Post Syndicated from Suleman Ahmad original https://blog.cloudflare.com/ssl-tls-recommender/
Seven years ago, Cloudflare made HTTPS availability for any Internet property easy and free with Universal SSL. At the time, few websites — other than those that processed sensitive data like passwords and credit card information — were using HTTPS because of how difficult it was to set up.
However, as we all started using the Internet for more and more private purposes (communication with loved ones, financial transactions, shopping, healthcare, etc.) the need for encryption became apparent. Tools like Firesheep demonstrated how easily attackers could snoop on people using public Wi-Fi networks at coffee shops and airports. The Snowden revelations showed the ease with which governments could listen in on unencrypted communications at scale. We have seen attempts by browser vendors to increase HTTPS adoption such as the recent announcement by Chromium for loading websites on HTTPS by default. Encryption has become a vital part of the modern Internet, not just to keep your information safe, but to keep you safe.
When it was launched, Universal SSL doubled the number of sites on the Internet using HTTPS. We are building on that with SSL/TLS Recommender, a tool that guides you to stronger configurations for the backend connection from Cloudflare to origin servers. Recommender has been available in the SSL/TLS tab of the Cloudflare dashboard since August 2020 for self-serve customers. Over 500,000 zones are currently signed up. As of today, it is available for all customers!
How Cloudflare connects to origin servers
Cloudflare operates as a reverse proxy between clients (“visitors”) and customers’ web servers (“origins”), so that Cloudflare can protect origin sites from attacks and improve site performance. This happens, in part, because visitor requests to websites proxied by Cloudflare are processed by an “edge” server located in a data center close to the client. The edge server either responds directly back to the visitor, if the requested content is cached, or creates a new request to the origin server to retrieve the content.
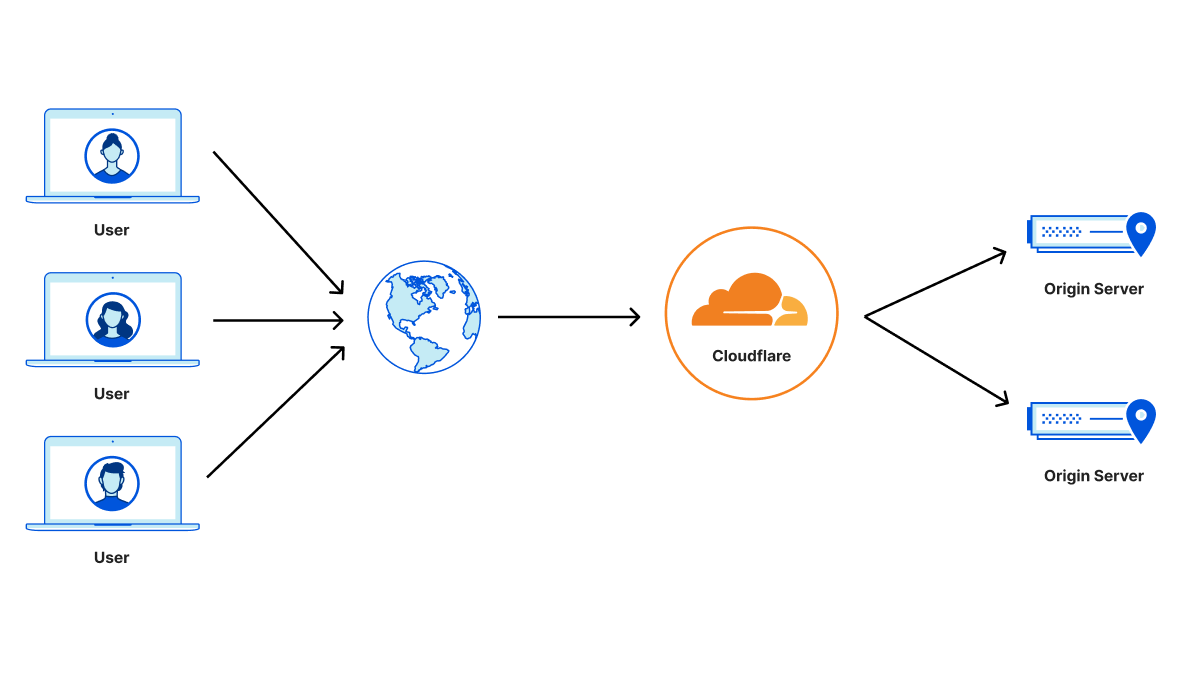
The backend connection to the origin can be made with an unencrypted HTTP connection or with an HTTPS connection where requests and responses are encrypted using the TLS protocol (historically known as SSL). HTTPS is the secured form of HTTP and should be used whenever possible to avoid leaking information or allowing content tampering by third-party entities. The origin server can further authenticate itself by presenting a valid TLS certificate to prevent active monster-in-the-middle attacks. Such a certificate can be obtained from a certificate authority such as Let’s Encrypt or Cloudflare’s Origin CA. Origins can also set up authenticated origin pull, which ensures that any HTTPS requests outside of Cloudflare will not receive a response from your origin.
Cloudflare Tunnel provides an even more secure option for the connection between Cloudflare and origins. With Tunnel, users run a lightweight daemon on their origin servers that proactively establishes secure and private tunnels to the nearest Cloudflare data centers. With this configuration, users can completely lock down their origin servers to only receive requests routed through Cloudflare. While we encourage customers to set up tunnels if feasible, it’s important to encourage origins with more traditional configurations to adopt the strongest possible security posture.
Detecting HTTPS support
You might wonder, why doesn’t Cloudflare always connect to origin servers with a secure TLS connection? To start, some origin servers have no TLS support at all (for example, certain shared hosting providers and even government sites have been slow adopters) and rely on Cloudflare to ensure that the client request is at least encrypted over the Internet from the browser to Cloudflare’s edge.
Then why don’t we simply probe the origin to determine if TLS is supported? It turns out that many sites only partially support HTTPS, making the problem non-trivial. A single customer site can be served from multiple separate origin servers with differing levels of TLS support. For instance, some sites support HTTPS on their landing page but serve certain resources only over unencrypted HTTP. Further, site content can differ when accessed over HTTP versus HTTPS (for example, http://example.com and https://example.com can return different results).
Such content differences can arise due to misconfiguration on the origin server, accidental mistakes by developers when migrating their servers to HTTPS, or can even be intentional depending on the use case.
A study by researchers at Northeastern University, the Max Planck Institute for Informatics, and the University of Maryland highlights reasons for some of these inconsistencies. They found that 1.5% of surveyed sites had at least one page that was unavailable over HTTPS — despite the protocol being supported on other pages — and 3.7% of sites served different content over HTTP versus HTTPS for at least one page. Thus, always using the most secure TLS setting detected on a particular resource could result in unforeseen side effects and usability issues for the entire site.
We wanted to tackle all such issues and maximize the number of TLS connections to origin servers, but without compromising a website’s functionality and performance.

Configuring the SSL/TLS encryption mode
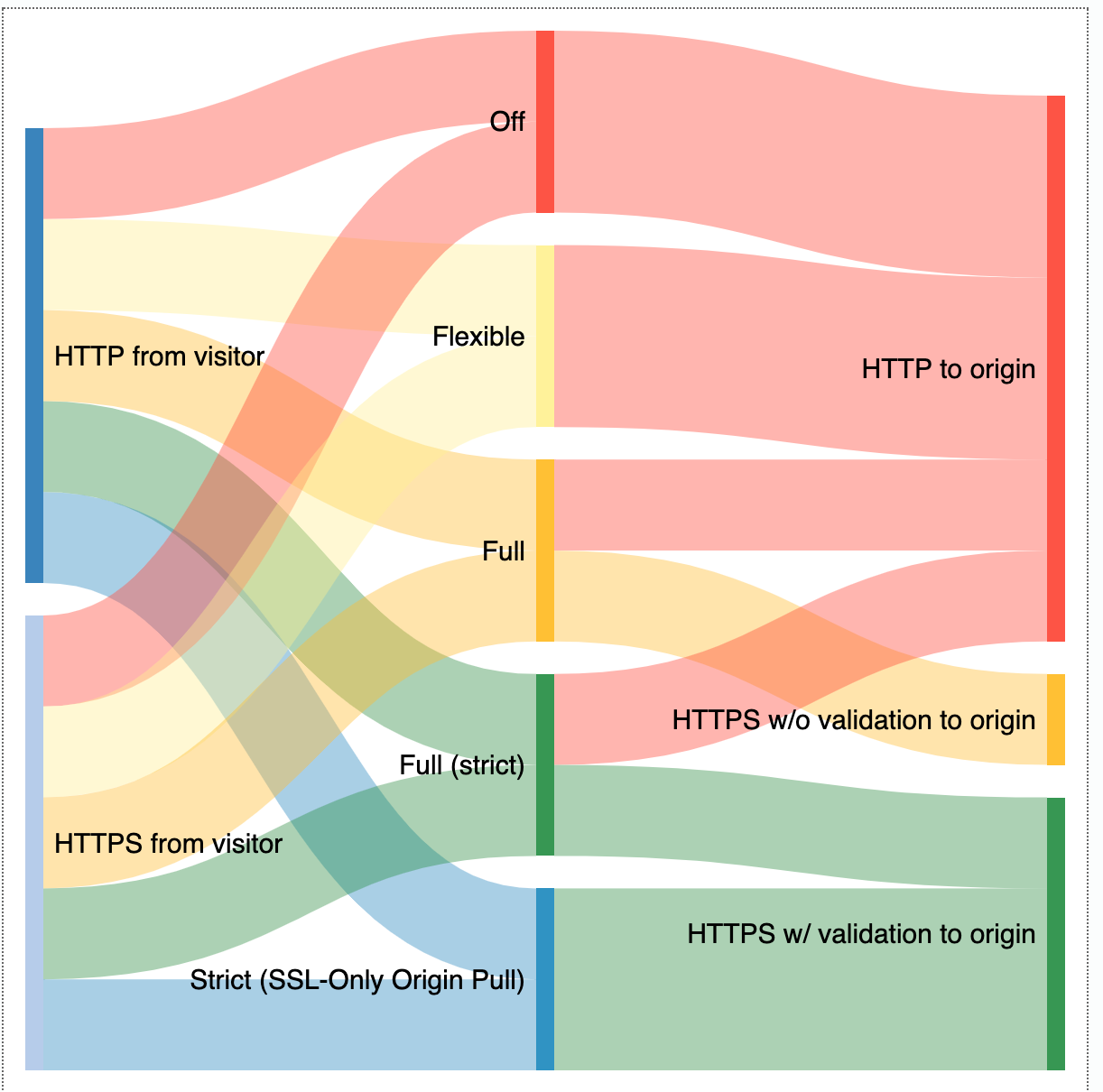
Cloudflare relies on customers to indicate the level of TLS support at their origins via the zone’s SSL/TLS encryption mode. The following SSL/TLS encryption modes can be configured from the Cloudflare dashboard:
- Off indicates that client requests reaching Cloudflare as well as Cloudflare’s requests to the origin server should only use unencrypted HTTP. This option is never recommended, but is still in use by a handful of customers for legacy reasons or testing.
- Flexible allows clients to connect to Cloudflare’s edge via HTTPS, but requests to the origin are over HTTP only. This is the most common option for origins that do not support TLS. However, we encourage customers to upgrade their origins to support TLS whenever possible and only use Flexible as a last resort.
- Full enables encryption for requests to the origin when clients connect via HTTPS, but Cloudflare does not attempt to validate the certificate. This is useful for origins that have a self-signed or otherwise invalid certificate at the origin, but leaves open the possibility for an active attacker to impersonate the origin server with a fake certificate. Client HTTP requests result in HTTP requests to the origin.
- Full (strict) indicates that Cloudflare should validate the origin certificate to fully secure the connection. The origin certificate can either be issued by a public CA or by Cloudflare Origin CA. HTTP requests from clients result in HTTP requests to the origin, exactly the same as in Full mode. We strongly recommend Full (strict) over weaker options if supported by the origin.
- Strict (SSL-Only Origin Pull) causes all traffic to the origin to go over HTTPS, even if the client request was HTTP. This differs from Full (strict) in that HTTP client requests will result in an HTTPS request to the origin, not HTTP. Most customers do not need to use this option, and it is available only to Enterprise customers. The preferred way to ensure that no HTTP requests reach your origin is to enable Always Use HTTPS in conjunction with Full or Full (strict) to redirect visitor HTTP requests to the HTTPS version of the content.
The SSL/TLS encryption mode is a zone-wide setting, meaning that Cloudflare applies the same policy to all subdomains and resources. If required, you can configure this setting more granularly via Page Rules. Misconfiguring this setting can make site resources unavailable. For instance, suppose your website loads certain assets from an HTTP-only subdomain. If you set your zone to Full or Full (strict), you might make these assets unavailable for visitors that request the content over HTTPS, since the HTTP-only subdomain lacks HTTPS support.
Importance of secure origin connections
When an end-user visits a site proxied by Cloudflare, there are two connections to consider: the front-end connection between the visitor and Cloudflare and the back-end connection between Cloudflare and the customer origin server. The front-end connection typically presents the largest attack surface (for example, think of the classic example of an attacker snooping on a coffee shop’s Wi-Fi network), but securing the back-end connection is equally important. While all SSL/TLS encryption modes (except Off) secure the front-end connection, less secure modes leave open the possibility of malicious activity on the backend.
Consider a zone set to Flexible where the origin is connected to the Internet via an untrustworthy ISP. In this case, spyware deployed by the customer’s ISP in an on-path middlebox could inspect the plaintext traffic from Cloudflare to the origin server, potentially resulting in privacy violations or leaks of confidential information. Upgrading the zone to Full or a stronger mode to encrypt traffic to the ISP would help prevent this basic form of snooping.
Similarly, consider a zone set to Full where the origin server is hosted in a shared hosting provider facility. An attacker colocated in the same facility could generate a fake certificate for the origin (since the certificate isn’t validated for Full) and deploy an attack technique such as ARP spoofing to direct traffic intended for the origin server to an attacker-owned machine instead. The attacker could then leverage this setup to inspect and filter traffic intended for the origin, resulting in site breakage or content unavailability. The attacker could even inject malicious JavaScript into the response served to the visitor to carry out other nefarious goals. Deploying a valid Cloudflare-trusted certificate on the origin and configuring the zone to use Full (strict) would prevent Cloudflare from trusting the attacker’s fake certificate in this scenario, preventing the hijack.
Since a secure backend only improves your website security, we strongly encourage setting your zone to the highest possible SSL/TLS encryption mode whenever possible.
Balancing functionality and security
When Universal SSL was launched, Cloudflare’s goal was to get as many sites away from the status quo of HTTP as possible. To accomplish this, Cloudflare provisioned TLS certificates for all customer domains to secure the connection between the browser and the edge. Customer sites that did not already have TLS support were defaulted to Flexible, to preserve existing site functionality. Although Flexible is not recommended for most zones, we continue to support this option as some Cloudflare customers still rely on it for origins that do not yet support TLS. Disabling this option would make these sites unavailable. Currently, the default option for newly onboarded zones is Full if we detect a TLS certificate on the origin zone, and Flexible otherwise.
Further, the SSL/TLS encryption mode configured at the time of zone sign-up can become suboptimal as a site evolves. For example, a zone might switch to a hosting provider that supports origin certificate installation. An origin server that is able to serve all content over TLS should at least be on Full. An origin server that has a valid TLS certificate installed should use Full (strict) to ensure that communication between Cloudflare and the origin server is not susceptible to monster-in-the-middle attacks.
The Research team combined lessons from academia and our engineering efforts to make encryption easy, while ensuring the highest level of security possible for our customers. Because of that goal, we’re proud to introduce SSL/TLS Recommender.
SSL/TLS Recommender
Cloudflare’s mission is to help build a better Internet, and that includes ensuring that requests from visitors to our customers’ sites are as secure as possible. To that end, we began by asking ourselves the following question: how can we detect when a customer is able to use a more secure SSL/TLS encryption mode without impacting site functionality?
To answer this question, we built the SSL/TLS Recommender. Customers can enable Recommender for a zone via the SSL/TLS tab of the Cloudflare dashboard. Using a zone’s currently configured SSL/TLS option as the baseline for expected site functionality, the Recommender performs a series of checks to determine if an upgrade is possible. If so, we email the zone owner with the recommendation. If a zone is currently misconfigured — for example, an HTTP-only origin configured on Full — Recommender will not recommend a downgrade.
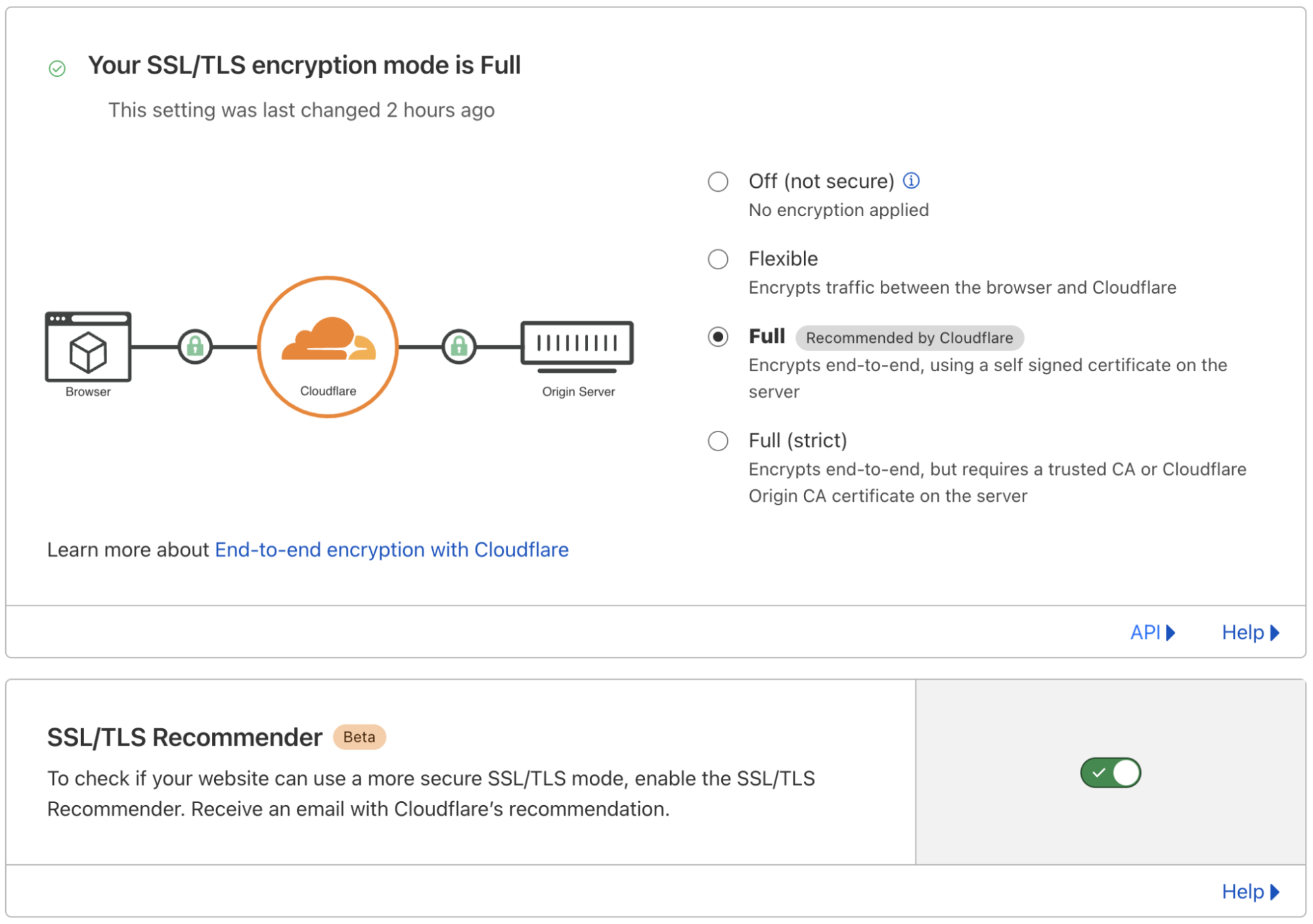
The checks that Recommender runs are determined by the site’s currently configured SSL/TLS option.
The simplest check is to determine if a customer can upgrade from Full to Full (strict). In this case, all site resources are already served over HTTPS, so the check comprises a few simple tests of the validity of the TLS certificate for the domain and all subdomains (which can be on separate origin servers).
The check to determine if a customer can upgrade from Off or Flexible to Full is more complex. A site can be upgraded if all resources on the site are available over HTTPS and the content matches when served over HTTP versus HTTPS. Recommender carries out this check as follows:
- Crawl customer sites to collect links. For large sites where it is impractical to scan every link, Recommender tests only a subset of links (up to some threshold), leading to a trade-off between performance and potential false positives. Similarly, for sites where the crawl turns up an insufficient number of links, we augment our results with a sample of links from recent visitors requests to the zone to provide a high-confidence recommendation. The crawler uses the user agent Cloudflare-SSLDetector and has been added to Cloudflare’s list of known good bots. Similar to other Cloudflare crawlers, Recommender ignores robots.txt (except for rules explicitly targeting the crawler’s user agent) to avoid negatively impacting the accuracy of the recommendation.
- Download the content of each link over both HTTP and HTTPS. Recommender makes only idempotent GET requests when scanning origin servers to avoid modifying server resource state.
- Run a content similarity algorithm to determine if the content matches. The algorithm is adapted from a research paper called “A Deeper Look at Web Content Availability and Consistency over HTTP/S” (TMA Conference 2020) and is designed to provide an accurate similarity score even for sites with dynamic content.
Recommender is conservative with recommendations, erring on the side of maintaining current site functionality rather than risking breakage and usability issues. If a zone is non-functional, the zone owner blocks all types of bots, or if misconfigured SSL-specific Page Rules are applied to the zone, then Recommender will not be able to complete its scans and provide a recommendation. Therefore, it is not intended to resolve issues with website or domain functionality, but rather maximize your zone’s security when possible.
Please send questions and feedback to [email protected]. We’re excited to continue this line of work to improve the security of customer origins!
Mentions
While this work is led by the Research team, we have been extremely privileged to get support from all across the company!
Special thanks to the incredible team of interns that contributed to SSL/TLS Recommender. Suleman Ahmad (now full-time), Talha Paracha, and Ananya Ghose built the current iteration of the project and Matthew Bernhard helped to lay the groundwork in a previous iteration of the project.