Post Syndicated from BeardedTinker original https://www.youtube.com/watch?v=ewSDpmDirpE
Server Core Counts Going Supernova by Q1 2025
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/server-core-counts-going-supernova-by-q1-2025-intel-amd-arm-nvidia-ampere/
Server CPU core counts are exploding like a supernova beyond historical trendlines. This is becoming a wild ride even looking out 3 quarters
The post Server Core Counts Going Supernova by Q1 2025 appeared first on ServeTheHome.
Unsolved Chemistry Problems
Post Syndicated from xkcd.com original https://xkcd.com/2943/

Lower Your Risk of SMS Fraud with Country Level Blocking and Amazon Pinpoint
Post Syndicated from Brett Ezell original https://aws.amazon.com/blogs/messaging-and-targeting/lower-your-risk-of-sms-fraud-with-country-level-blocking-and-amazon-pinpoint/
As a developer, marketing professional, or someone in the communications space, you’re likely familiar with the importance of SMS messaging in engaging customers and driving valuable interactions. However, you may have also encountered the growing challenge of artificially inflated traffic (AIT), also known as SMS pumping. A new report co-authored by
Enea revealed that AIT is so widespread within the SMS ecosystem that 19.8B-35.7B fraudulent messages were sent by bad actors in 2023, incurring substantial costs of over $1 billion. In this blog post, we’ll explore how you can use
Protect configurations, a powerful set of capabilities within
Amazon Pinpoint SMS, that provides granular control over which destination countries your SMS, MMS, and voice messages can be sent to.
Enea revealed that AIT is so widespread within the SMS ecosystem that 19.8B-35.7B fraudulent messages were sent by bad actors in 2023, incurring substantial costs of over $1 billion. In this blog post, we’ll explore how you can use
Protect configurations, a powerful set of capabilities within
Amazon Pinpoint SMS, that provides granular control over which destination countries your SMS, MMS, and voice messages can be sent to.
 ” width=”1252″ height=”889″>
” width=”1252″ height=”889″>
What is SMS Pumping, aka Artificially Inflated Traffic (AIT)?
AIT, or SMS pumping, is a type of fraud where bad actors use bots to generate large volumes of fake SMS traffic. These bots target businesses’ whose websites, apps, and other assets have forms or other mechanisms that trigger SMS being sent out. Common use cases for SMS such as one-time passwords (OTPs), app download links, promotion signups, etc. are all targets for these bad actors to “pump” SMS and send out fraudulent messages. The goal is to artificially inflate the number of SMS messages a business sends, resulting in increased costs and a negative impact on the sender’s reputation. In the realm of SMS-based artificially inflated traffic (AIT), the prevalent method for bad actors to profit involves colluding with parties in the SMS delivery chain to receive a portion of the revenue generated from each fraudulent message sent.
 ” width=”1280″ height=”720″>
” width=”1280″ height=”720″>
AIT poses several challenges for businesses:
-
Overspending: The fake SMS traffic generated by AIT bots results in businesses paying for messages that yield no actual results.
-
Interrupted service: Large volumes of AIT can force businesses to temporarily halt SMS services, disrupting legitimate customer communications.
-
Diverted focus: Dealing with AIT can shift businesses’ attention away from core operations and priorities.
-
Reduced deliverability rates due to the messages never being interacted with and/or large volumes of SMS being sent quickly.
How does Protect mitigate AIT?
Amazon Pinpoint’s Protect feature allows you to control which countries you can send messages to. This is beneficial if your customers are located in specific countries.
With Protect, you can create a list of country rules that either allow or block messages to each destination country. These country rules can be applied to SMS, MMS, and voice messages sent from your AWS account. The Protect configurations you create enable precise control over which destination countries your messages can be sent to. This helps mitigate the impact of AIT by allowing you to tailor where you do or do not send.
Protect offers flexibility in how the country rules are applied. You can apply them at the account level, the configuration set level, or the individual message level. This enables you to customize your AIT mitigation strategy to best fit your business needs and messaging patterns.
By leveraging Protect within Amazon Pinpoint, you can help ensure the integrity and cost-effectiveness of your SMS, MMS, and voice communications.
Account-level Protect Configuration
The simplest approach is to create a Protect configuration and associate it as the account default. This means the allow/block rules defined in that configuration will be applied across all messages sent from your account, unless overridden. This is an effective option if you only need one set of country rules applied universally.
Configuration set-specific Protect configuration
You can associate a Protect configuration with one or more of your Pinpoint SMS configuration sets. This allows you to apply different country rules to distinct messaging flows or use cases within your application without changing your existing code if you are already using Config Sets. It also enables more detailed logging and monitoring of the Protect configuration’s impact, such as:
- Error Logs: Logging of any errors or issues encountered when messages are sent, providing insights into how the Protect configuration is affecting message delivery.
- Audit Logs: Records of all configuration changes, access attempts, and other relevant activities related to the Protect configuration, allowing for comprehensive auditing and monitoring.
- Usage Metrics: Tracking of usage statistics, such as the number of messages sent to different countries, the impact of the Protect configuration on message volumes, and other usage-related data.
- Compliance and Policy Enforcement Logs: Documentation of how the Protect configuration is enforcing compliance with messaging policies and regulations, including any instances where messages are blocked or allowed based on the configuration rules.
Dynamic Protect configuration per message
If your needs are even more specific, you can create a Protect configuration without any association, and then specify its ID when sending messages via the Pinpoint APIs (e.g. SendMediaMessage, SendTextMessage, SendVoiceMessage). This gives you the ability to dynamically choose the Protect configuration to apply for each individual message, providing the ultimate flexibility.
Regardless of the approach, the core benefit of Protect configurations is the ability to precisely control which destination countries your messages may be sent to. Blocking countries where you don’t have a presence or where SMS pricing is high eliminates your exposure to fraudulent AIT traffic originating from those regions. This helps protect your messaging budget, maintain service continuity, and focus your efforts on legitimate customer interactions.
Who should use Protect configurations?
Protect configurations are designed to benefit a wide range of AWS customers, particularly those who:
- Send SMS messages to a limited number of countries: If your business primarily operates in a few specific countries, Protect configurations can help you easily block SMS messages to countries where you don’t have a presence, reducing the risk of AIT.
- Have experienced AIT issues in the past: If your business has been a target of SMS pumping, Protect configurations can help you regain control over your SMS communications and prevent future AIT attacks.
- Want to proactively protect their SMS messaging: Even if you haven’t encountered AIT issues yet, Protect configurations can help you stay ahead of the curve and maintain the integrity of your SMS communications.
How to create a country rules list with Protect configuration
To begin building a list of country rules that allow or block messages to specific destination countries, you start by creating a new Protect configuration. There are two ways to accomplish this, either by using the console, or the API.
Option 1 – Using the AWS Console
Console Scenario: My account is out of the sandbox and I only want to send to 1 country – United Kingdom (iso:GB) using the SenderID “DEMOTP”.
At a high level, we will follow the three steps outlined below for each method. In our examples, we used a SenderID as our Originator. However, it should be noted that the same process can be achieved using any originator you’d like. i.e. SenderID, Phone pool, Phone number, 10DLC, short code, etc.
- Create SenderID (Optional if you already have one)
- Create Protect Configuration
- Send Test Message via console
Using the AWS Console
1) Create SenderID for United Kingdom (GB)
- Pinpoint SMS Console – Request Originator
- Select United Kingdom (GB) and follow the prompts for a SenderID. DO NOT select Two-way SMS Messaging
- Enter Sender ID – Example: DEMOTP
- Confirm and Request
2) Create default Protect Configuration
- Pinpoint SMS Console – Create protect configuration
- Name Protect Configuration
- Select all countries by toggling checkbox in search bar
 ” width=”863″ height=”521″>
” width=”863″ height=”521″>
-
- Search for Country=United Kingdom then deselect United Kingdom
 ” width=”865″ height=”582″>
” width=”865″ height=”582″>
-
- Set as Account Default and select Create protect configuration
 ” width=”1497″ height=”1173″>
” width=”1497″ height=”1173″>
3) Send a test message with SMS simulator
Note: The Pinpoint SMS Simulator provides special phone numbers you can use to send test text messages and receive realistic event records, all within the confines of the Amazon Pinpoint service. These simulator phone numbers are designed to stay entirely within the Pinpoint SMS ecosystem, ensuring your test messages don’t get sent over the carrier network.
You can use these simulator phone numbers to send both SMS and MMS messages, allowing you to thoroughly validate your message content, workflow, and event handling. The responses you receive back will mimic either success or fail depending on which destination simulator number you send to.
- From the Pinpoint SMS Console SMS Simulator page,
- For Originator, Choose Sender ID, and select your Sender ID created from earlier.
- Under Destination number, select Simulator numbers and choose United Kingdom (GB). Enter a test message in the Message body.
- Finally, choose send test message. This should prompt a green “Success” banner at the top of your page.
 ” width=”1336″ height=”1313″>
” width=”1336″ height=”1313″>
-
- Conversely, follow the previous test message steps, and instead attempt to send to anywhere other than the United Kingdom (GB). In this example, Australia (AU)
- As shown below in the screenshot this one is blocked since you have configured to only send to GB.
 ” width=”1333″ height=”1364″>
” width=”1333″ height=”1364″>
Option 2 – Using the V2 API and CLI
V2 API Scenario:
My account is out of the sandbox and I want to BLOCK only 1 country – Australia (AU) while using the SenderID “DEMOTP”.
My account is out of the sandbox and I want to BLOCK only 1 country – Australia (AU) while using the SenderID “DEMOTP”.
1) Create SenderID for GB
Note: before using the CLI remember to configure your access and secret key using
aws configure
Windows users should use PowerShell over cmd to test
- Use RequestSenderId to create the same Sender Id as previously made via the console.
Response:
2) Create default Protect Configuration
- Use CreateProtectConfiguration to create a default Protect Configuration.
Response:
- Add AU as BLOCKED on protect configuration.
Response:
Optimizing Email Deliverability: A User-Centric Approach to List Management and Monitoring
Post Syndicated from Brett Ezell original https://aws.amazon.com/blogs/messaging-and-targeting/optimizing-email-deliverability-a-user-centric-approach-to-list-management-and-monitoring/
Amazon SES Best Practices: Top 5 Best Practices for List Management“. While the fundamental principles of effective email list management remain relevant, the landscape has evolved significantly over the past nine years. This updated post aims to provide
Amazon Simple Email Services (SES) customers with the latest best practices and insights to ensure high deliverability and maintain a strong sender reputation.
Some of the key changes and updates included in this 2024 version are:
- Guidance on protecting sign-up forms with CAPTCHA to prevent bot and bad actor sign-ups
- Heightened importance of monitoring bounce rates, complaint rates, and delivery delays due to new requirements from several mailbox providers (MBPs)
- Introduction to Amazon SES’s Virtual Deliverability Manager (VDM) tool, and a quick explanation how it can help identify deliverability issues
- Updated recommendations on maintaining an engaged subscriber list which includes proactively removing inactive recipients
- Emphasis on the industry-wide adoption of mandatory one-click unsubscribe features and the benefits they provide
- Reinforcement of the need to grow email lists organically and avoid the use of purchased/non-consensual lists
By following the best practices outlined in this updated guide, Amazon SES customers can ensure their email campaigns have the best chance at successfully reaching the inbox. Following these best practices will also help build trust with their subscribers which should result in higher returns on their email marketing investment.
In this blog post, we’ll review the following updated best practices to help you maintain a strong email-sending reputation and ensure high deliverability, including:
- Use Confirmed Opt-in (AKA, Double Opt-in )
- Carefully Monitor Bounces, Complaints, and Delivery Delays
- Maintain an Engaged Subscriber List by Removing Inactive Recipients
- Make Unsubscribing Easy to Maintain a Clean, Compliant List
- Build Trust by Growing Your List Organically
Use Confirmed Opt-in (AKA, Double Opt-in )
Targeting active and engaged users is one of the most effective ways to maintain a strong sender reputation. This time-tested best practice is known as confirmed opt-in (also known as double opt-in). This process is quick to implement and highly effective. When a user signs up for a newsletter or special offer using their email address via a form on your website, you should verify the legitimacy of the email address by sending a verification email to the provided address and asking the requestor to click a link that confirms their consent to receive your emails. By clicking this link, the email address owner explicitly provides their consent to receiving email notifications. Once the recipient verifies the request, you then add their email address to your active mailing list. Most users are now familiar with this type of verification, and legitimate recipients will have no trouble confirming their interest.
Our guidance regarding the confirmed opt-in best practice has evolved due to the prevalence of online bots and bad actors. To maintain a strong sender reputation, we now recommend protecting your web sign-up forms with a CAPTCHA (or similar mechanism). This helps ensure the requests to join your mailing list come from a real human, not a ‘bot or some form of automation or deception. Only after a requestor proves they are human would you accept their email address and then send the verification email. This additional layer of protection prevents bots and bad actors from signing up users without their consent.
CAPTCHA has become a foundational element of the double opt-in process. Protecting the sign-up process with a CAPTCHA will limit the number of unsolicited confirmation messages sent to users, and subsequently reduce the chances of mailbox providers labeling the confirmation messages as spam. If the confirmation messages are blocked by MBPs, then the double opt-in process simply isn’t viable.
 ” width=”1611″ height=”680″>
” width=”1611″ height=”680″>
Figure 1: AWS WAF CAPTCHA examples.
By verifying the legitimacy of your email recipients upfront through confirmed opt-in, you will reduce the number of invalid recipient bounces associated with fake emails, typographical errors, and illegitimate sign-ups by bad actors and bots. This is crucial, as these types of invalid addresses can negatively impact your sending reputation.
 ” width=”964″ height=”732″>
” width=”964″ height=”732″>
Figure 2: A diagram showing the ideal confirmed opt-in architecture to limit risk of bot abuse.
- Adding a CAPTCHA on the sign-up web form proves that a human is interacting with the sign-up process.
- Ensuring the link is clicked proves that a person or application with access to the mailbox was able to click the link.
- Requiring the recipient to enter the correct one-time passcode, commonly referred to as OTP, into the web form proves that the human requesting sign-up is the same as the person confirming the sign-up
- Monitoring bounce, complaint, and delivery delay events proves that the email address is valid and that there are not recipients who are marking the confirmation messages as spam.
- Use a subdomain for sending the confirmation messages to limit reputational impact on deliverability in case there are signs of web form abuse
- If there are signs of web form abuse, give recipients an easy option to report abuse so that they don’t mark the messages as spam.
Confirmed opt-in ensures you only send to subscribers who have explicitly consented to receive your messages. By honoring their subscription preferences, you further reduce the chances of complaints. Providing recipients with an easy, one-click unsubscribe option is crucial, as it demonstrates your commitment to respecting their communication preferences.
Many successful senders capitalize on the verification window by immediately sending a welcome email. This offers two key benefits:
-
- Boost Engagement: While conveying a warm welcome, the email subtly re-engages the new subscriber, and keeps your brand fresh in their mind.
- Double-Duty Verification: These emails often include a call-to-action (CTA) that serves as additional verification and validation of the recipient’s interest in receiving your emails.
- Increases Trust in your Brand: By offering an easy way to unsubscribe from the welcome email, it gives recipients confidence that they will be able to unsubscribe at any time.
Carefully Monitor Bounces, Complaints, and Delivery Delays
Update: Monitoring these metrics has become substantially more important due to recent changes by mailbox providers. As of February 2024, Google, Yahoo, Microsoft and other MBPs now require all bulk-senders to keep their spam complaint rates below 0.3%. These MBPs explain that maintaining a low spam complaint rate benefits both senders and recipients by enhancing email deliverability, preserving sender reputation, and fostering a more positive user experience for their in-box subscribers.
To fully understand the latest industry standards and requirements, we recommend:
- Read the Overview: Get a quick grasp of the key compliance guidelines
- Watch the Webinar: Dive deeper into the specific details and best practices presented by the AWS and Gmail teams.
Amazon SES provides real-time feedback on bounces, complaints, and delivery delay events through its event publishing feature. This enables you to quickly identify and remove problematic email addresses, ensuring you maintain a clean and healthy subscriber list.
If you receive a hard bounce or a complaint, it’s essential to remove that email address from your list and investigate the root cause. For example, a sudden increase in bounce and/or complaint rates for new subscriptions may indicate an issue with fake sign-ups. In such cases, leveraging confirmed opt-in (the BCP, or best current practice, of list building) can help discourage this problem. By using a separate domain for your signups and OTPs, you can distinguish bounces and complaints from sign-ups and other transactional message types, in comparison to your marketing or promotional messages.. More can be found here.
Amazon SES’s Virtual Deliverability Manager (VDM) is an Amazon SES feature that helps senders identify deliverability trends and potential deliverability issues without the need to build additional dashboards. VDM provides deep insights into your sending data and offers actionable recommendations to improve deliverability. VDM helps monitor bounce rates, complaint rates, and other key performance indicators (KPIs) to support email delivery success metrics. VDM allows senders to explore deliverability issues, including the ability to drill down from account level statistics all the way down to the individual message level. This will help identify problematic emails without needing to sift through all of your deliverability data. Key capabilities include:
- Bounce Details: Use VDM to identify bounced emails by recipient addresses, timestamps. and SMTP response codes. These are received directly from the recipient mailbox providers. Users can then group emails by bounce type (permanent and transient) and recipient domains to analyze and take correct action before before smaller deliverability events like message delays turn into larger problems like messages being blocked by the MBPs.
- Complaints: Identify recipients who marked emails as spam so they can be removed from the active mailing list.
- Note: for metric tracking tied specifically to Gmail recipients, customers should also be monitoring Google Postmaster Tools to track their reputation and keep their spam complaint rates low.
- Delivery Metrics: Monitor delivery attempts, retries, and success to make informed decisions based on real-time data to continuously improve deliverability.
VDM proactively flags potential problems like bounces and complaints that could harm your sender reputation and delivery rates. By addressing these issues early, you can verify that your emails consistently reach the inbox, instead of the spam folder.
While VDM is a paid service for Amazon SES customers, there is a free tier that provides a flexible way to test out the tool without any expenses or commitments.
To dive deeper into VDM consult these resources:
- Explore the Improve Email Deliverability with VDM: resource to learn about the feature’s capabilities and benefits.
- Discover how to Access VDM and DMARC Reports Outside of the AWS Console using Amazon QuickSight.
For additional guidance on SES bounce and complaint monitoring, refer to the following resources:
Amazon SES Documentation:
Amazon SES Blog Posts:
Maintain an Engaged Subscriber List by Removing Inactive Recipients
As an email marketer, you must operate under the assumption that if a subscriber is not opening your emails, or is no longer engaging with the calls-to-action in your emails, they are no longer interested in the content that you are sending. Subscribers who fall into this category should be periodically removed from your mailing lists to help ensure your subscriber lists are healthy and engaged. Increase campaign success and deliverability by periodically reviewing and updating your subscription lists with this two-pronged approach:
Track Subscriber Engagement with Amazon SES
Amazon SES provides methods to monitor your sending activity using events, metrics, and statistics. These monitoring methods can be used to measure the rates at which your customers engage with the emails you send. For example, you can identify your overall open and click through rates by utilizing SES’ event publishing when using custom email domains that you associate with configuration sets as discussed in the SES documentation.
 ” width=”661″ height=”341″>
” width=”661″ height=”341″>
Figure 3: Serverless Architecture to Analyze Amazon SES events
To track your email sending activities at a granular level, refer to the AWS blog post, Analyzing Amazon SES event data with AWS Analytics Services.
Proactively Remove Non-Engaging Subscribers
Imagine a scenario where a subscriber signs up for your email list but never engages by opening or clicking through your messages. This lack of activity could indicate the subscriber’s loss of interest. To address this, we recommend you set a reasonable timeframe for engagement based on your industry standards (e.g., 6 months of no opens or clicks). However, this timeframe may need to be adjusted depending on how regularly you send emails to your subscribers. For instance, if you send a daily newsletter, a 6-month period of inactivity may be too long before removing the subscriber. Conversely, if you only send monthly updates, a 6-month window may be more appropriate. The key is to find the right balance – remove subscribers who have clearly lost interest, but don’t be too hasty in culling your list if they simply don’t engage as frequently as your regular email cadence. By tailoring the engagement timeframe to your specific email frequency, you can ensure your subscriber list remains active and engaged.
Consider a “Win-back” Email Campaign
Before removing completely inactive subscribers from your list, consider sending them a special “win-back” email. This final attempt to re-engage them can be an effective strategy to win-back valuable subscribers. The win-back email should have a clear and compelling call-to-action, encouraging recipients to re-engage with the messages you are sending to them. This could include updating their preferences or confirming their interest in your messages. By giving these subscribers another chance, you may be able to reactivate a portion of your list and retain those recipients. However, if the win-back email fails to elicit a response, it’s best to remove those addresses from your active mailing list to maintain a healthy, engaged subscriber base.
Even subscribers who originally opted in through a confirmed double opt-in process can become inactive over time. Occasionally these email addresses are abandoned and can be converted into spam traps by the domain owner. Spam traps are email addresses used by organizations to identify senders who may not be following best practices for list building and long-term list hygiene. If you continue to email these inactive addresses, several negative consequences can occur. our domain could be at risk of generating poor reputation at a mailbox provider, or end up on a real-time blocklist, which may impact deliverability to multiple mailbox providers. In some cases, this could result in your Amazon SES service being suspended.
Proactively removing non-engaging subscribers is the only way to avoid these potential pitfalls and maintain a strong sender reputation.
For a deeper dive into the topic, refer to the following resources:
When you proactively remove subscribers who fail to interact with your emails, you are better able to keep your subscriber base fresh and engaged, improving your overall deliverability and campaign success rates. As an added benefit, pruning inactive subscribers reduces your email sending costs, as you’ll only be reaching out to genuinely interested subscribers, improving the return on investment from your email campaigns.
Removing inactive subscribers is a powerful complement to your confirmed opt-in practices, helping you maintain a healthy, high-performing email list.
Make Unsubscribing Easy to Maintain a Clean, Compliant List
Update: Providing recipients with clear, easy-to-use unsubscribe options has become even more crucial due to recent changes by major email providers.
As of February 2024, Google and Yahoo now require all bulk email senders to include a prominent unsubscribe link within their messages. In June 2024 the implementation of one-click unsubscribe headers (as defined by RFC 2369 and RFC 8058) also become mandatory across the industry.
 ” width=”1800″ height=”563″>
” width=”1800″ height=”563″>
Figure 4: A diagram of one-click unsubscribe flow.
The new industry wide bulk sender requirements ultimately benefit both senders and recipients by:
- Reducing Spam Complaints – Easy unsubscribe options decrease the likelihood of frustrated recipients marking your emails as spam. This helps maintain a positive sender reputation.
- Improving Sender Reputation – A clean email list with engaged and consented subscribers keeps your sender reputation healthy, ensuring your messages consistently reach the inbox rather than the spam folder.
It is critical you respect your audience’s wishes as they relate to your email sending. When you offer recipients a straightforward, easy unsubscribe path to manage their communication preferences, it will allow you keep your email lists clean and compliant which helps you maintain a strong sender reputation. Many regions, including the US, Canada, and parts of Europe and Asia, have adopted laws requiring senders to provide clear, accessible unsubscribe mechanisms. Adhering to these regulations helps you avoid potential legal issues related to your sending and local messaging laws.
Amazon SES provides a basic, subscription management capability that supports the Bulk Sender Requirements as outlined in the SES documentation. Some SES customers have opted to develop & deploy their own custom, more comprehensive systems, to process end-user unsubscribe requests. For a deeper dive into the topic, refer to the AWS blog post Using one-click unsubscribe with Amazon SES.
Build Trust by Growing Your List Organically
Avoid the Temptation of Shortcuts
It may be tempting to take shortcuts, such as using purchased email lists from brokers. However, these “opt-in” addresses often belong to recipients who signed up for the broker’s list, not yours. Relying on these non-organic lists can lead to disastrous consequences:
- Spam Complaints: Recipients who never consented to receive your emails are much more likely to mark them as spam, harming your sender reputation.
- Legal Issues: Many countries, especially with the new <0.3% spam rate requirement, have strict laws prohibiting the use of non-consensual email lists.
- Unsubscribes and Lost Trust: Sending unwanted emails can result in high unsubscribe rates and damage your brand’s reputation.
Focus on Building Your List Organically
Instead of acquiring lists from brokers, focus on building your email list organically by following the best practices we’ve discussed, such as confirmed opt-in and clear unsubscribe options. This will help you attract and retain engaged subscribers who genuinely want to receive your content, fostering trust and a positive sender-to-recipient relationship.
Respect Individual Preferences
It’s crucial to respect each recipient’s communication preferences, even within your own organization. Just because someone signed up for emails from Brand A doesn’t mean they want to receive messages from Brand B, even if both brands are from the same company. Sending these types of cross-brand unsolicited emails can harm your reputation and lead to spam complaints. To avoid this common pitfall, build separate email lists for each of your brands. This ensures recipients only receive the content they’ve explicitly opted-in for, strengthening their trust and increasing engagement.
The long-term benefits of an organically grown, engaged email list are well documented and include improved deliverability, higher open/click rates and better return on your email marketing investments.
Land in Inboxes, Not Spam Folders: The Power of Streamlined List Management
Throughout this updated guide, we’ve explored five essential best practices for email list management that can help Amazon SES customers maintain a strong sender reputation and ensure high deliverability.
We initially discussed the importance of confirmed opt-in (or double opt-in), and how incorporating CAPTCHA has become a foundational element to protect against bot and bad actor sign-ups. By verifying the legitimacy of your subscribers upfront, you minimize the impact of invalid addresses and reduce the chances of complaints as a result of form abuse.
Next, we emphasized the heightened need to carefully monitor key metrics like bounces, complaints, and delivery delays. We discussed email management tools and features like Amazon SES Virtual Deliverability Manager that can provide critical deliverability insight into your email program. Addressing deliverability issues early is crucial to preserving your sender reputation and keeping your messages flowing to the inbox.
We also covered strategies for maintaining an engaged subscriber list, including proactively removing inactive recipients and considering targeted “winback” campaigns. Keeping your list fresh and responsive pays dividends in the form of better inbox placement and campaign performance.
Making unsubscribing easy for recipients has likewise become an essential practice, not just for compliance but also for building trust and reducing spam complaints. The one-click unsubscribe standards now required by mailbox providers work to the benefit of both senders and recipients.
Lastly, we stressed the importance of organic list growth over shortcuts like purchased email lists. Respecting individual preferences, even within your own brand, helps you attract and retain subscribers who are genuinely interested in your content.
By adhering to these five best practices of email list management, you’ll be able to build and maintain a marketing asset in the form of an email list that will provide you a long-term channel for communicating with your customers and end-users.
If you have any questions or need further guidance, feel free to reach out to us via the
SES Forums or in the comments section of this blog post. We’re here to help you navigate the evolving email landscape and unlock the full potential of your Amazon SES investment.
SES Forums or in the comments section of this blog post. We’re here to help you navigate the evolving email landscape and unlock the full potential of your Amazon SES investment.
About the Authors

Brett Ezell is your friendly neighborhood Solutions Architect at AWS, where he specializes in helping customers optimize their SMS and email campaigns using Amazon Pinpoint and Amazon Simple Email Service. As a former US Navy veteran, Brett brings a unique perspective to his work, ensuring customers receive tailored solutions to meet their needs. In his free time, Brett enjoys live music, collecting vinyl, and the challenges of a good workout. And, as a self-proclaimed comic book aficionado, he can often be found combing through his local shop for new books to add to his collection.

Zip is an Amazon Pinpoint and Amazon Simple Email Service Sr. Specialist Solutions Architect at AWS. Outside of work he enjoys time with his family, cooking, mountain biking and plogging.

Jesse Thompson is an Email Deliverability Manager with the Amazon Simple Email Service team. His background is in enterprise development and operations, with a focus on email abuse mitigation and encouragement of authenticity practices with open standard protocols. Jesse’s favorite activity outside of technology is recreational curling.
Round 2: A Survey of Causal Inference Applications at Netflix
Post Syndicated from Netflix Technology Blog original https://netflixtechblog.com/round-2-a-survey-of-causal-inference-applications-at-netflix-fd78328ee0bb
At Netflix, we want to ensure that every current and future member finds content that thrills them today and excites them to come back for more. Causal inference is an essential part of the value that Data Science and Engineering adds towards this mission. We rely heavily on both experimentation and quasi-experimentation to help our teams make the best decisions for growing member joy.
Building off of our last successful Causal Inference and Experimentation Summit, we held another week-long internal conference this year to learn from our stunning colleagues. We brought together speakers from across the business to learn about methodological developments and innovative applications.
We covered a wide range of topics and are excited to share five talks from that conference with you in this post. This will give you a behind the scenes look at some of the causal inference research happening at Netflix!
Metrics Projection for Growth A/B Tests
Mihir Tendulkar, Simon Ejdemyr, Dhevi Rajendran, David Hubbard, Arushi Tomar, Steve Beckett, Judit Lantos, Cody Chapman, Ayal Chen-Zion, Apoorva Lal, Ekrem Kocaguneli, Kyoko Shimada
Experimentation is in Netflix’s DNA. When we launch a new product feature, we use — where possible — A/B test results to estimate the annualized incremental impact on the business.
Historically, that estimate has come from our Finance, Strategy, & Analytics (FS&A) partners. For each test cell in an experiment, they manually forecast signups, retention probabilities, and cumulative revenue on a one year horizon, using monthly cohorts. The process can be repetitive and time consuming.
We decided to build out a faster, automated approach that boils down to estimating two pieces of missing data. When we run an A/B test, we might allocate users for one month, and monitor results for only two billing periods. In this simplified example, we have one member cohort, and we have two billing period treatment effects (𝜏.cohort1,period1 and 𝜏.cohort1,period2, which we will shorten to 𝜏.1,1 and 𝜏.1,2, respectively).
To measure annualized impact, we need to estimate:
- Unobserved billing periods. For the first cohort, we don’t have treatment effects (TEs) for their third through twelfth billing periods (𝜏.1,j , where j = 3…12).
- Unobserved sign up cohorts. We only observed one monthly signup cohort, and there are eleven more cohorts in a year. We need to know both the size of these cohorts, and their TEs (𝜏.i,j, where i = 2…12 and j = 1…12).
For the first piece of missing data, we used a surrogate index approach. We make a standard assumption that the causal path from the treatment to the outcome (in this case, Revenue) goes through the surrogate of retention. We leverage our proprietary Retention Model and short-term observations — in the above example, 𝜏.1,2 — to estimate 𝜏.1,j , where j = 3…12.
For the second piece of missing data, we assume transportability: that each subsequent cohort’s billing-period TE is the same as the first cohort’s TE. Note that if you have long-running A/B tests, this is a testable assumption!
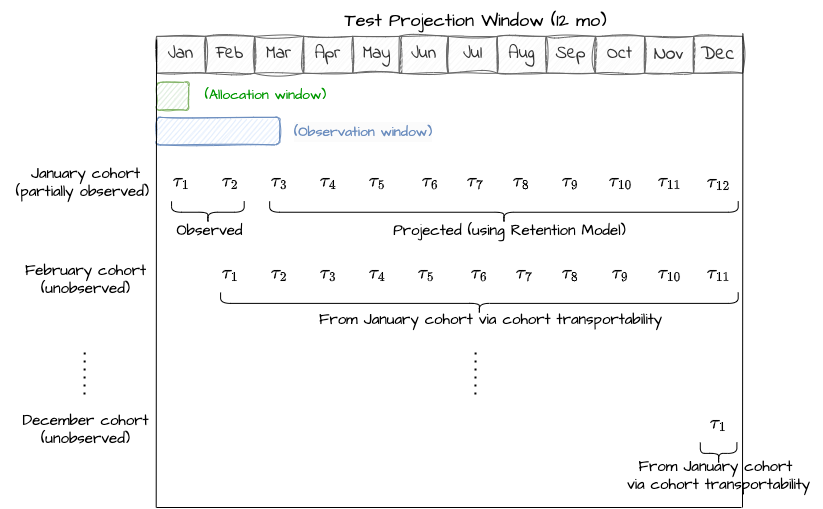
Now, we can put the pieces together. For the first cohort, we project TEs forward. For unobserved cohorts, we transport the TEs from the first cohort and collapse our notation to remove the cohort index: 𝜏.1,1 is now written as just 𝜏.1. We estimate the annualized impact by summing the values from each cohort.
We empirically validated our results from this method by comparing to long-running AB tests and prior results from our FS&A partners. Now we can provide quicker and more accurate estimates of the longer term value our product features are delivering to members.
A Systematic Framework for Evaluating Game Events
In Netflix Games DSE, we are asked many causal inference questions after an intervention has been implemented. For example, how did a product change impact a game’s performance? Or how did a player acquisition campaign impact a key metric?
While we would ideally conduct AB tests to measure the impact of an intervention, it is not always practical to do so. In the first scenario above, A/B tests were not planned before the intervention’s launch, so we needed to use observational causal inference to assess its effectiveness. In the second scenario, the campaign is at the country level, meaning everyone in the country is in the treatment group, which makes traditional A/B tests inviable.
To evaluate the impacts of various game events and updates and to help our team scale, we designed a framework and package around variations of synthetic control.
For most questions in Games, we have game-level or country-level interventions and relatively little data. This means most pre-existing packages that rely on time-series forecasting, unit-level data, or instrumental variables are not useful.
Our framework utilizes a variety of synthetic control (SC) models, including Augmented SC, Robust SC, Penalized SC, and synthetic difference-in-differences, since different approaches can work best in different cases. We utilize a scale-free metric to evaluate the performance of each model and select the one that minimizes pre-treatment bias. Additionally, we conduct robustness tests like backdating and apply inference measures based on the number of control units.
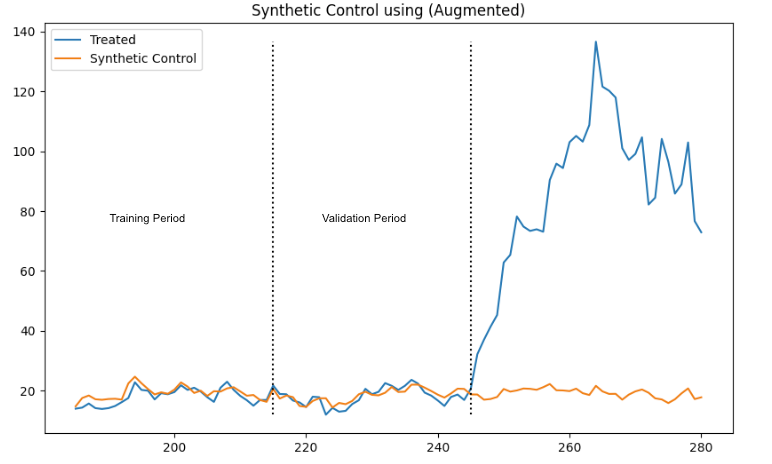
This framework and package allows our team, and other teams, to tackle a broad set of causal inference questions using a consistent approach.
Double Machine Learning for Weighing Metrics Tradeoffs
Apoorva Lal, Winston Chou, Jordan Schafer
As Netflix expands into new business verticals, we’re increasingly seeing examples of metric tradeoffs in A/B tests — for example, an increase in games metrics may occur alongside a decrease in streaming metrics. To help decision-makers navigate scenarios where metrics disagree, we developed a method to compare the relative importance of different metrics (viewed as “treatments”) in terms of their causal effect on the north-star metric (Retention) using Double Machine Learning (DML).
In our first pass at this problem, we found that ranking treatments according to their Average Treatment Effects using DML with a Partially Linear Model (PLM) could yield an incorrect ranking when treatments have different marginal distributions. The PLM ranking would be correct if treatment effects were constant and additive. However, when treatment effects are heterogeneous, PLM upweights the effects for members whose treatment values are most unpredictable. This is problematic for comparing treatments with different baselines.
Instead, we discretized each treatment into bins and fit a multiclass propensity score model. This lets us estimate multiple Average Treatment Effects (ATEs) using Augmented Inverse-Propensity-Weighting (AIPW) to reflect different treatment contrasts, for example the effect of low versus high exposure.
We then weight these treatment effects by the baseline distribution. This yields an “apples-to-apples” ranking of treatments based on their ATE on the same overall population.
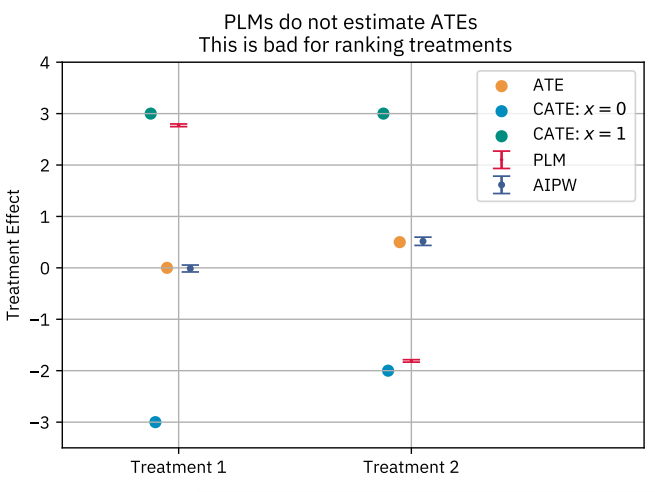
In the example above, we see that PLM ranks Treatment 1 above Treatment 2, while AIPW correctly ranks the treatments in order of their ATEs. This is because PLM upweights the Conditional Average Treatment Effect for units that have more unpredictable treatment assignment (in this example, the group defined by x = 1), whereas AIPW targets the ATE.
Survey AB Tests with Heterogeneous Non-Response Bias
Andreas Aristidou, Carolyn Chu
To improve the quality and reach of Netflix’s survey research, we leverage a research-on-research program that utilizes tools such as survey AB tests. Such experiments allow us to directly test and validate new ideas like providing incentives for survey completion, varying the invitation’s subject-line, message design, time-of-day to send, and many other things.
In our experimentation program we investigate treatment effects on not only primary success metrics, but also on guardrail metrics. A challenge we face is that, in many of our tests, the intervention (e.g. providing higher incentives) and success metrics (e.g. percent of invited members who begin the survey) are upstream of guardrail metrics such as answers to specific questions designed to measure data quality (e.g. survey straightlining).
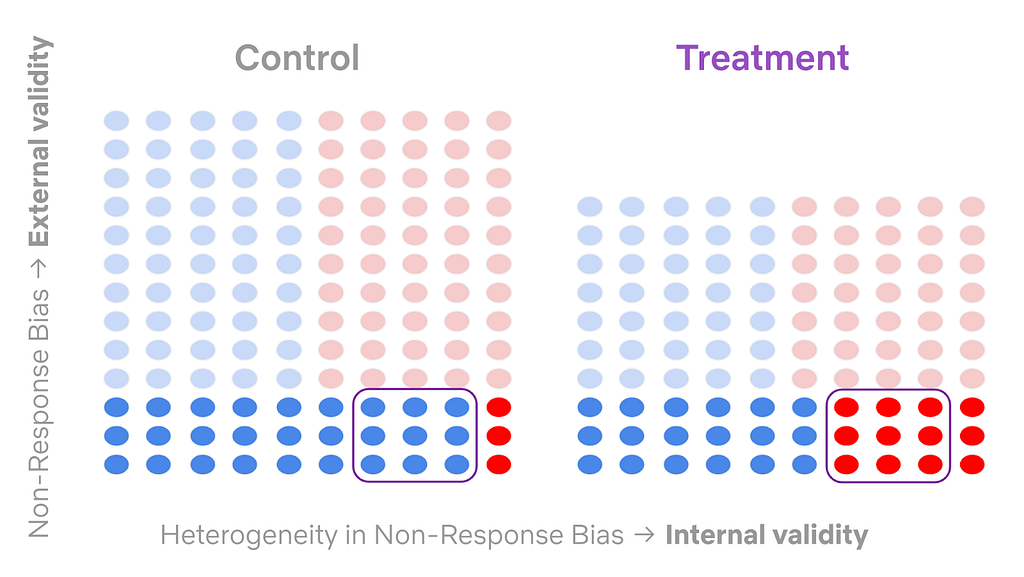
In such a case, the intervention may (and, in fact, we expect it to) distort upstream metrics (especially sample mix), the balance of which is a necessary component for the identification of our downstream guardrail metrics. This is a consequence of non-response bias, a common external validity concern with surveys that impacts how generalizable the results can be.
For example, if one group of members — group X — responds to our survey invitations at a significantly lower rate than another group — group Y — , then average treatment effects will be skewed towards the behavior of group Y. Further, in a survey AB test, the type of non-response bias can differ between control and treatment groups (e.g. different groups of members may be over/under represented in different cells of the test), thus threatening the internal validity of our test by introducing a covariate imbalance. We call this combination heterogeneous non-response bias.
To overcome this identification problem and investigate treatment effects on downstream metrics, we leverage a combination of several techniques. First, we look at conditional average treatment effects (CATE) for particular sub-populations of interest where confounding covariates are balanced in each strata.
In order to examine the average treatment effects, we leverage a combination of propensity scores to correct for internal validity issues and iterative proportional fitting to correct for external validity issues. With these techniques, we can ensure that our surveys are of the highest quality and that they accurately represent our members’ opinions, thus helping us build products that they want to see.
Design: The Intersection of Humans and Technology
A design talk at a causal inference conference? Why, yes! Because design is about how a product works, it is fundamentally interwoven into the experimentation platform at Netflix. Our product serves the huge variety of internal users at Netflix who run — and consume the results of — A/B tests. Thus, choosing how to enable our users to take action and how we present data in the product is critical to decision-making via experimentation.
If you were to display some numbers and text, you might opt to show it in a tabular format.

While there is nothing inherently wrong with this presentation, it is not as easily digested as something more visual.
If your goal is to illustrate that those three numbers add up to 100%, and thus are parts of a whole, then you might choose a pie chart.
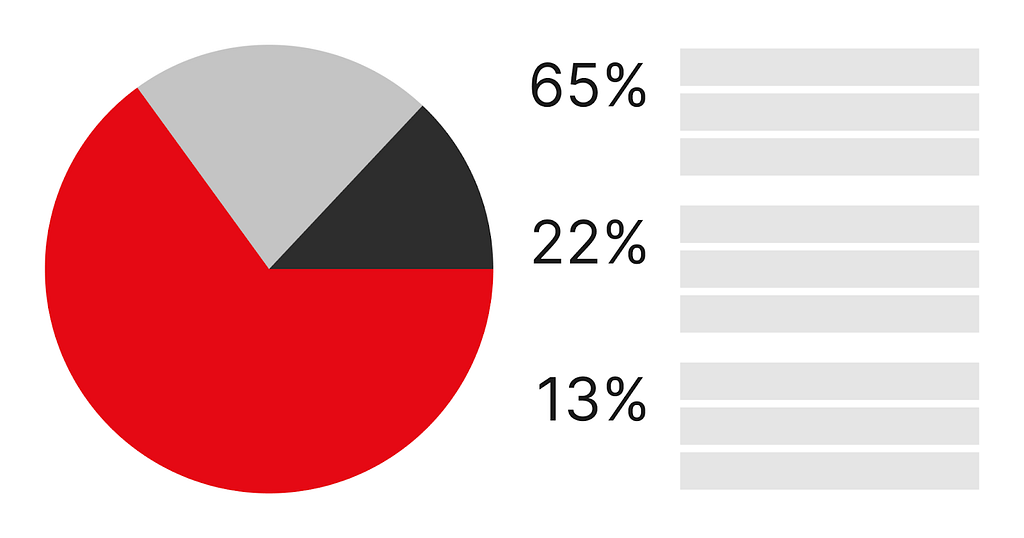
If you wanted to show how these three numbers combine to illustrate progress toward a goal, then you might choose a stacked bar chart.
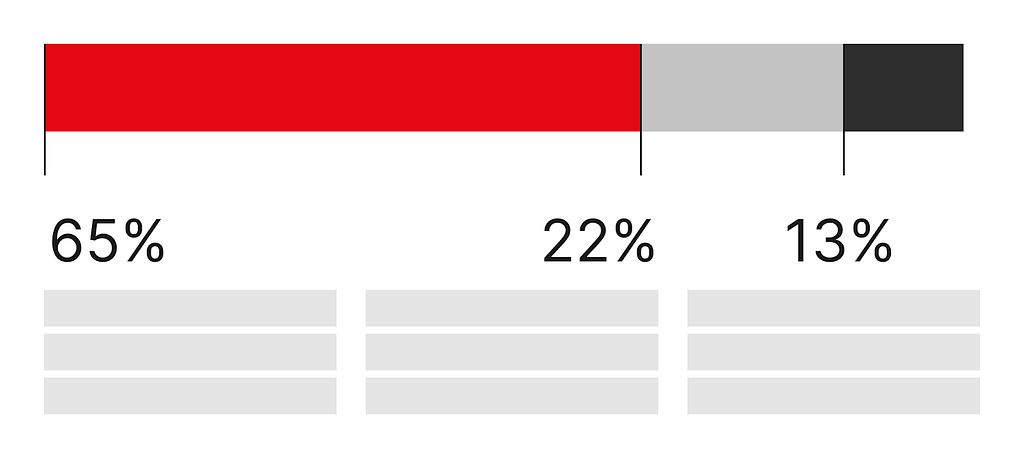
Alternatively, if your goal was to compare these three numbers against each other, then you might choose a bar chart instead.
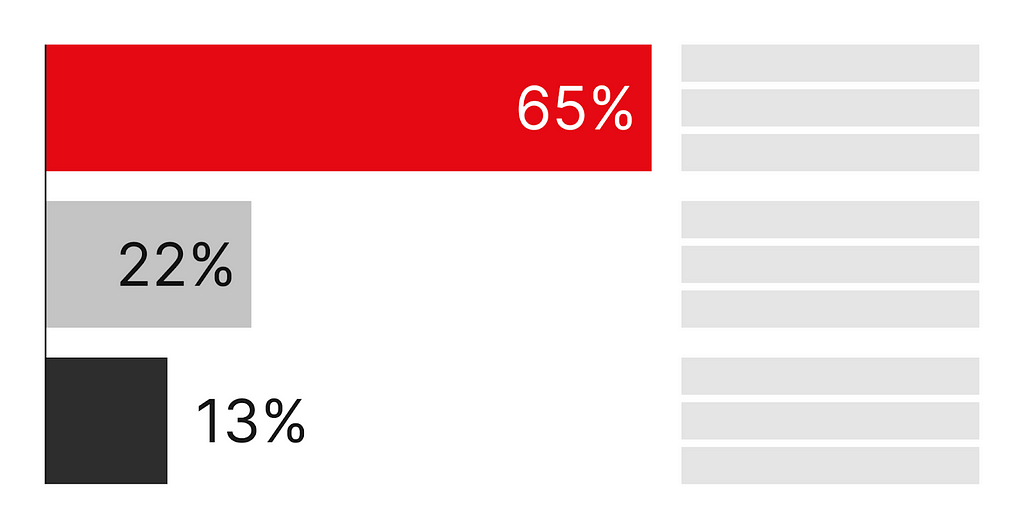
All of these show the same information, but the choice of presentation changes how easily a consumer of an infographic understands the “so what?” of the point you’re trying to convey. Note that there is no “right” solution here; rather, it depends on the desired takeaway.
Thoughtful design applies not only to static representations of data, but also to interactive experiences. In this example, a single item within a long form could be represented by having a pre-filled value.
Alternatively, the same functionality could be achieved by displaying a default value in text, with the ability to edit it.

While functionally equivalent, this UI change shifts the user’s narrative from “Is this value correct?” to “Do I need to do something that is not ‘normal’?” — which is a much easier question to answer. Zooming out even more, thoughtful design addresses product-level choices like if a person knows where to go to accomplish a task. In general, thoughtful design influences product strategy.
Design permeates all aspects of our experimentation product at Netflix, from small choices like color to strategic choices like our roadmap. By thoughtfully approaching design, we can ensure that tools help the team learn the most from our experiments.
External Speaker: Kosuke Imai
In addition to the amazing talks by Netflix employees, we also had the privilege of hearing from Kosuke Imai, Professor of Government and Statistics at Harvard, who delivered our keynote talk. He introduced the “cram method,” a powerful and efficient approach to learning and evaluating treatment policies using generic machine learning algorithms.
Measuring causality is a large part of the data science culture at Netflix, and we are proud to have many stunning colleagues who leverage both experimentation and quasi-experimentation to drive member impact. The conference was a great way to celebrate each other’s work and highlight the ways in which causal methodology can create value for the business.
To stay up to date on our work, follow the Netflix Tech Blog, and if you are interested in joining us, we are currently looking for new stunning colleagues to help us entertain the world!
![]()
Round 2: A Survey of Causal Inference Applications at Netflix was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Dutch political websites hit by cyber attacks as EU voting starts
Post Syndicated from João Tomé original https://blog.cloudflare.com/dutch-political-websites-hit-by-cyber-attacks-as-eu-voting-starts

The 2024 European Parliament election started in the Netherlands today, June 6, 2024, and will continue through June 9 in the other 26 countries that are part of the European Union. Cloudflare observed DDoS attacks targeting multiple election or politically-related Internet properties on election day in the Netherlands, as well as the preceding day.
These elections are highly anticipated. It’s also the first European election without the UK after Brexit.
According to news reports, several websites of political parties in the Netherlands suffered cyberattacks on Thursday, with a pro-Russian hacker group called HackNeT claiming responsibility.
On June 5 and 6, 2024, Cloudflare systems automatically detected and mitigated DDoS attacks that targeted at least three politically-related Dutch websites. Significant attack activity targeted two of them, and is described below.
A DDoS attack, short for Distributed Denial of Service attack, is a type of cyber attack that aims to take down or disrupt Internet services such as websites or mobile apps and make them unavailable for users. DDoS attacks are usually done by flooding the victim’s server with more traffic than it can handle. To learn more about DDoS attacks and other types of attacks, visit our Learning Center.
Attackers typically use DDoS attacks but also exploit other vulnerabilities and types of attacks simultaneously.
Daily DDoS mitigations on June 5 reached over 1 billion HTTP requests in the Netherlands, most of which targeted two election or political party websites. The attack continued on June 6. Attacks on one website peaked on June 5 at 14:00 UTC (16:00 local time) with 115 million requests per hour, with the attack lasting around four hours. Attacks on another politically-related website peaked at the same time at 65 million requests per hour.
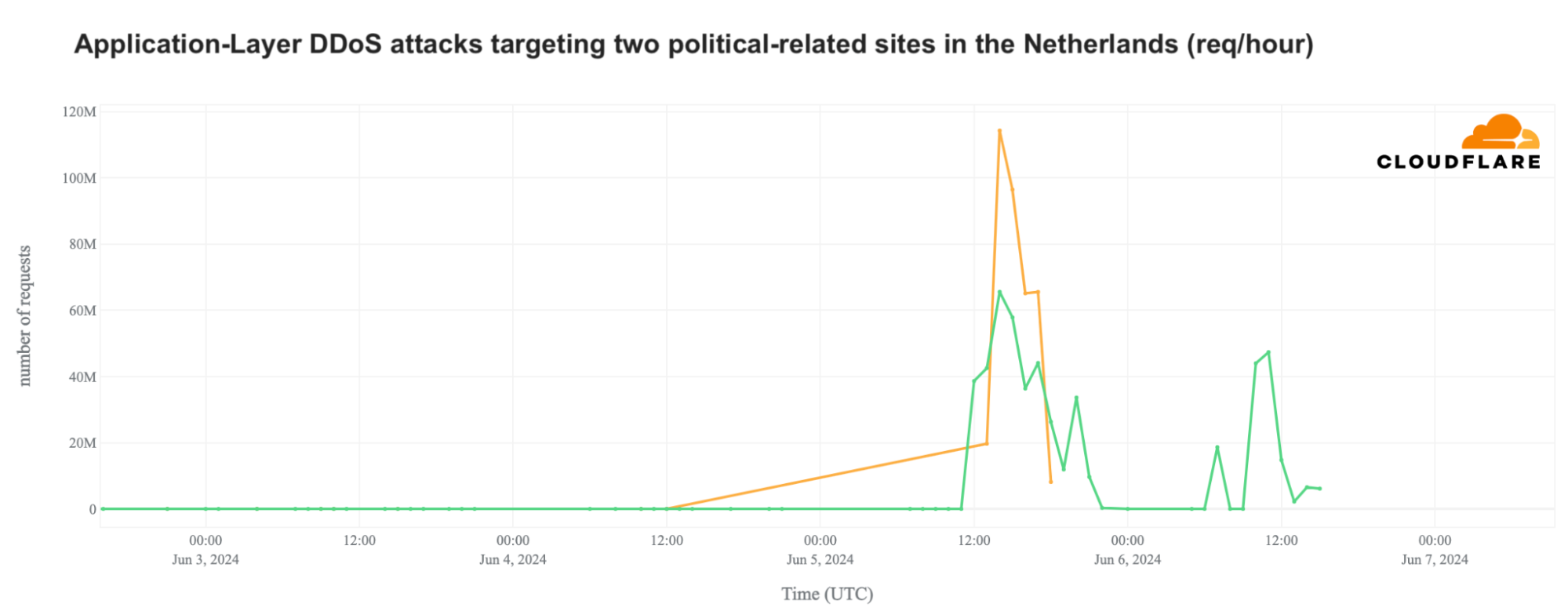
On June 6, the first politically-related site with the highest peak on June 5 referenced above was attacked again for several hours. The main attack peak occurred at 11:00 UTC (13:00 local time), with 44 million requests per hour.
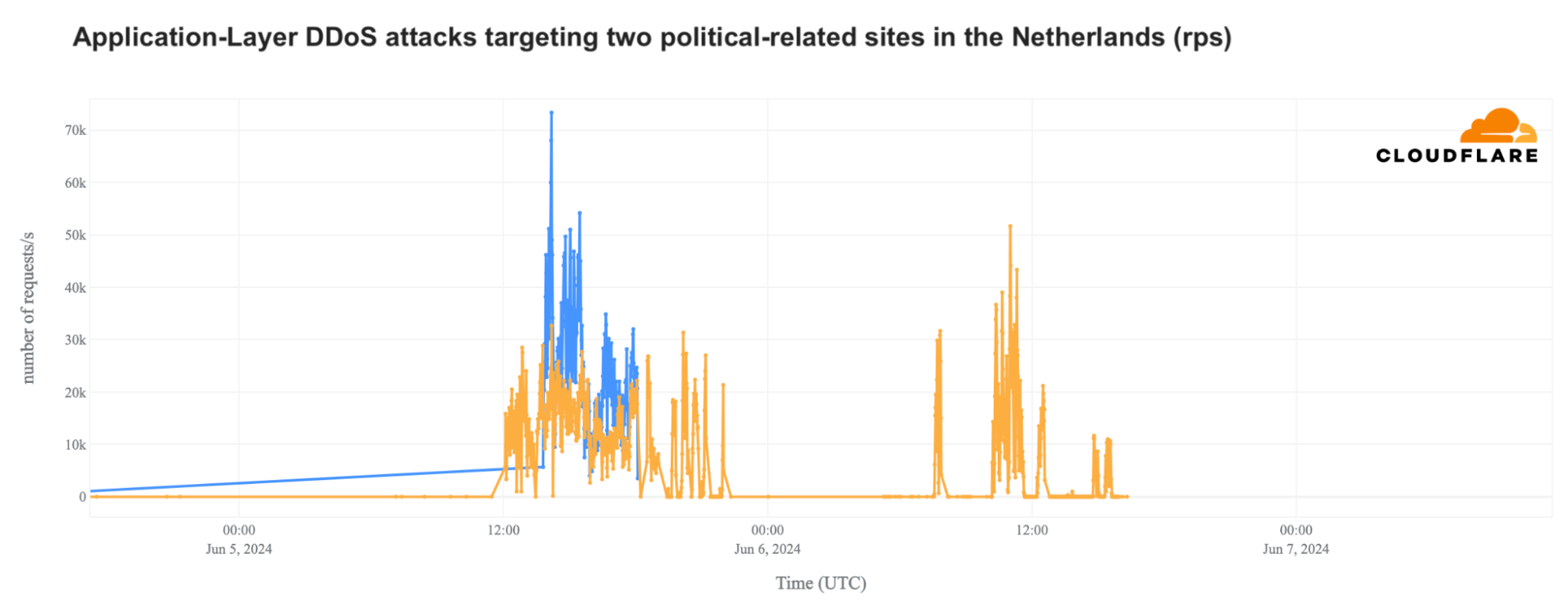
The main June 5 DDoS attack on one of the websites peaked at 14:13 UTC (16:13 local time), reaching 73,000 requests per second (rps) in an attack that lasted for a few hours. This attack is illustrated by the blue line in the graph below, which shows that it ramped slowly over the first half of the day, and then appeared to abruptly stop at 18:06. And on June 6, the main attack on the second website peaked at 11:01 UTC (13:01 local time) with 52,000 rps.
Geopolitical motivations
Elections, geopolitical changes, and disputes also impact the online world and cyberattacks. Our DDoS threat report for Q1 2024 gives a few recent examples. One notable case was the 466% surge in DDoS attacks on Sweden after its acceptance into the NATO alliance, mirroring the pattern observed during Finland’s NATO accession in 2023.
As we’ve seen in recent years, real-world conflicts, disputed and highly anticipated elections, and wars are always accompanied by cyberattacks. We reported (1, 2) on an increase in cyberattacks following the start of the Israel-Hamas war on October 7, 2023. We’ve put together a list of recommendations to optimize your defenses against DDoS attacks, and you can also follow our step-by-step wizards to secure your applications and prevent DDoS attacks.
If you want to follow more trends and insights about the Internet and elections in particular, you can check Cloudflare Radar, and more specifically our new 2024 Elections Insights report, that we’re keeping up to date as national elections take place throughout the year.
Simplify risk and compliance assessments with the new common control library in AWS Audit Manager
Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/simplify-risk-and-compliance-assessments-with-the-new-common-control-library-in-aws-audit-manager/
With AWS Audit Manager, you can map your compliance requirements to AWS usage data and continually audit your AWS usage as part of your risk and compliance assessment. Today, Audit Manager introduces a common control library that provides common controls with predefined and pre-mapped AWS data sources.
The common control library is based on extensive mapping and reviews conducted by AWS certified auditors, verifying that the appropriate data sources are identified for evidence collection. Governance, Risk and Compliance (GRC) teams can use the common control library to save time time when mapping enterprise controls into Audit Manager for evidence collection, reducing their dependence on information technology (IT) teams.
Using the common control library, you can view the compliance requirements for multiple frameworks (such as PCI or HIPAA) associated with the same common control in one place, making it easier to understand your audit readiness across multiple frameworks simultaneously. In this way, you don’t need to implement different compliance standard requirements individually and then review the resulting data multiple times for different compliance regimes.
Additionally, by using controls from this library, you automatically inherit improvements as Audit Manager updates or adds new data sources, such as additional AWS CloudTrail events, AWS API calls, AWS Config rules, or maps additional compliance frameworks to common controls. This eliminates the efforts required by GRC and IT teams to constantly update and manage evidence sources and makes it easier to benefit from additional compliance frameworks that Audit Manager adds to its library.
Let’s see how this works in practice with an example.
Using AWS Audit Manager common control library
A common scenario for an airline is to implement a policy so that their customer payments, including in-flight meals and internet access, can only be taken via credit card. To implement this policy, the airline develops an enterprise control for IT operations that says that “customer transactions data is always available.” How can they monitor whether their applications on AWS meet this new control?
Acting as their compliance officer, I open the Audit Manager console and choose Control library from the navigation bar. The control library now includes the new Common category. Each common control maps to a group of core controls that collect evidence from AWS managed data sources and makes it easier to demonstrate compliance with a range of overlapping regulations and standards. I look through the common control library and search for “availability.” Here, I realize the airline’s expected requirements map to common control High availability architecture in the library.

I expand the High availability architecture common control to see the underlying core controls. There, I notice this control doesn’t adequately meet all the company’s needs because Amazon DynamoDB is not in this list. DynamoDB is a fully managed database, but given extensive usage of DynamoDB in their application architecture, they definitely want their DynamoDB tables to be available when their workload grows or shrinks. This might not be the case if they configured a fixed throughput for a DynamoDB table.
I look again through the common control library and search for “redundancy.” I expand the Fault tolerance and redundancy common control to see how it maps to core controls. There, I see the Enable Auto Scaling for Amazon DynamoDB tables core control. This core control is relevant for the architecture that the airline has implemented but the whole common control is not needed.

Additionally, common control High availability architecture already includes a couple of core controls that check that Multi-AZ replication on Amazon Relational Database Service (RDS) is enabled, but these core controls rely on an AWS Config rule. This rule doesn’t work for this use case because the airline does not use AWS Config. One of these two core controls also uses a CloudTrail event, but that event does not cover all scenarios.

As the compliance officer, I would like to collect the actual resource configuration. To collect this evidence, I briefly consult with an IT partner and create a custom control using a Customer managed source. I select the api-rds_describedbinstances API call and set a weekly collection frequency to optimize costs.

Implementing the custom control can be handled by the compliance team with minimal interaction needed from the IT team. If the compliance team has to reduce their reliance on IT, they can implement the entire second common control (Fault tolerance and redundancy) instead of only selecting the core control related to DynamoDB. It might be more than what they need based on their architecture, but the acceleration of velocity and reduction of time and effort for both the compliance and IT teams is often a bigger benefit than optimizing the controls in place.
I now choose Framework library in the navigation pane and create a custom framework that includes these controls. Then, I choose Assessments in the navigation pane and create an assessment that includes the custom framework. After I create the assessment, Audit Manager starts collecting evidence about the selected AWS accounts and their AWS usage.
By following these steps, a compliance team can precisely report on the enterprise control “customer transactions data is always available” using an implementation in line with their system design and their existing AWS services.
Things to know
The common control library is available today in all AWS Regions where AWS Audit Manager is offered. There is no additional cost for using the common control library. For more information, see AWS Audit Manager pricing.
This new capability streamlines the compliance and risk assessment process, reducing the workload for GRC teams and simplifying the way they can map enterprise controls into Audit Manager for evidence collection. To learn more, see the AWS Audit Manager User Guide.
— Danilo
How Do You Solve a Problem Like Homelessness?
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=I_WXtVM5Ggs
Secure file sharing solutions in AWS: A security and cost analysis guide, Part 1
Post Syndicated from Sumit Bhati original https://aws.amazon.com/blogs/security/how-to-securely-transfer-files-with-presigned-urls/
July 28, 2025: This post has been updated and expanded into a comprehensive two-part series covering multiple AWS file sharing solutions. This new series provides in-depth analysis of security and cost considerations to help you make informed decisions based on your requirements.
Note: This is Part 1 of a two-part post. You can read Part 2 here.
Sharing files with an outside entity—to share data between business partners or facilitate customer access to files—is a common use case for Amazon Web Services (AWS) customers. Organizations must balance security, cost, and usability. In a business-to-business data sharing scenario, these challenges become even more complex because human interaction is often minimal or absent, requiring robust automated solutions. Many AWS services offer multiple options for granting access. The one that’s best for your use case depends on multiple factors.
This post helps you decide which AWS services to use to implement a file sharing approach that suits your business needs. We focus on security controls and cost implications, describe some of the trade-offs, and highlight key differences to help you make an informed decision based on your specific requirements. We go through each option, highlighting their strengths and limitations, and provide guidance on choosing the right solution for your use case.
Understand your needs first
The first step in designing an AWS file sharing solution is to develop a clear understanding of your requirements and constraints. Because there are several possible design patterns and a number of different AWS services to consider, you need to start by identifying and prioritizing the features that you need. Gather the following information to guide your approach:
Access patterns and scale
When planning for access patterns and scale, there are a few key factors to keep in mind. First, consider how files are shared—machine-to-machine, human-to-machine, or human-to-human—because that impacts security and performance. Then, think about transfer frequency—are files exchanged only once a day, or are thousands moving every hour? If download control matters, setting limits on how often a file can be accessed might be necessary. File sizes also play a role, from typical everyday transfers to the largest files you need to support. Finally, total data volume shapes how much information you’ll be transferring on a regular basis.
Technical requirements
Your choice of solution will be influenced by technical constraints and capabilities. Protocol requirements often drive initial decisions, such as whether you need SFTP, FTPS, or HTTPS access. Consider existing systems that must interface with your solution and how they’ll connect. Performance considerations span several dimensions: acceptable latency for file transfers, geographic distribution of your users, bandwidth requirements, and whether you need built-in retry mechanisms for failed transfers. Additionally, think about how many simultaneous transfers your solution needs to support.
Security and compliance
Security and compliance requirements will definitely influence your file sharing strategy. Consider who controls encryption keys—whether managed by AWS or your organization—and what key rotation policies are needed. Authentication needs often vary—you might be authenticating individual users, specific systems, or entire business entities, using methods ranging from passwords to API keys, multi-factor authentication, or certificates. Your audit requirements will influence your choices in logging and monitoring capabilities. You might have geographic considerations like data sovereignty requirements, storage location restrictions, and access controls that consider the recipient’s location. If your data is subject to a law, like GDPR in Europe or HIPAA in the United States, or if your data is regulated by a standard like the Payment Card Industry’s Data Security Standard (PCI-DSS), you will need to consult with your own legal and compliance advisors to see what is required. When assessing risk tolerance, consider the security triad of confidentiality, integrity, and availability—some use cases might tolerate brief periods of unavailability but cannot risk data exposure, while others prioritize continuous availability.
Operational requirements
Day-to-day operations bring their own set of considerations. File retention policies determine how long data needs to be kept, while auto-deletion capabilities might be necessary for managing storage and compliance. Consider what kind of reporting and monitoring of file transfer activities you need. Do you need monthly reports, daily reports or perhaps detailed real-time tracking of transfer activities. By adding handling and notification systems, you can help make sure that problems are caught and addressed promptly. Disaster recovery requirements, expressed through recovery point objectives (RPO) and recovery time objectives (RTO), help determine the resilience needed in your solution.
Business constraints
Your solution must operate within your business constraints, such as budget limitations, technical limitations, timelines, available expertise, and service level agreements (SLAs). Budget limitations include initial implementation costs and ongoing operational expenses. Consider other parties’ technical limitations—they might use specific protocols such as SFTP, require mobile device compatibility, or operate older systems that have limited cryptographic capabilities. Implementation timelines influence choices between managed services that can be deployed quickly and custom solutions that require more time and expertise. The expertise available for solution maintenance is also a consideration. SLAs for file transfers might specify availability and performance requirements that you’re obligated to meet. To meet these constraints, you must estimate how much your file sharing needs will grow over time and determine if you need a regional or a global solution.
By carefully considering these aspects, you’ll be better prepared to evaluate different AWS file sharing solutions and select the one that best fits your use case. Understanding your requirements for uploads and downloads will help determine if your use case can be supported through a single AWS service or needs a combination of services.
Solutions
Let’s start by looking at the various file sharing mechanisms that AWS supports. The following table identifies the key AWS services needed for each solution, describes the security and cost implications of the solutions, and describes their complexity and protocol support capabilities. The following table shows the solutions described in this post.
| Solution | AWS services | Security features | Cost* | Region control |
| AWS Transfer Family | Transfer Family, Amazon S3, API Gateway, and Lambda | Managed security, encryption in transit and at rest, IAM integration, and custom authentication | $0.30 per hour per protocol, data transfer fees, and storage costs | Can deploy to specific AWS Regions, can only transfer files to and from S3 buckets in the same Region |
| Transfer Family web apps | Transfer Family, S3, and CloudFront | Browser-based access, IAM Identity Center integration, and S3 Access Grants | Pay-per-file operation, CloudFront costs, and storage costs | Uses CloudFront (global) for web access, but backend components can be Region-specific |
| Amazon S3 pre-signed URLs | S3 | Time-limited URLs, IAM controls for URL generation, and HTTPS | S3 request and data transfer fees | Can be restricted to specific Regions |
| Serverless application with Amazon S3 presigned URLs | S3, AWS Lambda, and API Gateway | Time-limited URLs, HTTPS, IAM controls, customizable authentication | Pay per request and minimal infrastructure cost | Components can be Region-specific |
The following table shows the solutions described in Part 2.
| Solution | AWS services | Security features | Cost* | Region control |
| CloudFront signed URLs | CloudFront, Amazon S3, and Lambda | Optional edge security using AWS Lambda@Edge, AWS WAF integration, SSL/TLS, geo restrictions, and AWS Shield Standard (included automatically) | Content delivery network (CDN) costs, request pricing, and data transfer fees | Global service by design; origin can be AWS Region-specific |
| Amazon VPC endpoint service | PrivateLink, VPC, and NLB | Complete network isolation, private connectivity, and multi-layer security | Endpoint hourly charges, NLB costs, and data processing fees | Service endpoints are strictly Region-specific; must create endpoints in each Region where access is needed |
| S3 Access Points | S3, IAM, VPC (for VPC-specific access points) |
|
|
|
* Pricing information provided is based on AWS service rates at the time of publication and is intended as an estimation only. Additional costs may be incurred depending on your specific implementation and usage patterns. For the most current and accurate pricing details, please consult the official AWS pricing pages for each service mentioned.
Let’s examine the solutions in detail.
AWS Transfer Family
AWS Transfer Family is a managed file transfer service for SFTP, FTPS, and AS2 protocols. It integrates directly with Amazon Simple Storage Service (Amazon S3) for storage and supports custom identity providers for authentication through Amazon API Gateway and AWS Lambda.
As shown in Figure 1, when a user initiates a file transfer, Transfer Family authenticates them through the configured identity provider using API Gateway and Lambda. After authentication succeeds, the service maps the user to an AWS Identity and Access Management (IAM) role that defines their S3 bucket access permissions. The service encrypts data in transit using TLS 1.2 and data at rest using S3 server-side encryption.
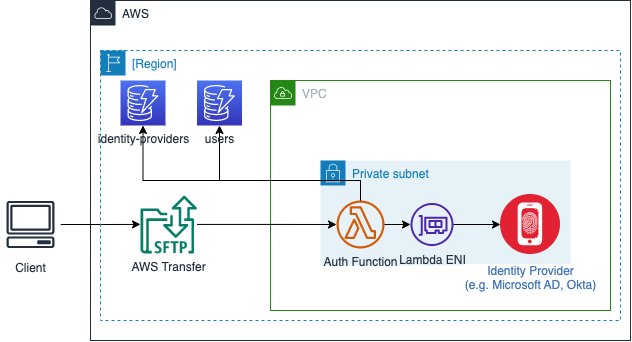
Figure 1: AWS Transfer Family architecture
Transfer Family automatically handles scaling from zero to thousands of concurrent users, manages high availability across Availability Zones, and minimizes infrastructure management. It records detailed metrics and logs in Amazon CloudWatch for monitoring and auditing, supporting compliance requirements with activity tracking.
It’s important to note that Transfer Family also offers service-managed authentication. This simpler setup stores user credentials (passwords or SSH keys) directly in Transfer Family, minimizing the need for external identity providers. Service-managed authentication is best suited if you have a small number of users or no existing identity management system, or when you want to have a disconnected identity system and don’t want to give external partners an account in your identity provider system.
Pros
One of the biggest advantages of Transfer Family is how it provides the reliability and scalability of Amazon S3 for storing your data, while keeping that data available to existing client applications and workflows. The service integrates with existing authentication systems through custom identity providers, while maintaining security through IAM policies. Its auto-scaling capabilities handle variable workloads, from occasional transfers to high-volume scenarios.
Transfer Family also offers detailed CloudWatch logging and audit trails for file transfer activities, which should be sufficient for most logging and audit needs. It encrypts data in transit using TLS 1.2 and at rest using Amazon S3 server-side encryption. You can implement fine-grained access controls through IAM roles and integrate with AWS Organizations for multi-account management. The service supports VPC endpoints for secure internal access and custom domain names for branded endpoints.
Because data is stored in S3, some of your requirements will be fulfilled by configuring S3, not the Transfer Family services. Data retention (for example, avoiding deletion and scheduling deletion) is achieved through S3 Object Lock and S3 Lifecycle Events.
Cons
The pricing structure of Transfer Family includes $0.30 per hour for each protocol you enable and data transfer fees based on data volume. There can be additional charges for custom domain names. If you use VPC endpoints for secure internal access to Amazon S3, there will also be VPC data charges. If you have high-volume transfers or multiple endpoints across AWS Regions, you will face increased costs. Because the data ultimately lives in S3; S3 storage and request pricing applies as well.
Custom identity provider implementations (such as SAML or OAuth) add latency to authentication processes, affecting transfer initiation times. This authentication process requires additional configuration and introduces extra steps and latency during transfer initiation compared to service-managed authentication.
The Regional nature of Transfer Family means you must choose between deploying in a single Region (simpler management but potential latency for global users) or multiple Regions (better performance but higher costs at $0.30 per protocol per hour per Region). Multi-Region can serve as a disaster recovery strategy or when Regional data isolation is needed.
Transfer Family web apps
Transfer Family web apps provide browser-based access to Amazon S3, enabling users to upload and download files through a web interface. With the web apps, you can create a branded, secure, and highly available portal for your users to browse, upload, and download data in S3. Web apps are built using Storage Browser for S3 and offer the same user functionalities in a fully managed offering without having to write code or host your own application.
When a user accesses the web application, authentication occurs through AWS IAM Identity Center, and S3 Access Grants determine their permissions to specific S3 buckets or prefixes. The access grant permissions can be either read-only or read and write. After authentication succeeds, users can upload or download files directly through the web interface. The service uses Amazon CloudFront for content delivery and implements SSL/TLS encryption for data transfers, while S3 provides server-side encryption for data at rest. Figure 2 shows a simplified Transfer Family web app architecture.
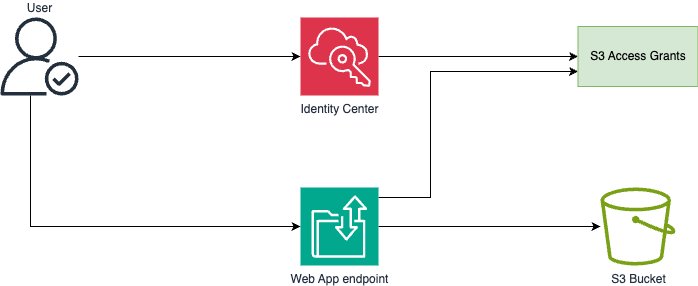
Figure 2: Simplified Transfer Family web app architecture
The web application automatically scales to accommodate varying numbers of users and provides high availability through the CloudFront global edge network. It minimizes the need for custom web application development and provides logging through AWS CloudTrail and CloudWatch. You can customize the user experience by implementing custom domains through CloudFront distributions.
Transfer Family web apps support multiple authentication methods, with IAM Identity Center being one of the primary options. While Identity Center provides simplified user management and integration with existing identity providers. It also provides useful mechanisms such as multi-factor authentication (MFA), strong password policies, and resetting lost passwords. It’s not the only authentication method available; you can also use custom identity providers for authentication, providing flexibility in how you manage user access to the web application.
Pros
Transfer Family web apps minimize the need to build and maintain custom web interfaces for Amazon S3 file sharing. It provides seamless integration with IAM Identity Center for user management and authentication, enabling you to use existing identity providers. The service offers fine-grained access control through S3 Access Grants, allowing precise permission management at the bucket and prefix level. Its integration with CloudFront provides global availability and enhanced performance, while CloudTrail logging offers audit capabilities.
The service provides robust security features including SSL/TLS encryption, CORS policy management, and optional integration with AWS WAF for protection against bots, web scrapers, DDoS events, and more. You can implement custom domains for branded experiences and use CloudFront security features including DDoS protection using AWS Shield. The web interface offers intuitive file management capabilities without requiring client software or that users have technical expertise.
Cons
Transfer Family web apps require using IAM Identity Center, which might require additional setup and configuration if you’re not currently using this service. The web interface currently requires the Identity Center identities to live in the same AWS account as the S3 buckets. That might create design challenges if you want to keep identities in one AWS account and data storage in another. Implementation requires careful cross-origin resource sharing (CORS) configuration for each S3 bucket.
The service incurs costs for both Transfer Family and associated services, including CloudFront distribution and data transfer fees. Custom domain implementation requires additional configuration and SSL certificate management through AWS Certificate Manager (ACM). The web interface is well suited for humans to upload or download, but it’s not as good for automated workflows that transfer files from machine to machine. You must carefully manage user assignments and access grants to maintain security, adding administrative overhead.
S3 pre-signed URLs
Amazon S3 pre-signed URLs enable secure, time-limited access to objects in S3 without requiring the file recipient to have an identity in your identity systems. The URLs are generated using the AWS SDK or AWS Command Line Interface (AWS CLI), granting specific permissions (GET, PUT) that are valid for up to seven days. When accessing files, S3 validates the cryptographically signed parameters in these URLs before permitting access to objects. This provides a direct method for secure file sharing through HTTPS endpoints.
The solution requires only an S3 bucket and appropriate IAM permissions for URL generation. S3 handles the authentication of the pre-signed URL parameters and manages access to objects. File transfers occur directly between users and S3 through HTTPS endpoints, with the pre-signed URL controlling the access patterns.
Amazon S3 provides security features including server-side encryption, access logging, and CloudTrail integration. The security of pre-signed URLs is primarily managed through expiration times and specific operation permissions defined during URL generation.
Pros
Amazon S3 pre-signed URLs follow a straightforward pay-per-use pricing model, charging only for S3 storage, requests, and data transfers. For example, if you create pre-signed URLs but the object isn’t actually downloaded, you pay storage costs as usual, but you don’t pay transfer costs. The solution uses the native scalability of S3 to handle varying numbers of concurrent users without additional infrastructure. you can implement granular access controls through URL expiration times and specific operation permissions (GET, PUT, DELETE).
Access is controlled through URL expiration enforcement. Amazon S3 server access logging and CloudTrail integration enable audit capabilities. The solution’s simplicity makes it ideal for basic file sharing needs while maintaining security and scalability.
Cons
A pre-signed URL can be used by anyone who has access to the URL. That’s the goal of this design: You don’t need to have an identity for the user. Pre-signed URLs can be reused an unlimited number of times until they expire. To improve security, short expiration times can limit the potential for URL re-use. Shorter expiration times, however, require the recipient to download the file soon after the URL is created.
When implementing this solution, you should establish processes for secure URL generation and distribution. Set your URL expiration times based on realistic expectations about how quickly your recipients will download the files. A web or mobile app where the user selects a link to download something (such as a document, an image, a data file) and they expect the download to start immediately is a good candidate for this design.
The solution works with files up to 5 GB for single operations. To share a file larger than 5 GB, you must split the file into multiple parts, issue multiple pre-signed URLs, and then the recipient must download all the parts and join the parts together correctly. This isn’t a good solution for sharing large files. Also, distributing large files as a single download can be difficult if the recipient doesn’t have good connectivity. Amazon S3 can start an object download from the middle of the object, but selecting a pre-signed URL cannot. So, if the recipient transfers 1 GB out of a 2 GB download, and then their connection is disrupted, they cannot pick up where they left off. They will restart from the beginning, which is undesirable. Overall, this design is unsuitable for transmitting large files over unreliable internet connections.
You should enable appropriate monitoring through Amazon S3 access logs and CloudTrail to track usage patterns and meet security compliance.
This solution is particularly effective if you’re seeking straightforward, secure file sharing capabilities where the files are small enough to download in one request, and where you have a secure mechanism to share the download URLs.
Serverless web application with S3 presigned URLs
Amazon S3 presigned URLs combined with a custom web application enable secure, time-limited access to S3 objects. The application generates URLs that grant specific S3 permissions (GET, PUT) for between one minute and seven days. When requesting file access, the application authenticates users and generates presigned URLs using the AWS SDK with defined permissions and expiration times.
The web application uses API Gateway and Lambda functions for authentication and URL generation. Amazon S3 validates the cryptographically signed parameters in these URLs before permitting access to objects. File transfers occur directly between users and S3 through HTTPS endpoints, with the application controlling the access patterns. The architecture is shown in Figure 3.
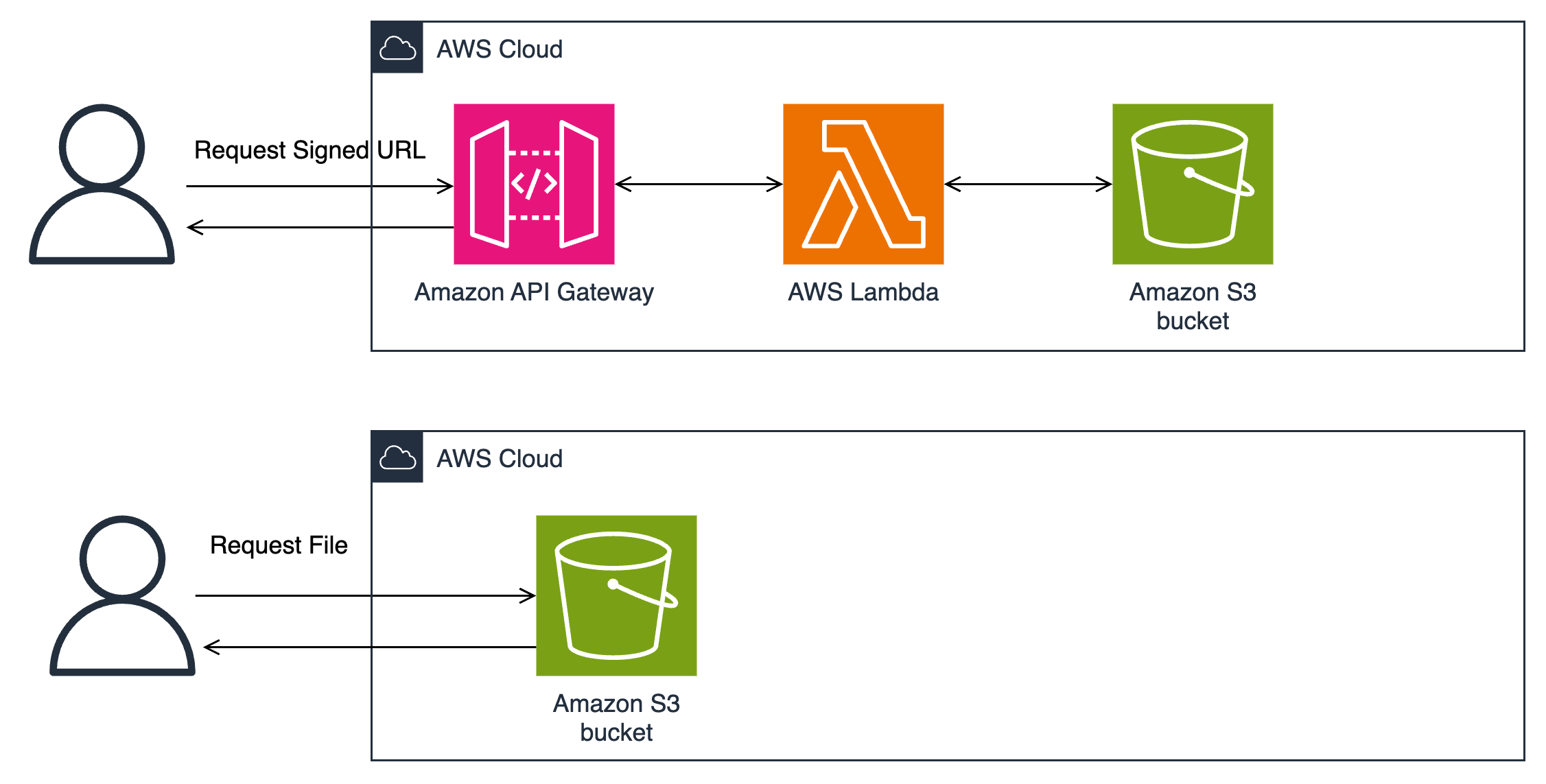
Figure 3: Amazon S3 pre-signed URLs architecture
The web application can implement security controls including request logging, rate limiting (requests per second), and authentication workflows. CloudWatch logs record API access patterns and Lambda execution metrics, while Amazon S3 access logging records object-level operations.
Pros
Amazon S3 presigned URLs follow a pay-per-use pricing model. This solution charges only for API Gateway requests, Lambda executions, and S3 operations performed. The serverless architecture scales automatically from zero to thousands of concurrent users without infrastructure management. You can implement custom security controls and business logic for specific access requirements through API Gateway authorizers (using custom identity solutions or Amazon Cognito) and Lambda functions.
The solution enforces security through URL expiration (maximum seven days), IAM policies restricting URL generation permissions, and HTTPS encryption for data transfers. Custom authentication workflows integrate with existing identity providers (SAML, OIDC). Additional security features include IP-based restrictions, required request headers, and request validation through AWS WAF. This solution would be good, for example, if you have a variety of files or a variety of buckets and you’re trying to build a unified front-end where people can download various files without knowing which bucket the files are stored in or what URL expiration time is appropriate. You can configure the frontend to look at tags on objects, tags on buckets, object names, or another attribute that fits your use case, and then choose a URL expiration time based on that attribute. For example, objects from buckets tagged Data Classification: Restricted might expire after 1 minute, whereas objects from buckets tagged Data Classification: Public might be valid for 7 days.
Cons
Building a custom web application requires developing and maintaining the code for URL generation, authentication, and error handling logic. The application must track URL expiration times and implement mechanisms that permit retries for failed transfers. Monitoring systems must track URL usage, detect abuse patterns, and send alerts for security violations through CloudWatch metrics and logs.
One limitation of this solution is the 10 MB size limit imposed by API Gateway. This affects how your application handles file uploads and downloads. For uploads, files under 10 MB can be uploaded directly through API Gateway. Larger files require implementing multipart uploads, where the client splits the file into chunks and sends each chunk separately. For downloads, files under 10 MB can be downloaded directly through API Gateway but for larger files, your application should generate a pre-signed URL for direct Amazon S3 access, bypassing API Gateway.
URL generation errors or misconfigured IAM permissions can expose objects to unauthorized access. The HTTPS-only protocol limits integration with SFTP and FTPS clients. Files larger than 5 GB require multipart upload implementation, and network interruptions need custom resume logic. This design will incur some extra charges if the number of file transfers are the millions. Lambda functions cost $0.20 per million requests, and API Gateway costs $1.00 per million requests. Analyze your expected access patterns to determine whether these extra costs will be significant and if they’re worth the additional flexibility of custom transfer logic.
Decision matrix: When to use each solution
The following table summarizes the characteristics of the solutions presented in the two parts of this post. See Part 2 for full descriptions of the solutions not covered in Part 1.
| Characteristics | Transfer Family | Transfer Family web app | S3 pre-signed URLs (Direct) | Serverless web application with S3 pre-signed URL | CloudFront signed URLs (Part 2) | VPC endpoint service (Part 2) | S3 Object Lambda (Part 2) |
| Protocol support | SFTP, FTPS, and AS2 | HTTPS (web-based) | HTTPS | HTTPS | HTTPS with CDN | A TCP-based protocol | HTTPS |
| Global distribution | Global endpoint support | CloudFront integration | Global S3 access | Global S3 access | Global edge network acceleration | Direct AWS backbone access | Global S3 access with Regional endpoints |
| Pricing model | Hourly service rate and usage | Pay per file operation | Pay-per-request | Pay-per-request and application costs | Pay-per-request with caching savings | Hourly endpoint rate and usage | No additional charge for access points; standard S3 request pricing applies |
| Content processing | Direct S3 integration | Built-in web interface | Direct S3 access | Custom app processing | Edge-based file processing | Access files through private network | Direct S3 access with customized permissions per access point |
| Authentication options | Custom IdP and service-managed | IAM Identity Center | IAM | Custom authentication possible | IAM, custom authentication, and edge validation | VPC security controls and custom authentication | IAM policies, VPC endpoint policies, resource-based policies |
| Upload capabilities | Unlimited file size | Web interface upload | Up to 5 GB direct and multipart for larger | Up to 10 MB using API Gateway | Optimized for global ingestion | Unlimited file size over private connection | Same as standard S3 |
| Download capabilities | Unlimited file size | Browser-based downloads | Up to 5 GB using a single URL | Up to 10 MB using API Gateway | Accelerated downloads using global edge locations | Unlimited file size over private connection | Same as standard S3 with customized access controls |
| Example use cases |
|
|
|
|
|
|
|
The following list gives you a quick overview of the strengths of each solution presented in the two parts of this post.
- Transfer Family is the optimal choice for organizations that require legacy file transfer protocols such as SFTP, FTPS, or AS2 protocols, and you must integrate with existing authentication systems. It’s ideal for scenarios with strict compliance and audit requirements, where operational overhead needs to be minimized. While the solution comes with higher costs because of its managed service nature, it’s often the lowest-friction option to support existing enterprise use cases that depend on these protocols.
- Transfer Family web apps suit organizations that need browser-based file sharing without custom development. They integrate with IAM Identity Center for user authentication and uses Amazon S3 Access Grants for permission management. The solution works well for internal document sharing, client portals, and scenarios requiring a branded web interface. While limited to web browser access, they provide built-in features like MFA and password management without infrastructure maintenance.
- Amazon S3 pre-signed URLs excel in scenarios where simplicity, cost-effectiveness, and temporary access are key requirements. This solution is ideal if you’re seeking a straightforward file sharing mechanism without the need for custom application development or additional infrastructure. This approach shines in environments that require a quick implementation of secure file sharing and cost-effective solutions with minimal overhead.
- Serverless web application with S3 presigned URLs best serves scenarios where cost optimization is paramount and the HTTPS protocol meets your requirements. This solution shines in environments that need simple, direct file sharing capabilities with quick implementation timelines. It’s particularly effective for moderate usage patterns where serverless architecture can provide cost benefits. The solution’s simplicity makes it ideal for web applications and scenarios where complex file transfer protocols aren’t necessary, though careful consideration must be given to its 10 MB file size limitation for single operations using API Gateway.
In Part 2:
- CloudFront signed URLs excel in situations that demand global content distribution with high performance requirements. This solution is the clear choice when your architecture needs built-in DDoS protection and performance optimization through caching. It’s particularly valuable when content delivery speed is crucial and you require security at edge locations. The solution’s global reach and caching capabilities make it cost-effective for large-scale content distribution, though it’s primarily optimized for download scenarios rather than uploads.
- Amazon VPC endpoint service is the preferred choice if you require complete network isolation and maximum security. This solution is ideal when you need support for custom protocols while maintaining private network connectivity. It’s particularly suitable for scenarios with extremely high security requirements and when you have the necessary resources to managed networking configurations. While this solution requires significant expertise and investment, it provides the highest level of security and control for sensitive data transfers.
- S3 Access Points are best suited for scenarios that require simplified data access management at scale. This solution excels when you need to provide different access patterns to the same underlying data for multiple applications or user groups. It’s ideal if you prefer a structured approach to permissions and need network-level access controls. While primarily focused on simplifying complex access scenarios without modifying bucket policies, it offers unique capabilities for VPC-restricted access and granular permissions management, though subject to certain service limits and configuration requirements.
Conclusion
In this first part of a two-part post, you’ve learned about multiple solutions for secure file sharing using AWS services and the pros and cons of each. You can find additional options in Part 2. The optimal solution depends on your specific organizational requirements, technical capabilities, and budget constraints. You don’t have to choose just one option, you can implement multiple solutions to address different use cases, creating a file sharing strategy that balances security, cost, and operational efficiency.
Additional resources:
- Implement custom identity providers with AWS Transfer Family
- Set web apps for AWS Transfer Family
- Securely download and upload objects using Amazon S3 pre-signed URLs
- Build secure direct upload solutions from web applications to Amazon S3
- Restrict access to content with CloudFront signed URLs
- Create private service access with VPC endpoint services
- Transform data with S3 Object Lambda Access Points
- Process data as it’s retrieved with Amazon S3 Object Lambda
If you have feedback about this post, submit comments in the Comments section below.
Сънуват ли джихадистите девици?
Post Syndicated from Атанас Шиников original https://www.toest.bg/sanuvat-li-dzhihadistite-devici/

Тези дни зачитам едно от любимите ми възрожденски четива, гротесково-ироничната „Видрица“ на Минчо Кънчев, българския революционен юначен поп. Предполагам, че на турски може да го наречем нещо като папаз бабаит. Записките му от Диарбекир винаги са ми напомняли на нашенска версия на големите западни ориенталисти, пътуващи на изток. Веднъж, разказва той, заточен по Анадола,
не знам тези турски ходжи, молли, дервиши какъв сън сънували,
ама отишли в гробищата да питат техния войнстващ светец Гази Хамза ба̀ба какво да правят. Та явно починалият светец, от чиятo сабя капела кръв, им казал, че Пророкът бил сърдит, задето гяурите не били избити.
И самият Минчо Кънчев, при всичките му бабаитлъци, обрисува себе си като сънуващ човек. Че и приписва сънища на други участници. Каймакаминът сънува дякона Паисий (онзи, грешния предател, да не се бърка с автора на „История славянобългарска“) като обращенец в правата вяра. Самият дякон Паисий се сънува като повишен в чин владика. Накрая тия сънища се схождат трагично в убийството на дякона, извършено от Димитър Общи.
От камбанарията на скептика подозирам, че разказите носят белезите на типична реторическа хватка. Без значение от коя страна на религиозната бариера стоиш, като искаш да вмъкнеш нещо скандално или да си измислиш оправдание, го поднасяш, облечено във формулата „сънувах“. Едновременно е авторитетно и недоказуемо. Та затова и „какъв сън сънували“ може да значи просто „какво са си наумили“. Сънищата на каймакамина и дякона Паисий са потвърждение на една заслужена смъртна казън. Сънищата на самия поп Минчо свидетелстват за неговата героично-мъченическа съдба.
Но всъщност „ходжите, моллите и дервишите“ сънуват, и то много.
Далеч преди поп Минчо Кънчев. Защото са част от огромна и непрекъсната традиция на разбиране за ролята на сънищата сред мюсюлманите, която започва с фигурата на самия Пророк. Като че ли в пясъците на Арабия от седмото столетие след Христа традициите на сънуване, тълкуване и съответно впрягане на тълкуванията в публична употреба придобиват нова съдържателност.
Коранът, подобно на Библията (че кой от нас не е чел за сънищата на Йосиф, за „седемте добри и седемте лоши години“, за „колоса на глинени крака“ от съня на пророк Даниил или за съня на жената на Пилат от Евангелието?), дава изобилен материал относно виденията по време на сън. Даже използва поне четири термина за това. Първият от тях е буквално „видение“ (ру’йа); на второ място срещаме думата манам (просто „сън“ в смисъл на „състояние на заспалост“ и „видение по време на сън“), а инцидентно срещаме и преносното бушра, означаващо първоначално „добра новина“, интерпретирано веднъж като видение в сън. И накрая, за „лоши сънища“ Коранът използва най-популярната днес в арабския език дума за сън – хулм.
Доколкото самият Пророк Мохамед твърди, че „стъпва в обувките“ на пророческата мисия на библейските пророци, често пъти разказите за сънища в Писанието на мюсюлманите са свързани с персонажи, заети от библейския разказ, като Ибрахим (библ. Авраам) или Юсуф (библ. Йосиф). А разказите за Мохамед, т.нар. Сунна – онова, което мюсюлманите, особено в суннизма, твърдят, че той е казал, направил, одобрил или порицал, – са истински трамплин към развиване на детайлна традиция за разбиране на тази мъглява, но неотменна част от човешкия живот.
Да надзърнем например в т.нар. Достоверен (Сахих) сборник на Ал-Бухари от IX век. В него имаме огромен раздел под надслов „Тълкуванието на сънищата“, който съдържа няколко десетки предания (хадиси). Появяват се нови категории сънища (например „добри сънища“, мубашшират), обяснява се какво място заемат в живота на правоверните. Добрият, верен сън е от Аллах, а лошият сън е само от дявола. „Добрите сънища на праведните са една четирийсет и шеста част от пророчеството“; ако човек види сън, който му се харесва, значи той е от Аллах. И не е възможно човек да види самия Пророк в съня си и този сън да е от дявола.
Сунната задава и рамката на нещо друго – появяват се конкретни напътствия как да се разбира това или онова, видяно по време на сън. Ако вярващият сънува дявола, трябва да плюе наляво и да помоли Аллах за убежище. Същото предписание следва да се изпълни при всеки лош сън. Дрехата, носена от съратниците на Мухаммад, в сън представя ислямската религия; зелената градина също представя правоверието; черната разчорлена жена е представена като чумата.
Докато спях, ми връчиха чаша с мляко, което започнах да пия, докато млякото не започна да струи от ноктите ми,
казва Пророкът. После дал остатъка на неговия съратник и бъдещ халиф Умар. Запитан как тълкува това, Мохамед отговорил, че млякото е символ на религиозното познание.
Конкретни събития от времето на Пророка се обясняват чрез сън.
Видях се насън да размахвам меч, който се счупи по средата. После го размахах пак и той се възстанови по-хубав от преди.
В първия случай, пояснява той, счупеният меч символизира падналите мюсюлмани в претърпяното поражение в битката при Ухуд през 625 г., докато във втория очевидно става въпрос за последвалата победа, дарена на правоверните.
Въз основа на зададените рамки в първоначалната мюсюлманска общност се развива и огромна традиция за употреба на сънищата с най-разнообразна цел. В крайна сметка, ако нещо се появява с авторитета на самия Бог в Корана и после е утвърдено чрез думите и делата на Пророка, не е ли редно да породи след себе си традиция? Обикновено така работи религиозното мислене. Може да го премисляш, може да го променяш, може да го реинтерпретираш, но трудно може да го изхвърлиш и да се откажеш от него. Поне трябва да се потрудиш върху аргументацията защо го правиш.
С времето се появяват такива емблематични съчинения, като „Тълкувания на сънищата“ на Ибн Сирин от VIII век, върху когото стъпват всички по-нататъшни усилия. Умението за разбиране на сънищата и тяхната връзка с реалността е засвидетелствана и от факта, че през XII век Ал-Халлал съставя биографичен речник на тълкувателите на сънища, а философът Ибн Сина или богословът Ал-Газзали от епохата на късните Абасиди посвещават значителни усилия на ситуирането на сънищата в живота на правоверните. Дори Ибн Халдун от XV столетие сл.Хр., иначе познат като трезв, повратлив дипломат и историк (и досаден кошмар за всеки студент в българската арабистика), отделя част от прословутото си „Встъпление“ на наречената от него „наука за тълкуване на сънищата“. Съновникът на богослова Ан-Набулси, живял на границата между XVII и XVIII век, надгражда този на Ибн Сирин и до днес се преиздава с голям успех. Сега по-ясно може да си представим защо мюсюлманите сънуват. Сънуват от времето на Мохамед до днес.
Сънуват всякакви неща. Или поне казват, че ги сънуват.
През август 1068 г. например богословът Ибн ал-Банна в Багдад записва в личния си дневник, че един човек го посещава с молба за разтълкуването на „страшен, велик сън“. В него се виждал слон с две крила, телосложение и ръст на човек, с голяма мъжественост (фалос), който се спуска над река Тигър. Ибн ал-Банна записва веднага значението на съня. Няма начин слонът да не е султанът Алп Арслан, а двете му крила – неговите двама сина. Голямата му мъжественост, която впрочем в съня спадала и се връщала към обичайния си размер, била неговата огромна репутация и авторитет. Малко след това в дневника са отбелязани и други сънища в около двайсет различни разказа – например зелени скакалци с бисери в устата. Пак Ибн Банна научава в сън, че шейх от общността е преследван от еретици.

Ако пък зачетем Ан-Набулси, може да видим и че в пространството на сънищата се появяват неща, които наяве не са много легитимни. Но са изпълнени със смисъл.
Ето например как се сънува прасето в култура, която му отрежда презряно ъгълче на творението и го възприема като греховно (харам).
Прасето, казва богословът, може да те навести насън под всякаква форма. Обикновено означава проклет, силен, лукав враг, който никак не държи на думата си. Но ако човек е яхнал прасе насън, щял да вземе пари, и то много. Ама няма да бъдат чисти пари, нали? Ако ядеш насън, и знаеш, че кусаш възбранената пържола печена или готвена по друг начин, пак ще вземеш чрез търговия много пари. Но по непозволен начин.
Дивото прасе подсказва идващ голям дъжд и студ, ако пътуваш по суша или плаваш по морето. За онзи, който има противоречие, някаква дрязга или вражда, показва, че врагът му е силен, злобен, с мръсен език. Ако жителите на селата сънуват прасе, значи, че идват усилни, трудни времена, а ако някой, който сади разсад, сънува прасе, този разсад не е както трябва. По подобен начин, ако някой, който иска да се жени, сънува прасе, значи, че не се жени за подходящата жена. Защото
прасето насън може да обозначава и жена.
И месото на прасето насън се услажда. Затова, който сънува, че яде печено свинско, значи ще се сдобие с бърза полза. А който съзре насън прасе в постелята си, ще се сноши с юдейка. Малките прасенца също имат място в сънищата. Означават големи грижи за онзи, който ги притежава или ги вижда. Домашното прасе обаче може да значи урожай. Ако просто виждаш прасе насън, значи, че си повелител над народ от юдеи и християни. За онзи, който е решил да влезе в конфликт с жена си и види насън мъжко прасе или свиня, значи, че ще се разведе. Възможно е прасето да бъде разтълкувано и като човек измежду юдеите и християните, или пак ако го видиш насън, да означава зло, нещастие, недоволство и скръб, възбранена печалба. Но ако е свинка, може да значи и многобройно потомство. В случай че насън пострадаш от прасе, значи ще пострадаш от християнин.
Който обаче насън порази прасе, ще получи подкрепа и възможност за влияние от човек с голям авторитет. Който владее много прасета, ще получи много пари накуп. Има и вероятност насън да се превърнеш в прасе. Тогава ще получиш пари и други облаги, но ще бъде заедно с унижения и злощастия във вярата. Ако се сражаваш с прасе, ще надделееш над враг, който угнетява. Ядене на свинско, освен придобиването на пари с мътен произход и по нечестен начин, може да значи и че ще извършиш нечестие. Ако малки прасенца влязат в къщата ти и из двора, значи при теб ще дойдат слугите на султана, тъй че трябва да внимаваш. И обратното – ако насън изгонваш прасенца от двора, ще се откажеш от султанската работа.
Ан-Набулси, когото чета в арабския оригинал, отскоро може да четете в частичен превод на английски от Ясмин Сийл, която през 2022 г. получи литературен грант от клуба „ПЕН“ за превода под поетичното заглавие If You See Them Fall to Earth. Не знам дали там може да откриете откъса за нечистото животно, но за мен е важно признанието за превод на арабски класици от османската епоха на езика на съвремието. При което арабските автори придобиват нова актуалност.
А моето подозрение около разказите за сънища на поп Минчо Кънчев и ходжите се оказва нелишено от основания.
Пророкът може и да затваря вратата за по-нататъшно пророчество от начина, по който бива изпратен от Аллах на земята, и това да обезкуражава част от общността. За да ги насърчи обаче, той отбелязва, че остават „добрите новини“ (мубашшират), а те на свой ред се обясняват по-късно като „видения насън, разкрити на благочестиви мюсюлмани“ и като „част от пророчеството“. Това вдъхва увереност в сънищата като средство, което предоставя водителство за общността и в частност може да реши конкретни предизвикателства пред нея.
Много по-лесно е да се позовеш на сън при оправдаването на дадено действие или обяснение на събитие, отколкото да намериш предание от Пророка (хадис), което да го подкрепя. Защото механизмът за обявяване на хадисите за достоверни е предмет на твърде тежък критически поглед към гарантирането на достоверността на механизма на тяхното предаване (иснад) чрез авторитети, стигащи до времето на Мохамед¹. Оттук и логичното заключение, че онова, което авторът не може да каже, опирайки се на своя собствен авторитет, може да подкрепи чрез външен източник чрез разказването на сън и видение².
1 Kinberg, Leah. “Dreams”, EI3, p. 97–98.
2 Ibid., p. 97.
Водещо изображение: Али Парники сънува шейх Сафи в компанията на Пророка Мохамед, биографичен ръкопис за живота на шейх Сафи ад-Дин Исхак Ардабили, илюстрация от XVI век
В рубриката „Ориент кафе“ Атанас Шиников поднася любопитни теми, свързани не толкова с горещата политика, колкото с историята и културата на Близкия изток. А той, древен и днешен, е по-близко до нас и съвремието ни, отколкото си представяме.
[$] A generic ring buffer for the kernel
Post Syndicated from corbet original https://lwn.net/Articles/976836/
The kernel’s user-space ABI does not lack for ring buffers; they have been
defined for subsystems like BPF, io_uring, perf,
and tracing, for
example. Naturally, each of those ring buffers is unique, with no common
interface between them. The natural response to this ABI proliferation is,
of course, to add yet another ring buffer as the generic option; that is
the intent of this
patch series from Kent Overstreet adding a new set of system calls for
ring buffers.
Security updates for Thursday
Post Syndicated from jake original https://lwn.net/Articles/977442/
Security updates have been issued by AlmaLinux (cockpit, kernel, kernel-rt, libxml2, ruby:3.1, and tomcat), Debian (libarchive, pillow, and tinyproxy), Fedora (apptainer), Mageia (amavisd-new and libxml2), Oracle (edk2), Red Hat (booth, cockpit, kernel-rt, less, libxml2, nghttp2, ruby:3.1, ruby:3.3, and tomcat), Slackware (kernel), and Ubuntu (atril, bluez, frr, gdk-pixbuf, openjdk-17, openjdk-21, openjdk-8, openjdk-lts, qemu, and unixodbc).
Espionage with a Drone
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/06/espionage-with-a-drone.html
The US is using a World War II law that bans aircraft photography of military installations to charge someone with doing the same thing with a drone.
Top Tier Wi-Fi 7 Access Point – U7 Pro Max Overview
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=0S0kjegtivA
Backblaze Live Read: The Game Changer for Live Media Cloud Workflows
Post Syndicated from Elton Carneiro original https://backblaze.com/blog/announcing-b2-live-read/

Every sports fan knows that when something incredible happens on the field/ice/court, we want to see the replay right now. But many of us don’t know the impressive efforts that live media teams undertake to deliver clips in real time to all of us on whatever viewing platform we might prefer. Today, Backblaze is excited to make the work of live media production (and the end results) a lot easier with our latest innovation.
Announcing Backblaze B2 Live Read
Backblaze B2 Live Read is a patent-pending service that gives media production teams working on live events the ability to access, edit, and transform media content while it is being uploaded into Backblaze B2 Cloud Storage. This means that teams can start working on content far faster than they could before, without having to drastically change their workflows and tools, massively speeding up their time to engagement and revenue.
This is a game changer for live media teams, who are passionate about bringing content to their audience as soon as possible. It means they don’t need to worry as screen resolutions continue to expand, ranging from 4K to 8K and beyond. It also reduces the need for having production teams on-site to minimize latency, which could be extremely costly depending on the venue.
Previously, producers had to wait hours or days before they could access uploaded data, or they had to rely on cost-prohibitive and complicated options that often required on-premises storage. That’s no longer necessary. This innovation will make it faster and less expensive to:
- Create near real-time highlight clips for news segments, in-app replays, and much more.
- Tap into talent where they are versus trying to find local talent to produce events.
- Promote content for on-demand sales within minutes of presentations at live events.
- Distribute teasers for buzz on social media before talent has even left the venue.
For our customers, turnaround time is essential, and Live Read promises to speed up workflows and operations for producers across the industry. We’re incredibly excited to offer this innovative feature to boost performance and accelerate our customers’ business engagements.”
Richard Andes, VP, Product Management, Telestream
Coming soon inside your favorite tools
We designed Live Read to be easily accessible directly via the Backblaze S3 Compatible API and/or seamlessly within the user interface of launch partners including Telestream, Glookast, and Mimir. These platforms, along with CineDeck, Alteon, Hedge, Hiscale, MoovIT, and many others to come, are enabling Live Read within their platforms soon.
If you want to use Live Read, you can join our private preview.
How does it work?
Previously, media teams were forced to either wait for uploads to complete or use on-premises storage. Now, Live Read uniquely supports accessing parts of each growing file or growing object as it is uploaded so there’s no need to wait for the full file upload to complete. And, when the full upload is complete, it’s accessible like any other file in a Backblaze B2 Cloud Storage Bucket, with no middleware or proprietary software needed.
Here’s a short video showing both how Live Read works on a conceptual level, as well as a live demo showing how one app can upload video data to Backblaze B2 using Live Read while a second app reads the uploaded video data:
For those of you who want to dig deeper into the code samples you saw in the video, here is some example code that uses the Amazon SDK for Python, Boto3, to start uploading data with Live Read. If you’re familiar with Amazon S3, you’ll recognize that this is a standard multipart upload apart from the add_custom_header handler function and the call to register it with Boto3’s event system:
def add_custom_header(params, **_kwargs):
"""
Add the Live Read custom headers to the outgoing request.
See https://boto3.amazonaws.com/v1/documentation/api/latest/guide/events.html
"""
params['headers']['x-backblaze-live-read-enabled'] = 'true'
client = boto3.client('s3')
client.meta.events.register('before-call.s3.CreateMultipartUpload', add_custom_header)
response = client.create_multipart_upload(Bucket='my-video-files', Key='liveread.mp4')
upload_id = response['UploadId']
# Now upload data as usual with repeated calls to client.upload_part()
As it processes the call to create_multipart_upload(), Boto3 calls the add_custom_header() handler function, which adds a custom HTTP header, x-backblaze-live-read-enabled, with the value true, to the S3 API request. The custom HTTP header signals to Backblaze B2 that this is a Live Read upload. As with standard multipart uploads, the data is uploaded in parts between 5MB and 5GB in size. To facilitate reading data efficiently, all parts except the last one must have the same size.
Since this is a Live Read upload, as soon as a part is uploaded, it is accessible for downloading.
An app that downloads the file needs to send the same custom HTTP header when it retrieves data. For example:
def add_custom_header(params, **_kwargs):
"""
Add the Live Read custom headers to the outgoing request.
See https://boto3.amazonaws.com/v1/documentation/api/latest/guide/events.html
"""
params['headers']['x-backblaze-live-read-enabled'] = 'true'
client = boto3.client('s3')
client.meta.events.register('before-call.s3.GetObject', add_custom_header)
# Read the first 1 KiB of the file
response = client.get_object(
Bucket='my-video-files',
Key='liveread.mp4',
Range='bytes=0-1023'
)
Note that you must supply either Range or PartNumber to specify a portion of the file when you download data using Live Read. If you request a range or part that does not exist, then Backblaze B2 responds with a 416 Range Not Satisfiable error, just as you might expect. On receiving this error, an app reading the file might repeatedly retry the request, waiting for a short interval after each unsuccessful request.
The source code for the applications is available as open source at https://github.com/backblaze-b2-samples/live-read-demo/.
How much does it cost?
Live Read upload capacity is offered in $15/TB increments—and the capacity is only consumed when an upload is marked for Live Read. Standard uploads are free, as usual. After uploading is complete, the data stored in Backblaze B2 is billed as normal. From a cost perspective, this represents significant savings versus the workflows that production teams must currently follow to achieve anything close to the functionality delivered by Live Read.
And it’s not just for live media
Beyond media, the Live Read API can support breakthroughs across development and IT workloads. For example, organizations maintaining large data logs or surveillance footage backups have often had to parse them into hundreds or thousands of small files each day in order to have quick access when needed—but with Live Read, they can now move to far more manageable single files per day or hour while preserving ability to access parts immediately after they are written.
What’s next
For those interested in Live Read, you can sign up for the private preview here. We’ll continue to report as we add more integrations and we’ll share stories as customers succeed with the new feature. Until then, feel free to ask any question you have in the comments below.
Want to see more?
Join Pat Patterson, Chief Technical Evangelist, and Elton Carneiro, Senior Director of Partnerships, on January 26, 2024 at 10:00 a.m. PT to learn more in real time. Can’t make it live? Sign up anyway and we’ll send a recording straight to your inbox.

The post Backblaze Live Read: The Game Changer for Live Media Cloud Workflows appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
#Бетономорие ПП-ДБ и Сглобката са прокарали и покровителстват незаконен строеж на огромно селище в залива на Корал
Post Syndicated from Екип на Биволъ original https://bivol.bg/grad_koral.html
четвъртък 6 юни 2024

Само два месеца преди Кирил Петков да подаде оставка като Mинистър-председател на Република България на 27 юни 2022 г., непосредствено зад плаж Корал, ударно започва да изниква огромен строеж на…
Indian Elections: Last Week Tonight with John Oliver (HBO)
Post Syndicated from LastWeekTonight original https://www.youtube.com/watch?v=JTwaXIUepdk
Zabbix 7.0 – Everything You Need to Know
Post Syndicated from Michael Kammer original https://blog.zabbix.com/zabbix-7-0-everything-you-need-to-know/28210/
After plenty of breathless anticipation, we’re proud to announce the release of the latest major Zabbix version – the new and improved Zabbix 7.0 LTS. This release is the direct result of user feedback and delivers a variety of improvements, including cloud-native Zabbix proxy scalability, website transaction monitoring, improved data collection speed and scalability, new dashboard widgets, major network discovery speed improvements, new templates and integrations, and more!
Without further ado, let’s take a whistle-stop tour of what you need to know:
Table of Contents
Synthetic end-user web monitoring
Busy enterprises can now monitor multiple websites and applications by defining flexible multi-step browser-based scenarios. 7.0 LTS also makes it easy to capture screenshots of the current website state, collect and visualize website performance and availability metrics, extract, monitor, and analyze web application data, and get alerts when issues are discovered.
Zabbix proxy high availability and load balancing
When it’s time to expand, Zabbix 7.0 LTS makes it easy to scale a Zabbix environment, guaranteeing 100% availability with automatic proxy load balancing and high availability features, including the ability to assign hosts to load-balanced proxy groups and seamlessly scale a Zabbix environment by deploying additional proxies.
Faster, more efficient Zabbix proxies
Zabbix proxy now fully supports in-memory data storage for collected metrics. Users can choose from Disk, Memory, and Hybrid proxy buffer modes, all of which are ideal for embedded hardware. In addition, memory mode enables the support of edge computing use cases. Users can expect 10-100x better proxy performance by switching to memory or hybrid modes, depending on allocated hardware.
Centralized control of data collection timeouts
Centralizing control of data collection timeouts enables better support for metrics and custom checks, taking longer data collection time intervals. Data collection timeouts can be defined per item-type and overridden per proxy or on an individual item level. In addition, timeouts are now fully configurable in the Zabbix GUI or via Zabbix API.
Faster and more scalable data collection
Synchronous poller processes have been replaced with asynchronous pollers, which improves the speed and scalability of metric polling, particularly for agent, SNMP, and HTTP checks. The next metric can now be polled before waiting for a response from a previously requested metric, and up to 1,000 concurrent checks can now be supported per poller process.
New ways to visualize data
A variety of new dashboard widgets have been introduced, with the goal of giving users detailed information about their monitored metrics and infrastructure at a glance.

Dynamic dashboard widget navigation
Speaking of dashboard widgets, a new communication framework has also been introduced for dashboard widgets, enabling communication between widgets, allowing a widget to serve as a data source for other widgets, and dynamically updating information displayed in a dashboard widget based on the data source.
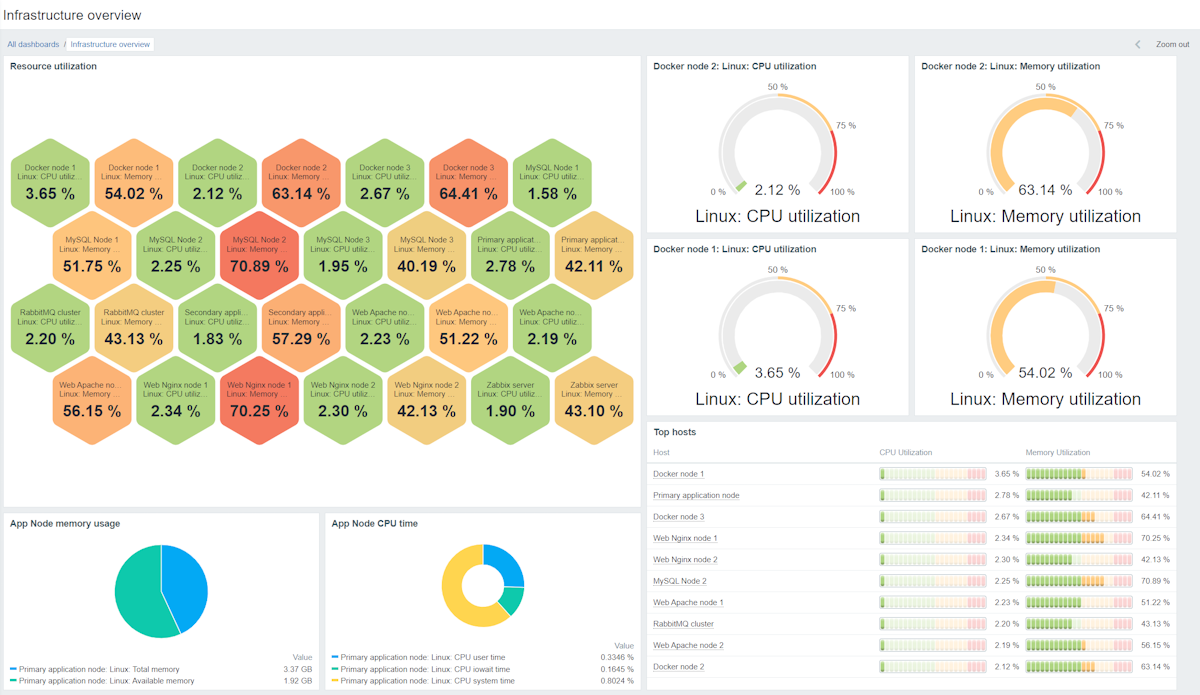
Faster network discovery
Discovering services and hosts has never been easier, thanks to support of parallelization while performing network discovery. Concurrency support allows for massive improvements in network discovery speed and simplifies host and service discovery while scanning large network segments.
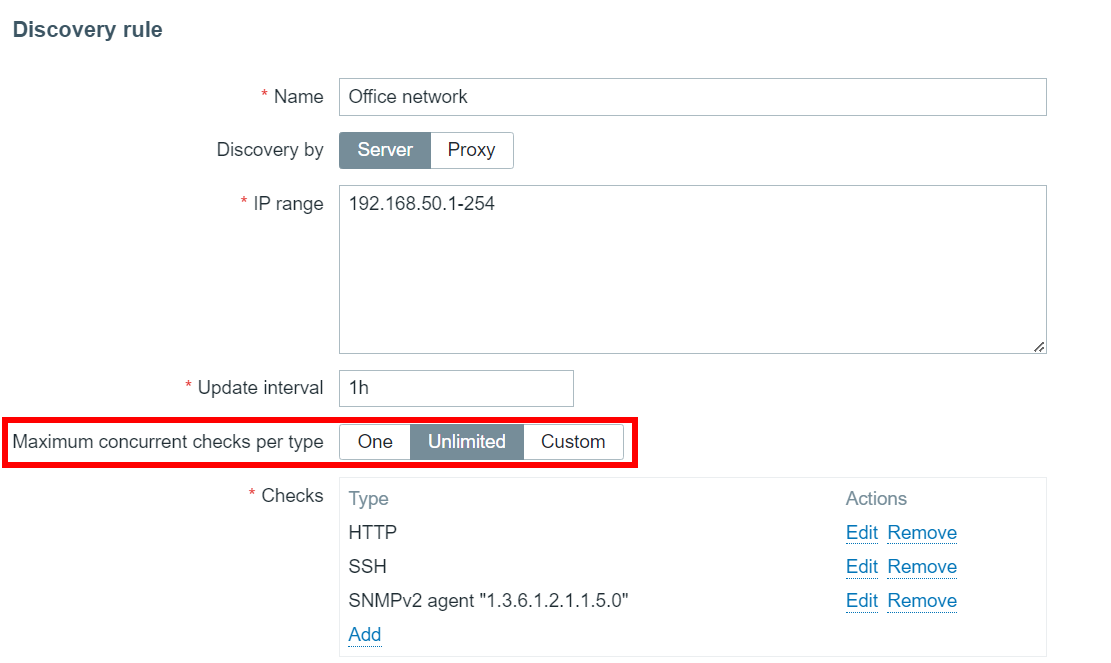
Better security via enterprise-grade multi-factor authentication
Out-of-the box support of multi-factor authentication enables enterprise-grade security and added flexibility for configuring user authentication methods. Support MFA providers include time-based one-time Password (TOTP) and Duo Universal Prompt authentication.
More flexible resource discovery and management
Low-level discovery has received a variety of improvements, which enable enhanced host configuration and management flexibility when discovering hosts in complex environments, such as VMware or Kubernetes.
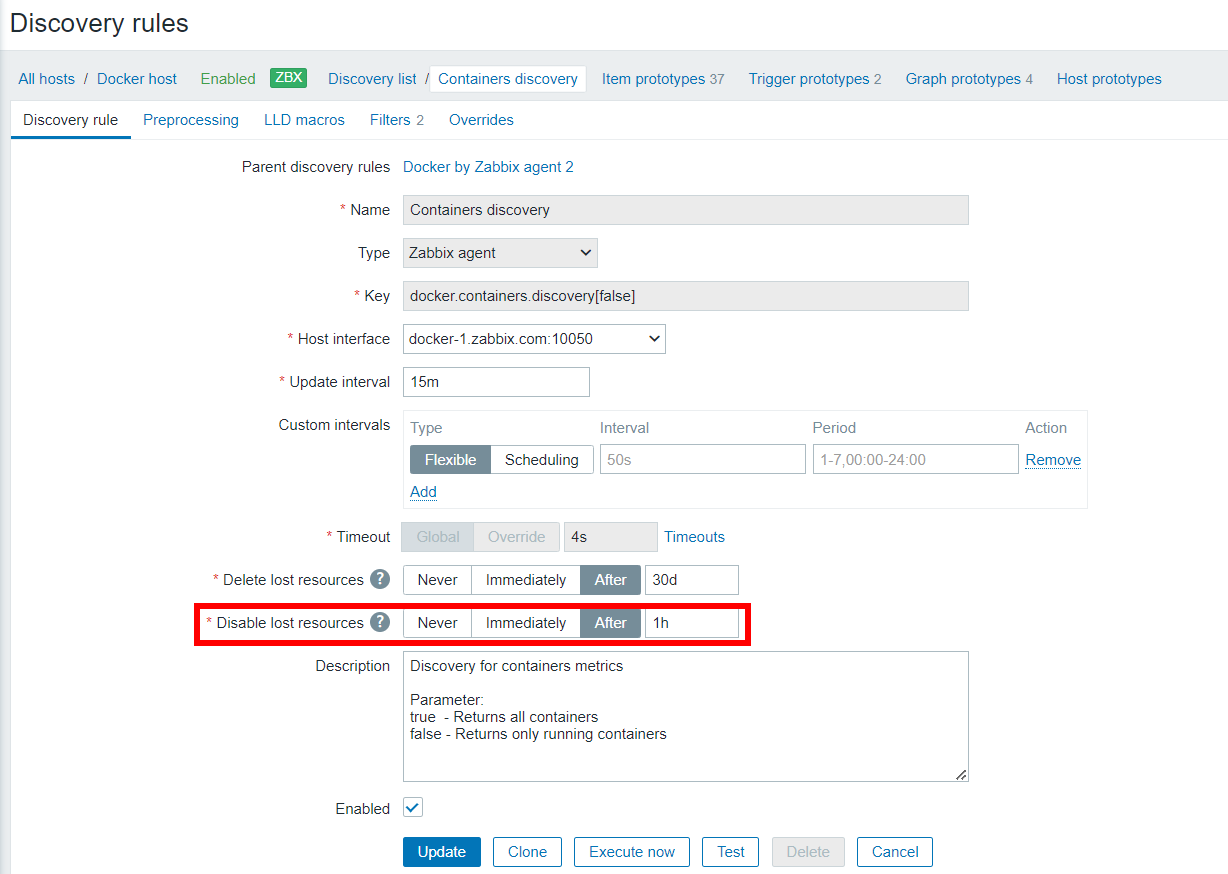
New templates and integrations
In response to user demand, Zabbix 7.0 LTS comes pre-packaged with a range of new templates for the most popular vendors and cloud providers.

Zabbix 7.0 training updates
All Zabbix training materials have been updated based on the new functionalities that have been added to the product since Zabbix 6.0.
Everyone is welcome to sharpen their skills, but if you’re a Zabbix 6.0 Certified Specialist or Certified Professional you can master Zabbix 7.0 LTS in just one day with our Upgrade Courses. As a 7.0 Specialist, you’ll be able to automate user provisioning with the Just-in-time (JIT) feature, monitor websites with new synthetic end-user monitoring, leverage new visualization features, and enhance the speed and performance of your data collection.
The 7.0 Certified Professional course covers proxy group configuration with high availability and load balancing, improved proxy data collection, new SNMP bulk monitoring, and enhanced host discovery for VMware, Kubernetes, and Cloud infrastructures.
We’re also happy to organize private trainings for organizations of any size, so don’t hesitate to get in touch!
Upcoming 7.0 events
If you’re looking for more information regarding Zabbix 7.0, you’re in luck! You can tune in to the “What’s new in Zabbix 7.0” webinar on June 11 at 12 PM CST or June 12 at 10 AM EEST. If you’d prefer a more hands-on approach, the following workshops are also available:
• “Zabbix Proxy High-availability and Load Balancing” (June 18, 6 PM EEST)
• “New Web Monitoring Features in Zabbix 7.0” (June 20, 6 PM EEST)
While you’re at it, feel free to explore Zabbix 7.0 LTS webinars and workshops in other languages. You can also check out worldwide events related to Zabbix 7.0 LTS, including our free in-person meetup in Riga on June 19 and Zabbix Summit 2024 this fall.
Ready to upgrade or migrate?
With a brand-new version out, there’s never been a better time to take advantage of our upgrade or migration services. Let our team take the risk out of migrating or upgrading to 7.0, giving you the latest version at a lower cost and with minimal disruption to your organization.
Need a consultation about the latest version?
Not sure about how to get the most out of Zabbix 7.0? Our expert consultants can answer any questions related to the architecture of your infrastructure, the implementation of a back-up strategy, and your capacity planning, while providing strategic advice on which 7.0 services are right for you.
Make your contribution as a translator
The Documentation 7.0 translation project is now live, which means that you can help localize Zabbix 7.0 documentation in multiple languages. Your efforts will help make Zabbix accessible to users around the globe, and you’ll also receive a reward for your contributions. The guidelines, which contain essential information about the project, are available here.
Useful links
To see what else is in store for the future, have a look at the Zabbix roadmap.
You can find the instructions and download the new version on the Download page.
Detailed, step-by-step upgrade instructions are available on our Upgrade procedure page.
Learn about new features and changes introduced in Zabbix 7.0 LTS by visiting the What’s new in Zabbix 7.0 page.
The What’s new documentation section provides a detailed description of the new features.
Take a look at the release notes to see the full list of new features and improvements.
The post Zabbix 7.0 – Everything You Need to Know appeared first on Zabbix Blog.
Protecting vulnerable communities for 10 years with Project Galileo
Post Syndicated from Jocelyn Woolbright original https://blog.cloudflare.com/galileo10anniversaryradardashboard

In celebration of Project Galileo’s 10th anniversary, we want to give you a snapshot of what organizations that work in the public interest experience on an everyday basis when it comes to keeping their websites online. With this, we are publishing the Project Galileo 10th anniversary Radar dashboard with the aim of providing valuable insights to researchers, civil society members, and targeted organizations, equipping them with effective strategies for protecting both internal information and their public online presence.

Key Statistics
- Under Project Galileo, we protect more than 2,600 Internet properties in 111 countries.
- Between May 1, 2023, and March 31, 2024, Cloudflare blocked 31.93 billion cyber threats against organizations protected under Project Galileo. This is an average of nearly 95.89 million cyber attacks per day over the 11-month period.
- When looking at the different organizational categories, journalism and media organizations were the most attacked, accounting for 34% of all attacks targeting the Internet properties protected under the Project in the last year, followed by human rights organizations at 17%.
- On October 11, 2023, Cloudflare detected one of the largest attacks we’ve seen against an organization under Project Galileo, targeting a prominent independent journalism website covering stories in Russia and across Eastern Europe. We identified a DDoS attack that peaked at 7 million requests per second, with an attack duration of 7 minutes. In total, 1.9 billion DDoS requests targeting the attacked organization were mitigated that day.
- We saw two attacks against an organization that manages vital Internet infrastructure in the Middle East. We mitigated 177 million DDoS requests targeting the organization over a three-hour period in October 2023. The second attack in December 2023 reached 42.6 million requests that were mitigated over a two-hour period.
- We observed an attack targeting LGBT Foundation, a UK-based LGBTQ+ organization, during the beginning of Pride Month in June 2023. Cloudflare mitigated 144.7 million requests to this organization on June 2, 2023. In addition to this spike in June, we also saw another attack on August 26, 2023, which coincided with Manchester Pride. This second attack peaked at 1.46 million requests per second before finally subsiding on August 29.
This year, we broke down the dashboard into several sections:
- Global civil society and human rights organizations
- Global journalism and media organizations
- Organizations based in Ukraine
- Organizations in Israel and Palestine
- Voting rights organizations based in the United States
Check out the full report here.
Highlights of the Report
Protecting free speech and a free press
The number of journalists imprisoned worldwide has grown in recent years. Reporters are increasingly at risk of being censored or shut down by governments or falling victim to cyberattacks. Project Galileo started as an initiative to protect free expression online. It’s grown to not only protect journalists, but also organizations working in the public interest such as voting rights groups, environmental activists, human rights defenders and more. We’ve seen journalists targeted on the Internet for various reasons, often stemming from the sensitive and impactful nature of their work. To that end, we’ve partnered with prominent organizations such as Internews, Center for International Media Assistance, International Press Institute, International Media Support, and many more to identify where our services are needed.
“Truth is the first casualty of war”
As the conflict in Ukraine continues, Cloudflare has been providing protection to journalists reporting on the conflict, human rights organizations helping refugees on the ground, and groups that have built mobile apps giving people early warnings of missile strikes.
Among them is Russian-born Galina Timchenko, co-founder, CEO, and owner of independent news outlet Meduza. A recent investigation by Access Now and the Citizen Lab reveals Timchenko had her iPhone infected with NSO Group’s Pegasus spyware during a trip to Berlin, Germany around February 10, 2023. This is the first documented case of Pegasus infection against a Russian journalist, which shows the growing suspicions among European Union governments regarding Russian civil society in exile. Labeled as an “undesirable organization” and blocked by the Russian government, Meduza operates out of Latvia to maintain editorial independence as it continues to publish news focused on covering stories in Russia and the former Soviet Union, including the conflict in Ukraine.
Meduza is an example of an important organization that lacks the resources to protect itself against intensive online attacks. On a single day in October 2023, Meduza came under DDoS attack peaking at 7 million requests per second and lasting 7 minutes—an onslaught which would have disabled the site under normal circumstances.
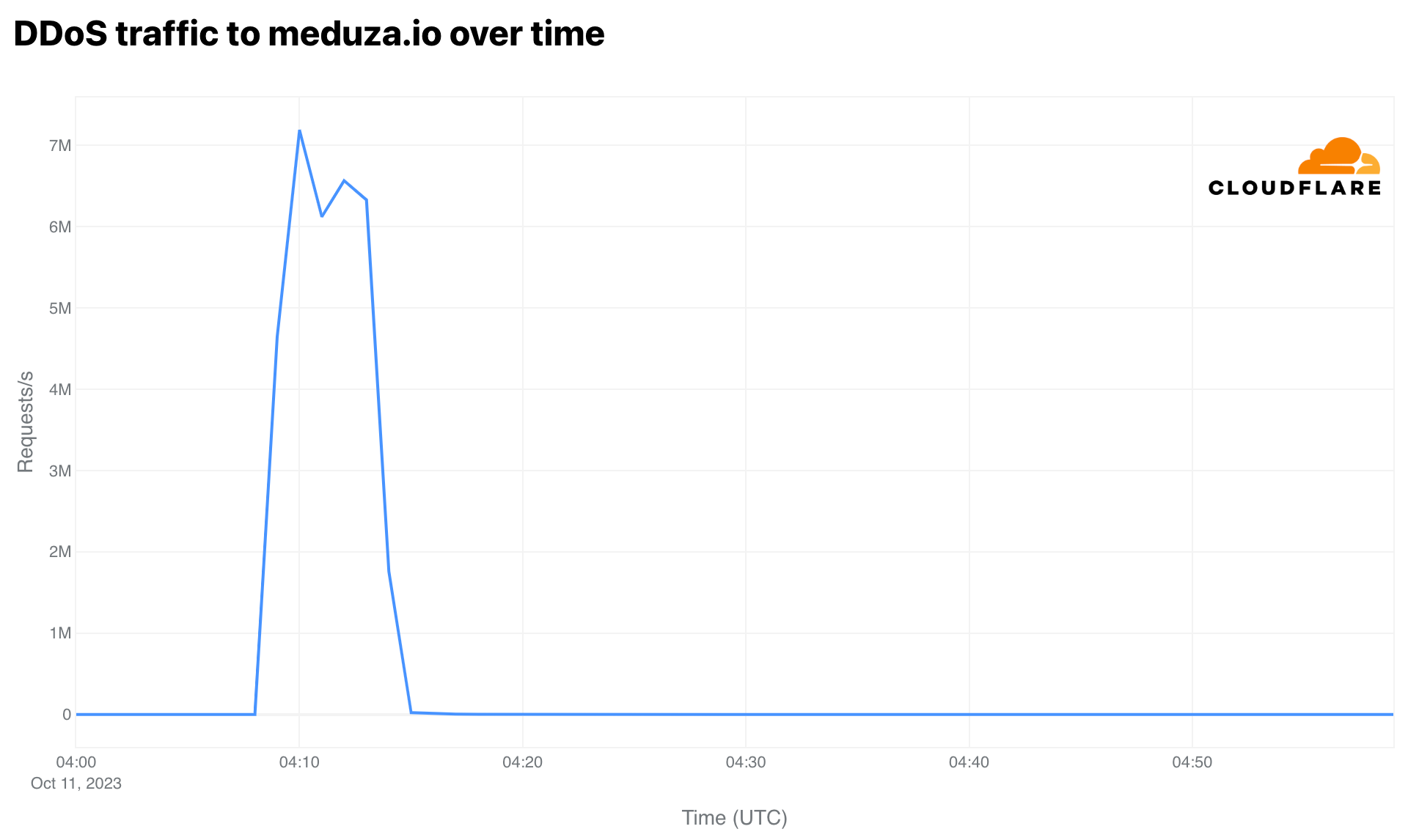
Protecting organizations in a time of conflict
We’ve reported on patterns of wartime violence coinciding with cyberattacks. Unfortunately, these trends have continued during the war between Israel and Hamas, and the humanitarian crisis in Gaza. Under Project Galileo, we protect a range of organizations based in the region that work to provide emergency response service, vital equipment for hospitals, crowdfunding platforms supporting the Muslim community worldwide, and more. We saw an increase in traffic after October 7, 2023, to both Israeli and Palestinian organizations, coinciding with the start of the Israel-Hamas war.
As we explored the data further, we saw an attack against a prominent organization based in the United Kingdom that works to secure Palestinian human rights, observing two dates on which there was an increase in mitigated traffic. The first, on October 15, 2023, coincided with the national demonstration in London in support of Palestine. We see in the first spike the requests go from 0 to 44,500 mitigated requests per second within two minutes. When we took a closer look, we identified that many of the requests were mitigated by Cloudflare’s Security Level, a product that uses the threat score (IP reputation) to decide whether to present a challenge to the visitor. The second spike, on February 21, 2024, coincided with UK lawmakers calling for cease-fire in the Israel-Hamas war. This peaked at 10,500 mitigations per second that lasted 40 minutes with an average of 6,638 requests per second.
As we reviewed the data, we saw two attacks against an organization that manages vital Internet infrastructure in the Middle East. Attacking infrastructure entities like domain name registries and registrars is not new, as we saw in Ukraine during the beginning of the war in March 2022, and follows an unsettling trend of targeting broad swaths of a country’s Internet infrastructure.
We saw two notable spikes in traffic, the first in October and second in December 2023. The first attack took place in three waves on October 18 and 19th, peaking around 78,500 requests per second. In total, the attack went from 2.48 million requests to 177.42 million requests mitigated per day.
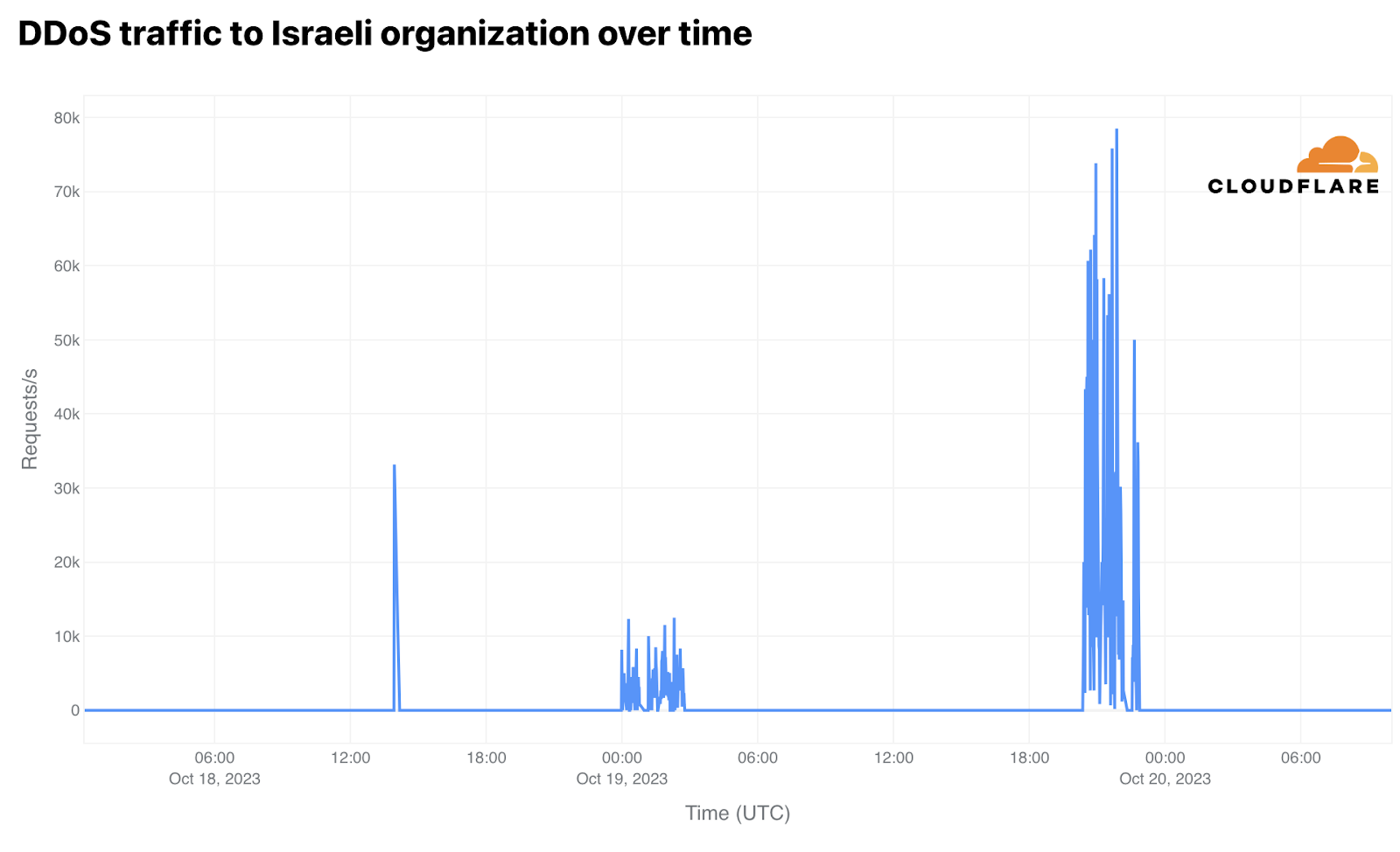
On December 20-21, 2023, there was an attack that lasted more than 2 hours, averaging 8,600 requests per second throughout that period, reaching as high as 13,830 requests per second. In total, this attack saw 42.6 million daily requests mitigated.
And more…
Here we’ve provided just a snapshot of what organizations see on a daily basis when it comes to keeping their websites online. For more information on attacks against organizations protected under Project Galileo, check out the full Radar report.
If you are an organization looking for protection under Project Galileo, please visit our website: cloudflare.com/galileo.
Response:
3) Send test message
Response:
Response – (ConflictException):
Conclusion
As SMS messaging continues to play a crucial role in customer engagement and authentication, protecting your communications from AIT is more important than ever. Amazon Pinpoint Protect provides a powerful and user-friendly solution to help you mitigate the impact of SMS pumping, ensuring the integrity of your SMS channels and preserving your business’ reputation and resources. Whether you’re a small business or a large enterprise, Pinpoint Protect is a valuable tool to have in your arsenal as you navigate the evolving landscape of SMS messaging.
To get started with Pinpoint SMS Protect, visit the Amazon Pinpoint SMS documentation or reach out to your AWS account team. And don’t forget to let us know in the comments how Protect configurations has helped you combat AIT and strengthen your SMS communications.
A few resources to help you plan for your SMS program:
About the Author
Brett Ezell is your friendly neighborhood Solutions Architect at AWS, where he specializes in helping customers optimize their SMS and email campaigns using Amazon Pinpoint and Amazon Simple Email Service. As a former US Navy veteran, Brett brings a unique perspective to his work, ensuring customers receive tailored solutions to meet their needs. In his free time, Brett enjoys live music, collecting vinyl, and the challenges of a good workout. And, as a self-proclaimed comic book aficionado, he can often be found combing through his local shop for new books to add to his collection.