Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/aws-local-zones-and-aws-outposts-choosing-the-right-technology-for-your-edge-workload/
This blog post is written by Joe Sacco, Senior Technical Account Manager.
The AWS Global Cloud Infrastructure includes 30 Launched Regions, 96 Availability Zones (AZs), 410+ Points of Presence with 400+ Edge Locations, and 13 Regional Edge Caches. With over 200 AWS services, most customer workloads can run in the AWS Regions. However, for some location-sensitive workloads with low-latency or data residency requirements, and when an AWS Region isn’t close enough, AWS offers two additional infrastructure options: AWS Local Zones and AWS Outposts. Although Local Zones and Outposts solve for similar problems, we’ll review use cases as well as the services and features available that can help you decide which offering best suits your needs.
Let’s start with an overview of Local Zones and Outposts.
What are Local Zones?
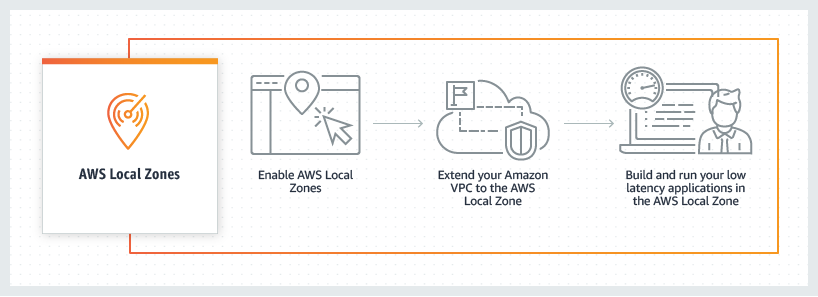
Local Zones are a new type of infrastructure deployment that places AWS compute, storage, database, and other select AWS services in large metropolitan areas closer to end users. This gives you access to single-digit millisecond latency with the use of AWS Direct Connect and the ability to meet data residency requirements. Local Zones are also connected to their parent Region via AWS’s redundant and high bandwidth private network. This gives applications running in Local Zones fast, secure, and seamless access to a complete list of services in the parent Region.
Unlike Outposts, which you deploy within your datacenter or a co-location of your choice, Local Zones are owned, managed, and operated by AWS. Local Zones eliminate the need for you to manage power, connectivity, and capacity. Furthermore, you can provision workloads on a Local Zone from your AWS Management Console just as you would for AZs and Regions today.
 What is Outposts?
What is Outposts?
Outposts is a family of fully managed solutions delivering AWS infrastructure and services to virtually any on-premises or edge location for a truly consistent hybrid experience. Outposts lets you run some AWS services locally and connect to a broad range of services available in the local AWS Region. Outposts comes in two types of offerings: Outposts rack and Outposts servers, with which you can run applications and workloads on-premises using the same AWS infrastructure, services, tools, and APIs as in AWS Regions.
The Outposts rack is available as an industry standard 42U form factor. It provides the same AWS infrastructure, services, tools, and APIs to your data center or co-location space that you would find in an AWS Region.

The Outposts servers come in a 1U or 2U form factor and are designed for locations that have limited space or smaller capacity requirements. Both support different compute instances, as detailed in the Outposts servers feature page.
 Customer use cases
Customer use cases
Now that we have an overview of both Local Zones and Outposts service offerings, let’s dive into use cases, the differences between them, and how your business can leverage each to accomplish your workloads requirements.
Low latency
Customers today require low latency computing for workloads, such as medical imaging, transaction processing for Enterprise Resource Planning (ERP) applications, enterprise migration with hybrid architecture, real-time multiplayer gaming, telco network function virtualization, and regulated gaming workloads.
Outposts can meet ultra-low latency requirements. This is accomplished by bringing AWS services on premises and to the edge at Outpost Sites. An Outpost site is the physical location where your Outpost operates, and it can be local within one of your data centers or at a co-location facility of your choice.
When accessing from within the same metro, Local Zones will provide you with a low, single millisecond latency experience when communicating with your applications. Latency between Local Zones and AWS Regions or Local Zones and on-premises environments varies, and these will depend on how close the nearest Local Zone is as well as the type of modality used for the connection (Public Internet, VPN, and AWS Direct Connect). You should always choose the closest Local Zone location to achieve the lowest possible latency. For use cases such as mobile gaming, you can utilize Local Zones by deploying your applications to a Local Zone location nearest to your end users. Local Zones are generally available in 17 metros across the US, 4 outside the US, and we are continuing to launch Local Zones in 30 cities across 25 countries. Check out updates for more general availability of Local Zones.
Data residency
On occasion, data must remain in a specific geographic region for regulatory or information security reasons. Healthcare and other regulated industries, such as financial services or Oil & Gas, have specific data residency requirements.
Outposts helps meet a customer’s data residency requirements because it’s installed on premises and essentially brings AWS to where the data currently resides. This allows you to pick and control where your workloads run, and where your data will stay. Check out the full list of countries and territories where Outposts is available on the FAQs page of Outposts rack and the FAQs page of Outposts servers.
Local Zones bring AWS closer or within a customer’s geographic boundary in a fully AWS owned and operated mode. Although Local Zones can help meet data residency use cases in some scenarios, data residency requirements vary depending on the jurisdictions. Therefore, you should work closely with your compliance and information security teams when choosing the Local Zone location in which to deploy your regulated workloads.
Migration and modernization
When trying to migrate to the cloud and modernize your stack, some workloads can be challenging. Often there are on-premises applications which are difficult to move into Regions due to latency-sensitive system intermittencies between their various components. As dependencies arise, you may choose to segment these migrations into smaller pieces. Then this will require latency-sensitive connectivity between the various parts of the application.
Outposts and Local Zones both allow for a gradual migration and modernization of your stack. You can choose to migrate parts of their workloads while still maintaining latency-sensitive connectivity between components until the entirety is ready to move.
Factors in selecting Local Zones or Outposts
Choosing between Local Zones and Outposts will depend on the following factors, and you should examine all of them together when selecting a service for your use case.
- Latency requirements
Local Zones can achieve low single millisecond latency when accessing within the same metro. On the other hand, Outposts can achieve ultra-low latency requirements when deployed within your datacenter or at a co-location facility of your choice. When selecting one over the other, you must work backward from your goal and workload requirements.
If you’re conducting a migration and modernization strategy which requires ultra-low latency between a workloads application and database tiers that are difficult to migrate to the AWS Regions, then Outposts would be the right solution for you.
Alternatively, if your workload involves streaming live broadcasts to end users which requires low single millisecond latency, but your end users are located where an AWS Region isn’t available, then Local Zones distributed across various metros would work best to serve your content.
- Availability of services needed to support your workload
Local Zones and Outposts differ with their list of supported AWS services, and you must review your workload’s service requirements when determining the best fit for you. For example, if a customer has a computer vision workload that requires storing and retrieving large volumes of images locally using Amazon Simple Storage Service (Amazon S3), then Outposts and certain Local Zones meet this requirement while other Local Zones don’t. Learn how you can use Amazon S3 on Outposts for computer vision workloads.
Outposts rack and servers support different sets of AWS services locally. You can view comparisons between them, or visit the Outposts servers and Outposts rack feature sites for more details.
Local Zones’ features vary depending on the location in which you choose to deploy. You can view more details and a full list of supported features and services per location on our Local Zones features page.
- Investment and management of infrastructure on-premises
Management of the infrastructure and prerequisites are another factor when considering which AWS service best suits your needs.
Outposts is ordered through AWS, and it requires installation in a customer’s on-premises datacenter or co-location provider of their choice. Outposts rack installation is handled by AWS, while Outposts servers installation is done by the customer or a third-party of their choosing. There are power and redundant networking requirements for the Outpost Site, as well as a required subscription to AWS Enterprise Support or On-Ramp Support.
Local Zones infrastructure is fully-managed by AWS, including the power, networking, and capacity. This reduces operational management as well as the overhead cost for customers. An Enterprise support agreement isn’t required to utilize Local Zones.
You should always choose Regions or Local Zones if your use case allows, and use Outposts when a Region or Local Zone isn’t a good fit. If both Outposts and Local Zones fit a customer’s use case and requirements, then Local Zones will be the preferred choice.
- Regulations, compliance, and information security
If a Local Zone is either unavailable or unable to meet your residency requirements within your geographic boundary consider Outposts, which can be deployed to a data center or co-location facility of your choice. Data residency requirements can be a factor based on your industry and the regulations to which your workload must adhere. Furthermore, you should work closely with your compliance and information security teams when choosing between Local Zones or Outposts.
Conclusion
Whether you’re dealing with latency-sensitive applications, data residency requirements, or a migration and modernization strategy, AWS provides options and flexibility for you to leverage the same AWS infrastructure, services, APIs, and tools to metro areas and on-premises locations with Local Zones and Outposts.
The decision of which technology to use will depend on several factors that we discussed above. You must work across teams within your organization to make sure that the latency requirements (low single millisecond latency within a metro for Local Zones vs the ultra low latency of Outposts when deployed close to or within your datacenter), data reseidency needs, installation prerequisites, and availability of services to support your workload are met.
Once these factors are taken into account, and you have made a choice, visit our product pages for Outposts and Local Zones with information on how you can get started.












































 Srikanth Baheti is a Specialized World Wide Sr. Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing.
Srikanth Baheti is a Specialized World Wide Sr. Solution Architect for Amazon QuickSight. He started his career as a consultant and worked for multiple private and government organizations. Later he worked for PerkinElmer Health and Sciences & eResearch Technology Inc, where he was responsible for designing and developing high traffic web applications, highly scalable and maintainable data pipelines for reporting platforms using AWS services and Serverless computing. Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.
Raji Sivasubramaniam is a Sr. Solutions Architect at AWS, focusing on Analytics. Raji is specialized in architecting end-to-end Enterprise Data Management, Business Intelligence and Analytics solutions for Fortune 500 and Fortune 100 companies across the globe. She has in-depth experience in integrated healthcare data and analytics with wide variety of healthcare datasets including managed market, physician targeting and patient analytics.