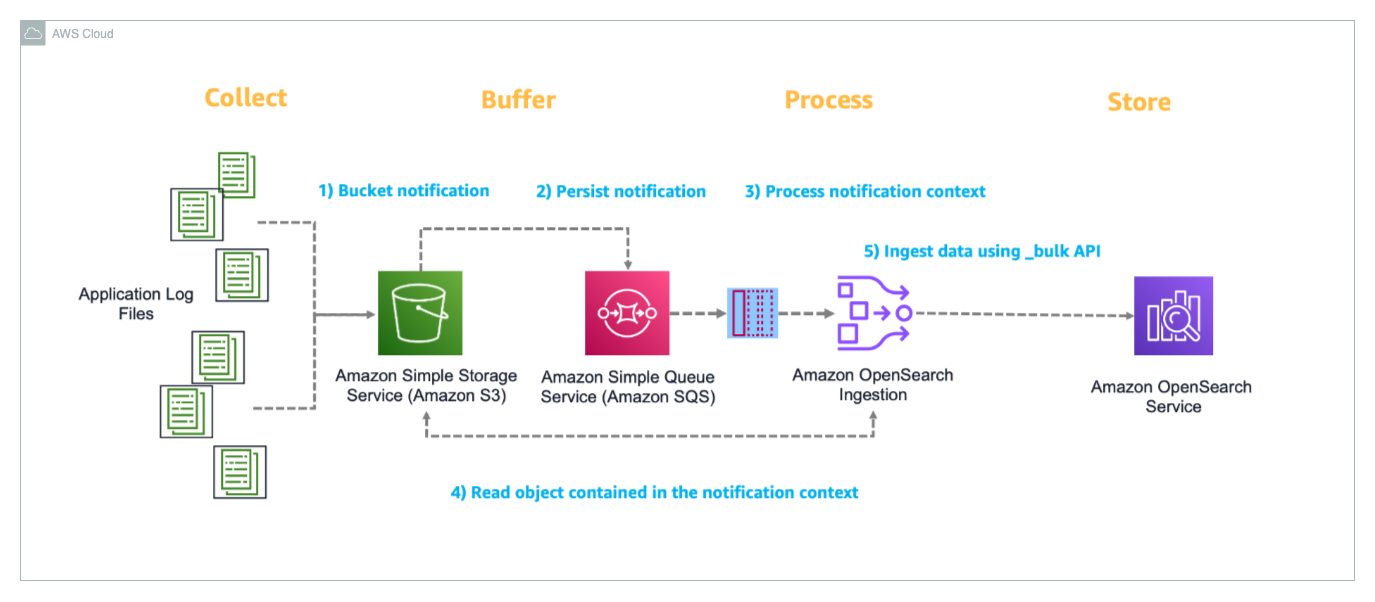
Post Syndicated from Brett Ezell original https://aws.amazon.com/blogs/messaging-and-targeting/a-complete-guide-to-resource-sharing-for-aws-end-user-messaging/
Introduction
Do you need to send SMS across multiple AWS accounts? Or have you ever wanted to use the same specific 10DLC phone number or branded Sender ID across those accounts? Perhaps your development team needs to test an application in a sandbox account using a production-ready number, or you’re migrating a workload to a new account and need to ensure your customer communications aren’t disrupted. Centralizing your messaging resources across accounts improves efficiency and branding, while lowering the risk in compliance gaps..
In this step-by-step guide, we will show how to solve this challenge by sharing your AWS End User Messaging resources across multiple AWS accounts using AWS Resource Access Manager (AWS RAM). By creating a single sharing account for your messaging resources—like phone numbers, Sender IDs, and opt-out lists—and securely sharing them with your other “consuming” accounts, you can build a more efficient, secure, and scalable communication platform.
Common Use Cases for Resource Sharing
Important: resource sharing with AWS RAM is a regional feature. You can only share resources with accounts within the same AWS Region where those resources are located.
Centralizing and sharing resources is a powerful pattern that addresses several common customer needs:
- Testing in a Sandbox Environment: Allows development teams to test applications using production-ready phone numbers or Sender IDs in an isolated sandbox account, without giving them access to production configurations.
- Simplified Registration and Onboarding: Share an existing pre-registered 10DLC number or Sender ID with a new account that has not yet completed its own registration process, enabling it to start sending messages more quickly.
- Seamless Account Transitions: When migrating an application or workload to a new AWS account, you can share the existing origination identities. This makes certain that your phone numbers and Sender IDs remain consistent during the transition, preventing any disruption to your customer-facing communications.
This guide will walk you through the step-by-step process of sharing your AWS End User Messaging resources.
Shareable AWS End User Messaging Resources
You can share the following AWS End User Messaging resources using AWS RAM:
- Phone Numbers: Share your dedicated short codes, 10DLCs, long codes, and toll-free numbers. This allows different accounts to send messages using a centralized pool of numbers.
- Sender IDs: Share alphanumeric sender IDs to maintain consistent branding in one-way SMS messages across your accounts.
- Opt-out Lists: Centralize your opt-out management to ensure regulatory compliance. When a user opts out of messaging from one account, they are opted out across all accounts using that shared list. This is especially powerful when used with pools, as you can associate a pool with a specific opt-out list, ensuring all numbers in that pool adhere to the same primary list. As a best practice, you should create and share a dedicated opt-out list rather than relying on the default list for each account.
- Pools: Share your pools of phone numbers and sender IDs to manage origination identities at scale. Pools provide benefits like automatic failover and apply settings like opt-out lists or two-way SMS configurations to the entire pool.
- Important: for a shared Opt-out list or pool to be functional, all of its member resources (the phone numbers and/or Sender IDs within it) must also be included in the same AWS RAM resource share.
Understanding AWS RAM Fundamentals
Before sharing your End User Messaging resources, it’s essential to understand the core concepts of AWS RAM.
- Resource Share: This is the central component in AWS RAM. A resource share consists of three elements:
- The resources to be shared (such as phone numbers, or opt-out lists).
- The principals (AWS accounts, OUs, or an entire organization) with whom you are sharing.
- The managed permissions that define what actions the principals can perform on the shared resources.
Important: The supported resources of AWS End User Messaging are shareable with AWS accounts, Organizations, and OUs, but not with individual AWS Identity and Access Management (IAM) roles or users. This restriction ensures that resource sharing remains at the account level, maintaining clear boundaries and simplifying access management for your End User Messaging infrastructure.
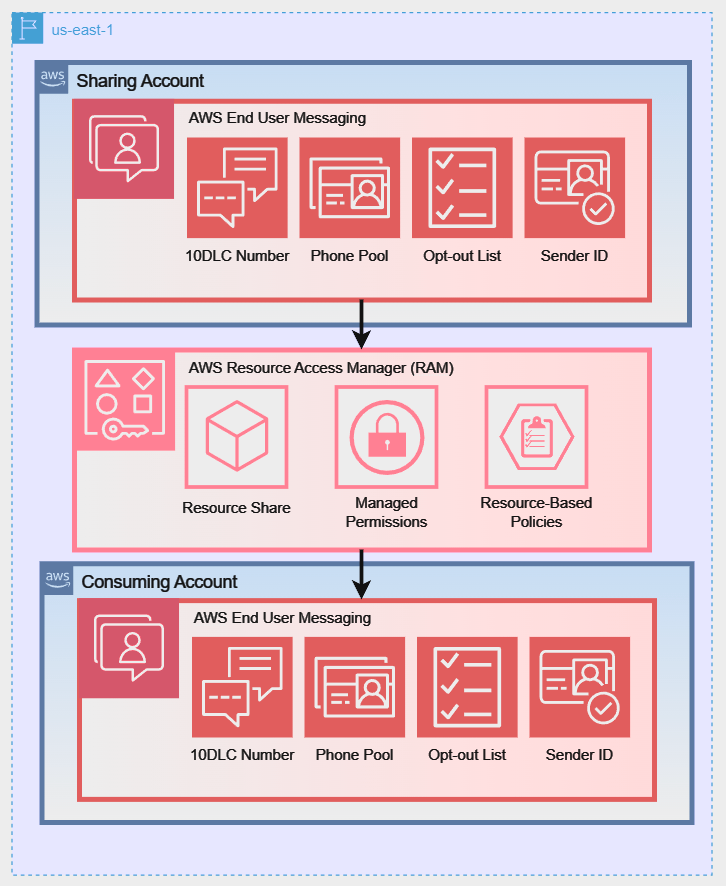
- Sharing Account vs. Consuming Account:
- The sharing account (or owner account) is the AWS account that owns the resources and creates the resource share.
- When a principal (such as an AWS account) is granted access to a resource share, it becomes a consuming account. It can use the shared resources according to the permissions granted and pays for its own usage of those resources, not for the resources themselves. For example: The consuming account pays for the volume of SMS sent by a shared number but the sharing account pays for any fees associated with owning that actual number.
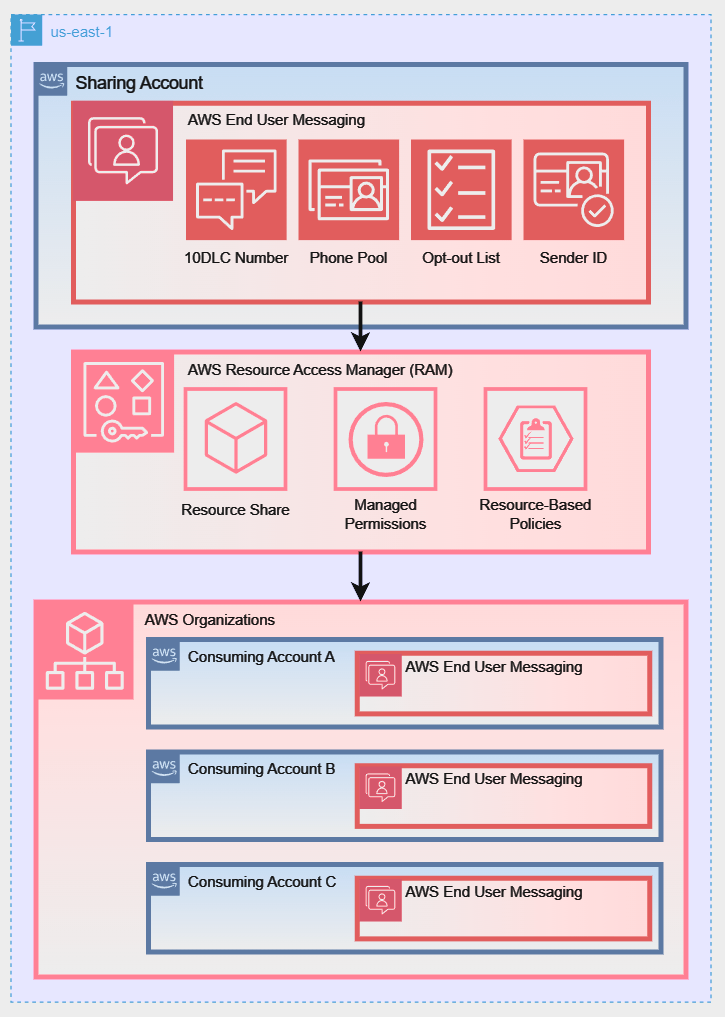
- AWS Organizations Integration: While you can share resources with individual AWS accounts, the most powerful way to use AWS RAM is in conjunction with AWS Organizations. This service allows you to centrally manage and govern multiple AWS accounts under a single umbrella. When you enable sharing within your organization, you can share resources with all accounts in the organization, or with specific Organizational Units (OUs), seamlessly and without needing to send and accept individual invitations. This sharing is only possible between accounts that reside in the same AWS Region.
- Managed Permissions: AWS RAM uses managed permissions to control access.
- AWS managed permissions are predefined permission sets created and maintained by AWS for common use cases. For AWS End User Messaging, the key permission is
AWSRAMDefaultPermissionSmsVoice, which allows consumers to use the resources for sending messages but not for deleting or modifying them.
- Customer managed permissions can be created for more granular control over shared resources.
- Resource-Based Policies: Behind the scenes, AWS RAM works by creating and managing resource-based policies for you. These policies are what actually grant the consuming accounts access to the shared resources.
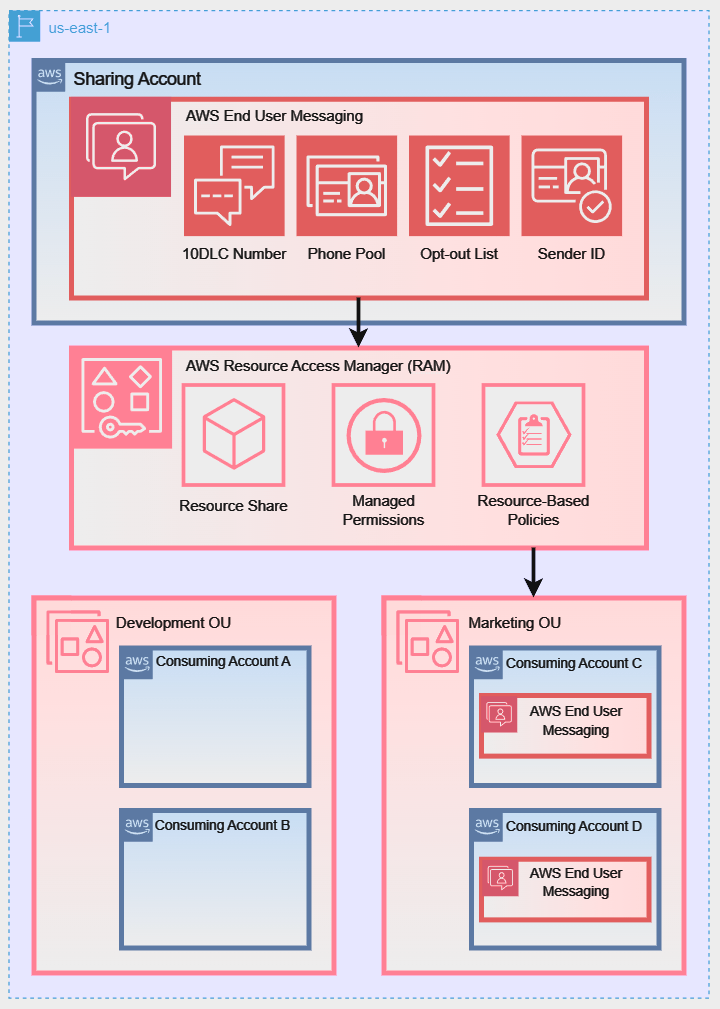
To better illustrate these sharing models, the following diagrams show how a Sharing Account can share its AWS End User Messaging resources using different strategies:
Diagram 1: Direct Account-to-Account Sharing:

Diagram 2: Sharing with an Entire AWS Organization:

Diagram 3: Sharing with a Specific Organizational Unit (OU):

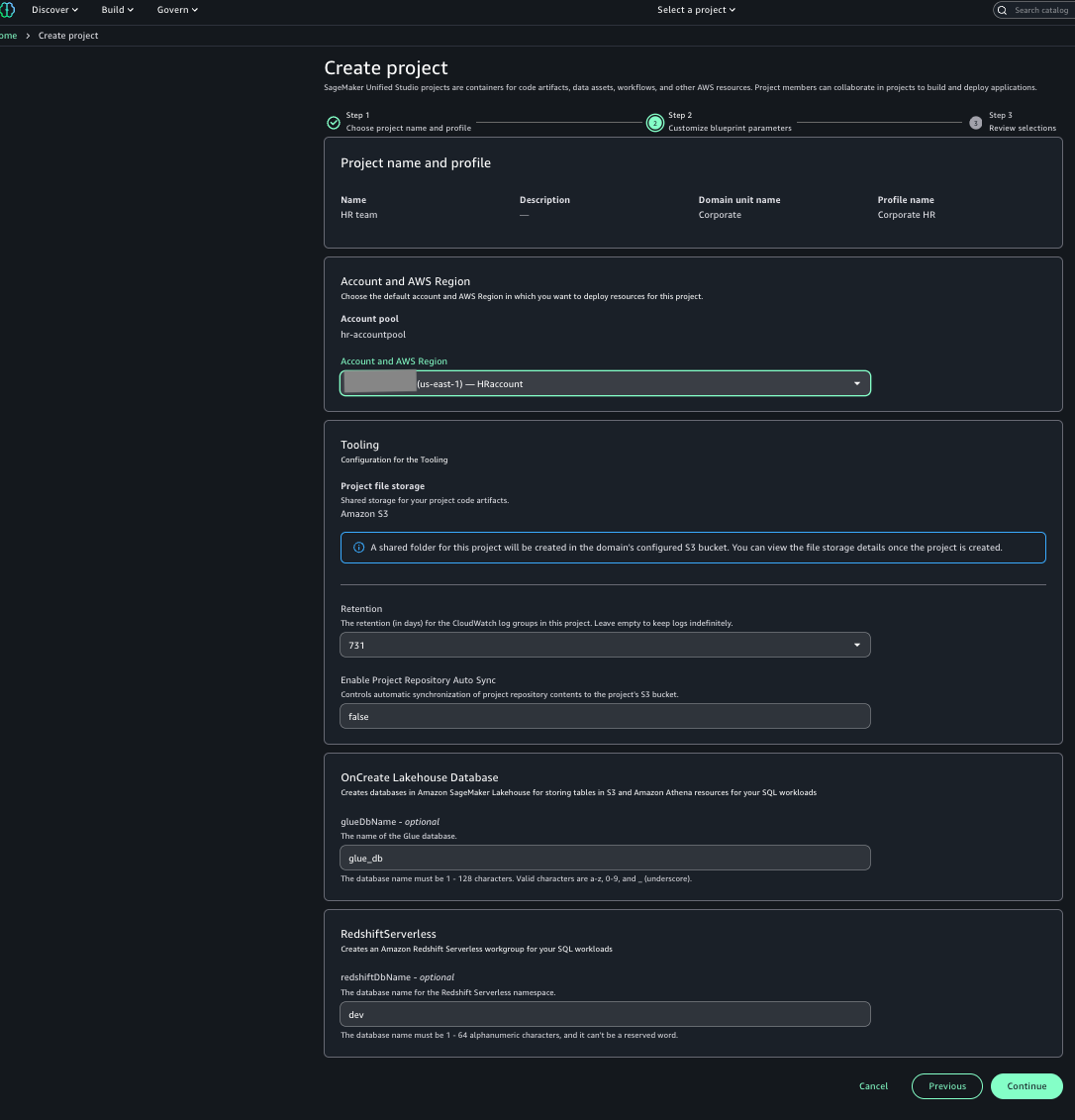
Prerequisites and Setup
For the following walkthrough, we will demonstrate how to configure the setup for Diagram 1: Direct Account-to-Account Sharing. However, the steps for managing and using the resource share are similar for all three scenarios. Before you begin, ensure your environment is set up correctly.
Note for AWS Organizations Users: When your account is managed by AWS Organizations, you can take advantage of that to share resources more easily. With or without Organizations, a user can share with individual accounts. However, if your account is in an organization, then you can share with individual accounts, or with all accounts in the organization or in an OU without having to enumerate each account.
If you plan to share resources using AWS Organizations (as shown in Diagram 2 or Diagram 3), you must complete the following prerequisite steps from your organization’s management account before creating a resource share:
1. Enable all features in your organization:
aws organizations enable-all-features
2. Enable resource sharing with AWS RAM: This creates the necessary service-linked role.
aws ram enable-sharing-with-aws-organization
1. Required IAM Permissions
The IAM user or role performing these actions needs permissions for both AWS RAM and AWS End User Messaging. The following policy grants the necessary permissions to manage resource shares.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RAMResourceShareManagement",
"Effect": "Allow",
"Action": [
"ram:UpdateResourceShare",
"ram:DeleteResourceShare",
"ram:AssociateResourceShare",
"ram:DisassociateResourceShare"
],
"Resource": "arn:aws:ram:*:*:resource-share/*"
},
{
"Sid": "DiscoveryAndCreationPermissions",
"Effect": "Allow",
"Action": [
"ram:CreateResourceShare",
"ram:GetResourceShares",
"ram:ListResources",
"organizations:ListAccounts",
"organizations:DescribeOrganization",
"pinpoint-sms-voice-v2:DescribePhoneNumbers",
"pinpoint-sms-voice-v2:DescribeSenderIds",
"pinpoint-sms-voice-v2:DescribeOptOutLists",
"pinpoint-sms-voice-v2:DescribePools"
],
"Resource": "*"
}
]
}
Note on Least Privilege: This policy follows the security best practice of granting least privilege. The first statement scopes modification permissions to only AWS RAM resource shares. The second statement grants permissions for discovery actions (like Describe* and List*) and the ram:CreateResourceShare action, which require "Resource": "*" as they do not operate on a specific, pre-existing resource.
2. Regionality Requirement
Important Reminder: resource sharing with AWS RAM is a regional feature. You can only share resources with accounts within the same AWS Region where those resources are located.
For example, a resource in us-east-1 can only be shared with other accounts in us-east-1, regardless of where those accounts operate other resources. Ensure that the resources you intend to share and the accounts that you anticipate sharing with are each considering the same Region for this process.
Creating and Managing Resource Shares (Sharing Account Actions)
This section provides a step-by-step guide to sharing your resources using the AWS CLI. We will walk through creating a resource share, associating and disassociating resources, and checking the status of your shares.
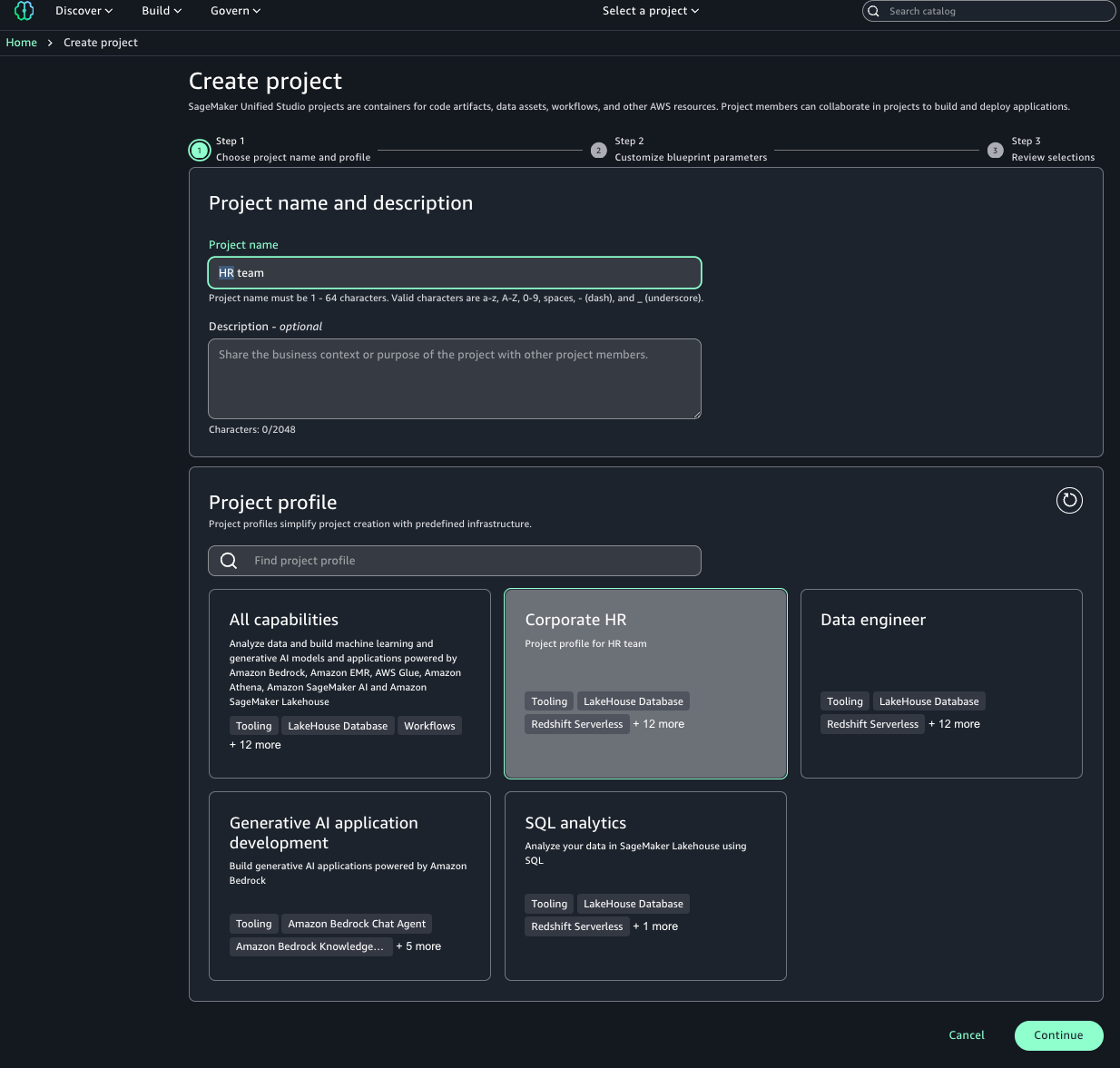
Step 1: Create an Empty Resource Share
First, create the resource share. Think of this as an empty container. You will associate principals (the consuming accounts) and resources (the phone numbers, etc.) with this share.
In the command below, we will create a share named EUM-Shared-Resources for an external account.
# Create a resource share and grant default End User Messaging permissions # Replace 123456789012 with the consuming account's ID
aws ram create-resource-share \
--name "EUM-Shared-Resources" \
--principals "123456789012" \
--permission-arns "arn:aws:ram::aws:permission/AWSRAMDefaultPermissionSmsVoice" \
--allow-external-principals \
--region us-east-1
--principals: Specify one or more AWS account IDs.--allow-external-principals: This flag is required when sharing with accounts that are not part of your AWS Organization.
Expected Response: A successful command returns a JSON object describing the new resource share. Note that allowExternalPrincipals is now true.
{
"resourceShare": {
"resourceShareArn": "arn:aws:ram:us-east-1:111122223333:resource-share/a1b2c3d4-5678-90ab-cdef-example11111",
"name": "EUM-Shared-Resources",
"owningAccountId": "111122223333",
"allowExternalPrincipals": false,
"status": "ACTIVE",
"tags": [],
"featureSet": "STANDARD"
}
}
For the following sections and when specifying resource ARNs, ensure you’re using the correct format for AWS End User Messaging resources:
- Phone numbers:
arn:aws:sms-voice:region:account-id:phone-number/phonenumber-id
- Sender IDs:
arn:aws:sms-voice:region:account-id:sender-id/senderid
- Opt-out lists:
arn:aws:sms-voice:region:account-id:opt-out-list/optoutlist-id
- Pools:
arn:aws:sms-voice:region:account-id:pool/pool-id
Replace ‘region‘, ‘account-id‘, and the specific resource IDs with your actual values.
Step 2: Associate Resources with the Share
Now that you have your “container,” you can add resources to it. The associate-resource-share command links one or more of your End User Messaging resources to the share you just created, making them available to the principals.
# Define the ARN of the resource share from the previous step
RESOURCE_SHARE_ARN="arn:aws:ram:us-east-1:111122223333:resource-share/a1b2c3d4-5678-90ab-cdef-111111111111"
# Associate a phone number and a pool with the share # Replace the resource-arns with your actual resource ARNs
aws ram associate-resource-share \
--resource-share-arn "$RESOURCE_SHARE_ARN" \
--resource-arns \
"arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4" \
"arn:aws:sms-voice:us-east-1:111122223333:pool/pool-b2c3d4e5" \
--region us-east-1
Expected Response: A successful association returns a JSON object confirming the association and showing its status. The status will initially be ASSOCIATING and will transition to ASSOCIATED once complete.
Note: The association process is asynchronous. We’ll show you how to verify the completion status in the next step using the get-resource-shares and list-resources commands. It’s important to confirm the status has changed to ASSOCIATED before attempting to use the shared resources.
Step 3: Verify the Status and contents of the Share
Before making changes, it’s good practice to verify what’s in the share. Use get-resource-shares to check the status and list-resources to see the contents. This process helps ensure that all intended resources are properly associated and accessible to the principals you’ve designated.
# Verify the association status is ASSOCIATED
aws ram get-resource-shares \
--resource-owner SELF \
--name "EUM-Shared-Resources" \
--association-status ASSOCIATED \
--region us-east-1
Expected Response: If the command returns no results, wait a few moments and try again. The association process is typically quick but can sometimes take up to a few minutes.
{
"resourceShares": [
{
"resourceShareArn": "arn:aws:ram:us-east-1:111122223333:resource-share/12345678-abcd-1234-efgh-111122223333",
"name": "EUM-Shared-Resources",
"owningAccountId": "111122223333",
"allowExternalPrincipals": true,
"status": "ACTIVE",
"creationTime": "2023-07-01T12:00:00.000Z",
"lastUpdatedTime": "2023-07-01T12:00:00.000Z",
"featureSet": "STANDARD"
}
]
}
Review the output carefully to ensure all intended resources are listed. If any resources are missing, you may need to reassociate them using the associate-resource-share command.
Expected Response (list-resources): This command will return a list of JSON objects, each representing a resource in the share.
# List the ARNs of all resources currently in the share
aws ram list-resources \
--resource-owner SELF \
--resource-share-arns "$RESOURCE_SHARE_ARN" \
--region us-east-1
Review the output carefully to ensure all intended resources are listed. If any resources are missing, you may need to reassociate them using the associate-resource-share command.
# List the ARNs of all resources currently in the share
aws ram list-resources \
--resource-owner SELF \
--resource-share-arns "$RESOURCE_SHARE_ARN" \
--region us-east-1
Expected Response (list-resources): This command will return a list of JSON objects, each representing a resource in the share.
{
"resources": [
{
"arn": "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4",
"type": "sms-voice:PhoneNumber",
"resourceShareArn": "arn:aws:ram:us-east-1:111122223333:resource-share/a1b2c3d4-5678-90ab-cdef-example11111",
"status": "AVAILABLE"
},
{
"arn": "arn:aws:sms-voice:us-east-1:111122223333:pool/pool-b2c3d4e5",
"type": "sms-voice:Pool",
"resourceShareArn": "arn:aws:ram:us-east-1:111122223333:resource-share/a1b2c3d4-5678-90ab-cdef-example11111",
"status": "AVAILABLE"
}
]
}
Step 4: Disassociate Specific Resources from the Share
To stop sharing a specific resource, you use the disassociate-resource-share command. You must provide the ARN of the resource you wish to remove. This gives you granular control, allowing you to remove one resource while continuing to share others.
# Disassociate only the phone number from the share
aws ram disassociate-resource-share \
--resource-share-arn "$RESOURCE_SHARE_ARN" \
--resource-arns "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4" \
--region us-east-1
Expected Response: The response will be nearly identical to the associate response, confirming the disassociation request. The status will be DISASSOCIATING.
{
"resourceShareAssociations": [
{
"resourceShareArn": "arn:aws:ram:us-east-1:111122223333:resource-share/a1b2c3d4-5678-90ab-cdef-example11111",
"associatedEntity": "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4",
"associationType": "RESOURCE",
"status": "DISASSOCIATING",
"external": false
}
]
}
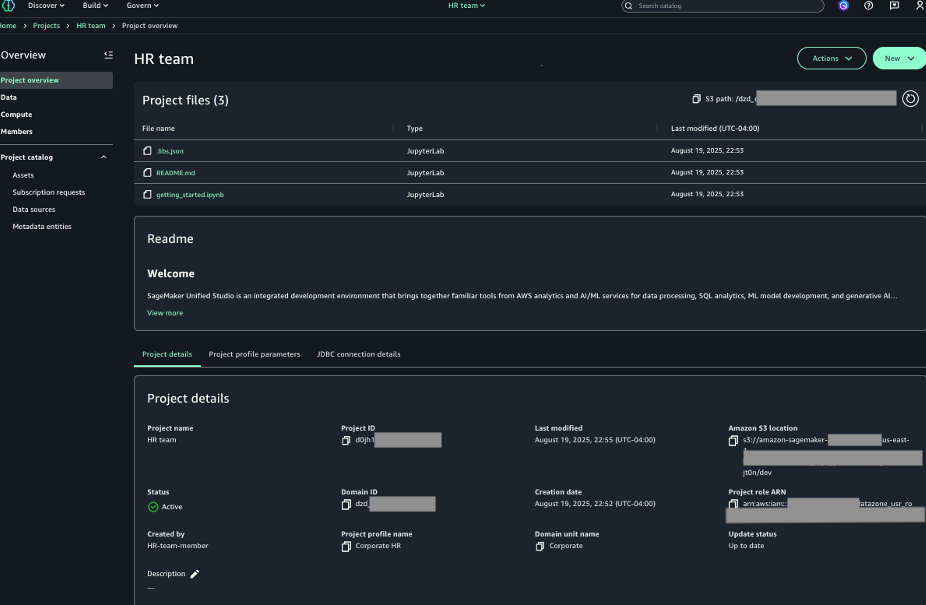
How to Use Shared Resources
Once resources are shared, users in the consuming accounts can discover and use them for sending messages.
Step 1: Discovering Shared Resources
From a consuming account, you can list resources that have been shared with you by using the --filters parameter in the describe-* commands.
Note: Shared resources are discoverable via the AWS CLI and SDKs but will not appear in the AWS Management Console of the consuming account. This is expected behavior, as the resources are owned by the sharing account.
# List phone numbers shared with your account
aws pinpoint-sms-voice-v2 describe-phone-numbers \
--filters Name=shared-with-me,Values=true \
--region us-east-1
# List sender IDs shared with your account
aws pinpoint-sms-voice-v2 describe-sender-ids \
--filters Name=shared-with-me,Values=true \
--region us-east-1
# List pools shared with your account
aws pinpoint-sms-voice-v2 describe-pools \
--filters Name=shared-with-me,Values=true \
--region us-east-1
# List shared opt-out lists with region specification
aws pinpoint-sms-voice-v2 describe-opt-out-lists \
--filters Name=shared-with-me,Values=true \
--region us-east-1
Expected Response: The command returns a JSON object listing the shared resources, including their ARNs, which you will need for sending messages.
{
"PhoneNumbers": [
{
"PhoneNumberArn": "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4",
"PhoneNumberId": "phonenumber-a1b2c3d4",
"PhoneNumber": "+12065550100",
"Status": "ACTIVE",
"MessageType": "TRANSACTIONAL",
"TwoWayEnabled": true,
"CreatedTimestamp": "2023-10-26T14:34:56.123Z"
}
]
}
Step 2: Sending Messages with Shared Resources
Important: When using shared resources, consuming accounts must specify the full ARN of the shared resource in API calls. This differs from resource owners, who can use either the resource ID, ARN, or the number directly. You can specify the ARN of an individual phone number or a pool as the origination-identity.
# Send an SMS using a shared Phone Number ARN (consuming account MUST use ARN)
aws pinpoint-sms-voice-v2 send-text-message \
--destination-phone-number "+12065550199" \
--origination-identity "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4" \
--message-body "Hello from a shared number!" \
--region us-east-1
# Send an SMS using a shared Pool ARN (consuming account MUST use ARN)
aws pinpoint-sms-voice-v2 send-text-message \
--destination-phone-number "+12065550199" \
--origination-identity "arn:aws:sms-voice:us-east-1:111122223333:pool/pool-b2c3d4e5" \
--message-body "Hello from a shared pool!" \
--region us-east-1
Expected Response: A successful send-text-message call will return a MessageId, which confirms that the service has accepted the message for delivery.
{
"MessageId": "a1b2c3d4-5678-90ab-cdef-example22222"
}
Message Delivery Reporting:
Once a message is sent, understanding its delivery status is crucial for ensuring your communications are effective. AWS End User Messaging provides several mechanisms for tracking message delivery, giving you a multi-layered approach to reporting.
Delivery Receipts (DLRs):
For traditional, carrier-provided Delivery Receipts (DLRs), which can sometimes take up to 72 hours to be returned, you must configure an event destination. This is the most common method for confirming that a message has reached the recipient’s handset, and is achieved through a Configuration Set.
For shared resources:
- The configuration set must be created and managed in the sharing account.
- The consuming account must then reference the ARN of the configuration set when sending messages.
# Example for consuming account
aws pinpoint-sms-voice-v2 send-text-message
--destination-phone-number "+12065550199"
--origination-identity "arn:aws:sms-voice:us-east-1:111122223333:phone-number/phonenumber-a1b2c3d4"
--message-body "Hello from a shared number!"
--configuration-set-name "arn:aws:sms-voice:us-east-1:111122223333:configuration-set/MyConfigSet"
--region us-east-1
For a detailed walkthrough, see our companion blog post, How to Send SMS Using Configuration Sets with AWS End User Messaging.
Message Feedback:
For more immediate, application-driven insights, you can use the Message Feedback feature. This allows you to programmatically mark messages as “delivered” based on a user’s action, such as using a one-time password (OTP) or clicking a link in the message. This provides a real-time confirmation loop that is independent of carrier DLRs.
Amazon CloudWatch:
To monitor these events at scale, you can stream them to Amazon CloudWatch Logs to track key performance indicators like the number of messages sent and delivered, and to set up alerts based on your specific business needs.
To set up comprehensive reporting:
- Configure an event destination for DLRs and detailed status events.
- Set up CloudWatch dashboards and alerts for ongoing monitoring.
This multi-layered approach provides both immediate feedback and long-term delivery insights, allowing you to optimize your messaging strategy and quickly identify potential delivery issues.
Troubleshooting Common Issues
- Permission Denied Errors: If a consuming account cannot access a shared resource, verify that the consuming account’s IAM policies include the necessary permissions. Here’s an example policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"pinpoint-sms-voice-v2:SendTextMessage",
"pinpoint-sms-voice-v2:SendVoiceMessage",
"pinpoint-sms-voice-v2:DescribePhoneNumbers",
"pinpoint-sms-voice-v2:DescribeSenderIds",
"pinpoint-sms-voice-v2:DescribeOptOutLists",
"pinpoint-sms-voice-v2:DescribePools"
],
"Resource": "*"
}
]
}
- Resource Not Visible: Remember that shared resources do not appear in the consuming account’s AWS Management Console. If the
describe-* commands with the shared-with-me filter return no results, ensure the resource share status is ACTIVE in the sharing account.
- If sharing via AWS Organizations, confirm the consuming account is correctly placed in the specified OU. You can find more information on managing OUs in the AWS Organizations User Guide.
- CLI Command Fails: If a command fails with a “not found” or “invalid parameter” error, it is often due to an incorrect ARN. Double-check that the ARNs for resources, principals, and the resource share itself are correct. A
Permission Denied error, on the other hand, points to an IAM policy issue..
Best Practices and Considerations
- Security: Always follow the principle of least privilege. Use AWS managed permissions like
AWSRAMDefaultPermissionSmsVoice where possible and create customer-managed permissions only for specific, granular requirements.
- Cost: The sharing account is billed for provisioning the resources (e.g., the monthly cost of a phone number). Consuming accounts are billed for their usage of those shared resources (e.g., the cost per message sent). There are no additional costs for using AWS RAM.
- Throughput and Quotas: Resource throughput quotas (e.g., messages per second) are shared along with the resource. High volume sending from multiple consuming accounts using the same shared number or pool, could collectively hit the service quota, which may result in throttling. Plan your usage accordingly or request quota increases if necessary.
Conclusion
This guide has equipped you to centralize your AWS End User Messaging resources using AWS Resource Access Manager. By implementing this strategy, you can directly address the common challenges of a multi-account environment: maintaining consistent branding with shared Sender IDs, ensuring comprehensive compliance with centralized opt-out lists, and reducing operational overhead by managing resources in one place.
We have walked through the entire lifecycle, from the initial prerequisites in AWS Organizations and IAM, to the step-by-step CLI commands for creating shares, associating resources, and enabling consuming accounts to use them. By applying these techniques and keeping the best practices for security and throughput in mind, you are now able to build a more efficient, secure, and scalable communication platform across your entire AWS ecosystem.
 David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner.
David Victoria is a Senior Technical Product Manager with Amazon SageMaker at AWS. He focuses on improving administration and governance capabilities needed for customers to support their analytics systems. He is passionate about helping customers realize the most value from their data in a secure, governed manner. Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
Leonardo David Gomez Virahonda is a Principal Analytics Specialist Solutions Architect at AWS, with a strong focus on data governance. He helps organizations across industries implement effective governance strategies using AWS services like Amazon DataZone, AWS Glue, Lake Formation, and SageMaker Catalog. Leonardo’s work spans metadata management, data lineage, access control, and compliance—empowering customers to make their data secure, discoverable, and ready for analytics and AI. He regularly shares best practices through technical blogs, enablement content, and sessions at AWS events like re:Invent and regional Summits.
 Lauren Mullennex is a Senior GenAI/ML Specialist Solutions Architect at AWS. She has over a decade of experience in ML, DevOps, and infrastructure. She is a published author of a book on computer vision. Outside of work, you can find her traveling and hiking with her two dogs.
Lauren Mullennex is a Senior GenAI/ML Specialist Solutions Architect at AWS. She has over a decade of experience in ML, DevOps, and infrastructure. She is a published author of a book on computer vision. Outside of work, you can find her traveling and hiking with her two dogs. Siddharth Gupta is heading Generative AI within SageMaker’s Unified Experiences. His focus is on driving agentic experiences, where AI systems act autonomously on behalf of users to accomplish complex tasks. Previously, he led edge machine learning solutions at AWS. This cutting-edge work aims to revolutionize how developers and data scientists interact with AI, creating more intuitive data integrations and powerful tools for building and deploying machine learning models. An alumnus of the University of Illinois at Urbana-Champaign, he brings extensive experience from his roles at Yahoo, Glassdoor, and Twitch. You can reach out to him on LinkedIn.
Siddharth Gupta is heading Generative AI within SageMaker’s Unified Experiences. His focus is on driving agentic experiences, where AI systems act autonomously on behalf of users to accomplish complex tasks. Previously, he led edge machine learning solutions at AWS. This cutting-edge work aims to revolutionize how developers and data scientists interact with AI, creating more intuitive data integrations and powerful tools for building and deploying machine learning models. An alumnus of the University of Illinois at Urbana-Champaign, he brings extensive experience from his roles at Yahoo, Glassdoor, and Twitch. You can reach out to him on LinkedIn. Ishneet Kaur is a Software Development Manager on the Amazon SageMaker Unified Studio team. She leads the engineering team to design and build GenAI capabilities in SageMaker Unified Studio
Ishneet Kaur is a Software Development Manager on the Amazon SageMaker Unified Studio team. She leads the engineering team to design and build GenAI capabilities in SageMaker Unified Studio Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like Amazon EMR, Amazon EFA, and Amazon RDS. Currently, he is focused on improving the SageMaker inference experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like Amazon EMR, Amazon EFA, and Amazon RDS. Currently, he is focused on improving the SageMaker inference experience. In his spare time, he enjoys hiking and marathons. Mukul Prasad is a Senior Applied Science Manager in the AWS Agentic AI organization. He leads the Data Processing Agents Science team developing DevOps agents to simplify and optimize the customer journey in using AWS Big Data processing services including Amazon EMR, AWS Glue, and Amazon SageMaker Unified Studio. Outside of work, Mukul enjoys food, travel, photography, and Cricket.
Mukul Prasad is a Senior Applied Science Manager in the AWS Agentic AI organization. He leads the Data Processing Agents Science team developing DevOps agents to simplify and optimize the customer journey in using AWS Big Data processing services including Amazon EMR, AWS Glue, and Amazon SageMaker Unified Studio. Outside of work, Mukul enjoys food, travel, photography, and Cricket. Murali Narayanaswamy is a Principal Machine Learning Scientist in the Agentic AI organization in AWS working on products including Amazon Bedrock, Amazon SageMaker Unified Studio, Amazon Redshift and Amazon RDS. His research interests lie at the intersection of AI, optimization, learning and inference particularly using them to understand, model and combat noise and uncertainty in real world applications and Reinforcement Learning in practice and at scale. Broadly, he works on using ideas from online algorithms, optimization under uncertainty, control theory, game theory, artificial intelligence, graphical models and estimation theory to solve important problems at Amazon scale.
Murali Narayanaswamy is a Principal Machine Learning Scientist in the Agentic AI organization in AWS working on products including Amazon Bedrock, Amazon SageMaker Unified Studio, Amazon Redshift and Amazon RDS. His research interests lie at the intersection of AI, optimization, learning and inference particularly using them to understand, model and combat noise and uncertainty in real world applications and Reinforcement Learning in practice and at scale. Broadly, he works on using ideas from online algorithms, optimization under uncertainty, control theory, game theory, artificial intelligence, graphical models and estimation theory to solve important problems at Amazon scale. Necibe Ahat is a Senior AI/ML Specialist Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Necibe helps customers to advance their generative AI and machine learning journey. She has a background in computer science with 15 years of industry experience helping customers ideate, design, build and deploy solutions at scale. She is a passionate inclusion and diversity advocate.
Necibe Ahat is a Senior AI/ML Specialist Solutions Architect at AWS, working with Healthcare and Life Sciences customers. Necibe helps customers to advance their generative AI and machine learning journey. She has a background in computer science with 15 years of industry experience helping customers ideate, design, build and deploy solutions at scale. She is a passionate inclusion and diversity advocate. Vipin Mohan is a Principal Product Manager at Amazon Web Services, where he leads generative AI product strategy. He specializes in building AI/ML products, container platforms, and search technologies that serve thousands of customers. Outside of work, he mentors aspiring product managers, enjoys reading about financial investing and entrepreneurship, and loves exploring the world through the eyes of his two kids.
Vipin Mohan is a Principal Product Manager at Amazon Web Services, where he leads generative AI product strategy. He specializes in building AI/ML products, container platforms, and search technologies that serve thousands of customers. Outside of work, he mentors aspiring product managers, enjoys reading about financial investing and entrepreneurship, and loves exploring the world through the eyes of his two kids.





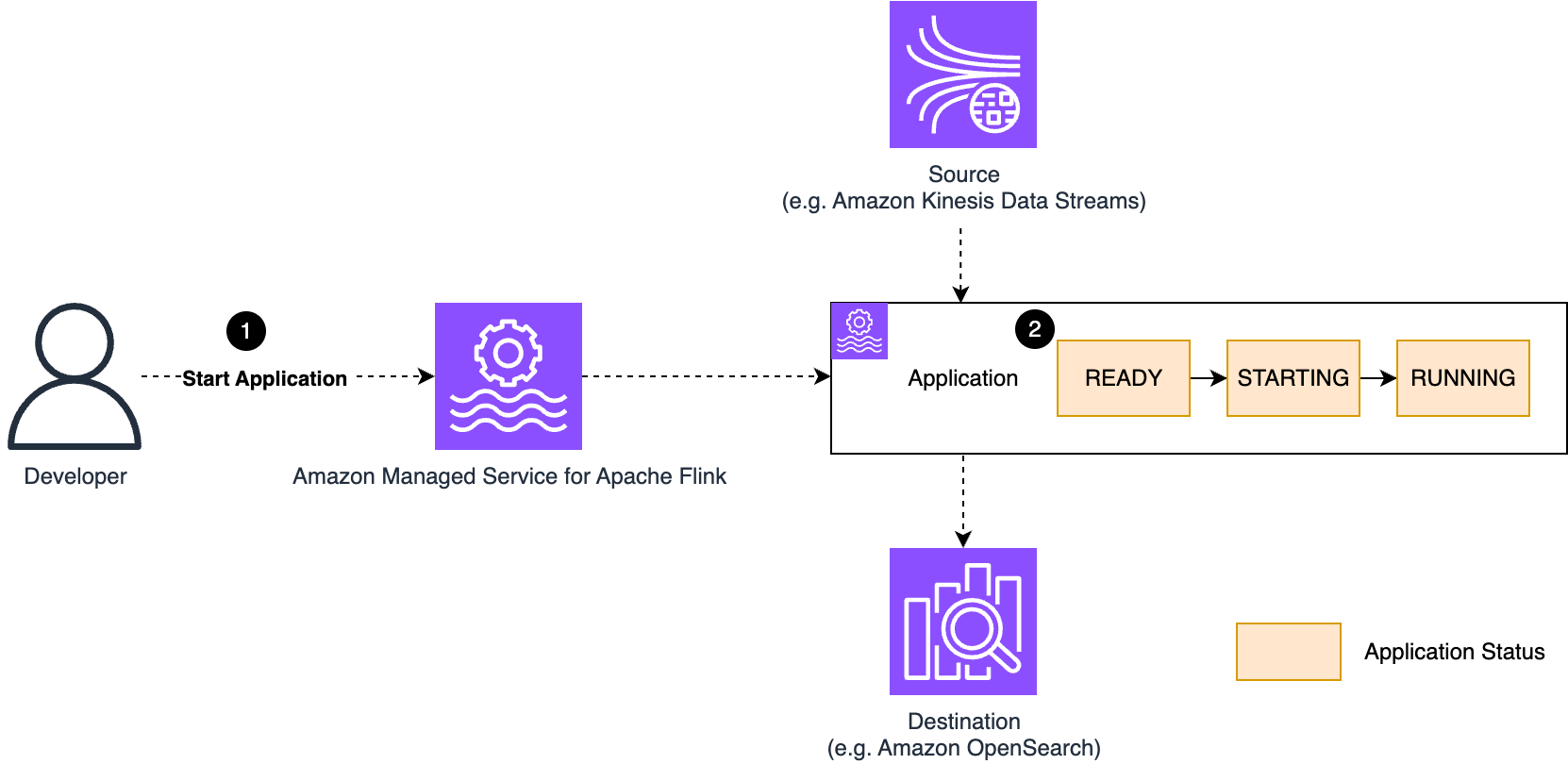
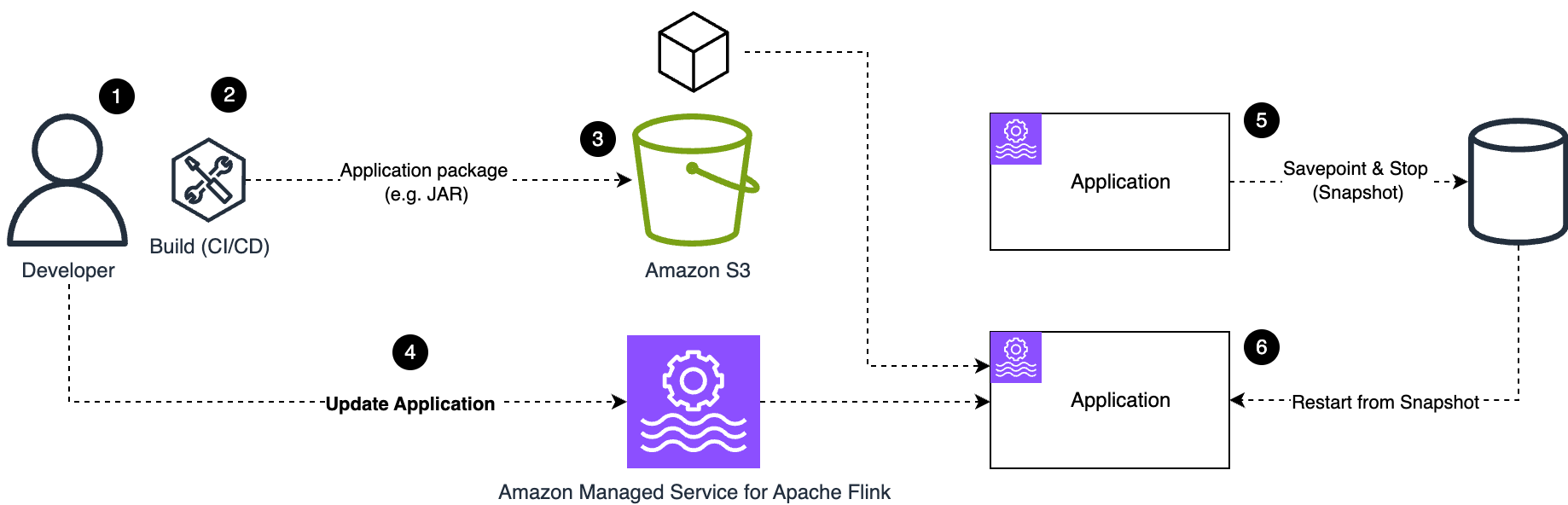
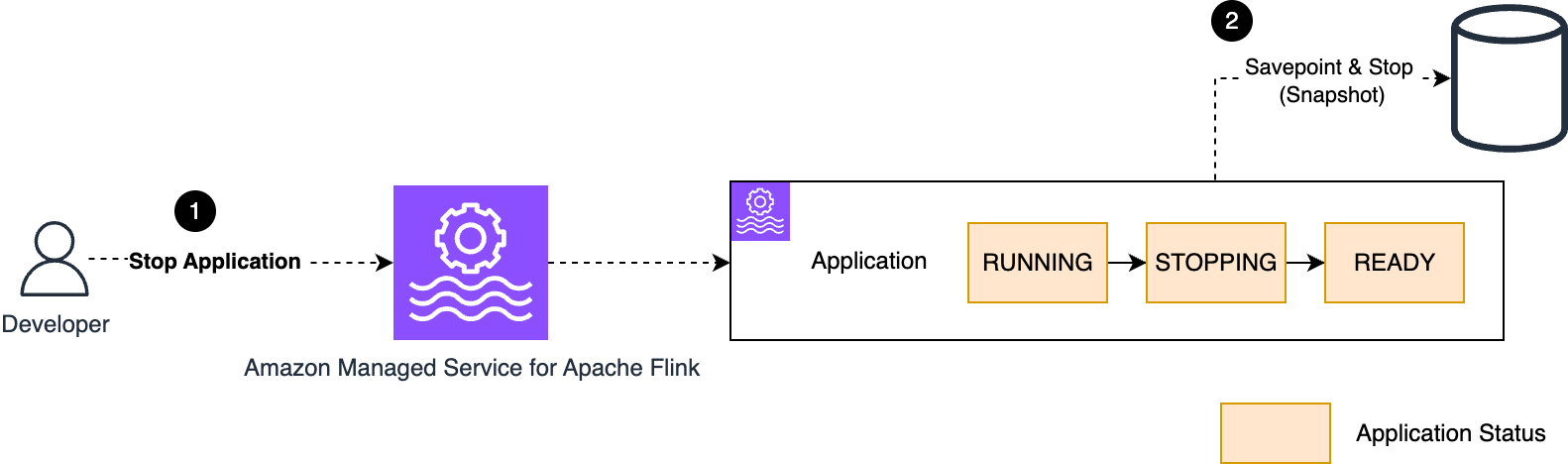
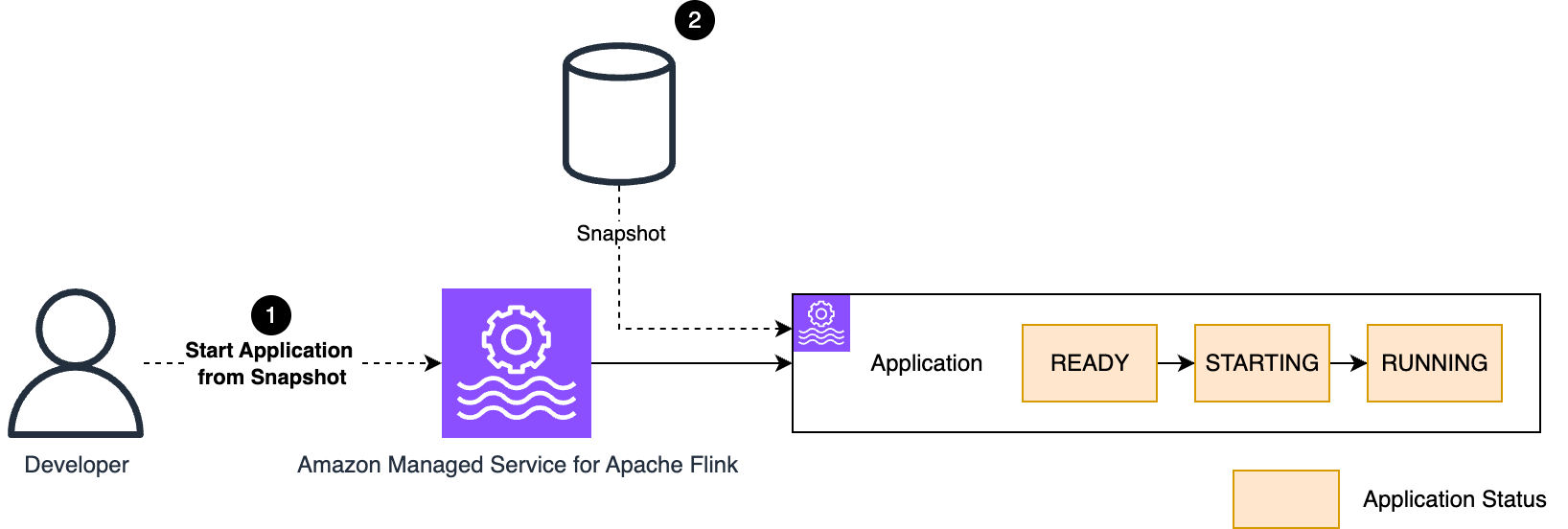

 Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges. Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS.
Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS. Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges.
Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges. Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
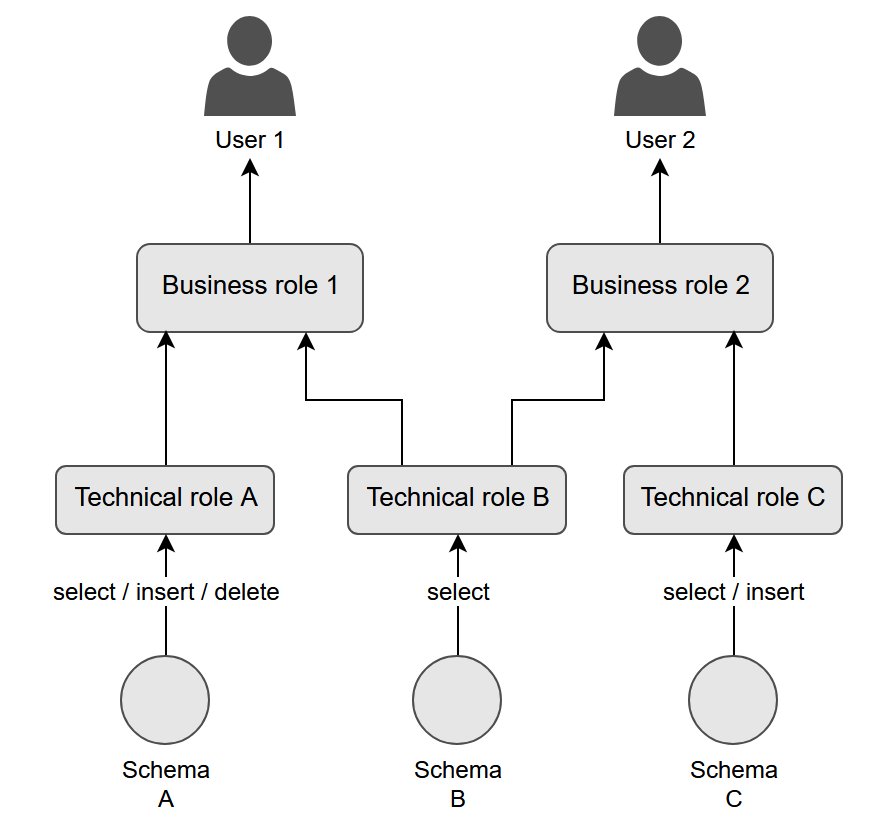
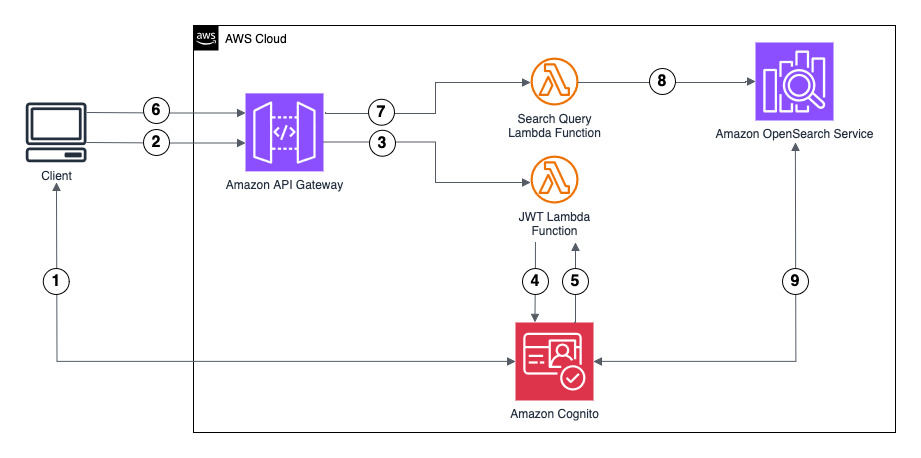
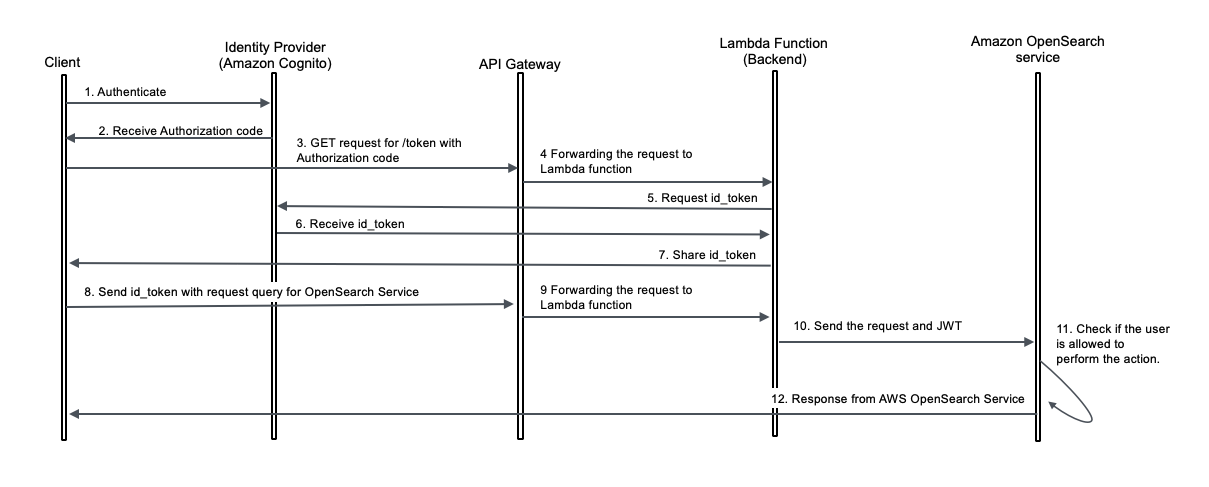



 Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors.
Ramya Bhat is a Data Analytics Consultant at AWS, specializing in the design and implementation of cloud-based data platforms. She builds enterprise-grade solutions across search, data warehousing, and ETL that enable organizations to modernize data ecosystems and derive insights through scalable analytics. She has delivered customer engagements across healthcare, insurance, fintech, and media sectors. Shubhansu Sawaria is a Sr. Delivery Consultant – SRC at AWS, based in Bangalore, India. He specializes in designing and implementing comprehensive AWS Cloud security solutions. He has developed security solutions for startups, banks, and healthcare organizations. His expertise helps organizations elevate their cloud security infrastructures, achieve compliance objectives, and provide robust data protection.
Shubhansu Sawaria is a Sr. Delivery Consultant – SRC at AWS, based in Bangalore, India. He specializes in designing and implementing comprehensive AWS Cloud security solutions. He has developed security solutions for startups, banks, and healthcare organizations. His expertise helps organizations elevate their cloud security infrastructures, achieve compliance objectives, and provide robust data protection. Soujanya Konka is a Sr. Solutions Architect and Analytics Specialist at AWS, focused on helping customers build their ideas in the cloud. She has expertise in designing and implementing enterprise search solutions and advanced data analytics at scale.
Soujanya Konka is a Sr. Solutions Architect and Analytics Specialist at AWS, focused on helping customers build their ideas in the cloud. She has expertise in designing and implementing enterprise search solutions and advanced data analytics at scale.

 Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community. Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges. Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.