
Enabling developers to scan code from the CLI on their machines
Expanding automation based on event-driven detections in multi-cloud environments
Providing unified visibility and robust context across multi-cloud environments
Automating workflows so organizations can gain maximum efficiency
3 keys to consolidating cloud risk assessment
In an effort to help this emerging market become more mainstream and easier to operationalize, we believe there are 3 main things that organizations need to be able to do when it comes to cloud security.
1. Shift left
Prevent problems before they happen by providing a single, consistent set of security checks throughout the CI/CD pipeline to uncover misconfigurations and policy violations without delaying deployment. Not only does this help solve issues at their root cause and prevent them from happening over and over again, but it also makes for a better working relationship between the security team and the DevOps organization that is trying to move fast and innovate. By shifting left, organizations save money, and security teams are able to give developers the information and tools they need to make the right decisions as early as possible, avoiding delays later in the deployment or operationalizing stages of the CI/CD pipeline.
2. Reduce noise
Security teams need more context and simpler insights so they can actually understand the top risks in their environment. By unifying visibility across the entire cloud footprint, normalizing the terminology across each different cloud environment, and then providing rich context about interconnected assets, security teams can vastly simplify risk assessment and decision-making across even the most complex cloud and container environments.
3. Automate workflows
Finally, the ephemeral nature and speed of change in cloud environments has outstripped the human capability to manage and remediate issues manually. This means organizations need to automate DevSecOps best practices by leveraging precise automation that speeds up remediation, reduces busywork, and allows the security team to focus on the bigger picture.
By bringing together enhanced risk assessment of Kubernetes and containers, shifting further left with a CLI integration, and expanding event-based detections into the cloud-native security platform, Rapid7 is making it easier for teams to consolidate visibility and maintain consistent controls across even the most complex cloud environments.
Stay ahead of security in the modern threat landscape by ensuring cloud security as an ongoing process, and reduce your attack surface by building the necessary security measures early in an application’s life cycle.
Cloud and container technologies are being increasingly embraced by organizations around the globe because of the efficiency, superior visibility, and control they provide to DevOps and IT teams.
While DevOps teams see the benefits of cloud and container solutions, these tools create a learning curve for their security colleagues. Because of this, security teams often want to slow down adoption while they figure out a strategy for maintaining security and compliance in these new fast-moving environments.
Container and Kubernetes (K8s) environments are already fairly complex as it is, and layering multiple additional security tools into the mix makes it even more challenging from a management perspective. Organizations need to find a way to enable their DevOps teams to move quickly and take advantage of the benefits of containers and K8s, while staying within the parameters the security team needs to maintain compliance with organizational policy.
This challenge goes beyond technology. These teams need to find a solution that allows them to work together well, doesn’t over-complicate their working relationship, and lets both sides get what they want with minimal overhead.
A holistic approach to Kubernetes security
As an open-source container orchestration system for automating deployment, scaling, and management of containerized applications, Kubernetes is extremely powerful. However, organizations must carefully balance their eagerness to embrace the dynamic, self-service nature of Kubernetes with the real-life need to manage and mitigate security and compliance risk.
Rapid7’s recent introduction of InsightCloudSec intelligently unifies both CSPM and CWPP functionalities, thus enabling a holistic approach for protecting valuable assets in the cloud — one that includes Kubernetes and workload security.
In retrospect, 2020 was a tipping point for the Kubernetes community, with a massive increase in adoption across the globe. Many companies, seeking an efficient, cost-effective way to make this huge shift to the cloud, turned to Kubernetes. But this in turn created a growing need to remove Kubernetes security blind spots. For this reason, we’ve introduced Kubernetes Guardrails.
With Kubernetes Security Guardrails, organizations are equipped with a multi-cluster vulnerability scanner that covers rich Kubernetes security best practices and compliance policies, such as CIS Benchmarks. As part of Rapid7’s InsightCloudSec solution, this new capability introduces a platform-based and easy-to-maintain solution for Kubernetes security that is deployed in minutes and is fully streamlined in the Kubernetes pipeline.
Securing Kubernetes with InsightCloudSec
Kubernetes Security Guardrails is the most comprehensive solution for all relevant Kubernetes security requirements, designed from a DevOps perspective with in-depth visibility for security teams.
InsightCloudSec is designed to be an agentless state machine, seamlessly applied to any computing environment — public cloud or private software-defined infrastructure.
InsightCloudSec continually interacts with the APIs to gather information about the state of the hosts and the Kubernetes clusters of interest. These hosts can be GCP, AWS, Azure, or a private data center that can expose infrastructure information via an API.
Integrated within minutes, the Kubernetes Guardrails functionality simplifies the security assessment for the entire Kubernetes environment and the CI/CD pipeline, while also creating baseline profiles for each cluster, and highlighting and scoring security risks, misconfigurations, and hygiene drifts.
Both DevOps and Security teams enjoy the continuous and dynamic analysis of their Kubernetes deployments, all while seamlessly complying with regulatory requirements for Kubernetes.
With Kubernetes Guardrails, Dev teams are able to create a snapshot of cluster risks, delivered with a detailed list of misconfigurations, while detecting real-time hygiene and conformance drifts for deployments running on any cloud environment. Some of the most common use cases include:
Kubernetes vulnerability scanning
Hunting misplaced secrets and excessive secret access
Workload hardening (from pod security to network policies)
Istio security and configuration best practices
Ingress controllers security
Kubernetes API server access privileges
Kubernetes operators best practices
RBAC controls and misconfigurations
Ready to drive cloud security forward?
Rapid7 is proud to introduce a Kubernetes security solution that encapsulates all-in-one capabilities and unmatched coverage for all things Kubernetes.
With a security-first approach and strict compliance adherence, Kubernetes Guardrails enable a better understanding and control over distributed projects, and help organizations maintain smooth business operations.
This post is written by Kinnar Sen, Senior EC2 Spot Specialist Solutions Architect
Apache Flink is a distributed data processing engine for stateful computations for both batch and stream data sources. Flink supports event time semantics for out-of-order events, exactly-once semantics, backpressure control, and optimized APIs. Flink has connectors for third-party data sources and AWS Services, such as Apache Kafka, Apache NiFi, Amazon Kinesis, and Amazon MSK. Flink can be used for Event Driven (Fraud Detection), Data Analytics (Ad-Hoc Analysis), and Data Pipeline (Continuous ETL) applications. Amazon Elastic Kubernetes Service (Amazon EKS) is the chosen deployment option for many AWS customers for Big Data frameworks such as Apache Spark and Apache Flink. Flink has native integration with Kubernetes allowing direct deployment and dynamic resource allocation.
In this post, I illustrate the deployment of scalable, highly available (HA), resilient, and cost optimized Flink application using Kubernetes via Amazon EKS and Amazon EC2 Spot Instances (Spot). Learn how to save money on big data streaming workloads by implementing this solution.
Overview
Amazon EC2 Spot Instances
Amazon EC2 Spot Instances let you take advantage of spare EC2 capacity in the AWS Cloud and are available at up to a 90% discount compared to On-Demand Instances. Spot Instances receive a two-minute warning when these instances are about to be reclaimed by Amazon EC2. There are many graceful ways to handle the interruption. Recently EC2 Instance rebalance recommendation has been added to send proactive notifications when a Spot Instance is at elevated risk of interruption.Spot Instances are a great way to scale up and increase throughput of Big Data workloads and has been adopted by many customers.
Apache Flink and Kubernetes
Apache Flink is an adaptable framework and it allows multiple deployment options and one of them being Kubernetes. Flink framework has a couple of key building blocks.
Job Client submits the job in form of a JobGraph to the Job Manager.
Job Manager plays the role of central work coordinator which distributes the job to the Task Managers.
Task Managers are the worker component, which runs the operators for source, transformations and sinks.
External components which are optional such as Resource Provider, HA Service Provider, Application Data Source, Sinks etc., and this varies with the deployment mode and options.
Flink supports different deployment (Resource Provider) modes when running on Kubernetes. In this blog we will use the Standalone Deployment mode, as we just want to showcase the functionality. We recommend first-time users however to deploy Flink on Kubernetes using the Native Kubernetes Deployment.
Flink can be run in different modes such as Session, Application, and Per-Job. The modes differ in cluster lifecycle, resource isolation and execution of the main() method. Flink can run jobs on Kubernetes via Application and Session Modes only.
Application Mode: This is a lightweight and scalable way to submit an application on Flink and is the preferred way to launch application as it supports better resource isolation. Resource isolation is achieved by running a cluster per job. Once the application shuts down all the Flink components are cleaned up.
Session Mode: This is a long running Kubernetes deployment of Flink. Multiple applications can be launched on a cluster and the applications competes for the resources. There may be multiple jobs running on a TaskManager in parallel. Its main advantage is that it saves time on spinning up a new Flink cluster for new jobs, however if one of the Task Managers fails it may impact all the jobs running on that.
Amazon EKS
Amazon EKS is a fully managed Kubernetes service. EKS supports creating and managing Spot Instances using Amazon EKS managed node groups following Spot best practices. This enables you to take advantage of the steep savings and scale that Spot Instances provide for interruptible workloads. EKS-managed node groups require less operational effort compared to using self-managed nodes. You can learn more in the blog “Amazon EKS now supports provisioning and managing EC2 Spot Instances in managed node groups.”
Apache Flink and Spot
Big Data frameworks like Spark and Flink are distributed to manage and process high volumes of data. Designed for failure, they can run on machines with different configurations, inherently resilient and flexible. Spot Instances can optimize runtimes by increasing throughput, while spending the same (or less). Flink can tolerate interruptions using restart and failover strategies.
Fault Tolerance
Fault tolerance is implemented in Flink with the help of check-pointing the state. Checkpoints allow Flink to recover state and positions in the streams. There are two per-requisites for check-pointing a persistent data source (Apache Kafka, Amazon Kinesis) which has the ability to replay data and a persistent distributed storage to store state (Amazon Simple Storage Service (Amazon S3), HDFS).
Cost Optimization
Job Manager and Task Manager are key building blocks of Flink. The Task Manager is the compute intensive part and Job Manager is the orchestrator. We would be running Task Manager on Spot Instances and Job Manager on On Demand Instances.
Scaling
Flink supports elastic scaling via Reactive Mode, Task Managers can be added/removed based on metrics monitored by an external service monitor like Horizontal Pod Autoscaling (HPA). When scaling up new pods would be added, if the cluster has resources they would be scheduled it not then they will go in pending state. Cluster Autoscaler (CA) detects pods in pending state and new nodes will be added by EC2 Auto Scaling. This is ideal with Spot Instances as it implements elastic scaling with higher throughput in a cost optimized way.
Tutorial: Running Flink applications in a cost optimized way
In this tutorial, I review steps, which help you launch cost optimized and resilient Flink workloads running on EKS via Application mode. The streaming application will read dummy Stock ticker prices send to an Amazon Kinesis Data Stream by Amazon Kinesis Data Generator, try to determine the highest price within a per-defined window, and output will be written onto Amazon S3 files.
The configuration files can be found in this github location. To run the workload on Kubernetes, make sure you have eksctl and kubectl command line utilities installed on your computer or on an AWS Cloud9 environment. You can run this by using an AWS IAM user or role that has the Administrator Access policy attached to it, or check the minimum required permissions for using eksctl. The Spot node groups in the Amazon EKS cluster can be launched both in a managed or a self-managed way, in this post I use the EKS Managed node group for Spot Instances.
Steps
When we deploy Flink in Application Mode it runs as a single application. The cluster is exclusive for the job. We will be bundling the user code in the Flink image for that purpose and upload in Amazon Elastic Container Registry (Amazon ECR). Amazon ECR is a fully managed container registry that makes it easy to store, manage, share, and deploy your container images and artifacts anywhere.
1. Build the Amazon ECR Image
Login using the following cmd and don’t forget to replace the AWS_REGION and AWS_ACCOUNT_ID with your details.
Download the Docker file. I am using multistage docker build here. The sample code is from Github’s Amazon Kinesis Data Analytics Java examples. I modified the code to allow checkpointing and change the sliding window interval. Build and push the docker image using the following instructions.
First, I must create an access policy to allow the Flink application to read/write from Amazon fFS3 and read Kinesis data streams. Download the Amazon S3 policy file from here and modify the <<output folder>> to an Amazon S3 bucket which you have to create.
Run the following to create the policy. Note the ARN.
aws iam create-policy --policy-name flink-demo-policy --policy-document file://flink-demo-policy.json
3. Cluster and node groups deployment
Create an EKS cluster using the following command:
The cluster takes approximately 15 minutes to launch.
Create the node group using the nodeGroup config file. I am using multiple nodeGroups of different sizes to adapt Spot best practice of diversification. Replace the <<Policy ARN>> string using the ARN string from the previous step.
eksctl create nodegroup -f managedNodeGroups.yml
Download the Cluster Autoscaler and edit it to add the cluster-name (flink-demo)
This install folder here has all the YAML files required to deploy a standalone Flink cluster. Run the install.sh file. This will deploy the cluster with a JobManager, a pool of TaskManagers and a Service exposing JobManager’s ports.
The JobManager runs on OnDemand and TaskManager on Spot. As the cluster is launched in Application Mode, if a node is interrupted only one job will be restarted.
Autoscaling is enabled by the use of ‘Reactive Mode’. Horizontal Pod Autoscaler is used to monitor the CPU load and scale accordingly.
Check-pointing is enabled which allows Flink to save state and be fault tolerant.
7. Create Amazon Kinesis data stream and send dummy data
Log in to AWS Management Console and create a Kinesis data stream name ‘ExampleInputStream’. Kinesis Data Generator is used to send data to the data stream. The template of the dummy data can be found here. Once this sends data the Flink application starts processing.
Observations
Spot Interruptions
If there is an interruption then the Flick application will be restarted using check-pointed data. The JobManager will restore the job as highlighted in the following log. The node will be replaced automatically by the Managed Node Group.
One will be able to observe the graceful restart in the Flink UI.
AutoScaling
You can observe the elastic scaling using logs. The number of TaskManagers in the Flink UI will also reflect the scaling state.
Cleanup
If you are trying out the tutorial, run the following steps to make sure that you don’t encounter unwanted costs.
Run the delete.sh file.
Delete the EKS cluster and the node groups:
eksctl delete cluster --name flink-demo
Delete the Amazon S3 Access Policy:
aws iam delete-policy --policy-arn <<POLICY ARN>>
Delete the Amazon S3 Bucket:
aws s3 rb --force s3://<<S3_BUCKET>>
Delete the CloudFormation stack related to Kinesis Data Generator named ‘Kinesis-Data-Generator-Cognito-User’
Delete the Kinesis Data Stream.
Conclusion
In this blog, I demonstrated how you can run Flink workloads on a Kubernetes Cluster using Spot Instances, achieving scalability, resilience, and cost optimization. To cost optimize your Flink based big data workloads you should start thinking about using Amazon EKS and Spot Instances.
Kubernetes Role-Based Access Control (RBAC) is a method of regulating access to computer or network resources based on the roles of individual users within your organization. RBAC authorization uses the rbac.authorization.k8s.io API group to drive authorization decisions, allowing you to dynamically configure policies through the Kubernetes API. This is all quite useful, but Kubernetes RBAC is often viewed as complex and not very user-friendly.
Introducing Your Swiss Army Knife for RBAC Controls
InsightCloudSec’s RBAC tool is an all-in-one open-source tool for analyzing Kubernetes RBAC policies and simplifying any complexities associated with Kubernetes RBAC.
InsightCloudSec’s RBAC tool significantly simplifies querying, analyzing, and generating RBAC policies. It is available as a standalone tool or as a kubectl Krew Plugin.
Visualize Cluster RBAC Policies and Usage
A Kubernetes RBAC command can be used to analyze cluster policies and how they are being used and generate a simple relationship graph.
By default, rbac-tool viz will connect to the local cluster (pointed by kubeconfig) and create a RBAC graph of the actively running workload on all namespaces except kube-system.
Examples
# Scan the cluster pointed by the kubeconfig context 'myctx'
rbac-tool viz --cluster-context myctx
# Scan and create a PNG image from the graph
rbac-tool viz --outformat dot --exclude-namespaces=soemns && cat rbac.dot | dot -Tpng > rbac.png && google-chrome rbac.png
Analyze Risky RBAC Permission
The command rbac-tool analysis analyzes RBAC permissions and highlights overly permissive principals, risky permissions, or any specific permissions that are not desired by cluster operators.
The command allows the use of a custom analysis rule set, as well as the ability to define custom exceptions (global and per-rule), and can integrate into deployment tools such as GitOps and automation analysis tasks in order to detect undesired permission changes, unexpected drifts, or risky roles.
Examples
# Analyze the cluster pointed by the kubeconfig context 'myctx' with the internal analysis rule set
rbac-tool analysis --cluster-context myctx
Query Who Can Perform Certain Kubernetes API Actions
The command rbac-tool who-can enables operators to simply query which subjects/principals are allowed to perform a certain action based on the presently configured RBAC policies.
Examples
# Who can read ConfigMap resources
rbac-tool who-can get configmaps
# Who can watch Deployments
rbac-tool who-can watch deployments.apps
# Who can read the Kubernetes API endpoint /apis
rbac-tool who-can get /apis
# Who can read a secret resource by the name some-secret
rbac-tool who-can get secret/some-secret
A Flat and Simple View of RBAC Permissions
The command rbac-tool policy-rules aggregates the policies and relationships from the various RBAC resources, and provides a flat view of the allowed permissions for any given User/ServiceAccount/Group.
Examples
# List policy rules for system unauthenticated group
rbac-tool policy-rules -e '^system:unauth'
Output:
Generate RBAC Policies Easily
Kubernetes RBAC lacks the notion of denying semantics, which means generating an RBAC policy that says “Allow everything except THIS” is not as straightforward as one would imagine.
Here are some examples that capture how rbac-tool generate can help:
Generate a ClusterRole policy that allows users to read everything except secrets and services
Generate a Role policy that allows create, update, get, list (read/write) everything except Secrets, Services, Ingresses, and NetworkPolicies
Generate a Role policy that allows create, update, get, list (read/write) everything except StatefulSets
Command Line Examples
Examples generated against Kubernetes cluster v1.16 deployed using KIND:
# Generate a ClusterRole policy that allows users to read everything except secrets and services
rbac-tool gen --deny-resources=secrets.,services. --allowed-verbs=get,list
# Generate a Role policy that allows create, update, get, list (read/write) everything except Secrets, Services, NetworkPolicies in core,Apps and networking.k8s.io API groups
rbac-tool gen --generated-type=Role --deny-resources=secrets.,services.,networkpolicies.networking.k8s.io --allowed-verbs=* --allowed-groups=,extensions,apps,networking.k8s.i
# Generate a Role policy that allows create, update, get, list (read/write) everything except StatefulSets
rbac-tool gen --generated-type=Role --deny-resources=apps.statefulsets --allowed-verbs=*
Example output
# Generate a Role policy that allows create, update, get, list (read/write) everything except Secrets, Services, NetworkPolicies in core,Apps & networking.k8s.io API groups
rbac-tool gen --generated-type=Role --deny-resources=secrets.,services.,networkpolicies.networking.k8s.io --allowed-verbs=* --allowed-groups=,extensions,apps,networking.k8s.io
Output:
Another useful policy generation command is rbac-tool auditgen, which can generate RBAC policy from Kubernetes audit events.
Conclusion
InsightCloudSec’s RBAC tool fills various gaps that exist in the Kubernetes native tools, and addresses common RBAC-related use cases. This RBAC tool is an all-in-one solution that helps practitioners to perform RBAC analysis, querying, and policy curation.
You’ve got your full Swiss army knife now—what are you waiting for?
Check out this link for more information and a step-by-side installation guide.
Cloud and container technology provide tremendous flexibility, speed, and agility, so it’s not surprising that organizations around the globe are continuing to embrace cloud and container technology. Many organizations are using multiple tools to secure their often complex cloud and container environments, while struggling to maintain the flexibility, speed, and agility required to keep security intact.
Cloud Security Just Got Better!
In addition to acquiring DivvyCloud, a top-tier Cloud Security Posture Management (CSPM) platform in 2020, Rapid7 recently announced another successful acquisition— joining forces with Alcide, a leading Kubernetes security start-up that offers advanced Cloud Workload Protection Platform (CWPP) capabilities.
Rapid7 is taking the lead in the CSPM space by leveraging both DivvyCloud’s and Alcide’s capabilities and incorporating them into a single platform: InsightCloudSec, your one-stop shop for superior cloud security solutions.
In retrospect, 2020 was a tipping point for the Kubernetes community, with a massive increase in adoption across the globe. Many companies, seeking an efficient, cost-effective way to make this huge shift to the cloud, turned to Kubernetes. But this in turn created a growing need to remove the Kubernetes security blind spots. It is for this reason that we are introducing Kubernetes Security Guardrails.
With Kubernetes Security Guardrails, organizations are equipped with a multi-cluster vulnerability scanner that covers rich Kubernetes security best practices and compliance policies, such as CIS Benchmarks. As part of Rapid7’s InsightCloudSec solution, this new ability introduces a platform-based and easy-to-maintain solution for Kubernetes security that is deployed in minutes and is fully streamlined in the Kubernetes pipeline.
Securing Kubernetes With InsightCloudSec
Kubernetes Security Guardrails is the most comprehensive solution for all relevant Kubernetes security requirements, designed from a DevOps perspective with in-depth visibility for security teams. Integrated within minutes, Kubernetes Guardrails simplifies the security assessment for the entire Kubernetes environment and the CI/CD pipeline while creating baseline profiles for each cluster, highlighting and scoring security risks, misconfigurations, and hygiene drifts.
Both DevOps and Security teams enjoy the continuous and dynamic analysis of their Kubernetes deployments, all while seamlessly complying with regulatory requirements for Kubernetes such as PCI, GDPR, and HIPAA.
With Kubernetes Guardrails, Dev teams are able to create a snapshot of cluster risks, delivered with a detailed list of misconfigurations, while detecting real-time hygiene and conformance drifts for deployments running on any cloud environment.
Some of the most common use cases include:
Kubernetes vulnerability scanning
Hunting misplaced secrets and excessive secret access
Workload hardening (from pod security to network policies)
Istio security and configuration best practices
Ingress controllers security
Kubernetes API server access privileges
Kubernetes operators best practices
RBAC controls and misconfigurations
Rapid7 proudly brings forward a Kubernetes security solution that encapsulates all-in-one capabilities with incomparable coverage for all things Kubernetes.
With a security-first approach and a strict compliance adherence, Kubernetes Guardrails enable a better understanding and control over distributed projects, and help organizations maintain smooth business operations.
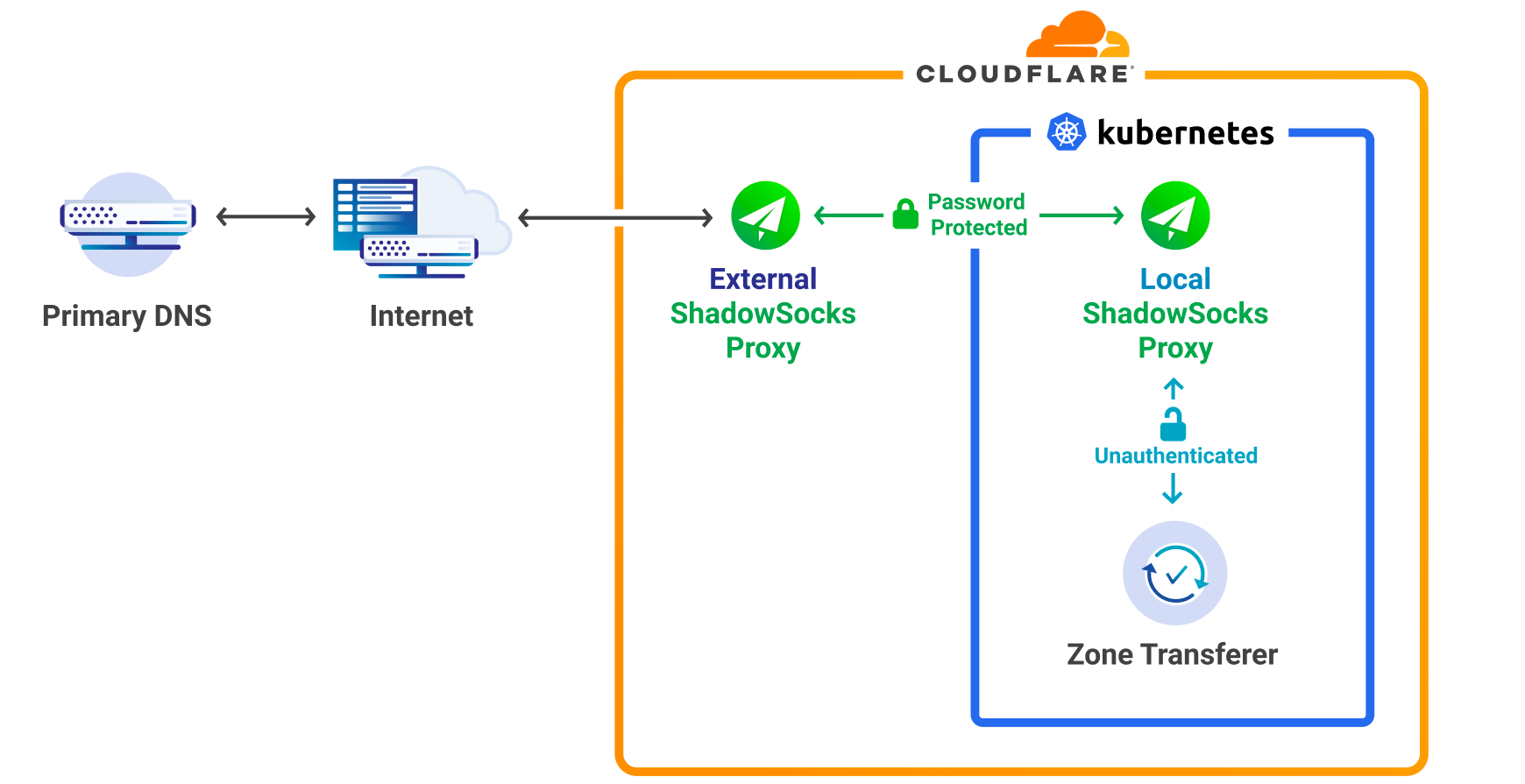
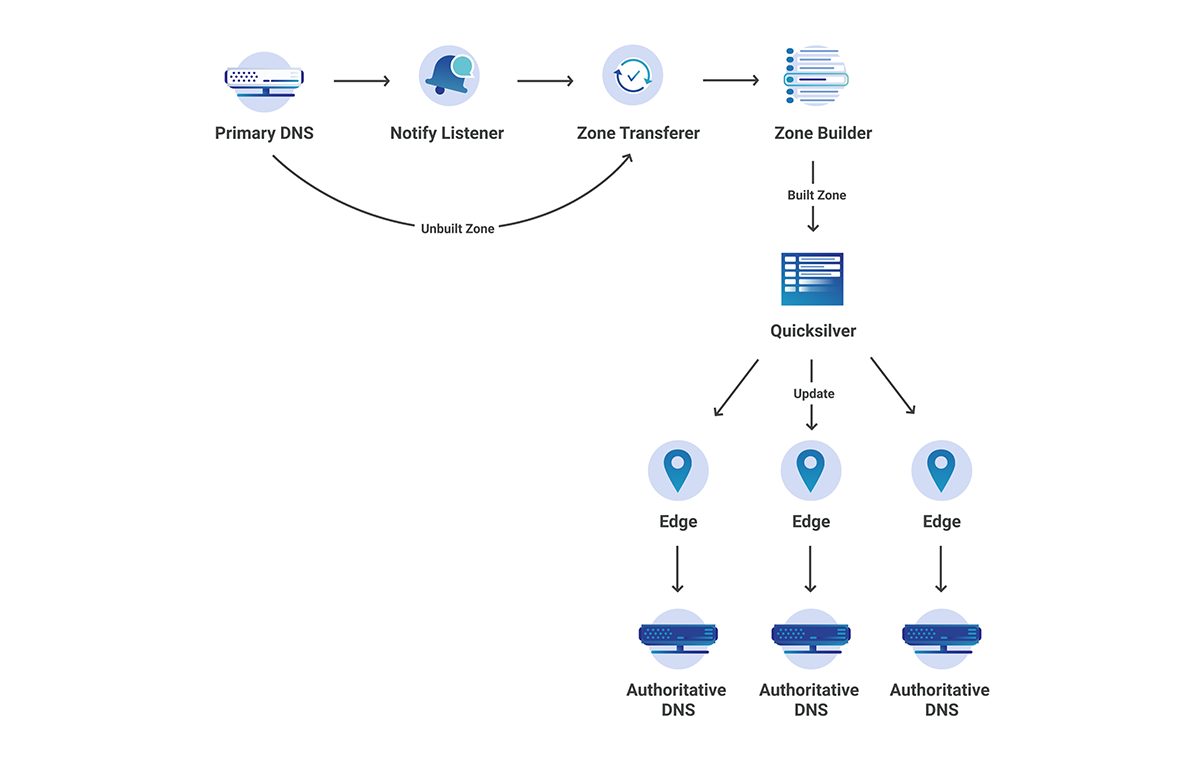
We use Kubernetes to run many of the diverse services that help us control Cloudflare’s edge. We have five geographically diverse clusters, with hundreds of nodes in our largest cluster. These clusters are self-managed on bare-metal machines which gives us a good amount of power and flexibility in the software and integrations with Kubernetes. However, it also means we don’t have a cloud provider to rely on for virtualizing or managing the nodes. This distinction becomes even more prominent when considering all the different reasons that nodes degrade. With self-managed bare-metal machines, the list of reasons that cause a node to become unhealthy include:
Hardware failures
Kernel-level software failures
Kubernetes cluster-level software failures
Degraded network communication
Software updates are required
Resource exhaustion1
Unhappy Nodes
We have plenty of examples of failures in the aforementioned categories, but one example has been particularly tedious to deal with. It starts with the following log line from the kernel:
unregister_netdevice: waiting for lo to become free. Usage count = 1
The issue is further observed with the number of network interfaces on the node owned by the Container Network Interface (CNI) plugin getting out of proportion with the number of running pods:
$ ip link | grep cali | wc -l
1088
This is unexpected as it shouldn’t exceed the maximum number of pods allowed on a node (we use the default limit of 110). While this issue is interesting and perhaps worthy of a whole separate blog, the short of it is that the Linux network interfaces owned by the CNI are not getting cleaned up after a pod terminates.
Some history on this can be read in a Docker GitHub issue. We found this seems to plague nodes with a longer uptime, and after rebooting the node it would be fine for about a month. However, with a significant number of nodes, this was happening multiple times per day. Each instance would need rebooting, which means going through our worker reboot procedure which looked like this:
Cordon off the affected node to prevent new workloads from scheduling on it.
Collect any diagnostic information for later investigation.
Drain the node of current workloads.
Reboot and wait for the node to come back.
Verify the node is healthy.
Re-enable scheduling of new workloads to the node.
While solving the underlying issue would be ideal, we needed a mitigation to avoid toil in the meantime — an automated node remediation process.
Existing Detection and Remediation Solutions
While not complicated, the manual remediation process outlined previously became tedious and distracting, as we had to reboot nodes multiple times a day. Some manual intervention is unavoidable, but for cases matching the following, we wanted automation:
Generic worker nodes
Software issues confined to a given node
Already researched and diagnosed issues
Limiting automatic remediation to generic worker nodes is important as there are other node types in our clusters where more care is required. For example, for control-plane nodes the process has to be augmented to check etcd cluster health and ensure proper redundancy for components servicing the Kubernetes API. We are also going to limit the problem space to known software issues confined to a node where we expect automatic remediation to be the right answer (as in our ballooning network interface problem). With that in mind, we took a look at existing solutions that we could use.
Node Problem Detector
Node problem detector is a daemon that runs on each node that detects problems and reports them to the Kubernetes API. It has a pluggable problem daemon system such that one can add their own logic for detecting issues with a node. Node problems are distinguished between temporary and permanent problems, with the latter being persisted as status conditions on the Kubernetes node resources.2
Draino and Cluster-Autoscaler
Draino as its name implies, drains nodes but does so based on Kubernetes node conditions. It is meant to be used with cluster-autoscaler which then can add or remove nodes via the cluster plugins to scale node groups.
Kured
Kured is a daemon that looks at the presence of a file on the node to initiate a drain, reboot and uncordon of the given node. It uses a locking mechanism via the Kubernetes API to ensure only a single node is acted upon at a time.
Cluster-API
The Kubernetes cluster-lifecycle SIG has been working on the cluster-api project to enable declaratively defining clusters to simplify provisioning, upgrading, and operating multiple Kubernetes clusters. It has a concept of machine resources which back Kubernetes node resources and furthermore has a concept of machine health checks. Machine health checks use node conditions to determine unhealthy nodes and then the cluster-api provider is then delegated to replace that machine via create and delete operations.
Proof of Concept
Interestingly, with all the above except for Kured, there is a theme of pluggable components centered around Kubernetes node conditions. We wanted to see if we could build a proof of concept using the existing theme and solutions. For the existing solutions, draino with cluster-autoscaler didn’t make sense in a non-cloud environment like our bare-metal set up. The cluster-api health checks are interesting, however they require a more complete investment into the cluster-api project to really make sense. That left us with node-problem-detector and kured. Deploying node-problem-detector was simple, and we ended up testing a custom-plugin-monitor like the following:
With that in place, the actual remediation needed to happen. Kured seemed to do most everything we needed, except that it was looking at a file instead of Kubernetes node conditions. We hacked together a patch to change that and tested it successfully end to end — we had a working proof of concept!
Revisiting Problem Detection
While the above worked, we found that node-problem-detector was unwieldy because we were replicating our existing monitoring into shell scripts and node-problem-detector configuration. A 2017 blog post describes Cloudflare’s monitoring stack, although some things have changed since then. What hasn’t changed is our extensive usage of Prometheus and Alertmanager.
For the network interface issue and other issues we wanted to address, we already had the necessary exported metrics and alerting to go with them. Here is what our already existing alert looked like3:
Note that we use a “notify” label to drive the routing logic in Alertmanager. However, that got us asking, could we just route this to a Kubernetes node condition instead?
Introducing Sciuro
Sciuro is our open-source replacement of node-problem-detector that has one simple job: synchronize Kubernetes node conditions with currently firing alerts in Alertmanager. Node problems can be defined with a more holistic view and using already existing exporters such as node exporter, cadvisor or mtail. It also doesn’t run on affected nodes which allows us to rely on out-of-band remediation techniques. Here is a high level diagram of how Sciuro works:
Starting from the top, nodes are scraped by Prometheus, which collects those metrics and fires relevant alerts to Alertmanager. Sciuro polls Alertmanager for alerts with a matching receiver, matches them with a corresponding node resource in the Kubernetes API and updates that node’s conditions accordingly.
In more detail, we can start by defining an alert in Prometheus like the following:
Note the two differences from the previous alert. First, we use a new name with a more sensitive trigger. The idea is that we want automatic node remediation to try fixing the node first as soon as possible, but if the problem worsens or automatic remediation is failing, humans will still get notified to act. The second difference is that instead of notifying chat rooms, we route to a target called “node-condition-k8s”.
Sciuro then comes into play, polling the Altertmanager API for alerts matching the “node-condition-k8s” receiver. The following shows the equivalent using amtool:
$ amtool alert query -r node-condition-k8s
Alertname Starts At Summary
CalicoTooManyInterfacesEarly 2021-05-11 03:25:21 UTC Kubernetes node worker1a has too many Calico interfaces
Note the node and instance labels which Sciuro will use for matching with the corresponding Kubernetes node. Sciuro uses the excellent controller-runtime to keep track of and update node sources in the Kubernetes API. We can observe the updated node condition on the status field via kubectl:
$ kubectl get node worker1a -o json | jq '.status.conditions[] | select(.type | test("^AlertManager"))'
{
"lastHeartbeatTime": "2021-05-11T03:31:20Z",
"lastTransitionTime": "2021-05-11T03:26:53Z",
"message": "[P6] Kubernetes node worker1a has too many Calico interfaces",
"reason": "AlertIsFiring",
"status": "True",
"type": "AlertManager_CalicoTooManyInterfacesEarly"
}
One important note is Sciuro added the AlertManager_ prefix to the node condition type to prevent conflicts with other node condition types. For example, DiskPressure, a kubelet managed condition, could also be an alert name. Sciuro will also properly update heartbeat and transition times to reflect when it first saw the alert and its last update. With node conditions synchronized by Sciuro, remediation can take place via one of the existing tools. As mentioned previously we are using a modified version of Kured for now.
We’re happy to announce that we’ve open sourced Sciuro, and it can be found on GitHub where you can read the code, find the deployment instructions, or open a Pull Request for changes.
Managing Node Uptime
While we began using automatic node remediation for obvious problems, we’ve expanded its purpose to additionally keep node uptime low. Low node uptime is desirable to further reduce drift on nodes, keep the node initialization process well-oiled, and encourage the best deployment practices on the Kubernetes clusters. To expand on the last point, services that are deployed with best practices and in a high availability fashion should see negligible impact when a single node leaves the cluster. However, services that are not deployed with best practices will most likely have problems especially if they rely on singleton pods. By draining nodes more frequently, it introduces regular chaos that encourages best practices. To enable this with automatic node remediation the following alert was defined:
There is a bit of juggling with the kube_node_roles metric in the above to isolate the alert to generic worker nodes, but at a high level it looks at node_boot_time_seconds, a metric from prometheus node_exporter. Again the notify label is configured to send to node conditions which kicks off the automatic node remediation. One further detail is the priority here is set to “9” which is of lower precedence than our other alerts. Note that the message field of the node condition is prefixed with the alert priority in brackets. This allows the remediation process to take priority into account when choosing which node to remediate first, which is important because Kured uses a lock to act on a single node at a time.
Wrapping Up
In the past 30 days, we’ve used the above automatic node remediation process to action 571 nodes. That has saved our humans a considerable amount of time. We’ve also been able to reduce the time to repair for some issues as automatic remediation can act at all times of the day and with a faster response time.
As mentioned before, we’re open sourcing Sciuro and its code can be found on GitHub. We’re open to issues, suggestions, and pull requests. We do have some ideas for future improvements. For Sciuro, we may look to reduce latency which is mainly due to polling and potentially add a push model from Altermanager although this isn’t a need we’ve had yet. For the larger node remediation story, we hope to do an overhaul of the remediating component. As mentioned previously, we are currently using a fork of kured, but a future replacement component should include the following:
Use out-of-band management interfaces to be able to shut down and power on nodes without a functional operating system.
Move from decentralized architecture to a centralized one that can integrate more complicated logic. This might include being able to act on entire failure domains in parallel.
Handle specialized nodes such as masters or storage nodes.
Finally, we’re looking for more people passionate about Kubernetes to join our team. Come help us push Kubernetes to the next level to serve Cloudflare’s many needs!
1Exhaustion can be applied to hardware resources, kernel resources, or logical resources like the amount of logging being produced. 2Nearly all Kubernetes objects have spec and status fields. The status field is used to describe the current state of an object. For node resources, typically the kubelet manages a conditions field under the status field for reporting things like if the node is ready for servicing pods. 3The format of the following alert is documented on Prometheus Alerting Rules.
DevSecOps software factory implementation can significantly vary depending on the application, infrastructure, architecture, and the services and tools used. In a previous post, I provided an end-to-end DevSecOps pipeline for a three-tier web application deployed with AWS Elastic Beanstalk. The pipeline used cloud-native services along with a few open-source security tools. This solution is similar, but instead uses a containers-based approach with additional security analysis stages. It defines a software factory using Kubernetes along with necessary AWS Cloud-native services and open-source third-party tools. Code is provided in the GitHub repo to build this DevSecOps software factory, including the integration code for third-party scanning tools.
DevOps is a combination of cultural philosophies, practices, and tools that combine software development with information technology operations. These combined practices enable companies to deliver new application features and improved services to customers at a higher velocity. DevSecOps takes this a step further by integrating and automating the enforcement of preventive, detective, and responsive security controls into the pipeline.
In a DevSecOps factory, security needs to be addressed from two aspects: security of the software factory, and security in the software factory. In this architecture, we use AWS services to address the security of the software factory, and use third-party tools along with AWS services to address the security in the software factory. This AWS DevSecOps reference architecture covers DevSecOps practices and security vulnerability scanning stages including secret analysis, SCA (Software Composite Analysis), SAST (Static Application Security Testing), DAST (Dynamic Application Security Testing), RASP (Runtime Application Self Protection), and aggregation of vulnerability findings into a single pane of glass.
The focus of this post is on application vulnerability scanning. Vulnerability scanning of underlying infrastructure such as the Amazon Elastic Kubernetes Service (Amazon EKS) cluster and network is outside the scope of this post. For information about infrastructure-level security planning, refer to Amazon Guard Duty, Amazon Inspector, and AWS Shield.
You can deploy this pipeline in either the AWS GovCloud (US) Region or standard AWS Regions. All listed AWS services are authorized for FedRamp High and DoD SRG IL4/IL5.
Security and compliance
Thoroughly implementing security and compliance in the public sector and other highly regulated workloads is very important for achieving an ATO (Authority to Operate) and continuously maintain an ATO (c-ATO). DevSecOps shifts security left in the process, integrating it at each stage of the software factory, which can make ATO a continuous and faster process. With DevSecOps, an organization can deliver secure and compliant application changes rapidly while running operations consistently with automation.
Security and compliance are shared responsibilities between AWS and the customer. Depending on the compliance requirements (such as FedRamp or DoD SRG), a DevSecOps software factory needs to implement certain security controls. AWS provides tools and services to implement most of these controls. For example, to address NIST 800-53 security controls families such as access control, you can use AWS Identity Access and Management (IAM) roles and Amazon Simple Storage Service (Amazon S3) bucket policies. To address auditing and accountability, you can use AWS CloudTrail and Amazon CloudWatch. To address configuration management, you can use AWS Config rules and AWS Systems Manager. Similarly, to address risk assessment, you can use vulnerability scanning tools from AWS.
The following table is the high-level mapping of the NIST 800-53 security control families and AWS services that are used in this DevSecOps reference architecture. This list only includes the services that are defined in the AWS CloudFormation template, which provides pipeline as code in this solution. You can use additional AWS services and tools or other environmental specific services and tools to address these and the remaining security control families on a more granular level.
#
NIST 800-53 Security Control Family – Rev 5
AWS Services Used (In this DevSecOps Pipeline)
1
AC – Access Control
AWS IAM, Amazon S3, and Amazon CloudWatch are used.
Not implemented, but services like AWS Lambda, and Amazon CloudWatch Events can be used.
13
MA – Maintenance
N/A
14
MP – Media Protection
N/A
15
PS – Personnel Security
N/A
16
PE – Physical and Environmental Protection
N/A
17
PL – Planning
N/A
18
PM – Program Management
N/A
19
PT – PII Processing and Transparency
N/A
20
SR – SupplyChain Risk Management
N/A
Services and tools
In this section, we discuss the various AWS services and third-party tools used in this solution.
CI/CD services
For continuous integration and continuous delivery (CI/CD) in this reference architecture, we use the following AWS services:
AWS CodeBuild – A fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy.
AWS CodePipeline – A fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates.
AWS Lambda – A service that lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
Amazon Simple Notification Service – Amazon SNS is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
Amazon S3 – Amazon S3 is storage for the internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web.
AWS Systems Manager Parameter Store – Parameter Store provides secure, hierarchical storage for configuration data management and secrets management.
Continuous testing tools
The following are open-source scanning tools that are integrated in the pipeline for the purpose of this post, but you could integrate other tools that meet your specific requirements. You can use the static code review tool Amazon CodeGuru for static analysis, but at the time of this writing, it’s not yet available in AWS GovCloud and currently supports Java and Python.
Anchore (SCA and SAST) – Anchore Engine is an open-source software system that provides a centralized service for analyzing container images, scanning for security vulnerabilities, and enforcing deployment policies.
Amazon Elastic Container Registry image scanning – Amazon ECR image scanning helps in identifying software vulnerabilities in your container images. Amazon ECR uses the Common Vulnerabilities and Exposures (CVEs) database from the open-source Clair project and provides a list of scan findings.
Git-Secrets (Secrets Scanning) – Prevents you from committing sensitive information to Git repositories. It is an open-source tool from AWS Labs.
OWASP ZAP (DAST) – Helps you automatically find security vulnerabilities in your web applications while you’re developing and testing your applications.
Snyk (SCA and SAST) – Snyk is an open-source security platform designed to help software-driven businesses enhance developer security.
Sysdig Falco (RASP) – Falco is an open source cloud-native runtime security project that detects unexpected application behavior and alerts on threats at runtime. It is the first runtime security project to join CNCF as an incubation-level project.
You can integrate additional security stages like IAST (Interactive Application Security Testing) into the pipeline to get code insights while the application is running. You can use AWS partner tools like Contrast Security, Synopsys, and WhiteSource to integrate IAST scanning into the pipeline. Malware scanning tools, and image signing tools can also be integrated into the pipeline for additional security.
Continuous logging and monitoring services
The following are AWS services for continuous logging and monitoring used in this reference architecture:
Amazon CloudWatch Events – Delivers a near-real-time stream of system events that describe changes in AWS resources
The following are AWS auditing and governance services used in this reference architecture:
AWS CloudTrail – Enables governance, compliance, operational auditing, and risk auditing of your AWS account.
AWS Config – Allows you to assess, audit, and evaluate the configurations of your AWS resources.
AWS Identity and Access Management – Enables you to manage access to AWS services and resources securely. With IAM, you can create and manage AWS users and groups, and use permissions to allow and deny their access to AWS resources.
Operations services
The following are the AWS operations services used in this reference architecture:
AWS CloudFormation – Gives you an easy way to model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles, by treating infrastructure as code.
Amazon ECR – A fully managed container registry that makes it easy to store, manage, share, and deploy your container images and artifacts anywhere.
Amazon EKS – A managed service that you can use to run Kubernetes on AWS without needing to install, operate, and maintain your own Kubernetes control plane or nodes. Amazon EKS runs up-to-date versions of the open-source Kubernetes software, so you can use all of the existing plugins and tooling from the Kubernetes community.
AWS Security Hub – Gives you a comprehensive view of your security alerts and security posture across your AWS accounts. This post uses Security Hub to aggregate all the vulnerability findings as a single pane of glass.
AWS Systems Manager Parameter Store – Provides secure, hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, Amazon Machine Image (AMI) IDs, and license codes as parameter values.
Pipeline architecture
The following diagram shows the architecture of the solution. We use AWS CloudFormation to describe the pipeline as code.
Kubernetes DevSecOps Pipeline Architecture
The main steps are as follows:
When a user commits the code to CodeCommit repository, a CloudWatch event is generated, which triggers CodePipeline to orchestrate the events.
CodeBuild packages the build and uploads the artifacts to an S3 bucket.
CodeBuild scans the code with git-secrets. If there is any sensitive information in the code such as AWS access keys or secrets keys, CodeBuild fails the build.
CodeBuild creates the container image and perform SCA and SAST by scanning the image with Snyk or Anchore. In the provided CloudFormation template, you can pick one of these tools during the deployment. Please note, CodeBuild is fully enabled for a “bring your own tool” approach.
(4a) If there are any vulnerabilities, CodeBuild invokes the Lambda function. The function parses the results into AWS Security Finding Format (ASFF) and posts them to Security Hub. Security Hub helps aggregate and view all the vulnerability findings in one place as a single pane of glass. The Lambda function also uploads the scanning results to an S3 bucket.
(4b) If there are no vulnerabilities, CodeBuild pushes the container image to Amazon ECR and triggers another scan using built-in Amazon ECR scanning.
CodeBuild retrieves the scanning results.
(5a) If there are any vulnerabilities, CodeBuild invokes the Lambda function again and posts the findings to Security Hub. The Lambda function also uploads the scan results to an S3 bucket.
(5b) If there are no vulnerabilities, CodeBuild deploys the container image to an Amazon EKS staging environment.
After the deployment succeeds, CodeBuild triggers the DAST scanning with the OWASP ZAP tool (again, this is fully enabled for a “bring your own tool” approach).
(6a) If there are any vulnerabilities, CodeBuild invokes the Lambda function, which parses the results into ASFF and posts it to Security Hub. The function also uploads the scan results to an S3 bucket (similar to step 4a).
If there are no vulnerabilities, the approval stage is triggered, and an email is sent to the approver for action via Amazon SNS.
After approval, CodeBuild deploys the code to the production Amazon EKS environment.
During the pipeline run, CloudWatch Events captures the build state changes and sends email notifications to subscribed users through Amazon SNS.
CloudTrail tracks the API calls and sends notifications on critical events on the pipeline and CodeBuild projects, such as UpdatePipeline, DeletePipeline, CreateProject, and DeleteProject, for auditing purposes.
AWS Config tracks all the configuration changes of AWS services. The following AWS Config rules are added in this pipeline as security best practices:
CODEBUILD_PROJECT_ENVVAR_AWSCRED_CHECK – Checks whether the project contains environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. The rule is NON_COMPLIANT when the project environment variables contain plaintext credentials. This rule ensures that sensitive information isn’t stored in the CodeBuild project environment variables.
CLOUD_TRAIL_LOG_FILE_VALIDATION_ENABLED – Checks whether CloudTrail creates a signed digest file with logs. AWS recommends that the file validation be enabled on all trails. The rule is noncompliant if the validation is not enabled. This rule ensures that pipeline resources such as the CodeBuild project aren’t altered to bypass critical vulnerability checks.
Security of the pipeline is implemented using IAM roles and S3 bucket policies to restrict access to pipeline resources. Pipeline data at rest and in transit is protected using encryption and SSL secure transport. We use Parameter Store to store sensitive information such as API tokens and passwords. To be fully compliant with frameworks such as FedRAMP, other things may be required, such as MFA.
Security in the pipeline is implemented by performing the Secret Analysis, SCA, SAST, DAST, and RASP security checks. Applicable AWS services provide encryption at rest and in transit by default. You can enable additional controls on top of these wherever required.
In the next section, I explain how to deploy and run the pipeline CloudFormation template used for this example. As a best practice, we recommend using linting tools like cfn-nag and cfn-guard to scan CloudFormation templates for security vulnerabilities. Refer to the provided service links to learn more about each of the services in the pipeline.
Prerequisites
Before getting started, make sure you have the following prerequisites:
An EKS cluster environment with your application deployed. In this post, we use PHP WordPress as a sample application, but you can use any other application.
Sysdig Falco installed on an EKS cluster. Sysdig Falco captures events on the EKS cluster and sends those events to CloudWatch using AWS FireLens. For implementation instructions, see Implementing Runtime security in Amazon EKS using CNCF Falco. This step is required only if you need to implement RASP in the software factory.
An Amazon ECR repo to store container images and scan for vulnerabilities. Enable vulnerability scanning on image push in Amazon ECR. You can enable or disable the automatic scanning on image push via the Amazon ECR
The provided buildspec-*.yml files for git-secrets, Anchore, Snyk, Amazon ECR, OWASP ZAP, and your Kubernetes deployment .yml files uploaded to the root of the application code repository. Please update the Kubernetes (kubectl) commands in the buildspec files as needed.
A Snyk API key if you use Snyk as a SAST tool.
The Lambda function uploaded to an S3 bucket. We use this function to parse the scan reports and post the results to Security Hub.
An OWASP ZAP URL and generated API key for dynamic web scanning.
An application web URL to run the DAST testing.
An email address to receive approval notifications for deployment, pipeline change notifications, and CloudTrail events.
To deploy the pipeline, complete the following steps:
Download the CloudFormation template and pipeline code from the GitHub repo.
Sign in to your AWS account if you have not done so already.
On the CloudFormation console, choose Create Stack.
Choose the CloudFormation pipeline template.
Choose Next.
Under Code, provide the following information:
Code details, such as repository name and the branch to trigger the pipeline.
The Amazon ECR container image repository name.
Under SAST, provide the following information:
Choose the SAST tool (Anchore or Snyk) for code analysis.
If you select Snyk, provide an API key for Snyk.
Under DAST, choose the DAST tool (OWASP ZAP) for dynamic testing and enter the API token, DAST tool URL, and the application URL to run the scan.
Under Lambda functions, enter the Lambda function S3 bucket name, filename, and the handler name.
For STG EKS cluster, enter the staging EKS cluster name.
For PRD EKS cluster, enter the production EKS cluster name to which this pipeline deploys the container image.
Under General, enter the email addresses to receive notifications for approvals and pipeline status changes.
Choose Next.
Complete the stack.
After the pipeline is deployed, confirm the subscription by choosing the provided link in the email to receive notifications.
Pipeline CloudFormation Parameters
The provided CloudFormation template in this post is formatted for AWS GovCloud. If you’re setting this up in a standard Region, you have to adjust the partition name in the CloudFormation template. For example, change ARN values from arn:aws-us-gov to arn:aws.
Running the pipeline
To trigger the pipeline, commit changes to your application repository files. That generates a CloudWatch event and triggers the pipeline. CodeBuild scans the code and if there are any vulnerabilities, it invokes the Lambda function to parse and post the results to Security Hub.
When posting the vulnerability finding information to Security Hub, we need to provide a vulnerability severity level. Based on the provided severity value, Security Hub assigns the label as follows. Adjust the severity levels in your code based on your organization’s requirements.
0 – INFORMATIONAL
1–39 – LOW
40– 69 – MEDIUM
70–89 – HIGH
90–100 – CRITICAL
The following screenshot shows the progression of your pipeline.
DevSecOps Kubernetes CI/CD Pipeline
Secrets analysis scanning
In this architecture, after the pipeline is initiated, CodeBuild triggers the Secret Analysis stage using git-secrets and the buildspec-gitsecrets.yml file. Git-Secrets looks for any sensitive information such as AWS access keys and secret access keys. Git-Secrets allows you to add custom strings to look for in your analysis. CodeBuild uses the provided buildspec-gitsecrets.yml file during the build stage.
SCA and SAST scanning
In this architecture, CodeBuild triggers the SCA and SAST scanning using Anchore, Snyk, and Amazon ECR. In this solution, we use the open-source versions of Anchore and Snyk. Amazon ECR uses open-source Clair under the hood, which comes with Amazon ECR for no additional cost. As mentioned earlier, you can choose Anchore or Snyk to do the initial image scanning.
Scanning with Anchore
If you choose Anchore as a SAST tool during the deployment, the build stage uses the buildspec-anchore.yml file to scan the container image. If there are any vulnerabilities, it fails the build and triggers the Lambda function to post those findings to Security Hub. If there are no vulnerabilities, it proceeds to next stage.
Anchore Lambda Code Snippet
Scanning with Snyk
If you choose Snyk as a SAST tool during the deployment, the build stage uses the buildspec-snyk.yml file to scan the container image. If there are any vulnerabilities, it fails the build and triggers the Lambda function to post those findings to Security Hub. If there are no vulnerabilities, it proceeds to next stage.
Snyk Lambda Code Snippet
Scanning with Amazon ECR
If there are no vulnerabilities from Anchore or Snyk scanning, the image is pushed to Amazon ECR, and the Amazon ECR scan is triggered automatically. Amazon ECR lists the vulnerability findings on the Amazon ECR console. To provide a single pane of glass view of all the vulnerability findings and for easy administration, we retrieve those findings and post them to Security Hub. If there are no vulnerabilities, the image is deployed to the EKS staging cluster and next stage (DAST scanning) is triggered.
ECR Lambda Code Snippet
DAST scanning with OWASP ZAP
In this architecture, CodeBuild triggers DAST scanning using the DAST tool OWASP ZAP.
After deployment is successful, CodeBuild initiates the DAST scanning. When scanning is complete, if there are any vulnerabilities, it invokes the Lambda function, similar to SAST analysis. The function parses and posts the results to Security Hub. The following is the code snippet of the Lambda function.
Zap Lambda Code Snippet
The following screenshot shows the results in Security Hub. The highlighted section shows the vulnerability findings from various scanning stages.
Vulnerability Findings in Security Hub
We can drill down to individual resource IDs to get the list of vulnerability findings. For example, if we drill down to the resource ID of SASTBuildProject*, we can review all the findings from that resource ID.
SAST Vulnerabilities in Security Hub
If there are no vulnerabilities in the DAST scan, the pipeline proceeds to the manual approval stage and an email is sent to the approver. The approver can review and approve or reject the deployment. If approved, the pipeline moves to next stage and deploys the application to the production EKS cluster.
Aggregation of vulnerability findings in Security Hub provides opportunities to automate the remediation. For example, based on the vulnerability finding, you can trigger a Lambda function to take the needed remediation action. This also reduces the burden on operations and security teams because they can now address the vulnerabilities from a single pane of glass instead of logging into multiple tool dashboards.
Along with Security Hub, you can send vulnerability findings to your issue tracking systems such as JIRA, Systems Manager SysOps, or can automatically create an incident management ticket. This is outside the scope of this post, but is one of the possibilities you can consider when implementing DevSecOps software factories.
RASP scanning
Sysdig Falco is an open-source runtime security tool. Based on the configured rules, Falco can detect suspicious activity and alert on any behavior that involves making Linux system calls. You can use Falco rules to address security controls like NIST SP 800-53. Falco agents on each EKS node continuously scan the containers running in pods and send the events as STDOUT. These events can be then sent to CloudWatch or any third-party log aggregator to send alerts and respond. For more information, see Implementing Runtime security in Amazon EKS using CNCF Falco. You can also use Lambda to trigger and automatically remediate certain security events.
The following screenshot shows Falco events on the CloudWatch console. The highlighted text describes the Falco event that was triggered based on the default Falco rules on the EKS cluster. You can add additional custom rules to meet your security control requirements. You can also trigger responsive actions from these CloudWatch events using services like Lambda.
Falco alerts in CloudWatch
Cleanup
This section provides instructions to clean up the DevSecOps pipeline setup:
In this post, I presented an end-to-end Kubernetes-based DevSecOps software factory on AWS with continuous testing, continuous logging and monitoring, auditing and governance, and operations. I demonstrated how to integrate various open-source scanning tools, such as Git-Secrets, Anchore, Snyk, OWASP ZAP, and Sysdig Falco for Secret Analysis, SCA, SAST, DAST, and RASP analysis, respectively. To reduce operations overhead, I explained how to aggregate and manage vulnerability findings in Security Hub as a single pane of glass. This post also talked about how to implement security of the pipeline and in the pipeline using AWS Cloud-native services. Finally, I provided the DevSecOps software factory as code using AWS CloudFormation.
Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.
Grab’s engineering teams currently own and manage more than 250+ microservices. Depending on the business problems that each team tackles, our development ecosystem ranges from Golang, Java, and everything in between.
Although there are centralised systems that help automate most of the build and deployment tasks, there are still some teams working on different technologies that manage their own build, test and deployment systems at different maturity levels. Managing a varied build and deploy ecosystems brings their own challenges.
Build challenges
Broken external dependencies.
Non-reproducible builds due to changes in AMI, configuration keys and other build parameters.
Missing security permissions between different repositories.
Deployment challenges
Varied deployment environments necessitating a bigger learning curve.
Managing the underlying infrastructure as code.
Higher downtime when bringing the systems up after a scale down event.
Grab’s appetite for customer obsession and quality drives the engineering teams to innovate and deliver value rapidly. The time that the team spends in fixing build issues or deployment-related tasks has a direct impact on the time they spend on delivering business value.
Introduction to containerisation
Using the Container architecture helps the team deploy and run multiple applications, isolated from each other, on the same virtual machine or server and with much less overhead.
At Grab, both the platform and the core engineering teams wanted to move to the containerisation architecture to achieve the following goals:
Support to build and push container images during the CI process.
Create a standard virtual machine image capable of running container workloads. The AMI is maintained by a central team and comes with Grab infrastructure components such as (DataDog, Filebeat, Vault, etc.).
A deployment experience which allows existing services to migrate to container workload safely by initially running both types of workloads concurrently.
The core engineering teams wanted to adopt container workloads to achieve the following benefits:
Provide a containerised version of the service that can be run locally and on different cloud providers without any dependency on Grab’s internal (runtime) tooling.
Allow reuse of common Grab tools in different projects by running the zero dependency version of the tools on demand whenever needed.
Allow a more flexible staging/dev/shadow deployment of new features.
Adoption of containerisation
Engineering teams at Grab use the containerisation model to build and deploy services at scale. Our containerisation effort helps the development teams move faster by:
Providing a consistent environment across development, testing and production
Deploying software efficiently
Reducing infrastructure cost
Abstracting OS dependency
Increasing scalability between cloud vendors
When we started using containers we realised that building smaller containers had some benefits over bigger containers. For example, smaller containers:
Include only the needed libraries and therefore are more secure.
Build and deploy faster as they can be pulled to the running container cluster quickly.
Utilise disk space and memory efficiently.
During the course of containerising our applications, we noted that some service binaries appeared to be bigger (~110 MB) than they should be. For a statically-linked Golang binary, that’s pretty big! So how do we figure out what’s bloating the size of our binary?
Go binary size visualisation tool
In the course of poking around for tools that would help us analyse the symbols in a Golang binary, we found go-binsize-viz based on this article. We particularly liked this tool, because it utilises the existing Golang toolchain (specifically, Go tool nm) to analyse imports, and provides a straightforward mechanism for traversing through the symbols present via treemap. We will briefly outline the steps that we did to analyse a Golang binary here.
First, build your service using the following command (important for consistency between builds):
$ go build -a -o service_name ./path/to/main.go
Next, copy the binary over to the cloned directory of go-binsize-viz repository.
#!/usr/bin/env bash## This script needs more input parsing, but it serves the needs for now.#mkdir dist
# step 1
go tool nm -size$1 | c++filt > dist/$1.symtab
# step 2
python3 tab2pydic.py dist/$1.symtab > dist/$1-map.py
# step 3# must be data.js
python3 simplify.py dist/$1-map.py > dist/$1-data.js
rm data.js
ln-s dist/$1-data.js data.js
Running this script creates a dist folder where each intermediate step is deposited, and a data.js symlink in the top-level directory which points to the consumable .js file by treemap.html.
# top-level directory
$ ll
-rw-r--r-- 1 stan.halka staff 1.1K Aug 20 09:57 README.md
-rw-r--r-- 1 stan.halka staff 6.7K Aug 20 09:57 app3.js
-rw-r--r-- 1 stan.halka staff 1.6K Aug 20 09:57 cockroach_sizes.html
lrwxr-xr-x 1 stan.halka staff 65B Aug 25 16:49 data.js -> dist/v2.0.709356.segments-paxgroups-macos-master-go1.13-data.js
drwxr-xr-x 8 stan.halka staff 256B Aug 25 16:49 dist
...
# dist folder
$ ll dist
total 71728
drwxr-xr-x 8 stan.halka staff 256B Aug 25 16:49 .
drwxr-xr-x 21 stan.halka staff 672B Aug 25 16:49 ..
-rw-r--r-- 1 stan.halka staff 4.2M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13-data.js
-rw-r--r-- 1 stan.halka staff 3.4M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13-map.py
-rw-r--r-- 1 stan.halka staff 11M Aug 25 16:37 v2.0.709356.segments-paxgroups-macos-master-go1.13.symtab
As you can probably tell from the file names, these steps were explored on the segments-paxgroups service, which is a microservice used for segment information at Grab. You can ignore the versioning metadata, branch name, and Golang information embedded in the name.
Finally, run a local python3 server to visualise the binary components.
$ python3 -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
So now that we have a methodology to consistently generate a service binary, and a way to explore the symbols present, let’s dive in!
Of the 103MB binary produced, 81MB are recognisable, with 66MB recognised as Golang (UNKNOWN is present, and also during parsing there were a fair number of warnings. Note that we haven’t spent enough time with the tool to understand why we aren’t able to recognise and index all the symbols present).
The next step is to figure out where the symbols are coming from. There’s a bunch of Grab-internal stuff that for the sake of this blog isn’t necessary to go into, and it was reasonably easy to come to the right answer based on the intuitiveness of the go-binsize-viz tool.
This visualisation shows us the source of how 11 MB of symbols are sneaking into the segments-paxgroups binary.
Every message format for any service that reads from, or writes to, streams at Grab is included in every service binary! Not cloud native!
How did this happen?
The short answer is that Golang doesn’t import only the symbols that it requires, but rather all the symbols defined within an imported directory and transitive symbols as well. So, when we think we’re importing just one directory, if our code structure doesn’t follow principles of encapsulation or isolation, we end up importing 11 MB of symbols that we don’t need! In our case, this occurred because a generic Message interface was included in the same directory with all the auto-generated code you see in the pretty picture above.
The Streams team did an awesome job of restructuring the code, which when built again, led to this outcome:
The go-binsize-viz utility offers a treemap representation for imported symbols, and is very useful in determining what symbols are contributing to the overall size.
Code architecture matters: Keep binaries as small as possible!
To reduce your binary size, follow these best practices:
Structure your code so that the interfaces and common classes/utilities are imported from different locations than auto-generated classes.
Avoid huge, flat directory structures.
If it’s a platform offering and has too many interwoven dependencies, try to decouple the actual platform offering from the company specific instantiations. This fosters creating isolated, minimalistic code.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
This post is written by Kinnar Sen, Senior Solutions Architect, EC2 Spot
Apache Spark is an open-source, distributed processing system used for big data workloads. It provides API operations to perform multiple tasks such as streaming, extract transform load (ETL), query, machine learning (ML), and graph processing. Spark supports four different types of cluster managers (Spark standalone, Apache Mesos, Hadoop YARN, and Kubernetes), which are responsible for scheduling and allocation of resources in the cluster. Spark can run with native Kubernetes support since 2018 (Spark 2.3). AWS customers that have already chosen Kubernetes as their container orchestration tool can also choose to run Spark applications in Kubernetes, increasing the effectiveness of their operations and compute resources.
In this post, I illustrate the deployment of scalable, resilient, and cost optimized Spark application using Kubernetes via Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon EC2 Spot Instances. Learn how to save money on big data workloads by implementing this solution.
Overview
Amazon EC2 Spot Instances
Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity in the AWS Cloud. Spot Instances are available at up to a 90% discount compared to On-Demand Instance prices. Capacity pools are a group of EC2 instances that belong to particular instance family, size, and Availability Zone (AZ). If EC2 needs capacity back for On-Demand Instance usage, Spot Instances can be interrupted by EC2 with a two-minute notification. There are many graceful ways to handle the interruption to ensure that the application is well architected for resilience and fault tolerance. This can be automated via the application and/or infrastructure deployments. Spot Instances are ideal for stateless, fault tolerant, loosely coupled and flexible workloads that can handle interruptions.
Amazon Elastic Kubernetes Service
Amazon EKS is a fully managed Kubernetes service that makes it easy for you to run Kubernetes on AWS without needing to install, operate, and maintain your own Kubernetes control plane. It provides a highly available and scalable managed control plane. It also provides managed worker nodes, which let you create, update, or terminate shut down worker nodes for your cluster with a single command. It is a great choice for deploying flexible and fault tolerant containerized applications. Amazon EKS supports creating and managing Amazon EC2 Spot Instances using Amazon EKS-managed node groups following Spot best practices. This enables you to take advantage of the steep savings and scale that Spot Instances provide for interruptible workloads running in your Kubernetes cluster. Using EKS-managed node groups with Spot Instances requires less operational effort compared to using self-managed nodes. In addition to launching Spot Instances in managed node groups, it is possible to specify multiple instance types in EKS managed node groups. You can find more in this blog.
Apache Spark and Kubernetes
When a spark application is submitted to the Kubernetes cluster the following happens:
A Spark driver is created.
The driver and the run within pods.
The Spark driver then requests for executors, which are scheduled to run within pods. The executors are managed by the driver.
The application is launched and once it completes, the executor pods are cleaned up. The driver pod persists the logs and remains in a completed state until the pod is cleared by garbage collection or manually removed. The driver in a completed stage does not consume any memory or compute resources.
When a spark application runs on clusters managed by Kubernetes, the native Kubernetes scheduler is used. It is possible to schedule the driver/executor pods on a subset of available nodes. The applications can be launched either by a vanilla ‘spark submit’, a workflow orchestrator like Apache Airflow or the spark operator. I use vanilla ‘spark submit’ in this blog. is also able to schedule Spark applications on EKS clusters as described in this launch blog, but Amazon EMR on EKS is out of scope for this post.
Cost optimization
For any organization running big data workloads there are three key requirements: scalability, performance, and low cost. As the size of data increases, there is demand for more compute capacity and the total cost of ownership increases. It is critical to optimize the cost of big data applications. Big Data frameworks (in this case, Spark) are distributed to manage and process high volumes of data. These frameworks are designed for failure, can run on machines with different configurations, and are inherently resilient and flexible.
If Spark deploys on Kubernetes, the executor pods can be scheduled on EC2 Spot Instances and driver pods on On-Demand Instances. This reduces the overall cost of deployment – Spot Instances can save up to 90% over On-Demand Instance prices. This also enables faster results by scaling out executors running on Spot Instances. Spot Instances, by design, can be interrupted when EC2 needs the capacity back. If a driver pod is running on a Spot Instance, which is interrupted then the application fails and the application must be re-submitted. To avoid this situation, the driver pod can be scheduled on On-Demand Instances only. This adds a layer of resiliency to the Spark application running on Kubernetes. To cost optimize the deployment, all the executor pods are scheduled on Spot Instances as that’s where the bulk of compute happens. Spark’s inherent resiliency has the driver launch new executors to replace the ones that fail due to Spot interruptions.
There are a couple of key points to note here.
The idea is to start with minimum number of nodes for both On-Demand and Spot Instances (one each) and then auto-scale usingCluster Autoscaler and EC2 Auto Scaling Cluster Autoscaler for AWS provides integration with Auto Scaling groups. If there are not sufficient resources, the driver and executor pods go into pending state. The Cluster Autoscaler detects pods in pending state and scales worker nodes within the identified Auto Scaling group in the cluster using EC2 Auto Scaling.
The scaling for On-Demand and Spot nodes is exclusive of one another. So, if multiple applications are launched the driver and executor pods can be scheduled in different node groups independently per the resource requirements. This helps reduce job failures due to lack of resources for the driver, thus adding to the overall resiliency of the system.
Using EKS Managed node groups
This requires significantly less operational effort compared to using self-managed nodegroup and enables:
Auto enforcement of Spot best practices like Capacity Optimized allocation strategy, Capacity Rebalancing and use multiple instances types.
Proactive replacement of Spot nodes using rebalance notifications.
Managed draining of Spot nodes via re-balance recommendations.
The nodes are auto-labeled so that the pods can be scheduled with NodeAffinity.
eks.amazonaws.com/capacityType: SPOT
eks.amazonaws.com/capacityType: ON_DEMAND
Now that you understand the products and best practices of used in this tutorial, let’s get started.
Tutorial: running Spark in EKS managed node groups with Spot Instances
In this tutorial, I review steps, which help you launch cost optimized and resilient Spark jobs inside Kubernetes clusters running on EKS. I launch a word-count application counting the words from an Amazon Customer Review dataset and write the output to an Amazon S3 folder. To run the Spark workload on Kubernetes, make sure you have eksctl and kubectl installed on your computer or on an AWS Cloud9 environment. You can run this by using an AWS IAM user or role that has the AdministratorAccess policy attached to it, or check the minimum required permissions for using eksctl. The spot node groups in the Amazon EKS cluster can be launched both in a managed or a self-managed way, in this post I use the former. The config files for this tutorial can be found here. The job is finally launched in cluster mode.
Create Amazon S3 Access Policy
First, I must create an Amazon S3 access policy to allow the Spark application to read/write from Amazon S3. Amazon S3 Access is provisioned by attaching the policy by ARN to the node groups. This associates Amazon S3 access to the NodeInstanceRole and, hence, the node groups then have access to Amazon S3. Download the Amazon S3 policy file from here and modify the <<output folder>> to an Amazon S3 bucket you created. Run the following to create the policy. Note the ARN.
aws iam create-policy --policy-name spark-s3-policy --policy-document file://spark-s3.json
Cluster and node groups deployment
Create an EKS cluster using the following command:
The cluster takes approximately 15 minutes to launch.
Create the nodegroup using the nodeGroup config file. Replace the <<Policy ARN>> string using the ARN string from the previous step.
eksctl create nodegroup -f managedNodeGroups.yml
Scheduling driver/executor pods
The driver and executor pods can be assigned to nodes using affinity. PodTemplates can be used to configure the detail, which is not supported by Spark launch configuration by default. This feature is available from Spark 3.0.0, requiredDuringScheduling node affinity is used to schedule the driver and executor jobs. Sample podTemplates have been uploaded here.
Launching a Spark application
Create a service account. The spark driver pod uses the service account to create and watch executor pods using Kubernetes API server.
podTemplateFile is used here, which enables scheduling of the driver pods to On-Demand Instances and executor pods to Spot Instances.
Spark provides a mechanism to allocate dynamically resources dynamically based on workloads. In the latest release of Spark (3.0.0), dynamicAllocation can be used with Kubernetes cluster manager. The executors that do not store, active, shuffled files can be removed to free up the resources. DynamicAllocation works well in tandem with Cluster Autoscaler for resource allocation and optimizes resource for jobs. We are using dynamicAllocation here to enable optimized resource sharing.
The application file and output are both in Amazon S3.
Spark Event logs are redirected to Amazon S3. Spark on Kubernetes creates local temporary files for logs and removes them once the application completes. The logs are redirected to Amazon S3 and Spark History Server can be used to analyze the logs. Note, you can create more instrumentation using tools like Prometheus and Grafana to monitor and manage the cluster.
Observations
EC2 Spot Interruptions
The following diagram and log screenshot details from Spark History server showcases the behavior of a Spark application in case of an EC2 Spot interruption.
Four Spark applications launched in parallel in a cluster and one of the Spot nodes was interrupted. A couple of executor pods were terminated shut down in three of the four applications, but due to the resilient nature of Spark new executors were launched and the applications finished almost around the same time. The Spark Driver identified the shut down executors, which handled the shuffle files and relaunched the tasks running on those executors.
The Spark Driver identified the shut down executors, which handled the shuffle files and relaunched the tasks running on those executors.
Dynamic Allocation
Dynamic Allocation works with the caveat that it is an experimental feature.
Cost Optimization
Cost Optimization is achieved in several different ways from this tutorial.
Use of 100% Spot Instances for the Spark executors
Use of dynamicAllocation along with cluster autoscaler does make optimized use of resources and hence save cost
With the deployment of one driver and executor nodes to begin with and then scaling up on demand reduces the waste of a continuously running cluster
Cluster Autoscaling
Cluster Autoscaling is triggered as it is designed when there are pending (Spark executor) pods.
If you are trying out the tutorial, run the following steps to make sure that you don’t encounter unwanted costs.
Delete the EKS cluster and the nodegroups with the following command:
eksctl delete cluster --name sparkonk8
Delete the Amazon S3 Access Policy with the following command:
aws iam delete-policy --policy-arn <<POLICY ARN>>
Delete the Amazon S3 Output Bucket with the following command:
aws s3 rb --force s3://<<S3_BUCKET>>
Conclusion
In this blog, I demonstrated how you can run Spark workloads on a Kubernetes Cluster using Spot Instances, achieving scalability, resilience, and cost optimization. To cost optimize your Spark based big data workloads, consider running spark application using Kubernetes and EC2 Spot Instances.
As previously discussed on the Netflix Tech Blog, Titus is the Netflix container orchestration system. It runs a wide variety of workloads from various parts of the company — everything from the frontend API for netflix.com, to machine learning training workloads, to video encoders. In Titus, the hosts that workloads run on are abstracted from our users. The Titus platform maintains large pools of homogenous node capacity to run user workloads, and the Titus scheduler places workloads. This abstraction allows the compute team to influence the reliability, efficiency, and operability of the fleet via the scheduler. The hosts that run workloads are called Titus “agents.” In this post, we describe how Titus agents leverage user namespaces to improve the overall security of the Titus agent fleet.
Titus’s Multi-Tenant Clusters
The Titus agent fleet appears to users as a homogenous pool of capacity. Titus internally employs a cellular bulkhead architecture for scalability, so the fleet is composed of multiple cells. Many bulkhead architectures partition their cells on tenants, where a tenant is defined as a team and their collection of applications. We do not take this approach, and instead, we partition our cells to balance load. We do this for reliability, scalability, and efficiency reasons.
Titus is a multi-tenant system, allowing multiple teams and users to run workloads on the system, and ensuring they can all co-exist while still providing guarantees about security and performance. Much of this comes down to isolation, which comes in multiple forms. These forms include performance isolation (ensuring workloads do not degrade one another’s performance), capacity isolation (ensuring that a given tenant can acquire resources when they ask for them), fault isolation (ensuring that the failure of a part of the system doesn’t cause the whole system to fail), and security isolation (ensuring that the compromise of one tenant’s workload does not affect the security of other tenants). This post focuses on our approaches to security isolation.
Secure Multi-tenancy
One of Titus’s biggest concerns with multi-tenancy is security isolation. We want to allow different kinds of containers from different tenants to run on the same instance. Security isolation in containers has been a contentious topic. Despite the risks, we’ve chosen to leverage containers as part of our security boundary. To offset the risks brought about by the container security boundary, we employ some additional protections.
The building blocks of multi-tenancy are Linux namespaces, the very technology that makes LXC, Docker, and other kinds of containers possible. For example, the PID namespace makes it so that a process can only see PIDs in its own namespace, and therefore cannot send kill signals to random processes on the host. In addition to the default Docker namespaces (mount, network, UTS, IPC, and PID), we employ user namespaces for added layers of isolation. Unfortunately, these default namespace boundaries are not sufficient to prevent container escape, as seen in CVEs like CVE-2015–2925. These vulnerabilities arise due to the complexity of interactions between namespaces, a large number of historical decisions during kernel development, and leaky abstractions like the proc filesystem in Linux. Composing these security isolation primitives correctly is difficult, so we’ve looked to other layers for additional protection.
Running many different workloads multi-tenant on a host necessitates the prevention lateral movement, a technique in which the attacker compromises a single piece of software running in a container on the system, and uses that to compromise other containers on the same system. To mitigate this, we run containers as unprivileged users — making it so that users cannot use “root.” This is important because, in Linux, UID 0 (or root’s privileges), do not come from the mere fact that the user is root, but from capabilities. These capabilities are tied to the current process’s credentials. Capabilities can be added via privilege escalation (e.g., sudo, file capabilities) or removed (e.g., setuid, or switching namespaces). Various capabilities control what the root user can do. For example, the CAP_SYS_BOOT capability controls the ability of a given user to reboot the machine. There are also more common capabilities that are granted to users like CAP_NET_RAW, which allows a process the ability to open raw sockets. A user can automatically have capabilities added when they execute specific files via file capabilities. For example, on a stock Ubuntu system, the ping command needs CAP_NET_RAW:
One of the most powerful capabilities in Linux is CAP_SYS_ADMIN, which is effectively equivalent to having superuser access. It gives the user the ability to do everything from mounting arbitrary filesystems, to accessing tracepoints that can expose vital information about the Linux kernel. Other powerful capabilities include CAP_CHOWN and CAP_DAC_OVERRIDE, which grant the capability to manipulate file permissions.
In the kernel, you’ll often see capability checks spread throughout the code, which looks something like this:
Notice this function doesn’t check if the user is root, but if the task has the CAP_SYS_ADMIN capability before allowing it to execute.
Docker takes the approach of using an allow-list to define which capabilities a container receives. These can be extended or attenuated by the user. Even the default capabilities that are defined in the Docker profile can be abused in certain situations. When we looked into running workloads as unprivileged users without many of these capabilities, we found that it was a non-starter. Various pieces of software used elevated capabilities for FUSE, low-level packet monitoring, and performance tracing amongst other use cases. Programs will usually start with capabilities, perform any activities that require those capabilities, and then “drop” them when the process no longer needs them.
User Namespaces
Fortunately, Linux has a solution — User Namespaces. Let’s go back to that kernel code example earlier. The pcrlock function called the capable function to determine whether or not the task was capable. This function is defined as:
This checks if the task has this capability relative to the init_user_ns. The init_user_ns is the namespace that processes are initialially spawned in, as it’s the only user namespace that exists at kernel startup time. User namespaces are a mechanism to split up the init_user_ns UID space. The interface to set up the mappings is via a “uid_map” and “gid_map” that’s exposed via /proc. The mapping looks something like this:
This allows UIDs in user-namespaced containers to be mapped to host UIDs. A variety of translations occur, but from the container’s perspective, everything is from the perspective of the UID ranges (otherwise known as extents) that are mapped. This is powerful in a few ways:
It allows you to make certain UIDs off-limits to the container — if a UID is not mapped in the user namespace to a real UID, and you try to examine a file on disk with it, it will show up as overflowuid / overflowgid, a UID and GID specified in /proc/sys to indicate that it cannot be mapped into the current working space. Also, the container cannot setuid to a UID that can access files owned by that “outside uid.”
From the user namespace’s perspective, the container’s root user appears to be UID 0, and the container can use the entire range of UIDs that are mapped into that namespace.
Kernel subsystems can then proceed to call ns_capable with the specific user namespace that is tied to the resource. Many capability checks are now done to a user namespace that is relative to the resource being manipulated. This, in turn, allows processes to exercise certain privileges without having any privileges in the init user namespace. Even if the mapping is the same across many different namespaces, capability checks are still done relative to a specific user namespace.
One critical aspect of understanding how permissions work is that every namespace belongs to a specific user namespace. For example, let’s look at the UTS namespace, which is responsible for controlling the hostname:
The namespace has a relationship with a particular user namespace. The ability for a user to manipulate the hostname is based on whether or not the process has the appropriate capability in that user namespace.
Let’s Get Into It
We can examine how the interaction of namespaces and users work ourselves. To set the hostname in the UTS namespace, you need to have CAP_SYS_ADMIN in its user namespace. We can see this in action here, where an unprivileged process doesn’t have permission to set the hostname:
The reason for this is that the process does not have CAP_SYS_ADMIN. According to /proc/self/status, the effective capability set of this process is empty:
Now, let’s try to set up a user namespace, and see what happens:
Immediately, you’ll notice the command prompt says the current user is root, and that the id command agrees. Can we set the hostname now?
We still cannot set the hostname. This is because the process is still in the initial UTS namespace. Let’s see if we can unshare the UTS namespace, and set the hostname:
This is now successful, and the process is in an isolated UTS namespace with the hostname “foo.” This is because the process now has all of the capabilities that a traditional root user would have, except they are relative to the new user namespace we created:
If we inspect this process from the outside, we can see that the process still runs as the unprivileged user, and the hostname in the original outside namespace hasn’t changed:
From here, we can do all sorts of things, like mount filesystems, create other new namespaces, and in fact, we can create an entire container environment. Notice how no privilege escalation mechanism was used to perform any of these actions. This approach is what some people refer to as “rootless containers.”
Road to Implementation
We began work to enable user namespaces in early 2017. At the time we had a naive model that was simpler. This simplicity was possible because we were running without user namespaces:
This approach mirrored the process layout and boundaries of contemporary container orchestration systems. We had a shared metrics daemon on the machine that reached in and polled metrics from the container. User access was done by exposing an SSH daemon, and automatically doing nsenter on the user’s behalf to drop them into the container. To expose files to the container we would use bind mounts. The same mechanism was used to expose configuration, such as secrets.
This had the benefit that much of our software could be installed in the host namespace, and only manage files in the that namespace. The container runtime management system (Titus) was then responsible for configuring Docker to expose the right files to the container via bind mounts. In addition to that, we could use our standard metrics daemons on the host.
Although this model was easy to reason about and write software for, it had several shortcomings that we addressed by shifting everything to running inside of the container’s unprivileged user namespace. The first shortcoming was that all of the host daemons now needed to be aware of the UID translation, and perform the proper setuid or chown calls to transition across the container boundary. Second, each of these transitions represented a security risk. If the SSH daemon only partially transitioned into the container namespace by changing into the container’s pid namespace, it would leave its /proc accessible. This could then be used by a malicious attacker to escape.
With user namespaces, we can improve our security posture and reduce the complexity of the system by running those daemons in the container’s unprivileged user namespace, which removes the need to cross the namespace boundaries. In turn, this removes the need to correctly implement a cross-namespace transition mechanism thus, reducing the risk of introducing container escapes.
We did this by moving aspects of the container runtime environment into the container. For example, we run an SSH daemon per container and a metrics daemon per container. These run inside of the namespaces of the container, and they have the same capabilities and lifecycle as the workloads in the container. We call this model “System Services” — one can think of it as a primordial version of pods. By the end of 2018, we had moved all of our containers to run in unprivileged user namespaces successfully.
Why is this useful?
This may seem like another level of indirection that just introduces complexity, but instead, it allows us to leverage an extremely useful concept — “unprivileged containers.” In unprivileged containers, the root user starts from a baseline in which they don’t automatically have access to the entire system. This means that DAC, MAC, and seccomp policies are now an extra layer of defense against accessing privileged aspects of the system — not the only layer. As new privileges are added, we do not have to add them to an exclusion list. This allows our users to write software where they can control low-level system details in their own containers, rather than forcing all of the complexity up into the container runtime.
Use Case: FUSE
Netflix internally uses a purpose built FUSE filesystem called MezzFS. The purpose of this filesystem is to provide access to our content for a variety of encoding tools. Most of these encoding tools are designed to interact with the POSIX filesystem API. Our Media Cloud Engineering team wanted to leverage containers for a new platform they were building, called Archer. Archer, in turn, uses MezzFS, which needs FUSE, and at the time, FUSE required that the user have CAP_SYS_ADMIN in the initial user namespace. To accommodate the use case from our internal partner, we had to run them in a dedicated cluster where they could run privileged containers.
In 2017, we worked with our partner, Kinvolk, to have patches added to the Linux kernel that allowed users to safely use FUSE from non-init user namespaces. They were able to successfully upstream these patches, and we’ve been using them in production. From our user’s perspective, we were able to seamlessly move them into an unprivileged environment that was more secure. This simplified operations, as this workload was no longer considered exceptional, and could run alongside every other workload in the general node pool. In turn, this allowed the media encoding team access to a massive amount of compute capacity from the shared clusters, and better reliability due to the homogeneous nature of the deployment.
Use Case: Unintended Privileges
Many CVEs related to granting containers unintended privileges have been released in the past few years:
CVE-2019–5736: Privilege escalation via overwriting host runc binary
CVE-2018–10892: Access to /proc/acpi, allowing an attacker to modify hardware configuration
There will certainly be more vulnerabilities in the future, as is to be expected in any complex, quickly evolving system. We already use the default settings offered by Docker, such as AppArmor, and seccomp, but by adding user namespaces, we can achieve a superior defense-in-depth security model. These CVEs did not affect our infrastructure because we were using user namespaces for all of our containers. The attenuation of capabilities in the init user namespace performed as intended and stopped these attacks.
The Future
There are still many bits of the Kernel that are receiving support for user namespaces or enhancements making user namespaces easier to use. Much of the work left to do is focused on filesystems and container orchestration systems themselves. Some of these changes are slated for upcoming kernel releases. Work is being done to add unprivileged mounts to overlayfs allowing for nested container builds in a user namespace with layers. Future work is going on to make the Linux kernel VFS layer natively understand ID translation. This will make user namespaces with different ID mappings able to access the same underlying filesystem by shifting UIDs through a bind mount. Our partners at Kinvolk are also working on bringing user namespaces to Kubernetes.
Today, a variety of container runtimes support user namespaces. Docker can set up machine-wide UID mappings with separate user namespaces per container, as outlined in their docs. Any OCI compliant runtime such as Containerd / runc, Podman, and systemd-nspawn support user namespaces. Various container orchestration engines also support user namespaces via their underlying container runtimes, such as Nomad and Docker Swarm.
As part of our move to Kubernetes, Netflix has been working with Kinvolk on getting user namespaces to work under Kubernetes. You can follow this work via the KEP discussion here, and Kinvolk has more information about running user namespaces under Kubernetes on their blog. We look forward to evolving container security together with the Kubernetes community.
Maintaining a server fleet the size of Cloudflare’s is an operational challenge, to say the least. Anything we can do to lower complexity and improve efficiency has effects for our SRE (Site Reliability Engineer) and Data Center teams that can be felt throughout a server’s 4+ year lifespan.
At the Cloudflare Core, we process logs to analyze attacks and compute analytics. In 2020, our Core servers were in need of a refresh, so we decided to redesign the hardware to be more in line with our Gen X edge servers. We designed two major server variants for the core. The first is Core Compute 2020, an AMD-based server for analytics and general-purpose compute paired with solid-state storage drives. The second is Core Storage 2020, an Intel-based server with twelve spinning disks to run database workloads.
Core Compute 2020
Earlier this year, we blogged about our 10th generation edge servers or Gen X and the improvements they delivered to our edge in both performance and security. The new Core Compute 2020 server leverages many of our learnings from the edge server. The Core Compute servers run a variety of workloads including Kubernetes, Kafka, and various smaller services.
Configuration Changes (Kubernetes)
Previous Generation Compute
Core Compute 2020
CPU
2 x Intel Xeon Gold 6262
1 x AMD EPYC 7642
Total Core / Thread Count
48C / 96T
48C / 96T
Base / Turbo Frequency
1.9 / 3.6 GHz
2.3 / 3.3 GHz
Memory
8 x 32GB DDR4-2666
8 x 32GB DDR4-2933
Storage
6 x 480GB SATA SSD
2 x 3.84TB NVMe SSD
Network
Mellanox CX4 Lx 2 x 25GbE
Mellanox CX4 Lx 2 x 25GbE
Configuration Changes (Kafka)
Previous Generation (Kafka)
Core Compute 2020
CPU
2 x Intel Xeon Silver 4116
1 x AMD EPYC 7642
Total Core / Thread Count
24C / 48T
48C / 96T
Base / Turbo Frequency
2.1 / 3.0 GHz
2.3 / 3.3 GHz
Memory
6 x 32GB DDR4-2400
8 x 32GB DDR4-2933
Storage
12 x 1.92TB SATA SSD
10 x 3.84TB NVMe SSD
Network
Mellanox CX4 Lx 2 x 25GbE
Mellanox CX4 Lx 2 x 25GbE
Both previous generation servers were Intel-based platforms, with the Kubernetes server based on Xeon 6262 processors, and the Kafka server based on Xeon 4116 processors. One goal with these refreshed versions was to converge the configurations in order to simplify spare parts and firmware management across the fleet.
As the above tables show, the configurations have been converged with the only difference being the number of NVMe drives installed depending on the workload running on the host. In both cases we moved from a dual-socket configuration to a single-socket configuration, and the number of cores and threads per server either increased or stayed the same. In all cases, the base frequency of those cores was significantly improved. We also moved from SATA SSDs to NVMe SSDs.
Core Compute 2020 Synthetic Benchmarking
The heaviest user of the SSDs was determined to be Kafka. The majority of the time Kafka is sequentially writing 2MB blocks to the disk. We created a simple FIO script with 75% sequential write and 25% sequential read, scaling the block size from a standard page table entry size of 4096KB to Kafka’s write size of 2MB. The results aligned with what we expected from an NVMe-based drive.
Core Compute 2020 Production Benchmarking
Cloudflare runs many of our Core Compute services in Kubernetes containers, some of which are multi-core. By transitioning to a single socket, problems associated with dual sockets were eliminated, and we are guaranteed to have all cores allocated for any given container on the same socket.
Another heavy workload that is constantly running on Compute hosts is the Cloudflare CSAM Scanning Tool. Our Systems Engineering team isolated a Compute 2020 compute host and the previous generation compute host, had them run just this workload, and measured the time to compare the fuzzy hashes for images to the NCMEC hash lists and verify that they are a “miss”.
Because the CSAM Scanning Tool is very compute intensive we specifically isolated it to take a look at its performance with the new hardware. We’ve spent a great deal of effort on software optimization and improved algorithms for this tool but investing in faster, better hardware is also important.
In these heatmaps, the X axis represents time, and the Y axis represents “buckets” of time taken to verify that it is not a match to one of the NCMEC hash lists. For a given time slice in the heatmap, the red point is the bucket with the most times measured, the yellow point the second most, and the green points the least. The red points on the Compute 2020 graph are all in the 5 to 8 millisecond bucket, while the red points on the previous Gen heatmap are all in the 8 to 13 millisecond bucket, which shows that on average, the Compute 2020 host is verifying hashes significantly faster.
Core Storage 2020
Another major workload we identified was ClickHouse, which performs analytics over large datasets. The last time we upgraded our servers running ClickHouse was back in 2018.
Configuration Changes
Previous Generation
Core Storage 2020
CPU
2 x Intel Xeon E5-2630 v4
1 x Intel Xeon Gold 6210U
Total Core / Thread Count
20C / 40T
20C / 40T
Base / Turbo Frequency
2.2 / 3.1 GHz
2.5 / 3.9 GHz
Memory
8 x 32GB DDR4-2400
8 x 32GB DDR4-2933
Storage
12 x 10TB 7200 RPM 3.5” SATA
12 x 10TB 7200 RPM 3.5” SATA
Network
Mellanox CX4 Lx 2 x 25GbE
Mellanox CX4 Lx 2 x 25GbE
CPU Changes
For ClickHouse, we use a 1U chassis with 12 x 10TB 3.5” hard drives. At the time we were designing Core Storage 2020 our server vendor did not yet have an AMD version of this chassis, so we remained on Intel. However, we moved Core Storage 2020 to a single 20 core / 40 thread Xeon processor, rather than the previous generation’s dual-socket 10 core / 20 thread processors. By moving to the single-socket Xeon 6210U processor, we were able to keep the same core count, but gained 17% higher base frequency and 26% higher max turbo frequency. Meanwhile, the total CPU thermal design profile (TDP), which is an approximation of the maximum power the CPU can draw, went down from 165W to 150W.
On a dual-socket server, remote memory accesses, which are memory accesses by a process on socket 0 to memory attached to socket 1, incur a latency penalty, as seen in this table:
Previous Generation
Core Storage 2020
Memory latency, socket 0 to socket 0
81.3 ns
86.9 ns
Memory latency, socket 0 to socket 1
142.6 ns
N/A
An additional advantage of having a CPU with all 20 cores on the same socket is the elimination of these remote memory accesses, which take 76% longer than local memory accesses.
Memory Changes
The memory in the Core Storage 2020 host is rated for operation at 2933 MHz; however, in the 8 x 32GB configuration we need on these hosts, the Intel Xeon 6210U processor clocks them at 2666 MH. Compared to the previous generation, this gives us a 13% boost in memory speed. While we would get a slightly higher clock speed with a balanced, 6 DIMMs configuration, we determined that we are willing to sacrifice the slightly higher clock speed in order to have the additional RAM capacity provided by the 8 x 32GB configuration.
Storage Changes
Data capacity stayed the same, with 12 x 10TB SATA drives in RAID 0 configuration for best throughput. Unlike the previous generation, the drives in the Core Storage 2020 host are helium filled. Helium produces less drag than air, resulting in potentially lower latency.
Core Storage 2020 Synthetic benchmarking
We performed synthetic four corners benchmarking: IOPS measurements of random reads and writes using 4k block size, and bandwidth measurements of sequential reads and writes using 128k block size. We used the fio tool to see what improvements we would get in a lab environment. The results show a 10% latency improvement and 11% IOPS improvement in random read performance. Random write testing shows 38% lower latency and 60% higher IOPS. Write throughput is improved by 23%, and read throughput is improved by a whopping 90%.
Previous Generation
Core Storage 2020
% Improvement
4k Random Reads (IOPS)
3,384
3,758
11.0%
4k Random Read Mean Latency (ms, lower is better)
75.4
67.8
10.1% lower
4k Random Writes (IOPS)
4,009
6,397
59.6%
4k Random Write Mean Latency (ms, lower is better)
63.5
39.7
37.5% lower
128k Sequential Reads (MB/s)
1,155
2,195
90.0%
128k Sequential Writes (MB/s)
1,265
1,558
23.2%
CPU frequencies
The higher base and turbo frequencies of the Core Storage 2020 host’s Xeon 6210U processor allowed that processor to achieve higher average frequencies while running our production ClickHouse workload. A recent snapshot of two production hosts showed the Core Storage 2020 host being able to sustain an average of 31% higher CPU frequency while running ClickHouse.
Previous generation (average core frequency)
Core Storage 2020 (average core frequency)
% improvement
Mean Core Frequency
2441 MHz
3199 MHz
31%
Core Storage 2020 Production benchmarking
Our ClickHouse database hosts are continually performing merge operations to optimize the database data structures. Each individual merge operation takes just a few seconds on average, but since they’re constantly running, they can consume significant resources on the host. We sampled the average merge time every five minutes over seven days, and then sampled the data to find the average, minimum, and maximum merge times reported by a Compute 2020 host and by a previous generation host. Results are summarized below.
ClickHouse merge operation performance improvement (time in seconds, lower is better)
Time
Previous generation
Core Storage 2020
% improvement
Mean time to merge
1.83
1.15
37% lower
Maximum merge time
3.51
2.35
33% lower
Minimum merge time
0.68
0.32
53% lower
Our lab-measured CPU frequency and storage performance improvements on Core Storage 2020 have translated into significantly reduced times to perform this database operation.
Conclusion
With our Core 2020 servers, we were able to realize significant performance improvements, both in synthetic benchmarking outside production and in the production workloads we tested. This will allow Cloudflare to run the same workloads on fewer servers, saving CapEx costs and data center rack space. The similarity of the configuration of the Kubernetes and Kafka hosts should help with fleet management and spare parts management. For our next redesign, we will try to further converge the designs on which we run the major Core workloads to further improve efficiency.
Special thanks to Will Buckner and Chris Snook for their help in the development of these servers, and to Tim Bart for validating CSAM Scanning Tool’s performance on Compute.
In 2016, we launched the Cloudflare Origin CA, a certificate authority optimized for making it easy to secure the connection between Cloudflare and an origin server. Running our own CA has allowed us to support fast issuance and renewal, simple and effective revocation, and wildcard certificates for our users.
Out of the box, managing TLS certificates and keys within Kubernetes can be challenging and error prone. The secret resources have to be constructed correctly, as components expect secrets with specific fields. Some forms of domain verification require manually rotating secrets to pass. Once you’re successful, don’t forget to renew before the certificate expires!
cert-manager is a project to fill this operational gap, providing Kubernetes resources that manage the lifecycle of a certificate. Today we’re releasing origin-ca-issuer, an extension to cert-manager integrating with Cloudflare Origin CA to easily create and renew certificates for your account’s domains.
Origin CA Integration
Creating an Issuer
After installing cert-manager and origin-ca-issuer, you can create an OriginIssuer resource. This resource creates a binding between cert-manager and the Cloudflare API for an account. Different issuers may be connected to different Cloudflare accounts in the same Kubernetes cluster.
This creates a new OriginIssuer named “prod-issuer” that issues certificates using ECDSA signatures, and the secret “service-key” in the same namespace is used to authenticate to the Cloudflare API.
Signing an Origin CA Certificate
After creating an OriginIssuer, we can now create a Certificate with cert-manager. This defines the domains, including wildcards, that the certificate should be issued for, how long the certificate should be valid, and when cert-manager should renew the certificate.
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: example-com
namespace: default
spec:
# The secret name where cert-manager
# should store the signed certificate.
secretName: example-com-tls
dnsNames:
- example.com
# Duration of the certificate.
duration: 168h
# Renew a day before the certificate expiration.
renewBefore: 24h
# Reference the Origin CA Issuer you created above,
# which must be in the same namespace.
issuerRef:
group: cert-manager.k8s.cloudflare.com
kind: OriginIssuer
name: prod-issuer
Once created, cert-manager begins managing the lifecycle of this certificate, including creating the key material, crafting a certificate signature request (CSR), and constructing a certificate request that will be processed by the origin-ca-issuer.
When signed by the Cloudflare API, the certificate will be made available, along with the private key, in the Kubernetes secret specified within the secretName field. You’ll be able to use this certificate on servers proxied behind Cloudflare.
Extra: Ingress Support
If you’re using an Ingress controller, you can use cert-manager’s Ingress support to automatically manage Certificate resources based on your Ingress resource.
apiVersion: networking/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/issuer: prod-issuer
cert-manager.io/issuer-kind: OriginIssuer
cert-manager.io/issuer-group: cert-manager.k8s.cloudflare.com
name: example
namespace: default
spec:
rules:
- host: example.com
http:
paths:
- backend:
serviceName: examplesvc
servicePort: 80
path: /
tls:
# specifying a host in the TLS section will tell cert-manager
# what DNS SANs should be on the created certificate.
- hosts:
- example.com
# cert-manager will create this secret
secretName: example-tls
Building an External cert-manager Issuer
An external cert-manager issuer is a specialized Kubernetes controller. There’s no direct communication between cert-manager and external issuers at all; this means that you can use any existing tools and best practices for developing controllers to develop an external issuer.
We’ve decided to use the excellent controller-runtime project to build origin-ca-issuer, running two reconciliation controllers.
OriginIssuer Controller
The OriginIssuer controller watches for creation and modification of OriginIssuer custom resources. The controllers create a Cloudflare API client using the details and credentials referenced. This client API instance will later be used to sign certificates through the API. The controller will periodically retry to create an API client; once it is successful, it updates the OriginIssuer’s status to be ready.
CertificateRequest Controller
The CertificateRequest controller watches for the creation and modification of cert-manager’s CertificateRequest resources. These resources are created automatically by cert-manager as needed during a certificate’s lifecycle.
The controller looks for Certificate Requests that reference a known OriginIssuer, this reference is copied by cert-manager from the origin Certificate resource, and ignores all resources that do not match. The controller then verifies the OriginIssuer is in the ready state, before transforming the certificate request into an API request using the previously created clients.
On a successful response, the signed certificate is added to the certificate request, and which cert-manager will use to create or update the secret resource. On an unsuccessful request, the controller will periodically retry.
Learn More
Up-to-date documentation and complete installation instructions can be found in our GitHub repository. Feedback and contributions are greatly appreciated. If you’re interested in Kubernetes at Cloudflare, including building controllers like these, we’re hiring.
Earlier this year we hosted the first serverless themed virtual event, the Serverless-First Function. We enjoyed the opportunity to virtually connect with our customers so much that we want to do it again. This time, we’re expanding the scope to feature serverless, containers, and front-end development content. The Modern Applications Online Event is scheduled for November 4-5, 2020.
This free, two-day event addresses how to build and operate modern applications at scale across your organization, enabling you to become more agile and respond to change faster. The event covers topics including serverless application development, containers best practices, front-end web development and more. If you missed the containers or serverless virtual events earlier this year, this is great opportunity to watch the content and interact directly with expert moderators. The full agenda is listed below.
Move fast and ship things: Using serverless to increase speed and agility within your organization In this session, Adrian Cockcroft demonstrates how you can use serverless to build modern applications faster than ever. Cockcroft uses real-life examples and customer stories to debunk common misconceptions about serverless.
Eliminating busywork at the organizational level: Tips for using serverless to its fullest potential In this session, David Yanacek discusses key ways to unlock the full benefits of serverless, including building services around APIs and using service-oriented architectures built on serverless systems to remove the roadblocks to continuous innovation.
Faster Mobile and Web App Development with AWS Amplify In this session, Brice Pellé, introduces AWS Amplify, a set of tools and services that enables mobile and front-end web developers to build full stack serverless applications faster on AWS. Learn how to accelerate development with AWS Amplify’s use-case centric open-source libraries and CLI, and its fully managed web hosting service with built-in CI/CD.
Built Serverless-First: How Workgrid Software transformed from a Liberty Mutual project to its own global startup Connected through a central IT team, Liberty Mutual has embraced serverless since AWS Lambda’s inception in 2014. In this session, Gillian McCann discusses Workgrid’s serverless journey—from internal microservices project within Liberty Mutual to independent business entity, all built serverless-first. Introduction by AWS Principal Serverless SA, Sam Dengler.
Market insights: A conversation with Forrester analyst Jeffrey Hammond & Director of Product for Lambda Ajay Nair In this session, guest speaker Jeffrey Hammond and Director of Product for AWS Lambda, Ajay Nair, discuss the state of serverless, Lambda-based architectural approaches, Functions-as-a-Service platforms, and more. You’ll learn about the high-level and enduring enterprise patterns and advancements that analysts see driving the market today and determining the market in the future.
AWS Fargate Platform Version 1.4 In this session we will go through a brief introduction of AWS Fargate, what it is, its relation to EKS and ECS and the problems it addresses for customers. We will later introduce the concept of Fargate “platform versions” and we will then dive deeper into the new features that the new platform version 1.4 enables.
Persistent Storage on Containers Containerizing applications that require data persistence or shared storage is often challenging since containers are ephemeral in nature, are scaled in and out dynamically, and typically clear any saved state when terminated. In this session you will learn about Amazon Elastic File System (EFS), a fully managed, elastic, highly-available, scalable, secure, high-performance, cloud native, shared file system that enables data to be persisted separately from compute for your containerized applications.
Security Best Practices on Amazon ECR In this session, we will cover best practices with securing your container images using ECR. Learn how user access controls, image assurance, and image scanning contribute to securing your images.
Application Level Design
Thursday, November 5, 2020, 9:00 AM – 1:00 PM PT
Building a Live Streaming Platform with Amplify Video In this session, learn how to build a live-streaming platform using Amplify Video and the platform powering it, AWS Elemental Live. Amplify video is an open source plugin for the Amplify CLI that makes it easy to incorporate video streaming into your mobile and web applications powered by AWS Amplify.
Building Serverless Web Applications In this session, follow along as Ben Smith shows you how to build and deploy a completely serverless web application from scratch. The application will span from a mobile friendly front end to complex business logic on the back end.
Automating serverless application development workflows In this talk, Eric Johnson breaks down how to think about CI/CD when building serverless applications with AWS Lambda and Amazon API Gateway. This session will cover using technologies like AWS SAM to build CI/CD pipelines for serverless application back ends.
Observability for your serverless applications In this session, Julian Wood walks you through how to add monitoring, logging, and distributed tracing to your serverless applications. Join us to learn how to track platform and business metrics, visualize the performance and operations of your application, and understand which services should be optimized to improve your customer’s experience.
Happy Building with AWS Copilot The hard part’s done. You and your team have spent weeks pouring over pull requests, building micro-services and containerizing them. Congrats! But what do you do now? How do you get those services on AWS? Copilot is a new command line tool that makes building, developing and operating containerized apps on AWS a breeze. In this session, we’ll talk about how Copilot helps you and your team set up modern applications that follow AWS best practices
CDK for Kubernetes The CDK for Kubernetes (cdk8s) is a new open-source software development framework for defining Kubernetes applications and resources using familiar programming languages. Applications running on Kubernetes are composed of dozens of resources maintained through carefully maintained YAML files. As applications evolve and teams grow, these YAML files become harder and harder to manage. It’s also really hard to reuse and create abstractions through config files — copying & pasting from previous projects is not the solution! In this webinar, the creators of cdk8s show you how to define your first cdk8s application, define reusable components called “constructs” and generally say goodbye (and thank you very much) to writing in YAML.
Machine Learning on Amazon EKS Amazon EKS has quickly emerged as a leading choice for machine learning workloads. In this session, we’ll walk through some of the recent ML related enhancements the Kubernetes team at AWS has released. We will then dive deep with walkthroughs of how to optimize your machine learning workloads on Amazon EKS, including demos of the latest features we’ve contributed to popular open source projects like Spark and Kubeflow
Deep Dive on Amazon ECS Capacity Providers In this talk, we’ll dive into the different ways that ECS Capacity Providers can enable teams to focus more on their core business, and less on the infrastructure behind the scenes. We’ll look at the benefits and discuss scenarios where Capacity Providers can help solve the problems that customers face when using container orchestration. Lastly, we’ll review what features have been released with Capacity Providers, as well as look ahead at what’s to come.
Earlier this year, we took you on a journey on how we built and deployed our event sourcing and stream processing framework at Grab. We’re happy to share that we’re able to reliably maintain our uptime and continue to service close to 400 billion events a week. We haven’t stopped there though. To ensure that we can scale our framework as the Grab business continuously grows, we have spent efforts optimizing our infrastructure.
In this article, we will dive deeper into our Kubernetes infrastructure setup for our stream processing framework. We will cover why and how we focus on optimal scalability and availability of our infrastructure.
Quick Architecture Recap
The Coban platform provides lightweight Golang plugin architecture-based data processing pipelines running in Kubernetes. These are essentially Kafka consumer pods that consume data, process it, and then materialize the results into various sinks (RDMS, other Kafka topics).
Anatomy of a Processing Pod
Each stream processing pod (the smallest unit of a pipeline’s deployment) has three top level components:
Trigger: An interface that connects directly to the source of the data and converts it into an event channel.
Runtime: This is the app’s entry point and the orchestrator of the pod. It manages the worker pools, triggers, event channels, and lifecycle events.
Pipeline plugin: This is provided by the user, and conforms to a contract that the platform team publishes. It contains the domain logic for the pipeline and houses the pipeline orchestration defined by a user based on our Stream Processing Framework.
Optimal Scaling
We initially architected our Kubernetes setup around horizontal pod autoscaling (HPA), which scales the number of pods per deployment based on CPU and memory usage. HPA keeps CPU and memory per pod specified in the deployment manifest and scales horizontally as the load changes.
These were the areas of application wastage we observed on our platform:
As Grab’s traffic is uneven, we’d always have to provision for peak traffic. As users would not (or could not) always account for ramps, they would be fairly liberal with setting limit values (CPU and memory), leading to resource wastage.
Pods often had uneven traffic distribution despite fairly even partition load distribution in Kafka. The Stream Processing Framework(SPF) is essentially Kafka consumers consuming from Kafka topics, hence the number of pods scaling in and out resulted in unequal partition load per pod.
Vertically Scaling with Fixed Number of Pods
We initially kept the number of pods for a pipeline equal to the number of partitions in the topic the pipeline consumes from. This ensured even distribution of partitions to each pod providing balanced consumption. In order to abstract this from the end user, we automated the application deployment process to directly call the Kafka API to fetch the number of partitions during runtime.
After achieving a fixed number of pods for the pipeline, we wanted to move away from HPA. We wanted our pods to scale up and down as the load increases or decreases without any manual intervention. Vertical pod autoscaling (VPA) solves this problem as it relieves us from any manual operation for setting up resources for our deployment.
We just deploy the application and let VPA handle the resources required for its operation. It’s known to not be very susceptible to quick load changes as it trains its model to monitor the deployment’s load trend over a period of time before recommending an optimal resource. This process ensures the optimal resource allocation for our pipelines considering the historic trends on throughput.
We saw a ~45% reduction in our total resource usage vs resource requested after moving to VPA with a fixed number of pods from HPA.
Managing Availability
We broadly classify our workloads as latency sensitive (critical) and latency tolerant (non-critical). As a result, we could optimize scheduling and cost efficiency using priority classes and overprovisioning on heterogeneous node types on AWS.
Kubernetes Priority Classes
The main cost of running EKS in AWS is attributed to the EC2 machines that form the worker nodes for the Kubernetes cluster. Running On-Demand brings all the guarantees of instance availability but it is definitely very expensive. Hence, our first action to drive cost optimisation was to include Spot instances in our worker node group.
With the uncertainty of losing a spot instance, we started assigning priority to our various applications. We then let the user choose the priority of their pipeline depending on their use case. Different priorities would result in different node affinity to different kinds of instance groups (On-Demand/Spot). For example, Critical pipelines (latency sensitive) run on On-Demand worker node groups and Non-critical pipelines (latency tolerant) on Spot instance worker node groups.
We use priority class as a method of preemption, as well as a node affinity that chooses a certain priority pipeline for the node group to deploy to.
Overprovisioning
With spot instances running we realised a need to make our cluster quickly respond to failures. We wanted to achieve quick rescheduling of evicted pods, hence we added overprovisioning to our cluster. This means we keep some noop pods occupying free space running in our worker node groups for the quick scheduling of evicted or deploying pods.
The overprovisioned pods are the lowest priority pods, thus can be preempted by any pod waiting in the queue for scheduling. We used cluster proportional autoscaler to decide the right number of these overprovisioned pods, which scales up and down proportionally to cluster size (i.e number of nodes and CPU in worker node group). This relieves us from tuning the number of these noop pods as the cluster scales up or down over the period keeping the free space proportional to current cluster capacity.
Lastly, overprovisioning also helped improve the deployment time because there is no dependency on the time required for Auto Scaling Groups (ASG) to add a new node to the cluster every time we want to deploy a new application.
Future Improvements
Evolution is an ongoing process. In the next few months, we plan to work on custom resources for combining VPA and fixed deployment size. Our current architecture setup works fine for now, but we would like to create a more tuneable in-house CRD(Custom Resource Definition) for VPA that incorporates rightsizing our Kubernetes deployment horizontally.
Authored By Shubham Badkur on behalf of the Coban team at Grab – Ryan Ooi, Karan Kamath, Hui Yang, Yuguang Xiao, Jump Char, Jason Cusick, Shrinand Thakkar, Dean Barlan, Shivam Dixit, Andy Nguyen, and Ravi Tandon.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
What makes a project successful? For developers building cloud-native applications, successful projects thrive on transparent, consistent, and rigorous collaboration. That collaboration is one of the reasons that many open source projects, like Docker containers and Kubernetes, grow to become standards for how we build, deliver, and operate software. Our Open Source Guides and Introduction to innersourcing are great first steps to setting up and encouraging these best practices in your own projects.
However, a common challenge that application developers face is manually testing against inconsistent environments. Accurately testing Kubernetes applications can differ from one developer’s environment to another, and implementing a rigorous and consistent environment for end-to-end testing isn’t easy. It can also be very time consuming to spin up and down Kubernetes clusters. The inconsistencies between environments and the time required to spin up new Kubernetes clusters can negatively impact the speed and quality of cloud-native applications.
Building a transparent CI process
On GitHub, integration and testing becomes a little easier by combining GitHub Actions with open source tools. You can treat Actions as the native continuous integration and continuous delivery (CI/CD) tool for your project, and customize your Actions workflow to include automation and validation as next steps.
Since Actions can be triggered based on nearly any GitHub event, it’s also possible to build in accountability for updating tests and fixing bugs. For example, when a developer creates a pull request, Actions status checks can automatically block the merge if the test fails.
Here are a few more examples:
Branch protection rules in the repository help enforce certain workflows, such as requiring more than one pull request review or requiring certain status checks to pass before allowing a pull request to merge.
GitHub Actions are natively configured to act as status checks when they’re set up to trigger `on: [pull_request]`.
Continuous integration (CI) is extremely valuable as it allows you to run tests before each pull request is merged into production code. In turn, this will reduce the number of bugs that are pushed into production and increases confidence that newly introduced changes will not break existing functionality.
But transparency remains key: Requiring CI status checks on protected branches provides a clearly-defined, transparent way to let code reviewers know if the commits meet the conditions set for the repository—right in the pull request view.
Using community-powered workflows
Now that we’ve thought through the simple CI policies, automated workflows are next. Think of an Actions workflow as a set of “plug and play” open sourced, automated steps contributed by the community. You can use them as they are, or customize and make them your own. Once you’ve found the right one, open sourced Actions can be plugged into your workflow with the`- uses: repo/action-name` field.
You might ask, “So how do I find available Actions that suit my needs?”
As you’re building automation and CI pipelines, take advantage of Marketplace to find pre-built Actions provided by the community. Examples of pre-built Actions span from a Docker publish and the kubectl CLI installation to container scans and cloud deployments. When it comes to cloud-native Actions, the list keeps growing as container-based development continues to expand.
Testing with kind
Testing is a critical part of any CI/CD pipeline, but running tests in Kubernetes can absorb the extra time that automation saves. Enter kind. kind stands for “Kubernetes in Docker.” It’s an open source project from the Kubernetes special interest group (SIGs) community, and a tool for running local Kubernetes clusters using Docker container “nodes.” Creating a kind cluster is a simple way to run Kubernetes cluster and application testing—without having to spin up a complete Kubernetes environment.
As the number of Kubernetes users pushing critical applications to production grows, so does the need for a repeatable, reliable, and rigorous testing process. This can be accomplished by combining the creation of a homogenous Kubernetes testing environment with kind, the community-powered Marketplace, and the native and transparent Actions CI process.
Bringing it all together with kind and Actions
Come see kind and Actions at work during our next GitHub Demo Day live stream on October 16, 2020 at 11am PT. I’ll walk you through how to easily set up automated and consistent tests per pull request, including how to use kind with Actions to automatically run end-to-end tests across a common Kubernetes environment.
If you already understand how Secondary DNS works, please feel free to skip this section. It does not provide any Cloudflare-specific information.
Secondary DNS has many use cases across the Internet; however, traditionally, it was used as a synchronized backup for when the primary DNS server was unable to respond to queries. A more modern approach involves focusing on redundancy across many different nameservers, which in many cases broadcast the same anycasted IP address.
Secondary DNS involves the unidirectional transfer of DNS zones from the primary to the Secondary DNS server(s). One primary can have any number of Secondary DNS servers that it must communicate with in order to keep track of any zone updates. A zone update is considered a change in the contents of a zone, which ultimately leads to a Start of Authority (SOA) serial number increase. The zone’s SOA serial is one of the key elements of Secondary DNS; it is how primary and secondary servers synchronize zones. Below is an example of what an SOA record might look like during a dig query.
example.com 3600 IN SOA ashley.ns.cloudflare.com. dns.cloudflare.com.
2034097105 // Serial
10000 // Refresh
2400 // Retry
604800 // Expire
3600 // Minimum TTL
Each of the numbers is used in the following way:
Serial – Used to keep track of the status of the zone, must be incremented at every change.
Refresh – The maximum number of seconds that can elapse before a Secondary DNS server must check for a SOA serial change.
Retry – The maximum number of seconds that can elapse before a Secondary DNS server must check for a SOA serial change, after previously failing to contact the primary.
Expire – The maximum number of seconds that a Secondary DNS server can serve stale information, in the event the primary cannot be contacted.
Minimum TTL – Per RFC 2308, the number of seconds that a DNS negative response should be cached for.
Using the above information, the Secondary DNS server stores an SOA record for each of the zones it is tracking. When the serial increases, it knows that the zone must have changed, and that a zone transfer must be initiated.
Serial Tracking
Serial increases can be detected in the following ways:
The fastest way for the Secondary DNS server to keep track of a serial change is to have the primary server NOTIFY them any time a zone has changed using the DNS protocol as specified in RFC 1996, Secondary DNS servers will instantly be able to initiate a zone transfer.
Another way is for the Secondary DNS server to simply poll the primary every “Refresh” seconds. This isn’t as fast as the NOTIFY approach, but it is a good fallback in case the notifies have failed.
One of the issues with the basic NOTIFY protocol is that anyone on the Internet could potentially notify the Secondary DNS server of a zone update. If an initial SOA query is not performed by the Secondary DNS server before initiating a zone transfer, this is an easy way to perform an amplification attack. There is two common ways to prevent anyone on the Internet from being able to NOTIFY Secondary DNS servers:
Using transaction signatures (TSIG) as per RFC 2845. These are to be placed as the last record in the extra records section of the DNS message. Usually the number of extra records (or ARCOUNT) should be no more than two in this case.
Using IP based access control lists (ACL). This increases security but also prevents flexibility in server location and IP address allocation.
Generally NOTIFY messages are sent over UDP, however TCP can be used in the event the primary server has reason to believe that TCP is necessary (i.e. firewall issues).
Zone Transfers
In addition to serial tracking, it is important to ensure that a standard protocol is used between primary and Secondary DNS server(s), to efficiently transfer the zone. DNS zone transfer protocols do not attempt to solve the confidentiality, authentication and integrity triad (CIA); however, the use of TSIG on top of the basic zone transfer protocols can provide integrity and authentication. As a result of DNS being a public protocol, confidentiality during the zone transfer process is generally not a concern.
Authoritative Zone Transfer (AXFR)
AXFR is the original zone transfer protocol that was specified in RFC 1034 and RFC 1035 and later further explained in RFC 5936. AXFR is done over a TCP connection because a reliable protocol is needed to ensure packets are not lost during the transfer. Using this protocol, the primary DNS server will transfer all of the zone contents to the Secondary DNS server, in one connection, regardless of the serial number. AXFR is recommended to be used for the first zone transfer, when none of the records are propagated, and IXFR is recommended after that.
Incremental Zone Transfer (IXFR)
IXFR is the more sophisticated zone transfer protocol that was specified in RFC 1995. Unlike the AXFR protocol, during an IXFR, the primary server will only send the secondary server the records that have changed since its current version of the zone (based on the serial number). This means that when a Secondary DNS server wants to initiate an IXFR, it sends its current serial number to the primary DNS server. The primary DNS server will then format its response based on previous versions of changes made to the zone. IXFR messages must obey the following pattern:
Current latest SOA
Secondary server current SOA
DNS record deletions
Secondary server current SOA + changes
DNS record additions
Current latest SOA
Steps 2,3,4,5,6 can be repeated any number of times, as each of those represents one change set of deletions and additions, ultimately leading to a new serial.
IXFR can be done over UDP or TCP, but again TCP is generally recommended to avoid packet loss.
How Does Secondary DNS Work at Cloudflare?
The DNS team loves microservice architecture! When we initially implemented Secondary DNS at Cloudflare, it was done using Mesos Marathon. This allowed us to separate each of our services into several different marathon apps, individually scaling apps as needed. All of these services live in our core data centers. The following services were created:
Zone Transferer – responsible for attempting IXFR, followed by AXFR if IXFR fails.
Zone Transfer Scheduler – responsible for periodically checking zone SOA serials for changes.
Rest API – responsible for registering new zones and primary nameservers.
In addition to the marathon apps, we also had an app external to the cluster:
Notify Listener – responsible for listening for notifies from primary servers and telling the Zone Transferer to initiate an AXFR/IXFR.
Each of these microservices communicates with the others through Kafka.
Figure 1: Secondary DNS Microservice Architecture
Once the zone transferer completes the AXFR/IXFR, it then passes the zone through to our zone builder, and finally gets pushed out to our edge at each of our 200 locations.
Although this current architecture worked great in the beginning, it left us open to many vulnerabilities and scalability issues down the road. As our Secondary DNS product became more popular, it was important that we proactively scaled and reduced the technical debt as much as possible. As with many companies in the industry, Cloudflare has recently migrated all of our core data center services to Kubernetes, moving away from individually managed apps and Marathon clusters.
What this meant for Secondary DNS is that all of our Marathon-based services, as well as our NOTIFY Listener, had to be migrated to Kubernetes. Although this long migration ended up paying off, many difficult challenges arose along the way that required us to come up with unique solutions in order to have a seamless, zero downtime migration.
Challenges When Migrating to Kubernetes
Although the entire DNS team agreed that kubernetes was the way forward for Secondary DNS, it also introduced several challenges. These challenges arose from a need to properly scale up across many distributed locations while also protecting each of our individual data centers. Since our core does not rely on anycast to automatically distribute requests, as we introduce more customers, it opens us up to denial-of-service attacks.
The two main issues we ran into during the migration were:
How do we create a distributed and reliable system that makes use of kubernetes principles while also making sure our customers know which IPs we will be communicating from?
When opening up a public-facing UDP socket to the Internet, how do we protect ourselves while also preventing unnecessary spam towards primary nameservers?.
Issue 1:
As was previously mentioned, one form of protection in the Secondary DNS protocol is to only allow certain IPs to initiate zone transfers. There is a fine line between primary servers allow listing too many IPs and them having to frequently update their IP ACLs. We considered several solutions:
Allowlist all Cloudflare IPs and dynamically update
Proxy egress traffic
Ultimately we decided to proxy our egress traffic from k8s, to the DNS primary servers, using static proxy addresses. Shadowsocks-libev was chosen as the SOCKS5 implementation because it is fast, secure and known to scale. In addition, it can handle both UDP/TCP and IPv4/IPv6.
Figure 2: Shadowsocks proxy Setup
The partnership of k8s and Shadowsocks combined with a large enough IP range brings many benefits:
Horizontal scaling
Efficient load balancing
Primary server ACLs only need to be updated once
It allows us to make use of kubernetes for both the Zone Transferer and the Local ShadowSocks Proxy.
Shadowsocks proxy can be reused by many different Cloudflare services.
Issue 2:
The Notify Listener requires listening on static IPs for NOTIFY Messages coming from primary DNS servers. This is mostly a solved problem through the use of k8s services of type loadbalancer, however exposing this service directly to the Internet makes us uneasy because of its susceptibility to attacks. Fortunately DDoS protection is one of Cloudflare’s strengths, which lead us to the likely solution of dogfooding one of our own products, Spectrum.
Spectrum provides the following features to our service:
Figure 3: Spectrum interaction with Notify Listener
Figure 3 shows two interesting attributes of the system:
Spectrum <-> k8s IPv4 only:
This is because our custom k8s load balancer currently only supports IPv4; however, Spectrum has no issue terminating the IPv6 connection and establishing a new IPv4 connection.
Spectrum <-> k8s routing decisions based of L4 protocol:
This is because k8s only supports one of TCP/UDP/SCTP per service of type load balancer. Once again, spectrum has no issues proxying this correctly.
One of the problems with using a L4 proxy in between services is that source IP addresses get changed to the source IP address of the proxy (Spectrum in this case). Not knowing the source IP address means we have no idea who sent the NOTIFY message, opening us up to attack vectors. Fortunately, Spectrum’s proxy protocol feature is capable of adding custom headers to TCP/UDP packets which contain source IP/Port information.
As we are using miekg/dns for our Notify Listener, adding proxy headers to the DNS NOTIFY messages would cause failures in validation at the DNS server level. Alternatively, we were able to implement custom read and write decorators that do the following:
Reader: Extract source address information on inbound NOTIFY messages. Place extracted information into new DNS records located in the additional section of the message.
Writer: Remove additional records from the DNS message on outbound NOTIFY replies. Generate a new reply using proxy protocol headers.
There is no way to spoof these records, because the server only permits two extra records, one of which is the optional TSIG. Any other records will be overwritten.
Figure 4: Proxying Records Between Notifier and Spectrum
This custom decorator approach abstracts the proxying away from the Notify Listener through the use of the DNS protocol.
Although knowing the source IP will block a significant amount of bad traffic, since NOTIFY messages can use both UDP and TCP, it is prone to IP spoofing. To ensure that the primary servers do not get spammed, we have made the following additions to the Zone Transferer:
Always ensure that the SOA has actually been updated before initiating a zone transfer.
Only allow at most one working transfer and one scheduled transfer per zone.
Additional Technical Challenges
Zone Transferer Scheduling
As shown in figure 1, there are several ways of sending Kafka messages to the Zone Transferer in order to initiate a zone transfer. There is no benefit in having a large backlog of zone transfers for the same zone. Once a zone has been transferred, assuming no more changes, it does not need to be transferred again. This means that we should only have at most one transfer ongoing, and one scheduled transfer at the same time, for any zone.
If we want to limit our number of scheduled messages to one per zone, this involves ignoring Kafka messages that get sent to the Zone Transferer. This is not as simple as ignoring specific messages in any random order. One of the benefits of Kafka is that it holds on to messages until the user actually decides to acknowledge them, by committing that messages offset. Since Kafka is just a queue of messages, it has no concept of order other than first in first out (FIFO). If a user is capable of reading from the Kafka topic concurrently, it is entirely possible that a message in the middle of the queue be committed before a message at the end of the queue.
Most of the time this isn’t an issue, because we know that one of the concurrent readers has read the message from the end of the queue and is processing it. There is one Kubernetes-related catch to this issue, though: pods are ephemeral. The kube master doesn’t care what your concurrent reader is doing, it will kill the pod and it’s up to your application to handle it.
Consider the following problem:
Figure 5: Kafka Partition
Read offset 1. Start transferring zone 1.
Read offset 2. Start transferring zone 2.
Zone 2 transfer finishes. Commit offset 2, essentially also marking offset 1.
Restart pod.
Read offset 3 Start transferring zone 3.
If these events happen, zone 1 will never be transferred. It is important that zones stay up to date with the primary servers, otherwise stale data will be served from the Secondary DNS server. The solution to this problem involves the use of a list to track which messages have been read and completely processed. In this case, when a zone transfer has finished, it does not necessarily mean that the kafka message should be immediately committed. The solution is as follows:
Keep a list of Kafka messages, sorted based on offset.
If finished transfer, remove from list:
If the message is the oldest in the list, commit the messages offset.
Figure 6: Kafka Algorithm to Solve Message Loss
This solution is essentially soft committing Kafka messages, until we can confidently say that all other messages have been acknowledged. It’s important to note that this only truly works in a distributed manner if the Kafka messages are keyed by zone id, this will ensure the same zone will always be processed by the same Kafka consumer.
Life of a Secondary DNS Request
Although Cloudflare has a large global network, as shown above, the zone transferring process does not take place at each of the edge datacenter locations (which would surely overwhelm many primary servers), but rather in our core data centers. In this case, how do we propagate to our edge in seconds? After transferring the zone, there are a couple more steps that need to be taken before the change can be seen at the edge.
Zone Builder – This interacts with the Zone Transferer to build the zone according to what Cloudflare edge understands. This then writes to Quicksilver, our super fast, distributed KV store.
Authoritative Server – This reads from Quicksilver and serves the built zone.
Figure 7: End to End Secondary DNS
What About Performance?
At the time of writing this post, according to dnsperf.com, Cloudflare leads in global performance for both Authoritative and Resolver DNS. Here, Secondary DNS falls under the authoritative DNS category here. Let’s break down the performance of each of the different parts of the Secondary DNS pipeline, from the primary server updating its records, to them being present at the Cloudflare edge.
Primary Server to Notify Listener – Our most accurate measurement is only precise to the second, but we know UDP/TCP communication is likely much faster than that.
NOTIFY to Zone Transferer – This is negligible
Zone Transferer to Primary Server – 99% of the time we see ~800ms as the average latency for a zone transfer.
Figure 8: Zone XFR latency
4. Zone Transferer to Zone Builder – 99% of the time we see ~10ms to build a zone.
Figure 9: Zone Build time
5. Zone Builder to Quicksilver edge: 95% of the time we see less than 1s propagation.
Figure 10: Quicksilver propagation time
End to End latency: less than 5 seconds on average. Although we have several external probes running around the world to test propagation latencies, they lack precision due to their sleep intervals, location, provider and number of zones that need to run. The actual propagation latency is likely much lower than what is shown in figure 10. Each of the different colored dots is a separate data center location around the world.
Figure 11: End to End Latency
An additional test was performed manually to get a real world estimate, the test had the following attributes:
Primary server: NS1 Number of records changed: 1 Start test timer event: Change record on NS1 Stop test timer event: Observe record change at Cloudflare edge using dig Recorded timer value: 6 seconds
Conclusion
Cloudflare serves 15.8 trillion DNS queries per month, operating within 100ms of 99% of the Internet-connected population. The goal of Cloudflare operated Secondary DNS is to allow our customers with custom DNS solutions, be it on-premise or some other DNS provider, to be able to take advantage of Cloudflare’s DNS performance and more recently, through Secondary Override, our proxying and security capabilities too. Secondary DNS is currently available on the Enterprise plan, if you’d like to take advantage of it, please let your account team know. For additional documentation on Secondary DNS, please refer to our support article.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

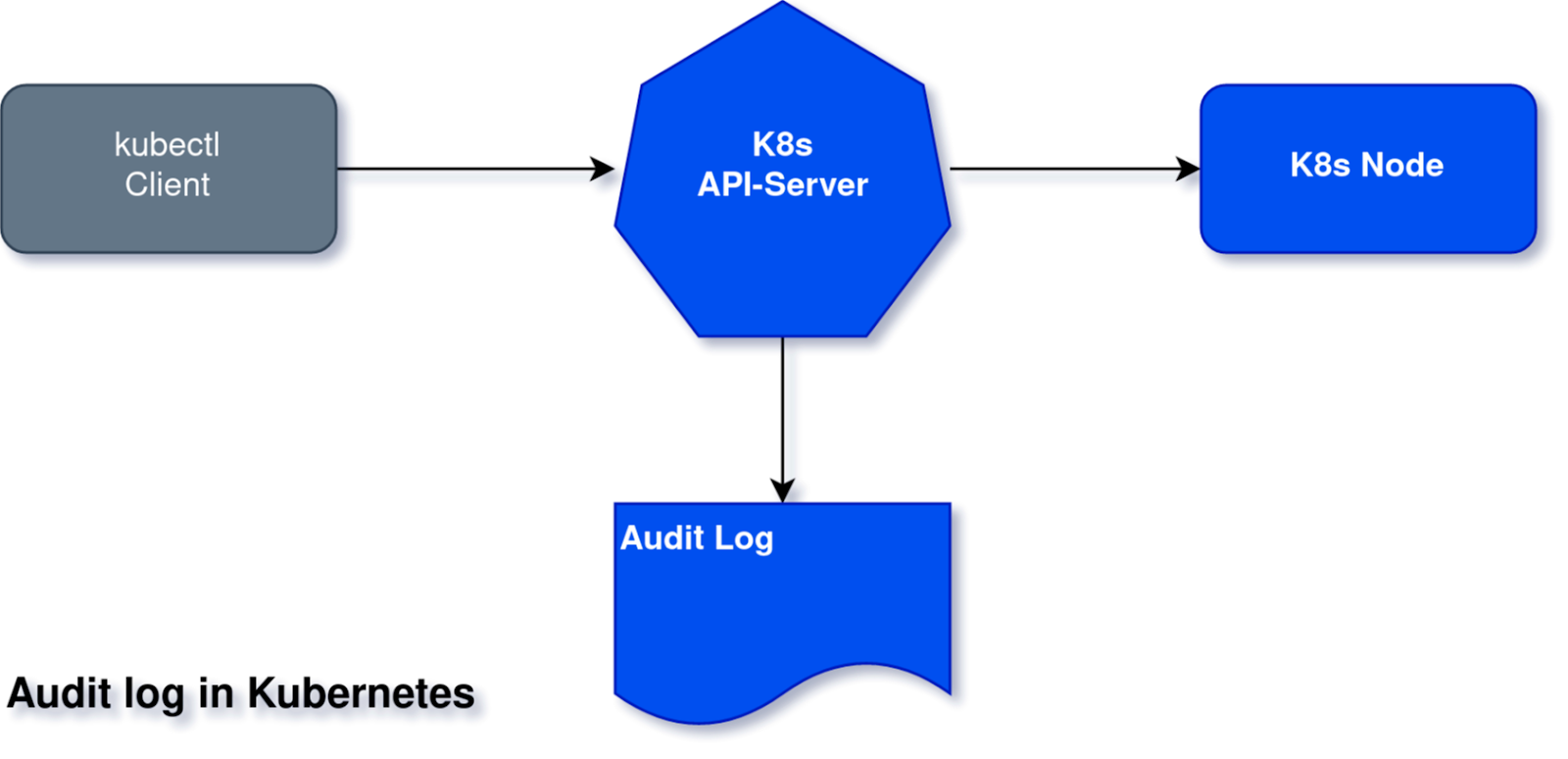

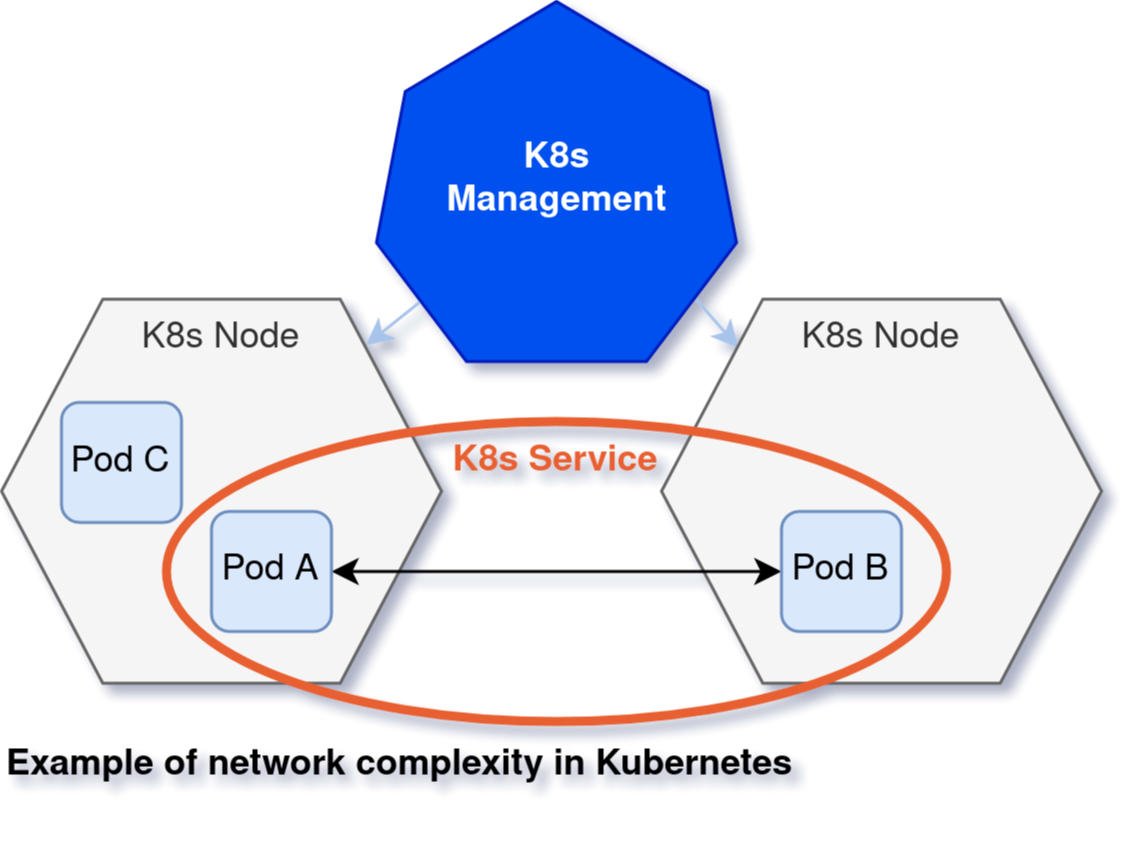

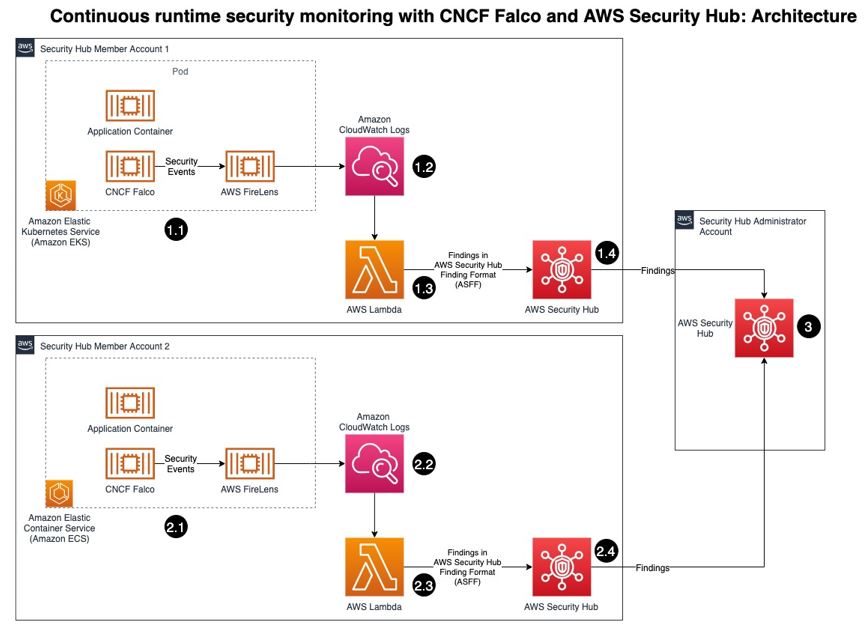





















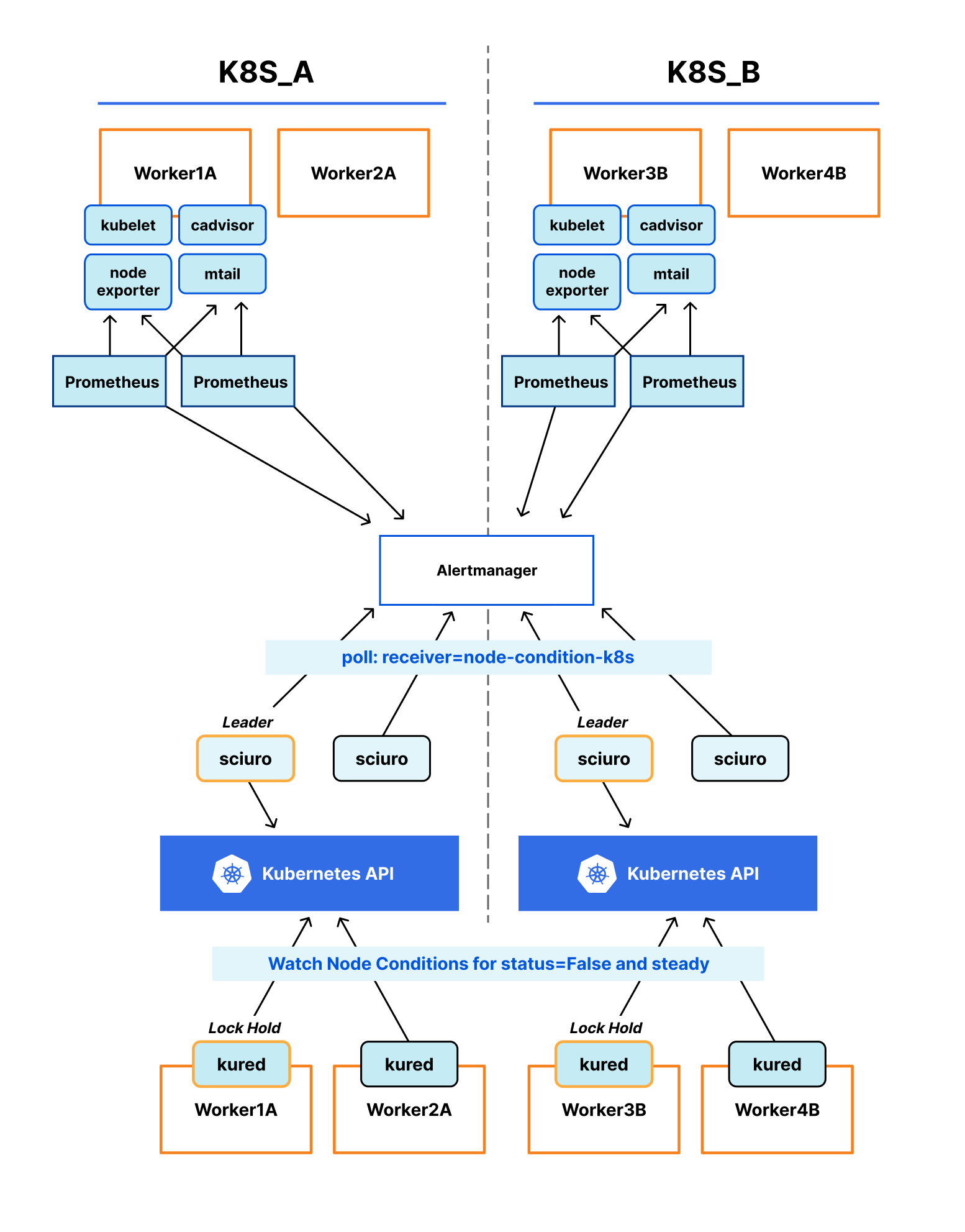










 Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.
Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.