Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=Y0zSLTTMNGM
Диана Димова от „Мисия Криле“: Пролетта започва с една птичка
Post Syndicated from Ина Иванова original https://www.toest.bg/diana-dimova-ot-misia-krile-proletta-zapochva-s-edna-ptichka/

Екипът на Фондация „Мисия Криле“ е на първа линия, когато става въпрос за майки с деца, опитващи се да се спасят от домашно насилие, за хора, изпаднали в крайна бедност, или за големи бежански вълни, като тези от Сирия, Афганистан и Украйна. Екипът е почти неизменен от основаването на фондацията през 2018 г.
Председателка на организацията, чието седалище е в Стара Загора, е Диана Димова – отдадена социална работничка, майка и жена с кауза, която говори ясно, тихо и задълбочено по трудните теми.
За нея всичко започва преди 27 години, когато в родната ѝ Стара Загора се появяват бездомни деца, живеещи в района на гарата. Диана и други млади хора започват да ги хранят. Оттогава започва и дейността ѝ в помощ на хора от уязвими групи.
Днес част от „Мисия Криле“ е основаният преди 20 години център Комплекс за социални услуги, на който Диана Димова е директорка. Той е оказал подкрепа на над 6000 жени и деца в риск.
В началото на годината представители на екипа на Фондация „Мисия Криле“ се опитаха да спасят бедстващи тийнейджъри, търсещи убежище, но поради бездействието на институциите децата починаха.
Диана Димова и колегите ѝ създават и Консултативен център в град Харманли – в подкрепа на хора, търсещи и получили убежище в страната. Защото на практика дори онези, които получат хуманитарен или бежански статут, остават в повечето случаи отхвърлени или невидими за обществото.
В предварителния ни разговор Диана Димова сподели с мен, че често намира утеха в книгата „Джонатан Ливингстън Чайката“. Героят на Ричард Бах е изхвърлен от ятото си за това, че се рее, вместо да изпълнява обичайните за чайка задължения. Наказан е да остане в изгнание на един остров. Там освен небесните ширини, сред които продължава да лети, Чайката намира съмишленици. И разбира, че грешката не е у него.
Най-впечатляващ обаче е завършекът на романа – Джонатан Ливингстън осъзнава, че трябва да се върне, че мисията му всъщност е да бъде там, сред враждебното ято, където е бил най-неразбран. Диана продължава да размишлява върху това:
Да се опитваш да кажеш своите послания и да променяш твоята общност. Това е най-голямото предизвикателство на живота ми. Мисля, че ако живеем само за себе си, нищо не сме постигнали. Всеки трябва през своята къщурка да прави опити да стане светът по-добър, а може, всеки един от нас може.
Каква мечтаехте да станете, когато бяхте дете?
Като голяма част от момичетата на моята възраст си мечтаех да работя с деца, да помагам на деца. И понеже нямаше кой знае колко разнообразни професии тогава, единственият основен модел, който виждахме, беше детската учителка. Това присъстваше не само в мечтите, а и в игрите от моето детство. Ако сравним игрите, които играят децата днес, и игрите, които предпочитахме ние като деца, ще открием големи разлики. Защото малките играят моделите, които са възприели, личи кои са моделите за подражание и какви са ценностите на възрастните около тях.
За съжаление, много от образите, които ние имахме като деца, тези ореоли, които поставяхме на някои професии или на определени личности, се развенчаха с времето и от перспективата на съвремието. Ако се върна назад, виждам колко много неща, в които аз съм вярвала или които съм боготворяла, се оказаха фалшиви идоли и маски.
Това е голямата тема: какво играят децата ни и в какво вярват, какви са ценностите за тях. И тя се отнася и до нас – обяснява какви игри играят възрастните хора днес, кои са техните модели на подражание и как това се превръща в стил на живот.
От години работите с деца в бежански центрове. На какво играят те?
Като социален работник, като човек, който работи на първа линия с деца и възрастни, които преживяват или са преживели различни страдания, ми прави впечатление, че са забравили да мечтаят.
Може да играе дете, което има мечти – без да имаш перспектива и фантазии за едно илюзорно или по-красиво, по-щастливо бъдеще, няма как.
Децата в бежанските центрове трудно могат да символизират в игра своите представи за по-добър живот. Те често използват демонстрацията на сила, на власт над другия, над връстника, който може да се окаже заплаха, и се чувстват длъжни да му демонстрират своите граници, норми и правила. Ние организираме спортни събития, отваряме чрез спорта пространство за деца бежанци, за да могат да изразяват емоциите си. Те мислят, че ние играем с тях, но всъщност се опитваме да им помогнем да се лекуват.
В нашия екип на „Мисия Криле“ имаме двама колеги треньори от Сирия, които работят много активно с деца бежанци чрез спорт, фитнес и футбол.
Прави ми впечатление на състезания колко силно удрят топката тийнейджърите, колко много имат да изразят от себе си и същевременно колко малко пространство имат за това.
В арт ателиетата децата използват по-ярки цветове, понякога натискат силно, до степен да скъсат листа, което говори за това, което преживяват.
В света, в който живеем, като че ли няма място да изразяваме емоции. И още нещо – има голяма пропаст между нас, възрастните, и съвременните деца. Грешка е да правим автоматични препратки към нашето детство, защото то е коренно различно от тяхното. Независимо дали сме психолози, социални работници, независимо дали работим с български, ромски деца, деца бежанци, е огромно предизвикателство да сме любопитни към тях и да се опитаме да разберем техния свят, а не да ги назидаваме какви трябва да бъдат през перспективата на живота, който ние сме имали. Най-полезни са ми били моментите, когато съм ги изслушвала, за да намеря пътя заедно с тях, когато те ми позволят да ги придружа за известен период, докато намерим посоката, тъй като те се лутат.
Какво научихте за себе си от битките, които водите за другите?
Много – и за себе си, и за близкия ми кръг, и за враговете си. Колко издръжливост има в мен. Понякога в ситуация, в която мисля, че ще се разпадна на парчета, разбирам, че всъщност съм на средата на пътя. Трудните моменти ни показват, че не сме толкова безпомощни, беззащитни и слаби, а че имаме повече сила, отколкото дори предполагаме.
Може би една птичка не може да направи пролет, но пролетта може да започва с една птичка и капката може да разбие скалата с постоянство. Вярвам, че човек може да преобърне света. Вярвам, че войната може да спре с решението на един човек. Колкото и клиширано да звучи, смятам, че злото не може да трае вечно, колкото и всемогъщо да изглежда.
Кое Ви окрилява и кое Ви обезсърчава?
Аз все по активно търся неща, които да ме вдъхновят, които да ме очароват, които да ми върнат усещането за смисъл, мотивация. В последните години силно вдъхновение получавам, когато правим различни общностни събития, където има хора от различни култури – да готвят, танцуват или спортуват заедно. Изпитвам силно вълнение, защото много вярвам в идеята за многообразието. Смятам, че то е богатство и ако сме по-отворени едни към други, можем да почерпим от чуждия опит, от човека с различна вяра, ако щете, или на различна възраст. Всичко, което се иска от нас, е просто да сме любопитни и отворени към различния.
Бих добавила още едно нещо, което много ми помага. Аз силно вярвам в християнските добродетели. И търся да се съюзявам със съмишленици, вместо да губя енергия да воювам с великани.
Огорчава ме едно огромно неразбиране, което все повече се засилва като усещане в мен – че онова, което правя, не просто е неразбираемо, не просто е неприемливо. А е недопустимо. Посланията, които чувам от различни кръгове по различен начин, мненията, които достигат до мен, когато говоря за моите каузи, са, че това, което правя, може да е заплаха за обществото или за националната сигурност, че съм национален предател. Това са неща, които мен лично ме изненадаха, защото не подозирах, че има хора, които могат да възприемат по-слабите като заплаха, независимо дали става въпрос за жена – жертва на насилие, дали за изоставено от родителите си дете, за бежанци, или за роми.
От какво се страхуваме като общество и счупва ли се митът за българското гостоприемство, когато говорим за бежанци?
Тук е еднакво отношението към чужд човек, който е влязъл на територията на страната да търси убежище, или към човек от изолиран ромски квартал, който не го е напускал от 12 години и се страхува да слезе до центъра на големия град.
Има голяма съпротива от различни групи, мога само да подозирам какъв е техният мотив и откъде се захранват с такива идеи. Някои имат икономически интереси. Втори живеят в конспиративни теории, включително в ригиден, закостенял свят, в който другият е заплаха и приемането му може да означава загуба на собствената идентичност. Така че от тази гледна точка разбирам тяхното поведение, но не го оправдавам – защото в света, в който живеем, когато се даде пространство на този тип мислене и говорене, то може да взриви буквално цялата планета.
Отдавна ме вълнува тази тема. Не съм намерила пътя как да се справя с това разочарование. И като мине малко време и си почина, си казвам: всъщност това е, за което живея. Нямам друг път и друг живот. Това е моята мисия. Да помагам на слабите и невидимите да бъдат тук и сега и мнозинството да се съобрази с тях, да ги приеме като равни. Да защитавам правата на слабите и да се боря за тяхното благополучие. Най-общо казано, това е човечността. Нищо повече.
Да се върнем на темата за страха?
Истински смелите хора са се научили да яздят страха си, да го контролират, за да го насочат в една или друга посока. Страхът е като диво животно и научиш ли се да го яздиш, той може да ти свърши добра работа, да те предпазва от неблагополучия. За мен хората, които успяват да не се парализират от страх, съумяват да кажат какво мислят, а това става все по-трудно във времето, в което живеем. Особено в интернет. Виждаме как са тормозени хора заради липсата на истинска свобода на словото. В последните месеци разбрах, че държавни агенции към Министерския съвет се използват активно като бухалки срещу активисти и хора, които огласяват престъпления. Не бива да има област от обществения живот, в която гражданите да се страхуват да зададат въпрос.
Аз задавам въпроси в една много трудна област и разказвам истории, които са достигнали до мен през хората, на които помагам, именно мигранти и бежанци, търсещи убежище и закрила – за това какво се случва по границите и в болниците.
И аз, и моите колеги се опитваме да усилваме на гласа на онези, които нямат такъв или чийто глас е много тих, макар за нас лично да става все по-трудно и рисковано да го правим.
Вярвам в равнопоставеността, в справедливостта и ще се боря за това, докато имам сили.
По-силният внушава много убедително, че е всемогъщ и държи всички лостове да се саморазправи с теб, но много често не е така. И когато си мислим, че сме сами, не е така. Вярвайте ми, злото просто не може да трае вечно. Не е възможно.
Какво винаги носи в чантата си Диана Димова?
Първо, аз непрекъснато сменям различни торби, раници и обикновено все съм забравила нещо в някоя друга чанта. Но все пак с мен винаги е лаптопът, защото много често пътувам и имам важни неща, които е ключово да се случат. Което означава, че непрекъснато съм в работен режим. Често нося хапчета за главоболие. В портмонето ми винаги е снимката на моя син и тя ми е много скъпа. Той е далеч от мен, замина да работи в Брюксел след една менторска програма преди година и половина. Не разбирах хората, които пътуват и се разделят, но и на мен ми се случи. Така че най-близкият до сърцето ми човек е символично с мен с тази снимка.
Дигитално евро, следене и ценности
Post Syndicated from Bozho original https://blog.bozho.net/blog/4473
Тъй като конспиративните теории за еврото от няколко дни са „на стероиди“, ето една контра-конспиративна теория. За тези, които не приемат аргументите, че дигиталното евро няма да се ползва за проследяване, тъй като в самия регламент има изрични текстове за анонимност на офлайн плащанията и липса на централна проследимост на трансакциите.
Ами ако „лошият ЕС“ реши да следи кеша? Всяка банкнота има индивидуален номер. Т.е. всяка банкнота е проследима. Банкоматът ще знае на кого са отпуснати дадени банкноти. В магазина могат много лесно тези номера да се сканират и така да се следи потокът им. На касите може да се въведе задължително показване на лична карта, така че дори рестото да е ясно при кого отива.
Или дори лицево разпознаване, вързано с базата данни със снимки на МВР. И може НАП да затваря магазини, които не изпълняват тези исиквания. (А, чакай, лошият ЕС на практика забрани лицевото разпознаване на обществени места, но сигурно това е заблуждаваща маневра)
Затова – никакъв кеш. Ще ни следят с него какво купуваме. Не веднага, но един ден… Така че само в злато. Хм, те пък и кюлчетата си имат серийни номера. Значи бартери.
Между другото, следят ви и в момента какво купувате. Дори като плащате с наложен платеж. И дори когато не сте го купили онлайн, а само сте си хо харесали. (Благодарение на проследяващите бисквитки, за които бъдещият председател на КЗЛД нищо не знаеше)
Само че не ви следи лошият ЕС, а Гугъл и Фейсбук, които лошият ЕС глобява заради неправомерно обработване на лични данни.
Следят ви и къде ходите. През GPS-a и през клетките на телефоните. Благодарение на ЕС можете да забраните да се записват данните от GPS-a централно. А благодарение на съда на ЕС, държавите трябва да ограничат телекомите в събиране на данни за местоположение доста под 6 месеца, именно за да не може да се анализира поведение.
Не е въпрос на технологии. Не е въпрос да измислим конспиративна теория как някой централно ще ни следи – има стотици начини за това и без дигитално евро. Въпрос на ценности е. А ценностите на европейските народи не допускат тоталитаризъм. Защото са го допускали в миналото и са видели какво следва. И това стои в колективната ни памет (защото и ние сме европейци).
Материалът Дигитално евро, следене и ценности е публикуван за пръв път на БЛОГодаря.
ASUS AI Pod NVIDIA GB300 NVL72 at NVIDIA GTC 2025
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/asus-ai-pod-nvidia-gb300-nvl72-at-nvidia-gtc-2025/
We saw the ASUS AI Pod, a NVIDIA GB300 NVL72 rack at NVIDIA GTC along with new HGX B200 and HGX B300 systems at NVIDIA GTC 2025
The post ASUS AI Pod NVIDIA GB300 NVL72 at NVIDIA GTC 2025 appeared first on ServeTheHome.
Can You Run the 94GB NVIDIA H100 NVL PCIe as a Single GPU
Post Syndicated from John Lee original https://www.servethehome.com/can-you-run-the-94gb-nvidia-h100-nvl-pcie-as-a-single-gpu/
We tried running the 94GB NVIDIA H100 NVL PCIe card as a single GPU without the NVLink bridge, and it worked, as expected
The post Can You Run the 94GB NVIDIA H100 NVL PCIe as a Single GPU appeared first on ServeTheHome.
Violet Gibson’s Bad Aim.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=6uVIjhL5zH0
Death of The Largest Battleship Ever Built
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=Fn-M3d6AO0A
Comic for 2025.04.08 – Graph
Post Syndicated from Explosm.net original https://explosm.net/comics/graph
New Cyanide and Happiness Comic
Enhance Agentforce data security with Private Connect for Salesforce Data Cloud and Amazon Redshift – Part 3
Post Syndicated from Yogesh Dhimate original https://aws.amazon.com/blogs/big-data/enhance-agentforce-data-security-with-private-connect-for-salesforce-data-cloud-and-amazon-redshift-part-3/
Data protection is a high priority, particularly as organizations face increasing cybersecurity threats. Maintaining the security of customer data is top priority for AWS and Salesforce. With AWS PrivateLink, Salesforce Private Connect eliminates common security risks associated with public endpoints. Salesforce Private Connect now works with Salesforce Data Cloud to keep your customer data secure when using with key services like Agentforce.
In Part 2 of this series, we discussed the architecture and implementation details of cross-Region data sharing between Salesforce Data Cloud and AWS accounts. In this post, we discuss how to create AWS endpoint services to improve data security with Private Connect for Salesforce Data Cloud.
Solution overview
In this example, we configure PrivateLink for an Amazon Redshift instance to enable direct, private connectivity from Salesforce Data Cloud. AWS recommends that organizations use an Amazon Redshift managed VPC endpoint (powered by PrivateLink) to privately access a Redshift cluster or serverless workgroup. For details about best practices, refer to Enable private access to Amazon Redshift from your client applications in another VPC.
However, some organizations might prefer to use PrivateLink managed by themselves—for example, a Redshift managed VPC endpoint is not yet available in Salesforce Data Cloud, and you need to manage your PrivateLink connection. This post focuses on the solution to configure self-managed PrivateLink between Salesforce Data Cloud and Amazon Redshift in your AWS account to establish private connectivity.
The following architecture diagram shows the steps for setting up private connectivity between Salesforce Data Cloud and Amazon Redshift in your AWS account.

To set up private connectivity between Salesforce Data Cloud and Amazon Redshift, we use the following resources:
Prerequisites
To complete the steps in this post, you must already have Amazon Redshift running in a private subnet and have the permissions to manage it.
Create a security group for the Network Load Balancer
The security group acts as a virtual firewall. The only traffic that reaches the instance is the traffic allowed by the security group rules. To enhance the security posture, you only want to allow traffic to Redshift instances. Complete the following steps to create a security group for your Network Load Balancer (NLB):
- On the Amazon VPC console, choose Security groups in the navigation pane.
- Choose Create security group.
- Enter a name and description for the security group.
- For VPC, use the same virtual private cloud (VPC) as your Redshift cluster.
- For Inbound rules, add a rule to allow traffic to ingress the listening port 5439 on the load balancer.

- For Outbound rules, add a rule to allow traffic to your Redshift instance.

- Choose Create security group.
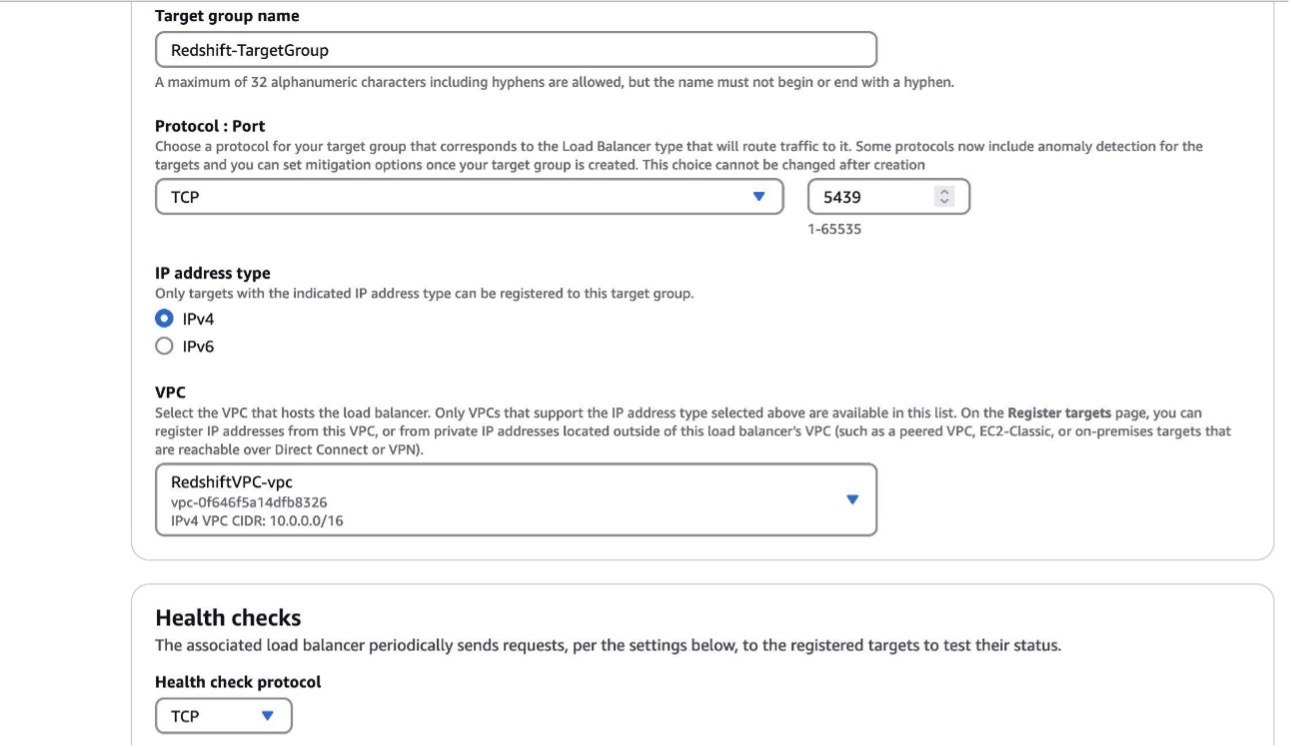
Create a target group
Complete the following steps to create a target group:
- On the Amazon EC2 console, under Load balancing in the navigation pane, choose Target groups.
- Choose Create target group.
- For Choose a target type, select IP addresses.

- For Protocol: Port, choose TCP and port 5436 (if your Redshift cluster runs on a different port, change the port accordingly).
- For IP address type, select IPv4.
- For VPC, choose the same VPC as your Redshift cluster.
- Choose Next.
- For Enter an IPv4 address from a VPC subnet, enter your Amazon Redshift IP address.
To locate this address, navigate to your cluster details on the Amazon Redshift console, choose the Properties tab, and under Network and security settings, expand VPC endpoint connection details and copy the private address of the network interface. If you’re using Amazon Redshift Serverless, navigate to the workgroup home page. The Amazon Redshift IPv4 addresses can be located in the Network and security section under Data access when you choose VPC endpoint ID.

- After you add the IP address, choose Include as pending below, then choose Create target group.

Create a load balancer
Complete the following steps to create a load balancer:
- On the Amazon EC2 console, choose Load balancers in the navigation pane.
- Choose Create load balancer.
- Choose Network.
- For Load balancer name, enter a name.
- For Scheme, select Internal.
- For Load balancer address type, select IPv4.
- For VPC, use the VPC that your target group is in.

- For Availably Zones, select the Availability Zone where the Redshift cluster is running.
- For Security groups, choose the security group you created in the previous step.
- For Listener details, add a listener that points to the target group created in the last step:
- For Protocol, choose TCP.
- For Port, use 5439.
- For Default action, choose Redshift-TargetGroup.
- Choose Create load balancer.


Make sure that the registered targets in the target group are healthy before proceeding. Also make sure that the target group has a target for all Availability Zones in your AWS Region or the NLB has the Cross-zone load balancing attribute enabled.

In the load balancer’s security setting, make sure that Enforce inbound rules on PrivateLink traffic is off.

Create an endpoint service
Complete the following steps to create an endpoint service:
- On the Amazon VPC console, choose Endpoint services in the navigation pane.
- Choose Create endpoint service.
- For Load balancer type, choose Network.
- For Available load balancers, select the load balancer you created in the last step
- From Supported Regions, select an additional region if Data Cloud isn’t hosted in the same AWS region as the Redshift instance. For additional settings leave Acceptance required.
If this is selected, later, when the Salesforce Data Cloud endpoint is created to connect to the endpoint service, you will need to come back to this page to accept the connection. If not selected, the connection will be built directly.
- For Supported IP address type, select IPv4.
- Choose Create.

Next, you need to allow Salesforce principals.
- After you create the endpoint service, choose Allow principals.
- In another browser, navigate to Salesforce Data Cloud Setup.
- Under External Integrations, access the new Private Connect menu item.
- Create a new private network route to Amazon Redshift.

- Copy the principal ID.

- Return to the endpoint service creation page.
- For Principals to add, enter the principal ID.
- Copy the endpoint service name.
- Choose Allow principals.

- Return to the Salesforce Data Cloud private network configuration page.
- For Route Name, enter the endpoint service name.
- Choose Save.

The route status should show as Allocating.

If you opted to accept connections in the previous step, you will now need to accept the connection from Salesforce Data Cloud.
- On the Amazon VPC console, navigate to the endpoint service.
- On the Endpoint connections tab, locate your pending connection request.

- Accept the endpoint connection request from Salesforce Data Cloud.

Navigate to the Salesforce Data Cloud setup and wait 30 seconds, then refresh the private connect route so the status shows as Ready.

You can now use this route when creating a connection with Amazon Redshift. For additional details, refer to Part 1 of this series.

Amazon Redshift federation PrivateLink failover
Now that we have discussed how to configure PrivateLink to use with Private Connect for Salesforce Data Cloud, let’s discuss Amazon Redshift federation PrivateLink failover scenarios.
You can choose to deploy your Redshift clusters in three different deployment modes:
- Amazon Redshift provisioned in a Single-AZ RA3 cluster
- Amazon Redshift provisioned in a Multi-AZ RA3 cluster
- Amazon Redshift Serverless
PrivateLink relies on a customer managed NLB connected to service endpoints using IP address target groups. The target group has the IP addresses of your Redshift instance. If there is a change in IP address targets, the NLB target group must be updated to the new IP addresses associated with the service. Failover behavior for Amazon Redshift will differ based on the deployment mode you employ.
This section describes PrivateLink failover scenarios for these three deployment modes.
Amazon Redshift provisioned in a Single-AZ RA3 cluster
RA3 nodes support provisioned cluster VPC endpoints, which decouple the backend infrastructure from the cluster endpoint used for access. When you create or restore an RA3 cluster, Amazon Redshift uses a port within the ranges of 5431–5455 or 8191–8215. When the cluster is set to a port in one of these ranges, Amazon Redshift automatically creates a VPC endpoint in your AWS account for the cluster and attaches network interfaces with a private IP for each Availability Zone in the cluster. For the PrivateLink configuration, you use the IP associated with the VPC endpoint as the target for the frontend NLB. You can identify the IP address of the VPC endpoint on the Amazon Redshift console or by doing a describe-clusters query on the Redshift cluster.


Amazon Redshift will not remove a network interface associated with a VPC endpoint unless you add an additional subnet to an existing Availability Zone or remove a subnet using Amazon Redshift APIs. We recommend that you don’t add multiple subnets to an Availability Zone to avoid disruption. There might be failover scenarios where additional network interfaces are added to a VPC endpoint.
In RA3 clusters, the nodes are automatically recovered and replaced as needed by Amazon Redshift. The cluster’s VPC endpoint will not change even if the leader node is replaced.
Cluster relocation is an optional feature that allows Amazon Redshift to move a cluster to another Availability Zone without any loss of data or changes to your applications. When cluster relocation is turned on, Amazon Redshift might choose to relocate clusters in some situations. In particular, this happens where issues in the current Availability Zone prevent optimal cluster operation or to improve service availability. You can also invoke the relocation function in cases where resource constraints in a given Availability Zone are disrupting cluster operations. When a Redshift cluster is relocated to a new Availability Zone, the new cluster has the same VPC endpoint but a new network interface is added in the new Availability Zone. The new private address should be added to the NLB’s target group to optimize availability and performance.

In the case that a cluster has failed and can’t be recovered automatically, you have to initiate a restore of the cluster from a previous snapshot. This action generates a new cluster with a new DNS name, connection string, and VPC endpoint and IP address for the cluster. You have to update the NLB with the new IP for the VPC endpoint of the new cluster.
Amazon Redshift provisioned in a Multi-AZ RA3 cluster
Amazon Redshift supports Multi-AZ deployments for provisioned RA3 clusters. By using Multi-AZ deployments, your Redshift data warehouse can continue operating in failure scenarios when an unexpected event happens in an Availability Zone. A Multi-AZ deployment deploys compute resources in two Availability Zones, and these compute resources can be accessed through a single endpoint. In the case of a failure of the primary nodes, Multi-AZ clusters will make secondary nodes primary and deploy a new secondary stack in another Availability Zone. The following diagram illustrates this architecture.

Multi-AZ clusters deploy VPC endpoints that point to network interfaces in two Availability Zones, which should be configured as a part of the NLB target group. To configure the VPC endpoints in the NLB target group, you can identify the IP addresses of the VPC endpoint using the Amazon Redshift console or by doing a describe-clusters query on the Redshift cluster. In a failover scenario, VPC endpoint IPs will not change and the NLB doesn’t require an update.
Amazon Redshift will not remove a network interface associated with a VPC endpoint unless you add an additional subnet in to an existing Availability Zone or remove a subnet using Amazon Redshift APIs. We recommend that you don’t add multiple subnets to an Availability Zone to avoid disruption.

Amazon Redshift Serverless
Redshift Serverless provides managed infrastructure. You can perform the get-workgroup query to get the workgroup’s VpcEndpoint IPs. IPs should be configured in the target group of the PrivateLink NLB. Because this is a managed service, the failover is managed by AWS. During the event of an underlying Availability Zone failure, the workgroup might get a new set of IPs. You can frequently query the workgroup configuration or DNS record for the Redshift cluster to check if IP addresses have changed and update the NLB accordingly.

Automating IP address management
In scenarios where Amazon Redshift operations might change the IP address of the endpoint needed for Amazon Redshift connectivity, you can automate the update of NLB network targets by monitoring the results for cluster DNS resolution, using describe-cluster or get-workgroup queries, and using an AWS Lambda function to update the NLB target group configuration.
You can periodically (on a schedule) query the DNS of the Redshift cluster for IP address resolution. Use a Lambda function to compare and update the IP target groups for the NLB. For an example of this solution, see Hostname-as-Target for Network Load Balancers.
For legacy DS2 clusters where the IP address of the leader node must be explicitly monitored, you can configure Amazon CloudWatch metrics to monitor the HealthStatus of the leader node. You can configure the metric to trigger an alarm, which alerts an Amazon Simple Notification Service (Amazon SNS) topic and invokes a Lambda function to reconcile the NLB target group.
For backup and restore patterns, you can create a rule in Amazon EventBridge triggered on the RestoreFromClusterSnapshot API action, which invokes a Lambda function to update the NLB with the new IP addresses of the cluster.
For a cluster relocation pattern, you can trigger an event based on the Amazon Redshift ModifyCluster availability-zone-relocation API action.
Conclusion
In this post, we discussed how to use AWS endpoint services to improve data security with Private Connect for Salesforce Data Cloud. If you are currently using the Salesforce Data Cloud zero-copy integration with Amazon Redshift, we recommend you follow the steps provided in this post to make the network connection between Salesforce and AWS secure. Reach out to your Salesforce and AWS support teams if you need additional support to implement this solution.
About the authors
 Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Salesforce. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence.
Yogesh Dhimate is a Sr. Partner Solutions Architect at AWS, leading technology partnership with Salesforce. Prior to joining AWS, Yogesh worked with leading companies including Salesforce driving their industry solution initiatives. With over 20 years of experience in product management and solutions architecture Yogesh brings unique perspective in cloud computing and artificial intelligence.
 Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
 Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
 Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
 Drew Loika is a Director of Product Management at Salesforce and has spent over 15 years delivering customer value via data platforms and services. When not diving deep with customers on what would help them be more successful, he enjoys the acts of making, growing, and exploring the great outdoors.
Drew Loika is a Director of Product Management at Salesforce and has spent over 15 years delivering customer value via data platforms and services. When not diving deep with customers on what would help them be more successful, he enjoys the acts of making, growing, and exploring the great outdoors.
AWS completes the 2025 Cyber Essentials Plus certification
Post Syndicated from Tariro Dongo original https://aws.amazon.com/blogs/security/aws-completes-the-2025-cyber-essentials-plus-certification/
Amazon Web Services (AWS) is pleased to announce the successful renewal of the United Kingdom Cyber Essentials Plus certification. The Cyber Essentials Plus certificate is valid for one year until March 21, 2026.
Cyber Essentials Plus is a UK Government-backed, industry-supported certification scheme intended to help organizations demonstrate organizational cybersecurity against common cybersecurity threats. An independent third-party auditor certified by Information Assurance for Small and Medium Enterprises (IASME) completed the audit. The scope of our Cyber Essentials Plus certificate covers the AWS corporate network for the United Kingdom and Ireland.
AWS compliance status is available on (1) the IASME Website by searching for “Amazon Web Services,” (2) the AWS Cyber Essentials Plus compliance page, and (3) AWS Artifact. AWS Artifact is a self-service portal for on-demand access to AWS compliance reports. Sign in to AWS Artifact in the AWS Management Console, or learn more at Getting Started with AWS Artifact.
AWS strives to continuously improve its compliance programs to help you meet your architectural and regulatory needs. Contact your AWS account team for questions.
To learn more about our compliance and security programs, see AWS Compliance Programs. As always, we value your feedback and questions; reach out to the AWS Compliance team through the Contact Us page.
If you have feedback about this post, submit comments in the Comments section below.
Announcing the General Availability of the Amazon EventBridge Scheduler L2 Construct
Post Syndicated from Svenja Raether original https://aws.amazon.com/blogs/devops/announcing-the-general-availability-of-the-amazon-eventbridge-scheduler-l2-construct/
Today we’re announcing the general availability (GA) of the Amazon EventBridge Scheduler and Targets Level 2 (L2) constructs in the AWS Cloud Development Kit (AWS CDK) construct library. EventBridge Scheduler is a serverless scheduler that enables users to schedule tasks and events at scale. Prior to the launch of these L2 constructs, developers had to define all relevant properties (via L1 constructs) across schedules and provide the glue logic between resources when defining their AWS CDK applications. The graduated constructs make it easier for users to configure EventBridge schedules, groups, and targets for AWS service integrations. They follow the AWS CDK L2 higher-level API design simplifications and provide a backwards-compatible guarantee across minor versions. Developers can use those alongside other existing stable AWS CDK constructs ready for production use.
Background
The AWS Cloud Development Kit (CDK) is an open-source software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. It contains pre-written modular and reusable cloud components known as constructs. Constructs are the basic building blocks representing one or more AWS CloudFormation resources and their configuration. They are available in different abstraction levels. L1 constructs are the lowest-level constructs which map directly to AWS CloudFormation resources without abstractions. L2 constructs are thoughtfully developed and provide a higher-level abstraction through an intuitive intent-based API. They leverage default property configurations, best practice security policies, and convenience methods that make it simpler and quicker to define and deploy resources.
Amazon EventBridge Scheduler is a serverless scheduler that allows users to create, run, and manage tasks from one central, managed service. With EventBridge Scheduler, users can create schedules using cron and rate expressions for recurring patterns, or configure one-time invocations. EventBridge supports templated and universal targets. Templated targets include common API operations across a group of core AWS services, such as publishing a message to an Amazon Simple Notification Service (Amazon SNS) topic or invoking an AWS Lambda function. Universal targets are customized triggers supporting more than 270 AWS services and over 6,000 API operations on a schedule. Users can use schedule groups to organize their schedules.
With the L2 constructs for Amazon EventBridge Scheduler and Targets, it becomes even simpler for users to configure and integrate those resources into their CDK applications. Let’s explore the benefits by looking at some examples.
Using the L2 EventBridge Scheduler construct
We introduce two use cases for the EventBridge Scheduler and Targets L2 constructs to demonstrate their usage within common scenarios. Each example is equipped with sample code, emphasizing the simplifications achieved by the L2 constructs.
Example 1 – One time reminder through Amazon SNS
In the first use case, users want to configure one-time notifications to receive reminders of their favorite conferences at a specific time, for example a user may want to set a reminder one month before the start of AWS re:Invent to be reminded of their participation.
The example below uses the EventBridge Scheduler construct with a templated Amazon SNS target. The target applies an on-time schedule configuration and is configured with an Amazon Simple Queue Service (Amazon SQS) dead-letter queue to capture and retry failed events. The schedule payload is encrypted using a customer-managed AWS Key Management Service (AWS KMS) key.
const snsTarget = new targets.SnsPublish(topic, {
input: ScheduleTargetInput.fromObject({
message: "Reminder: AWS re:Invent starts in one month.",
}),
deadLetterQueue: deadLetterQueue,
});
const schedule = new Schedule(this, "ReminderSchedule", {
description:
"This schedule publishes a one-time notification to an Amazon SNS topic.",
schedule: ScheduleExpression.at(
new Date(2025, 10, 1), // Nov 01, 2025
cdk.TimeZone.AMERICA_LOS_ANGELES
),
target: snsTarget,
key: key,
});
From the code example, we can see that well-defined interfaces for ScheduleTargetInput, and ScheduleExpression make it easy to select matching configuration values.
The SnsPublish target and Schedule constructs seamlessly integrate with the existing L2 constructs for Amazon SNS, Amazon SQS, and Amazon KMS. They abstract away the gluing logic used to configure the target API operation, dead-letter queue, and encryption settings with correct references. Instead of manually crafting permissions, the construct generates an AWS Identity and Access Management (IAM) execution role with the minimum necessary permissions to interact with the templated target, as shown in the policy below.
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sns:Publish",
"Resource": "arn:aws:sns:us-east-1:123456789012:<TOPIC_NAME>",
"Effect": "Allow"
},
{
"Action": "kms:Decrypt",
"Resource": "arn:aws:kms:us-east-1:123456789012:key/<UUID>",
"Effect": "Allow"
},
{
"Action": "sqs:SendMessage",
"Resource": "arn:aws:sqs:us-east-1:123456789012:<QUEUE_NAME>",
"Effect": "Allow"
}
]
}The construct sets default properties. For example, it applies default configurations for the retry policy if not explicitly stated. As shown in Figure 1, the above defined schedule has been defined with a 1-day maximum event retention time and 185 maximum retries.

Example 2 – Start / Stop EC2 instance during business hours
In the second scenario, a recurring cron schedule is used to automatically stop Amazon EC2 instances during the business hours of a specific time zone.
The example below uses the EventBridge Scheduler construct with a universal target to perform the Amazon EC2 stopInstance API operation. It creates a custom schedule group to organize the schedules by time zone and allows an Amazon Lambda function to read all schedules in it for administrative purposes.
const group = new ScheduleGroup(this, "ScheduleGroup", {
scheduleGroupName: "Europe-London",
});
new Schedule(this, "Schedule", {
schedule: ScheduleExpression.cron({
minute: "0",
hour: "23",
timeZone: cdk.TimeZone.EUROPE_LONDON,
}),
target: new targets.Universal({
service: "ec2",
action: "stopInstances",
input: ScheduleTargetInput.fromObject({
InstanceIds: [ec2Instance.instanceId],
}),
}),
scheduleGroup: group,
});
group.grantReadSchedules(lambdaFunction);
Similar to the first example, the ScheduleExpression and ScheduleTargetInput help users to define the correct input types. The universal target is one of the options allowed by the scheduler-target constructs that allow users to perform SDK API operations on AWS services such as Amazon EC2.
The ScheduleGroup construct is used to create the group, which is used as a property on the Schedule construct. The group implements convenience methods that allow simplified permissions management. The example above grants read permissions for the schedule group to an Amazon Lambda function, which is applied to the resources without additional configuration.
Community Shout-Outs
The CDK team would like to give a huge shout-out to the awesome members of the community that contributed to this construct to help get it where it is today! Thank you to:
Conclusion
In this post, we introduced the general availability of the AWS CDK L2 construct for Amazon EventBridge Scheduler and Targets. We showcased practical implementations of the new construct, leveraging two example use cases. For more details on the EventBridge Scheduler L2 construct and examples of its use, see the Scheduler CDK Documentation.
If you’re new to AWS CDK and want to get started, we highly recommend checking out the CDK documentation and the CDK workshop.
[$] An update on pahole
Post Syndicated from daroc original https://lwn.net/Articles/1016243/
Pahole (originally “Poke-a-hole”) is a Swiss Army knife for exploring and
editing debug information. Pahole is also currently involved
in the kernel’s build process to rearrange the information
produced by various compilers into a form useful to the BPF verifier, although
there are plans to render it unnecessary.
Pahole maintainer Arnaldo Carvalho de Melo shared some status
updates about the project at the 2025 Linux Storage, Filesystem,
Memory-Management, and BPF summit. Interested readers can find his slides
here.
Fifty Years of Open Source Software Supply Chain Security (Queue)
Post Syndicated from corbet original https://lwn.net/Articles/1016715/
ACM Queue looks at
the security problem in the light of a report on Multics security that
was published in 1974.
We are all struggling with a massive shift that has happened in the
past 10 or 20 years in the software industry. For decades, software
reuse was only a lofty goal. Now it’s very real. Modern
programming environments such as Go, Node, and Rust have made it
trivial to reuse work by others, but our instincts about
responsible behaviors have not yet adapted to this new reality.The fact that the 1974 Multics review anticipated many of the
problems we face today is evidence that these problems are
fundamental and have no easy answers. We must work to make
continuous improvements to open source software supply chain
security, making attacks more and more difficult and expensive.
Amazon Nova Reel 1.1: Featuring up to 2-minutes multi-shot videos
Post Syndicated from Elizabeth Fuentes original https://aws.amazon.com/blogs/aws/amazon-nova-reel-1-1-featuring-up-to-2-minutes-multi-shot-videos/
At re:Invent 2024, we announced Amazon Nova models, a new generation of foundation models (FMs), including Amazon Nova Reel, a video generation model that creates short videos from text descriptions and optional reference images (together, the “prompt”).
Today, we introduce Amazon Nova Reel 1.1, which provides quality and latency improvements in 6-second single-shot video generation, compared to Amazon Nova Reel 1.0. This update lets you generate multi-shot videos up to 2-minutes in length with consistent style across shots. You can either provide a single prompt for up to a 2-minute video composed of 6-second shots, or design each shot individually with custom prompts. This gives you new ways to create video content through Amazon Bedrock.
Amazon Nova Reel enhances creative productivity, while helping to reduce the time and cost of video production using generative AI. You can use Amazon Nova Reel to create compelling videos for your marketing campaigns, product designs, and social media content with increased efficiency and creative control. For example, in advertising campaigns, you can produce high-quality video commercials with consistent visuals and timing using natural language.
To get started with Amazon Nova Reel 1.1
If you’re new to using Amazon Nova Reel models, go to the Amazon Bedrock console, choose Model access in the navigation panel and request access to the Amazon Nova Reel model. When you get access to Amazon Nova Reel, it applies both to 1.0 and 1.1.

After gaining access, you can try Amazon Nova Reel 1.1 directly from the Amazon Bedrock console, AWS SDK, or AWS Command Line Interface (AWS CLI).
To test the Amazon Nova Reel 1.1 model in the console, choose Image/Video under Playgrounds in the left menu pane. Then choose Nova Reel 1.1 as the model and input your prompt to generate video.

Amazon Nova Reel 1.1 offers two modes:
- Multishot Automated – In this mode, Amazon Nova Reel 1.1 accepts a single prompt of up to 4,000 characters and produces a multi-shot video that reflects that prompt. This mode doesn’t accept an input image.
- Multishot Manual – For those who desire more direct control over a video’s shot composition, with manual mode (also referred to as storyboard mode), you can specify a unique prompt for each individual shot. This mode does accept an optional starting image for each shot. Images must have a resolution of 1280×720. You can provide images in base64 format or from an Amazon Simple Storage Service (Amazon S3) location.
For this demo, I use the AWS SDK for Python (Boto3) to invoke the model using the Amazon Bedrock API and StartAsyncInvoke operation to start an asynchronous invocation and generate the video. I used GetAsyncInvoke to check on the progress of a video generation job.
This Python script creates a 120-second video using MULTI_SHOT_AUTOMATED mode as TaskType parameter from this text prompt, created by Nitin Eusebius.
import random import time import boto3 AWS_REGION = "us-east-1" MODEL_ID = "amazon.nova-reel-v1:1" SLEEP_SECONDS = 15 # Interval at which to check video gen progress S3_DESTINATION_BUCKET = "s3://<your bucket here>" video_prompt_automated = "Norwegian fjord with still water reflecting mountains in perfect symmetry. Uninhabited wilderness of Giant sequoia forest with sunlight filtering between massive trunks. Sahara desert sand dunes with perfect ripple patterns. Alpine lake with crystal clear water and mountain reflection. Ancient redwood tree with detailed bark texture. Arctic ice cave with blue ice walls and ceiling. Bioluminescent plankton on beach shore at night. Bolivian salt flats with perfect sky reflection. Bamboo forest with tall stalks in filtered light. Cherry blossom grove against blue sky. Lavender field with purple rows to horizon. Autumn forest with red and gold leaves. Tropical coral reef with fish and colorful coral. Antelope Canyon with light beams through narrow passages. Banff lake with turquoise water and mountain backdrop. Joshua Tree desert at sunset with silhouetted trees. Iceland moss- covered lava field. Amazon lily pads with perfect symmetry. Hawaiian volcanic landscape with lava rock. New Zealand glowworm cave with blue ceiling lights. 8K nature photography, professional landscape lighting, no movement transitions, perfect exposure for each environment, natural color grading" bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION) model_input = { "taskType": "MULTI_SHOT_AUTOMATED", "multiShotAutomatedParams": {"text": video_prompt_automated}, "videoGenerationConfig": { "durationSeconds": 120, # Must be a multiple of 6 in range [12, 120] "fps": 24, "dimension": "1280x720", "seed": random.randint(0, 2147483648), }, } invocation = bedrock_runtime.start_async_invoke( modelId=MODEL_ID, modelInput=model_input, outputDataConfig={"s3OutputDataConfig": {"s3Uri": S3_DESTINATION_BUCKET}}, ) invocation_arn = invocation["invocationArn"] job_id = invocation_arn.split("/")[-1] s3_location = f"{S3_DESTINATION_BUCKET}/{job_id}" print(f"\nMonitoring job folder: {s3_location}") while True: response = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn) status = response["status"] print(f"Status: {status}") if status != "InProgress": break time.sleep(SLEEP_SECONDS) if status == "Completed": print(f"\nVideo is ready at {s3_location}/output.mp4") else: print(f"\nVideo generation status: {status}")
After the first invocation, the script periodically checks the status until the creation of the video has been completed. I pass a random seed to get a different result each time the code runs.
I run the script:
Status: InProgress
. . .
Status: Completed
Video is ready at s3://<your bucket here>/<job_id>/output.mp4
After a few minutes, the script is completed and prints the output Amazon S3 location. I download the output video using the AWS CLI:
aws s3 cp s3://<your bucket here>/<job_id>/output.mp4 output_automated.mp4This is the video that this prompt generated:
In the case of MULTI_SHOT_MANUAL mode as TaskType parameter, with a prompt for multiples shots and a description for each shot, it is not necessary to add the variable durationSeconds.
Using the prompt for multiples shots, created by Sanju Sunny.
I run Python script:
import random import time import boto3 def image_to_base64(image_path: str): """ Helper function which converts an image file to a base64 encoded string. """ import base64 with open(image_path, "rb") as image_file: encoded_string = base64.b64encode(image_file.read()) return encoded_string.decode("utf-8") AWS_REGION = "us-east-1" MODEL_ID = "amazon.nova-reel-v1:1" SLEEP_SECONDS = 15 # Interval at which to check video gen progress S3_DESTINATION_BUCKET = "s3://<your bucket here>" video_shot_prompts = [ # Example of using an S3 image in a shot. { "text": "Epic aerial rise revealing the landscape, dramatic documentary style with dark atmospheric mood", "image": { "format": "png", "source": { "s3Location": {"uri": "s3://<your bucket here>/images/arctic_1.png"} }, }, }, # Example of using a locally saved image in a shot { "text": "Sweeping drone shot across surface, cracks forming in ice, morning sunlight casting long shadows, documentary style", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_2.png")}, }, }, { "text": "Epic aerial shot slowly soaring forward over the glacier's surface, revealing vast ice formations, cinematic drone perspective", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_3.png")}, }, }, { "text": "Aerial shot slowly descending from high above, revealing the lone penguin's journey through the stark ice landscape, artic smoke washes over the land, nature documentary styled", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_4.png")}, }, }, { "text": "Colossal wide shot of half the glacier face catastrophically collapsing, enormous wall of ice breaking away and crashing into the ocean. Slow motion, camera dramatically pulling back to reveal the massive scale. Monumental waves erupting from impact.", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_5.png")}, }, }, { "text": "Slow motion tracking shot moving parallel to the penguin, with snow and mist swirling dramatically in the foreground and background", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_6.png")}, }, }, { "text": "High-altitude drone descent over pristine glacier, capturing violent fracture chasing the camera, crystalline patterns shattering in slow motion across mirror-like ice, camera smoothly aligning with surface.", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_7.png")}, }, }, { "text": "Epic aerial drone shot slowly pulling back and rising higher, revealing the vast endless ocean surrounding the solitary penguin on the ice float, cinematic reveal", "image": { "format": "png", "source": {"bytes": image_to_base64("arctic_8.png")}, }, }, ] bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION) model_input = { "taskType": "MULTI_SHOT_MANUAL", "multiShotManualParams": {"shots": video_shot_prompts}, "videoGenerationConfig": { "fps": 24, "dimension": "1280x720", "seed": random.randint(0, 2147483648), }, } invocation = bedrock_runtime.start_async_invoke( modelId=MODEL_ID, modelInput=model_input, outputDataConfig={"s3OutputDataConfig": {"s3Uri": S3_DESTINATION_BUCKET}}, ) invocation_arn = invocation["invocationArn"] job_id = invocation_arn.split("/")[-1] s3_location = f"{S3_DESTINATION_BUCKET}/{job_id}" print(f"\nMonitoring job folder: {s3_location}") while True: response = bedrock_runtime.get_async_invoke(invocationArn=invocation_arn) status = response["status"] print(f"Status: {status}") if status != "InProgress": break time.sleep(SLEEP_SECONDS) if status == "Completed": print(f"\nVideo is ready at {s3_location}/output.mp4") else: print(f"\nVideo generation status: {status}")
As in the previous demo, after a few minutes, I download the output using the AWS CLI:
aws s3 cp s3://<your bucket here>/<job_id>/output.mp4 output_manual.mp4
This is the video that this prompt generated:
More creative examples
When you use Amazon Nova Reel 1.1, you’ll discover a world of creative possibilities. Here are some sample prompts to help you begin:
Color Burst, created by Nitin Eusebius
prompt = "Explosion of colored powder against black background. Start with slow-motion closeup of single purple powder burst. Dolly out revealing multiple powder clouds in vibrant hues colliding mid-air. Track across spectrum of colors mixing: magenta, yellow, cyan, orange. Zoom in on particles illuminated by sunbeams. Arc shot capturing complete color field. 4K, festival celebration, high-contrast lighting"
Shape Shifting, created by Sanju Sunny
All example videos have music added manually before uploading, by the AWS Video team.
Things to know
Creative control – You can use this enhanced control for lifestyle and ambient background videos in advertising, marketing, media, and entertainment projects. Customize specific elements such as camera motion and shot content, or animate existing images.
Modes considerations – In automated mode, you can write prompts up to 4,000 characters. For manual mode, each shot accepts prompts up to 512 characters, and you can include up to 20 shots in a single video. Consider planning your shots in advance, similar to creating a traditional storyboard. Input images must match the 1280×720 resolution requirement. The service automatically delivers your completed videos to your specified S3 bucket.
Pricing and availability – Amazon Nova Reel 1.1 is available in Amazon Bedrock in the US East (N. Virginia) AWS Region. You can access the model through the Amazon Bedrock console, AWS SDK, or AWS CLI. As with all Amazon Bedrock services, pricing follows a pay-as-you-go model based on your usage. For more information, refer to Amazon Bedrock pricing.
Ready to start creating with Amazon Nova Reel? Visit the Amazon Nova Reel AWS AI Service Cards to learn more and dive into the Generating videos with Amazon Nova. Explore Python code examples in the Amazon Nova model cookbook repository, enhance your results using the Amazon Nova Reel prompting best practices, and discover video examples in the Amazon Nova Reel gallery—complete with the prompts and reference images that brought them to life.
The possibilities are endless, and we look forward to seeing what you create! Join our growing community of builders at community.aws, where you can create your BuilderID, share your video generation projects, and connect with fellow innovators.
— Eli
How is the News Blog doing? Take this 1 minute survey!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
ML-KEM post-quantum TLS now supported in AWS KMS, ACM, and Secrets Manager
Post Syndicated from Alex Weibel original https://aws.amazon.com/blogs/security/ml-kem-post-quantum-tls-now-supported-in-aws-kms-acm-and-secrets-manager/
Amazon Web Services (AWS) is excited to announce that the latest hybrid post-quantum key agreement standards for TLS have been deployed to three AWS services. Today, AWS Key Management Service (AWS KMS), AWS Certificate Manager (ACM), and AWS Secrets Manager endpoints now support Module-Lattice-Based Key-Encapsulation Mechanism (ML-KEM) for hybrid post-quantum key agreement in non-FIPS endpoints in all AWS Regions in the aws partition. The AWS Secrets Manager Agent, built on AWS SDK for Rust now also has opt-in support for hybrid post-quantum key agreement. With this, customers can bring secrets into their applications with end-to-end post-quantum enabled TLS.
These three services were chosen because they are security-critical AWS services with the most urgent need for post-quantum confidentiality. These three AWS services have previously deployed support for CRYSTALS-Kyber, the predecessor of ML-KEM. Support for CRYSTALS-Kyber will continue through 2025, but will be removed across all AWS service endpoints in 2026 in favor of ML-KEM.
Our migration to post-quantum cryptography
AWS is committed to following our post-quantum cryptography migration plan. As part of this commitment, and part of the AWS post-quantum shared responsibility model, AWS plans to deploy support for ML-KEM to all AWS services with HTTPS endpoints over the coming years. AWS customers must update their TLS clients and SDKs to offer ML-KEM when connecting to AWS service HTTPS endpoints. This will protect against future harvest now, decrypt later threats posed by quantum computing advancements. Meanwhile, AWS service HTTPS endpoints will be responsible for selecting ML-KEM when offered by clients.
Our commitment to negotiate hybrid post-quantum key agreement algorithms is enabled by AWS Libcrypto (AWS-LC), our open-source FIPS-140-3-validated cryptographic library used throughout AWS, and s2n-tls, our open-source TLS implementation used across AWS service HTTPS endpoints. AWS-LC has been awarded multiple FIPS certificates from NIST (#4631, #4759, and #4816), and was the first open-source cryptographic module to include ML-KEM in a FIPS 140-3 validation.
The effect of hybrid post-quantum ML-KEM on TLS performance
Migrating from an Elliptic Curve Diffie-Hellman (ECDH)-only key agreement to an ECDH+ML-KEM hybrid key agreement necessarily requires that the TLS handshake send more data and perform more cryptographic operations. Switching from a classical to a hybrid post-quantum key agreement will transfer approximately 1600 additional bytes during the TLS handshake and will require approximately 80–150 microseconds more compute time to perform ML-KEM cryptographic operations. This is a one-time TLS connection startup cost and is amortized over the lifetime of the TLS connection across the HTTP requests sent over that connection.
AWS is working to provide a smooth migration to hybrid post-quantum key agreement for TLS. This work includes performing benchmarks on example workloads to help customers understand the impact of enabling hybrid post-quantum key agreement with ML-KEM.
Using the AWS SDK for Java v2, AWS has measured the number of AWS KMS GenerateDataKey requests per second that a single thread can issue serially between an Amazon Elastic Compute Cloud (Amazon EC2) C6in.metal client and the public AWS KMS endpoint. Both the client and server were in the us-west-2 Region. Classical TLS connections to AWS KMS negotiated the P256 elliptic curve for key agreement, and hybrid post-quantum TLS connections negotiated the X25519 elliptic curve with ML-KEM-768 for their hybrid key agreement. Your own performance characteristics might differ and will depend on your environment, including your instance type, your workload profiles, the amount of parallelism and number of threads used, and your network location and capacity. The HTTP request transaction rates were measured with TLS connection reuse both enabled and disabled.
Figure 1 shows the number of requests per second issued at different percentiles when TLS 1.3 connection reuse is disabled. It shows that in the worst-case scenario—when the cost of a TLS handshake is never amortized and every HTTP request must perform a full TLS handshake—enabling hybrid post-quantum TLS decreases the transactions per second (TPS) by about 2.3 percent on average, from 108.7 TPS to 106.2 TPS.
 Figure 1: AWS KMS GenerateDataKey requests per second without TLS connection reuse
Figure 1: AWS KMS GenerateDataKey requests per second without TLS connection reuse
Figure 2 shows the number of requests per second issued at different percentiles when TLS connection reuse is enabled. Reusing TLS connections and amortizing the cost of a TLS handshake over many HTTP requests is the default setting in the AWS SDK for Java v2. We show that enabling hybrid post-quantum TLS when using default SDK settings leaves the TPS rate almost unchanged, with only a 0.05 percent decrease on average, from 216.1 TPS to 216.0 TPS.
 Figure 2: AWS KMS GenerateDataKey requests per second with TLS connection reuse
Figure 2: AWS KMS GenerateDataKey requests per second with TLS connection reuse
Our results show that the performance impact of enabling hybrid post-quantum TLS is negligible when using typical configuration settings in your SDK. Our measurements show that enabling hybrid post-quantum TLS for a default-case example workload only lowered maximum TPS rate by 0.05 percent. Our results also show that overriding SDK defaults to force the worst-case scenario of performing a new TLS handshake for every request only decreased maximum TPS rate by 2.3 percent.
The following table shows the benchmark data that we measured. Each benchmark performed 500 one-second TPS measurements for varying TLS key agreement settings and TLS connection reuse settings. The measurements used v2.30.22 of the AWS SDK for Java v2. The TLS key agreement was switched between classical and hybrid post-quantum by toggling the postQuantumTlsEnabled() configuration. TLS connection reuse was toggled by injecting a Connection: close HTTP header into each HTTP request. This header forces the TLS connection to be shut down after each HTTP request and requires that a new TLS connection be created for each HTTP request.
| TLS key agreement | TLS conn resuse | Total HTTP requests | Average (TPS) | p01 (TPS) | p10 (TPS) | p25 (TPS) | p50 (TPS) | p75 (TPS) | p90 (TPS) | p99 (TPS) |
|---|---|---|---|---|---|---|---|---|---|---|
| Classical (P256) | No | 54,367 | 108.7 | 78 | 86 | 96 | 102 | 129 | 137 | 145 |
| Hybrid post-quantum (X25519MLKEM768) | No | 53,106 | 106.2 | 76 | 85 | 93 | 100 | 126 | 134 | 141 |
| Classical (P256) | Yes | 108,052 | 216.1 | 181 | 194 | 200 | 216 | 233 | 240 | 245 |
| Hybrid post-quantum (X25519MLKEM768) | Yes | 107,994 | 216 | 177 | 194 | 200 | 216 | 233 | 239 | 245 |
Removing support for draft post-quantum standards
AWS service endpoints with support for CRYSTALS-Kyber, the predecessor of ML-KEM, will continue to support CRYSTALS-Kyber through 2025. We will slowly phase out support for the pre-standard CRYSTALS-Kyber implementations after customers have moved to the ML-KEM standard. Customers using previous versions of the AWS SDK for Java with CRYSTALS-Kyber support should upgrade to the latest SDK versions that have ML-KEM support. No code changes are necessary for customers using a generally available release of the AWS SDK for Java v2 to upgrade from CRYSTALS-Kyber to ML-KEM.
Customers currently negotiating CRYSTALS-Kyber who do not upgrade their AWS Java SDK v2 clients by 2026 will see their clients gracefully fall back to a classical key agreement once CRYSTALS-Kyber is removed from AWS service HTTPS endpoints.
How to use hybrid post-quantum key agreement
If using the AWS SDK for Rust, you can enable the hybrid post-quantum key agreement by adding the rustls package to your crate and enabling the prefer-post-quantum feature flag. See the rustls documentation for more information.
If using the AWS SDK for Java 2.x, you can enable hybrid post-quantum key agreement by calling .postQuantumTlsEnabled(true) when building your AWS Common Runtime HTTP client.
Step 1: Add the AWS Common Runtime HTTP client to your Java dependencies.
Add the AWS Common Runtime HTTP client to your Maven dependencies. We recommend using the latest available version. Use version 2.30.22 or greater to enable the use of ML-KEM.
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>aws-crt-client</artifactId>
<version>2.30.22<version>
</dependency>
Step 2: Enable post-quantum TLS in your Java SDK client configuration
When configuring your AWS service client, use the AwsCrtAsyncHttpClient configured with post-quantum TLS.
// Configure an AWS Common Runtime HTTP client with Post-Quantum TLS enabled
SdkAsyncHttpClient awsCrtHttpClient = AwsCrtAsyncHttpClient.builder()
.postQuantumTlsEnabled(true)
.build();
// Create an AWS service client that uses the AWS Common Runtime client
KmsAsyncClient kmsAsync = KmsAsyncClient.builder()
.httpClient(awsCrtHttpClient)
.build();
// Make a request over a TLS connection that uses post-quantum key agreement
ListKeysReponse keys = kmsAsync.listKeys().get();
See the KMS PQ TLS example application for an end-to-end example of a post-quantum TLS setup.
Things to try
Here are some ideas about how to use this post-quantum-enabled client:
- Run load tests and benchmarks. The AwsCrtAsyncHttpClient is heavily optimized for performance and uses AWS Libcrypto on Linux-based environments. If you aren’t already using the AwsCrtAsyncHttpClient, try it today to see the performance benefits compared to the default SDK HTTP client. After using AwsCrtAsyncHttpClient, enable post-quantum TLS support. See if using AwsCrtAsyncHttpClient with post-quantum TLS is an overall performance gain to using the default SDK HTTP client without post-quantum TLS.
- Try connecting from different network locations. Depending on the network path that your request takes, you might discover that intermediate hosts, proxies, or firewalls with deep packet inspection (DPI) block the request. If this is the case, you might need to work with your security team or IT administrators to update firewalls in your network to unblock these new TLS algorithms. We want to hear from you about how your infrastructure interacts with this new variant of TLS traffic.
Conclusion
Support for ML-KEM-based hybrid key agreement has been deployed to three security-critical AWS service endpoints. The performance impact of enabling hybrid post-quantum TLS is likely to be negligible when TLS connection reuse is enabled. Our measurements showed only a 0.05 percent decrease to maximum transactions per second when calling AWS KMS GenerateDataKey.
Starting with version 2.30.22, the AWS SDK for Java v2 now supports ML-KEM-based hybrid key agreement on Linux-based platforms when using the AWS Common Runtime HTTP client. Try enabling post quantum key agreement for TLS in your Java SDK client configuration today.
AWS plans to deploy support for ML-KEM-based hybrid post-quantum key agreement to every AWS service HTTPS endpoint over the coming years as part of our post-quantum cryptography migration plan. AWS customers will be responsible for updating their TLS clients and SDKs to help ensure that ML-KEM key agreement is offered when connecting to AWS service HTTPS endpoints. This will protect against future harvest now, decrypt later threats posed by quantum computing advancements.
For additional information, blog posts, and periodic updates on our post-quantum cryptography migration, keep watching the AWS Post-Quantum Cryptography page. To learn more about post-quantum cryptography with AWS, contact the post-quantum cryptography team.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Security, Identity, & Compliance re:Post or contact AWS Support.
Additional resources:
- AWS Post-Quantum Cryptography
- AWS post-quantum cryptography migration plan
- Customer compliance and security during the post-quantum cryptographic migration
- AWS-LC FIPS 3.0: First cryptographic library to include ML-KEM in FIPS 140-3 validation
- The impact of data-heavy, post-quantum TLS 1.3 on the Time-To-Last-Byte of real-world connections
- AWS Workshop: Using Post-Quantum Cryptography on AWS
- NIST FIPS 203, Module-Lattice-Based Key-Encapsulation Mechanism Standard (ML-KEM)
If you have feedback about this post, submit comments in the Comments section below.
Lewis Howes | Make Money Easy | Talks at Google
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=qoYNyDU0gso
AWS Weekly Review: Amazon EKS, Amazon OpenSearch, Amazon API Gateway, and more (April 7, 2025)
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/aws-weekly-review-amazon-eks-amazon-opensearch-amazon-api-gateway-and-more-april-7-2025/
AWS Summit season starts this week! These free events are now rolling out worldwide, bringing our cloud computing community together to connect, collaborate, and learn. Whether you prefer joining us online or in-person, these gatherings offer valuable opportunities to expand your AWS knowledge. I will be attending the Summit in Paris this week, the biggest cloud conference in France, and the London Summit at the end of the month. We will have a small podcast recording studio where I will interview French and British customers to produce new episodes for the AWS Developers Podcast and le podcast  AWS
AWS  en
en  .
.
Register today!
But for now, let’s look at last week’s new announcements.
Last week’s launches
At KubeCon London, we introduced the EKS Community Add-Ons Catalog, making it simpler for Kubernetes users to enhance their Amazon EKS clusters with powerful open-source tools. This catalog streamlines the installation of essential add-ons like metrics-server, kube-state-metrics, prometheus-node-exporter, cert-manager, and external-dns. By integrating these community-driven add-ons directly into the EKS console and AWS command line interface (AWS CLI), customers can reduce operational complexity and accelerate deployment while maintaining flexibility and security. This launch reflects AWS’s commitment to the Kubernetes community, providing seamless access to trusted open-source solutions without the overhead of manual installation and maintenance.
Amazon Q Developer now integrates with Amazon OpenSearch Service to enhance operational analytics by enabling natural language exploration and AI-assisted data visualization. This integration simplifies the process of querying and visualizing operational data, reducing the learning curve associated with traditional query languages and tools. During incident responses, Amazon Q Developer offers contextual summaries and insights directly within the alerts interface, facilitating quicker analysis and resolution. This advancement allows engineers to focus more on innovation by streamlining troubleshooting processes and improving monitoring infrastructure.
Amazon API Gateway now supports dual-stack (IPv4 and IPv6) endpoints across all endpoint types, custom domains, and management APIs in both commercial and AWS GovCloud (US) Regions. This enhancement allows REST, HTTP, and WebSocket APIs, as well as custom domains, to handle requests from both IPv4 and IPv6 clients, facilitating a smoother transition to IPv6 and addressing IPv4 address scarcity. Additionally, AWS continues its commitment to IPv6 adoption with recent updates, including AWS Identity and Access Management (IAM) introducing dual-stack public endpoints for seamless connections over IPv4 and IPv6, and AWS Resource Access Manager (RAM) enabling customers to manage resource shares using IPv6 addresses. Amazon Security Lake customers can also now use Internet Protocol version 6 (IPv6) addresses via new dual-stack endpoints to configure and manage the service. These advancements collectively ensure broader compatibility and future-proofing of network infrastructure.
Amazon SES has introduced support for email attachments in its v2 APIs, enabling users to include files like PDFs and images directly in their emails without manually constructing MIME messages. This enhancement simplifies the process of sending rich email content and reduces implementation complexity. Amazon Simple Email Service (Amazon SES) supports attachments in all AWS Regions where the service is available.
Amazon Neptune has updated its Service Level Agreement (SLA) to offer a 99.99% Monthly Uptime Percentage for Multi-AZ DB Instance, Multi-AZ DB Cluster, and Multi-AZ Graph configurations, up from the previous 99.9%. This enhancement demonstrates the commitment AWS has to providing highly available and reliable graph database services for mission-critical applications. The improved SLA is now available in all AWS Regions where Amazon Neptune is offered.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS events
Check your calendar and sign up for upcoming AWS events.
AWS GenAI Lofts are collaborative spaces and immersive experiences that showcase AWS expertise in cloud computing and AI. They provide startups and developers with hands-on access to AI products and services, exclusive sessions with industry leaders, and valuable networking opportunities with investors and peers. Find a GenAI Loft location near you and don’t forget to register.
Browse all upcoming AWS led in-person and virtual events here.
That’s all for this week. Check back next Monday for another Weekly Roundup!
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!
How is the News Blog doing? Take this 1 minute survey!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Converting embedded SQL in Java applications with Amazon Q Developer
Post Syndicated from Suruchi Saxena original https://aws.amazon.com/blogs/devops/converting-embedded-sql-in-java-applications-with-amazon-q-developer/
As organizations modernize their database infrastructure, migrating from systems like Oracle to open source solutions such as PostgreSQL is becoming increasingly common. However, this transition presents a significant challenge: discovering and converting embedded SQL within existing Java applications to ensure compatibility with the new database system. Manual conversion of this code is time-consuming, error-prone, and can lead to extended downtime during migration. The process involves cautiously updating numerous SQL statements interwoven in Java code, which can take weeks depending on the application’s size and complexity. This manual approach is highly susceptible to errors, potentially introducing subtle bugs that are difficult to detect. It also requires deep expertise in both source and target database systems. Furthermore, ensuring consistency across the entire codebase during manual conversion is challenging. This can lead to inconsistencies in coding style, performance optimizations, and error handling. These factors combined make the SQL conversion process a significant bottleneck in database migration projects, often delaying modernization efforts and impacting business agility.
Solution
To address these challenges, AWS has introduced an innovative new capability: SQL code conversion using Amazon Q Developer in conjunction with AWS Database Migration Service (AWS DMS). This solution automates the process of transforming embedded SQL in Java applications, significantly reducing the time and effort required for database migrations.
Amazon Q Developer, a generative AI–powered assistant for software development that integrates directly into your Integrated Development Environment (IDE), offers a range of features to enhance developer productivity, including code generation, refactoring, and transformations such as java version upgrades and now SQL code conversion. It analyzes Java code, identifies embedded SQL statements, and automates conversion from the source dialect (e.g. Oracle) to the target dialect (e.g. PostgreSQL). This automation dramatically accelerates the conversion process, potentially reducing weeks of tedious work to just hours of effort.
The solution minimizes human error by leveraging AI algorithms trained on extensive SQL datasets, ensuring a level of consistency and accuracy difficult to achieve manually. It also allows developers to focus on higher-value tasks such as architecture optimization and performance tuning, rather than getting bogged down in the minutiae of SQL syntax differences. When combined with AWS Database Migration Service, which handles schema conversion and data replication, this solution creates a comprehensive migration workflow. It addresses not just code conversion but the entire database migration lifecycle, providing a streamlined path from legacy systems to modern database architectures. By automating SQL conversion, ensuring consistency across the codebase, and integrating with broader migration tools, this feature significantly simplifies the technical aspects of database migration. It aligns with organizational goals of improving efficiency, reducing costs, and maintaining competitiveness in an evolving technological landscape, making it a powerful tool for organizations undertaking database modernization projects.
Overview
To illustrate the power of this solution, let’s consider part of an application written in Java that manages shopping cart functionality for online retail operations using embedded Oracle SQL for database operations. The system allows customers to maintain their shopping carts, manage items, and handle basic e-commerce operations. In our sample application, we look at sections of code from a CartDAO.java class which has multiple Oracle-specific SQL queries. It demonstrates various Oracle-specific SQL features including regular expressions, XML handling, hierarchical queries, and analytical functions. These features make the code particularly optimized for Oracle databases. We’ll need to convert this SQL in order for it to be compatible PostgreSQL. Let’s explore each of these methods.
Method 1:
createItem is a basic insertion method that uses Oracle’s SYSDATE function to automatically timestamp the record. This is Oracle’s built-in function for current date and time.
public void createItem() throws SQLException {
String sql = "INSERT INTO item (name, description, updated_date) VALUES (?, ?, SYSDATE)";
Connection conn = getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, "Sparkling Water");
pstmt.setDouble(2, 5.0);
pstmt.executeUpdate();
System.out.println("Data inserted successfully");
}Method 2:
getMfgCodes is a method which uses Oracle’s SUBSTR function to retrieve the first three characters of an item name.
public List<String> getMfgCodes() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT DISTINCT(SUBSTR(name, 1, 3)) AS mfg_code FROM item";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
List<String> mfg_codes = new ArrayList<String>();
while (rs.next()) {
mfg_codes.add(rs.getString("mfg_code"));
}
return mfg_codes;
}
Method 3:
findItemsByRegex leverages Oracle’s REGEXP_LIKE function, which provides pattern matching capabilities beyond standard SQL. This is used for complex string searching that would be difficult with simple LIKE clauses.
public List<String> findItemsByRegex(String pattern) throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name FROM item WHERE REGEXP_LIKE(name, ?)";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, pattern);
ResultSet rs = pstmt.executeQuery();
List<String> names = new ArrayList<String>();
while (rs.next()) {
names.add(rs.getString("name"));
}
return names;
}Method 4:
cleanItemDescriptions uses Oracle’s advanced regular expression capabilities through REGEXP_REPLACE. It specifically uses Oracle’s character class syntax [[:punct:]] to identify punctuation marks, which is an Oracle-specific implementation of POSIX regular expressions.
public void cleanItemDescriptions() throws SQLException {
Connection conn = getConnection();
String sql = "UPDATE item SET description = REGEXP_REPLACE(description, "
+" '([[:punct:]]{2,}|\\s{2,})', ' ') "
+" WHERE REGEXP_LIKE(description, '([[:punct:]]{2,}|\\s{2,})') ";
try (Statement stmt = conn.createStatement()) {
int rowsUpdated = stmt.executeUpdate(sql);
System.out.println("Cleaned descriptions for " + rowsUpdated + " items");
}
}Method 5:
This function retrieves the top 3 most expensive items for each premium category from the ‘item’ table using Oracle’s analytical RANK() function. It creates a formatted string for each item containing the premium category, item name, price, and its rank within its category. The results are stored in a List and returned.
public List<String> getTopItemsByCategory() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT * FROM (SELECT name, premium, price,RANK() OVER (PARTITION BY premium"
+" ORDER BY price DESC) as price_rank FROM item) WHERE price_rank <= 3";
List<String> topItems = new ArrayList<>();
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql))
while (rs.next()) {
String result = String.format("Premium: %s, Item: %s, Price: %.2f, Rank: %d",
rs.getString("premium"),
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("price_rank"));
topItems.add(result);
}
}
return topItems;
}Method 6:
The SQL query in the findItemsByPriceRange method performs a targeted search and ranking operation on the item table in the database. It begins by filtering items to only those within a specific price bracket.
public List<String> findItemsByPriceRange() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name, price, RANK() OVER (ORDER BY price) as price_rank FROM item"
+ "WHERE price BETWEEN ? AND ?";
List<String> items = new ArrayList<>();
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, 50.0);
pstmt.setDouble(2, 75.0);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
String result = String.format("Item: %s, Price: %.2f, Rank: %d",
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("price_rank"));
items.add(result);
}
}
return items;
}Method 7:
This function demonstrates Oracle’s ROWNUM pseudo-column, which is a specific Oracle database feature used to limit the number of rows returned by a query. The function retrieves the first N items from the ‘item’ table by using ROWNUM <= ? in the WHERE clause.
public List<String> getFirstNItems(int n) throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name FROM item WHERE ROWNUM <= ?";
List<String> items = new ArrayList<>();
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, n);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
items.add(rs.getString("name"));
}
}
return items;
}Our goal is to convert these embedded Oracle specific queries to PostgreSQL queries.
Solution Walkthrough
Prerequisites
Before beginning the conversion process, ensure you have installed and configured Amazon Q in your IDE by following the setup guide. Your source codebase must be a Java application containing embedded Oracle SQL statements that you plan to migrate to PostgreSQL. The transformation specifically targets Oracle SQL syntax within Java code, so verify your application meets these requirements. Complete your database schema migration using AWS DMS Schema Conversion before starting the code transformation process. This crucial step creates the foundation for your PostgreSQL database structure.
Convert Embedded SQL
Open your Java application containing embedded SQL statements in your IDE where Amazon Q is installed. Access the Amazon Q chat panel by selecting the Amazon Q icon in your IDE interface. Start the transformation process by typing /transform in the chat panel. When prompted, specify ‘SQL conversion’ as your transformation type. Amazon Q validates your Java application’s eligibility for SQL conversion before proceeding.

Upload your schema metadata file when prompted by Amazon Q. The chat interface provides detailed instructions for retrieving this file from your previous DMS schema conversion process. Select your project containing embedded SQL and the corresponding database schema file from the dropdown menus in the chat panel. Amazon Q displays the detected database schema details for your confirmation. Take a moment to verify these details are accurate before proceeding with the conversion.

The SQL conversion process would begin, during which Amazon Q analyzes and transforms your Oracle SQL statements into PostgreSQL-compatible syntax.

For this application, Amazon Q was able to detect 7 Oracle specific queries in the code and was able to process them to the corresponding PostgreSQL queries. It generated a conversion summary of the embedded SQL statements processed, and shared recommended actions for 2 queries that needed further inspection.
Amazon Q presented a comprehensive diff view showing all proposed changes to the embedded SQL. Review each modification in the diff view carefully. After your review, accept the changes to update your codebase. Amazon Q generates a detailed transformation summary documenting all modifications made during the conversion.

Let’s take a look at how each of SQL statements within each function got converted to be compatible with PostgreSQL.
Method 1:
The key difference in this query involves the transition from Oracle’s SYSDATE function to PostgreSQL’s CLOCK_TIMESTAMP() with time zone handling. While SYSDATE in Oracle returns the current date and time of the database server, the PostgreSQL version uses CLOCK_TIMESTAMP() which provides the actual current time and explicitly handles timezone conversion through AT TIME ZONE.
public void createItem() throws SQLException {
String sql = "INSERT INTO admin.item (name, description, updated_date) VALUES (?, ?,
(CLOCK_TIMESTAMP() AT TIME ZONE COALESCE(CURRENT_SETTING('aws_oracle_ext.tz',
TRUE), 'UTC'))::TIMESTAMP(0))";
Connection conn = getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
//pstmt.setInt(1, 1);
pstmt.setString(1, "Sparkling Water");
pstmt.setDouble(2, 5.0);
pstmt.executeUpdate();
System.out.println("Data inserted successfully");
}Method 2:
The key change in the next query involves using an extension pack added by the DMS Schema Conversion process which emulates source database functions. This is referenced using the fully qualified function name aws_oracle_ext.substr instead of the simple SUBSTR. The aws_oracle_ext schema contains Oracle-compatible functions to maintain compatibility with Oracle SQL syntax. Additionally, the table reference has been made more specific by including the schema name admin.item instead of just item, which helps avoid ambiguity in multi-schema environments.
public List<String> getMfgCodes() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT DISTINCT (aws_oracle_ext.substr(name, 1, 3)) AS mfg_code FROM
admin.item";
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql);
List<String> mfg_codes = new ArrayList<String>();
while (rs.next()) {
mfg_codes.add(rs.getString("mfg_code"));
}
return mfg_codes;
}Method 3:
The next transformation demonstrates several important adaptations required for Oracle-compatible regular expression functionality in AWS. The key changes include: REGEXP_LIKE function has been replaced with its AWS Oracle extension equivalent aws_oracle_ext.regexp_like. Explicit type casting to TEXT has been added using the PostgreSQL-style cast operator:: TEXT for both the column name and the parameter. The schema qualifier admin has been added to the table name and extra parentheses have been added around the arguments for proper type handling. These modifications ensure that regular expression pattern matching works correctly in the AWS environment while maintaining Oracle-like functionality. The explicit TEXT type casting is particularly important as it ensures proper data type handling during the regular expression comparison operations.
public List<String> findItemsByRegex(String pattern) throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name FROM admin.item WHERE aws_oracle_ext.regexp_like((name)::TEXT,
(?::TEXT)::TEXT)";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setString(1, pattern);
ResultSet rs = pstmt.executeQuery();
List<String> names = new ArrayList<String>();
while (rs.next()) {
names.add(rs.getString("name"));
}
return names;
}Method 4:
The next conversion shows several sophisticated adaptations required for Oracle-compatible regular expression functionality. The changes include the addition of the aws_oracle_ext schema prefix to both regexp_replace and regexp_like functions. The introduction of the E prefix before string literals containing escape sequences, which is PostgreSQL’s syntax for enabling escape sequence interpretation. Additional escaping of backslashes (from \s to \\s) has been added to properly handle whitespace matching in the AWS environment. Explicit type casting to TEXT using ::TEXT has been added for all arguments in both the regexp_replace and regexp_like functions. The schema qualifier admin has been added to the table name. Single quotes around the replacement space character have been wrapped with parentheses. These modifications ensure that the regular expression replacement and matching operations work correctly in the AWS environment while maintaining Oracle-like functionality. The pattern itself is designed to replace multiple consecutive punctuation marks or whitespace characters with a single space character.
public void cleanItemDescriptions() throws SQLException {
Connection conn = getConnection();
String sql = "UPDATE admin.item SET description =
aws_oracle_ext.regexp_replace((description)::TEXT,
(E'([[:punct:]]{2,}|\\\\s{2,})')::TEXT,
('')::TEXT) WHERE aws_oracle_ext.regexp_like((description)::TEXT,
(E'([[:punct:]]{2,}|\\\\s{2,})')::TEXT)";
try (Statement stmt = conn.createStatement()) {
int rowsUpdated = stmt.executeUpdate(sql);
System.out.println("Cleaned descriptions for " + rowsUpdated + " items");
}
}Method 5:
The next transformation shows a few key modifications required for proper execution in PostgreSQL. The addition of an explicit alias AS var_sbq for the derived subquery, which is required in PostgreSQL systems to properly reference derived tables The schema qualifier admin has also been added to the table name item.
public List<String> getTopItemsByCategory() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT * FROM (SELECT name, premium, price, RANK() OVER (PARTITION BY
premium ORDER BY price DESC) AS price_rank FROM admin.item) AS var_sbq WHERE
price_rank <= 3";
List<String> topItems = new ArrayList<>();
try (Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(sql)) {
while (rs.next()) {
String result = String.format("Premium: %s, Item: %s, Price: %.2f, Rank: %d",
rs.getString("premium"),
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("price_rank"));
topItems.add(result);
}
}
return topItems;
}Method 6:
The next transformation demonstrates a few important modifications for PostgreSQL compatibility: The addition of explicit type casting using ::NUMERIC for both parameters in the BETWEEN clause, which ensures proper numeric comparison and helps prevent type conversion issues The schema qualifier admin has been added to the table name item The window function RANK() syntax remains unchanged as it’s standard ANSI SQL.
public List<String> findItemsByPriceRange() throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name, price, RANK() OVER (ORDER BY price) AS price_rank FROM
admin.item WHERE price BETWEEN ?::NUMERIC AND ?::NUMERIC";
List<String> items = new ArrayList<>();
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setDouble(1, 50.0);
pstmt.setDouble(2, 75.0);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
String result = String.format("Item: %s, Price: %.2f, Rank: %d",
rs.getString("name"),
rs.getDouble("price"),
rs.getInt("price_rank"));
items.add(result);
}
}
return items;
}Method 7:
The next transformation shows several significant changes for PostgreSQL compatibility. The Oracle-specific ROWNUM syntax has been replaced with the standard SQL LIMIT clause. A CASE expression has been added to handle input validation. TRUNC(?::NUMERIC) converts the input parameter to a numeric value and removes any decimal places. The CASE statement ensures that only positive numbers are accepted. If the input is less than or equal to 0, it returns 0 (effectively no rows). The schema qualifier admin has been added to the table name. The parameter is now used twice in the query (once for comparison and once for the actual limit). Type casting to NUMERIC has been added for safer numeric handling.
public List<String> getFirstNItems(int n) throws SQLException {
Connection conn = getConnection();
String sql = "SELECT name FROM admin.item LIMIT CASE WHEN TRUNC(?::NUMERIC) > 0 THEN
TRUNC(?::NUMERIC) ELSE 0 END";
List<String> items = new ArrayList<>();
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, n);
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
items.add(rs.getString("name"));
}
}
return items;
}End-to-End Testing
After completing the SQL code conversion, update your application’s database connection settings to point to your new PostgreSQL database. This includes modifying connection strings, updating database credentials, and adjusting any database-specific configuration parameters.
Execute your application’s comprehensive test suite to validate the converted SQL statements. The test suite should cover all database interactions, ensuring queries return expected results and maintain proper data integrity. Pay particular attention to complex queries, stored procedure calls, and transaction management scenarios. Conduct thorough testing of your application’s critical paths. Focus on core business workflows that heavily depend on database operations. Test edge cases and error conditions to verify proper exception handling with the new PostgreSQL database. As a best practice recommendation, implement detailed monitoring of your application logs during testing. Watch for any SQL-related errors, unexpected query behavior, or performance degradation.
Conclusion
The combination of Amazon Q Developer and AWS DMS represents a significant leap forward in database migration technology. By automating the conversion of embedded SQL, we’ve addressed one of the most time-consuming and error-prone aspects of moving from Oracle to PostgreSQL.
Key benefits of this approach include:
- Reduced migration time: What once took weeks can now be accomplished in days or hours
- Improved accuracy: AI-powered conversion minimizes human error
- Cost savings: Less developer time spent on manual code updates shortening modernization and upgrade initiatives
- Seamless integration: Works within your existing development environment
As organizations continue to modernize their database infrastructure, services like Amazon Q Developer will play a crucial role in ensuring smooth, efficient migrations. By leveraging the power of AI to handle complex code transformations, developers can focus on adding value to their applications rather than getting bogged down in the intricacies of SQL dialect differences. We encourage you to try Amazon Q Developer using the Amazon Q User Guide for your next database migration project and experience firsthand the benefits of automated SQL code conversion.
About the Authors
Serverless ICYMI 2025 Q1
Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/serverless-icymi-2025-q1/
Welcome to the 28th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. At the end of a quarter, we share the most recent product launches, feature enhancements, blog posts, videos, live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, check out what happened in Q4 2024 here.

Serverless calendar Q1 2025
AWS Step Functions
The AWS Step Functions team continues to improve developer experience. Workflow Studio is now available within Visual Studio Code (VS Code) through the AWS Toolkit extension.

AWS Step Functions in IDE
You can now design, test, and deploy your Step Functions workflows without leaving your IDE. The extension provides a drag-and-drop interface with all the familiar Workflow Studio capabilities, making it even easier to build state machines locally.
To get started, install the AWS Toolkit for Visual Studio Code and visit the user guide on Workflow Studio integration.
Step Functions private integrations now allows you to integrate applications seamlessly across private networks, on-premises infrastructure, and cloud platforms. Learn more in a blog post and explanation video.

AWS Step Functions private integrations video
Step Functions now integrates with 36 more AWS services that support user messaging capabilities. You can orchestrate notifications through Amazon SNS, Amazon SQS, Amazon EventBridge, Amazon Pinpoint, and more, all using the optimized integrations you’re familiar with.
Step Functions has increased the default quota for state machines and activities from 10,000 to 100,000 per AWS account. This tenfold increase means you can create more workflows to automate your business processes without worrying about hitting quota limits.
Distributed Map is expanding capabilities by adding support for JSON Lines (JSONL) format. JSONL, a highly efficient text-based format, stores structured data as individual JSON objects separated by newlines, making it particularly suitable for processing large datasets.

AWS Step Functions Distributed Map
Distributed Map can also process data from a broader range of delimited file formats stored in Amazon S3 and offers new output transformations for greater control over result formatting.
Developer Tools
Serverless Land patterns are now available directly within VS Code.

You no longer need to switch between your IDE and external resources when building serverless architectures. Browse, search, and implement pre-built serverless patterns directly in VS Code.

Example Serverless Pattern
AWS Lambda
Learn how AWS Lambda handles billions of invocations.

AWS Lambda asynchronous invocations
This blog post provides recommendations and insights for implementing highly distributed applications based on the Lambda service team’s experience building its robust asynchronous event processing system. It dives into challenges you might face, solution techniques, and best practices for handling noisy neighbors.
A new video walks through using the enhanced local IDE experience for Lambda developers.

AWS Lambda new IDE experience
The VS Code extension for Lambda now supports live tailing of CloudWatch Logs directly in your IDE following on from previous support for Live Tail in the Lambda console. Watch logs in real-time as your functions execute, making debugging and troubleshooting more efficient than ever.
You can now enable Application Performance Monitoring (APM) for Java and .NET runtimes using Amazon CloudWatch Application Signals.

Amazon CloudWatch Application Signals for Java and .NET AWS Lambda runtimes
This provides deep visibility into your function’s performance, including method-level tracing, memory profiling, and automated anomaly detection.
Amazon Bedrock features
Multi-agent collaboration is now available in Bedrock as a preview, enabling you to create systems where multiple AI agents work together to solve complex problems. Agents can specialize in different domains, share context, and coordinate their actions to achieve goals that would be difficult for a single agent.
RAG evaluation is now generally available. This provides metrics to assess and improve your retrieval augmented generation pipelines. GraphRAG for Bedrock Knowledge Bases is now generally available, allowing you to enhance retrievals with graph-based context.
Amazon Bedrock Flows now supports multi-turn conversations, allowing you to build dynamic AI applications that maintain context across multiple user interactions. Bedrock data automation is now generally available, streamlining the process of preparing, ingesting, and maintaining data for your GenAI applications. Bedrock now offers LLM-as-a-judge capability for model evaluation, providing automated assessment of model outputs without requiring human reviewers. Compare different models or prompt strategies against your specific criteria at scale.
Bedrock’s capabilities are now integrated into the Amazon SageMaker Unified Studio, creating a seamless experience for machine learning practitioners who want to incorporate foundation models into their workflows. Access Bedrock models, fine-tuning, and evaluation directly from SageMaker.
Amazon Nova is a new generation of state-of-the-art foundation models that deliver frontier intelligence and industry leading price-performance. Nova has expanded its tool use and converse API capabilities, making it easier for developers to build AI assistants that can use external tools to complete tasks.
Amazon Bedrock Guardrails image content filters are now generally available. Define and enforce boundaries for your AI applications with controls for both text and image content, ensuring outputs align with your organization’s policies.
Bedrock Knowledge Bases now supports using your existing OpenSearch clusters as the vector storage backend. This integration allows you to leverage your investments in OpenSearch while benefiting from the managed RAG capabilities of Bedrock.
New Amazon Bedrock models
- Anthropic’s Claude 3.7 Sonnet hybrid reasoning allows you to toggle between standard and extended thinking modes. In standard mode, it functions as an upgraded version of Claude 3.5 Sonnet. While in extended thinking mode, it employs self-reflection to achieve improved results across a wide range of tasks.
- DeepSeek R1, an advanced model specialized in research and scientific reasoning excels at complex problem-solving tasks and technical content generation.
- Cohere Embed 3 models are now available in both multilingual and English-specific versions. These embedding models support text and images, providing more accurate representation for multimodal content and improving retrieval augmented generation (RAG) applications.
- Ray2, Luma AI’s new visual AI model is capable of creating realistic visuals with fluid, natural movement. You can use it for image understanding, 3D scene reconstruction, and visual content generation, opening new possibilities for immersive and visual applications.
- Bedrock now supports fine-tuning of Meta’s latest Llama 3.2 models. These upgraded models deliver improved performance across reasoning, coding, and multilingual tasks while being more efficient with computational resources.
Amazon Q Developer
Amazon Q Developer is now available as a CLI agent, bringing AI-assisted development to the command line. Get contextual recommendations, generate shell commands, and solve coding problems without leaving your terminal.

Amazon Q CLI
Amazon Q Developer transformation now supports upgrading Java applications using Maven to Java 21. It offers enhanced code suggestions, refactoring, and optimization recommendations for applications using the latest Java features, like virtual threads and pattern matching.
AWS AppSync
AWS AppSync Events now supports events publishing for WebSocket APIs, enabling real-time publish-subscribe functionality. This feature makes it easier to build applications requiring instant updates, like chat applications, collaborative tools, and real-time dashboards.

AWS AppSync Events
There are new AWS Cloud Development Kit (AWS CDK) L2 constructs for AppSync WebSocket APIs. These make it simpler to define and deploy real-time APIs using infrastructure as code. These high-level constructs handle the details of WebSocket connections, authorization, and messaging patterns.
Amazon SNS
Amazon SNS now supports high throughput mode for SNS FIFO topics, with default throughput matching SNS standard topics. When you enable high-throughput mode, SNS FIFO topics will maintain order within message group, while reducing the de-duplication scope to the message-group level.
Amazon EventBridge
Amazon EventBridge now supports direct delivery to targets across AWS accounts, simplifying multi-account architectures. This reduces latency and improves reliability when routing events between accounts in your organization.

Amazon EventBridge cross account
The EventBridge console now features event source discovery, making it easier to find and visualize available event sources in your AWS environment. This tool helps you identify potential event producers and understand the event schemas they emit.
AWS Amplify
AWS Amplify now offers a TypeScript data client optimized for server-side Lambda functions, providing type-safe access to your data sources. This client reduces code complexity and improves reliability when working with databases and APIs in server environments.
Serverless compute blog posts
January
February
March
- Introducing an enhanced local IDE experience for AWS Step Functions
- Optimizing network footprint in serverless applications
- Simplifying private API integrations with Amazon EventBridge and AWS Step Functions
Serverless Office Hours weekly livestream
February
- Feb 18 – What’s new in Serverless for 2025
- Feb 25 – AWS Step Functions: What’s new
March
- Mar 4 – Scaling Apache Kafka processing
- Mar 11 – Local AWS step functions dev
- Mar 18 – New private API integrations
- Mar 25 – Data processing with AWS Step Functions
Still looking for more?
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Developer Advocacy team members who work on Serverless to see the latest news, follow conversations, and interact with the team.
- Eric Johnson: @edjgeek
- Julian Wood: @julian_wood
- Marcia Villalba: @mavi888uy
- Gunnar Grosch: @GunnarGrosch
- Cobus Bernard: @cobusbernard
- Darko Mesaros: @darko.rup12.net
- James Ward: @jamesward
- Marcelo Palladino: https://www.linkedin.com/in/mfpalladino
- Salih Gueler: @salihgueler
- Romain Jourdan: @rjourdan_net
- Sebastien Stormacq: @sebsto
- Vinicius Senger: @siliconvini
And finally, visit the Serverless Land for all your serverless needs.
[$] Three ways to rework the swap subsystem
Post Syndicated from corbet original https://lwn.net/Articles/1016136/
The kernel’s swap subsystem is complex and highly optimized — though not
always optimized for today’s workloads. In three adjacent sessions during
the memory-management track of the 2025 Linux Storage, Filesystem,
Memory-Management, and BPF Summit, Kairui Song, Nhat Pham, and Usama Arif
all talked about some of the problems that they are trying to solve in the
Linux swap subsystem. In the first two cases, the solutions take the form of
an additional layer of indirection in the kernel’s swap map; the third,
which enables swap-in of large folios, may or may not be worthwhile in the
end.