Post Syndicated from Kesha Williams original https://aws.amazon.com/blogs/architecture/deploying-service-mesh-based-architectures-using-aws-app-mesh-and-amazon-ecs/
This International Women’s Day, we’re featuring more than a week’s worth of posts that highlight female builders and leaders. We’re showcasing women in the industry who are building, creating, and, above all, inspiring, empowering, and encouraging everyone—especially women and girls—in tech.
Service-mesh-based architectures provide visibility and control for microservices (a group of loosely coupled services that function together to make an application operate) by providing a consistent way to route and monitor traffic between them. They often appear in concert with containers and microservices in modern, cloud-native development. Containers help simplify the build, test, and deploy phases of the code pipeline for a given microservice. Microservices also offer many benefits over monoliths: faster speed-to-market; better resiliency; increased scalability; and independent, reusable components.
Despite these benefits, not all organizations use containers and microservices. Why? Because refactoring monoliths can be architecturally challenging. It increases the complexity of your workload by adding many, sometimes thousands, of services. These services must then be monitored. The services also have to communicate with each other, so you need to properly route and monitor traffic. Adding services also means there are more APIs and databases that need protection.
If this sounds like an issue you’ve encountered or one you might need help with in the future, you’ll benefit from using a service mesh, a dedicated infrastructure layer for governing microservices and facilitating service-to-service communications. In this post, we’ll explain how to use AWS App Mesh to provide visibility and control for microservices by providing a consistent way to route and monitor traffic between them.
How will a service mesh help me govern my workload?
A service mesh helps you run a fast, reliable, and secure network of microservices, and it can help alleviate many of the pain points encountered when running microservices:
- Decouples governance from business logic
- Adds service discovery
- Maintains load balancing
- Provides traffic control
- Provides additional observability and monitoring capabilities
- Adds resiliency and health checks
- Increases security
How does a service mesh work?
A service mesh consists of two high-level components: a control plane and a data plane.
The control plane manages all of the individual microservices in the data plane and provides processes to manipulate and observe the entire application.
The data plane intercepts and processes calls between the different microservices. The data plane is typically implemented as a proxy, which runs alongside each microservice as a sidecar. A sidecar is a container that is automatically injected into the microservice at run time.
Architecture walkthrough
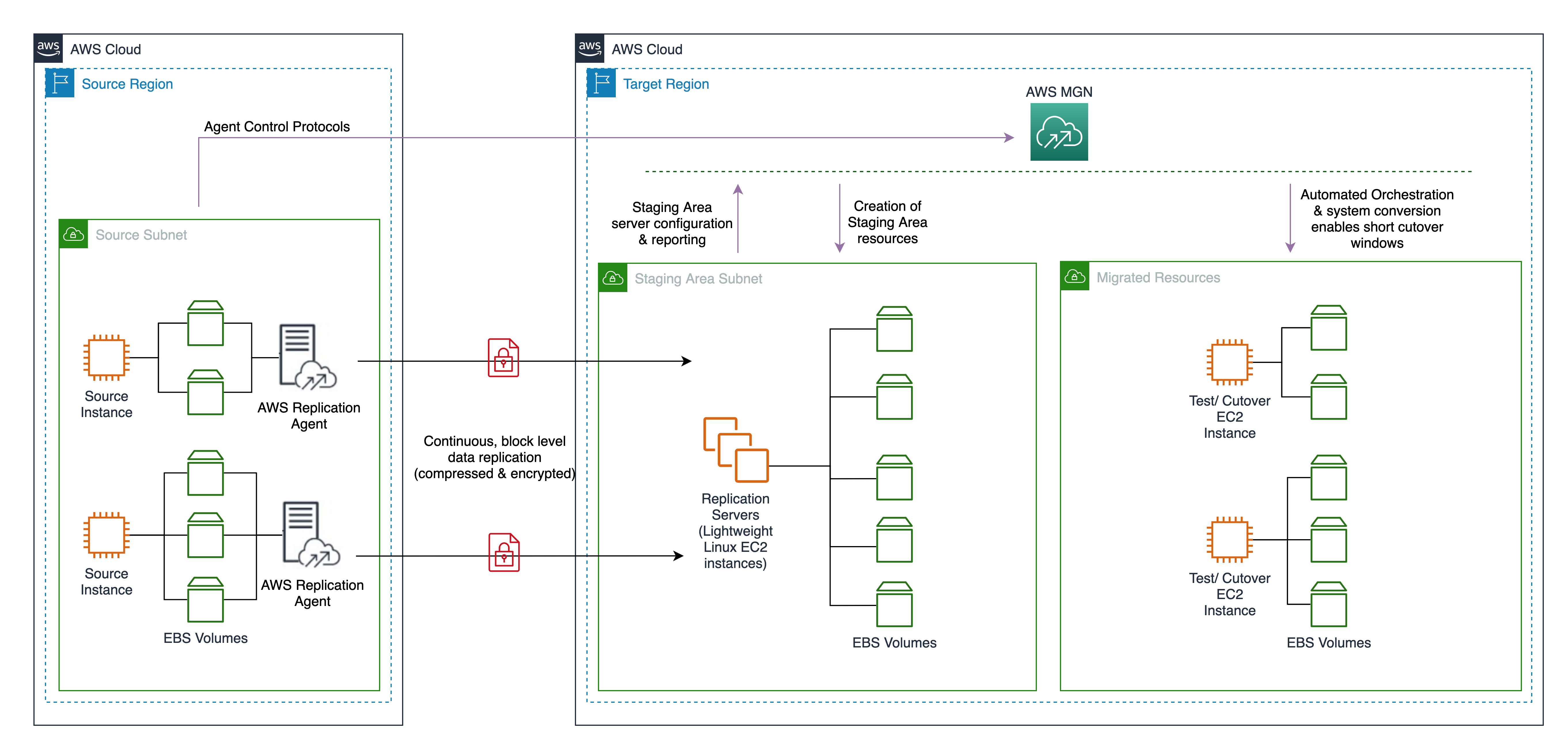
The example architecture in Figure 1 shows a microservices architecture for an Ordering application. It contains four microservices: Inventory, Order, and UI.
This example is a deliberately small and simple example to explore the concepts. Here’s how it works:
- The control plane is the central component that manages all the individual microservices in the data plane.
- The data plane intercepts and processes calls between the different microservices.
- App Mesh forms the service mesh and supports the services registered with AWS Cloud Map.
- AWS Cloud Map provides service discovery.
- Containers are defined in an ECS task definition.
- Envoy is the service mesh proxy that is deployed alongside the microservice container.
- The application container represents the application components that run in a Docker container.
- Service communication traces are made available to AWS X-Ray.
- Service-level logs and metrics are made available to Amazon CloudWatch.
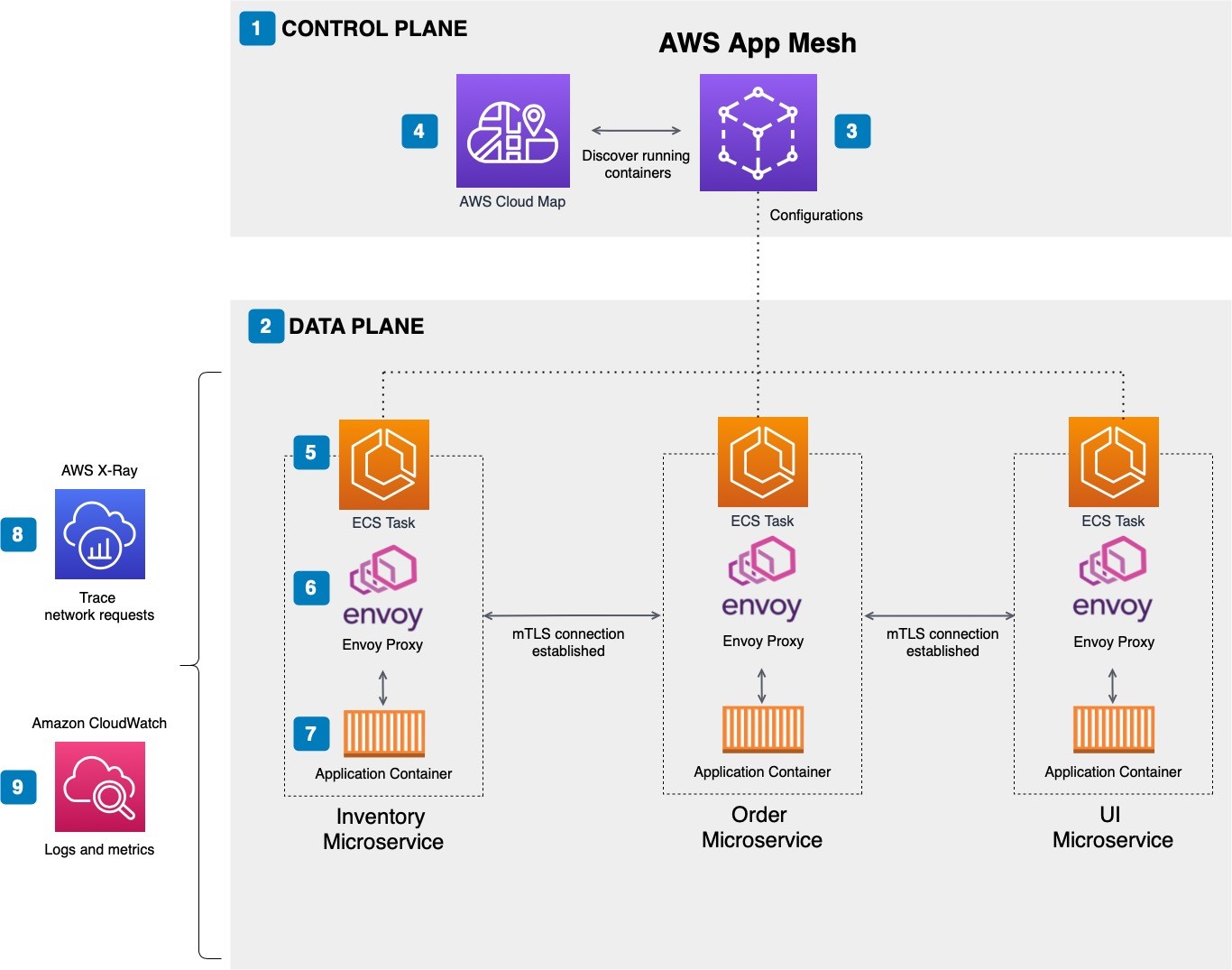
Figure 1. Microservices architecture for an Ordering application managed by App Mesh
Implementing the service mesh with App Mesh
To use App Mesh, you’ll need to have an existing service running on Amazon Elastic Container Service (Amazon ECS) and be registered with AWS Cloud Map.
App Mesh forms a service mesh for your application by providing an AWS-managed control plane. The control plane helps you run microservices by providing consistent visibility and network traffic controls for each microservice in your application.
App Mesh separates the logic needed for monitoring and controlling communications into a proxy that runs sideloaded to every microservice. App Mesh works with an open-source, high-performing network proxy called Envoy. After implementing your service mesh, you’ll update your services to use Envoy, which requires the services to communicate with each other through the proxy instead of directly with each other. All service-to-service traffic goes through the Envoy proxy allowing traffic routes to be configured and metrics, logs, and traces exported.
Components
There are several components needed to support the service mesh:
- Virtual services – Virtual services are abstractions of actual microservices provided by a virtual node through a virtual router.
- Virtual nodes – Virtual nodes are logical pointers to a particular task group, like an Amazon ECS service. You’ll need to provide the service discovery name found in AWS Cloud Map to connect your microservice.
- Envoy proxy – The Envoy proxy configures your microservice task group to use App Mesh’s virtual routers and nodes.
- Virtual routers – Virtual routers route traffic for one or more virtual services within your mesh.
- Routes – Routes are used by the virtual router to match requests and direct traffic to one or more virtual nodes.
Integrating App Mesh with Amazon ECS
App Mesh integrates with your containerized microservices running on Amazon ECS (and other compute services). Amazon ECS is a container orchestration service that helps you deploy, manage, and scale containerized applications.
With Amazon ECS, your containers are defined in a task definition; you’ll need to add an Envoy proxy Docker container image to the task definition and register the microservices for discovery through AWS Cloud Map.
Conclusion
This post shows how App Mesh helps you solve some of the most common pitfalls of managing microservice architectures. It also shows you how to use App Mesh to provide visibility and control for microservices on AWS by providing a consistent way to route and monitor traffic between them.
App Mesh works as the control plane and uses the open-source Envoy proxy to provide the data plane that intercepts and processes calls between the different microservices. Through integrations with CloudWatch and X-Ray, you’re able to capture application-level metrics, logs, and traces.
Ready to get started? Check out the Learning AWS App Mesh post on the Database blog, the Using Service Meshes in AWS whitepaper, and Introduction to AWS App Mesh AWS Online Tech Talk to learn more. You can connect with Kesha on LinkedIn if you have questions.
Looking for more architecture content? AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!