Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/running-next-js-applications-with-serverless-services-on-aws/
This is written by Julian Bonilla, Senior Solutions Architect, and Matthew de Anda, Startup Solutions Architect.
React is a popular JavaScript library used to create single-page applications (SPAs). React focuses on helping to build UIs, but leaves it up to developers to decide how to accomplish other aspects involved with developing a SPA.
Next.js is a React framework to help provide more structure and solve common application requirements such as routing and data fetching. Next.js also provides multiple types of rendering methods – Static Site Generation (SSG), Server-Side Rendering (SSR), Incremental Static Regeneration (ISR), and Client-Side Rendering (CSR).
This post demonstrates how to build a Next.js application with Serverless services on AWS and explains Next.js Server-Side rendering. To deploy this solution and to provision the AWS resources, you can use either AWS Serverless Application Model (AWS SAM) or AWS Cloud Development Kit (CDK). Both are open-source frameworks to automate AWS deployment. AWS SAM is a declarative framework for building serverless applications and CDK is an imperative framework to define cloud application resources using familiar programming languages.
Overview
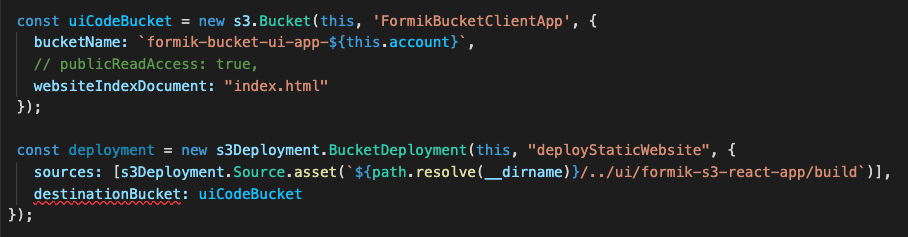
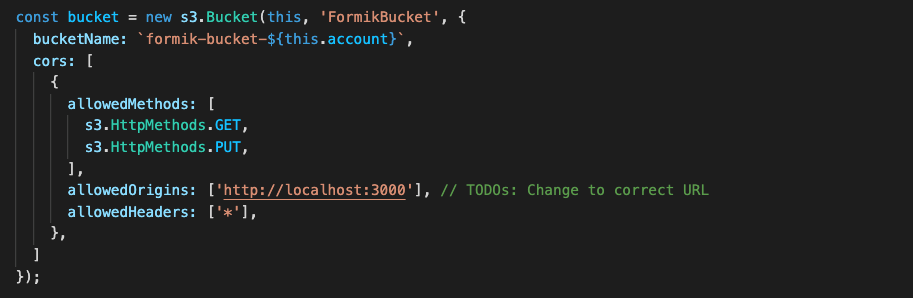
To render a Next.js application, you use Amazon S3, Amazon CloudFront, Amazon API Gateway, and AWS Lambda. Static resources are hosted in a private S3 bucket with a CloudFront distribution. Since static sources are generated at build time, this takes advantage of CloudFront so browsers can load these files cached on the network edge instead of from the server.
The Next.js application components that uses server-side rendering is rendered with a Lambda function using AWS Lambda Web Adapter. The CloudFront distribution is configured to forward requests to the API Gateway endpoint, which then calls the Lambda function.

- Static files (for example, CSS, JavaScript, and HTML) are mapped to
/_next/static/*and/public/*. - Server-side rendering is mapped with default behavior (*).
- The AWS Lambda Adapter runs Next.js Output File Tracing.
What’s Next.js?
Next.js is a React framework that creates a more opinionated approach to building web applications while providing additional structure and features such as Server-Side Rendering and Static Site Generation.
These additional rendering options provide more flexibility over the typical ways a React application is built, which is to render in the client’s browser with JavaScript. This can help in scenarios where customers have JavaScript disabled and can improve search engine optimization (SEO). While you can implement SSR in React applications, Next.js makes it simpler for developers.
Next.js rendering strategies
These are the different rendering strategies offered by Next.js:
- Static Site Generation generates static resources at build time and is a good rendering strategy for static content that rarely changes and SEO.
- Server-Side Rendering generates each page on-demand at request time and is good for pages that are dynamic. Since from the browser perspective it’s still pre-rendered, like Static Site Generation, it’s also good for SEO.
- Incremental Static Regeneration is a new rendering strategy that is good for apps with many pages where build times are high. With Incremental Static Regeneration, you can build page per-page without needing to rebuild the entire app.
- Client-Side Rendering is the typical rendering strategy where the application is rendered in the browser with JavaScript. Next.js lets you choose the appropriate rendering method page-by-page. When a Next.js application is built, Next.js transforms the application to production-optimized files. You have HTML for statically generated pages, JavaScript for rendering on the server, JavaScript for rendering on the client, and CSS files.
Next.js also supports static HTML export, which has no server side component. Features that require a server are not supported with this approach. These apps can be hosted from S3 and CloudFront.
The remainder of this post focuses on Static Site Generation and Server-Side Rendering.
Next.js application project structure
Understanding how Next.js structures projects can give insight into how you deploy the application. A page is a React Component exported from files in the “pages” directory. These files are also used for routing where pages/index.js is routed to / route.
By default, these pages are pre-rendered. Static assets, such as images, are stored under “public” directory and can be referenced from /. Since these files are best stored in persistent storage and backed by a content delivery network (CDN), you can add a prefix in the implementation to distinguish these static files.
To create dynamic routes, add brackets to a page file – for example, pages/user/[id].js. This creates a statically generated page with the path /user/<id> where <id> can be dynamic.
API routes provide a way to create an API endpoint and are located in the pages/api directory. When building, Next.js generates an optimized version of your application under the .next directory. Static files not stored in the public directory are in .next/static. These static files are expected to be uploaded as _next/static to a CDN.
No other code in the .next/directory should be uploaded to a CDN because that would expose server code and other configuration.
Implementation
Next.js pre-renders HTML for every page using Static Site Generation or Server-side Rendering. For Static Site Generation, pages are rendered at build time and can be cached in CloudFront. Server-side rendered pages are rendered at request time, and typically fetch data from downstream resources on each request.
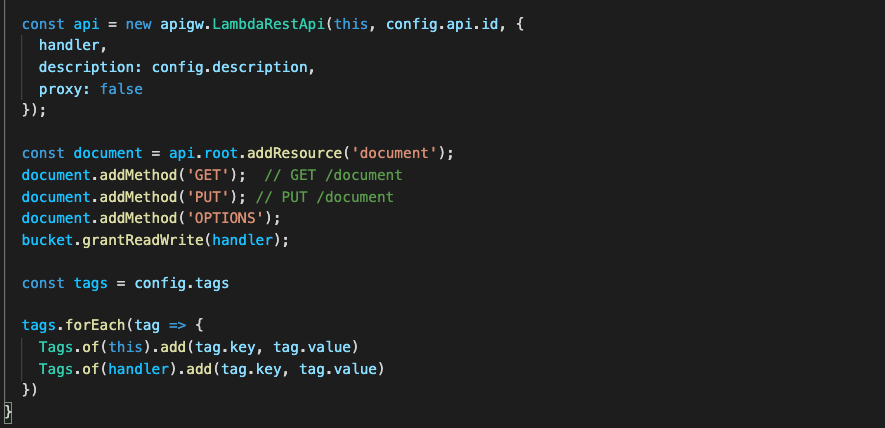
Clients connect to a CloudFront distribution, which is configured to forward requests for static resources to S3 and all other requests to API Gateway. API Gateway forwards requests to the Next.js application running on Lambda, which performs the server-side rendering.
At build time, Next.js Output File Tracing determines the minimal set of files needed for deploying to Lambda. The files are automatically copied to a standalone directory and must be enabled in next.config.js.
const nextConfig = {
reactStrictMode: true,
output: 'standalone',
}
module.exports = nextConfig
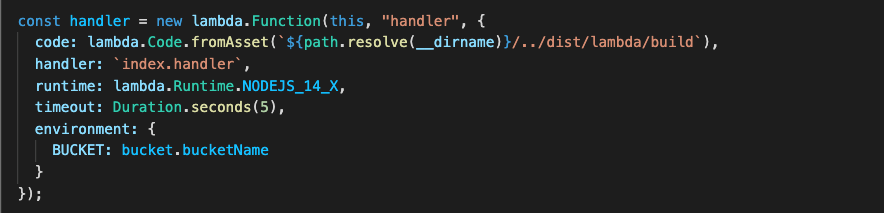
Since the Next.js application is essentially a webserver, this example uses the AWS Lambda Web Adapter as a Lambda layer to convert incoming events from API Gateway to HTTP requests that Next.js can process.
Once processed, the AWS Lambda Web Adapter converts the HTTP response back to a Lambda event response. The Lambda handler is configured to run the minimal server.js file created by the standalone build step.
The CloudFront distribution has two origins: one for the S3 bucket and another for the API Gateway. Two behaviors are created to specify path patterns to route static content produced by Next.js and static resources stored under the public/static directory. Next.js uses the public directory under root to serve static assets such as images.
These assets are then served under / so if you add public/me.png, it would be served at /me.png. This makes it harder to create a CloudFront behavior for these assets. One workaround is to create a static directory under the public directory and then map it to the CloudFront behavior. The default(*) path pattern behavior has the origin set to API Gateway with caching disabled.
Prerequisites and deployment
Refer to the project in its GitHub repository for instructions to deploy the solution using AWS SAM or AWS CDK. Multiple resources are provisioned for you as part of the deployment, and it takes several minutes to complete. The example Next.js application deployed is created using Create Next App.
Understanding the Next.js Application
To create a new page, you create a file under the pages directory and that creates a route based on the name (e.g. pages/hello.js creates route /hello). To create dynamic routes, create a file following the project’s example of pages/posts/[id].js to produce routes for posts/1, posts/2, and so forth.
For API routes, any file added to the directory pages/api is mapped to /api/* and becomes an API endpoint. These are server-side only bundles hosted by API Gateway and Lambda.
Conclusion
This blog shows how to run Next.js applications using S3, CloudFront, API Gateway, and Lambda. This architecture supports building Next.js applications that can use static-site generation, server-side rendering, and client-side rendering. The blog also covers how you can use open-source frameworks, AWS SAM and CDK, to build and deploy your Next.js applications.
If your organization is looking for a fully managed hosting of your Next.js applications, AWS Amplify Hosting supports Next.js. If interested in learning more about server-side rendering and micro-frontends, see Server-side rendering micro-frontends – the architecture.
For more serverless learning resources, visit Serverless Land.













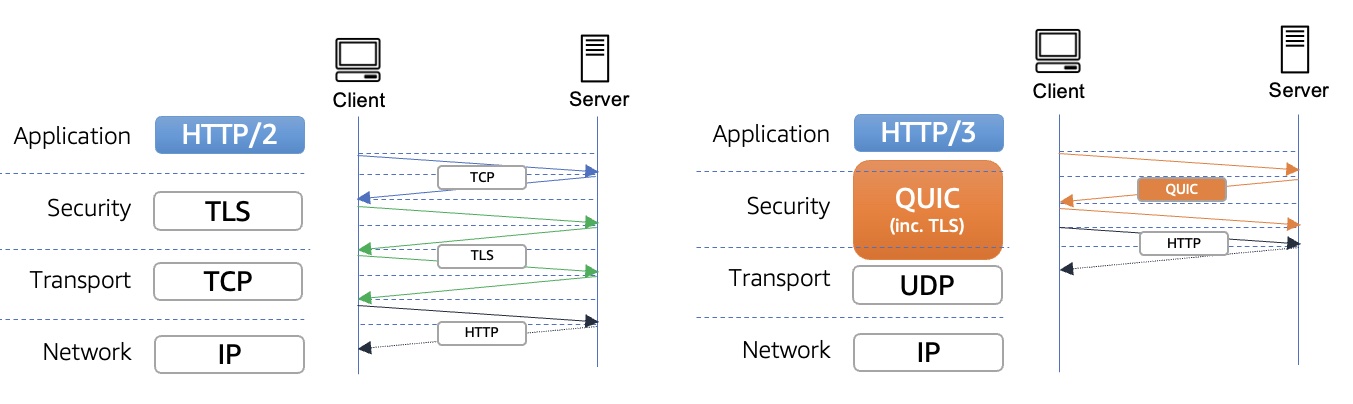




 One-year anniversary of CloudFront Functions – I can’t believe it’s been
One-year anniversary of CloudFront Functions – I can’t believe it’s been 











 The
The