Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/implementing-mutual-tls-for-java-based-aws-lambda-functions-2/
This post is written by Dhiraj Mahapatro, Senior Specialist SA, Serverless and Christian Mueller, Principal Solutions Architect
Modern secure applications establish network connections to other services through HTTPS. This ensures that the application connects to the right party and encrypts the data before sending it over the network.
You might not want unauthenticated users to connect to your service as a service provider. One solution to this requirement is to use mutual TLS (Transport Layer Security). Mutual TLS (or mTLS) is a common security mechanism that uses client certificates to add an authentication layer. This allows the service provider to verify the client’s identity cryptographically.
The purpose of mutual TLS in serverless
mTLS refers to two parties authenticating each other at the same time when establishing a connection. By default, the TLS protocol only proves the identity of the server to a client using X.509 certificates. With mTLS, a client must prove its identity to the server to communicate. This helps support a zero-trust policy to protect against adversaries like man-in-the-middle attacks.
mTLS is often used in business-to-business (B2B) applications and microservices, where interservice communication needs mutual authentication of parties. In Java, you see the following error when the server expects a certificate, but the client does not provide one:
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
This blog post explains multiple ways to implement a Java-based AWS Lambda function that uses mTLS to authenticate with a third-party internal or external service. The sample application and this post explain the advantages and tradeoffs of each approach.
The KeyStore and TrustStore in Java
The TrustStore is used to store certificate public keys from a certificate authority (CA) or trusted servers. A client can verify the public certificate presented by the server in a TLS connection. A KeyStore stores private key and identity certificates that a specific application uses to prove the client’s identity.
The stores contain opposite certificates. The TrustStore holds the identification certificates that identify others, while the KeyStore holds the identification certificates that identify itself.
Overview
To start, you create certificates. For brevity, this sample application uses a script that uses OpenSSL and Java’s keytool for self-signed certificates from a CA. You store the generated keys in Java KeyStore and TrustStore. However, the best practice for creating and maintaining certificates and private CA is to use AWS Certificate Manager and AWS Certificate Manager Private Certificate Authority.
You can find the details of the script in the README file.
The following diagram shows the use of KeyStore and TrustStore in the client Lambda function, and the server running on Fargate.

KeyStore and TrustStore
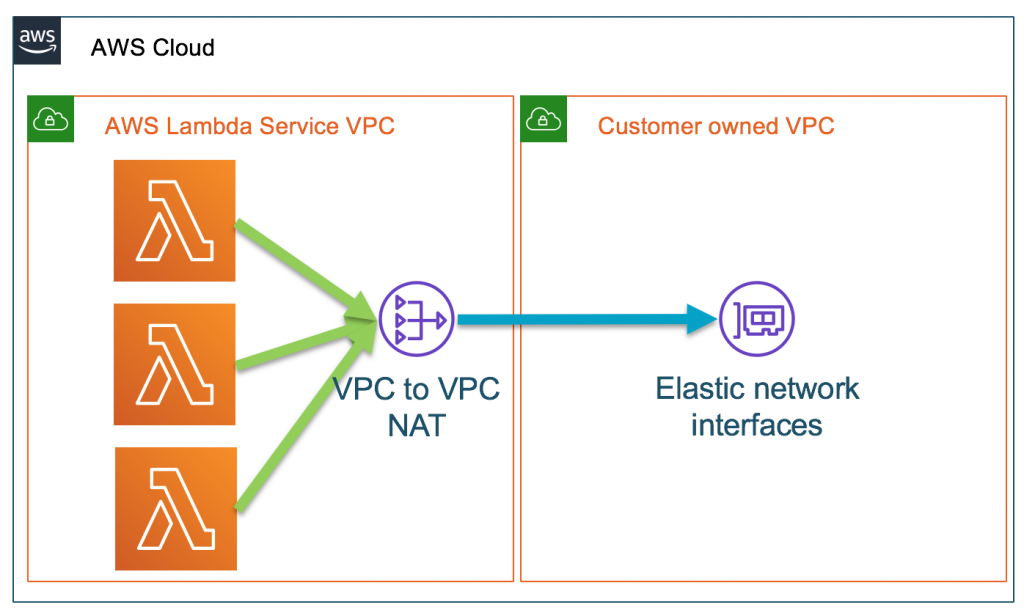
The demo application contains several Lambda functions. The Lambda functions act as clients to services provided by Fargate behind an Amazon Network Load Balancer (NLB) running in a private Amazon VPC. Amazon Route 53 private hosted zones are used to resolve selected hostnames. You attach the Lambda functions to this VPC to resolve the hostnames for the NLB. To learn more, read how AWS Lambda uses Hyperplane elastic network interfaces to work with custom VPC.
The following examples refer to portions of InfrastructureStack.java and the implementation in the corresponding Lambda functions.
Providing a client certificate in a Lambda function artifact
The first option is to provide the KeyStore and TrustStore in a Lambda functions’ .zip artifact. You provide specific Java environment variables within the Lambda configuration to instruct the JVM to load and trust your provided Keystore and TrustStore. The JVM uses these settings instead of the Java Runtime Environment’s (JRE) default settings (use a stronger password for your use case):
"-Djavax.net.ssl.keyStore=./client_keystore_1.jks -Djavax.net.ssl.keyStorePassword=secret -Djavax.net.ssl.trustStore=./client_truststore.jks -Djavax.net.ssl.trustStorePassword=secret"
The JRE uses this KeyStore and TrustStore to build a default SSLContext. The HttpClient uses this default SSLContext to create a TLS connection to the backend service running on Fargate.
The following architecture diagram shows the sample implementation. It consists of an Amazon API Gateway endpoint with a Lambda proxy integration that calls a backend Fargate service running behind an NLB.

Providing a client certificate in a Lambda function artifact
This is a basic approach for a prototype. However, it has a few shortcomings related to security and separation of duties. The KeyStore contains the private key, and the password is exposed to the source code management (SCM) system, which is a security concern. Also, it is the Lambda function owner’s responsibility to update the certificate before its expiration. You can address these concerns about separation of duties with the following approach.
Providing the client certificate in a Lambda layer
In this approach, you separate the responsibility between two entities. The Lambda function owner and the KeyStore and TrustStore owner.
The KeyStore and TrustStore owner provides the certificates securely to the function developer who may be working in a separate AWS environment. For simplicity, the demo application uses the same AWS account.
The KeyStore and TrustStore owner achieves this by using AWS Lambda layers. The KeyStore and TrustStore owner packages and uploads the certificates as a Lambda layer and only allows access to authorized functions. The Lambda function owner does not access the KeyStore or manage its lifecycle. The KeyStore and TrustStore owner’s responsibility is to release a new version of this layer when necessary and inform users.

Providing the client certificate in a Lambda layer
The KeyStore and TrustStore are extracted under the path /opt as part of including a Lambda layer. The Lambda function can now use the layer as:
Function lambdaLayerFunction = new Function(this, "LambdaLayerFunction", FunctionProps.builder()
.functionName("lambda-layer")
.handler("com.amazon.aws.example.AppClient::handleRequest")
.runtime(Runtime.JAVA_11)
.architecture(ARM_64)
.layers(singletonList(lambdaLayerForService1cert))
.vpc(vpc)
.code(Code.fromAsset("../software/2-lambda-using-separate-layer/target/lambda-using-separate-layer.jar"))
.memorySize(1024)
.environment(Map.of(
"BACKEND_SERVICE_1_HOST_NAME", BACKEND_SERVICE_1_HOST_NAME,
"JAVA_TOOL_OPTIONS", "-Djavax.net.ssl.keyStore=/opt/client_keystore_1.jks -Djavax.net.ssl.keyStorePassword=secret -Djavax.net.ssl.trustStore=/opt/client_truststore.jks -Djavax.net.ssl.trustStorePassword=secret"
))
.timeout(Duration.seconds(10))
.logRetention(RetentionDays.ONE_WEEK)
.build());
The KeyStore and TrustStore passwords are still supplied as environment variables and stored in the SCM system, which is against best practices. You can address this with the next approach.
Storing passwords securely in AWS Systems Manager Parameter Store
AWS Systems Manager Parameter Store provides secure, hierarchical storage for configuration data and secret management. You can use Parameter Store to store the KeyStore and TrustStore passwords instead of environment variables. The Lambda function uses an IAM policy to access Parameter Store and gets the passwords as a secure string during the Lambda initialization phase.
With this approach, you build a custom SSLContext after retrieving the KeyStore and TrustStore passwords from the Parameter Store. Once you create SSLContext, provide that to the HttpClient you use to connect with the backend service:
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(5))
.sslContext(sslContext)
.build();You can also use a VPC interface endpoint for AWS Systems Manager to keep the traffic from your Lambda function to Parameter Store internal to AWS. The following diagram shows the interaction between AWS Lambda and Parameter Store.
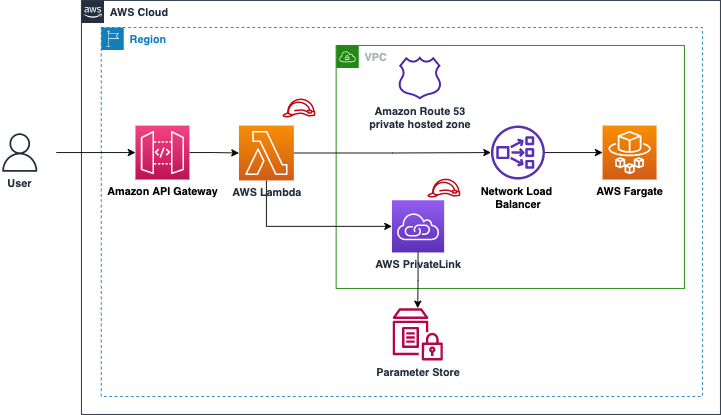
Storing passwords securely in AWS Systems Manager Parameter Store
This approach works for Lambda functions interacting with a single backend service requiring mTLS. However, it is common in a modern microservices architecture to integrate with multiple backend services. Sometimes, these services require a client to assume different identities by using different KeyStores. The next approach explains how to handle the multiple services scenario.
Providing multiple client certificates in Lambda layers
You can provide multiple KeyStore and TrustStore pairs within multiple Lambda layers. All layers attached to a function are merged when provisioning the function. Ensure your KeyStore and TrustStore names are unique. A Lambda function can use up to five Lambda layers.
Similar to the previous approach, you load multiple KeyStores and TrustStores to construct multiple SSLContext objects. You abstract the common logic to create an SSLContext object in another Lambda layer. Now, the Lambda function calling two different backend services uses 3 Lambda layers:
- Lambda layer for backend service 1 (under
/opt) - Lambda layer for backend service 2 (under
/opt) - Lambda layer for the SSL utility that takes the KeyStore, TrustStore, and their passwords to return an SSLContext object
SSL utility Lambda layer provides the getSSLContext default method in a Java interface. The Lambda function implements this interface. Now, you create a dedicated HTTP client per service.
The following diagram shows your final architecture:

Providing multiple client certificates in Lambda layers
Prerequisites
To run the sample application, you need:
To build and provision the stack:
- Clone the git repository.
- Create the two root CA’s, client, and server certificates.
- Build and package all examples.
- Provision the AWS infrastructure (make sure that Docker is running).
git clone https://github.com/aws-samples/serverless-mutual-tls.git
cd serverless-mutual-tls./scripts/1-create-certificates.sh./scripts/2-build_and_package-functions.sh./scripts/3-provision-infrastructure.shVerification
Verify that the API endpoints are working and using mTLS by running these commands from the base directory:
export API_ENDPOINT=$(cat infrastructure/target/outputs.json | jq -r '.LambdaMutualTLS.apiendpoint')To see the error when mTLS is not used in the Lambda function, run:
curl -i $API_ENDPOINT/lambda-no-mtlsThe preceding curl command responds with an HTTP status code 500 and plain body as:
PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
For successful usage of mTLS as shown in the previous use cases, run:
curl -i $API_ENDPOINT/lambda-only
curl -i $API_ENDPOINT/lambda-layer
curl -i $API_ENDPOINT/lambda-parameter-store
curl -i $API_ENDPOINT/lambda-multiple-certificatesThe last curl command responds with an HTTP status code 200 and body as:
[
{"hello": "from backend service 1"},
{"hello": "from backend service 2"}
]
Additional security
You can add additional controls via Java environment variables. Compliance standards like PCI DSS in financial services require customers to exercise more control over the underlying negotiated protocol and ciphers.
Some of the useful Java environment variables to troubleshoot SSL/TLS connectivity issues in a Lambda function are:
-Djavax.net.debug=all
-Djavax.net.debug=ssl,handshake
-Djavax.net.debug=ssl:handshake:verbose:keymanager:trustmanager
-Djavax.net.debug=ssl:record:plaintext
You can enforce a specific minimum version of TLS (for example, v1.3) to meet regulatory requirements:
-Dhttps.protocols=TLSv1.3
Alternatively, programmatically construct your SSLContext inside the Lambda function:
SSLContext sslContext = SSLContext.getInstance("TLSv1.3");You can also use the following Java environment variable to limit the use of weak cipher suites or unapproved algorithms, and explicitly provide the supported cipher suites:
You achieve the same programmatically with the following code snippet:
httpClient = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(5))
.sslContext(sslContext)
.sslParameters(new SSLParameters(new String[]{
"TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256",
"TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384",
"TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA",
………
}))
.build();Cleaning up
The stack creates a custom VPC and other related resources. Clean up after usage to avoid the ongoing cost of running these services. To clean up the infrastructure and the self-generated certificates, run:
./scripts/4-delete-certificates.sh
./scripts/5-deprovision-infrastructure.shConclusion
mTLS in Java using KeyStore and TrustStore is a well-established approach for using client certificates to add an authentication layer. This blog highlights the four approaches that you can take to implement mTLS using Java-based Lambda functions.
Each approach addresses the separation of concerns required while implementing mTLS with additional security features. Use an approach that suits your needs, organizational security best practices, and enterprise requirements. Refer to the demo application for additional details.
For more serverless learning resources, visit Serverless Land.