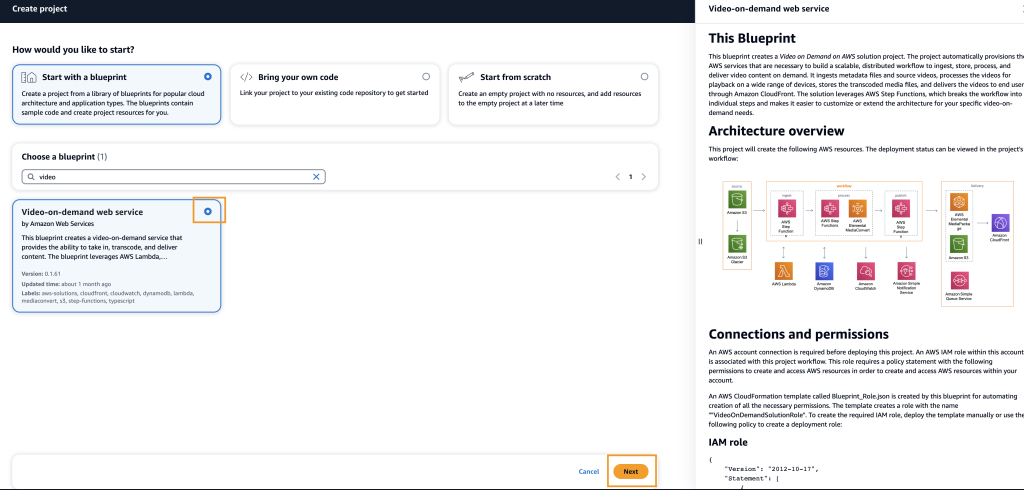
Post Syndicated from Brendan Jenkins original https://aws.amazon.com/blogs/devops/best-practices-for-prompt-engineering-with-amazon-codewhisperer/
Generative AI coding tools are changing the way developers accomplish day-to-day development tasks. From generating functions to creating unit tests, these tools have helped customers accelerate software development. Amazon CodeWhisperer is an AI-powered productivity tools for the IDE and command line that helps improve developer productivity by providing code recommendations based on developers’ natural language comments and surrounding code. With CodeWhisperer, developers can simply write a comment that outlines a specific task in plain English, such as “create a lambda function to upload a file to S3.”
When writing these input prompts to CodeWhisperer like the natural language comments, one important concept is prompt engineering. Prompt engineering is the process of refining interactions with large language models (LLMs) in order to better refine the output of the model. In this case, we want to refine our prompts provided to CodeWhisperer to produce better code output.
In this post, we’ll explore how to take advantage of CodeWhisperer’s capabilities through effective prompt engineering in Python. A well-crafted prompt lets you tap into the tool’s full potential to boost your productivity and help generate the correct code for your use case. We’ll cover prompt engineering best practices like writing clear, specific prompts and providing helpful context and examples. We’ll also discuss how to iteratively refine prompts to produce better results.
Prompt Engineering with CodeWhisperer
We will demonstrate the following best practices when it comes to prompt engineering with CodeWhisperer.
- Keep your prompt specific and concise
- Additional context in prompts
- Utilizing multiple comments
- Context taken from comments and code
- Generating unit tests with cross file context
- Prompts with cross file context
Prerequisites
The following prerequisites are required to experiment locally:
- An AWS Account
- Visual Studio Code or supported JetBrains IDEs
- Enable CodeWhisperer locally in your IDE
- Python
CodeWhisperer User Actions
Reference the following user actions documentation for CodeWhisperer user actions according to your IDE. In this documentation, you will see how to accept a recommendation, cycle through recommendation options, reject a recommendation, and manually trigger CodeWhisperer.
Keep prompts specific & concise
In this section, we will cover keeping your prompt specific and concise. When crafting prompts for CodeWhisperer, conciseness while maintaining objectives in your prompt is important. Overly complex prompts lead to poor results. A good prompt contains just enough information to convey the request clearly and concisely. For example, if you prompt CodeWhisperer “create a function that eliminates duplicates lines in a text file”. This is an example of a specific and concise prompt. On the other hand, a prompt such as “create a function to look for lines of code that are seen multiple times throughout the file and delete them” may be unclear and overly wordy. In summary, focused, straightforward prompts helps CodeWhisperer understand exactly what you want and provide better outputs.
In this example, we would like to write a function in Python that will open a CSV file and store the contents into a dictionary. We will use the following simple and concise prompt that will guide CodeWhisperer to generate recommendations. Please use the left/right arrow key to cycle through the various recommendations before you hit tab to accept the recommendation.
Example 1:
Sample comment:
#load the csv file content in a dictionarySample solution:
#load the csv file content in a dictionary
import csv
def csv_to_dict(csv_file):
with open(csv_file, 'r') as f:
reader = csv.DictReader(f)
return list(reader)
Simple and concise prompts are crucial in prompt engineering because they help CodeWhisperer understand the key information without confusion from extraneous details. Simplicity and brevity enable faster iteration and allow prompts to maximize impact within character limits.
Additional context in prompts
In this section, we will cover how additional context can aid in prompt engineering. While specific and concise prompts are crucial, some additional context can aid CodeWhisperer comprehension. Concrete examples also guide CodeWhisperer if it struggles to infer expectations from just a brief prompt.
In this example, we would like to add additional context to Example 1 where we stored the CSV file content into a dictionary. Now, we have additional requirements to store the csv file content in alphabetical order and return the list keys from the dictionary. Take a look at the sample prompt below. Judicious context helps CodeWhisperer to produce higher-quality, tailored results.
Example 2:
Sample comment:
#load the csv file content in a dictionary in alphabetical order and return the list of keysSample solution:
#load the csv file content in a dictionary in alphabetical order and return the list of keys
import csv
def csv_to_dict(file_name):
def read_csv_file(file_name):
with open(file_name, 'r') as csv_file:
csv_reader = csv.DictReader(csv_file)
csv_dict = {}
for row in csv_reader:
csv_dict[row['name']] = row
return csv_dict
Providing additional context through background details and examples can be beneficial when crafting prompts for CodeWhisperer, as long as the extra information adds useful clarity rather than obscuring the core request. The right balance of brevity and pointed contextual signals can help CodeWhisperer generate more tailored, high-quality results.
Utilizing multiple comments
In this section, we will cover how multiple comments can be a useful technique in prompt engineering. When used strategically, multiple comments allow prompt engineers to offer more context without sacrificing brevity or cluttering the prompt.
Say we would like to open a CSV file and return the list of lines in alphabetical order, remove duplicate lines, and insert a period at the end of each line from the CSV file. Take a look at the sample CodeWhisperer prompt below. Notice how you can break up multiple requirements into separate comments.
Example 3:
Sample comment:
#open a csv file and return a list of lines in alphabetical order
#Remove duplicate lines
#Insert a period at the end of each line
Sample solution:
#open a csv file and return a list of lines in alphabetical order
#Remove duplicate lines
#Insert a period at the end of each line
def open_csv(filename):
with open(filename) as f:
lines = f.readlines()
lines = list(set(lines))
lines = sorted(lines)
for i in range(len(lines)):
lines[i] = lines[i].rstrip() + '.'
return lines
Multiple comments allow prompt engineers to add extended context and guidance for CodeWhisperer while keeping prompts succinct.
Context taken from comments and code
In this section, we will cover how CodeWhisperer’s context goes beyond just your comment and also looks at the surrounding code, including other functions, imports, and more. This broader context helps guide CodeWhisperer towards implementing the use case you intend with your comment.
We will now see how additional code in our project affects the responses. This time around, we will import the Pandas library to see how it effects our recommendation as compared to the previous section.
Example 4:
Sample Comment:
import pandas as pd
#open a csv file and return a list of lines in alphabetical order
#Insert a period at the end of each line
#Replace duplicate lines with a single line
Sample solution:
import pandas as pd
#open a csv file and return a list of lines in alphabetical order
#Insert a period at the end of each line
#Replace duplicate lines with a single line
def open_csv(filename):
df = pd.read_csv(filename)
df = df.sort_values(by='line')
df = df.drop_duplicates(subset='line')
df['line'] = df['line'] + '.'
return df['line'].tolist()
By seeing Pandas imported, CodeWhisperer understands our intent is likely to leverage it in the solution. This allows it to provide a more relevant recommendation using Pandas functions like read_csv(), sort_values(), and drop_duplicates().
Overall, surrounding code context gives CodeWhisperer additional clues for the implementation you have in mind with your high-level instructions.
Prompts with cross file context
In the previous section, we saw how we were able to utilize the surrounding code that CodeWhisperer takes in as context to generate a function for our use case. In this section, we will use that same concept to generate unit tests for the function we’ve built utilizing CodeWhisperers cross file context capability. This section will demonstrate how we can use cross file context with our prompts for use cases like test driven development.
In this example, we will prompt CodeWhisperer to write a comment referencing the open_csv function in order to write unit tests. In this case, there will be a new python file in the project directory for unit testing. We will assume the file we have been working out of is “example4.py”, and the new file is “unittest.py”. We will incorporate the following comments in “unittest.py”.
Example 5:
Sample Comment in unittest.py:
#create unit tests for the open_csv function from example4.py fileSample solution in unittest.py:
#create unit tests for the open_csv function from example4.py file
class TestOpenCsv(unittest.TestCase):
def test_open_csv(self):
self.assertEqual(open_csv('example4.csv'), ['a.', 'b.', 'c.'])
self.assertEqual(open_csv('example4.csv'), ['a.', 'b.', 'c.', 'd.'])
Notice how CodeWhisperer is using context from one file to generate code recommendation in another file. By specifying the open_csv function within the comment of the “unittest.py”, CodeWhisperer was able to analyze the function, understand its purpose and interface, and generate a set of basic unit tests to validate it. With our prompts, we were able to utilize CodeWhisperers cross file context to help us generate unit tests.
Chain of thought prompting
Chain of thought prompting is a prompt engineering technique that allows large language models (LLMs) to have more natural, contextual outputs by linking multiple prompts together to solve a complex problem. In regard to CodeWhisperer, we can use this technique to break a very complex coding task down into smaller steps, allowing CodeWhisperer to provide more accurate suggestions to the use case.
In this example, we will examine a code snippet generated by CodeWhisperer that contains multiple comments. Our intention is to prompt the user to input a filename, ensure it’s a csv and alphanumeric, then process it with the logging.info method. We will analyze the output using both the chain of thought approach and a single comment.
Example 6:
Chain of thought prompt approach:
Comment 1 – “Take a user’s input using the input() function and store it in a variable called filename”
import logging
# Take a users input using the input() function and store it in a variable called filename
filename = input("Enter the name of the file you want to read: ")
Comment 2 – create a function that will take a filename as an input
import logging
# Take a users input using the input() function and store it in a variable called filename
filename = input("Enter the name of the file you want to read: ")
#create a function that will take a filename as an input
def open_file(filename):
Comment 3 – validate the input using the isalnum() method and ensure the file ends in .csv then process the file using logging.info()
import logging
# Take a users input using the input() function and store it in a variable called filename
filename = input("Enter the name of the file you want to read: ")
#create a function that will take a filename as an input
def open_file(filename):
#validate the input using the isalnum() method and ensure the file ends in .csv then process the file using logging.info()
if filename.isalnum() and filename.endswith('.csv'):
lines = open_csv(filename)
logging.info(lines)
return lines
else:
print('Invalid file name')
return None
Single prompt approach:
import logging
'''
Using the input() function and store it in a variable called filename and create a function
that will validate the input using the isalnum() method and ensure the file ends in .csv then process
the file accordingly.
'''
def validate_file(filename):
if filename.isalnum() and filename.endswith('.csv'):
return True
else:
return False
When analyzing these side-by-side, we see that with the chain of thought prompt approach, we used multiple comments to allow CodeWhisperer to implement all our requirements including the user input, input validation, .csv verification, and logging as we broke it down into steps for CodeWhisperer to implement. On the other hand, in the case where we had a single comment implementing multiple requirements, it didn’t take all the requirements into account for this slightly more complex problem.
In conclusion, chain of thought prompting allows large language models like CodeWhisperer to produce more accurate code pertaining to the use case by breaking down complex problems into logical steps. Guiding the model through comments and prompts helps it focus on each part of the task sequentially. This results in code that is more accurate to the desired functionality compared to a single broad prompt.
Conclusion
Effective prompt engineering is key to getting the most out of powerful AI coding assistants like Amazon CodeWhisperer. Following prompt best practices, we’ve covered like using clear language, providing context, and iteratively refining prompts can help CodeWhisperer generate high-quality code tailored to your specific needs. Analyzing all the code options CodeWhisperer provides you flexibility to select the optimal approach.