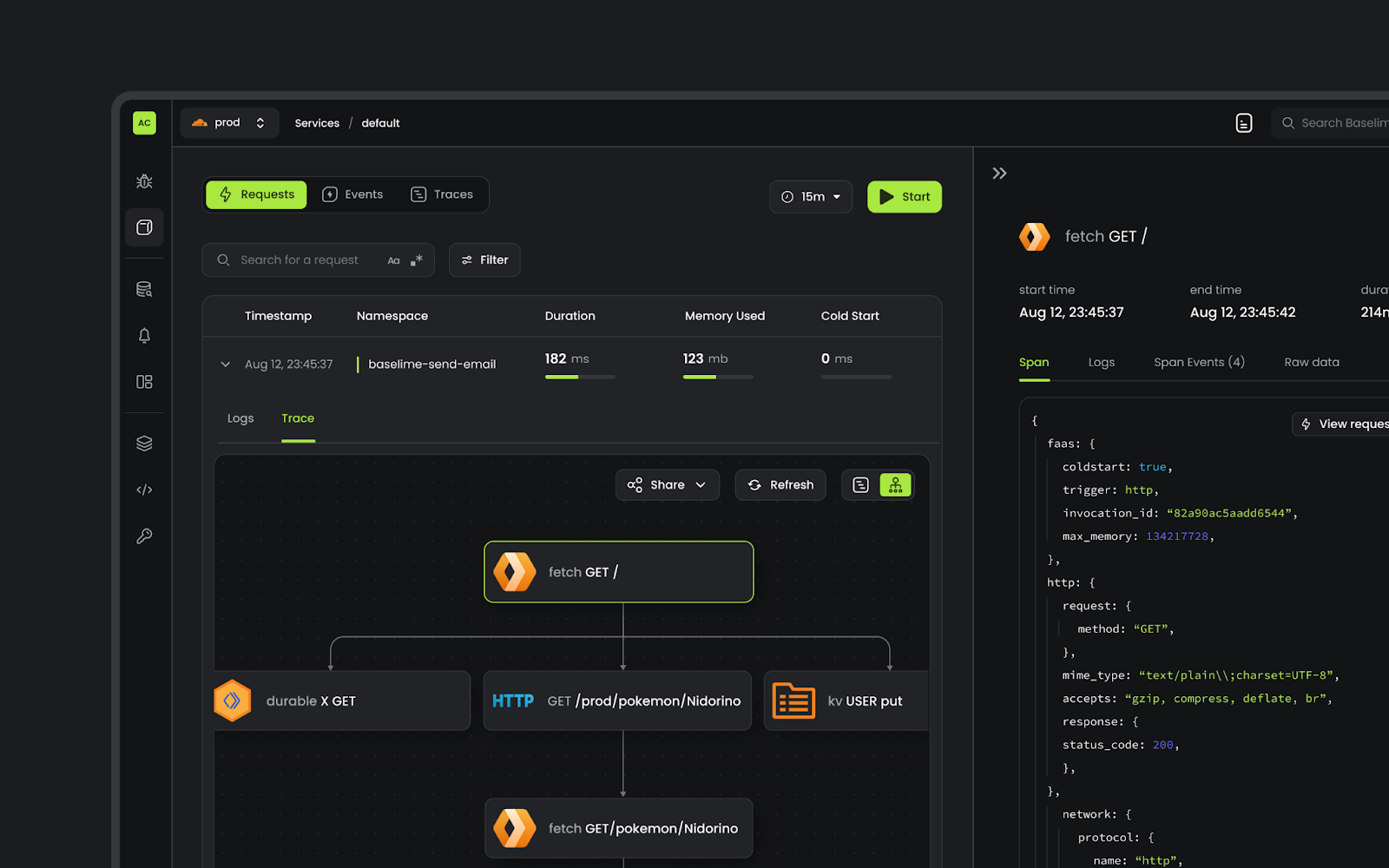
Post Syndicated from Boris Tane original https://blog.cloudflare.com/80-percent-lower-cloud-cost-how-baselime-moved-from-aws-to-cloudflare
When Baselime joined Cloudflare in April 2024, our architecture had evolved to hundreds of AWS Lambda functions, dozens of databases, and just as many queues. We were drowning in complexity and our cloud costs were growing fast. We are now building Baselime and Workers Observability on Cloudflare and will save over 80% on our cloud compute bill. The estimated potential Cloudflare costs are for Baselime, which remains a stand-alone offering, and the estimate is based on the Workers Paid plan. Not only did we achieve huge cost savings, we also simplified our architecture and improved overall latency, scalability, and reliability.
|
Daily Cost |
Before (AWS) |
After (Cloudflare) |
|
Compute |
$650 – AWS Lambda |
$25 – Cloudflare Workers |
|
CDN |
$140 – Cloudfront |
$0 – Free |
|
Data Stream + Analytics database |
$1,150 – Kinesis Data Stream + EC2 |
$300 – Workers Analytics Engine |
|
Total |
$1,940 |
$325 (83% cost reduction) |
Table 1: Daily Costs Comparison ($USD)
When we joined Cloudflare, we immediately saw a surge in usage, and within the first week following the announcement, we were processing over a billion events daily and our weekly active users tripled.
As the platform grew, so did the challenges of managing real-time observability with new scalability, reliability, and cost considerations. This drove us to rebuild Baselime on the Cloudflare Developer Platform, where we could innovate quickly while reducing operational overhead.
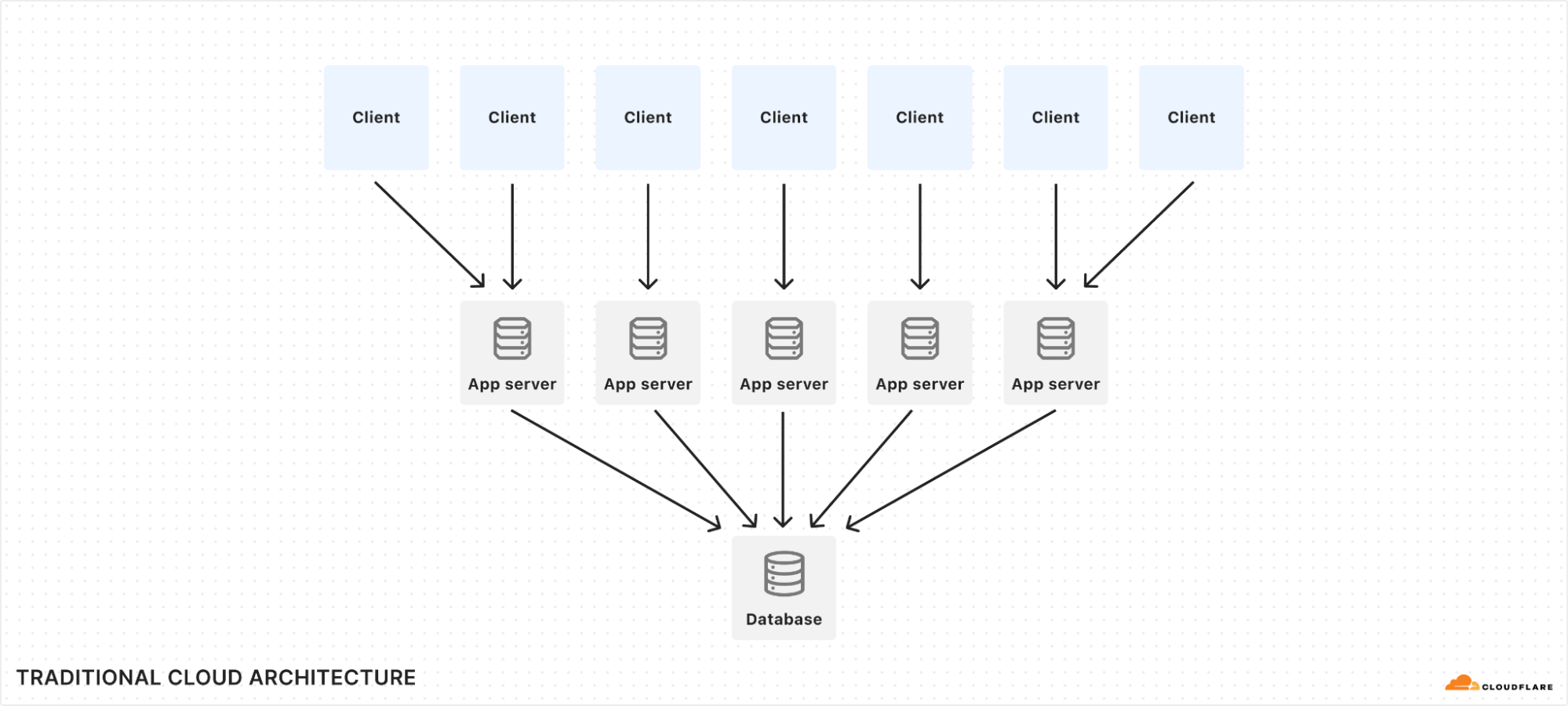
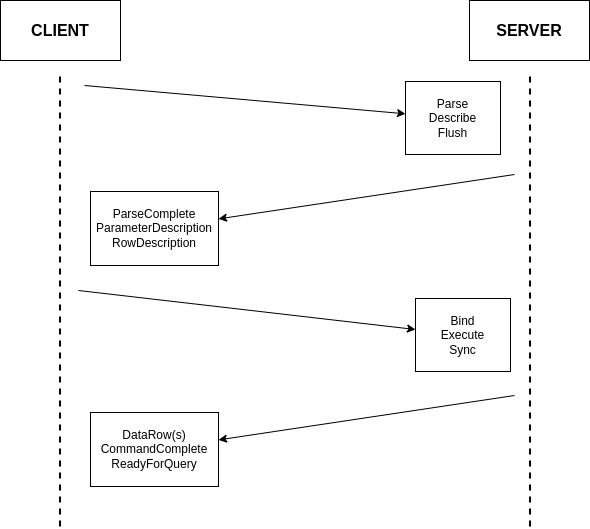
Our initial architecture was all on Amazon Web Services (AWS). We’ll focus here on the data pipeline, which covers ingestion, processing, and storage of tens of billions of events daily.
This pipeline was built on top of AWS Lambda, Cloudfront, Kinesis, EC2, DynamoDB, ECS, and ElastiCache.

Figure1: Initial data pipeline architecture
The key elements are:
-
Data receptors: Responsible for receiving telemetry data from multiple sources, including OpenTelemetry, Cloudflare Logpush, CloudWatch, Vercel, etc. They cover validation, authentication, and transforming data from each source into a common internal format. The data receptors were deployed either on AWS Lambda (using function URLs and Cloudfront) or ECS Fargate depending on the data source.
-
Kinesis Data Stream: Responsible for transporting the data from the receptors to the next step: data processing.
-
Processor: A single AWS Lambda function responsible for enriching and transforming the data for storage. It also performed real-time error tracking and detecting patterns in logs.
-
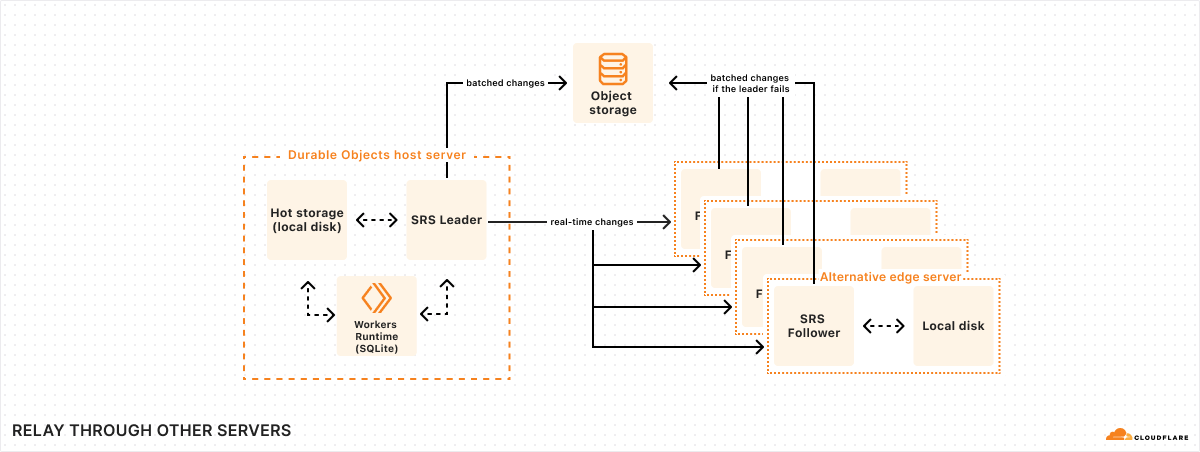
ClickHouse cluster: All the telemetry data was ultimately indexed and stored in a self-hosted ClickHouse cluster on EC2.
In addition to these key elements, the existing stack also included orchestration with Firehose, S3 buckets, SQS, DynamoDB and RDS for error handling, retries, and storing metadata.
While this architecture served us well in the early days, it started to show major cracks as we scaled our solution to more and larger customers.
Handling retries at the interface between the data receptors and the Kinesis Data Stream was complex, requiring introducing and orchestrating Firehose, S3 buckets, SQS, and another Lambda function.
Self-hosting ClickHouse also introduced major challenges at scale, as we continuously had to plan our capacity and update our setup to keep pace with our growing user base whilst attempting to maintain control over costs.
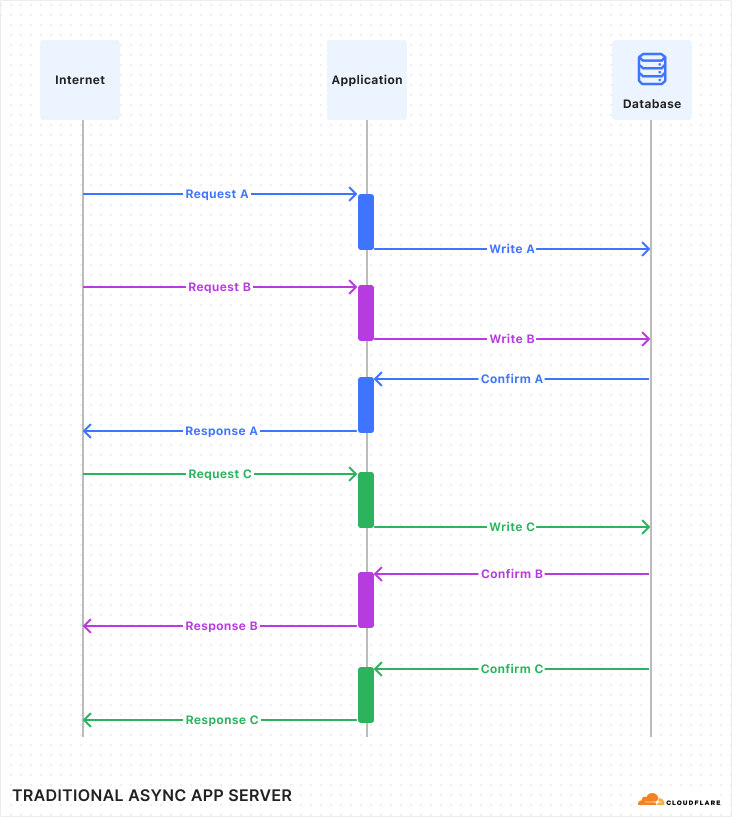
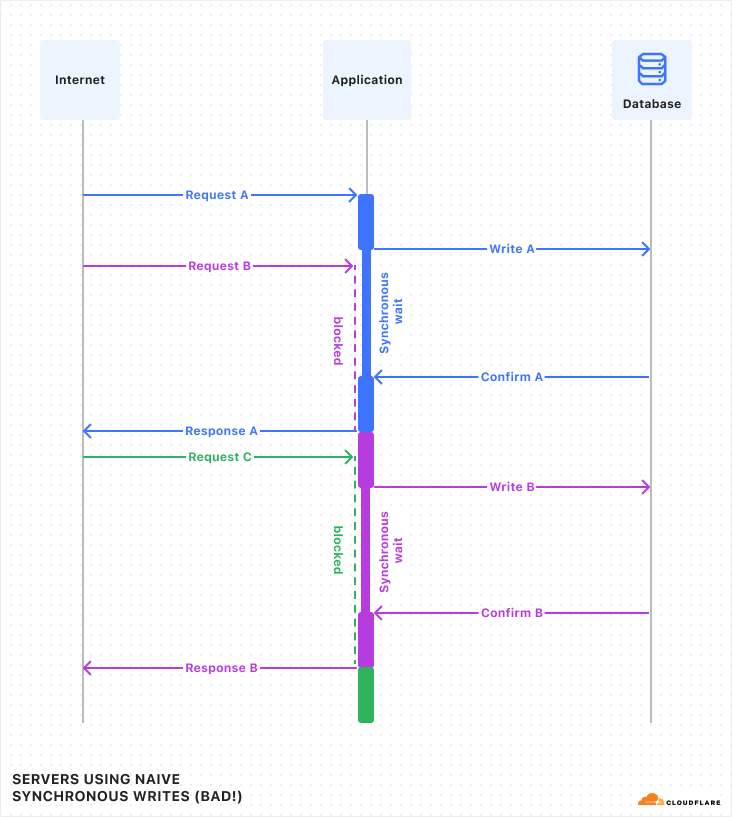
Costs began scaling unpredictably with our growing workloads, especially in AWS Lambda, Kinesis, and EC2, but also in less obvious ways, such as in Cloudfront (required for a custom domain in front of Lambda function URLs) and DynamoDB. Specifically, the time spent on I/O operations in AWS Lambda was a particularly costly piece. At every step, from the data receptors to the ClickHouse cluster, moving data to the next stage required waiting for a network request to complete, accounting for over 70% of wall time in the Lambda function.
In a nutshell, we were continuously paged by our alerts, innovating at a slower pace, and our costs were out of control.
Additionally, the entire solution was deployed in a single AWS region: eu-west-1. As a result, all developers located outside continental Europe were experiencing high latency when emitting logs and traces to Baselime.
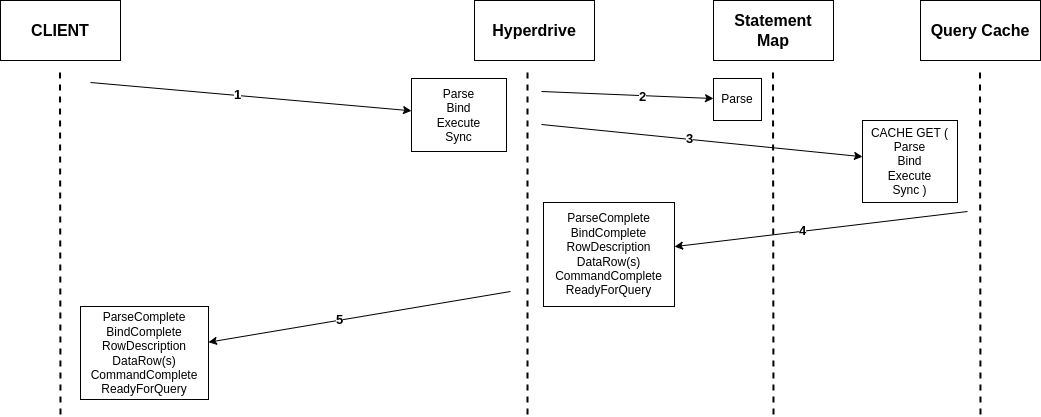
The shift to the Cloudflare Developer Platform enabled us to rethink our architecture to be exceptionally fast, globally distributed, and highly scalable, without compromising on cost, complexity, or agility. This new architecture is built on top of Cloudflare primitives.

Figure 2: Modern data pipeline architecture
Cloudflare Workers are now at the core of everything we do. All the data receptors and the processor run in Workers. Workers minimize cold-start times and are deployed globally by default. As such, developers always experience lower latency when emitting events to Baselime.
Additionally, we heavily use JavaScript-native RPC for data transfer between steps of the pipeline. It’s low-latency, lightweight, and simplifies communication between components. This further simplifies our architecture, as separate components behave more as functions within the same process, rather than completely separate applications.
export default {
async fetch(request: Request, env: Bindings, ctx: ExecutionContext): Promise<Response> {
try {
const { err, apiKey } = auth(request);
if (err) return err;
const data = {
workspaceId: apiKey.workspaceId,
environmentId: apiKey.environmentId,
events: request.body
};
await env.PROCESSOR.ingest(data);
return success({ message: "Request Accepted" }, 202);
} catch (error) {
return failure({ message: "Internal Error" });
}
},
};Code Block 1: Simplified data receptor using JavaScript-native RPC to execute the processor.
Workers also expose a Rate Limiting binding that enables us to automatically add rate limiting to our services, which we previously had to build ourselves using a combination of DynamoDB and ElastiCache.
Moreover, we heavily use ctx.waitUntil within our Worker invocations, to offload data transformation outside the request / response path. This further reduces the latency of calls developers make to our data receptors.
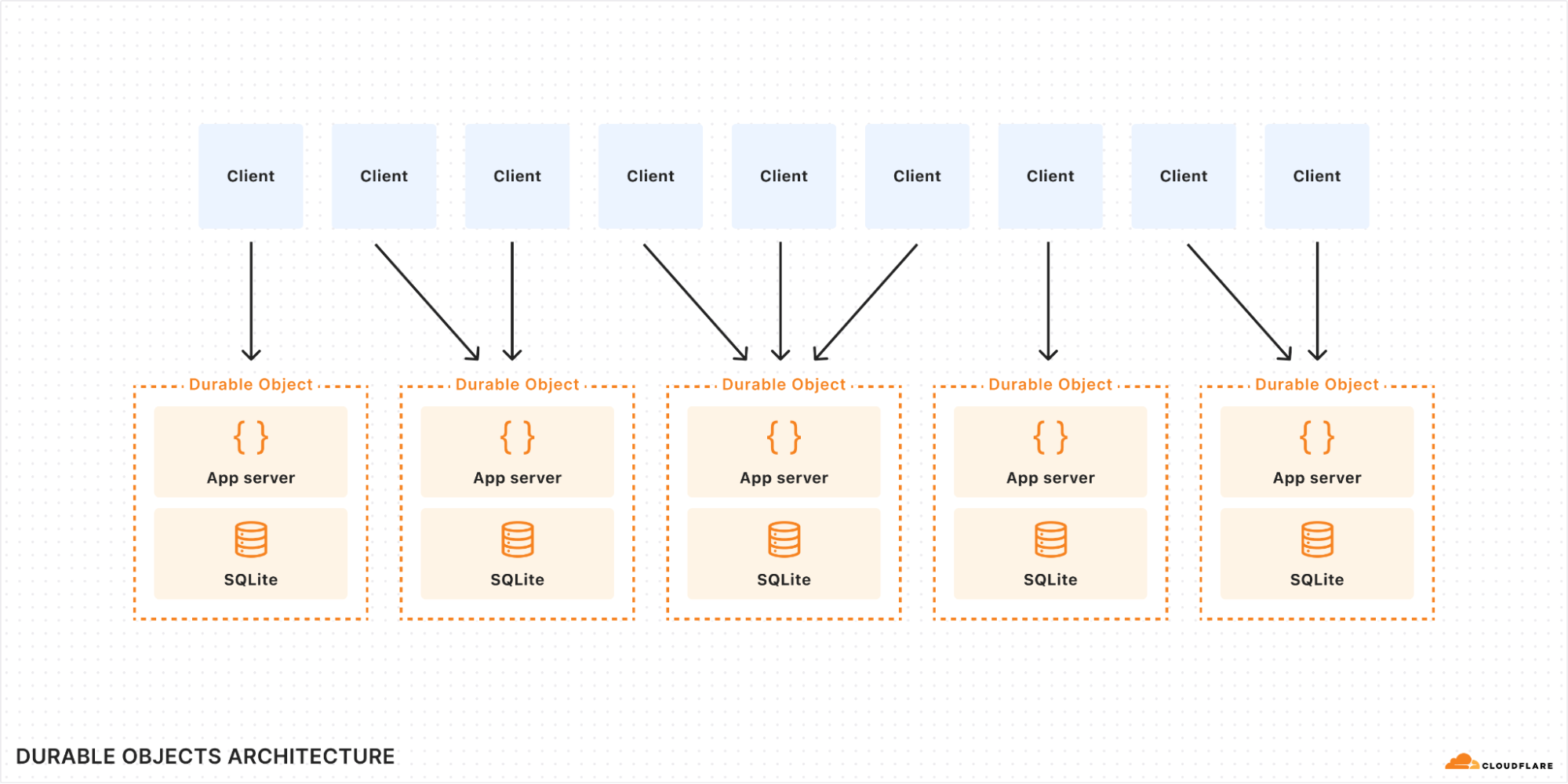
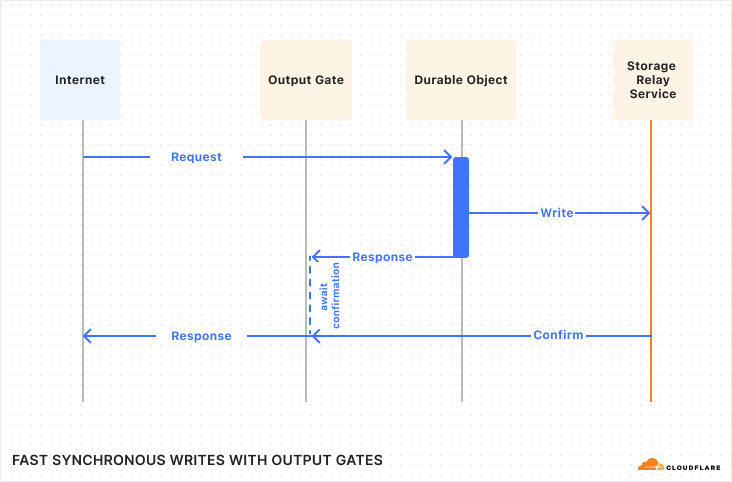
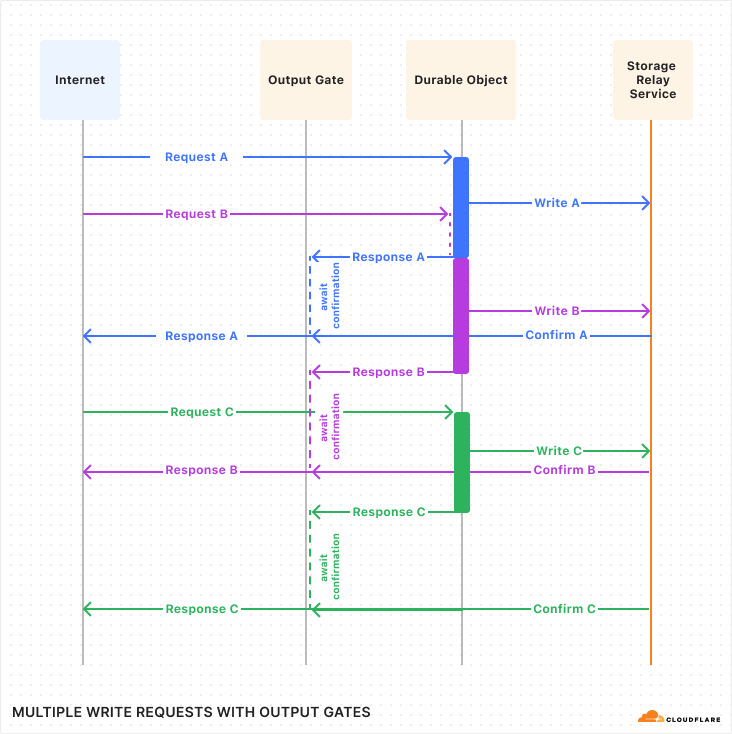
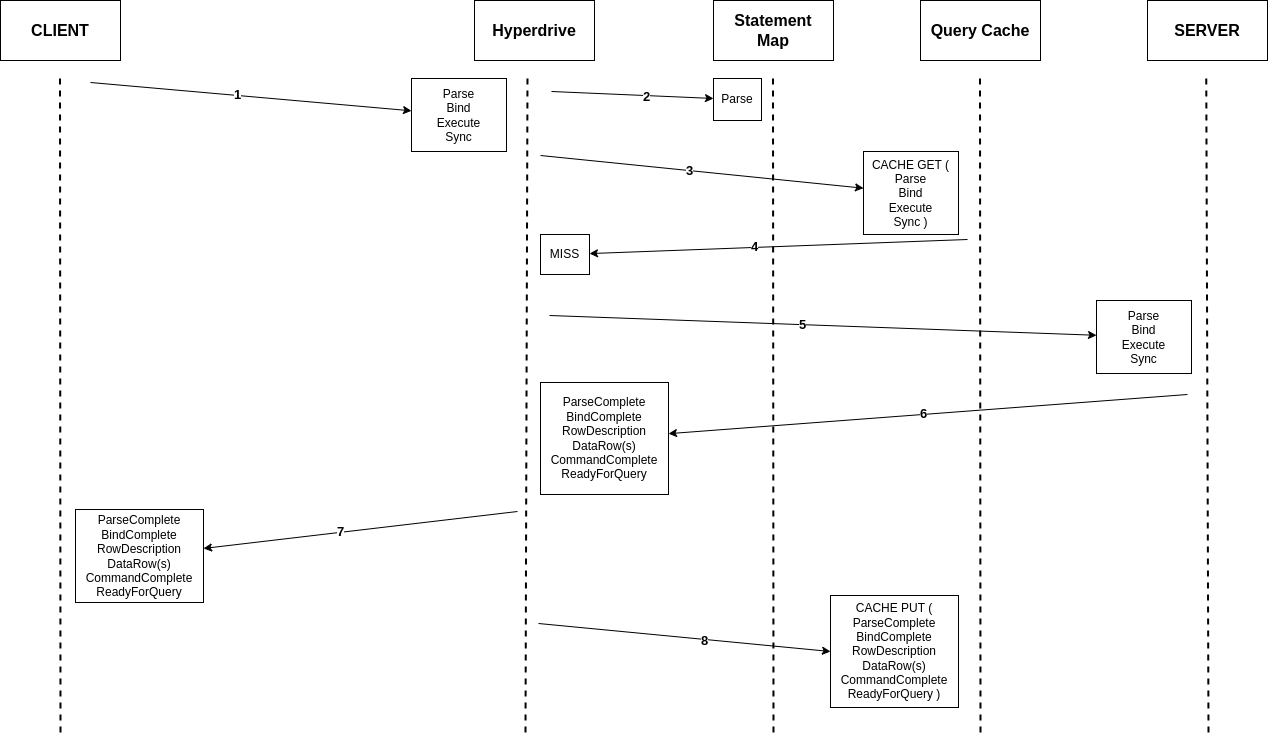
Durable Objects is a unique service within the Cloudflare Developer Platform, as it enables building stateful applications in a serverless environment. We use Durable Objects in the data pipelines for both real-time error tracking and detecting log patterns.
For instance, to track errors in real-time, we create a durable object for each new type of error, and this durable object is responsible for keeping track of the frequency of the error, when to notify customers, and the notification channels for the error. This implementation with a single building block removes the need for ElastiCache, Kinesis, and multiple Lambda functions to coordinate protecting the RDS database from being overwhelmed by a high frequency error.

Figure 3: Real-time error detection architecture comparison
Durable Objects gives us precise control over consistency and concurrency of managing state in the data pipeline.
In addition to the data pipeline, we use Durable Objects for alerting. Our previous architecture required orchestrating EventBridge Scheduler, SQS, DynamoDB and multiple AWS Lambda functions, whereas with Durable Objects, everything is handled within the alarm handler.
Though managing our own ClickHouse cluster was technically interesting and challenging, it took us away from building the best observability developer experience. With this migration, more of our time is spent enhancing our product and none is spent managing server instances.
Workers Analytics Engine lets us synchronously write events to a scalable high-cardinality analytics database. We built on top of the same technology that powers Workers Analytics Engine. We also made internal changes to Workers Analytics Engine to natively enable high dimensionality in addition to high cardinality.
Moreover, Workers Analytics Engine and our solution leverages Cloudflare’s ABR analytics. ABR stands for Adaptive Bit Rate, and enables us to store telemetry data in multiple tables with varying resolutions, from 100% to 0.0001% of the data. Querying the table with 0.0001% of the data will be several orders of magnitudes faster than the table with all the data, with a corresponding trade-off in accuracy. As such, when a query is sent to our systems, Workers Analytics Engine dynamically selects the most appropriate table to run the query, optimizing both query time and accuracy. Users always get the most accurate result with optimal query time, regardless of the size of their dataset or the timeframe of the query. Compared to our previous system, which was always running queries on the full dataset, the new system now delivers faster queries across our entire user base and use cases.
In addition to these core services (Workers, Durable Objects, Workers Analytics Engine), the new architecture leverages other building blocks from the Cloudflare Developer Platform. Queues for asynchronous messaging, decoupling services and enabling an event-driven architecture; D1 as our main database for transactional data (queries, alerts, dashboards, configurations, etc.); Workers KV for fast distributed storage; Hono for all our APIs, etc.
Baselime is built on an event-driven architecture, where every user action triggers an event. It operates on the principle that every user action is recorded as an event and emitted to the rest of the system — whether it’s creating a user, editing a dashboard, or performing any other action. Migrating to Cloudflare involved transitioning our event-driven architecture without compromising uptime and data consistency. Previously, this was powered by AWS EventBridge and SQS, and we moved entirely to Cloudflare Queues.
We followed the strangler fig pattern to incrementally migrate the solution from AWS to Cloudflare. It consists of gradually replacing specific parts of the system with newer services, with minimal disruption to the system. Early in the process, we created a central Cloudflare Queue which acted as the backbone for all transactional event processing during the migration. Every event, whether a new user signup or a dashboard edit, was funneled into this Queue. From there, events were dynamically routed, each event to the relevant part of the application. User actions were synced into D1 and KV, ensuring that all user actions were mirrored across both AWS and Cloudflare during the transition.
This syncing mechanism enabled us to maintain consistency and ensure that no data was lost as users continued to interact with Baselime.
Here’s an example of how events are processed:
export default {
async queue(batch, env) {
for (const message of batch.messages) {
try {
const event = message.body;
switch (event.type) {
case "WORKSPACE_CREATED":
await workspaceHandler.create(env, event.data);
break;
case "QUERY_CREATED":
await queryHandler.create(env, event.data);
break;
case "QUERY_DELETED":
await queryHandler.remove(env, event.data);
break;
case "DASHBOARD_CREATED":
await dashboardHandler.create(env, event.data);
break;
//
// Many more events...
//
default:
logger.info("Matched no events", { type: event.type });
}
message.ack();
} catch (e) {
if (message.attempts < 3) {
message.retry({ delaySeconds: Math.ceil(30 ** message.attempts / 10), });
} else {
logger.error("Failed handling event - No more retrys", { event: message.body, attempts: message.attempts }, e);
}
}
}
},
} satisfies ExportedHandler<Env, InternalEvent>;Code Block 2: Simplified internal events processing during migration.
We migrated the data pipeline from AWS to Cloudflare with an outside-in method: we started with the data receptors and incrementally moved the data processor and the ClickHouse cluster to the new architecture. We began writing telemetry data (logs, metrics, traces, wide-events, etc.) to both ClickHouse (in AWS) and to Workers Analytics Engine simultaneously for the duration of the retention period (30 days).
The final step was rewriting all of our endpoints, previously hosted on AWS Lambda and ECS containers, into Cloudflare Workers. Once those Workers were ready, we simply switched the DNS records to point to the Workers instead of the existing Lambda functions.
Despite the complexity, the entire migration process, from the data pipeline to all re-writing API endpoints, took our then team of 3 engineers less than three months.
After switching the data receptors from AWS to Cloudflare in early June 2024, our AWS Lambda cost was reduced by over 85%. These costs were primarily driven by I/O time the receptors spent sending data to a Kinesis Data Stream in the same region.

Figure 4: Baselime daily AWS Lambda cost [note: the gap in data is the result of AWS Cost Explorer losing data when the parent organization of the cloud accounts was changed.]
Moreover, we used Cloudfront to enable custom domains pointing to the data receptors. When we migrated the data receptors to Cloudflare, there was no need for Cloudfront anymore. As such, our Cloudfront cost was reduced to $0.

Figure 5: Baselime daily Cloudfront cost [note: the gap in data is the result of AWS Cost Explorer losing data when the parent organization of the cloud accounts was changed.]
If we were a regular Cloudflare customer, we estimate that our daily Cloudflare Workers bill would be around \$25 after the switch, against \$790 on AWS: over 95% cost reduction. These savings are primarily driven by the Workers pricing model, since Workers charge for CPU time, and the receptors are primarily just moving data, and as such, are mostly I/O bound.
To evaluate the cost impact of switching from self-hosting ClickHouse to using Workers Analytics Engine, we need to take into account not only the EC2 instances, but also the disk space, networking, and the Kinesis Data Stream cost.
We completed this switch in late August, achieving over 95% cost reduction in both the Kinesis Data Stream and all EC2 related costs.

Figure 6: Baselime daily Kinesis Data Stream cost [note: the gap in data is the result of AWS Cost Explorer losing data when the parent organization of the cloud accounts was changed.]

Figure 7: Baselime daily EC2 cost [note: the gap in data is the result of AWS Cost Explorer losing data when the parent organization of the cloud accounts was changed.]
If we were a regular Cloudflare customer, we estimate that our daily Workers Analytics Engine cost would be around \$300 after the switch, compared to \$1150 on AWS, a cost reduction of over 70%.
Not only did we significantly reduce costs by migrating to Cloudflare, but we also improved performance across the board. Responses to users are now faster, with real-time event ingestion happening across Cloudflare’s network, closer to our users. Responses to users querying their data are also much faster, thanks to Cloudflare’s deep expertise in operating ClickHouse at scale.
Most importantly, we’re no longer bound by limitations in throughput or scale. We launched Workers Logs on September 26, 2024, and our system now handles a much higher volume of events than before, with no sacrifices in speed or reliability.
These cost savings are outstanding as is, and do not include the total cost of ownership of those systems. We significantly simplified our systems and our codebase, as the platform is taking care of more for us. We’re paged less, we spend less time monitoring infrastructure, and we can focus on delivering product improvements.
Migrating Baselime to Cloudflare has transformed how we build and scale our platform. With Workers, Durable Objects, Workers Analytics Engine, and other services, we now run a fully serverless, globally distributed system that’s more cost-efficient and agile. This shift has significantly reduced our operational overhead and enabled us to iterate faster, delivering better observability tooling to our users.
You can start observing your Cloudflare Workers today with Workers Logs. Looking ahead, we’re excited about the features we will deliver directly in the Cloudflare Dashboard, including real-time error tracking, alerting, and a query builder for high-cardinality and dimensionality events. All coming by early 2025.