Post Syndicated from Andrew Repp original https://blog.cloudflare.com/elephants-in-tunnels-how-hyperdrive-connects-to-databases-inside-your-vpc-networks
With September’s announcement of Hyperdrive’s ability to send database traffic from Workers over Cloudflare Tunnels, we wanted to dive into the details of what it took to make this happen.
Accessing your data from anywhere in Region Earth can be hard. Traditional databases are powerful, familiar, and feature-rich, but your users can be thousands of miles away from your database. This can cause slower connection startup times, slower queries, and connection exhaustion as everything takes longer to accomplish.
Cloudflare Workers is an incredibly lightweight runtime, which enables our customers to deploy their applications globally by default and renders the cold start problem almost irrelevant. The trade-off for these light, ephemeral execution contexts is the lack of persistence for things like database connections. Database connections are also notoriously expensive to spin up, with many round trips required between client and server before any query or result bytes can be exchanged.
Hyperdrive is designed to make the centralized databases you already have feel like they’re global while keeping connections to those databases hot. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
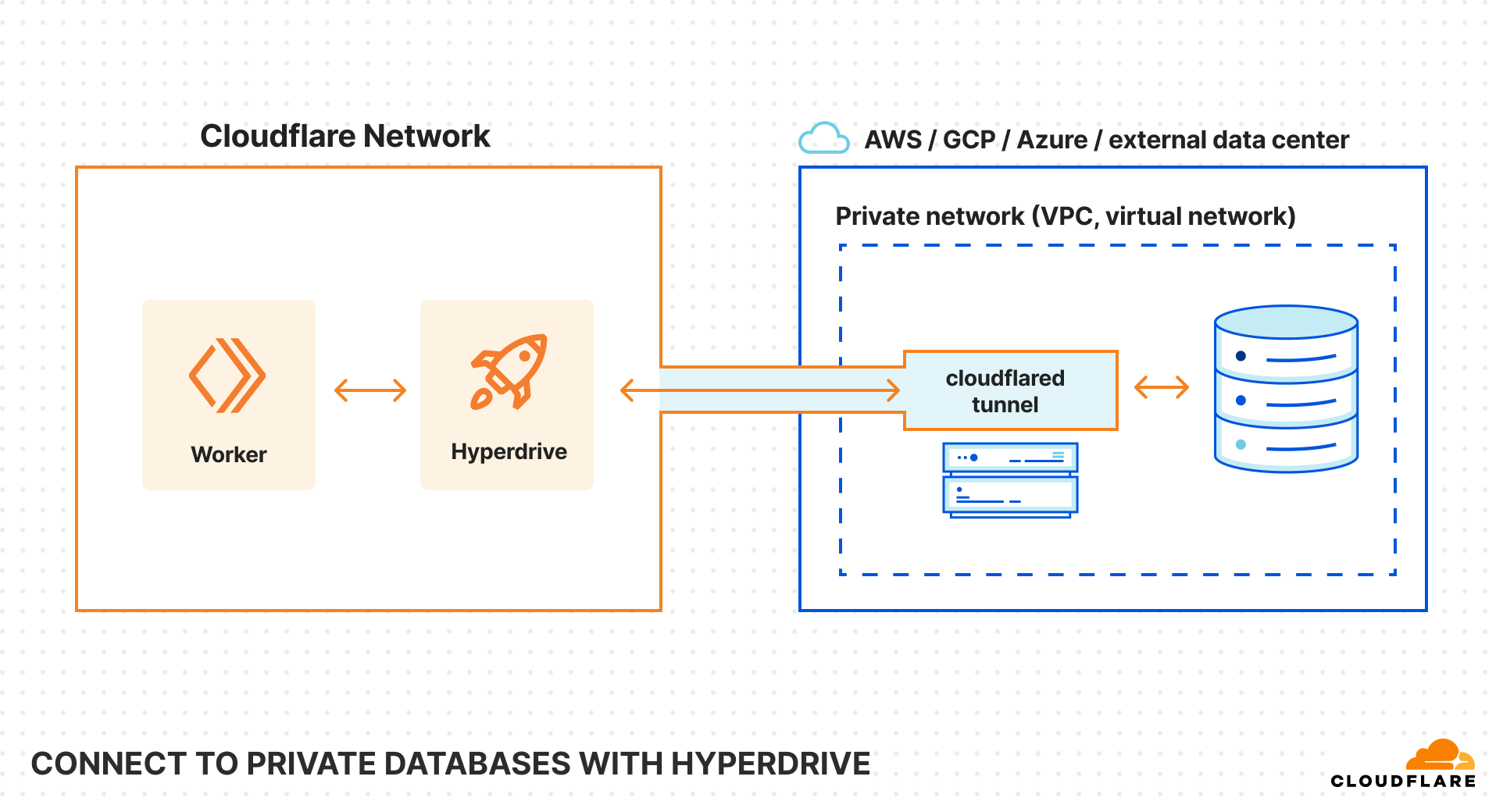
For something as sensitive as your database, exposing access to the public Internet can be uncomfortable. It is common to instead host your database on a private network, and allowlist known-safe IP addresses or configure GRE tunnels to permit traffic to it. This is complex, toilsome, and error-prone.
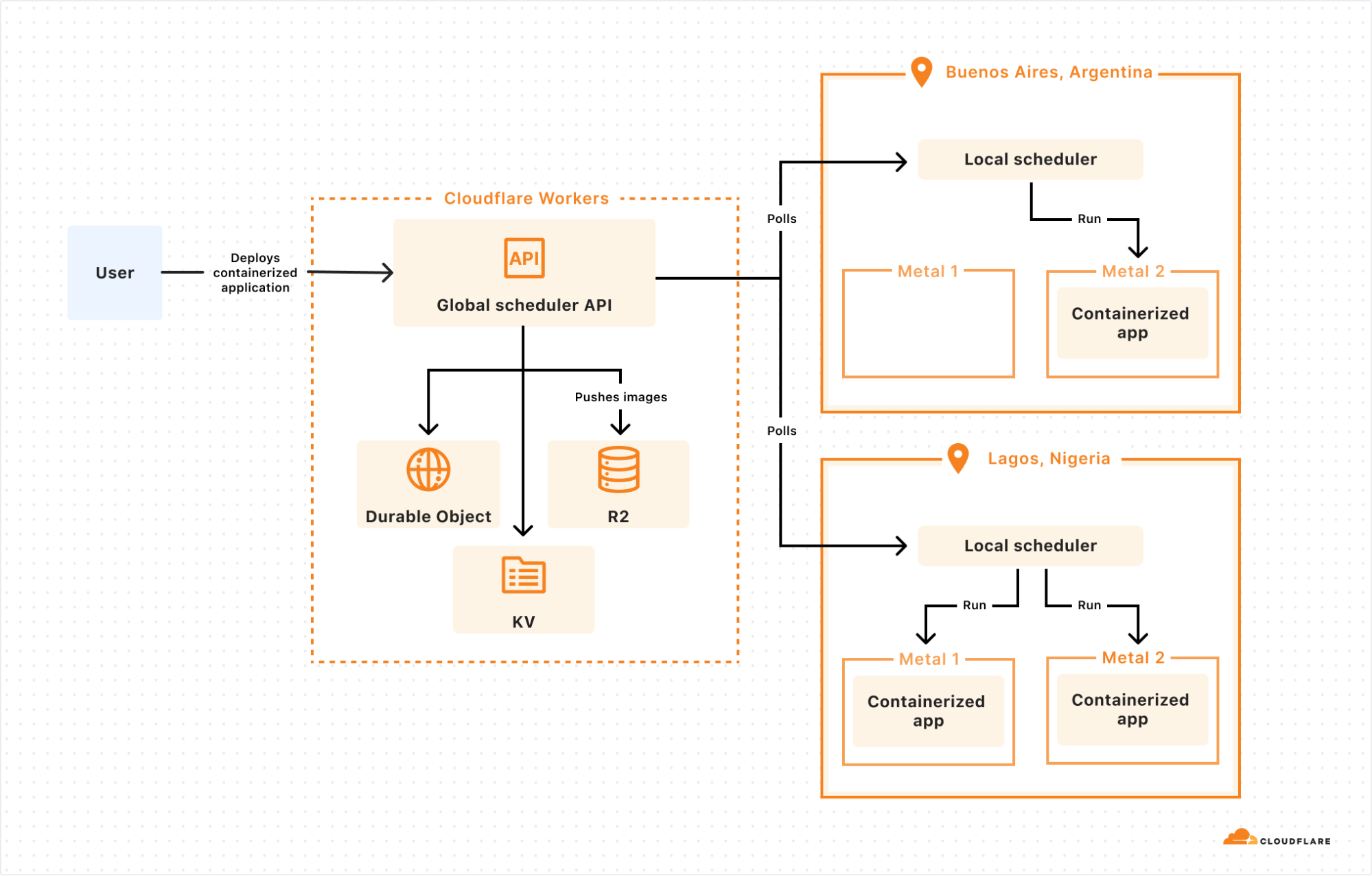
On Cloudflare’s Developer Platform, we strive for simplicity and ease-of-use. We cannot expect all of our customers to be experts in configuring networking solutions, and so we went in search of a simpler solution. Being your own customer is rarely a bad choice, and it so happens that Cloudflare offers an excellent option for this scenario: Tunnels.
Cloudflare Tunnel is a Zero Trust product that creates a secure connection between your private network and Cloudflare. Exposing services within your private network can be as simple as running a cloudflared binary, or deploying a Docker container running the cloudflared image we distribute.

Integrating with Tunnels to support sending Postgres directly through them was a bit of a new challenge for us. Most of the time, when we use Tunnels internally (more on that later!), we rely on the excellent job cloudflared does of handling all of the mechanics, and we just treat them as pipes. That wouldn’t work for Hyperdrive, though, so we had to dig into how Tunnels actually ingress traffic to build a solution.
Hyperdrive handles Postgres traffic using an entirely custom implementation of the Postgres message protocol. This is necessary, because we sometimes have to alter the specific type or content of messages sent from client to server, or vice versa. Handling individual bytes gives us the flexibility to implement whatever logic any new feature might need.
An additional, perhaps less obvious, benefit of handling Postgres message traffic as just bytes is that we are not bound to the transport layer choices of some ORM or library. One of the nuances of running services in Cloudflare is that we may want to egress traffic over different services or protocols, for a variety of different reasons. In this case, being able to egress traffic via a Tunnel would be pretty challenging if we were stuck with whatever raw TCP socket a library had established for us.
The way we accomplish this relies on a mainstay of Rust: traits (which are how Rust lets developers apply logic across generic functions and types). In the Rust ecosystem, there are two traits that define the behavior Hyperdrive wants out of its transport layers: AsyncRead and AsyncWrite. There are a couple of others we also need, but we’re going to focus on just these two. These traits enable us to code our entire custom handler against a generic stream of data, without the handler needing to know anything about the underlying protocol used to implement the stream. So, we can pass around a WebSocket connection as a generic I/O stream, wherever it might be needed.
As an example, the code to create a generic TCP stream and send a Postgres startup message across it might look like this:
/// Send a startup message to a Postgres server, in the role of a PG client.
/// https://www.postgresql.org/docs/current/protocol-message-formats.html#PROTOCOL-MESSAGE-FORMATS-STARTUPMESSAGE
pub async fn send_startup<S>(stream: &mut S, user_name: &str, db_name: &str, app_name: &str) -> Result<(), ConnectionError>
where
S: AsyncWrite + Unpin,
{
let protocol_number = 196608 as i32;
let user_str = &b"user\0"[..];
let user_bytes = user_name.as_bytes();
let db_str = &b"database\0"[..];
let db_bytes = db_name.as_bytes();
let app_str = &b"application_name\0"[..];
let app_bytes = app_name.as_bytes();
let len = 4 + 4
+ user_str.len() + user_bytes.len() + 1
+ db_str.len() + db_bytes.len() + 1
+ app_str.len() + app_bytes.len() + 1 + 1;
// Construct a BytesMut of our startup message, then send it
let mut startup_message = BytesMut::with_capacity(len as usize);
startup_message.put_i32(len as i32);
startup_message.put_i32(protocol_number);
startup_message.put(user_str);
startup_message.put_slice(user_bytes);
startup_message.put_u8(0);
startup_message.put(db_str);
startup_message.put_slice(db_bytes);
startup_message.put_u8(0);
startup_message.put(app_str);
startup_message.put_slice(app_bytes);
startup_message.put_u8(0);
startup_message.put_u8(0);
match stream.write_all(&startup_message).await {
Ok(_) => Ok(()),
Err(err) => {
error!("Error writing startup to server: {}", err.to_string());
ConnectionError::InternalError
}
}
}
/// Connect to a TCP socket
let stream = match TcpStream::connect(("localhost", 5432)).await {
Ok(s) => s,
Err(err) => {
error!("Error connecting to address: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let _ = send_startup(&mut stream, "db_user", "my_db").await;With this approach, if we wanted to encrypt the stream using TLS before we write to it (upgrading our existing TcpStream connection in-place, to an SslStream), we would only have to change the code we use to create the stream, while generating and sending the traffic would remain unchanged. This is because SslStream also implements AsyncWrite!
/// We're handwaving the SSL setup here. You're welcome.
let conn_config = new_tls_client_config()?;
/// Encrypt the TcpStream, returning an SslStream
let ssl_stream = match tokio_boring::connect(conn_config, domain, stream).await {
Ok(s) => s,
Err(err) => {
error!("Error during websocket TLS handshake: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let _ = send_startup(&mut ssl_stream, "db_user", "my_db").await;WebSocket is an application layer protocol that enables bidirectional communication between a client and server. Typically, to establish a WebSocket connection, a client initiates an HTTP request and indicates they wish to upgrade the connection to WebSocket via the “Upgrade” header. Then, once the client and server complete the handshake, both parties can send messages over the connection until one of them terminates it.
Now, it turns out that the way Cloudflare Tunnels work under the hood is that both ends of the tunnel want to speak WebSocket, and rely on a translation layer to convert all traffic to or from WebSocket. The cloudflared daemon you spin up within your private network handles this for us! For Hyperdrive, however, we did not have a suitable translation layer to send Postgres messages across WebSocket, and had to write one.
One of the (many) fantastic things about Rust traits is that the contract they present is very clear. To be AsyncRead, you just need to implement poll_read. To be AsyncWrite, you need to implement only three functions (poll_write, poll_flush, and poll_shutdown). Further, there is excellent support for WebSocket in Rust built on top of the tungstenite-rs library.
Thus, building our custom WebSocket stream such that it can share the same machinery as all our other generic streams just means translating the existing WebSocket support into these poll functions. There are some existing OSS projects that do this, but for multiple reasons we could not use the existing options. The primary reason is that Hyperdrive operates across multiple threads (thanks to the tokio runtime), and so we rely on our connections to also handle Send, Sync, and Unpin. None of the available solutions had all five traits handled. It turns out that most of them went with the paradigm of Sink and Stream, which provide a solid base from which to translate to AsyncRead and AsyncWrite. In fact some of the functions overlap, and can be passed through almost unchanged. For example, poll_flush and poll_shutdown have 1-to-1 analogs, and require almost no engineering effort to convert from Sink to AsyncWrite.
/// We use this struct to implement the traits we need on top of a WebSocketStream
pub struct HyperSocket<S>
where
S: AsyncRead + AsyncWrite + Send + Sync + Unpin,
{
inner: WebSocketStream<S>,
read_state: Option<ReadState>,
write_err: Option<Error>,
}
impl<S> AsyncWrite for HyperSocket<S>
where
S: AsyncRead + AsyncWrite + Send + Sync + Unpin,
{
fn poll_flush(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<io::Result<()>> {
match ready!(Pin::new(&mut self.inner).poll_flush(cx)) {
Ok(_) => Poll::Ready(Ok(())),
Err(err) => Poll::Ready(Err(Error::new(ErrorKind::Other, err))),
}
}
fn poll_shutdown(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<io::Result<()>> {
match ready!(Pin::new(&mut self.inner).poll_close(cx)) {
Ok(_) => Poll::Ready(Ok(())),
Err(err) => Poll::Ready(Err(Error::new(ErrorKind::Other, err))),
}
}
}
With that translation done, we can use an existing WebSocket library to upgrade our SslStream connection to a Cloudflare Tunnel, and wrap the result in our AsyncRead/AsyncWrite implementation. The result can then be used anywhere that our other transport streams would work, without any changes needed to the rest of our codebase!
That would look something like this:
let websocket = match tokio_tungstenite::client_async(request, ssl_stream).await {
Ok(ws) => Ok(ws),
Err(err) => {
error!("Error during websocket conn setup: {}", err.to_string());
return ConnectionError::InternalError;
}
};
let websocket_stream = HyperSocket::new(websocket));
let _ = send_startup(&mut websocket_stream, "db_user", "my_db").await;An observant reader might have noticed that in the code example above we snuck in a variable named request that we passed in when upgrading from an SslStream to a WebSocketStream. This is for multiple reasons. The first reason is that Tunnels are assigned a hostname and use this hostname for routing. The second and more interesting reason is that (as mentioned above) when negotiating an upgrade from HTTP to WebSocket, a request must be sent to the server hosting the ingress side of the Tunnel to perform the upgrade. This is pretty universal, but we also add in an extra piece here.
At Cloudflare, we believe that secure defaults and defense in depth are the correct ways to build a better Internet. This is why traffic across Tunnels is encrypted, for example. However, that does not necessarily prevent unwanted traffic from being sent into your Tunnel, and therefore egressing out to your database. While Postgres offers a robust set of access control options for protecting your database, wouldn’t it be best if unwanted traffic never got into your private network in the first place?
To that end, all Tunnels set up for use with Hyperdrive should have a Zero Trust Access Application configured to protect them. These applications should use a Service Token to authorize connections. When setting up a new Hyperdrive, you have the option to provide the token’s ID and Secret, which will be encrypted and stored alongside the rest of your configuration. These will be presented as part of the WebSocket upgrade request to authorize the connection, allowing your database traffic through while preventing unwanted access.
This can be done within the request’s headers, and might look something like this:
let ws_url = format!("wss://{}", host);
let mut request = match ws_url.into_client_request() {
Ok(req) => req,
Err(err) => {
error!(
"Hostname {} could not be parsed into a valid request URL: {}",
host,
err.to_string()
);
return ConnectionError::InternalError;
}
};
request.headers_mut().insert(
"CF-Access-Client-Id",
http::header::HeaderValue::from_str(&client_id).unwrap(),
);
request.headers_mut().insert(
"CF-Access-Client-Secret",
http::header::HeaderValue::from_str(&client_secret).unwrap(),
);
If you’ve been reading the blog for a long time, some of this might sound a bit familiar. This isn’t the first time that we’ve sent Postgres traffic across a tunnel, it’s something most of us do from our laptops regularly. This works very well for interactive use cases with low traffic volume and a high tolerance for latency, but historically most of our products have not been able to employ the same approach.
Cloudflare operates many data centers around the world, and most services run in every one of those data centers. There are some tasks, however, that make the most sense to run in a more centralized fashion. These include tasks such as managing control plane operations, or storing configuration state. Nearly every Cloudflare product houses its control plane information in Postgres clusters run centrally in a handful of our data centers, and we use a variety of approaches for accessing that centralized data from elsewhere in our network. For example, many services currently use a push-based model to publish updates to Quicksilver, and work through the complexities implied by such a model. This has been a recurring challenge for any team looking to build a new product.
Hyperdrive’s entire reason for being is to make it easy to access such central databases from our global network. When we began exploring Tunnel integrations as a feature, many internal teams spoke up immediately and strongly suggested they’d be interested in using it themselves. This was an excellent opportunity for Cloudflare to scratch its own itch, while also getting a lot of traffic on a new feature before releasing it directly to the public. As always, being “customer zero” means that we get fast feedback, more reliability over time, stronger connections between teams, and an overall better suite of products. We jumped at the chance.
As we rolled out early versions of Tunnel integration, we worked closely with internal teams to get them access to it, and fixed any rough spots they encountered. We’re pleased to share that this first batch of teams have found great success building new or refactored products on Hyperdrive over Tunnels. For example: if you’ve already tried out Workers Builds, or recently submitted an abuse report, you’re among our first users! At the time of this writing, we have several more internal teams working to onboard, and we on the Hyperdrive team are very excited to see all the different ways in which fast and simple connections from Workers to a centralized database can help Cloudflare just as much as they’ve been helping our external customers.
Cloudflare is on a mission to make the Internet faster, safer, and more reliable. Hyperdrive was built to make connecting to centralized databases from the Workers runtime as quick and consistent as possible, and this latest development is designed to help all those who want to use Hyperdrive without directly exposing resources within their virtual private clouds (VPCs) on the public web.
To this end, we chose to build a solution around our suite of industry-leading Zero Trust tools, and were delighted to find how simple it was to implement in our runtime given the power and extensibility of the Rust trait system.
Without waiting for the ink to dry, multiple teams within Cloudflare have adopted this new feature to quickly and easily solve what have historically been complex challenges, and are happily operating it in production today.
And now, if you haven’t already, try setting up Hyperdrive across a Tunnel, and let us know what you think in the Hyperdrive Discord channel!