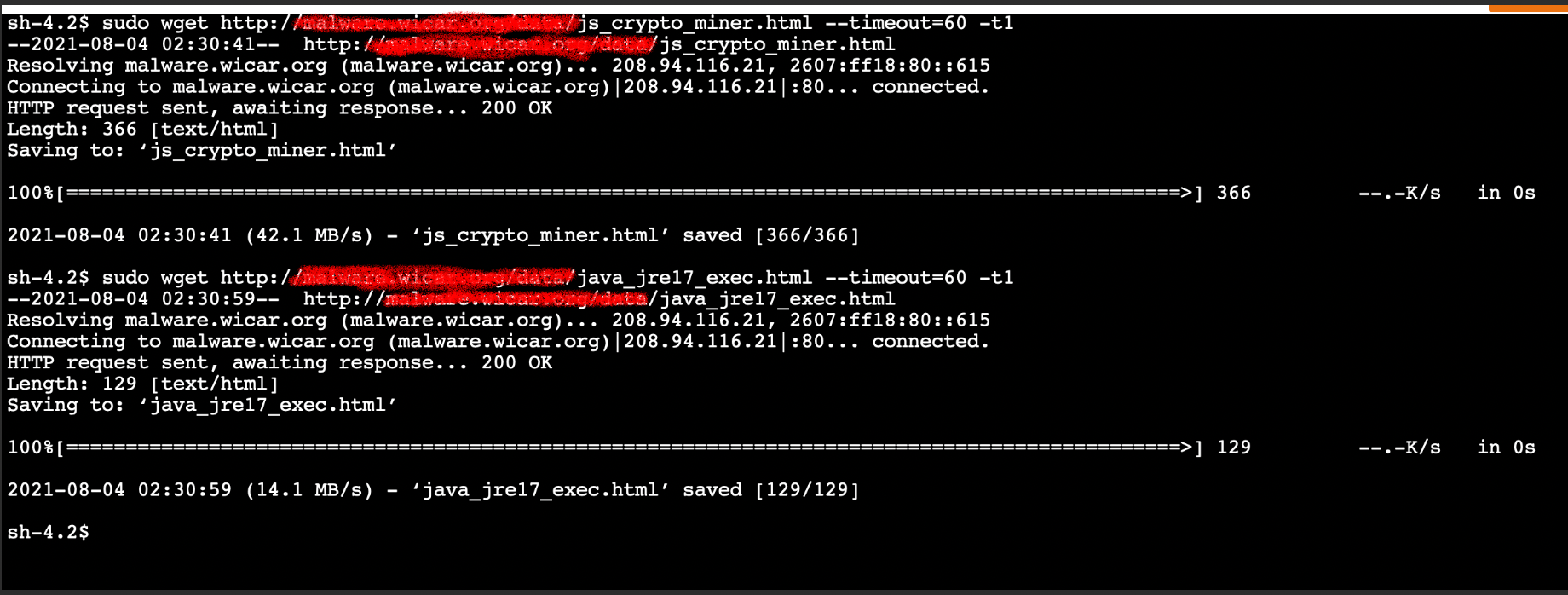
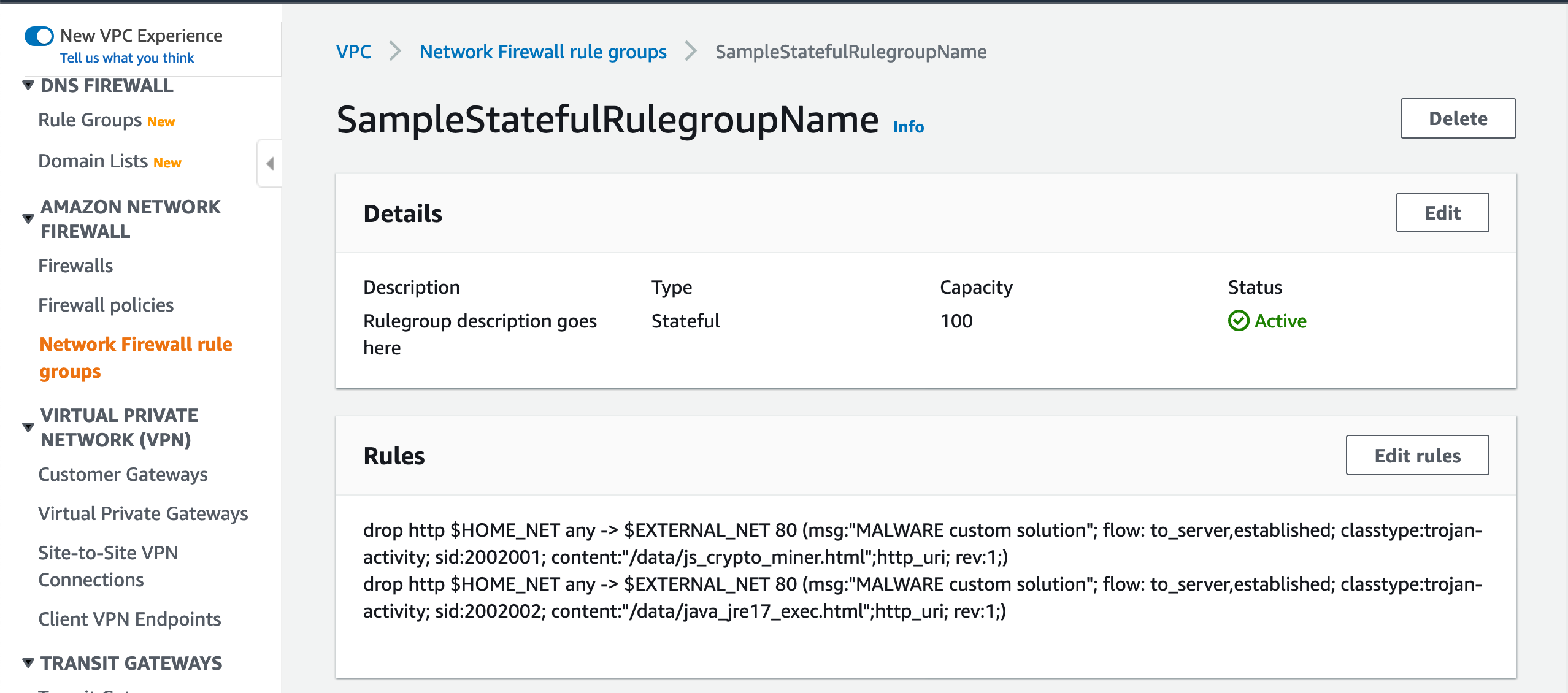
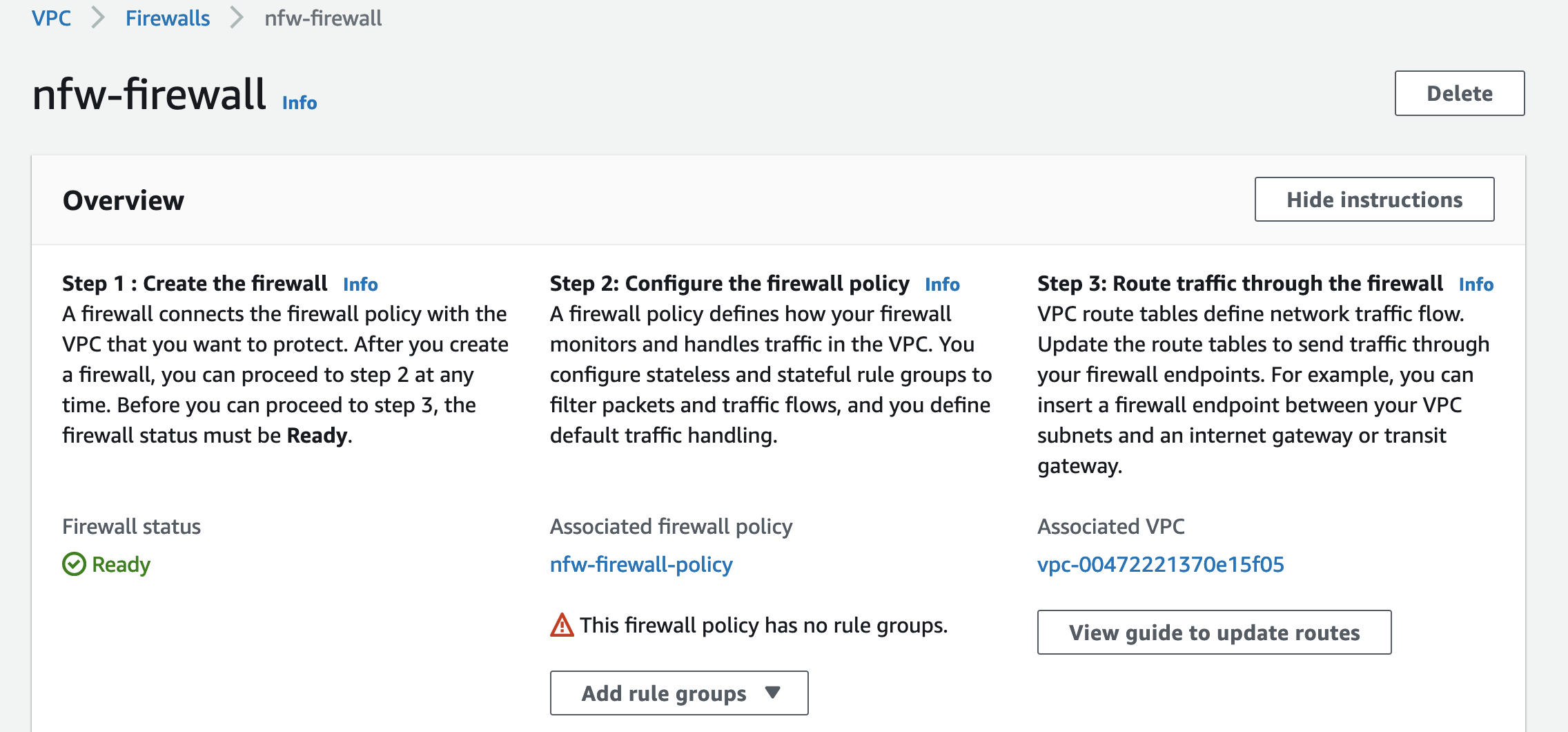
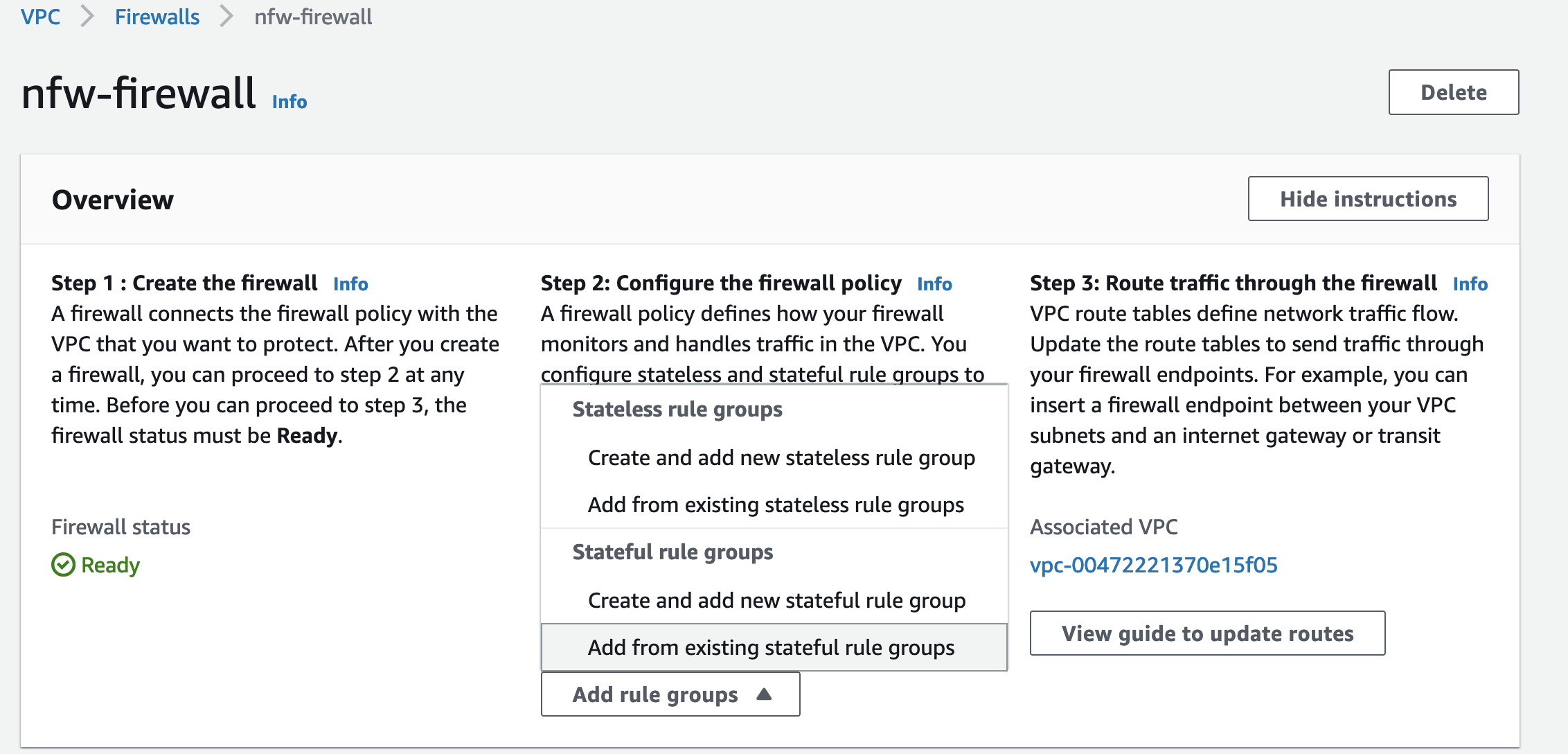
Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/building-serverless-multi-region-websocket-apis/
This post is written by Ben Freiberg, Senior Solutions Architect, and Marcus Ziller, Senior Solutions Architect.
Many modern web applications use the WebSocket protocol for bidirectional communication between frontend clients and backends. The fastest way to get started with WebSockets on AWS is to use WebSocket APIs powered by Amazon API Gateway.
This serverless solution allows customers to get started with WebSockets without having the complexity of running a WebSocket API. WebSocket APIs are a Regional service bound to a single Region, which may affect latency and resilience for some workloads.
This post shows how to build a multi-regional WebSocket API for a global real-time chat application.
Overview of the solution
This solution uses AWS Cloud Development Kit (CDK). This is an open source software development framework to model and provision cloud application resources. Using the CDK can reduce the complexity and amount of code needed to automate the deployment of resources.
This solution uses AWS Lambda, Amazon API Gateway, Amazon DynamoDB, and Amazon EventBridge.
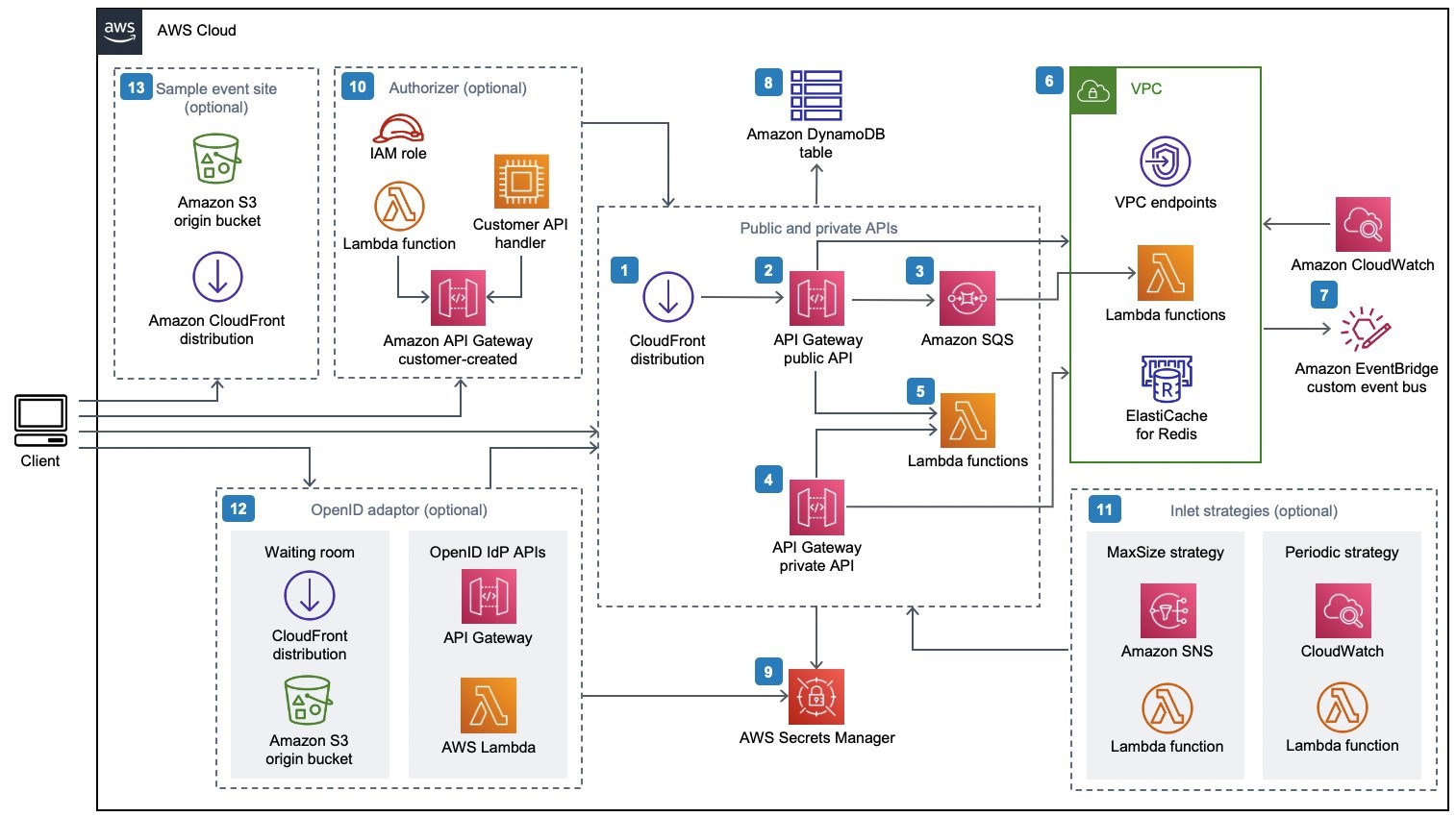
This diagram outlines the workflow implemented in this blog:
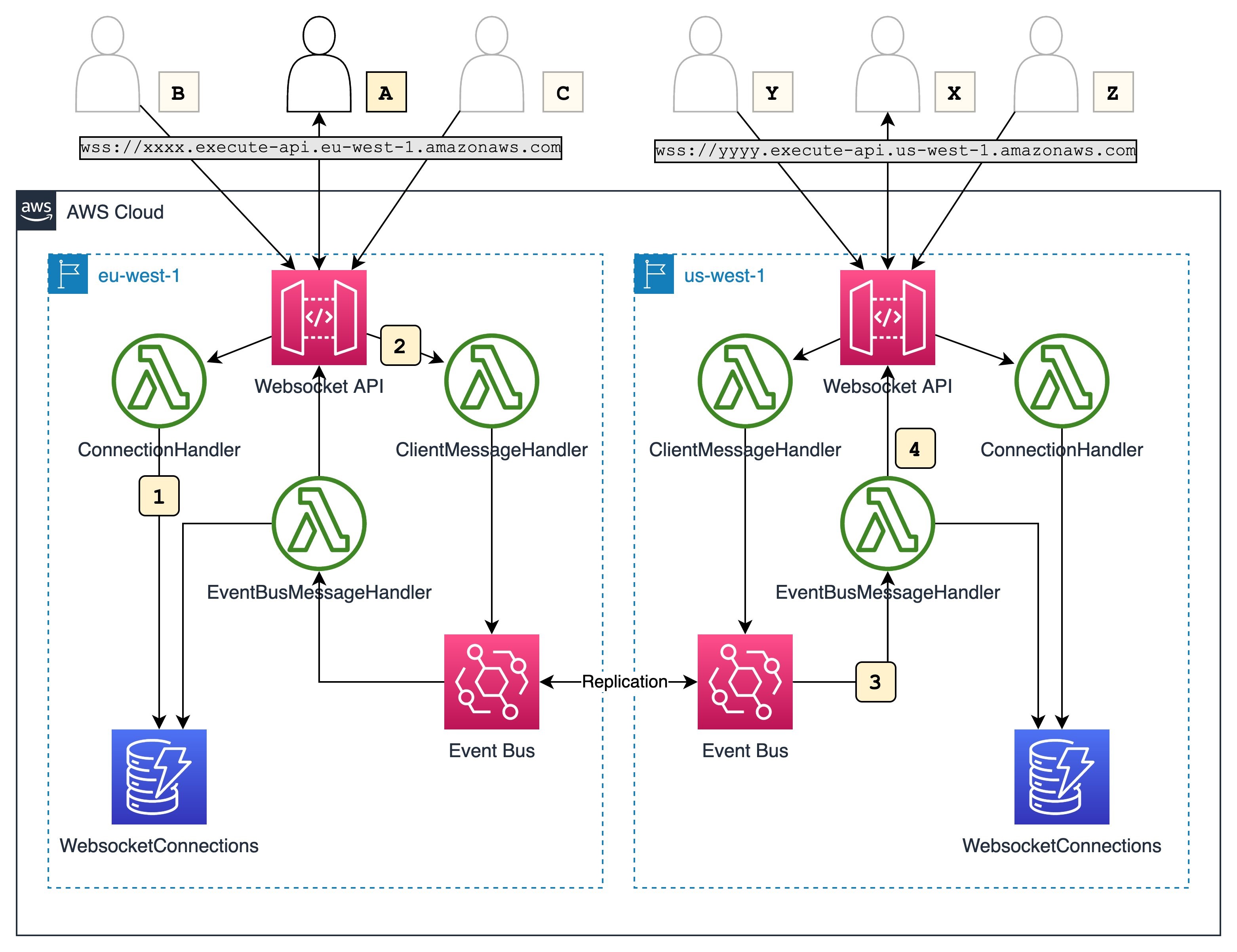
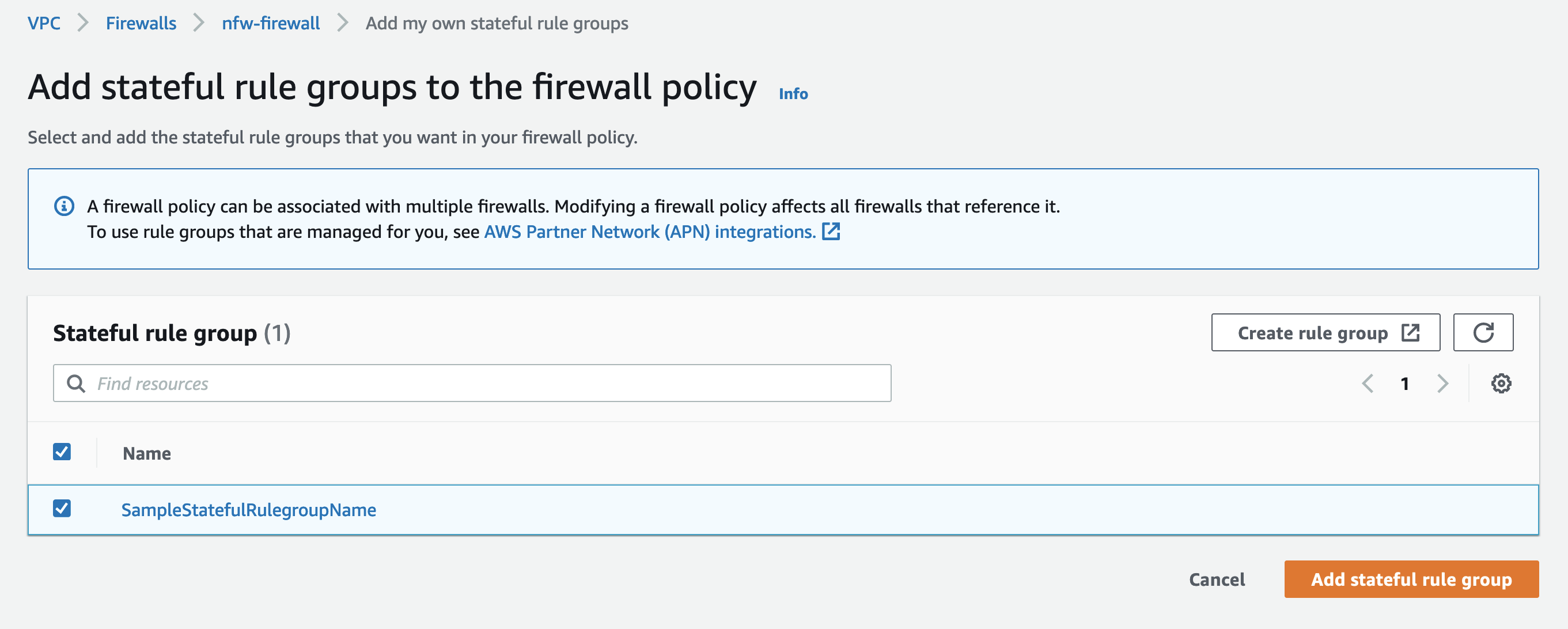
- Users across different Regions establish WebSocket connections to an API endpoint in a Region. For every connection, the respective API Gateway invokes the
ConnectionHandlerLambda function, which stores the connection details in a Regional DynamoDB table. - User A sends a chat message via the established WebSocket connection. The API Gateway invokes the
ClientMessageHandlerLambda function with the received message. The Lambda function publishes an event to an EventBridge event bus that contains the message and theconnectionIdof the message sender. - The event bus invokes the
EventBusMessageHandlerLambda function, which pushes the received message to all other clients connected in the Region. It also replicates the event into us-west-1. EventBusMessageHandlerin us-west-1 receives and send it out to all connected clients in the Region via the same mechanism.
Walkthrough
The following walkthrough explains the required components, their interactions and how the provisioning can be automated via CDK.
For this walkthrough, you need:
- An AWS account
- Installed Node.js
- Installed git
- AWS CDK installed
Checkout and deploy the sample stack:
- After completing the prerequisites, clone the associated GitHub repository by running the following command in a local directory:
git clone [email protected]/aws-samples/multi-region-websocket-api - Open the repository in your preferred editor and review the contents of the
srcandcdkfolder. - Follows the instructions in the README.md to deploy the stack.
The following components are deployed in your account for every specified Region. If you didn’t change the default, the Regions are eu-west-1 and us-west-1.
API Gateway for WebSocket connectivity
API Gateway is a fully managed service that makes it easier for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the “front door” for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
WebSocket APIs serve as a stateful frontend for an AWS service, in this case AWS Lambda. A Lambda function is used for the WebSocket endpoint that maintains a persistent connection to handle message transfer between the backend service and clients. The WebSocket API invokes the backend based on the content of the messages that it receives from client apps.
There are three predefined routes that can be used: $connect, $disconnect, and $default.
const connectionLambda = new lambda.Function(..);
const requestHandlerLambda = new lambda.Function(..);
const webSocketApi = new apigwv2.WebSocketApi(this, 'WebsocketApi', {
apiName: 'WebSocketApi',
description: 'A regional Websocket API for the multi-region chat application sample',
connectRouteOptions: {
integration: new WebSocketLambdaIntegration('connectionIntegration', connectionLambda.fn),
},
disconnectRouteOptions: {
integration: new WebSocketLambdaIntegration('disconnectIntegration', connectionLambda.fn),
},
defaultRouteOptions: {
integration: new WebSocketLambdaIntegration('defaultIntegration', requestHandlerLambda.fn),
},
});
const websocketStage = new apigwv2.WebSocketStage(this, 'WebsocketStage', {
webSocketApi,
stageName: 'dev',
autoDeploy: true,
});$connect and $disconnect are used by clients to initiate or end a connection with the API Gateway. Each route has a backend integration that is invoked for the respective event. In this example, a Lambda function gets invoked with details of the event. The following code snippet shows how you can track each of the connected clients in an Amazon DynamoDB table. Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale.
// Simplified example for brevity
// Visit GitHub repository for complete code
function connectionHandler(event: APIGatewayEvent) {
if (eventType === 'CONNECT') {
await dynamoDbClient.put({
Item: {
connectionId,
chatId: 'DEFAULT',
ttl: Math.round(Date.now() / 1000 + 3600) // TTL of one hour
},
});
}
if (eventType === 'DISCONNECT') {
await dynamoDbClient.delete({
TableName: process.env.TABLE_NAME!,
Key: {
connectionId,
chatId: 'DEFAULT',
},
})
}
return ..
}
The $default route is used when the route selection expression produces a value that does not match any of the other route keys in your API routes. For this post, we use it as a default route for all messages sent to the API Gateway by a client. For each message, a Lambda function is invoked with an event of the following format.
{
"requestContext": {
"routeKey": "$default",
"messageId": "GXLKJfX4FiACG1w=",
"eventType": "MESSAGE",
"messageDirection": "IN",
"connectionId": "GXLKAfX1FiACG1w=",
"apiId": "3m4dnp0wy4",
"requestTimeEpoch": 1632812813588,
// some fields omitted for brevity
},
"body": "{ .. }",
"isBase64Encoded": false
}
EventBridge for cross-Region message distribution
The Lambda function uses the AWS SDK to publish the message data in event.body to EventBridge. EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale. It delivers a stream of real-time data from event sources to targets. You can set up routing rules to determine where to send your data to build application architectures that react in real time to your data sources with event publishers and consumers decoupled.
The following CDK code defines routing rules on the event bus that is applied for every event with source ChatApplication and detail type ChatMessageReceived.
new events.Rule(this, 'ProcessRequest', {
eventBus,
enabled: true,
ruleName: 'ProcessChatMessage',
description: 'Invokes a Lambda function for each chat message to push the event via websocket and replicates the event to event buses in other regions.',
eventPattern: {
detailType: ['ChatMessageReceived'],
source: ['ChatApplication'],
},
targets: [
new LambdaFunction(processLambda.fn),
...additionalEventBuses,
],
});
Intra-Region message delivery
The first target is a Lambda function that sends the message out to clients connected to the API Gateway endpoint in the same Region where the message was received.
To that end, the function first uses the AWS SDK to query DynamoDB for active connections for a given chatId in its AWS Region. It then removes the connectionId of the message sender from the list and calls postToConnection(..) for the remaining connection ids to push the message to the respective clients.
export async function handler(event: EventBridgeEvent<'EventResponse', ResponseEventDetails>): Promise<any> {
const connections = await getConnections(event.detail.chatId);
connections
.filter((cId: string) => cId !== event.detail.senderConnectionId)
.map((connectionId: string) => gatewayClient.postToConnection({
ConnectionId: connectionId,
Data: JSON.stringify({ data: event.detail.message }),
})
}
Inter-Region message delivery
To send messages across Regions, this solution uses EventBridge’s cross-Region event routing capability. Cross-Region event routing allows you to replicate events across Regions by adding an event bus in another Region as the target of a rule. In this case, the architecture is a mesh of event buses in all Regions so that events in every event bus are replicated to all other Regions.
A message sent to an event bus in a Region is replicated to the event buses in the other Regions and trigger the intra-region workflow that I described earlier. However, to avoid infinite loops the EventBridge service implements circuit breaker logic that prevents infinite loops of event buses sending messages back and forth. Thus, only ProcessRequestLambda is invoked as a rule target. The function receives the message via its invocation event and looks up the active WebSocket connections in its Region. It then pushes the message to all relevant clients.
This process happens in every Region so that the initial message is delivered to every connected client with at-least-once semantics.
Improving resilience
The architecture of this solution is resilient to service disruptions in a Region. In such an event, all clients connected to the affected Region reconnect to an unaffected Region and continue to receive events. Although this isn’t covered in the CDK code, you can also set up Amazon Route 53 health checks to automate DNS failover to a healthy Region.
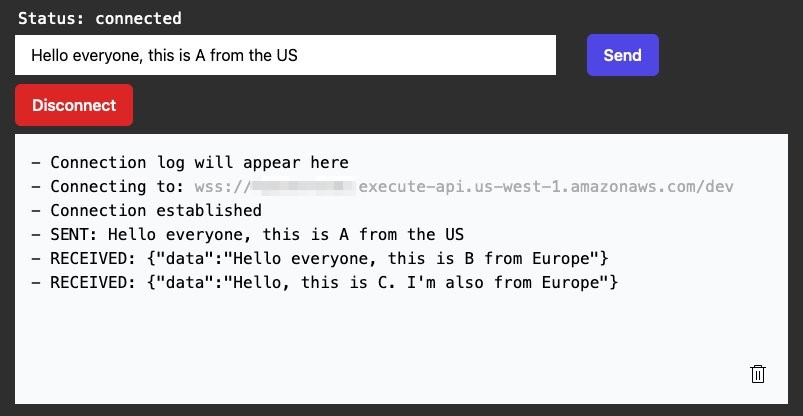
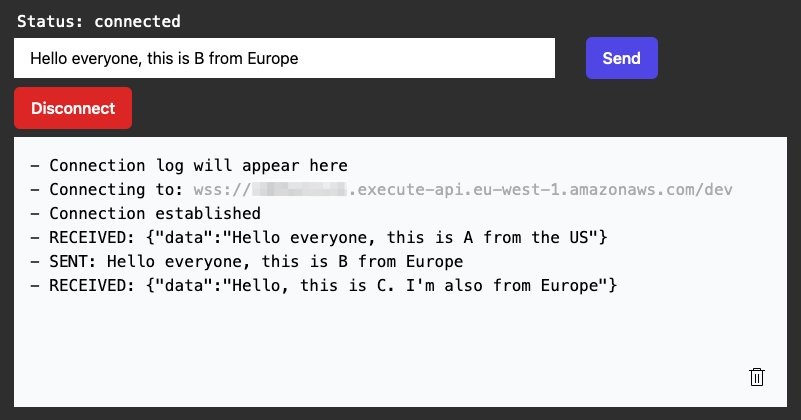
Testing the workflow
You can use any WebSocket client to test the application. Here you can see three clients, one connected to the us-west-1 API Gateway endpoint and two connected to the eu-west-1 endpoint. Each one sends a message to the application and every other client receives it, regardless of the Region it is connected to.

Cleaning up
Most services used in this blog post have an allowance in the AWS Free Tier. Be sure to check potential costs of this solution and delete the stack if you don’t need it anymore. Instructions on how to do this are included inside the README in the repository.
Conclusion
This blog post shows how to use the AWS serverless platform to build a multi-regional chat application over WebSockets. With the cross-Region event routing of EventBridge the architecture is resilient as well as extensible.
For more resources on how to get the most out of the AWS serverless platform, visit Serverless Land.



















 Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.
Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.








![git clone CodeCommit repo to Cloud9 using git clone command, readme.md file is created locally and pushed back to CodeCommit repo]](https://d2908q01vomqb2.cloudfront.net/7719a1c782a1ba91c031a682a0a2f8658209adbf/2022/02/02/Picture7.png)