Post Syndicated from Adam Thomas original https://aws.amazon.com/blogs/devops/smithy-server-and-client-generator-for-typescript/
We’re excited to announce the Developer Preview of Smithy’s server and client generators for TypeScript. This enables developers to write concise, type-safe code in the same model-first manner that AWS has used to develop its services. Smithy is AWS’s open-source Interface Definition Language (IDL) for web services. AWS uses Smithy and its internal predecessor to model services, generate server scaffolding, and generate rich clients in multiple languages, such as the AWS SDKs.
If you’re unfamiliar with Smithy, check out the Smithy website and watch an introductory talk from Michael Dowling, Smithy’s Principal Engineer.
This post will demonstrate how you can write a simple Smithy model, write a service that implements the model, deploy it to AWS Lambda, and call it using a generated client.
What can the server generator do for me?
Using Smithy and its server generator unlocks model-first development. Model-first development puts your customers first. This forces you to define your interface first rather than let your API to become implicitly defined by your implementation choices.
Smithy’s server generator for TypeScript enables development at a higher level of abstraction. By making serialization, deserialization, and routing an implementation detail in generated code, service developers can focus on writing code against modeled types, rather than against raw HTTP requests. Your business logic and unit tests will be cleaner and more readable, and the way that your messages are represented on the wire is defined explicitly by a protocol, not implicitly by your JSON parser.
The server generator also lets you leverage TypeScript’s type safety. Not only is the business logic of your service written against strongly typed interfaces, but also you can reference your service’s types in your AWS Cloud Development Kit (AWS CDK) definition. This makes sure that your stack will fail at build time rather than deployment time if it’s out of sync with your model.
Finally, using Smithy for service generation lets you ship clients in Smithy’s growing portfolio of generated clients. We’re unveiling a developer preview of the client generator for TypeScript today as well, and we’ll continue to unveil more implementations in the future.
The architecture of a Smithy service
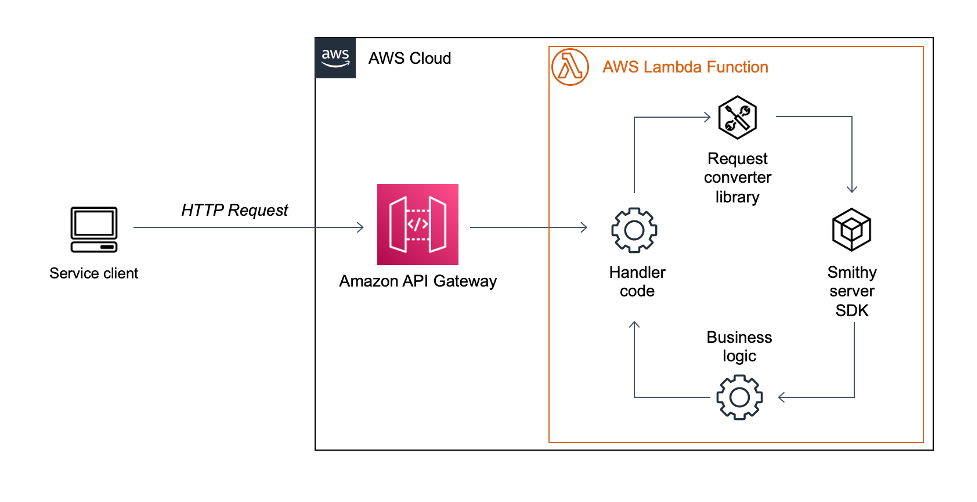
A Smithy service looks much like any other web service running on Lambda behind Amazon API Gateway. The difference lies in the code itself. Where a standard service might use a generic deserializer to parse an incoming request and bind it to an object, a Smithy service relies on code generation for deserialization, serialization, validation, and the object model itself. These functions are generated into a standalone library known as a Smithy server SDK. Using a server SDK with one of AWS’s prepackaged request converters, service developers can focus on their business logic, rather than the undifferentiated heavy lifting of parsing and generating HTTP requests and responses.

Walkthrough
This post will walk you through the process of building and using a Smithy service, from modeling to deployment.
By the end, you should be able to:
- Model a simple REST service in Smithy
- Generate a Smithy server SDK for TypeScript
- Implement a service in Lambda using the generated server SDK
- Deploy the service to AWS using the AWS CDK
- Generate a client SDK, and use it to call the deployed service
The complete example described in this post can be found here.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Checking out the sample repository
Create a new repository from the template repository here.
To clone the application in your browser
- Open https://github.com/aws-samples/smithy-server-generator-typescript-sample in your browser
- Select “Use this template” in the top right-hand corner
- Fill out the form, and select “Create repository from template”
- Clone your new repository from GitHub by following the instructions in the “Code” dropdown
Exploring and setting up the sample application
The sample application is split into three separate submodules:
- model – contains the Smithy model that defines the service
- Server – contains the code generation setup, application logic, and CDK stack for the service
- typescript-client – contains the code generation setup for a rich client generated in TypeScript
To bootstrap the sample application and run the initial build
- Open a terminal and navigate to the root of the sample application
- Run the following command:
./gradlew build && yarn install
- Wait until the build finishes successfully
Modeling a service using Smithy
In an IDE of your choice, open the file at model/src/main/smithy/main.smithy. This file defines the interface for the sample web service, a service that can echo strings back to the caller, as well as provide the string length.
The service definition forms the root of a Smithy model. It defines the operations that are available to clients, as well as common errors that are thrown by all of the operations in a service.
@sigv4(name: "execute-api")
@restJson1
service StringWizard {
version: "2018-05-10",
operations: [Echo, Length],
errors: [ValidationException],
}
This service uses the @sigv4 trait to indicate that calls must be signed with AWS Signature V4. In the sample application, API Gateway’s Identity and Access Management (IAM) Authentication support provides this functionality.
@restJson1 indicates the protocol supported by this service. RestJson1 is Smithy’s built-in protocol for RESTful web services that use JSON for requests and responses.
This service advertises two operations: Echo and Length. Furthermore, it indicates that every operation on the service must be expected to throw ValidationException, if an invalid input is supplied.
Next, let’s look at the definition of the Length operation and its input type.
/// An operation that computes the length of a string
/// provided on the URI path
@readonly
@http(code: 200, method: "GET", uri: "/length/{string}",)
operation Length {
input: LengthInput,
output: LengthOutput,
errors: [PalindromeException],
}
@input
structure LengthInput {
@required
@httpLabel
string: String,
}
This operation uses the @http trait to model how requests are processed with restJson1, including the method (GET) and how the URI is formed (using a label to bind the string field from LengthInput to a path segment). HTTP binding with Smithy can be explored in depth at Smithy’s documentation page.
Note that this operation can also throw a PalindromeException, which we’ll explore in more detail when we check out the business logic.
Updating the Smithy model to add additional constraints to the input
Smithy constraint traits are used to enable additional validation for input types. Server SDKs automatically perform validation based on the Smithy constraints in the model. Let’s add a new constraint to the input for the Length operation. Moreover, let’s make sure that only alphanumeric characters can be passed in by the caller.
- Open model/src/main/smithy/main.smithy in an editor
- Add a @pattern constraint to the string member of Length input. It should look like this:
structure LengthInput {
@required
@httpLabel
@pattern(“^[a-zA-Z0-9]$”)
string: String,
}
- Open a terminal, and navigate to the root of the sample application
- Run the following command:
yarn build
- Wait for the build to finish successfully
Using the Smithy Server Generator for TypeScript
The key component of a Smithy web service is its code generator, which translates the Smithy model into actual code. You’ve already run the code generator – it runs every time that you build the sample application.
The codegen directory inside of the server submodule is where the Smithy Server Generator for TypeScript is configured and run. The server generator uses Smithy Build to build, and it’s configured by smithy-build.json.
{
"version" : "1.0",
"outputDirectory" : "build/output",
"projections" : {
"ts-server" : {
"plugins": {
"typescript-ssdk-codegen" : {
"package" : "@smithy-demo/string-wizard-service-ssdk",
"packageVersion": "0.0.1"
}
}
},
"apigateway" : {
"plugins" : {
"openapi": {
"service": "software.amazon.smithy.demo#StringWizard",
"protocol": "aws.protocols#restJson1",
"apiGatewayType" : "REST"
}
}
}
}
}
This smithy-build configures two projections. The ts-server projection generates the server SDK by invoking the typescript-ssdk-codegen plugin. The package and packageVersion arguments are used to generate an npm package that you can add as a dependency in your server code.
The OpenAPI projection configures Smithy’s OpenAPI converter to generate a file that can be imported into API Gateway to host this service. It uses Smithy’s ability to extend models via the imports keyword to extend the base model with an additional API Gateway configuration. The generated OpenAPI specification is used by the CDK stack, which we’ll explore later.
If you open package.json in the server submodule, then you’ll notice this line in the dependencies section:
"@smithy-demo/string-wizard-service-ssdk": "workspace:server/codegen/build/smithyprojections/server-codegen/ts-server/typescript-ssdk-codegen"
The key, @smithy-demo/string-wizard-service-ssdk, matches the package key in the smithy-build.json file. The value uses Yarn’s workspaces feature to set up a local dependency on the generated server SDK. This lets you use the server SDK as a standalone npm dependency without publishing it to a repository. Since we bundle the server application into a zip file before uploading it to Lambda, you can treat the server SDK as an implementation detail that isn’t published externally.
We won’t get into the details here, but you can see the specifics of how the code generator is invoked by looking at the regenerate:ssdk script in the server’s package.json, as well as the build.gradle file in the server’s codegen directory.
Implementing an operation using a server SDK
The server generator takes care of the undifferentiated heavy lifting of writing a Smithy service. However, there are still two tasks left for the service developer: writing the Lambda entrypoint, and implementing the operation’s business logic.
First, let’s look at the entrypoint for the Length operation. Open server/src/length_handler.ts in an editor. You should see the following content:
import { getLengthHandler } from "@smithy-demo/string-wizard-service-ssdk";
import { APIGatewayProxyHandler } from "aws-lambda";
import { LengthOperation } from "./length";
import { getApiGatewayHandler } from "./apigateway";
// This is the entry point for the Lambda Function that services the LengthOperation
export const lambdaHandler: APIGatewayProxyHandler = getApiGatewayHandler(getLengthHandler(LengthOperation));
If you’ve written a Lambda entry-point before, then exporting a function of type APIGatewayProxyHandler will be familiar to you. However, there are a few new pieces here. First, we have a function from the server SDK, called getLengthHandler, that takes a Smithy Operation type and returns a ServiceHandler. Operation is the interface that the server SDK uses to encapsulate business logic. The core task of implementing a Smithy service is to implement Operations. ServiceHandler is the interface that encapsulates the generated logic of a server SDK. It’s the black box that handles serialization, deserialization, error handling, validation, and routing.
The getApiGatewayHandler function simply invokes the request and response conversion logic, and then builds a custom context for the operation. We won’t go into their details here.
Next, let’s explore the operation implementation. Open server/src/length.ts in an editor. You should see the following content:
import { Operation } from "@aws-smithy/server-common";
import {
LengthServerInput,
LengthServerOutput,
PalindromeException,
} from "@smithy-demo/string-wizard-service-ssdk";
import { HandlerContext } from "./apigateway";
import { reverse } from "./util";
// This is the implementation of business logic of the LengthOperation
export const LengthOperation: Operation<LengthServerInput, LengthServerOutput, HandlerContext> = async (
input,
context
) => {
console.log(`Received Length operation from: ${context.user}`);
if (input.string != undefined && input.string === reverse(input.string)) {
throw new PalindromeException({ message: "Cannot handle palindrome" });
}
return {
length: input.string?.length,
};
};
Let’s look at this implementation piece-by-piece. First, the function type Operation<LengthServerInput, LengthServerOutput, HandlerContext> provides the type-safe interface for our business logic. LengthServerInput and LengthServerOutput are the code generated types that correspond to the input and output types for the Length operation in our Smithy model. If we use the wrong type arguments for the Operation, then it will fail type checks against the getLengthHandler function in the entry-point. If we try to access the incorrect properties on the input, then we’ll also see type checker failures. This is one of the core tenets of the Smithy Server Generator for TypeScript: writing a web service should be as strongly typed as writing anything else.
Next, let’s look at the section that validates that the input isn’t a palindrome:
if (input.string != undefined && input.string === reverse(input.string)) {
throw new PalindromeException({ message: "Cannot handle palindrome" });
}
Although the server SDK can validate the input against Smithy’s constraint traits, there is no constraint trait for rejecting palindromes. Therefore, we must include this validation in our business logic. Our Smithy model includes a PalindromeException definition that includes a message member. This is generated as a standard subclass of Error with a constructor that takes in a message that your operation implementation can throw like any other error. This will be caught and properly rendered as a response by the server SDK.
Finally, there’s the return statement. Since the Smithy model defines LengthOutput as a structure containing an integer member called length, we return an object that has the same structural type here.
Note that this business logic doesn’t have to consider serialization, or the wire format of the request or response, let alone anything else related to HTTP or API Gateway. The unit tests in src/length/length.spec.ts reflect this. They’re the same standard unit tests as you would write against any other TypeScript class. The server SDK lets you write your business logic at a higher level of abstraction, thus simplifying your unit testing and letting your developers focus on their business logic rather than the messy details.
Deploying the sample application
The sample application utilizes the AWS CDK to deploy itself to your AWS account. Explore the CDK definition in server/lib/cdk-stack.ts. An in-depth exploration of the stack is out of the scope for this post, but it looks largely like any other AWS application that deploys TypeScript code to Lambda behind API Gateway.
The key difference is that the cdk stack can rely on a generated OpenAPI definition for the API Gateway resource. This makes sure that your deployed application always matches your Smithy model. Furthermore, it can use the server SDK’s generated types to make sure that every modeled operation has an implementation deployed to Lambda. This means that forgetting to wire up the implementation for a new operation becomes a compile-time failure, rather than a runtime one.
To deploy the sample application from the command line
-
- Open a terminal and navigate to the server directory of your sample application.
- Run the following command:
yarn cdk deploy
- The cdk will display a list of security-sensitive resources that will be deployed to your account. These consist mostly of AWS Identity and Access Management (IAM) roles used by your Lambda functions for execution. Enter
y to continue deploying the application to your account.
- When it has completed, the CDK will print your new application’s endpoint and the CloudFormation stack containing your application to the console. It will look something like the following:
Outputs:
StringWizardService.StringWizardApiEndpoint59072E9B
= https://RANDOMSTRING.execute-api.us-west-2.amazonaws.com/prod/
Stack ARN:
arn:aws:cloudformation:us-west-2:YOURACCOUNTID:stack/StringWizardService/SOME-UUID
- Log on to your AWS account in the AWS Management Console.
- Navigate to the Lambda console. You should see two new functions: one that starts with StringWizardService-EchoFunction, and one that starts with StringWizardService-EchoFunction. These are the implementations of your Smithy service’s operations.
- Navigate to the Amazon API Gateway console. You should see a new REST API named StringWizardAPI, with Resources
POST /echo and GET /length/{string}, corresponding to your Smithy model.
Calling the sample application with a generated client
The last piece of the Smithy puzzle is the strongly-typed generated client generated by the Smithy Client Generator for TypeScript. It’s located in the typescript-client folder, which has a codegen folder that uses SmithyBuild to generate a client in much the same manner as the server.
The sample application ships with a simple wrapper script for the length operation that uses the generated client to build a rudimentary CLI. Open the typescript-client/bin/length.ts file in your editor. The contents will look like the following:
#!/usr/bin/env node
import {LengthCommand, StringWizardClient} from "@smithy-demo/string-client";
const client = new StringWizardClient({endpoint: process.argv[2]});
client.send(new LengthCommand({
string: process.argv[3]
})).catch((err) => {
console.log("Failed with error: " + err);
process.exit(1);
}).then((res) => {
process.stderr.write(res.length?.toString() ?? "0");
});
If you’ve used the AWS SDK for JavaScript v3, this will look familiar. This is because it’s generated using the Smithy Client Generator for TypeScript!
From the code, you can see that the CLI takes two positional arguments: the endpoint for the deployed application, and an input string. Let’s give it a spin.
To call the deployed application using the generated client
- Open a terminal and navigate to the typescript-client directory.
- Run the following command to build the client:
yarn build
- Using the endpoint output by the CDK in the Deploying the sample application section above, run the following command:
yarn run str-length https://RANDOMSTRING.execute-api.us-west-2.amazonaws.com/prod/ foo
- You should see an output of 3, the length of foo.
- Next, trigger anerror by calling your endpoint with a palindrome by running the following command:
yarn run str-length https://RANDOMSTRING.execute-api.us-west-2.amazonaws.com/prod/ kayak
- You should see the following output:
Failed with error: PalindromeException: Cannot handle palindrome
Cleaning up
To avoid incurring future charges, delete the resources.
To delete the sample application using the CDK
- Open a terminal and navigate to the server directory.
- Run the following command:
yarn cdk destroy StringWizardService
- Answer y to the prompt
Are you sure you want to delete: StringWizardService (y/n)?
- Wait for the CDK to complete the deletion of your CloudFormation stack. You should see the following when it has completed:
✅ StringWizardService: destroyed
Conclusion
You have now used a Smithy model to define a service, explored how a generated server SDK can simplify your web service development, deployed the service to the AWS Cloud using the AWS CDK, and called the service using a strongly-typed generated client.
If you aren’t familiar with Smithy, but you want to learn more, then don’t forget to check out the documentation or the introductory video.
To learn more about the Smithy Server Generator for TypeScript, check out its documentation.
If you have feature requests, bug reports, feedback of any kind, or would like to contribute, head over to the GitHub repository.








































 Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports.
Edvin Hallvaxhiu is a Senior Global Security Architect with AWS Professional Services and is passionate about cybersecurity and automation. He helps customers build secure and compliant solutions in the cloud. Outside work, he likes traveling and sports. Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney.
Rahul Shaurya is a Senior Big Data Architect with AWS Professional Services. He helps and works closely with customers building data platforms and analytical applications on AWS. Outside of work, Rahul loves taking long walks with his dog Barney. Andrea Montanari is a Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS.
Andrea Montanari is a Big Data Architect with AWS Professional Services. He actively supports customers and partners in building analytics solutions at scale on AWS. María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud.
María Guerra is a Big Data Architect with AWS Professional Services. Maria has a background in data analytics and mechanical engineering. She helps customers architecting and developing data related workloads in the cloud. Pushpraj is a Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.
Pushpraj is a Data Architect with AWS Professional Services. He is passionate about Data and DevOps engineering. He helps customers build data driven applications at scale.