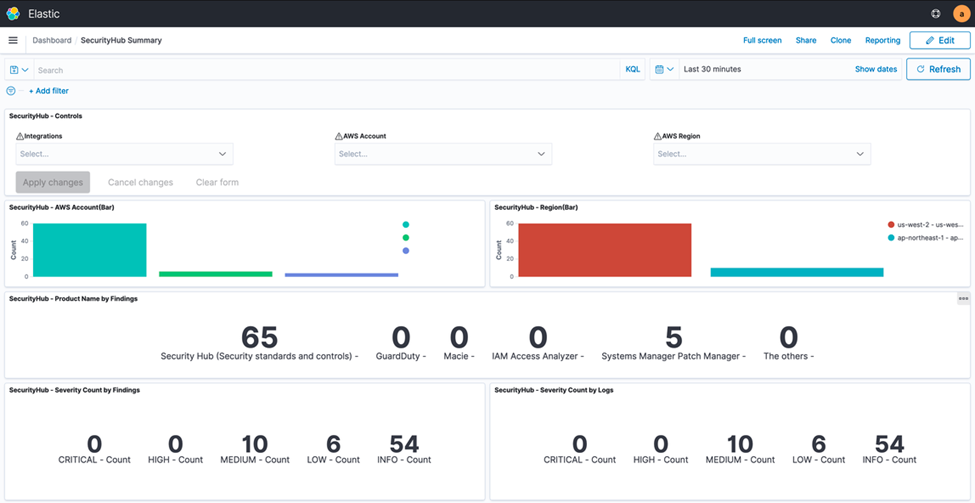
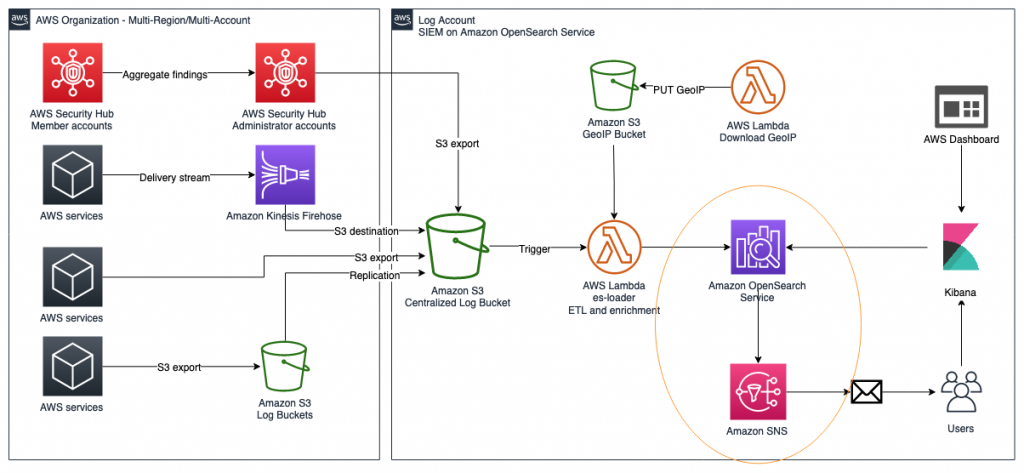
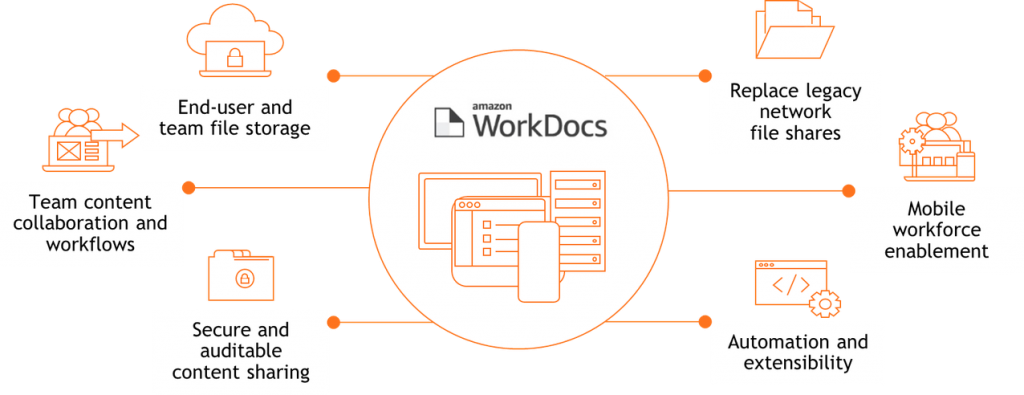
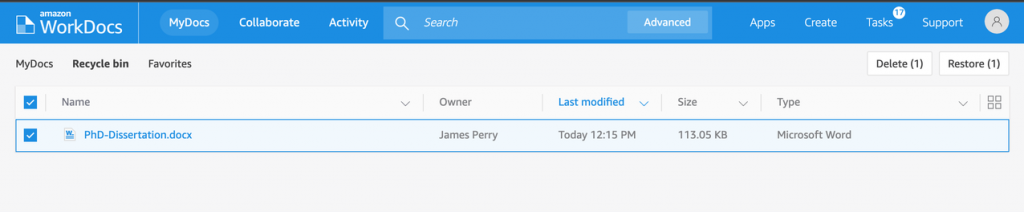
Post Syndicated from Jeb Benson original https://aws.amazon.com/blogs/security/how-to-let-builders-create-iam-resources-while-improving-security-and-agility-for-your-organization/
Many organizations restrict permissions to create and manage AWS Identity and Access Management (IAM) resources to a group of privileged users or a central team. This post explains how you can safely grant these permissions to builders – the people who are developing, testing, launching, and managing cloud infrastructure – to speed up your development, increase your agility, and improve your application security. In addition, you will use an example application stack to see how IAM permissions boundaries can help establish a secure, yet agile work environment for builders.
An example application stack
Defining and creating IAM resources within the application stack allows your builders to craft policies and roles that grant least privilege to application resources. When builders are entitled to create IAM resources, it is straightforward for them to scope policies by referencing the application resources directly in the IAM policies in the same template.
To illustrate this point you will build a simple “hello world” serverless application. The application includes an AWS Step Functions state machine that, once executed, will invoke an AWS Lambda function. You will use this example application along with some IAM policies and IAM roles to illustrate how you can use permissions boundaries to safely grant IAM privileges to builders.
In this example AWS CloudFormation template, the Resource element in MyStateMachineExecutionRole, which is specified as the role for MyStateMachine, includes a reference to the Amazon Resource Name (ARN) of MyLambdaFunction. This is a great example of the principle of least privilege as MyStateMachine will only have permissions to invoke MyLambdaFunction. Making this association is straightforward because the IAM, Step Functions, and Lambda resources are defined together in the same template.
Example application template
In an organization that uses a centralized approach to IAM management, a builder would not be able to deploy this example application because the roles the builders are granted prohibit IAM actions related to creating and managing roles and policies. This creates three key challenges for the organization:
- Builders often rely on a security or cloud team to create IAM resources. This approach adds an additional burden to that team which slows down development while builders wait for the roles and policies to be created, and encourages the team to grant overly-broad permissions so that they don’t have to be involved in the precise details of changes on a daily basis.
- IAM resources must be created before the rest of the stack, which makes it much more difficult to create least-privilege policies and roles.
- The code for IAM and application infrastructure is maintained separately, which requires extra coordination when creating and updating workloads.
Removing these challenges can simplify your cloud development, lower the amount of overhead and coordination required across your organization, and improve your security posture. Further, reducing the burden on your security team can free up time for them to focus on enforcing additional data perimeters and implementing best practices from the security pillar of the AWS Well-Architected Framework.
Use permissions boundaries on application roles created by builders
So how can your organization shift to a decentralized approach to IAM management and allow builders to safely create application IAM policies and roles, as well as prevent builders from being able to escalate their own privileges? This is a scenario where permissions boundaries should be used.
Permissions boundaries allow an IAM policy to be attached to an IAM role to enforce limits on the permissions that role can be granted. The permissions boundary itself does not grant any permissions – it’s just a guardrail that defines the maximum entitlements. You can create a builder policy that requires a specified permissions boundary be attached to any application roles that a builder creates, effectively setting the maximum permissions on any role that a builder can generate. The permissions for any application roles created will be the intersection of the application policies and the permissions boundary associated with the application role. Said another way, a permission granted in the application policy must also be granted in the permissions boundary, or else it will be implicitly denied according to the policy evaluation logic.
The set of permissions required for builder roles (assumed by actual people or CI/CD pipelines) to deploy infrastructure and develop applications are different than those required for application roles (assumed by workloads/applications) to execute within applications and workflows. If you think of permissions in terms of control plane actions involved in creating, deleting, and modifying resources, versus data plane actions needed to execute the daily business of those resources, builder and application roles typically operate more on the control plane and data plane, respectively. While permissions policies attached to application roles should be tightly scoped to include only those actions needed to perform a specific task, policies for permissions boundaries should be highly reusable and include a broad set of permissions across a suite of services that a variety of applications might need. In addition, it is a best practice to not share roles between humans and services. To summarize, policies for builder and application roles should be designed with the following criteria in mind:
| Policy | Role | Permissions | Scope | Reusability | User |
| builder | builder | control plane | broad | high | human |
| application | application | data plane | specific | low | service |
| application-boundary | application | data plane | broad | high | application role |
Following the steps in this section, you will create:
- A builder policy that grants builders permissions for services needed to deploy and manage applications, and to create and manage IAM policies and roles for those applications.
- An application-boundary policy that defines the extent of the permissions any application role created by a builder can have.
- A builder role with the builder policy attached as the permissions policy, the application-boundary policy attached as a permissions boundary, and a trust policy that allows anyone in the account to assume the builder role.
Create the builder IAM resources
In this first procedure, you will use CloudFormation to create the builder and application-boundary IAM policies, and the builder IAM role.
To launch the builder IAM stack
- Open a Linux terminal with the AWS Command Line Interface (CLI) installed and AWS credentials configured for a user or role that has permissions to create IAM resources.
- Launch the builder IAM stack by using the following command:
The builder policy you created uses paths to organize IAM policies and roles into isolated “spaces” that can be specified as resource constraints. It also requires roles to have a permissions boundary attached. This approach helps manage role delegation and prevents builders from escalating their privileges or modifying roles that may be used by other teams.
Note that paths can only be added to IAM resources using the AWS CLI or APIs – not via the console. If this is an issue, another option is to specify that policies and roles start with a specific phrase, for example “application-roles-*”. Just be sure to use different phrases for the builder, application, and permissions boundaries resources to maintain isolation and prevent builders from being able to escalate their privileges.
The builder policy also includes some basic control plane permissions, while the application-boundary policy you created includes permissions used across a suite of services that a typical serverless application might need. However, both policies are only meant to demonstrate the concepts in this blog post. In practice, you will need to create policies that more accurately reflect the permissions needed by builder and application roles in your organization. See the example-permissions-boundaries repository on the AWS Samples GitHub site for more ideas.
Use the builder role to launch an application stack
In this section you will assume the builder role and verify that you can launch the application stack, including the application roles, but only if the required permissions boundary and path are specified.
To test launching a stack that creates application roles
- Assume the builder role by using the following set of commands (copy and paste into the terminal as a single block). This step uses the jq program, which is available in most operating system package repositories.
You will use this role for all of the following procedures up until the “Clean up” section. If, during the course of this exercise, you get an error that “The security token included in the request is expired”, create a new terminal and repeat this step to get a fresh set of credentials.
The trust policy for the builder role allows any principal in the account to assume it. You can use a combination of the Principal and Condition attributes to further reduce its scope. Normally builder roles are assumed directly via federation or AWS SSO.
- Check that the you have now assumed the builder role by using the following command:
- Launch the example application stack by using the following command:
- If things are set up correctly, the stack will fail. To confirm, check the StackStatus by using the following command – it should show ROLLBACK_IN_PROGRESS or ROLLBACK_COMPLETE.
- The stack failed to create because the builder role you assumed does not have permissions to create the two application roles without specifying the /application_roles/ path and attaching a permissions boundary with /permissions_boundaries/ in the path. To see the details, use the following command:
- If the original stack did not create successfully, you will not be able to update it, so you will need to delete it instead by using the following command:
- Launch a new stack with an updated template that includes the required path and permissions boundary by using the following command:
- After a few minutes, confirm the stack was successfully created by using the following command and verifying StackStatus is CREATE_COMPLETE:
To verify the application is working
- Start an execution of the state machine and verify the application is working by using the following commands. Run them one at a time to allow the execution to finish.
If the output is “\”Hello Builder!\””, then the application is working.
Test that a builder can’t escalate their privileges
In this section, you will test scenarios where a builder attempts, intentionally or not, to escalate their privileges by first modifying the policies attached to the builder role and then extending the permissions of an application role beyond the permissions boundary.
To test updating a builder policy attached to the builder role
- Create an environment variable for your AWS account number, which will be used in several of the steps below, using the following command:
- Retrieve the builder policy and save it to a file by using the following command:
- Add the following JSON block to the “Statement” array in the builder-policy.json file and save the changes.
- Try to update the builder policy and set it as the default version by using the following command:
You should get an AccessDenied error because the builder role can only modify policies in the /application_policies/ space.
To test adding an application policy to the builder role
- Save a copy of builder-policy.json as a new file called sneaky-policy.json using the following command:
- Create the new policy using the following command:
You should not get an error in this step because you are creating a new policy that complies with the resource constraint for the statement that includes the iam:CreatePolicy permission in the builder policy. But, it’s just a policy for now – it can’t have any effect unless attached to a role.
- Now try to attach this new policy to the builder role by using the following command:
You should get an error because you’re attempting to attach a policy to a role that’s not in the /application-roles/ space, in this case the builder role.
To test modifying an application role with actions outside the permissions boundary
In this procedure, you will attempt to escalate the privileges of the MyLambdaFunctionExecutionRole by adding an action (s3:CreateBucket) that is outside of the permissions boundary attached to the role and then attempting to execute that action when MyLambdaFunction is invoked.
- Update the builder-application stack by using the following command:
- After a few minutes, confirm the stack was successfully updated by using the following command and verifying StackStatus is UPDATE_COMPLETE:
- Start an execution of the state machine and verify the result by using the following commands. Run them one at a time to allow the execution to finish.
The status should be FAILED. Remember – the effective permissions for any application roles will be the intersection of the attached permissions policies and the permissions boundary. Thus, this execution failed because even though you were able to modify the inline policy of the Lambda function to add s3:CreateBucket, since that action is not allowed in the application-boundary policy attached to the Lambda as a permissions boundary, the request to create an S3 bucket was denied.
- Get the name of the latest log stream by using the following commands:
- To verify the actual error was due to a lack of permissions, get the event message by using the following command, replacing <value> with the value of the log stream copied in the step above. If using a bash terminal, you will need to escape any dollar signs in <value> with a backslash character:
The error should read [ERROR] ClientError: An error occurred (AccessDenied) when calling the CreateBucket operation: Access Denied, which confirms that the permissions boundary prevented you from escalating your privileges as a builder via an application role.
You have now verified that you can safely allow builders to create IAM policies and roles!
Clean up
After you have finished testing, clean up the resources created in this example. Because the builder role does not have permissions to delete builder policies and roles, you will need to assume a different role that can manage IAM resources to complete step 3 below. If you create a new terminal session, make sure the AWS_ACCOUNT environment variable is set.
To clean up
- Delete the builder-application stack by using the following command:
- Delete the sneaky-policy by using the following command:
- Delete the builder-iam stack by using the following command:
Service control policies
Permissions boundaries are applied to individual IAM users or roles within an account. If your organization has multiple accounts, you must create and maintain these boundaries in each account for each individual user or role. But what if you’d like to apply a subset of these rules or others across some or all of your accounts? In this case, you could use service control policies (SCPs), which are a feature of AWS Organizations, to provide central control over the maximum available permissions for multiple accounts in your organization. By organizing accounts into organizational units (OUs), which are groups of accounts that serve an application or service, you can apply service control policies (SCPs) to create targeted governance boundaries for your OUs. To learn more about creating SCPs, see Get more out of service control policies in a multi-account environment in the AWS Security Blog.
Additional tools
Creating and managing tightly scoped policies and roles is an ongoing process that requires a lot of thought and attention to detail. AWS IAM enables fine-grained access control to AWS services, and permissions boundaries are an advanced feature. There is no substitute for actual testing like you performed in the “Test that a builder can’t escalate their privileges” section above, however you can also use the IAM Policy Simulator as a tool to test policies and determine whether or not specific actions are allowed for a given user, group, or role. Additional tools you can use to create, audit, and update IAM policies include:
- Access Advisor – to review when services and actions were last accessed.
- Access Analyzer – to help identify resources in your organization and accounts that are shared with an external identity, validate IAM policies against policy grammar and best practices, and generate IAM policies based on access activity in your AWS CloudTrail logs.
- AWS Cloud Development Kit (CDK) – has built-in convenience methods to help you follow best practices, including the ability to generate least-privilege policies for cloud applications with a single line of code.
- Open Source tools like cfn-nag and cdk-nag – to inspect CloudFormation templates and CDK applications for patterns that may indicate insecure infrastructure, for example IAM policies that are too permissive.
Conclusion
In this post, you learned how to put policies and guardrails in place that will allow your organization to grant IAM permissions to builders. These changes will enable your builders to develop and deploy cloud infrastructure and applications more rapidly, and will help strengthen your organization’s security culture by extending the responsibility to a broader group. To learn more about creating, testing, and refining IAM policies and permissions boundaries, see Creating IAM policies, Testing IAM policies, and Refining permissions using access information in the IAM User Guide, and IAM policy types: How and when to use them in the AWS Security Blog.