Post Syndicated from Srinivas Manepalli original https://aws.amazon.com/blogs/devops/building-end-to-end-aws-devsecops-ci-cd-pipeline-with-open-source-sca-sast-and-dast-tools/
DevOps is a combination of cultural philosophies, practices, and tools that combine software development with information technology operations. These combined practices enable companies to deliver new application features and improved services to customers at a higher velocity. DevSecOps takes this a step further, integrating security into DevOps. With DevSecOps, you can deliver secure and compliant application changes rapidly while running operations consistently with automation.
Having a complete DevSecOps pipeline is critical to building a successful software factory, which includes continuous integration (CI), continuous delivery and deployment (CD), continuous testing, continuous logging and monitoring, auditing and governance, and operations. Identifying the vulnerabilities during the initial stages of the software development process can significantly help reduce the overall cost of developing application changes, but doing it in an automated fashion can accelerate the delivery of these changes as well.
To identify security vulnerabilities at various stages, organizations can integrate various tools and services (cloud and third-party) into their DevSecOps pipelines. Integrating various tools and aggregating the vulnerability findings can be a challenge to do from scratch. AWS has the services and tools necessary to accelerate this objective and provides the flexibility to build DevSecOps pipelines with easy integrations of AWS cloud native and third-party tools. AWS also provides services to aggregate security findings.
In this post, we provide a DevSecOps pipeline reference architecture on AWS that covers the afore-mentioned practices, including SCA (Software Composite Analysis), SAST (Static Application Security Testing), DAST (Dynamic Application Security Testing), and aggregation of vulnerability findings into a single pane of glass. Additionally, this post addresses the concepts of security of the pipeline and security in the pipeline.
You can deploy this pipeline in either the AWS GovCloud Region (US) or standard AWS Regions. As of this writing, all listed AWS services are available in AWS GovCloud (US) and authorized for FedRAMP High workloads within the Region, with the exception of AWS CodePipeline and AWS Security Hub, which are in the Region and currently under the JAB Review to be authorized shortly for FedRAMP High as well.
Services and tools
In this section, we discuss the various AWS services and third-party tools used in this solution.
CI/CD services
For CI/CD, we use the following AWS services:
- AWS CodeBuild – A fully managed continuous integration service that compiles source code, runs tests, and produces software packages that are ready to deploy.
- AWS CodeCommit – A fully managed source control service that hosts secure Git-based repositories.
- AWS CodeDeploy – A fully managed deployment service that automates software deployments to a variety of compute services such as Amazon Elastic Compute Cloud (Amazon EC2), AWS Fargate, AWS Lambda, and your on-premises servers.
- AWS CodePipeline – A fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates.
- AWS Lambda – A service that lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
- Amazon Simple Notification Service – Amazon SNS is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
- Amazon Simple Storage Service – Amazon S3 is storage for the internet. You can use Amazon S3 to store and retrieve any amount of data at any time, from anywhere on the web.
- AWS Systems Manager Parameter Store – Parameter Store gives you visibility and control of your infrastructure on AWS.
Continuous testing tools
The following are open-source scanning tools that are integrated in the pipeline for the purposes of this post, but you could integrate other tools that meet your specific requirements. You can use the static code review tool Amazon CodeGuru for static analysis, but at the time of this writing, it’s not yet available in GovCloud and currently supports Java and Python (available in preview).
- OWASP Dependency-Check – A Software Composition Analysis (SCA) tool that attempts to detect publicly disclosed vulnerabilities contained within a project’s dependencies.
- SonarQube (SAST) – Catches bugs and vulnerabilities in your app, with thousands of automated Static Code Analysis rules.
- PHPStan (SAST) – Focuses on finding errors in your code without actually running it. It catches whole classes of bugs even before you write tests for the code.
- OWASP Zap (DAST) – Helps you automatically find security vulnerabilities in your web applications while you’re developing and testing your applications.
Continuous logging and monitoring services
The following are AWS services for continuous logging and monitoring:
- AWS CloudWatch Logs – Allows you to monitor, store, and access your log files from EC2 instances, AWS CloudTrail, Amazon Route 53, and other sources
- AWS CloudWatch Events – Delivers a near-real-time stream of system events that describe changes in AWS resources
Auditing and governance services
The following are AWS auditing and governance services:
- AWS CloudTrail – Enables governance, compliance, operational auditing, and risk auditing of your AWS account.
- AWS Identity and Access Management – Enables you to manage access to AWS services and resources securely. With IAM, you can create and manage AWS users and groups, and use permissions to allow and deny their access to AWS resources.
- AWS Config – Allows you to assess, audit, and evaluate the configurations of your AWS resources.
Operations services
The following are AWS operations services:
- AWS Security Hub – Gives you a comprehensive view of your security alerts and security posture across your AWS accounts. This post uses Security Hub to aggregate all the vulnerability findings as a single pane of glass.
- AWS CloudFormation – Gives you an easy way to model a collection of related AWS and third-party resources, provision them quickly and consistently, and manage them throughout their lifecycles, by treating infrastructure as code.
- AWS Systems Manager Parameter Store – Provides secure, hierarchical storage for configuration data management and secrets management. You can store data such as passwords, database strings, Amazon Machine Image (AMI) IDs, and license codes as parameter values.
- AWS Elastic Beanstalk – An easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS. This post uses Elastic Beanstalk to deploy LAMP stack with WordPress and Amazon Aurora MySQL. Although we use Elastic Beanstalk for this post, you could configure the pipeline to deploy to various other environments on AWS or elsewhere as needed.
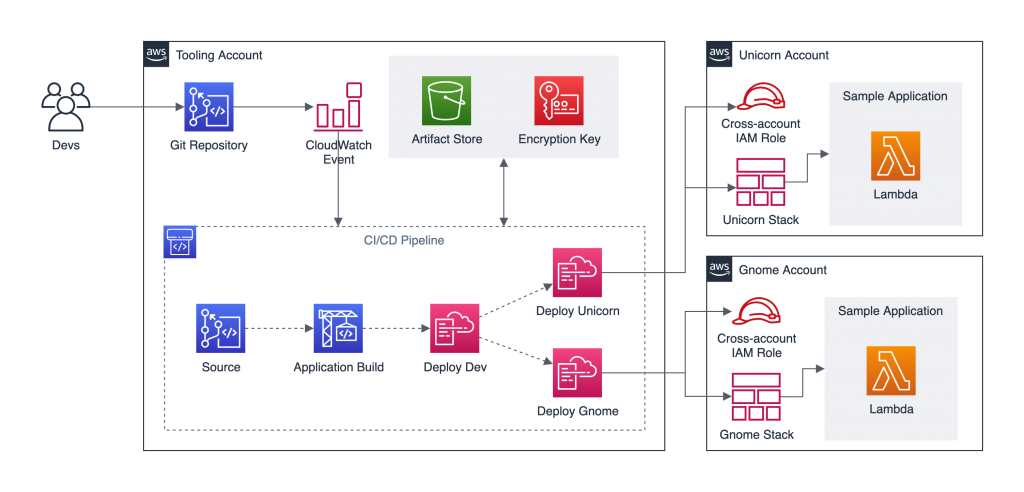
Pipeline architecture
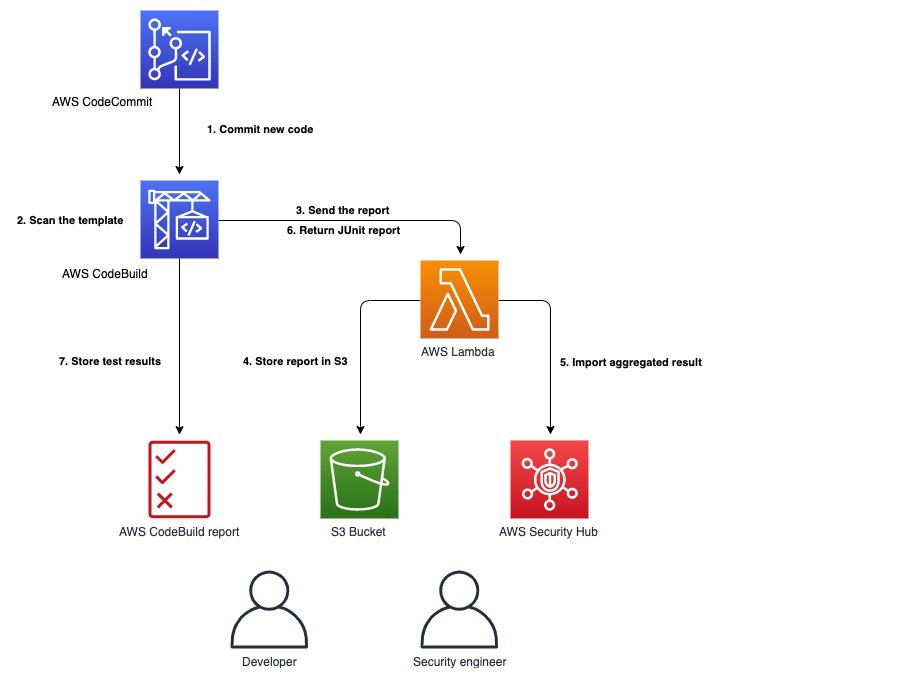
The following diagram shows the architecture of the solution.
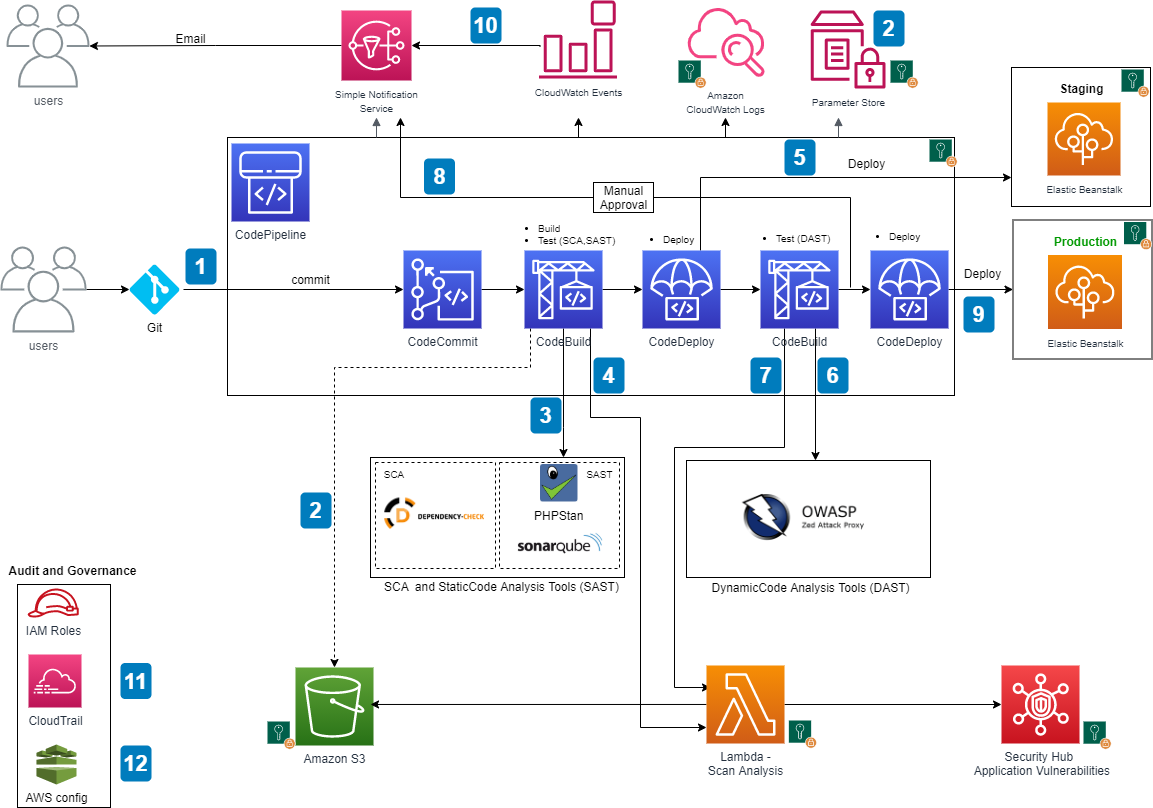
AWS DevSecOps CICD pipeline architecture
The main steps are as follows:
- When a user commits the code to a CodeCommit repository, a CloudWatch event is generated which, triggers CodePipeline.
- CodeBuild packages the build and uploads the artifacts to an S3 bucket. CodeBuild retrieves the authentication information (for example, scanning tool tokens) from Parameter Store to initiate the scanning. As a best practice, it is recommended to utilize Artifact repositories like AWS CodeArtifact to store the artifacts, instead of S3. For simplicity of the workshop, we will continue to use S3.
- CodeBuild scans the code with an SCA tool (OWASP Dependency-Check) and SAST tool (SonarQube or PHPStan; in the provided CloudFormation template, you can pick one of these tools during the deployment, but CodeBuild is fully enabled for a bring your own tool approach).
- If there are any vulnerabilities either from SCA analysis or SAST analysis, CodeBuild invokes the Lambda function. The function parses the results into AWS Security Finding Format (ASFF) and posts it to Security Hub. Security Hub helps aggregate and view all the vulnerability findings in one place as a single pane of glass. The Lambda function also uploads the scanning results to an S3 bucket.
- If there are no vulnerabilities, CodeDeploy deploys the code to the staging Elastic Beanstalk environment.
- After the deployment succeeds, CodeBuild triggers the DAST scanning with the OWASP ZAP tool (again, this is fully enabled for a bring your own tool approach).
- If there are any vulnerabilities, CodeBuild invokes the Lambda function, which parses the results into ASFF and posts it to Security Hub. The function also uploads the scanning results to an S3 bucket (similar to step 4).
- If there are no vulnerabilities, the approval stage is triggered, and an email is sent to the approver for action.
- After approval, CodeDeploy deploys the code to the production Elastic Beanstalk environment.
- During the pipeline run, CloudWatch Events captures the build state changes and sends email notifications to subscribed users through SNS notifications.
- CloudTrail tracks the API calls and send notifications on critical events on the pipeline and CodeBuild projects, such as UpdatePipeline, DeletePipeline, CreateProject, and DeleteProject, for auditing purposes.
- AWS Config tracks all the configuration changes of AWS services. The following AWS Config rules are added in this pipeline as security best practices:
- CODEBUILD_PROJECT_ENVVAR_AWSCRED_CHECK – Checks whether the project contains environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY. The rule is NON_COMPLIANT when the project environment variables contains plaintext credentials.
- CLOUD_TRAIL_LOG_FILE_VALIDATION_ENABLED – Checks whether CloudTrail creates a signed digest file with logs. AWS recommends that the file validation be enabled on all trails. The rule is noncompliant if the validation is not enabled.
Security of the pipeline is implemented by using IAM roles and S3 bucket policies to restrict access to pipeline resources. Pipeline data at rest and in transit is protected using encryption and SSL secure transport. We use Parameter Store to store sensitive information such as API tokens and passwords. To be fully compliant with frameworks such as FedRAMP, other things may be required, such as MFA.
Security in the pipeline is implemented by performing the SCA, SAST and DAST security checks. Alternatively, the pipeline can utilize IAST (Interactive Application Security Testing) techniques that would combine SAST and DAST stages.
As a best practice, encryption should be enabled for the code and artifacts, whether at rest or transit.
In the next section, we explain how to deploy and run the pipeline CloudFormation template used for this example. Refer to the provided service links to learn more about each of the services in the pipeline. If utilizing CloudFormation templates to deploy infrastructure using pipelines, we recommend using linting tools like cfn-nag to scan CloudFormation templates for security vulnerabilities.
Prerequisites
Before getting started, make sure you have the following prerequisites:
- Elastic Beanstalk environments with an application deployed. In this post, we use WordPress, but you can use any other application. For more information, see Deploying a high-availability WordPress website with an external Amazon RDS database to Elastic Beanstalk.
- A CodeCommit repo with your application code. For more information, see Create an AWS CodeCommit repository.
- The provided buildspec-*.yml files, sonar-project.properties file, json file, and phpstan.neon file uploaded to the root of the application code repository.
- The Lambda function uploaded to a S3 bucket. We use this function to parse the scanning reports and post the results to Security Hub.
- A SonarQube URL and generated API token for code scanning.
- An OWASP ZAP URL and generated API key for dynamic web scanning.
- An application web URL to run the DAST testing.
- An email address to receive approval notifications for deployment, pipeline change notifications, and CloudTrail events.
- AWS Config and Security Hub enabled. For instructions, see Managing the Configuration Recorder and Enabling Security Hub manually, respectively.
Deploying the pipeline
To deploy the pipeline, complete the following steps: Download the CloudFormation template and pipeline code from GitHub repo.
- Log in to your AWS account if you have not done so already.
- On the CloudFormation console, choose Create Stack.
- Choose the CloudFormation pipeline template.
- Choose Next.
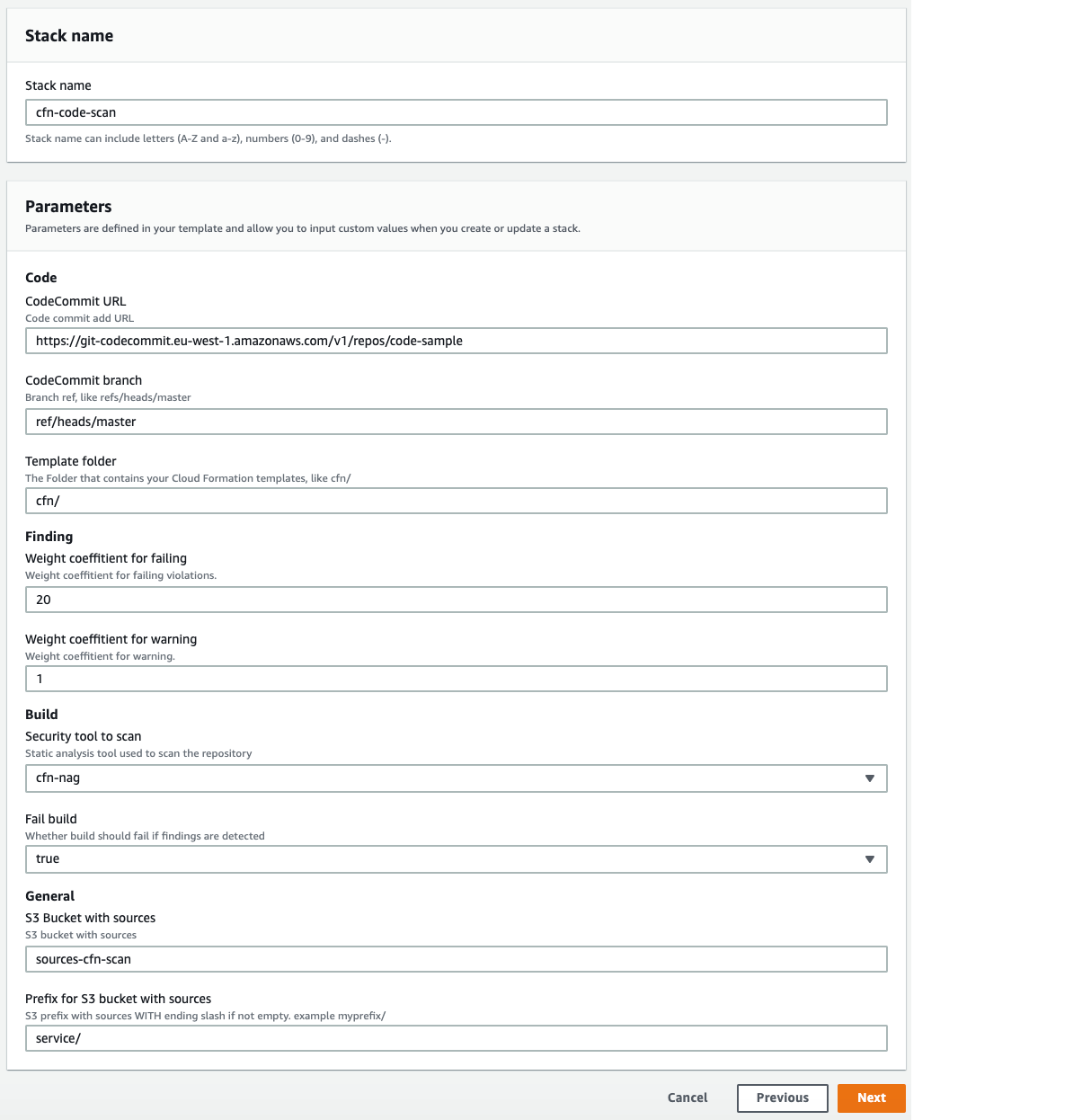
- Provide the stack parameters:
- Under Code, provide code details, such as repository name and the branch to trigger the pipeline.
- Under SAST, choose the SAST tool (SonarQube or PHPStan) for code analysis, enter the API token and the SAST tool URL. You can skip SonarQube details if using PHPStan as the SAST tool.
- Under DAST, choose the DAST tool (OWASP Zap) for dynamic testing and enter the API token, DAST tool URL, and the application URL to run the scan.
- Under Lambda functions, enter the Lambda function S3 bucket name, filename, and the handler name.
- Under STG Elastic Beanstalk Environment and PRD Elastic Beanstalk Environment, enter the Elastic Beanstalk environment and application details for staging and production to which this pipeline deploys the application code.
- Under General, enter the email addresses to receive notifications for approvals and pipeline status changes.


CloudFormation template deployment
After the pipeline is deployed, confirm the subscription by choosing the provided link in the email to receive the notifications.
The provided CloudFormation template in this post is formatted for AWS GovCloud. If you’re setting this up in a standard Region, you have to adjust the partition name in the CloudFormation template. For example, change ARN values from arn:aws-us-gov to arn:aws.
Running the pipeline
To trigger the pipeline, commit changes to your application repository files. That generates a CloudWatch event and triggers the pipeline. CodeBuild scans the code and if there are any vulnerabilities, it invokes the Lambda function to parse and post the results to Security Hub.
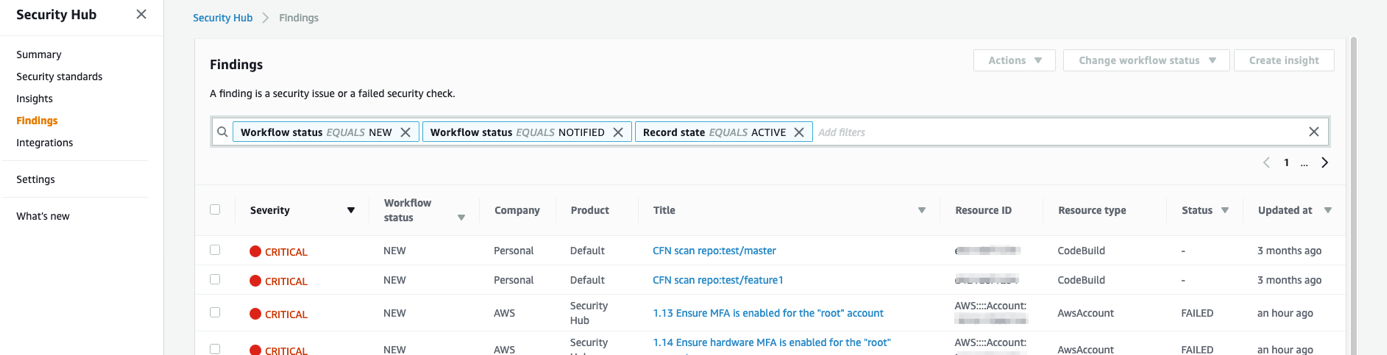
When posting the vulnerability finding information to Security Hub, we need to provide a vulnerability severity level. Based on the provided severity value, Security Hub assigns the label as follows. Adjust the severity levels in your code based on your organization’s requirements.
- 0 – INFORMATIONAL
- 1–39 – LOW
- 40– 69 – MEDIUM
- 70–89 – HIGH
- 90–100 – CRITICAL
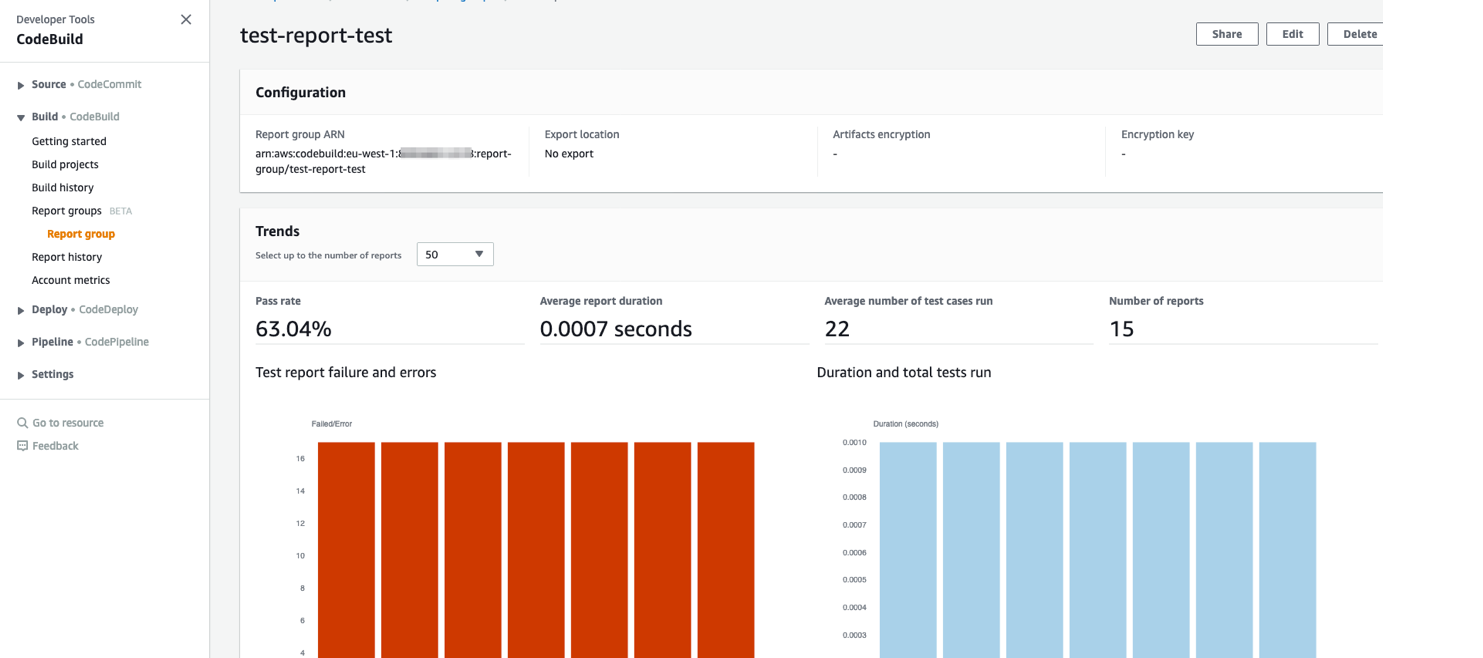
The following screenshot shows the progression of your pipeline.

CodePipeline stages
SCA and SAST scanning
In our architecture, CodeBuild trigger the SCA and SAST scanning in parallel. In this section, we discuss scanning with OWASP Dependency-Check, SonarQube, and PHPStan.
Scanning with OWASP Dependency-Check (SCA)
The following is the code snippet from the Lambda function, where the SCA analysis results are parsed and posted to Security Hub. Based on the results, the equivalent Security Hub severity level (normalized_severity) is assigned.

Lambda code snippet for OWASP Dependency-check
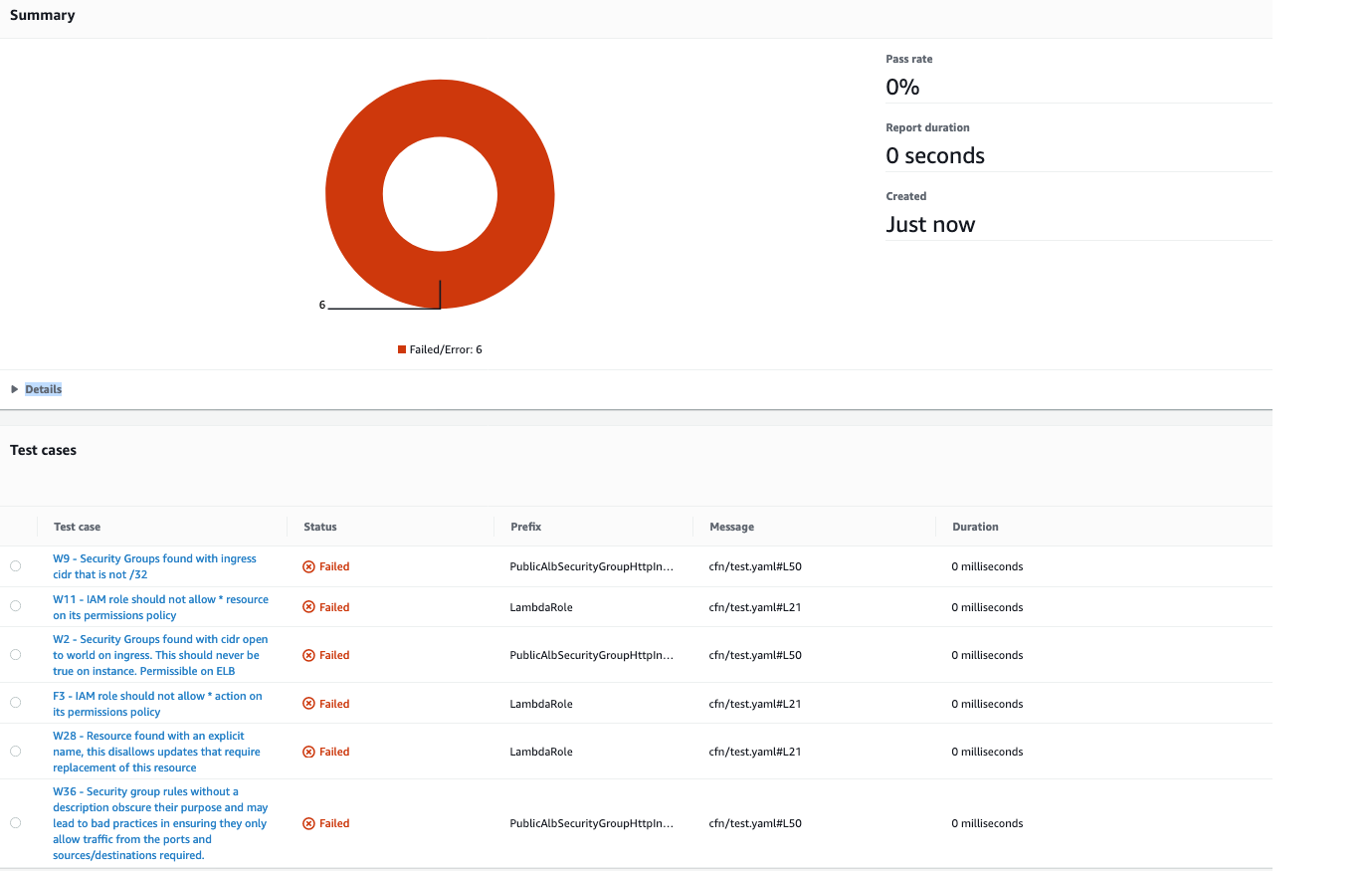
You can see the results in Security Hub, as in the following screenshot.

SecurityHub report from OWASP Dependency-check scanning
Scanning with SonarQube (SAST)
The following is the code snippet from the Lambda function, where the SonarQube code analysis results are parsed and posted to Security Hub. Based on SonarQube results, the equivalent Security Hub severity level (normalized_severity) is assigned.

Lambda code snippet for SonarQube
The following screenshot shows the results in Security Hub.

SecurityHub report from SonarQube scanning
Scanning with PHPStan (SAST)
The following is the code snippet from the Lambda function, where the PHPStan code analysis results are parsed and posted to Security Hub.

Lambda code snippet for PHPStan
The following screenshot shows the results in Security Hub.

SecurityHub report from PHPStan scanning
DAST scanning
In our architecture, CodeBuild triggers DAST scanning and the DAST tool.
If there are no vulnerabilities in the SAST scan, the pipeline proceeds to the manual approval stage and an email is sent to the approver. The approver can review and approve or reject the deployment. If approved, the pipeline moves to next stage and deploys the application to the provided Elastic Beanstalk environment.
Scanning with OWASP Zap
After deployment is successful, CodeBuild initiates the DAST scanning. When scanning is complete, if there are any vulnerabilities, it invokes the Lambda function similar to SAST analysis. The function parses and posts the results to Security Hub. The following is the code snippet of the Lambda function.

Lambda code snippet for OWASP-Zap
The following screenshot shows the results in Security Hub.

SecurityHub report from OWASP-Zap scanning
Aggregation of vulnerability findings in Security Hub provides opportunities to automate the remediation. For example, based on the vulnerability finding, you can trigger a Lambda function to take the needed remediation action. This also reduces the burden on operations and security teams because they can now address the vulnerabilities from a single pane of glass instead of logging into multiple tool dashboards.
Conclusion
In this post, I presented a DevSecOps pipeline that includes CI/CD, continuous testing, continuous logging and monitoring, auditing and governance, and operations. I demonstrated how to integrate various open-source scanning tools, such as SonarQube, PHPStan, and OWASP Zap for SAST and DAST analysis. I explained how to aggregate vulnerability findings in Security Hub as a single pane of glass. This post also talked about how to implement security of the pipeline and in the pipeline using AWS cloud native services. Finally, I provided the DevSecOps pipeline as code using AWS CloudFormation. For additional information on AWS DevOps services and to get started, see AWS DevOps and DevOps Blog.
 Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.
Srinivas Manepalli is a DevSecOps Solutions Architect in the U.S. Fed SI SA team at Amazon Web Services (AWS). He is passionate about helping customers, building and architecting DevSecOps and highly available software systems. Outside of work, he enjoys spending time with family, nature and good food.






























 Ease of development
Ease of development