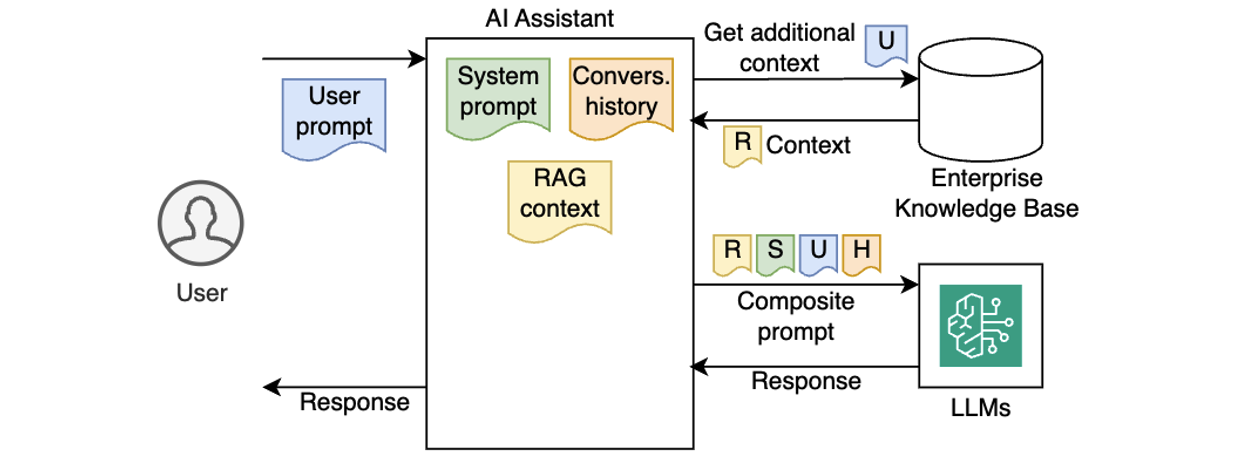
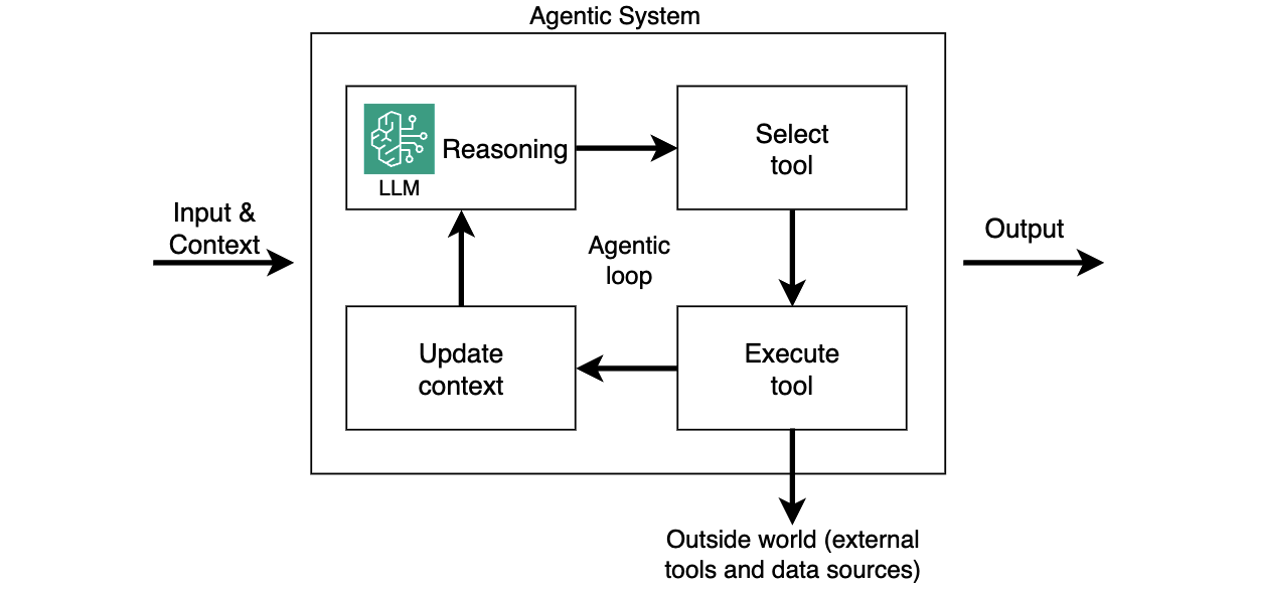
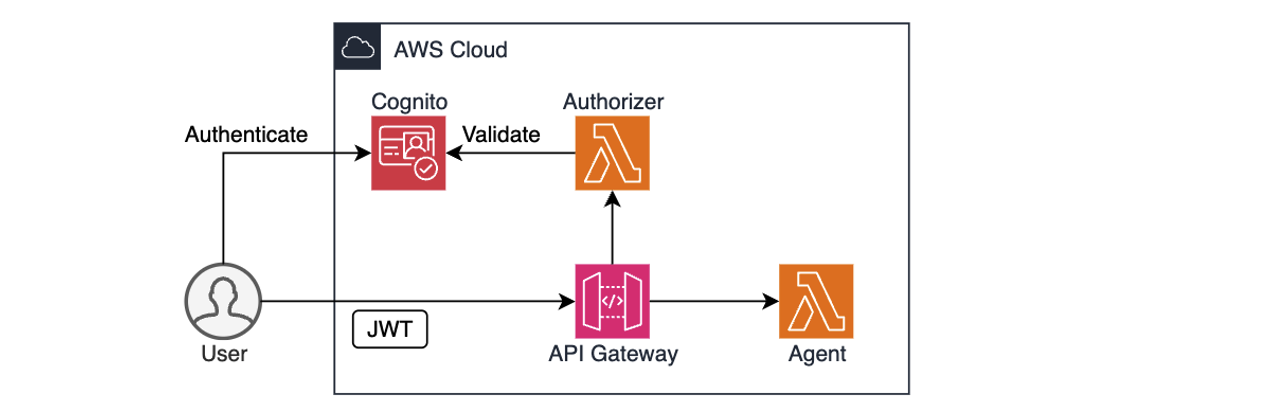
Post Syndicated from Ramesh H Singh original https://aws.amazon.com/blogs/big-data/use-account-agnostic-reusable-project-profiles-in-amazon-sagemaker-to-streamline-governance/
Amazon SageMaker now supports account-agnostic project profiles, so you can create reusable project templates across multiple AWS accounts and organizational units. In this post, we demonstrate how account-agnostic project profiles can help you simplify and streamline the management of SageMaker project creation while maintaining security and governance features. We walk through the technical steps to configure account-agnostic, reusable project profiles, helping you maximize the flexibility of your SageMaker deployments.
New feature: Account-agnostic project profiles
Previously, SageMaker provided the ability to create project profiles, which required selecting an AWS account and AWS Region at the time of profile creation. This feature provides you the flexibility to insert the AWS account and Region dynamically when creating projects.
SageMaker now supports generic, account-agnostic project profiles (templates) in SageMaker domains, so domain administrators can define project configurations one time and reuse them across multiple AWS accounts and Regions.
Project profiles are no longer tied to a specific AWS account or Region. Instead, platform teams can reference an account pool—a new domain entity that enables dynamic account and Region selection at the time of project creation, based on custom enterprise authorization policies or user-specific logic. This decoupling of profile definitions from static deployment settings is designed to simplify governance, reduce duplication, and accelerate onboarding across large-scale data and machine learning (ML) environments.
Account-agnostic project profiles offer the following key benefits:
- Project creators benefit from a more flexible experience – During project creation, project creators can select from a personalized list of authorized AWS accounts and Regions, powered by custom resolution strategies or predefined account pools.
- The feature streamlines project profile governance – This model is intended to enable organizations operating across many different accounts to scale efficiently across those accounts, while preserving organization’s centralized control and permission boundaries.
Customer spotlight
As a large data-driven organization, Bayer AG looks to harness the power of data, analytics, and ML to help researchers and engineers accelerate pharmaceutical innovation. With the ability to create account agnostic templates and reusable templates in SageMaker, the research teams at Bayer can innovate faster without platform and engineering overhead.
“At Bayer, we use Amazon SageMaker Unified Studio as a unified, governed workspace that brings together data from multiple AWS accounts—enabling our users to run analytics, build pipelines, and train models as part of their day-to-day work. With the new capability to create account-agnostic templates, our platform team can publish reusable templates once, and teams can select the right authorized AWS account at project creation—without relying on platform hand-offs. This will support faster onboarding, improved agility, and consistent governance as we scale ML across our global operations.”
— Avinash Reddy Erupaka, Principal Engineering Lead, Drug Innovation Platform, Bayer
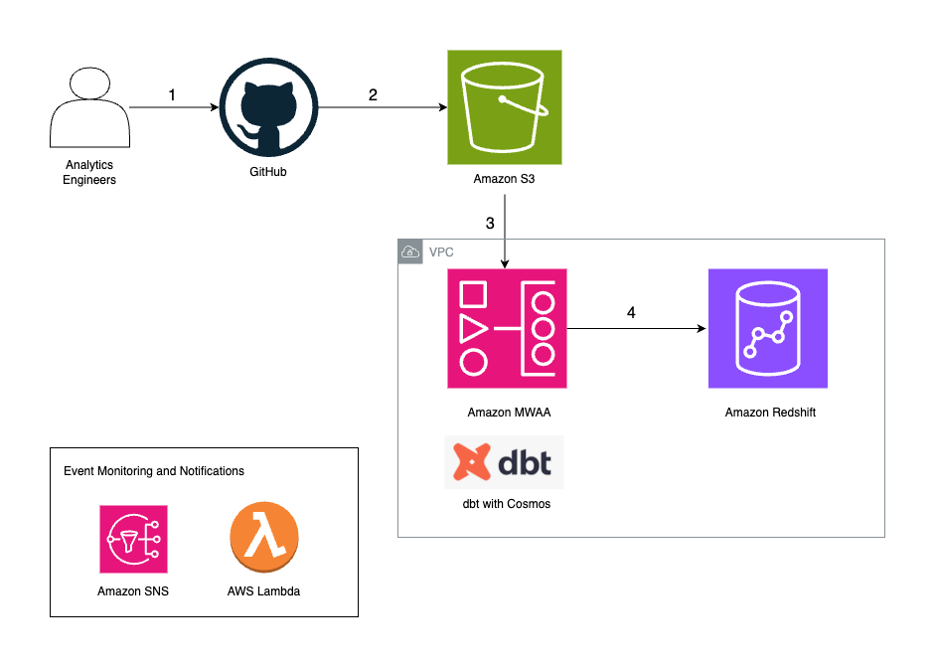
Solution overview
For our example use case, a leading pharmaceutical company has implemented SageMaker to manage their enterprise-wide data governance initiatives. The organization faces the complex challenge of managing thousands of AWS accounts across their global operations.
To streamline this process, their platform administrator needs to develop a system of reusable project profiles that map to specific account pools, organized according to the company’s organizational structure. For instance, they’ve created a specialized Corporate HR project profile tailored to meet the Corporate HR team’s specific requirements, as well as a comprehensive Data Engineer project profile designed for data engineering teams operating across North America, Asia-Pacific, and European Regions. This strategic approach helps data engineers efficiently create new projects using these preconfigured profiles while selecting from pre-authorized account and Region combinations. This structure strikes an optimal balance between operational flexibility and enhanced security and governance features.
In the following sections, we provide a detailed, step-by-step implementation guide for this solution.
Prerequisites
For this walkthrough, you must have the following prerequisites:
- An AWS account – If you don’t have an account, you can create one. The account should have permission to do the following:
- Create and manage SageMaker domains
- Create and manage AWS Identity and Access Management (IAM) roles
- Create and invoke AWS Lambda functions (optional)
- SageMaker domain – For instructions, refer to Create a domain – quick setup.
- AWS CLI installed – The AWS Command Line Interface (AWS CLI) version 2.11 or later.
- Python installed – Python 3.8 or later (if using custom Lambda handlers).
- IAM permissions – The following IAM permissions are required:
sagemaker:CreateProjectsagemaker:CreateProjectProfiledatazone:CreateAccountPool
Platform administrator tasks
The platform administrator is responsible for two key setup tasks: creating account pools and establishing project profiles associated with these pools. This section provides the steps to accomplish both crucial processes.
Create account pools
There are two ways to create account pools:
- For static account sources, provide a list of accounts and Regions
- For dynamic account sources, use a custom Lambda handler to authorize account and Region pair information
As of this writing, the creation, update, and deletion of account pools are only supported in the AWS CLI.
For creating account pools, use the create-account-pool command and provide the resources. We used the following commands to create account pools for our example use case. Replace the relevant values with your own resources, such as domain identifier, account, and Region.
First, create the account pool hr-accountpool with a single AWS account. In the following command, the parameter MANUAL refers to the mechanism by which an account is chosen from the pool at project creation time. Because the platform admin is manually choosing the accounts, the resolution strategy is set to MANUAL.
Next, create the account pool namer-data-engg-pool with multiple AWS accounts. Use the same code to create account pools for the EMEA and APAC Regions:
You will use these account pools in subsequent steps to create project profiles.
To verify account pool creation, use the following command:
If you have an external permissioning system, you can use the following custom Lambda command to create your account pool that will dynamically resolve during project creation:
Create project profiles and account pool assignments
In this step, we establish project profiles and connect them to authorized account pools. There are three possible scenarios for setting up project profiles.
Scenario 1: Project profile associated with a single account pool
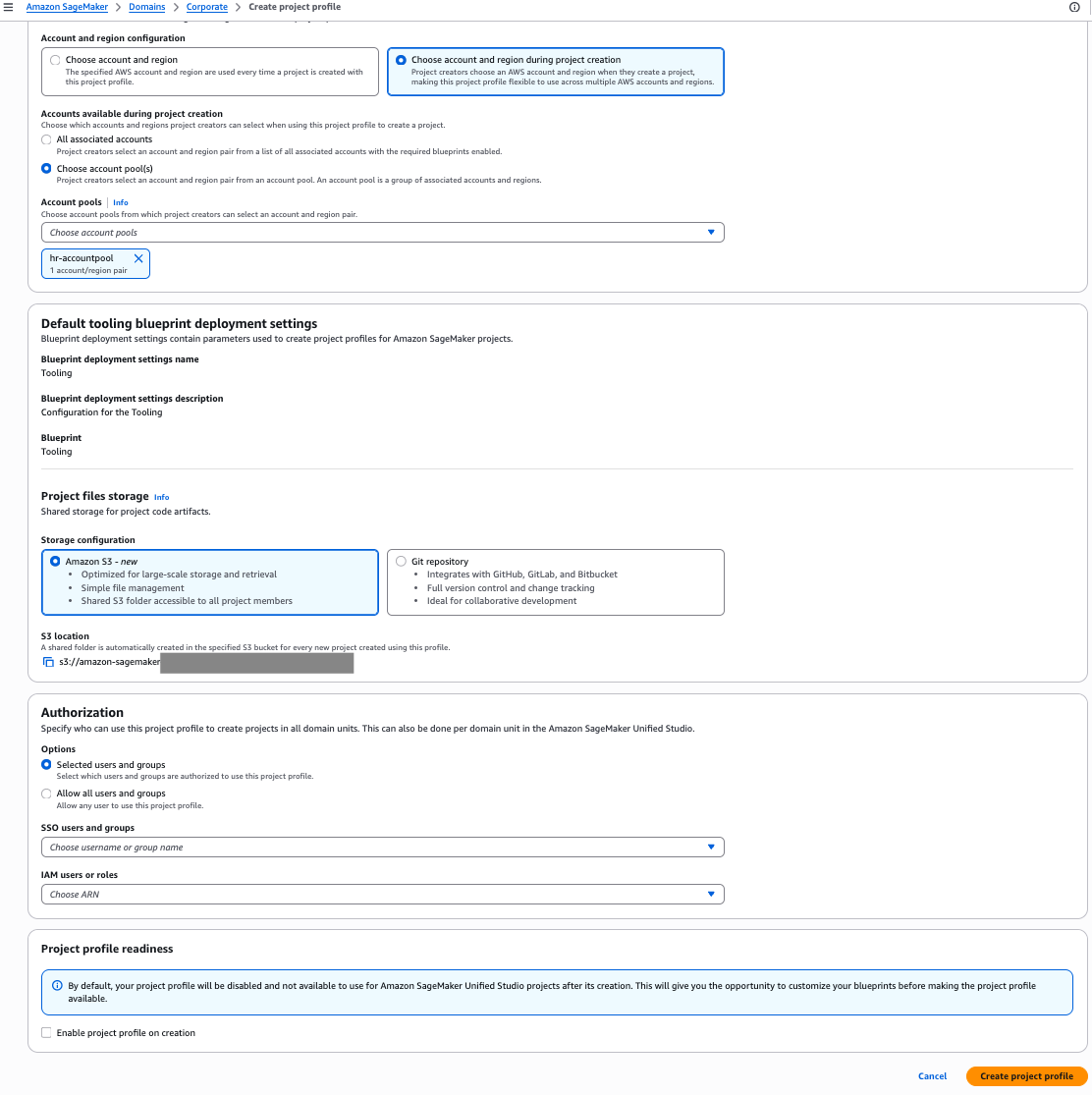
This is the simplest configuration, where one project profile is mapped to a single account pool. In the following steps, we create a project profile for the Corporate HR team and tie it to the HR account pool:
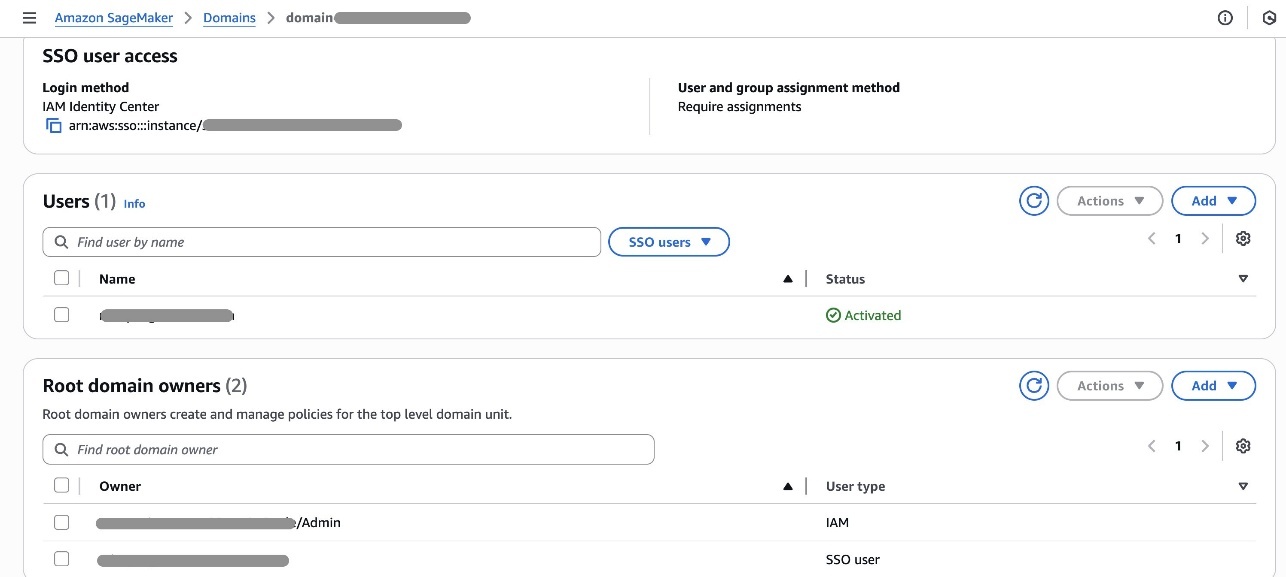
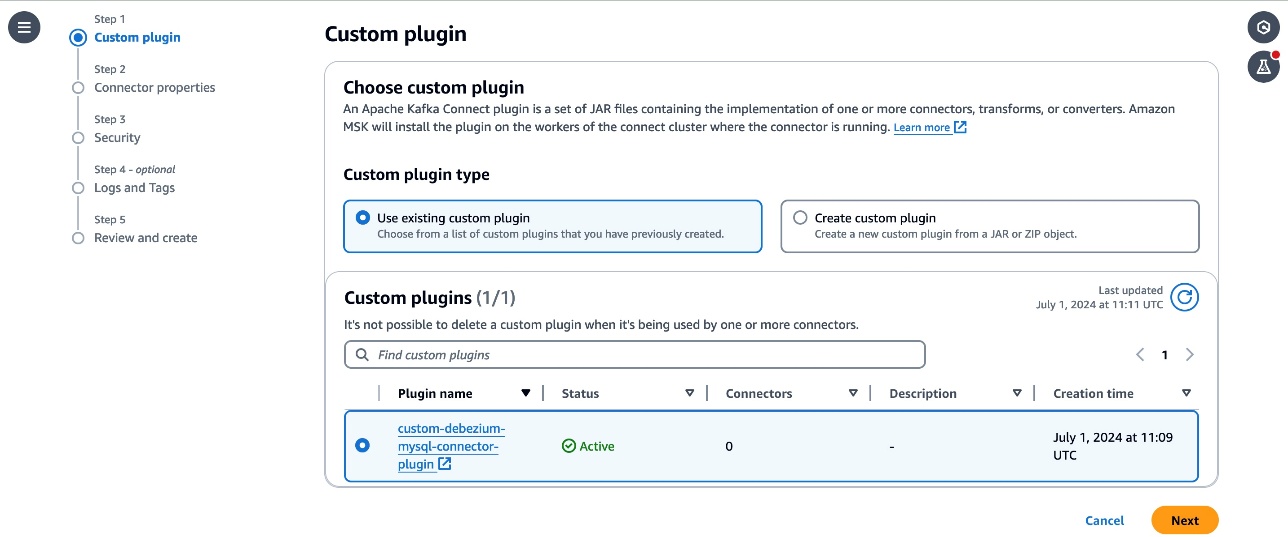
- On the SageMaker console, choose Domains in the navigation pane.
- On the Project profiles tab, choose Create.

- Enter a name and description for your profile.
- Choose an appropriate project profile template that aligns with your project’s needs.
- Select Choose account and region during project creation.
- Select Choose account pool(s) and choose the account pool you created for the HR team.
- Leave the remaining settings as default and choose Create project profile.
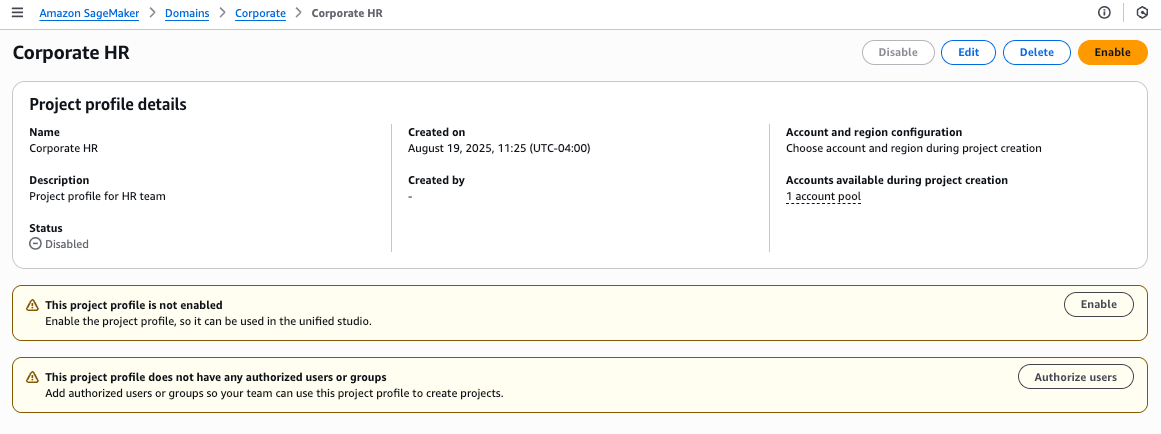
- On the project details page, choose Enable to activate your profile.
- Choose Enable in the confirmation pop-up to proceed.
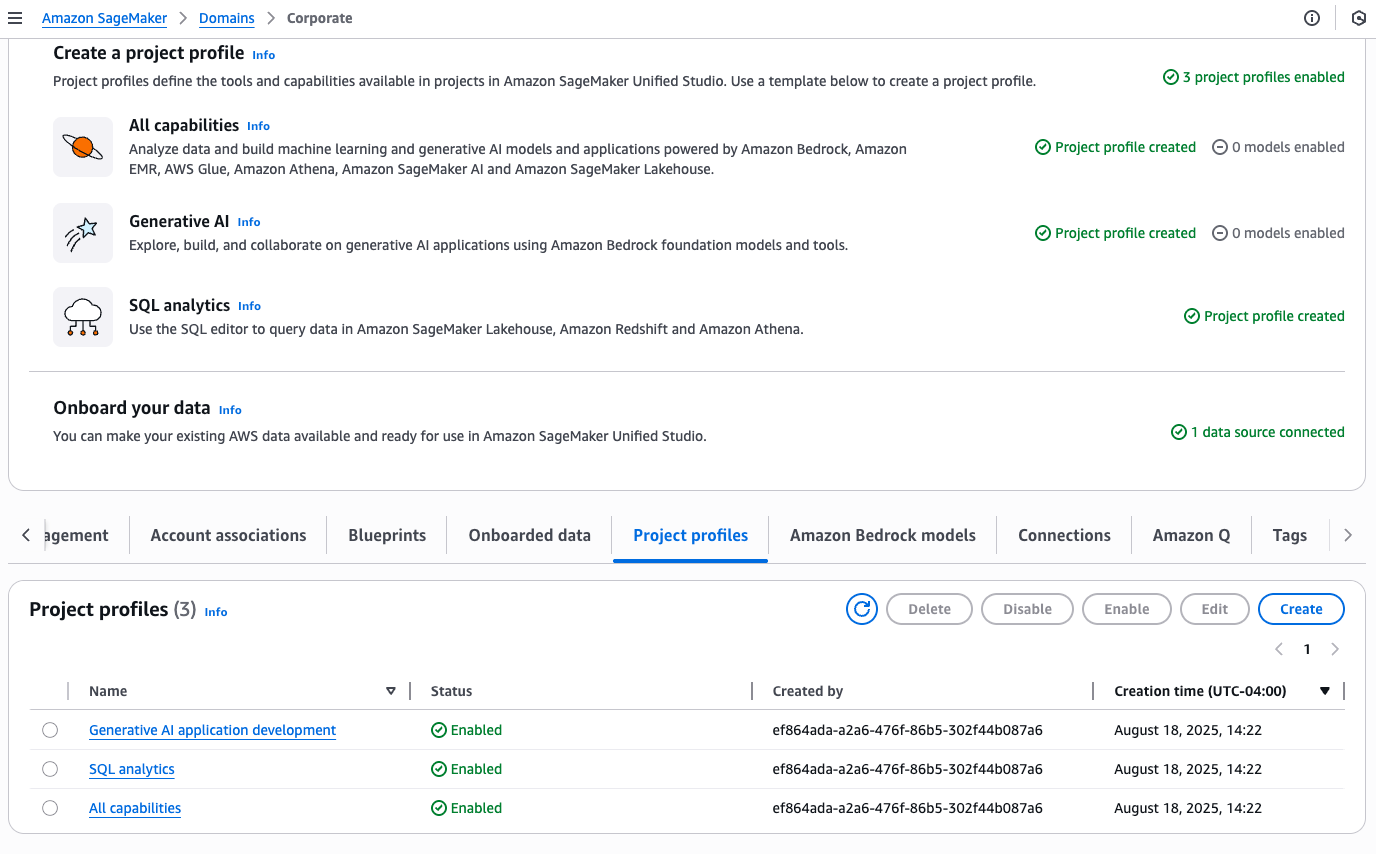
You will see a success message confirming that the Corporate HR profile has been created and linked to one account pool.
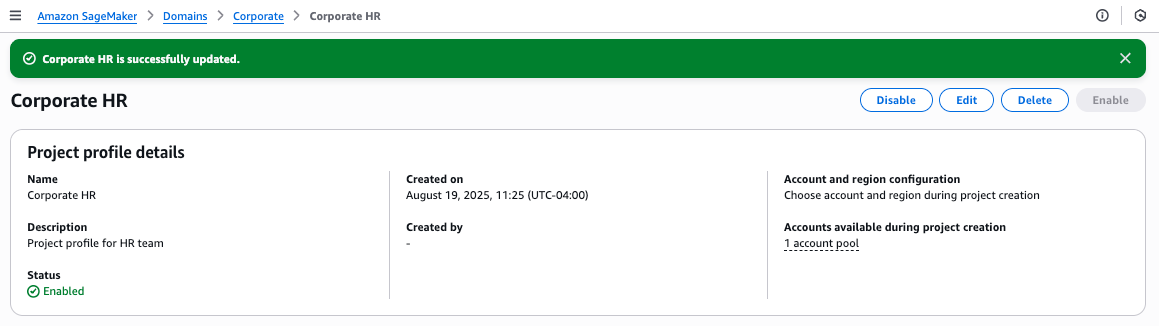
On the Project profiles tab, you should now see your newly created Corporate HR profile listed among the available project profiles.
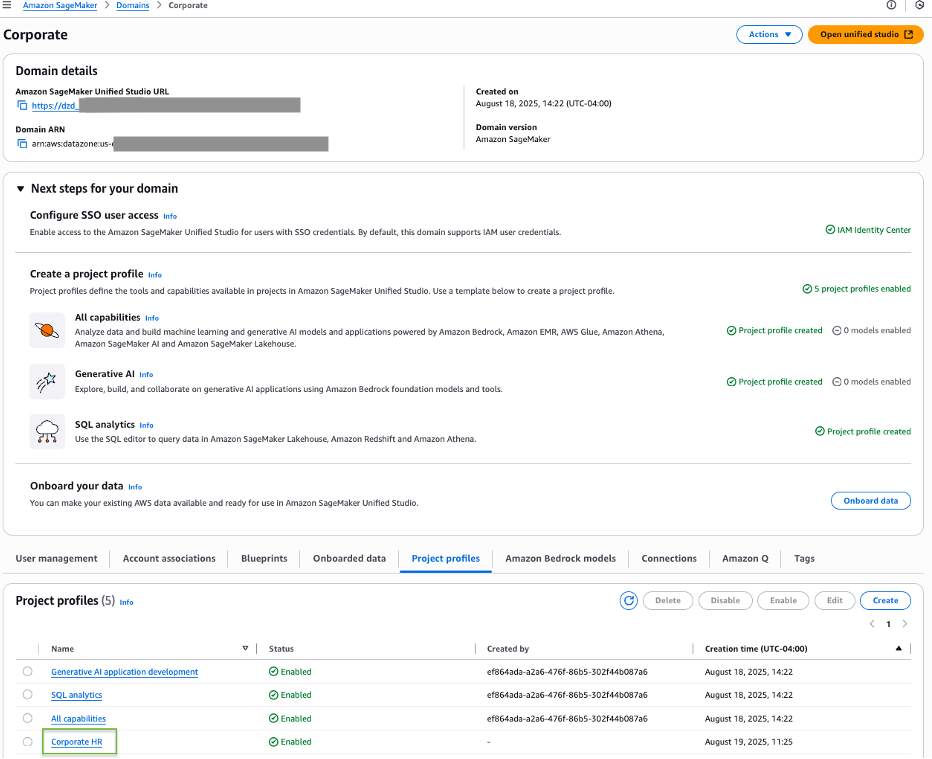
To explore further, navigate to the Corporate HR project profile and choose the Blueprints tab to see a list of available blueprints. Choose a blueprint to view its details.
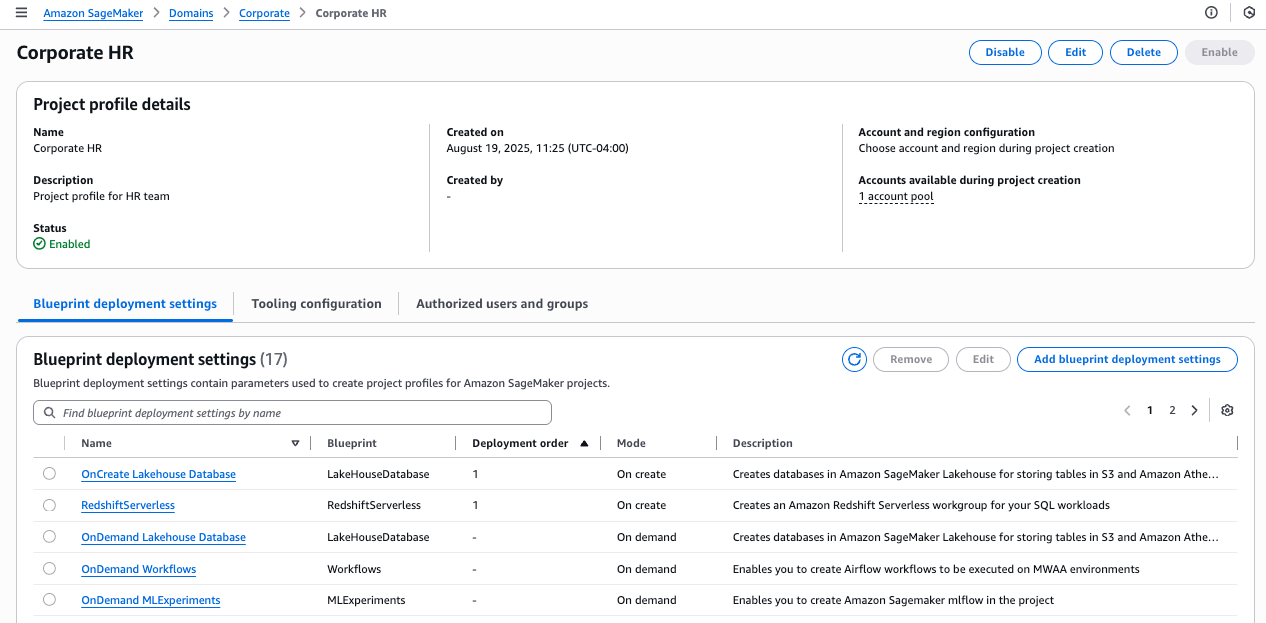
On the blueprint details page, the blueprint shows as deployable to the single account pool you associated with this project profile.
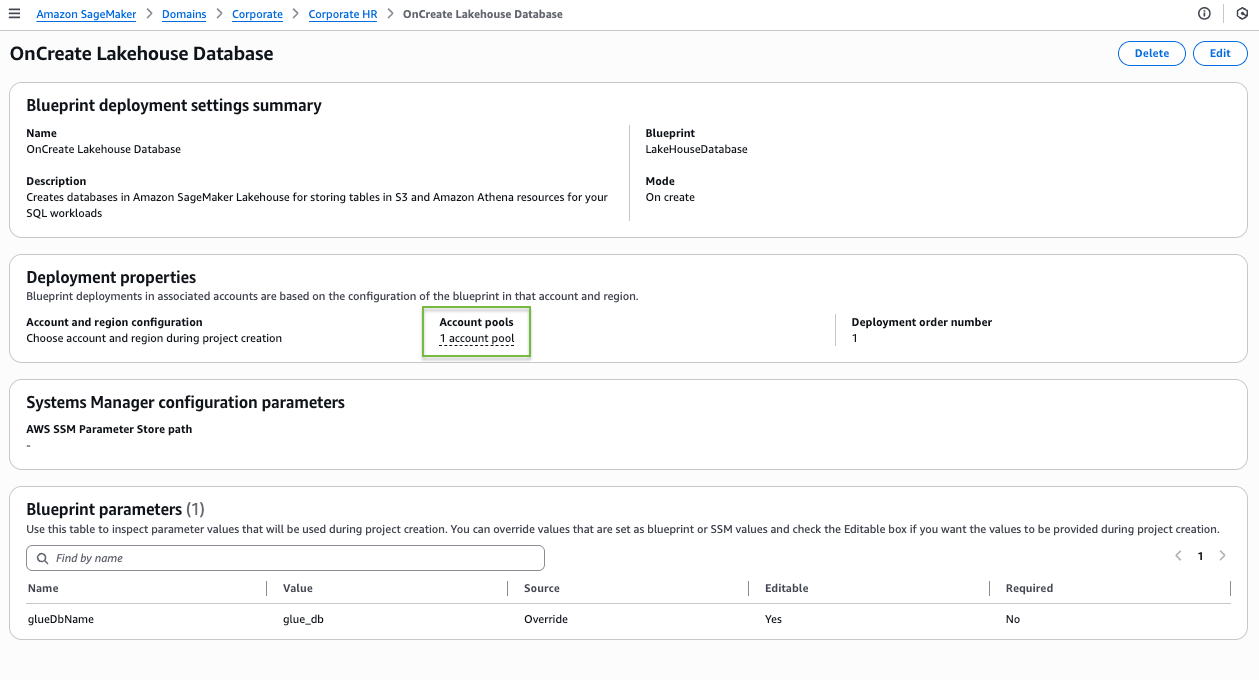
Scenario 2: Project profile associated with multiple account pools
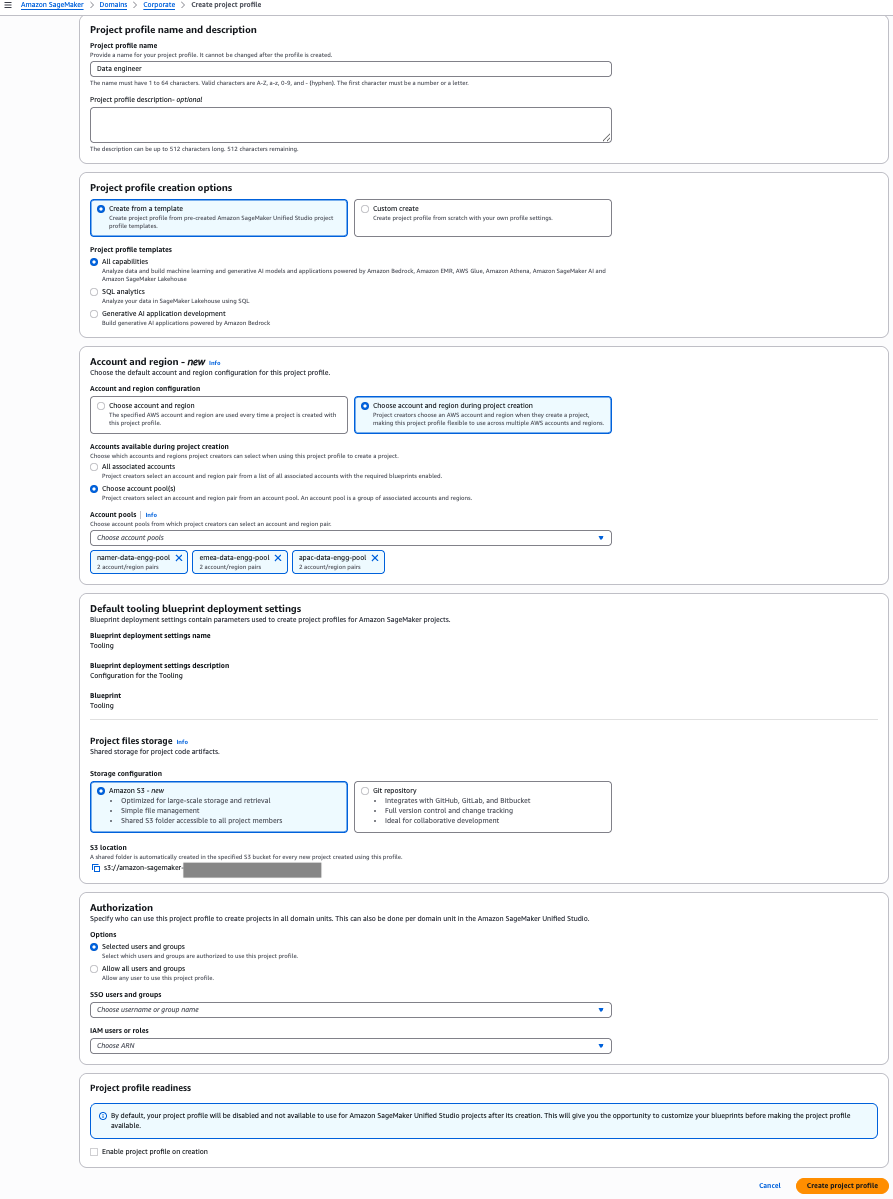
In this example, we create a project profile for a global Data Engineering team, connecting it to three Regional account pools: NAMER (North America), APAC (Asia Pacific), and EMEA (Europe, Middle East, and Africa). Complete the following steps:
- On the SageMaker console, choose Domains in the navigation pane.
- On the Project profiles tab, choose Create.
- Enter a name and description for your profile.
- Choose an appropriate project profile template that aligns with your project’s needs.
- Select Choose account and region during project creation.
- Select Choose account pool(s) and choose all three Regional pools:
- NAMER Data Engineering team
- EMEA Data Engineering team
- APAC Data Engineering team
- Leave the remaining settings as default and choose Create project profile.
- On the project details page, choose Enable to activate your profile.
- Choose Enable in the confirmation pop-up to proceed.
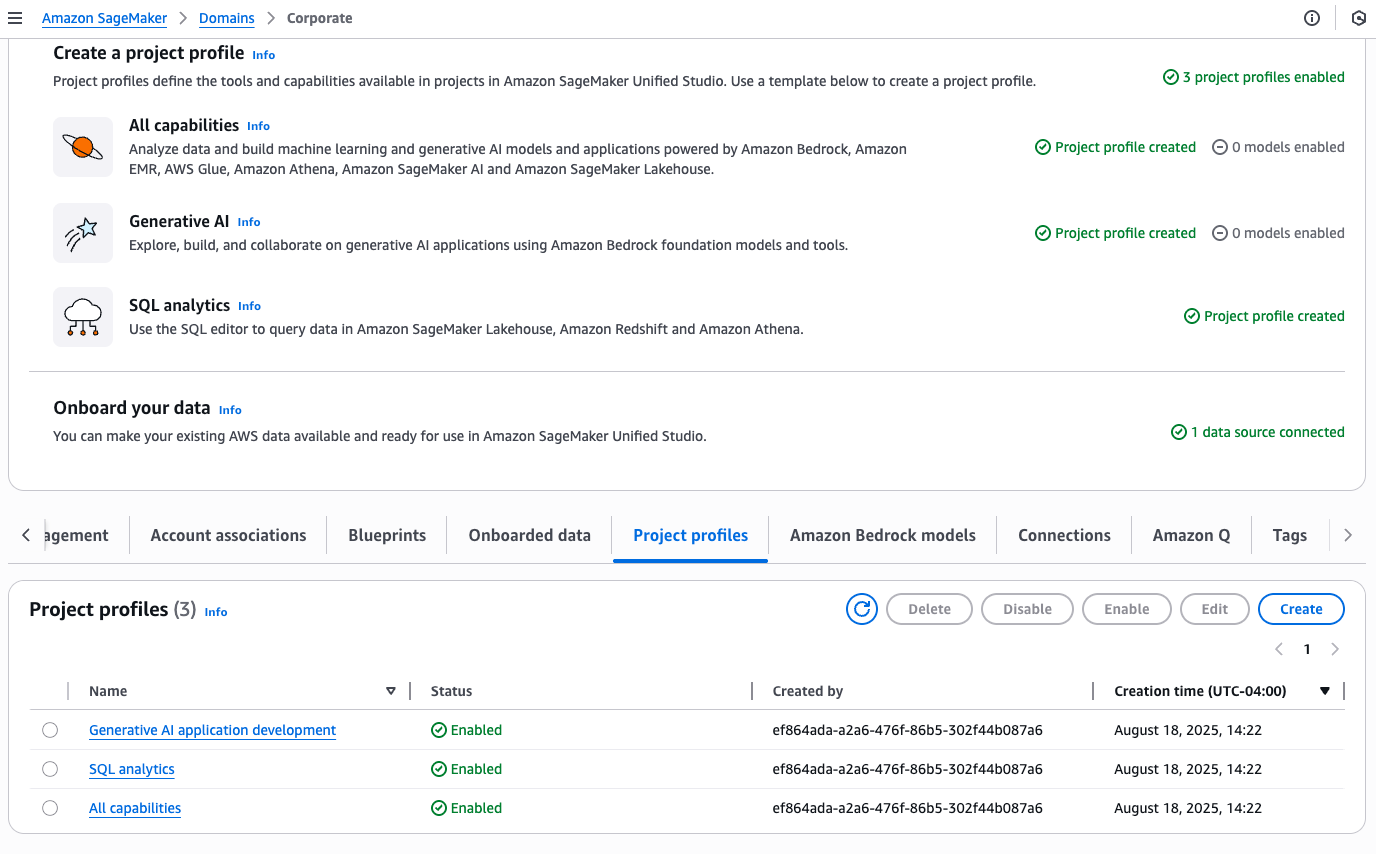
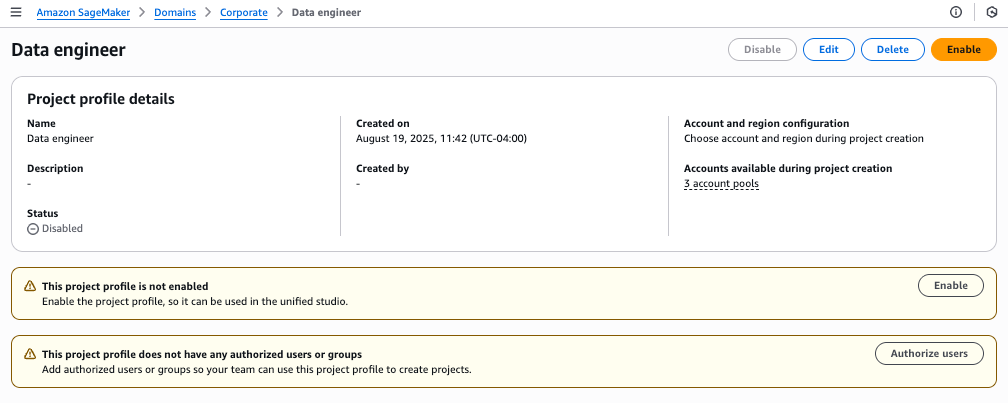
You will see a success message confirming the Data Engineer profile creation. The profile will show connections to all three Regional account pools.
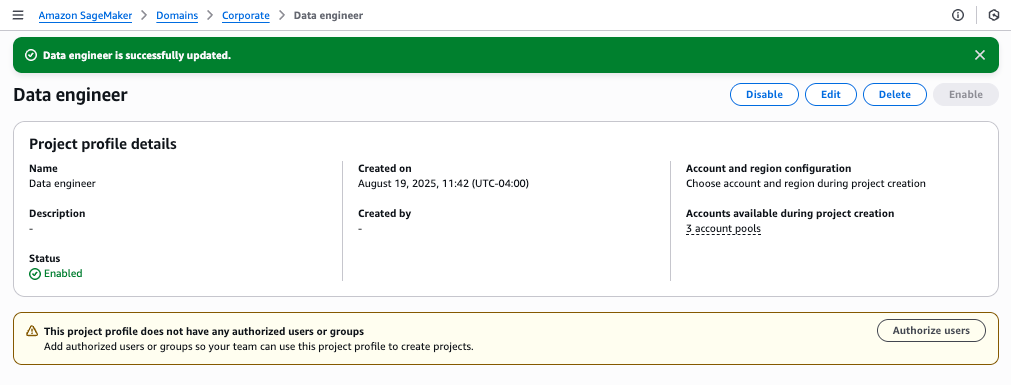
You can find your new profile listed on the Project profiles tab.
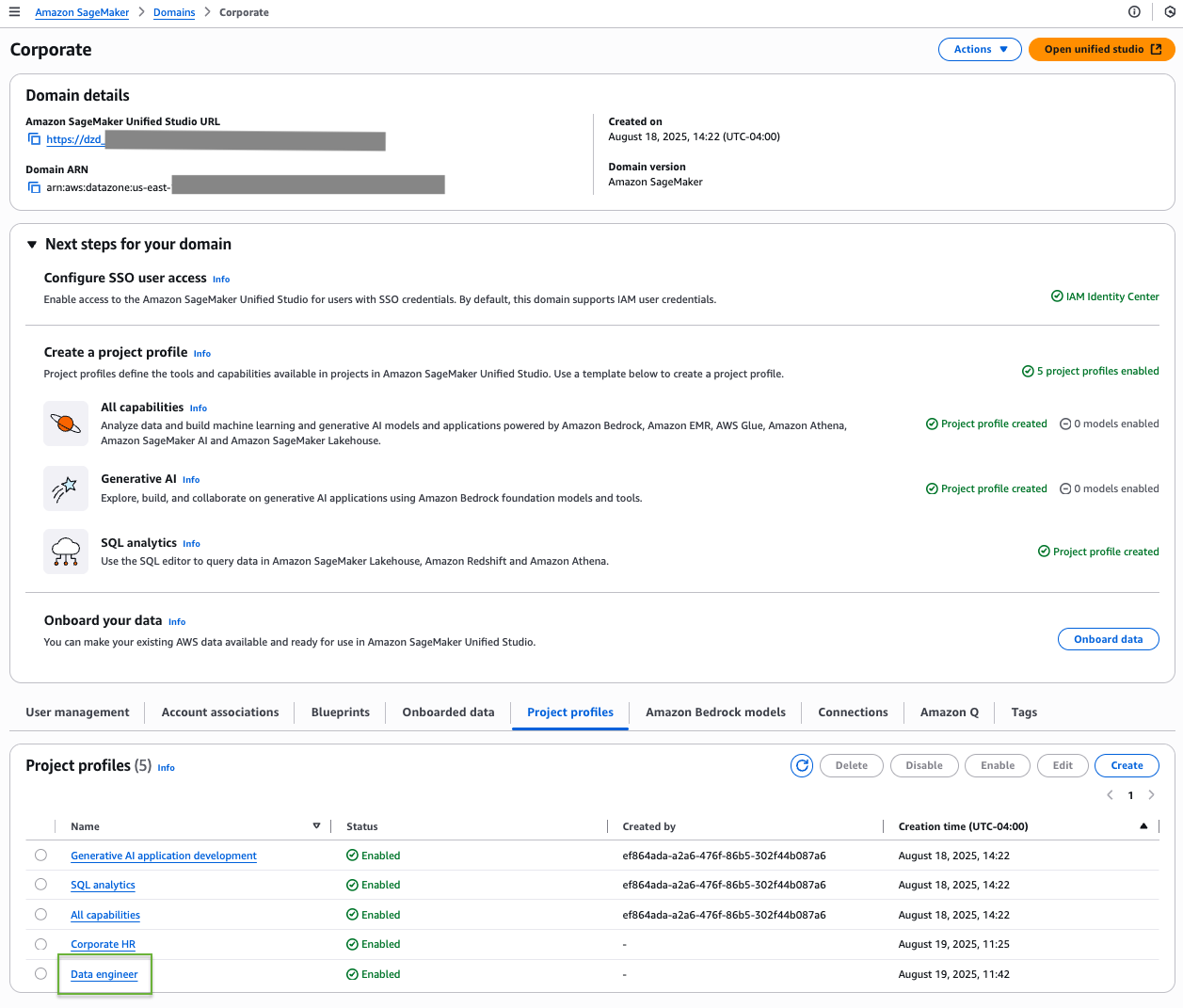
Navigate to your project profile and choose the Blueprints tab to see a list of available blueprints. Choose a blueprint to view its details.
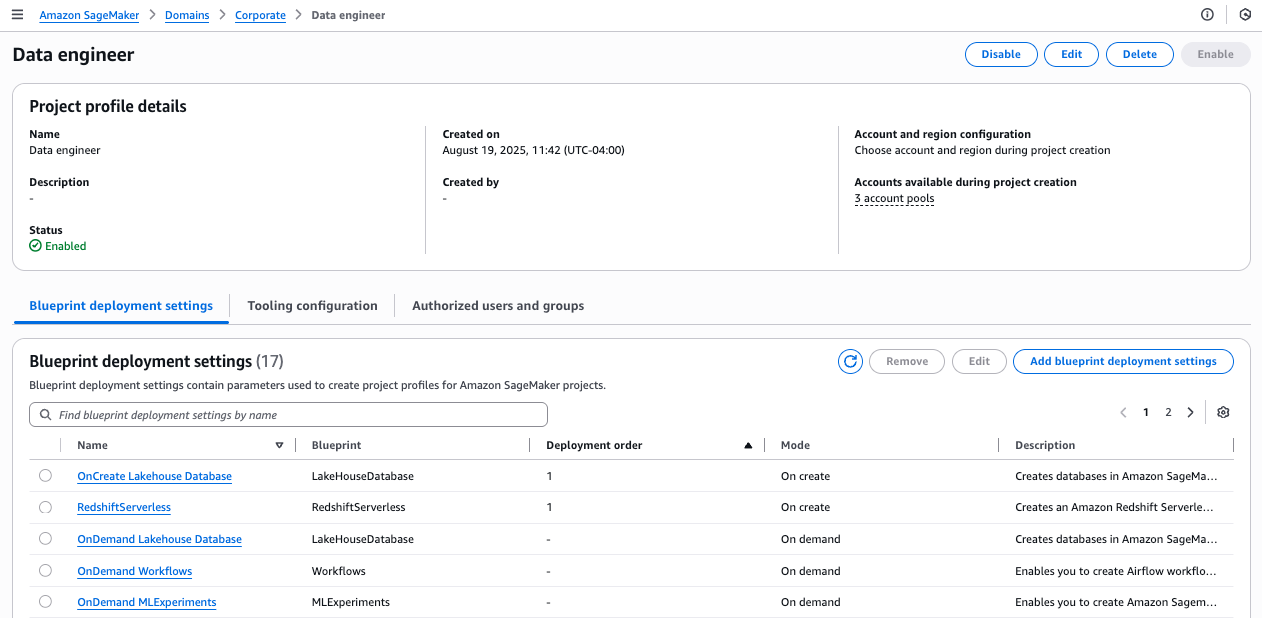
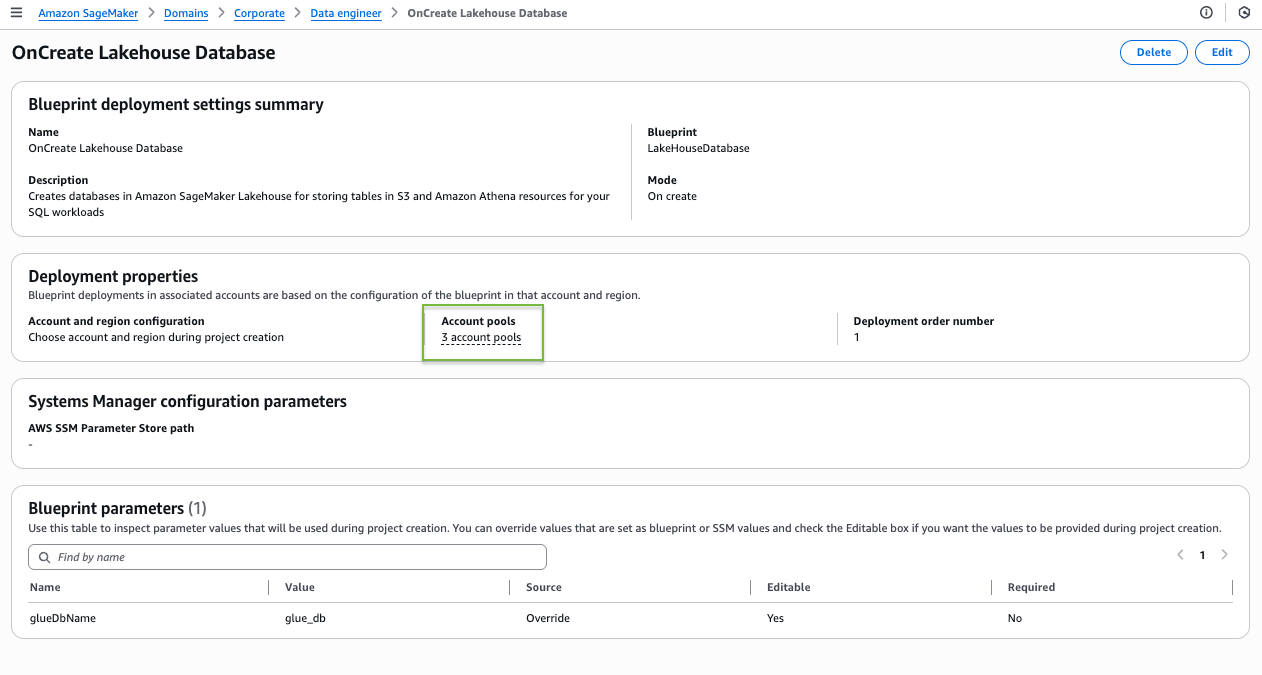
On the blueprint details page, the blueprint shows as deployable to the three account pools you associated with this project profile.
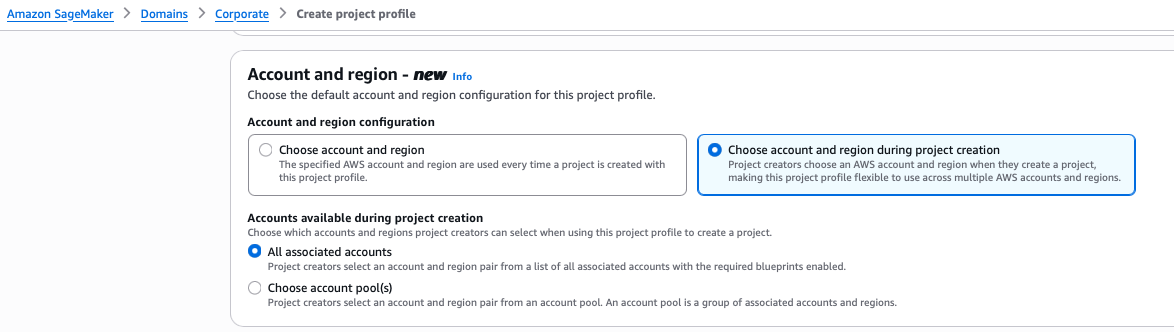
Scenario 3: Project profile with all associated accounts
In this scenario, we create a project profile linked to all the associated accounts for this domain. Complete the following steps:
- On the SageMaker console, choose Domains in the navigation pane.
- On the Project profiles tab, choose Create.
- Enter a name and description for your profile.
- Choose an appropriate project profile template that aligns with your project’s needs.
- Select Choose account and region during project creation.
- Select All associated accounts.
- Leave the remaining settings as default and choose Create project profile.
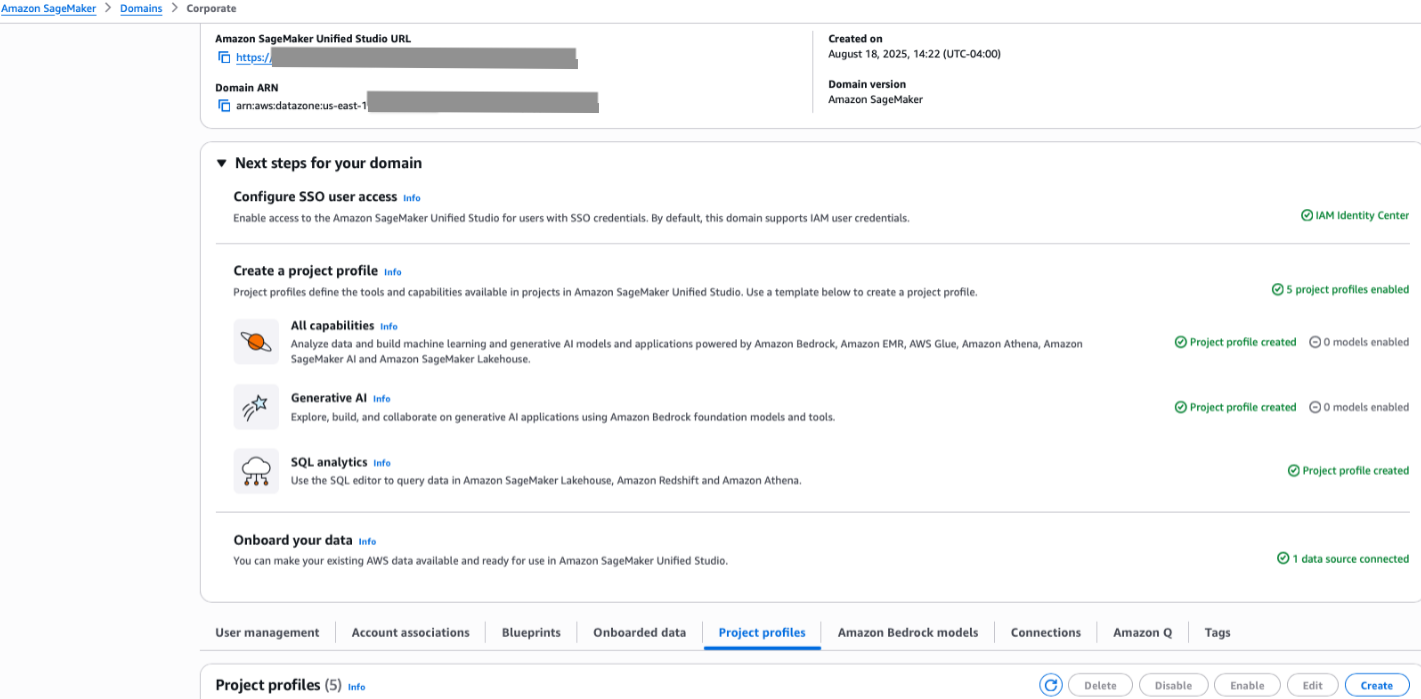
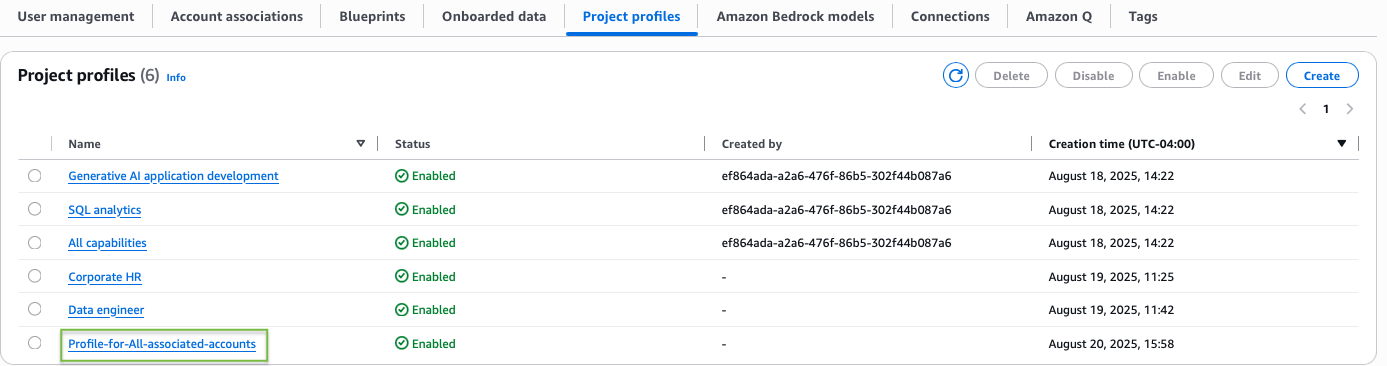
You can find your new profile listed on the Project profiles tab.
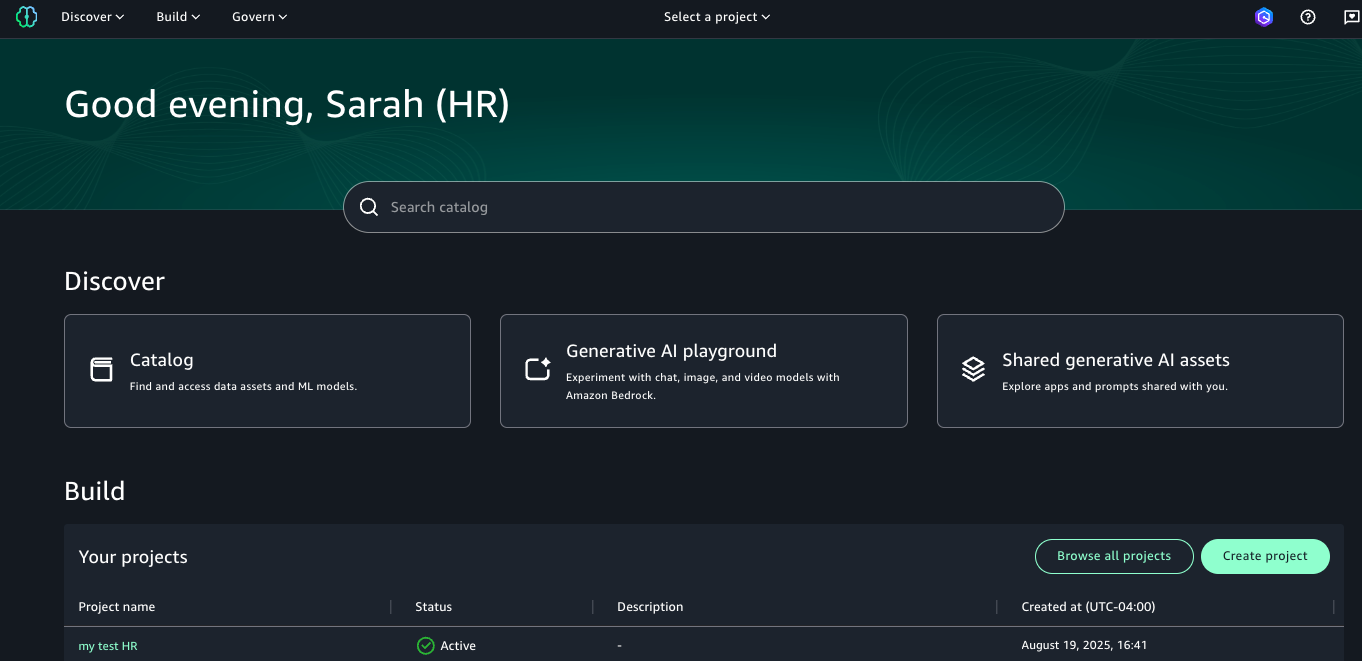
Project owner tasks
Now that the administrator has created project profiles for the account pools, project owners can log in to SageMaker to create projects for their account pools. In this section, we demonstrate the procedure to create a project using an account-agnostic project profile with a single account pool. You can use the same procedure to create projects using an account-agnostic project profile with multiple account pools.
For this scenario, Sarah from HR will create a project for the HR team, using the Corporate HR team profile that is associated with the HR account pool.
- On the SageMaker portal, choose Create project.
- Enter a name and optional description.
- Choose the Corporate HR project profile.
- Choose Continue.
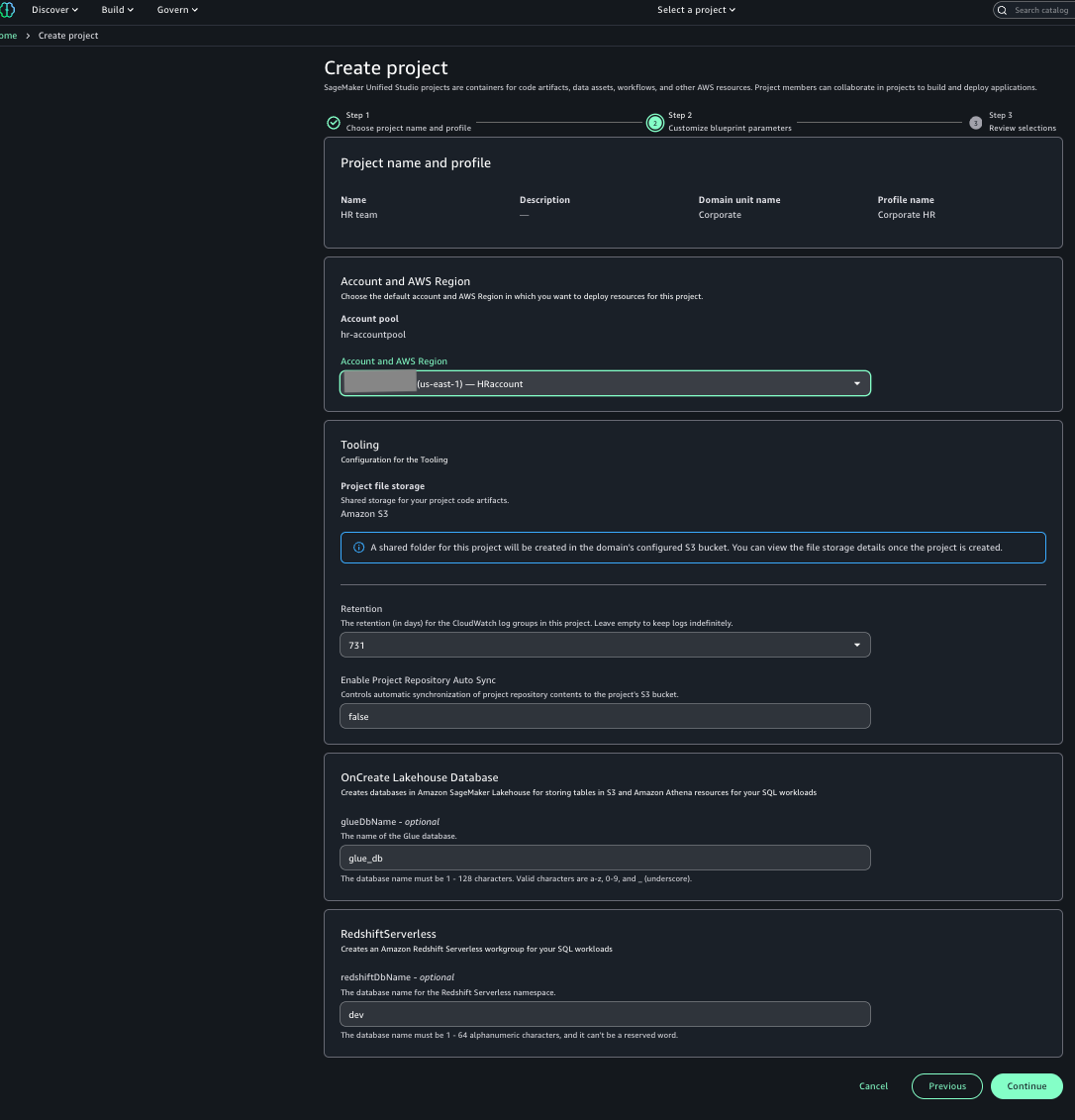
- For Account and AWS Region, choose the HR account.
- Choose Continue.
- Review the information and choose Create project.
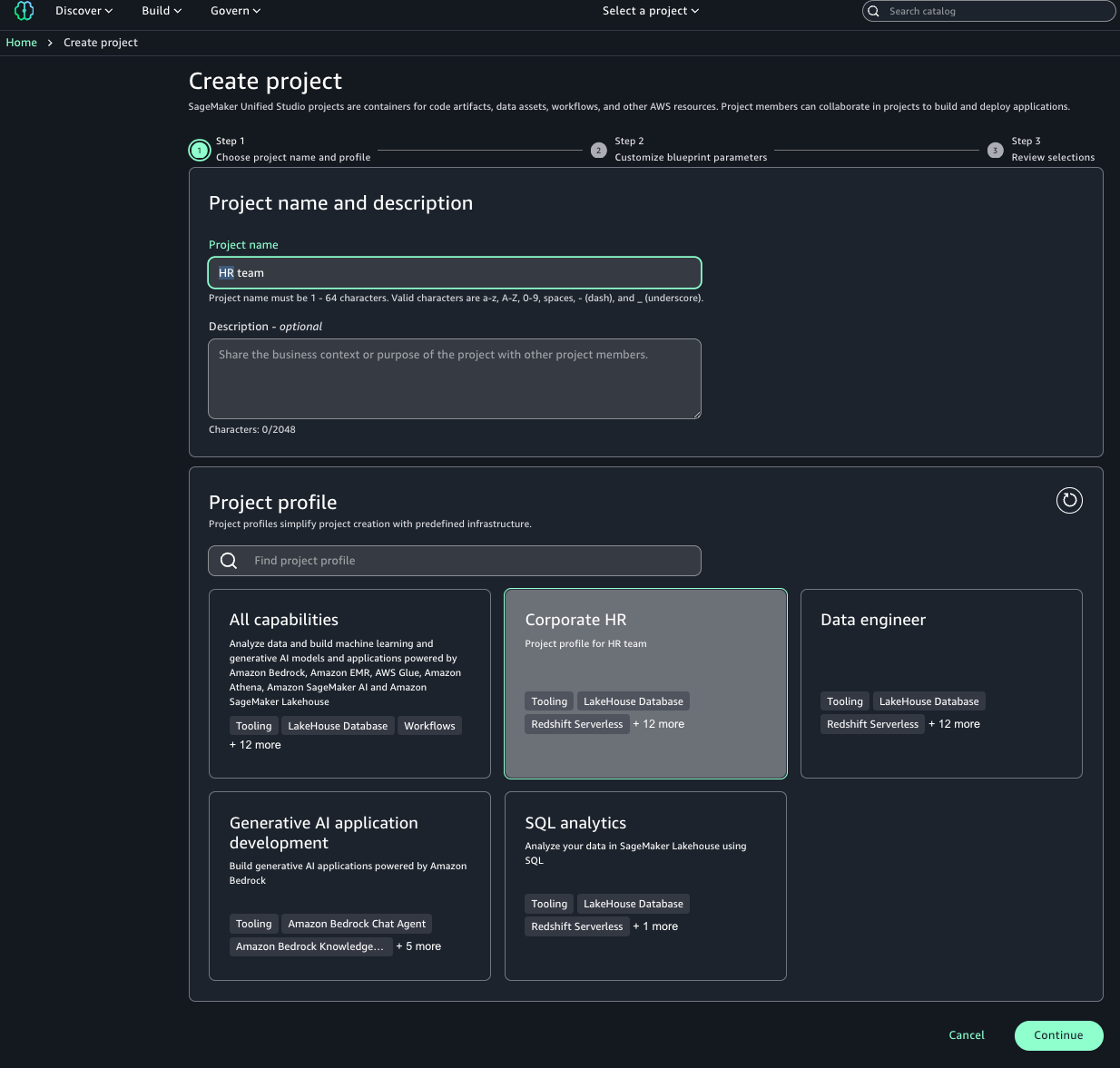

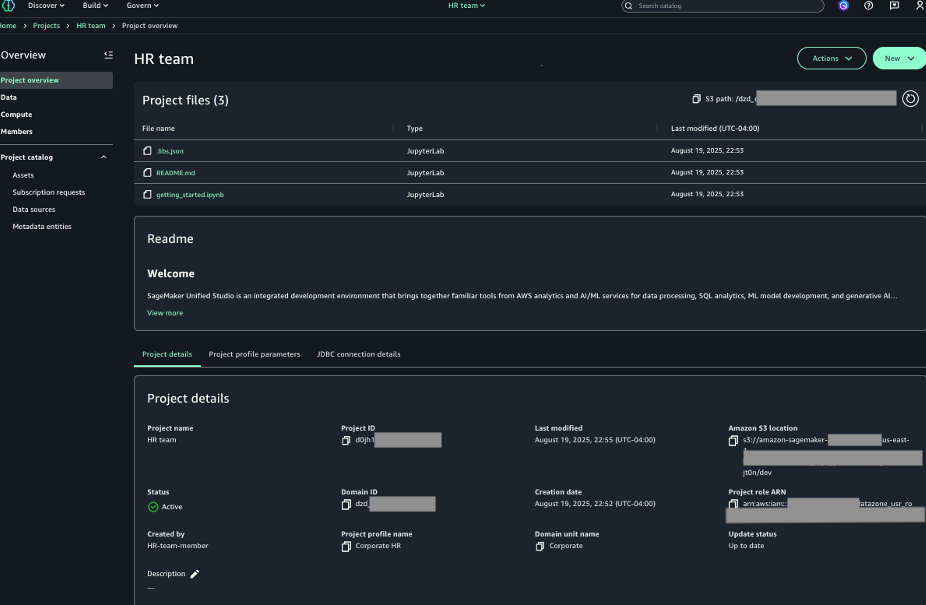
You can view the successfully created project.
Clean up
To clean up resources, complete the following steps:
- Delete the projects using the AWS CLI:
- Delete the account pools:
Conclusion
In this post, we discussed how account-agnostic project profiles can help organizations simplify and streamline the management of SageMaker project creation while maintaining enhanced security and governance features. To learn more about account-agnostic project profiles in SageMaker, refer to Account pools in Amazon SageMaker Unified Studio, and demo: account-agnostic project profile in Amazon SageMaker.
 Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges. Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS.
Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS. Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges.
Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges. Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
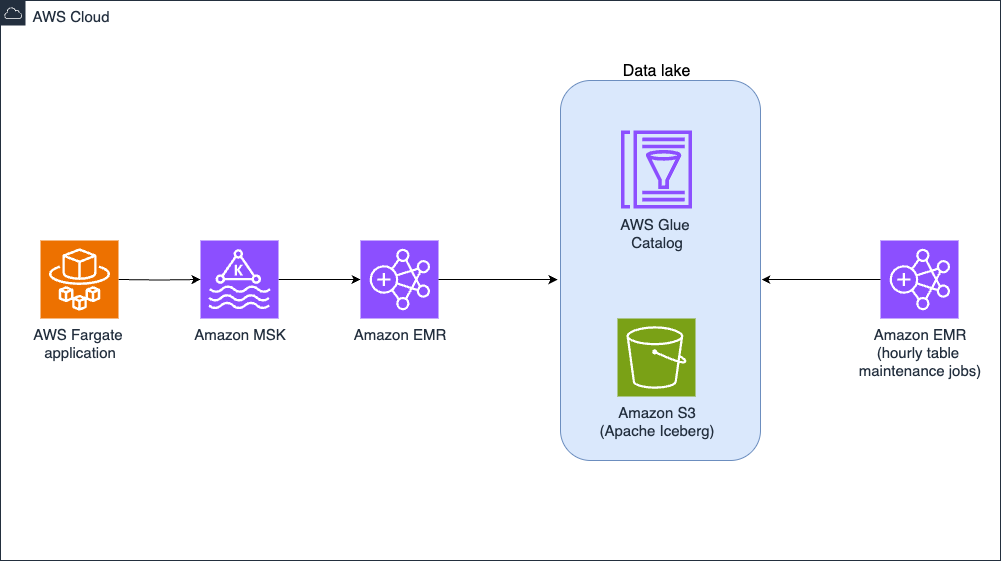
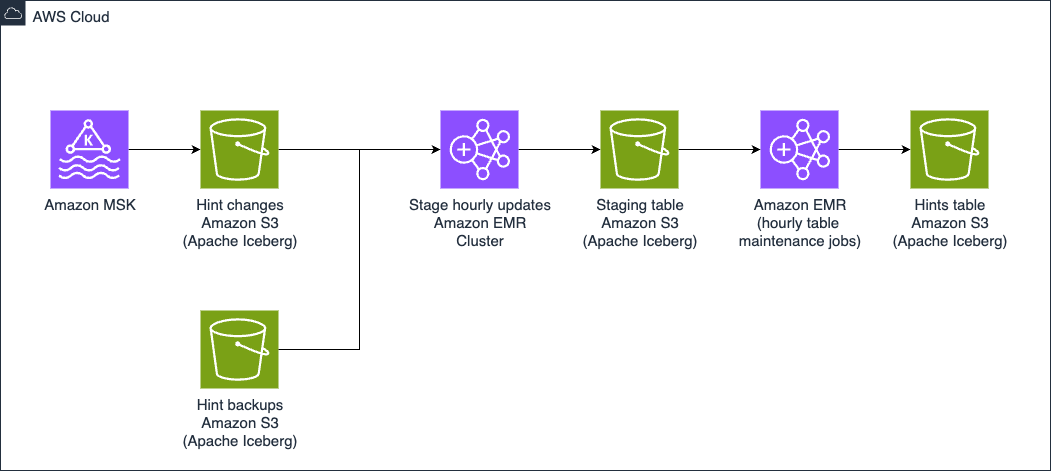
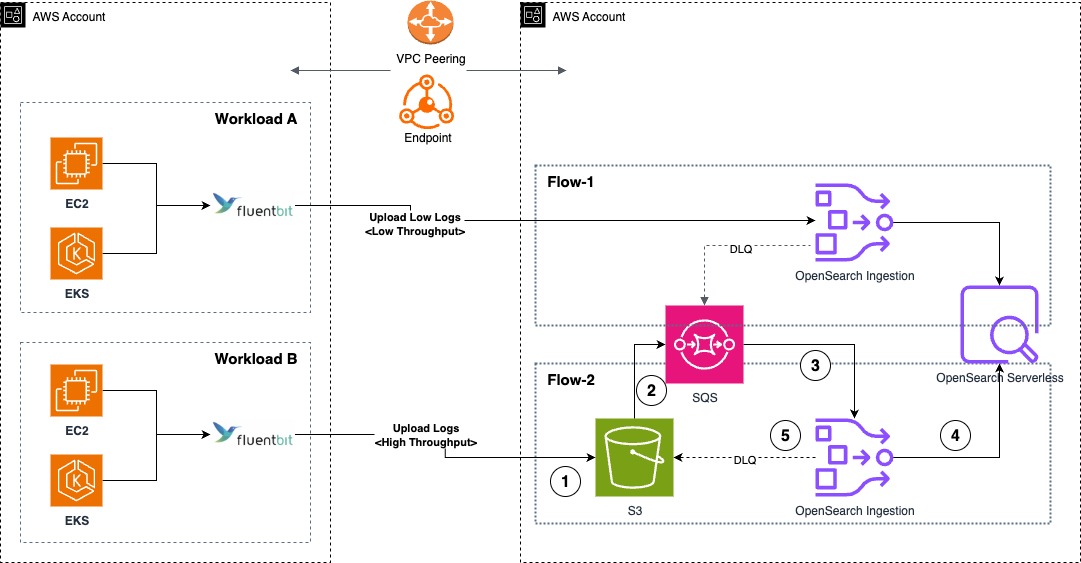

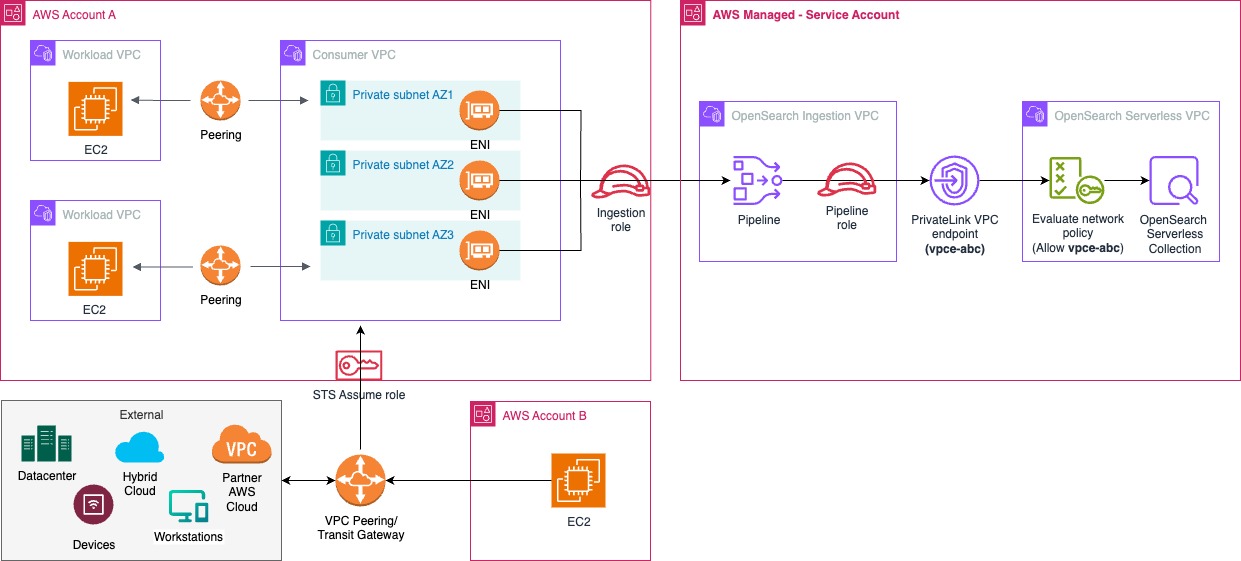
 Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community. Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges. Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.






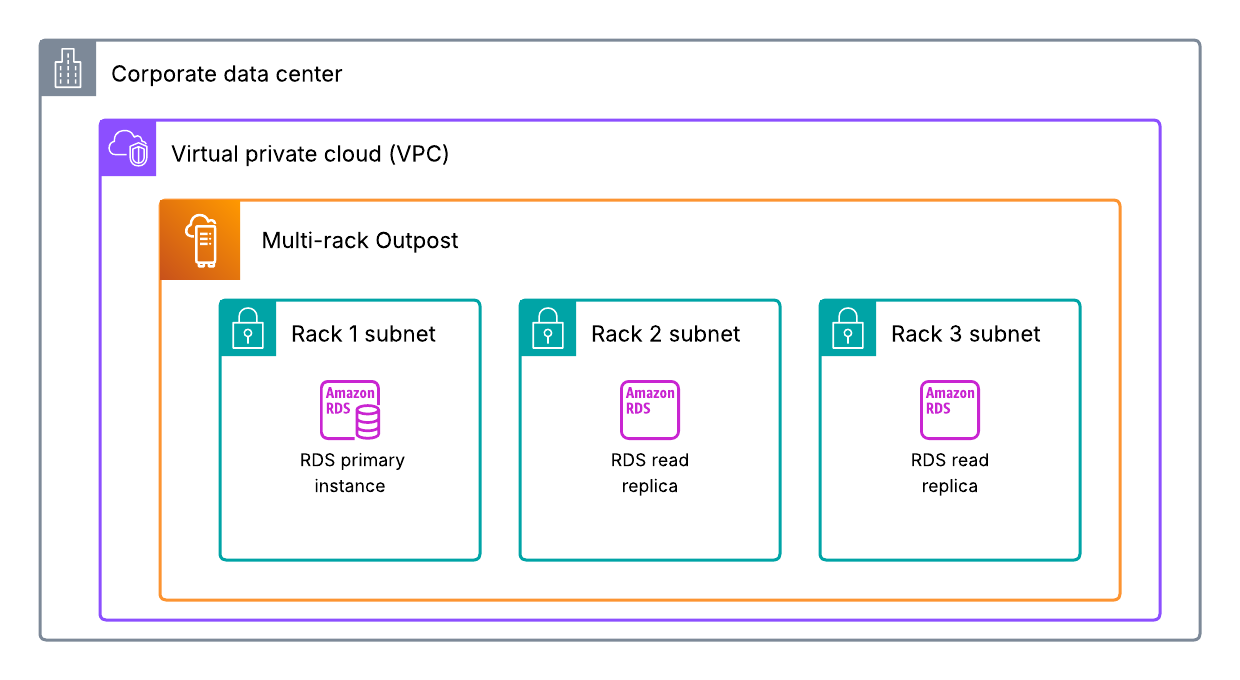
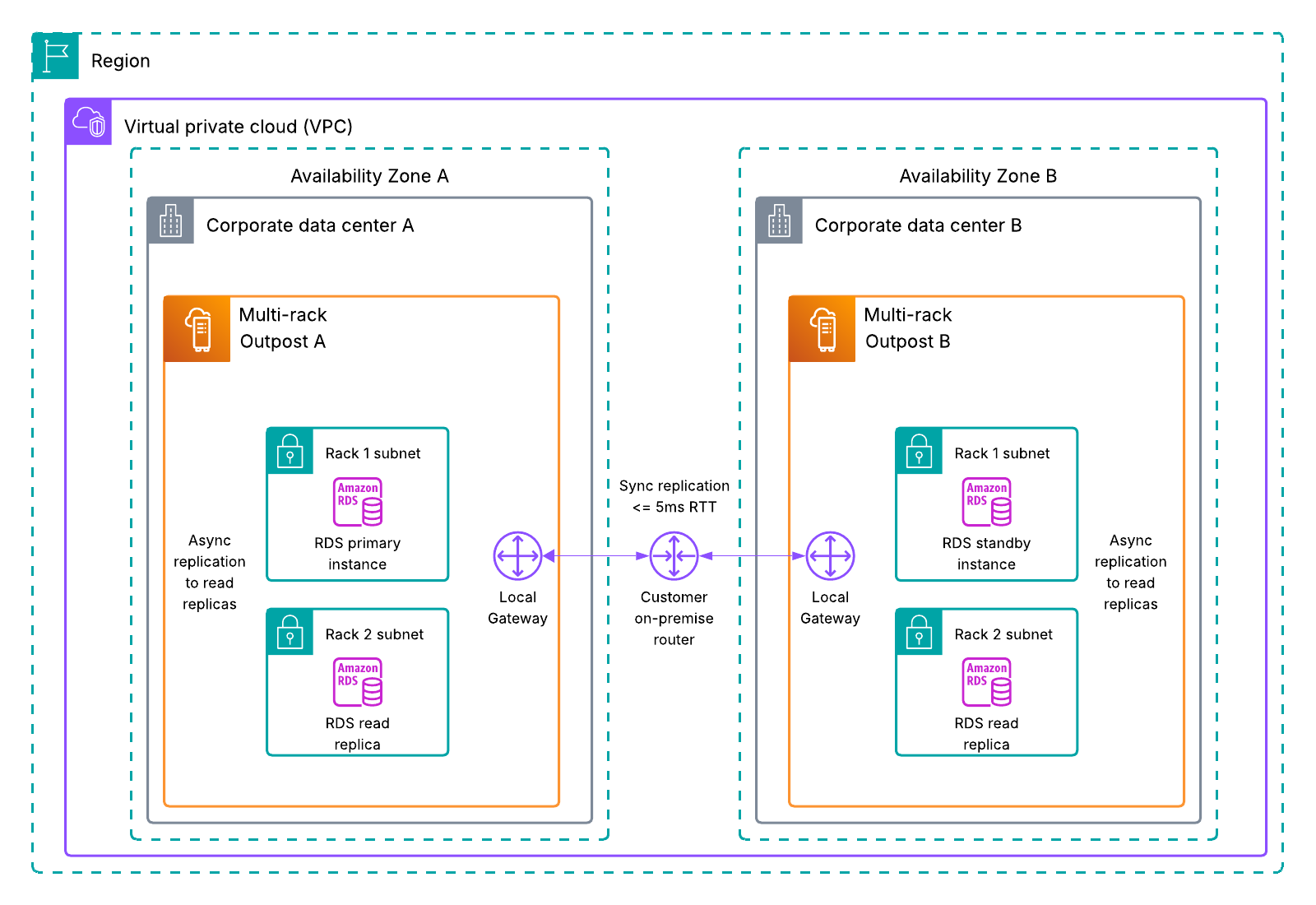
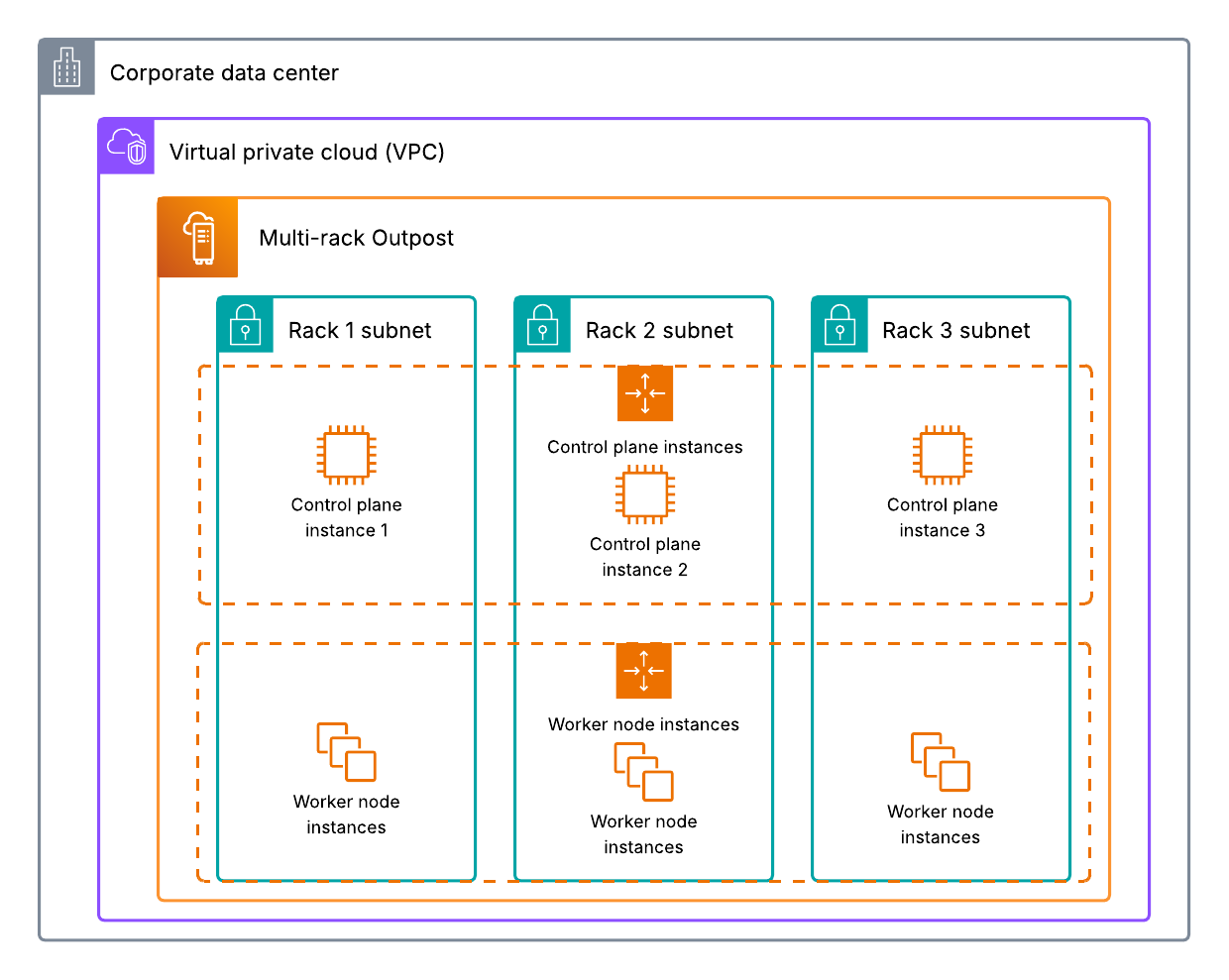
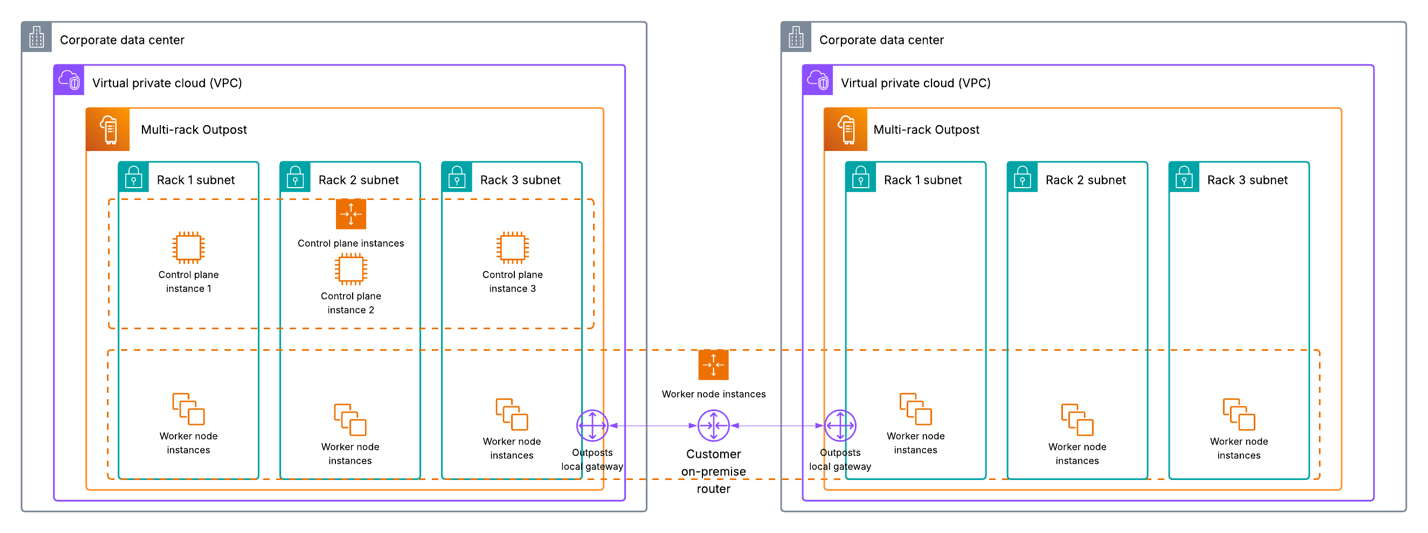





 Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS.
Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS. Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications. Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement. Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.
Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.
 Gagan Brahmi is a Specialist Senior Solutions Architect at Amazon Web Services (AWS), specializing in Data Analytics and AI/ML solutions. With over 20 years in information technology, he helps customers architect scalable, high-performance analytics platforms using distributed data processing, real-time streaming technologies, and machine learning services on AWS. When not designing cloud solutions, Gagan enjoys exploring new places with his family.
Gagan Brahmi is a Specialist Senior Solutions Architect at Amazon Web Services (AWS), specializing in Data Analytics and AI/ML solutions. With over 20 years in information technology, he helps customers architect scalable, high-performance analytics platforms using distributed data processing, real-time streaming technologies, and machine learning services on AWS. When not designing cloud solutions, Gagan enjoys exploring new places with his family. Arun Shanmugam is a Senior Analytics Solutions Architect at AWS, with a focus on building modern data architecture. He has been successfully delivering scalable data analytics solutions for customers across diverse industries. Outside of work, Arun is an avid outdoor enthusiast who actively engages in CrossFit, road biking, and cricket.
Arun Shanmugam is a Senior Analytics Solutions Architect at AWS, with a focus on building modern data architecture. He has been successfully delivering scalable data analytics solutions for customers across diverse industries. Outside of work, Arun is an avid outdoor enthusiast who actively engages in CrossFit, road biking, and cricket. George Oakes is a Senior Hybrid Solutions Architect at AWS, with a focus on edge, on-premise, and low latency architectures. He has been successfully delivering scalable hybrid AWS solutions for customers across diverse industries. Outside of work, George is an avid outdoor enthusiast who enjoys hiking and visiting parks and UNESCO sites around.
George Oakes is a Senior Hybrid Solutions Architect at AWS, with a focus on edge, on-premise, and low latency architectures. He has been successfully delivering scalable hybrid AWS solutions for customers across diverse industries. Outside of work, George is an avid outdoor enthusiast who enjoys hiking and visiting parks and UNESCO sites around.
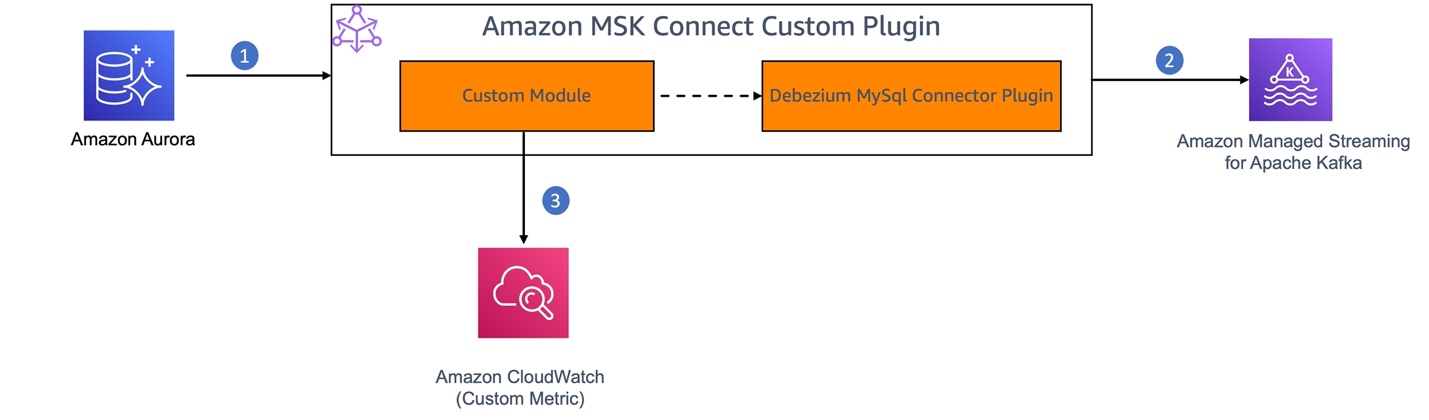
 Jaydev Nath is a Solutions Architect at AWS, where he works with ISV customers to build secure, scalable, reliable, and cost-efficient cloud solutions. He brings strong expertise in building SaaS architecture on AWS with a focus on Generative AI and data analytics technologies to help deliver practical, valuable business outcomes for customers.
Jaydev Nath is a Solutions Architect at AWS, where he works with ISV customers to build secure, scalable, reliable, and cost-efficient cloud solutions. He brings strong expertise in building SaaS architecture on AWS with a focus on Generative AI and data analytics technologies to help deliver practical, valuable business outcomes for customers. David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights.
David John Chakram is a Principal Solutions Architect at AWS. He specializes in building data platforms and architecting seamless data ecosystems. With a profound passion for databases, data analytics, and machine learning, he excels at transforming complex data challenges into innovative solutions and driving businesses forward with data-driven insights. Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.
Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.