Post Syndicated from Rahul Sarda original https://aws.amazon.com/blogs/big-data/implement-fine-grained-access-control-in-amazon-sagemaker-studio-and-amazon-emr-using-apache-ranger-and-microsoft-active-directory/
Amazon SageMaker Studio is a fully integrated development environment (IDE) for machine learning (ML) that enables data scientists and developers to perform every step of the ML workflow, from preparing data to building, training, tuning, and deploying models. SageMaker Studio comes with built-in integration with Amazon EMR, enabling data scientists to interactively prepare data at petabyte scale using frameworks such as Apache Spark, Hive, and Presto right from SageMaker Studio notebooks. With Amazon SageMaker, developers, data scientists, and SageMaker Studio users can access both raw data stored in Amazon Simple Storage Service (Amazon S3), and cataloged tabular data stored in a Hive metastore easily. SageMaker Studio’s support for Apache Ranger creates a simple mechanism for applying fine-grained access control to the raw and cataloged data with grant and revoke policies administered from a friendly web interface.
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.
With this capability, multiple SageMaker Studio users can connect to the same EMR cluster, gaining access only to data granted to their user or group, with audit records captured and visible in Amazon CloudWatch. This multi-tenant environment is possible through user session isolation that prevents users from accessing datasets and cluster resources allocated to other users. Ultimately, organizations can provision fewer clusters, reduce administrative overhead, and increase cluster utilization, saving staff time and cloud costs.
Solution overview
We demonstrate this solution with an end-to-end use case using a sample ecommerce dataset. The dataset is available within provided AWS CloudFormation templates and consists of transactional ecommerce data (products, orders, customers) cataloged in a Hive metastore.
The solution utilizes two data analyst personas, Alex and Tina, each tasked with different analysis requiring fine-grained limitations on dataset access:
- Tina, a data scientist on the marketing team, is tasked with building a model for customer lifetime value. Data access should only be permitted to non-sensitive customer, product, and orders data.
- Alex, a data scientist on the sales team, is tasked to generate product demand forecast, requiring access to product and orders data. No customer data is required.
The following figure illustrates our desired fine-grained access.

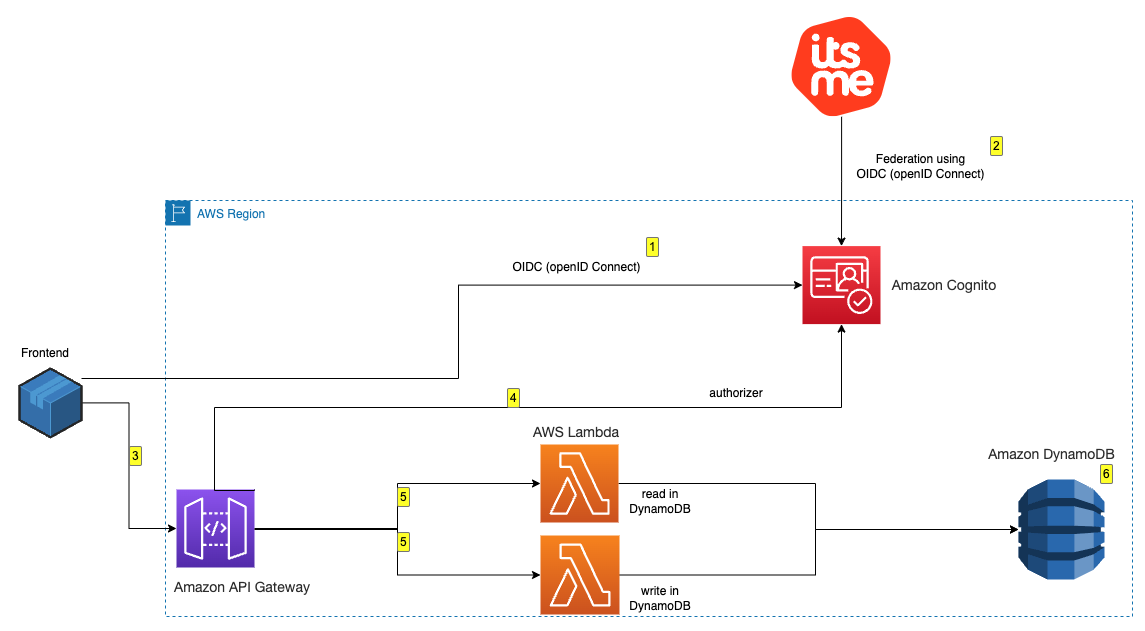
The following diagram illustrates the solution architecture.
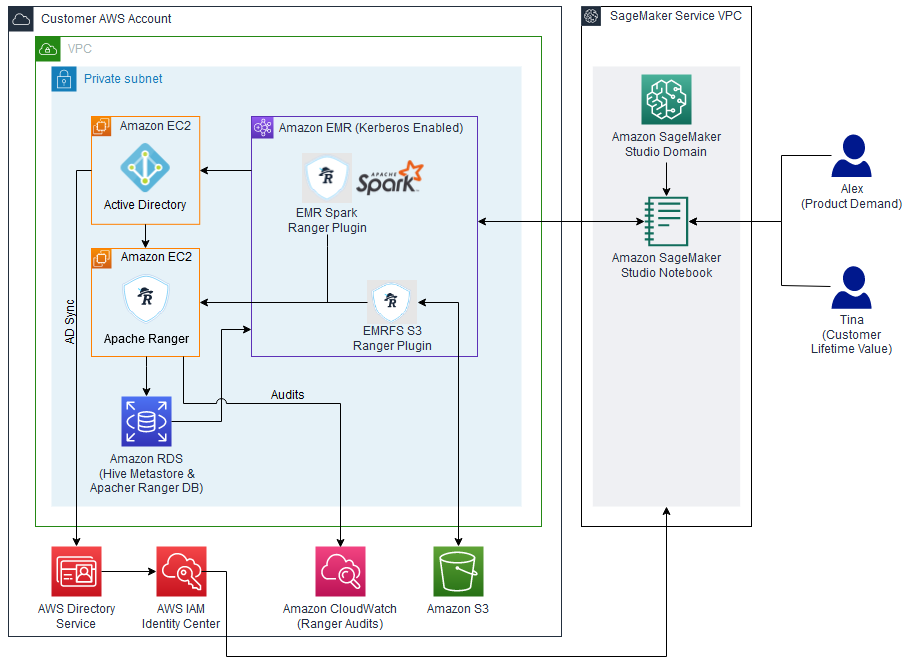
The architecture is implemented as follows:
- Microsoft Active Directory – Used to manage user authentication, select AWS application access, and user and group membership for Apache Ranger secured data authorization
- Apache Ranger – Used to monitor and manage comprehensive data security across the Hadoop and Amazon EMR platform
- Amazon EMR – Used to retrieve, prepare, and analyze data from the Hive metastore using Spark
- SageMaker Studio – An integrated IDE with purpose-built tools to build AI/ML models.
The following sections walk through the setup of the architectural components for this solution using the CloudFormation stack.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account
- An AWS Identity and Access Management (IAM) user with administrator access
Create resources with AWS CloudFormation
To build the solution within your environment, use the provided CloudFormation templates to create the required AWS resources.
Note that running these CloudFormation templates and the following configuration steps will create AWS resources that may incur charges. Additionally, all the steps should be run in the same Region.
Template 1
This first template creates the following resources and takes approximately 15 minutes to complete:
- A Multi-AZ, multi-subnet VPC infrastructure, with managed NAT gateways in the public subnet for each Availability Zone
- S3 VPC endpoints and Elastic Network Interfaces
- A Windows Active Directory domain controller using Amazon Elastic Compute Cloud (Amazon EC2) with cross-realm trust
- A Linux Bastion host (Amazon EC2) in an auto scaling group
To deploy this template, complete the following steps:
- Sign in to the AWS Management Console.
- On the Amazon EC2 console, create an EC2 key pair.
- Choose Launch Stack :

- Select the target Region
- Verify the stack name and provide the following parameters:
- The name of the key pair you created.
- Passwords for cross-realm trust, the Windows domain admin, LDAP bind, and default AD user. Be sure to record these passwords to use in future steps.
- Select a minimum of three Availability Zones based on the chosen Region.
- Review the remaining parameters. No changes are required for the solution, but you may change parameter values if desired.
- Choose Next and then choose Next again.
- Review the parameters.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names and I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND.
- Choose Submit.
Template 2
The second template creates the following resources and takes approximately 30–60 minutes to complete:
- An Amazon Relational Database Service (Amazon RDS) for MySQL database used for Apache Ranger and Hive metastore
- A self-managed standalone Apache Ranger server (2.x only)
- SSL keys and certs uploaded to AWS Secrets Manager to encrypt traffic between the Ranger server and agents
- A Kerberos-enabled EMR cluster with AWS managed Ranger plugins
To deploy this template, complete the following steps:
- Choose Launch Stack :
- Select the target Region
- Verify the stack name and provide the following parameters:
- Key pair name (created earlier).
LDAPHostPrivateIPaddress, which can be found in the output section of the Windows AD CloudFormation stack.- Passwords for the Windows domain admin, cross-realm trust, AD domain user, and LDAP bind. Use the same passwords as you did for the first CloudFormation template.
- Passwords for the RDS for MySQL database and KDC admin. Record these passwords; they may be needed in future steps.
- Log directory for the EMR cluster.
- VPC (it contains the name of the CloudFormation stack)
- Subnet details (align the subnet name with the parameter name).
- Set
AppsEMRto Hadoop, Spark, Hive, Livy, Hue, and Trino. - Leave
RangerAdminPasswordas is.
- Review the remaining parameters. No changes are required beyond what is mentioned, but you may change parameter values if desired.
- Choose Next, then choose Next again.
- Review the parameters.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names and I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND.
- Choose Submit.
Integrate Active Directory with AWS accounts using IAM Identity Center
To enable users to sign in to SageMaker with Active Directory credentials, a connection between IAM Identity Center and Active Directory must be established.
To connect to Microsoft Active Directory, we set up AWS Directory Service using AD Connector.
- On the Directory Service console, choose Directories in the navigation pane.
- Choose Set up directory.
- For Directory types, select AD Connector.
- Choose Next.

- For Directory size, select the appropriate size for AD Connector. For this post, we select Small.
- Choose Next.

- Choose the VPC and private subnets where the Windows AD domain controller resides.
- Choose Next.

- In the Active Directory information section, enter the following details (this information can be retrieved on the Outputs tab of the first CloudFormation template):
- For Directory DNS Name, enter
awsemr.com. - For Directory NetBIOS name, enter
awsemr. - For DNS IP addresses, enter the IPv4 private IP address from AD Controller.
- Enter the service account user name and password that you provided during stack creation.
- For Directory DNS Name, enter
- Choose Next.

- Review the settings and choose Create directory.




After the directory is created, you will see its status as Active on the Directory Services console.
Set up AWS Organizations
AWS Organizations supports IAM Identity Center in only one Region at a time. To enable IAM Identity Center in this Region, you must first delete the IAM Identity Center configuration if created in another Region. Do not delete an existing IAM Identity Center configuration unless you are sure it will not negatively impact existing workloads.
- Navigate to the IAM Identity Center console.
- If IAM Identity Center has not been activated previously, choose Enable. If an organization does not exist, an alert appears to create one.
- Choose Create AWS organization.
- Choose Settings in the navigation pane.
- On the Identity source tab, on the Actions menu, choose Change identity source.

- For Choose identity source, select Active Directory.
- Choose Next.
- For Existing Directories, choose AWSEMR.COM.
- Choose Next.

- To confirm the change, enter
ACCEPTin the confirmation input box, then choose Change identity source. Upon completion, you will be redirected to Settings, where you receive the alertConfigurable AD sync paused. - Choose Resume sync.

- Choose Settings in the navigation pane.
- On the Identity source tab, on the Actions menu, choose Manage sync.

- Choose Add users and groups to specify the users and groups to sync from Active Directory to IAM Identity Center.

- On the Users tab, enter
tinaand choose Add. - Enter
alexand choose Add. - Choose Submit.
- On the Groups tab, enter
datascienceand choose Add. - Choose Submit.








After your users and groups are synced to IAM Identity Center, you can see them by choosing Users or Groups in the navigation pane on the IAM Identity Center console. When they’re available, you can assign them access to AWS accounts and cloud applications. The initial sync may take up to 5 minutes.
Set up a SageMaker domain using IAM Identity Center
To set up a SageMaker domain, complete the following steps:
- On the SageMaker console, choose Domains in the navigation pane.
- Choose Create domain.
- Choose Standard setup, then choose Configure.

- For Domain Name, enter a unique name for your domain.
- For Authentication, choose AWS IAM Identity Center.
- Choose Create a new role for the default execution role.
- In the Create an IAM Role popup, choose Any S3 bucket.
- Choose Create role.
- Copy the role details to be used in next section for adding a policy for EMR cluster access.
- In the Network and storage section, specify the following:
- Choose the VPC that you created using the first CloudFormation template.
- Choose a private subnet in an Availability Zone supported by SageMaker.
- Use the default security group (
sg-XXXX). - Choose VPC only.

Note that there is a public domain called AWSEMR.COM that will conflict with the one created for this solution if Public internet only is selected.
- Leave all other options as default and choose Next.
- In the Studio settings section, accept the defaults and choose Next.
- In the RStudio settings section, accept the defaults and choose Next.
- In the Canvas setting section, accept the defaults and choose Submit.
Add a policy to provide SageMaker Studio access to the EMR cluster
Complete the following steps to give SageMaker Studio access to the EMR cluster:
- On the IAM console, choose Roles in the navigation pane.
- Search and choose for the role you copied earlier (
<AmazonSageMaker-ExecutionRole- XXXXXXXXXXXXXXX>). - On the Permissions tab, choose Add permissions and Attach policy.
- Search for and choose the policy
AmazonEMRFullAccessPolicy_v2. - Choose Add permissions.


Add users and groups to access the domain
Complete the following steps to give users and groups access to the domain:
- On the SageMaker console, choose Domains in the navigation pane.
- Choose the domain you created earlier.
- On the Domain details page, choose Assign users and groups.

- On the Users tab, select the users
tinaandalex. - On the Groups tab, select the group
datascience. - Choose Assign users and groups.



Configure Spark data access rights in Apache Ranger
Now that the AWS environment is set up, we configure Hive dataset security using Apache Ranger.
To start, collect the Apache Ranger URL details to access the Ranger admin console:
- On the Amazon EC2 console, choose Resources in the navigation pane, then Instance (running).
- Choose the Ranger server EC2 instance and copy the private IP DNS name (IPv4 only).
Next, connect to the Windows domain controller to use the connected VPC to access the Ranger admin console. This is done by logging in to the Windows server and launching a web browser. - Install the Remote Desktop Services client on your computer to connect with Windows Server.
- Authorize inbound traffic from your computer to the Windows AD domain controller EC2 instance.
- On the Amazon EC2 console, choose Resources in the navigation pane, then Instance (running).
- Choose on the Windows Domain Controller (DC1) EC2 instance ID and copy the public IP DNS name (IPv4 only).
- Use Microsoft Remote Desktop to log in to the Windows domain controller:
- Computer – Use the public IP DNS name (IPv4 only).
- Username – Enter
awsadmin. - Password – Use the password you set during the first CloudFormation template setup.
- Disable the Enhanced Security Configuration for Internet Explorer.
- Launch Internet Explorer and navigate to the Ranger admin console using the private IP DNS name (IPv4 only) associated with the Ranger server noted earlier and port 6182 (for example,
https://<RangerServer Private IP DNS name>:6182). - Choose Continue to this website (not recommended) if you receive a security alert.
- Log in using the default user name and password. During the first logon, you should modify your password and store it securely.
- In the top Ranger banner, choose Settings and Users/Groups/Roles.
- Confirm Tina and Alex are listed as users with a User Source of External.
- Confirm the
datasciencegroup is listed as a group with Group Source of External.
If the Tina or Alex users aren’t listed, follow the Apache Ranger troubleshooting instructions in the appendix at the end of this post.
Dataset policies
The Apache Ranger access policy model consists of two major components: specification of the resources a policy is applied to, such as files and directories, databases, tables, and columns, services, and so on, and the specification of access conditions (permissions) for specific users and groups.
Configure your dataset policy with the following steps:
- On the Ranger admin console, choose the Ranger icon in the top banner to return to the main page.
- Choose the service name
amazonemrsparkinsideAMAZON-EMR-SPARK. - Choose Add New Policy and add a new policy with the following parameters:
- For Policy Name, enter
Data Science Policy. - For Database, enter
staginganddefault. - For EMR Spark Table, enter
productsandorders. - For EMR Spark Column, enter
*. - In the Allow Conditions section, for Select User, enter
tinaandalex, and for Permissions, enterselect and read.
- For Policy Name, enter
- Choose Add.

When using Internet Explorer & adding a new policy, you may receive the errorSCRIPT438: Object doesn't support property or method 'assign'. In this case, install and use an alternate browser such as Firefox or Chrome. - Choose Add New Policy and add a new policy for
tina:- For Policy Name, enter
Customer Demographics Policy. - For Database, enter
staging. - For EMR Spark Table, enter
Customers. - For EMR Spark Column, choose
customer_id,first_name,last_name,region, andstate. - In the Allow Conditions section, for Select User, enter
Tinaand for Permissions, enterselect and read.
- For Policy Name, enter
- Choose Add.



Configure Amazon S3 data access rights in Apache Ranger
Complete the following steps to configure Amazon S3 data access rights:
- On the Ranger admin console, choose the Ranger icon in the top banner to return to the main page.
- Choose the service name
amazonemrs3insideAMAZON-EMR-EMRFS. - Choose Add New Policy and add a policy for the
datasciencegroup as follows:- For Policy Name, enter
Data Science S3 Policy. - For S3 resource, enter the following:
aws-bigdata-blog/artifacts/aws-blog-emr-ranger/data/staging/productsaws-bigdata-blog/artifacts/aws-blog-emr-ranger/data/staging/orders
- In the Allow Conditions, section, for Select User, enter
tinaandalex, and for Permissions, enterGetObjectandListObjects.
- For Policy Name, enter
- Choose Add.

- Choose Add New Policy and add a new policy for
tina:- For Policy Name, enter
Customer Demographics S3 Policy. - For S3 resource, enter
aws-bigdata-blog/artifacts/aws-blog-emr-ranger/data/staging/customers. - In the Allow Conditions section, for Select User, enter Tina and for Permissions, enter
GetObjectandListObjects.
- For Policy Name, enter
- Choose Add.



Configure Amazon S3 user working folders
While working with data, users often require data storage for interim results. To provide each user with a private working directory, complete the following steps:
- On the Ranger admin console, choose Ranger icon in the top banner to return to the main page.
- Choose the service name
amazonemrs3insideAMAZON-EMR-EMRFS. - Choose Add New Policy and add a policy for
{USER}as follows:- For Policy Name, enter
User Directory S3 Policy. - For S3 resource, enter
<Bucket Name>/data/{USER}(use a bucket within the account). - Enable Recursive.
- In the Allow Conditions, section, for Select User, enter
{USER}and for Permissions, enterGetObject,ListObjects,PutObject, andDeleteObject.
- For Policy Name, enter
- Choose Add.


Use the user access login URL
Users attempting to access shared AWS applications via IAM Identity Center need to first log in to the AWS environment with a custom link using their Active Directory user name and password. The link needed can be found on the IAM Identity Center console.
- On the IAM Identity Center console, choose Settings in the navigation pane.
- On the Identity source tab, locate the user login link under AWS access portal URL.
Test role-based data access
To review, data scientist Tina needs to build a customer lifetime value model, which requires access to orders, product, and non-sensitive customer data. Data scientist Alex only needs access to orders and product data to build a product demand model.
In this section, we test the data access levels for each role.
Data scientist Tina
Complete the following steps:
- Log in using the URL you located in the previous step.
- Enter Microsoft AD user [email protected] and your password.
- Choose the Amazon SageMaker Studio tile.
- In the SageMaker Studio UI, start a notebook:
- Choose File, New, and Notebook.
- For Image, choose SparkMagic.
- For Kernel, choose PySpark.
- For Instance Type, choose ml.t3.medium.
- Choose Select.
- When the notebook kernel starts, connect to the EMR cluster by running the following code:
The EMR cluster ID details can be found on the Outputs tab of the EMR cluster CloudFormation stack created with the second template.
- Enter Microsoft AD
[email protected]and your password. (Note that[email protected]is case-sensitive.) - Choose Connect.


Now we can test Tina’s data access.
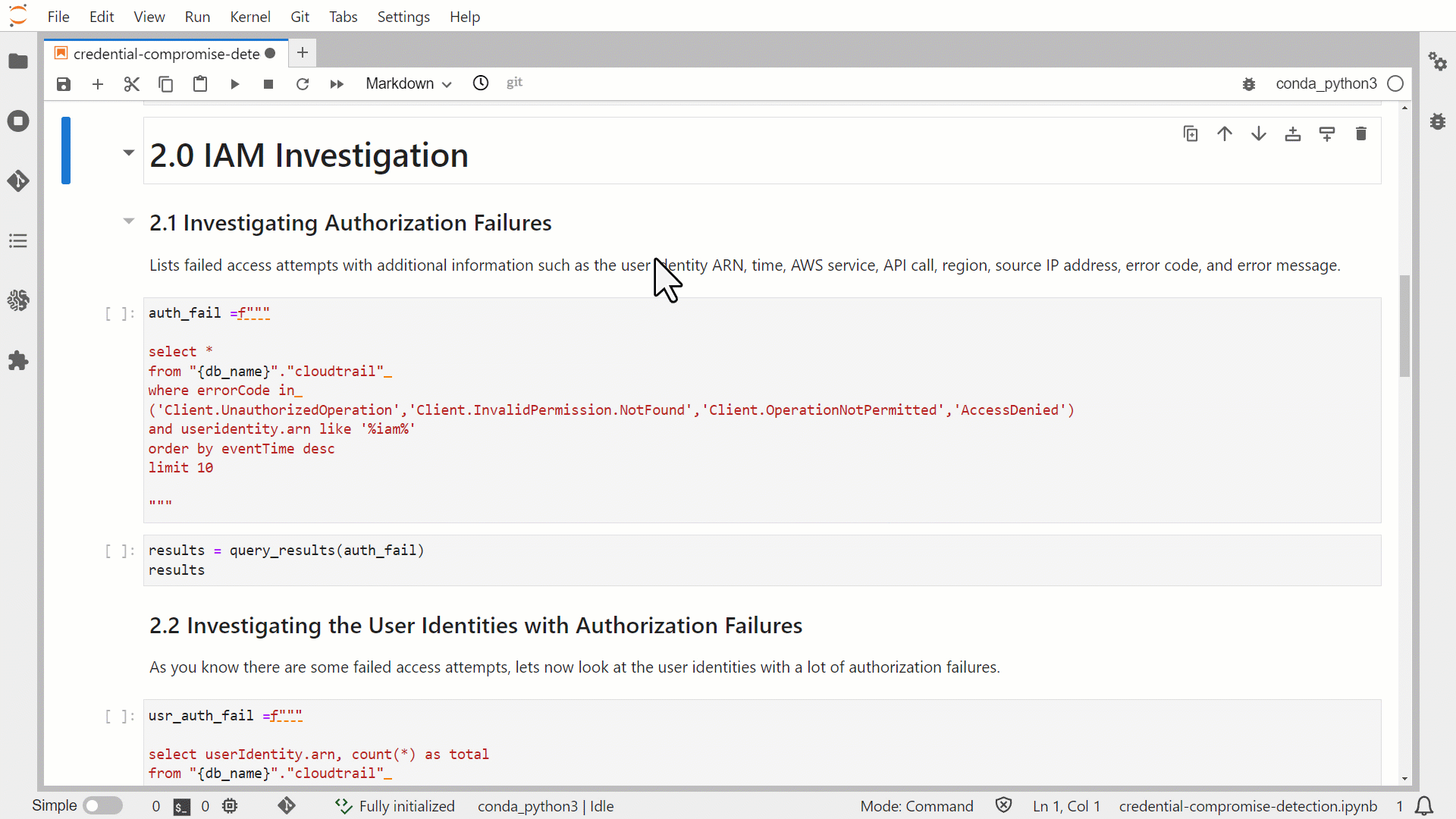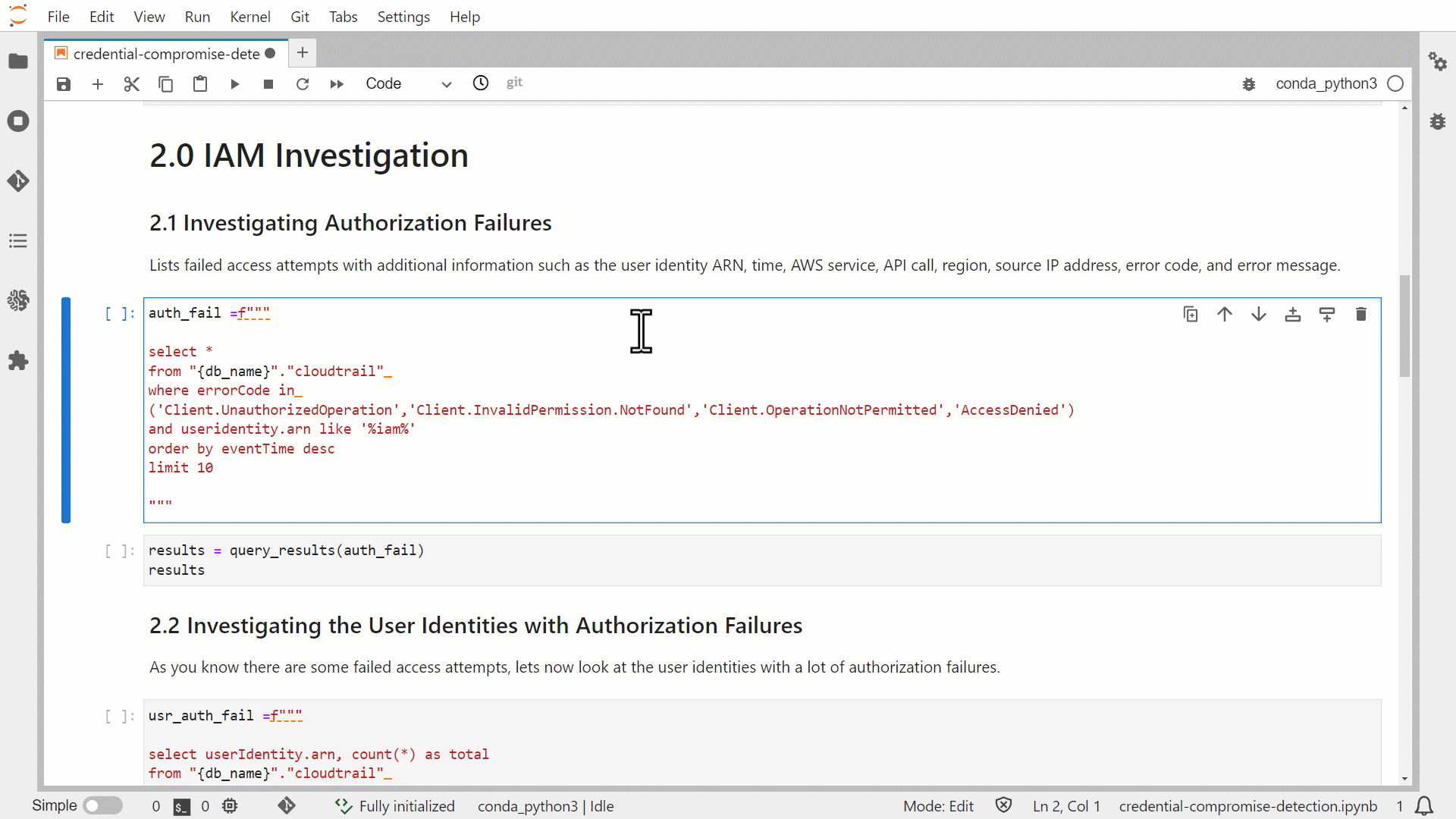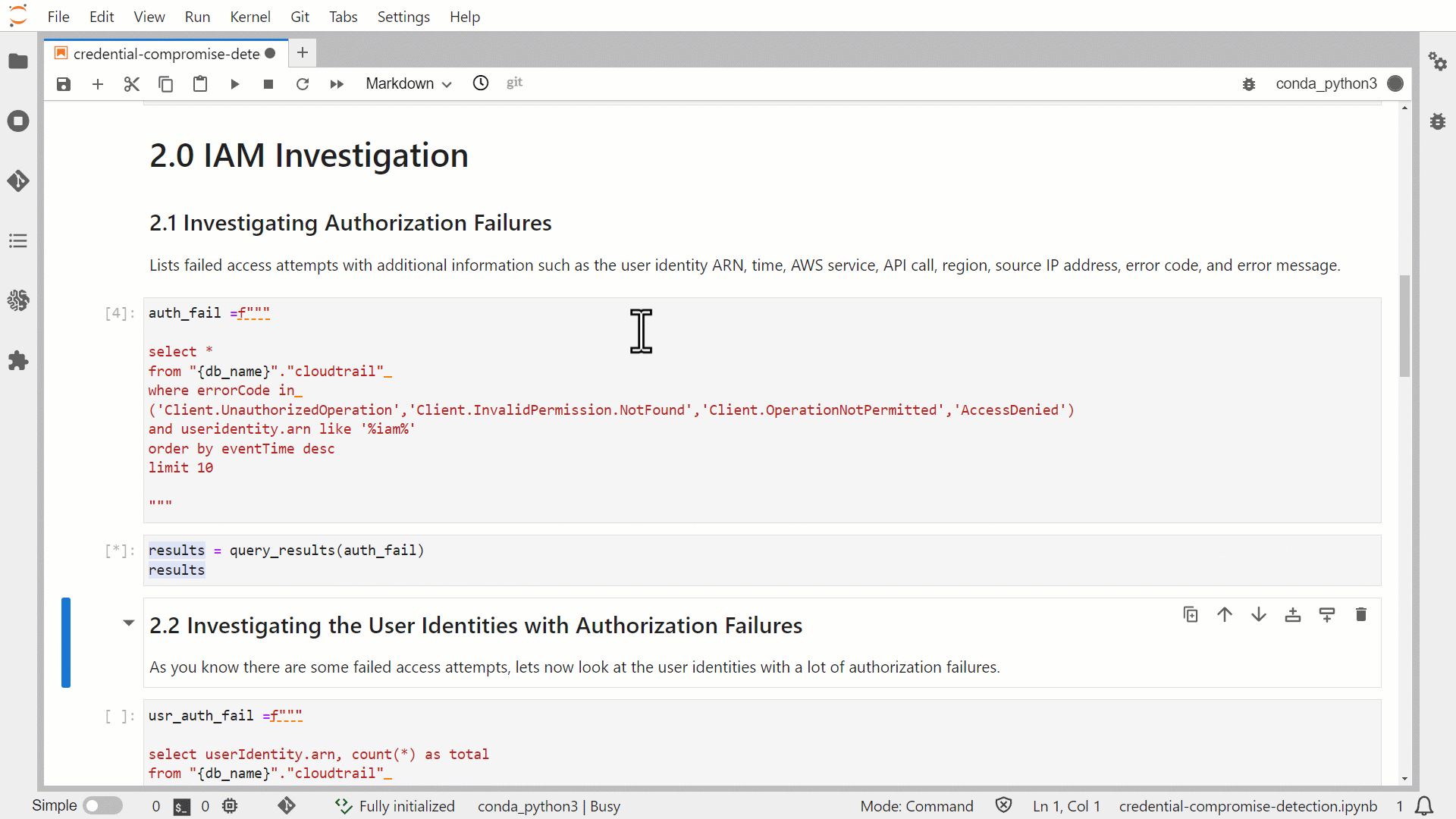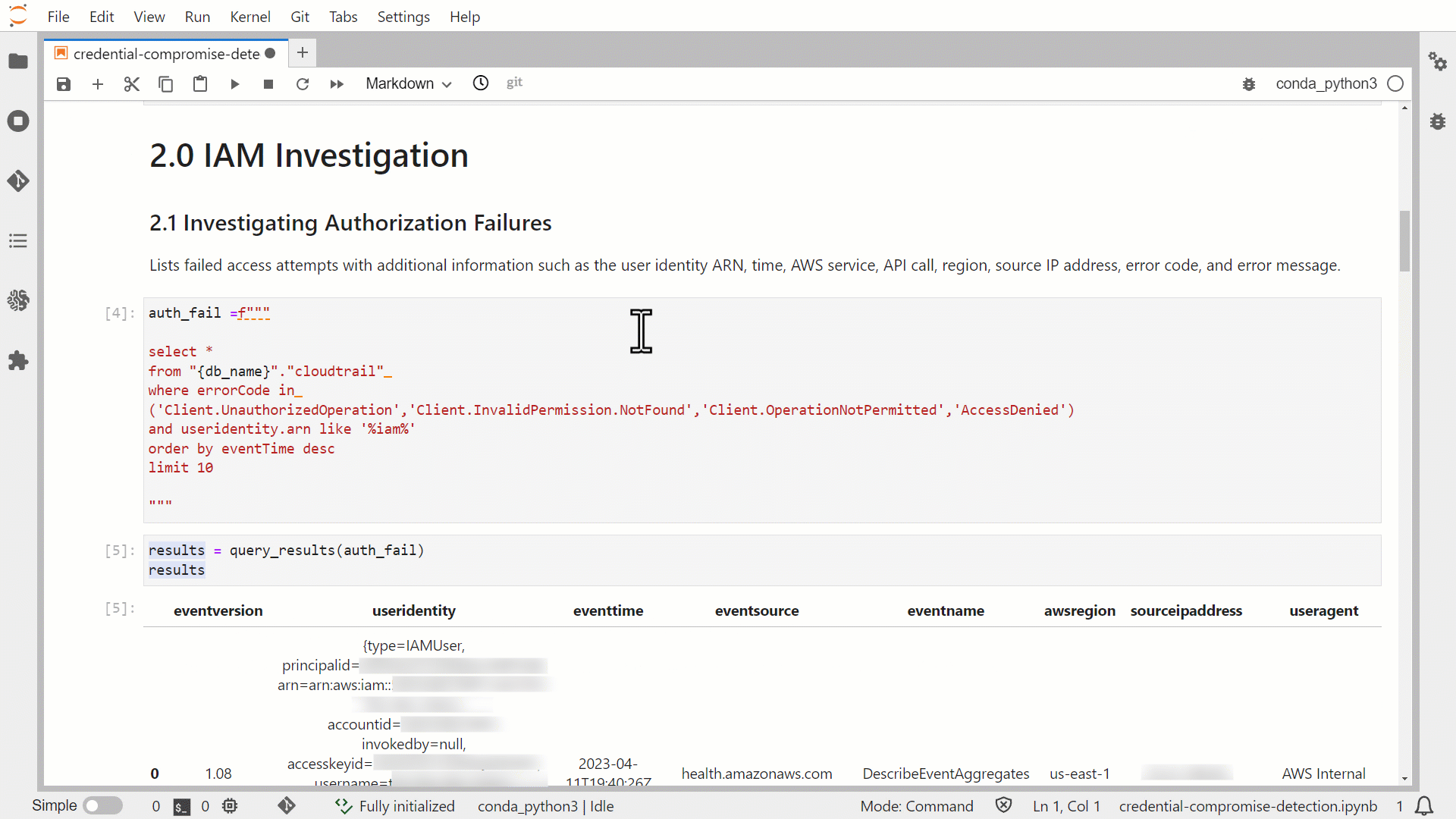
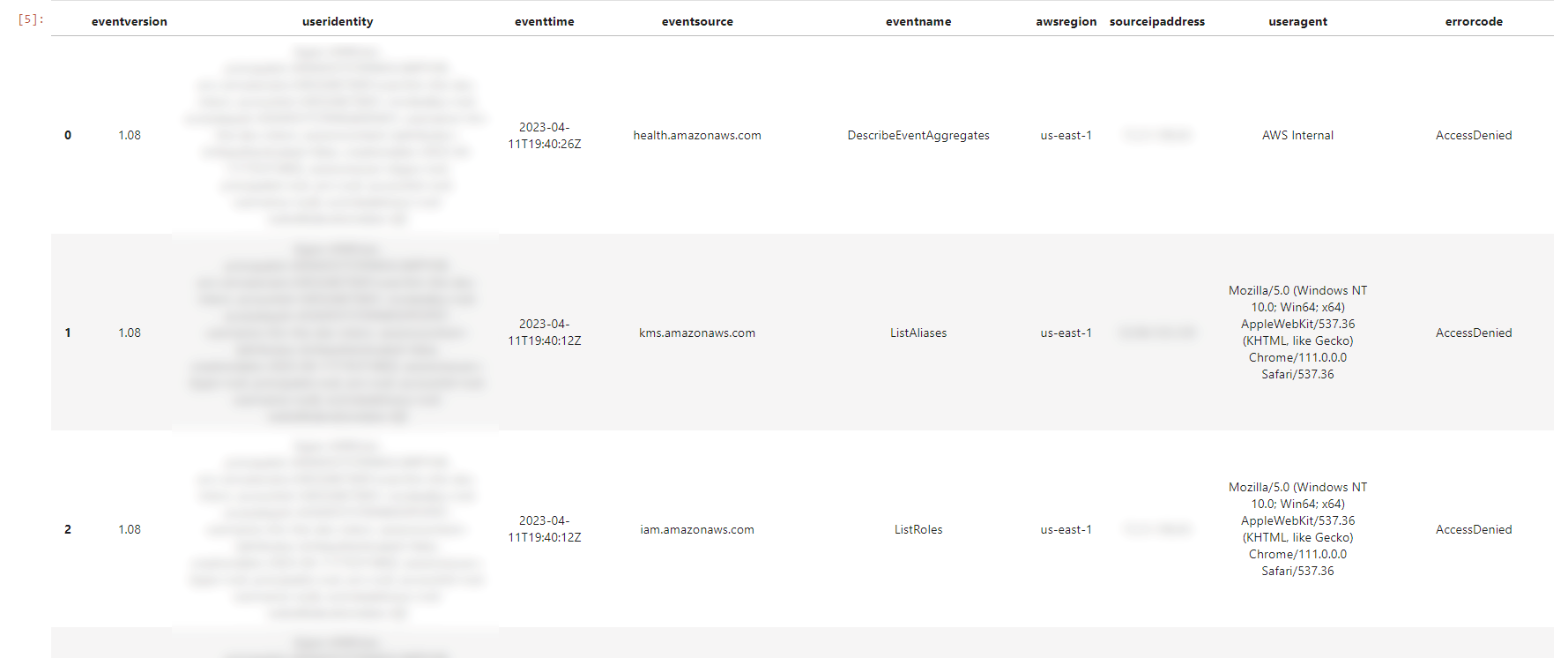
- In a new cell, enter the following query and run the cell:
Returned data will indicate the table objects accessible to Tina.
- In a new cell, run the following:
Returned data will include columns Tina has been granted access.
Let’s test Tina’s access to customer data.
- In a new cell, run the following:
The preceding query will result in an Access Denied error due to the inclusion of sensitive data columns.
During ad hoc analysis and model building, it’s common for users to create temporary datasets that need to be persisted for a short period. Let’s test Tina’s ability to create a working dataset and store results in a private working directory.
- In a new cell, run the following:
- Before running the following code, update the S3 path variable <bucket name> to correspond to an S3 location within your local account:
The preceding query writes the created dataset as Parquet files in the S3 bucket specified.
Data scientist: Alex
Complete the following steps:
- Log in using the URL you located in the previous step.
- Enter Microsoft AD user
[email protected]and your password. - Choose the Amazon SageMaker Studio tile.
- In the SageMaker Studio UI, start a notebook:
- Choose File, New, and Notebook.
- For Image, choose SparkMagic.
- For Kernel, choose PySpark.
- For Instance Type, choose ml.t3.medium.
- Choose Select.
- When the notebook kernel starts, connect to the EMR cluster by running the following code:
- Enter Microsoft AD
[email protected]and your password (note that[email protected]is case-sensitive). - Choose Connect. Now we can test Alex’s data access.
- In a new cell, enter the following query and run the cell:
Returned data will indicate the table objects accessible to Alex. Note that the customers table is missing.
- In a new cell, run the following:
Returned data will include columns Alex has been granted access.
Let’s test Alex’s access to customer data.
- In a new cell, run the following:
The preceding query will result in an Access Denied error because Alex doesn’t have access to customers.
We can verify Ranger is responsible for the denial by looking at the CloudWatch logs.

Now that you can successfully access data, feel free to interactively explore, visualize, prepare, and model the data using the different user personas.
Clean up
When you’re finished experimenting with this solution, clean up your resources:
- Shut down and update SageMaker Studio and Studio apps. Ensure that all apps created as part of this post are deleted before deleting the stack.
- Change the identity source for IAM Identity Center back to Identity Center Directory.
- Delete the directory AWSEMR.COM from Directory Services.
- Empty the S3 buckets created by the CloudFormation stacks.
- Delete the stacks via the AWS CloudFormation console for the non-nested stacks starting in reverse order.
Conclusion
This post showed how you can implement fine-grained access control in SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory. We also demonstrated how multiple SageMaker Studio users can connect to the same EMR cluster and access different tables and columns using Apache Ranger, wherein each user is scoped with permissions matching their individual level of access to data. In addition, we demonstrated how the individual users can access separate S3 folders for storing their intermediate data. We detailed the steps required to set up the integration and provided CloudFormation templates to set up the base infrastructure from end to end.
To learn more about using Amazon EMR with SageMaker Studio, refer to Prepare Data using Amazon EMR. We encourage you to try out this new functionality, and connect with the Machine Learning & AI community if you have any questions or feedback!
Appendix: Apache Ranger troubleshooting
The sync between Active Directory and Apache Ranger is set for every 24 hours. To force a sync, complete the following steps:
- Connect to the Apache Ranger server using SSH. This can be done using directly or Session Manager, a capability of AWS Systems Manager, or through AWS Cloud9.
- Once connected, issue the following commands:
- To confirm the sync, open the Ranger console as an admin.
- Choose Audit in the top banner.
- Choose the User Sync tab and confirm the event time.
About the Authors
 Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys spending time with his family, stay healthy, running and road cycling.
Rahul Sarda is a Senior Analytics & ML Specialist at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys spending time with his family, stay healthy, running and road cycling.
 Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.
Varun Rao Bhamidimarri is a Sr Manager, AWS Analytics Specialist Solutions Architect team. His focus is helping customers with adoption of cloud-enabled analytics solutions to meet their business requirements. Outside of work, he loves spending time with his wife and two kids, stay healthy, mediate and recently picked up gardening during the lockdown.







 ) in the toolbar at the top of the console.
) in the toolbar at the top of the console.















 Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems.
Ashley Zhou is a Software Development Engineer at AWS. She is interested in data analytics and distributed systems. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building analytics and data mesh solutions on AWS and sharing them with the community.

































 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.












 Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud.
Anirban Sinha is a Senior Technical Account Manager at AWS. He is passionate about building scalable data warehouses and big data solutions working closely with customers. He works with large ISVs customers, in helping them build and operate secure, resilient, scalable, and high-performance SaaS applications in the cloud. Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse.
Phil Bates is a Senior Analytics Specialist Solutions Architect at AWS. He has more than 25 years of experience implementing large-scale data warehouse solutions. He is passionate about helping customers through their cloud journey and using the power of ML within their data warehouse. Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.
Gaurav Singh is a Senior Solutions Architect at AWS, specializing in AI/ML and Generative AI. Based in Pune, India, he focuses on helping customers build, deploy, and migrate ML production workloads to SageMaker at scale. In his spare time, Gaurav loves to explore nature, read, and run.

 Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services.
Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services. Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.

 Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book
Sakti Mishra is a Principal Solutions Architect at AWS, where he helps customers modernize their data architecture and define their end-to-end data strategy, including data security, accessibility, governance, and more. He is also the author of the book  Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a strong passion for data and machine learning operations. She brings a wealth of experience and enthusiasm to help enterprises build effective data and ML strategies. In her spare time, Bhavana enjoys spending time with her family and engaging in various activities such as traveling, hiking, gardening, and watching documentaries. Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS customers make informed choices and trade-offs about accelerating their data, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time with her family—usually on tennis courts. Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.
Daniel Bruno is a Principal Resident Architect at AWS. He had been building analytics and machine learning solutions for over 20 years and splits his time helping customers build data science programs and designing impactful ML products.




 This will start a new session with the updated parameters.
This will start a new session with the updated parameters.



 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS analytics services. Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.
Raj Devnath is a Product Manager at AWS on Amazon Athena. He is passionate about building products customers love and helping customers extract value from their data. His background is in delivering solutions for multiple end markets, such as finance, retail, smart buildings, home automation, and data communication systems.












 Amar is a Senior Solutions Architect at Amazon AWS in the UK. He works across power, utilities, manufacturing and automotive customers on strategic implementations, specializing in using AWS Streaming and advanced data analytics solutions, to drive optimal business outcomes.
Amar is a Senior Solutions Architect at Amazon AWS in the UK. He works across power, utilities, manufacturing and automotive customers on strategic implementations, specializing in using AWS Streaming and advanced data analytics solutions, to drive optimal business outcomes.



