With GitHub Actions, you can automate, customize, and run software development workflows directly within a repository. Workflows are defined using YAML and are stored alongside your code. I’ll discuss the specifics of how you can set up and use GitHub actions within a repository in the sections that follow.
The cfn-policy-validator tool is a command-line tool that takes an AWS CloudFormation template, finds and parses the IAM policies that are attached to IAM roles, users, groups, and resources, and then runs the policies through IAM Access Analyzerpolicy checks. Implementing IAM policy validation checks at the time of code check-in helps shift security to the left (closer to the developer) and shortens the time between when developers commit code and when they get feedback on their work.
Let’s walk through an example that checks the policies that are attached to an IAM role in a CloudFormation template. In this example, the cfn-policy-validator tool will find that the trust policy attached to the IAM role allows the role to be assumed by external principals. This configuration could lead to unintended access to your resources and data, which is a security risk.
Prerequisites
To complete this example, you will need the following:
A GitHub account
An AWS account, and an identity within that account that has permissions to create the IAM roles and resources used in this example
Step 1: Create a repository that will host the CloudFormation template to be validated
To begin with, you need to create a GitHub repository to host the CloudFormation template that is going to be validated by the cfn-policy-validator tool.
In the upper-right corner of the page, in the drop-down menu, choose New repository. For Repository name, enter a short, memorable name for your repository.
(Optional) Add a description of your repository.
Choose either the option Public (the repository is accessible to everyone on the internet) or Private (the repository is accessible only to people access is explicitly shared with).
Choose Initialize this repository with: Add a README file.
Choose Create repository. Make a note of the repository’s name.
Step 2: Clone the repository locally
Now that the repository has been created, clone it locally and add a CloudFormation template.
To clone the repository locally and add a CloudFormation template:
Open the command-line tool of your choice.
Use the following command to clone the new repository locally. Make sure to replace <GitHubOrg> and <RepositoryName> with your own values.
Change in to the directory that contains the locally-cloned repository.
cd <RepositoryName>
Now that the repository is locally cloned, populate the locally-cloned repository with the following sample CloudFormation template. This template creates a single IAM role that allows a principal to assume the role to perform the S3:GetObject action.
Use the following command to create the sample CloudFormation template file.
WARNING: This sample role and policy should not be used in production. Using a wildcard in the principal element of a role’s trust policy would allow any IAM principal in any account to assume the role.
Notice that AssumeRolePolicyDocument refers to a trust policy that includes a wildcard value in the principal element. This means that the role could potentially be assumed by an external identity, and that’s a risk you want to know about.
Step 3: Vend temporary AWS credentials for GitHub Actions workflows
In order for the cfn-policy-validator tool that’s running in the GitHub Actions workflow to use the IAM Access Analyzer API, the GitHub Actions workflow needs a set of temporary AWS credentials. The AWS Credentials for GitHub Actions action helps address this requirement. This action implements the AWS SDK credential resolution chain and exports environment variables for other actions to use in a workflow. Environment variable exports are detected by the cfn-policy-validator tool.
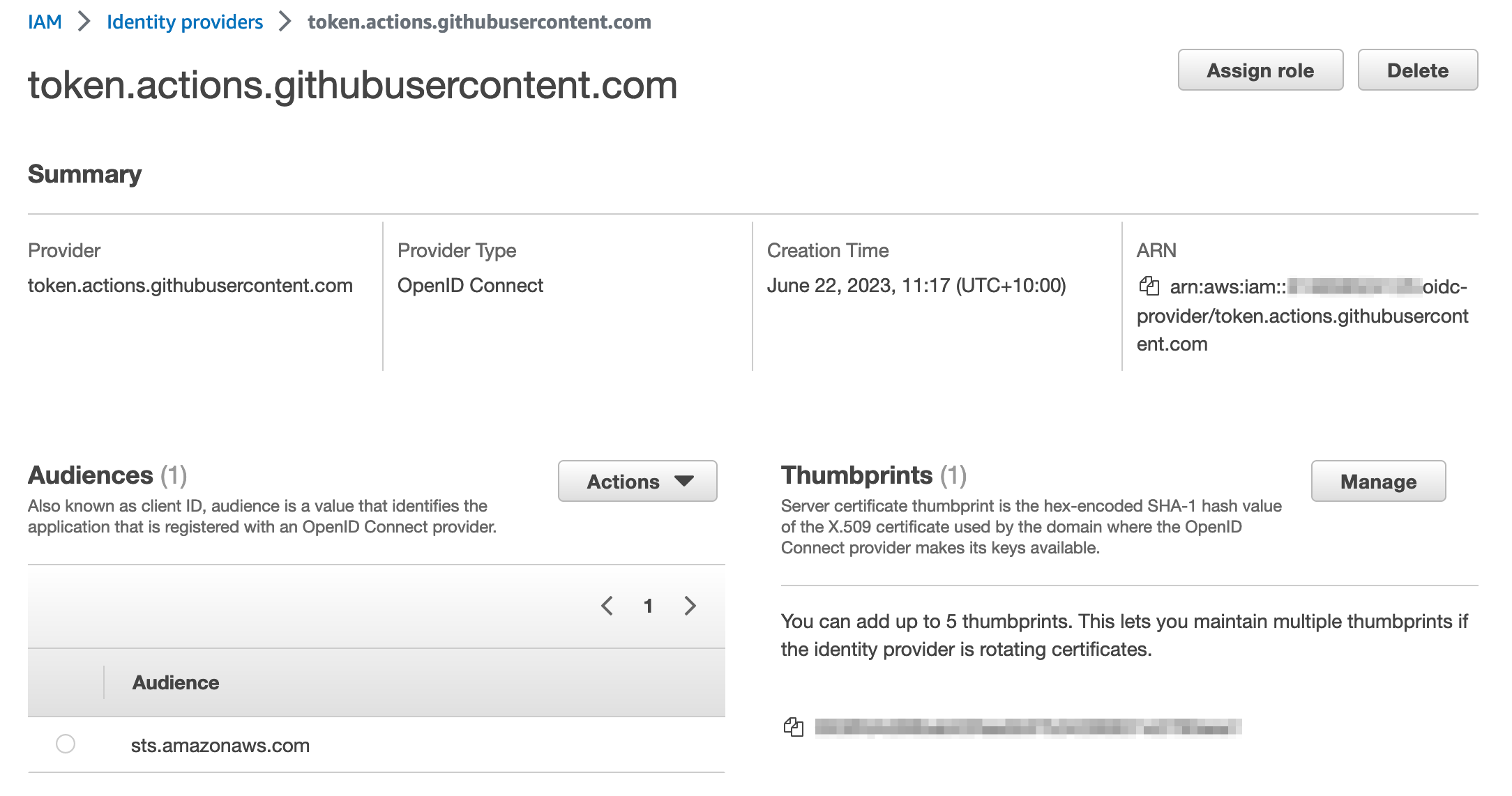
AWS Credentials for GitHub Actions supports four methods for fetching credentials from AWS, but the recommended approach is to use GitHub’s OpenID Connect (OIDC) provider in conjunction with a configured IAM identity provider endpoint.
To configure an IAM identity provider endpoint for use in conjunction with GitHub’s OIDC provider:
In the left-hand menu, choose Identity providers, and then choose Add provider.
For Provider type, choose OpenID Connect.
For Provider URL, enter https://token.actions.githubusercontent.com
Choose Get thumbprint.
For Audiences, enter sts.amazonaws.com
Choose Add provider to complete the setup.
At this point, make a note of the OIDC provider name. You’ll need this information in the next step.
After it’s configured, the IAM identity provider endpoint should look similar to the following:
Figure 1: IAM Identity provider details
Step 4: Create an IAM role with permissions to call the IAM Access Analyzer API
In this step, you will create an IAM role that can be assumed by the GitHub Actions workflow and that provides the necessary permissions to run the cfn-policy-validator tool.
To create the IAM role:
In the IAM console, in the left-hand menu, choose Roles, and then choose Create role.
For Trust entity type, choose Web identity.
In the Provider list, choose the new GitHub OIDC provider that you created in the earlier step. For Audience, select sts.amazonaws.com from the list.
After you’ve attached the new policy, choose Next.
Note: For a full explanation of each of these actions and a CloudFormation template example that you can use to create this role, see the IAM Policy Validator for AWS CloudFormation GitHub project.
The default policy you just created allows GitHub Actions from organizations or repositories outside of your control to assume the role. To align with the IAM best practice of granting least privilege, let’s scope it down further to only allow a specific GitHub organization and the repository that you created earlier to assume it.
Replace the policy to look like the following, but don’t forget to replace {AWSAccountID}, {GitHubOrg} and {RepositoryName} with your own values.
At this point, you’ve created and configured the following resources:
A GitHub repository that has been locally cloned and filled with a sample CloudFormation template.
An IAM identity provider endpoint for use in conjunction with GitHub’s OIDC provider.
A role that can be assumed by GitHub actions, and a set of associated permissions that allow the role to make requests to IAM Access Analyzer to validate policies.
Step 5: Create a definition for the GitHub Actions workflow
The workflow runs steps on hosted runners. For this example, we are going to use Ubuntu as the operating system for the hosted runners. The workflow runs the following steps on the runner:
The workflow checks out the CloudFormation template by using the community actions/checkout action.
The workflow then uses the aws-actions/configure-aws-credentials GitHub action to request a set of credentials through the IAM identity provider endpoint and the IAM role that you created earlier.
The workflow runs a validation against the CloudFormation template by using the cfn-policy-validator tool.
The workflow is defined in a YAML document. In order for GitHub Actions to pick up the workflow, you need to place the definition file in a specific location within the repository: .github/workflows/main.yml. Note the “.” prefix in the directory name, indicating that this is a hidden directory.
To create the workflow:
Use the following command to create the folder structure within the locally cloned repository:
mkdir -p .github/workflows
Create the sample workflow definition file in the .github/workflows directory. Make sure to replace <AWSAccountID> and <AWSRegion> with your own information.
Push the local changes to the remote GitHub repository.
git push
After the changes are pushed to the remote repository, go back to https://github.com and open the repository that you created earlier. In the top-right corner of the repository window, there is a small orange indicator, as shown in Figure 2. This shows that your GitHub Actions workflow is running.
Figure 2: GitHub repository window with the orange workflow indicator
Because the sample CloudFormation template used a wildcard value “*” in the principal element of the policy as described in the section Step 2: Clone the repository locally, the orange indicator turns to a red x (shown in Figure 3), which signals that something failed in the workflow.
Figure 3: GitHub repository window with the red cross workflow indicator
Choose the red x to see more information about the workflow’s status, as shown in Figure 4.
Figure 4: Pop-up displayed after choosing the workflow indicator
Choose Details to review the workflow logs.
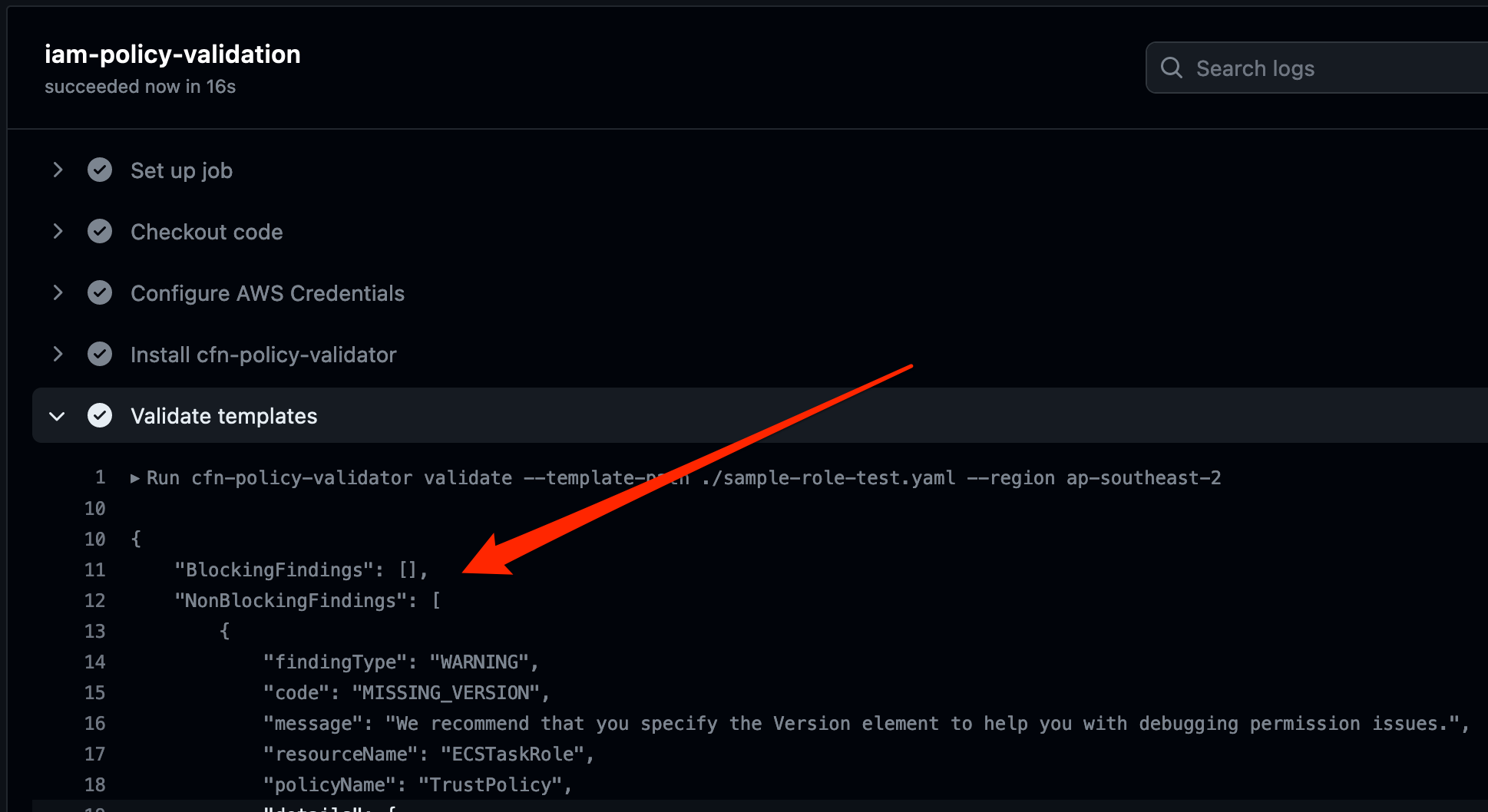
In this example, the Validate templates step in the workflow has failed. A closer inspection shows that there is a blocking finding with the CloudFormation template. As shown in Figure 5, the finding is labelled as EXTERNAL_PRINCIPAL and has a description of Trust policy allows access from external principals.
Figure 5: Details logs from the workflow showing the blocking finding
To remediate this blocking finding, you need to update the principal element of the trust policy to include a principal from your AWS account (considered a zone of trust). The resources and principals within your account comprises of the zone of trust for the cfn-policy-validator tool. In the initial version of sample-role.yaml, the IAM roles trust policy used a wildcard in the Principal element. This allowed principals outside of your control to assume the associated role, which caused the cfn-policy-validator tool to generate a blocking finding.
In this case, the intent is that principals within the current AWS account (zone of trust) should be able to assume this role. To achieve this result, replace the wildcard value with the account principal by following the remaining steps.
Open sample-role.yaml by using your preferred text editor, such as nano.
nano sample-role.yaml
Replace the wildcard value in the principal element with the account principal arn:aws:iam::<AccountID>:root. Make sure to replace <AWSAccountID> with your own AWS account ID.
Add the updated file, commit the changes, and push the updates to the remote GitHub repository.
git add sample-role.yaml
git commit -m ‘replacing wildcard principal with account principal’
git push
After the changes have been pushed to the remote repository, go back to https://github.com and open the repository. The orange indicator in the top right of the window should change to a green tick (check mark), as shown in Figure 6.
Figure 6: GitHub repository window with the green tick workflow indicator
This indicates that no blocking findings were identified, as shown in Figure 7.
Figure 7: Detailed logs from the workflow showing no more blocking findings
Conclusion
In this post, I showed you how to automate IAM policy validation by using GitHub Actions and the IAM Policy Validator for CloudFormation. Although the example was a simple one, it demonstrates the benefits of automating security testing at the start of the development lifecycle. This is often referred to as shifting security left. Identifying misconfigurations early and automatically supports an iterative, fail-fast model of continuous development and testing. Ultimately, this enables teams to make security an inherent part of a system’s design and architecture and can speed up product development workflows.
In addition to the example I covered today, IAM Policy Validator for CloudFormation can validate IAM policies by using a range of IAM Access Analyzer policy checks. For more information about these policy checks, see Access Analyzer reference policy checks.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
July 27, 2023: This post was originally published February 5, 2015, and received a major update July 31, 2023.
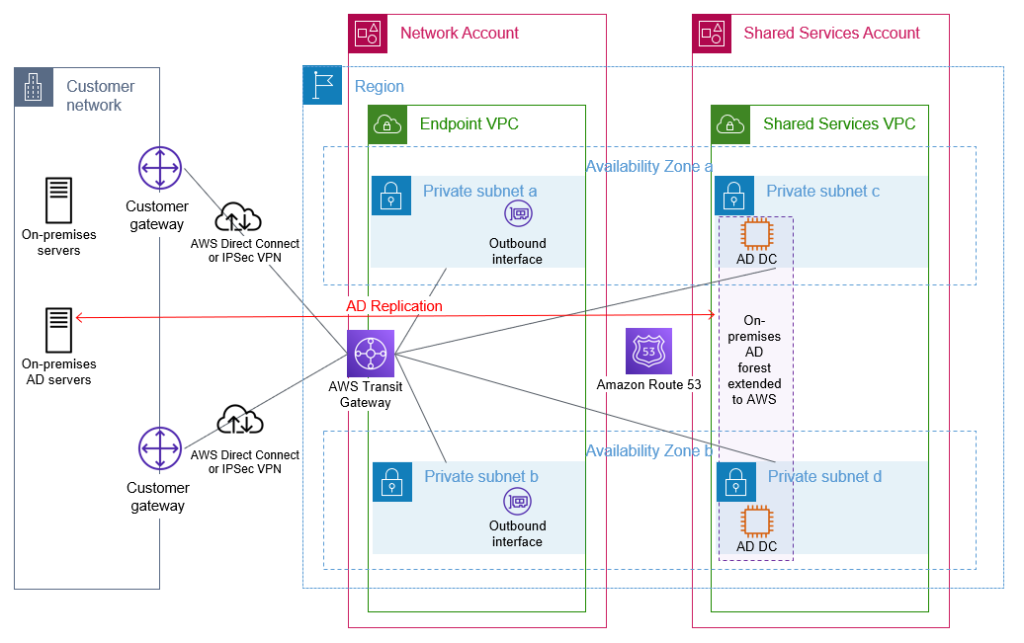
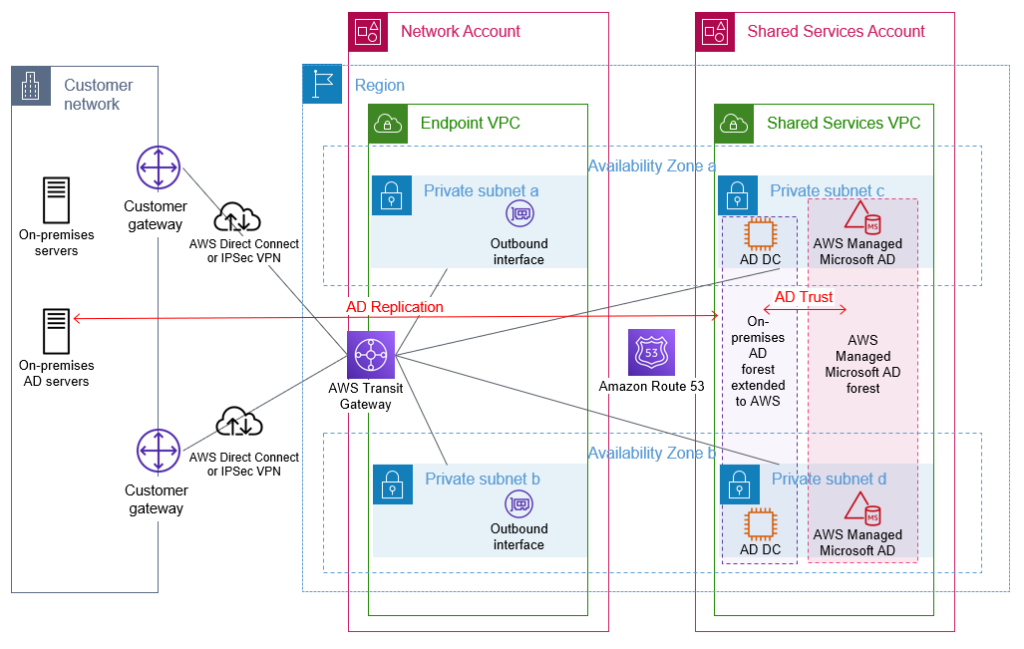
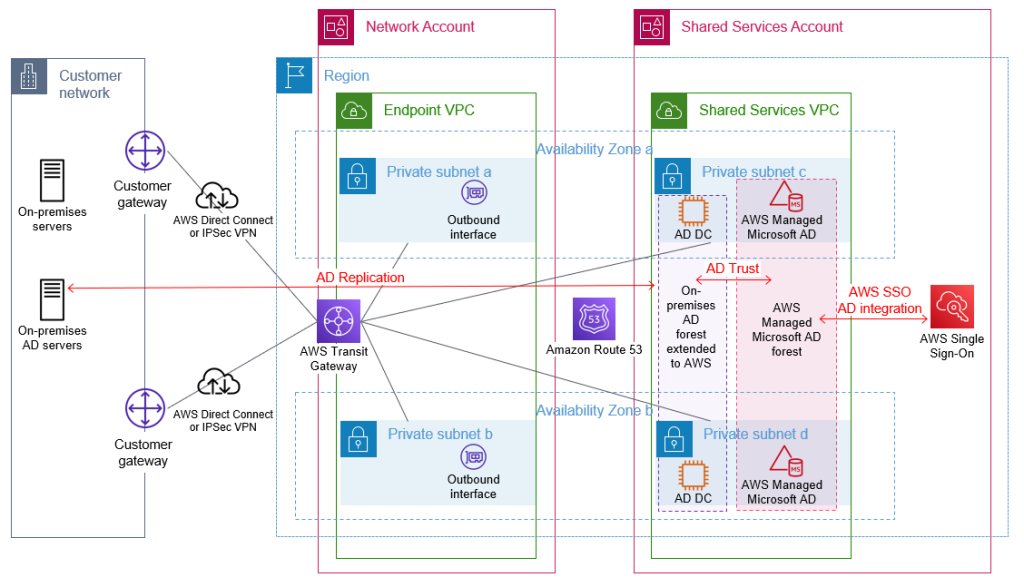
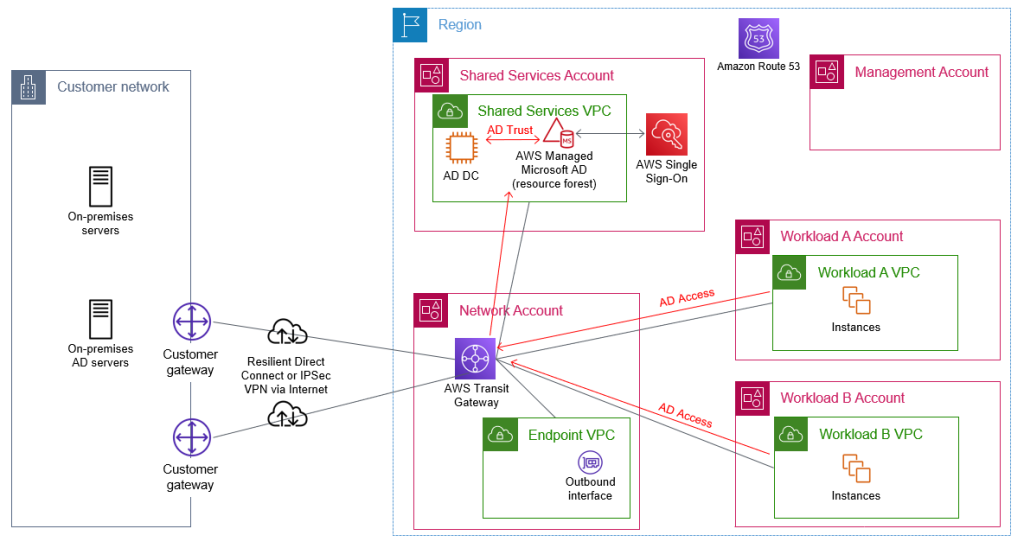
As an Amazon Web Services (AWS) administrator, it’s crucial for you to implement robust protective controls to maintain your security configuration. Employing a detective control mechanism to monitor changes to the configuration serves as an additional safeguard in case the primary protective controls fail. Although some changes are expected, you might want to review unexpected changes or changes made by a privileged user. AWS Identity and Access Management (IAM) is a service that primarily helps manage access to AWS services and resources securely. It does provide detailed logs of its activity, but it doesn’t inherently provide real-time alerts or notifications. Fortunately, you can use a combination of AWS CloudTrail, Amazon EventBridge, and Amazon Simple Notification Service (Amazon SNS) to alert you when changes are made to your IAM configuration. In this blog post, we walk you through how to set up EventBridge to initiate SNS notifications for IAM configuration changes. You can also have SNS push messages directly to ticketing or tracking services, such as Jira, Service Now, or your preferred method of receiving notifications, but that is not discussed here.
In any AWS environment, many activities can take place at every moment. CloudTrail records IAM activities, EventBridge filters and routes event data, and Amazon SNS provides notification functionality. This post will guide you through identifying and setting alerts for IAM changes, modifications in authentication and authorization configurations, and more. The power is in your hands to make sure you’re notified of the events you deem most critical to your environment. Here’s a quick overview of how you can invoke a response, shown in Figure 1.
Figure 1: Simple architecture diagram of actors and resources in your account and the process for sending notifications through IAM, CloudTrail, EventBridge, and SNS.
Log IAM changes with CloudTrail
Before we dive into implementation, let’s briefly understand the function of AWS CloudTrail. It records and logs activity within your AWS environment, tracking actions such as IAM role creation, deletion, or modification, thereby offering an audit trail of changes.
With this in mind, we’ll discuss the first step in tracking IAM changes: establishing a log for each modification. In this section, we’ll guide you through using CloudTrail to create these pivotal logs.
In this post, you’re going to start by creating a CloudTrail trail with the Management events type selected, and read and write API activity selected. If you already have a CloudTrail trail set up with those attributes, you can use that CloudTrail trail instead.
Figure 2: Use the CloudTrail dashboard to create a trail
In the Trail name field, enter a display name for your trail and then select Create a new S3 bucket. Leave the default settings for the remaining trail attributes.
Figure 3: Set the trail name and storage location
Under Event type, select Management events. Under API activity, select Read and Write.
Choose Next.
Figure 4: Choose which events to log
Set up notifications with Amazon SNS
Amazon SNS is a managed service that provides message delivery from publishers to subscribers. It works by allowing publishers to communicate asynchronously with subscribers by sending messages to a topic, a logical access point, and a communication channel. Subscribers can receive these messages using supported endpoint types, including email, which you will use in the blog example today.
Now that you’ve set up CloudTrail to log IAM changes, the next step is to establish a mechanism to notify you about these changes in real time.
To set up notifications
Open the Amazon SNS console and choose Topics.
Create a new topic. Under Type, select Standard and enter a name for your topic. Keep the defaults for the rest of the options, and then choose Create topic.
Figure 5: Select Standard as the topic type
Navigate to your topic in the topic dashboard, choose the Subscriptions tab, and then choose Create subscription.
Figure 6: Choose Create subscription
For Topic ARN, select the topic you created previously, then under Protocol, select Email and enter the email address you want the alerts to be sent to.
Figure 7: Select the topic ARN and add an endpoint to send notifications to
After your subscription is created, go to the mailbox you designated to receive notifications and check for a verification email from the service. Open the email and select Confirm subscription to verify the email address and complete setup.
Initiate events with EventBridge
Amazon EventBridge is a serverless service that uses events to connect application components. EventBridge receives an event (an indicator of a change in environment) and applies a rule to route the event to a target. Rules match events to targets based on either the structure of the event, called an event pattern, or on a schedule.
Events that come to EventBridge are associated with an event bus. Rules are tied to a single event bus, so they can only be applied to events on that event bus. Your account has a default event bus that receives events from AWS services, and you can create custom event buses to send or receive events from a different account or AWS Region.
In this part of our post, you’ll use EventBridge to devise a rule for initiating SNS notifications based on IAM configuration changes.
To create an EventBridge rule
Go to the EventBridge console and select EventBridge Rule, and then choose Create rule.
Figure 8: Use the EventBridge console to create a rule
Enter a name for your rule, keep the defaults for the rest of rule details, and then choose Next.
Figure 9: Rule detail screen
Under Target 1, select AWS service.
In the dropdown list for Select a target, select SNS topic, select the topic you created previously, and then choose Next.
Figure 10: Target with target type of AWS service and target topic of SNS topic selected
Under Event source, select AWS events or EventBridge partner events.
Figure 11: Event pattern with AWS events or EventBridge partner events selected
Under Event pattern, verify that you have the following selected.
For Event source, select AWS services.
For AWS service, select IAM.
For Event type, select AWS API Call via CloudTrail.
Select the radio button for Any operation.
Figure 12: Event pattern details selected
Now that you’ve set up EventBridge to monitor IAM changes, test it by creating a new user or adding a new policy to an IAM role and see if you receive an email notification.
Centralize EventBridge alerts by using cross-account alerts
If you have multiple accounts, you should be evaluating using AWS Organizations. (For a deep dive into best practices for using AWS Organizations, we recommend reading this AWS blog post.)
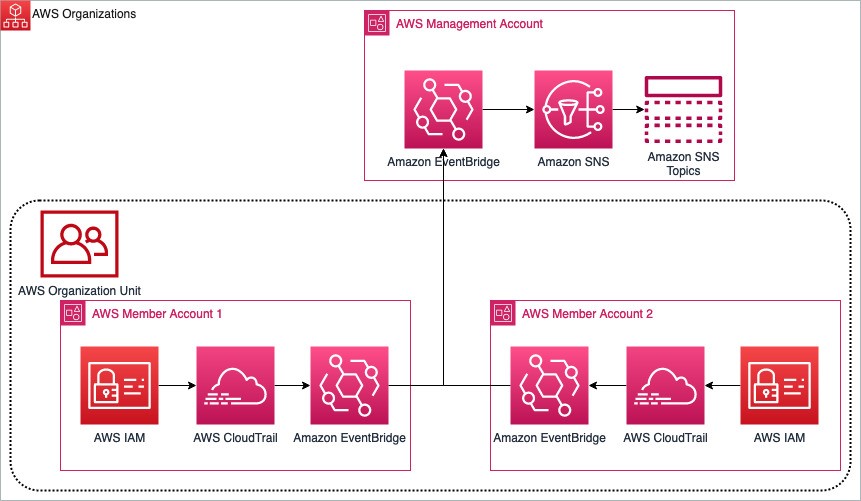
By standardizing the implementation to channel alerts from across accounts to a primary AWS notification account, you can use a multi-account EventBridge architecture. This allows aggregation of notifications across your accounts through sender and receiver accounts. Figure 13 shows how this works. Separate member accounts within an AWS organizational unit (OU) have the same mechanism for monitoring changes and sending notifications as discussed earlier, but send notifications through an EventBridge instance in another account.
Figure 13: Multi-account EventBridge architecture aggregating notifications between two AWS member accounts to a primary management account
In this blog post example, you monitor calls to IAM.
The filter pattern you selected while setting up EventBridge matches CloudTrail events for calls to the IAM service. Calls to IAM have a CloudTrail eventSource of iam.amazonaws.com, so IAM API calls will match this pattern. You will find this simple default filter pattern useful if you have minimal IAM activity in your account or to test this example. However, as your account activity grows, you’ll likely receive more notifications than you need. This is when filtering only the relevant events becomes essential to prioritize your responses. Effectively managing your filter preferences allows you to focus on events of significance and maintain control as your AWS environment grows.
Monitor changes to IAM
If you’re interested only in changes to your IAM account, you can modify the event pattern inside EventBridge, the one you used to set up IAM notifications, with an eventName filter pattern, shown following.
This filter pattern will only match events from the IAM service that begin with Add, Change, Create, Deactivate, Delete, Enable, Put, Remove, Update, or Upload. For more information about APIs matching these patterns, see the IAM API Reference.
To edit the filter pattern to monitor only changes to IAM
Open the EventBridge console, navigate to the Event pattern, and choose Edit pattern.
Figure 14: Modifying the event pattern
Add the eventName filter pattern from above to your event pattern.
Figure 15: Use the JSON editor to add the eventName filter pattern
Monitor changes to authentication and authorization configuration
Monitoring changes to authentication (security credentials) and authorization (policy) configurations is critical, because it can alert you to potential security vulnerabilities or breaches. For instance, unauthorized changes to security credentials or policies could indicate malicious activity, such as an attempt to gain unauthorized access to your AWS resources. If you’re only interested in these types of changes, use the preceding steps to implement the following filter pattern.
This filter pattern matches calls to IAM that modify policy or create, update, upload, and delete IAM elements.
Conclusion
Monitoring IAM security configuration changes allows you another layer of defense against the unexpected. Balancing productivity and security, you might grant a user broad permissions in order to facilitate their work, such as exploring new AWS services. Although preventive measures are crucial, they can potentially restrict necessary actions. For example, a developer may need to modify an IAM role for their task, an alteration that could pose a security risk. This change, while essential for their work, may be undesirable from a security standpoint. Thus, it’s critical to have monitoring systems alongside preventive measures, allowing necessary actions while maintaining security.
Create an event rule for IAM events that are important to you and have a response plan ready. You can refer to Security best practices in IAM for further reading on this topic.
Updated on July 6, 2023: This post has been updated to reflect the current guidance around the usage of S3 ACL and to include S3 Access Points and the Block Public Access for accounts and S3 buckets.
Updated on April 27, 2023: Amazon S3 now automatically enables S3 Block Public Access and disables S3 access control lists (ACLs) for all new S3 buckets in all AWS Regions.
Updated on January 8, 2019: Based on customer feedback, we updated the third paragraph in the “What about S3 ACLs?” section to clarify permission management.
In this post, we will discuss Amazon S3 Bucket Policies and IAM Policies and its different use cases. This post will assist you in distinguishing between the usage of IAM policies and S3 bucket policies. We will also discuss how these policies integrate with some default S3 bucket security settings like automatically enabling S3 Block Public Access and disabling S3 access control lists (ACLs).
IAM policies vs. S3 bucket policies
AWS access is managed by setting IAM policies and linking them to IAM identities (users, groups of users, or roles) or AWS resources. A policy is an object in AWS that when associated with an identity or resource, defines their permissions. IAM policies specify what actions are allowed or denied on what AWS resources (e.g. user Alice can read objects from the “Production” bucket but can’t write objects in the “Dev” bucket whereas user Bob can have full access to S3).
S3 bucket policies, on the other hand, are resource-based policies that you can use to grant access permissions to your Amazon S3 buckets and the objects in it. S3 bucket policies can allow or deny requests based on the elements in the policy.(e.g. allow user Alice to PUT but not DELETE objects in the bucket).
Note: You attach S3 bucket policies at the bucket level (i.e. you can’t attach a bucket policy to an S3 object), but the permissions specified in the bucket policy apply to all the objects in the bucket. You can also specify permissions at the object level by putting an object as the resource in the Bucket policy.
IAM policies and S3 bucket policies are both used for access control and they’re both written in JSON using the AWS access policy language. Let’s look at an example policy of each type:
Sample S3 Bucket Policy
This S3 bucket policy enables any IAM principal (user or role) in account 111122223333 to use the Amazon S3 GET Bucket (List Objects) operation.
Note that the S3 bucket policy includes a “Principal” element, which lists the principals that bucket policy controls access for. The “Principal” element is unnecessary in an IAM policy, because the principal is by default the entity that the IAM policy is attached to.
S3 bucket policies (as the name would imply) only control access to S3 resources for the bucket they’re attached to, whereas IAM policies can specify nearly any AWS action. One of the neat things about AWS is that you can actually apply both IAM policies and S3 bucket policies simultaneously, with the ultimate authorization being the least-privilege union of all the permissions (more on this in the section below titled “How does authorization work with multiple access control mechanisms?”).
When to use IAM policies vs. S3 policies
Use IAM policies if:
You need to control access to AWS services other than S3. IAM policies will be easier to manage since you can centrally manage all of your permissions in IAM, instead of spreading them between IAM and S3.
You have numerous S3 buckets each with different permissions requirements. IAM policies will be easier to manage since you don’t have to define a large number of S3 bucket policies and can instead rely on fewer, more detailed IAM policies.
You prefer to keep access control policies in the IAM environment.
Your IAM policies bump up against the size limit (up to 2 kb for users, 5 kb for groups, and 10 kb for roles). S3 supports bucket policies of up 20 kb.
You prefer to keep access control policies in the S3 environment.
You want to apply common security controls to all principals who interact with S3 buckets, such as restricting the IP addresses or VPC a bucket can be accessed from.
If you’re still unsure of which to use, consider which audit question is most important to you:
If you’re more interested in “What can this user do in AWS?” then IAM policies are probably the way to go. You can easily answer this by looking up an IAM user and then examining their IAM policies to see what rights they have.
If you’re more interested in “Who can access this S3 bucket?” then S3 bucket policies will likely suit you better. You can easily answer this by looking up a bucket and examining the bucket policy.
Whichever method you choose, we recommend staying as consistent as possible. Auditing permissions becomes more challenging as the number of IAM policies and S3 bucket policies grows.
What about S3 ACLs?
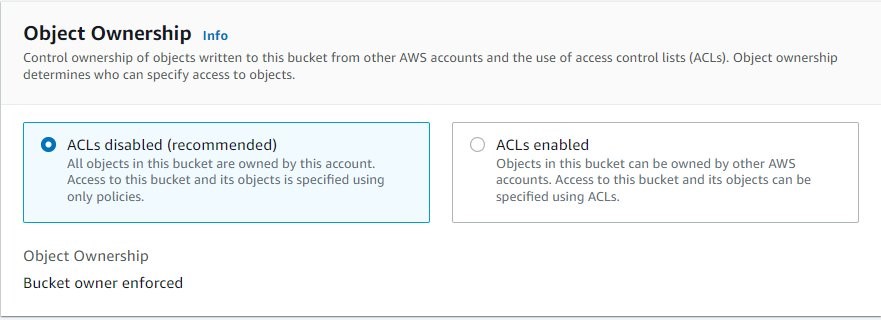
An S3 ACL is a sub-resource that’s attached to every S3 bucket and object. It defines which AWS accounts or groups are granted access and the type of access. You can attach S3 ACLs to both buckets and individual objects within a bucket to manage permissions for those objects. As a general rule, AWS recommends using S3 bucket policies or IAM policies for access control. S3 ACLs is a legacy access control mechanism that predates IAM. By default, Object Ownership is set to the Bucket owner enforced setting and all ACLs are disabled, as can be seen below.
A majority of modern use cases in Amazon S3 no longer require the use of ACLs, and we recommend that you keep ACLs disabled by applying the Bucket owner enforced setting. This approach simplifies permissions management: you can use policies to more easily control access to every object in your bucket, regardless of who uploaded the objects in your bucket. When ACLs are disabled, the bucket owner owns all the objects in the bucket and manages access to data exclusively using access management policies.
S3 bucket policies and IAM policies define object-level permissions by providing those objects in the Resource element in your policy statements. The statement will apply to those objects in the bucket. Consolidating object-specific permissions into one policy (as opposed to multiple S3 ACLs) makes it simpler for you to determine effective permissions for your users and roles.
You can disable ACLs on both newly created and already existing buckets. For newly created buckets, ACLs are disabled by default. In the case of an existing bucket that already has objects in it, after you disable ACLs, the object and bucket ACLs are no longer part of an access evaluation, and access is granted or denied on the basis of policies.
S3 Access Points and S3 Access
In some cases customers have use cases with complex entitlement: Amazon s3 is used to store shared datasets where data is aggregated and accessed by different applications, individuals or teams for different use cases. Managing access to this shared bucket requires a single bucket policy that controls access for dozens to hundreds of applications with different permission levels. As an application set grows, the bucket policy becomes more complex, time consuming to manage, and needs to be audited to make sure that changes don’t have an unexpected impact on another application.
These customers need additional policy space for access to their data, and that buckets. To support these use cases, Amazon S3 provides a feature called Amazon S3 Access Points. Amazon S3 access points simplify data access for any AWS service or customer application that stores data in S3.
Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations, such as GetObject and PutObject. Each access point has distinct permissions and network controls that S3 applies for any request that is made through that access point. Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket.
Amazon S3 access points support AWS Identity and Access Management (IAM) resource policies that allow you to control the use of the access point by resource, user, or other conditions. For an application or user to be able to access objects through an access point, both the access point and the underlying bucket must permit the request.
Note that Adding an S3 access point to a bucket doesn’t change the bucket’s ehaviour when the bucket is accessed directly through the bucket’s name or Amazon Resource Name (ARN). All existing operations against the bucket will continue to work as before. Restrictions that you include in an access point policy apply only to requests made through that access point.
Sample Access point policy
This access point policy grants the IAM user Alice permissions to GET and PUT objects through the access point ‘my-access-point’ in account 111122223333.
Public access is granted to buckets and objects through access control lists (ACLs), bucket policies, access point policies, or all. In order to ensure that public access to this bucket and its objects is blocked, you can turn on Block all public on both the bucket level or the account level.
The Amazon S3 Block Public Access feature provides settings for access points, buckets, and accounts to help you manage public access to Amazon S3 resources. By default, new buckets, access points, and objects don’t allow public access. However, users can modify bucket policies, access point policies, or object permissions to allow public access. S3 Block Public Access settings override these policies and permissions so that you can limit public access to these resources.
With S3 Block Public Access, account administrators and bucket owners can easily set up centralized controls to limit public access to their Amazon S3 resources that are enforced regardless of how the resources are created.
If you apply a setting to an account, it applies to all buckets and access points that are owned by that account. Similarly, if you apply a setting to a bucket, it applies to all access points associated with that bucket.
Block Public Access for buckets
These settings apply only to this bucket and its access points. AWS recommends that you turn on Block all public access, but before applying any of these settings, ensure that your applications will work correctly without public access. If you require some level of public access to this bucket or objects within, you can customize the individual settings below to suit your specific storage use cases.
You can use the S3 console, AWS CLI, AWS SDKs, and REST API to grant public access to one or more buckets. This setting is on by default at the account creation, as can be seen below (using the S3 console).
Turning off this session will create a warning in the account, as AWS recommends this setting to be turned un unless public access is required for specific and verified use cases such as static website hosting.
This setting can also be turned on for existing buckets. In the AWS Management Console this is done by opening the Amazon S3 console at https://console.aws.amazon.com/s3/, choosing the name of the bucket you want, choosing the Permissions tab. And Choosing Edit to change the public access settings for the bucket.
Block Public Access for accounts
In order to ensure that public access to all your S3 buckets and objects is blocked, turn on Block all public access. These settings apply account-wide for all current and future buckets and access points. AWS recommends that you turn on Block all public access, but before applying any of these settings, ensure that your applications will work correctly without public access. If you require some level of public access to your buckets or objects, you can customize the individual settings below to suit your specific storage use cases.
You can use the S3 console, AWS CLI, AWS SDKs, and REST API to configure block public access settings for all the buckets in your account. This setting can be turned on in the AWS Management Console by opening the Amazon S3 console at https://console.aws.amazon.com/s3/, and clicking Block Public Access setting for this account on the left panel. And Choosing Edit to change the public access settings for the bucket.
When working with AWS organizations, you can prevent people from modifying the Block Public Access on the account level by adding a Service control policy (SCP) that denies editing this. An example of such a SCP can be seen below:
How does authorization work with multiple access control mechanisms?
Whenever an AWS principal issues a request to S3, the authorization decision depends on the union of all the IAM policies, S3 bucket policies, and S3 ACLs that apply as well as if Block Public Access is enabled on either the account, bucket or access point.
In accordance with the principle of least-privilege, decisions default to DENY and an explicit DENY always trumps an ALLOW. For example, if an IAM policy grants access to an object, the S3 bucket policies denies access to that object, and there is no S3 ACL, then access will be denied. Similarly, if no method specifies an ALLOW, then the request will be denied by default. Only if no method specifies a DENY and one or more methods specify an ALLOW will the request be allowed.
When Amazon S3 receives a request to access a bucket or an object, it determines whether the bucket or the bucket owner’s account has a block public access setting applied. If the request was made through an access point, Amazon S3 also checks for block public access settings for the access point. If there is an existing block public access setting that prohibits the requested access, Amazon S3 rejects the request.
This diagram illustrates the authorization process.
We hope that this post clarifies some of the confusion around the various ways you can control access to your S3 environment.
Using IAM Access Analyzer for S3 to review bucket access
Another interesting feature that can be used is IAM Access Analyzer for S3 to review bucket access. You can use IAM Access Analyzer for S3 to review buckets with bucket ACLs, bucket policies, or access point policies that grant public access. IAM Access Analyzer for S3 alerts you to buckets that are configured to allow access to anyone on the internet or other AWS accounts, including AWS accounts outside of your organization. For each public or shared bucket, you receive findings that report the source and level of public or shared access.
In IAM Access Analyzer for S3, you can block all public access to a bucket with a single click. You can also drill down into bucket-level permission settings to configure granular levels of access. For specific and verified use cases that require public or shared access, you can acknowledge and record your intent for the bucket to remain public or shared by archiving the findings for the bucket.
Have you ever wanted to initiate change in an Amazon Web Services (AWS) account after you update a GitHub repository, or deploy updates in an AWS application after you merge a commit, without the use of AWS Identity and Access Management (IAM) user access keys? If you configure an OpenID Connect (OIDC) identity provider (IdP) inside an AWS account, you can use IAM roles and short-term credentials, which removes the need for IAM user access keys.
In this blog post, we will walk you through the steps needed to configure a specific GitHub repo to assume an individual role in an AWS account to preform changes. You will learn how to create an OIDC-trusted connection that is scoped to an individual GitHub repository, and how to map the repository to an IAM role in your account. You will create the OIDC connection, IAM role, and trust relationship two ways: with the AWS Management Console and with the AWS Command Line Interface (AWS CLI).
This post focuses on creating an IAM OIDC identity provider for GitHub and demonstrates how to authorize access into an AWS account from a specific branch and repository. You can use OIDC IdPs for workflows that support the OpenID Connect standard, such as Google or Salesforce.
Prerequisites
To follow along with this blog post, you should have the following prerequisites in place:
GitHub is an external provider that is independent from AWS. To use GitHub as an OIDC IdP, you will need to complete four steps to access AWS resources from your GitHub repository. Then, for the fifth and final step, you will use AWS CloudTrail to audit the role that you created and used in steps 1–4.
Create an OIDC provider in your AWS account. This is a trust relationship that allows GitHub to authenticate and be authorized to perform actions in your account.
Create an IAM role in your account. You will then scope the IAM role’s trust relationship to the intended parts of your GitHub organization, repository, and branch for GitHub to assume and perform specific actions.
Assign a minimum level of permissions to the role.
Create a GitHub Actions workflow file in your repository that can invoke actions in your account.
Audit the role’s use with Amazon CloudTrail logs.
Step 1: Create an OIDC provider in your account
The first step in this process is to create an OIDC provider which you will use in the trust policy for the IAM role used in this action.
(Optional) For Add tags, you can add key–value pairs to help you identify and organize your IdPs. To learn more about tagging IAM OIDC IdPs, see Tagging OpenID Connect (OIDC) IdPs.
Verify the information that you entered. Your console should match the screenshot in Figure 1. After verification, choose Add provider.
Note: Each provider is a one-to-one relationship to an external IdP. If you want to add more IdPs to your account, you can repeat this process.
Figure 1: Steps to configure the identity provider
Once you are taken back to the Identity providers page, you will see your new IdP as shown in Figure 2. Select your provider to view its properties, and make note of the Amazon Resource Name (ARN). You will use the ARN later in this post. The ARN will look similar to the following:
You can add GitHub as an IdP in your account with a single AWS CLI command. The following code will perform the previous steps outlined for the console, with the same results. For the value —thumbprint-list, you will use the GitHub OIDC thumbprint 938fd4d98bab03faadb97b34396831e3780aea1.
aws iam create-open-id-connect-provider --url
"https://token.actions.GitHubusercontent.com" --thumbprint-list
"6938fd4d98bab03faadb97b34396831e3780aea1" --client-id-list
'sts.amazonaws.com'
Both of the preceding methods will add an IdP in your account. You can view the provider on the Identity providers page in the IAM console.
Step 2: Create an IAM role and scope the trust policy
You can create an IAM role with either the IAM console or the AWS CLI. If you choose to create the IAM role with the AWS CLI, you will scope the Trust Relationship Policy before you create the role.
In the IAM console, on the Identity providers screen, choose the Assign role button for the newly created IdP.
Figure 3: Assign a role to the identity provider
In the Assign role for box, choose Create a new role, and then choose Next, as shown in the following figure.
Figure 4: Create a role from the Identity provider page
The Create role page presents you with a few options. Web identity is already selected as the trusted entity, and the Identity provider field is populated with your IdP. In the Audience list, select sts.amazonaws.com, and then choose Next.
On the Permissions page, choose Next. For this demo, you won’t add permissions to the role.
(Optional) On the Tags page, add tags to this new role, and then choose Next: Review.
On the Create role page, add a role name. For this demo, enter GitHubAction-AssumeRoleWithAction. Optionally add a description.
To create the role, choose Create role.
Next, you’ll scope the IAM role’s trust policy to a single GitHub organization, repository, and branch.
To scope the trust policy (IAM console)
In the IAM console, open the newly created role and choose Edit trust relationship.
On the Edit trust policy page, modify the trust policy to allow your unique GitHub organization, repository, and branch to assume the role. This example trusts the GitHub organization <aws-samples>, the repository named <EXAMPLEREPO>, and the branch named <ExampleBranch>. Update the Federated ARN with the GitHub IdP ARN that you copied previously.
In the AWS CLI, use the example trust policy shown above for the console. This policy is designed to limit access to a defined GitHub organization, repository, and branch.
Create and save a JSON file with the example policy to your local computer with the file name trustpolicyforGitHubOIDC.json.
Run the following command to create the role.
aws iam create-role --role-name GitHubAction-AssumeRoleWithAction --assume-role-policy-document file://C:\policies\trustpolicyforGitHubOIDC.json
Step 3: Assign a minimum level of permissions to the role
For this example, you won’t add permissions to the IAM role, but will assume the role and call STS GetCallerIdentity to demonstrate a GitHub action that assumes the AWS role.
If you’re interested in performing additional actions in your account, you can add permissions to the role you created, GitHubAction-AssumeRoleWithAction. Common actions for workflows include calling AWS Lambda functions or pushing files to an Amazon Simple Storage Service (Amazon S3) bucket. For more information about using IAM to apply permissions, see Policies and permissions in IAM.
Step 4: Create a GitHub action to invoke the AWS CLI
GitHub actions are defined as methods that you can use to automate, customize, and run your software development workflows in GitHub. The GitHub action that you create will authenticate into your account as the role that was created in Step 2: Create the IAM role and scope the trust policy.
To create a GitHub action to invoke the AWS CLI:
Create a basic workflow file, such as main.yml, in the .github/workflows directory of your repository. This sample workflow will assume the GitHubAction-AssumeRoleWithAction role, to perform the action aws sts get-caller-identity. Your repository can have multiple workflows, each performing different sets of tasks. After GitHub is authenticated to the role with the workflow, you can use AWS CLI commands in your account.
Paste the following example workflow into the file.
# This is a basic workflow to help you get started with Actions
name:Connect to an AWS role from a GitHub repository
# Controls when the action will run. Invokes the workflow on push events but only for the main branch
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
env:
AWS_REGION : <"us-east-1"> #Change to reflect your Region
# Permission can be added at job level or workflow level
permissions:
id-token: write # This is required for requesting the JWT
contents: read # This is required for actions/checkout
jobs:
AssumeRoleAndCallIdentity:
runs-on: ubuntu-latest
steps:
- name: Git clone the repository
uses: actions/checkout@v3
- name: configure aws credentials
uses: aws-actions/[email protected]
with:
role-to-assume: <arn:aws:iam::111122223333:role/GitHubAction-AssumeRoleWithAction> #change to reflect your IAM role’s ARN
role-session-name: GitHub_to_AWS_via_FederatedOIDC
aws-region: ${{ env.AWS_REGION }}
# Hello from AWS: WhoAmI
- name: Sts GetCallerIdentity
run: |
aws sts get-caller-identity
Modify the workflow to reflect your AWS account information:
AWS_REGION: Enter the AWS Region for your AWS resources.
role-to-assume: Replace the ARN with the ARN of the AWS GitHubAction role that you created previously.
In the example workflow, if there is a push or pull on the repository’s “main” branch, the action that you just created will be invoked.
Figure 5 shows the workflow steps in which GitHub does the following:
Authenticates to the IAM role with the OIDC IdP in the Region that was defined in the workflow file in the step configure aws credentials.
Calls aws sts get-caller-identity in the step Hello from AWS. WhoAmI… Run AWS CLI sts GetCallerIdentity.
Figure 5: Results of GitHub action
Step 5: Audit the role usage: Query CloudTrail logs
The final step is to view the AWS CloudTrail logs in your account to audit the use of this role.
To view the event logs for the GitHub action:
In the AWS Management Console, open CloudTrail and choose Event History.
In the Lookup attributes list, choose Event source.
In the search bar, enter sts.amazonaws.com.
Figure 6: Find event history in CloudTrail
You should see the GetCallerIdentity and AssumeRoleWithWebIdentity events, as shown in Figure 6. The GetCallerIdentity event is the Hello from AWS. step in the GitHub workflow file. This event shows the workflow as it calls aws sts get-caller-identity. The AssumeRoleWithWebIdentity event shows GitHub authenticating and assuming your IAM role GitHubAction-AssumeRoleWithAction.
You can also view one event at a time.
To view the AWS CLI GetCallerIdentity event:
In the Lookup attributes list, choose User name.
In the search bar, enter the role-session-name, defined in the workflow file in your repository. This is not the IAM role name, because this role-session-name is defined in line 30 of the workflow example. In the workflow example for this blog post, the role-session-name is GitHub_to_AWS_via_FederatedOIDC.
You can now see the first event in the CloudTrail history.
Figure 7: View the get caller identity in CloudTrail
To view the AssumeRoleWithWebIdentity event
In the Lookup attributes list, choose User name.
In the search bar, enter the GitHub organization, repository, and branch that is defined in the IAM role’s trust policy. In the example outlined earlier, the user name is repo:aws-samples/EXAMPLE:ref:refs/heads/main.
You can now see the individual event in the CloudTrail history.
Figure 8: View the assume role call in CloudTrail
Conclusion
When you use IAM roles with OIDC identity providers, you have a trusted way to provide access to your AWS resources. GitHub and other OIDC providers can generate temporary security credentials to update resources and infrastructure inside your accounts.
In this post, you learned how to use the federated access to assume a role inside AWS directly from a workflow action file in a GitHub repository. With this new IdP in place, you can begin to delete AWS access keys from your IAM users and use short-term credentials.
After you read this post, we recommend that you follow the AWS Well Architected Security Pillar IAM directive to use programmatic access to AWS services using temporary and limited-privilege credentials. If you deploy IAM federated roles instead of AWS user access keys, you follow this guideline and issue tokens by the AWS Security Token Service. If you have feedback on this post, leave a comment below and let us know how you would like to see OIDC workflows expanded to help your IAM needs.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Today AWS launched two new global condition context keys that make it simpler for you to write policies in which Amazon Elastic Compute Cloud (Amazon EC2) instance credentials work only when used on the instance to which they are issued. These new condition keys are available today in all AWS Regions, as well as AWS GovCloud and China partitions.
Using these new condition keys, you can write service control policies (SCPs) or AWS Identity and Access Management (IAM) policies that restrict the virtual private clouds (VPCs) and private IP addresses from which your EC2 instance credentials can be used, without hard-coding VPC IDs or IP addresses in the policy. Previously, you had to list specific VPC IDs and IP addresses in the policy if you wanted to use it to restrict where EC2 credentials were used. With this new approach, you can use less policy space and reduce the time spent on updates when your list of VPCs and network ranges changes.
In this blog post, we will show you how to use these new condition keys in an SCP and a resource policy to help ensure that the IAM role credentials assigned to your EC2 instances can only be used from the instances to which they were issued.
New global condition keys
The two new condition keys are as follows:
aws:EC2InstanceSourceVPC — This single-valued condition key contains the VPC ID to which an EC2 instance is deployed.
aws:EC2InstanceSourcePrivateIPv4 — This single-valued condition key contains the primary IPv4 address of an EC2 instance.
These new conditions are available only for use with credentials issued to an EC2 instance. You don’t have to make configuration changes to activate the new condition keys.
Let’s start by reviewing some existing IAM conditions and how to combine them with the new conditions. When requests are made to an AWS service over a VPC endpoint, the value of the aws:SourceVpc condition key is the ID of the VPC into which the endpoint is deployed. The value of the aws:VpcSourceIP condition key is the IP address from which the endpoint receives the request. The aws:SourceVpc and aws:VpcSourceIP keys are null when requests are made through AWS public service endpoints. These condition keys relate to dynamic properties of the network path by which your AWS Signature Version 4-signed request reached the API endpoint. For a list of AWS services that support VPC endpoints, see AWS services that integrate with AWS PrivateLink.
The two new condition keys relate to dynamic properties of the EC2 role credential itself. By using the two new credential-relative condition keys with the existing network path-relative aws:SourceVPC and aws:VpcSourceIP condition keys, you can create SCPs to help ensure that credentials for EC2 instances are only used from the EC2 instances to which they were issued. By writing policies that compare the two sets of dynamic values, you can configure your environment such that requests signed with an EC2 instance credential are denied if they are used anywhere other than the EC2 instance to which they were issued.
Policy examples
In the following SCP example, access is denied if the value of aws:SourceVpc is not equal to the value of aws:ec2InstanceSourceVPC, or if the value of aws:VpcSourceIp is not equal to the value of aws:ec2InstanceSourcePrivateIPv4. The policy uses aws:ViaAWSService to allow certain AWS services to take action on your behalf when they use your role’s identity to call services, such as when Amazon Athena queries Amazon Simple Storage Service (Amazon S3).
Because we encase aws:SourceVpc and aws:VpcSourceIp in “${}” in these policies, they are treated as a variable using the value in the request being made. However, in the IAM policy language, the operator on the left side of a comparison is implicitly treated as a variable, while the operator on the right side must be explicitly declared as a variable. The “Null” operator on the ec2:SourceInstanceARN condition key is designed to ensure that this policy only applies to EC2 instance roles, and not roles used for other purposes, such as those used in AWS Lambda functions.
The two deny statements in this example form a logical “or” statement, such that either a request from a different VPC or a different IP address evaluates in a deny. But functionally, they act in an “and” fashion. To be allowed, a request must satisfy both the VPC-based and the IP-based conditions because failure of either denies the call. Because VPC IDs are globally unique values, it’s reasonable to use the VPC-based condition without the private IP condition. However, you should avoid evaluating only the private IP condition without also evaluating the VPC condition. Private IPs can be the same across different environments, so aws:ec2InstanceSourcePrivateIPv4 is safe to use only in conjunction with the VPC-based condition.
If you have specific EC2 instance roles that you want to exclude from the statement, you can apply exception logic through tags or role names.
The following example applies to roles used as EC2 instance roles, except those with a tag of exception-to-vpc-ip where the value is equal to true by using the aws:PrincipalTag condition key. The three condition operators (StringNotEquals, Null, and BoolIfExists) in the same condition block are evaluated with a logical AND operation, and if either of the tests doesn’t evaluate, then the deny statement doesn’t apply. Hence, EC2 instance roles with a principal tag of exception-to-vpc-ip equal to true are not subject to this SCP.
You can apply exception logic to other attributes of your IAM roles. For example, you can use the aws:PrincipalArn condition key to exempt certain roles based on their AWS account. You can also specify where you want this SCP to be applied in your AWS Organizations organization. You can apply SCPs directly to accounts, organizational units, or organizational roots. For more information about inheritance when applying SCPs in Organizations, see Understanding policy inheritance.
You can also apply exception logic to your SCP statements at the IAM Action. The following example statement restricts an EC2 instance’s credential usage to only the instance from which it was issued, except for calls to IAM by using a NotAction element. You should use this exception logic if an AWS service doesn’t have a VPC endpoint, or if you don’t want to use VPC endpoints to access a particular service.
Because these new condition keys are global condition keys, you can use the keys in all relevant AWS policy types, such as the following policy for an S3 bucket. When using this as a bucket policy, make sure to replace <DOC-EXAMPLE-BUCKET> with the ARN of your S3 bucket.
This policy restricts access to your S3 bucket to EC2 instance roles that are used only from the instance to which they were vended. Like the previous policy examples, there are two deny statements in this example to form a logical “or” statement but a functional “and” statement, because a request must come from the same VPC and same IP address of the instance that it was issued to, or else it evaluates to a deny.
Conclusion
In this blog post, you learned about the newly launchedaws:ec2InstanceSourceVPC and aws:ec2InstanceSourcePrivateIPv4 condition keys. You also learned how to use them with SCPs and resource policies to limit the usage of your EC2 instance roles to the instances from which they originated when requests are made over VPC endpoints. Because these new condition keys are global condition keys, you can use them in all relevant AWS policy types. These new condition keys are available today in all Regions, as well as AWS GovCloud and China partitions.
In this post, we continue with our recommendations for using AWS Identity and Access Management (IAM) APIs. In part 1 of this two-part series, we described how you could create IAM resources and use them soon after for authorization decisions. We also described options for monitoring and responding to IAM resource changes for entire accounts. Now, in part 2 of this post, we’ll cover the API throttling behavior of IAM and AWS Security Token Service (AWS STS) and how you can effectively plan your usage of these APIs. We’ll also cover the features of IAM that enable you to right-size the permissions granted to principals in your organization and assess external access to your resources.
Increase your usage of IAM APIs
If you’re a developer or a security engineer, you might find yourself writing more and more automation that interacts with IAM APIs. Other engineers, teams, or applications might also call the IAM APIs within the same account or cross-account. Over time, anyone calling the APIs in your account incrementally increases the number of requests per second. If so, IAM might send a “Rate exceeded” error that indicates you have exceeded a certain threshold of API calls per second. This is called API throttling.
Understand IAM API throttling
API throttling occurs when you exceed the call rate limits for an API. AWS uses API throttling to limit requests to a service. Like many AWS services, IAM limits API requests to maintain the performance of the service, and to ensure fair usage across customers. IAM and AWS STS independently implement a token bucket algorithm for throttling, in which a bucket of virtual tokens is refilled every second. Each token represents a non-throttled API call that you can make. The number of tokens that a bucket holds and the refill rate depends on the API. For each IAM API, a number of token buckets might apply.
We refer to this simply as rate-limiting criteria. Essentially, there are several rate-limiting criteria that are considered when evaluating whether a customer is generating more traffic than the service allows. The following are some examples of these criteria:
The account where the API is called
The account for read or write APIs (depending on whether the API is a read or write operation)
The account from which AssumeRole was called prior to the API call (for example, third-party cross-account calls)
The account from which AssumeRole was called prior to the API call for read APIs
The API and organization where the API is called
Understand STS API throttling
Although IAM has criteria pertaining to the account from which AssumeRole was called, IAM has its own API rate limits that are distinct from AWS STS. Therefore, the preceding criteria are IAM-specific and are separate from the throttling that can occur if you call STS APIs. IAM is also a global service, and the limits are not Region-aware. In contrast, while STS has a single global endpoint, every Region has its own STS endpoint with its own limits.
The STS rate-limiting criteria pertain to each account and endpoint for API calls. For example, if you call the AssumeRole API against the sts.ap-northeast-1.amazonaws.com endpoint, STS will evaluate the rate-limiting criteria associated with that account and the ap-northeast-1 endpoint. Other STS API requests that you perform under the same account and endpoint will also count towards these criteria. However, if you make a request from the same account to a different regional endpoint or the global endpoint, that request will count against different criteria.
Note: AWS recommends that you use the STS regional endpoints instead of the STS global endpoint. Regional endpoints have several benefits, including redundancy and reduced latency. To learn more about other benefits, see Managing AWS STS in an AWS Region.
How multiple criteria affect throttling
The preceding examples show the different ways that IAM and STS can independently limit requests. Limits might be applied at the account level and across read or write APIs. More than one rate-limiting criterion is typically associated with an API call, with each request counted against each rate-limiting criterion independently. This means that if the requests-per-second exceeds the applicable criteria, then API throttling occurs and returns a rate-limiting error.
How to address IAM and STS API throttling
In this section, we’ll walk you through some strategies to reduce IAM and STS API throttling.
Query for top callers
With AWS CloudTrail Lake, your organization can aggregate, store, and query events recorded by CloudTrail for auditing, security investigation, and operational troubleshooting. To monitor API throttling, you can run a simple query that identifies the top callers of IAM and STS.
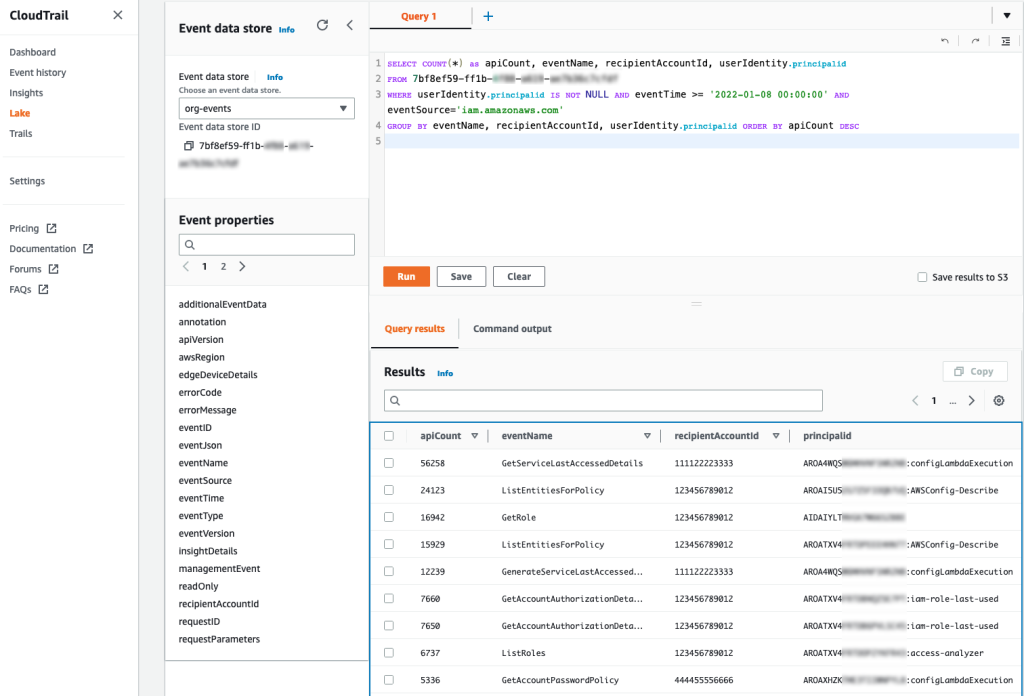
For example, you can make a SQL-based query in the CloudTrail console to identify the top callers of IAM, as shown in Figure 1. This query includes the API count, API event name, and more that are made to IAM (shown under eventSource). In this example, the top result is a call to GetServiceLastAccessedDetails, which occurred 163 times. The result includes the account ID and principal ID that made those requests.
To reduce call throttling, you need to know when you exceed a rate limit. You can identify when you are being throttled by catching the RateLimitExceeded exception in your API calls. Or, you can send your application logs to Amazon CloudWatch Logs and then configure a metric filter to record each time that throttling occurs, for later analysis or notification. Ideally, you should do this across your applications, and log this information centrally so that you can investigate whether calls from a specific account (such as your central monitoring account) are affecting API availability across your other accounts by exceeding a rate-limiting criterion in those accounts.
Call your APIs with a less aggressive retry strategy
In the AWS SDKs, you can use the existing retry library and provide a custom base for the initial sleep done between API calls. For example, you can set a custom configuration for the backoff or edit the defaults directly. The default SDK_DEFAULT_THROTTLED_BASE_DELAY is 500 milliseconds (ms) in the relevant Java SDK file, but if you’re experiencing throttling consistently, we recommend a minimum 1000 ms for the throttled base delay. You can change this value or implement a custom configuration through the PredefinedBackoffStrategies.SDKDefaultBackoffStrategy() class, which is referenced in the same file. As another example, in the Javascript SDK, you can edit the base retry of the retryDelayOptions configuration in the AWS.Config class, as described in the documentation.
The difference between making these changes and using the SDK defaults is that the custom base provides a less aggressive retry. You shouldn’t retry multiple requests that are throttled during the same one-second window. If the API has other applicable rate-limiting criteria, you can potentially exceed those limits as well, preventing other calls in your account from performing requests. Lastly, be careful that you don’t implement your own retry or backoff logic on top of the SDK retry or backoff logic because this could make throttling worse — instead, you should override the SDK defaults.
Reduce the number of requests by using max items
For some APIs, you can increase the number of items returned by a single API call. Consider the example of the GetServiceLastAccessedDetails API. This API returns a lot of data, but the results are truncated by default to 100 items, ordered alphabetically by the service namespace. If the number of items returned is greater than 100, then the results are paginated, and you need to make multiple requests to retrieve the paginated results individually. But if you increase the value of the MaxItems parameter, you can decrease the number of requests that you need to make to obtain paginated results.
AWS has hundreds of services, so you should set the value of the MaxItems parameter no higher than your application can handle (the response size could be large). At the time of our testing, the results were no longer truncated when this value was 300. For this particular API, IAM might return fewer results, even when more results are available. This means that your code still needs to check whether the results are paginated and make an additional request if paginated results are available.
Consistent use of the MaxItems parameter across AWS APIs can help reduce your total number of API requests. The MaxItems parameter is also available through the GetOrganizationsAccessReport operation, which defaults to 100 items but offers a maximum of 1000 items, with the same caveat that fewer results might be returned, so check for paginated results.
Smooth your high burst traffic
In the table from part 1 of this post, we stated that you should evaluate IAM resources every 24 hours. However, if you use a simple script to perform this check, you could initiate a throttling event. Consider the following fictional example:
As a member of ExampleCorp’s Security team, you are working on a task to evaluate the company’s IAM resources through some custom evaluation scripts. The scripts run in a central security account. ExampleCorp has 1000 accounts. You write automation that assumes a role in every account to run the GetAccountAuthorizationDetails API call. Everything works fine during development on a few accounts, but you later build a dashboard to graph the data. To get the results faster for the dashboard, you update your code to run concurrently every hour. But after this change, you notice that many requests result in the throttling error “Rate exceeded.” Other security teams see “Rate exceeded” errors in their application logs, too.
Can you guess what happened? When you tried to make the requests faster, you used concurrency to make the requests run in parallel. By initiating this large number of requests simultaneously, you exceeded the rate-limiting criteria for the security account from which the sts:AssumeRole action was called prior to the GetAccountAuthorizationDetails API call.
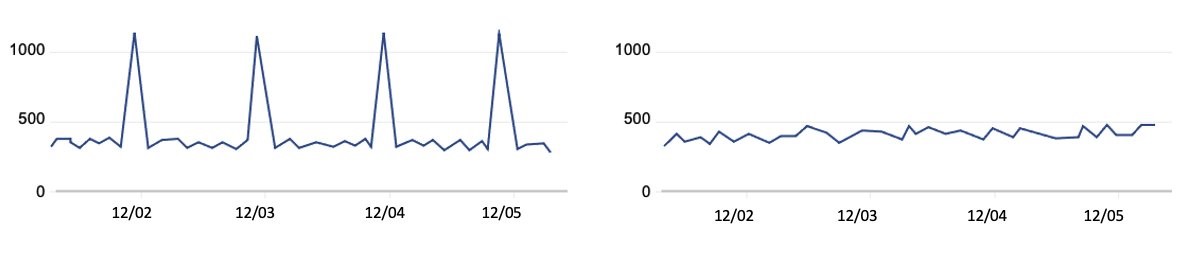
To address scenarios like this, we recommend that you set your own client-side limitations when you need to make a large number of API requests. You can spread these calls out so that they happen sequentially and avoid large spikes. For example, if you run checks every 24 hours, make sure that the calls don’t happen at exactly midnight. Figure 2 shows two different ways to distribute API volume over time:
Figure 2: Call volume that periodically spikes compared to evenly-distributed call volume
The graph on the left represents a large, recurring API call volume, with calls occurring at roughly the same time each day—such as 1000 requests at midnight every 24 hours. However, if you intend to make these 1000 requests consistently every 24 hours, you can spread them out over the 24-hour period. This means that you could make about 41 requests every hour, so that 41 accounts are queried at 00:00 UTC, another 41 the next hour, and so on. By using this strategy, you can make these requests blend into your other traffic, as shown in the graph on the right, rather than create large spikes. In summary, your automation scheduler should avoid large spikes and distribute API requests evenly over the 24-hour period. Using queues such as those provided by Amazon Simple Queue Service (Amazon SQS) can also help, and when errors are identified, you can put them in a dead letter queue to try again later.
Some IAM APIs have rate-limiting criteria for API requests made from the account from which the AssumeRole was called prior to the call. We recommend that you serially iterate over the accounts in your organization to avoid throttling. To continue with our example, you should iterate the 41 accounts one-by-one each hour, rather than running 41 calls at once, to reduce spikes in your request rates.
Recommendations specific to STS
You can adjust how you use AWS STS to reduce your number of API calls. When you write code that calls the AssumeRole API, you can reuse the returned credentials for future requests because the credentials might still be valid. Imagine that you have an event-driven application running in a central account that assumes a role in a target account and does an API call for each event that occurs in that account. You should consider reusing the credentials returned by the AssumeRole call for each subsequent call in the target account, especially if calls in the central accounts are being throttled. You can do this for AssumeRole calls because there is no service-side limit to the number of credentials that you can create and use. Whether it’s one credential or many, you need to use and store these carefully. You can also adjust the role session duration, which determines how long the role’s credentials are valid. This value can be up to 12 hours, depending on the maximum session duration configured on the role. If you reuse short-term credentials or adjust the session duration, make sure that you evaluate these changes from a security perspective as you optimize your use of STS to reduce API call volume.
Use case #3: Pare down permissions for least-privileged access
Let’s assume that you want to evaluate your organization’s IAM resources with some custom evaluation scripts. AWS has native functionality that can reduce your need for a custom solution. Let’s take a look at some of these that can help you accomplish these goals.
Identify unintended external sharing
To identify whether resources in your accounts, such as IAM roles and S3 buckets, have been shared with external entities, you can use IAM Access Analyzer instead of writing your own checks. With IAM Access Analyzer, you can identify whether resources are accessible outside your account or even your entire organization. Not only can you identify these resources on-demand, but IAM Access Analyzer proactively re-analyzes resources when their policies change, and reports new findings. This can help you feel confident that you will be notified of new external sharing of supported resources, so that you can act quickly to investigate. For more details, see the IAM Access Analyzer user guide.
Right-size permissions
You can also use IAM Access Analyzer to help right-size the permissions policies for key roles in your accounts. IAM Access Analyzer has a policy generation feature that allows you to generate a policy by analyzing your CloudTrail logs to identify actions used from over 140 services. You can compare this generated policy with the existing policy to see if permissions are unused, and if so, remove them.
You can perform policy generation through the API or the IAM console. For example, you can use the console to navigate to the role that you want to analyze, and then choose Generate policy to start analyzing the actions used over a specified period. Actions that are missing from the generated policy are permissions that can be potentially removed from the existing policy, after you confirm your changes with those who administer the IAM role. To learn more about generating policies based on CloudTrail activity, see IAM Access Analyzer makes it easier to implement least privilege permissions by generating IAM policies based on access activity.
Conclusion
In this two-part series, you learned more about how to use IAM so that you can test and query IAM more efficiently. In this post, you learned about the rate-limiting criteria for IAM and STS, to help you address API throttling when increasing your usage of these services. You also learned how IAM Access Analyzer helps you identify unintended resource sharing while also generating policies that serve as a baseline for principals in your account. In part 1, you learned how to quickly create IAM resources and use them when refining permissions. You also learned how to get information about IAM resources and respond to IAM changes through the various services integrated with IAM. Lastly, when calling IAM directly, you learned about bulk APIs, which help you efficiently retrieve the state of your principals and policies. We hope these posts give you valuable insights about IAM to help you better monitor, review, and secure access to your AWS cloud environment!
In this two-part blog post, we’ll provide recommendations for using AWS Identity and Access Management (IAM) APIs, and we’ll share useful details on how IAM works so that you can use it more effectively. For example, you might be creating new IAM resources such as roles and policies through automation and notice a delay for resource propagations. Or you might be building a custom cloud security monitoring solution that uses IAM APIs to evaluate the security and compliance of your AWS accounts, and you want to know how to do that without exceeding limits. Although these are just a few example use cases, the insights described in this post are intended to help you avoid anti-patterns when building scalable cloud services that use IAM APIs.
In this post, we describe how to create IAM resources and use them soon after for authorization decisions. We also describe options for monitoring and responding to IAM resource changes for entire accounts. In part 2, we’ll cover the API throttling behavior of IAM and AWS Security Token Service (AWS STS) and how you can effectively plan your usage of these APIs. Let’s dive in!
Use case 1: Create IAM resources and attempt to use them immediately
If you’re a cloud developer, you create and use IAM resources when you develop applications on AWS. For your application to interact with AWS services, you need to grant IAM permissions to your application. Your application—whether it runs on AWS Lambda, Amazon Elastic Compute Cloud (Amazon EC2), or another service—will need an associated IAM role and policy that provide the necessary permissions.
Imagine that you want to create least privilege policies for your application. You begin by deploying new or updated IAM resources, such as roles and policies, along with your application updates, and you automate this process to speed up testing and development.
During development, you begin removing unnecessary policy permissions, with your automation testing the updated permissions. However, you notice that some of your updates do not immediately take effect. The following sections address why this occurs and provide insights to help you architect for other scenarios.
Understand the IAM control plane and data plane
Let’s first learn more about the control plane and data plane in IAM. The control plane involves operations to create, read, update, and delete IAM resources, and it’s how you get the current state of IAM. When you invoke IAM APIs, you interact with the control plane. This includes any API that falls under the iam:* namespace. The data plane, in contrast, consists of the authorization system that is used at scale to grant access to the broader set of AWS services and resources. This includes the AWS STS APIs, which have their own sts:* namespace.
When you call the IAM control plane APIs to create, update, or delete resources, you can expect a read-after-write consistent response. This means that you can retrieve (read) the resource and its latest updates immediately after it’s written. In contrast, the IAM data plane, where authorizations occur, is eventually consistent. This means that there will be a delay for IAM resource changes, such as updates to roles and policies, to propagate and reflect in the authorizations that follow. The delay can be several seconds or longer. Because of this, you need to allow for propagation time when you test changes to IAM resources. To learn more about the control plane and data plane of IAM, see Resilience in AWS Identity and Access Management.
Note: Because calls to AWS APIs rely on IAM to check permissions, the availability and scalability of the data plane are paramount. In 2011, the “can the caller do this?” function handled a couple of thousand requests per second. Today, as new services continue to launch and the number of AWS customers increases, AWS Identity handles over half a billion API calls per second worldwide, and the number is growing. Eventually consistent design enables the IAM data plane to maintain the high availability and low latency needed to evaluate permissions on AWS.
This is why when architecting your application, we recommend that you don’t depend on control plane actions such as resource updates for critical parts of your application’s workflow. Instead, you should architect to take advantage of the data plane, which includes STS and the authorization system of IAM. In the next section, we describe how you can do this.
Test permissions with STS scope-down policies
IAM role sessions have a feature called a session policy, which takes effect immediately when a role is assumed. This is an optional policy that you can provide to scope down the role’s existing identity policies, with the permissions being the intersection of the role’s identity-based policies and the session policy. By using session policies, you get specific, scoped-down credentials from a single pre-existing role without having to create new roles or identity policies for each particular session’s use case. You can use session policies for your application or when you test which least privilege policies are best for your application.
Let’s walk through an example of when to use session policies for permissions testing. Imagine that you need permissions that require very specific, fine-grained conditions to attain your ideal least privilege policy. You might iterate on the policy several times, making updates and testing the changes over and over again. If you update a policy attached to a role, you need to wait for these changes to propagate to the IAM data plane. But if you instead specify a scope-down policy when assuming the pre-existing role prior to testing, you can immediately test and observe the effects of your permissions changes. Immediate testing is possible because your role and its original policy have already propagated to the data plane, enabling you to iterate over various scoped-down session policies that operate against the IAM data plane.
Use STS session policies to assume a role with the AWS CLI
There are two ways to provide a session policy during the AssumeRole process: you can provide an inline policy document or the Amazon Resource Names (ARNs) of managed session policies. The following example shows how to do this through the AWS Command Line Interface (AWS CLI), by passing in a policy document along with the AssumeRole call. If you use this example policy, make sure to replace <123456789012> and <DOC-EXAMPLE-BUCKET> with your own information.
In this example, we provide a previously created role ARN named s3-full-access, which provides full access to Amazon Simple Storage Service (Amazon S3). We can further restrict the role’s permissions by supplying a policy with the optional --policy option. The inline policy document only allows the GetObject request against the S3 bucket named <DOC-EXAMPLE-BUCKET>. The effective permissions for the returned session are the intersection of the role’s identity-based policies and our provided session policy. Therefore, the role session’s permissions are limited to only performing the GetObject request against the <DOC-EXAMPLE-BUCKET>.
Note: The combined size of the passed inline policy document and all passed managed policy ARN characters cannot exceed 2,048 characters. You can reduce the size of the JSON policy document by removing unnecessary whitespace and shortening or removing tags associated with your session.
Use case 2: Monitor and respond to IAM resources for entire accounts
You might need to periodically audit the state of your IAM resources, such as roles and policies, including whether these IAM resources have changed, in a single account or across your entire organization. For example, you might want to check whether roles have overly broad access to actions and resources. Or you might want to monitor IAM resource creation and updates to respond to security-relevant permission changes. In this section, you will learn how to choose the right tool for auditing and monitoring IAM resources across accounts. You will learn about the AWS services that support this use case, the benefits of polling compared to event-based architectures, and powerful APIs that aggregate common information.
Respond to configuration changes with an event-driven approach
Sometimes you might need to perform actions relatively quickly based on IAM changes. For example, you might need to check if a trust policy for a newly created or updated role allows cross-account access. In cases like this, you can use AWS Config rules, AWS CloudTrail, or Amazon EventBridge to detect state changes and perform actions based on these state changes. You can use AWS Config rules to evaluate whether a resource complies with the conditions that you specify. If it doesn’t comply, you can provide a workflow to remediate the non-compliance. With CloudTrail, you can monitor your account’s API calls, and log API calls for your accounts with AWS Organizations integration. EventBridge works closely with CloudTrail and helps you create rules that match incoming events and send them to targets, such as Lambda, where your code can perform analysis or automated remediation. You can even filter out events from your accounts and send them to a central account’s event bus for processing. For an example of how to use EventBridge with IAM Access Analyzer to remediate cross-account access in a role’s trust policy, see Automate resolution for IAM Access Analyzer cross-account access findings on IAM roles. Which feature you choose depends on whether you need to monitor one account or all accounts in your organization, as well as which solution you are more comfortable building with.
One caveat to an event-driven approach is that if many events occur over a short period and your application responds to each event with an IAM API call of its own, you could eventually be throttled by IAM. To address this, you can queue up your responding API calls, distribute them over a longer period, or aggregate them to reduce API call volume. For example, if some of your calls are write APIs (such as UpdateAssumeRolePolicy or CreatePolicyVersion) or read APIs (such as GetRole or GetRolePolicy), you can call them serially with a delay between calls. If you need the latest status on a large number of principals and policies, you can call IAM bulk APIs such as GetAccountAuthorizationDetails, which will return data to you for principals and policies and their relationships in your organization. This approach helps you avoid throttling and querying the IAM control plane with unnecessary and redundant API calls. You will learn more about throttling and how to address it in part two of this post.
Retrieve point-in-time resource information with AWS Config
AWS Config helps you assess, audit, and evaluate the configuration of your AWS resources. It also offers multi-account, multi-Region data aggregation and is integrated with AWS Organizations. With AWS Config, you can create rules that detect and respond to changes. AWS Config also keeps an inventory of AWS resource configurations that you can query through its API, so that you don’t need to make direct API calls to each resource’s service. AWS Config also offers the ability to return the status of resources from multiple accounts and AWS Regions. As shown in Figure 1, you can use the AWS Config console to run a simple SQL-like statement for details on the IAM roles in your entire organization.
Figure 1: Run a query on IAM roles in AWS Config
The preceding results also show associated resources, such as the inline and attached policies for the IAM roles. Alternatively, you can obtain these results from the SDK or CLI. The following query that uses the CLI is equivalent to the preceding query that uses the console. If you use this query, make sure to replace DOC-EXAMPLE-CONFIG-AGGREGATOR> with your AWS Config aggregator.
The preceding command returns the details of roles in your organization’s accounts, including the full policy document for the associated inline policy. It also returns the customer-managed policy names and their ARNs, for which you can view the policy documents and versions by using the BatchGetResourceConfig API. Note that AWS Config doesn’t provide the AWS-managed policy documents. However, these are common across accounts, and we will show you how to query that data later in this section.
To query the status of roles in your organization, you need to have AWS Config enabled in each account. You also need an aggregator to monitor your accounts with your organization’s management account or a delegated administrator account. For more details on how to set up AWS Config, see the AWS Config developer guide. After you set up AWS Config, you can periodically call the AWS Config APIs to get a snapshot of the current or prior state of your resources. Furthermore, you can periodically pull the snapshot records and evaluate this information in other tools outside of AWS Config. So before you directly use the IAM APIs to get IAM information, consider using AWS Config—this is what it’s for!
Retrieve IAM resource information directly from IAM
As previously noted, AWS Config can give you a bulk view of your AWS and IAM resources. Additionally, CloudTrail and EventBridge can detect AWS and IAM resource changes and help you act on them. If you need data from IAM beyond what these services offer, you can query the IAM APIs directly to get the latest information on your resources.
A few key APIs can help you audit IAM resources more efficiently, especially in bulk. The first is GetAccountAuthorizationDetails, which enables you to retrieve the principals in your account, their associated inline policy documents (if any), attached managed policies, and their relationships to each other. This API reduces the need to individually call ListRolePolicies and ListAttachedRolePolicies for each role in an account. GetAccountAuthorizationDetails also returns the role trust policy document for roles in the results. Finally, GetAccountAuthorizationDetails allows you to filter the result set. For example, if you don’t need information relating to groups or AWS managed policies, you can exclude these from the API response. You can do this by using the filter parameter to only include the details that you need at the time.
Another useful API is GenerateServiceLastAccessedDetails. This API gives you details about when an IAM resource (user, group, role, or policy) was last used in an attempt to access AWS services. You can use this API to identify roles that are unused and remove them if you don’t need them. IAM Access Analyzer, which you will learn about later in this post, also uses the same information.
The following table summarizes the key APIs that you can use, rather than building your own code that loops for this information individually.
Submit a job through the GenerateServiceLastAccessedDetails API which returns a JobId; then retrieve the results after the job completes. Pass ACTION_LEVEL as the required Granularity parameter.
Spread total number of requests evenly across 24 hours
Note: In the table, we suggest that you perform some of these API requests once every 24 hours as a starting point. You might prefer to perform your own analysis at a longer time interval, such as every 48 hours, but we don’t recommend requesting it more often than every 24 hours because these resources (and therefore the details in the responses) don’t change often. These APIs are suitable for periodic, point-in-time collection of information. If you need faster detection of information from GetAccountAuthorizationDetails, consider whether AWS Config rules or EventBridge will fit your needs. For GetServiceLastAccessedDetails, recent activity usually appears within four hours, so more frequent requests are unlikely to provide much value.
Use of these APIs can help you avoid writing code that loops through results to make individual read API calls for each principal, policy, and policy version in an account, which could result in tens of thousands of API requests and call throttling. Instead of iterating over each resource, you should use solutions that return bulk data, such as GetAccountAuthorizationDetails, AWS Config, or an AWS Partner Network solution. However, if you’re experiencing throttling, you will learn some practical considerations on how to handle that later in this post.
Inspect IAM resources across multiple accounts and organizations
Your use case might require that you inspect IAM resources across multiple accounts in your organization. Or perhaps you are an independent software vendor and need to build a software-as-a-service tool to evaluate IAM resources across many organizations. The following considerations can help you address use cases like these.
AWS Organizations integration
Previously, you learned of the benefits of the “service last accessed data” that the GenerateServiceLastAccessedDetails and GetServiceLastAccessedDetails APIs provide. But what if you want to pull this data for multiple accounts in your organization? IAM has bulk APIs that support querying this data across your entire organization, so you don’t need to assume a role in each account to generate the request. To generate a report for entities (organization root, organizational unit, or account) or policies in your organization, use the GenerateOrganizationsAccessReport operation, which returns a JobId that is passed as a parameter to the GetOrganizationsAccessReport operation to check if the report has been generated. When the job status is marked complete, you can retrieve the report.
AWS managed policies
Many customers use AWS managed policies because they align to common job functions. AWS creates and administers these policies, which have their own ARNs, such as arn:aws:iam::aws:policy/AWSCodeCommitPowerUser. AWS managed policies are available for every account, and they are the same for every account. AWS updates them when new services and API operations are introduced. Updated policies are recorded and visible as a new version, so you only need to query for the current AWS managed policies once per evaluation cycle, rather than once per account. Therefore, if you’re evaluating hundreds or thousands of accounts, you shouldn’t include the AWS managed policies and their policy versions in your query. Doing so would result in thousands of redundant API requests and could cause throttling. Instead, you can query the AWS managed policies once and then reuse the results across your analysis and evaluation by caching the results for a period of time (for example, every 24 hours) in your application before requesting them again to check for updates. Because AWS managed policies are available through the GetAccountAuthorizationDetails API, you don’t need to query for the AWS managed policies or their versions as a separate action.
Multi-account limits
The preceding table lists the frequency of API requests as “per account” in many places. If you’re calling IAM APIs by assuming a role in other accounts from a central account, some IAM APIs have rate-limiting criteria that apply to API requests performed from the assuming account (the central account). To query data from multiple accounts, we recommend that you serially iterate over the accounts one-by-one to avoid throttling. You’ll learn more about this strategy, as well as throttling, in part 2 of this blog post.
Conclusion
In this post, you learned about different aspects of IAM and best practices to test and query IAM efficiently. With STS session policies, you can test different policies to help achieve least privilege access. With AWS Config, EventBridge, CloudTrail, and CloudTrail Lake, you can audit your IAM resources and respond to changes while reducing the number of IAM API calls that you make. If you need to call IAM directly, you can use IAM bulk APIs for more efficient retrieval of your resource state. You can learn more about IAM and best practices in part 2 of blog post: How to monitor and query IAM resources at scale – Part 2.
Ransomware events have significantly increased over the past several years and captured worldwide attention. Traditional ransomware events affect mostly infrastructure resources like servers, databases, and connected file systems. However, there are also non-traditional events that you may not be as familiar with, such as ransomware events that target data stored in Amazon Simple Storage Service (Amazon S3). There are important steps you can take to help prevent these events, and to identify possible ransomware events early so that you can take action to recover. The goal of this post is to help you learn about the AWS services and features that you can use to protect against ransomware events in your environment, and to investigate possible ransomware events if they occur.
Ransomware is a type of malware that bad actors can use to extort money from entities. The actors can use a range of tactics to gain unauthorized access to their target’s data and systems, including but not limited to taking advantage of unpatched software flaws, misuse of weak credentials or previous unintended disclosure of credentials, and using social engineering. In a ransomware event, a legitimate entity’s access to their data and systems is restricted by the bad actors, and a ransom demand is made for the safe return of these digital assets. There are several methods actors use to restrict or disable authorized access to resources including a) encryption or deletion, b) modified access controls, and c) network-based Denial of Service (DoS) attacks. In some cases, after the target’s data access is restored by providing the encryption key or transferring the data back, bad actors who have a copy of the data demand a second ransom—promising not to retain the data in order to sell or publicly release it.
In the next sections, we’ll describe several important stages of your response to a ransomware event in Amazon S3, including detection, response, recovery, and protection.
After a bad actor has obtained credentials, they use AWS API actions that they iterate through to discover the type of access that the exposed IAM principal has been granted. Bad actors can do this in multiple ways, which can generate different levels of activity. This activity might alert your security teams because of an increase in API calls that result in errors. Other times, if a bad actor’s goal is to ransom S3 objects, then the API calls will be specific to Amazon S3. If access to Amazon S3 is permitted through the exposed IAM principal, then you might see an increase in API actions such as s3:ListBuckets, s3:GetBucketLocation, s3:GetBucketPolicy, and s3:GetBucketAcl.
Analysis
In this section, we’ll describe where to find the log and metric data to help you analyze this type of ransomware event in more detail.
When a ransomware event targets data stored in Amazon S3, often the objects stored in S3 buckets are deleted, without the bad actor making copies. This is more like a data destruction event than a ransomware event where objects are encrypted.
There are several logs that will capture this activity. You can enable AWS CloudTrail event logging for Amazon S3 data, which allows you to review the activity logs to understand read and delete actions that were taken on specific objects.
In addition, if you have enabled Amazon CloudWatch metrics for Amazon S3 prior to the ransomware event, you can use the sum of the BytesDownloaded metric to gain insight into abnormal transfer spikes.
Another way to gain information is to use the region-DataTransfer-Out-Bytes metric, which shows the amount of data transferred from Amazon S3 to the internet. This metric is enabled by default and is associated with your AWS billing and usage reports for Amazon S3.
Next, we’ll walk through how to respond to the unintended disclosure of IAM access keys. Based on the business impact, you may decide to create a second set of access keys to replace all legitimate use of those credentials so that legitimate systems are not interrupted when you deactivate the compromised access keys. You can deactivate the access keys by using the IAM console or through automation, as defined in your incident response plan. However, you also need to document specific details for the event within your secure and private incident response documentation so that you can reference them in the future. If the activity was related to the use of an IAM role or temporary credentials, you need to take an additional step and revoke any active sessions. To do this, in the IAM console, you choose the Revoke active session button, which will attach a policy that denies access to users who assumed the role before that moment. Then you can delete the exposed access keys.
In addition, you can use the AWS CloudTrail dashboard and event history (which includes 90 days of logs) to review the IAM related activities by that compromised IAM user or role. Your analysis can show potential persistent access that might have been created by the bad actor. In addition, you can use the IAM console to look at the IAM credential report (this report is updated every 4 hours) to review activity such as access key last used, user creation time, and password last used. Alternatively, you can use Amazon Athena to query the CloudTrail logs for the same information. See the following example of an Athena query that will take an IAM user Amazon Resource Number (ARN) to show activity for a particular time frame.
SELECT eventtime, eventname, awsregion, sourceipaddress, useragent
FROM cloudtrail
WHERE useridentity.arn = 'arn:aws:iam::1234567890:user/Name' AND
-- Enter timeframe
(event_date >= '2022/08/04' AND event_date <= '2022/11/04')
ORDER BY eventtime ASC
Recovery
After you’ve removed access from the bad actor, you have multiple options to recover data, which we discuss in the following sections. Keep in mind that there is currently no undelete capability for Amazon S3, and AWS does not have the ability to recover data after a delete operation. In addition, many of the recovery options require configuration upon bucket creation.
S3 Versioning
Using versioning in S3 buckets is a way to keep multiple versions of an object in the same bucket, which gives you the ability to restore a particular version during the recovery process. You can use the S3 Versioning feature to preserve, retrieve, and restore every version of every object stored in your buckets. With versioning, you can recover more easily from both unintended user actions and application failures. Versioning-enabled buckets can help you recover objects from accidental deletion or overwrite. For example, if you delete an object, Amazon S3 inserts a delete marker instead of removing the object permanently. The previous version remains in the bucket and becomes a noncurrent version. You can restore the previous version. Versioning is not enabled by default and incurs additional costs, because you are maintaining multiple copies of the same object. For more information about cost, see the Amazon S3 pricing page.
AWS Backup
Using AWS Backup gives you the ability to create and maintain separate copies of your S3 data under separate access credentials that can be used to restore data during a recovery process. AWS Backup provides centralized backup for several AWS services, so you can manage your backups in one location. AWS Backup for Amazon S3 provides you with two options: continuous backups, which allow you to restore to any point in time within the last 35 days; and periodic backups, which allow you to retain data for a specified duration, including indefinitely. For more information, see Using AWS Backup for Amazon S3.
Protection
In this section, we’ll describe some of the preventative security controls available in AWS.
S3 Object Lock
You can add another layer of protection against object changes and deletion by enabling S3 Object Lock for your S3 buckets. With S3 Object Lock, you can store objects using a write-once-read-many (WORM) model and can help prevent objects from being deleted or overwritten for a fixed amount of time or indefinitely.
AWS Backup Vault Lock
Similar to S3 Object lock, which adds additional protection to S3 objects, if you use AWS Backup you can consider enabling AWS Backup Vault Lock, which enforces the same WORM setting for all the backups you store and create in a backup vault. AWS Backup Vault Lock helps you to prevent inadvertent or malicious delete operations by the AWS account root user.
Amazon S3 Inventory
To make sure that your organization understands the sensitivity of the objects you store in Amazon S3, you should inventory your most critical and sensitive data across Amazon S3 and make sure that the appropriate bucket configuration is in place to protect and enable recovery of your data. You can use Amazon S3 Inventory to understand what objects are in your S3 buckets, and the existing configurations, including encryption status, replication status, and object lock information. You can use resource tags to label the classification and owner of the objects in Amazon S3, and take automated action and apply controls that match the sensitivity of the objects stored in a particular S3 bucket.
MFA delete
Another preventative control you can use is to enforce multi-factor authentication (MFA) delete in S3 Versioning. MFA delete provides added security and can help prevent accidental bucket deletions, by requiring the user who initiates the delete action to prove physical or virtual possession of an MFA device with an MFA code. This adds an extra layer of friction and security to the delete action.
Use IAM roles for short-term credentials
Because many ransomware events arise from unintended disclosure of static IAM access keys, AWS recommends that you use IAM roles that provide short-term credentials, rather than using long-term IAM access keys. This includes using identity federation for your developers who are accessing AWS, using IAM roles for system-to-system access, and using IAM Roles Anywhere for hybrid access. For most use cases, you shouldn’t need to use static keys or long-term access keys. Now is a good time to audit and work toward eliminating the use of these types of keys in your environment. Consider taking the following steps:
Create an inventory across all of your AWS accounts and identify the IAM user, when the credentials were last rotated and last used, and the attached policy.
Disable and delete all AWS account root access keys.
Rotate the credentials and apply MFA to the user.
Re-architect to take advantage of temporary role-based access, such as IAM roles or IAM Roles Anywhere.
Review attached policies to make sure that you’re enforcing least privilege access, including removing wild cards from the policy.
Server-side encryption with customer managed KMS keys
Another protection you can use is to implement server-side encryption with AWS Key Management Service (SSE-KMS) and use customer managed keys to encrypt your S3 objects. Using a customer managed key requires you to apply a specific key policy around who can encrypt and decrypt the data within your bucket, which provides an additional access control mechanism to protect your data. You can also centrally manage AWS KMS keys and audit their usage with an audit trail of when the key was used and by whom.
GuardDuty protections for Amazon S3
You can enable Amazon S3 protection in Amazon GuardDuty. With S3 protection, GuardDuty monitors object-level API operations to identify potential security risks for data in your S3 buckets. This includes findings related to anomalous API activity and unusual behavior related to your data in Amazon S3, and can help you identify a security event early on.
Conclusion
In this post, you learned about ransomware events that target data stored in Amazon S3. By taking proactive steps, you can identify potential ransomware events quickly, and you can put in place additional protections to help you reduce the risk of this type of security event in the future.
When you use a centralized identity provider (IdP) for human user access, changes that an identity administrator makes to a user within the IdP won’t invalidate the user’s existing active Amazon Web Services (AWS) sessions. This is due to the nature of session durations that are configured on assumed roles. This situation presents a challenge for identity administrators.
When you configure IAM roles, you have the option of configuring a maximum session duration that specifies how long a session is valid. By default, the temporary credentials provided to the user will last for one hour, but you can change this to a value of up to 12 hours.
When a user assumes a role in AWS by using their IdP credentials, that role’s credentials will remain valid for the length of their session duration. It’s convenient for end users to have a maximum session duration set to 12 hours, because this prevents their sessions from frequently timing out and then requiring re-login. However, a longer session duration also poses a challenge if you, as an identity administrator, attempt to revoke or modify a user’s access to AWS from your IdP.
For example, user John Doe is leaving the company and you want to verify that John has his privileges within AWS revoked. If John has access to IAM roles with long-session durations, then he might have residual access to AWS despite having his session revoked or his user identity deleted within the IdP. Perhaps John assumed a role for his daily work at 8 AM and then you revoked his credentials within the IdP at 9 AM. Because John had already assumed an AWS role, he would still have access to AWS through that role for the duration of the configured session, 8 PM if the session was configured for 12 hours. Therefore, as a security best practice, AWS recommends that you do not set the session duration length longer than is needed. This example is displayed in Figure 1.
Figure 1: Session duration overview
In order to restrict access despite the session duration being active, you could update the roles that are assumable from an IdP with a deny-all policy or delete the role entirely. However, this is a disruptive action for the users that have access to this role. If the role was deleted or the policy was updated to deny all, then users would no longer be able to assume the role or access their AWS environment. Instead, the recommended approach is to revoke access based on the specific user’s principalId or sourceIdentity values.
The principalId is the unique identifier for the entity that made the API call. When requests are made with temporary credentials, such as assumed roles through IdPs, this value also includes the session name, such as [email protected]. The sourceIdentity identifies the original user identity that is making the request, such as a user who is authenticated through SAML federation from an IdP. As a best practice, AWS recommends that you configure this value within the IdP, because this improves traceability for user sessions within AWS. You can find more information on this functionality in the blog post, How to integrate AWS STS SourceIdentity with your identity provider.
Identify the principalId and sourceIdentity by using CloudTrail
You can use AWS CloudTrail to review the actions taken by a user, role, or AWS service that are recorded as events. In the following procedure, you will use CloudTrail to identify the principalId and sourceIdentity contained in the CloudTrail record contents for your IdP assumed role.
To identify the principalId and sourceIdentity by using CloudTrail
Assume a role in AWS by signing in through your IdP.
In this event record, you can see that principalId is “AROATVGBKRLCHXEXAMPLE:[email protected]” and sourceIdentity was specified as “[email protected]”. Now that you have these values, let’s explore how you can revoke access by using SCP and IAM policies.
Use an SCP to deny users based on IdP user name or revoke session token
First, you will create an SCP, a policy that can be applied to an organization to offer central control of the maximum available permissions across the accounts in the organization. More information on SCPs, including steps to create and apply them, can be found in the AWS Organizations User Guide.
The SCP will have a deny-all statement with a condition for aws:userid, which will evaluate the principalId field; and a condition for aws:SourceIdentity, which will evaluate the sourceIdentity field. In the following example SCP, the users John Doe and Mary Major are prevented from accessing AWS, in member accounts, regardless of their session duration, because each action will check against their aws:userid and aws:SourceIdentity values and be denied accordingly.
Use an IAM policy to revoke access in the AWS Organizations management account
SCPs do not affect users or roles in the AWS Organizations management account and instead only affect the member accounts in the organization. Therefore, using an SCP alone to deny access may not be sufficient. However, identity administrators can revoke access in a similar way within their management account by using the following procedure.
To create an IAM policy in the management account
Sign in to the AWS Management Console by using your AWS Organizations management account credentials.
At this point, the user actions on the IdP assumable roles within the AWS organization have been blocked. However, there is still an edge case if the target users use role chaining (use an IdP assumedRole credential to assume a second role) that uses a different RoleSessionName than the one assigned by the IdP. In a role chaining situation, the users will still have access by using the cached credentials for the second role.
This is where the sourceIdentity field is valuable. After a source identity is set, it is present in requests for AWS actions that are taken during the role session. The value that is set persists when a role is used to assume another role (role chaining). The value that is set cannot be changed during the role session. Therefore, it’s recommended that you configure the sourceIdentity field within the IdP as explained previously. This concept is shown in Figure 3.
Figure 3: Role chaining with sourceIdentity configured
A user assumes an IAM role via their IdP (#1), and the CloudTrail record displays sourceIdentity: [email protected] (#2). When the user assumes a new role within AWS (#3), that CloudTrail record continues to display sourceIdentity: [email protected] despite the principalId changing (#4).
However, if a second role is assumed in the account through role chaining and the sourceIdentity is not set, then it’s recommended that you revoke the issued session tokens for the second role. In order to do this, you can use the SCP policy at the end of this section, SCP to revoke active sessions for assumed roles. When you use this policy, the issued credentials related to the roles specified will be revoked for the users currently using them, and only users who were not denied through the previous SCP or IAM policies restricting their aws:userid will be able to reassume the target roles to obtain a new temporary credential.
If you take this approach, you will need to use an SCP to apply across the organization’s member accounts. The SCP must have the human-assumable roles for role chaining listed and a token issue time set to a specific time when you want users’ access revoked. (Normally, this time window would be set to the present time to immediately revoke access, but there might be circumstances in which you wish to revoke the access at a future date, such as when a user moves to a new project or team and therefore requires different access levels.) In addition, you will need to follow the same procedures in your management account by creating a customer-managed policy by using the same JSON with the condition statement for aws:PrincipalArn removed. Then attach the customer managed policy to the individual roles that are human-assumable through role chaining.
In this blog post, I demonstrated how you can revoke a federated user’s active AWS sessions by using SCPs and IAM policies that restrict the use of the aws:userid and aws:SourceIdentity condition keys. I also shared how you can handle a role chaining situation with the aws:TokenIssueTime condition key.
This exercise demonstrates the importance of configuring the session duration parameter on IdP assumed roles. As a security best practice, you should set the session duration to no longer than what is needed to perform the role. In some situations, that could mean an hour or less in a production environment and a longer session in a development environment. Regardless, it’s important to understand the impact of configuring the maximum session duration in the user’s environment and also to have proper procedures in place for revoking a federated user’s access.
This post also covered the recommendation to set the sourceIdentity for assumed roles through the IdP. This value cannot be changed during role sessions and therefore persists when a user conducts role chaining. Following this recommendation minimizes the risk that a user might have assumed another role with a different session name than the one assigned by the IdP and helps prevent the edge case scenario of revoking active sessions based on TokenIssueTime.
You should also consider other security best practices, described in the Security Pillar of the AWS Well-Architected Framework, when you revoke users’ AWS access. For example, rotating credentials such as IAM access keys in situations in which IAM access keys are regularly used and shared among users. The example solutions in this post would not have prevented a user from performing AWS actions if that user had IAM access keys configured for a separate IAM user in the environment. Organizations should limit long-lived security credentials such as IAM keys and instead rotate them regularly or avoid their use altogether. Also, the concept of least privilege is highly important to limit the access that users have and scope it solely to the requirements that are needed to perform their job functions. Lastly, you should adopt a centralized identity provider coupled with the AWS IAM Identity Center (successor to AWS Single Sign-On) service in order to centralize identity management and avoid the need for multiple credentials for users.
If you’re a SaaS vendor, you may need to store and process personal and sensitive data for large numbers of customers across different geographies. When processing sensitive data at scale, you have an increased responsibility to secure this data end-to-end. Client-side encryption of data, such as your customers’ contact information, provides an additional mechanism that can help you protect your customers and earn their trust.
Amazon DynamoDB supports data encryption at rest using encryption keys stored in AWS KMS. This functionality helps reduce operational burden and complexity involved in protecting sensitive data. In this post, you’ll learn about the benefits of adding client-side encryption to achieve end-to-end encryption in transit and at rest for your data, from its source to storage in DynamoDB. Client-side encryption helps ensure that your plaintext data isn’t available to any third party, including AWS.
You can use the Amazon DynamoDB Encryption Client to implement client-side encryption with DynamoDB. In the solution in this post, client-side encryption refers to the cryptographic operations that are performed on the application-side in the application’s Lambda function, before the data is sent to or retrieved from DynamoDB. The solution in this post uses the DynamoDB Encryption Client with the Direct KMS Materials Provider so that your data is encrypted by using AWS KMS. However, the underlying concept of the solution is not limited to the use of the DynamoDB Encryption Client, you can apply it to any client-side use of AWS KMS, for example using the AWS Encryption SDK.
For detailed information about using the DynamoDB Encryption Client, see the blog post How to encrypt and sign DynamoDB data in your application. This is a great place to start if you are not yet familiar with DynamoDB Encryption Client. If you are unsure about whether you should use client-side encryption, see Client-side and server-side encryption in the Amazon DynamoDB Encryption Client Developer Guide to help you with the decision.
AWS KMS encryption context
AWS KMS gives you the ability to add an additional layer of authentication for your AWS KMS API decrypt operations by using encryption context. The encryption context is one or more key-value pairs of additional data that you want associated with AWS KMS protected information.
Encryption context helps you defend against the risks of ciphertexts being tampered with, modified, or replaced — whether intentionally or unintentionally. Encryption context helps defend against both an unauthorized user replacing one ciphertext with another, as well as problems like operational events. To use encryption context, you specify associated key-value pairs on encrypt. You must provide the exact same key-value pairs in the encryption context on decrypt, or the operation will fail. Encryption context is not secret, and is not an access-control mechanism. The encryption context is a means of authenticating the data, not the caller.
The Direct KMS Materials Provider used in this blog post transparently generates a unique data key by using AWS KMS for each item stored in the DynamoDB table. It automatically sets the item’s partition key and sort key (if any) as AWS KMS encryption context key-value pairs.
The solution in this blog post relies on the partition key of each table item being defined in the encryption context. If you encrypt data with your own implementation, make sure to add your tenant ID to the encryption context in all your AWS KMS API calls.
Attribute-based access control (ABAC) is an authorization strategy that defines permissions based on attributes. In AWS, these attributes are called tags. In the solution in this post, ABAC helps you create tenant-isolated access policies for your application, without the need to provision tenant specific AWS IAM roles.
If you are a SaaS vendor expecting large numbers of tenants, it is important that your underlying architecture can cost effectively scale with minimal complexity to support the required number of tenants, without compromising on security. One way to meet these criteria is to store your tenant data in a single pooled DynamoDB table, and to encrypt the data using a single AWS KMS key.
Using a single shared KMS key to read and write encrypted data in DynamoDB for multiple tenants reduces your per-tenant costs. This may be especially relevant to manage your costs if you have users on your organization’s free tier, with no direct revenue to offset your costs.
When you use shared resources such as a single pooled DynamoDB table encrypted by using a single KMS key, you need a mechanism to help prevent cross-tenant access to the sensitive data. This is where you can use ABAC for AWS. By using ABAC, you can build an application with strong tenant isolation capabilities, while still using shared and pooled underlying resources for storing your sensitive tenant data.
You can find the solution described in this blog post in the aws-dynamodb-encrypt-with-abac GitHub repository. This solution uses ABAC combined with KMS encryption context to provide isolation of tenant data, both at rest and at run time. By using a single KMS key, the application encrypts tenant data on the client-side, and stores it in a pooled DynamoDB table, which is partitioned by a tenant ID.
Solution Architecture
Figure 1: Components of solution architecture
The presented solution implements an API with a single AWS Lambda function behind an Amazon API Gateway, and implements processing for two types of requests:
GET request: fetch any key-value pairs stored in the tenant data store for the given tenant ID.
POST request: store the provided key-value pairs in the tenant data store for the given tenant ID, overwriting any existing data for the same tenant ID.
It also uses the DynamoDB Encryption Client for Python, which includes several helper classes that mirror the AWS SDK for Python (Boto3) classes for DynamoDB. This solution uses the EncryptedResource helper class which provides Boto3 compatible get_item and put_item methods. The helper class is used together with the KMS Materials Provider to handle encryption and decryption with AWS KMS transparently for the application.
Note: This example solution provides no authentication of the caller identity. See chapter “Considerations for authentication and authorization” for further guidance.
How it works
Figure 2: Detailed architecture for storing new or updated tenant data
As requests are made into the application’s API, they are routed by API Gateway to the application’s Lambda function (1). The Lambda function begins to run with the IAM permissions that its IAM execution role (DefaultExecutionRole) has been granted. These permissions do not grant any access to the DynamoDB table or the KMS key. In order to access these resources, the Lambda function first needs to assume the ResourceAccessRole, which does have the necessary permissions. To implement ABAC more securely in this use case, it is important that the application maintains clear separation of IAM permissions between the assumed ResourceAccessRole and the DefaultExecutionRole.
As the application assumes the ResourceAccessRole using the AssumeRole API call (2), it also sets a TenantID session tag. Session tags are key-value pairs that can be passed when you assume an IAM role in AWS Simple Token Service (AWS STS), and are a fundamental core building block of ABAC on AWS. When the session credentials (3) are used to make a subsequent request, the request context includes the aws:PrincipalTag context key, which can be used to access the session’s tags. The chapter “The ResourceAccessRole policy” describes how the aws:PrincipalTag context key is used in IAM policy condition statements to implement ABAC for this solution. Note that for demonstration purposes, this solution receives the value for the TenantID tag directly from the request URL, and it is not authenticated.
The trust policy of the ResourceAccessRole defines the principals that are allowed to assume the role, and to tag the assumed role session. Make sure to limit the principals to the least needed for your application to function. In this solution, the application Lambda function is the only trusted principal defined in the trust policy.
Next, the Lambda function prepares to encrypt or decrypt the data (4). To do so, it uses the DynamoDB Encryption Client. The KMS Materials Provider and the EncryptedResource helper class are both initialized with sessions by using the temporary credentials from the AssumeRole API call. This allows the Lambda function to access the KMS key and DynamoDB table resources, with access restricted to operations on data belonging only to the specific tenant ID.
Finally, using the EncryptedResource helper class provided by the DynamoDB Encryption Library, the data is written to and read from the DynamoDB table (5).
Considerations for authentication and authorization
The solution in this blog post intentionally does not implement authentication or authorization of the client requests. Instead, the requested tenant ID from the request URL is passed as the tenant identity. Your own applications should always authenticate and authorize tenant requests. There are multiple ways you can achieve this.
Modern web applications commonly use OpenID Connect (OIDC) for authentication, and OAuth for authorization. JSON Web Tokens (JWTs) can be used to pass the resulting authorization data from client to the application. You can validate a JWT when using AWS API Gateway with one of the following methods:
Regardless of the chosen method, you must be able to map a suitable claim from the user’s JWT, such as the subject, to the tenant ID, so that it can be used as the session tag in this solution.
The ResourceAccessRole policy
A critical part of the correct operation of ABAC in this solution is with the definition of the IAM access policy for the ResourceAccessRole. In the following policy, be sure to replace <region>, <account-id>, <table-name>, and <key-id> with your own values.
The policy defines two access statements, both of which apply separate ABAC conditions:
The first statement grants access to the DynamoDB table with the condition that the partition key of the item matches the TenantID session tag in the caller’s session.
The second statement grants access to the KMS key with the condition that one of the key-value pairs in the encryption context of the API call has a key called tenant_id with a value that matches the TenantID session tag in the caller’s session.
Warning: Do not use a ForAnyValue or ForAllValues set operator with the kms:EncryptionContext single-valued condition key. These set operators can create a policy condition that does not require values you intend to require, and allows values you intend to forbid.
Deploying and testing the solution
Prerequisites
To deploy and test the solution, you need the following:
After you have the prerequisites installed, run the following steps in a command line environment to deploy the solution. Make sure that your AWS CLI is configured with your AWS account credentials. Note that standard AWS service charges apply to this solution. For more information about pricing, see the AWS Pricing page.
To deploy the solution into your AWS account
Use the following command to download the source code:
git clone https://github.com/aws-samples/aws-dynamodb-encrypt-with-abac
cd aws-dynamodb-encrypt-with-abac
(Optional) You will need an AWS CDK version compatible with the application (2.37.0) to deploy. The simplest way is to install a local copy with npm, but you can also use a globally installed version if you already have one. To install locally, use the following command to use npm to install the AWS CDK:
With the application deployed, you can test the solution by making API calls against the API URL that you captured from the deployment output. You can start with a simple HTTP POST request to insert data for a tenant. The API expects a JSON string as the data to store, so make sure to post properly formatted JSON in the body of the request.
An example request using curl -command looks like:
curl https://<api url>/prod/tenant/<tenant-name> -X POST --data '{"email":"<[email protected]>"}'
You can then read the same data back with an HTTP GET request:
curl https://<api url>/prod/tenant/<tenant-name>
You can store and retrieve data for any number of tenants, and can store as many attributes as you like. Each time you store data for a tenant, any previously stored data is overwritten.
Additional considerations
A tenant ID is used as the DynamoDB table’s partition key in the example application in this solution. You can replace the tenant ID with another unique partition key, such as a product ID, as long as the ID is consistently used in the IAM access policy, the IAM session tag, and the KMS encryption context. In addition, while this solution does not use a sort key in the table, you can modify the application to support a sort key with only a few changes. For more information, see Working with tables and data in DynamoDB.
Clean up
To clean up the application resources that you deployed while testing the solution, in the solution’s home directory, run the command cdk destroy.
In this post, you learned a method for simple and cost-efficient client-side encryption for your tenant data. By using the DynamoDB Encryption Client, you were able to implement the encryption with less effort, all while using a standard Boto3 DynamoDB Table resource compatible interface.
Adding to the client-side encryption, you also learned how to apply attribute-based access control (ABAC) to your IAM access policies. You used ABAC for tenant isolation by applying conditions for both the DynamoDB table access, as well as access to the KMS key that is used for encryption of the tenant data in the DynamoDB table. By combining client-side encryption with ABAC, you have increased your data protection with multiple layers of security.
You can start experimenting today on your own by using the provided solution. If you have feedback about this post, submit comments in the Comments section below. If you have questions on the content, consider submitting them to AWS re:Post
Want more AWS Security news? Follow us on Twitter.
Now, you can add multiple MFA devices to AWS account root users and AWS Identity and Access Management (IAM) users in your AWS accounts. This helps you to raise the security bar in your accounts and limit access management to highly privileged principals, such as root users. Previously, you could only have one MFA device associated with root users or IAM users, but now you can associate up to eight MFA devices of the currently supported types with root users and IAM users.
In this blog post, we review the current MFA features for IAM, share use cases for multiple MFA devices, and show you how to manage and sign in with the additional MFA devices for better resiliency and flexibility.
Overview of MFA for IAM
First, let’s recap some of the benefits and available MFA configurations for IAM.
The use of MFA is an important security best practice on AWS. With MFA, you have an additional layer of protection to help prevent unauthorized individuals from gaining access to your systems and data. MFA can help protect your AWS environments if a password associated with your root user or IAM user became compromised.
To help meet different customer needs, AWS supports three types of MFA devices for IAM, including FIDO security keys, virtual authenticator applications, and time-based one-time password (TOTP) hardware tokens. You should select the device type that aligns with your security and operational requirements. You can associate different types of MFA devices with an IAM principal.
Use cases for multiple MFA devices
There are several use cases in which associating multiple MFA devices with an IAM principal is beneficial to the security and operational efficiency of your organization, such as the following:
In the event of a lost, stolen, or inaccessible MFA device, you can use one of the remaining MFA devices to access the account without performing the AWS account recovery procedure. If an MFA device is lost or stolen, it’s best practice to disassociate the lost or stolen device from the root users or IAM users that it’s associated with.
Geographically dispersed teams, or teams working remotely, can use hardware-based MFA to access AWS, without shipping a single hardware device or coordinating a physical exchange of a single hardware device between team members.
If the holder of an MFA device isn’t available, you can maintain access to your root users and IAM users by using a different MFA device associated with an IAM principal.
You can store additional MFA devices in a secure physical location, such as a vault or safe, while retaining physical access to another MFA device for redundancy.
How to manage multiple MFA devices in IAM
You can register up to eight MFA devices, in any combination of the currently supported MFA types, with your root users and IAM users.
For Multi-factor authentication (MFA), choose Assign MFA device.
Select the type of MFA device that you want to use and then choose Next.
With multiple MFA devices, you only need one MFA device to sign in to the console or to create a session through the AWS Command Line Interface (AWS CLI) as that principal.
You don’t need to make permissions changes in order for your organization to start taking advantage of multiple MFA devices. The root users and IAM users in your accounts that manage MFA devices today can use their existing IAM permissions to enable additional MFA devices.
Changes to Cloudtrail log entries
In support of this new feature, the identifier of the MFA device used will now be added to the console sign-in events of the root user and IAM user that use MFA. With these changes to AWS CloudTrail log entries, you can now view both the user and the MFA device used to authenticate to AWS. This provides better traceability and audibility for your accounts.
You can find this information in the MFAIdentifier field in CloudTrail, within additionalEventData. You don’t need to take action for this information to be logged. The following is a sample log from CloudTrail that includes the MFAIdentifier.
For Additional verification required, select the type of MFA device that you want to use to continue authenticating, and then choose Next:
Figure 1: MFA device selection when authenticating to the console as an IAM user or root user with different types of MFA devices available
You will then be prompted to authenticate with the type of device that you selected.
Figure 2: Prompt to authenticate with a FIDO security key
Conclusion
In this blog post, you learned about the new multiple MFA devices feature in IAM, and how to set up and manage multiple MFA devices in IAM. Associating multiple MFA devices with your root users and IAM users can make it simpler for you to manage access to them. This feature is available now for AWS customers, except for customers operating in AWS GovCloud (US) Regions or in the AWS China Regions. For more information about how to configure multiple MFA devices on your root users and IAM users, see the documentation on MFA in IAM. There is no extra charge to use MFA devices in IAM.
AWS Identity and Access Management (IAM) is changing an aspect of how role trust policy evaluation behaves when a role assumes itself. Previously, roles implicitly trusted themselves from a role trust policy perspective if they had identity-based permissions to assume themselves. After receiving and considering feedback from customers on this topic, AWS is changing role assumption behavior to always require self-referential role trust policy grants. This change improves consistency and visibility with regard to role behavior and privileges. This change allows customers to create and understand role assumption permissions in a single place (the role trust policy) rather than two places (the role trust policy and the role identity policy). It increases the simplicity of role trust permission management: “What you see [in the trust policy] is what you get.”
Therefore, beginning today, for any role that has not used the identity-based behavior since June 30, 2022, a role trust policy must explicitly grant permission to all principals, including the role itself, that need to assume it under the specified conditions. Removal of the role’s implicit self-trust improves consistency and increases visibility into role assumption behavior.
Most AWS customers will not be impacted by the change at all. Only a tiny percentage (approximately 0.0001%) of all roles are involved. Customers whose roles have recently used the previous implicit trust behavior are being notified, beginning today, about those roles, and may continue to use this behavior with those roles until February 15, 2023, to allow time for making the necessary updates to code or configuration. Or, if these customers are confident that the change will not impact them, they can opt out immediately by substituting in new roles, as discussed later in this post.
The first part of this post briefly explains the change in behavior. The middle sections answer practical questions like: “why is this happening?,” “how might this change impact me?,” “which usage scenarios are likely to be impacted?,” and “what should I do next?” The usage scenario section is important because it shows that, based on our analysis, the self-assuming role behavior exhibited by code or human users is very likely to be unnecessary and counterproductive. Finally, for security professionals interested in better understanding the reasons for the old behavior, the rationale for the change, as well as its possible implications, the last section reviews a number of core IAM concepts and digs in to additional details.
What is changing?
Until today, an IAM role implicitly trusted itself. Consider the following role trust policy attached to the role named RoleA in AWS account 123456789012.
This role trust policy grants role assumption access to the role named RoleB in the same account. However, if the corresponding identity-based policy for RoleA grants the sts:AssumeRole action with respect to itself, then RoleA could also assume itself. Therefore, there were actually two roles that could assume RoleA: the explicitly permissioned RoleB, and RoleA, which implicitly trusted itself as a byproduct of the IAM ownership model (explained in detail in the final section). Note that the identity-based permission that RoleA must have to assume itself is not required in the case of RoleB, and indeed an identity-based policy associated with RoleB that references other roles is not sufficient to allow RoleB to assume them. The resource-based permission granted by RoleA’s trust policy is both necessary and sufficient to allow RoleB to assume RoleA.
Although earlier we summarized this behavior as “implicit self-trust,” the key point here is that the ability of Role A to assume itself is not actually implicit behavior. The role’s self-referential permission had to be explicit in one place or the other (or both): either in the role’s identity-based policy (perhaps based on broad wildcard permissions), or its trust policy. But unlike the case with other principals and role trust, an IAM administrator would have to look in two different policies to determine whether a role could assume itself.
As of today, for any new role, or any role that has not recently assumed itself while relying on the old behavior, IAM administrators must modify the previously shown role trust policy as follows to allow RoleA to assume itself, regardless of the privileges granted by its identity-based policy:
This change makes role trust behavior clearer and more consistent to understand and manage, whether directly by humans or as embodied in code.
How might this change impact me?
As previously noted, most customers will not be impacted by the change at all. For those customers who do use the prior implicit trust grant behavior, AWS will work with you to eliminate your usage prior to February 15, 2023. Here are more details for the two cases of customers who have not used the behavior, and those who have.
If you haven’t used the implicit trust behavior since June 30, 2022
Beginning today, if you have not used the old behavior for a given role at any time since June 30, 2022, you will now experience the new behavior. Those existing roles, as well as any new roles, will need an explicit reference in their own trust policy in order to assume themselves. If you have roles that are used only very occasionally, such as once per quarter for a seldom-run batch process, you should identify those roles and if necessary either remove the dependency on the old behavior or update their role trust policies to include the role itself prior to their next usage (see the second sample policy above for an example).
If you have used the implicit trust behavior since June 30, 2022
If you have a role that has used the implicit trust behavior since June 30, 2022, then you will continue to be able to do so with that role until February 15, 2023. AWS will provide you with notice referencing those roles beginning today through your AWS Health Dashboard and will also send an email with the relevant information to the account owner and security contact. We are allowing time for you to make any necessary changes to your existing processes, code, or configurations to prepare for removal of the implicit trust behavior. If you can’t change your processes or code, you can continue to use the behavior by making a configuration change—namely, by updating the relevant role trust policies to reference the role itself. On the other hand, you can opt out of the old behavior at any time by creating a new role with a different Amazon Resource Name (ARN) with the desired identity-based and trust-policy-based permissions and substituting it for any older role that was identified as using the implicit trust behavior. (The new role will not be allow-listed, because the allow list is based on role ARNs.) You can also modify an existing allow-listed role’s trust policy to explicitly deny access to itself. See the “What should I do next?” section for more information.
Notifications and retirement
As we previously noted, starting today, accounts with existing roles that use the implicit self-assume role assumption behavior will be notified of this change by email and through their AWS Health Dashboard. Those roles have been allow-listed, and so for now their behavior will continue as before. After February 15, 2023, the old behavior will be retired for all roles and all accounts. IAM Documentation has been updated to make clear the new behavior.
After the old behavior is retired from the allow-listed roles and accounts, role sessions that make self-referential role assumption calls will fail with an Access Denied error unless the role’s trust policy explicitly grants the permission directly through a role ARN. Another option is to grant permission indirectly through an ARN to the root principal in the trust policy that acts as a delegation of privilege management, after which permission grants in identity-based policies determine access, similar to the typical cross-account case.
Which usage scenarios are likely to be impacted?
Users often attach an IAM role to an Amazon Elastic Compute Cloud (Amazon EC2) instance, an Amazon Elastic Container Service (Amazon ECS) task, or AWS Lambda function. Attaching a role to one of these runtime environments enables workloads to use short-term session credentials based on that role. For example, when an EC2 instance is launched, AWS automatically creates a role session and assigns it to the instance. An AWS best practice is for the workload to use these credentials to issue AWS API calls without explicitly requesting short-term credentials through sts:AssumeRole calls.
However, examples and code snippets commonly available on internet forums and community knowledge sharing sites might incorrectly suggest that workloads need to call sts:AssumeRole to establish short-term sessions credentials for operation within those environments.
We analyzed AWS Security Token Service (AWS STS) service metadata about role self-assumption in order to understand the use cases and possible impact of the change. What the data shows is that in almost all cases this behavior is occurring due to unnecessarily reassuming the role in an Amazon EC2, Amazon ECS, Amazon Elastic Kubernetes Services (EKS), or Lambda runtime environment already provided by the environment. There are two exceptions, discussed at the end of this section under the headings, “self-assumption with a scoped-down policy” and “assuming a target compute role during development.”
There are many variations on this theme, but overall, most role self-assumption occurs in scenarios where the person or code is unnecessarily reassuming the role that the code was already running as. Although this practice and code style can still work with a configuration change (by adding an explicit self-reference to the role trust policy), the better practice will almost always be to remove this unnecessary behavior or code from your AWS environment going forward. By removing this unnecessary behavior, you save CPU, memory, and network resources.
Common mistakes when using Amazon EKS
Some users of the Amazon EKS service (or possibly their shell scripts) use the command line interface (CLI) command aws eks get-token to obtain an authentication token for use in managing a Kubernetes cluster. The command takes as an optional parameter a role ARN. That parameter allows a user to assume another role other than the one they are currently using before they call get-token. However, the CLI cannot call that API without already having an IAM identity. Some users might believe that they need to specify the role ARN of the role they are already using. We have updated the Amazon EKS documentation to make clear that this is not necessary.
Common mistakes when using AWS Lambda
Another example is the use of an sts:AssumeRole API call from a Lambda function. The function is already running in a preassigned role provided by user configuration within the Lambda service, or else it couldn’t successfully call any authenticated API action, including sts:AssumeRole. However, some Lambda functions call sts:AssumeRole with the target role being the very same role that the Lambda function has already been provided as part of its configuration. This call is unnecessary.
AWS Software Development Kits (SDKs) all have support for running in AWS Lambda environments and automatically using the credentials provided in that environment. We have updated the Lambda documentation to make clear that such STS calls are unnecessary.
Common mistakes when using Amazon ECS
Customers can associate an IAM role with an Amazon ECS task to give the task AWS credentials to interact with other AWS resources.
We detected ECS tasks that call sts:AssumeRole on the same role that was provided to the ECS task. Amazon ECS makes the role’s credentials available inside the compute resources of the ECS task, whether on Amazon EC2 or AWS Fargate, and these credentials can be used to access AWS services or resources as the IAM role associated with the ECS talk, without being called through sts:AssumeRole. AWS handles renewing the credentials available on ECS tasks before the credentials expire. AWS STS role assumption calls are unnecessary, because they simply create a new set of the same temporary role session credentials.
AWS SDKs all have support for running in Amazon ECS environments and automatically using the credentials provided in that ECS environment. We have updated the Amazon ECS documentation to make clear that calling sts:AssumeRole for an ECS task is unnecessary.
Common mistakes when using Amazon EC2
Users can configure an Amazon EC2 instance to contain an instance profile. This instance profile defines the IAM role that Amazon EC2 assigns the compute instance when it is launched and begins to run. The role attached to the EC2 instance enables your code to send signed requests to AWS services. Without this attached role, your code would not be able to access your AWS resources (nor would it be able to call sts:AssumeRole). The Amazon EC2 service handles renewing these temporary role session credentials that are assigned to the instance before they expire.
We have observed that workloads running on EC2 instances call sts:AssumeRole to assume the same role that is already associated with the EC2 instance and use the resulting role-session for communication with AWS services. These role assumption calls are unnecessary, because they simply create a new set of the same temporary role session credentials.
AWS SDKs all have support for running in Amazon EC2 environments and automatically using the credentials provided in that EC2 environment. We have updated the Amazon EC2 documentation to make clear that calling sts:AssumeRole for an EC2 instance with a role assigned is unnecessary.
For information on creating an IAM role, attaching that role to an EC2 instance, and launching an instance with an attached role, see “IAM roles for Amazon EC2” in the Amazon EC2 User Guide.
Other common mistakes
If your use case does not use any of these AWS execution environments, you might still experience an impact from this change. We recommend that you examine the roles in your account and identify scenarios where your code (or human use through the AWS CLI) results in a role assuming itself. We provide Amazon Athena and AWS CloudTrail Lake queries later in this post to help you locate instances where a role assumed itself. For each instance, you can evaluate whether a role assuming itself is the right operation for your needs.
Self-assumption with a scoped-down policy
The first pattern we have observed that is not a mistake is the use of self-assumption combined with a scoped-down policy. Some systems use this approach to provide different privileges for different use cases, all using the same underlying role. Customers who choose to continue with this approach can do so by adding the role to its own trust policy. While the use of scoped-down policies and the associated least-privilege approach to permissions is a good idea, we recommend that customers switch to using a second generic role and assume that role along with the scoped-down policy rather than using role self-assumption. This approach provides more clarity in CloudTrail about what is happening, and limits the possible iterations of role assumption to one round, since the second role should not be able to assume the first. Another possible approach in some cases is to limit subsequent assumptions is by using an IAM condition in the role trust policy that is no longer satisfied after the first role assumption. For example, for Lambda functions, this would be done by a condition checking for the presence of the “lambda:SourceFunctionArn” property; for EC2, by checking for presence of “ec2:SourceInstanceARN.”
Assuming an expected target compute role during development
Another possible reason for role self-assumption may result from a development practice in which developers attempt to normalize the roles that their code is running in between scenarios in which role credentials are not automatically provided by the environment, and scenarios where they are. For example, imagine a developer is working on code that she expects to run as a Lambda function, but during development is using her laptop to do some initial testing of the code. In order to provide the same execution role as is expected later in product, the developer might configure the role trust policy to allow assumption by a principal readily available on the laptop (an IAM Identity Center role, for example), and then assume the expected Lambda function execution role when the code is initializing. The same approach could be used on a build and test server. Later, when the code is deployed to Lambda, the actual role is already available and in use, but the code need not be modified in order to provide the same post-role-assumption behavior that existing outside of Lambda: the unmodified code can automatically assume what is in this case the same role, and proceed. While this approach is not illogical, as with the scope-down policy case we recommend that customers configure distinct roles for assumption both in development and test environments as well as later production environments. Again, this approach provides more clarity in CloudTrail about what is happening, and limits the possible iterations of role assumption to one round, since the second role should not be able to assume the first.
What should I do next?
If you receive an email or AWS Health Dashboard notification for an account, we recommend that you review your existing role trust policies and corresponding code. For those roles, you should remove the dependency on the old behavior, or if you can’t, update those role trust policies with an explicit self-referential permission grant. After the grace period expires on February 15, 2023, you will no longer be able to use the implicit self-referential permission grant behavior.
If you currently use the old behavior and need to continue to do so for a short period of time in the context of existing infrastructure as code or other automated processes that create new roles, you can do so by adding the role’s ARN to its own trust policy. We strongly encourage you to treat this as a temporary stop-gap measure, because in almost all cases it should not be necessary for a role to be able to assume itself, and the correct solution is to change the code that results in the unnecessary self-assumption. If for some reason that self-service solution is not sufficient, you can reach out to AWS Support to seek an accommodation of your use case for new roles or accounts.
If you make any necessary code or configuration changes and want to remove roles that are currently allow-listed, you can also ask AWS Support to remove those roles from the allow list so that their behavior follows the new model. Or, as previously noted, you can opt out of the old behavior at any time by creating a new role with a different ARN that has the desired identity-based and trust-policy–based permissions and substituting it for the allow-listed role. Another stop-gap type of option is to add an explicit deny that references the role to its own trust policy.
If you would like to understand better the history of your usage of role self-assumption in a given account or organization, you can follow these instructions on querying CloudTrail data with Athena and then use the following Athena query against your account or organization CloudTrail data, as stored in Amazon Simple Storage Services (Amazon S3). The results of the query can help you understand the scenarios and conditions and code involved. Depending on the size of your CloudTrail logs, you may need to follow the partitioning instructions to query subsets of your CloudTrail logs sequentially. If this query yields no results, the role self-assumption scenario described in this blog post has never occurred within the analyzed CloudTrail dataset.
SELECT eventid, eventtime, userIdentity.sessioncontext.sessionissuer.arn as RoleARN, split_part(userIdentity.principalId, ':', 2) as RoleSessionName from cloudtrail_logs t CROSS JOIN UNNEST(t.resources) unnested (resources_entry) where eventSource = 'sts.amazonaws.com' and eventName = 'AssumeRole' and userIdentity.type = 'AssumedRole' and errorcode IS NULL and substr(userIdentity.sessioncontext.sessionissuer.arn,12) = substr(unnested.resources_entry.ARN,12)
As another option, you can follow these instructions to set up CloudTrail Lake to perform a similar analysis. CloudTrail Lake allows richer, faster queries without the need to partition the data. As of September 20, 2022, CloudTrail Lake now supports import of CloudTrail logs from Amazon S3. This allows you to perform a historical analysis even if you haven’t previously enabled CloudTrail Lake. If this query yields no results, the scenario described in this blog post has never occurred within the analyzed CloudTrail dataset.
SELECT eventid, eventtime, userIdentity.sessioncontext.sessionissuer.arn as RoleARN, userIdentity.principalId as RoleIdColonRoleSessionName from $EDS_ID where eventSource = 'sts.amazonaws.com' and eventName = 'AssumeRole' and userIdentity.type = 'AssumedRole' and errorcode IS NULL and userIdentity.sessioncontext.sessionissuer.arn = element_at(resources,1).arn
Understanding the change: more details
To better understand the background of this change, we need to review the IAM basics of identity-based policies and resource-based policies, and then explain some subtleties and exceptions. You can find additional overview material in the IAM documentation.
The structure of each IAM policy follows the same basic model: one or more statements with an effect (allow or deny), along with principals, actions, resources, and conditions. Although the identity-based and resource-based policies share the same basic syntax and semantics, the former is associated with a principal, the latter with a resource. The main difference between the two is that identity-based policies do not specify the principal, because that information is supplied implicitly by associating the policy with a given principal. On the other hand, resource policies do not specify an arbitrary resource, because at least the primary identifier of the resource (for example, the bucket identifier of an S3 bucket) is supplied implicitly by associating the policy with that resource. Note that an IAM role is the only kind of AWS object that is both a principal and a resource.
In most cases, access to a resource within the same AWS account can be granted by either an identity-based policy or a resource-based policy. Consider an Amazon S3 example. An identity-based policy attached to an IAM principal that allows the s3:GetObject action does not require an equivalent grant in the S3 bucket resource policy. Conversely, an s3:GetObject permission grant in a bucket’s resource policy is all that is needed to allow a principal in the same account to call the API with respect to that bucket; an equivalent identity-based permission is not required. Either the identity-based policy or the resource-based policy can grant the necessary permission. For more information, see IAM policy types: How and when to use them.
However, in order to more tightly govern access to certain security-sensitive resources, such as AWS Key Management Service (AWS KMS) keys and IAM roles, those resource policies need to grant access to the IAM principal explicitly, even within the same AWS account. A role trust policy is the resource policy associated with a role that specifies which IAM principals can assume the role by using one of the sts:AssumeRole* API calls. For example, in order for RoleB to assume RoleA in the same account, whether or not RoleB’s identity-based policy explicitly allows it to assume RoleA, RoleA’s role trust policy must grant access to RoleB. Within the same account, an identity-based permission by itself is not sufficient to allow assumption of a role. On the other hand, a resource-based permission—a grant of access in the role trust policy—is sufficient. (Note that it’s possible to construct a kind of hybrid permission to a role by using both its resource policy and other identity-based policies. In that case, the role trust policy grants permission to the root principal ARN; after that, the identity-based policy of a principal in that account would need to explicitly grant permission to assume that role. This is analogous to the typical cross-account role trust scenario.)
Until now, there has been a nonintuitive exception to these rules for situations where a role assumes itself. Since a role is both a principal (potentially with an identity-based policy) and a resource (with a resource-based policy), it is in the unique position of being both a subject and an object within the IAM system, as well as being an object owned by itself rather than its containing account. Due to this ownership model, roles with identity-based permission to assume themselves implicitly trusted themselves as resources, and vice versa. That is to say, roles that had the privilege as principals to assume themselves implicitly trusted themselves as resources, without an explicit self-referential Allow in the role trust policy. Conversely, a grant of permission in the role trust policy was sufficient regardless of whether there was a grant in the same role’s identity-based policy. Thus, in the self-assumption case, roles behaved like most other resources in the same account: only a single permission was required to allow role self-assumption, either on the identity side or the resource side of their dual-sided nature. Because of a role’s implicit trust of itself as a resource, the role’s trust policy—which might otherwise limit assumption of the role with properties such as actions and conditions—was not applied, unless it contained an explicit deny of itself.
The following example is a role trust policy attached to the role named RoleA in account 123456789012. It grants explicit access only to the role named RoleB.
Assuming that the corresponding identity-based policy for RoleA granted the sts:AssumeRole action with regard to RoleA, this role trust policy provided that there were two roles that could assume RoleA: RoleB (explicitly referenced in the trust policy) and RoleA (assuming it was explicitly referenced in its identity policy). RoleB could assume RoleA only if it had the principal tag project:BlueSkyProject because of the trust policy condition. (The sts:TagSession permission is needed here in case tags need to be added by the caller as parted of the RoleAssumption call.) RoleA, on the other hand, did not need to meet that condition because it relied on a different explicit permission—the one granted in the identity-based policy. RoleA would have needed the principal tag project:BlueSkyProject to meet the trust policy condition if and only if it was relying on the trust policy to gain access through the sts:AssumeRole action; that is, in the case where its identity-based policy did not provide the needed privilege.
As we previously noted, after considering feedback from customers on this topic, AWS has decided that requiring self-referential role trust policy grants even in the case where the identity-based policy also grants access is the better approach to delivering consistency and visibility with regard to role behavior and privileges. Therefore, as of today, role assumption behavior requires an explicit self-referential permission in the role trust policy, and the actions and conditions within that policy must also be satisfied, regardless of the permissions expressed in the role’s identity-based policy. (If permissions in the identity-based policy are present, they must also be satisfied.)
Requiring self-reference in the trust policy makes role trust policy evaluation consistent regardless of which role is seeking to assume the role. Improved consistency makes role permissions easier to understand and manage, whether through human inspection or security tooling. This change also eliminates the possibility of continuing the lifetime of an otherwise temporary credential without explicit, trackable grants of permission in trust policies. It also means that trust policy constraints and conditions are enforced consistently, regardless of which principal is assuming the role. Finally, as previously noted, this change allows customers to create and understand role assumption permissions in a single place (the role trust policy) rather than two places (the role trust policy and the role identity policy). It increases the simplicity of role trust permission management: “what you see [in the trust policy] is what you get.”
Continuing with the preceding example, if you need to allow a role to assume itself, you now must update the role trust policy to explicitly allow both RoleB and RoleA. The RoleA trust policy now looks like the following:
Without this new principal grant, the role can no longer assume itself. The trust policy conditions are also applied, even if the role still has unconditioned access to itself in its identity-based policy.
Conclusion
In this blog post we’ve reviewed the old and new behavior of role assumption in the case where a role seeks to assume itself. We’ve seen that, according to our analysis of service metadata, the vast majority of role self-assumption behavior that relies solely on identity-based privileges is totally unnecessary, because the code (or human) who calls sts:AssumeRole is already, without realizing it, using the role’s credentials to call the AWS STS API. Eliminating that mistake will improve performance and decrease resource consumption. We’ve also explained in more depth the reasons for the old behavior and the reasons for making the change, and provided Athena and CloudTrail Lake queries that you can use to examine past or (in the case of allow-listed roles) current self-assumption behavior in your own environments. You can reach out to AWS Support or your customer account team if you need help in this effort.
If you currently use the old behavior and need to continue to do so, your primary option is to create an explicit allow for the role in its own trust policy. If that option doesn’t work due to operational constraints, you can reach out to AWS Support to seek an accommodation of your use case for new roles or new accounts. You can also ask AWS Support to remove roles from the allow-list if you want their behavior to follow the new model.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new IAM-tagged discussion on AWS re:Post or contact AWS Support.
AWS would like to thank several customers and partners who highlighted this behavior as something they found surprising and unhelpful, and asked us to consider making this change. We would also like to thank independent security researcher Ryan Gerstenkorn who engaged with AWS on this topic and worked with us prior to this update.
Want more AWS Security news? Follow us on Twitter.
Maintaining AWS Identity and Access Management (IAM) resources is similar to keeping your garden healthy over time. Having visibility into your IAM resources, especially the resources that are no longer used, is important to keep your AWS environment secure. Proactively detecting and responding to unused IAM roles helps you prevent unauthorized entities from gaining access to your AWS resources. In this post, I will show you how to apply resource tags on IAM roles and deploy serverless technologies on AWS to detect unused IAM roles and to require the owner of the IAM role (identified through tags) to take action.
You can use this solution to check for unused IAM roles in a standalone AWS account. As you grow your workloads in the cloud, you can run this solution for multiple AWS accounts by using AWS Organizations. In this solution, you use AWS Control Tower to create an AWS Organizations organization with a Security organizational unit (OU), and a Security account in this OU. In this blog post, you deploy the solution in the Security account belonging to a Security OU of an organization.
For more information and recommended best practices, see the blog post Managing the multi-account environment using AWS Organizations and AWS Control Tower. Following this best practice, you can create a Security OU, in which you provision one or more Security and Audit accounts that are dedicated for security automation and audit activities on behalf of the entire organization.
Solution architecture
The architecture diagram in Figure 1 demonstrates the solution workflow.
Figure 1: Solution workflow for standalone account or member account of an AWS Organization.
The solution is triggered periodically by an Amazon EventBridgescheduled rule and invokes a series of actions. You specify the frequency (in number of days) when you create the EventBridge rule. There are two options to run this solution, based on the needs of your organization.
Option 1: For a standalone account
Choose this option if you would like to check for unused IAM roles in a single AWS account. This AWS account might or might not belong to an organization or OU. In this blog post, I refer to this account as the standalone account.
You should deploy the solution to the standalone Security account, which has appropriate admin permission to audit other accounts and manage security automation.
Because this solution uses AWS CloudFormationStackSets, you need to grant self-managed permissions to create stack sets in standalone accounts. Specifically, you need to establish a trust relationship between the standalone Security account and the standalone account by creating the AWSCloudFormationStackSetAdministrationRole IAM role in the standalone Security account, and the AWSCloudFormationStackSetExecutionRole IAM role in the standalone account.
You need to have AWS Security Hub enabled in your standalone Security account, and you need to deploy the solution in the same AWS Region as your Security Hub dashboard.
You need a tagging enforcement in place for IAM roles. This solution uses an IAM tag key Owner to identify the email address of the owner. The value of this tag key should be the email address associated with the owner of the IAM role. If the Owner tag isn’t available, the notification email is sent to the email address that you provided in the parameter ITSecurityEmail when you provisioned the CloudFormation stack.
This solution uses Amazon Simple Email Service (Amazon SES) to send emails to the owner of the IAM roles. The destination address needs to be verified with Amazon SES. With Amazon SES, you can verify identity at the individual email address or at the domain level.
An EventBridge rule triggers the AWS Lambda function LambdaCheckIAMRole in the standalone Security account. The LambdaCheckIAMRolefunction assumes a role in the standalone account. This role is named after the Cloudformation stack name that you specify when you provision the solution. Then LambdaCheckIAMRole calls the IAM API action GetAccountAuthorizationDetails to get the list of IAM roles in the standalone account, and parses the data type RoleLastUsed to retrieve the date, time, and the Region in which the roles were last used. If the last time value is not available, the IAM role is skipped. Based on the CloudFormation parameter MaxDaysForLastUsed that you provide, LambdaCheckIAMRole determines if the last time used is greater than the MaxDaysForLastUsed value. LambdaCheckIAMRole also extracts tags associated with the IAM roles, and retrieves the email address of the IAM role owner from the value of the tag key Owner. If there is no Owner tag, then LambdaCheckIAMRole sends an email to a default email address provided by you from the CloudFormation parameter ITSecurityEmail.
Option 2: For all member accounts that belong to an organization or an OU
Choose this option if you want to check for unused IAM roles in every member account that belongs to an AWS Organizations organization or OU.
Prerequisites
You need to have an AWS Organizations organization with a dedicated Security account that belongs to a Security OU. For this blog post, I refer to this account as the Security account.
You should deploy the solution to the Security account that has appropriate admin permission to audit other accounts and to manage security automation.
Because this solution uses CloudFormation StackSets to create stack sets in member accounts of the organization or OU that you specify, the Security account in the Security OU needs to be granted CloudFormation delegated admin permission to create AWS resources in this solution.
You need Security Hub enabled in your Security account, and you need to deploy the solution in the same Region as your Security Hub dashboard.
You need tagging enforcement in place for IAM roles. This solution uses the IAM tag key Owner to identify the owner email address. The value of this tag key should be the email address associated with the owner of the IAM role. If the Owner tag isn’t available, the notification email will be sent to the email address that you provided in the parameter ITSecurityEmail when you provisioned the CloudFormation stack.
This solution uses Amazon SES to send emails to the owner of the IAM roles. The destination address needs to be verified with Amazon SES. With Amazon SES, you can verify identity at the individual email address or at the domain level.
An EventBridge rule triggers the Lambda function LambdaGetAccounts in the Security account to collect the account IDs of member accounts that belong to the organization or OU. LambdaGetAccounts sends those account IDs to an SNS topic. Each account ID invokes the Lambda function LambdaCheckIAMRole once.
Similar to the process for Option 1, LambdaCheckIAMRole in the Security account assumes a role in the member account(s) of the organization or OU, and checks the last time that IAM roles in the account were used.
In both options, if an IAM role is not currently used, the function LambdaCheckIAMRole generates a Security Hub finding, and performs BatchImportFindings for all findings to Security Hub in the Security account. At the same time, the Lambda function starts an AWS Step Functions state machine execution. Each execution is for an unused IAM role following this naming convention: [target-account-id]-[unused IAM role name]-[time the execution created in Unix format]
You should avoid running this solution against special IAM roles, such as a break-glass role or a disaster recovery role. In the CloudFormation parameter RolePatternAllowedlist, you can provide a list of role name patterns to skip the check.
Use a Step Functions state machine to process approval
Figure 2 shows the state machine workflow for owner approval.
Figure 2: Owner approval state machine workflow
After the solution identifies an unused IAM role, it creates a Step Functions state machine execution. Figure 2 demonstrates the workflow of the execution. After the execution starts, the first Lambda taskNotifyOwner (powered by the Lambda function NotifyOwnerFunction) sends an email to notify the IAM role owner. This is a callback task that pauses the execution until a taskToken is returned. The maximum pause for a callback task is 1 year. The execution waits until the owner responds with a decision to delete or keep the role, which is captured by a private API endpoint in Amazon API Gateway. You can configure a timeout to avoid waiting for callback task execution.
With a private API endpoint, you can build a REST API that is only accessible within your Amazon Virtual Private Cloud (Amazon VPC), or within your internal network connected to your VPC. Using a private API endpoint will prevent anyone from outside of your internal network from selecting this link and deleting the role. You can implement authentication and authorization with API Gateway to make sure that only the appropriate owner can delete a role.
If the owner denies role deletion, then the role remains intact until the next automation cycle runs, and the state machine execution stops immediately with a Fail status. If the owner approves role deletion, the next Lambda task Approve (powered by the function ApproveFunction) checks again if the role is not currently used. If the role isn’t in use, the Lambda task Approve attaches an IAM policy DenyAllCheckUnusedIAMRoleSolution to deny the role to perform any actions, and waits for 30 days. During this wait time, you can restore the IAM role by removing the IAM policy DenyAllCheckUnusedIAMRoleSolution from the role. The Step Functions state machine execution for this role is still in progress until the wait time expires.
After the wait time expires, the state machine execution invokes the Validate task. The Lambda function ValidateFunction checks again if the role is not in use after the amount of time calculated by adding MaxDaysForLastUsed and the preceding wait time. It also checks if the IAM policy DenyAllCheckUnusedIAMRoleSolution is attached to the role. If both of these conditions are true, the Lambda function follows a process to detach the IAM policies and delete the role permanently. The role can’t be recovered after deletion.
Note: To restore a role that has been marked for deletion, detach the DenyAll IAM policy from the role.
To deploy the solution using the AWS CLI
Clone git repo from AWS Samples to get source code and CloudFormation templates.
git clone https://github.com/aws-samples/aws-blog-automate-iam-role-deletion
cd /aws-blog-automate-iam-role-deletion
Run the AWS CLI command below to upload CloudFormation templates and Lambda code to a S3 bucket in the Security Account. The S3 bucket needs to be in the same Region where you will deploy the solution.
To deploy the solution for a single account, use the following commands. Be sure to replace <YOUR_BUCKET_NAME> and <PATH_TO_UPLOAD_CODE> with your own values.
#Deploy solution for a single target AWS Account
aws cloudformation package \
--template-file solution_scope_account.yml \
--s3-bucket <YOUR_BUCKET_NAME> \
--s3-prefix <PATH_TO_UPLOAD_CODE> \
--output-template-file solution_scope_account.template
To deploy the solution for an organization or OU, use the following commands. Be sure to replace <YOUR_BUCKET_NAME> and <PATH_TO_UPLOAD_CODE> with your own values.
#Deploy solution for an Organization/OU
aws cloudformation package \
--template-file solution_scope_organization.yml \
--s3-bucket <YOUR_BUCKET_NAME> \
--s3-prefix <PATH_TO_UPLOAD_CODE> \
--output-template-file solution_scope_organization.template
Validate the template generated by the CloudFormation package.
To validate the solution for a single account, use the following commands.
#Deploy solution for a single target AWS Account
aws cloudformation validate-template —template-body file://solution_scope_account.template
To validate the solution for an organization or OU, use the following commands.
#Deploy solution for an Organization/OU
aws cloudformation validate-template —template-body file://solution_scope_organization.template
Deploy the solution in the same Region that you use for Security Hub. The stack takes 30 minutes to complete deployment.
To deploy the solution for a single account, use the following commands. Be sure to replace all of the placeholders with your own values.
#Deploy solution for a single target AWS Account
aws cloudformation deploy \
--template-file solution_scope_account.template \
--stack-name <UNIQUE_STACK_NAME> \
--region <REGION> \
--capabilities CAPABILITY_NAMED_IAM CAPABILITY_AUTO_EXPAND \
--parameter-overrides AccountId='<STANDALONE ACCOUNT ID>' \
Frequency=<DAYS> MaxDaysForLastUsed=<DAYS> \
ITSecurityEmail='<YOUR IT TEAM EMAIL>' \
RolePatternAllowedlist='<ALLOWED PATTERN>'
To deploy the solution for an organization, run the following commands to create CloudFormation stack in the Security Account of the organization.
The solution is triggered by an EventBridge scheduled rule, so it doesn’t perform the checks immediately. To test the solution right away after the CloudFormation stacks are successfully created, follow these steps.
To manually trigger the automation for a single account
Navigate to the AWS Lambda console and choose the function <CloudFormation stackname>-LambdaCheckIAMRole.
Choose Test.
Choose New event.
For Name, enter a name for the event, and provide the current time in UTC Date Time format YYYY-MM-DDTHH:MM:SSZ. For example{“time”: “2022-01-22T04:36:52Z”}. The Lambda function uses this value to calculate how much time has passed since the last time that a role was used. Figure 5 shows an example of configuring a test event.
Figure 5: Configure test event for standalone account
Choose Test.
To manually trigger the automation for an organization or OU
Choose the function [CloudFormation stackname]-LambdaGetAccounts.
Choose Test.
Choose New event.
For Name, enter a name for the event. Leave the default values for the remaining fields.
Choose Test.
Respond to unused IAM roles
After you’ve triggered the Lambda function, the automation runs the necessary checks. For each unused IAM role, it creates a Step Functions state machine execution.
To see the list of Step Functions state machine executions
Choose state machine [CloudFormation stackname]OnwerApprovalStateMachine.
Under the Executions tab, you will see the list of executions in running state following this naming convention: [target-account-id]-[unused IAM role name]-[time the execution created in Unix format]. Figure 6 shows an example list of executions.
Figure 6: Each unused IAM role generates an execution in the Step Functions state machine
Each execution sends out an email notification to the IAM role owner (if available through the Owner tag) or to the IT security email address that you provided in the CloudFormation stack parameter ITSecurityEmail. The email content is:
Subject: Please take action on this unused IAM Role
Hello!
This IAM Role arn:aws:iam::<AWS account>:role/<role name> is not in use for more than 60 days.
Can you please delete the role by following this link: Approve link
Or keep this role by following this link: Deny Link
In the email, the Approve link and Deny link is the hyperlink to a private API endpoint with a parameter taskToken. If you try to access these links publicly, they won’t work. When you access the link, the taskToken is provided to the private API endpoint, which updates the Step Functions state machine.
To test the approval action using an API Gateway test
Navigate to the AWS Step Functions console. Under State machines, choose the state machine that has the name [CloudFormation stackname]OwnerApprovalStateMachine
On the Executions tab, there is a list of executions. Each execution represents a workflow for one IAM role, as shown in Figure 6. Choose the execution name that includes the IAM role name in the email that you received earlier.
Scroll down to Execution event history.
Expand the Step Notify Owner, enter TaskScheduled, find the item taskToken, and copy its value to a notepad, as shown in Figure 7.
Choose the API that has a name similar to [CloudFormation stackname]-PrivateAPIGW-[unique string]-ApprovalEndpoint.
Choose which action to test: Deny or Approve.
To test the Deny action, under /deny resource, choose the GET method.
To test the Approve action, under /approve resource, choose the GET method.
Choose Test.
Under Query Strings, enter taskToken= and paste the taskToken you copied earlier from the state machine execution. Figure 8 shows how to pass the taskToken to API Gateway.
Figure 8: Provide taskToken to API Gateway Method
Choose Test. After you test, the state machine resumes the workflow and finishes the automation. You won’t be able to change the action.
Navigate to the AWS Step Functions console. Choose the state machine and go to the state machine execution.
If you choose to deny the role deletion, the execution immediately stops as Fail.
If you choose to approve the role deletion, the execution moves to the Wait task. This task removes IAM policies associated to the role and waits for a period of time before moving to the next task. By default, the wait time is 30 days. To change this number, go to the Lambda function [CloudFormation stackname]ApproveFunction, and update the variable wait_time_stamp.
After the waiting period expires, the state machine triggers the Validate task to do a final validation on the role before deleting it. If the Validate task decides that the role is being used, it leaves the role intact. Otherwise, it deletes the role permanently.
Conclusion
In this blog post, you learned how serverless services such as Lambda, Step Functions, and API Gateway can work together to build security automation. We recommend testing this solution as a starting point. Then, you can build more features on top of the sample code and templates to customize it to perform checks, following guidance from your IT security team.
Here are a few suggestions that you can take to extend this solution.
This solution uses a private API Gateway to handle the approval response from the IAM role owner. You need to establish private connectivity between your internal network and AWS to invoke a private API Gateway. For instructions, see How to invoke a private API.
AWS Single Sign-On (AWS SSO) is now AWS IAM Identity Center. Amazon Web Services (AWS) is changing the name to highlight the service’s foundation in AWS Identity and Access Management (IAM), to better reflect its full set of capabilities, and to reinforce its recommended role as the central place to manage access across AWS accounts and applications. Although the technical capabilities of the service haven’t changed with this announcement, we want to take the opportunity to walk through some of the important features that drive our recommendation to consider IAM Identity Center your front door into AWS.
If you’ve worked with AWS accounts, chances are that you’ve worked with IAM. This is the service that handles authentication and authorization requests for anyone who wants to do anything in AWS. It’s a powerful engine, processing half a billion API calls per second globally, and it has underpinned and secured the growth of AWS customers since 2011. IAM provides authentication on a granular basis—by resource, within each AWS account. Although this gives you unsurpassed ability to tailor permissions, it also requires that you establish permissions on an account-by-account basis for credentials (IAM users) that are also defined on an account-by-account basis.
As AWS customers increasingly adopted a multi-account strategy for their environments, in December 2017 we launched AWS Single Sign-On (AWS SSO)—a service built on top of IAM to simplify access management across AWS accounts. In the years since, customer adoption of multi-account AWS environments continued to increase the need for centralized access control and distributed access management. AWS SSO evolved accordingly, adding integrations with new identity providers, AWS services, and applications; features for the consistent management of permissions at scale; multiple compliance certifications; and availability in most AWS Regions. The variety of use cases supported by AWS SSO, now known as AWS IAM Identity Center, makes it our recommended way to manage AWS access for workforce users.
IAM Identity Center, just like AWS SSO before it, is offered at no extra charge. You can follow along with our walkthrough in your own console by choosing Getting started on the console main page. If you don’t have the service enabled, you will be prompted to choose Enable IAM Identity Center, as shown in Figure 1.
Figure 1: IAM Identity Center Getting Started page
Freedom to choose your identity source
Once you’re in the IAM Identity Center console, you can choose your preferred identity source for use across AWS, as shown in Figure 2. If you already have a workforce directory, you can continue to use it by connecting, or federating, it. You can connect to the major cloud identity providers, including Okta, Ping Identity, Azure AD, JumpCloud, CyberArk, and OneLogin, as well as Microsoft Active Directory Domain Services. If you don’t have or don’t want to use a workforce directory, you have the option to create users in Identity Center. Whichever source you decide to use, you connect or create it in one place for use in multiple accounts and AWS or SAML 2.0 applications.
Figure 2 Choosing and connecting your identity source
Management of fine-grained permissions at scale
As noted before, IAM Identity Center builds on the per-account capabilities of IAM. The difference is that in IAM Identity Center, you can define and assign access across multiple AWS accounts. For example, permission sets create IAM roles and apply IAM policies in multiple AWS accounts, helping to scale the access of your users securely and consistently.
You can use predefined permission sets based on AWS managed policies, or custom permission sets, where you can still start with AWS managed policies but then tailor them to your needs.
Recently, we added the ability to use IAM customer managed policies (CMPs) and permissions boundary policies as part of Identity Center permission sets, as shown in Figure 3. This helps you improve your security posture by creating larger and finer-grained policies for least privilege access and by tailoring them to reference the resources of the account to which they are applied. By using CMPs, you can maintain the consistency of your policies, because CMP changes apply automatically to the permission sets and roles that use the CMP. You can govern your CMPs and permissions boundaries centrally, and auditors can find, monitor, and review them in one place. If you already have existing CMPs for roles you manage in IAM, you can reuse them without the need to create, review, and approve new inline policies.
Figure 3: Specify permission sets in IAM Identity Center
By default, users and permission sets in IAM Identity Center are administered by the management account in an organization in AWS Organizations. This management account has the power and authority to manage member accounts in the organization as well. Because of the power of this account, it is important to exercise least privilege and tightly control access to it. If you are managing a complex organization supporting multiple operations or business units, IAM Identity Center allows you to delegate a member account that can administer user permissions, reducing the need to access the AWS Organizations management account for daily administrative work.
One place for application assignments
If your workforce uses Identity Center enabled applications, such as Amazon Managed Grafana, Amazon SageMaker Studio, or AWS Systems Manager Change Manager, you can assign access to them centrally, through IAM Identity Center, and your users can have a single sign-on experience.
If you do not have a separate cloud identity provider, you have the option to use IAM Identity Center as a single place to manage user assignments to SAML 2.0-based cloud applications, such as top-tier customer relationship management (CRM) applications, document collaboration tools, and productivity suites. Figure 4 shows this option.
Figure 4: Assign users to applications in IAM Identity Center
Conclusion
IAM Identity Center (the successor to AWS Single Sign-On) is where you centrally create or connect your workforce users once, and manage their access to multiple AWS accounts and applications. It’s our recommended front door into AWS, because it gives you the freedom to choose your preferred identity source for use across AWS, helps you strengthen your security posture with consistent permissions across AWS accounts and applications, and provides a convenient experience for your users. Its new name highlights the service’s foundation in IAM, while also reflecting its expanded capabilities and recommended role.
AWS Identity and Access Management (IAM) has now made it easier for you to use IAM roles for your workloads that are running outside of AWS, with the release of IAM Roles Anywhere. This feature extends the capabilities of IAM roles to workloads outside of AWS. You can use IAM Roles Anywhere to provide a secure way for on-premises servers, containers, or applications to obtain temporary AWS credentials and remove the need for creating and managing long-term AWS credentials.
In this post, I will briefly discuss how IAM Roles Anywhere works. I’ll mention some of the common use cases for IAM Roles Anywhere. And finally, I’ll walk you through an example scenario to demonstrate how the implementation works.
Background
To enable your applications to access AWS services and resources, you need to provide the application with valid AWS credentials for making AWS API requests. For workloads running on AWS, you do this by associating an IAM role with Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS), or AWS Lambda resources, depending on the compute platform hosting your application. This is secure and convenient, because you don’t have to distribute and manage AWS credentials for applications running on AWS. Instead, the IAM role supplies temporary credentials that applications can use when they make AWS API calls.
IAM Roles Anywhere enables you to use IAM roles for your applications outside of AWS to access AWS APIs securely, the same way that you use IAM roles for workloads on AWS. With IAM Roles Anywhere, you can deliver short-term credentials to your on-premises servers, containers, or other compute platforms. When you use IAM Roles Anywhere to vend short-term credentials you can remove the need for long-term AWS access keys and secrets, which can help improve security, and remove the operational overhead of managing and rotating the long-term credentials. You can also use IAM Roles Anywhere to provide a consistent experience for managing credentials across hybrid workloads.
In this post, I assume that you have a foundational knowledge of IAM, so I won’t go into the details here about IAM roles. For more information on IAM roles, see the IAM documentation.
How does IAM Roles Anywhere work?
IAM Roles Anywhere relies on public key infrastructure (PKI) to establish trust between your AWS account and certificate authority (CA) that issues certificates to your on-premises workloads. Your workloads outside of AWS use IAM Roles Anywhere to exchange X.509 certificates for temporary AWS credentials. The certificates are issued by a CA that you register as a trust anchor (root of trust) in IAM Roles Anywhere. The CA can be part of your existing PKI system, or can be a CA that you created with AWS Certificate Manager Private Certificate Authority (ACM PCA).
Your application makes an authentication request to IAM Roles Anywhere, sending along its public key (encoded in a certificate) and a signature signed by the corresponding private key. Your application also specifies the role to assume in the request. When IAM Roles Anywhere receives the request, it first validates the signature with the public key, then it validates that the certificate was issued by a trust anchor previously configured in the account. For more details, see the signature validation documentation.
After both validations succeed, your application is now authenticated and IAM Roles Anywhere will create a new role session for the role specified in the request by calling AWS Security Token Service (AWS STS). The effective permissions for this role session are the intersection of the target role’s identity-based policies and the session policies, if specified, in the profile you create in IAM Roles Anywhere. Like any other IAM role session, it is also subject to other policy types that you might have in place, such as permissions boundaries and service control policies (SCPs).
There are typically three main tasks, performed by different personas, that are involved in setting up and using IAM Roles Anywhere:
Initial configuration of IAM Roles Anywhere – This task involves creating a trust anchor, configuring the trust policy of the role that IAM Roles Anywhere is going to assume, and defining the role profile. These activities are performed by the AWS account administrator and can be limited by IAM policies.
Provisioning of certificates to workloads outside AWS – This task involves ensuring that the X.509 certificate, signed by the CA, is installed and available on the server, container, or application outside of AWS that needs to authenticate. This is performed in your on-premises environment by an infrastructure admin or provisioning actor, typically by using existing automation and configuration management tools.
Using IAM Roles Anywhere – This task involves configuring the credential provider chain to use the IAM Roles Anywhere credential helper tool to exchange the certificate for session credentials. This is typically performed by the developer of the application that interacts with AWS APIs.
I’ll go into the details of each task when I walk through the example scenario later in this post.
Common use cases for IAM Roles Anywhere
You can use IAM Roles Anywhere for any workload running in your data center, or in other cloud providers, that requires credentials to access AWS APIs. Here are some of the use cases we think will be interesting to customers based on the conversations and patterns we have seen:
Send security findings from on-premises sources to AWS Security Hub
Enable hybrid workloads to access AWS services over the course of phased migrations
Example scenario and walkthrough
To demonstrate how IAM Roles Anywhere works in action, let’s walk through a simple scenario where you want to call S3 APIs to upload some data from a server in your data center.
Prerequisites
Before you set up IAM Roles Anywhere, you need to have the following requirements in place:
The certificate bundle of your own CA, or an active ACM PCA CA in the same AWS Region as IAM Roles Anywhere
An end-entity certificate and associated private key available on the on-premises server
Administrator permissions for IAM roles and IAM Roles Anywhere
Setup
Here I demonstrate how to perform the setup process by using the IAM Roles Anywhere console. Alternatively, you can use the AWS API or Command Line Interface (CLI) to perform these actions. There are three main activities here:
Create a trust anchor
Create and configure a role that trusts IAM Roles Anywhere
Under Trust anchors, choose Create a trust anchor.
On the Create a trust anchor page, enter a name for your trust anchor and select the existing AWS Certificate Manager Private CA from the list. Alternatively, if you want to use your own external CA, choose External certificate bundle and provide the certificate bundle.
Figure 1: Create a trust anchor in IAM Roles Anywhere
To create and configure a role that trusts IAM Roles Anywhere
Using the AWS Command Line Interface (AWS CLI), you are going to create an IAM role with appropriate permissions that you want your on-premises server to assume after authenticating to IAM Roles Anywhere. Save the following trust policy as rolesanywhere-trust-policy.json on your computer.
Save the following identity-based policy as onpremsrv-permissions-policy.json. This grants the role permissions to write objects into the specified S3 bucket.
You can optionally use condition statements based on the attributes extracted from the X.509 certificate to further restrict the trust policy to control the on-premises resources that can obtain credentials from IAM Roles Anywhere. IAM Roles Anywhere sets the SourceIdentity value to the CN of the subject (onpremsrv01 in my example). It also sets individual session tags (PrincipalTag/) with the derived attributes from the certificate. So, you can use the principal tags in the Condition clause in the trust policy as additional authorization constraints.
For example, the Subject for the certificate I use in this post is as follows.
Subject: … O = Example Corp., OU = SecOps, CN = onpremsrv01
So, I can add condition statements like the following into the trust policy (rolesanywhere-trust-policy.json):
On the Create a profile page, enter a name for the profile.
For Roles, select the role that you created in the previous step (ExampleS3WriteRole).
5. Optionally, you can define session policies to further scope down the sessions delivered by IAM Roles Anywhere. This is particularly useful when you configure the profile with multiple roles and want to restrict permissions across all the roles. You can add the desired session polices as managed policies or inline policy. Here, for demonstration purpose, I add an inline policy to only allow requests coming from my specified IP address.
Figure 2: Create a profile in IAM Roles Anywhere
At this point, IAM Roles Anywhere setup is complete and you can start using it.
Use IAM Roles Anywhere
IAM Roles Anywhere provides a credential helper tool that can be used with the process credentials functionality that all current AWS SDKs support. This simplifies the signing process for the applications. See the IAM Roles Anywhere documentation to learn how to get the credential helper tool.
To test the functionality first, run the credential helper tool (aws_signing_helper) manually from the on-premises server, as follows.
Figure 3: Running the credential helper tool manually
You should successfully receive session credentials from IAM Roles Anywhere, similar to the example in Figure 3. Once you’ve confirmed that the setup works, update or create the ~/.aws/config file and add the signing helper as a credential_process. This will enable unattended access for the on-premises server. To learn more about the AWS CLI configuration file, see Configuration and credential file settings.
To verify that the config works as expected, call the aws sts get-caller-identity AWS CLI command and confirm that the assumed role is what you configured in IAM Roles Anywhere. You should also see that the role session name contains the Serial Number of the certificate that was used to authenticate (cc:c3:…:85:37 in this example). Finally, you should be able to copy a file to the S3 bucket, as shown in Figure 4.
Figure 4: Verify the assumed role
Audit
As with other AWS services, AWS CloudTrail captures API calls for IAM Roles Anywhere. Let’s look at the corresponding CloudTrail log entries for the activities we performed earlier.
The first log entry I’m interested in is CreateSession, when the on-premises server called IAM Roles Anywhere through the credential helper tool and received session credentials back.
You can see that the cert, along with other parameters, is sent to IAM Roles Anywhere and a role session along with temporary credentials is sent back to the server.
The next log entry we want to look at is the one for the s3:PutObject call we made from our on-premises server.
In addition to the CloudTrail logs, there are several metrics and events available for you to use for monitoring purposes. To learn more, see Monitoring IAM Roles Anywhere.
Additional notes
You can disable the trust anchor in IAM Roles Anywhere to immediately stop new sessions being issued to your resources outside of AWS. Certificate revocation is supported through the use of imported certificate revocation lists (CRLs). You can upload a CRL that is generated from your CA, and certificates used for authentication will be checked for their revocation status. IAM Roles Anywhere does not support callbacks to CRL Distribution Points (CDPs) or Online Certificate Status Protocol (OCSP) endpoints.
Another consideration, not specific to IAM Roles Anywhere, is to ensure that you have securely stored the private keys on your server with appropriate file system permissions.
Conclusion
In this post, I discussed how the new IAM Roles Anywhere service helps you enable workloads outside of AWS to interact with AWS APIs securely and conveniently. When you extend the capabilities of IAM roles to your servers, containers, or applications running outside of AWS you can remove the need for long-term AWS credentials, which means no more distribution, storing, and rotation overheads.
I mentioned some of the common use cases for IAM Roles Anywhere. You also learned about the setup process and how to use IAM Roles Anywhere to obtain short-term credentials.
If you have any questions, you can start a new thread on AWS re:Post or reach out to AWS Support.
Register now with discount code SALFNj7FaRe to get $150 off your full conference pass to AWS re:Inforce. For a limited time only and while supplies last.
AWS re:Inforce 2022 will take place in-person in Boston, MA, on July 26 and 27 and will include some exciting identity and access management sessions. AWS re:Inforce 2022 features content in the following five areas:
The identity and access management track will showcase how quickly you can get started to securely manage access to your applications and resources as you scale on AWS. You will hear from customers about how they integrate their identity sources and establish a consistent identity and access strategy across their on-premises environments and AWS. Identity experts will discuss best practices for establishing an organization-wide data perimeter and simplifying access management with the right permissions, to the right resources, under the right conditions. You will also hear from AWS leaders about how we’re working to make identity, access control, and resource management simpler every day. This post highlights some of the identity and access management sessions that you can add to your agenda. To learn about sessions from across the content tracks, see the AWS re:Inforce catalog preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and are delivered by AWS experts, builders, customers, and partners. Breakout sessions typically conclude with 10–15 minutes of Q&A.
IAM201: Security best practices with AWS IAM AWS IAM is an essential service that helps you securely control access to your AWS resources. In this session, learn about IAM best practices like working with temporary credentials, applying least-privilege permissions, moving away from users, analyzing access to your resources, validating policies, and more. Leave this session with ideas for how to secure your AWS resources in line with AWS best practices.
IAM301: AWS Identity and Access Management (IAM) the practical way Building secure applications and workloads on AWS means knowing your way around AWS Identity and Access Management (AWS IAM). This session is geared toward the curious builder who wants to learn practical IAM skills for defending workloads and data, with a technical, first-principles approach. Gain knowledge about what IAM is and a deeper understanding of how it works and why.
IAM302: Strategies for successful identity management at scale with AWS SSO Enterprise organizations often come to AWS with existing identity foundations. Whether new to AWS or maturing, organizations want to better understand how to centrally manage access across AWS accounts. In this session, learn the patterns many customers use to succeed in deploying and operating AWS Single Sign-On at scale. Get an overview of different deployment strategies, features to integrate with identity providers, application system tags, how permissions are deployed within AWS SSO, and how to scale these functionalities using features like attribute-based access control.
IAM304: Establishing a data perimeter on AWS, featuring Vanguard Organizations are storing an unprecedented and increasing amount of data on AWS for a range of use cases including data lakes, analytics, machine learning, and enterprise applications. They want to make sure that sensitive non-public data is only accessible to authorized users from known locations. In this session, dive deep into the controls that you can use to create a data perimeter that allows access to your data only from expected networks and by trusted identities. Hear from Vanguard about how they use data perimeter controls in their AWS environment to meet their security control objectives.
IAM305: How Guardian Life validates IAM policies at scale with AWS Attend this session to learn how Guardian Life shifts IAM security controls left to empower builders to experiment and innovate quickly, while minimizing the security risk exposed by granting over-permissive permissions. Explore how Guardian validates IAM policies in Terraform templates against AWS best practices and Guardian’s security policies using AWS IAM Access Analyzer and custom policy checks. Discover how Guardian integrates this control into CI/CD pipelines and codifies their exception approval process.
IAM306: Managing B2B identity at scale: Lessons from AWS and Trend Micro Managing identity for B2B multi-tenant solutions requires tenant context to be clearly defined and propagated with each identity. It also requires proper onboarding and automation mechanisms to do this at scale. Join this session to learn about different approaches to managing identities for B2B solutions with Amazon Cognito and learn how Trend Micro is doing this effectively and at scale.
IAM307: Automating short-term credentials on AWS, with Discover Financial Services As a financial services company, Discover Financial Services considers security paramount. In this session, learn how Discover uses AWS Identity and Access Management (IAM) to help achieve their security and regulatory obligations. Learn how Discover manages their identities and credentials within a multi-account environment and how Discover fully automates key rotation with zero human interaction using a solution built on AWS with IAM, AWS Lambda, Amazon DynamoDB, and Amazon S3.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
IAM351: Using AWS SSO and identity services to achieve strong identity management Organizations often manage human access using IAM users or through federation with external identity providers. In this builders’ session, explore how AWS SSO centralizes identity federation across multiple AWS accounts, replaces IAM users and cross-account roles to improve identity security, and helps administrators more effectively scope least privilege. Additionally, learn how to use AWS SSO to activate time-based access and attribute-based access control.
IAM352: Anomaly detection and security insights with AWS Managed Microsoft AD This builders’ session demonstrates how to integrate AWS Managed Microsoft AD with native AWS services like Amazon CloudWatch Logs and Amazon CloudWatch metrics and alarms, combined with anomaly detection, to identify potential security issues and provide actionable insights for operational security teams.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
IAM231: Prevent unintended access: AWS IAM Access Analyzer policy validation In this chalk talk, walk through ways to use AWS IAM Access Analyzer policy validation to review IAM policies that do not follow AWS best practices. Learn about the Access Analyzer APIs that help validate IAM policies and how to use these APIs to prevent IAM policies from reaching your AWS environment through mechanisms like AWS CloudFormation hooks and CI/CD pipeline controls.
IAM232: Navigating the consumer identity first mile using Amazon Cognito Amazon Cognito allows you to configure sign-in and sign-up experiences for consumers while extending user management capabilities to your customer-facing application. Join this chalk talk to learn about the first steps for integrating your application and getting started with Amazon Cognito. Learn best practices to manage users and how to configure a customized branding UI experience, while creating a fully managed OpenID Connect provider with Amazon Cognito.
IAM331: Best practices for delegating access on AWS This chalk talk demonstrates how to use built-in capabilities of AWS Identity and Access Management (IAM) to safely allow developers to grant entitlements to their AWS workloads (PassRole/AssumeRole). Additionally, learn how developers can be granted the ability to take self-service IAM actions (CRUD IAM roles and policies) with permissions boundaries.
IAM332: Developing preventive controls with AWS identity services Learn about how you can develop and apply preventive controls at scale across your organization using service control policies (SCPs). This chalk talk is an extension of the preventive controls within the AWS identity services guide, and it covers how you can meet the security guidelines of your organization by applying and developing SCPs. In addition, it presents strategies for how to effectively apply these controls in your organization, from day-to-day operations to incident response.
IAM333: IAM policy evaluation deep dive In this chalk talk, learn how policy evaluation works in detail and walk through some advanced IAM policy evaluation scenarios. Learn how a request context is evaluated, the pros and cons of different strategies for cross-account access, how to use condition keys for actions that touch multiple resources, when to use principal and aws:PrincipalArn, when it does and doesn’t make sense to use a wildcard principal, and more.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
IAM271: Applying attribute-based access control using AWS IAM This workshop provides hands-on experience applying attribute-based access control (ABAC) to achieve a secure and scalable authorization model on AWS. Learn how and when to apply ABAC, which is native to AWS Identity and Access Management (IAM). Also learn how to find resources that could be impacted by different ABAC policies and session tagging techniques to scale your authorization model across Regions and accounts within AWS.
IAM371: Building a data perimeter to allow access to authorized users In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different AWS Identity and Access Management (IAM) and network control. Learn where and how to implement the appropriate controls based on different risk scenarios. Discover how to implement these controls as service control policies, identity- and resource-based policies, and virtual private cloud endpoint policies.
IAM372: How and when to use different IAM policy types In this workshop, learn how to identify when to use various policy types for your applications. Work through hands-on labs that take you through a typical customer journey to configure permissions for a sample application. Configure policies for your identities, resources, and CI/CD pipelines using permission delegation to balance security and agility. Also learn how to configure enterprise guardrails using service control policies.
If these sessions look interesting to you, join us in Boston by registering for re:Inforce 2022. We look forward to seeing you there!
In this blog post, we will walk you through a scenario and explain when you should use which policy type, and who should own and manage the policy. You will learn when to use the more common policy types: identity-based policies, resource-based policies, permissions boundaries, and AWS Organizations service control policies (SCPs).
Different policy types and when to use them
AWS has different policy types that provide you with powerful flexibility, and it’s important to know how and when to use each policy type. It’s also important for you to understand how to structure your IAM policy ownership to avoid a centralized team from becoming a bottleneck. Explicit policy ownership can allow your teams to move more quickly, while staying within the secure guardrails that are defined centrally.
Service control policies overview
Service control policies (SCPs) are a feature of AWS Organizations. AWS Organizations is a service for grouping and centrally managing the AWS accounts that your business owns. SCPs are policies that specify the maximum permissions for an organization, organizational unit (OU), or an individual account. An SCP can limit permissions for principals in member accounts, including the AWS account root user.
Permissions boundaries are an advanced IAM feature in which you set the maximum permissions that an identity-based policy can grant to an IAM principal. When you set a permissions boundary for a principal, the principal can perform only the actions that are allowed by both its identity-based policies and its permissions boundaries.
A permissions boundary is a type of identity-based policy that doesn’t directly grant access. Instead, like an SCP, a permissions boundary acts as a guardrail for your IAM principals that allows you to set coarse-grained access controls. A permissions boundary is typically used to delegate the creation of IAM principals. Delegation enables other individuals in your accounts to create new IAM principals, but limits the permissions that can be granted to the new IAM principals.
Identity-based policies overview
Identity-based policies are policy documents that you attach to a principal (roles, users, and groups of users) to control what actions a principal can perform, on which resources, and under what conditions. Identity-based policies can be further categorized into AWS managed policies, customer managed policies, and inline policies. AWS managed policies are reusable identity-based policies that are created and managed by AWS. You can use AWS managed policies as a starting point for building your own identity-based policies that are specific to your organization. Customer managed policies are reusable identity-based policies that can be attached to multiple identities. Customer managed policies are useful when you have multiple principals with identical access requirements. Inline policies are identity-based policies that are attached to a single principal. Use inline-policies when you want to create least-privilege permissions that are specific to a particular principal.
You will have many identity-based policies in your AWS account that are used to enable access in scenarios such as human access, application access, machine learning workloads, and deployment pipelines. These policies should be fine-grained. You use these policies to directly apply least privilege permissions to your IAM principals. You should write the policies with permissions for the specific task that the principal needs to accomplish.
Resource-based policies overview
Resource-based policies are policy documents that you attach to a resource such as an S3 bucket. These policies grant the specified principal permission to perform specific actions on that resource and define under what conditions this permission applies. Resource-based policies are inline policies. For a list of AWS services that support resource-based policies, see AWS services that work with IAM.
Resource-based policies are optional for many workloads that don’t span multiple AWS accounts. Fine-grained access within a single AWS account is typically granted with identity-based policies. AWS Key Management Service (AWS KMS)keys and IAM role trust policies are two exceptions, and both of these resources must have a resource-based policy even when the principal and the KMS key or IAM role are in the same account. IAM roles and KMS keys behave this way as an extra layer of protection that requires the owner of the resource (key or role) to explicitly allow or deny principals from using the resource. For other resources that support resource-based policies, here are some use cases where they are most commonly used:
Applying an additional layer of protection for resources that store sensitive data, such as AWS Secrets Manager secrets or an S3 bucket with sensitive data. You can use a resource-based policy to deny access to IAM principals that shouldn’t have access to sensitive data, even if granted access by an identity-based policy. An explicit deny in an IAM policy always overrides an allow.
How to implement different policy types
In this section, we will walk you through an example of a design that includes all four of the policy types explained in this post.
The example that follows shows an application that runs on an Amazon Elastic Compute Cloud (Amazon EC2) instance and needs to read from and write files to an S3 bucket in the same account. The application also reads (but doesn’t write) files from an S3 bucket in a different account. The company in this example, Example Corp, uses a multi-account strategy, and each application has its own AWS account. The architecture of the application is shown in Figure 1.
Figure 1: Sample application architecture that needs to access S3 buckets in two different AWS accounts
There are three teams that participate in this example: the Central Cloud Team, the Application Team, and the Data Lake Team. The Central Cloud Team is responsible for the overall security and governance of the AWS environment across all AWS accounts at Example Corp. The Application Team is responsible for building, deploying, and running their application within the application account (111111111111) that they own and manage. Likewise, the Data Lake Team owns and manages the data lake account (222222222222) that hosts a data lake at Example Corp.
With that background in mind, we will walk you through an implementation for each of the four policy types and include an explanation of which team we recommend own each policy. The policy owner is the team that is responsible for creating and maintaining the policy.
Service control policies
The Central Cloud Team owns the implementation of the security controls that should apply broadly to all of Example Corp’s AWS accounts. At Example Corp, the Central Cloud Team has two security requirements that they want to apply to all accounts in their organization:
All AWS API calls must be encrypted in transit.
Accounts can’t leave the organization on their own.
The Central Cloud Team chooses to implement these security invariants using SCPs and applies the SCPs to the root of the organization. The first statement in Policy 1 denies all requests that are not sent using SSL (TLS). The second statement in Policy 1 prevents an account from leaving the organization.
This is only a subset of the SCP statements that Example Corp uses. Example Corp uses a deny list strategy, and there must also be an accompanying statement with an Effect of Allow at every level of the organization that isn’t shown in the SCP in Policy 1.
Policy 1: SCP attached to AWS Organizations organization root
The Central Cloud Team wants to make sure that they don’t become a bottleneck for the Application Team. They want to allow the Application Team to deploy their own IAM principals and policies for their applications. The Central Cloud Team also wants to make sure that any principals created by the Application Team can only use AWS APIs that the Central Cloud Team has approved.
At Example Corp, the Application Team deploys to their production AWS environment through a continuous integration/continuous deployment (CI/CD) pipeline. The pipeline itself has broad access to create AWS resources needed to run applications, including permissions to create additional IAM roles. The Central Cloud Team implements a control that requires that all IAM roles created by the pipeline must have a permissions boundary attached. This allows the pipeline to create additional IAM roles, but limits the permissions that the newly created roles can have to what is allowed by the permissions boundary. This delegation strikes a balance for the Central Cloud Team. They can avoid becoming a bottleneck to the Application Team by allowing the Application Team to create their own IAM roles and policies, while ensuring that those IAM roles and policies are not overly privileged.
An example of the permissions boundary policy that the Central Cloud Team attaches to IAM roles created by the CI/CD pipeline is shown below. This same permissions boundary policy can be centrally managed and attached to IAM roles created by other pipelines at Example Corp. The policy describes the maximum possible permissions that additional roles created by the Application Team are allowed to have, and it limits those permissions to some Amazon S3 and Amazon Simple Queue Service (Amazon SQS) data access actions. It’s common for a permissions boundary policy to include data access actions when used to delegate role creation. This is because most applications only need permissions to read and write data (for example, writing an object to an S3 bucket or reading a message from an SQS queue) and only sometimes need permission to modify infrastructure (for example, creating an S3 bucket or deleting an SQS queue). As Example Corp adopts additional AWS services, the Central Cloud Team updates this permissions boundary with actions from those services.
Policy 2: Permissions boundary policy attached to IAM roles created by the CI/CD pipeline
In the next section, you will learn how to enforce that this permissions boundary is attached to IAM roles created by your CI/CD pipeline.
Identity-based policies
In this example, teams at Example Corp are only allowed to modify the production AWS environment through their CI/CD pipeline. Write access to the production environment is not allowed otherwise. To support the different personas that need to have access to an application account in Example Corp, three baseline IAM roles with identity-based policies are created in the application accounts:
A role for the CI/CD pipeline to use to deploy application resources.
A read-only role for the Central Cloud Team, with a process for temporary elevated access.
A read-only role for members of the Application Team.
All three of these baseline roles are owned, managed, and deployed by the Central Cloud Team.
The Central Cloud Team is given a default read-only role (CentralCloudTeamReadonlyRole) that allows read access to all resources within the account. This is accomplished by attaching the AWS managed ReadOnlyAccess policy to the Central Cloud Team role. You can use the IAM console to attach the ReadOnlyAccess policy, which grants read-only access to all services. When a member of the team needs to perform an action that is not covered by this policy, they follow a temporary elevated access process to make sure that this access is valid and recorded.
A read-only role is also given to developers in the Application Team (DeveloperReadOnlyRole) for analysis and troubleshooting. At Example Corp, developers are allowed to have read-only access to Amazon EC2, Amazon S3, Amazon SQS, AWS CloudFormation, and Amazon CloudWatch. Your requirements for read-only access might differ. Several AWS services offer their own read-only managed policies, and there is also the previously mentioned AWS managed ReadOnlyAccess policy that grants read only access to all services. To customize read-only access in an identity-based policy, you can use the AWS managed policies as a starting point and limit the actions to the services that your organization uses. The customized identity-based policy for Example Corp’s DeveloperReadOnlyRole role is shown below.
Policy 3: Identity-based policy attached to a developer read-only role to support human access and troubleshooting
The CI/CD pipeline role has broad access to the account to create resources. Access to deploy through the CI/CD pipeline should be tightly controlled and monitored. The CI/CD pipeline is allowed to create new IAM roles for use with the application, but those roles are limited to only the actions allowed by the previously discussed permissions boundary. The roles, policies, and EC2 instance profiles that the pipeline creates should also be restricted to specific role paths. This enables you to enforce that the pipeline can only modify roles and policies or pass roles that it has created. This helps prevent the pipeline, and roles created by the pipeline, from elevating privileges by modifying or passing a more privileged role. Pay careful attention to the role and policy paths in the Resource element of the following CI/CD pipeline role policy (Policy 4). The CI/CD pipeline role policy also provides some example statements that allow the passing and creation of a limited set of service-linked roles (which are created in the path /aws-service-role/). You can add other service-linked roles to these statements as your organization adopts additional AWS services.
Policy 4: Identity-based policy attached to CI/CD pipeline role
In addition to the three baseline roles with identity-based policies in place that you’ve seen so far, there’s one additional IAM role that the Application Team creates using the CI/CD pipeline. This is the role that the application running on the EC2 instance will use to get and put objects from the S3 buckets in Figure 1. Explicit ownership allows the Application Team to create this identity-based policy that fits their needs without having to wait and depend on the Central Cloud Team. Because the CI/CD pipeline can only create roles that have the permissions boundary policy attached, Policy 5 cannot grant more access than the permissions boundary policy allows (Policy 2).
If you compare the identity-based policy attached to the EC2 instance’s role (Policy 5 on left) with the permissions boundary policy described previously (Policy 2 on the right), you can see that the actions allowed by the EC2 instance’s role are also allowed by the permissions boundary policy. Actions must be allowed by both policies for the EC2 instance to perform the s3:GetObject and s3:PutObject actions. Access to create a bucket would be denied even if the role attached to the EC2 instance was given permission to perform the s3:CreateBucket action because the s3:CreateBucket action exceeds the permissions allowed by the permissions boundary.
Policy 5: Identity-based policy bound by permissions boundary and attached to the application’s EC2 instance
The only resource-based policy needed in this example is attached to the bucket in the account external to the application account (DOC-EXAMPLE-BUCKET2 in the data lake account in Figure 1). Both the identity-based policy and resource-based policy must grant access to an action on the S3 bucket for access to be allowed in a cross-account scenario. The bucket policy below only allows the GetObject action to be performed on the bucket, regardless of what permissions the application’s role (ApplicationRole) is granted from its identity-based policy (Policy 5).
This resource-based policy is owned by the Data Lake Team that owns and manages the data lake account (222222222222) and the policy (Policy 6). This allows the Data Lake Team to have complete control over what teams external to their AWS account can access their S3 bucket.
Policy 6: Resource-based policy attached to S3 bucket in external data lake account (222222222222)
No resource-based policy is needed on the S3 bucket in the application account (DOC-EXAMPLE-BUCKET1 in Figure 1). Access for the application is granted to the S3 bucket in the application account by the identity-based policy on its own. Access can be granted by either an identity-based policy or a resource-based policy when access is within the same AWS account.
Putting it all together
Figure 2 shows the architecture and includes the seven different policies and the resources they are attached to. The table that follows summarizes the various IAM policies that are deployed to the Example Corp AWS environment, and specifies what team is responsible for each of the policies.
Figure 2: Sample application architecture with CI/CD pipeline used to deploy infrastructure
The numbered policies in Figure 2 correspond to the policy numbers in the following table.
Policy number
Policy description
Policy type
Policy owner
Attached to
1
Enforce SSL and prevent member accounts from leaving the organization for all principals in the organization
Service control policy (SCP)
Central Cloud Team
Organization root
2
Restrict maximum permissions for roles created by CI/CD pipeline
Permissions boundary
Central Cloud Team
All roles created by the pipeline (ApplicationRole)
3
Scoped read-only policy
Identity-based policy
Central Cloud Team
DeveloperReadOnlyRole IAM role
4
CI/CD pipeline policy
Identity-based policy
Central Cloud Team
CICDPipelineRole IAM role
5
Policy used by running application to read and write to S3 buckets
Identity-based policy
Application Team
ApplicationRole on EC2 instance
6
Bucket policy in data lake account that grants access to a role in application account
Resource-based policy
Data Lake Team
S3 Bucket in data lake account
7
Broad read-only policy
Identity-based policy
Central Cloud Team
CentralCloudTeamReadonlyRole IAM role
Conclusion
In this blog post, you learned about four different policy types: identity-based policies, resource-based policies, service control policies (SCPs), and permissions boundary policies. You saw examples of situations where each policy type is commonly applied. Then, you walked through a real-life example that describes an implementation that uses these policy types.
You can use this blog post as a starting point for developing your organization’s IAM strategy. You might decide that you don’t need all of the policy types explained in this post, and that’s OK. Not every organization needs to use every policy type. You might need to implement policies differently in a production environment than a sandbox environment. The important concepts to take away from this post are the situations where each policy type is applicable, and the importance of explicit policy ownership. We also recommend taking advantage of policy validation in AWS IAM Access Analyzer when writing IAM policies to validate your policies against IAM policy grammar and best practices.
For more information, including the policies described in this solution and the sample application, see the how-and-when-to-use-aws-iam-policy-blog-samples GitHub respository. The repository walks through an example implementation using a CI/CD pipeline with AWS CodePipeline.
Customers often ask for guidance on permissions boundaries in AWS Identity and Access Management (IAM) and when, where, and how to use them. A permissions boundary is an IAM feature that helps your centralized cloud IAM teams to safely empower your application developers to create new IAM roles and policies in Amazon Web Services (AWS). In this blog post, we cover this common use case for permissions boundaries, some best practices to consider, and a few things to avoid.
Background
Developers often need to create new IAM roles and policies for their applications because these applications need permissions to interact with AWS resources. For example, a developer will likely need to create an IAM role with the correct permissions for an Amazon Elastic Compute Cloud (Amazon EC2) instance to report logs and metrics to Amazon CloudWatch. Similarly, a role with accompanying permissions is required for an AWS Glue job to extract, transform, and load data to an Amazon Simple Storage Service (Amazon S3) bucket, or for an AWS Lambda function to perform actions on the data loaded to Amazon S3.
Before the launch of IAM permissions boundaries, central admin teams, such as identity and access management or cloud security teams, were often responsible for creating new roles and policies. But using a centralized team to create and manage all IAM roles and policies creates a bottleneck that doesn’t scale, especially as your organization grows and your centralized team receives an increasing number of requests to create and manage new downstream roles and policies. Imagine having teams of developers deploying or migrating hundreds of applications to the cloud—a centralized team won’t have the necessary context to manually create the permissions for each application themselves.
Because the use case and required permissions can vary significantly between applications and workloads, customers asked for a way to empower their developers to safely create and manage IAM roles and policies, while having security guardrails in place to set maximum permissions. IAM permissions boundaries are designed to provide these guardrails so that even if your developers created the most permissive policy that you can imagine, such broad permissions wouldn’t be functional.
By setting up permissions boundaries, you allow your developers to focus on tasks that add value to your business, while simultaneously freeing your centralized security and IAM teams to work on other critical tasks, such as governance and support. In the following sections, you will learn more about permissions boundaries and how to use them.
Permissions boundaries
A permissions boundary is designed to restrict permissions on IAM principals, such as roles, such that permissions don’t exceed what was originally intended. The permissions boundary uses an AWS or customer managed policy to restrict access, and it’s similar to other IAM policies you’re familiar with because it has resource, action, and effect statements. A permissions boundary alone doesn’t grant access to anything. Rather, it enforces a boundary that can’t be exceeded, even if broader permissions are granted by some other policy attached to the role. Permissions boundaries are a preventative guardrail, rather than something that detects and corrects an issue. To grant permissions, you use resource-based policies (such as S3 bucket policies) or identity-based policies (such as managed or in-line permissions policies).
The predominant use case for permissions boundaries is to limit privileges available to IAM roles created by developers (referred to as delegated administrators in the IAM documentation) who have permissions to create and manage these roles. Consider the example of a developer who creates an IAM role that can access all Amazon S3 buckets and Amazon DynamoDB tables in their accounts. If there are sensitive S3 buckets in these accounts, then these overly broad permissions might present a risk.
To limit access, the central administrator can attach a condition to the developer’s identity policy that helps ensure that the developer can only create a role if the role has a permissions boundary policy attached to it. The permissions boundary, which AWS enforces during authorization, defines the maximum permissions that the IAM role is allowed. The developer can still create IAM roles with permissions that are limited to specific use cases (for example, allowing specific actions on non-sensitive Amazon S3 buckets and DynamoDB tables), but the attached permissions boundary prevents access to sensitive AWS resources even if the developer includes these elevated permissions in the role’s IAM policy. Figure 1 illustrates this use of permissions boundaries.
Figure 1: Implementing permissions boundaries
The central IAM team adds a condition to the developer’s IAM policy that allows the developer to create a role only if a permissions boundary is attached to the role.
The developer creates a role with accompanying permissions to allow access to an application’s Amazon S3 bucket and DynamoDB table. As part of this step, the developer also attaches a permissions boundary that defines the maximum permissions for the role.
Resource access is granted to the application’s resources.
Resource access is denied to the sensitive S3 bucket.
You can use the following policy sample for your developers to allow the creation of roles only if a permissions boundary is attached to them. Make sure to replace <YourAccount_ID> with an appropriate AWS account ID; and the <DevelopersPermissionsBoundary>, with your permissions boundary policy.
Put together, you can use the following permissions policy for your developers to get started with permissions boundaries. This policy allows your developers to create downstream roles with an attached permissions boundary. The policy further denies permissions to detach, delete, or modify the attached permissions boundary policy. Remember, nothing is implicitly allowed in IAM, so you need to allow access permissions for any other actions that your developers require. To learn about allowing access permissions for various scenarios, see Example IAM identity-based policies in the documentation.
You can build on these concepts and apply permissions boundaries to different organizational structures and functional units. In the example shown in Figure 2, the developer can only create IAM roles if a permissions boundary associated to the business function is attached to the IAM roles. In the example, IAM roles in function A can only perform Amazon EC2 actions and Amazon DynamoDB actions, and they don’t have access to the Amazon S3 or Amazon Relational Database Service (Amazon RDS) resources of function B, which serve a different use case. In this way, you can make sure that roles created by your developers don’t exceed permissions outside of their business function requirements.
Figure 2: Implementing permissions boundaries in multiple organizational functions
Best practices
You might consider restricting your developers by directly applying permissions boundaries to them, but this presents the risk of you running out of policy space. Permissions boundaries use a managed IAM policy to restrict access, so permissions boundaries can only be up to 6,144 characters long. You can have up to 10 managed policies and 1 permissions boundary attached to an IAM role. Developers often need larger policy spaces because they perform so many functions. However, the individual roles that developers create—such as a role for an AWS service to access other AWS services, or a role for an application to interact with AWS resources—don’t need those same broad permissions. Therefore, it is generally a best practice to apply permissions boundaries to the IAM roles created by developers, rather than to the developers themselves.
There are better mechanisms to restrict developers, and we recommend that you use IAM identity policies and AWS Organizations service control policies (SCPs) to restrict access. In particular, the Organizations SCPs are a better solution here because they can restrict every principal in the account through one policy, rather than separately restricting individual principals, as permissions boundaries and IAM identity policies are confined to do.
You should also avoid replicating the developer policy space to a permissions boundary for a downstream IAM role. This, too, can cause you to run out of policy space. IAM roles that developers create have specific functions, and the permissions boundary can be tailored to common business functions to preserve policy space. Therefore, you can begin to group your permissions boundaries into categories that fit the scope of similar application functions or use cases (such as system automation and analytics), and allow your developers to choose from multiple options for permissions boundaries, as shown in the following policy sample.
Finally, it is important to understand the differences between the various IAM resources available. The following table lists these IAM resources, their primary use cases and managing entities, and when they apply. Even if your organization uses different titles to refer to the personas in the table, you should have separation of duties defined as part of your security strategy.
IAM resource
Purpose
Owner/maintainer
Applies to
Federated roles and policies
Grant permissions to federated users for experimentation in lower environments
Central team
People represented by users in the enterprise identity provider
IAM workload roles and policies
Grant permissions to resources used by applications, services
Developer
IAM roles representing specific tasks performed by applications
Permissions boundaries
Limit permissions available to workload roles and policies
Central team
Workload roles and policies created by developers
IAM users and policies
Allowed only by exception when there is no alternative that satisfies the use case
Central team plus senior leadership approval
Break-glass access; legacy workloads unable to use IAM roles
Conclusion
This blog post covered how you can use IAM permissions boundaries to allow your developers to create the roles that they need and to define the maximum permissions that can be given to the roles that they create. Remember, you can use AWS Organizations SCPs or deny statements in identity policies for scenarios where permissions boundaries are not appropriate. As your organization grows and you need to create and manage more roles, you can use permissions boundaries and follow AWS best practices to set security guard rails and decentralize role creation and management. Get started using permissions boundaries in IAM.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
This blog post outlines how to use your existing Microsoft Active Directory (AD) to reliably authenticate access to your Amazon Web Services (AWS) accounts, infrastructure running on AWS, and third-party applications. The architecture we describe is designed to be highly available and extends access to your existing AD to AWS, enabling your users to use their existing credentials to access authorized AWS resources and applications.
Many customers rely on AD as their single source of truth for IT identity management. HR automation processes are often already in place to automatically add, update, and remove employee access within an organization’s AD as staffing changes occur. Using a single source of truth as the basis for all authentication and authorization, both on-premises and in the cloud, makes it easier to manage access across multiple applications and services, because you are creating, managing, and revoking access from a single location. For example, if someone leaves your organization, you can revoke access for all applications and services (including AWS accounts) from one location. Additionally, this reduces risks associated with stranded or forgotten credentials, or users needing to remember multiple different sets of credentials.
Microsoft Active Directory (AD) is deployed on Microsoft Windows Server servers called domain controllers, which replicate the contents of the directory between the domain controllers that are hosting the AD domain. Multiple domain controllers are deployed within a domain to improve the availability and performance of the directory. The AD infrastructure should be designed to provide sufficiently high levels of availability and performance, because it governs access to your organization’s IT resources. This typically requires the placement of at least one domain controller in every customer hosting location, because the lack of availability of your identity store is likely to cause authentication and authorization failures, which in turn prevent access to resources.
These design principles align with the Security Pillar of the AWS Well-Architected Framework, which is focused on implementing a strong identity foundation. The Security Pillar guidance states that you should centralize identity management and aim to eliminate reliance on long-term static credentials. By using your existing AD, you can benefit from centralized identity management and your existing group-based permissions for access to your AWS accounts. Applications that are running on domain-joined servers can use their AD service account credentials when they access other domain-joined resources, which removes the need for those credentials to be stored in application configuration files. As your AWS usage grows, it is important to give serious consideration to effective identity management, both for access to AWS and AWS resources, and for your instances that are running on AWS.
By extending your existing Active Directory to AWS, you can continue to use your existing Active Directory user credentials and group policies to manage your Microsoft Windows Server servers, whether those servers are running on-premises or on AWS, and extend these capabilities to authenticate and authorize access to the AWS Management Console and third-party applications.
This post covers networking requirements and connectivity setup to enable network connectivity to your on-premises AD; the approach to extending your AD to AWS; integrating AWS Single Sign-On with your AD; and joining Amazon Elastic Compute Cloud (Amazon EC2) instances to AD. As part of the setup, you will add additional domain controllers running on Amazon EC2 instances to your existing AD, for availability and latency reasons. You will also build a resource forest to enable your existing AD identities to access AD-integrated AWS services and resources. This enables you to have a highly available single identity source as the source of truth for your user authentication.
Networking prerequisites to extend your Active Directory to AWS
To enable Active Directory–related network communication, network connectivity needs to be established between your on-premises network and your AWS environment. You need to ensure there is connectivity between the on-premises network that is hosting your existing domain controllers and the Amazon Virtual Private Cloud (Amazon VPC) VPC that will host your AD infrastructure on AWS. Typically, hybrid network connectivity is configured within a network account within your organization, where the multiple AWS accounts within your organization are managed by using AWS Organizations. This network account effectively sits between your on-premises network and the resources, including the AD infrastructure, that are deployed in AWS.
You can provide connectivity between your on-premises network and your network account by using AWS Site-to-Site VPN or AWS Direct Connect connections. For an overview of the options to connect your on-premises network to AWS, refer to Amazon Virtual Private Cloud Connectivity Options. The necessary routing and firewall rules need to be configured to allow connectivity between these subnets and the on-premises network that is hosting your existing domain controllers. AWS recommends that you have highly resilient, fault-tolerant connectivity with dynamic routing between your on-premises network and your AWS network. You can achieve high resiliency through the use of redundant AWS Direct Connect connections, or, for less critical workloads, a VPN connection might offer sufficient resilience.
We recommend AWS Transit Gateway to provide connectivity between your AWS accounts. A transit gateway will be in your network account and then shared with your other AWS accounts that have VPCs that require access to on-premises networks or other VPCs. This enables a hub and spoke network architecture, which is used to provide connectivity both between your VPCs as needed and between your VPCs and your on-premises network. You will create a VPC, which we will refer to within this blog as the endpoint VPC, with subnets across two Availability Zones, within the network account. This endpoint VPC will be used later by Amazon Route 53 outbound endpoints for DNS resolution of AD-hosted DNS zones. Other documentation might refer to this endpoint VPC by alternative names, such as outbound VPC or egress VPC.
Your AD infrastructure that is running on AWS is typically deployed within a shared services account, sometimes referred to as an operations account. Within this shared services account, you will create a shared services VPC with at least two subnets within different Availability Zones to host your domain controller infrastructure on AWS. Your domain controller availability is increased when your architecture is configured to use multiple Availability Zones. You will attach this shared services VPC to the transit gateway that is shared from your network account. This VPC attachment provides connectivity between this VPC and your on-premises network through the transit gateway and network account. You will need to configure the subnet route table(s) and transit gateway route table(s) appropriately to provide IP connectivity between the shared services VPC and your on-premises network.
The sample architecture shown in Figure 1 illustrates the use of a transit gateway with two AWS Direct Connect connections to provide resilient connectivity between an on-premises network, the network account, and a VPC within the shared services account.
Figure 1: Foundational network connectivity between on-premises and AWS VPCs
Active Directory relies heavily on Domain Name System (DNS) services and typically hosts its own DNS services on domain controllers. To establish name resolution of your AD-hosted DNS domains from within your VPCs, you should use Route 53 Resolver with outbound resolver endpoints and forwarding rules. Forwarding rules specify the domain name queries to forward from your VPCs to DNS servers that are authoritative for your AD DNS names. The queries will be forwarded through the outbound endpoints. The outbound endpoints will be configured in the network account on the endpoint VPC, and use the previously configured network connectivity to communicate with your existing DNS servers. You will configure your existing DNS servers as targets in the forwarding rules. Configuring Route 53 Resolver with the appropriate forwarding rules will help to enable seamless DNS resolution between your on-premises and AWS hosted resources. You need to share the Route 53 Resolver rules with your organization so that they can be used by your other AWS accounts. These shared rules are then associated with your VPCs, which need to be able to resolve names within AD-hosted DNS domains. Refer to the AWS Hybrid DNS with Active Directory technical guide for detailed step-by-step configuration guidance.
Figure 2 shows a sample flow of a DNS query from an Amazon Elastic Compute Cloud (Amazon EC2) instance through Route 53 Resolver and an outbound interface when resolving an on-premises domain name that matches a forwarding rule. In this example, the domain controllers are also the DNS servers, but splitting the DNS and AD servers is also fully supported.
Figure 2: Flow of a DNS query matching a forwarding rule through a Route 53 outbound endpoint
The flow is as follows:
An Amazon EC2 instance sends a DNS request for an internal name, such as ad.example.com, to the Route 53 Resolver address within the VPC.
Route 53 matches this query against a forwarding rule and directs the query through the configured outbound interface.
The query is sent from the outbound interface towards the target IP address, configured in the forwarding rule, of a server that is authoritative for the domain name.
This target DNS server receives the query and responds.
To extend your existing AD to AWS, domain controllers on Amazon EC2 instances are required, because AWS Managed Microsoft AD does not support being added to an existing forest. An AWS Managed Microsoft AD resource forest is required to enable integration with AWS services that offer AD integration. This is discussed in more detail in the following sections.
Extend your on-premises AD to AWS
Your first step is to build additional AD domain controllers for your existing AD domain(s) on Amazon EC2 instances that are running Microsoft Windows Server. You would then manage these domain controllers along with your existing domain controllers. By running additional domain controllers within AWS, you remove dependencies on network links and improve reliability and performance of your directory for infrastructure that is running within AWS. Communication between the domain controllers and other domain-joined resources within AWS is designed to remain within the AWS Region. AWS recommends that a minimum of two domain controllers, spread across multiple Availability Zones for resilience, are deployed. You should deploy the domain controllers into the subnets within the shared services VPC.
Depending on your capacity planning considerations and availability goals, you may choose to deploy more than two domain controllers. The number of users, servers, and applications that access your directory will influence the required number of domain controllers. Security considerations, including the required TCP/IP ports, and management options are discussed in the blog post Securely extend and access on-premises Active Directory domain controllers in AWS.
These new domain controllers will be in a new AD site, which includes all your VPC CIDR blocks within your chosen AWS Region. In Active Directory, a site represents a group of IP subnets that are connected with fast and highly reliable network connectivity. Site information is used to locate domain controllers closest to the client, to reduce latency and unnecessary network traffic. AWS recommends that your VPCs within an AWS Region belong to the same new Active Directory site, consisting only of your IP ranges within the chosen AWS Region, and that consistent site names are used in all AD forests that are connected by trusts. Further details are available in the section Designing Active Directory sites and services topology in Active Directory Domain Services on AWS and in Designing the Site Topology.
Update targets in Route 53 Resolver rules
After you have deployed AD-integrated DNS servers to these domain controllers and opened the required TCP/IP ports on the associated security groups, you can update the targets in your Route 53 Resolver forwarding rules to use the IP addresses of these servers. This will improve performance and reliability of DNS resolution, by removing the need for DNS resolution traffic to flow between AWS and on-premises infrastructure.
Figure 3 shows Amazon EC2 instances that are configured as AD domain controllers within a shared services VPC. After they are configured, these domain controllers will replicate with the on-premises domain controllers, using the connectivity that is provided through the transit gateway.
Figure 3: On-premises AD extended to AWS by deploying additional domain controllers
Build a resource forest for AWS hosted infrastructure and applications
When you select and launch this directory type, it is created as a highly available pair of domain controllers that are connected to your virtual private cloud (VPC). The domain controllers run in different Availability Zones in your choice of AWS Region. Host monitoring and recovery, data replication, snapshots, and software updates are automatically configured and managed for you. AWS Managed Microsoft AD is available in Standard and Enterprise Editions.
The AWS Managed Microsoft AD will be shared with your accounts within your organization to enable your other AWS accounts to access this directory and benefit from the features and services outlined previously.
With correct AD site configuration in both forests, communication between the AWS Managed Microsoft AD domain controllers and other domain-joined resources within AWS, and your existing domain’s domain controllers, remains within the chosen AWS Region. This is designed to keep your data within AWS in the country of your chosen AWS Region, to help to address possible data residency concerns.
An example of this architecture is depicted in Figure 4.
Figure 4: AWS Managed Microsoft AD resource forest with trust to on-premises AD
Manage access to your AWS accounts
AWS Single Sign-On (AWS SSO) enables you to centrally manage access across your AWS organization. You can choose to manage access just to your AWS accounts, or to your cloud applications as well. You can create user identities directly in AWS SSO, access your existing identifies by connecting AWS SSO to your existing Active Directory domain, or you can federate them from your Active Directory Federation Services (AD FS) or a standards-based identity provider, such as Okta Universal Directory or Azure AD. Your workforce users get a user portal to access all of their assigned AWS accounts or cloud applications. AWS SSO can be flexibly configured to run alongside or replace AWS account access management through AWS Identity and Access Management (IAM).
Identity federation is a system of trust between two parties for the purpose of authenticating third parties, such as users, and conveying information that is needed to authorize their access to resources. In this system, an identity provider (IdP) is responsible for user authentication, and a service provider (SP), such as a service or an application, controls access to resources. AWS SSO automates the setup of the identity federation that is used to provide authorized users access to your AWS accounts. AWS SSO is acting as an IdP when AWS SSO is connected to your AD and used to give access to your AWS accounts.
Although you can create users and groups directly within AWS SSO, a best practice is to use your existing identity single source of truth to simplify user and permission management. Connecting AWS SSO through to your Active Directory, which has been extended to AWS, will allow authentication of users for access to your AWS accounts to take place entirely within the AWS Region. This practice is designed to reduce dependencies on hybrid networking and resources located on-premises or in other hosting locations.
You should enforce secure access to the user portal, AWS SSO integrated apps, and the AWS CLI by enabling multi-factor authentication (MFA). AWS SSO MFA supports various MFA types, including client-side authenticator apps, security keys, and built-in authenticators. Using MFA is recommended as part of configuring strong sign-in mechanisms.
Connect AWS SSO to your Active Directory
You can connect AWS SSO to your Active Directory on AWS by using AD Connector, or through an AWS Managed Microsoft AD. Using AD Connector is often the primary mechanism considered by customers, but given the lack of support for multi-domain environments as used in this post, this blog post recommends using AWS Managed Microsoft AD.
When you use AWS Managed Microsoft AD with AWS SSO, AWS SSO requires two-way trusts to be in place between this AWS Managed Microsoft AD forest and any other forest that contains the user identities that will authenticate through AWS SSO.
Before AWS SSO supported delegated administration, AWS SSO had to be configured within the management account of your AWS organization, and required the connected AWS Managed Microsoft AD directory to also be within your organization’s management account.
With the announcement of AWS SSO delegated administration support, AWS SSO and the connected AWS Managed Microsoft AD can be configured in an account other than your management account. This post recommends using your shared services account as the AWS SSO delegated administration account. Doing so will enable AWS SSO to use the AWS Managed Microsoft AD that you configured within the shared services account in the preceding Build a resource forest for AWS hosted infrastructure and applications section.
This follows the AWS guidance to avoid deploying workloads to the organization’s management account and to limit access to the management account. Using a delegated administration account for AWS SSO reduces the need for regular access to the management account.
From within your management account, your shared services account needs to be registered as the AWS SSO delegated administration account. You can then configure and manage AWS SSO from within your shared services account. The AWS SSO delegated administration account can manage permissions across your organization, apart from assigning permissions to access the management account. Assignment of permissions to access the management account through AWS SSO needs to be configured from within the management account itself.
Permission sets are a way to define permissions centrally in AWS SSO so that they can be applied to all your AWS accounts. After you have created your permission sets, you will assign them to your Active Directory groups to grant access to the respective AWS accounts, using the defined permission set persona. Your users will then use the AWS SSO user portal to authenticate with their AD credentials and can choose which of the assigned AWS accounts and personas they wish to access. Users can configure AWS CLI to use AWS SSO to access the roles they have been assigned.
Figure 5 shows the complete architecture covered in this blog post. The diagram includes AWS SSO within the shared services account connected to the AWS Managed Microsoft AD that is used to provide access to the forests that contain your user identities.
Figure 5: Complete AD architecture with trusts and AWS SSO using AD as the identity source
Access domain-joined infrastructure resources
By joining your Windows Server servers to your Active Directory resource domain, you can centralize the management of your servers by using native Microsoft tooling. Joining your Amazon EC2 Windows instances to your domain enables you to continue using existing tools, such as group policies, to manage your server estate both on-premises and in AWS.
VPCs with workloads that need to be domain joined, to access on-premises networks, or to access other VPCs will need appropriate network connectivity and DNS configuration in place. You can enable network connectivity between workload VPCs and the shared services VPC and other on-premises networks by attaching your VPCs to the transit gateway shared from the networking account. You can enable DNS resolution of your AD domains by attaching the Route 53 Resolver rules, shared from the networking account, to your workload VPCs.
Join instances to your AD domain
Amazon EC2 Windows instances can be manually or seamlessly joined to your resource domain. Manually joining an instance involves the same steps that you would follow on-premises. Seamlessly joining instances requires the AWS Systems Manager agent, which is installed by default in AWS provided Windows AMIs, on the Amazon EC2 instance and an attached instance profile with sufficient permissions. This instance profile should include the AmazonSSMManagedInstanceCore and AmazonSSMDirectoryServiceAccess policies.
In order to join the domain, either manually or seamlessly, the Amazon EC2 instance must be able to resolve the DNS name for your AD domain. This DNS resolution was enabled by the attachment of the correctly configured shared Route 53 Resolver rules to the workload VPCs. Seamlessly joining instances to the domain also requires that your shared services account AWS Managed Microsoft AD directory be shared with the workload account that contains the Amazon EC2 instances.
After your instances are joined to the domain, applications running on the servers will be able to access other domain-joined resources, if authorized by AD, through the connectivity that is provided by the transit gateway attachment on the workload VPC.
Applications that need to access AWS resources that are not domain joined, such as objects in Amazon Simple Storage Service (Amazon S3), should make use of temporary credentials associated with the attached instance profile to access AWS resources. By using these IAM temporary credentials, you can avoid using static long-term credentials. When an application requires access to credentials or other secrets, and cannot use AD or IAM temporary credentials, such as for database logins or for third-party API tokens, use a service designed to handle management of secrets, such as AWS Secrets Manager. See the AWS Well-Architected Security Pillar Identity Management documentation for further guidance.
Figure 6 shows Active Directory access through the transit gateway. The Route 53 forwarding rules, which are shared from the shared services account, are associated with the workload VPCs to enable DNS resolution of Active Directory–integrated DNS domains. Not shown in the diagram is the sharing of the AWS Managed Microsoft AD for the resource forest with the workload accounts.
Figure 6: Flow of AD network traffic through the transit gateway within the network account
Access applications and third-party services
You might have existing applications that rely on Active Directory or LDAP for user authentication. When you extend your Active Directory environment to AWS, these existing applications can be deployed to your AWS environment, and they will be able to authenticate the users of the application against your AD.
You might already be using a third-party identity provider, such as Azure AD or Okta, to provide your users with access to AWS services such as AWS Client VPN or to third-party business applications such as those on the AWS SSO Cloud applications page. These third-party identity providers will typically offer an agent to replicate or synchronize necessary user information from your Active Directory to their service, in order to offer federated authentication for your users. Using these agents to replicate from your existing Active Directory means that you are still using your Active Directory as the single source of truth. To ensure reliable authentication, you should follow the vendor’s recommendations for the high-availability setup of their agent.
Figure 7 shows the steps that occur when you use AWS SSO to provide identity federation to a web application.
Figure 7: Example flow for identify federation that uses AWS SSO
Conclusion
This post highlights the importance of implementing a cloud authentication and authorization architecture that addresses the variety of requirements for an organization’s AWS Cloud environment. In addition to console access, this post highlights the importance of considering how you will:
Perform authentication to AWS based Windows and Linux instances
Integrate AWS services that need Windows-based authentication capabilities
Integrate authentication for internal user applications
Provide a single identity source as the source of truth for all AWS user authentication
Enable MFA for user authentication
The proposed approach provides a highly available Active Directory (AD) infrastructure, running on AWS and integrated with your existing AD, which addresses these considerations. The approach helps you to attain reduced latencies and higher levels of availability by removing dependencies on on-premises resources, other hosting locations, and external network links. This design stores the identity information that is contained within your existing AD in your chosen AWS Region and country, across multiple Availability Zones, which can also help you meet your data residency requirements.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Many organizations restrict permissions to create and manage AWS Identity and Access Management (IAM) resources to a group of privileged users or a central team. This post explains how you can safely grant these permissions to builders – the people who are developing, testing, launching, and managing cloud infrastructure – to speed up your development, increase your agility, and improve your application security. In addition, you will use an example application stack to see how IAM permissions boundaries can help establish a secure, yet agile work environment for builders.
An example application stack
Defining and creating IAM resources within the application stack allows your builders to craft policies and roles that grant least privilege to application resources. When builders are entitled to create IAM resources, it is straightforward for them to scope policies by referencing the application resources directly in the IAM policies in the same template.
To illustrate this point you will build a simple “hello world” serverless application. The application includes an AWS Step Functions state machine that, once executed, will invoke an AWS Lambda function. You will use this example application along with some IAM policies and IAM roles to illustrate how you can use permissions boundaries to safely grant IAM privileges to builders.
In this example AWS CloudFormation template, the Resource element in MyStateMachineExecutionRole, which is specified as the role for MyStateMachine, includes a reference to the Amazon Resource Name (ARN) of MyLambdaFunction. This is a great example of the principle of least privilege as MyStateMachine will only have permissions to invoke MyLambdaFunction. Making this association is straightforward because the IAM, Step Functions, and Lambda resources are defined together in the same template.
In an organization that uses a centralized approach to IAM management, a builder would not be able to deploy this example application because the roles the builders are granted prohibit IAM actions related to creating and managing roles and policies. This creates three key challenges for the organization:
Builders often rely on a security or cloud team to create IAM resources. This approach adds an additional burden to that team which slows down development while builders wait for the roles and policies to be created, and encourages the team to grant overly-broad permissions so that they don’t have to be involved in the precise details of changes on a daily basis.
IAM resources must be created before the rest of the stack, which makes it much more difficult to create least-privilege policies and roles.
The code for IAM and application infrastructure is maintained separately, which requires extra coordination when creating and updating workloads.
Removing these challenges can simplify your cloud development, lower the amount of overhead and coordination required across your organization, and improve your security posture. Further, reducing the burden on your security team can free up time for them to focus on enforcing additional data perimeters and implementing best practices from the security pillar of the AWS Well-Architected Framework.
Use permissions boundaries on application roles created by builders
So how can your organization shift to a decentralized approach to IAM management and allow builders to safely create application IAM policies and roles, as well as prevent builders from being able to escalate their own privileges? This is a scenario where permissions boundaries should be used.
Permissions boundaries allow an IAM policy to be attached to an IAM role to enforce limits on the permissions that role can be granted. The permissions boundary itself does not grant any permissions – it’s just a guardrail that defines the maximum entitlements. You can create a builder policy that requires a specified permissions boundary be attached to any application roles that a builder creates, effectively setting the maximum permissions on any role that a builder can generate. The permissions for any application roles created will be the intersection of the application policies and the permissions boundary associated with the application role. Said another way, a permission granted in the application policy must also be granted in the permissions boundary, or else it will be implicitly denied according to the policy evaluation logic.
The set of permissions required for builder roles (assumed by actual people or CI/CD pipelines) to deploy infrastructure and develop applications are different than those required for application roles (assumed by workloads/applications) to execute within applications and workflows. If you think of permissions in terms of control plane actions involved in creating, deleting, and modifying resources, versus data plane actions needed to execute the daily business of those resources, builder and application roles typically operate more on the control plane and data plane, respectively. While permissions policies attached to application roles should be tightly scoped to include only those actions needed to perform a specific task, policies for permissions boundaries should be highly reusable and include a broad set of permissions across a suite of services that a variety of applications might need. In addition, it is a best practice to not share roles between humans and services. To summarize, policies for builder and application roles should be designed with the following criteria in mind:
Policy
Role
Permissions
Scope
Reusability
User
builder
builder
control plane
broad
high
human
application
application
data plane
specific
low
service
application-boundary
application
data plane
broad
high
application role
Following the steps in this section, you will create:
A builder policy that grants builders permissions for services needed to deploy and manage applications, and to create and manage IAM policies and roles for those applications.
An application-boundary policy that defines the extent of the permissions any application role created by a builder can have.
A builder role with the builder policy attached as the permissions policy, the application-boundary policy attached as a permissions boundary, and a trust policy that allows anyone in the account to assume the builder role.
Create the builder IAM resources
In this first procedure, you will use CloudFormation to create the builder and application-boundary IAM policies, and the builder IAM role.
To launch the builder IAM stack
Open a Linux terminal with the AWS Command Line Interface (CLI) installed and AWS credentials configured for a user or role that has permissions to create IAM resources.
Launch the builder IAM stack by using the following command:
The builder policy you created uses paths to organize IAM policies and roles into isolated “spaces” that can be specified as resource constraints. It also requires roles to have a permissions boundary attached. This approach helps manage role delegation and prevents builders from escalating their privileges or modifying roles that may be used by other teams.
Note that paths can only be added to IAM resources using the AWS CLI or APIs – not via the console. If this is an issue, another option is to specify that policies and roles start with a specific phrase, for example “application-roles-*”. Just be sure to use different phrases for the builder, application, and permissions boundaries resources to maintain isolation and prevent builders from being able to escalate their privileges.
The builder policy also includes some basic control plane permissions, while the application-boundary policy you created includes permissions used across a suite of services that a typical serverless application might need. However, both policies are only meant to demonstrate the concepts in this blog post. In practice, you will need to create policies that more accurately reflect the permissions needed by builder and application roles in your organization. See the example-permissions-boundaries repository on the AWS Samples GitHub site for more ideas.
Use the builder role to launch an application stack
In this section you will assume the builder role and verify that you can launch the application stack, including the application roles, but only if the required permissions boundary and path are specified.
To test launching a stack that creates application roles
Assume the builder role by using the following set of commands (copy and paste into the terminal as a single block). This step uses the jq program, which is available in most operating system package repositories.
You will use this role for all of the following procedures up until the “Clean up” section. If, during the course of this exercise, you get an error that “The security token included in the request is expired”, create a new terminal and repeat this step to get a fresh set of credentials.
The trust policy for the builder role allows any principal in the account to assume it. You can use a combination of the Principal and Condition attributes to further reduce its scope. Normally builder roles are assumed directly via federation or AWS SSO.
Check that the you have now assumed the builder role by using the following command:
aws sts get-caller-identity
Launch the example application stack by using the following command:
If things are set up correctly, the stack will fail. To confirm, check the StackStatus by using the following command – it should show ROLLBACK_IN_PROGRESS or ROLLBACK_COMPLETE.
The stack failed to create because the builder role you assumed does not have permissions to create the two application roles without specifying the /application_roles/ path and attaching a permissions boundary with /permissions_boundaries/ in the path. To see the details, use the following command:
If the original stack did not create successfully, you will not be able to update it, so you will need to delete it instead by using the following command:
Start an execution of the state machine and verify the application is working by using the following commands. Run them one at a time to allow the execution to finish.
If the output is “\”Hello Builder!\””, then the application is working.
Test that a builder can’t escalate their privileges
In this section, you will test scenarios where a builder attempts, intentionally or not, to escalate their privileges by first modifying the policies attached to the builder role and then extending the permissions of an application role beyond the permissions boundary.
To test updating a builder policy attached to the builder role
Create an environment variable for your AWS account number, which will be used in several of the steps below, using the following command:
You should not get an error in this step because you are creating a new policy that complies with the resource constraint for the statement that includes the iam:CreatePolicy permission in the builder policy. But, it’s just a policy for now – it can’t have any effect unless attached to a role.
Now try to attach this new policy to the builder role by using the following command:
aws iam attach-role-policy \
--role-name builder \
--policy-arn arn:aws:iam::$AWS_ACCOUNT:policy/application_policies/sneaky-policy
You should get an error because you’re attempting to attach a policy to a role that’s not in the /application-roles/ space, in this case the builder role.
To test modifying an application role with actions outside the permissions boundary
In this procedure, you will attempt to escalate the privileges of the MyLambdaFunctionExecutionRole by adding an action (s3:CreateBucket) that is outside of the permissions boundary attached to the role and then attempting to execute that action when MyLambdaFunction is invoked.
Update the builder-application stack by using the following command:
Start an execution of the state machine and verify the result by using the following commands. Run them one at a time to allow the execution to finish.
The status should be FAILED. Remember – the effective permissions for any application roles will be the intersection of the attached permissions policies and the permissions boundary. Thus, this execution failed because even though you were able to modify the inline policy of the Lambda function to add s3:CreateBucket, since that action is not allowed in the application-boundary policy attached to the Lambda as a permissions boundary, the request to create an S3 bucket was denied.
Get the name of the latest log stream by using the following commands:
To verify the actual error was due to a lack of permissions, get the event message by using the following command, replacing <value> with the value of the log stream copied in the step above. If using a bash terminal, you will need to escape any dollar signs in <value> with a backslash character:
The error should read [ERROR] ClientError: An error occurred (AccessDenied) when calling the CreateBucket operation: Access Denied, which confirms that the permissions boundary prevented you from escalating your privileges as a builder via an application role.
You have now verified that you can safely allow builders to create IAM policies and roles!
Clean up
After you have finished testing, clean up the resources created in this example. Because the builder role does not have permissions to delete builder policies and roles, you will need to assume a different role that can manage IAM resources to complete step 3 below. If you create a new terminal session, make sure the AWS_ACCOUNT environment variable is set.
To clean up
Delete the builder-application stack by using the following command:
Permissions boundaries are applied to individual IAM users or roles within an account. If your organization has multiple accounts, you must create and maintain these boundaries in each account for each individual user or role. But what if you’d like to apply a subset of these rules or others across some or all of your accounts? In this case, you could use service control policies (SCPs), which are a feature of AWS Organizations, to provide central control over the maximum available permissions for multiple accounts in your organization. By organizing accounts into organizational units (OUs), which are groups of accounts that serve an application or service, you can apply service control policies (SCPs) to create targeted governance boundaries for your OUs. To learn more about creating SCPs, see Get more out of service control policies in a multi-account environment in the AWS Security Blog.
Additional tools
Creating and managing tightly scoped policies and roles is an ongoing process that requires a lot of thought and attention to detail. AWS IAM enables fine-grained access control to AWS services, and permissions boundaries are an advanced feature. There is no substitute for actual testing like you performed in the “Test that a builder can’t escalate their privileges” section above, however you can also use the IAM Policy Simulator as a tool to test policies and determine whether or not specific actions are allowed for a given user, group, or role. Additional tools you can use to create, audit, and update IAM policies include:
Access Advisor – to review when services and actions were last accessed.
Access Analyzer – to help identify resources in your organization and accounts that are shared with an external identity, validate IAM policies against policy grammar and best practices, and generate IAM policies based on access activity in your AWS CloudTrail logs.
AWS Cloud Development Kit (CDK) – has built-in convenience methods to help you follow best practices, including the ability to generate least-privilege policies for cloud applications with a single line of code.
Open Source tools like cfn-nag and cdk-nag – to inspect CloudFormation templates and CDK applications for patterns that may indicate insecure infrastructure, for example IAM policies that are too permissive.
Conclusion
In this post, you learned how to put policies and guardrails in place that will allow your organization to grant IAM permissions to builders. These changes will enable your builders to develop and deploy cloud infrastructure and applications more rapidly, and will help strengthen your organization’s security culture by extending the responsibility to a broader group. To learn more about creating, testing, and refining IAM policies and permissions boundaries, see Creating IAM policies, Testing IAM policies, and Refining permissions using access information in the IAM User Guide, and IAM policy types: How and when to use them in the AWS Security Blog.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.