Post Syndicated from Milind Dabhole original https://aws.amazon.com/blogs/security/enabling-ai-adoption-at-scale-through-enterprise-risk-management-framework-part-2/
In Part 1 of this series, we explored the fundamental risks and governance considerations. In this part, we examine practical strategies for adapting your enterprise risk management framework (ERMF) to harness generative AI’s power while maintaining robust controls.
This part covers:
- Adapting your ERMF for the cloud
- Adapting your ERMF for generative AI
- Sustainable Risk Management
By the end of this post, you’ll have a roadmap for scaling generative AI adoption securely and responsibly.
Adapting your ERMF for the cloud
Before diving into generative AI-specific controls, it’s crucial to understand the fundamental infrastructure that enables these technologies. Cloud computing is the foundational infrastructure that has made generative AI possible and accessible at scale. The development and deployment of large language models and other generative AI systems require massive computational resources, vast amounts of data storage, and sophisticated distributed processing capabilities that cloud systems can efficiently provide.
Cloud technology differs from on-premises IT solutions, and the relationship between financial institutions and cloud service providers is also different from the relationship with a traditional outsourcing provider.
These differences change the nature of many risks that financial institutions face and how they manage them. However, if cloud technology is implemented in the right way, it can reduce risk and provide tools to help Chief Risk Officers (CROs) to manage risk too.
You can read more about how your ERMF needs to change for large scale cloud adoption in Is your Enterprise Risk Management Framework ready for the Cloud?
Adapting your ERMF for generative AI
Organizations adopting generative AI can use their enterprise risk management framework to realize business value while maintaining appropriate controls. This approach allows you to build on existing risk management practices while addressing generative AI’s unique characteristics.
For a structured approach to cloud-enabled AI transformation, the AWS Cloud Adoption Framework for AI, ML, and generative AI (AWS CAF for AI) provides detailed implementation guidance aligned with enterprise risk management principles. For a detailed user guide, see AWS User Guide to Governance, Risk and Compliance for Responsible AI Adoption within Financial Services Industries, available in AWS Artifact using your AWS sign in. AWS Artifact provides AWS security and compliance reports, helping organizations maintain compliance through best practices.
When it comes to model management and the AI system lifecycle, customers can consult ISO42001 AI Management, Section A6. This section encompasses capturing the objective and processes for the responsible design and development of AI systems, including criteria and requirements for each stage of the AI system life cycle. This guidance can help organizations verify that their model management practices align with industry standards for responsible AI development.
From a business leader’s perspective, incorporating generative AI considerations into your ERMF helps establish documented good practices, implement effective controls, and maintain transparency about usage across the enterprise. This enables both responsible innovation and prudent risk management. Here’s how organizations are approaching this:
Generative AI policy and governance foundations in ERMF
In the field of generative AI, organizations establish both guardrails for innovation and clear accountability for risk management. The three lines of defense model provides the structure for implementing these foundational elements:
- Acceptable use framework for your organization: Clear direction on appropriate generative AI use helps organizations manage risks while enabling innovation. The range of use cases for generative AI is large and likely to expand over the years, making it essential to have clear guidance on what applications are permitted and under what conditions. As organizations explore these opportunities, their framework can evolve with their experience and maturity.
- Risk accountability: The generative AI lifecycle—from use case selection through implementation and ongoing monitoring—requires clear ownership across business and control functions. While organizations can establish specific generative AI oversight mechanisms, these should integrate with existing governance structures. Risk reporting and accountability for generative AI initiatives should flow through established enterprise risk committees and governance boards, helping to facilitate consistent risk management across the organization rather than creating isolated pockets of oversight.
Implementation approach for generative AI: Putting principles into practice
Building on the three lines of defense model discussed earlier, organizations can adapt their risk management practices to address the unique characteristics of generative AI while using industry best practices and frameworks. This often involves evolving existing controls and introducing new ones specific to generative AI. AWS services have built-in capabilities that support these enhanced governance, risk management, and compliance requirements, helping organizations to implement controlled and responsible generative AI solutions. This includes, for example, Amazon Bedrock Guardrails, among many others.
Building on the risk areas we outlined earlier, we now explore how organizations can implement controls for each of these areas. For each, we describe the principle and the practical implementation considerations. While organizations might prioritize these areas differently based on their use cases and risk appetite, together they provide a framework for responsible generative AI adoption through ERMF.
While we explore high-level control principles that follow, technical teams can review the AWS Well-Architected Framework – Generative AI Lens for detailed architectural guidance that supports these governance objectives.
Fairness
Generative AI systems can deliver equitable outcomes across different stakeholder groups, helping organizations build trust and meet expectations. Organizations can support this by setting up clear fairness metrics for specific use cases, regularly assessing training data for bias, and closely monitoring performance across different groups. For high-stakes applications, additional checks can help facilitate fair treatment across diverse populations.
Amazon Bedrock Guardrails provides configurable safeguards to help maintain fair and unbiased outputs, with customizable thresholds to match different use case requirements. Amazon Bedrock provides comprehensive model evaluation tools including model cards with detailed bias metrics, to assess bias across demographic groups. Amazon Bedrock includes built-in prompt datasets like the Bias in Open-ended Language Generation Dataset (BOLD), which automatically evaluates fairness across key areas such as profession, gender, race, and various ideologies. These capabilities integrate with Amazon SageMaker Clarify for comprehensive bias detection and mitigation, supported by built-in bias metrics and reporting.
Explainability
Generative AI systems can provide understanding of their decision-making processes, supporting accountability and effective oversight. Explainability is essential for all generative AI systems—whether using custom-built or pre-built models, particularly for complex models like transformer networks.
Organizations can implement practical controls by establishing clear explainability thresholds based on use case risk levels. This remains an active industry challenge, with ongoing research and evolving approaches. For critical business applications, tailoring explanations to different stakeholders while maintaining accuracy can improve understanding and trust.
Amazon Bedrock provides tools that help identify which factors influenced the generative AI’s decisions, while maintaining detailed records of system inputs and outputs. For complex workflows, Chain-of-Thought (CoT) reasoning traces are available through Amazon Bedrock Agents, showing the step-by-step logic behind each decision. Organizations can monitor how responses are generated in real time. For Retrieval-Augmented Generation (RAG) applications, which optimize AI outputs by referencing specific knowledge bases, Amazon Bedrock Knowledge Bases automatically includes references and links to source materials used in generating responses.
Privacy and security
Generative AI systems benefit from strong privacy and security measures to protect sensitive information and help prevent unauthorized access or data exposure. These systems can potentially generate content or unintentionally reveal confidential data, which organizations can proactively manage.
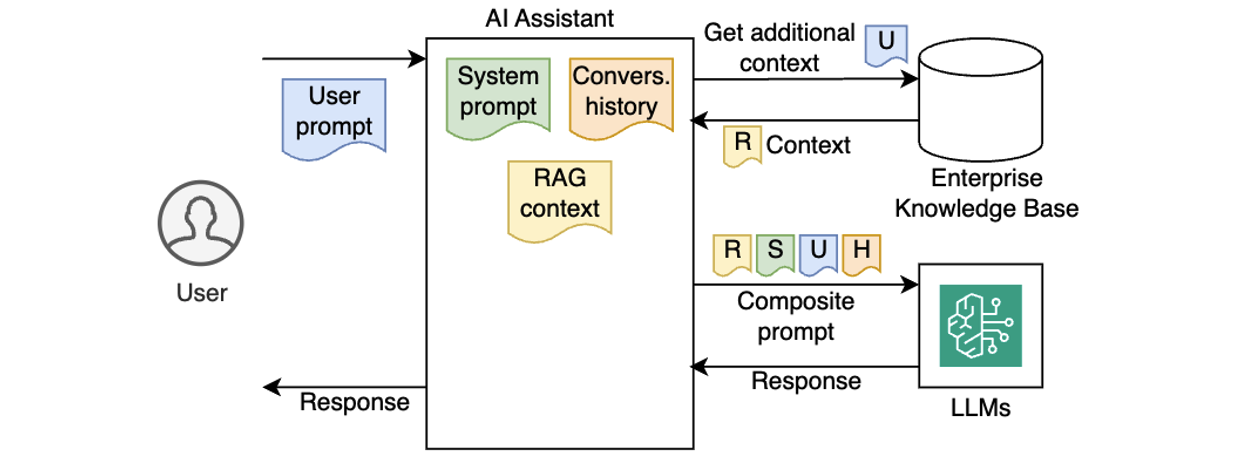
Organizations can set up multi-layered protection strategies, including access controls, content filtering, and data privacy safeguards. This can involve creating company-wide standards for prompt engineering to help prevent harmful outputs, using techniques like RAG to control information sources, and using automated systems to detect and protect personal information. Regular testing and validation, especially to comply with regulations like GDPR, can be part of the development and deployment process.
Amazon Bedrock implements multiple security layers including private endpoints with Amazon Virtual Private Cloud (Amazon VPC) support, fine-grained AWS Identity and Access Management (IAM) access control, and end-to-end encryption. Importantly, it maintains no persistent storage of prompt or completion data and helps preserve model provider isolation.
Amazon Bedrock Guardrails provides sensitive information filters that can detect and protect personally identifiable information (PII) through automated input rejection, response redaction, and configurable regex patterns, supporting various use cases while maintaining data privacy. Organizations like Genesys demonstrate these capabilities at scale, maintaining GDPR compliance while processing 1.5 billion monthly customer interactions through Amazon Bedrock.
For detailed security considerations, see Generative AI Security Scoping Matrix, which provides a comprehensive framework for assessing and addressing generative AI security risks.
Safety
Generative AI systems can be designed and operated with safeguards to avoid harm to individuals, and communities. This includes addressing risks of generating dangerous, illegal, or abusive content, and helping to prevent system misuse.
Organizations can implement specific safety measures through predeployment content filtering, real-time safety boundaries with prompt constraints, and output classification systems to detect and block dangerous content. Context-aware content moderation considers the specific application domain, while automated detection can identify potential safety violations before content generation. Ongoing monitoring and updating of these controls help address evolving capabilities and potential risks of generative AI systems.
Amazon Bedrock Guardrails delivers industry-leading safety protections across text and images, blocking up to 85 percent more harmful content on top of native protections provided by foundation models (FMs). Additional safety controls include token limits to avoid excessive responses, rate limiting against misuse, and moderation endpoints for content screening.
For full practical implementation guidance on building safety controls, see Build safe and responsible generative AI applications with guardrails.
Controllability
Organizations can maintain appropriate control over generative AI systems to make sure that they work as intended and can be adjusted or stopped if issues arise. This helps manage risks and maintain system reliability.
A multi-layered approach to control includes implementing technical safeguards and operational processes. Organizations can control model behaviour by adjusting parameters such as temperature (controlling output randomness), and sampling methods like top-k or top-p (managing output diversity). Clear operational boundaries define the system’s scope of action, while human-in-the-loop validation provides oversight for critical applications.
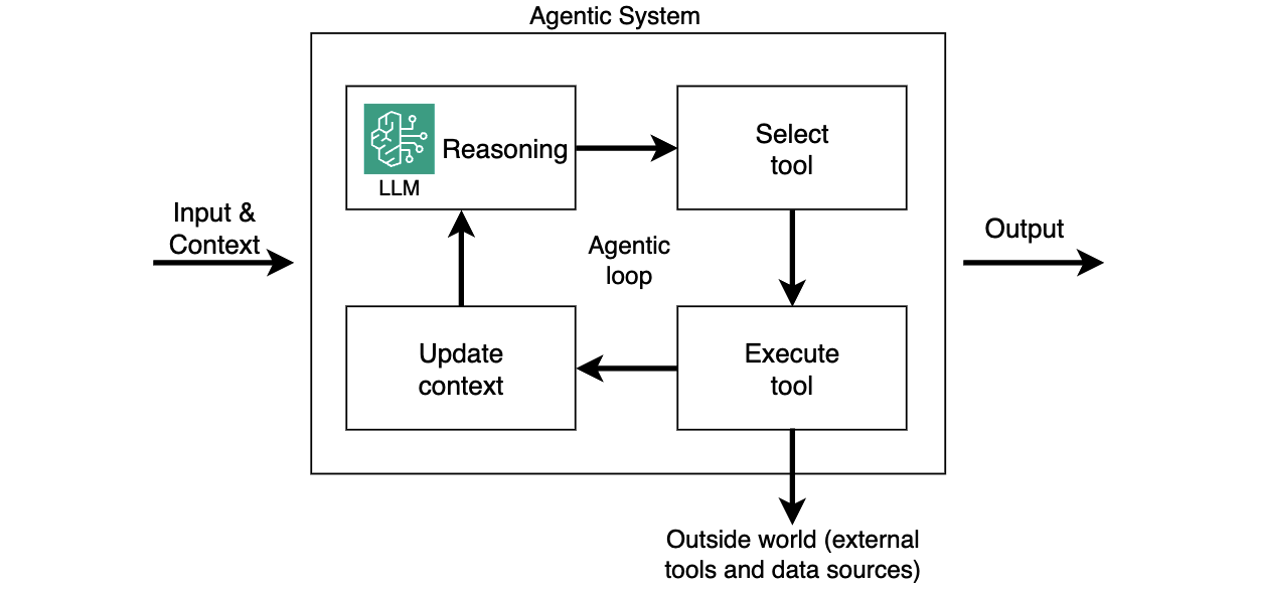
For effective control, organizations can establish parameter thresholds tailored to different use cases, implement rapid adjustment mechanisms, and create clear escalation procedures. Amazon Bedrock enhances control through customizable agent prompts and reasoning techniques, and the ability to break complex tasks into smaller, manageable components. Organizations can choose between structured workflows or flexible agent-based approaches. Regular comparison of outputs against established benchmarks helps maintain system reliability.
This balanced approach supports creative AI outputs while helping to facilitate consistent performance within defined quality limits. This helps prevent service degradation and business disruption while minimizing inefficiencies.
Control capabilities are further enhanced through Amazon CloudWatch monitoring integration and robust knowledge base version control. The capabilities of Amazon Bedrock, including LLM-as-a-judge features, help organizations assess and optimize their generative AI applications efficiently.
Veracity and robustness
Generative AI systems can produce reliable and accurate outputs, even when faced with unexpected or challenging inputs. This helps maintain trust and helps maintain the system’s usefulness across various applications.
Organizations can implement a combination of technical and procedural controls to enhance both system robustness and output reliability. This includes establishing clear parameter thresholds for different use cases, implementing human-in-the-loop validation for critical applications, and regularly comparing outputs against established ground truths. The framework specifies when and how these controls are applied based on the use case criticality and required level of accuracy.
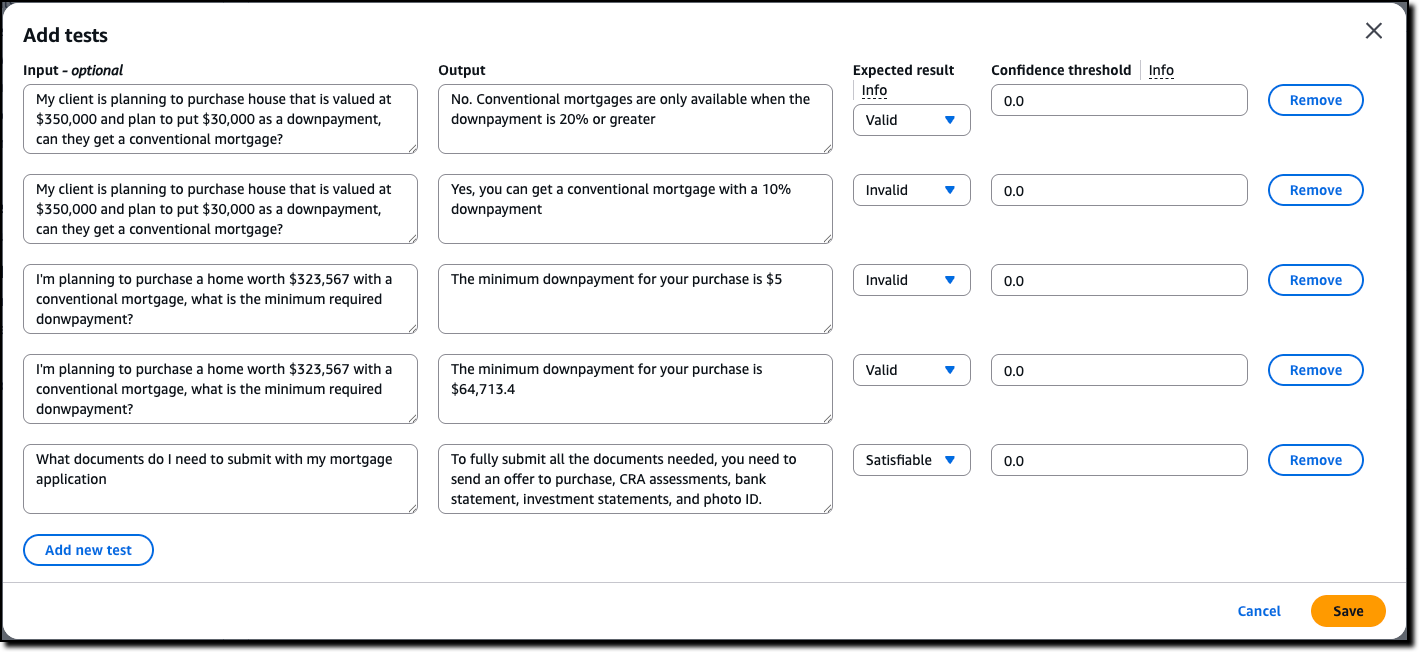
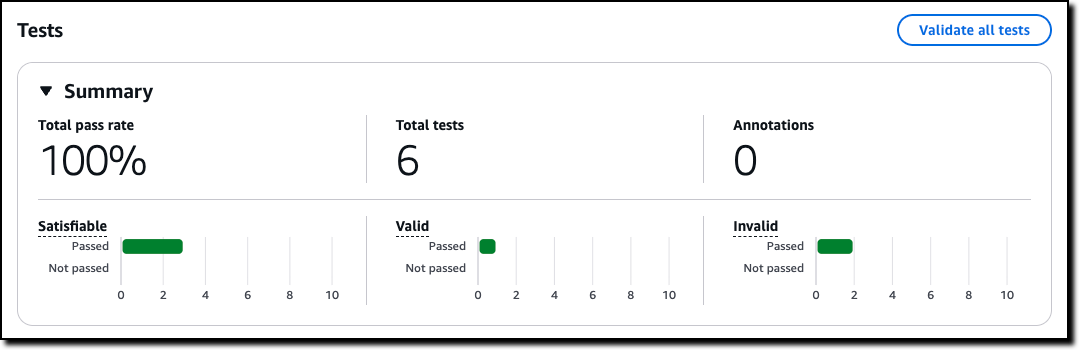
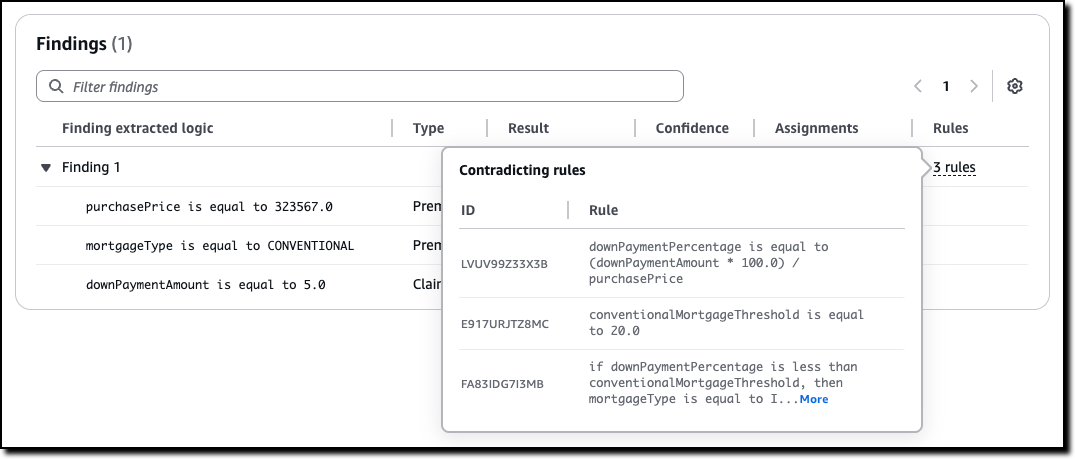
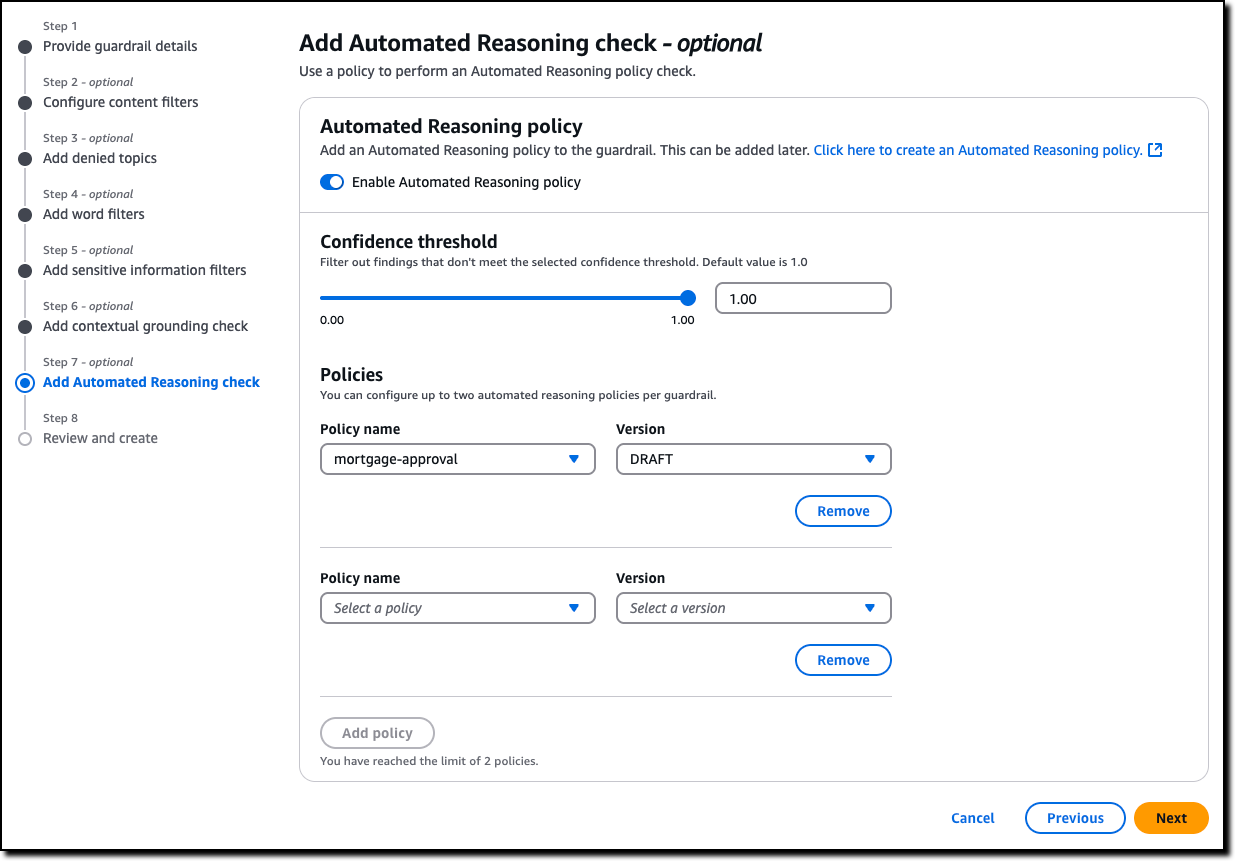
Amazon Bedrock Guardrails improves veracity by helping to prevent factual errors through automated reasoning checks that deliver up to 99 percent accuracy in detecting correct responses from models, using mathematical logic and formal verification techniques. This capability supports processing of large documents up to 80,000 tokens and includes automated scenario generation for comprehensive testing.
Amazon Bedrock also includes sophisticated input sanitization features and supports adversarial testing through AWS testing tools integration.
Governance
Effective governance of generative AI systems helps manage risks, maintain accountability, and align AI use with organizational values and regulations. This covers the entire AI lifecycle, from development to deployment and ongoing operation.
Organizations can create clear governance structures, including defined roles for AI oversight, regular risk assessments, and ways to engage with stakeholders. This involves integrating AI governance into existing risk management practices and making sure of compliance with relevant laws and standards. Because AI technology is evolving rapidly, regular reviews and updates to governance practices are essential to address new capabilities, emerging risks, and changing regulatory requirements. This includes providing appropriate training and skill development for system users.
AWS has achieved of ISO/IEC 42001 certification, demonstrating our commitment to systematic governance approaches in AI implementation. Governance features in Amazon Bedrock include comprehensive model provenance tracking, detailed AWS CloudTrail audit logging, and streamlined model deployment approval workflows integrated with AWS Organizations. AWS Audit Manager provides pre-built frameworks to assess generative AI implementation against best practices.
Transparency
Generative AI systems can operate transparently, helping stakeholders understand system capabilities, limitations, and the context of AI-generated outputs. This builds trust and enables informed decision-making by users and affected parties.
Organizations can implement specific transparency measures including comprehensive model documentation detailing intended use cases, known limitations, and performance boundaries. Clear AI disclosure practices should describe when and how AI is being used and what data is being processed. Regular performance reporting can include accuracy rates, error patterns, and bias assessments.
For customer-facing applications, transparency includes providing clear indicators of AI-generated content, documenting how decisions are made, and establishing processes for users to question or challenge outputs. Maintaining detailed version histories of model updates and changes in system behavior helps track the evolution of AI capabilities and their impacts over time.
From the AWS side of the Shared Responsibility Model, transparency is supported through AWS AI Service Cards and detailed documentation of model characteristics. Amazon Bedrock enhances this with comprehensive logging and monitoring capabilities to track model behavior and performance metrics.
Unified risk management
These eight areas are interconnected and mutually reinforcing within the enterprise risk management framework. While organizations might prioritize them differently based on their use cases and risk appetite, together they provide a comprehensive approach to responsible generative AI adoption. For detailed technical guidance, standards, and compliance requirements, see the AWS guidance documents in Resources for technical implementation, at the end of this blog post, that support implementation across these areas.
AI risk management in practice: Building organizational capability
Successful implementation of generative AI systems involves integrating risk management practices across the organization. This includes establishing processes for measuring outcomes and risks and preparing the organization to adapt as technology evolves. Effective risk management depends on building appropriate knowledge and skills at all levels of the organization.
Organizations can create clear pathways from proof of concept to production by aligning with the three lines of defense model. The ERMF provides broad parameters for reliability, safety, and privacy, which business units can adapt for their specific use cases.
To build and maintain lasting capability for both current and future generative AI adoption, organizations can focus on:
- Developing incident response plans for AI-specific scenarios
- Building expertise through training and certification programs
- Regular review and updates of risk management practices
These elements, when woven into the organization’s operating fabric, create sustainable practices that evolve with advancing technology and emerging risks.
Sustainable risk management: Making your ERMF generative AI-ready
Governance, risk, and compliance (GRC) leaders, Chief Risk Officers (CROs), and Chief Internal Auditors (CIAs) can provide sustained executive sponsorship for generative AI adoption. Long-term capability building extends beyond technology and innovation hubs to encompass business and control functions. Clear direction from leadership helps organizations balance generative AI opportunities with appropriate risk management.
Organizations benefit from viewing generative AI as a transformative capability that touches many functions rather than as isolated initiatives. This approach supports sustainable integration of enterprise-wide governance approaches for generative AI, avoiding the limitations of short-term projects with restricted scope and impact.
Organizations can successfully implement generative AI while maintaining their risk management obligations through controlled, well-defined use cases. TP ICAP’s Parameta division demonstrates this approach in their regulatory compliance implementation. By focusing initially on a highly regulated area, maintaining clear governance controls, and making sure there was human oversight in the compliance review process, they established a framework for responsible AI adoption. This led to creating dedicated oversight roles for AI initiatives, strengthening their governance structure for future AI implementations.
Similarly, Rocket Mortgage’s implementation of AWS services for their AI tool Rocket Logic – Synopsis demonstrates how organizations can use Amazon Bedrock for responsible AI integration at scale. This approach enabled them to maintain stringent data security and compliance measures while saving 40,000 team hours annually through automated processes.
Action checklist for sustainable generative AI implementation:
- ERMF foundations: Assess and enhance your risk framework’s readiness for generative AI, including acceptable use guidelines and clear accountabilities
- Technical controls: Begin with core controls such as Amazon Bedrock Guardrails and expand based on specific use cases and risk profiles
- Organizational capability: Develop broad expertise through training and oversight mechanisms across business and control functions
- Monitoring and measurement: Create dashboards for key risk indicators and maintain regular reviews
- Integration strategy: Align generative AI controls with existing processes and organizational strategy
Conclusion
This two-part series has explored the critical importance of integrating generative AI governance into enterprise risk management frameworks. In Part 1, we introduced the unique risks and governance considerations associated with generative AI adoption. Part 2 has provided a comprehensive guide for adapting your ERMF to address these challenges effectively.
We’ve outlined practical strategies for scaling generative AI adoption securely and responsibly, covering key areas such as fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. By implementing these strategies and following the action checklist provided, organizations can build sustainable practices that evolve with advancing technology and emerging risks.
Organizations that integrate generative AI governance into their ERMF as described in this post are better positioned to accelerate innovation and operational efficiency while protecting against key risks such as data exposure, model hallucinations, and regulatory non-compliance. This balanced approach enables organizations to capture the transformative potential of generative AI while maintaining the robust controls essential for financial services institutions.
For foundational concepts and risk considerations, see Part 1.
Customer success stories
- Genesys: Successfully integrated Amazon Bedrock while maintaining GDPR compliance
- TP ICAP/Parameta: Transformed regulatory compliance processes with controlled generative AI implementation
- Rocket Mortgage’s implementation of Amazon Bedrock for responsible AI integration at scale
Resources for technical implementation
- AWS Responsible Use of AI Guide
- AWS Cloud Adoption Framework for Artificial Intelligence, Machine Learning and generative AI
- AWS Well-Architected Framework – Generative AI Lens
- AWS Machine Learning Blog: Build safe and responsible generative AI applications with guardrails
- Generative AI Security Scoping Matrix
- Minimize AI hallucinations and deliver up to 99% verification accuracy with Automated Reasoning checks
- Amazon Bedrock Guardrails supports multimodal toxicity detection with image support
- New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock
- Navigating the security landscape of generative AI (whitepaper)
- The AWS User Guide to Governance, Risk and Compliance for Responsible AI Adoption within Financial Services Industries (available in AWS Artifact using your AWS sign in)
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.


























{kind=link}