Today, customers in regulated industries face the challenge of defining and enforcing controls needed to meet compliance and security requirements while empowering engineers to make their design choices. In addition to addressing risk, reliability, performance, and resiliency requirements, organizations may also need to comply with frameworks and standards such as PCI DSS and NIST 800-53.
Building controls that account for service relationships and their dependencies is time-consuming and expensive. Sometimes customers restrict engineering access to AWS services and features until their cloud architects identify risks and implement their own controls.
To make that easier, today we are launching comprehensive controls management in AWS Control Tower. You can use it to apply managed preventative, detective, and proactive controls to accounts and organizational units (OUs) by service, control objective, or compliance framework. AWS Control Tower does the mapping between them on your behalf, saving time and effort.
With this new capability, you can now also use AWS Control Tower to turn on AWS Security Hub detective controls across all accounts in an OU. In this way, Security Hub controls are enabled in every AWS Region that AWS Control Tower governs.
Let’s see how this works in practice.
Using AWS Control Tower Comprehensive Controls Management In the AWS Control Tower console, there is a new Controls library section. There, I choose All controls. There are now more than three hundred controls available. For each control, I see which AWS service it is related to, the control objective this control is part of, the implementation (such as AWS Config rule or AWS CloudFormationGuard rule), the behavior (preventive, detective, or proactive), and the frameworks it maps to (such as NIST 800-53 or PCI DSS).
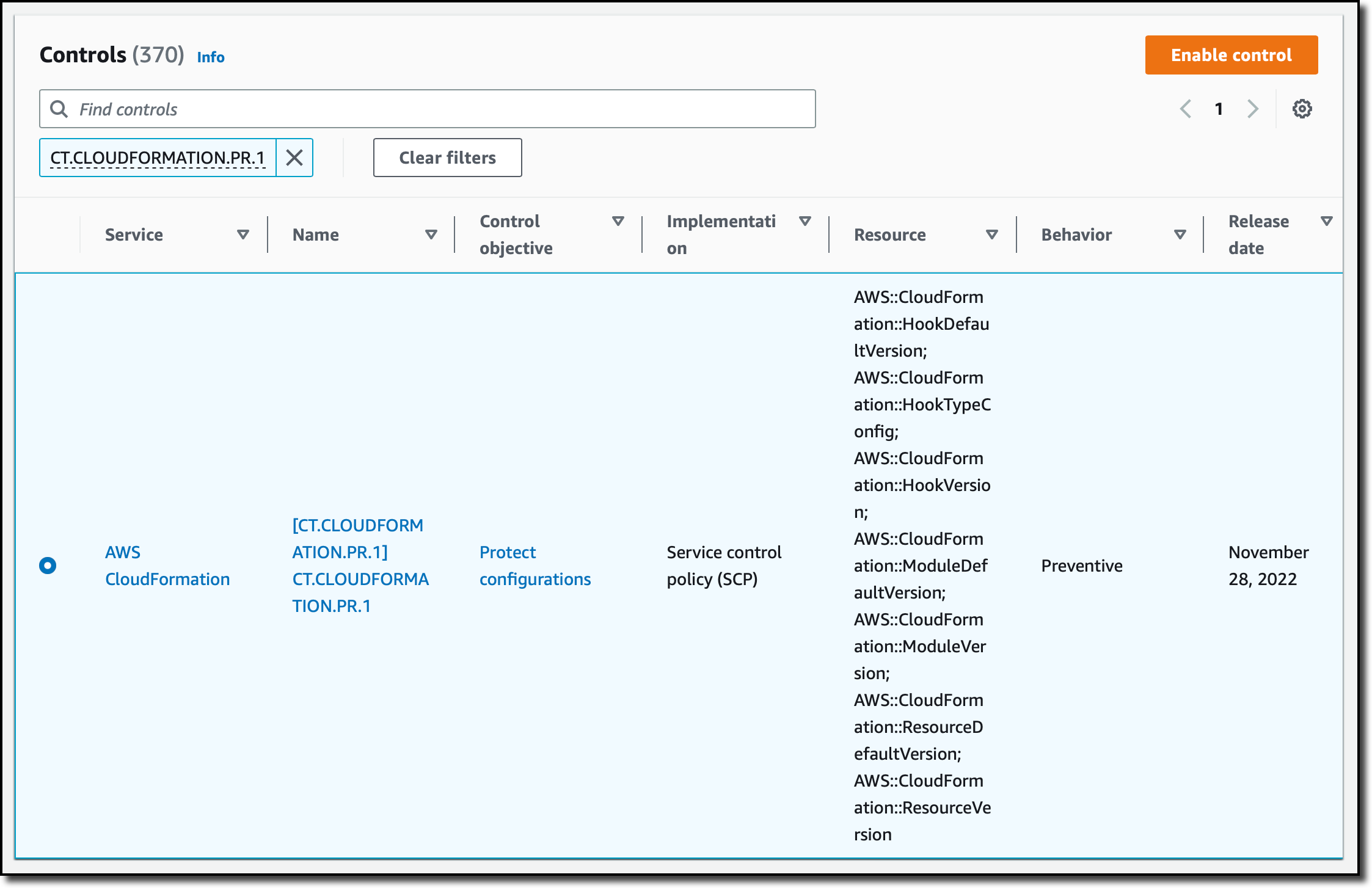
In the Find controls search box, I look for a preventive control called CT.CLOUDFORMATION.PR.1. This control uses a service control policy (SCP) to protect controls that use CloudFormation hooks and is required by the control that I want to turn on next. Then, I choose Enable control.
Then, I select the OU for which I want to enable this control.
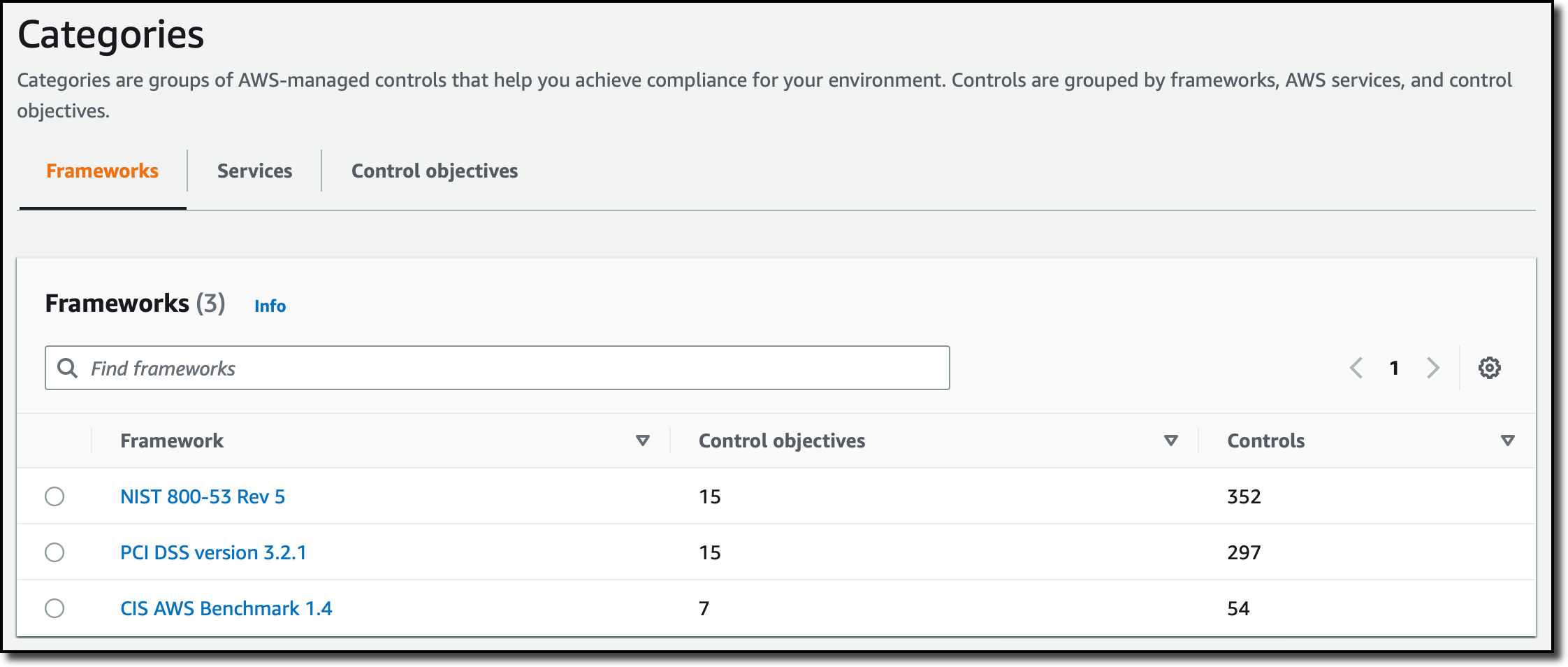
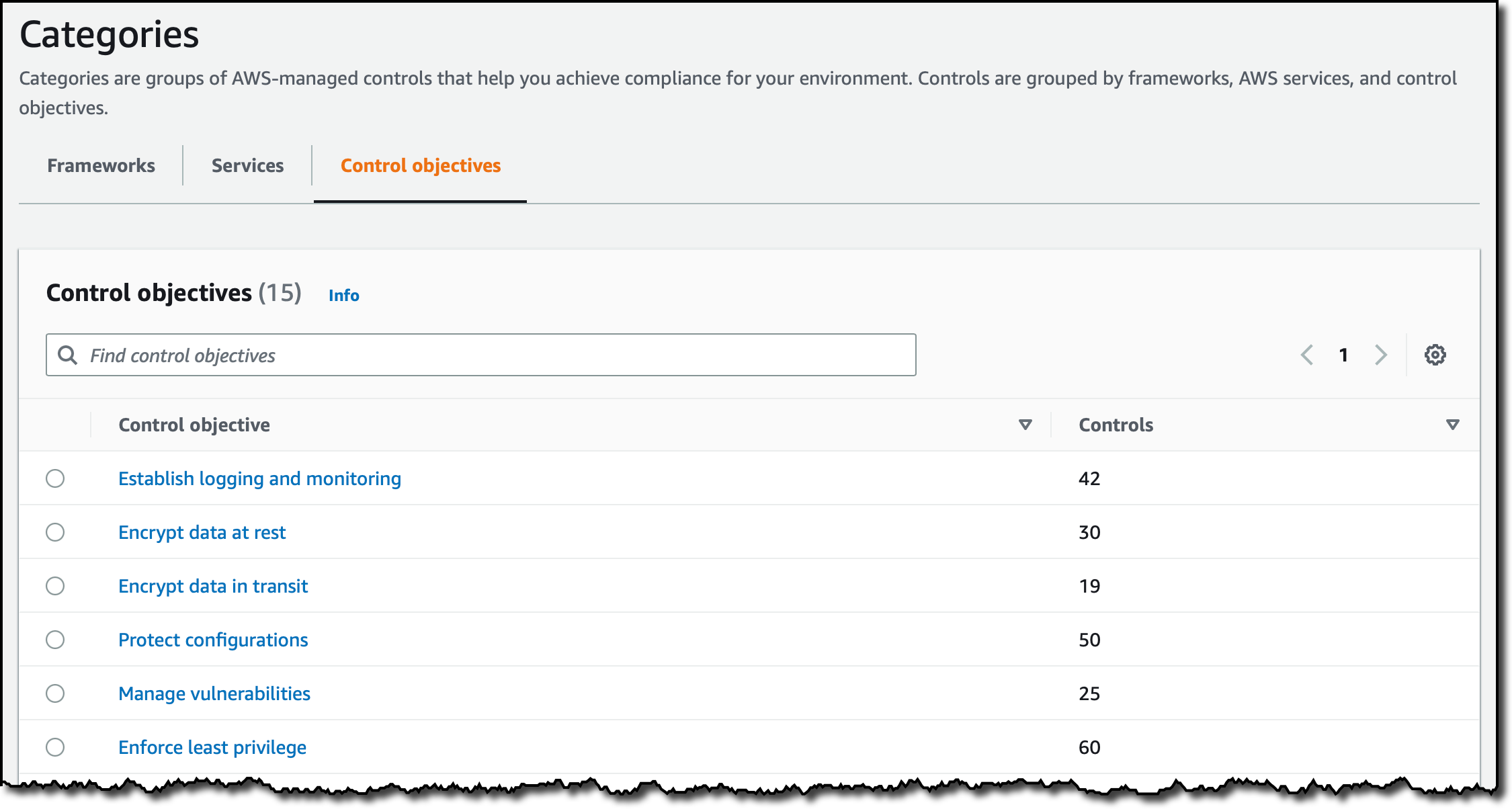
Now that I have set up this control, let’s see how controls are presented in the console in categories. I choose Categories in the navigation pane. There, I can browse controls grouped as Frameworks, Services, and Control objectives. By default, the Frameworks tab is selected.
I select a framework (for example, PCI DSS version 3.2.1) to see all the related controls and control objectives. To implement a control, I can select the control from the list and choose Enable control.
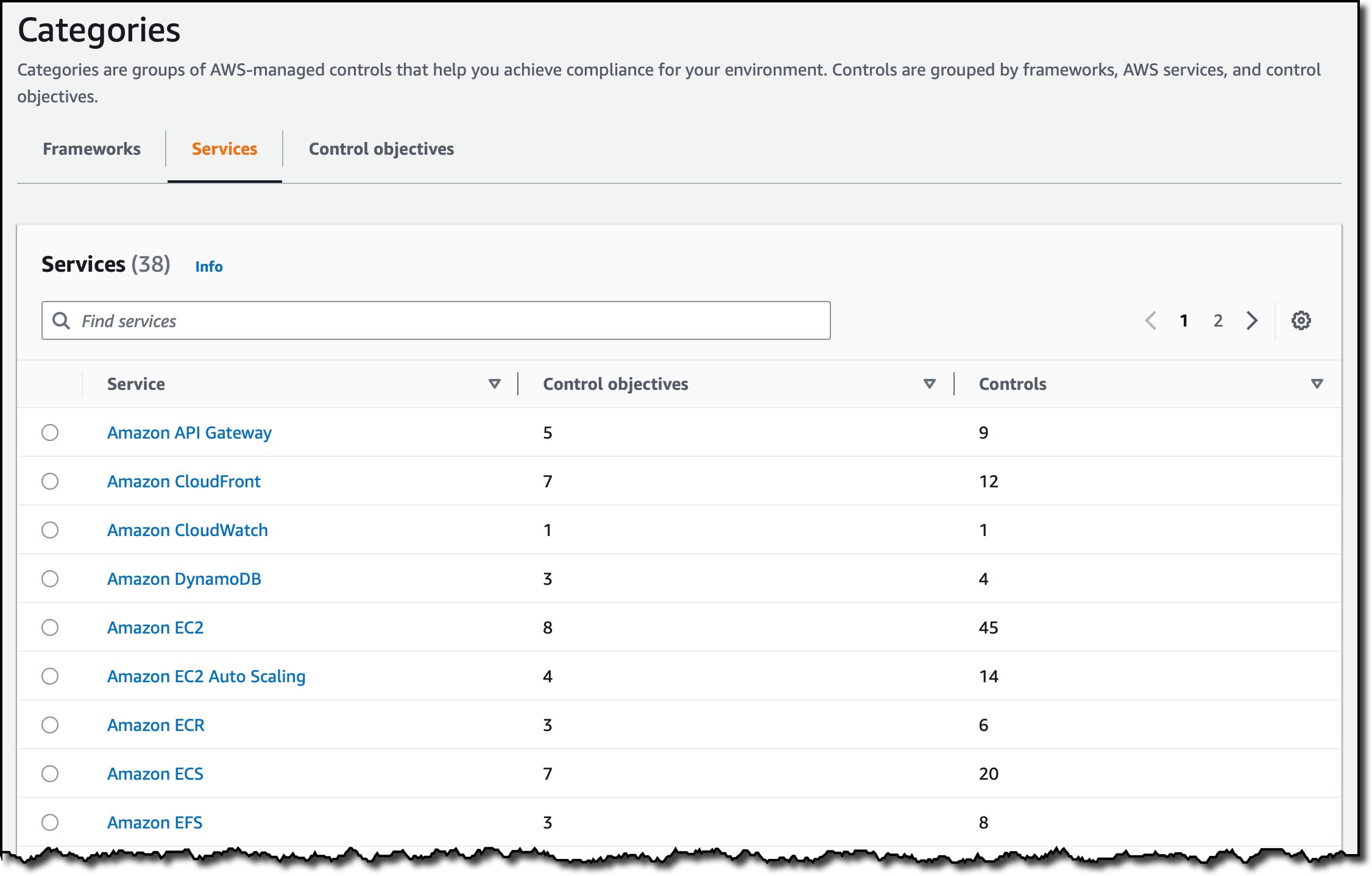
I can also manage controls by AWS service. When I select the Services tab, I see a list of AWS services and the related control objectives and controls.
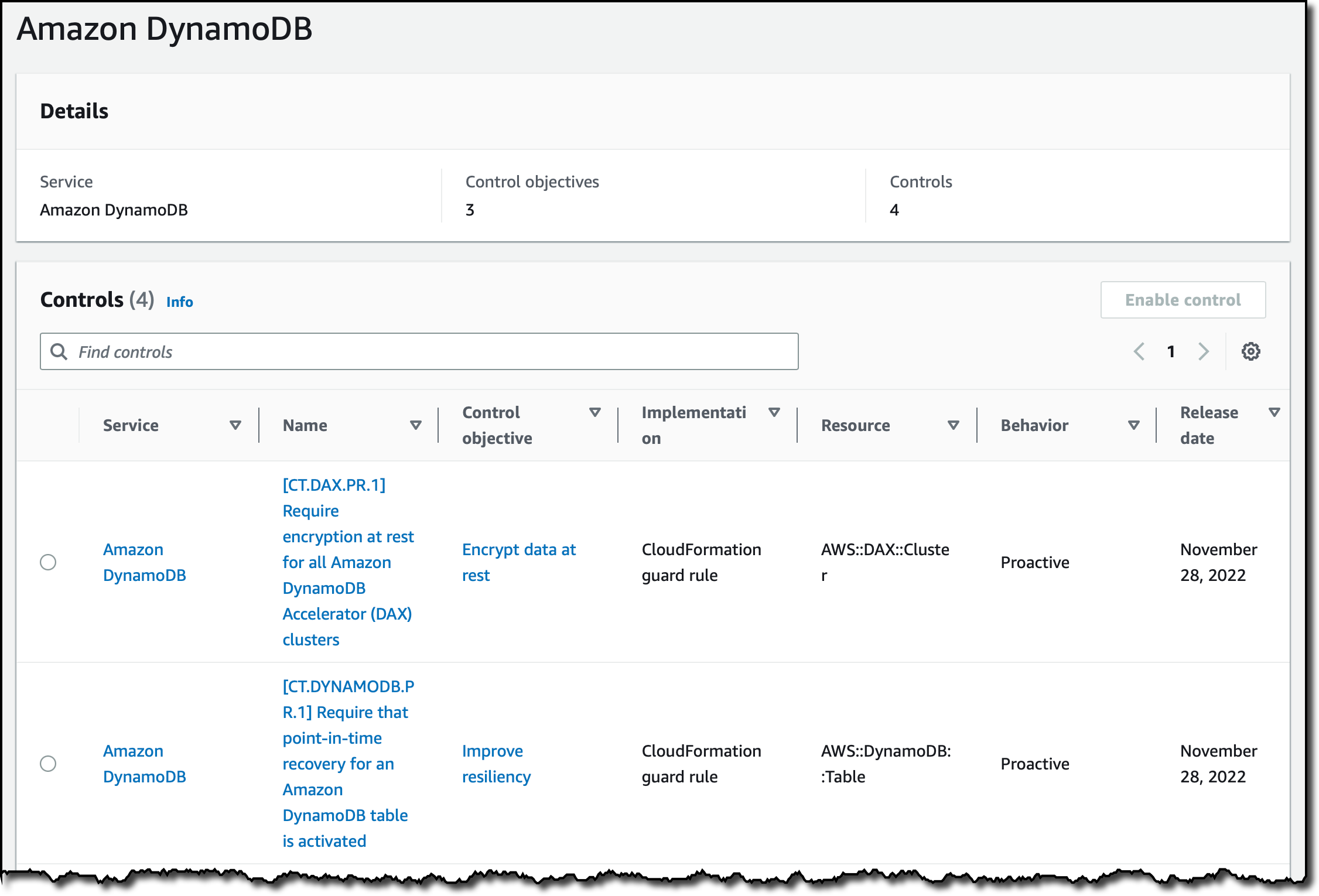
I choose Amazon DynamoDB to see the controls that I can turn on for this service.
I select the Control objectives tab. When I need to assess a control objective, this is where I have access to the list of related controls to turn on.
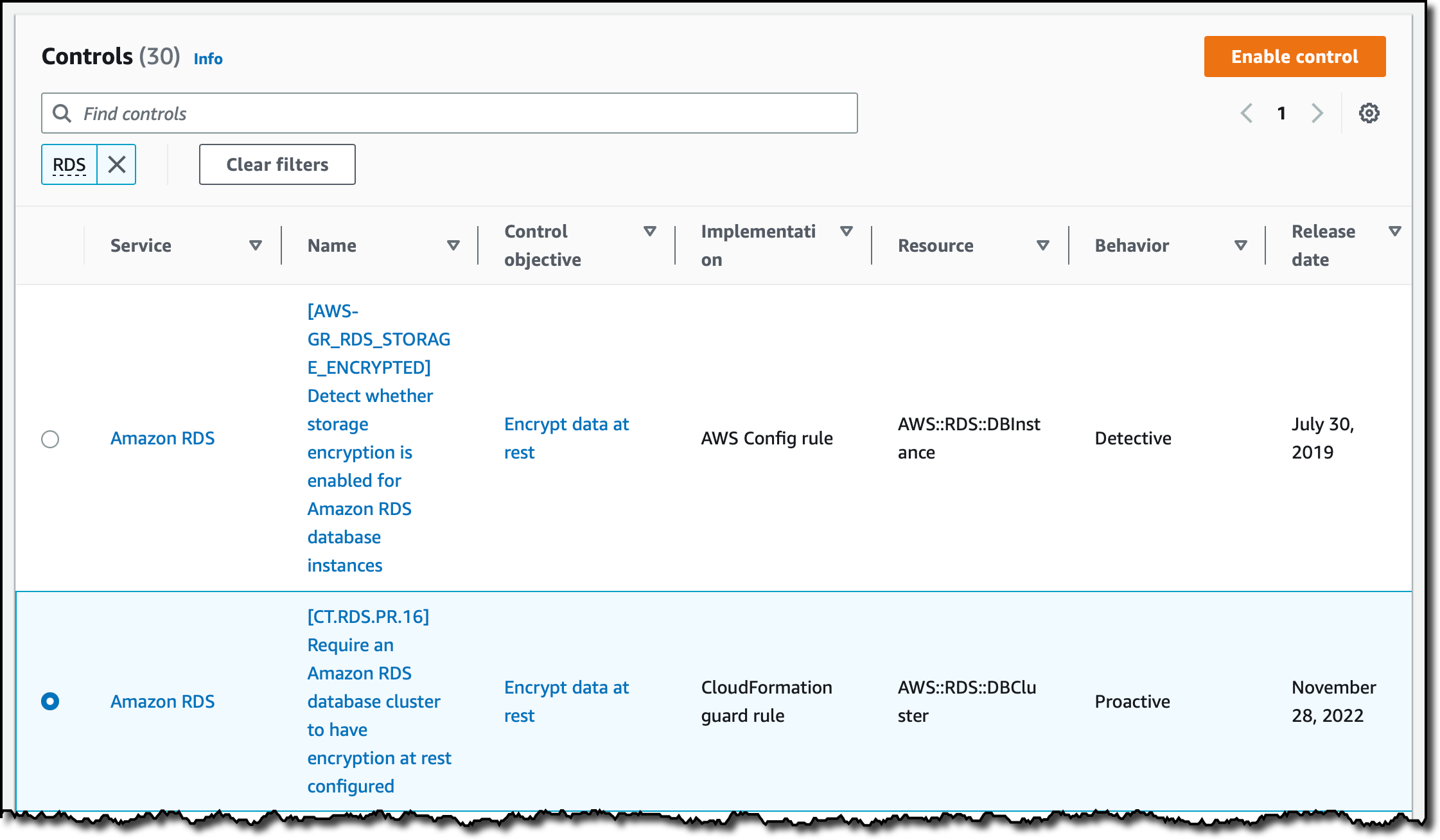
I choose Encrypt data at rest to see and search through the available controls for that control objective. I can also check which services are covered in this specific case. I type RDS in the search bar to find the controls related to Amazon Relational Database Service (RDS) for this control objective.
I choose CT.RDS.PR.16 – Require an Amazon RDS database cluster to have encryption at rest configured and then Enable control.
I select the OU for which I want to enable the control for, and I proceed. All the AWS accounts in this organization’s OU will have this control enabled in all the Regions that AWS Control Tower governs.
After a few minutes, the AWS Control Tower setup is updated. Now, the accounts in this OU have proactive control CT.RDS.PR.16 turned on. When an account in this OU deploys a CloudFormation stack, any Amazon RDS database cluster has to have encryption at rest configured. Because this control is proactive, it’ll be checked by a CloudFormation hook before the deployment starts. This saves a lot of time compared to a detective control that would find the issue only when the CloudFormation deployment is in progress or has terminated. This also improves my security posture by preventing something that’s not allowed as opposed to reacting to it after the fact.
Availability and Pricing Comprehensive controls management is available in preview today in all AWS Regions where AWS Control Tower is offered. These enhanced control capabilities reduce the time it takes you to vet AWS services from months or weeks to minutes. They help you use AWS by undertaking the heavy burden of defining, mapping, and managing the controls required to meet the most common control objectives and regulations.
There is no additional charge to use these new capabilities during the preview. However, when you set up AWS Control Tower, you will begin to incur costs for AWS services configured to set up your landing zone and mandatory controls. For more information, see AWS Control Tower pricing.
With Amazon Redshift, you can analyze data in the cloud at any scale. Amazon Redshift offers native data protection capabilities to protect your data using automatic and manual snapshots. This works great by itself, but when you’re using other AWS services, you have to configure more than one tool to manage your data protection policies.
To make this easier, I am happy to share that we added support for Amazon Redshift in AWS Backup. AWS Backup allows you to define a central backup policy to manage data protection of your applications and can now also protect your Amazon Redshift clusters. In this way, you have a consistent experience when managing data protection across all supported services. If you have a multi-account setup, the centralized policies in AWS Backup let you define your data protection policies across all your accounts within your AWS Organizations. To help you meet your regulatory compliance needs, AWS Backup now includes Amazon Redshift in its auditor-ready reports. You also have the option to use AWS Backup Vault Lock to have immutable backups and prevent malicious or inadvertent changes.
Let’s see how this works in practice.
Using AWS Backup with Amazon Redshift The first step is to turn on the Redshift resource type for AWS Backup. In the AWS Backup console, I choose Settings in the navigation pane and then, in the Service opt-in section, Configure resources. There, I toggle the Redshift resource type on and choose Confirm.
Now, I can create or update a backup plan to include the backup of all, or some, of my Redshift clusters. In the backup plan, I can define how often these backups should be taken and for how long they should be kept. For example, I can have daily backups with one week of retention, weekly backups with one month of retention, and monthly backups with one year of retention.
I can also create on-demand backups. Let’s see this with more details. I choose Protected resources in the navigation pane and then Create on-demand backup.
I select Redshift in the Resource type dropdown. In the Cluster identifier, I select one of my clusters. For this workload, I need two weeks of retention. Then, I choose Create on-demand backup.
My data warehouse is not huge, so after a few minutes, the backup job has completed.
I now see my Redshift cluster in the list of the resources protected by AWS Backup.
In the Protected resources list, I choose the Redshift cluster to see the list of the available recovery points.
When I choose one of the recovery points, I have the option to restore the full data warehouse or just a table into a new Redshift cluster.
I now have the possibility to edit the cluster and database configuration, including security and networking settings. I just update the cluster identifier, otherwise the restore would fail because it must be unique. Then, I choose Restore backup to start the restore job.
After some time, the restore job has completed, and I see the old and the new clusters in the Amazon Redshift console. Using AWS Backup gives me a simple centralized way to manage data protection for Redshift clusters as well as many other resources in my AWS accounts.
There is no additional cost for using AWS Backup compared to the native snapshot capability of Amazon Redshift. Your overall costs depend on the amount of storage and retention you need. For more information, see AWS Backup pricing.
We’ve always believed that for the cloud to realize its full potential it would be essential that customers have control over their data. Giving customers this sovereignty has been a priority for AWS since the very beginning when we were the only major cloud provider to allow customers to control the location and movement of their data. The importance of this foundation has only grown over the last 16 years as the cloud has become mainstream, and governments and standards bodies continue to develop security, data protection, and privacy regulations.
Today, having control over digital assets, or digital sovereignty, is more important than ever.
As we’ve innovated and expanded to offer the world’s most capable, scalable, and reliable cloud, we’ve continued to prioritize making sure customers are in control and able to meet regulatory requirements anywhere they operate. What this looks like varies greatly across industries and countries. In many places around the world, like in Europe, digital sovereignty policies are evolving rapidly. Customers are facing an incredible amount of complexity, and over the last 18 months, many have told us they are concerned that they will have to choose between the full power of AWS and a feature-limited sovereign cloud solution that could hamper their ability to innovate, transform, and grow. We firmly believe that customers shouldn’t have to make this choice.
This is why today we’re introducing the AWS Digital Sovereignty Pledge—our commitment to offering all AWS customers the most advanced set of sovereignty controls and features available in the cloud.
AWS already offers a range of data protection features, accreditations, and contractual commitments that give customers control over where they locate their data, who can access it, and how it is used. We pledge to expand on these capabilities to allow customers around the world to meet their digital sovereignty requirements without compromising on the capabilities, performance, innovation, and scale of the AWS Cloud. At the same time, we will continue to work to deeply understand the evolving needs and requirements of both customers and regulators, and rapidly adapt and innovate to meet them.
Sovereign-by-design
Our approach to delivering on this pledge is to continue to make the AWS Cloud sovereign-by-design—as it has been from day one. Early in our history, we received a lot of input from customers in industries like financial services and healthcare—customers who are among the most security- and data privacy-conscious organizations in the world—about what data protection features and controls they would need to use the cloud. We developed AWS encryption and key management capabilities, achieved compliance accreditations, and made contractual commitments to satisfy the needs of our customers. As customers’ requirements evolve, we evolve and expand the AWS Cloud. A couple of recent examples include the data residency guardrails we added to AWS Control Tower (a service for governing AWS environments) late last year, which give customers even more control over the physical location of where customer data is stored and processed. In February 2022, we announced AWS services that adhere to the Cloud Infrastructure Service Providers in Europe (CISPE) Data Protection Code of Conduct, giving customers an independent verification and an added level of assurance that our services can be used in compliance with the General Data Protection Regulation (GDPR). These capabilities and assurances are available to all AWS customers.
We pledge to continue to invest in an ambitious roadmap of capabilities for data residency, granular access restriction, encryption, and resilience:
1. Control over the location of your data
Customers have always controlled the location of their data with AWS. For example, currently in Europe, customers have the choice to deploy their data into any of eight existing Regions. We commit to deliver even more services and features to protect our customers’ data. We further commit to expanding on our existing capabilities to provide even more fine-grained data residency controls and transparency. We will also expand data residency controls for operational data, such as identity and billing information.
2. Verifiable control over data access
We have designed and delivered first-of-a-kind innovation to restrict access to customer data. The AWS Nitro System, which is the foundation of AWS computing services, uses specialized hardware and software to protect data from outside access during processing on Amazon Elastic Compute Cloud (Amazon EC2). By providing a strong physical and logical security boundary, Nitro is designed to enforce restrictions so that nobody, including anyone in AWS, can access customer workloads on EC2. We commit to continue to build additional access restrictions that limit all access to customer data unless requested by the customer or a partner they trust.
3. The ability to encrypt everything everywhere
Currently, we give customers features and controls to encrypt data, whether in transit, at rest, or in memory. All AWS services already support encryption, with most also supporting encryption with customer managed keys that are inaccessible to AWS. We commit to continue to innovate and invest in additional controls for sovereignty and encryption features so that our customers can encrypt everything everywhere with encryption keys managed inside or outside the AWS Cloud.
4. Resilience of the cloud
It is not possible to achieve digital sovereignty without resiliency and survivability. Control over workloads and high availability are essential in the case of events like supply chain disruption, network interruption, and natural disaster. Currently, AWS delivers the highest network availability of any cloud provider. Each AWS Region is comprised of multiple Availability Zones (AZs), which are fully isolated infrastructure partitions. To better isolate issues and achieve high availability, customers can partition applications across multiple AZs in the same AWS Region. For customers that are running workloads on premises or in intermittently connected or remote use cases, we offer services that provide specific capabilities for offline data and remote compute and storage. We commit to continue to enhance our range of sovereign and resilient options, allowing customers to sustain operations through disruption or disconnection.
Earning trust through transparency and assurances
At AWS, earning customer trust is the foundation of our business. We understand that protecting customer data is key to achieving this. We also know that trust must continue to be earned through transparency. We are transparent about how our services process and transfer data. We will continue to challenge requests for customer data from law enforcement and government agencies. We provide guidance, compliance evidence, and contractual commitments so that our customers can use AWS services to meet compliance and regulatory requirements. We commit to continuing to provide the transparency and business flexibility needed to meet evolving privacy and sovereignty laws.
Navigating changes as a team
Helping customers protect their data in a world with changing regulations, technology, and risks takes teamwork. We would never expect our customers to go it alone. Our trusted partners play a prominent role in bringing solutions to customers. For example, in Germany, T-Systems (part of Deutsche Telekom) offers Data Protection as a Managed Service on AWS. It provides guidance to ensure data residency controls are properly configured, offering services for the configuration and management of encryption keys and expertise to help guide their customers in addressing their digital sovereignty requirements in the AWS Cloud. We are doubling down with local partners that our customers trust to help address digital sovereignty requirements.
We are committed to helping our customers meet digital sovereignty requirements. We will continue to innovate sovereignty features, controls, and assurances within the global AWS Cloud and deliver them without compromise to the full power of AWS.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
French version
AWS Digital Sovereignty Pledge: le contrôle sans compromis
Nous avons toujours pensé que pour que le cloud révèle son entier potentiel, il était essentiel que les clients aient le contrôle de leurs données. Garantir à nos clients cette souveraineté a été la priorité d’AWS depuis l’origine, lorsque nous étions le seul grand fournisseur de cloud à permettre aux clients de contrôler la localisation et le flux de leurs données. L’importance de cette démarche n’a cessé de croître ces 16 dernières années, à mesure que le cloud s’est démocratisé et que les gouvernements et les organismes de régulation ont développé des réglementations en matière de sécurité, de protection des données et de confidentialité.
Aujourd’hui, le contrôle des ressources numériques, ou souveraineté numérique, est plus important que jamais.
Tout en innovant et en nous développant pour offrir le cloud le plus performant, évolutif et fiable au monde, nous avons continué à ériger comme priorité la garantie que nos clients gardent le contrôle et soient en mesure de répondre aux exigences réglementaires partout où ils opèrent. Ces exigences varient considérablement selon les secteurs et les pays. Dans de nombreuses régions du monde, comme en Europe, les politiques de souveraineté numérique évoluent rapidement. Les clients sont confrontés à une incroyable complexité. Au cours des dix-huit derniers mois, ils nous ont rapporté qu’ils craignaient de devoir choisir entre les vastes possibilités offertes par les services d’AWS et une solution aux fonctionnalités limitées qui pourrait entraver leur capacité à innover, à se transformer et à se développer. Nous sommes convaincus que les clients ne devraient pas avoir à faire un tel choix.
C’est pourquoi nous présentons aujourd’hui l’AWS Digital Sovereignty Pledge – notre engagement à offrir à tous les clients AWS l’ensemble le plus avancé d’outils et de fonctionnalités de contrôle disponibles dans le cloud au service de la souveraineté.
AWS propose déjà une série de fonctionnalités de protection des données, de certifications et d’engagements contractuels qui donnent à nos clients le plein contrôle de la localisation de leurs données, de leur accès et de leur utilisation. Nous nous engageons à développer ces capacités pour permettre à nos clients du monde entier de répondre à leurs exigences en matière de souveraineté numérique, sans faire de compromis sur les capacités, les performances, l’innovation et la portée du cloud AWS. En parallèle, nous continuerons à travailler pour comprendre en profondeur l’évolution des besoins et des exigences des clients et des régulateurs, et nous nous adapterons et innoverons rapidement pour y répondre.
Souverain dès la conception
Pour respecter l’AWS Digital Sovereignty Pledge, notre approche est de continuer à rendre le cloud AWS souverain dès sa conception, comme il l’a été dès le premier jour. Aux débuts de notre histoire, nous recevions de nombreux commentaires de nos clients de secteurs tels que les services financiers et la santé – des clients qui comptent parmi les organisations les plus soucieuses de la sécurité et de la confidentialité des données dans le monde – sur les fonctionnalités et les contrôles de protection des données dont ils auraient besoin pour leur utilisation du cloud. Nous avons développé des compétences en matière de chiffrement et de gestion des données, obtenu des certifications de conformité et pris des engagements contractuels pour répondre aux besoins de nos clients. Nous développons le cloud AWS à mesure que les exigences des clients évoluent. Nous pouvons citer, parmi les exemples récents, les data residency guardrails (les garde-fous de la localisation des données) que nous avons ajoutés en fin d’année dernière à l’AWS Control Tower (un service de gestion des environnements AWS) et qui donnent aux clients davantage de contrôle sur l’emplacement physique de leurs données, où elles sont stockées et traitées. En février 2022, nous avons annoncé de nouveaux services AWS adhérant au Code de Conduite sur la protection des données de l’association CISPE (Cloud Infrastructure Service Providers in Europe (CISPE)). Ils apportent à nos clients une vérification indépendante et un niveau de garantie supplémentaire attestant que nos services peuvent être utilisés conformément au Règlement général sur la protection des données (RGPD). Ces capacités et ces garanties sont disponibles pour tous les clients d’AWS.
Nous nous engageons à poursuivre nos investissements conformément à une ambitieuse feuille de route pour le, , développement de capacités au service de la localisation des données, de la restriction d’accès granulaire (pratique consistant à accorder à des utilisateurs spécifiques différents niveaux d’accès à une ressource particulière), de chiffrement et de résilience :
1. Contrôle de l’emplacement de vos données
AWS a toujours permis à ses clients de contrôler l’emplacement de leurs données. Aujourd’hui en Europe, par exemple, les clients ont le choix de déployer leurs données dans l’une des huit Régions existantes. Nous nous engageons à fournir encore plus de services et de capacités pour protéger les données de nos clients. Nous nous engageons également à développer nos capacités existantes pour fournir des contrôles de localisation des données encore plus précis et transparents. Nous allons également étendre les contrôles de localisation des données pour les données opérationnelles, telles que les informations relatives à l’identité et à la facturation.
2. Contrôle fiable de l’accès aux données
Nous avons conçu et fourni une innovation unique en son genre pour restreindre l’accès aux données clients. Le système AWS Nitro, qui constitue la base des services informatiques d’AWS, utilise du matériel et des logiciels spécialisés pour protéger les données contre tout accès extérieur pendant leur traitement sur les serveurs EC2. En fournissant une solide barrière de sécurité physique et logique, Nitro est conçu pour empêcher, y compris au sein d’AWS, l’accès à ces données sur EC2. Nous nous engageons à continuer à développer des restrictions d’accès supplémentaires qui limitent tout accès aux données de nos clients, sauf indication contraire de la part du client ou de l’un de ses prestataires de confiance.
3. La possibilité de tout chiffrer, partout
Aujourd’hui, nous offrons à nos clients des fonctionnalités et des outils de contrôle pour chiffrer les données, qu’elles soient en transit, au repos ou en mémoire. Tous les services AWS prennent déjà en charge le chiffrement, la plupart permettant également le chiffrement sur des clés gérées par le client et inaccessibles à AWS. Nous nous engageons à continuer d’innover et d’investir dans des outils de contrôle au service de la souveraineté et des fonctionnalités de chiffrement supplémentaires afin que nos clients puissent chiffrer l’ensemble de leurs données partout, avec des clés de chiffrement gérées à l’intérieur ou à l’extérieur du cloud AWS.
4. La résilience du cloud
La souveraineté numérique est impossible sans résilience et sans capacités de continuité d’activité lors de crise majeure. Le contrôle des charges de travail et la haute disponibilité de réseau sont essentiels en cas d’événements comme une rupture de la chaîne d’approvisionnement, une interruption du réseau ou encore une catastrophe naturelle. Actuellement, AWS offre la plus haute disponibilité de réseau de tous les fournisseurs de cloud. Chaque Région AWS est composée de plusieurs zones de disponibilité (AZ), qui sont des portions d’infrastructure totalement isolées. Pour mieux isoler les difficultés et obtenir une haute disponibilité de réseau, les clients peuvent répartir les applications sur plusieurs zones dans la même Région AWS. Pour les clients qui exécutent des charges de travail sur place ou dans des cas d’utilisation à distance ou connectés par intermittence, nous proposons des services qui offrent des capacités spécifiques pour les données hors ligne, le calcul et le stockage à distance. Nous nous engageons à continuer d’améliorer notre gamme d’options souveraines et résilientes, permettant aux clients de maintenir leurs activités en cas de perturbation ou de déconnexion.
Gagner la confiance par la transparence et les garanties
Chez AWS, gagner la confiance de nos clients est le fondement de notre activité. Nous savons que la protection des données de nos clients est essentielle pour y parvenir. Nous savons également que leur confiance s’obtient par la transparence. Nous sommes transparents sur la manière dont nos services traitent et transfèrent leurs données. Nous continuerons à nous contester les demandes de données des clients émanant des autorités judiciaires et des organismes gouvernementaux. Nous fournissons des conseils, des preuves de conformité et des engagements contractuels afin que nos clients puissent utiliser les services AWS pour répondre aux exigences de conformité et de réglementation. Nous nous engageons à continuer à fournir la transparence et la flexibilité commerciale nécessaires pour répondre à l’évolution du cadre réglementaire relatif à la confidentialité et à la souveraineté des données.
Naviguer en équipe dans un monde en perpétuel changement
Aider les clients à protéger leurs données dans un monde où les réglementations, les technologies et les risques évoluent nécessite un travail d’équipe. Nous ne pouvons-nous résoudre à ce que nos clients relèvent seuls ces défis. Nos partenaires de confiance jouent un rôle prépondérant dans l’apport de solutions aux clients. Par exemple, en Allemagne, T-Systems (qui fait partie de Deutsche Telekom) propose la protection des données en tant que service géré sur AWS. L’entreprise fournit des conseils pour s’assurer que les contrôles de localisation des données sont correctement configurés, offrant des services pour la configuration en question, la gestion des clés de chiffrements et une expertise pour aider leurs clients à répondre à leurs exigences de souveraineté numérique dans le cloud AWS. Nous redoublons d’efforts avec les partenaires locaux en qui nos clients ont confiance pour les aider à répondre à ces exigences de souveraineté numérique.
Nous nous engageons à aider nos clients à répondre aux exigences de souveraineté numérique. Nous continuerons d’innover en matière de fonctionnalités, de contrôles et de garanties de souveraineté dans le cloud mondial d’AWS, tout en fournissant sans compromis et sans restriction la pleine puissance d’AWS.
German version
AWS Digital Sovereignty Pledge: Kontrolle ohne Kompromisse
Wir waren immer der Meinung, dass die Cloud ihr volles Potenzial nur dann erschließen kann, wenn Kunden die volle Kontrolle über ihre Daten haben. Diese Datensouveränität des Kunden genießt bei AWS schon seit den Anfängen der Cloud Priorität, als wir der einzige große Anbieter waren, bei dem Kunden sowohl Kontrolle über den Speicherort als auch über die Übertragung ihrer Daten hatten. Die Bedeutung dieser Grundsätze hat über die vergangenen 16 Jahre stetig zugenommen: Die Cloud ist im Mainstream angekommen, sowohl Gesetzgeber als auch Regulatoren entwickeln ihre Vorgaben zu IT-Sicherheit und Datenschutz stetig weiter.
Kontrolle bzw. Souveränität über digitale Ressourcen ist heute wichtiger denn je.
Unsere Innovationen und Entwicklungen haben stets darauf abgezielt, unseren Kunden eine Cloud zur Verfügung zu stellen, die skalierend und zugleich verlässlich global nutzbar ist. Dies beinhaltet auch unseren Kunden die Kontrolle zu gewährleisten die sie benötigen, damit sie alle ihre regulatorischen Anforderungen erfüllen können. Regulatorische Anforderungen sind länder- und sektorspezifisch. Vielerorts – wie auch in Europa – entstehen neue Anforderungen und Regularien zu digitaler Souveränität, die sich rasant entwickeln. Kunden sehen sich einer hohen Anzahl verschiedenster Regelungen ausgesetzt, die eine enorme Komplexität mit sich bringen. Innerhalb der letzten achtzehn Monate haben sich viele unserer Kunden daher mit der Sorge an uns gewandt, vor eine Wahl gestellt zu werden: Entweder die volle Funktionalität und Innovationskraft von AWS zu nutzen, oder auf funktionseingeschränkte „souveräne“ Cloud-Lösungen zurückzugreifen, deren Kapazität für Innovation, Transformation, Sicherheit und Wachstum aber limitiert ist. Wir sind davon überzeugt, dass Kunden nicht vor diese „Wahl“ gestellt werden sollten.
Deswegen stellen wir heute den „AWS Digital Sovereignty Pledge“ vor – unser Versprechen allen AWS Kunden, ohne Kompromisse die fortschrittlichsten Souveränitäts-Kontrollen und Funktionen in der Cloud anzubieten.
AWS bietet schon heute eine breite Palette an Datenschutz-Funktionen, Zertifizierungen und vertraglichen Zusicherungen an, die Kunden Kontrollmechanismen darüber geben, wo ihre Daten gespeichert sind, wer darauf Zugriff erhält und wie sie verwendet werden. Wir werden diese Palette so erweitern, dass Kunden überall auf der Welt, ihre Anforderungen an Digitale Souveränität erfüllen können, ohne auf Funktionsumfang, Leistungsfähigkeit, Innovation und Skalierbarkeit der AWS Cloud verzichten zu müssen. Gleichzeitig werden wir weiterhin daran arbeiten, unser Angebot flexibel und innovativ an die sich weiter wandelnden Bedürfnisse und Anforderungen von Kunden und Regulatoren anzupassen.
Sovereign-by-design
Wir werden den „AWS Digital Sovereignty Pledge“ so umsetzen, wie wir das seit dem ersten Tag machen und die AWS Cloud gemäß unseres „sovereign-by-design“ Ansatz fortentwickeln. Wir haben von Anfang an, durch entsprechende Funktions- und Kontrollmechanismen für spezielle IT-Sicherheits- und Datenschutzanforderungen aus den verschiedensten regulierten Sektoren Lösungen gefunden, die besonders sensiblen Branchen wie beispielsweise dem Finanzsektor oder dem Gesundheitswesen frühzeitig ermöglichten, die Cloud zu nutzen. Auf dieser Basis haben wir die AWS Verschlüsselungs- und Schlüsselmanagement-Funktionen entwickelt, Compliance-Akkreditierungen erhalten und vertragliche Zusicherungen gegeben, welche die Bedürfnisse unserer Kunden bedienen. Dies ist ein stetiger Prozess, um die AWS Cloud auf sich verändernde Kundenanforderungen anzupassen. Ein Beispiel dafür sind die Data Residency Guardrails, um die wir AWS Control Tower Ende letzten Jahres erweitert haben. Sie geben Kunden die volle Kontrolle über die physikalische Verortung ihrer Daten zu Speicherungs- und Verarbeitungszwecken. Dieses Jahr haben wir einen Katalog von AWS Diensten veröffentlicht, die den Cloud Infrastructure Service Providers in Europe (CISPE) erfüllen. Damit verfügen Kunden über eine unabhängige Verifizierung und zusätzliche Versicherung, dass unsere Dienste im Einklang mit der DSGVO verwendet werden können. Diese Instrumente und Nachweise stehen schon heute allen AWS Kunden zur Verfügung.
Wir haben uns ehrgeizige Ziele für unsere Roadmap gesetzt und investieren kontinuierlich in Funktionen für die Verortung von Daten (Datenresidenz), granulare Zugriffsbeschränkungen, Verschlüsselung und Resilienz:
1. Kontrolle über den Ort der Datenspeicherung
Bei AWS hatten Kunden immer schon die Kontrolle über Datenresidenz, also den Ort der Datenspeicherung. Aktuell können Kunden ihre Daten z.B. in 8 bestehenden Regionen innerhalb Europas speichern, von denen 6 innerhalb der Europäischen Union liegen. Wir verpflichten uns dazu, noch mehr Dienste und Funktionen zur Verfügung zustellen, die dem Schutz der Daten unserer Kunden dienen. Ebenso verpflichten wir uns, noch granularere Kontrollen für Datenresidenz und Transparenz auszubauen. Wir werden auch zusätzliche Kontrollen für Daten einführen, die insbesondere die Bereiche Identitäts- und Abrechnungs-Management umfassen.
2. Verifizierbare Kontrolle über Datenzugriffe
Mit dem AWS Nitro System haben wir ein innovatives System entwickelt, welches unberechtigte Zugriffsmöglichkeiten auf Kundendaten verhindert: Das Nitro System ist die Grundlage der AWS Computing Services (EC2). Es verwendet spezialisierte Hardware und Software, um den Schutz von Kundendaten während der Verarbeitung auf EC2 zu gewährleisten. Nitro basiert auf einer starken physikalischen und logischen Sicherheitsabgrenzung und realisiert damit Zugriffsbeschränkungen, die unautorisierte Zugriffe auf Kundendaten auf EC2 unmöglich machen – das gilt auch für AWS als Betreiber. Wir werden darüber hinaus für weitere AWS Services zusätzliche Mechanismen entwickeln, die weiterhin potentielle Zugriffe auf Kundendaten verhindern und nur in Fällen zulassen, die explizit durch Kunden oder Partner ihres Vertrauens genehmigt worden sind.
3. Möglichkeit der Datenverschlüsselung überall und jederzeit
Gegenwärtig können Kunden Funktionen und Kontrollen verwenden, die wir zur Verschlüsselung von Daten während der Übertragung, persistenten Speicherungen oder Verarbeitung in flüchtigem Speicher anbieten. Alle AWS Dienste unterstützen schon heute Datenverschlüsselung, die meisten davon auf Basis der Customer Managed Keys – d.h. Schlüssel, die von Kunden verwaltet werden und für AWS nicht zugänglich sind. Wir werden auch in diesem Bereich weiter investieren und Innovationen vorantreiben. Es wird zusätzliche Kontrollen für Souveränität und Verschlüsselung geben, damit unsere Kunden alles jederzeit und überall verschlüsseln können – und das mit Schlüsseln, die entweder durch AWS oder durch den Kunden selbst bzw. ausgewählte Partner verwaltet werden können.
4. Resilienz der Cloud
Digitale Souveränität lässt sich nicht ohne Ausfallsicherheit und Überlebensfähigkeit herstellen. Die Kontrolle über Workloads und hohe Verfügbarkeit z.B. in Fällen von Lieferkettenstörungen, Netzwerkausfällen und Naturkatastrophen ist essenziell. Aktuell bietet AWS die höchste Netzwerk-Verfügbarkeit unter allen Cloud-Anbietern. Jede AWS Region besteht aus mehreren Availability Zones (AZs), die jeweils vollständig isolierte Partitionen unserer Infrastruktur sind. Um Probleme besser zu isolieren und eine hohe Verfügbarkeit zu erreichen, können Kunden Anwendungen auf mehrere AZs in derselben Region verteilen. Kunden, die Workloads on-premises oder in Szenarien mit sporadischer Netzwerk-Anbindung betreiben, bieten wir Dienste an, welche auf Offline-Daten und Remote Compute und Storage Anwendungsfälle angepasst sind. Wir werden unser Angebot an souveränen und resilienten Optionen ausbauen und fortentwickeln, damit Kunden den Betrieb ihrer Workloads auch bei Trennungs- und Disruptionsszenarien aufrechterhalten können.
Vertrauen durch Transparenz und Zusicherungen
Der Aufbau eines Vertrauensverhältnisses mit unseren Kunden, ist die Grundlage unserer Geschäftsbeziehung bei AWS. Wir wissen, dass der Schutz der Daten unserer Kunden der Schlüssel dazu ist. Wir wissen auch, dass Vertrauen durch fortwährende Transparenz verdient und aufgebaut wird. Wir bieten schon heute transparenten Einblick, wie unsere Dienste Daten verarbeiten und übertragen. Wir werden auch in Zukunft Anfragen nach Kundendaten durch Strafverfolgungsbehörden und Regierungsorganisationen konsequent anfechten. Wir bieten Rat, Compliance-Nachweise und vertragliche Zusicherungen an, damit unsere Kunden AWS Dienste nutzen und gleichzeitig ihre Compliance und regulatorischen Anforderungen erfüllen können. Wir werden auch in Zukunft die Transparenz und Flexibilität an den Tag legen, um auf sich weiterentwickelnde Datenschutz- und Soveränitäts-Regulierungen passende Antworten zu finden.
Den Wandel als Team bewältigen
Regulatorik, Technologie und Risiken sind stetigem Wandel unterworfen: Kunden dabei zu helfen, ihre Daten in diesem Umfeld zu schützen, ist Teamwork. Wir würden nie erwarten, dass unsere Kunden das alleine bewältigen müssen. Unsere Partner genießen hohes Vertrauen und spielen eine wichtige Rolle dabei, Lösungen für Kunden zu entwickeln. Zum Beispiel bietet T-Systems in Deutschland Data Protection as a Managed Service auf AWS an. Das Angebot umfasst Hilfestellungen bei der Konfiguration von Kontrollen zur Datenresidenz, Zusatzdienste im Zusammenhang mit der Schlüsselverwaltung für kryptographische Verfahren und Rat bei der Erfüllung von Anforderungen zu Datensouveränität in der AWS Cloud. Wir werden die Zusammenarbeit mit lokalen Partnern, die besonderes Vertrauen bei unseren gemeinsamen Kunden genießen, intensivieren, um bei der Erfüllung der Digitalen Souveräntitätsanforderungen zu unterstützen.
Wir verpflichten uns dazu unseren Kunden bei der Erfüllung ihre Anforderungen an digitale Souveränität zu helfen. Wir werden weiterhin Souveränitäts-Funktionen, Kontrollen und Zusicherungen für die globale AWS Cloud entwickeln, die das gesamte Leistungsspektrum von AWS erschließen.
Italian version
AWS Digital Sovereignty Pledge: Controllo senza compromessi
Abbiamo sempre creduto che, affinché il cloud possa realizzare in pieno il potenziale, sia essenziale che i clienti abbiano il controllo dei propri dati. Offrire ai clienti questa “sovranità” è sin dall’inizio una priorità per AWS, da quando eravamo l’unico grande cloud provider a consentire ai clienti di controllare la localizzazione e lo spostamento dei propri dati. L’importanza di questo principio è aumentata negli ultimi 16 anni, man mano che il cloud ha iniziato a diffondersi e i governi e gli organismi di standardizzazione hanno continuato a sviluppare normative in materia di sicurezza, protezione dei dati e privacy.
Oggi, avere il controllo sulle risorse digitali, sulla sovranità digitale, è più importante che mai.
Nell’innovare ed espandere l’offerta cloud più completa, scalabile e affidabile al mondo, la nostra priorità è stata assicurarci che i clienti – ovunque operino – abbiano il controllo e siano in grado di soddisfare i requisiti normativi. Il contesto varia notevolmente tra i settori e i paesi. In molti luoghi del mondo, come in Europa, le politiche di sovranità digitale si stanno evolvendo rapidamente. I clienti stanno affrontando un crescente livello di complessità, e negli ultimi diciotto mesi molti di essi ci hanno detto di essere preoccupati di dover scegliere tra usare AWS in tutta la sua potenza e una soluzione cloud sovrana con funzionalità limitate che potrebbe ostacolare la loro capacità di innovazione, trasformazione e crescita. Crediamo fermamente che i clienti non debbano fare questa scelta.
Ecco perché oggi presentiamo l’AWS Digital Sovereignty Pledge, il nostro impegno a offrire a tutti i clienti AWS l’insieme più avanzato di controlli e funzionalità sulla sovranità digitale disponibili nel cloud.
AWS offre già una gamma di funzionalità di protezione dei dati, accreditamenti e impegni contrattuali che consentono ai clienti di controllare la localizzazione, l’accesso e l’utilizzo dei propri dati. Ci impegniamo a espandere queste funzionalità per consentire ai clienti di tutto il mondo di soddisfare i propri requisiti di sovranità digitale senza compromettere le capacità, le prestazioni, l’innovazione e la scalabilità del cloud AWS. Allo stesso tempo, continueremo a lavorare per comprendere a fondo le esigenze e i requisiti in evoluzione sia dei clienti che delle autorità di regolamentazione, adattandoci e innovando rapidamente per soddisfarli.
Sovereign-by-design
Il nostro approccio per mantenere questo impegno è quello di continuare a rendere il cloud AWS “sovereign-by-design”, come è stato sin dal primo giorno. All’inizio della nostra storia, abbiamo ricevuto da clienti in settori come quello finanziario e sanitario – che sono tra le organizzazioni più attente al mondo alla sicurezza e alla privacy dei dati – molti input sulle funzionalità e sui controlli relativi alla protezione dei dati di cui necessitano per utilizzare il cloud. Abbiamo sviluppato le funzionalità di crittografia e gestione delle chiavi di AWS, ottenuto accreditamenti di conformità e preso impegni contrattuali per soddisfare le esigenze dei nostri clienti. Con l’evolversi delle loro esigenze, sviluppiamo ed espandiamo il cloud AWS.
Un paio di esempi recenti includono i data residency guardrail che abbiamo aggiunto a AWS Control Tower (un servizio per la gestione degli ambienti in AWS) alla fine dell’anno scorso, che offrono ai clienti un controllo ancora maggiore sulla posizione fisica in cui i dati dei clienti vengono archiviati ed elaborati. A febbraio 2022 abbiamo annunciato i servizi AWS che aderiscono al Codice di condotta sulla protezione dei dati dei servizi di infrastruttura cloud in Europa (CISPE), offrendo ai clienti una verifica indipendente e un ulteriore livello di garanzia che i nostri servizi possano essere utilizzati in conformità con il Regolamento generale sulla protezione dei dati (GDPR). Queste funzionalità e garanzie sono disponibili per tutti i clienti AWS.
Ci impegniamo a continuare a investire in una roadmap ambiziosa di funzionalità per la residenza dei dati, la restrizione granulare dell’accesso, la crittografia e la resilienza:
1. Controllo della localizzazione dei tuoi dati
I clienti hanno sempre controllato la localizzazione dei propri dati con AWS. Ad esempio, attualmente in Europa i clienti possono scegliere di distribuire i propri dati attraverso una delle otto Region AWS disponibili. Ci impegniamo a fornire ancora più servizi e funzionalità per proteggere i dati dei nostri clienti e ad espandere le nostre capacità esistenti per fornire controlli e trasparenza ancora più dettagliati sulla residenza dei dati. Estenderemo inoltre anche i controlli relativi ai dati operativi, come le informazioni su identità e fatturazione.
2. Controllo verificabile sull’accesso ai dati
Abbiamo progettato e realizzato un’innovazione unica nel suo genere per limitare l’accesso ai dati dei clienti. Il sistema AWS Nitro, che è alla base dei servizi informatici di AWS, utilizza hardware e software specializzati per proteggere i dati dall’accesso esterno durante l’elaborazione su EC2. Fornendo un solido limite di sicurezza fisico e logico, Nitro è progettato per applicare restrizioni in modo che nessuno, nemmeno in AWS, possa accedere ai carichi di lavoro dei clienti su EC2. Ci impegniamo a continuare a creare ulteriori restrizioni di accesso che limitino tutti gli accessi ai dati dei clienti, a meno che non sia richiesto dal cliente o da un partner di loro fiducia.
3. La capacità di criptare tutto e ovunque
Attualmente, offriamo ai clienti funzionalità e controlli per criptare i dati, che siano questi in transito, a riposo o in memoria. Tutti i servizi AWS già supportano la crittografia, e la maggior parte supporta anche la crittografia con chiavi gestite dal cliente, non accessibili per AWS. Ci impegniamo a continuare a innovare e investire in controlli aggiuntivi per la sovranità e le funzionalità di crittografia in modo che i nostri clienti possano criptare tutto e ovunque con chiavi di crittografia gestite all’interno o all’esterno del cloud AWS.
4. Resilienza del cloud
Non è possibile raggiungere la sovranità digitale senza resilienza e affidabilità. Il controllo dei carichi di lavoro e l’elevata disponibilità sono essenziali in caso di eventi come l’interruzione della catena di approvvigionamento, l’interruzione della rete e i disastri naturali. Attualmente AWS offre il più alto livello di disponibilità di rete rispetto a qualsiasi altro cloud provider. Ogni regione AWS è composta da più zone di disponibilità (AZ), che sono partizioni di infrastruttura completamente isolate. Per isolare meglio i problemi e ottenere un’elevata disponibilità, i clienti possono partizionare le applicazioni tra più AZ nella stessa Region AWS. Per i clienti che eseguono carichi di lavoro in locale o in casi d’uso remoti o connessi in modo intermittente, offriamo servizi che forniscono funzionalità specifiche per i dati offline e l’elaborazione e lo storage remoti. Ci impegniamo a continuare a migliorare la nostra gamma di opzioni per la sovranità del dato e la resilienza, consentendo ai clienti di continuare ad operare anche in caso di interruzioni o disconnessioni.
Guadagnare fiducia attraverso trasparenza e garanzie
In AWS, guadagnare la fiducia dei clienti è alla base della nostra attività. Comprendiamo che proteggere i dati dei clienti è fondamentale per raggiungere questo obiettivo, e sappiamo che la fiducia si guadagna anche attraverso la trasparenza. Per questo siamo trasparenti su come i nostri servizi elaborano e spostano i dati. Continueremo ad opporci alle richieste relative ai dati dei clienti provenienti dalle forze dell’ordine e dalle agenzie governative. Forniamo linee guida, prove di conformità e impegni contrattuali in modo che i nostri clienti possano utilizzare i servizi AWS per soddisfare i requisiti normativi e di conformità. Ci impegniamo infine a continuare a fornire la trasparenza e la flessibilità aziendali necessarie a soddisfare l’evoluzione delle leggi sulla privacy e sulla sovranità del dato.
Gestire i cambiamenti come un team
Aiutare i clienti a proteggere i propri dati in un mondo caratterizzato da normative, tecnologie e rischi in evoluzione richiede un lavoro di squadra. Non ci aspetteremmo mai che i nostri clienti lo facessero da soli. I nostri partner di fiducia svolgono un ruolo di primo piano nel fornire soluzioni ai clienti. Ad esempio in Germania, T-Systems (parte di Deutsche Telekom) offre un servizio denominato Data Protection as a Managed Service on AWS. Questo fornisce indicazioni per garantire che i controlli di residenza dei dati siano configurati correttamente, offrendo servizi per la configurazione e la gestione delle chiavi di crittografia, oltre a competenze per aiutare i clienti a soddisfare i requisiti di sovranità digitale nel cloud AWS, per i quali stiamo collaborando con partner locali di cui i nostri clienti si fidano.
Ci impegniamo ad aiutare i nostri clienti a soddisfare i requisiti di sovranità digitale. Continueremo a innovare le funzionalità, i controlli e le garanzie di sovranità del dato all’interno del cloud AWS globale e a fornirli senza compromessi sfruttando tutta la potenza di AWS.
Japanese version
AWS Digital Sovereignty Pledge(AWSのデジタル統制に関するお客様との約束): 妥協のない管理
작성자: Matt Garman, 아마존웹서비스(AWS) 마케팅 및 글로벌 서비스 담당 수석 부사장
아마존웹서비스(AWS)는 클라우드가 지닌 잠재력이 최대로 발휘되기 위해서는 고객이 반드시 자신의 데이터를 제어할 수 있어야 한다고 항상 믿어 왔습니다. AWS는 서비스 초창기부터 고객이 데이터의 위치와 이동을 제어할 수 있도록 허용하는 유일한 주요 클라우드 공급업체였고 지금까지도 고객에게 이러한 권리를 부여하는 것을 최우선 과제로 삼고 있습니다. 클라우드가 주류가 되고 정부 및 표준 제정 기관이 보안, 데이터 보호 및 개인정보보호 규정을 지속적으로 발전시키면서 지난 16년간 이러한 원칙의 중요성은 더욱 커졌습니다.
오늘날 디지털 자산 또는 디지털 주권 제어는 그 어느 때보다 중요합니다.
AWS는 세계에서 가장 우수하고 확장 가능하며 신뢰할 수 있는 클라우드를 제공하기 위한 혁신과 서비스 확대에 주력하면서, 고객이 사업을 운영하는 모든 곳에서 스스로 통제할 수 있을 뿐 아니라 규제 요구 사항을 충족할 수 있어야 한다는 점을 언제나 최우선 순위로 여겨왔습니다. AWS의 이러한 기업 철학은 개별 산업과 국가에 따라 상당히 다른 모습으로 표출됩니다. 유럽을 비롯해 전 세계 많은 지역에서 디지털 주권 정책이 빠르게 진화하고 있습니다. 고객은 엄청난 복잡성에 직면해 있으며, 지난 18개월 동안 많은 고객들은 AWS의 모든 기능을 갖춘 클라우드 서비스와 혁신, 변화, 성장을 저해할 수 있는 제한적 기능의 클라우드 솔루션 중 하나를 선택해야만 할 수도 있다는 우려가 있다고 말하였습니다. 하지만 AWS는 고객이 이러한 선택을 해서는 안 된다는 굳건한 믿음을 가지고 있습니다.
이것이 바로 오늘, 모든 AWS 고객에게 클라우드 기술에서 가장 발전된 형태의 디지털 주권 제어와 기능을 제공하겠다는 약속인, “AWS 디지털 주권 서약”을 소개하는 이유입니다.
AWS는 이미 고객이 데이터 위치, 데이터에 액세스가 가능한 인력 및 데이터 이용 방식을 제어할 수 있는 다양한 데이터 보호 기능, 인증 및 계약상 의무를 제공하고 있습니다. 또한 전 세계 고객이 AWS 클라우드의 기능, 성능, 혁신 및 규모에 영향을 주지 않으면서 디지털 주권 관련 요건을 충족할 수 있도록 기존 데이터 보호 정책을 지속적으로 확대할 것을 약속합니다. 동시에 고객과 규제 기관의 변화하는 요구와 규제 요건을 깊이 이해하고 이를 충족하기 위해 신속하게 적응하고 혁신을 이어나가고자 합니다.
디지털 주권 보호를 위한 원천 설계
이 약속을 이행하기 위한 우리의 접근 방식은 처음부터 그러했듯이 AWS 클라우드를 애초부터 디지털 주권을 강화하는 방식으로 설계하는 것입니다. AWS는 사업 초기부터 금융 서비스 및 의료 업계와 같이 세계 최고 수준의 보안 및 데이터 정보 보호를 요구하는 조직의 고객으로부터 클라우드를 사용하는 데 필요한 데이터 보호 기능 및 제어에 관한 많은 의견을 수렴했습니다. AWS는 고객의 요구 사항을 충족하기 위하여 암호화 및 핵심적 관리 기능을 개발하고, 규정 준수 인증을 획득했으며, 계약상 의무를 제공하였습니다. 고객의 요구 사항이 변화함에 따라 AWS 클라우드도 진화하고 확장해 왔습니다. 최근의 몇 가지 예를 들면, 작년 말 AWS Control Tower(AWS 환경 관리 서비스)에 추가한 데이터 레지던시 가드레일이 있습니다. 이는 고객 데이터가 저장되고 처리되는 물리적 위치에 대한 제어 권한을 고객에게 훨씬 더 많이 부여하는 것을 목표로 합니다. 2022년 2월에는 유럽 클라우드 인프라 서비스(CISPE) 데이터 보호 행동 강령을 준수하는 AWS 서비스를 발표한 바 있습니다. 이것은 유럽연합의 개인정보보호규정(GDPR)에 따라 서비스를 사용할 수 있다는 독립적인 검증과 추가적 보증을 고객에게 제공하는 것입니다. 이러한 기능과 보증은 AWS의 모든 고객에게 적용됩니다.
AWS는 데이터 레지던시, 세분화된 액세스 제한, 암호화 및 복원력 기능의 증대를 위한 야심 찬 로드맵에 다음과 같이 계속 투자할 것을 약속합니다.
1. 데이터 위치에 대한 제어
고객은 항상 AWS를 통해 데이터 위치를 제어해 왔습니다. 예를 들어 현재 유럽에서는 고객이 기존 8개 리전 중 원하는 위치에 데이터를 배치할 수 있습니다. AWS는 고객의 데이터를 보호하기 위한 더 많은 서비스와 기능을 제공할 것을 약속합니다. 또한, 기존 기능을 확장하여 더욱 세분화된 데이터 레지던시 제어 및 투명성을 제공할 것을 약속합니다. 뿐만 아니라, ID 및 결제 정보와 같은 운영 데이터에 대한 데이터 레지던시 제어를 확대할 예정입니다.
2. 데이터 액세스에 대한 검증 가능한 제어
AWS는 고객 데이터에 대한 액세스를 제한하는 최초의 혁신적 설계를 제공했습니다. AWS 컴퓨팅 서비스의 기반인 AWS Nitro System은 특수 하드웨어 및 소프트웨어를 사용하여 EC2에서 처리하는 동안 외부 액세스로부터 데이터를 보호합니다. 강력한 물리적 보안 및 논리적 보안의 경계를 제공하는 Nitro는 AWS의 모든 사용자를 포함하여 누구도 EC2의 고객 워크로드에 액세스할 수 없도록 설계되었습니다. AWS는 고객 또는 고객이 신뢰하는 파트너의 요청이 있는 경우를 제외하고, 고객 데이터에 대한 모든 액세스를 제한하는 추가 액세스 제한을 계속 구축할 것을 약속합니다.
3. 모든 것을 어디서나 암호화하는 능력
현재 AWS는 전송 중인 데이터, 저장된 데이터 또는 메모리에 있는 데이터를 암호화할 수 있는 기능과 제어권을 고객에게 제공합니다. 모든 AWS 서비스는 이미 암호화를 지원하고 있으며, 대부분 AWS에서 액세스할 수 없는 고객 관리형 키를 사용한 암호화도 지원합니다. 또한 고객이 AWS 클라우드 내부 또는 외부에서 관리되는 암호화 키로 어디서든 어떤 것이든 것을 암호화할 수 있도록 디지털 주권 및 암호화 기능에 대한 추가 제어를 지속적으로 혁신하고 투자할 것을 약속합니다.
4. 클라우드의 복원력
복원력과 생존성 없이는 디지털 주권을 달성할 수 없습니다. 공급망 장애, 네트워크 중단 및 자연 재해와 같은 이벤트가 발생할 경우 워크로드 제어 및 고가용성은 매우 중요합니다. 현재 AWS는 모든 클라우드 공급업체 중 가장 높은 네트워크 가용성을 제공합니다. 각 AWS 리전은 완전히 격리된 인프라 파티션인 여러 가용 영역(AZ)으로 구성됩니다. 문제를 보다 효과적으로 격리하고 고가용성을 달성하기 위해 고객은 동일한 AWS 리전의 여러 AZ로 애플리케이션을 분할할 수 있습니다. 온프레미스 또는 간헐적으로 연결되거나 원격 사용 사례에서 워크로드를 실행하는 고객을 위해 오프라인 데이터와 원격 컴퓨팅 및 스토리지에 대한 특정 기능을 지원하는 서비스를 제공합니다. AWS는 고객이 중단되거나 연결이 끊기는 상황에도 운영을 지속할 수 있도록 자주적이고 탄력적인 옵션의 범위를 지속적으로 강화할 것을 약속합니다.
투명성과 보장을 통한 신뢰 확보
고객의 신뢰를 얻는 것이 AWS 비즈니스의 토대입니다. 이를 위해서는 고객 데이터를 보호하는 것이 핵심이라는 점을 잘 알고 있습니다. 투명성을 통해 계속 신뢰를 쌓아야 한다는 점 또한 잘 알고 있습니다. AWS는 서비스가 데이터를 처리하고 전송하는 방식을 투명하게 공개합니다. 법 집행 기관 및 정부 기관의 고객 데이터 제공 요청에 대하여 계속해서 이의를 제기할 것입니다. AWS는 고객이 AWS 서비스를 사용하여 규정 준수 및 규제 요건을 충족할 수 있도록 지침, 규정 준수 증거 및 계약상의 의무 이행을 제공합니다. AWS는 진화하는 개인 정보 보호 및 각 지역의 디지털 주권 규정을 준수하는 데 필요한 투명성과 비즈니스 유연성을 계속 제공할 것을 약속합니다.
팀 차원의 변화 모색
변화하는 규정, 기술 및 위험이 있는 환경에서 고객이 데이터를 보호할 수 있도록 하려면 팀워크가 필요합니다. 고객 혼자서는 절대 할 수 없는 일입니다. 신뢰할 수 있는 AWS의 파트너는 고객이 문제를 해결하는데 중요한 역할을 합니다. 예를 들어, 독일에서는 T-Systems(Deutsche Telekom의 일부)를 통해 AWS의 관리형 서비스로서의 데이터 보호를 제공합니다. 데이터 레지던시 제어가 올바르게 구성되도록 하기 위한 지침을 제공하고, 암호화 키의 구성 및 관리를 위한 서비스를 통해 고객이 AWS 클라우드에서 디지털 주권 요구 사항을 해결하는 데 도움이 되는 전문 지식을 제공합니다. AWS는 고객이 디지털 주권 요구 사항을 해결하는 데 도움이 될 수 있도록 신뢰할 수 있는 현지 파트너와 협력하고 있습니다.
AWS는 고객이 디지털 주권 요구 사항을 충족할 수 있도록 최선의 지원을 다하고있습니다. AWS는 글로벌 AWS 클라우드 내에서 주권 기능, 제어 및 보안을 지속적으로 혁신하고, AWS의 모든 기능에 대한 어떠한 타협 없이 이를 제공할 것입니다.
The CCCS is Canada’s authoritative source of cyber security expert guidance for the Canadian government, industry, and the general public. Public and commercial sector organizations across Canada rely on CCCS’s rigorous Cloud Service Provider (CSP) IT Security (ITS) assessment in their decisions to use cloud services. In addition, CCCS’s ITS assessment process is a mandatory requirement for AWS to provide cloud services to Canadian federal government departments and agencies.
The CCCS Cloud Service Provider Information Technology Security Assessment Process determines if the Government of Canada (GC) ITS requirements for the CCCS Medium cloud security profile (previously referred to as GC’s Protected B/Medium Integrity/Medium Availability [PBMM] profile) are met as described in ITSG-33 (IT security risk management: A lifecycle approach). As of November 2022, 132 AWS services in the Canada (Central) Region have been assessed by the CCCS and meet the requirements for the CCCS Medium cloud security profile. Meeting the CCCS Medium cloud security profile is required to host workloads that are classified up to and including the medium categorization. On a periodic basis, CCCS assesses new or previously unassessed services and reassesses the AWS services that were previously assessed to verify that they continue to meet the GC’s requirements. CCCS prioritizes the assessment of new AWS services based on their availability in Canada, and on customer demand for the AWS services. The full list of AWS services that have been assessed by CCCS is available on our Services in Scope for CCCS Assessment page.
To learn more about the CCCS assessment or our other compliance and security programs, visit AWS Compliance Programs. As always, we value your feedback and questions; you can reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below. Want more AWS Security news? Follow us on Twitter.
As described in an earlier blog post, Establishing a data perimeter on AWS, Amazon Web Services (AWS) offers a set of capabilities you can use to implement a data perimeter to help prevent unintended access. One type of unintended access that companies want to prevent is access to corporate data by users who do not belong to the company. A combination of AWS Identity and Access Management (AWS IAM) features and capabilities that can help you achieve this goal in AWS while fostering innovation and agility form the identity perimeter. In this blog post, I will provide an overview of some of the security risks the identity perimeter is designed to address, policy examples, and implementation guidance for establishing the perimeter.
The identity perimeter is a set of coarse-grained preventative controls that help achieve the following objectives:
Only trusted identities can access my resources
Only trusted identities are allowed from my network
Trusted identities encompass IAM principals that belong to your company, which is typically represented by an AWS Organizations organization. In AWS, an IAM principal is a person or application that can make a request for an action or operation on an AWS resource. There are also scenarios when AWS services perform actions on your behalf using identities that do not belong to your organization. You should consider both types of data access patterns when you create a definition of trusted identities that is specific to your company and your use of AWS services. All other identities are considered untrusted and should have no access except by explicit exception.
Security risks addressed by the identity perimeter
The identity perimeter helps address several security risks, including the following.
Unintended data disclosure due to misconfiguration. Some AWS services support resource-based IAM policies that you can use to grant principals (including principals outside of your organization) permissions to perform actions on the resources they are attached to. While this allows developers to configure resource-based policies based on their application requirements, you should ensure that access to untrusted identities is prohibited even if the developers grant broad access to your resources, such as Amazon Simple Storage Service (Amazon S3) buckets. Figure 1 illustrates examples of access patterns you would want to prevent—specifically, principals outside of your organization accessing your S3 bucket from a non-corporate AWS account, your on-premises network, or the internet.
Figure 1: Unintended access to your S3 bucket by identities outside of your organization
Unintended data disclosure through non-corporate credentials. Some AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2) and AWS Lambda, let you run code using the IAM credentials of your choosing. Similar to on-premises environments where developers might have access to physical and virtual servers, there is a risk that the developers can bring personal IAM credentials to a corporate network and attempt to move company data to personal AWS resources. For example, Figure 2 illustrates unintended access patterns where identities outside of your AWS Organizations organization are used to transfer data from your on-premises networks or VPC to an S3 bucket in a non-corporate AWS account.
Figure 2: Unintended access from your networks by identities outside of your organization
Implementing the identity perimeter
Before you can implement the identity perimeter by using preventative controls, you need to have a way to evaluate whether a principal is trusted and do this evaluation effectively in a multi-account AWS environment. IAM policies allow you to control access based on whether the IAM principal belongs to a particular account or an organization, with the following IAM condition keys:
The aws:PrincipalOrgID condition key gives you a succinct way to refer to all IAM principals that belong to a particular organization. There are similar condition keys, such as aws:PrincipalOrgPaths and aws:PrincipalAccount, that allow you to define different granularities of trust.
The aws:PrincipalIsAWSService condition key gives you a way to refer to AWS service principals when those are used to access resources on your behalf. For example, when you create a flow log with an S3 bucket as the destination, VPC Flow Logs uses a service principal, delivery.logs.amazonaws.com, which does not belong to your organization, to publish logs to Amazon S3.
In the context of the identity perimeter, there are two types of IAM policies that can help you ensure that the call to an AWS resource is made by a trusted identity:
Using the IAM condition keys and the policy types just listed, you can now implement the identity perimeter. The following table illustrates the relationship between identity perimeter objectives and the AWS capabilities that you can use to achieve them.
Data perimeter
Control objective
Implemented by using
Primary IAM capability
Identity
Only trusted identities can access my resources.
Resource-based policies
aws:PrincipalOrgID aws:PrincipalIsAWSService
Only trusted identities are allowed from my network.
VPC endpoint policies
Let’s see how you can use these capabilities to mitigate the risk of unintended access to your data.
Only trusted identities can access my resources
Resource-based policies allow you to specify who has access to the resource and what actions they can perform. Resource-based policies also allow you to apply identity perimeter controls to mitigate the risk of unintended data disclosure due to misconfiguration. The following is an example of a resource-based policy for an S3 bucket that limits access to only trusted identities. Make sure to replace <DOC-EXAMPLE-MY-BUCKET> and <MY-ORG-ID> with your information.
The Deny statement in the preceding policy has two condition keys where both conditions must resolve to true to invoke the Deny effect. This means that this policy will deny any S3 action unless it is performed by an IAM principal within your organization (StringNotEqualsIfExists with aws:PrincipalOrgID) or a service principal (BoolIfExists with aws:PrincipalIsAWSService). Note that resource-based policies on AWS resources do not allow access outside of the account by default. Therefore, in order for another account or an AWS service to be able to access your resource directly, you need to explicitly grant access permissions with appropriate Allow statements added to the preceding policy.
Only trusted identities are allowed from my network
When you access AWS services from on-premises networks or VPCs, you can use public service endpoints or connect to supported AWS services by using VPC endpoints. VPC endpoints allow you to apply identity perimeter controls to mitigate the risk of unintended data disclosure through non-corporate credentials. The following is an example of a VPC endpoint policy that allows access to all actions but limits the access to trusted identities only. Replace <MY-ORG-ID> with your information.
As opposed to the resource-based policy example, the preceding policy uses Allow statements to enforce the identity perimeter. This is because VPC endpoint policies do not grant any permissions but define the maximum access allowed through the endpoint. Your developers will be using identity-based or resource-based policies to grant permissions required by their applications. We use two statements in this example policy to invoke the Allow effect in two scenarios: if an action is performed by an IAM principal that belongs to your organization (StringEquals with aws:PrincipalOrgID in the AllowRequestsByOrgsIdentities statement) or if an action is performed by a service principal (Bool with aws:PrincipalIsAWSService in the AllowRequestsByAWSServicePrincipals statement). We do not use IfExists in the end of the condition operators in this case, because we want the condition elements to evaluate to true only if the specified keys exist in the request.
There might be circumstances when you want to grant access to your resources to principals outside of your organization. For example, you might be hosting a dataset in an Amazon S3 bucket that is being accessed by your business partners from their own AWS accounts. In order to support this access pattern, you can use the aws:PrincipalAccount condition key to include third-party account identities as trusted identities in a policy. This is shown in the following resource-based policy example. Replace <DOC-EXAMPLE-MY-BUCKET>, <MY-ORG-ID>, <THIRD-PARTY-ACCOUNT-A>, and <THIRD-PARTY-ACCOUNT-B> with your information.
The preceding policy adds the aws:PrincipalAccount condition key to the StringNotEqualsIfExists operator. You now have a Deny statement with three condition keys where all three conditions must resolve to true to invoke the Deny effect. Therefore, this policy denies any S3 action unless it is performed by an IAM principal that belongs to your organization (StringNotEqualsIfExists with aws:PrincipalOrgID), by an IAM principal that belongs to specified third-party accounts (StringNotEqualsIfExists with aws:PrincipalAccount), or a service principal (BoolIfExists with aws:PrincipalIsAWSService).
There might also be circumstances when you want to grant access from your networks to identities external to your organization. For example, your applications could be uploading or downloading objects to or from a third-party S3 bucket by using third-party generated pre-signed Amazon S3 URLs. The principal that generates the pre-signed URL will belong to the third-party AWS account. Similar to the previously discussed S3 bucket policy, you can extend your identity perimeter to include identities that belong to trusted third-party accounts by using the aws:PrincipalAccount condition key in your VPC endpoint policy.
Additionally, some AWS services make unauthenticated requests to AWS owned resources through your VPC endpoint. An example of such a pattern is Kernel Live Patching on Amazon Linux 2, which allows you to apply security vulnerability and critical bug patches to a running Linux kernel. Amazon EC2 makes an unauthenticated call to Amazon S3 to download packages from Amazon Linux repositories hosted on Amazon EC2 service-owned S3 buckets. To include this access pattern into your identity perimeter definition, you can choose to allow unauthenticated API calls to AWS owned resources in the VPC endpoint policies.
The following example VPC endpoint policy demonstrates how to extend your identity perimeter to include access to Amazon Linux repositories and to Amazon S3 buckets owned by a third-party. Replace <MY-ORG-ID>, <REGION>, <ACTION>, <THIRD-PARTY-ACCOUNT-A>, and <THIRD-PARTY-BUCKET-ARN> with your information.
The preceding example adds two new statements to the VPC endpoint policy. The AllowUnauthenticatedRequestsToAWSResources statement allows the s3:GetObject action on buckets that host Amazon Linux repositories. The AllowRequestsByThirdPartyIdentitiesToThirdPartyResources statement allows actions on resources owned by a third-party entity by principals that belong to the third-party account (StringEquals with aws:PrincipalAccount).
Note that identity perimeter controls do not eliminate the need for additional network protections, such as making sure that your private EC2 instances or databases are not inadvertently exposed to the internet due to overly permissive security groups.
Apart from preventative controls established by the identity perimeter, we also recommend that you configure AWS Identity and Access Management Access Analyzer. IAM Access Analyzer helps you identify unintended access to your resources and data by monitoring policies applied to supported resources. You can review IAM Access Analyzer findings to identify resources that are shared with principals that do not belong to your AWS Organizations organization. You should also consider enabling Amazon GuardDuty to detect misconfigurations or anomalous access to your resources that could lead to unintended disclosure of your data. GuardDuty uses threat intelligence, machine learning, and anomaly detection to analyze data from various sources in your AWS accounts. You can review GuardDuty findings to identify unexpected or potentially malicious activity in your AWS environment, such as an IAM principal with no previous history invoking an S3 API.
IAM policy samples
This AWS git repository contains policy examples that illustrate how to implement identity perimeter controls for a variety of AWS services and actions. The policy samples do not represent a complete list of valid data access patterns and are for reference purposes only. They are intended for you to tailor and extend to suit the needs of your environment. Make sure that you thoroughly test the provided example policies before you implement them in your production environment.
Deploying the identity perimeter at scale
As discussed earlier, you implement the identity perimeter as coarse-grained preventative controls. These controls typically need to be implemented for each VPC by using VPC endpoint policies and on all resources that support resource-based policies. The effectiveness of these controls relies on their ability to scale with the environment and to adapt to its dynamic nature.
The methodology you use to deploy identity perimeter controls will depend on the deployment mechanisms you use to create and manage AWS accounts. For example, you might choose to use AWS Control Tower and the Customizations for AWS Control Tower solution (CfCT) to govern your AWS environment at scale. You can use CfCT or your custom CI/CD pipeline to deploy VPC endpoints and VPC endpoint policies that include your identity perimeter controls.
Because developers will be creating resources such as S3 buckets and AWS KMS keys on a regular basis, you might need to implement automation to enforce identity perimeter controls when those resources are created or their policies are changed. One option is to use custom AWS Config rules. Alternatively, you can choose to enforce resource deployment through AWS Service Catalog or a CI/CD pipeline. With the AWS Service Catalog approach, you can have identity perimeter controls built into the centrally controlled products that are made available to developers to deploy within their accounts. With the CI/CD pipeline approach, the pipeline can have built-in compliance checks that enforce identity perimeter controls during the deployment. If you are deploying resources with your CI/CD pipeline by using AWS CloudFormation, see the blog post Proactively keep resources secure and compliant with AWS CloudFormation Hooks.
Regardless of the deployment tools you select, identity perimeter controls, along with other baseline security controls applicable to your multi-account environment, should be included in your account provisioning process. You should also audit your identity perimeter configurations periodically and upon changes in your organization, which could lead to modifications in your identity perimeter controls (for example, disabling a third-party integration). Keeping your identity perimeter controls up to date will help ensure that they are consistently enforced and help prevent unintended access during the entire account lifecycle.
Conclusion
In this blog post, you learned about the foundational elements that are needed to define and implement the identity perimeter, including sample policies that you can use to start defining guardrails that are applicable to your environment and control objectives.
Following are additional resources that will help you further explore the identity perimeter topic, including a whitepaper and a hands-on-workshop.
If you have any questions, comments, or concerns, contact AWS Support or browse AWS re:Post. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
In the weeks leading up to AWS re:invent 2022, I’ll share conversations I’ve had with some of the humans who work in AWS Security who will be presenting at the conference, and get a sneak peek at their work and sessions. In this profile, I interviewed Sarah Currey, Delivery Practice Manager in World Wide Professional Services (ProServe).
How long have you been at AWS and what do you do in your current role?
I’ve been at AWS since 2019, and I’m a Security Practice Manager who leads a Security Transformation practice dedicated to helping customers build on AWS. I’m responsible for leading enterprise customers through a variety of transformative projects that involve adopting AWS services to help achieve and accelerate secure business outcomes.
In this capacity, I lead a team of awesome security builders, work directly with the security leadership of our customers, and—one of my favorite aspects of the job—collaborate with internal security teams to create enterprise security solutions.
How did you get started in security?
I come from a non-traditional background, but I’ve always had an affinity for security and technology. I started off learning HTML back in 2006 for my Myspace page (blast from the past, I know) and in college, I learned about offensive security by dabbling in penetration testing. I took an Information Systems class my senior year, but otherwise I wasn’t exposed to security as a career option. I’m from Nashville, TN, so the majority of people I knew were in the music or healthcare industries, and I took the healthcare industry path.
I started my career working at a government affairs firm in Washington, D.C. and then moved on to a healthcare practice at a law firm. I researched federal regulations and collaborated closely with staffers on Capitol Hill to educate them about controls to protect personal health information (PHI), and helped them to determine strategies to adhere to security, risk, and compliance frameworks such as HIPAA and (NIST) SP 800-53. Government regulations can lag behind technology, which creates interesting problems to solve. But in 2015, I was assigned to a project that was planned to last 20 years, and I decided I wanted to move into an industry that operated as a faster pace—and there was no better place than tech.
From there, I moved to a startup where I worked as a Project Manager responsible for securely migrating customers’ data to the software as a service (SaaS) environment they used and accelerating internal adoption of the environment. I often worked with software engineers and asked, “why is this breaking?” so they started teaching me about different aspects of the service. I interacted regularly with a female software engineer who inspired me to start teaching myself to code. After two years of self-directed learning, I took the leap and quit my job to do a software engineering bootcamp. After the course, I worked as a software engineer where I transformed my security assurance skills into the ability to automate security. The cloud kept coming up in conversations around migrations, so I was curious and achieved software engineering and AWS certifications, eventually moving to AWS. Here, I work closely with highly regulated customers, such as those in healthcare, to advise them on using AWS to operate securely in the cloud, and work on implementing security controls to help them meet frameworks like NIST and HIPAA, so I’ve come full circle.
How do you explain your job to non-technical friends and family?
The general public isn’t sure how to define the cloud, and that’s no different with my friends and family. I get questions all the time like “what exactly is the cloud?” Since I love storytelling, I use real-world examples to relate it to their profession or hobbies. I might talk about the predictive analytics used by the NFL or, for my friends in healthcare, I talk about securing PHI.
However, my favorite general example is describing the AWS Shared Responsibility Model as a house. Imagine a house—AWS is responsible for security of the house. We’re responsible for the physical security of the house, and we build a fence, we make sure there is a strong foundation and secure infrastructure. The customer is the tenant—they can pay as they go, leave when they need to—and they’re responsible for running the house and managing the items, or data, in the house. So it’s my job to help the customer implement new ideas or technologies in the house to help them live more efficiently and securely. I advise them on how to best lock the doors, where to store their keys, how to keep track of who is coming in and out of the house with access to certain rooms, and how to protect their items in the house from other risks.
And for my friends that love Harry Potter, I just say that I work in the Defense Against the Dark Arts.
What are you currently working on that you’re excited about?
There are a lot of things in different spaces that I’m excited about.
One is that I’m part of a ransomware working group to provide an offering that customers can use to prepare for a ransomware event. Many customers want to know what AWS services and features they can use to help them protect their environments from ransomware, and we take real solutions that we’ve used with customers and scale them out. Something that’s really cool about Professional Services is that we’re on the frontlines with customers, and we get to see the different challenges and how we can relate those back to AWS service teams and implement them in our products. These efforts are exciting because they give customers tangible ways to secure their environments and workloads. I’m also excited because we’re focusing not just on the technology but also on the people and processes, which sometimes get forgotten in the technology space.
I’m a huge fan of cross-functional collaboration, and I love working with all the different security teams that we have within AWS and in our customer security teams. I work closely with the Amazon Managed Services (AMS) security team, and we have some very interesting initiatives with them to help our customers operate more securely in the cloud, but more to come on that.
Another exciting project that’s close to my heart is the Inclusion, Diversity, and Equity (ID&E) workstream for the U.S. It’s really important to me to not only have diversity but also inclusion, and I’m leading a team that is helping to amplify diverse voices. I created an Amplification Flywheel to help our employees understand how they can better amplify diverse voices in different settings, such as meetings or brainstorming sessions. The flywheel helps illustrate a process in which 1) an idea is voiced by an underrepresented individual, 2) an ally then amplifies the idea by repeating it and giving credit to the author, 3) others acknowledge the contribution, 4) this creates a more equitable workplace, and 5) the flywheel continues where individuals feel more comfortable sharing ideas in the future.
Within this workstream, I’m also thrilled about helping underrepresented people who already have experience speaking but who may be having a hard time getting started with speaking engagements at conferences. I do mentorship sessions with them so they can get their foot in the door and amplify their own voice and ideas at conferences.
You’re presenting at re:Invent this year. Can you give us a sneak peek of your session?
I’m partnering with Johnny Ray, who is an AMS Senior Security Engineer, to present a session called SEC203: Revitalize your security with the AWS Security Reference Architecture. We’ll be discussing how the AWS SRA can be used as a holistic guide for deploying the full complement of AWS security services in a multi-account environment. The AWS SRA is a living document that we continuously update to help customers revitalize their security best practices as they grow, scale, and innovate.
What do you hope attendees take away from your session?
Technology is constantly evolving, and the security space is no exception. As organizations adopt AWS services and features, it’s important to understand how AWS security services work together to improve your security posture. Attendees will be able to take away tangible ways to:
Define the target state of your security architecture
Review the capabilities that you’ve already designed and revitalize them with the latest services and features
Bootstrap the implementation of your security architecture
Start a discussion about organizational governance and responsibilities for security
Johnny and I will also provide attendees with a roadmap at the end of the session that gives customers a plan for the first week after the session, one to three months after the session, and six months after the session, so they have different action items to implement within their organization.
You’ve written about the importance of ID&E in the workplace. In your opinion, what’s the most effective way leaders can foster an inclusive work environment?
I’m super passionate about ID&E, because it’s really important and it makes businesses more effective and a better place to work as a whole. My favorite Amazon Leadership Principle is Earn Trust. It doesn’t matter if you Deliver Results or Insist on the Highest Standards if no one is willing to listen to you because you don’t have trust built up. When it comes to building an inclusive work environment, a lot of earning trust comes from the ability to have empathy, vulnerability, and humility—being able to admit when you made a mistake—with your teammates as well as with your customers. I think we have a unique opportunity at AWS to work closely with customers and learn about what they’re doing and their best practices with ID&E, and share our best practices.
We all make mistakes, we’re all learning, and that’s okay, but having the ability to admit when you’ve made a mistake, apologize, and learn from it makes a much better place to work. When it comes to intent versus impact, I love to give the example—going back to storytelling—of walking down the street and accidentally bumping into someone, causing them to drop their coffee. You didn’t intend to hurt them or spill their coffee; your intent was to keep walking down the street. However, the impact that you had was maybe they’re burnt now, maybe their coffee is all down their clothes, and you had a negative impact on them. Now, you want to apologize and maybe look up more while you’re walking and be more observant of your surroundings. I think this is a good example because sometimes when it comes to ID&E, it can become a culture of blame and that’s not what we want to do—we want to call people in instead of calling them out. I think that’s a great way to build an inclusive team.
You can have a diverse workforce, but if you don’t have inclusion and you’re not listening to people who are underrepresented, that’s not going to help. You need to make sure you’re practicing transformative leadership and truly wanting to change how people behave and think when it comes to ID&E. You want to make sure people are more kind to each other, rather than only checking the box on arbitrary diversity goals. It’s important to be authentic and curious about how you learn from others and their experiences, and to respect them and implement that into different ideas and processes. This is important to make a more equitable workplace.
I love learning from different ID&E leaders like Camille Leak, Aiko Bethea, and Brené Brown. They are inspirational to me because they all approach ID&E with vulnerability and tackle the uncomfortable.
What’s the thing you’re most proud of in your career?
I have two different things—one from a technology standpoint and one from a personal impact perspective.
On the technology side, one of the coolest projects I’ve been on is Change Healthcare, which is an independent healthcare technology company that connects payers, providers, and patients across the United States. They have an important job of protecting a lot of PHI and personally identifiable information (PII) for American citizens. Change Healthcare needed to quickly migrate its ClaimsXten claims processing application to the cloud to meet the needs of a large customer, and it sought to move an internal demo and training application environment to the cloud to enable self-service and agility for developers. During this process, they reached out to AWS, and I took the lead role in advising Change Healthcare on security and how they were implementing their different security controls and technical documentation. I led information security meetings on AWS services, because the processes were new to a lot of the employees who were previously working in data centers. Through working with them, I was able to cut down their migration hours by 58% by using security automation and reduce the cost of resources, as well. I oversaw security for 94 migration cutovers where no security events occurred. It was amazing to see that process and build a great relationship with the company. I still meet with Change Healthcare employees for lunch even though I’m no longer on their projects. For this work, I was awarded the “Above and Beyond the Call of Duty” award, which only three Amazonians get a year, so that was an honor.
From a personal impact perspective, it was terrifying to quit my job and completely change careers, and I dealt with a lot of imposter syndrome—which I still have every day, but I work through it. Something impactful that resulted from this move was that it inspired a lot of people in my network from non-technical backgrounds, especially underrepresented individuals, to dive into coding and pursue a career in tech. Since completing my bootcamp, I’ve had more than 100 people reach out to me to ask about my experience, and about 30 of them quit their job to do a bootcamp and are now software engineers in various fields. So, it’s really amazing to see the life-changing impact of mentoring others.
You do a lot of volunteer work. Can you tell us about the work you do and why you’re so passionate about it?
Absolutely! The importance of giving back to the community cannot be understated.
Over the last 13 years, I have fundraised, volunteered, and advocated in building over 40 different homes throughout the country with Habitat for Humanity. One of my most impactful volunteer experiences was in 2013. I volunteered with a nonprofit called Bike & Build, where we cycled across the United States to raise awareness and money for affordable housing efforts. From Charleston, South Carolina to Santa Cruz, California, the team raised over $158,000, volunteered 3,584 hours, and biked 4,256 miles over the course of three months. This was such an incredible experience to meet hundreds of people across the country and help empower them to learn about affordable housing and improve their lives. It also tested me so much emotionally, mentally, and physically that I learned a lot about myself in the process. Additionally, I was selected by Gap, Inc. to participate in an international Habitat build in Antigua, Guatemala in October of 2014.
I’m currently on the Associate Board of Gilda’s Club, which provides free cancer support to anyone in need. Corporate social responsibility is a passion of mine, and so I helped organize AWS Birthday Boxes and Back to School Bags volunteer events with Gilda’s Club of Middle Tennessee. We purchased and assembled birthday and back-to-school boxes for children whose caregiver was experiencing cancer, so their caregiver would have one less thing to worry about and make sure the child feels special during this tough time. During other AWS team offsites, I’ve organized volunteering through Nashville Second Harvest food bank and created 60 shower and winter kits for individuals experiencing homelessness through ShowerUp.
I also mentor young adult women and non-binary individuals with BuiltByGirls to help them navigate potential career paths in STEM, and I recently joined the Cyversity organization, so I’m excited to give back to the security community.
If you had to pick an industry outside of security, what would you want to do?
History is one of my favorite topics, and I’ve always gotten to know people by having an inquisitive mind. I love listening and asking curious questions to learn more about people’s experiences and ideas. Since I’m drawn to the art of storytelling, I would pick a career as a podcast host where I bring on different guests to ask compelling questions and feature different, rarely heard stories throughout history.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Elastic Kubernetes Service (Amazon EKS) is a managed service that you can use to run and scale container workloads by using Kubernetes in the AWS Cloud, which can help increase the speed of deployment and portability of modern applications. Amazon EKS provides secure, managed Kubernetes clusters on the AWS control plane by default. Kubernetes configurations such as pod security policies, runtime security, and network policies and configurations are specific for your organization’s use-case and securing them adequately would be a customer’s responsibility within AWS’ shared responsibility model.
Amazon GuardDuty can help you continuously monitor and detect suspicious activity related to AWS resources in your account. GuardDuty for EKS protection is a feature that you can enable within your accounts. When this feature is enabled, GuardDuty can help detect potentially unauthorized EKS activity resulting from misconfiguration of the control plane nodes or application.
In this post, we’ll walk through the events leading up to a real-world security issue that occurred due to EKS cluster misconfiguration, discuss how those misconfigurations could be used by a malicious actor, and how Amazon GuardDuty monitors and identifies suspicious activity throughout the EKS security event. In part 2 of the post, we’ll cover Amazon Detective investigation capabilities, possible remediation techniques, and preventative controls for EKS cluster related security issues.
Prerequisites
You must have AWS GuardDuty enabled in your AWS account in order to monitor and generate findings associated with an EKS cluster related security issue in your environment.
Before jumping into the security issue, it is important to understand how the AWS shared responsibility model applies to the Amazon EKS managed service. AWS is responsible for the EKS managed Kubernetes control plane and the infrastructure to deliver EKS in a secure and reliable manner. You have the ability to configure EKS and how it interacts with other applications and services, where you are responsible for making sure that secure configurations are being used.
The following scenario is based on a real-world observed event, where a malicious actor used Kubernetes compromise tactics and techniques to expose and access an EKS cluster. We use this example to show how you can use AWS security services to identify and investigate each step of this security event. For a security event in your own environment, the order of operations and the investigative and remediation techniques used might be different. The scenario is broken down into the following phases and associated MITRE ATT&CK tactics:
Phase 1 – EKS cluster misconfiguration
Phase 2 (Discovery) – Discovery of vulnerable EKS clusters
Phase 4 (Persistence) – Impact to persist unauthorized access to the cluster
Phase 5 (Impact) – Impact to manipulate resources for unauthorized activity
Phase 1 – EKS cluster misconfiguration
By default, when you provision an EKS cluster, the API cluster endpoint is set to public, meaning that it can be accessed from the internet. Despite being accessible from the internet, the endpoint is still considered secure because it requires all API requests to be authenticated by AWS Identity and Access Management (IAM) and then authorized by Kubernetes role-based access control (RBAC). Also, the entity (user or role) that creates the EKS cluster is automatically granted system:masters permissions, which allows the entity to modify the EKS cluster’s RBAC configuration.
This example scenario starts with a developer who has access to administer EKS clusters in an AWS account. The developer wants to work from their home network and doesn’t want to connect to their enterprise VPN for IAM role federation. They configure an EKS cluster API without setting up the proper authentication and authorization components. Instead, the developer grants explicit access to the system:anonymous user in the cluster’s RBAC configuration. (Alternatively, an unauthorized RBAC configuration could be introduced into your environment after a developer unknowingly installs a malicious helm chart from the internet without reviewing or inspecting it first.)
In Kubernetes anonymous requests, unauthenticated and unrejected HTTP requests are treated as anonymous access and are identified as a system:anonymous user belonging to a system:unauthenticated group. This means that any entity on the internet can access the cluster and make API requests that are permitted by the role. There aren’t many legitimate use cases for this type of activity, because it’s considered a best practice to use RBAC instead. Anonymous requests are primarily used for setting up health endpoints and custom authentication.
By monitoring EKS audit logs, GuardDuty identifies this activity and generates the finding Policy:Kubernetes/AnonymousAccessGranted, as shown in Figure 1. This finding informs you that a user on your Kubernetes cluster successfully created a ClusterRoleBinding or RoleBinding to bind the user system:anonymous to a role. This action enables unauthenticated access to the API operations permitted by the role.
Figure 1: Example GuardDuty finding for Kubernetes anonymous access granted
Phase 2 (Discovery) – Discovery of vulnerable EKS clusters
Port scanning is a method that malicious actors use to determine if resources are publicly exposed, with open ports and known vulnerabilities. As an increasing number of open-source tools allows users to search for endpoints connected to the internet, finding these endpoints has become even easier. Security teams can use these open-source tools to their advantage by proactively scanning for and identifying externally exposed resources in their organization.
This brings us to the discovery phase of our misconfigured EKS cluster. The discovery phase is defined by MITRE as follows: “Discovery consists of techniques an adversary may use to gain knowledge about the system and internal network. These techniques help adversaries observe the environment and orient themselves before deciding how to act.”
By granting system:anonymous access to the EKS cluster in our example, the developer allowed requests from any public unauthenticated source. This can result in external web crawlers probing the cluster API, which can often happen within seconds of the system:anonymous access being granted. GuardDuty identifies this activity and generates the finding Discovery:Kubernetes/SuccessfulAnonymousAccess, as shown in Figure 2. This finding informs you that an API operation to discover resources in a cluster was successfully invoked by the system:anonymous user. Remember, all API calls made by system:anonymous are unauthenticated, in addition to /healthz and /version calls that are always unauthenticated regardless of the user identity, and any entity can make use of this user within the EKS cluster.
In the screenshot, under the Action section in the finding details, you can see that the anonymous user made a get request to “/”. This is a generic request that is not specific to a Kubernetes cluster, which may indicate that the crawler is not specifically targeting Kubernetes clusters. You can further see that the Status code is 200, indicating that the request was successful. If this activity is malicious, then the actor is now aware that there is an exposed resource.
Figure 2: Example GuardDuty finding for Kubernetes successful anonymous access
Next, in this phase, you might start observing more targeted API calls for establishing initial access from unauthorized users. MITRE defines initial access as “techniques that use various entry vectors to gain their initial foothold within a network. Techniques used to gain a foothold include targeted spearphishing and exploiting weaknesses on public-facing web servers. Footholds gained through initial access may allow for continued access, like valid accounts and use of external remote services, or may be limited-use due to changing passwords.”
In our example, the malicious actor has established initial access for the EKS cluster which is evident in the next GuardDuty finding, CredentialAccess:Kubernetes/SuccessfulAnonymousAccess, as shown in Figure 3. This finding informs you that an API call to access credentials or secrets was successfully invoked by the system:anonymous user. The observed API call is commonly associated with the credential access tactic where an adversary is attempting to collect passwords, usernames, and access keys for a Kubernetes cluster.
You can see that in this GuardDuty finding, in the Action section, the Request uri is targeted at a Kubernetes cluster, specifically /api/v1/namespaces/kube-system/secrets. This request seems to be targeting the secrets management capabilities that are built into Kubernetes. You can find more information about this secrets management capability in the Kubernetes documentation.
Figure 3: Example GuardDuty finding for Kubernetes successful credential access from anonymous user
Phase 4 (Persistence) – Impact to persist unauthorized access to the cluster
The next phase of this scenario is likely to be an impact in the EKS cluster to enable persistence by the malicious actor. MITRE defines impact as “techniques that adversaries use to disrupt availability or compromise integrity by manipulating business and operational processes.” Following the MITRE definitions, “Persistence consists of techniques that adversaries use to keep access to systems across restarts, changed credentials, and other interruptions that could cut off their access. Techniques used for persistence include any access, action, or configuration changes that let them maintain their foothold on systems, such as replacing or hijacking legitimate code or adding startup code.”
In the GuardDuty finding Impact:Kubernetes/SuccessfulAnonymousAccess, shown in Figure 4, you can see the Kubernetes user details and Action sections that indicate that a successful Kubernetes API call was made to create a ClusterRoleBinding by the system:anonymous username. This finding informs you that a write API operation to tamper with resources was successfully invoked by the system:anonymous user. The observed API call is commonly associated with the impact stage of an attack, when an adversary is tampering with resources in your cluster. This activity shows that the system:anonymous user has now created their own role to enable persistent access the EKS cluster. If the user is malicious, they can now access the cluster even if access is removed in the RBAC configuration for the system:anonymous user.
Figure 4 Example GuardDuty finding for Kubernetes successful credential change by anonymous user
Phase 5 (Impact) – Impact to manipulate resources for unauthorized activity
The fifth phase of this scenario is where the unauthorized user is likely to focus on impact techniques in order to use the access for malicious purpose. MITRE says of the impact phase: “Techniques used for impact can include destroying or tampering with data. In some cases, business processes can look fine, but may have been altered to benefit the adversaries’ goals. These techniques might be used by adversaries to follow through on their end goal or to provide cover for a confidentiality breach.” Typically, once a malicious actor has access into a system, they will introduce malware to the system to manipulate the compromised resource and possibly also other resources.
With the introduction of GuardDuty Malware Protection, when an Amazon Elastic Compute Cloud (Amazon EC2) or container-related GuardDuty finding that indicates potentially suspicious activity is generated, an agentless scan on the volumes will initiate and detect the presence of malware. Existing GuardDuty customers need to enable Malware Protection, and for new customers this feature is on by default when they enable GuardDuty for the first time. Malware Protection comes with a 30-day free trial for both existing and new GuardDuty customers. You can see a list of findings that initiates a malware scan in the GuardDuty User Guide.
In this example, the malicious actor now uses access to the cluster to perform unauthorized cryptocurrency mining. GuardDuty monitors the DNS requests from the EC2 instances used to host the EKS cluster. This allows GuardDuty to identify a DNS request made to a domain name associated with a cryptocurrency mining pool, and generate the finding CryptoCurrency:EC2/BitcoinTool.B!DNS, as shown in Figure 5.
Figure 5: Example GuardDuty finding for EC2 instance querying bitcoin domain name
Because this is an EC2 related GuardDuty finding and GuardDuty Malware Protection is enabled in the account, GuardDuty then conducts an agentless scan on the volumes of the EC2 instance to detect malware. If the scan results in a successful detection of one or more malicious files, another GuardDuty finding for Execution:EC2/MaliciousFile is generated, as shown in Figure 6.
Figure 6: Example GuardDuty finding for detection of a malicious file on EC2
The first GuardDuty finding detects crypto mining activity, while the proceeding malware protection finding provides context on the malware associated with this activity. This context is very valuable for the incident response process.
Conclusion
In this post, we walked you through each of the five phases where we outlined how an initial misconfiguration could result in a malicious actor gaining control of EKS resources within an AWS account and how GuardDuty is able to continually monitor and detect the progression of the security event. As previously stated, this is just one example where a misconfiguration in an EKS cluster could result in a security event.
Now that you have a good understanding of GuardDuty capabilities to continuously monitor and detect EKS security events, you will need to establish processes and procedures to enable your security team to investigate these events. You can enable Amazon Detective to help accelerate your security team’s mean time to respond (MTTR) by providing an efficient mechanism to analyze, investigate, and identify the root cause of security events. Follow along in part 2 of this series, How to investigate and take action on an Amazon EKS cluster related security issue with Amazon Detective, where we’ll cover techniques you can use with Amazon Detective to identify impacted EKS resources in your AWS account, possible remediation actions to take on the cluster, and preventative controls you can implement.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a thread on Amazon GuardDuty re:Post.
Want more AWS Security news? Follow us on Twitter.
ENS is Spain’s National Security Framework. The ENS certification is regulated under the Spanish Royal Decree 3/2010 and is a compulsory requirement for central government customers in Spain. ENS establishes security standards that apply to government agencies and public organizations in Spain, and service providers on which Spanish public services depend. Updating and achieving this certification every year demonstrates our ongoing commitment to meeting the heightened expectations for cloud service providers set forth by the Spanish government.
We are happy to announce the addition of 17 services to the scope of our ENS High certification, for a new total of 166 services in scope. The certification now covers 25 Regions. Some of the additional security services in scope for ENS High include the following:
AWS CloudShell – a browser-based shell that makes it simpler to securely manage, explore, and interact with your AWS resources. With CloudShell, you can quickly run scripts with the AWS Command Line Interface (AWS CLI), experiment with AWS service APIs by using the AWS SDKs, or use a range of other tools for productivity.
AWS Cloud9 – a cloud-based integrated development environment (IDE) that you can use to write, run, and debug your code with just a browser. It includes a code editor, debugger, and terminal.
Amazon DevOps Guru – a service that uses machine learning to detect abnormal operating patterns so that you can identify operational issues before they impact your customers.
Amazon HealthLake – a HIPAA-eligible service that offers healthcare and life sciences companies a complete view of individual or patient population health data for query and analytics at scale.
AWS IoT SiteWise – a managed service that simplifies collecting, organizing, and analyzing industrial equipment data.
AWS achievement of the ENS High certification is verified by BDO Auditores S.L.P., which conducted an independent audit and confirmed that AWS continues to adhere to the confidentiality, integrity, and availability standards at its highest level.
As always, we are committed to bringing new services into the scope of our ENS High program based on your architectural and regulatory needs. If you have questions about the ENS program, reach out to your AWS account team or contact AWS Compliance.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
As Amazon Web Services (AWS) Security Solutions Architects, we get to talk to customers of all sizes and industries about how they want to improve their security posture and get visibility into their AWS resources. This blog post identifies the top three most commonly used Security Hub usage patterns and describes how you can use these to improve your strategy for identifying and managing findings.
Customers have told us they want to provide security and compliance visibility to the application owners in an AWS account or to the teams that use the account; others want a single-pane-of-glass view for their security teams; and other customers want to centralize everything into a security information and event management (SIEM) system, most often due to being in a hybrid scenario.
Security Hub findings are normalized into the AWS Security Findings Format (ASFF) so that users can review them in a standardized format. This reduces the need for time-consuming data conversion efforts and allows for flexible and consistent filtering of findings based on the attributes provided in the finding, as well as the use of customizable responsive actions. Partners who have integrations with Security Hub also send their findings to AWS using the ASFF to allow for consistent attribute definition and enforced criticality ratings, meaning that findings in Security Hub have a measurable rating. This helps to simplify the complexity of managing multiple findings from different providers.
Overview of the usage patterns
In this section, we outline the objectives for each usage pattern, list the typical stakeholders we have seen these patterns support, and discuss the value of deploying each one.
Usage pattern 1: Dashboard for application owners
Use Security Hub to provide visibility to application workload owners regarding the security and compliance posture of their AWS resources.
The application owner is often responsible for the security and compliance posture of the resources they have deployed in AWS. In our experience however, it is common for large enterprises to have a separate team responsible for defining security-related privileges and to not grant application owners the ability to modify configuration settings on the AWS account that is designated as the centralized Security Hub administration account. We’ll walk through how you can enable read-only access for application owners to use Security Hub to see the overall security posture of their AWS resources.
Stakeholders: Developers and cloud teams that are responsible for the security posture of their AWS resources. These individuals are often required to resolve security events and non-compliance findings that are captured with Security Hub.
Value adds for customers: Some organizations we have worked with put the onus on workload owners to own their security findings, because they have a better understanding of the nuances of the engineering, the business needs, and the overall risk that the security findings represent. This usage pattern gives the applications owners clear visibility into the security and compliance status of their workloads in the AWS accounts so that they can define appropriate mitigation actions with consideration to their business needs and risk.
Usage pattern 2: A single pane of glass for security professionals
Use Security Hub as a single pane of glass to view, triage, and take action on AWS security and compliance findings across accounts and AWS Regions.
Security Hub generates findings by running continuous, automated security checks based on supported industry standards. Additionally, Security Hub integrates with other AWS services to collect and correlate findings and uses over 60 partner integrations to simplify and prioritize findings. With these features, security professionals can use Security Hub to manage findings across their AWS landscape.
Stakeholders: Security operations, incident responders, and threat hunters who are responsible for monitoring compliance, as well as security events.
Value adds for customers: This pattern benefits customers who don’t have a SIEM but who are looking for a centralized model of security operations. By using Security Hub and aggregating findings across Regions into a single Security Hub dashboard, they get oversight of their AWS resources without the cost and complexity of managing a SIEM.
Usage pattern 3: Centralized routing to a SIEM solution
Use AWS Security Hub as a single aggregation point for security and compliance findings across AWS accounts and Regions, and route those findings in a normalized format to a centralized SIEM or log management tool.
Customers who have an existing SIEM capability and complex environments typically deploy this usage pattern. By using Security Hub, these customers gather security and compliance-related findings across the workloads in all their accounts, ingest those into their SIEM, and investigate findings or take response and remediation actions directly within their SIEM console. This mechanism also enables customers to define use cases for threat detection and analysis in a single environment, providing a holistic view of their risk.
Stakeholders: Security operations teams, incident responders, and threat hunters. This pattern supports a centralized model of security operations, where the responsibilities for monitoring and identifying both non-compliance with defined practice, as well as security events, fall within single teams within the organization.
Value adds for customers: When Security Hub aggregates the findings from workloads across accounts and Regions in a single place, those finding are normalized by using the ASFF. This means that findings are already normalized under a single format when they are sent to the SIEM. This enables faster analytics, use case definition, and dashboarding because analysts don’t have to create multi-tiered use cases for different finding structures across vendors and services.
The ASFF also enables streamlined response through security orchestration, automation, response (SOAR) tools or AWS native orchestration tools such as AWS EventBridge. With the ASFF, you can effortlessly parse and filter events based on an attribute and customize automation.
Overall, this usage pattern helps to improve the typical key performance indicators (KPIs) the SecOps function is measured against, such as Mean Time to Detect (MTTD) or Mean Time to Respond (MTTR) in the AWS environment.
Setting up each usage pattern
In this section, we’ll go over the steps for setting up each usage pattern
Usage pattern 1: Dashboard for application owners
Use the following steps to set up a Security Hub dashboard for an account owner, where the owner can view and take action on security findings.
Assign the AWS managed permission policy AWSSecurityHubReadOnlyAccess to the principal who will be assuming the role. Figure 1 shows an image of the permission statement.
Figure 1: Assign permissions
(Optional) Create custom insights in Security Hub. Using custom insights can provide a view of areas of interest for an application owner; however, creating a new insights view is not allowed unless the following additional set of permissions are granted to the application owner role or user.
Pattern 1 walkthrough: View the application owner’s security findings
After the read-only IAM policy has been created and applied, the application owner can access Security Hub to view the dashboard, which provides the application owner with a view of the overall security posture of their AWS resources. In this section, we’ll walk through the steps that the application owner can take to quickly view and assess the compliance and security of their AWS resources.
To view the application owner’s dashboard in Security Hub
Sign into the AWS Management Console and navigate to the AWS Security Hub service page. You will be presented with a summary of the findings. Then, depending on the security standards that are enabled, you will be presented with a view similar to the one shown in Figure 2.
Figure 2: Summary of aggregated Security Hub standard score
Security Hub generates its own findings by running automated and continuous checks against the rules in a set of supported security standards. On the Summary page, the Security standards card displays the security scores for each enabled standard. It also displays a consolidated security score that represents the proportion of passed controls to enabled controls across the enabled standards.
Choose the hyperlink of a security standard to get an additional summarized view, as shown in Figure 3.
Figure 3: Security Hubs standards summarized view
As you choose the hyperlinks for the specific findings, you will get additional details, along with recommended remediation instructions to take.
Figure 4: Example of finding details view
In the left menu of the Security Hub console, choose Findings to see the findings ranked according to severity. Choose the link text of the finding title to drill into the details and view additional information on possible remediation actions.
Figure 5: Findings example
In the left menu of the Security Hub console, choose Insights. You will be presented with a collection of related findings. Security Hub provides several managed insights to get you started with assessing your security posture. As shown in Figure 6, you can quickly see if your Amazon Simple Storage Service (Amazon S3) buckets have public write or read permissions. This is just one example of managed insights that help you quickly identify risks.
Figure 6: Insights view
You can create custom insights to track issues and resources that are specific to your environment. Note that creating custom insights requires IAM permissions, as described earlier in the Prerequisites for Pattern 1 section. Use the following steps to create a custom insight for compliance status.
To create a custom insight, use the Group By filter and select how you want your insights to be grouped together:
In the left menu of the Security Hub console, choose Insights, and then choose Create insight in the upper right corner.
By default, there will be filters included in the filter bar. Put the cursor in the filter bar, choose Group By, choose Compliance Status, and then choose Apply.
Figure 7: Creating a custom insight
For Insight name, enter a relevant name for your insight, and then choose Create insight. Your custom insight will be created.
In this scenario, you learned how application owners can quickly assess the resources in an AWS account and get details about security risks and recommended remediation steps. For a more hands-on walkthrough that covers how to use Security Hub, consider spending 2–3 hours going through this AWS Security Hub workshop.
Usage pattern 2: A single pane of glass for security professionals
To use Security Hub as a centralized source of security insight, we recommend that you choose to accept security data from the available integrated AWS services and third-party products that generate findings. Check the lists of available integrations often, because AWS continues to release new services that integrate with Security Hub. Figure 8 shows the Integrations page in Security Hub, where you can find information on how to accept findings from the many integrations that are available.
Figure 8: Security Hub integrations page
Solution architecture and workflow for pattern 2
As Figure 9 shows, you can visualize Security Hub as the centralized security dashboard. Here, Security Hub can act as both the consumer and issuer of findings. Additionally, if you have security findings you want sent to Security Hub that aren’t provided by a AWS Partner or AWS service, you can create a custom provider to provide the central visibility you need.
Figure 9: Security Hub findings flow
Because Security Hub is integrated with many AWS services and partner solutions, customers get improved security visibility across their AWS landscape. With the integration of Amazon Detective, it’s convenient for security analysts to use Security Hub as the centralized incident triage starting point. Amazon Detective is a security incident response service that can be used to analyze, investigate, and quickly identify the root cause of potential security issues or suspicious activities by collecting log data from AWS resources. To learn how to get started with Amazon Detective, we recommend watching this video.
Programmatically remediate high-volume workflows
Security teams increasingly rely on monitoring and automation to scale and keep up with the demands of their business. Using Security Hub, customers can configure automatic responses to findings based upon preconfigured rules. Security Hub gives you the option to create your own automated response and remediation solution or use the AWS provided solution, Security Hub Automated Response and Remediation (SHARR). SHARR is an extensible solution that provides predefined response and remediation actions (playbooks) based on industry compliance standards and best practices for security threats. For step-by-step instructions for setting up SHARR, refer to this blog post.
Routing to alerting and ticketing systems
For incidents you cannot or do not want to automatically remediate, either because the incident happened in an account with a production workload or some change control process must be followed, routing to an incident management environment may be necessary. The primary goal of incident response is reducing the time to resolution for critical incidents. Customers who use alerting or incident management systems can integrate Security Hub to streamline the time it takes to resolve incidents. ServiceNow ITSM, Slack and PagerDuty are examples of products that integrate with Security Hub. This allows for workflow processing, escalations, and notifications as required.
Additionally, Incident Manager, a capability of AWS Systems Manager, also provides response plans, an escalation path, runbook automation, and active collaboration to recover from incidents. By using runbooks, customers can set up and run automation to recover from incidents. This blog post walks through setting up runbooks.
Usage pattern 3: Centralized routing to a SIEM solution
Here, we will describe how to use Splunk as an AWS Partner SIEM solution. However, note that there are many other SIEM partners available in the marketplace; the instructions to route findings to those partners’ platforms will be available in their documentation.
Solution architecture and workflow for pattern 3
Figure 10: Security Hub findings ingestion to Splunk
Figure 10 shows the use of a Security Hub delegated administrator that aggregates findings across multiple accounts and Regions, as well as other AWS services such as GuardDuty, Amazon Macie, and Inspector. These findings are then sent to Splunk through a combination of Amazon EventBridge, AWS Lambda, and Amazon Kinesis Data Firehose.
Prerequisites for pattern 3
This solution has the following prerequisites:
Enable Security Hub in your accounts, with one account defined as the delegated admin for other accounts within AWS Organizations, and enable cross-Region aggregation.
Generate and deploy a CloudFormation template from Splunk’s automation, provided by Project Trumpet.
Enable cross-Region replication. This action can only be performed from within the delegated administrator account, or from within a standalone account that is not controlled by a delegated administrator. The aggregation Region must be a Region that is enabled by default.
Pattern 3 walkthrough: Set up centralized routing to a SIEM
To get started, first designate a Security Hub delegated administrator and configure cross-Region replication. Then you can configure integration with Splunk.
To designate a delegated administrator and configure cross-Region replication
Perform these steps to configure cross-Region replication:
Sign in to the account to which you delegated Security Hub administration, and in the console, navigate to the Security Hub dashboard in your desired aggregation Region. You must have the correct permissions to access Security Hub and make this change.
Choose Settings, choose Regions, and then choose Configure finding aggregation.
Select the radio button that displays the Region you are currently in, and then choose Save.
You will then be presented with all available Regions in which you can aggregate findings. Select the Regions you want to be part of the aggregation. You also have the option to automatically link future Regions that Security Hub becomes enabled in.
Choose Save.
You have now enabled multi-Region aggregation. Navigate back to the dashboard, where findings will start to be replicated into a single view. The time it takes to replicate the findings from the Regions will vary. We recommend waiting 24 hours for the findings to be replicated into your aggregation Region.
To configure integration with Splunk
Note: These actions require that you have appropriate permissions to deploy a CloudFormation template.
Navigate to https://splunktrumpet.github.io/ and enter your HEC details: the endpoint URL and HEC token. Leave Automatically generate the required HTTP Event Collector tokens on your Splunk environment unselected.
Under AWS data source configuration, select only AWS CloudWatch Events, with the Security Hub findings – Imported filter applied.
Download the CloudFormation template to your local machine.
Sign in to the AWS Management Console in the account and Region where your Security Hub delegated administrator and Region aggregation are configured.
Navigate to the CloudFormation console and choose Create stack.
Choose Template is ready, and then choose Upload a template file. Upload the CloudFormation template you previously downloaded from the Splunk Trumpet page.
In the CloudFormation console, on the Specify Details page, enter a name for the stack. Keep all the default settings, and then choose Next.
Keep all the default settings for the stack options, and then choose Next to review.
On the review page, scroll to the bottom of the page. Select the check box under the Capabilities section, next to the acknowledgment that AWS CloudFormation might create IAM resources with custom names.
The CloudFormation template will take approximately 15–20 minutes to complete.
Test the solution for pattern 3
If you have GuardDuty enabled in your account, you can generate sample findings. Security Hub will ingest these findings and invoke the EventBridge rule to push them into Splunk. Alternatively, you can wait for findings to be generated from the periodic checks that are performed by Security Hub. Figure 11 shows an example of findings displayed in the Security Hub dashboard in Splunk.
Figure 11: Example of the Security Hub dashboard in Splunk
Conclusion
AWS Security Hub provides multiple ways you can use to quickly assess and prioritize your security alerts and security posture. In this post, you learned about three different usage patterns that we have seen our customers implement to take advantage of the benefits and integrations offered by Security Hub. Note that these usage patterns are not mutually exclusive, but can be used together as needed.
To extend these solutions further, you can enrich Security Hub metadata with additional context by using tags, as described in this post. Configure Security Hub to ingest findings from a variety of AWS Partners to provide additional visibility and context to the overall status of your security posture. To start your 30-day free trial of Security Hub, visit AWS Security Hub.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, please start a new thread on the Security Hub forum or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Cybersecurity teams are often made up of different functions. Typically, these can include Governance, Risk & Compliance (GRC), Security Architecture, Assurance, and Security Operations, to name a few. Each function has its own specific tasks, but works towards a common goal—to partner with the rest of the business and help teams ship and run workloads securely.
In this blog post, I’ll focus on the role of the security operations (SecOps) function, and in particular, the considerations that you should look at when choosing the most suitable operating model for your enterprise and environment. This becomes particularly important when your organization starts to adapt and operate more workloads in the cloud.
Operational teams that manage business processes are the backbone of organizations—they pave the way for efficient running of a business and provide a solid understanding of which day-to-day processes are effective. Typically, these processes are defined within standard operating procedures (SOPs), also known as runbooks or playbooks, and business functions are centralized around them—think Human Resources, Accounting, IT, and so on. This is also true for cybersecurity and SecOps, which typically has operational oversight of security for the entire organization.
Teams adopt an operating model that inherently leans toward a delegated ownership of security when scaling and developing workloads in the cloud. The emergence of this type of delegation might cause you to re-evaluate your currently supported model, and when you do this, it’s important to understand what outcome you are trying to get to. You want to be able to quickly respond to and resolve security issues. You want to help application teams own their own security decisions. You also want to have centralized visibility of the security posture of your organization. This last objective is key to being able to identify where there are opportunities for improvement in tooling or processes that can improve the operation of multiple teams.
Three ways of designing the operating model for SecOps are as follows:
Centralized – A more traditional model where SecOps is responsible for identifying and remediating security events across the business. This can also include reviewing general security posture findings for the business, such as patching and security configuration issues.
Decentralized – Responsibility for responding to and remediating security events across the business has been delegated to the application owners and individual business units, and there is no central operations function. Typically, there will still be an overarching security governance function that takes more of a policy or principles view.
Hybrid – A mix of both approaches, where SecOps still has a level of responsibility and ownership for identifying and orchestrating the response to security events, while the responsibility for remediation is owned by the application owners and individual business units.
As you can see from these descriptions, the main distinction between the different models is in the team that is responsible for remediation and response. I’ll discuss the benefits and considerations of each model throughout this blog post.
The strategies and operating models that I talk about throughout this blog post will focus on the role of SecOps and organizations that operate in the cloud. It’s worth noting that these operating models don’t apply to any particular technology or cloud provider. Each model has its own benefits and challenges to consider; overall, you should aim to adopt an operating model that gets to the best business outcome, while managing risk and providing a path for continuous improvement.
Background: the centralized model
As you might expect, the most familiar and well-understood operating model for SecOps is a centralized one. Traditionally, SecOps has developed gradually from internal security staff who have a very good understanding of the mostly static on-premises infrastructure and corporate assets, such as employee laptops, servers, and databases.
Centralizing in this way provides organizations with a familiar operating model and structure. Over time, operating in this model across an industry has allowed teams to develop reliable SOPs for common security events. Analysts who deal with these incidents have a good understanding of the infrastructure, the environment, and the steps that are needed to resolve incidents. Every incident gives opportunities to update the SOPs and to share this knowledge and the lessons learned with the wider industry. This continuous feedback cycle has provided benefits to SecOps teams for many years.
When security issues occur, understanding the division of responsibility between the various teams in this model is extremely important for quick resolution and remediation. The Responsibility Assignment Matrix, also known as the RACI model, has defined roles—Responsible, Accountable, Consulted, and Informed. Utilizing a model like this will help align each employee, department, and business unit so that they are aware of their role and contact points when incidents do occur, and can use defined playbooks to quickly act upon incidents.
The pressure can be high during a security event, and incidents that involve production systems carry additional weight. Typically, in a centralized model, security events flow into a central queue that a security analyst will monitor. A common approach is the Security Operations Center (SOC), where events from multiple sources are displayed on screens and also trigger activity in the queue. Security incidents are acted upon by an experienced team that is well versed in SOPs and understands the importance of time sensitivity when dealing with such incidents. Additionally, a centralized SecOps team usually operates in a 24/7 model, which might be achieved by having teams in multiple time zones or with help from an MSSP (Managed Security Service Provider). Whichever strategy is followed, having experienced security analysts deal with security incidents is a great benefit, because experience helps to ensure efficient and thorough remediation of issues.
So, with context and background set—how does a centralized SOC look and feel when it operates in the cloud, and what are its challenges?
Centralized SOC in the cloud: the advantages
Cloud providers offer many solutions and capabilities for SOCs that operate in a centralized model. For example, you can monitor your organization’s cloud security posture as a whole, which allows for key performance indicator (KPI) benchmarking, both internally and industry wide. This can then help your organization target security initiatives, training, and awareness on lower-scoring areas.
Security orchestration, automation, and response (SOAR) is a phrase commonly used across the security industry, and the cloud unlocks this capability. Combining both native and third-party security services and solutions with automation facilitates quick resolution of security incidents. The use of SOAR means that only incidents that need human intervention are actually reviewed by the analysts. After investigation, if automation can be introduced on that alert, it’s quickly applied. Having a central place for automating alerts helps the organization to have a consistent and structured approach to the response for security events and gives analysts more time to focus on activities like threat hunting.
Additionally, such threat-hunting operations require a central security data lake or similar technology. As a result, the SecOps team helps to drive the centralization of data across the business, which is a traditional cybersecurity function.
Centralized SOC in the cloud: organizational considerations
Some KPIs that a traditional SOC would typically use are time to detect (TTD), time to acknowledge (TTA), and time to resolve (TTR). These have been good metrics that SecOps managers can use to understand and benchmark how well the SecOps team is performing, both internally and against industry benchmarks. As your organization starts to take advantage of the breadth and depth available within the cloud, how does this change the KPIs that you need to track? As stated earlier, the cloud makes it easier to track KPIs through increased visibility of your cloud footprint—although you should evaluate traditional KPIs to understand whether they still make sense to use. Some additional KPIs that should be considered are metrics that show increasing automation, reduction in human access, and the overall improvement in security posture.
Organizations should consider scaling factors for operational processes and capability in the centralized SOC model. Once benefits from adopting the cloud have been realized, organizations typically expand and scale up their cloud footprint aggressively. For a centralized SecOps team, this could cause a challenging battle between the wider business, which wants to expand, and the SOC, which needs the ability to fully understand and respond to issues in the environment. For example, most organizations will put together small proof of concepts (POCs) to showcase new architectures and their benefits, and these POCs may become available as blueprints for the wider organization to consume. When new blueprints are implemented, the centralized SecOps team should implement and rely on its automation capabilities to verify that the correct alerting, monitoring, and operational processes are in place.
Decentralization: all ownership with the application teams
Moving or designing workloads in the cloud provides organizations with many benefits, such as increased speed and agility, built-in native security, and the ability to launch globally in minutes. When looking at the decentralized model, business units should incorporate practices into their development pipelines to benefit from the security capabilities of the cloud. This is sometimes referred to as a shift left or DevSecOps approach—essentially building security best practices into every part of the development process, and as early as possible.
Placing the ownership of the SecOps function on the business units and application owners can provide some benefits. One immediate benefit is that the teams that create applications and architectures have first-hand knowledge and contextual awareness of their products. This knowledge is critical when security events occur, because understanding the expected behavior and information flows of workloads helps with quick remediation and resolution of issues. Having teams work on security incidents in the ways that best fit their operational processes can also increase speed of remediation.
Decentralization: organizational considerations
When considering the decentralized approach, there are some organizational considerations that you should be aware of:
Dedicated security analysts within a central SecOps function deal with security incidents day in and day out; they study the industry, have a keen eye on upcoming threats, and are also well versed in high-pressure situations. By decentralizing, you might lose the consistent, level-headed experience they offer during a security incident. Embedding security champions who have industry experience into each business unit can help ensure that security is considered throughout the development lifecycle and that incidents are resolved as quickly as possible.
Contextual information and root cause analysis from past incidents are vital data points. Having a centralized SecOps team makes it much simpler to get a broad view of the security issues affecting the whole organization, which improves the ability to take a signal from one business unit and apply that to other parts of the organization to understand if they are also vulnerable, and to help protect the organization in the future.
Decentralizing the SecOps responsibility completely can cause you to lose these benefits. As mentioned earlier, effective communication and an environment to share data is key to verifying that lessons learned are shared across business units—one way of achieving this effective knowledge sharing could be to set up a Cloud Center of Excellence (CCoE). The CCoE helps with broad information sharing, but the minimization of team hand-offs provided by a centralized SecOps function is a strong organizational mechanism to drive consistency.
Traditionally, in the centralized model, the SOC has 24/7 coverage of applications and critical business functions, which can require a large security staff. The need for 24/7 operations still exists in a decentralized model, and having to provide that capability in each application team or business unit can increase costs while making it more difficult to share information. In a decentralized model, having greater levels of automation across organizational processes can help reduce the number of humans needed for 24/7 coverage.
Blending the models: the hybrid approach
Most organizations end up using a hybrid operating model in one way or another. This model combines the benefits of the centralized and decentralized models, with clear responsibility and division of ownership between the business units and the central SecOps function.
This best-of-both-worlds scenario can be summarized by the statement “global monitoring, local response.” This means that the SecOps team and wider cybersecurity function guides the entire organization with security best practices and guardrails while also maintaining visibility for reporting, compliance, and understanding the security posture of the organization as a whole. Meanwhile, local business units have the tools, knowledge, and expertise available to confidently own remediation of security events for their applications.
In this hybrid model, you split delegation of ownership into two parts. First, the operational capability for security is centrally owned. This centrally owned capability builds upon the partnership between the application teams and the security organization, via the CCoE. This gives the benefits of consistency, tooling expertise, and lessons learned from past security incidents. Second, the resolution of day-to-day security events and security posture findings is delegated to the business units. This empowers the people closest to the business problem to own service improvement in ways that best suit that team’s way of working, whether that’s through ChatOps and automation, or through the tools available in the cloud. Examples of the types of events you might want to delegate for resolution are items such as patching, configuration issues, and workload-specific security events. It’s important to provide these teams with a well-defined escalation route to the central security organization for issues that require specialist security knowledge, such as forensics or other investigations.
A RACI is particularly important when you operate in this hybrid model. Making sure that there is a clear set of responsibilities between the business units and the SecOps team is crucial to avoid confusion when security incidents occur.
Conclusion
The cloud has the ability to unlock new capabilities for your organization. Increased security, speed, and agility and are just some of the benefits you can gain when you move workloads to the cloud. The traditional centralized SecOps model offers a consistent approach to security detection and response for your organization. Decentralization of the response provides application teams with direct exposure to the consequences of their design decisions, which can speed up improvement. The hybrid model, where application teams are responsible for the resolution of issues, can improve the time to fix issues while freeing up SecOps to continue their works. The hybrid operating model compliments the capabilities of the cloud, and enables application owners and business units to work in ways that best suit them while maintaining a high bar for security across the organization.
Whichever operating model and strategy you decide to embark on, it’s important to remember the core principles that you should aim for:
Enable effective risk management across the business
Drive security awareness and embed security champions where possible
When you scale, maintain organization-wide visibility of security events
Help application owners and business units to work in ways that work best for them
Work with application owners and business units to understand the cyber landscape
The cloud offers many benefits for your organization, and your security organization is there to help teams ship and operate securely. This confidence will lead to realized productivity and continued innovation—which is good for both internal teams and your customers.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile series, we interview AWS thought leaders who help keep our customers safe and secure. This interview features Jonathan “Koz” Kozolchyk, GM of Certificate Services, PKI Systems. Koz shares his insights on the current certificate landscape, his career at Amazon and within the security space, what he’s excited about for the upcoming AWS re:Invent 2022, his passion for home roasting coffee, and more.
How long have you been at AWS and what do you do in your current role? I’ve been with Amazon for 21 years and in AWS for 6. I run our Certificate Services organization. This includes managing services such as AWS Certificate Manager (ACM), AWS Private Certificate Authority (AWS Private CA), AWS Signer, and managing certificates and trust stores at scale for Amazon. I’ve been in charge of the internal PKI (public key infrastructure, our mix of public and private certs) for Amazon for nearly 10 years. This has given me lots of insight into how certificates work at scale, and I’ve enjoyed applying those learnings to our customer offerings.
How did you get started in the certificate space? What about it piqued your interest? Certificates were designed to solve two key problems: provide a secure identity and enable encryption in transit. These are both critical needs that are foundational to the operation of the internet. They also come with a lot of sharp edges. When a certificate expires, systems tend to fail. This can cause problems for Amazon and our customers. It’s a hard problem when you’re managing over a million certificates, and I enjoy the challenge that comes with that. I like turning hard problems into a delightful experience. I love the feedback we get from customers on how hands-free ACM is and how it just solves their problems.
How do you explain your job to your non-tech friends? I tell them I do two things. I run the equivalent of a department of motor vehicles for the internet, where I validate the identity of websites and issue secure documentation to prove the websites’ validity to others (the certificate). I’m also a librarian. I keep track of all of the certificates we issue and ensure that they never expire and that the private keys are always safe.
What are you currently working on that you’re excited about? I’m really excited about our AWS Private CA offering and the places we’re planning to grow the service. Running a certificate authority is hard—it requires careful planning and tight security controls. I love that AWS Private CA has turned this into a simple-to-use and secure system for customers. We’ve seen the number of customers expand over time as we’ve added more versatility for customers to customize certificates to meet a wide range of applications—including Kubernetes, Internet of Things, IAM Roles Anywhere (which provides a secure way for on-premises servers to obtain temporary AWS credentials and removes the need to create and manage long-term AWS credentials), and Matter, a new industry standard for connecting smart home devices. We’re also working on code signing and software supply chain security. Finally, we have some exciting features coming to ACM in the coming year that I think customers will really appreciate.
What’s been the most dramatic change you’ve seen in the industry? The biggest change has been the way that certificate pricing and infrastructure as code has changed the way we think about certificates. It used to be that a company would have a handful of certificates that they tracked in spreadsheets and calendar invites. Issuance processes could take days and it was okay. Now, every individual host, every run of an integration test may be provisioning a new certificate. Certificate validity used to last three years, and now customers want one-day certificates. This brings a new element of scale to not only our underlying architecture, but also the ways that we have to interact with our customers in terms of management controls and visibility. We’re also at the beginning of a new push for increased PKI agility. In the old days, PKI was brittle and slow to change. We’re seeing the industry move towards the ability to rapidly change roots and intermediates. You can see we’re pushing some of this now with our dynamic intermediate certificate authorities.
What would you say is the coolest AWS service or feature in the PKI space? Our customers love the way AWS Certificate Manager makes certificate management a hands-off automated affair. If you request a certificate with DNS validation, we’ll renew and deploy that certificate on AWS for as long as you’re using it and you’ll never lose sleep about that certificate.
Is there something you wish customers would ask you about more often? I’m always happy to talk about PKI design and how to best plan your private CAs and design. We like to say that PKI is the land of one-way doors. It’s easy to make a decision that you can’t reverse, and it could be years before you realize you’ve made a mistake. Helping customers avoid those mistakes is something we like to do.
I understand you’ll be at re:Invent 2022. What are you most looking forward to? Hands down it’s the customer meetings; we take customer feedback very seriously, and hearing what their needs are helps us define our solutions. We also have several talks in this space, including CON316 – Container Image Signing on AWS, SEC212 – Data Protection Grand Tour: Locks, Keys, Certs, and Sigs, and SEC213 – Understanding the evolution of cloud-based PKI. I encourage folks to check out these sessions as well as the re:Invent 2022 session catalog.
Do you have any tips for first-time re:Invent attendees? Wear comfortable shoes! It’s amazing how many steps you’ll put in.
How about outside of work, any hobbies? I understand you’re passionate about home coffee roasting. How did you get started? I do roast my own coffee—it’s a challenging hobby because you always have to be thinking 30 to 60 seconds ahead of what your data is showing you. You’re working off of sight and sound, listening to the beans and checking their color. When you make an adjustment to the roaster, you have to do it thinking where the beans will be in the future and not where they are now. I love the challenge that comes with it, and it gives me access to interesting coffee beans you wouldn’t normally see on store shelves. I got started with a used small home roaster because I thought I would enjoy it. I’ve since upgraded to a commercial “sample” roaster that lets me do larger batches.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the weeks leading up to AWS re:invent 2022, I’ll share conversations I’ve had with some of the humans who work in AWS Security who will be presenting at the conference, and get a sneak peek at their work and sessions. In this profile, I interviewed Reef D’Souza, Principal Solutions Architect.
How long have you been at AWS and what do you do in your current role?
I’ve been at AWS for about six and a half years. During my time here, I’ve worked in AWS Professional Services as a security consultant in New York and Los Angeles. I worked with customers in Financial Services, Healthcare, Telco, and Media & Entertainment to build security controls that align with the AWS Cloud Adoption Framework Security Epics (now Security Perspective) so that these customers could run highly regulated workloads on AWS. In the last two years, I’ve switched to a dual role of being a Solution Architect for Independent Software Vendors (ISVs) and Digital Native Businesses (DNBs) in Canada while helping them with their security and privacy.
How did you get started in security?
I started out trying to make it as a software developer but realized I enjoy breaking things apart with my skepticism of security claims. While I was getting my master’s degree in Information Systems, I started to specialize in applying machine learning (ML) to anomaly detection systems and then went on to application security vulnerability management and testing while working at different security startups in New York. My customers were mostly in financial services, looking to threat model their apps, prioritize their risks, and take action.
How do you explain your job to non-technical friends and family?
I tell them that I work with companies who tell me what they’re worried about, which includes stolen credit card data or healthcare data, and then help those customers put technology in place to prevent or detect a security event. This often goes down the path of comparing me to the television show Mr. Robot or fictional espionage scenarios. When I say I work for Amazon, I often get asked whether I can track packages down for Thanksgiving and the holiday season.
What are you currently working on that you’re excited about?
I’ve been diving deep into the world of privacy engineering. As an SA for software companies in Canada, many of whom want to launch in Europe and other parts of the world that have strict privacy regulations, it’s a frequent topic. However, privacy discussions are often steeped in legal-speak. My customers’ technical stakeholders say that it all sounds like English but doesn’t make any sense. So my goal is to help them understand privacy risks and translate these risks to mechanisms that can be implemented in customers’ workloads. The last cool thing I worked on with AWS Privacy specialists on the ProServe SAS team was a workshop for AWS re:Inforce 2022 this past July.
You’re presenting at re:Invent this year. Can you give us a sneak peek of your session?
My session is Securing serverless workloads on AWS. It’s a chalk talk that walks the attendee through the shared responsibility model for serverless applications built with AWS Lambda. We then dive deeper into how to threat model for security risks and use AWS services to secure the application and test for vulnerabilities in the CI/CD pipeline. I cover classic risks like the OWASP Top 10 and how customers must think about verifying trusted third-party libraries with AWS CodeArtifact, deploying trusted code by using AWS Signer, and identifying vulnerabilities in their code with Amazon CodeGuru.
What do you hope attendees take away from your session?
Customers with vulnerability management programs must grasp a paradigm shift that there are no servers to scan anymore. Here is where the lines are blurred between traditional vulnerability management and application security. I hope attendees of my sessions leave with a better understanding of their responsibilities in terms of risks and where AWS services can help them build secure applications and do so earlier in the development lifecycle.
Insist on the Highest Standards. Shoddy craftsmanship based on planning for short-term wins, inefficiency, and wasteful spending are massive pet peeves of mine. This principle ties so closely with Customer Obsession, because the quality of our work impacts the long-term trust that others place in us. When there is an issue, it motivates us to find the root cause and shows up in our focus on operational excellence.
What’s the best career advice you’ve ever received?
After I got out of graduate school, I entered the world thinking I knew everything. My first manager gave me the advice to keep asking questions, though. Knowing things doesn’t necessarily mean that your knowledge applies to a problem. You have to think beyond just a technical solution. When I joined Amazon, this felt natural as part of our Working Backwards process.
What’s the thing you’re most proud of in your career?
I worked on a COVID contact-tracing data lake project in the early stages of the pandemic. With some of the best security and data engineers on the team, we were able to threat model for the various components of the analytics environment, which housed data subject to HIPAA, the California Consumer Privacy Act (CCPA), the E.U. General Data Protection Regulation (GDPR) and many other healthcare and general privacy regulations. We released a working analytics solution within five or so months after March 2020. At the time, building these types of environments usually took over a year.
If you had to pick an industry outside of security, what would you want to do?
Motorcycle travel writing. It combines my favorite activities of meeting new people, learning new languages and cultures, trying new cuisines (cooking and eating), and sharing the experience with others.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
At Amazon Web Services (AWS), we’re committed to providing customers with continued assurance over the security, availability, and confidentiality of the AWS control environment. We’re proud to deliver the Fall 2022 System and Organizational Controls (SOC) 1, 2, and 3 reports, which cover April 1–September 30, 2022, to support our customers’ confidence in AWS services.
AWS has also updated the associated infrastructure supporting our in-scope products and services to reflect new edge locations, AWS Wavelength zones, and AWS Local Zones.
The Fall 2022 SOC reports include an additional seven services in scope, for a new total of 154 services. See the full list on our Services in Scope by Compliance Program page.
The following are the additional seven services now in scope for the Fall 2022 SOC reports:
AWS strives to bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If there are additional AWS services that you would like to see added to the scope of our SOC reports (or other compliance programs), reach out to your AWS representatives.
As always, we value your feedback and questions. Feel free to reach out to the team through the Contact Us page. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to-content, news, and feature announcements? Follow us on Twitter.
Your privacy considerations are at the core of our compliance work at Amazon Web Services (AWS), and we are focused on the protection of your content while using AWS services.
We are happy to announce that our Fall 2022 SOC 2 Type 2 Privacy report is now available. The report provides a third-party attestation of our system and the suitability of the design of our privacy controls. The SOC 2 Privacy Trust Service Criteria (TSC), developed by the American Institute of Certified Public Accountants (AICPA), establishes the criteria for evaluating controls that relate to how personal information is collected, used, retained, disclosed, and disposed of. For more information about our privacy commitments supporting the SOC 2 Type 2 report, see the AWS Customer Agreement.
The scope of the Fall 2022 SOC 2 Type 2 Privacy report includes information about how we handle the content that you upload to AWS, and how that content is protected across the services and locations that are in scope for the latest AWS SOC reports. AWS customers can download the SOC 2 Type 2 Privacy report through AWS Artifact in the AWS Management Console.
As always, we value your feedback and questions. Feel free to reach out to the compliance team through the AWS Compliance Contact Us page. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to-content, news, and feature announcements? Follow us on Twitter.
Now, you can add multiple MFA devices to AWS account root users and AWS Identity and Access Management (IAM) users in your AWS accounts. This helps you to raise the security bar in your accounts and limit access management to highly privileged principals, such as root users. Previously, you could only have one MFA device associated with root users or IAM users, but now you can associate up to eight MFA devices of the currently supported types with root users and IAM users.
In this blog post, we review the current MFA features for IAM, share use cases for multiple MFA devices, and show you how to manage and sign in with the additional MFA devices for better resiliency and flexibility.
Overview of MFA for IAM
First, let’s recap some of the benefits and available MFA configurations for IAM.
The use of MFA is an important security best practice on AWS. With MFA, you have an additional layer of protection to help prevent unauthorized individuals from gaining access to your systems and data. MFA can help protect your AWS environments if a password associated with your root user or IAM user became compromised.
To help meet different customer needs, AWS supports three types of MFA devices for IAM, including FIDO security keys, virtual authenticator applications, and time-based one-time password (TOTP) hardware tokens. You should select the device type that aligns with your security and operational requirements. You can associate different types of MFA devices with an IAM principal.
Use cases for multiple MFA devices
There are several use cases in which associating multiple MFA devices with an IAM principal is beneficial to the security and operational efficiency of your organization, such as the following:
In the event of a lost, stolen, or inaccessible MFA device, you can use one of the remaining MFA devices to access the account without performing the AWS account recovery procedure. If an MFA device is lost or stolen, it’s best practice to disassociate the lost or stolen device from the root users or IAM users that it’s associated with.
Geographically dispersed teams, or teams working remotely, can use hardware-based MFA to access AWS, without shipping a single hardware device or coordinating a physical exchange of a single hardware device between team members.
If the holder of an MFA device isn’t available, you can maintain access to your root users and IAM users by using a different MFA device associated with an IAM principal.
You can store additional MFA devices in a secure physical location, such as a vault or safe, while retaining physical access to another MFA device for redundancy.
How to manage multiple MFA devices in IAM
You can register up to eight MFA devices, in any combination of the currently supported MFA types, with your root users and IAM users.
For Multi-factor authentication (MFA), choose Assign MFA device.
Select the type of MFA device that you want to use and then choose Next.
With multiple MFA devices, you only need one MFA device to sign in to the console or to create a session through the AWS Command Line Interface (AWS CLI) as that principal.
You don’t need to make permissions changes in order for your organization to start taking advantage of multiple MFA devices. The root users and IAM users in your accounts that manage MFA devices today can use their existing IAM permissions to enable additional MFA devices.
Changes to Cloudtrail log entries
In support of this new feature, the identifier of the MFA device used will now be added to the console sign-in events of the root user and IAM user that use MFA. With these changes to AWS CloudTrail log entries, you can now view both the user and the MFA device used to authenticate to AWS. This provides better traceability and audibility for your accounts.
You can find this information in the MFAIdentifier field in CloudTrail, within additionalEventData. You don’t need to take action for this information to be logged. The following is a sample log from CloudTrail that includes the MFAIdentifier.
For Additional verification required, select the type of MFA device that you want to use to continue authenticating, and then choose Next:
Figure 1: MFA device selection when authenticating to the console as an IAM user or root user with different types of MFA devices available
You will then be prompted to authenticate with the type of device that you selected.
Figure 2: Prompt to authenticate with a FIDO security key
Conclusion
In this blog post, you learned about the new multiple MFA devices feature in IAM, and how to set up and manage multiple MFA devices in IAM. Associating multiple MFA devices with your root users and IAM users can make it simpler for you to manage access to them. This feature is available now for AWS customers, except for customers operating in AWS GovCloud (US) Regions or in the AWS China Regions. For more information about how to configure multiple MFA devices on your root users and IAM users, see the documentation on MFA in IAM. There is no extra charge to use MFA devices in IAM.
As we head into 2023, it’s time to think about lessons from this year and incorporate them into planning for the next year and beyond. At AWS, we continually learn from our customers, who influence the best practices that we share and the security services that we offer.
We heard that you’re looking for more prescriptive guidance, patterns, and trends that AWS Security is seeing in the industry, so I’m happy to share an ebook that I recently authored called Security Predictions in 2023 and Beyond. In this ebook, you’ll learn about what we think is next for the security industry and some high-level pointers on how you can stay ahead.
The last few years has brought rapid acceleration of digital transformation in a short time and forced organizations to manage disruptions to their business, such as the impact of remote work. As security and risk management leaders handle the recovery and renewal phases from the past two years, they must consider forward-looking strategic planning assumptions when allocating budget, selecting services, and prioritizing employee effort. We are now at an interesting point in time where it will take the right mix of technology and humans to shape the future of cybersecurity.
I encourage you to read through the ebook and consider how these predictions could influence strategic planning for your security program. Drop us your feedback in the comments or reach out to your account team with questions. You can also follow @AWSSecurityInfo for the latest from AWS Security, and you can find me at @mosescj58.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Automated scripts, known as bots, can generate significant volumes of traffic to your mobile applications, websites, and APIs. Targeted bots take this a step further by targeting website content, such as product availability or pricing.
Traffic from targeted bots can result in a poor user experience by competing against legitimate user traffic for website access to high-demand inventory, increasing business risk through chargebacks from fraudulent transactions, and increasing infrastructure costs.
In 2021, AWS released AWS WAF Bot Control for Common Bots to help you detect and control common bots. In October 2022, AWS released a new feature—AWS Bot Control for Targeted Bots—that can help you detect and protect against bots that use advanced techniques to actively avoid detection.
In this post, I provide an overview of Bot Control for Targeted Bots and show you how to enable Bot Control to detect and block both common and targeted bots.
Overview of Bot Control for Targeted Bots
Bot Control for Targeted Bots provides sophisticated bot detection and mitigation by creating an intelligent baseline of traffic patterns. Bot Control for Targeted Bots uses browser fingerprinting techniques and client-side JavaScript interrogation methods to help protect your application from advanced bots that mimic human traffic patterns and actively try to evade detection.
Bot Control detects anomalies in usage patterns and provides new flexible mitigation options to isolate bad bots. These options include dynamic rate-limiting, challenge actions, and the ability to block based on labels and confidence scores.
With Bot Control for Targeted Bots, you can use bot protection rules to allow verified common bot traffic and, at the same time, to challenge unwanted advanced bot traffic. You can achieve both tasks from the same configuration page without making application or architectural changes. You can also configure fine-grained rule sets. For example, you can configure blocking actions for high-risk bots while allowing for exceptions for known IP ranges.
This release also introduces token domains, which is the ability to use the same AWS WAF web ACL across multiple domain names and Amazon CloudFront distributions to simplify client-side configuration. For example, you can use token domains to accept tokens that are generated by www.example.com for api.example.com and vice versa. In addition, you can now specify a resource path directly in the managed rule configuration, enabling you to only require a token for API calls, but not for cached, content-like images.
Bot Control for Targeted Bots sends metrics to Amazon CloudWatch to identify application access trends. The metrics include the percentage of human traffic compared to bot traffic and the count of requests for sensitive web pages such as login and checkout pages. Each rule in Bot Control produces a unique label so that you can review CloudWatch metrics and filter logs to understand traffic patterns. By using these mechanisms, you can identify, isolate, and remediate operational issues.
Walkthrough
In this walkthrough, I will show you how to set up Bot Control for Targeted Bots to help protect a CloudFront distribution.
You will set up an AWS WAF web ACL with an AWS Managed Rule for Bot Control for Targeted Bots. The rule detects bots and then decides the appropriate action:
Dynamically rate limit verified bots – Based on traffic history, Bot Control creates an intelligent baseline and then applies rate limits to abnormally high volumes.
Enable the challenge action – You have a new option, called challenge, along with the already supported options of count, allow, block, and CAPTCHA. The challenge option initiates a process of challenge interstitial, which means that Bot Control provides a challenge to the browser and creates a domain token when the challenge is resolved.
Set up Bot Control for Targeted Bots
In this section, I will show you how to set up Bot Control for Targeted Bots by creating a new web ACL or editing an existing one.
To create a new web ACL, choose Create a new web ACL.
To edit an existing web ACL, choose the name of the ACL.
On the Rules tab, for the Add rules drop-down, select Add managed rule groups.
Add a Bot Control rule set to the web ACL. Choose Edit to edit the rule.
For Bot Control inspection level, select the inspection level for Bot Control. For this walkthrough, we chose Targeted to enable Bot Control for Targeted Bots.
Figure 1: Bot Control – Select inspection level
Review and select the actions to be taken on each category of bots detected, and then choose Save rule. In our example, we set allow, challenge, and count rules for the categories, as shown in Figure 2.
Figure 2: Bot Control – Select actions for each category
You can select different actions for each category based on your application security needs:
Allow: Allows the request to be sent to a protected resource.
Block: Blocks the request, returning an HTTP 403 (Forbidden) response.
Count: Allows the request to be sent to the protected resource while counting detections. The count shows you bot activity that is occurring without blocking or challenging. When you turn on rules for the first time, this information can help you see what the detections are, before you change the actions.
CAPTCHA and Challenge: use CAPTCHA puzzles and silent challenges with tokens to track successful client responses.
In this example you will configure a scope-down statement to apply Bot Control for a given URI path only.
On the same page in the step above, you can add a scope-down statement to ensure you use and incur Targeted Bots charges for the requests where you need protections. There are more examples of how to use scope-down statements in our documentation.
Select “Enable scope-down statement” and configure the rule to inspect the URI path as per figure 3.
Figure 3: Bot Control – Add the scope-down statement
To add domain names to be protected, scroll to the bottom of the web ACL and choose Edit. In the Token domain list – optional section, enter the domain name or names to which the token verification applies. Tokens that are generated are valid for these domains.
Create the SDK link for the AWS WAF integration
In this section, I’ll show you how to find the AWS WAF SDK and add it to your application pages.
The token SDK manages the token authorization and includes the tokens in the requests that you send to your protected resources. By adding the SDK link to application pages, you can help ensure that the remote procedure calls by your client contain a valid token.
To add the SDK to your application pages
In the AWS WAF console, in the left navigation pane, choose Application integration SDKs.
Under JavaScript SDK, copy the provided code snippet. This code snippet allows for creation of the cryptographic token in the background when the application loads for the first time, providing a better customer experience.
Add the code snippet to your pages. For example, paste the provided script code within the <head> section of the HTML.
When this integration is in place on your application’s pages, you can add AWS WAF rules in your web ACL to block requests that don’t contain a valid token. Replace the <Web ACL integration URL> with the provided integration URL from the AWS WAF console or copy the script tag from the console:
Figure 4 shows the SDK link for application pages.
Figure 4: Bot Control – Add SDK link to application pages
Review metrics
Now that you’ve set up the web ACL and application, you can use the bot visualization dashboard to review bot traffic patterns. Bot rules emit metrics corresponding to their labels, helping you identify which rule within the AWS Managed Rule for Bot Control for Targeted Bots initiated an action. You can also use these labels and rule actions to filter AWS WAF logs so that you can further examine a request.
To view AWS WAF metrics for the distribution
In the AWS WAF console, in the left navigation pane, select Web ACLs.
Select the web ACL that Bot Control is enabled on and then choose the Bot Control tab to view the metrics.
Figure 5: Bot Control – Review web ACL metrics
Best practices
In this section, I describe best practices for your Bot Control setup.
Set priority ordering of AWS WAF rules to help lower costs
You can set the priority of rule groups in a web ACL such that the order of the rule matches requests more efficiently. AWS WAF will take the action associated to the first rule it matches. If the incoming traffic matches the more wider criteria (such as IPset rules at priority 1), the associated action is taken. That request is never analyzed by the Bot Control rule and hence do not incur the bot control request analysis fees. For example, the following list shows rules ranked in order from highest priority (1) to lowest priority (5):
Use allow and deny lists – provide IP addresses to allow or deny
AWS Managed Rule groups for IP reputation – block bots and other threats
General rate limit – help prevent HTTP flood across the protected resource
AWS WAF Bot Control rule group – scoped-down to exclude static content such as images
Rate limit for login pages – scoped-down for specific URLs and HTTP POST methods
Figure 6 shows the prioritized rules in AWS WAF.
Figure 6: AWS WAF – Web ACL rule order
Use scope-down statements
You can use scope-down statements to limit the requests evaluated for a rule group. For example, a scope-down statement that excludes checking requests for static assets, such as images for a given URI and HTTP method (GET), can help reduce Bot Control costs.
Block requests without tokens
If a request has a token absent or is rejected, you can block that request. For example, you might want to block requests on login or payment processing pages. To block requests with a missing or rejected token, add a rule to run after the Bot Control rule to block requests matching the labels rejected and absent:
awswaf:managed:token:rejected – The request token is present but is either corrupt or has an expired challenge timestamp.
awswaf:managed:token:absent – The request doesn’t have a token.
Use SDK integration
After you add the token domains and the provided script to your application pages, you can add a rule to block requests that don’t have a token. Use of the SDK helps AWS WAF verify the client application with silent challenges and provide AWS token acquisition and management. The SDK provides the full functionality of both AWS WAF Bot Control and AWS WAF Fraud Control, reducing the need for multiple SDKs if either or both rule groups are used in the web ACL.
Create CloudWatch alarms
You can add CloudWatch alarms to help you assess whether there is activity outside of the norm for your application. For example, you can monitor for a high number of token-absent metrics for a given time period.
Configure a billing alarm
To help you track costs, you can configure a billing alarm that sends an alert when you have exceeded the threshold for your expected costs.
Pricing and availability
Bot Control for Targeted Bots is available today in AWS Regions where AWS WAF is available, excluding AWS GovCloud (US) and China Regions. For information on pricing, see AWS WAF Pricing.
Conclusion
In this post, you learned how to use Bot Control for Targeted Bots to add visibility into bot activity on your website or applications. With Bot Control for common and targeted bots, you can detect, challenge, and block unwanted bot activity. Because Bot Control is customizable, you can tailor how you address legitimate bots while protecting against bots that use advanced techniques to actively avoid detection. For more information and to get started today, see AWS WAF Bot Control.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the weeks leading up to AWS re:Invent 2022, I’m interviewing some of the humans who work in AWS Security, help keep our customers safe and secure, and also happen to be speaking at re:Invent. This interview is with Param Sharma, principal software engineer for AWS Private Certificate Authority (AWS Private CA). AWS Private CA enables you to create private certificate authority (CA) hierarchies, including root and subordinate CAs, without the investment and maintenance costs of operating an on-premises CA.
How long have you been at AWS and what do you do in your current role?
I’ve been here for more than eight years—I joined AWS in July 2014, working in AWS Security. These days, I work on public key infrastructure (PKI) and cryptography, focusing on products like AWS Certificate Manager (ACM) and AWS Private CA.
How did you get started in the world of security, specifically cryptography?
I had a very short stint with crypto during my university days—I presented a paper on steganography and cryptography back in 2002 or 2003. Security has been an integral part of developing and deploying large-scale web applications, which I’ve done throughout my career. But security took center stage in 2014 when I heard from an AWS recruiter about a new service being built that would make certificates easier. I had no clue what that service was, since it was confidential and hadn’t been launched yet, but it brought cryptography back into my life. I started working on this brand-new service, AWS Certificate Manager. I designed the operational security aspect of it and worked to make sure it could be used by millions of our customers and could be available and secure at the same time. I was the second person hired on the ACM team, and since then the team has grown significantly.
What was the most surprising or interesting thing you’ve worked on in your time at AWS?
It might not be surprising, but certainly interesting to me: I was the first engineer to be hired on the AWS Private CA team and I started studying the problem of how certificate authorities would work in the cloud. I had to think about how the customer experience would look, the service architecture design, the operational side of things like availability and security of customer data. Doing a 360-degree review of the service and writing the design document for a service that was eventually deployed in a multitude of AWS Regions was one of the most interesting things I have worked on at AWS. It continues to be an interesting challenge as we add new features—which tend to be like smaller AWS services in their own right even though they are features of AWS Private CA.
How do you explain to customers how to use AWS Private CA?
I start by explaining what a private certificate is. A private certificate provides a flexible way to identify almost anything in an organization without disclosing the name publicly. With AWS Private CA, AWS takes care of the undifferentiated heavy lifting involved in operating a private CA. We provide security configuration, management, and monitoring of highly available private CAs. The service also helps organizations avoid spending money on servers, hardware security modules (HSMs), operations, personnel, infrastructure, software training, and maintenance. Maintaining PKI administrators, for example, can cost hundreds or thousands of dollars per year. AWS Private CA simplifies the process of creating and managing these private CAs and certificates that are used to identify resources and provide a basis for trusted identity in communications.
In your opinion, what is the coolest feature of AWS Private CA?
That’s going to be really hard to pick! To me, the coolest feature is root CA, which gives customers the ability to create and manage root CAs in the cloud. Root CAs are used to create subordinate CAs for issuing identity certificates. And these private CAs can be used to identify resources in a private network within an organization. You can use these private certs on application services, devices, or even for identifying users for identity certificates.
AWS Private CA has evolved since its launch in 2018. What are some of the new ways you see customers using the service?
When AWS Private CA was launched in 2018, the primary feature was to create and manage subordinate CAs, which were signed offline outside of AWS Private CA. The secondary feature was to issue certificates for identifying endpoints for TLS/SSL communication. Over the last four or five years, I’ve seen use cases become more diversified, and the service has evolved as the customers’ needs have evolved. The biggest paradigm shift that I’ve seen is that customers are customizing certificates and using them to identify IoT devices or customer-managed Kubernetes clusters. The certificates can even be used on-premises for your Amazon Elastic Compute Cloud (Amazon EC2) instances or your on-premises servers, where you can use these services to encrypt the traffic in transit or at rest in certain cases. The other more recent use case I’ve started to see is customers using AWS Private CA with AWS Identity and Access Management Roles Anywhere, which launched in July 2022. Customers are using this combination to issue certificates for identity, which is tied to the credentials themselves.
I understand you’ll be speaking at re:Invent 2022. Can you tell us about your session there? What do you hope customers take away from your session?
I am doing two sessions at re:Invent this year. The first one, Understanding the evolution of cloud-based PKI use cases, is a chalk talk about how cloud-based PKI use cases have evolved over the last 5–10 years. This talk is mainly for PKI administrators, information security engineers, developers, managers, directors, and IoT security professionals who want to learn more about how X.509 digital certificates are used in the cloud. We will dive deep into how these certs are being used for normal TLS communication, device certificates, containers, or even certificates used for identity like in IAM Roles Anywhere. The second session is a breakout session called AWS data protection: Using locks, keys, signatures, and certificates. It puts a spotlight on what AWS offers in terms of cryptographic tools and PKI platforms that help our customers navigate their data protection and digital signing needs. This session will provide a ground-floor understanding of how to get this protection by default or when needed, and how can you build your own logs, keys, and signatures for you own cloud application.
What’s the thing you’re most proud of in your career?
I’m proud to work with some of the smartest people who, at the same time, are very humble and genuinely believe in making this world a better place for everyone.
Outside of your work in tech, what is something you’re interested in that might surprise people?
I have a five-year-old and a three-year-old, so whenever I get some time to myself between those two, I love to read and take long strolls. I’m a passionate advocate that every voice is unique and has value to share. I’m a diversity and inclusion ambassador at Amazon and as part of this program, I mentor underrepresented groups and help build a community with integrity and a willingness to listen to others, which provides a space for us to be ourselves without fear of judgement. I try to do volunteer work whenever possible, being involved in community service programs organized through my children’s school activities, or even participating in local community kitchens by cooking and serving food that is distributed through a local non-profit organization.
If you had to pick an industry outside of security, what would you want to do?
I would’ve been a teacher or worked with a non-profit organization mentoring and volunteering. I think volunteering gives me a sense of peace.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS Certificate Manager (ACM) is a managed service that enables you to provision, manage, and deploy public and private SSL/TLS certificates that you can use to securely encrypt network traffic. You can now use ACM to request Elliptic Curve Digital Signature Algorithm (ECDSA) certificates and associate the certificates with AWS services like Application Load Balancer (ALB) or Amazon CloudFront. As a result, you get the benefit of managed renewal, where ACM can automatically renew ECDSA certificates before they expire. Previously, you could only request certificates with an RSA 2048 key algorithm from ACM. ECDSA certificates could be imported to ACM, but imported certificates cannot use managed renewal.
You can request both ECDSA P-256 and P-384 certificates from ACM. If you do not request an ECDSA certificate, ACM will issue an RSA 2048 certificate by default.
In this blog post, we will briefly examine the differences between RSA and ECDSA certificates, discuss some important considerations when evaluating which certificate type to use, and walk through how you can request an ECDSA certificate and associate it with an application load balancer in AWS.
Cryptographic certificates overview
TLS certificates are used to secure network communications and establish the identity of websites over the internet, as well as the identity of resources on private networks. Public certificates that you request through ACM are obtained from Amazon Trust Services, which is an Amazon managed public certificate authority (CA).
Both public and private certificates can help customers identify resources on networks and secure communication between these resources. Public certificates identify resources on the public internet, whereas private certificates do the same for private networks. One key difference is that applications and browsers trust public certificates by default, but an administrator must explicitly configure applications and devices to trust private certificates.
RSA and ECDSA primer
RSA and ECDSA are two widely used public-key cryptographic algorithms—algorithms that use two different keys to encrypt and decrypt data. In the case of TLS, a public key is used to encrypt data, and a private key is used to decrypt data. Public key (or asymmetric key) algorithms are not as computationally efficient as symmetric key algorithms like AES. For this reason, public key algorithms like RSA and ECDSA are primarily used to exchange secrets between two parties initiating a TLS connection. These secrets are then used by both parties to decipher the same symmetric key that actually encrypts the data in transit.
RSA stands for Rivest, Shamir, and Adleman: the researchers who first publicly described this algorithm in 1977. The basic functionality of RSA relies on the idea that large prime numbers are very difficult to efficiently factor. ECDSA, or Elliptic Curve Digital Signature Algorithm, is based on certain unique mathematical properties of elliptic curves that make them very useful for cryptographic operations. The cryptographic utility of ECDSA comes from a concept called the discrete logarithm problem.
Considerations when choosing between RSA and ECDSA
What are the important differences between RSA and ECDSA certificates? When should you choose ECDSA certificates to encrypt network traffic? In this section, we’ll examine the security and performance considerations that help to determine whether ECDSA or RSA certificates are the best choice for your workload.
Security
In cryptography, security is measured as the computational work it takes to exhaust all possible values of a symmetric key in an ideal cipher. An ideal cipher is a theoretical algorithm that has no weaknesses, so you must try every possible key to discover which is the correct key. This is similar to the idea of “brute forcing” a password: trying every possible character combination to find the correct password.
Let’s imagine you have a 112-bit key ideal cipher, which means it would take 2112 tries to exhaust the key space—we would say this cipher has a 112-bit security strength. However, it is important to realize that security strength and key length are not always equal—meaning that an encryption key with a length of 112 bits will not always have a 112-bit security strength.
ECDSA provides higher security strength for lower computational cost. ECDSA P-256, for example, provides 128-bit security strength and is equivalent to an RSA 3072 key. Meanwhile, ECDSA P-384 provides 192-bit security strength, equivalent to the key associated with an RSA 7680 certificate. In other words, an ECDSA P-384 key would require 2192 tries to exhaust the key space.
The following table provides an in-depth comparison of the different security strengths for RSA key lengths and ECDSA curve types. Note that only RSA 2048 and ECDSA P-256 and P-384 are currently issued by ACM. However, ACM does support the import and usage of the other certificate types listed in the table. For more information, see Importing certificates into AWS Certificate Manager.
Security strength
RSA key length
ECDSA curve type
80-bit
1024
160
112-bit
2048
224
128-bit
3072
256
192-bit
7680
384
256-bit
15360
512
Performance
ECDSA provides a higher security strength (for a given key length) than RSA but does not add performance overhead. For example, ECDSA P-256 is as performant as RSA 2048 while providing security strength that is comparable to RSA 3072.
ECDSA certificates also have up to a 50% smaller certificate size when compared to RSA certificates, and are therefore more suitable to protect data-in-transit over low bandwidth or for applications with limited memory and storage, such as Internet of Things (IoT) devices.
Take a look at the following certificate examples; you can see the size difference between RSA and ECDSA certificates.
Consider a small IoT sensor device that tracks temperature in an office building. This device typically has very low storage capacity and compute power, so the smaller ECDSA certificate will be easier to process and store. In the case of an IoT device, you might not be able to store the entire RSA certificate chain on the device due to memory limitations and the larger size of RSA certificates. This can make it more difficult to validate the chain of trust for that certificate.
Using ECDSA, customers can take advantage of the smaller size of the certificates (and the certificate trust chain) and store the entire chain of trust on the IoT device itself, enabling the IoT device to more easily validate the certificate.
When should I use ECDSA certificates from ACM?
In general, you should consider using ECDSA certificates wherever possible, because they provide stronger security (for a given key length) compared to RSA, without impacting performance. You can also choose to issue ECDSA certificates from ACM to implement 128-bit or 192-bit TLS security, where previously you could request up to 112-bit security from ACM by using RSA 2048 certificates.
ECDSA certificates are strongly recommended for applications that need to securely send data over low-bandwidth connections, or when you are using IoT devices that might not have much memory or computational power to store and process the larger certificate sizes that RSA offers.
If your application is not ECDSA compatible, you will need to continue using RSA certificates. RSA 2048 remains the default certificate type issued by ACM, in order to prevent compatibility issues with legacy applications or with applications that do not support ECDSA certificate types. We will provide links to check if your application is compatible with ECDSA certificate types in the next section of this blog.
Getting started with ECDSA certificates
Modern browsers and operating systems are ECDSA compatible. That said, some custom applications might not be ECDSA compatible. You can check whether your calling application is ECDSA compatible by accessing the following links from your application:
When you access one of these links, you should see a message stating “Expected Status: good”. This indicates that the application is ECDSA compatible. See Figure 1 for an example of a successful result.
Figure 1: ECDSA application compatibility example
When you terminate your TLS traffic with ALB, you can work around compatibility concerns by binding both ECDSA and RSA certificates for a given domain. ALB will prioritize and present the ECDSA certificate when the calling application is ECDSA compatible and will use the RSA certificate if the calling application is not ECDSA compatible. We’ll walk through this configuration in the demonstration portion of this post.
How to request an ECDSA certificate from ACM
You can use the ACM console, APIs, or AWS Command Line Interface (AWS CLI) to issue public or private ECDSA P-256 and P-384 TLS certificates. When you request certificates by using the API or AWS CLI, you can use the request-certificate API action with either EC_prime256v1 or EC_secp384r1 as the key-algorithm parameter to request a P-256 or P-384 ECDSA certificate, respectively.
Certificates have a defined validity period, and ACM will attempt to renew certificates that were issued by ACM and that are in use before they expire. ACM will also attempt to automatically bind the renewed certificates with an integrated service. ACM issued private ECDSA certificates can also be exported and used on other workloads to terminate TLS traffic.
Associate an ECDSA certificate with an Application Load Balancer for TLS
To demonstrate how to request and use ECDSA certificates from ACM, let’s examine a common use case: requesting a public certificate from ACM and associating it with an ALB. This walkthrough will also include requesting an RSA 2048 certificate and associating it with the same ALB, to facilitate TLS connections for applications that do not support ECDSA. ALB will prioritize and present the ECDSA certificate when the calling application is ECDSA compatible, and will use the RSA certificate if the calling application is not ECDSA compatible.
Navigate to the ACM console and choose Request a certificate.
Choose Request a public certificate, and then choose Next.
For Fully qualified domain name, enter your domain name.
Choose DNS validation. DNS validation is recommended wherever possible, because it enables automatic renewal of ACM issued certificates with no action required by the domain owner. If you use Amazon Route 53, you can use ACM to directly update your DNS records. DNS-validated certificates will be renewed by ACM as long as the certificate is in use and the DNS record is in place.
Figure 2: Requesting a public ECDSA certificate
In the Key algorithm options section, select your preferred algorithm based on your security requirements:
ECDSA P-256 — Equivalent in security strength to RSA 3072
ECDSA P-384 — Equivalent in security strength to RSA 7680
Figure 3: Key algorithms
(Optional) Add tags to help you identify and manage your certificate. You can find more information on using tags in Tagging AWS resources in the AWS General Reference.
Choose Request to request the public certificate.
The certificate will now be in the Pending Validation state until the domain can be validated, either through DNS or email validation, depending on your selection in the previous steps. For information on how to validate ownership of the domain name or names, see Validating domain ownership in the AWS Certificate Manager User Guide.
Take note of the certificate ARN; you will need this later to identify the certificate.
To request an RSA 2048 certificate from ACM
To request a public RSA 2048 certificate, use the same steps noted in the preceding section, but select RSA 2048 in the Key algorithm options section.
Make sure that both certificates you request have the same fully qualified domain name.
For this post, we will use an Application Load Balancer. You can view more details on each type of Load Balancer, and see a feature-to-feature breakdown, on the Elastic Load Balancing features page.
For the Application Load Balancer type, choose Create.
Enter a name for your load balancer.
Select the scheme and IP address type of the application load balancer. For this post, we will choose Internet-facing for the scheme and use the IPv4 address type.
Under Default SSL/TLS certificate, verify thatFrom ACM is selected, and then in the drop-down list, select the RSA certificate you requested earlier.
Note: We are using the RSA certificate as the default so that the ALB will use this certificate if the connecting client does not support ECDSA or the Server Name Indication (SNI) protocol. This is to maximize availability and compatibility with legacy applications.
Figure 6: Secure listener settings
(Optional) Add tags to the Application Load Balancer.
Review your selections, and then choose Create load balancer.
Figure 7: Review and create load balancer
To associate the ECDSA certificate with the Application Load Balancer
In the EC2 console, select the new ALB you just created, and choose the Listeners tab.
In the SSL Certificate column, you should see the default certificate you added when you created the ALB. Choose View/edit certificates to see the full list of certificates associated with this ALB.
Figure 8: ALB listeners
Under Listener certificates for SNI, choose Add certificate.
Figure 9: Listener certificates for SNI
Under ACM and IAM certificates, select the ECDSA certificate you requested earlier.
Note: You can use the certificate ARN to identify the appropriate certificate.
Choose Include as pending below to add the ECDSA certificate to the listener.
Figure 10: Adding the ECDSA certificate to the load balancer listener
Under Listener certificates for SNI, confirm that the ECDSA certificate is listed as pending, and choose Add pending certificates.
Figure 11: Confirm addition of pending certificates
Great! We’ve used ACM to request a public ECDSA certificate and a public RSA 2048 certificate. Next, we associated both of these certificates with an Application Load Balancer to facilitate TLS communications between the load balancer and client devices.
If clients support the SNI protocol, the ALB uses a smart certificate selection algorithm. The load balancer will select the best certificate that the client can support from the certificate list. Certificate selection is based on the following criteria, in the following order:
Public key algorithm (prefer ECDSA over RSA)
Hashing algorithm (prefer SHA over MD5)
Key length (prefer the longest key)
Validity period
In the earlier example, this means if clients support SNI and ECDSA, the ECDSA certificate will be prioritized and presented to the client. If the client does not support SNI or ECDSA, the RSA certificate will be used to maximize compatibility with legacy applications.
Conclusion
In this blog post, we discussed the basic differences between RSA and ECDSA certificates, when you might choose ECDSA over RSA, and how you can use AWS Certificate Manager to request public or private ECDSA certificates. We also covered how to request a public ECDSA certificate from ACM and associate it with an Application Load Balancer. Finally, we showed you how to request an RSA 2048 certificate and associate it with the same load balancer to facilitate TLS for applications that do not support ECDSA certificates.
With the emergence of Docker in 2013, container technology has quickly moved from the experimentation phase into a viable production tool. Many customers are using containers to modernize their existing applications or as the foundations for new applications or services that they build. In this blog post, we’ll explore the process that Amazon Inspector takes to scan container images. We’ll also show how you can integrate Amazon Inspector into your containerized application build and deployment pipeline, and control pipeline steps based on the results of an Amazon Inspector container image scan.
Solution overview and walkthrough
The solution outlined in this post covers a deployment pipeline modeled in AWS CodePipeline. The source for the pipeline is AWS CodeCommit, and the build of the container image is performed by AWS CodeBuild. The solution uses a collection of AWS Lambda functions and an Amazon DynamoDB table to evaluate the container image status and make an automated decision about deploying the container image. Finally, the pipeline has a deploy stage that will deploy the container image into an Amazon Elastic Container Service (Amazon ECS) cluster. In this section, I’ll outline the key components of the solution and how they work. In the following section, Deploy the solution, I’ll walk you through how to actually implement the solution.
Although this solution uses AWS continuous integration and continuous delivery (CI/CD) services such as CodePipeline and CodeBuild, you can also build similar capabilities by using third-party CI/CD solutions. In addition to CodeCommit, other third-party code repositories such as GitHub or Amazon Simple Storage Service (Amazon S3) can be substituted in as a source for the pipeline.
Solution architecture
Figure 1 shows the high-level architecture of the solution, which integrates Amazon Inspector into a container build and deploy pipeline.
Figure 1: Overall container build and deploy architecture
The high-level workflow is as follows:
You commit the image definition to a CodeCommit repository.
An Amazon EventBridge rule detects the repository commit and initiates the container pipeline.
The source stage of the pipeline pulls the image definition and build instructions from the CodeCommit repository.
The build stage of the pipeline creates the container image and stores the final image in Amazon ECR.
The ContainerVulnerabilityAssessment stage sends out a request for approval by using an Amazon Simple Notification Service (Amazon SNS) topic. A Lambda function associated with the topic stores the details about the container image and the active pipeline, which will be needed in order to send a response back to the pipeline stage.
Amazon Inspector scans the Amazon ECR image for vulnerabilities.
The Lambda function receives the Amazon Inspector scan summary message, through EventBridge, and makes a decision on allowing the image to be deployed. The function retrieves the pipeline approval details so that the approve or reject message is sent to the correct active pipeline stage.
The Lambda function submits an Approved or Rejected status to the deployment pipeline.
CodePipeline deploys the container image to an Amazon ECS cluster and completes the pipeline successfully if an approval is received. The pipeline status is set to Failed if the image is rejected.
Container image build stage
Let’s now review the build stage of the pipeline that is associated with the Amazon Inspector container solution. When a new commit is made to the CodeCommit repository, an EventBridge rule, which is configured to look for updates to the CodeCommit repository, initiates the CodePipeline source action. The source action then collects files from the source repository and makes them available to the rest of the pipeline stages. The pipeline then moves to the build stage.
In the build stage, CodeBuild extracts the Dockerfile that holds the container definition and the buildspec.yaml file that contains the overall build instructions. CodeBuild creates the final container image and then pushes the container image to the designated Amazon ECR repository. As part of the build, the image digest of the container image is stored as a variable in the build stage so that it can be used by later stages in the pipeline. Additionally, the build process writes the name of the container URI, and the name of the Amazon ECS task that the container should be associated with, to a file named imagedefinitions.json. This file is stored as an artifact of the build and will be referenced during the deploy phase of the pipeline.
Now that the image is stored in an Amazon ECR repository, Amazon Inspector scanning begins to check the image for vulnerabilities.
The details of the build stage are shown in Figure 2.
Figure 2: The container build stage
Container image approval stage
After the build stage is completed, the ContainerVulnerabilityAssessment stage begins. This stage is lightweight and consists of one stage action that is focused on waiting for an Approved or Rejected message for the container image that was created in the build stage. The ContainerVulnerabilityAssessment stage is configured to send an approval request message to an SNS topic. As part of the approval request message, the container image digest, from the build stage, will be included in the comments section of the message. The image digest is needed so that approval for the correct container image can be submitted later. Figure 3 shows the comments section of the approval action where the container image digest is referenced.
Figure 3: Container image digest reference in approval action configuration
The SNS topic that the pipeline approval message is sent to is configured to invoke a Lambda function. The purpose of this Lambda function is to pull key details from the SNS message. Details retrieved from the SNS message include the pipeline name and stage, stage approval token, and the container image digest. The pipeline name, stage, and approval token are needed so that an approved or rejected response can be sent to the correct pipeline. The container image digest is the unique identifier for the container image and is needed so that it can be associated with the correct active pipeline. This information is stored in a DynamoDB table so that it can be referenced later when the step that assesses the result of an Amazon Inspector scan submits an approved or rejected decision for the container image. Figure 4 illustrates the flow from the approval stage through storing the pipeline approval data in DynamoDB.
Figure 4: Flow to capture container image approval details
This approval action will remain in a pending status until it receives an Approved or Rejected message or the timeout limit of seven days is reached. The seven-day timeout for approvals is the default for CodePipeline and cannot be changed. If no response is received in seven days, the stage and pipeline will complete with a Failed status.
Amazon Inspector and container scanning
When the container image is pushed to Amazon ECR, Amazon Inspector scans it for vulnerabilities.
In order to show how you can use the findings from an Amazon Inspector container scan in a build and deploy pipeline, let’s first review the workflow that occurs when Amazon Inspector scans a container image located in Amazon ECR.
Figure 5: Image push, scan, and notification workflow
The workflow diagram in Figure 5 outlines the steps that happen after an image is pushed to Amazon ECR all the way to messaging that the image has been successfully scanned and what the final scan results are. The steps in this workflow are as follows:
The final container image is pushed to Amazon ECR by an individual or as part of a build.
Amazon ECR sends a message indicating that a new image has been pushed.
The message about the new image is received by Amazon Inspector.
Amazon Inspector pulls a copy of the container image from Amazon ECR and performs a vulnerability scan.
When Amazon Inspector is done scanning the image, a message summarizing the severity of vulnerabilities that were identified during the container image scan is sent to Amazon EventBridge. You can create EventBridge rules that match the vulnerability summary message to route the message onto a target for notifications or to enable further action to be taken.
Here’s a sample EventBridge pattern that matches the scan summary message from Amazon Inspector.
This entire workflow, from ingesting the initial image to sending out the status on the Amazon Inspector scan, is fully managed. You just focus on how you want to use the Amazon Inspector scan status message to govern the approval and deployment of your container image.
The following is a sample of what the Amazon Inspector vulnerability summary message looks like. Note, in bold, the container image Amazon Resource Name (ARN), image repository ARN, message detail type, image digest, and the vulnerability summary.
After Amazon Inspector sends out the scan status event, a Lambda function receives and processes that event. This function needs to consume the Amazon Inspector scan status message and make a decision about whether the image can be deployed.
The eval_container_scan_results Lambda function serves two purposes: The first is to extract the findings from the Amazon Inspector scan message that invoked the Lambda function. The second is to evaluate the findings based on thresholds that are defined as parameters in the Lambda function definition. Based on the threshold evaluation, the container image will be flagged as either Approved or Rejected. Figure 6 shows examples of thresholds that are defined for different Amazon Inspector vulnerability severities, as part of the Lambda function.
Figure 6: Vulnerability thresholds defined in Lambda environment variables
Based on the container vulnerability image results, the Lambda function determines whether the image should be approved or rejected for deployment. The function will retrieve the details about the current pipeline that the image is associated with from the DynamoDB table that was populated by the image approval action in the pipeline. After the details about the pipeline are retrieved, an Approved or Rejected message is sent to the pipeline approval action. If the status is Approved, the pipeline continues to the deploy stage, which will deploy the container image into the defined environment for that pipeline stage. If the status is Rejected, the pipeline status is set to Rejected and the pipeline will end.
Figure 7 highlights the key steps that occur within the Lambda function that evaluates the Amazon Inspector scan status message.
Figure 7: Amazon Inspector scan results decision
Image deployment stage
If the container image is approved, the final image is deployed to an Amazon ECS cluster. The deploy stage of the pipeline is configured with Amazon ECS as the action provider. The deploy action contains the name of the Amazon ECS cluster and stage that the container image should be deployed to. The image definition file (imagedefinitions.json) that was created in the build stage is also listed in the deploy configuration. When the deploy stage runs, it will create a revision to the existing Amazon ECS task definition. This task definition contains the name of the Amazon ECR image that has been approved for deployment. The task definition is then deployed to the Amazon ECS cluster and service.
Deploy the solution
Now that you have an understanding of how the container pipeline solution works, you can deploy the solution to your own AWS account. This section will walk you through the steps to deploy the container approval pipeline, and show you how to verify that each of the key steps is working.
Step 1: Activate Amazon Inspector in your AWS account
The sample solution provided by this blog post requires that you activate Amazon Inspector in your AWS account. If this service is not activated in your account, learn more about the free trial and pricing for this service, and follow the steps in Getting started with Amazon Inspector to set up the service and start monitoring your account.
Step 2: Deploy the AWS CloudFormation template
For this next step, make sure you deploy the template within the AWS account and AWS Region where you want to test this solution.
To deploy the CloudFormation stack
Choose the following Launch Stack button to launch a CloudFormation stack in your account. Use the AWS Management Console navigation bar to choose the region you want to deploy the stack in.
Review the stack name and the parameters for the template. The parameters are pre-populated with the necessary values, and there is no need to change them.
Scroll to the bottom of the Quick create stack screen and select the checkbox next to I acknowledge that AWS CloudFormation might create IAM resources.
Choose Create stack. The deployment of this CloudFormation stack will take 3–5 minutes.
After the CloudFormation stack has deployed successfully, you can proceed to reviewing and interacting with the deployed solution.
Step 3: Review the container pipeline and supporting resources
The CloudFormation stack is designed to deploy a collection of resources that will be used for an initial container build. When the CodePipeline resource is created, it will automatically pull the assets from the CodeCommit repository and start the pipeline for the container image.
To review the pipeline and resources
In the CodePipeline console, navigate to the Region that the stack was deployed in.
Choose the pipeline named ContainerBuildDeployPipeline to show the full pipeline details.
Review the Source and Build stage, which will show a status of Succeeded.
Review the ContainerVulnerabilityAssessment stage, which will show as failed with a Rejected status in the Manual Approval step.
Figure 8 shows the full completed pipeline.
Figure 8: Rejected container pipeline
Choose the Details link in the Manual Approval stage to reveal the reasons for the rejection. An example review summary is shown in Figure 9.
Figure 9: Container pipeline approval rejection
Review findings in Amazon Inspector (Optional)
You can use the Amazon Inspector console to see the full findings detail for this container image, if needed.
From the list of repositories, choose the inspector-blog-images repository.
Choose the Image tag link to bring up a list of the individual vulnerabilities that were found within the container image. Figure 10 shows an example of the vulnerabilities list in the findings details.
Figure 10: Container image findings in Amazon Inspector
Step 4: Adjust the Amazon ECS desired count for the cluster service
Up to this point, you’ve deployed a pipeline to build and validate the container image, and you’ve seen an example of how the pipeline handles a container image that did not meet the defined vulnerability thresholds. Now you’ll deploy a new container image that will pass a vulnerability assessment and complete the pipeline.
The Amazon ECS service that the CloudFormation template deploys is initially created with the number of desired tasks set to 0. In order to allow the container pipeline to successfully deploy a container, you need to update the desired tasks value.
To adjust the task count in Amazon ECS (console)
In the Amazon ECS console, choose the link for the cluster, in this case InspectorBlogCluster.
On the Services tab, choose the link for the service named InspectorBlogService.
Choose the Update button. On the Configure service page, set Number of tasks to 1.
Choose Skip to review, and then choose Update Service.
To adjust the task count in Amazon ECS (AWS CLI)
Alternatively, you can run the following AWS CLI command to update the desired task count to 1. In order to run this command, you need the ARN of the Amazon ECS cluster, which you can retrieve from the Output tab of the CloudFormation stack that you created. You can run this command from the command line of an environment of your choosing, or by using AWS CloudShell. Make sure to replace <Cluster ARN> with your own value.
Deploying a new container image will involve pushing an updated Dockerfile to the ContainerComponentsRepo repository in CodeCommit. With CodeCommit you can interact by using standard Git commands from a command line prompt, and there are multiple approaches that you can take to connect to the AWS CodeCommit repository from the command line. For this post, in order to simplify the interactions with CodeCommit, you will be shown how to add an updated file directly through the CodeCommit console.
To add an updated Dockerfile to CodeCommit
In the CodeCommit console, choose the repository named ContainerComponentsRepo.
In the screen listing the repository files, choose the Dockerfile file link and choose Edit.
In the Edit a file form, overwrite the existing file contents with the following command: FROM public.ecr.aws/amazonlinux/amazonlinux:latest
In the Commit changes to main section, fill in the following fields.
Author name: your name
Email address: your email
Commit message: ‘Updated Dockerfile’
Figure 11 shows what the completed form should look like.
Figure 11: Complete CodeCommit entry for an updated Dockerfile
Choose Commit changes to save the new Dockerfile.
This update to the Dockerfile will immediately invoke a new instance of the container pipeline, where the updated container image will be pulled and evaluated by Amazon Inspector.
Step 6: Verify the container image approval and deployment
With a new pipeline initiated through the push of the updated Dockerfile, you can now review the overall pipeline to see that the container image was approved and deployed.
To see the full details in CodePipeline
In the CodePipeline console, choose the container-build-deploy pipeline. You should see the container pipeline in an active status. In about five minutes, you should see the ContainerVulnerabilityAssessment stage move to completed with an Approved status, and the deploy stage should show a Succeeded status.
To confirm that the final image was deployed to the Amazon ECS cluster, from the Deploy stage, choose Details. This will open a new browser tab for the Amazon ECS service.
In the Amazon ECS console, choose the Tasks tab. You should see a task with Last status showing RUNNING. This is confirmation that the image was successfully approved and deployed through the container pipeline. Figure 12 shows where the task definition and status are located.
Figure 12: Task status after deploying the container image
Choose the task definition to bring up the latest task definition revision, which was created by the deploy stage of the container pipeline.
Scroll down in the task definition screen to the Container definitions section. Note that the task is tied to the image you deployed, providing further verification that the approved container image was successfully deployed. Figure 13 shows where the container definition can be found and what you should expect to see.
Figure 13: Container associated with revised task definition
Clean up the solution
When you’re finished deploying and testing the solution, use the following steps to remove the solution stack from your account.
To delete images from the Amazon ECR repository
In the Amazon ECR console, navigate to the AWS account and Region where you deployed the solution.
Choose the link for the repository named inspector-blog-images.
Delete all of the images that are listed in the repository.
To delete objects in the CodePipeline artifact bucket
In the Amazon S3 console in your AWS account, locate the bucket whose name starts with blog-base-setup-codepipelineartifactstorebucket.
Delete the ContainerBuildDeploy folder that is in the bucket.
To delete the CloudFormation stack
In the CloudFormation console, delete the CloudFormation stack that was created to perform the steps in this post.
Conclusion
This post describes a solution that allows you to build your container images, have the images scanned for vulnerabilities by Amazon Inspector, and use the output from Amazon Inspector to determine whether the image should be allowed to be deployed into your environments.
This solution represents a pipeline with very simple build and deploy stages. Your pipeline will vary and may consist of multiple test stages and deployment stages for multiple environments. Additionally, the logic you use to determine whether a container image should be deployed may be different. The contents of this blog post are intended to help serve as a foundation that you can build on as you decide how to use Amazon Inspector for container vulnerability scanning. Feel free to use this guidance, and the example we provided, to extend the solution into your specific deployment pipeline.
If you have questions, contact AWS Support, or start a new thread on the AWS re:Post Amazon Inspector Forum. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.