Post Syndicated from Talia Nassi original https://aws.amazon.com/blogs/compute/exploring-serverless-patterns-for-amazon-dynamodb/
Amazon DynamoDB is a fully managed, serverless NoSQL database. In this post, you learn about the different DynamoDB patterns used in serverless applications, and use the recently launched Serverless Patterns Collection to configure DynamoDB as an event source for AWS Lambda.
Benefits of using DynamoDB as a serverless developer
DynamoDB is a serverless service that automatically scales up and down to adjust for capacity and maintain performance. It also has built-in high availability and fault tolerance. DynamoDB provides both provisioned and on-demand capacity modes so that you can optimize costs by specifying capacity per table, or paying for only the resources you consume. You are not provisioning, patching, or maintaining any servers.
Serverless patterns with DynamoDB
The recently launched Serverless Patterns Collection is a repository of serverless architecture examples that demonstrate integrating two or more AWS services. Each pattern uses either the AWS Serverless Application Model (AWS SAM) or AWS Cloud Development Kit (AWS CDK). These simplify the creation and configuration of the services referenced.
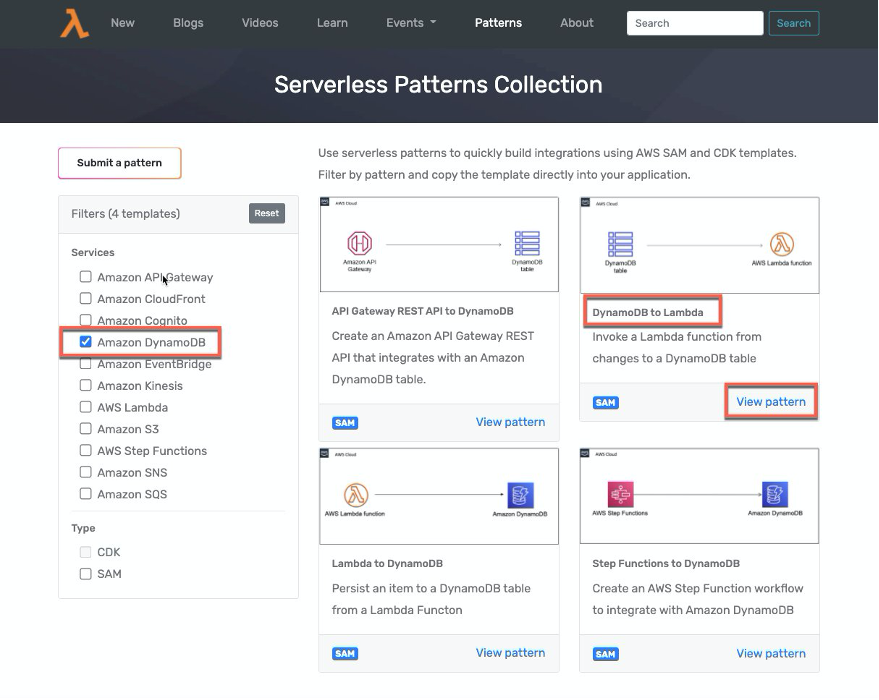
There are currently four patterns that use DynamoDB:

Amazon API Gateway REST API to Amazon DynamoDB
This pattern creates an Amazon API Gateway REST API that integrates with an Amazon DynamoDB table named “Music”. The API includes an API key and usage plan. The DynamoDB table includes a global secondary index named “Artist-Index”. The API integrates directly with the DynamoDB API and supports PutItem and Query actions. The REST API uses an AWS Identity and Access Management (IAM) role to provide full access to the specific DynamoDB table and index created by the AWS CloudFormation template. Use this pattern to store items in a DynamoDB table that come from the specified API.
AWS Lambda to Amazon DynamoDB
This pattern deploys a Lambda function, a DynamoDB table, and the minimum IAM permissions required to run the application. A Lambda function uses the AWS SDK to persist an item to a DynamoDB table.
AWS Step Functions to Amazon DynamoDB
This pattern deploys a Step Functions workflow that accepts a payload and puts the item in a DynamoDB table. Additionally, this workflow also shows how to read an item directly from the DynamoDB table, and contains the minimum IAM permissions required to run the application.
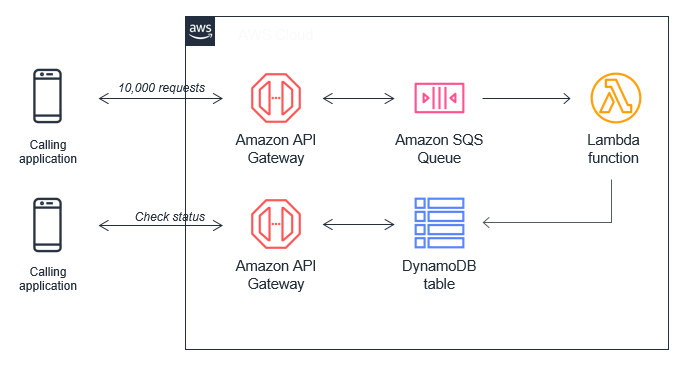
Amazon DynamoDB to AWS Lambda
This pattern deploys the following Lambda function, DynamoDB table, and the minimum IAM permissions required to run the application. The Lambda function is invoked whenever items are written or updated in the DynamoDB table. The changes are then sent to a stream. The Lambda function polls the DynamoDB stream. The function is invoked with a payload containing the contents of the table item that changed. We use this pattern in the following steps.
AWSTemplateFormatVersion: '2010-09-09'
Transform: 'AWS::Serverless-2016-10-31'
Description: An Amazon DynamoDB trigger that logs the updates made to a table.
Resources:
DynamoDBProcessStreamFunction:
Type: 'AWS::Serverless::Function'
Properties:
Handler: app.handler
Runtime: nodejs14.x
CodeUri: src/
Description: An Amazon DynamoDB trigger that logs the updates made to a table.
MemorySize: 128
Timeout: 3
Events:
MyDynamoDBtable:
Type: DynamoDB
Properties:
Stream: !GetAtt MyDynamoDBtable.StreamArn
StartingPosition: TRIM_HORIZON
BatchSize: 100
MyDynamoDBtable:
Type: 'AWS::DynamoDB::Table'
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
StreamSpecification:
StreamViewType: NEW_IMAGE
Setting up the Amazon DynamoDB to AWS Lambda Pattern
Prerequisites
For this tutorial, you need:
Downloading and testing the pattern
- From the Serverless Patterns home page, choose Amazon DynamoDB from the Filters menu. Then choose the DynamoDB to Lambda pattern.

- Clone the repository and change directories into the pattern’s directory.
git clone https://github.com/aws-samples/serverless-patterns/
cd serverless-patterns/dynamodb-lambda
- Run sam deploy –guided. This deploys your application. Keeping the responses blank chooses the default options displayed in the brackets.

- You see the following confirmation message once your stack is created.

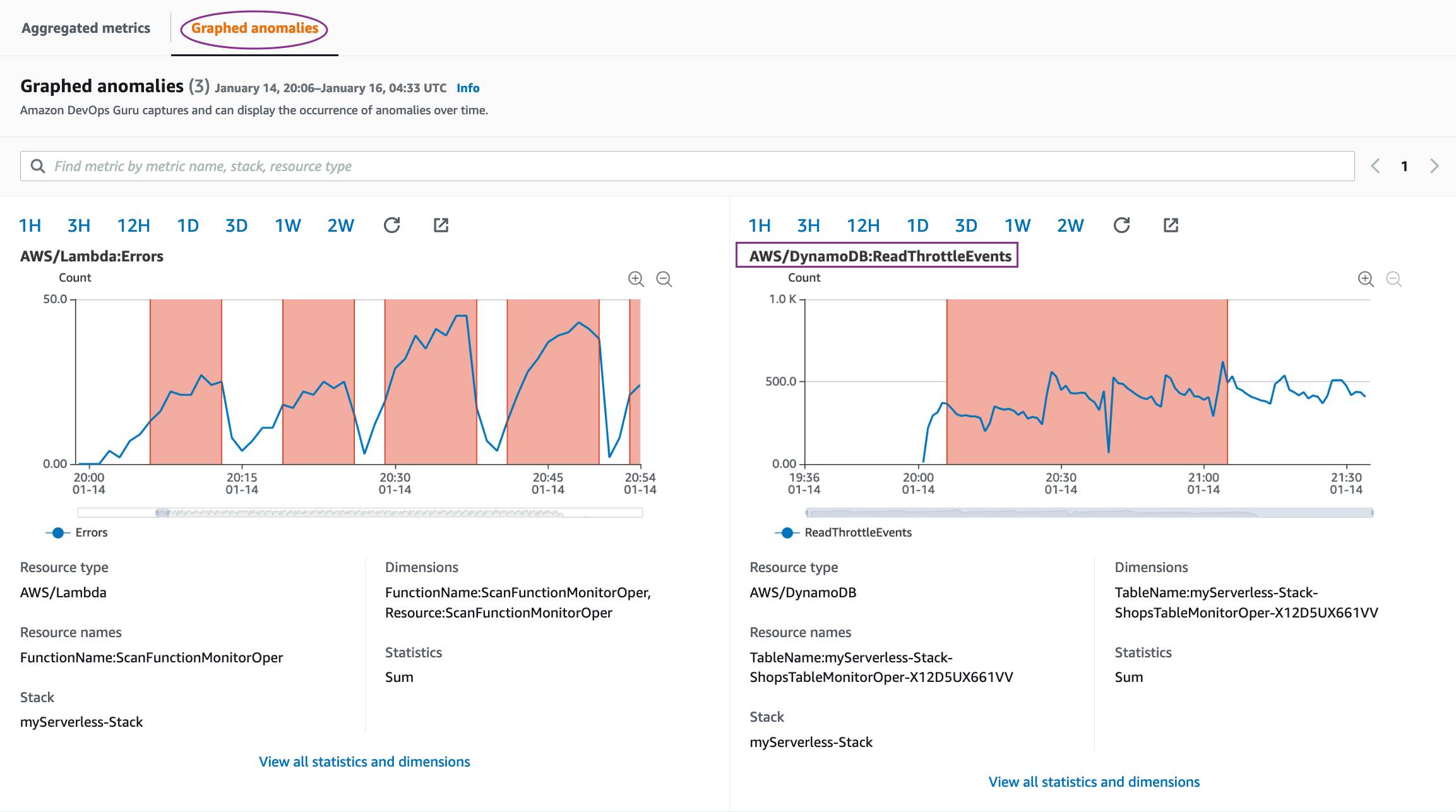
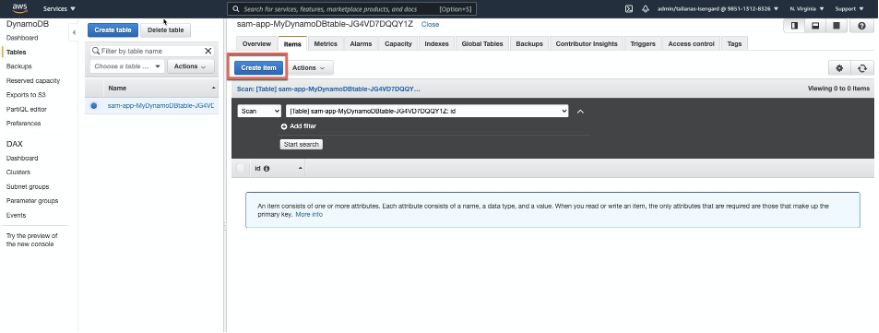
- Navigate to the DynamoDB Console and choose Tables. Select the newly created table.

- Choose the Items tab and choose Create Item.

- Add an item and choose Save.

- You see that item now in the DynamoDB table.

- Navigate to the Lambda console and choose your function.
- From the Monitor tab choose View logs in CloudWatch.

- You see the new image inserted into the DynamoDB table.









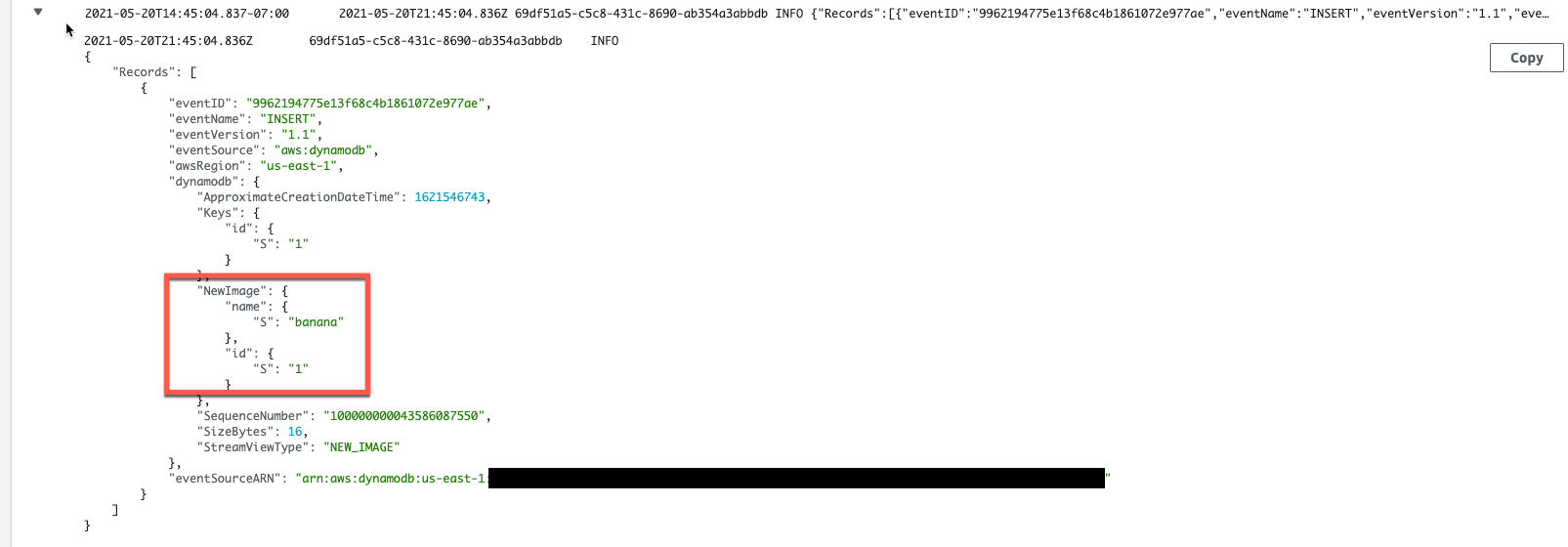
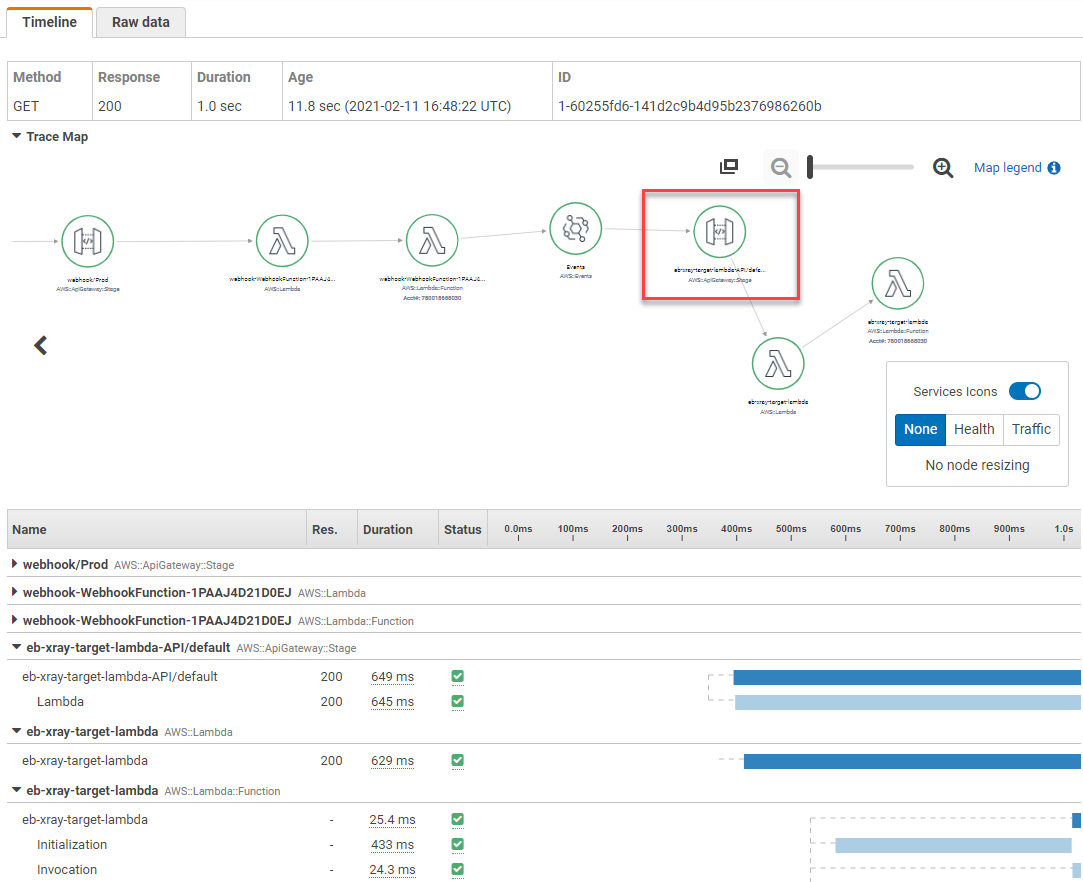
Anytime a new item is added to the DynamoDB table, the invoked Lambda function logs the event in Amazon Cloudwatch Logs.
Configuring the event source mapping for the DynamoDB table
An event source mapping defines how a particular service invokes a Lambda function. It defines how that service is going to invoke the function. In this post, you use DynamoDB as the event source for Lambda. There are a few specific attributes of a DynamoDB trigger.
The batch size controls how many items can be sent for each Lambda invocation. This template sets the batch size to 100, as shown in the following deployed resource. The batch window indicates how long to wait until it invokes the Lambda function.
These configurations are beneficial because they increase your capabilities of what the DynamoDB table can do. In a traditional trigger for a database, the trigger gets invoked once per row per trigger action. With this batching capability, you can control the size of each payload and how frequently the function is invoked.

Using DynamoDB capacity modes
DynamoDB has two read/write capacity modes for processing reads and writes on your tables: provisioned and on-demand. The read/write capacity mode controls how you pay for read and write throughput and how you manage capacity.
With provisioned mode, you specify the number of reads and writes per second that you require for your application. You can use automatic scaling to adjust the table’s provisioned capacity automatically in response to traffic changes. This helps to govern your DynamoDB use to stay at or below a defined request rate to obtain cost predictability.
Provisioned mode is a good option if you have predictable application traffic, or you run applications whose traffic is consistent or ramps gradually. To use provisioned mode in a DynamoDB table, enter ProvisionedThroughput as a property, and then define the read and write capacity:
MyDynamoDBtable:
Type: 'AWS::DynamoDB::Table'
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 5
WriteCapacityUnits: 5
StreamSpecification:
StreamViewType: NEW_IMAGE
With on-demand mode, DynamoDB accommodates workloads as they ramp up or down. If a workload’s traffic level reaches a new peak, DynamoDB adapts rapidly to accommodate the workload.
On-demand mode is a good option if you create new tables with unknown workload, or you have unpredictable application traffic. Additionally, it can be a good option if you prefer paying for only what you use. To use on-demand mode for a DynamoDB table, in the properties section of the template.yaml file, enter BillingMode: PAY_PER_REQUEST.
ApplicationTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: !Ref ApplicationTableName
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
Stream specification
When DynamoDB sends the payload to Lambda, you can decide the view type of the stream. There are three options: new images, old images, and new and old images. To view only the new updated changes to the table, choose NEW_IMAGES as the StreamViewType. To view only the old change to the table, choose OLD_IMAGES as the StreamViewType. To view both the old image and new image, choose NEW_AND_OLD_IMAGES as the StreamViewType.
ApplicationTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: !Ref ApplicationTableName
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_AND_OLD_IMAGES
Cleanup
Once you have completed this tutorial, be sure to remove the stack from CloudFormation with the commands shown below.

Submit a pattern to the Serverless Land Patterns Collection
While there are many patterns available to use from the Serverless Land website, there is also the option to create your own pattern and submit it. From the Serverless Patterns Collection main page, choose Submit a Pattern.
There you see guidance on how to submit. We have added many patterns from the community and we are excited to see what you build!
Conclusion
In this post, I explain the benefits of using DynamoDB patterns, and the different configuration settings, including batch size and batch window, that you can use in your pattern. I explain the difference between the two capacity modes, and I also show you how to configure a DynamoDB stream as an event source for Lambda by using the existing serverless pattern.
For more serverless learning resources, visit Serverless Land.