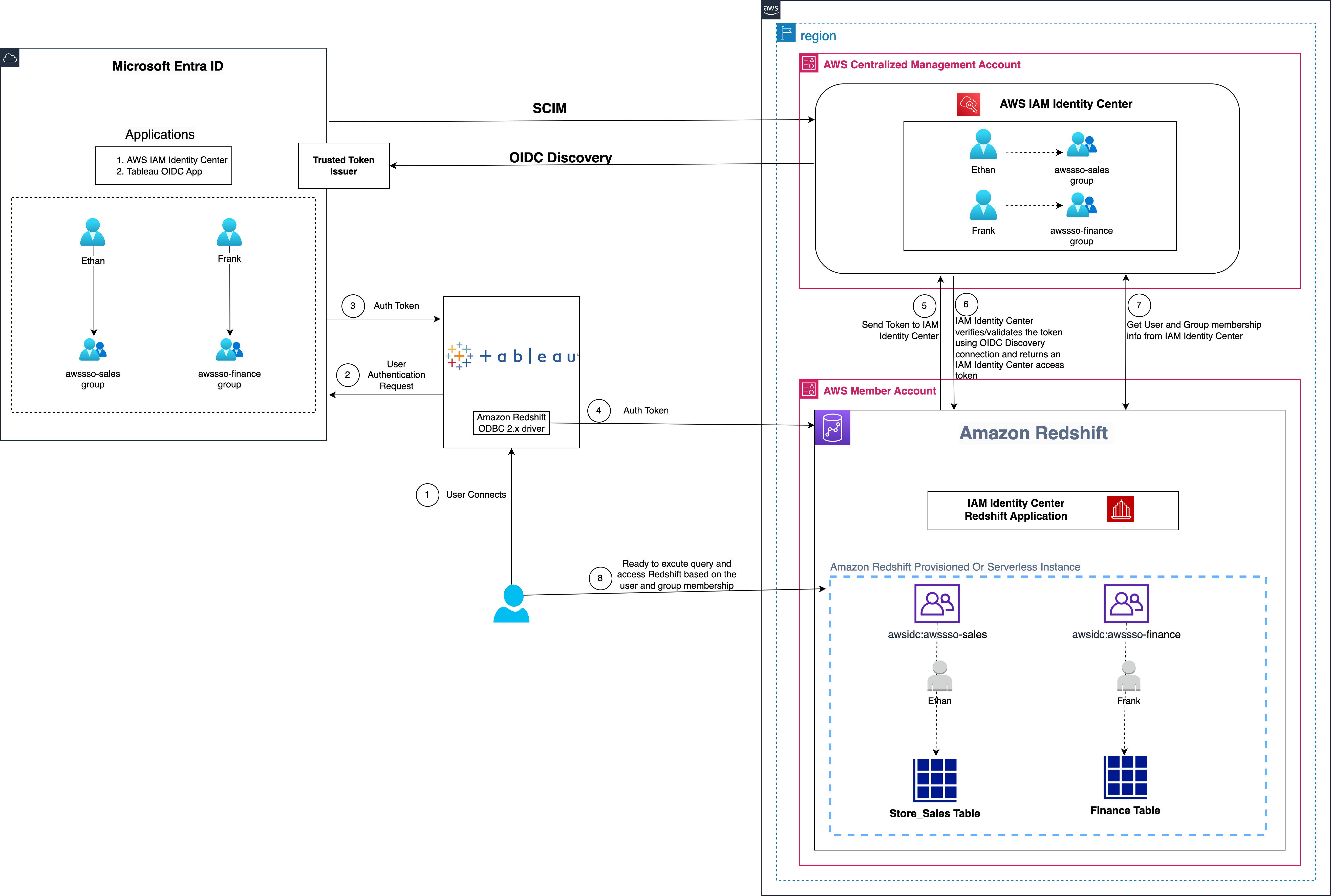
Post Syndicated from Salman Ahmed original https://aws.amazon.com/blogs/security/keep-your-firewall-rules-up-to-date-with-network-firewall-features/
AWS Network Firewall is a managed firewall service that makes it simple to deploy essential network protections for your virtual private clouds (VPCs) on AWS. Network Firewall automatically scales with your traffic, and you can define firewall rules that provide fine-grained control over network traffic.
When you work with security products in a production environment, you need to maintain a consistent effort to keep the security rules synchronized as you make modifications to your environment. To stay aligned with your organization’s best practices, you should diligently review and update security rules, but this can increase your team’s operational overhead.
Since the launch of Network Firewall, we have added new capabilities that simplify your efforts by using managed rules and automated methods to help keep your firewall rules current. This approach can streamline operations for your team and help enhance security by reducing the risk of failures stemming from manual intervention or customer automation processes. You can apply regularly updated security rules with just a few clicks, enabling a wide range of comprehensive protection measures.
In this blog post, I discuss three features—managed rule groups, prefix lists, and tag-based resource groups—offering an in-depth look at how Network Firewall operates to assist you in keeping your rule sets current and effective.
Prerequisites
If this is your first time using Network Firewall, make sure to complete the following prerequisites. However, if you already created rule groups, a firewall policy, and a firewall, then you can skip this section.
Network Firewall and AWS managed rule groups
AWS managed rule groups are collections of predefined, ready-to-use rules that AWS maintains on your behalf. You can use them to address common security use cases and help protect your environment from various types of threats. This can help you stay current with the evolving threat landscape and security best practices.
AWS managed rule groups are available for no additional cost to customers who use Network Firewall. When you work with a stateful rule group—a rule group that uses Suricata-compatible intrusion prevention system (IPS) specifications—you can integrate managed rules that help provide protection from botnet, malware, and phishing attempts.
AWS offers two types of managed rule groups: domain and IP rule groups and threat signature rule groups. AWS regularly maintains and updates these rule groups, so you can use them to help protect against constantly evolving security threats.
When you use Network Firewall, one of the use cases is to protect your outbound traffic from compromised hosts, malware, and botnets. To help meet this requirement, you can use the domain and IP rule group. You can select domain and IP rules based on several factors, such as the following:
- Domains that are generally legitimate but now are compromised and hosting malware
- Domains that are known for hosting malware
- Domains that are generally legitimate but now are compromised and hosting botnets
- Domains that are known for hosting botnets
The threat signature rule group offers additional protection by supporting several categories of threat signatures to help protect against various types of malware and exploits, denial of service attempts, botnets, web attacks, credential phishing, scanning tools, and mail or messaging attacks.
To use Network Firewall managed rules
- Update the existing firewall policy that you created as part of the Prerequisites for this post or create a new firewall policy.
- Add a managed rule group to your policy and select from Domain and IP rule groups or Threat signature rule groups.
Figure 1 illustrates the use of AWS managed rules. It shows both the domain and IP rule group and the threat signature rule group, and it includes one specific rule or category from each as a demonstration.

Figure 1: Network Firewall deployed with AWS managed rules
As shown in Figure 1, the process for using AWS managed rules has the following steps:
- The Network Firewall policy contains managed rules from the domain and IP rule groups and threat signature rule groups.
- If the traffic from a protected subnet passes the checks of the firewall policy as it goes to the Network Firewall endpoint, then it proceeds to the NAT gateway and the internet gateway (depicted with the dashed line in the figure).
- If traffic from a protected subnet fails the checks of the firewall policy, the traffic is dropped at the Network Firewall endpoint (depicted with the dotted line).
Inner workings of AWS managed rules
Let’s go deeper into the underlying mechanisms and processes that AWS uses for managed rules. After you configure your firewall with these managed rules, you gain the benefits of the up-to-date rules that AWS manages. AWS pulls updated rule content from the managed rules provider on a fixed cadence for domain-based rules and other managed rule groups.
The Network Firewall team operates a serverless processing pipeline powered by AWS Lambda. This processes the rules from the vendor source, first fetching them so that they can be manipulated and transformed into the managed rule groups. Then the rules are mapped to the appropriate category based on their metadata. The final rules are uploaded to Amazon Simple Storage Service (Amazon S3) to prepare for propagation in each AWS Region.
Finally, Network Firewall processes the rule group content Region by Region, updating the managed rule group object associated with your firewall with the new content from the vendor. For threat signature rule groups, subscribers receive an SNS notification, letting them know that the rules have been updated.
AWS handles the tasks associated with this process so you can deploy and secure your workloads while addressing evolving security threats.
Network Firewall and prefix lists
Network Firewall supports Amazon Virtual Private Cloud (Amazon VPC) prefix lists to simplify management of your firewall rules and policies across your VPCs. With this capability, you can define a prefix list one time and reference it in your rules later. For example, with prefix lists, you can group multiple CIDR blocks into a single object instead of managing them at an individual IP level by creating a prefix list for their specific use case.
AWS offers two types of prefix lists: AWS-managed prefix lists and customer-managed prefix lists. In this post, we focus on customer-managed prefix lists. With customer-managed prefix lists, you can define and maintain your own sets of IP address ranges to meet your specific needs. Although you operate these prefix lists and can add and remove IP addresses, AWS controls and maintains the integration of these prefix lists with Network Firewall.
To use a Network Firewall prefix list
- Create a prefix list.
- Update your existing rule group that you created as part of the Prerequisites for this post or create a new rule group.
- Use IP set references in Suricata compatible rule groups. In the IP set references section, select Edit, and in the Resource ID section, select the prefix list that you created.
Figure 2 illustrates Network Firewall deployed with a prefix list.

Figure 2: Network Firewall deployed with prefix list
As shown in Figure 2, we use the same design as in our previous example:
- We use a prefix list that is referenced in our rule group.
- The traffic from the protected subnet goes through the Network Firewall endpoint and NAT gateway and then to the internet gateway. As it passes through the Network Firewall endpoint, the firewall policy that contains the rule group determines if the traffic is allowed or not according to the policy.
Inner workings of prefix lists
After you configure a rule group that references a prefix list, Network Firewall automatically keeps the associated rules up to date. Network Firewall creates an IP set object that corresponds to this prefix list. This IP set object is how Network Firewall internally tracks the state of the prefix list reference, and it contains both resolved IP addresses from the source and additional metadata that’s associated with the IP set, such as which rule groups reference it. AWS manages these references and uses them to track which firewalls need to be updated when the content of these IP sets change.
The Network Firewall orchestration engine is integrated with prefix lists, and it works in conjunction with Amazon VPC to keep the resolved IPs up to date. The orchestration engine automatically refreshes IPs associated with a prefix list, whether that prefix list is AWS-managed or customer-managed.
When you use a prefix list with Network Firewall, AWS handles a significant portion of the work on your behalf. This managed approach simplifies the process while providing the flexibility that you need to customize the allow or deny list of IP addresses according to your specific security requirements.
Network Firewall and tag-based resource groups
With Network Firewall, you can now use tag-based resource groups to simplify managing your firewall rules. A resource group is a collection of AWS resources that are in the same Region, and that match the criteria specified in the group’s query. A tag-based resource group bases its membership on a query that specifies a list of resource types and tags. Tags are key value pairs that help identify and sort your resources within your organization.
In your stateful firewall rules, you can reference a resource group that you have created for a specific set of Amazon Elastic Compute Cloud (Amazon EC2) instances or elastic network interfaces (ENIs). When these resources change, you don’t have to update your rule group every time. Instead, you can use a tagging policy for the resources that are in your tag-based resource group.
As your AWS environment changes, it’s important to make sure that new resources are using the same egress rules as the current resources. However, managing the changing EC2 instances due to workload changes creates an operational overhead. By using tag-based resource groups in your rules, you can eliminate the need to manually manage the changing resources in your AWS environment.
To use Network Firewall resource groups with a stateful rule group
- Create Network Firewall resource groups – Create a resource group for each of two applications. For the example in this blog post, enter the name
rg-app-1for application 1, andrg-app-2for application 2. - Update your existing rule group that you created as a part of the Prerequisites for this post or create a new rule group. In the IP set references section, select Edit; and in the Resource ID section, choose the resource groups that you created in the previous step (rg-app-1 and rg-app-2).
Now as your EC2 instance or ENIs scale, those resources stay in sync automatically.
Figure 3 illustrates resource groups with a stateful rule group.

Figure 3: Network Firewall deployed with resource groups
As shown in Figure 3, we tagged the EC2 instances as app-1 or app-2. In your stateful rule group, restrict access to a website for app-2, but allow it for app-1:
- We use the resource group that is referenced in our rule group.
- The traffic from the protected subnet goes through the Network Firewall endpoint and the NAT gateway and then to the internet gateway. As it passes through the Network Firewall endpoint, the firewall policy that contains the rule group referencing the specific resource group determines how to handle the traffic. In the figure, the dashed line shows that the traffic is allowed while the dotted line shows it’s denied based on this rule.
Inner workings of resource groups
For tag-based resource groups, Network Firewall works with resource groups to automatically refresh the contents of the Network Firewall resource groups. Network Firewall first resolves the resources that are associated with the resource group, which are EC2 instances or ENIs that match the tag-based query specified. Then it resolves the IP addresses associated with these resources by calling the relevant Amazon EC2 API.
After the IP addresses are resolved, through either a prefix list or Network Firewall resource group, the IP set is ready for propagation. Network Firewall uploads the refreshed content of the IP set object to Amazon S3, and the data plane capacity (the hardware responsible for packet processing) fetches this new configuration. The stateful firewall engine accepts and applies these updates, which allows your rules to apply to the new IP set content.
By using tag-based resource groups within your workloads, you can delegate a substantial amount of your firewall management tasks to AWS, enhancing efficiency and reducing manual efforts on your part.
Considerations
- When you use a managed rule group in your firewall policy, you can edit the following setting: Set rule actions to alert. This will override all rule actions in the rule group to
alertwhich is useful for testing a rule group before using it control your traffic. - Managed rule groups count against the limit of stateful rules for each policy. For more information, see AWS Network Firewall quotas and setting rule group capacity in AWS Network Firewall.
- When working with prefix lists and resource groups, make sure that you understand the Limits for IP set references.
Conclusion
In this blog post, you learned how to use Network Firewall managed rule groups, prefix lists, and tag-based resource groups to harness the automation and user-friendly capabilities of Network Firewall. You also learned more detail about how AWS operates these features on your behalf, to help you deploy a simple-to-use and secure solution. Enhance your current or new Network Firewall deployments by integrating these features today.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.

























 Manjit Chakraborty is a Senior Solutions Architect at AWS. He is a Seasoned & Result driven professional with extensive experience in Financial domain having worked with customers on advising, designing, leading, and implementing core-business enterprise solutions across the globe. In his spare time, Manjit enjoys fishing, practicing martial arts and playing with his daughter.
Manjit Chakraborty is a Senior Solutions Architect at AWS. He is a Seasoned & Result driven professional with extensive experience in Financial domain having worked with customers on advising, designing, leading, and implementing core-business enterprise solutions across the globe. In his spare time, Manjit enjoys fishing, practicing martial arts and playing with his daughter. Neeraj Roy is a Principal Solutions Architect at AWS based out of London. He works with Global Financial Services customers to accelerate their AWS journey. In his spare time, he enjoys reading and spending time with his family.
Neeraj Roy is a Principal Solutions Architect at AWS based out of London. He works with Global Financial Services customers to accelerate their AWS journey. In his spare time, he enjoys reading and spending time with his family.


 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas. Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.
Aruna Govindaraju is an Amazon OpenSearch Specialist Solutions Architect and has worked with many commercial and open source search engines. She is passionate about search, relevancy, and user experience. Her expertise with correlating end-user signals with search engine behavior has helped many customers improve their search experience.








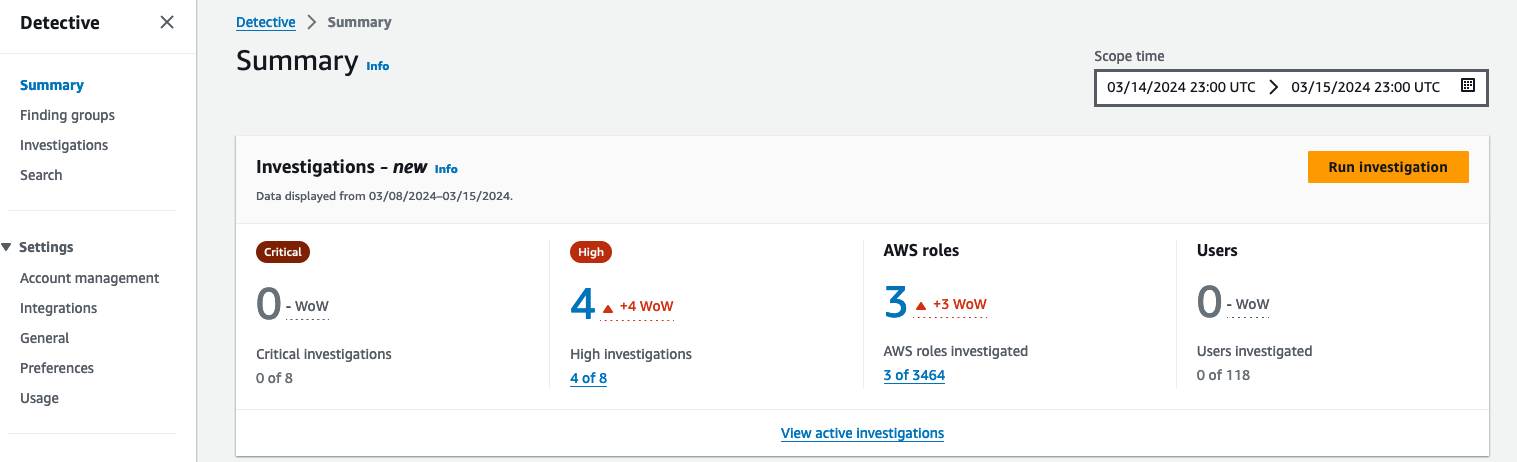
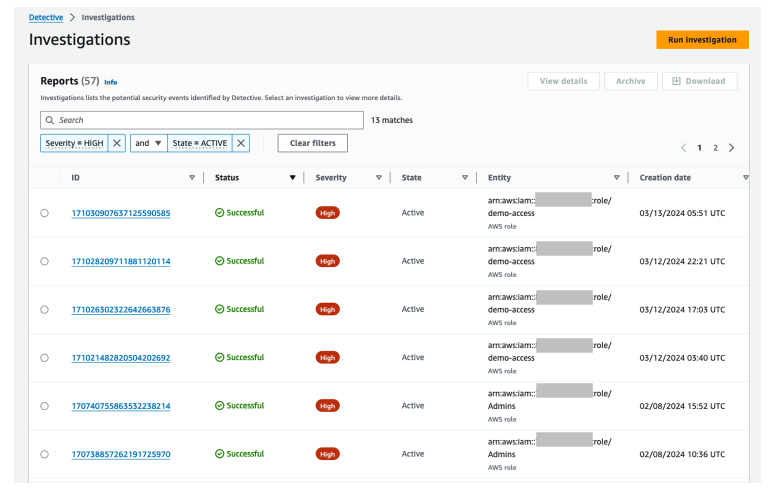
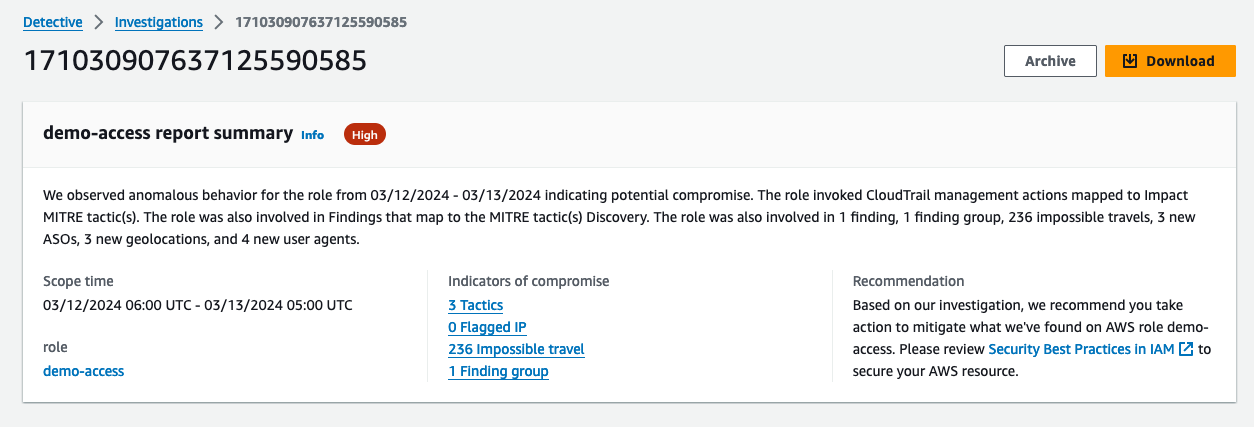
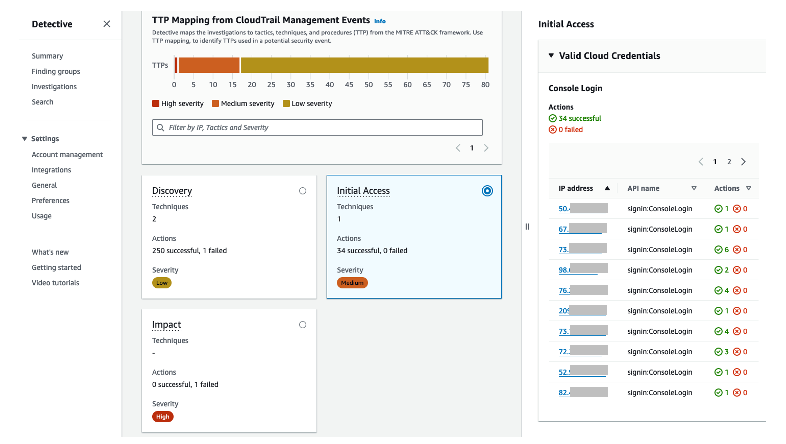
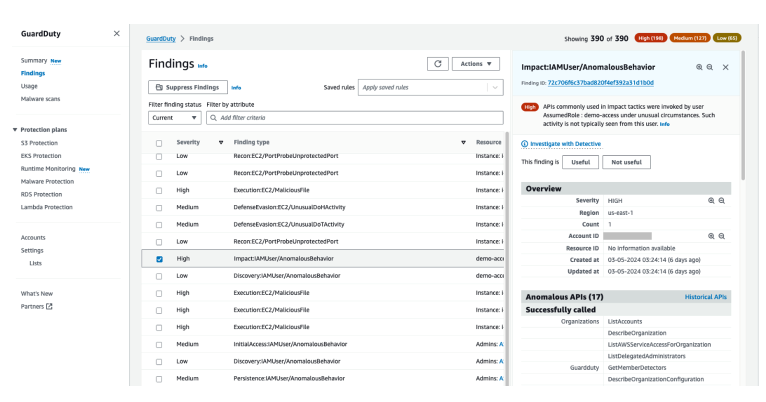
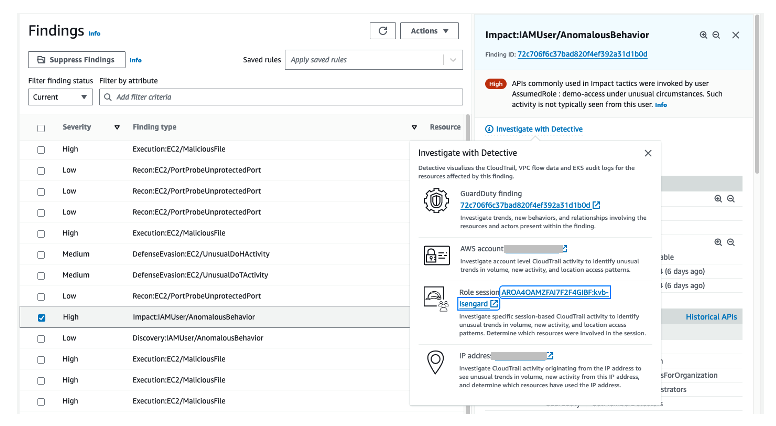
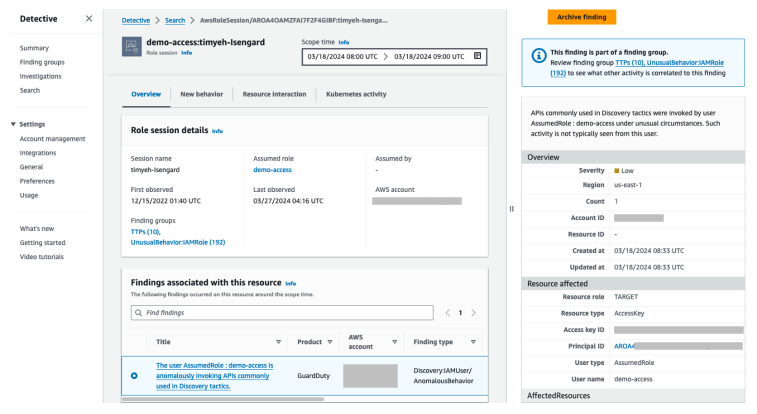
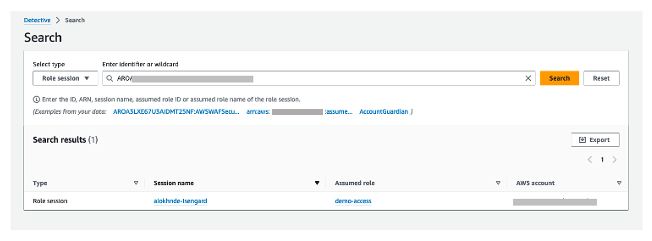
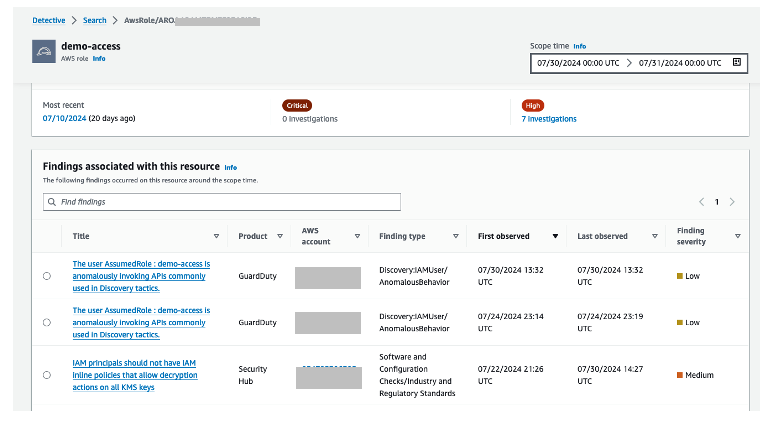
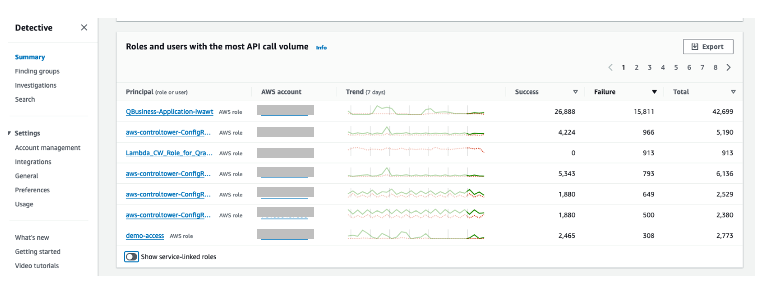
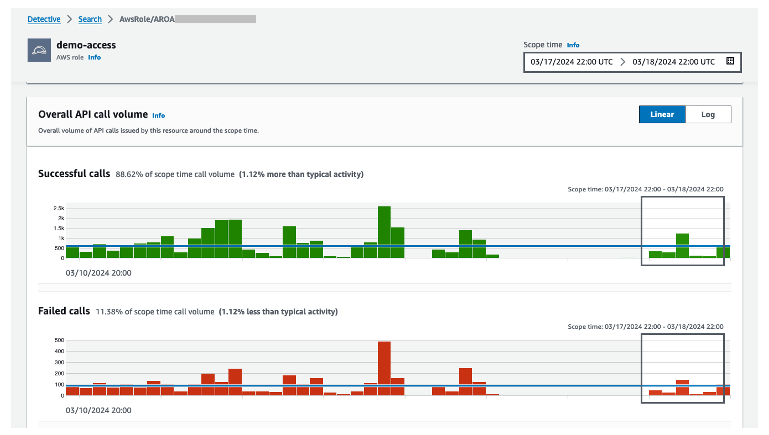
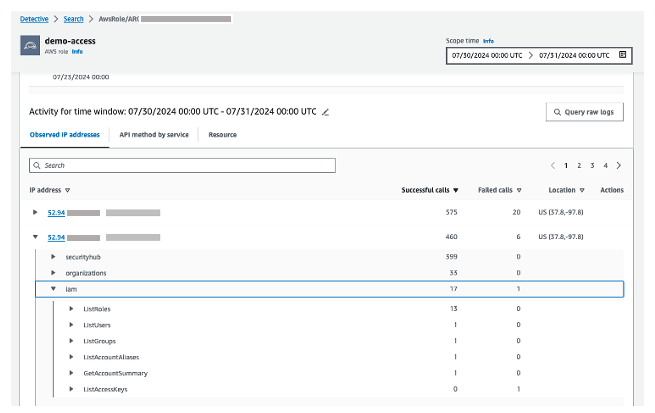
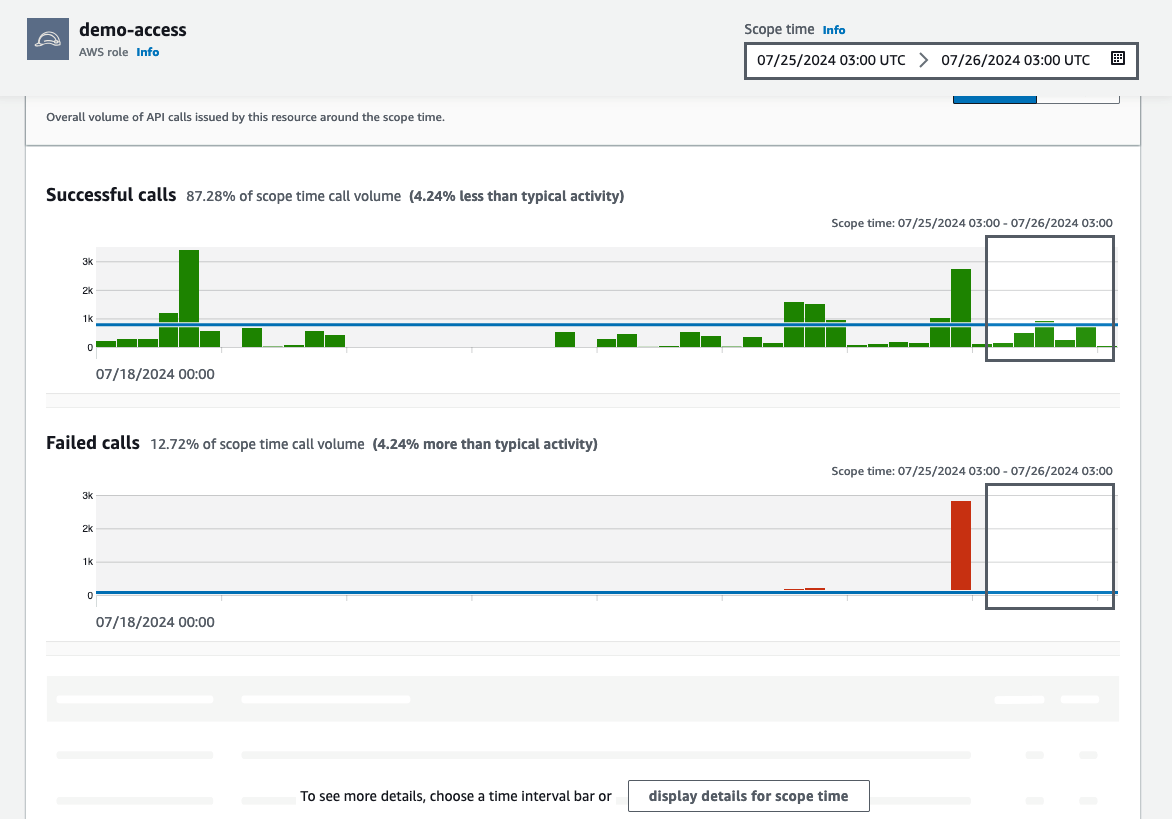 Figure 12: Overall API call volume during the specified scope time
Figure 12: Overall API call volume during the specified scope time















 Rajkumar Irudayaraj is a Senior Product Director at Salesforce with over 20 years of experience in data platforms and services, with a passion for delivering data-powered experiences to customers.
Rajkumar Irudayaraj is a Senior Product Director at Salesforce with over 20 years of experience in data platforms and services, with a passion for delivering data-powered experiences to customers. Sriram Sethuraman is a Senior Manager in Salesforce Data Cloud product management. He has been building products for over 9 years using big data technologies. In his current role at Salesforce, Sriram works on Zero Copy integration with major data lake partners and helps customers deliver value with their data strategies.
Sriram Sethuraman is a Senior Manager in Salesforce Data Cloud product management. He has been building products for over 9 years using big data technologies. In his current role at Salesforce, Sriram works on Zero Copy integration with major data lake partners and helps customers deliver value with their data strategies. Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven.
Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven. Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. Ravi works with strategic ISV partners, Salesforce and Tableau, to deliver innovative and well-architected products and solutions that help joint customers achieve their business and technical objectives.
Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. Ravi works with strategic ISV partners, Salesforce and Tableau, to deliver innovative and well-architected products and solutions that help joint customers achieve their business and technical objectives. Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music. Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field. Michael Chess is a Technical Product Manager at AWS Lake Formation. He focuses on improving data permissions across the data lake. He is passionate about enabling customers to build and optimize their data lakes to meet stringent security requirements.
Michael Chess is a Technical Product Manager at AWS Lake Formation. He focuses on improving data permissions across the data lake. He is passionate about enabling customers to build and optimize their data lakes to meet stringent security requirements. Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.







 Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community. Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.
Paul Villena is a Senior Analytics Solutions Architect in AWS with expertise in building modern data and analytics solutions to drive business value. He works with customers to help them harness the power of the cloud. His areas of interests are infrastructure as code, serverless technologies, and coding in Python.



 Diego Colombatto is a Senior Partner Solutions Architect at AWS. He brings more than 15 years of experience in designing and delivering Digital Transformation projects for enterprises. At AWS, Diego works with partners and customers advising how to leverage AWS technologies to translate business needs into solutions.
Diego Colombatto is a Senior Partner Solutions Architect at AWS. He brings more than 15 years of experience in designing and delivering Digital Transformation projects for enterprises. At AWS, Diego works with partners and customers advising how to leverage AWS technologies to translate business needs into solutions. Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.
Angel Conde Manjon is a Sr. EMEA Data & AI PSA, based in Madrid. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI. Tiziano Curci is a Manager, EMEA Data & AI PDS at AWS. He leads a team that works with AWS Partners (G/SI and ISV), to leverage the most comprehensive set of capabilities spanning databases, analytics and machine learning, to help customers unlock the through power of data through an end-to-end data strategy.
Tiziano Curci is a Manager, EMEA Data & AI PDS at AWS. He leads a team that works with AWS Partners (G/SI and ISV), to leverage the most comprehensive set of capabilities spanning databases, analytics and machine learning, to help customers unlock the through power of data through an end-to-end data strategy.
 Simon Peyer is a Solutions Architect at Amazon Web Services (AWS) based in Switzerland. He is a practical doer and passionate about connecting technology and people using AWS Cloud services. A special focus for him is data streaming and automations. Besides work, Simon enjoys his family, the outdoors, and hiking in the mountains.
Simon Peyer is a Solutions Architect at Amazon Web Services (AWS) based in Switzerland. He is a practical doer and passionate about connecting technology and people using AWS Cloud services. A special focus for him is data streaming and automations. Besides work, Simon enjoys his family, the outdoors, and hiking in the mountains.







 Rana Dutt is a Principal Solutions Architect at Amazon Web Services. He has a background in architecting scalable software platforms for financial services, healthcare, and telecom companies, and is passionate about helping customers build on AWS.
Rana Dutt is a Principal Solutions Architect at Amazon Web Services. He has a background in architecting scalable software platforms for financial services, healthcare, and telecom companies, and is passionate about helping customers build on AWS. Amar Surjit is a Senior Solutions Architect at Amazon Web Services (AWS), where he specializes in data analytics and streaming services. He advises AWS customers on architectural best practices, helping them design reliable, secure, efficient, and cost-effective real-time analytics data systems. Amar works closely with customers to create innovative cloud-based solutions that address their unique business challenges and accelerate their transformation journeys.
Amar Surjit is a Senior Solutions Architect at Amazon Web Services (AWS), where he specializes in data analytics and streaming services. He advises AWS customers on architectural best practices, helping them design reliable, secure, efficient, and cost-effective real-time analytics data systems. Amar works closely with customers to create innovative cloud-based solutions that address their unique business challenges and accelerate their transformation journeys. Diego Soares is a Principal Solutions Architect at AWS with over 20 years of experience in the IT industry. He has a background in infrastructure, security, and networking. Prior to joining AWS in 2021, Diego worked for Cisco, supporting financial services customers for over 15 years. He works with large financial institutions to help them achieve their business goals with AWS. Diego is passionate about how technology solves business challenges and provides beneficial outcomes by developing complex solution architectures.
Diego Soares is a Principal Solutions Architect at AWS with over 20 years of experience in the IT industry. He has a background in infrastructure, security, and networking. Prior to joining AWS in 2021, Diego worked for Cisco, supporting financial services customers for over 15 years. He works with large financial institutions to help them achieve their business goals with AWS. Diego is passionate about how technology solves business challenges and provides beneficial outcomes by developing complex solution architectures.
 Steve Phillips is a senior technical account manager at AWS in the North America region. Steve has worked with games customers for eight years and currently focuses on data warehouse architectural design, data lakes, data ingestion pipelines, and cloud distributed architectures.
Steve Phillips is a senior technical account manager at AWS in the North America region. Steve has worked with games customers for eight years and currently focuses on data warehouse architectural design, data lakes, data ingestion pipelines, and cloud distributed architectures. Sudipta Bagchi is a Sr. Specialist Solutions Architect at Amazon Web Services. He has over 14 years of experience in data and analytics, and helps customers design and build scalable and high-performant analytics solutions. Outside of work, he loves running, traveling, and playing cricket.
Sudipta Bagchi is a Sr. Specialist Solutions Architect at Amazon Web Services. He has over 14 years of experience in data and analytics, and helps customers design and build scalable and high-performant analytics solutions. Outside of work, he loves running, traveling, and playing cricket.