Post Syndicated from Matteo Luigi Restelli original https://aws.amazon.com/blogs/devops/validate-your-lambda-runtime-with-cloudformation-lambda-hooks/
Introduction
This post demonstrates how to leverage AWS CloudFormation Lambda Hooks to enforce compliance rules at provisioning time, enabling you to evaluate and validate Lambda function configurations against custom policies before deployment. Often these policies impact the way a software should be built, restricting language versions and runtimes. A great example is applying those policies on AWS Lambda, a serverless compute service for running code without having to provision or manage servers. While AWS Lambda already manages the deprecation of runtimes, preventing you from deploying unsupported runtimes, organizations may need to provide and enforce their specific compliance rules not directly linked to the deprecation of a specific language version.
Introducing Lambda Hooks
AWS CloudFormation Lambda Hooks are a powerful feature that allows developers to evaluate CloudFormation and AWS Cloud Control API operations against custom code implemented as Lambda functions. This capability enables proactive inspection of resource configurations before provisioning, enhancing security, compliance, and operational efficiency.
Lambda Hooks provide a mechanism to intercept and evaluate various CloudFormation operations, including resource operations, stack operations, and change set operations (they can also be used with Cloud Control API, but in this post we’re focusing on CloudFormation). By activating a Lambda Hook, CloudFormation creates an entry in your account’s registry as a private Hook, allowing you to configure it for specific AWS accounts and regions. When configuring Lambda Hooks, you can specify one or more Lambda functions to be invoked during the evaluation process. These functions can be in the same AWS account and Region as the Hook, or in another Account you own, provided proper permissions are set up. The evaluation process occurs at specific points in the CloudFormation Stack lifecycle. For instance, during stack creation, update, or deletion, the configured Lambda functions are invoked to assess the proposed changes against your defined compliance rules. Based on the evaluation results, the hook can either block the operation or issue a warning, allowing the operation to proceed.
Lambda Hooks evaluate resources before they are provisioned through CloudFormation, providing a pre-emptive layer of governance. This means that non-compliant resources are caught and prevented from being deployed, rather than requiring retroactive fixes. By leveraging Lambda Hooks, organizations can automate and standardize their compliance checks across all AWS accounts and regions. This centralized approach to policy enforcement ensures consistency and reduces the overhead of managing compliance manually.
Solution Overview
The following sections demonstrate a practical use case for AWS CloudFormation Lambda Hooks, focusing on enforcing compliance rules on AWS Lambda runtimes.
Meet AnyCompany, a forward-thinking enterprise with a robust set of compliance rules governing their software development practices. Among these rules is a strict policy on the use of specific AWS Lambda runtimes.
As they continue to embrace serverless architecture, AnyCompany faces a challenge: how to prevent the deployment of Lambda functions that use non-compliant runtimes. Given their commitment to AWS CloudFormation for deploying Lambda functions, AnyCompany is keen to leverage the power of AWS CloudFormation Lambda Hooks.
We’ll explore the setup process, demonstrate the hook in action, and discuss the broader implications for maintaining compliance in a dynamic cloud environment.
Architecture
The following architecture highlights the implementation of the Lambda Hook. In this implementation, we are using AWS CloudFormation Lambda Hooks to intercept the deployment of Lambda Functions and perform the compliance checks on these resources. The Lambda Hook will interact with an AWS Lambda Function, which will perform the compliance checks. Finally, we’re using AWS Systems Manager Parameter Store to store the Configuration Parameter which contains the list of permitted Lambda Runtimes.

Figure 1: Architecture of the Solution
- A Developer (or a CI/CD pipeline) deploys a CloudFormation stack containing Lambda functions.
- CloudFormation invokes the respective Lambda Hook, which is configured to intercept operations on AWS Lambda Resources. We are setting this hook to “FAIL” deployment in case checks are not successful.
- The Lambda Hook checks if the runtime of the Lambda is admitted or violates Company’s compliance. To do this, it checks if the runtime is present on a pre-configured list of admitted runtimes saved as Parameter in AWS Systems Manager Parameter Store. Keep in mind that we’re using SSM Parameter Store to store the configuration for this specific example, but other alternatives may be viable as well (Amazon DynamoDB, AWS Secrets Manager, or AppConfig lambda-function-settings-check Preventive Rule)
- The Lambda Hook, after checking runtime compliance, replies:
- With a failure, if the Lambda runtime is not compliant
- With a success, if the Lambda runtime is compliant
- Depending on the response of the Lambda Hook, the deployment may or not take place.
Repository Structure
You can find all the code for this solution at this link. Here’s the repository structure:
.
├── README.md
├── deploy.sh
├── cleanup.sh
├── hook-lambda
│ ├── index.ts
│ ├── package.json
│ ├── services
│ │ └── parameter-store.ts
│ └── tsconfig.json
├── sample
│ ├── deploy_sample.sh
│ ├── cleanup_sample.sh
│ └── lambda_template.yml
└── template.yml
- hook-lambda: directory containing all the code related to the CloudFormation Lambda Hook (Validation Lambda Function, and the CloudFormation template for the Solution)
- sample: directory containing the code of the sample used to test the CloudFormation Lambda Hook
- deploy.sh: utility script to deploy the Solution via AWS CLI
- cleanup.sh: utility script to clean up the AWS CloudFormation Hook infrastructure via the AWS CLI
- template.yml: AWS CloudFormation Template containing all the AWS Resources involved in the Solution
Prerequisites
You must have the following prerequisites for this solution:
- An AWS account or sign up to create and activate one.
- The following software installed on your development machine:
- Install the AWS Command Line Interface (AWS CLI) and configure it to point to your AWS account.
- Install Node.js and use a package manager such as npm.
- Appropriate AWS credentials for interacting with resources in your AWS account.
Walkthrough
Creating the AWS Lambda Validation Function – Lambda Code
The CloudFormation Lambda Hook interacts with a specific Lambda (referred to as Validation Lambda throughout the rest of this post), which gets invoked during CloudFormation CREATE and UPDATE STACK operations involving Lambda Functions. The goal is to check if these Lambda functions have runtimes that comply with AnyCompany’s rules.
Below is the detailed description of the steps that the Validation Lambda function handler follows (the code is written in Typescript).
First, the Validation Lambda retrieves an environment variable containing the SSM Parameter Store parameter name which contains the compliant runtimes list. Additionally, safety checks ensure that only Lambda Resources are considered and that their Runtime property is defined.
Note that both safety checks could be skipped, since the Hook should already be configured to interact only with Lambda Resources and the Lambda’s Runtime property is always required. However, they remain in place to demonstrate how to retrieve this information from the Lambda Hook event in your handler.
const parameterName = process.env.PERMITTED_RUNTIMES_PARAM;
if (!parameterName) {
throw new Error('Permitted Runtimes Parameter is not set');
}
const resourceProperties = event.requestData.targetModel.resourceProperties;
// Check if this is a Lambda function resource
if (event.requestData.targetType !== 'AWS::Lambda::Function') {
console.log("Resource is not a Lambda function, skipping");
return {
hookStatus: 'SUCCESS',
message: 'Not a Lambda function resource, skipping validation',
clientRequestToken: event.clientRequestToken
}
}
// Check runtime version compliance
const runtime = resourceProperties.Runtime;
if (!runtime) {
console.log("Runtime not defined, failing");
return {
hookStatus: 'FAILURE',
errorCode: 'NonCompliant',
message: 'Runtime is required for Lambda functions',
clientRequestToken: event.clientRequestToken
}
}
Then the Validation Lambda retrieves the value of the Configuration Parameter from SSM Parameter Store through a utility class called ParameterStoreService. For this post, consider that the value inside that Configuration Parameter is a list of strings, where each string contains one of the possible Lambda runtime values that you can find here (e.g. nodejs22.x,nodejs20.x,python3.11,python3.10,java17,java11,dotnet6). After retrieving the value, the Validation Lambda checks if the runtime of the Lambda Resource complies with the configured admitted runtimes. If the runtime is not compliant, you’ll receive a properly formatted response with FAILURE as hookStatus, otherwise the response will contain a SUCCESS hookStatus.
// Retrieve configuration from Parameter Store
const compliantRuntimes = await parameterStoreService.getParameterFromStore(parameterName);
// Check if Lambda runtime is permitted or not
if (!compliantRuntimes.includes(runtime)) {
console.log("Runtime " + runtime + " not compliant ");
return {
hookStatus: 'FAILURE',
errorCode: 'NonCompliant',
message: `Runtime ${runtime} is not compliant. Please use one of: ${compliantRuntimes.join(', ')}`,
clientRequestToken: event.clientRequestToken
}
}
return {
hookStatus: 'SUCCESS',
message: 'Runtime version compliance check passed',
clientRequestToken: event.clientRequestToken
}
For more information about the possible response values of CloudFormation Lambda Hooks Lambda, have a look at this link.
Creating the validation Lambda – Lambda CloudFormation definition
The Validation Lambda function will be deployed via CloudFormation, in the same Stack with the CloudFormation Lambda Hook definition and the AWS Systems Manager Parameter Store Parameter. Here’s the fragment of the CloudFormation Template containing its definition:
# Lambda Function
ValidationFunction:
Type: AWS::Lambda::Function
Properties:
Handler: index.handler
Role: !GetAtt LambdaExecutionRole.Arn
Code:
S3Bucket: !Ref DeploymentBucket
S3Key: hook-lambda.zip
Runtime: nodejs22.x
Timeout: 60
MemorySize: 128
Environment:
Variables:
PERMITTED_RUNTIMES_PARAM: !Ref ParameterStoreParamName
You’ll need to associate an IAM Role with proper permissions to access the AWS Systems Manager Parameter Store Parameter:
# Lambda Function Role
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
# IAM Policy to access Parameter Store
ParameterStoreAccessPolicy:
Type: AWS::IAM::RolePolicy
Properties:
RoleName: !Ref LambdaExecutionRole
PolicyName: ParameterStoreAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- ssm:GetParameter
Resource: !Sub arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter${ParameterStoreParamName}
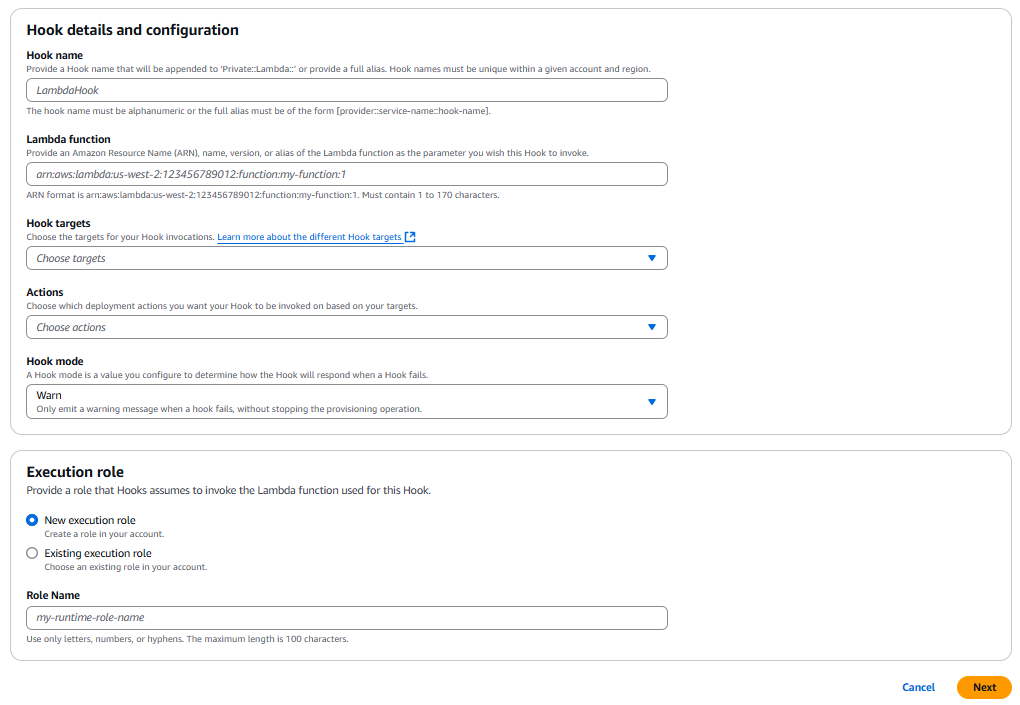
Creating the CloudFormation Lambda Hook
At this point, you only need to author a proper CloudFormation Lambda Hook. The Hook requires:
- To be activated during the CREATE and UPDATE CloudFormation operations,
- To consider only AWS::Lambda::Function CloudFormation resources
- To act during Pre Provisioning of CloudFormation templates
- To target Stack and Resource Operations
- Target the already defined Lambda Validation function
Here’s the definition in the CloudFormation template:
# Lambda Hook
ValidationHook:
Type: AWS::CloudFormation::LambdaHook
Properties:
Alias: Private::Lambda::LambdaResourcesComplianceValidationHook
LambdaFunction: !GetAtt ValidationFunction.Arn
ExecutionRole: !GetAtt HookExecutionRole.Arn
FailureMode: FAIL
HookStatus: ENABLED
TargetFilters:
Actions:
- CREATE
- UPDATE
InvocationPoints:
- PRE_PROVISION
TargetNames:
- AWS::Lambda::Function
TargetOperations:
- RESOURCE
- STACK
Please note that the above template contains a reference to an IAM Role because the Hook requires proper permissions to call the target (Lambda Function). Here’s the IAM Role definition:
# Hook Execution Role
HookExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: hooks.cloudformation.amazonaws.com
Action: sts:AssumeRole
# IAM Policy for Lambda Invocation
LambdaInvokePolicy:
Type: AWS::IAM::RolePolicy
Properties:
RoleName: !Ref HookExecutionRole
PolicyName: LambdaInvokePolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- lambda:InvokeFunction
Resource: !GetAtt ValidationFunction.Arn
Configuring the compliant runtimes – Using Systems Manager Parameter Store
AWS Systems Manager Parameter Store is a secure, hierarchical storage service for configuration data management and secrets management, allowing users to store and retrieve data such as configurations, database strings etc. as parameter values.
In this specific example, we’ll leverage Parameter Store to store our permitted Lambda runtimes configuration. This configuration value is a StringList parameter, containing a comma-separated list of permitted runtimes. Here’s the fragment of the CloudFormation template that defines the Parameter:
# Parameter Store Parameter
ConfigParameter:
Type: AWS::SSM::Parameter
Properties:
Name: !Ref ParameterStoreParamName
Type: StringList
Value: !Ref ParameterStoreDefaultValue
Description: "Configuration for Lambda Hook"
Please note the usage of CloudFormation parameters for the ‘Name’ and ‘Value’ properties, allowing for dynamic input when deploying the CloudFormation template.
Deploying the Solution
To deploy the solution you can leverage the script deploy.sh in the root folder of the repository. This script will perform the following actions:
- Compile and build the Validation Lambda Function
- Create an Amazon S3 Bucket to store the CloudFormation Template
- Upload the CloudFormation template and Lambda code to the S3 Bucket
- Deploy the CloudFormation template
Testing the Lambda Hook
To test the CloudFormation Lambda Hook, deploy a simple testing CloudFormation template containing a Hello World Lambda function. First, test the Lambda configured with a permitted Lambda runtime, then modify the template to configure the Lambda with a non-compliant runtime.
Here’s the initial definition of the testing CloudFormation Template:
# Lambda Function
HelloWorldFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: hello-world-function
Runtime: nodejs22.x
Handler: index.handler
Role: !GetAtt LambdaExecutionRole.Arn
Code:
ZipFile: |
exports.handler = async (event, context) => {
console.log('Hello World!');
const response = {
statusCode: 200,
body: JSON.stringify('Hello World!')
};
return response;
};
Timeout: 30
MemorySize: 128
Please note that the Runtime value is nodejs22.x, which is currently in the list of permitted runtimes. The expectation is that the deployment of this function will succeed.
Deploy this template via the AWS CLI:
aws cloudformation deploy \
--template-file ./lambda_template.yml \
--capabilities CAPABILITY_IAM \
--stack-name lambda-sample
Check the CloudFormation Console:

Figure 2: CloudFormation Console showing successful Stack deployment
As expected, the deployment was successful. You can also see that the CloudFormation Lambda Hook has been invoked by taking a look at the CloudWatch Logs:

Figure 3: Validation Lambda Function Logs with successful validation
Now modify the original sample Template in order to set a Lambda Runtime which is not inside the list of permitted runtimes:
# Lambda Function
HelloWorldFunction:
Type: AWS::Lambda::Function
Properties:
FunctionName: hello-world-function
Runtime: nodejs18.x
Handler: index.handler
Role: !GetAtt LambdaExecutionRole.Arn
Code:
ZipFile: |
exports.handler = async (event, context) => {
console.log('Hello World!');
const response = {
statusCode: 200,
body: JSON.stringify('Hello World!')
};
return response;
};
Timeout: 30
MemorySize: 128
Deploy this template via AWS CLI with the same command used before and check the CloudFormation Console:

Figure 4: CloudFormation Console showing failed Stack deployment due to Hook intervention
As expected, the deployment was not successful. The CloudFormation Lambda Hook has been invoked, and since the Lambda Runtime was not present in the permitted runtimes list, the deployment failed.
You can also see that the hook failed In the CloudWatch Logs:

Figure 5: Validation Lambda Function Logs with validation error
Cleaning up
To clean up the resources related to the sample, you can run the script cleanup_sample.sh inside the sample folder. This script will delete the sample’s CloudFormation Template through the AWS CLI.
To cleanup the resources related to the solution described above and based on AWS CloudFormation Lambda Hook, you can leverage the script cleanup.sh in the root folder of the repository. This script will perform the following actions:
- Delete the CloudFormation Stack
- Empty the S3 Bucket used for the deployment of the Stack
- Delete the S3 Bucket
Conclusion
In this post, you explored the implementation of CloudFormation Hooks to enforce runtime compliance in Lambda functions across your AWS infrastructure. By leveraging the Lambda hook’s capabilities, you learned how to create a preventative control that validates Lambda runtime configurations before deployment.
By activating the Lambda hook and implementing a custom Lambda function validator, you established an automated mechanism to ensure that only compliant runtimes are used within your organization’s Lambda functions during CloudFormation stack creation and updates. The solution’s integration with common development tools like AWS CLI, AWS SAM, CI/CD pipelines, and AWS CDK makes it straightforward to implement these controls within existing workflows, eliminating the need for manual runtime checks or post-deployment remediation.
The validation approach demonstrated in this post extends beyond Lambda runtimes and can be adapted to different AWS Resources supported by CloudFormation, allowing you to enforce policies on different infrastructure components offered by AWS.
About the author






























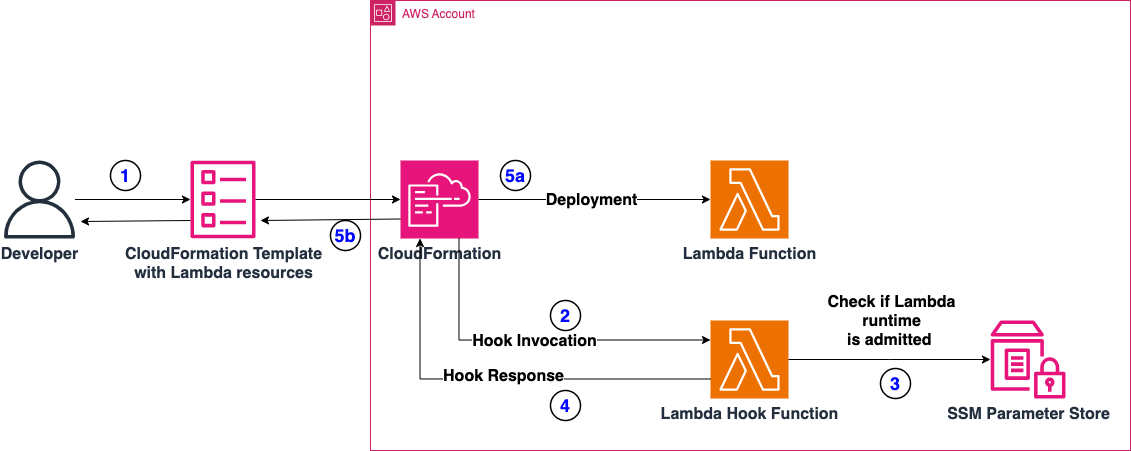
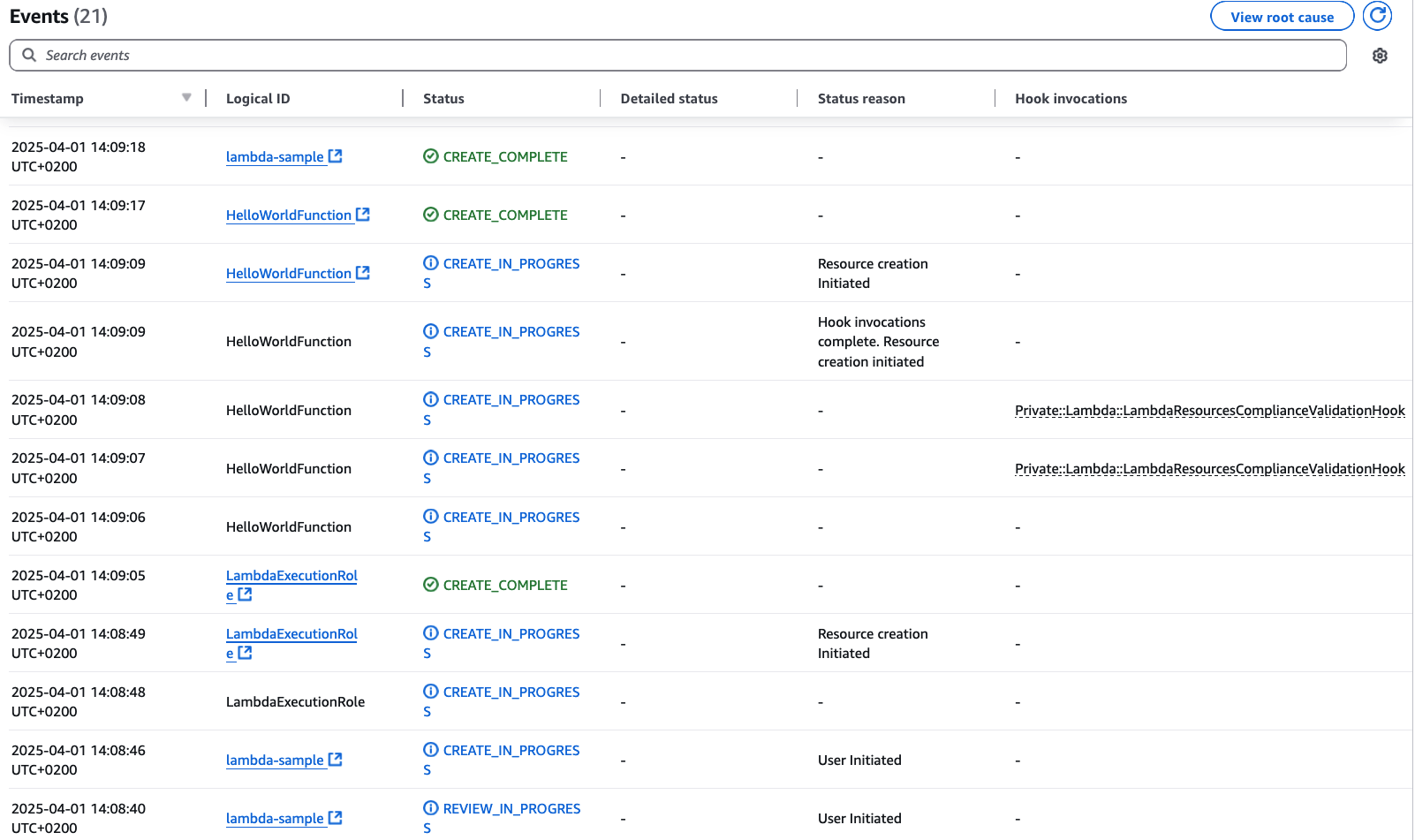
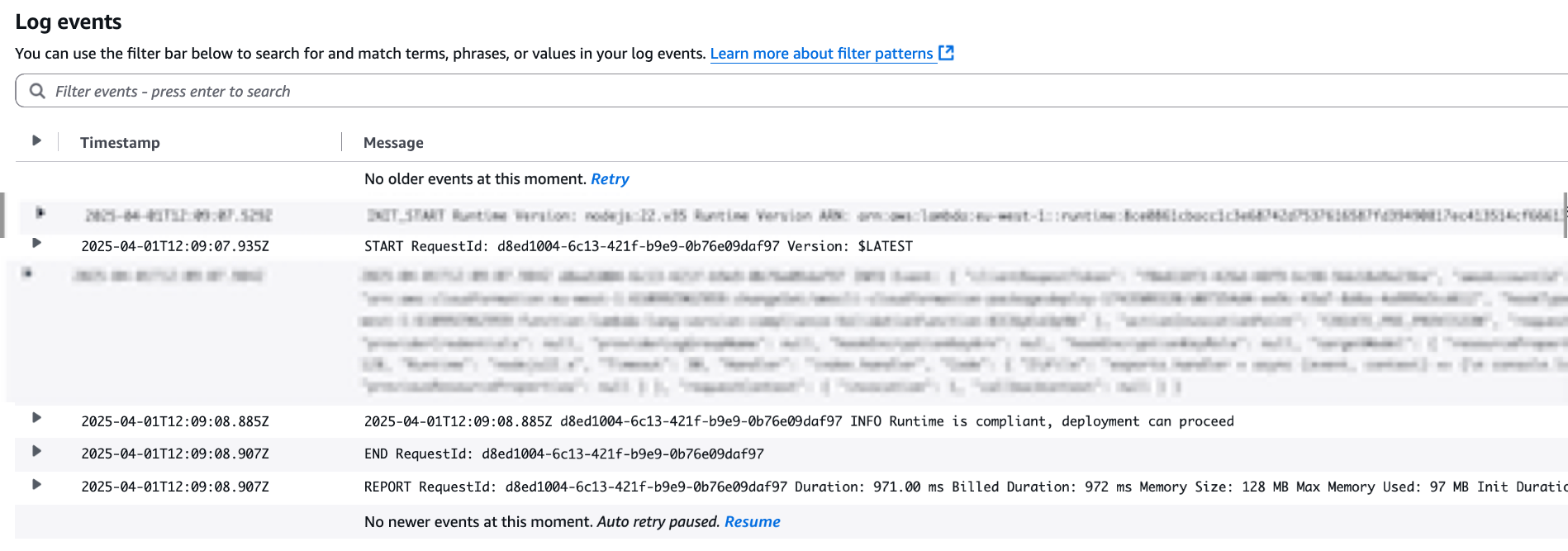
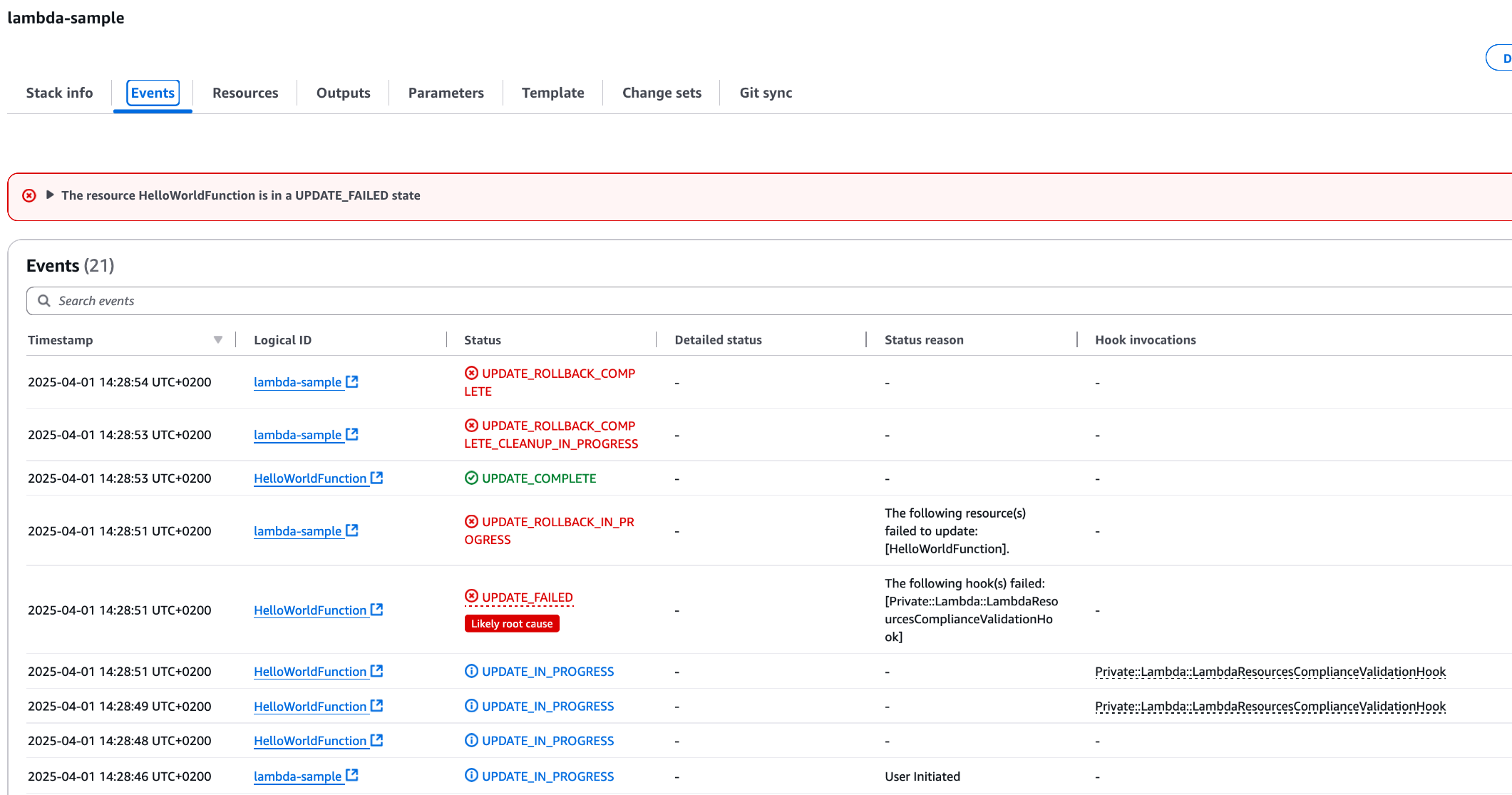
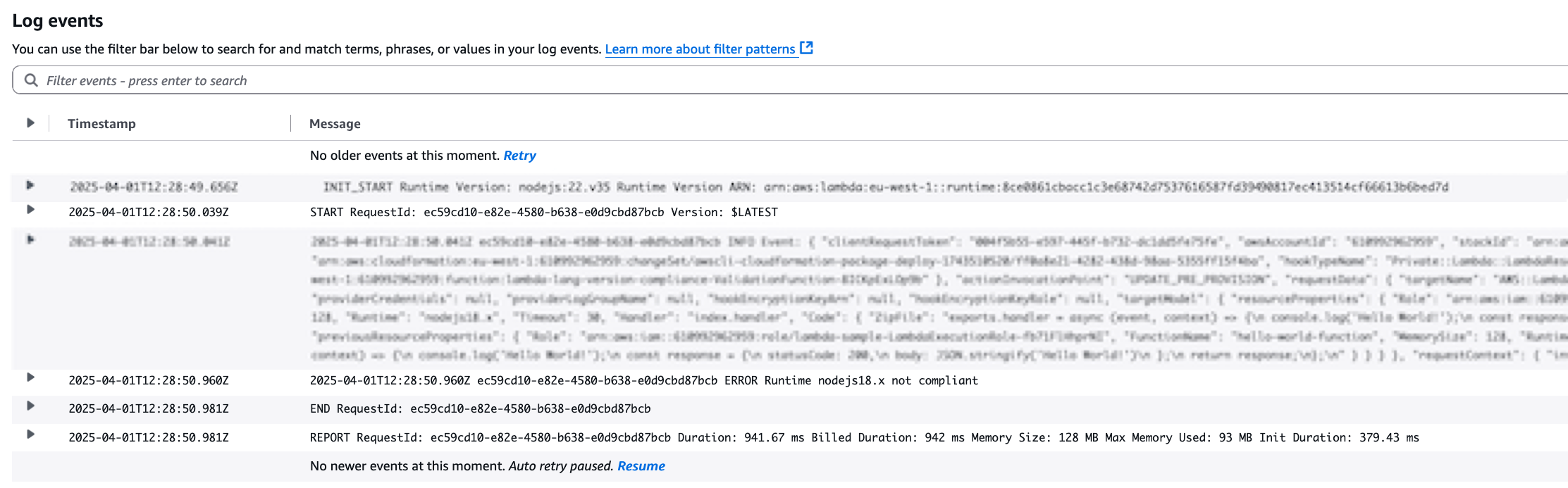







 Figure 4: CloudFormation troubleshooting with CloudTrail integration
Figure 4: CloudFormation troubleshooting with CloudTrail integration
 Figure 6: CloudFormation troubleshooting with Q feature
Figure 6: CloudFormation troubleshooting with Q feature

 Figure 9: IaC generator resource scan
Figure 9: IaC generator resource scan

 Figure 12: CloudFormation Hooks’ Lambda function feature
Figure 12: CloudFormation Hooks’ Lambda function feature
 Figure 14: CloudFormation Git sync with request review support feature
Figure 14: CloudFormation Git sync with request review support feature










![] Response from Amazon Q for the breakdown of EC2 costs in the last month](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2025/02/03/figure12.png)
























 Stella Hie is a Sr. Product Manager Technical for AWS Infrastructure as Code. She focuses on proactive control and governance space, working on delivering the best experience for customers to use AWS solutions safely. Outside of work, she enjoys hiking, playing piano, and watching live shows.
Stella Hie is a Sr. Product Manager Technical for AWS Infrastructure as Code. She focuses on proactive control and governance space, working on delivering the best experience for customers to use AWS solutions safely. Outside of work, she enjoys hiking, playing piano, and watching live shows.


























 Figure 3: CloudFormation’s create stack console wizard
Figure 3: CloudFormation’s create stack console wizard Figure 4: Real-time CloudFormation in-progress deployment timeline view
Figure 4: Real-time CloudFormation in-progress deployment timeline view 
 Figure 6: CloudFormation completed deployment timeline view
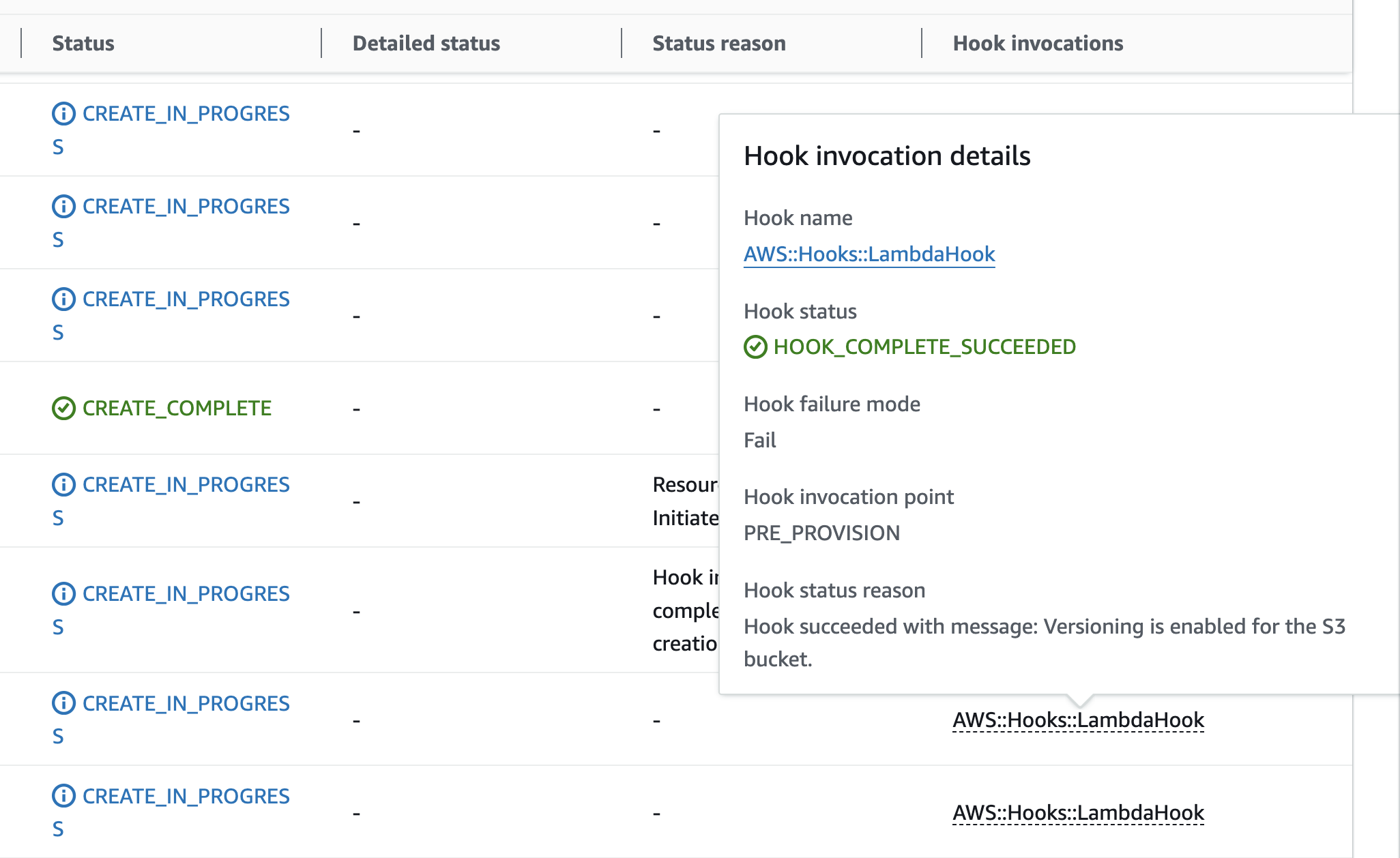
Figure 6: CloudFormation completed deployment timeline view  Figure 7: CloudFormation deployment timeline view – resource detail popover
Figure 7: CloudFormation deployment timeline view – resource detail popover