Post Syndicated from Sushant Majithia original https://aws.amazon.com/blogs/big-data/capacity-management-and-amazon-emr-managed-scaling-improvements-for-amazon-emr-on-ec2-clusters/
In 2022, we told you about the new enhancements we made in Amazon EMR Managed Scaling, which helped improve cluster utilization as well as reduced cluster costs. In 2023, we are happy to report that the Amazon EMR team has been hard at work. We worked backward from customer requirements and launched multiple new features to enhance your Amazon EMR on EC2 clusters capacity management and scaling experience.
Amazon EMR is the cloud big data solution for petabyte-scale data processing, interactive analytics, and machine learning (ML) using open-source frameworks such as Apache Spark, Apache Hive, and Presto. Customers asked us for features that would further improve the capacity management and scaling experience of their EMR on EC2 clusters, including their large, long-running clusters. We have been hard at work to meet those needs. The following are some of the key enhancements:
- Enhanced customer transparency and flexibility with provisioning timeout for Spot Instances
- Optimized task nodes scale-up for Amazon EMR on EC2 clusters launched with instance groups
- Improved job resiliency with enhanced protection for Spark Drivers
Let’s dive deeper and discuss the new Amazon EMR on EC2 features in detail.
Enhanced customer transparency and flexibility with provisioning timeout for Spot Instances
Many Amazon EMR customers use EC2 Spot Instances for their EMR on EC2 clusters to reduce costs. Spot Instances are spare Amazon Elastic Compute Cloud (Amazon EC2) compute capacity offered at discounts of up to 90% compared to On-Demand pricing. Amazon EMR offers you the capability to scale your cluster either manually or by using Automatic Scaling. You can also use the Amazon EMR Managed Scaling feature to automatically resize your cluster based on workload and utilization.
To enhance the customer experience when scaling up using Spot Instances, for EMR on EC2 clusters launched using instance fleets, you can now specify a provisioning timeout for Spot Instances. A provisioning timeout will tell Amazon EMR to stop provisioning Spot Instance capacity if the cluster exceeds a specified time threshold during cluster scaling operations. You can configure the Spot instance provisioning timeout for clusters getting resized manually or using Amazon EMR Managed Scaling and Auto Scaling.
Additionally, to provide better transparency, when the timeout period expires, Amazon EMR will also automatically send events to an Amazon CloudWatch Events stream. With these CloudWatch events, you can create rules that match events according to a specified pattern, and then route the events to targets to take action. To learn more, please refer to Customize a provisioning timeout period for cluster resize in Amazon EMR.
Please find summarized below the experience for different scenario’s when you configure a provisioning timeout period during resize for your Amazon EMR on EC2 cluster
| Scenario | Experience |
| Amazon EMR is able to provision the desired Spot capacity before expiration of the provisioning timeout | Amazon EMR automatically scales-up the cluster to the desired capacity and no action is needed from the customer |
| Amazon EMR is not able to provision any Spot capacity or only able to provision partial Spot capacity and the provisioning timeout has expired | If Amazon EMR can’t provision the required Spot capacity and the provisioning timeout has expired, Amazon EMR will cancel the resize request and stops it’s attempts to provision additional Spot capacity. Amazon EMR will also publish events to an Amazon CloudWatch Events stream. Customers can use these events to create rules and take appropriate actions |
| If the Spot instances in your Amazon EMR on EC2 clusters are interrupted as Amazon EC2 needs them back | Amazon EMR will automatically trigger a new resize request to rebalance your clusters by replacing instances with any of the available types in your cluster. Amazon EMR will also use the same provisioning resize timeout which was configured on the cluster. No action is needed from the customer. |
You should consider the criticality of capacity availability when specifying the provisioning timeout value:
- When your workload capacity availability is critical – To ensure the desired capacity is available, we recommend configuring the resize provisioning timeout based on the time it takes to run the application and application SLAs. For example, if application SLA is 60 minutes and it takes 30 minutes for the application to complete, you should set the resize provisioning timeout to 30 minutes or less. Amazon EMR will try to provision to get Spot capacity until the timeout expires (30 minutes or less) and publish a CloudWatch event so that you can take appropriate actions.
- When your workload is time flexible and capacity availability is not a factor – If the workload is time flexible and capacity availability is not a factor, to ensure the highest likelihood for getting the desired Spot capacity, you can configure a higher timeout value for the resize provisioning timeout.
Optimized task nodes scale-up for Amazon EMR on EC2 clusters launched with Instance groups
Instance groups offer a simpler setup to launch EMR on EC2 clusters. Each cluster launched using instance groups can include up to 50 instance groups: one primary instance group that contains one EC2 instance, a core instance group that contains one or more EC2 instances, and up to 48 optional task instance groups. You can scale each instance group by adding and removing EC2 instances manually, or you can set up automatic scaling. You can also use the Amazon EMR Managed Scaling feature to automatically resize your cluster based on workload and utilization.
To enhance the customer experience for instance groups on EMR on EC2 clusters when scaling up task nodes using Amazon EMR Managed Scaling, we have enhanced the managed scaling algorithm to choose the task instance groups that have the highest likelihood of acquiring capacity. Furthermore, when managed scaling is not able to acquire capacity with a single task instance group, to reduce any scale-up delays, Amazon EMR will automatically switch to another task group and fulfill the capacity by using multiple task instance groups. Consequently, the more flexible you are about your instance types, the higher the chances of provisioning capacity. To learn more, refer to Best practices for instance and Availability Zone flexibility.
Improved job resiliency with enhanced protection for Spark Drivers
In 2022, to improve the job resiliency when using Amazon EMR Managed Scaling, we enhanced managed scaling to be Spark shuffle data aware, which prevents scale-down of instances that store intermediate shuffle data for Apache Spark. This helps prevents job reattempts and recomputations, which leads to better performance and lower cost.
To further improve job resiliency when using Amazon EMR Managed Scaling, we have further enhanced managed scaling to be Spark Driver aware, which ensures that during cluster scale-down, Amazon EMR Managed Scaling prioritizes the scale-down of nodes that don’t have an active Spark Driver running on them. This helps minimize job failures and job retries, helping further improve performance and reduce costs. This enhancement is enabled by default for EMR clusters using Amazon EMR versions 5.34.0 and later, and Amazon EMR versions 6.4.0 and later.
To confirm which nodes in your cluster are running Spark Driver, you can visit the Spark History Server and filter for the driver on the Executors tab of your Spark application ID.
Conclusion
In this post, we highlighted the improvements that we made in capacity management and Amazon EMR Managed Scaling for EMR on EC2 clusters. We focused on improving job resiliency, enhanced flexibility and transparency when provisioning Spot Instances, and optimizing the scale-up experience when using managed scaling with instance groups on Amazon EMR on EC2 clusters. Although we have launched multiple features so far in 2023 and the pace of innovation continues to accelerate, it remains day 1 and we look forward to hearing from you on how these features help you unlock more value for your organizations. We invite you to try these new features and get in touch with us through your AWS account team if you have further comments.
About the authors
 Sushant Majithia is a Principal Product Manager for EMR at AWS.
Sushant Majithia is a Principal Product Manager for EMR at AWS.
 Ankur Goyal is a SDM with Amazon EMR Big Data Platform team. He builds large scale distributed applications and cluster optimization algorithms. Ankur is interested in topics of Analytics, Machine Learning and Forecasting.
Ankur Goyal is a SDM with Amazon EMR Big Data Platform team. He builds large scale distributed applications and cluster optimization algorithms. Ankur is interested in topics of Analytics, Machine Learning and Forecasting.
 Matthew Liem is a Senior Solution Architecture Manager at AWS.
Matthew Liem is a Senior Solution Architecture Manager at AWS.
 Tarun Chanana is an SDM with Amazon EMR Big Data Platform team.
Tarun Chanana is an SDM with Amazon EMR Big Data Platform team.












 Cristiane de Melo is a Solutions Architect Manager at AWS based in Bay Area, CA. She brings 25+ years of experience driving technical pre-sales engagements and is responsible for delivering results to customers. Cris is passionate about working with customers, solving technical and business challenges, thriving on building and establishing long-term, strategic relationships with customers and partners.
Cristiane de Melo is a Solutions Architect Manager at AWS based in Bay Area, CA. She brings 25+ years of experience driving technical pre-sales engagements and is responsible for delivering results to customers. Cris is passionate about working with customers, solving technical and business challenges, thriving on building and establishing long-term, strategic relationships with customers and partners. Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.
Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes. Nikita Sur is a Solutions Architect at AWS supporting a Strategic Customer. She is curious to learn new technologies to solve customer problems. She has a Master’s degree in Information Systems – Big Data Analytics and her passion is databases and analytics.
Nikita Sur is a Solutions Architect at AWS supporting a Strategic Customer. She is curious to learn new technologies to solve customer problems. She has a Master’s degree in Information Systems – Big Data Analytics and her passion is databases and analytics. Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS.
Zach Mitchell is a Sr. Big Data Architect. He works within the product team to enhance understanding between product engineers and their customers while guiding customers through their journey to develop their enterprise data architecture on AWS.
 Philipp Klose is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and helps them solve business problems by architecting serverless platforms. In this free time, Philipp spends time with his family and enjoys every geek hobby possible.
Philipp Klose is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and helps them solve business problems by architecting serverless platforms. In this free time, Philipp spends time with his family and enjoys every geek hobby possible. Daniel Wessendorf is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and is primarily specialized in machine learning and data architectures. In his free time, he enjoys swimming, hiking, skiing, and spending quality time with his family.
Daniel Wessendorf is a Global Solutions Architect at AWS based in Munich. He works with enterprise FSI customers and is primarily specialized in machine learning and data architectures. In his free time, he enjoys swimming, hiking, skiing, and spending quality time with his family. Marvin Gersho is a Senior Solutions Architect at AWS based in New York City. He works with a wide range of startup customers. He previously worked for many years in engineering leadership and hands-on application development, and now focuses on helping customers architect secure and scalable workloads on AWS with a minimum of operational overhead. In his free time, Marvin enjoys cycling and strategy board games.
Marvin Gersho is a Senior Solutions Architect at AWS based in New York City. He works with a wide range of startup customers. He previously worked for many years in engineering leadership and hands-on application development, and now focuses on helping customers architect secure and scalable workloads on AWS with a minimum of operational overhead. In his free time, Marvin enjoys cycling and strategy board games. Nathan Lichtenstein is a Senior Solutions Architect at AWS based in New York City. Primarily working with startups, he ensures his customers build smart on AWS, delivering creative solutions to their complex technical challenges. Nathan has worked in cloud and network architecture in the media, financial services, and retail spaces. Outside of work, he can often be found at a Broadway theater.
Nathan Lichtenstein is a Senior Solutions Architect at AWS based in New York City. Primarily working with startups, he ensures his customers build smart on AWS, delivering creative solutions to their complex technical challenges. Nathan has worked in cloud and network architecture in the media, financial services, and retail spaces. Outside of work, he can often be found at a Broadway theater.
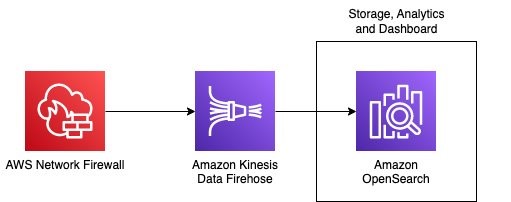
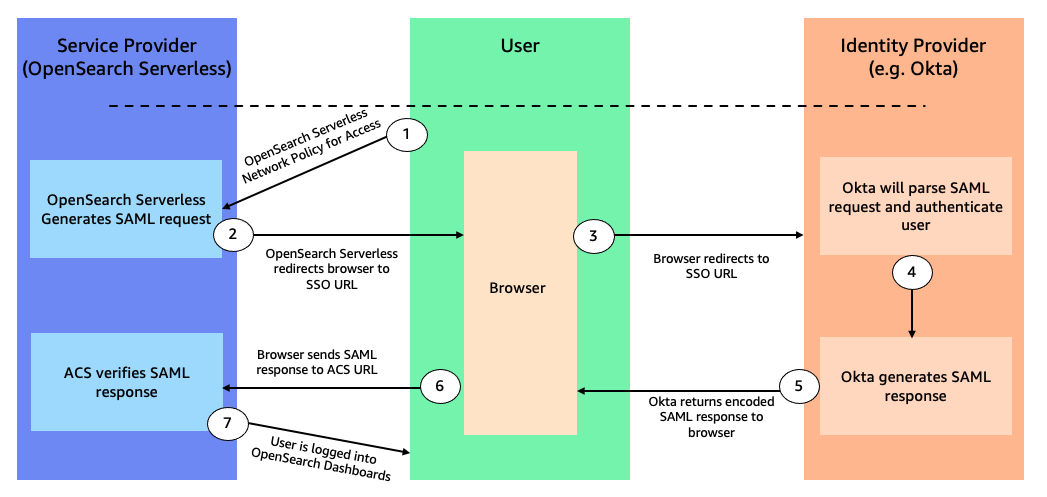
 Bharav Patel is a Specialist Solution Architect, Analytics at Amazon Web Services. He primarily works on Amazon OpenSearch Service and helps customers with key concepts and design principles of running OpenSearch workloads on the cloud. Bharav likes to explore new places and try out different cuisines.
Bharav Patel is a Specialist Solution Architect, Analytics at Amazon Web Services. He primarily works on Amazon OpenSearch Service and helps customers with key concepts and design principles of running OpenSearch workloads on the cloud. Bharav likes to explore new places and try out different cuisines.

 Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift.
Milind Oke is a Data Warehouse Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 17 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 17 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe. Kiran Chinta is a Software Development Manager at Amazon Redshift. He leads a strong team in query processing, SQL language, data security, and performance. Kiran is passionate about delivering products that seamlessly integrate with customers’ business applications with the right ease of use and performance. In his spare time, he enjoys reading and playing tennis.
Kiran Chinta is a Software Development Manager at Amazon Redshift. He leads a strong team in query processing, SQL language, data security, and performance. Kiran is passionate about delivering products that seamlessly integrate with customers’ business applications with the right ease of use and performance. In his spare time, he enjoys reading and playing tennis. Huichen Liu is a software development engineer on the Amazon Redshift query processing team. She focuses on query optimization, statistics and SQL language features. In her spare time, she enjoys hiking and photography.
Huichen Liu is a software development engineer on the Amazon Redshift query processing team. She focuses on query optimization, statistics and SQL language features. In her spare time, she enjoys hiking and photography.


























 Nikhil Agarwal is Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and working activity on technical solutions. He is also AI/ML enthusiastic and deep dives into customer’s ML-specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets.
Nikhil Agarwal is Sr. Technical Manager with Amazon Web Services. He is passionate about helping customers achieve operational excellence in their cloud journey and working activity on technical solutions. He is also AI/ML enthusiastic and deep dives into customer’s ML-specific use cases. Outside of work, he enjoys traveling with family and exploring different gadgets. Karthik Chemudupati is a Principal Technical Account Manager (TAM) with AWS, focused on helping customers achieve cost optimization and operational excellence. He has more than 19 years of IT experience in software engineering, cloud operations and automations. Karthik joined AWS in 2016 as a TAM and worked with more than dozen Enterprise Customers across US-West. Outside of work, he enjoys spending time with his family.
Karthik Chemudupati is a Principal Technical Account Manager (TAM) with AWS, focused on helping customers achieve cost optimization and operational excellence. He has more than 19 years of IT experience in software engineering, cloud operations and automations. Karthik joined AWS in 2016 as a TAM and worked with more than dozen Enterprise Customers across US-West. Outside of work, he enjoys spending time with his family. Gene Alpert is a Senior Analytics Specialist with AWS Enterprise Support. He has been focused on our Amazon OpenSearch Service customers and ecosystem for the past three years. Gene joined AWS in 2017. Outside of work he enjoys mountain biking, traveling, and playing Population:One in VR.
Gene Alpert is a Senior Analytics Specialist with AWS Enterprise Support. He has been focused on our Amazon OpenSearch Service customers and ecosystem for the past three years. Gene joined AWS in 2017. Outside of work he enjoys mountain biking, traveling, and playing Population:One in VR.





















































 Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys.
Aparajithan Vaidyanathan is a Principal Enterprise Solutions Architect at AWS. He supports enterprise customers migrate and modernize their workloads on AWS cloud. He is a Cloud Architect with 23+ years of experience designing and developing enterprise, large-scale and distributed software systems. He specializes in Machine Learning & Data Analytics with focus on Data and Feature Engineering domain. He is an aspiring marathon runner and his hobbies include hiking, bike riding and spending time with his wife and two boys. Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.
Hafiz Saadullah is a Principal Technical Product Manager at Amazon Web Services. Hafiz focuses on AWS Solutions, designed to help customers by addressing common business problems and use cases.






 Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking.
Aish Gunasekar is a Specialist Solutions architect with a focus on Amazon OpenSearch Service. Her passion at AWS is to help customers design highly scalable architectures and help them in their cloud adoption journey. Outside of work, she enjoys hiking and baking. Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.










 Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.


















 Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She likes building data lake solutions for AWS customers and partners. When not on the keyboard, she explores the latest science and technology trends and spends time with her family.






















 Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty.
Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty. Sundeep Kumar is a Sr. Data Architect, Data Lake at AWS, helping customers build data lake and analytics platform and solutions. When not building and designing data lakes, Sundeep enjoys listening music and playing guitar.
Sundeep Kumar is a Sr. Data Architect, Data Lake at AWS, helping customers build data lake and analytics platform and solutions. When not building and designing data lakes, Sundeep enjoys listening music and playing guitar.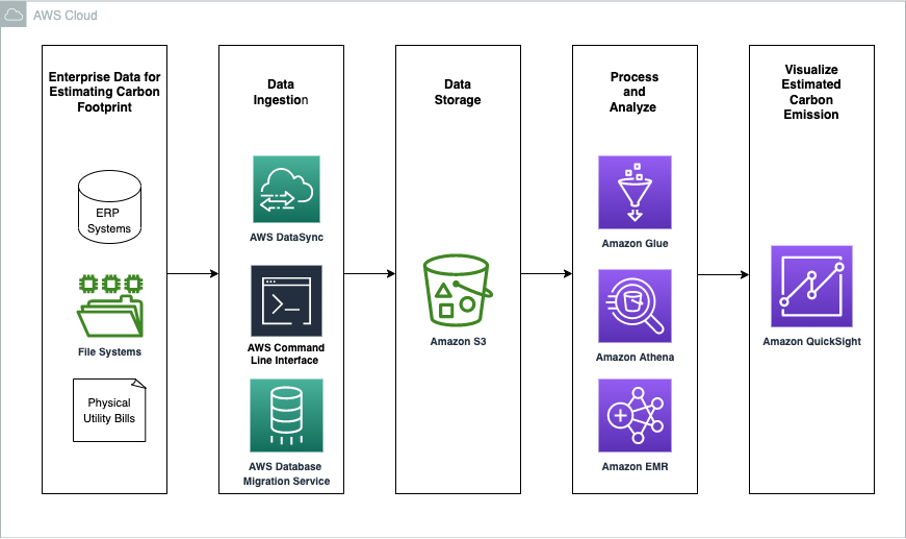

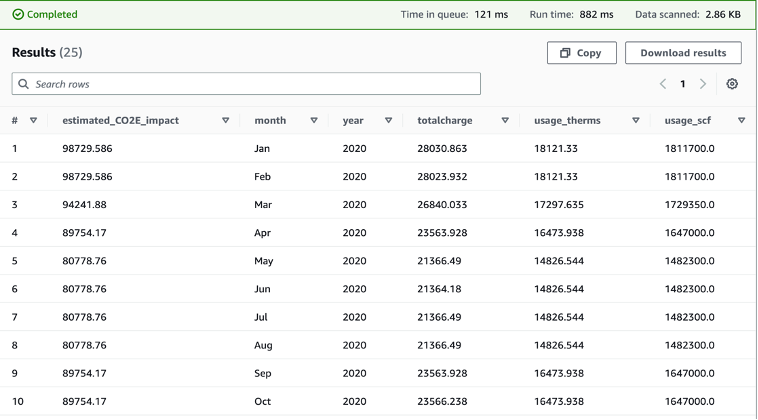
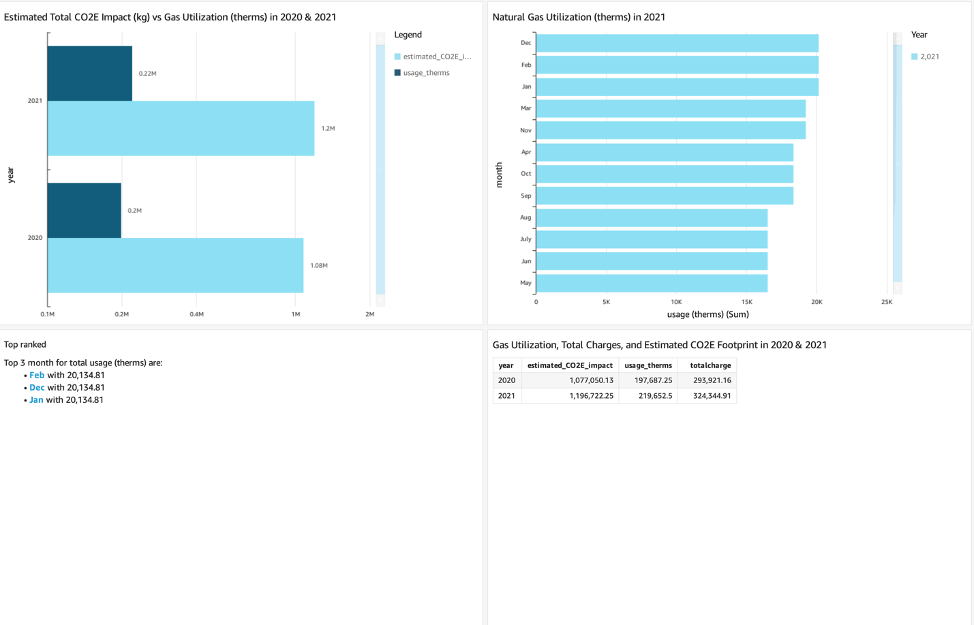
 Thomas Burns,
Thomas Burns,  Aileen Zheng is a Solutions Architect supporting US Federal Civilian Sciences customers at Amazon Web Services (AWS). She partners with customers to provide technical guidance on enterprise cloud adoption and strategy and helps with building well-architected solutions. She is also very passionate about data analytics and machine learning. In her free time, you’ll find Aileen doing pilates, taking her dog Mumu out for a hike, or hunting down another good spot for food! You’ll also see her contributing to projects to support diversity and women in technology.
Aileen Zheng is a Solutions Architect supporting US Federal Civilian Sciences customers at Amazon Web Services (AWS). She partners with customers to provide technical guidance on enterprise cloud adoption and strategy and helps with building well-architected solutions. She is also very passionate about data analytics and machine learning. In her free time, you’ll find Aileen doing pilates, taking her dog Mumu out for a hike, or hunting down another good spot for food! You’ll also see her contributing to projects to support diversity and women in technology.








 Nihar Sheth is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals.
Nihar Sheth is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enable customers to achieve their business goals. Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy.
Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy. Nisha Dekhtawala is a Partner Solutions Architect and data analytics specialist. She works with global consulting partners as their trusted advisor, providing technical guidance and support in building Well-Architected innovative industry solutions.
Nisha Dekhtawala is a Partner Solutions Architect and data analytics specialist. She works with global consulting partners as their trusted advisor, providing technical guidance and support in building Well-Architected innovative industry solutions.




















 Mitesh Patel is a Principal Solutions Architect at AWS with specialization in data analytics and machine learning. He is passionate about helping customers building scalable, secure and cost effective cloud native solutions in AWS to drive the business growth. He lives in DC Metro area with his wife and two kids.
Mitesh Patel is a Principal Solutions Architect at AWS with specialization in data analytics and machine learning. He is passionate about helping customers building scalable, secure and cost effective cloud native solutions in AWS to drive the business growth. He lives in DC Metro area with his wife and two kids. Sumitha AP is a Sr. Solutions Architect at AWS. She works with customers and help them attain their business objectives by designing secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS.
Sumitha AP is a Sr. Solutions Architect at AWS. She works with customers and help them attain their business objectives by designing secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS. Deepti Venuturumilli is a Sr. Solutions Architect in AWS. She works with commercial segment customers and AWS partners to accelerate customers’ business outcomes by providing expertise in AWS services and modernize their workloads. She focuses on data analytics workloads and setting up modern data strategy on AWS.
Deepti Venuturumilli is a Sr. Solutions Architect in AWS. She works with commercial segment customers and AWS partners to accelerate customers’ business outcomes by providing expertise in AWS services and modernize their workloads. She focuses on data analytics workloads and setting up modern data strategy on AWS. Deepthi Paruchuri is an AWS Solutions Architect based in NYC. She works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.
Deepthi Paruchuri is an AWS Solutions Architect based in NYC. She works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.