Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/simplifying-b2b-integrations-with-aws-step-functions-workflow-studio/
This post is written by Patrick Guha, Associate Solutions Architect, WWPS, Hamdi Hmimy, Associate Solutions Architect, WWPS, and Madhu Bussa, Senior Solutions Architect, WWPS.
B2B integration helps organizations with disparate technologies communicate and exchange business-critical information. However, organizations typically have few options in building their B2B pipeline infrastructure. Often, they use an out-of-the-box SaaS integration platform that may not meet all of their technical requirements. Other times, they code an entire pipeline from scratch.
AWS Step Functions offers a solution to this challenge. It provides both the code customizability of AWS Lambda with the low-code, visual building experience of Workflow Studio.
This post introduces a customizable serverless architecture for B2B integrations. It explains how the solution works and how it can save you time in building B2B integrations.
Overview
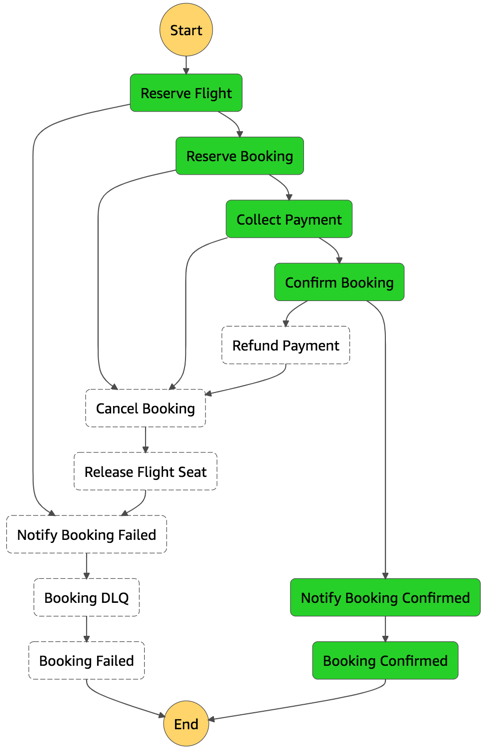
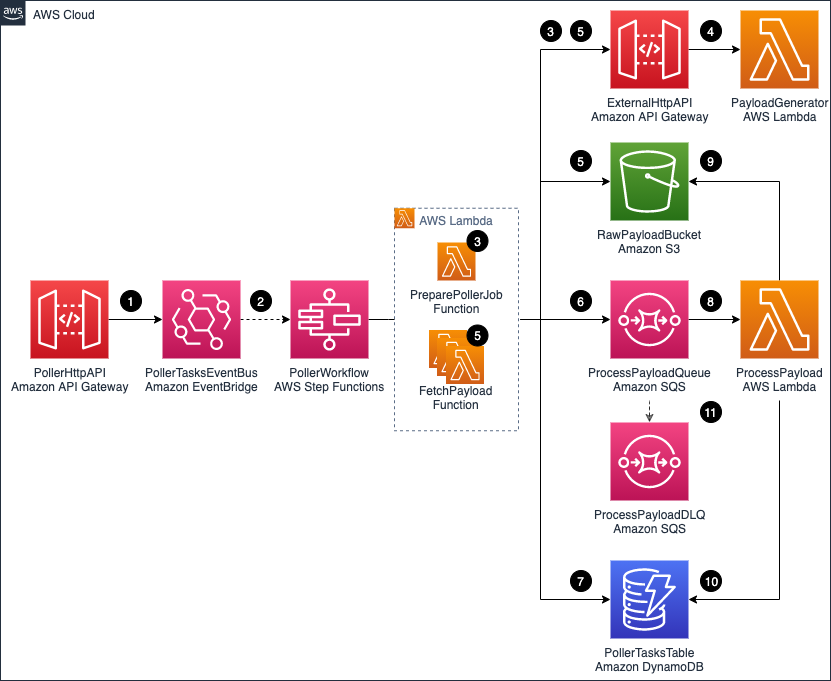
The following diagram illustrates components and interactions of the example application architecture:

This section describes building a configurable B2B integration pipeline with AWS serverless technologies. It walks through the components and discusses the flow of transactions from trading partners to a consolidated database.
Communication
The B2B integration pipeline accepts transactions both in batch (a single file with many transactions) and in real-time (a single transaction) modes. Batch communication is over open standard SFTP protocol, and real-time communication is over the REST/HTTPS protocol.
For batch communication needs, AWS Transfer Family provides managed support for file transfers directly between Amazon Simple Storage Service (S3) or Amazon Elastic File System (EFS). EFS provides a serverless, elastic file system that lets you share file data without provisioning or managing storage.
Amazon EventBridge provides serverless event bus functionality to automate specific actions in the B2B pipeline. In this case, batch transaction uploads from a partner trigger the B2B pipeline. When a file is put in S3 from the Transfer SFTP server, EventBridge captures the event and routes to a target Lambda function.
As batch transactions are saved via AWS Transfer SFTP to Amazon S3, AWS CloudTrail captures the events. It provides the underlying API requests as files are PUT into S3, which triggers the EventBridge rule created previously.
For real-time communication needs, Amazon API Gateway provides an API management layer, allowing you to manage the lifecycle of APIs. Trading partners can send their transactions to this API over the ubiquitous REST API protocol.
Processing
Amazon Simple Queue Service (SQS) is a fully managed queuing service that allows you to decouple applications. In this solution, SQS manages and stores messages to be processed individually.
Lambda is a fully managed serverless compute service that allows you to create business logic functions as needed. In this example, Lambda functions process the data from the pipeline to clean, format, and upload the transactions from SQS.
Step Functions manages the workflow of a B2B transaction. Step Functions is a low-code visual workflow service used to orchestrate AWS services, automate business processes, and build serverless applications. Workflows manage failures, retries, parallelization, service integrations, and observability so developers can focus on higher-value business logic.
API Gateway is used in the processing pipeline of the solution to enrich the transactions coming through the pipeline.
Amazon DynamoDB serves as the database for the solution. DynamoDB is a key-value and document database that can scale to virtually any number of requests. As the pipeline experiences a wide range of transaction throughputs, DynamoDB is a good solution to store processed transactions as they arrive.
Batch transaction flow
- A trading partner logs in to AWS Transfer SFTP and uploads a batch transaction file.
- An S3 bucket is populated with the batch transaction file.
- A CloudTrail data event captures the batch transaction file being PUT into S3.
- An EventBridge rule is triggered from the CloudTrail data event.
- Lambda is triggered from the EventBridge rule. It processes each message from the batch transaction file and sends individual messages to SQS.
- SQS stores each message from the file as it is passed through from Lambda.
- Lambda is triggered from each SQS incoming message, then invokes Step Functions to run through the following steps for each transaction.
- Lambda accepts and formats the transaction payload.
- API Gateway enriches the transaction.
- DynamoDB stores the transaction.
Single/real-time transaction flow
- A trading partner uploads a single transaction via an API Gateway REST API.
- API Gateway sends a single transaction to Lambda SQS writer function via proxy integration.
- SQS stores each message from the API POSTs.
- Lambda is triggered from each SQS incoming message. It invokes Step Functions to run through the workflow for each transaction.
- Lambda accepts and formats the transaction payload.
- API Gateway enriches the transaction.
- DynamoDB stores the transaction.
Exploring and testing the architecture
To explore and test the architecture, there is an AWS Serverless Application Model (AWS SAM) template. The AWS SAM template creates an AWS CloudFormation stack for you. This can help you save time building your own B2B pipeline, as you can deploy and customize the example application.
To deploy in your own AWS account:
- To install AWS SAM, visit the installation page.
- To deploy the AWS SAM template, navigate to the directory where the template is located. Run the following bash commands in the terminal:
git clone https://github.com/aws-samples/simplified-serverless-b2b-application cd simplified-serverless-b2b-application sam build sam deploy --guided --capabilities CAPABILITY_NAMED_IAM
Prerequisites
- Create an SSH key pair. To authenticate to the AWS Transfer SFTP server and upload files, you must generate an SSH key pair. Once created, you must copy the contents of the public key to the SshPublicKeyParameter displayed after running the sam deploy command. Follow the instructions to create an SSH key pair for Transfer.
- Copy batch and real-time input. The following XML content contains multiple example transactions to be processed in the batch workflow. Create an XML file on your machine with the following content:
<?xml version="1.0" encoding="UTF-8"?> <Transactions> <Transaction TransactionID="1"> <Notes>Transaction made between user 57 and user 732.</Notes> </Transaction> <Transaction TransactionID="2"> <Notes>Transaction made between user 9824 and user 2739.</Notes> </Transaction> <Transaction TransactionID="3"> <Notes>Transaction made between user 126 and user 543.</Notes> </Transaction> <Transaction TransactionID="4"> <Notes>Transaction made between user 5785 and user 839.</Notes> </Transaction> <Transaction TransactionID="5"> <Notes>Transaction made between user 83782 and user 547.</Notes> </Transaction> <Transaction TransactionID="6"> <Notes>Transaction made between user 64783 and user 1638.</Notes> </Transaction> <Transaction TransactionID="7"> <Notes>Transaction made between user 785 and user 7493.</Notes> </Transaction> <Transaction TransactionID="8"> <Notes>Transaction made between user 5473 and user 3829.</Notes> </Transaction> <Transaction TransactionID="9"> <Notes>Transaction made between user 3474 and user 9372.</Notes> </Transaction> <Transaction TransactionID="10"> <Notes>Transaction made between user 1537 and user 9473.</Notes> </Transaction> <Transaction TransactionID="11"> <Notes>Transaction made between user 2837 and user 7383.</Notes> </Transaction> </Transactions>Similarly, the following content contains a single transaction to be processed in the real-time workflow.
transactionId=12&transactionMessage= Transaction made between user 687 and user 329. - Download Cyberduck, an SFTP client, to upload the batch transaction file to the B2B pipeline.
Uploading the XML file to Transfer and POST to API Gateway
Use Cyberduck to upload the batch transaction file to the B2B pipeline. Follow the instructions here to upload the preceding transactions XML file. You can find the Transfer server endpoint in both the Transfer console and the Outputs section of the AWS SAM template.
Use the API Gateway console to test the POST method for the single transaction workflow. Navigate to API Gateway in the AWS Management Console and choose the REST API created by the AWS SAM template called SingleTransactionAPI.
In the Resources pane, view the methods. Choose the POST method. Next, choose the client Test bar on the left.
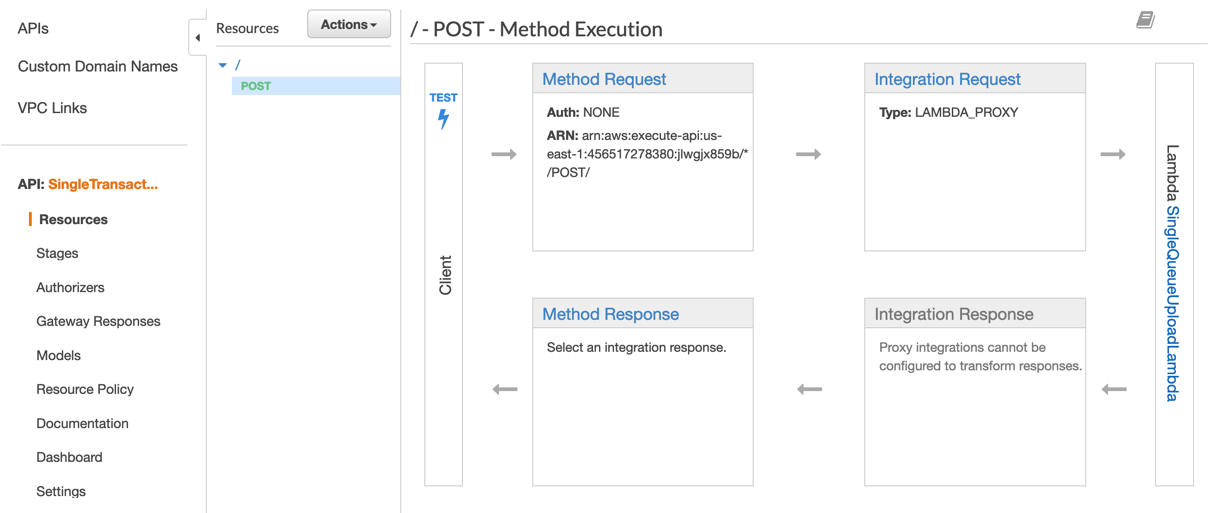
Copy the single real-time transaction into the Query Strings text box then choose Test. This sends the single transaction and starts the real-time workflow of the B2B pipeline.

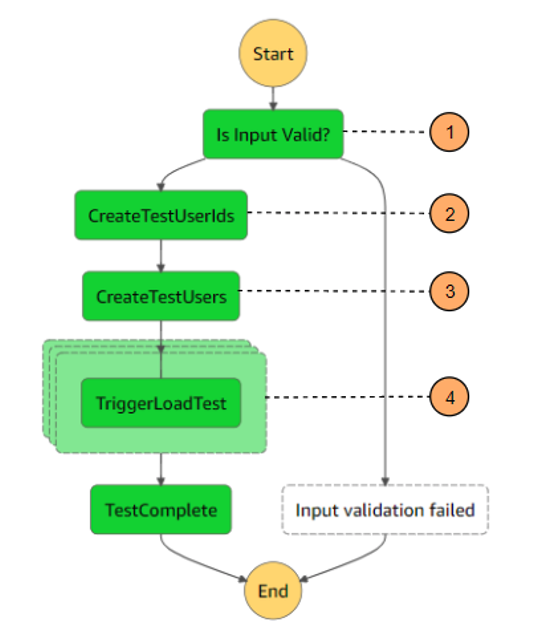
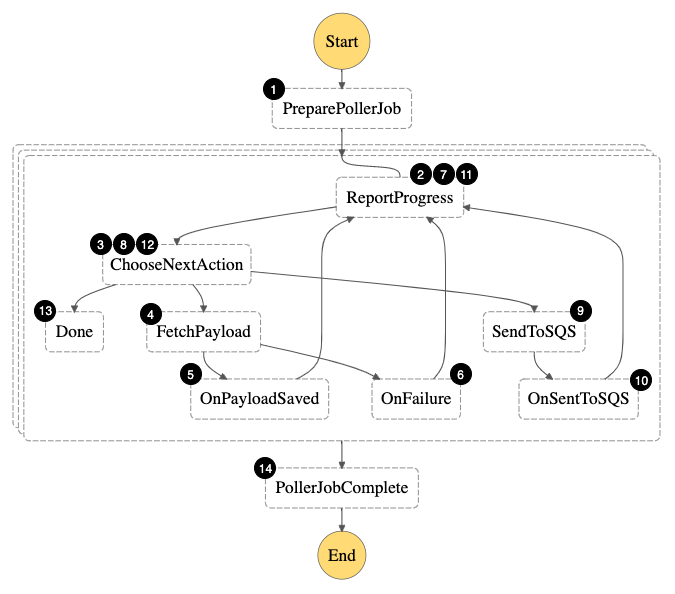
Viewing Step Functions executions
Navigate to the Step Functions console. Choose the state machine created by the AWS SAM template called StepFunctionsStateMachine.
In the Executions tab, you see a number of successful executions. Each transaction represents a Step Functions state machine execution. This means that every time a transaction is submitted by a trading partner to SQS, it is individually processed as a unique Step Functions state machine execution. This granularity is useful for tracking transactions.

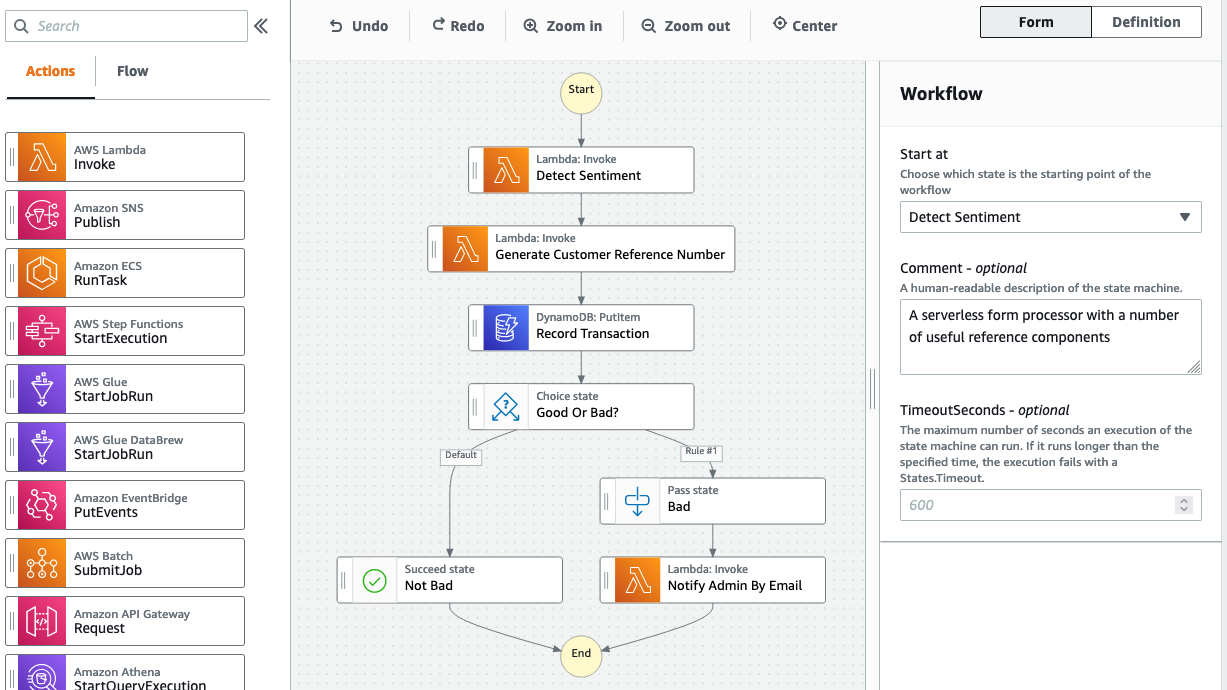
Viewing Workflow Studio
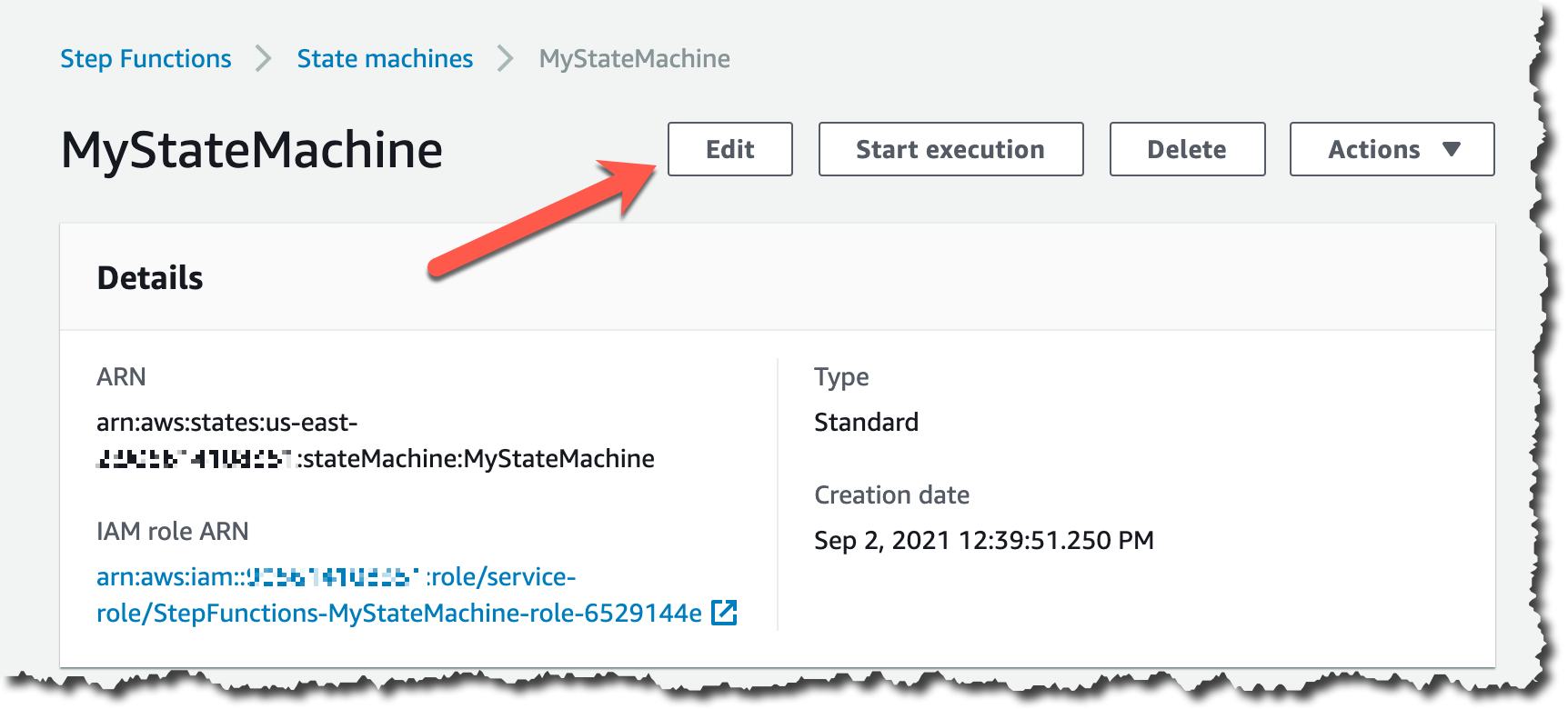
Next, view the Step Functions state machine definition. On the StepFunctionsStateMachine page, choose Edit. You see a code and visual representation of your workflow.
The code version uses Amazon States Language, allowing you to modify the state machine as needed. Choose the Workflow Studio button to get a visual representation of the services and integrations in the workflow.
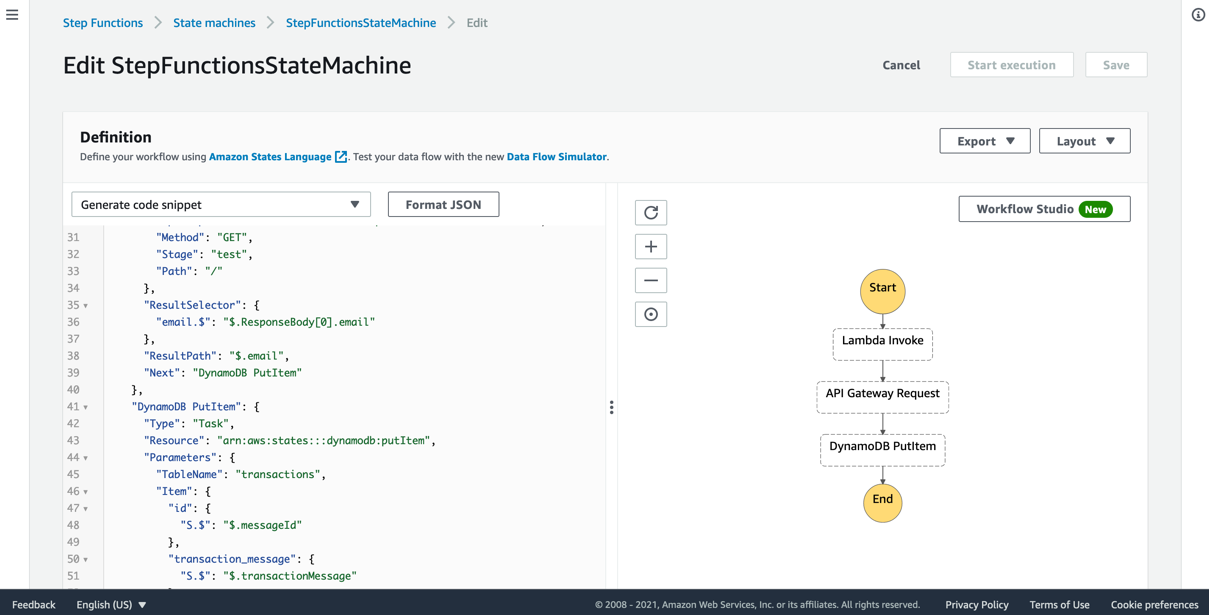
The Workflow Studio helps you to save time while building a B2B pipeline. There are over 40 different actions you can take on various AWS services and flow states that can provide additional logic to the workflow.

One of the largest benefits of Workflow Studio are the time-savings possible through built-in integrations to AWS services. This architecture includes two integrations: API Gateway request and DynamoDB PutItem.
Choose the API Gateway request state in the diagram. To make a request to the API Gateway REST API, you update the API Parameters section in Configuration. Previously, you may have used a Lambda function to perform this action, adding extra code to maintain a B2B pipeline.

The same is true for DynamoDB. Choose the DynamoDB PutItem state to view more. The configuration to put the item is made in the API Parameters section. To connect to any other AWS services via Actions, add Identity and Access Manager (IAM) permissions for Step Functions to access them. These examples include the necessary IAM permissions for Step Functions to both API Gateway and DynamoDB in the AWS SAM template.
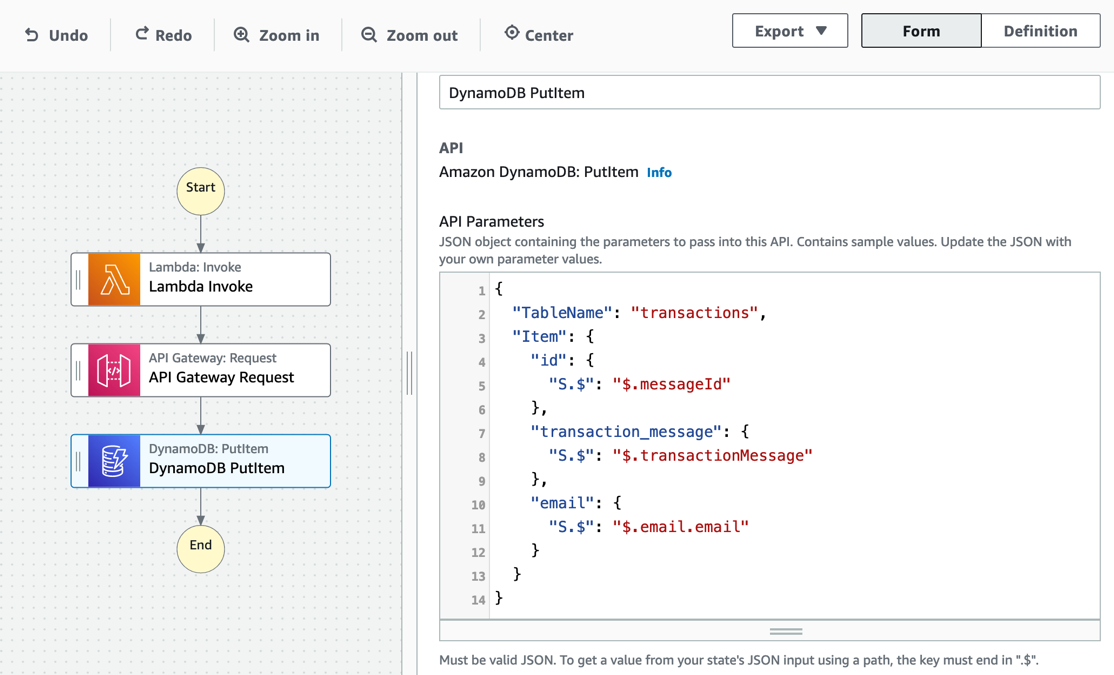
Cleaning up
To avoid ongoing charges to your AWS account, remove the created resources:
- Use the CloudFormation console to delete the stack created as part of this demo. Choose the stack, choose Delete, and then choose Delete stack.
- Navigate to the S3 console and both Empty then Delete S3 buckets created from the stack: [stackName]-cloudtrails3bucket-[uniqueId] and [stackName]-sftpservers3bucket-[uniqueId]
- Navigate to the CloudWatch console and delete the following log groups created from the stack: /aws/lambda/IntakeSingleTransactionLambdaFunction, /aws/lambda/SingleQueueUploadLambda, and /aws/lambda/TriggerStepFunctionsLambdaFunction.
Conclusion
This post shows an architecture to share your business data with your trading partners using API Gateway, AWS Transfer for SFTP, Lambda, and Step Functions. This architecture enables organizations to quickly on-board partners, build event-driven pipelines, and streamline business processes.
To learn more about B2B pipelines on AWS, read: https://aws.amazon.com/blogs/compute/integrating-b2b-using-event-notifications-with-amazon-sns/.
For more serverless learning resources, visit Serverless Land.














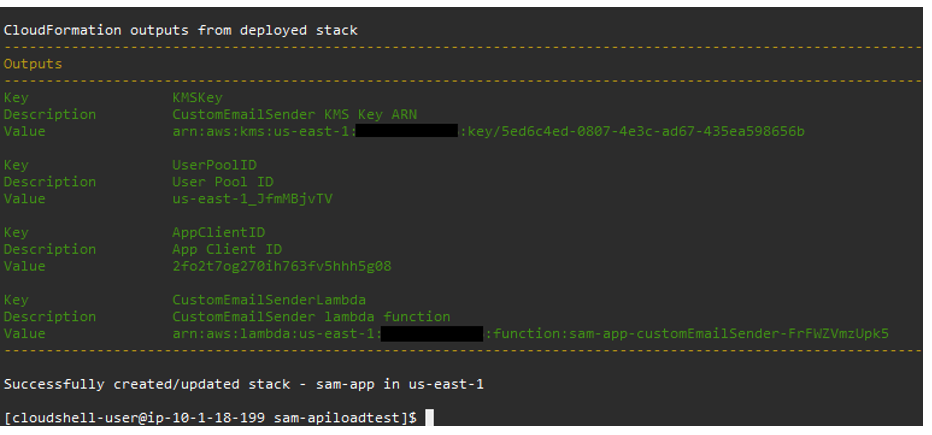
 After stack creation, you see
After stack creation, you see