Post Syndicated from Mark Paulsen original https://github.blog/2023-02-28-how-to-build-a-consistent-workflow-for-development-and-operations-teams/
In GitHub’s recent 2022 State of the Octoverse report, HashiCorp Configuration Language (HCL) was the fastest growing programming language on GitHub. HashiCorp is a leading provider of Infrastructure as Code (IaC) automation for cloud computing. HCL is HashiCorp’s configuration language used with tools like Terraform and Vault to deliver IaC capabilities in a human-readable configuration file across multi-cloud and on-premises environments.
HCL’s growth shows the importance of bringing together the worlds of infrastructure, operations, and developers. This was always the goal of DevOps. But in reality, these worlds remain siloed for many enterprises.
In this post we’ll look at the business and cultural influences that bring development and operations together, as well as security, governance, and networking teams. Then, we’ll explore how GitHub and HashiCorp can enable consistent workflows and guardrails throughout the entire CI/CD pipeline.
The traditional world of operations (Ops)
Armon Dadgar, co-founder of HashiCorp, uses the analogy of a tree to explain the traditional world of Ops. The trunk includes all of the shared and consistent services you need in an enterprise to get stuff done. Think of things like security requirements, Active Directory, and networking configurations. A branch represents the different lines of business within an enterprise, providing services and products internally or externally. The leaves represent the different environments and technologies where your software or services are deployed: cloud, on-premises, and container environment, among others.
In many enterprises, the communication channels and processes between these different business areas can be cumbersome and expensive. If there is a significant change to the infrastructure or architecture, multiple tickets are typically submitted to multiple teams for reviews and approvals across different parts of the enterprise. Change Advisory Boards are commonly used to protect the organization. The change is usually unable to proceed unless the documentation is complete. Commonly, there’s a set of governance logs and auditable artifacts which are required for future audits.
Wouldn’t it be more beneficial for companies if teams had an optimized, automated workflow that could be used to speed up delivery and empower teams to get the work done in a set of secure guardrails? This could result in significant time and cost savings, leading to added business value.
After all, a recent Forrester report found that over three years, using GitHub drove 433% ROI for a composite organization simply with the combined power of all GitHub’s enterprise products. Not to mention the potential for time savings and efficiency increase, along with other qualitative benefits that come with consistency and streamlining work.
Your products and services would be deployed through an optimized path with security and governance built-in, rather than a sluggish, manual and error-prone process. After all, isn’t that the dream of DevOps, GitOps, and Cloud Native?
Introducing IaC
Let’s use a different analogy. Think of IaC as the blueprint for resources (such as servers, databases, networking components, or PaaS services) that host our software and services.
If you were architecting a hospital or a school, you wouldn’t use the same overall blueprint for both scenarios as they serve entirely different purposes with significantly different requirements. But there are likely building blocks or foundations that can be reused across the two designs.
IaC solutions, such as HCL, allow us to define and reuse these building blocks, similarly to how we reuse methods, modules, and package libraries in software development. With it being IaC, we can start adopting the same recommended practices for infrastructure that we use when collaborating and deploying on applications.
After all, we know that teams that adopt DevOps methodologies will see improved productivity, cloud-enabled scalability, collaboration, and security.
A better way to deliver
With that context, let’s explore the tangible benefits that we gain in codifying our infrastructure and how they can help us transform our traditional Ops culture.
Storing code in repositories
Let’s start with the lowest-hanging fruit. With it being IaC, we can start storing infrastructure and architectural patterns in source code repositories such as GitHub. This gives us a single source of truth with a complete version history. This allows us to easily rollback changes if needed, or deploy a specific version of the truth from history.
Teams across the enterprise can collaborate in separate branches in a Git repository. Branches allow teams and individuals to be productive in “their own space” and not have to worry about negatively impacting the in-progress work of other teams, away from the “production” source of truth (typically, the main branch).
Terraform modules, the reusable building blocks mentioned in the last section, are also stored and versioned in Git repositories. From there, modules can be imported to the private registry in Terraform Cloud to make them easily discoverable by all teams. When a new release version is tagged in GitHub, it is automatically updated in the registry.
Collaborate early and often
As we discussed above, teams can make changes in separate branches to not impact the current state. But what happens when you want to bring those changes to the production codebase? If you’re unfamiliar with Git, then you may not have heard of a pull request before. As the name implies, we can “pull” changes from one branch into another.
Pull requests in GitHub are a great way to collaborate with other users in the team, being able to get peer reviews so feedback can be incorporated into your work. The pull request process is deliberately very social, to foster collaboration across the team.
In GitHub, you could consider setting branch protection rules so that direct changes to your main branch are not allowed. That way, all users must go through a pull request to get their code into production. You can even specify the minimum number of reviewers needed in branch protection rules.
Tip: you could use a special type of file, the CODEOWNERS file in GitHub, to automatically add reviewers to a pull request based on the files being edited. For example, all HCL files may need a review by the core infrastructure team. Or IaC configurations for line of business core banking systems might require review by a compliance team.
Unlike Change Advisory Boards, which typically take place on a specified cadence, pull requests become a natural part of the process to bring code into production. The quality of the decisions and discussions also evolves. Rather than being a “yes/no” decision with recommendations in an external system, the context and recommendations can be viewed directly in the pull request.
Collaboration is also critical in the provisioning process, and GitHub’s integrations with Terraform Cloud will help you scale these processes across multiple teams. Terraform Cloud offers workflow features like secure storage for your Terraform state and direct integration with your GitHub repositories for a turnkey experience around the pull request and merge lifecycle.
Bringing automated quality reviews into the process
Building on from the previous section, pull requests also allow us to automatically check the quality of the changes that are being proposed. It is common in software to check that the application still compiles correctly, that unit tests pass, that no security vulnerabilities are introduced, and more.
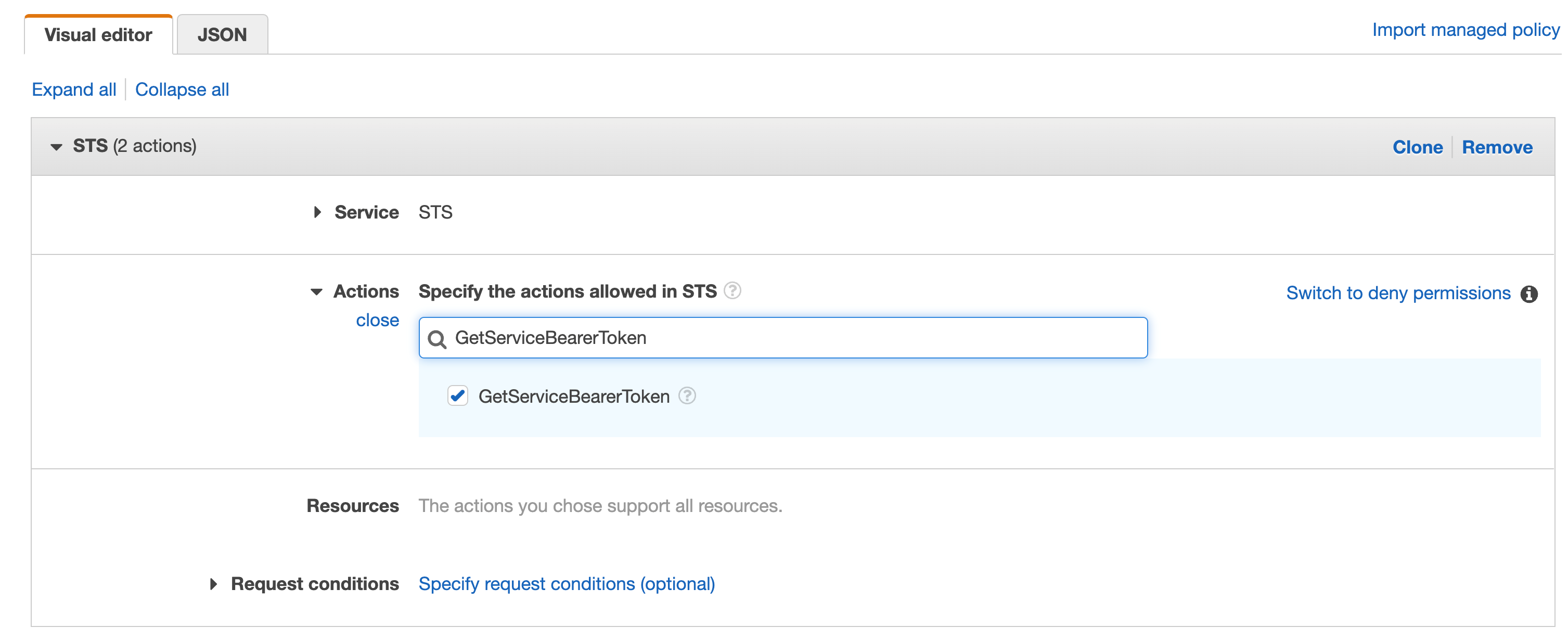
From an IaC perspective, we can bring similar automated checks into our process. This is achieved by using GitHub status checks and gives us a clear understanding of whether certain criteria has been met or not.
GitHub Actions are commonly used to execute some of these automated checks in pull requests on GitHub. To determine the quality of IaC, you could include checks such as:
- Validating that the code is syntactically correct (for example, Terraform validate).
- Linting the code to ensure a certain set of standards are being followed (for example, TFLint or Terraform format).
- Static code analysis to identify any misconfigurations in your infrastructure at “design time” (for example, tfsec or terrascan).
- Relevant unit or integration tests (using tools such as Terratest).
- Deploying the infrastructure into a “smoke test”environment to verify that the infrastructure configuration (along with a known set of parameters) results deploy into a desired state.
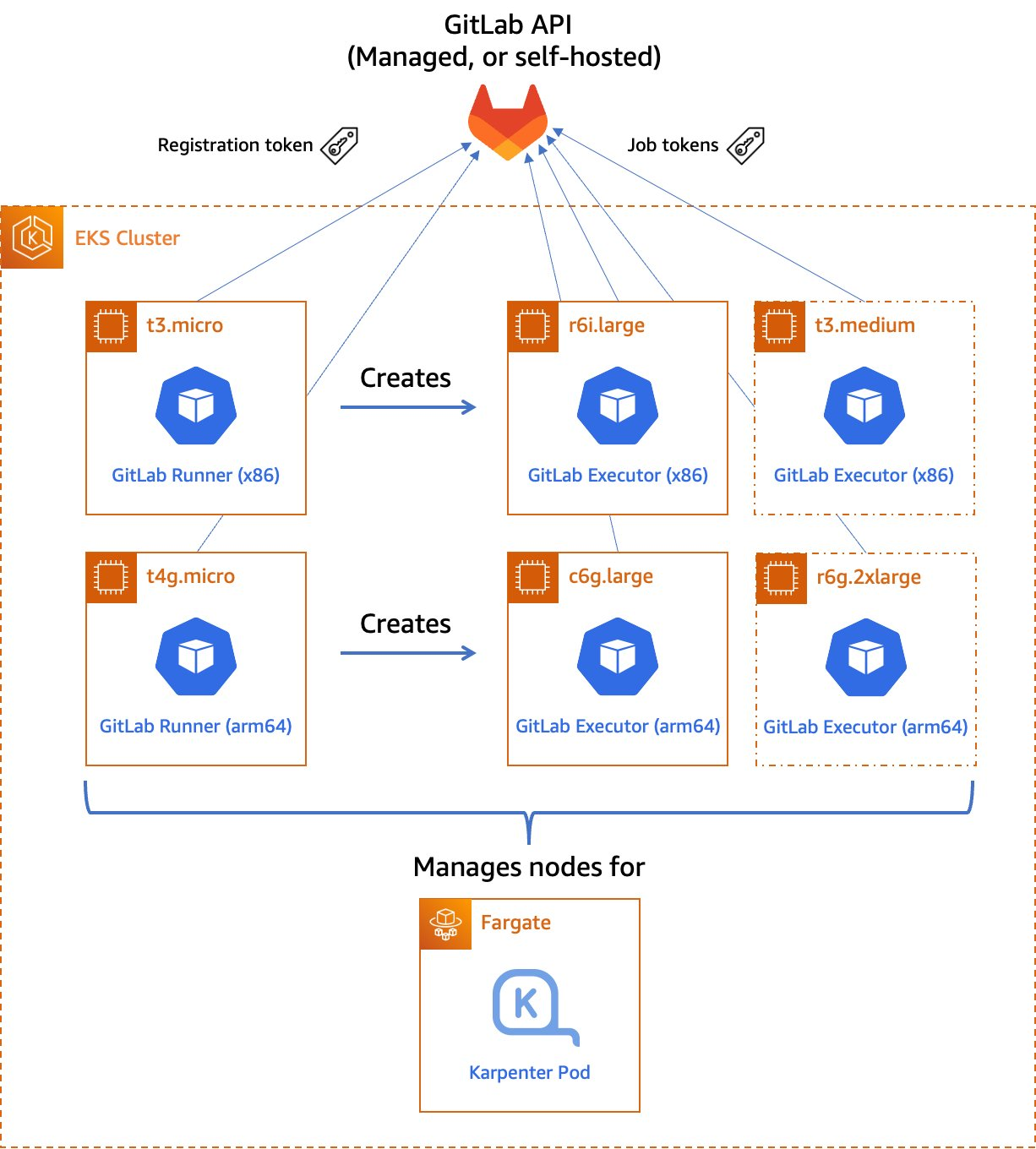
Getting started with Terraform on GitHub is easy. Versions of Terraform are installed on our Linux-based GitHub-hosted runners, and HashiCorp has an official GitHub Action to set up Terraform on a runner using a Terraform version that you specify.
Compliance as an automated check
We recently blogged about building compliance, security, and audit into your delivery pipelines and the benefits of this approach. When you add IaC to your existing development pipelines and workflows, you’ll have the ability to describe previously manual compliance testing and artifacts as code directly into your HCL configurations files.
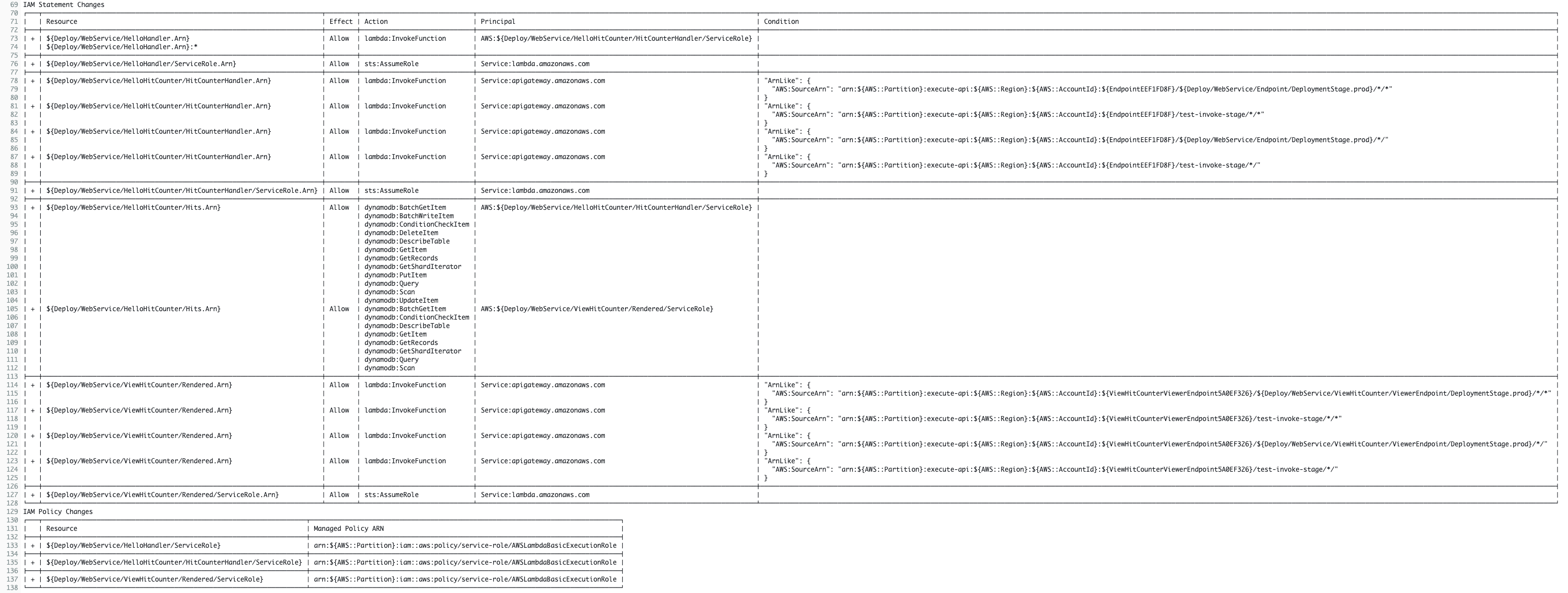
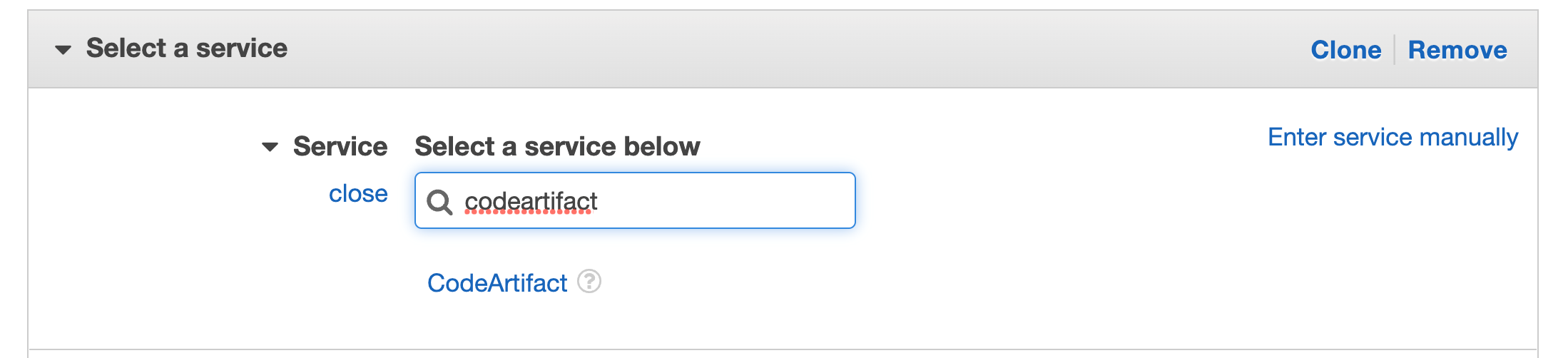
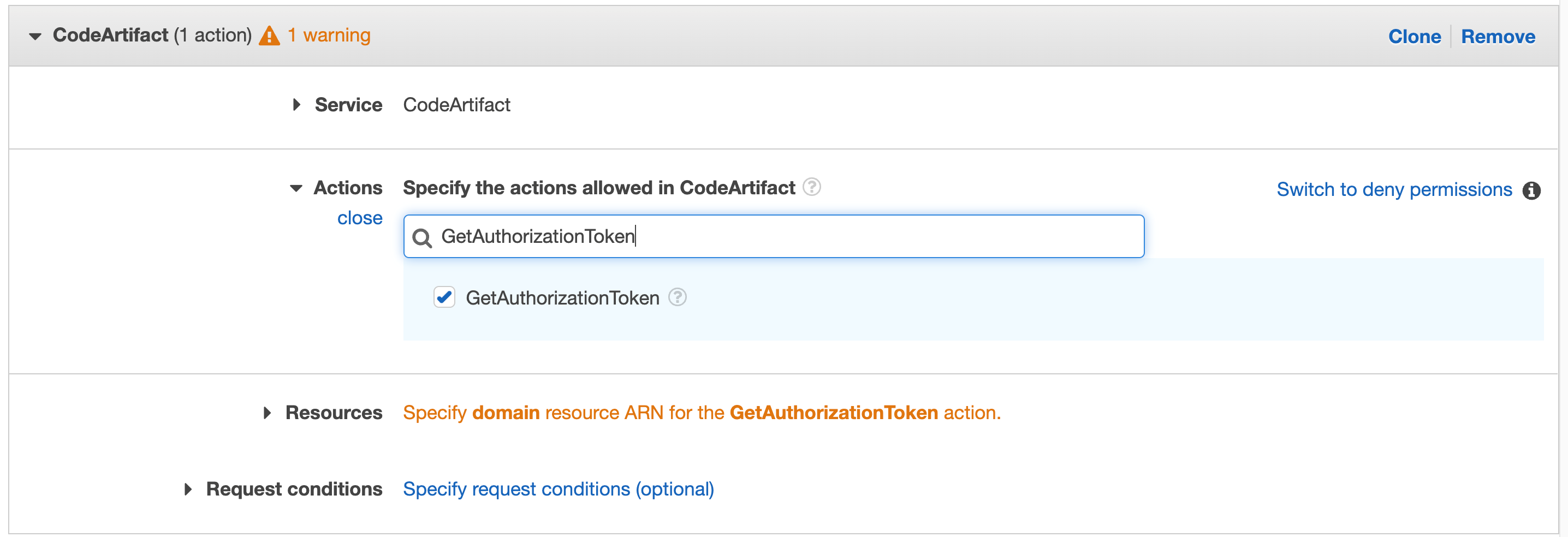
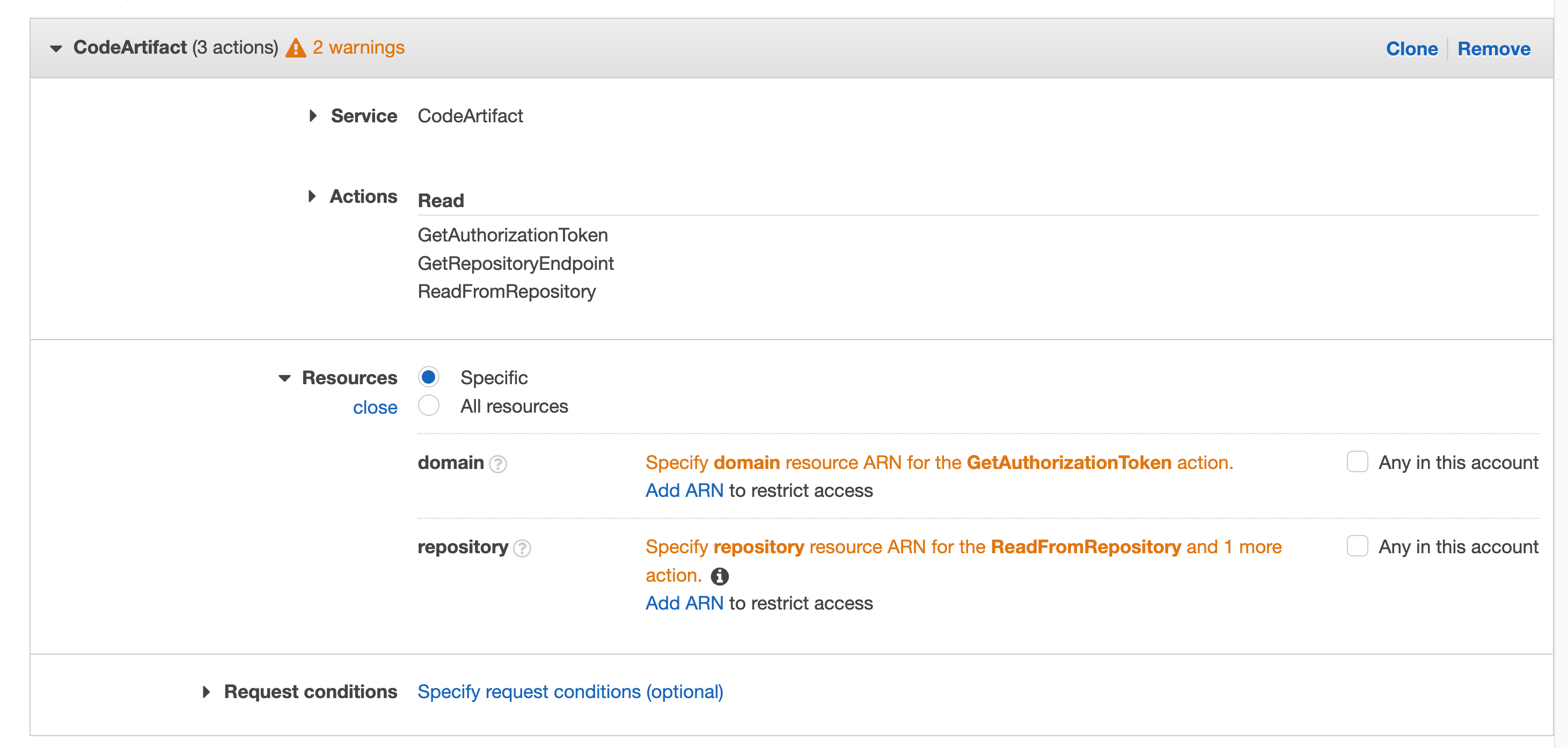
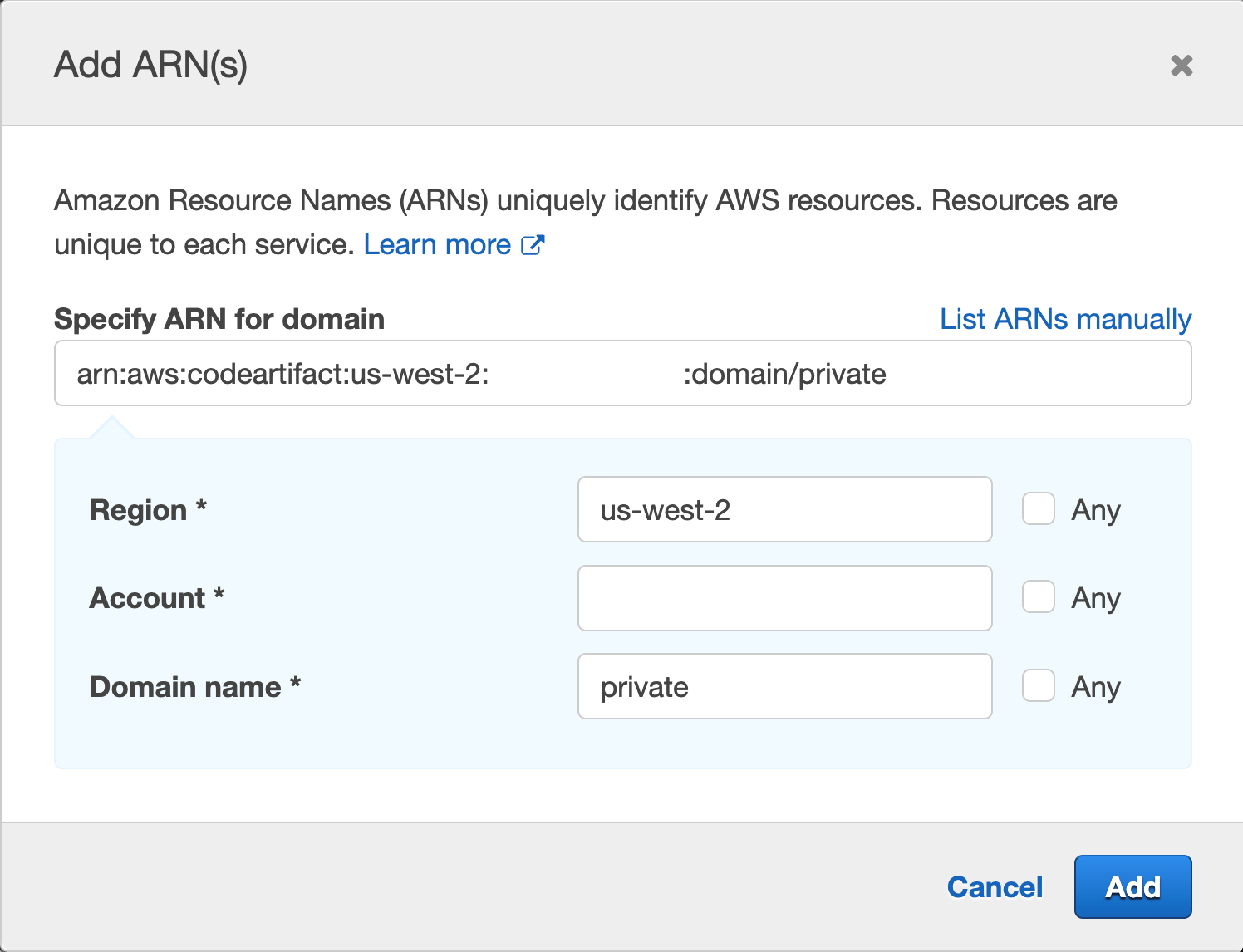
A natural extension to IaC, policy as code allows your security and compliance teams to centralize the definitions of your organization’s requirements. Terraform Cloud’s built-in support for the HashiCorp Sentinel and Open Policy Agent (OPA) frameworks allows policy sets to be automatically ingested from GitHub repositories and applied consistently across all provisioning runs. This ensures policies are applied before misconfigurations have a chance to make it to production.
An added bonus mentioned in another recent blog is the ability to leverage AI-powered compliance solutions to optimize your delivery even more. Imagine a future where generative AI could create compliance-focused unit-tests across your entire development and infrastructure delivery pipeline with no manual effort.
Security in the background
You may have heard of Dependabot, our handy tool to help you keep your dependencies up to date. But did you know that Dependabot supports Terraform? That means you could rely on Dependabot to help keep your Terraform provider and module versions up to date.
Checks complete, time to deploy
With the checks complete, it’s now time for us to deploy our new infrastructure configuration! Branching and deployment strategies is beyond the scope of this post, so we’ll leave that for another discussion.
However, GitHub Actions can help us with the deployment aspect as well! As we explained earlier, getting started with Terraform on GitHub is easy. Versions of Terraform are installed on our Linux-based GitHub-hosted runners, and HashiCorp has an official GitHub Action to set up Terraform on a runner using a Terraform version that you specify.
But you can take this even further! In Terraform, it is very common to use the command terraform plan to understand the impact of changes before you push them to production. terraform apply is then used to execute the changes.
Reviewing environment changes in a pull request
HashiCorp provides an example of automating Terraform with GitHub Actions. This example orchestrates a release through Terraform Cloud by using GitHub Actions. The example takes the output of the terraform plan command and copies the output into your pull request for approval (again, this depends on the development flow that you’ve chosen).
Reviewing environment changes using GitHub Actions environments
Let’s consider another example, based on the example from HashiCorp. GitHub Actions has a built-in concept of environments. Think of these environments as a logical mapping to a target deployment location. You can associate a protection rule with an environment so that an approval is given before deploying.
So, with that context, let’s create a GitHub Action workflow that has two environments—one which is used for planning purposes, and another which is used for deployment:
name: 'Review and Deploy to EnvironmentA'
on: [push]
jobs:
review:
name: 'Terraform Plan'
environment: environment_a_plan
runs-on: ubuntu-latest
steps:
- name: 'Checkout'
uses: actions/checkout@v2
- name: 'Terraform Setup'
uses: hashicorp/setup-terraform@v2
with:
cli_config_credentials_token: ${{ secrets.TF_API_TOKEN }}
- name: 'Terraform Init'
run: terraform init
- name: 'Terraform Format'
run: terraform fmt -check
- name: 'Terraform Plan'
run: terraform plan -input=false
deploy:
name: 'Terraform'
environment: environment_a_deploy
runs-on: ubuntu-latest
needs: [review]
steps:
- name: 'Checkout'
uses: actions/checkout@v2
- name: 'Terraform Setup'
uses: hashicorp/setup-terraform@v2
with:
cli_config_credentials_token: ${{ secrets.TF_API_TOKEN }}
- name: 'Terraform Init'
run: terraform init
- name: 'Terraform Plan'
run: terraform apply -auto-approve -input=false
Before executing the workflow, we can create an environment in the GitHub repository and associate protection rules with the environment_a_deploy. This means that a review is required before a production deployment.
Learn more
Check out HashiCorp’s Practitioner’s Guide to Using HashiCorp Terraform Cloud with GitHub for some common recommendations on getting started. And find out how we at GitHub are using Terraform to deliver mission-critical functionality faster and at lower cost.
























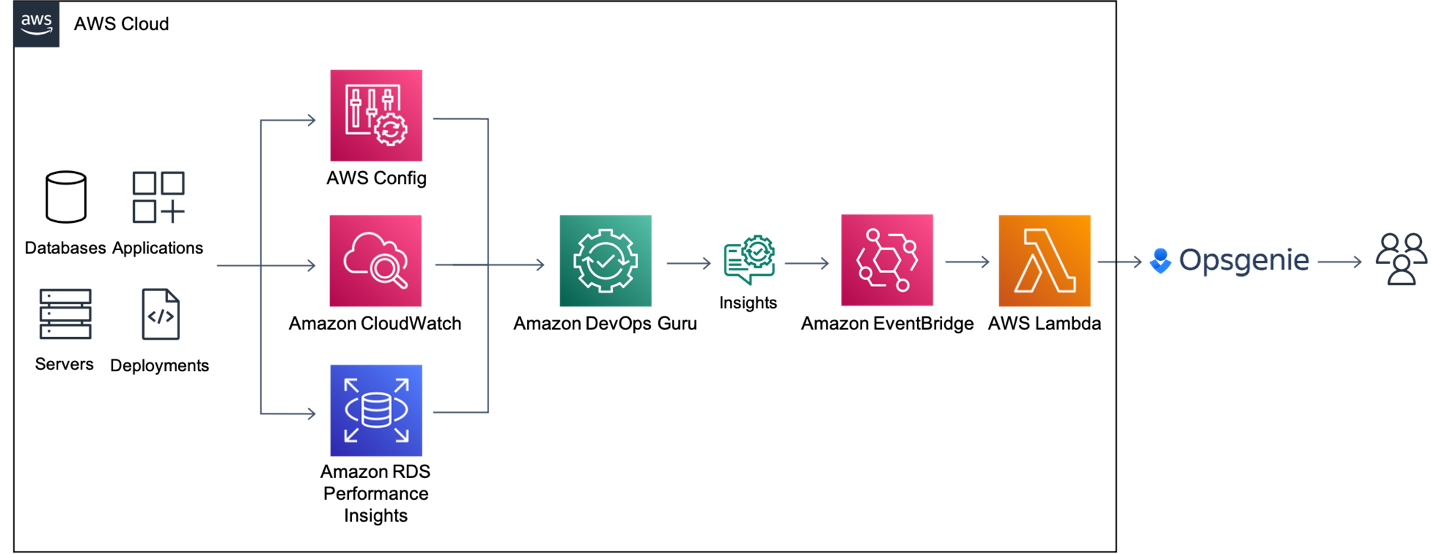


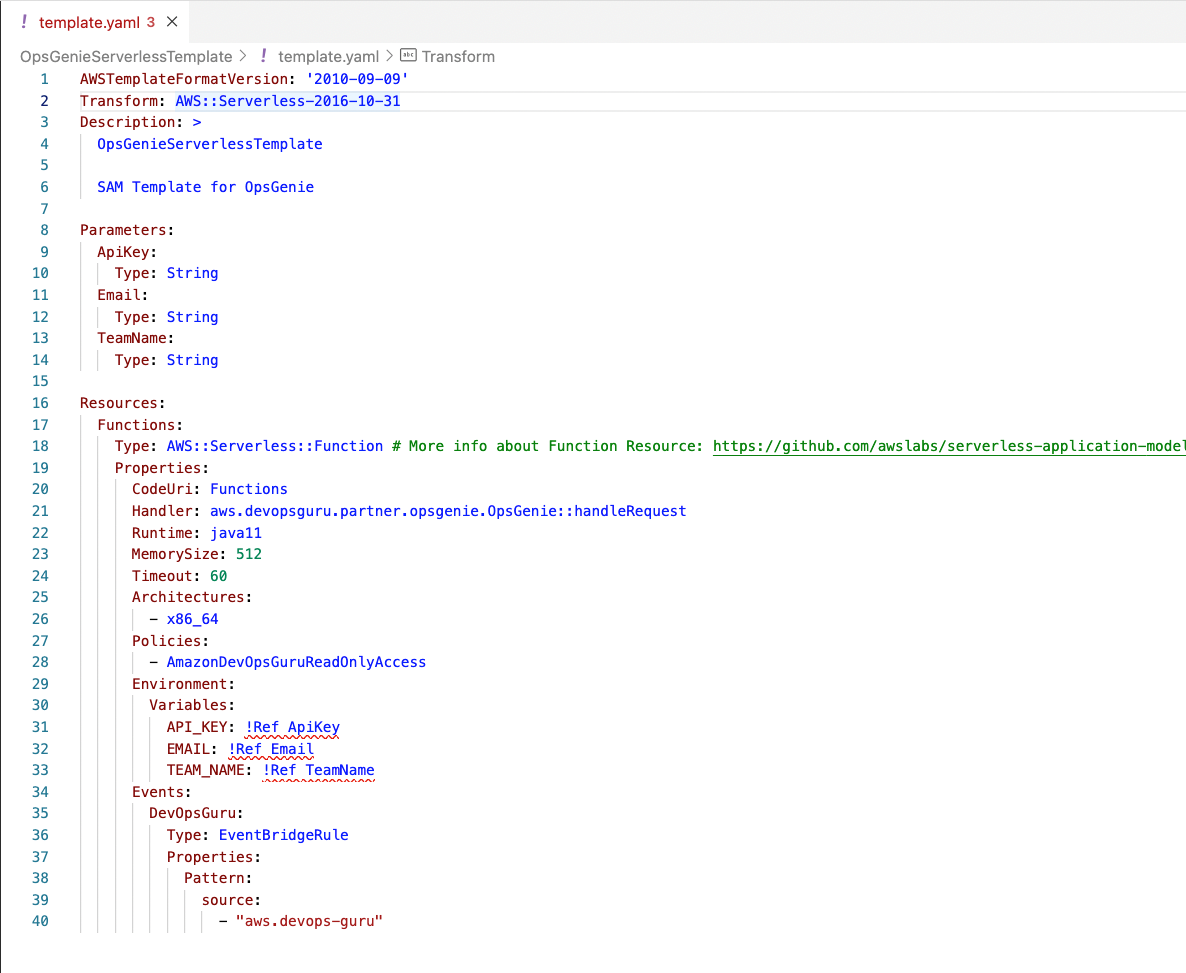
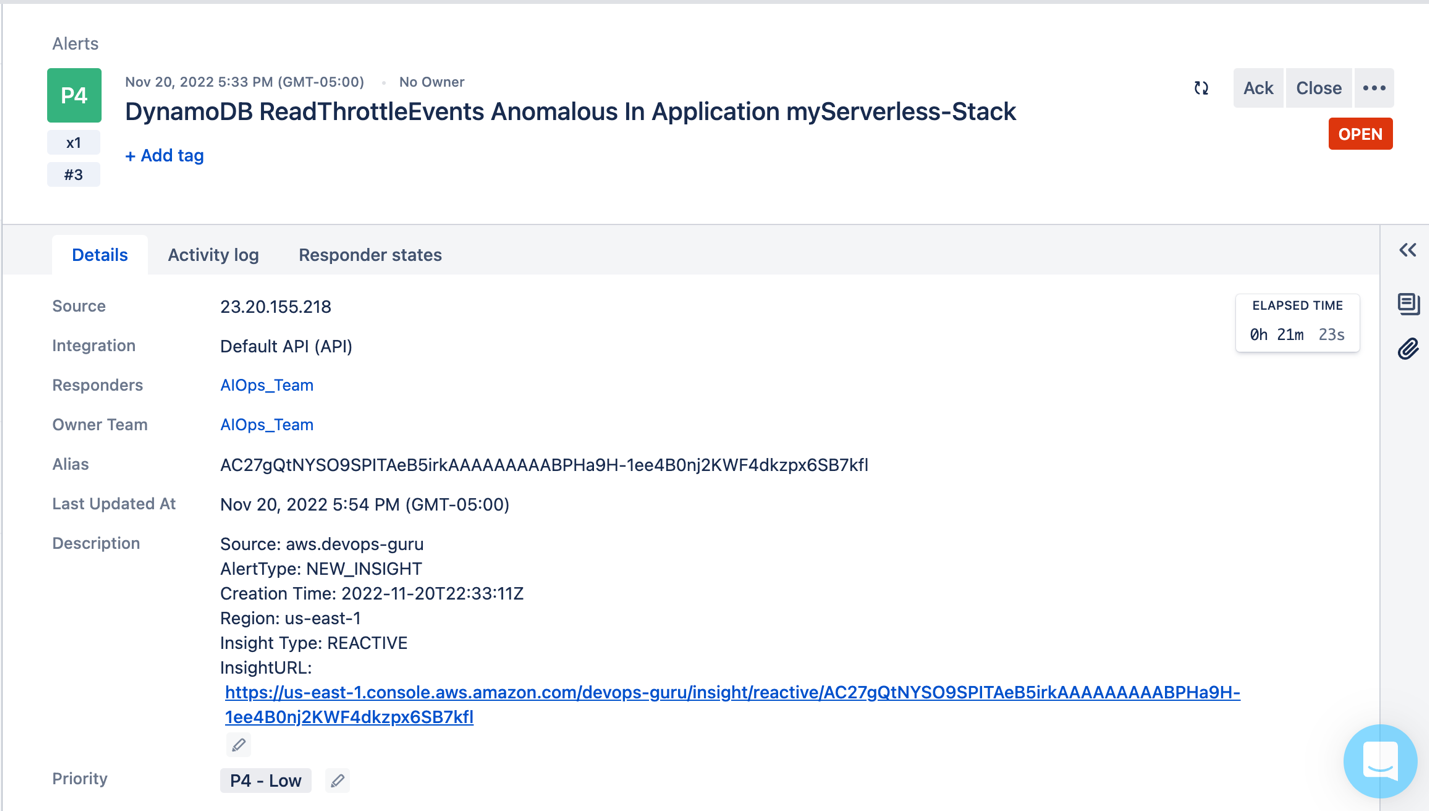









 Synthesis time: 3.05s
Synthesis time: 3.05s
 DevUsersStack
DevUsersStack
 Deployment failed: Error: Stack Deployments Failed: Error: The stack
named DevUsersStack failed creation, it may need to be manually deleted
from the AWS console:
ROLLBACK_COMPLETE:
User: arn:aws:sts::123456789012:assumed-role/cdk-hnb659fds-cfn-exec-role-123456789012-ap-southeast-2/AWSCloudFormation
is not authorized to perform: config:PutConfigRule on resource: access-keys-policy with an explicit deny in a
permissions boundary
Deployment failed: Error: Stack Deployments Failed: Error: The stack
named DevUsersStack failed creation, it may need to be manually deleted
from the AWS console:
ROLLBACK_COMPLETE:
User: arn:aws:sts::123456789012:assumed-role/cdk-hnb659fds-cfn-exec-role-123456789012-ap-southeast-2/AWSCloudFormation
is not authorized to perform: config:PutConfigRule on resource: access-keys-policy with an explicit deny in a
permissions boundary