Post Syndicated from Steffen Grunwald original https://aws.amazon.com/blogs/architecture/field-notes-monitoring-the-java-virtual-machine-garbage-collection-on-aws-lambda/
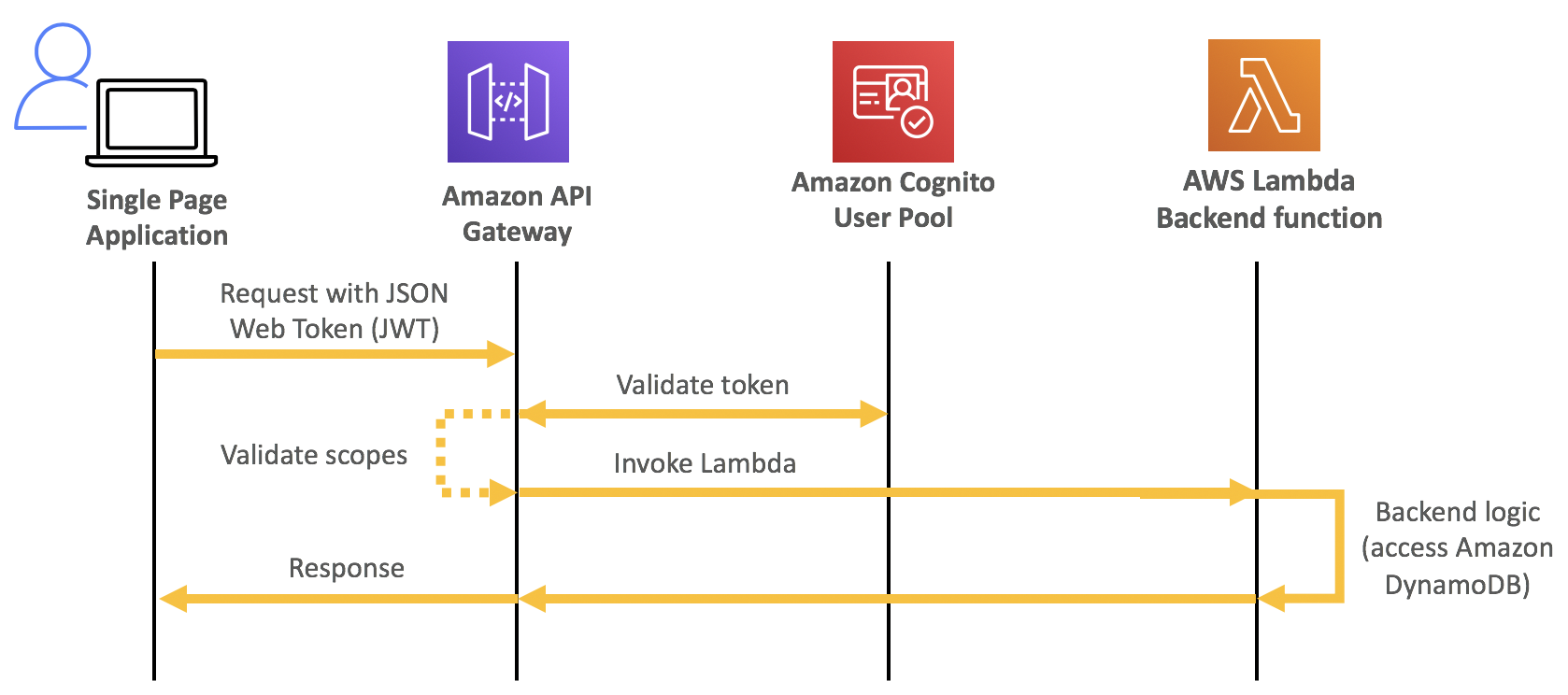
When you want to optimize your Java application on AWS Lambda for performance and cost the general steps are: Build, measure, then optimize! To accomplish this, you need a solid monitoring mechanism. Amazon CloudWatch and AWS X-Ray are well suited for this task since they already provide lots of data about your AWS Lambda function. This includes overall memory consumption, initialization time, and duration of your invocations. To examine the Java Virtual Machine (JVM) memory you require garbage collection logs from your functions. Instances of an AWS Lambda function have a short lifecycle compared to a long-running Java application server. It can be challenging to process the logs from tens or hundreds of these instances.
In this post, you learn how to emit and collect data to monitor the JVM garbage collector activity. Having this data, you can visualize out-of-memory situations of your applications in a Kibana dashboard like in the following screenshot. You gain actionable insights into your application’s memory consumption on AWS Lambda for troubleshooting and optimization.

The lifecycle of a JVM application on AWS Lambda
Let’s first revisit the lifecycle of the AWS Lambda Java runtime and its JVM:
- A Lambda function is invoked.
- AWS Lambda launches an execution context. This is a temporary runtime environment based on the configuration settings you provide, like permissions, memory size, and environment variables.
- AWS Lambda creates a new log stream in Amazon CloudWatch Logs for each instance of the execution context.
- The execution context initializes the JVM and your handler’s code.
You typically see the initialization of a fresh execution context when a Lambda function is invoked for the first time, after it has been updated, or it scales up in response to more incoming events.
AWS Lambda maintains the execution context for some time in anticipation of another Lambda function invocation. In effect, the service freezes the execution context after a Lambda function completes. It thaws the execution context when the Lambda function is invoked again if AWS Lambda chooses to reuse it.
During invocations, the JVM also maintains garbage collection as usual. Outside of invocations, the JVM and its maintenance processes like garbage collection are also frozen.
Garbage collection and indicators for your application’s health
The purpose of JVM garbage collection is to clean up objects in the JVM heap, which is the space for an application’s objects. It finds objects which are unreachable and deletes them. This frees heap space for other objects.
You can make the JVM log garbage collection activities to get insights into the health of your application. One example for this is the free heap after each garbage collection. If this metric keeps shrinking, it is an indicator for a memory leak – eventually turning into an OutOfMemoryError. If there is not enough of free heap, the JVM might be too busy with garbage collection instead of running your application code. Otherwise, a heap that is too big does indicate that there’s potential to decrease the memory configuration of your AWS Lambda function. This keeps garbage collection pauses low and provides a consistent response time.
The garbage collection logging can be configured via an environment variable as part of the AWS Lambda function configuration. The environment variable JAVA_TOOL_OPTIONS is considered by both the Java 8 and 11 JVMs. You use it to pass options that you would usually add to the command line when launching the JVM. The options to configure garbage collection logging and the output is specific to the Java version.
Java 11 uses the Unified Logging System (JEP 158 and JEP 271) which has been introduced in Java 9. Logging can be configured with the environment variable:
JAVA_TOOL_OPTIONS=-Xlog:gc+metaspace,gc+heap,gc:stdout:time,tags
The Serial Garbage Collector will output the logs:
[<TIMESTAMP>][gc] GC(4) Pause Full (Allocation Failure) 9M->9M(11M) 3.941ms (D)
[<TIMESTAMP>][gc,heap] GC(3) DefNew: 3063K->234K(3072K) (A)
[<TIMESTAMP>][gc,heap] GC(3) Tenured: 6313K->9127K(9152K) (B)
[<TIMESTAMP>][gc,metaspace] GC(3) Metaspace: 762K->762K(52428K) (C)
[<TIMESTAMP>][gc] GC(3) Pause Young (Allocation Failure) 9M->9M(21M) 23.559ms (D)
Prior to Java 9, including Java 8, you configure the garbage collection logging as follows:
JAVA_TOOL_OPTIONS=-XX:+PrintGCDetails -XX:+PrintGCDateStamps
The Serial garbage collector output in Java 8 is structured differently:
<TIMESTAMP>: [GC (Allocation Failure)
<TIMESTAMP>: [DefNew: 131042K->131042K(131072K), 0.0000216 secs] (A)
<TIMESTAMP>: [Tenured: 235683K->291057K(291076K), 0.2213687 secs] (B)
366725K->365266K(422148K), (D)
[Metaspace: 3943K->3943K(1056768K)], (C)
0.2215370 secs]
[Times: user=0.04 sys=0.02, real=0.22 secs]
<TIMESTAMP>: [Full GC (Allocation Failure)
<TIMESTAMP>: [Tenured: 297661K->36658K(297664K), 0.0434012 secs] (B)
431575K->36658K(431616K), (D)
[Metaspace: 3943K->3943K(1056768K)], 0.0434680 secs] (C)
[Times: user=0.02 sys=0.00, real=0.05 secs]
Independent of the Java version, the garbage collection activities are logged to standard out (stdout) or standard error (stderr). Logs appear in the AWS Lambda function’s log stream of Amazon CloudWatch Logs. The log contains the size of memory used for:
- A: the young generation
- B: the old generation
- C: the metaspace
- D: the entire heap
The notation is before-gc -> after-gc (committed heap). Read the JVM Garbage Collection Tuning Guide for more details.
Visualizing the logs in Amazon Elasticsearch Service
It is hard to fully understand the garbage collection log by just reading it in Amazon CloudWatch Logs. You must visualize it to gain more insight. This section describes the solution to achieve this.
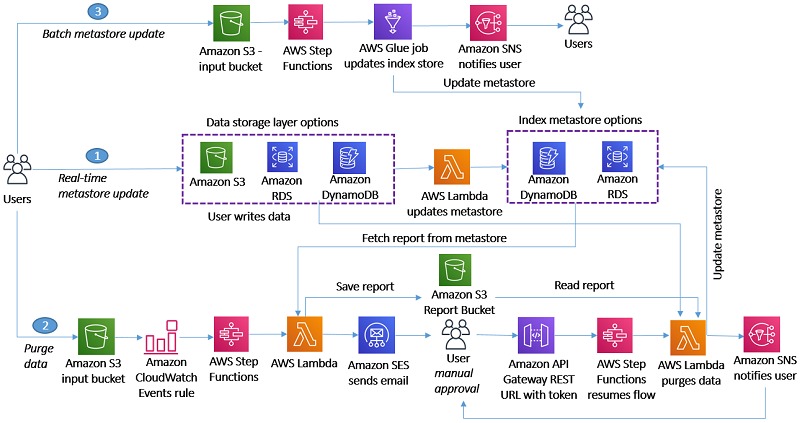
Solution Overview

Amazon CloudWatch Logs have a feature to stream CloudWatch Logs data to Amazon Elasticsearch Service via an AWS Lambda function. The AWS Lambda function for log transformation is subscribed to the log group of your application’s AWS Lambda function. The subscription filters for a pattern that matches the one of the garbage collection log entries. The log transformation function processes the log messages and puts it to a search cluster. To make the data easy to digest for the search cluster, you add code to transform and convert the messages to JSON. Having the data in a search cluster, you can visualize it with Kibana dashboards.
Get Started
To start, launch the solution architecture described above as a prepackaged application from the AWS Serverless Application Repository. It contains all resources ready to visualize the garbage collection logs for your Java 11 AWS Lambda functions in a Kibana dashboard. The search cluster consists of a single t2.small.elasticsearch instance with 10GB of EBS storage. It is protected with Amazon Cognito User Pools so you only need to add your user(s). The T2 instance types do not support encryption of data at rest.
Read the source code for the application in the aws-samples repository.
1. Spin up the application from the AWS Serverless Application Repository:

2. As soon as the application is deployed completely, the outputs of the AWS CloudFormation stack provide the links for the next steps. You will find two URLs in the AWS CloudFormation console called createUserUrl and kibanaUrl.

3. Use the createUserUrl link from the outputs, or navigate to the Amazon Cognito user pool in the console to create a new user in the pool.
a. Enter an email address as username and email. Enter a temporary password of your choice with at least 8 characters.
b. Leave the phone number empty and uncheck the checkbox to mark the phone number as verified.
c. If necessary, you can check the checkboxes to send an invitation to the new user or to make the user verify the email address.
d. Choose Create user.

4. Access the Kibana dashboard with the kibanaUrl link from the AWS CloudFormation stack outputs, or navigate to the Kibana link displayed in the Amazon Elasticsearch Service console.
a. In Kibana, choose the Dashboard icon in the left menu bar
b. Open the Lambda GC Activity dashboard.
You can test that new events appear by using the Kibana Developer Console:
POST gc-logs-2020.09.03/_doc
{
"@timestamp": "2020-09-03T15:12:34.567+0000",
"@gc_type": "Pause Young",
"@gc_cause": "Allocation Failure",
"@heap_before_gc": "2",
"@heap_after_gc": "1",
"@heap_size_gc": "9",
"@gc_duration": "5.432",
"@owner": "123456789012",
"@log_group": "/aws/lambda/myfunction",
"@log_stream": "2020/09/03/[$LATEST]123456"
}
5. When you go to the Lambda GC Activity dashboard you can see the new event. You must select the right timeframe with the Show dates link.

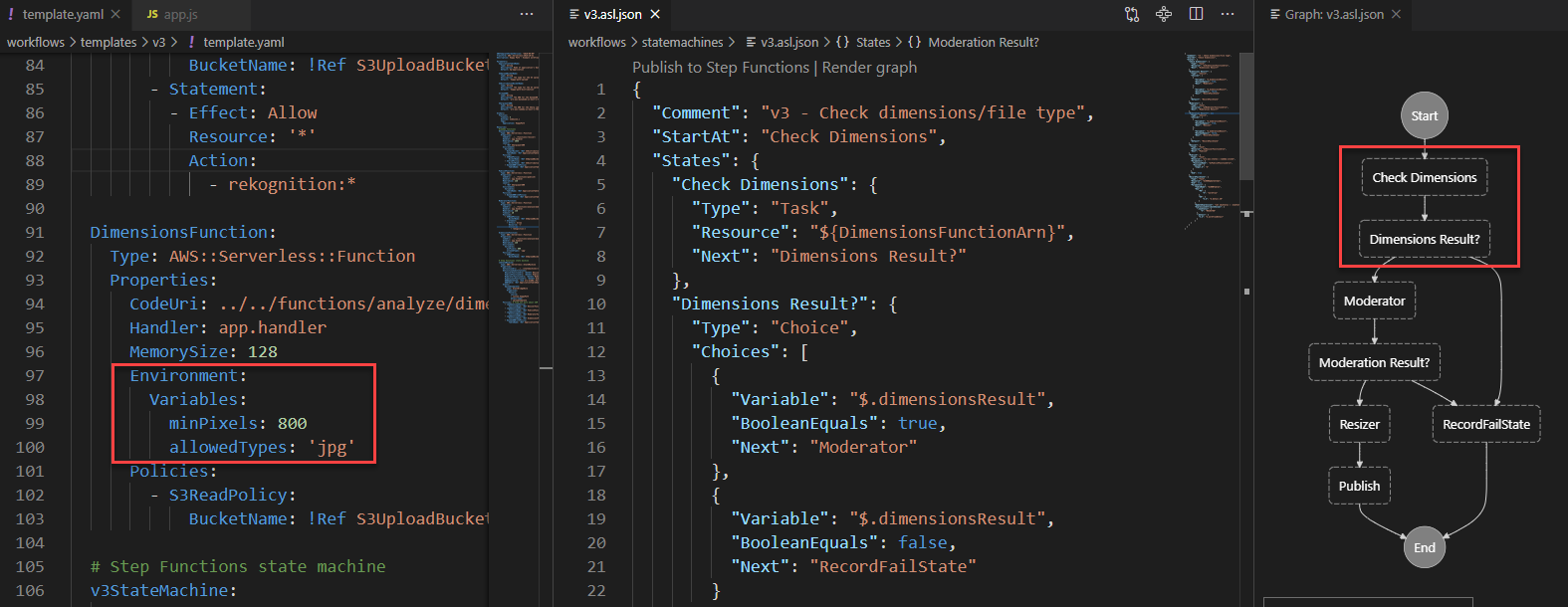
The dashboard consists of six tiles:
- In the Filters you optionally select the log group and filter for a specific AWS Lambda function execution context by the name of its log stream.
- In the GC Activity Count by Execution Context you see a heatmap of all filtered execution contexts by garbage collection activity count.
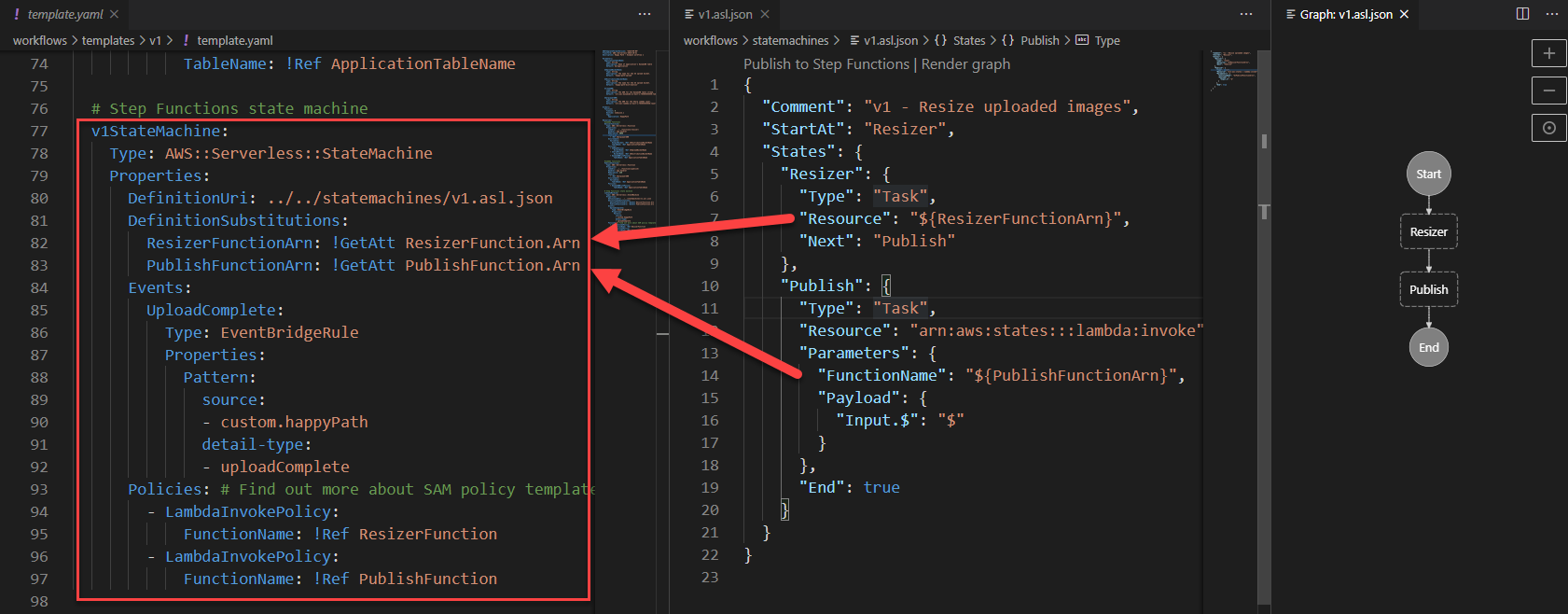
- The GC Activity Metrics display a graph for the metrics for all filtered execution contexts.
- The GC Activity Count shows the amount of garbage collection activities that are currently displayed.
- The GC Duration show the sum of the duration of all displayed garbage collection activities.
- The GC Activity Raw Data at the bottom displays the raw items as ingested into the search cluster for a further drill down.
Configure your AWS Lambda function for garbage collection logging
1. The application that you want to monitor needs to log garbage collection activities. Currently the solution supports logs from Java 11. Add the following environment variable to your AWS Lambda function to activate the logging.
JAVA_TOOL_OPTIONS=-Xlog:gc:stderr:time,tags
The environment variables must reflect this parameter like the following screenshot:

2. Go to the streamLogs function in the AWS Lambda console that has been created by the stack, and subscribe it to the log group of the function you want to monitor.

3. Select Add Trigger.
4. Select CloudWatch Logs as Trigger Configuration.
5. Input a Filter name of your choice.
6. Input "[gc" (including quotes) as the Filter pattern to match all garbage collection log entries.
7. Select the Log Group of the function you want to monitor. The following screenshot subscribes to the logs of the application’s function resize-lambda-ResizeFn-[...].

8. Select Add.
9. Execute the AWS Lambda function you want to monitor.
10. Refresh the dashboard in Amazon Elasticsearch Service and see the datapoint added manually before appearing in the graph.
Troubleshooting examples
Let’s look at an example function and draw some useful insights from the Java garbage collection log. The following diagrams show the Sample Amazon S3 function code for Java from the AWS Lambda documentation running in a Java 11 function with 512 MB of memory.
- An S3 event from a new uploaded image triggers this function.
- The function loads the image from S3, resizes it, and puts the resized version to S3.
- The file size of the example image is close to 2.8MB.
- The application is called 100 times with a pause of 1 second.
Memory leak
For the demonstration of a memory leak, the function has been changed to keep all source images in memory as a class variable. Hence the memory of the function keeps growing when processing more images:

In the diagram, the heap size drops to zero at timestamp 12:34:00. The Amazon CloudWatch Logs of the function reveal an error before the next call to your code in the same AWS Lambda execution context with a fresh JVM:
Java heap space: java.lang.OutOfMemoryError
java.lang.OutOfMemoryError: Java heap space
at java.desktop/java.awt.image.DataBufferByte.<init>(Unknown Source)
[...]
The JVM crashed and was restarted because of the error. You leverage primarily the Amazon CloudWatch Logs of your function to detect errors. The garbage collection log and its visualization provide additional information for root cause analysis:
Did the JVM run out of memory because a single image to resize was too large?
Or was the memory issue growing over time?
The latter could be an indication that you have a memory leak in your code.
The Heap size is too small
For the demonstration of a heap that was chosen too small, the memory leak from the preceding image has been resolved, but the function was configured to 128MB of memory. From the baseline of the heap to the maximum heap size, there are only approximately 5 MB used.

This will result in a high management overhead of your JVM. You should experiment with a higher memory configuration to find the optimal performance also taking cost into account. Check out AWS Lambda power tuning open source tool to do this in an automated fashion.
Finetuning the initial heap size
If you review the development of the heap size at the start of an execution context, this indicates that the heap size is continuously increased. Each heap size change is an expensive operation consuming time of your function. Over time, the heap size is changed as well. The garbage collector logs 502 activities, which take almost 17 seconds overall.

This on-demand scaling is useful on a local workstation where the physical memory is shared with other applications. On AWS Lambda, the configured memory is dedicated to your function, so you can use it to its full extent.
You can do so by setting the minimum and maximum heap size to a fixed value by appending the -Xms and -Xmx parameters to the environment variable we introduced before.
The heap is not the only part of the JVM that consumes memory, so you must experiment with this setting and closely monitor the performance.
Start with the heap size that you observe to be working from the garbage collection log. If you set the heap size too large, your function will not initialize at all or break unexpectedly. Remember that the ability to tweak JVM parameters might change with future service features.
Let’s set 400 MB of the 512 MB memory and examine the results:
JAVA_TOOL_OPTIONS=-Xlog:gc:stderr:time,tags -Xms400m -Xmx400m
The preceding dashboard shows that the overall garbage collection duration was reduced by about 95%. The garbage collector had 80% fewer activities.
The garbage collection log entries displayed in the dashboard reveal that exclusively minor garbage collection (Pause Young) activities were triggered instead of major garbage collections (Pause Full). This is expected as the images are immediately discarded after the download, resize, upload operation. The effect on the overall function durations of 100 invocations, is a 5% decrease on average in this specific case.

Cost estimation and clean up
Cost for the processing and transformation of your function’s Amazon CloudWatch Logs incurs when your function is called. This cost depends on your application and how often garbage collection activities are triggered. Read an estimate of the monthly cost for the search cluster. If you do not need the garbage collection monitoring anymore, delete the subscription filter from the log group of your AWS Lambda function(s). Also, delete the stack of the solution above in the AWS CloudFormation console to clean up resources.
Conclusion
In this post, we examined further sources of data to gain insights about the health of your Java application. We also demonstrated a pipeline to ingest, transform, and visualize this information continuously in a Kibana dashboard. As a next step, launch the application from the AWS Serverless Application Repository and subscribe it to your applications’ logs. Feel free to submit enhancements to the application in the aws-samples repository or provide feedback in the comments.
Field Notes provides hands-on technical guidance from AWS Solutions Architects, consultants, and technical account managers, based on their experiences in the field solving real-world business problems for customers.













 Ahmed Zamzam is a Solutions Architect with Amazon Web Services. He supports SMB customers in the UK in their digital transformation and their cloud journey to AWS, and specializes in Data Analytics. Outside of work, he loves traveling, hiking, and cycling.
Ahmed Zamzam is a Solutions Architect with Amazon Web Services. He supports SMB customers in the UK in their digital transformation and their cloud journey to AWS, and specializes in Data Analytics. Outside of work, he loves traveling, hiking, and cycling.













 George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus.
George Komninos is a Data Lab Solutions Architect at AWS. He helps customers convert their ideas to a production-ready data product. Before AWS, he spent 3 years at Alexa Information domain as a data engineer. Outside of work, George is a football fan and supports the greatest team in the world, Olympiacos Piraeus. Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.
Sakti Mishra is a Data Lab Solutions Architect at AWS. He helps customers architect data analytics solutions, which gives them an accelerated path towards modernization initiatives. Outside of work, Sakti enjoys learning new technologies, watching movies, and travel.



























































 Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.
Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.