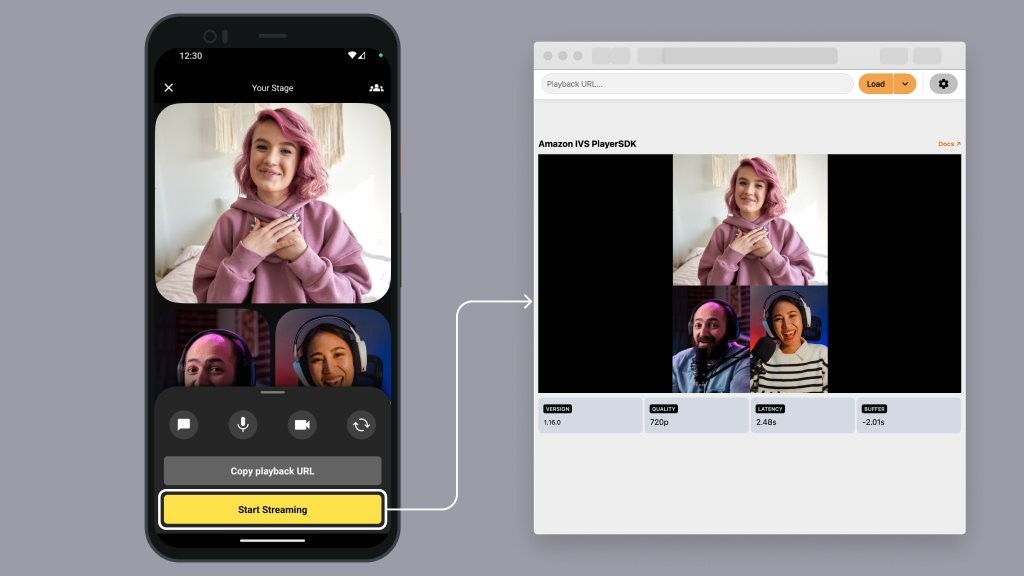
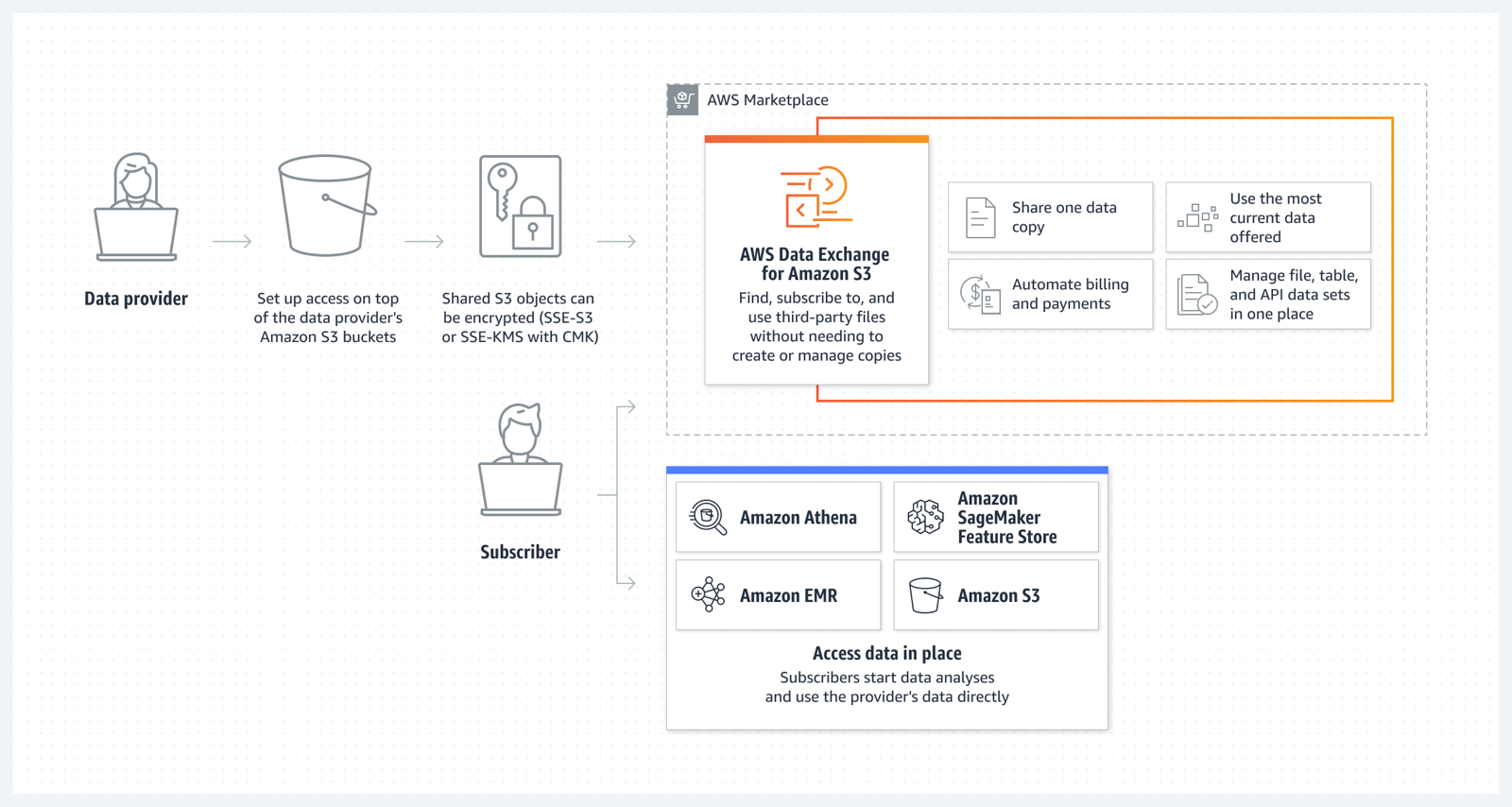
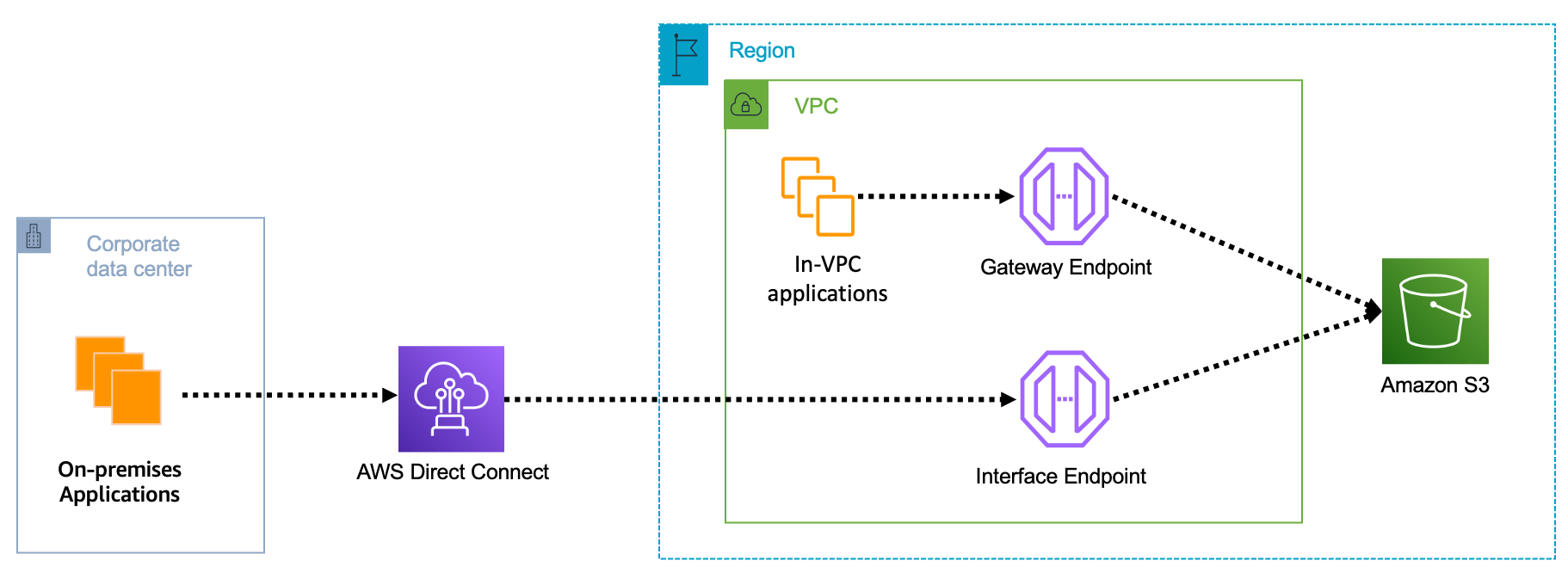
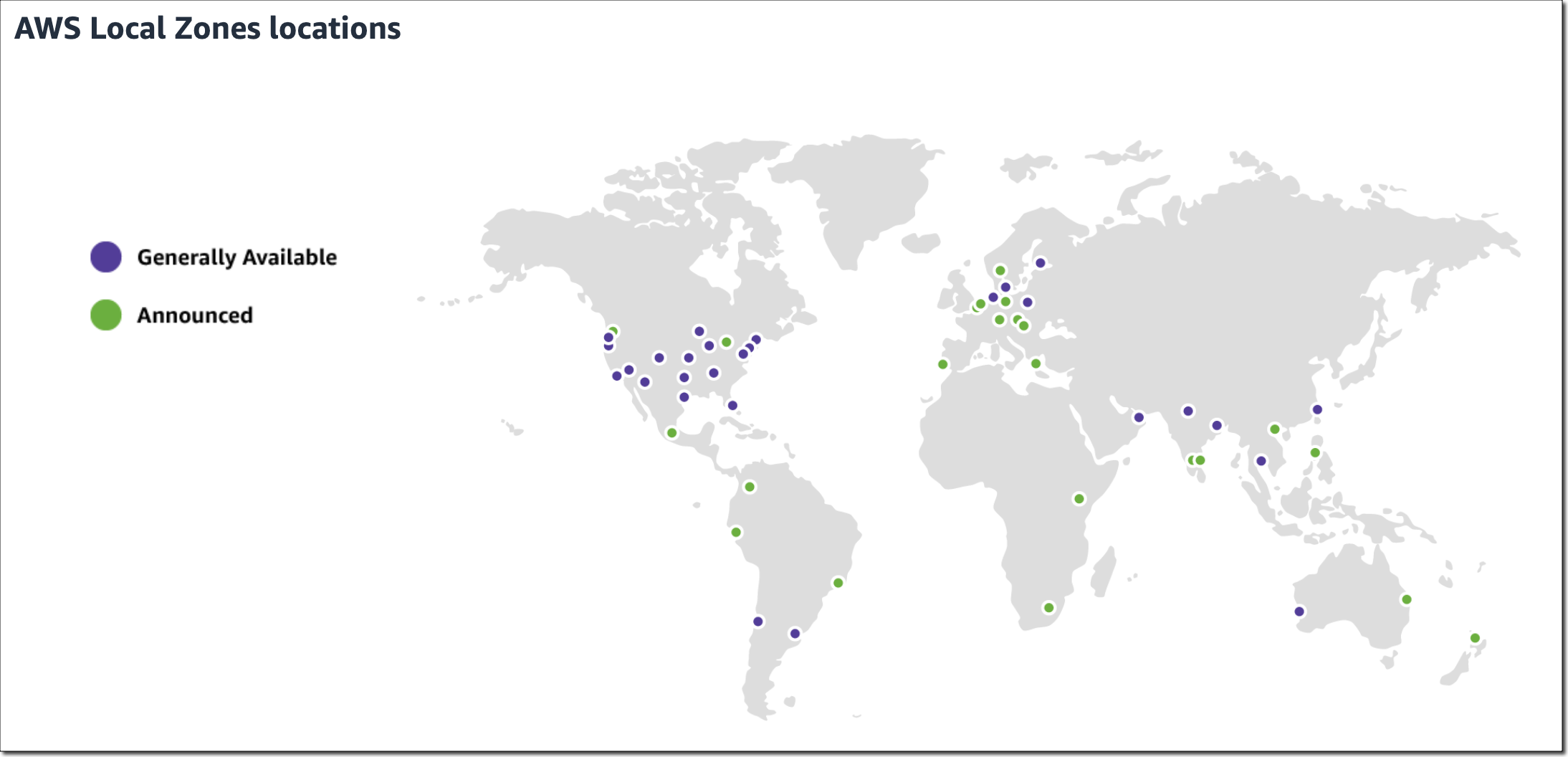
The US celebrated Independence Day last week on July 4 with fireworks and barbecues across the country. But fireworks weren’t the only thing that launched last week. Let’s have a look!
Last Week’s Launches Here are some launches that got my attention:
AWS Glue – AWS Glue Crawlers now supports Apache Iceberg tables. Apache Iceberg is an open-source table format for data stored in data lakes. You can now automatically register Apache Iceberg tables into AWS Glue Data Catalog by running the Glue Crawler. You can then query Glue Catalog Iceberg tables across various analytics engines and apply AWS Lake Formation fine-grained permissions when querying from Amazon Athena. Check out the AWS Glue Crawler documentation to learn more.
In addition, Amazon RDS for PostgreSQL Multi-AZ Deployments with two readable standbys now supports logical replication. With logical replication, you can stream data changes from Amazon RDS for PostgreSQL to other databases for use cases such as data consolidation for analytical applications, change data capture (CDC), replicating select tables rather than the entire database, or for replicating data between different major versions of PostgreSQL. Check out the Amazon RDS User Guide for more details.
Amazon CloudWatch – Amazon CloudWatch now supports Service Quotas in cross-account observability. With this, you can track and visualize resource utilization and limits across various AWS services from multiple AWS accounts within a region using a central monitoring account. You no longer have to track the quotas by logging in to individual accounts, instead from a central monitoring account, you can create dashboards and alarms for the AWS service quota usage across all your source accounts from a central monitoring account. Setup CloudWatch cross-account observability to get started.
Amazon SageMaker – You can now associate a SageMaker Model Card with a specific model version in SageMaker Model Registry. This lets you establish a single source of truth for your registered model versions, with comprehensive, centralized, and standardized documentation across all stages of the model’s journey on SageMaker, facilitating discoverability and promoting governance, compliance, and accountability throughout the model lifecycle. Learn more about SageMaker Model Cards in the developer guide.
Other AWS News Here are some additional blog posts and news items that you might find interesting:
Building generative AI applications for your startup – In this AWS Startups Blog post, Hrushikesh explains various approaches to build generative AI applications, and reviews their key component. Read the full post for the details.
Components of the generative AI landscape.
How Alexa learned to speak with an Irish accent – If you’re curious how Amazon researchers used voice conversation to generate Irish-accented training data in Alexa’s own voice, check out this Amazon Science Blog post.
AWS open-source news and updates – My colleague Ricardo writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Hong Kong (July 20), New York City (July 26), Taiwan (August 2-3), São Paulo (August 3), and Mexico City (August 30).
AWS Community Days – Join a community-led conference run by AWS user group leaders in your region: Malaysia (July 22), Philippines (July 29-30), Colombia (August 12), and West Africa (August 19).
AWS re:Invent (November 27 – December 1) – Join us to hear the latest from AWS, learn from experts, and connect with the global cloud community. Registration is now open.
Companies continue to adopt software as a service (SaaS) applications at a rapid clip, with recent research showing that the average SaaS portfolio now has at least 200 applications. While organizations purchase these purpose-built tools to make their employees more productive, they now must contend with growing security complexities, context switching, and data silos.
If your company faces these issues, or you want to avoid them in the future, join us on Tuesday, June 27, for a free-to-attend online event AWS Applications Innovation Day. AWS will stream the event simultaneously across multiple platforms, including LinkedIn Live, Twitter, YouTube, and Twitch. You can also join us in person in Seattle to hear from Dilip Kumar, Vice President of AWS Applications and an executive panel with AWS Partners Splunk, Asana, and Okta.
Applications Innovation Day is designed to give you the tools you need to improve how your organization uses and secures SaaS applications. Sessions throughout the day will show you how you can secure data while providing your employees with the best tools for the job. You’ll also learn how to support the right mix of applications to improve workforce collaboration, and how to use generative artificial intelligence securely and effectively to improve insights and enhance employee productivity.
We’ll start the virtual broadcast with a keynote from Dilip Kumar, Vice President of AWS Applications, who will discuss the way we use and govern SaaS applications at AWS. He’ll also discuss how we’ll make it easier to deploy purpose-built SaaS applications like Asana, Okta, Splunk, Zoom, and others across your business, including the announcement of some exciting new innovations from AWS.
AWS product leaders will present technical breakout sessions during the day on the productivity and security aspects of managing a SaaS application tech stack. Sessions will cover a wide range of topics, including how the nature of productivity at work is changing, how AI is transforming SaaS applications and collaboration, how you can improve your security observability across your applications, and how you can create custom analytics on SaaS application activity.
Overall, the event is a great opportunity for security leaders, IT administrators and operations leaders, and anyone leading digital workplace and transformation initiatives to learn how to better leverage and govern SaaS applications.
AWS Silicon Innovation Day is a one-day virtual event on June 21, 2023, that will allow you to better understand AWS Silicon and how you can use AWS’s unique Amazon EC2 chip offerings to your benefit. AWS has designed and developed purpose-built silicon specifically for the cloud.
During this event, you will have the opportunity to hear directly from senior leaders at AWS. Our panel of lead architects, engineers, customers, and analysts will provide insights into our silicon journey. Through deep dives into our cutting-edge silicon design and customer success stories, the panel will provide insights on security enhancements and cost-saving opportunities. Here are some of the highlights you can expect from this event.
Leadership session – To kick off the day, we have a Leadership session featuring Dave Brown, VP of Amazon EC2 and Dr. Ruba Borno, VP of WW Channels and Alliances joining us on stage. Dave will engage in a discussion with Ruba about how you can benefit from the innovation AWS delivers with its silicon technology.
AI/ML session – Gary Szilagyi, VP of Annapurna Labs will discuss with Nafea Bshara, co-founder of Annapurna Labs the utilization of chipset development by his team to create specialized chips for Generative AI, CPU, and the AWS Nitro system. He will highlight how you can harness the Annapurna mindset to develop not only CPUs but also tailor-made chips with specific purposes in mind.
Customer session – Jeff Barr, VP of AWS Evangelism, and Tiffany Wissner, Director of Product Marketing, will delve into insights from our customers. They will share anecdotes and experiences gathered from various sources, such as re:Invent, summits, and developer events, where you have expressed how you harnessed AWS silicon to drive your own remarkable innovations.
Networking session – JR Rivers, Senior Principal Engineer, and Madhura Kale, Senior Product Manager will shed light on the impact of silicon innovation, not only on the benefits you experience using our CPUs, GPUs, or Nitro System, but also on the transformation of AWS’s network infrastructure. They will delve into the realm of networking advancements, showcasing some of the latest innovations and highlighting the instrumental role played by AWS silicon in powering these developments.
Arm and Nitro Innovation session – Anthony Liguori, VP and Fellow, Nitro System architecture will be joined by Ali Saidi, Director of Annapurna Labs to discuss harnessing the power of hardware and software in tandem to drive the development of cutting-edge silicon technologies.
Analyst and Executive session – Raj Pai, VP of Amazon EC2 Product Management will engage in a conversation with an analyst, delving into the realm of silicon innovation in the cloud.
No advance registration is needed to participate in AWS Silicon Innovation Day, but you can add an event reminder to your calendar by registering on the event page. We sincerely hope that you will join us in embracing the excitement and seizing the valuable learning opportunities at this new event!
In the AWS Security Profile series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Matt Campagna, Senior Principal, Security Engineering, AWS Cryptography, and re:Inforce 2023 session speaker, who shares thoughts on data protection, cloud security, post-quantum cryptography, and more. Matthew was first profiled on the AWS Security Blog in 2019. This is part 1 of 3 in a series of interviews with our AWS Cryptography team.
What do you do in your current role and how long have you been at AWS?
I started at Amazon in 2013 as the first cryptographer at AWS. Today, my focus is on the cryptographic security of our customers’ data. I work across AWS to make sure that our cryptographic engineering meets our most sensitive customer needs. I lead our migration to quantum-resistant cryptography, and help make privacy-preserving cryptography techniques part of our security model.
How did you get started in the data protection and cryptography space? What about it piqued your interest?
I first learned about public-key cryptography (for example, RSA) during a math lesson about group theory. I found the mathematics intriguing and the idea of sending secret messages using only a public value astounding. My undergraduate and graduate education focused on group theory, and I started my career at the National Security Agency (NSA) designing and analyzing cryptologics. But what interests me most about cryptography is its ability to enable business by reducing risks. I look at cryptography as a financial instrument that affords new business cases, like e-commerce, digital currency, and secure collaboration. What enables Amazon to deliver for our customers is rooted in cryptography; our business exists because cryptography enables trust and confidentiality across the internet. I find this the most intriguing aspect of cryptography.
AWS has invested in the migration to post-quantum cryptography by contributing to post-quantum key agreement and post-quantum signature schemes to protect the confidentiality, integrity, and authenticity of customer data. What should customers do to prepare for post-quantum cryptography?
Our focus at AWS is to help ensure that customers can migrate to post-quantum cryptography as fast as prudently possible. This work started with inventorying our dependencies on algorithms that aren’t known to be quantum-resistant, like integer-factorization-based cryptography, and discrete-log-based cryptography, like ECC. Customers can rely on AWS to assist with transitioning to post-quantum cryptography for their cloud computing needs.
We recommend customers begin inventorying their dependencies on algorithms that aren’t quantum-resistant, and consider developing a migration plan, to understand if they can migrate directly to new post-quantum algorithms or if they should re-architect them. For the systems that are provided by a technology provider, customers should ask what their strategy is for post-quantum cryptography migration.
AWS offers post-quantum TLS endpoints in some security services. Can you tell us about these endpoints and how customers can use them?
Our open source TLS implementation, s2n-TLS, includes post-quantum hybrid key exchange (PQHKEX) in its mainline. It’s deployed everywhere that s2n is deployed. AWS Key Management Service, AWS Secrets Manager, and AWS Certificate Manager have enabled PQHKEX cipher suites in our commercial AWS Regions. Today customers can use the AWS SDK for Java 2.0 to enable PQHKEX on their connection to AWS, and on the services that also have it enabled, they will negotiate a post-quantum key exchange method. As we enable these cipher suites on additional services, customers will also be able to connect to these services using PQHKEX.
You are a frequent contributor to the Amazon Science Blog. What were some of your recent posts about?
In 2022, we published a post on preparing for post-quantum cryptography, which provides general information on the broader industry development and deployment of post-quantum cryptography. The post links to a number of additional resources to help customers understand post-quantum cryptography. The AWS Post-Quantum Cryptography page and the Science Blog are great places to start learning about post-quantum cryptography.
We also published a post highlighting the security of post-quantum hybrid key exchange. Amazon believes in evidencing the cryptographic security of the solutions that we vend. We are actively participating in cryptographic research to validate the security that we provide in our services and tools.
What’s been the most dramatic change you’ve seen in the data protection and post-quantum cryptography landscape since we talked to you in 2019?
Since 2019, there have been two significant advances in the development of post-quantum cryptography.
First, the National Institute of Standards and Technology (NIST) announced their selection of PQC algorithms for standardization. NIST expects to finish the standardization of a post-quantum key encapsulation mechanism (Kyber) and digital signature scheme (Dilithium) by 2024 as part of the Federal Information Processing Standard (FIPS). NIST will also work on standardization of two additional signature standards (FALCON and SPHINCS+), and continue to consider future standardization of the key encapsulation mechanisms BIKE, HQC, and Classical McEliece.
Second, the NSA announced their Commercial National Security Algorithm (CNSA) Suite 2.0, which includes their timelines for National Security Systems (NSS) to migrate to post-quantum algorithms. The NSA will begin preferring post-quantum solutions in 2025 and expect that systems will have completed migration by 2033. Although this timeline might seem far away, it’s an aggressive strategy. Experience shows that it can take 20 years to develop and deploy new high-assurance cryptographic algorithms. If technology providers are not already planning to migrate their systems and services, they will be challenged to meet this timeline.
What makes cryptography exciting to you?
Cryptography is a dynamic area of research. In addition to the business applications, I enjoy the mathematics of cryptography. The state-of-the-art is constantly progressing in terms of new capabilities that cryptography can enable, and the potential risks to existing cryptographic primitives. This plays out in the public sphere of cryptographic research across the globe. These advancements are made public and are accessible for companies like AWS to innovate on behalf of our customers, and protect our systems in advance of the development of new challenges to our existing crypto algorithms. This is happening now as we monitor the advancements of quantum computing against our ability to define and deploy new high-assurance quantum-resistant algorithms. For me, it doesn’t get more exciting than this.
Where do you see the cryptography and post-quantum cryptography space heading to in the future?
While NIST transitions from their selection process to standardization, the broader cryptographic community will be more focused on validating the cryptographic assurances of these proposed schemes for standardization. This is a critical part of the process. I’m optimistic that we will enter 2025 with new cryptographic standards to deploy.
There is a lot of additional cryptographic research and engineering ahead of us. Applying these new primitives to the cryptographic applications that use classical asymmetric schemes still needs to be done. Some of this work is happening in parallel, like in the IETF TLS working group, and in the ETSI Quantum-Safe Cryptography Technical Committee. The next five years should see the adoption of PQHKEX in protocols like TLS, SSH, and IKEv2 and certification of new FIPS hardware security modules (HSMs) for establishing new post-quantum, long-lived roots of trust for code-signing and entity authentication.
I expect that the selected primitives for standardization will also be used to develop novel uses in fields like secure multi-party communication, privacy preserving machine learning, and cryptographic computing.
With AWS re:Inforce 2023 around the corner, what will your session focus on? What do you hope attendees will take away from your session?
Session DAP302 – “Post-quantum cryptography migration strategy for cloud services” is about the challenge quantum computers pose to currently used public-key cryptographic algorithms and how the industry is responding. Post-quantum cryptography (PQC) offers a solution to this challenge, providing security to help protect against quantum computer cybersecurity events. We outline current efforts in PQC standardization and migration strategies. We want our customers to leave with a better understanding of the importance of PQC and the steps required to migrate to it in a cloud environment.
Is there something you wish customers would ask you about more often?
The question I am most interested in hearing from our customers is, “when will you have a solution to my problem?” If customers have a need for a novel cryptographic solution, I’m eager to try to solve that with them.
How about outside of work, any hobbies?
My main hobbies outside of work are biking and running. I wish I was as consistent attending to my hobbies as I am to my work desk. I am happier being able to run every day for a constant speed and distance as opposed to running faster or further tomorrow or next week. Last year I was fortunate enough to do the Cycle Oregon ride. I had registered for it twice before without being able to find the time to do it.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is back, and we can’t wait to welcome security builders to Anaheim, CA, on June 13 and 14. AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As an attendee, you will have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. re:Inforce 2023 features content across the following six areas:
Data protection
Governance, risk, and compliance
Identity and access management
Network and infrastructure security
Threat detection and incident response
Application security
The threat detection and incident response track is designed to showcase how AWS, customers, and partners can intelligently detect potential security risks, centralize and streamline security management at scale, investigate and respond quickly to security incidents across their environment, and unlock security innovation across hybrid cloud environments.
Breakout sessions, chalk talks, and lightning talks
TDR201 | Breakout session | How Citi advanced their containment capabilities through automation Incident response is critical for maintaining the reliability and security of AWS environments. To support the 28 AWS services in their cloud environment, Citi implemented a highly scalable cloud incident response framework specifically designed for their workloads on AWS. Using AWS Step Functions and AWS Lambda, Citi’s automated and orchestrated incident response plan follows NIST guidelines and has significantly improved its response time to security events. In this session, learn from real-world scenarios and examples on how to use AWS Step Functions and other core AWS services to effectively build and design scalable incident response solutions.
TDR202 | Breakout session | Wix’s layered security strategy to discover and protect sensitive data Wix is a leading cloud-based development platform that empowers users to get online with a personalized, professional web presence. In this session, learn how the Wix security team layers AWS security services including Amazon Macie, AWS Security Hub, and AWS Identity and Access Management Access Analyzer to maintain continuous visibility into proper handling and usage of sensitive data. Using AWS security services, Wix can discover, classify, and protect sensitive information across terabytes of data stored on AWS and in public clouds as well as SaaS applications, while empowering hundreds of internal developers to drive innovation on the Wix platform.
TDR203 | Breakout session | Vulnerability management at scale drives enterprise transformation Automating vulnerability management at scale can help speed up mean time to remediation and identify potential business-impacting issues sooner. In this session, explore key challenges that organizations face when approaching vulnerability management across large and complex environments, and consider the innovative solutions that AWS provides to help overcome them. Learn how customers use AWS services such as Amazon Inspector to automate vulnerability detection, streamline remediation efforts, and improve compliance posture. Whether you’re just getting started with vulnerability management or looking to optimize your existing approach, gain valuable insights and inspiration to help you drive innovation and enhance your security posture with AWS.
TDR204 | Breakout session | Continuous innovation in AWS detection and response services Join this session to learn about the latest advancements and most recent AWS launches in detection and response. This session focuses on use cases such as automated threat detection, continual vulnerability management, continuous cloud security posture management, and unified security data management. Through these examples, gain a deeper understanding of how you can seamlessly integrate AWS services into your existing security framework to gain greater control and insight, quickly address security risks, and maintain the security of your AWS environment.
TDR205 | Breakout session | Build your security data lake with Amazon Security Lake, featuring Interpublic Group Security teams want greater visibility into security activity across their entire organizations to proactively identify potential threats and vulnerabilities. Amazon Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in your account and allows you to use industry-leading AWS and third-party analytics and ML tools to gain insights from your data and identify security risks that require immediate attention. Discover how Security Lake can help you consolidate and streamline security logging at scale and speed, and hear from an AWS customer, Interpublic Group (IPG), on their experience.
TDR209 | Breakout session | Centralizing security at scale with Security Hub & Intuit’s experience As organizations move their workloads to the cloud, it becomes increasingly important to have a centralized view of security across their cloud resources. AWS Security Hub is a powerful tool that allows organizations to gain visibility into their security posture and compliance status across their AWS accounts and Regions. In this session, learn about Security Hub’s new capabilities that help simplify centralizing and operationalizing security. Then, hear from Intuit, a leading financial software company, as they share their experience and best practices for setting up and using Security Hub to centralize security management.
TDR210 | Breakout session | Streamline security analysis with Amazon Detective Join us to discover how to streamline security investigations and perform root-cause analysis with Amazon Detective. Learn how to leverage the graph analysis techniques in Detective to identify related findings and resources and investigate them together to accelerate incident analysis. Also hear a customer story about their experience using Detective to analyze findings automatically ingested from Amazon GuardDuty, and walk through a sample security investigation.
TDR310 | Breakout session | Developing new findings using machine learning in Amazon GuardDuty Amazon GuardDuty provides threat detection at scale, helping you quickly identify and remediate security issues with actionable insights and context. In this session, learn how GuardDuty continuously enhances its intelligent threat detection capabilities using purpose-built machine learning models. Discover how new findings are developed for new data sources using novel machine learning techniques and how they are rigorously evaluated. Get a behind-the-scenes look at GuardDuty findings from ideation to production, and learn how this service can help you strengthen your security posture.
TDR311 | Breakout session | Securing data and democratizing the alert landscape with an event-driven architecture Security event monitoring is a unique challenge for businesses operating at scale and seeking to integrate detections into their existing security monitoring systems while using multiple detection tools. Learn how organizations can triage and raise relevant cloud security findings across a breadth of detection tools and provide results to downstream security teams in a serverless manner at scale. We discuss how to apply a layered security approach to evaluate the security posture of your data, protect your data from potential threats, and automate response and remediation to help with compliance requirements.
TDR231 | Chalk talk | Operationalizing security findings at scale You enabled AWS Security Hub standards and checks across your AWS organization and in all AWS Regions. What should you do next? Should you expect zero critical and high findings? What is your ideal state? Is achieving zero findings possible? In this chalk talk, learn about a framework you can implement to triage Security Hub findings. Explore how this framework can be applied to several common critical and high findings, and take away mechanisms to prioritize and respond to security findings at scale.
TDR232 | Chalk talk | Act on security findings using Security Hub’s automation capabilities Alert fatigue, a shortage of skilled staff, and keeping up with dynamic cloud resources are all challenges that exist when it comes to customers successfully achieving their security goals in AWS. In order to achieve their goals, customers need to act on security findings associated with cloud-based resources. In this session, learn how to automatically, or semi-automatically, act on security findings aggregated in AWS Security Hub to help you secure your organization’s cloud assets across a diverse set of accounts and Regions.
TDR233 | Chalk talk | How LLA reduces incident response time with AWS Systems Manager Liberty Latin America (LLA) is a leading telecommunications company operating in over 20 countries across Latin America and the Caribbean. LLA offers communications and entertainment services, including video, broadband internet, telephony, and mobile services. In this chalk talk, discover how LLA implemented a security framework to detect security issues and automate incident response in more than 180 AWS accounts accessed by internal stakeholders and third-party partners using AWS Systems Manager Incident Manager, AWS Organizations, Amazon GuardDuty, and AWS Security Hub.
TDR432 | Chalk talk | Deep dive into exposed credentials and how to investigate them In this chalk talk, sharpen your detection and investigation skills to spot and explore common security events like unauthorized access with exposed credentials. Learn how to recognize the indicators of such events, as well as logs and techniques that unauthorized users use to evade detection. The talk provides knowledge and resources to help you immediately prepare for your own security investigations.
TDR332 | Chalk talk | Speed up zero-day vulnerability response In this chalk talk, learn how to scale vulnerability management for Amazon EC2 across multiple accounts and AWS Regions. Explore how to use Amazon Inspector, AWS Systems Manager, and AWS Security Hub to respond to zero-day vulnerabilities, and leave knowing how to plan, perform, and report on proactive and reactive remediations.
TDR333 | Chalk talk | Gaining insights from Amazon Security Lake You’ve created a security data lake, and you’re ingesting data. Now what? How do you use that data to gain insights into what is happening within your organization or assist with investigations and incident response? Join this chalk talk to learn how analytics services and security information and event management (SIEM) solutions can connect to and use data stored within Amazon Security Lake to investigate security events and identify trends across your organization. Leave with a better understanding of how you can integrate Amazon Security Lake with other business intelligence and analytics tools to gain valuable insights from your security data and respond more effectively to security events.
TDR431 | Chalk talk | The anatomy of a ransomware event Ransomware events can cost governments, nonprofits, and businesses billions of dollars and interrupt operations. Early detection and automated responses are important steps that can limit your organization’s exposure. In this chalk talk, examine the anatomy of a ransomware event that targets data residing in Amazon RDS and get detailed best practices for detection, response, recovery, and protection.
TDR221 | Lightning talk | Streamline security operations and improve threat detection with OCSF Security operations centers (SOCs) face significant challenges in monitoring and analyzing security telemetry data from a diverse set of sources. This can result in a fragmented and siloed approach to security operations that makes it difficult to identify and investigate incidents. In this lightning talk, get an introduction to the Open Cybersecurity Schema Framework (OCSF) and its taxonomy constructs, and see a quick demo on how this normalized framework can help SOCs improve the efficiency and effectiveness of their security operations.
TDR222 | Lightning talk | Security monitoring for connected devices across OT, IoT, edge & cloud With the responsibility to stay ahead of cybersecurity threats, CIOs and CISOs are increasingly tasked with managing cybersecurity risks for their connected devices including devices on the operational technology (OT) side of the company. In this lightning talk, learn how AWS makes it simpler to monitor, detect, and respond to threats across the entire threat surface, which includes OT, IoT, edge, and cloud, while protecting your security investments in existing third-party security tools.
TDR223 | Lightning talk | Bolstering incident response with AWS Wickr enterprise integrations Every second counts during a security event. AWS Wickr provides end-to-end encrypted communications to help incident responders collaborate safely during a security event, even on a compromised network. Join this lightning talk to learn how to integrate AWS Wickr with AWS security services such as Amazon GuardDuty and AWS WAF. Learn how you can strengthen your incident response capabilities by creating an integrated workflow that incorporates GuardDuty findings into a secure, out-of-band communication channel for dedicated teams.
TDR224 | Lightning talk | Securing the future of mobility: Automotive threat modeling Many existing automotive industry cybersecurity threat intelligence offerings lack the connected mobility insights required for today’s automotive cybersecurity threat landscape. Join this lightning talk to learn about AWS’s approach to developing an automotive industry in-vehicle, domain-specific threat intelligence solution using AWS AI/ML services that proactively collect, analyze, and deduce threat intelligence insights for use and adoption across automotive value chains.
Hands-on sessions (builders’ sessions and workshops)
TDR251 | Builders’ session | Streamline and centralize security operations with AWS Security Hub AWS Security Hub provides you with a comprehensive view of the security state of your AWS resources by collecting security data from across AWS accounts, Regions, and services. In this builders’ session, explore best practices for using Security Hub to manage security posture, prioritize security alerts, generate insights, automate response, and enrich findings. Come away with a better understanding of how to use Security Hub features and practical tips for getting the most out of this powerful service.
TDR351 | Builders’ session | Broaden your scope: Analyze and investigate potential security issues In this builders’ session, learn how you can more efficiently triage potential security issues with a dynamic visual representation of the relationship between security findings and associated entities such as accounts, IAM principals, IP addresses, Amazon S3 buckets, and Amazon EC2 instances. With Amazon Detective finding groups, you can group related Amazon GuardDuty findings to help reduce time spent in security investigations and in understanding the scope of a potential issue. Leave this hands-on session knowing how to quickly investigate and discover the root cause of an incident.
TDR352 | Builders’ session | How to automate containment and forensics for Amazon EC2 In this builders’ session, learn how to deploy and scale the self-service Automated Forensics Orchestrator for Amazon EC2 solution, which gives you a standardized and automated forensics orchestration workflow capability to help you respond to Amazon EC2 security events. Explore the prerequisites and ways to customize the solution to your environment.
TDR353 | Builders’ session | Detecting suspicious activity in Amazon S3 Have you ever wondered how to uncover evidence of unauthorized activity in your AWS account? In this builders’ session, join the AWS Customer Incident Response Team (CIRT) for a guided simulation of suspicious activity within an AWS account involving unauthorized data exfiltration and Amazon S3 bucket and object data deletion. Learn how to detect and respond to this malicious activity using AWS services like AWS CloudTrail, Amazon Athena, Amazon GuardDuty, Amazon CloudWatch, and nontraditional threat detection services like AWS Billing to uncover evidence of unauthorized use.
TDR354 | Builders’ session | Simulate and detect unwanted IMDS access due to SSRF Using appropriate security controls can greatly reduce the risk of unauthorized use of web applications. In this builders’ session, find out how the server-side request forgery (SSRF) vulnerability works, how unauthorized users may try to use it, and most importantly, how to detect it and prevent it from being used to access the instance metadata service (IMDS). Also, learn some of the detection activities that the AWS Customer Incident Response Team (CIRT) performs when responding to security events of this nature.
TDR341 | Code talk | Investigating incidents with Amazon Security Lake & Jupyter notebooks In this code talk, watch as experts live code and build an incident response playbook for your AWS environment using Jupyter notebooks, Amazon Security Lake, and Python code. Leave with a better understanding of how to investigate and respond to a security event and how to use these technologies to more effectively and quickly respond to disruptions.
TDR441 | Code talk | How to run security incident response in your Amazon EKS environment Join this Code Talk to get both an adversary’s and a defender’s point of view as AWS experts perform live exploitation of an application running on multiple Amazon EKS clusters, invoking an alert in Amazon GuardDuty. Experts then walk through incident response procedures to detect, contain, and recover from the incident in near real-time. Gain an understanding of how to respond and recover to Amazon EKS-specific incidents as you watch the events unfold.
TDR271-R | Workshop | Chaos Kitty: Gamifying incident response with chaos engineering When was the last time you simulated an incident? In this workshop, learn to build a sandbox environment to gamify incident response with chaos engineering. You can use this sandbox to test out detection capabilities, play with incident response runbooks, and illustrate how to integrate AWS resources with physical devices. Walk away understanding how to get started with incident response and how you can use chaos engineering principles to create mechanisms that can improve your incident response processes.
TDR371-R | Workshop | Threat detection and response on AWS Join AWS experts for a hands-on threat detection and response workshop using Amazon GuardDuty, AWS Security Hub, and Amazon Detective. This workshop simulates security events for different types of resources and behaviors and illustrates both manual and automated responses with AWS Lambda. Dive in and learn how to improve your security posture by operationalizing threat detection and response on AWS.
TDR372-R | Workshop | Container threat detection with AWS security services Join AWS experts for a hands-on container security workshop using AWS threat detection and response services. This workshop simulates scenarios and security events while using Amazon EKS and demonstrates how to use different AWS security services to detect and respond to events and improve your security practices. Dive in and learn how to improve your security posture when running workloads on Amazon EKS.
Browse the full re:Inforce catalog to get details on additional sessions and content at the event, including gamified learning, leadership sessions, partner sessions, and labs.
If you want to learn the latest threat detection and incident response best practices and updates, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
When setting up your email sending infrastructure and connections to APIs it is necessary to ensure proper setup. It is also important to ensure that after making changes to your sending pipeline that you verify that your application is working as expected. Not only is it important to test your sending processes, but it’s also important to test your monitoring to ensure that sending event tracking is working as intended. A common pitfall for email senders is that when they attempt to test their email sending infrastructure or event monitoring they send to invalid addresses and/or test accounts that generate no, or negative, reputation as a result of these sends.
The Amazon Simple Email Service (SES) provides you with an easy-to-use mechanism to accomplish these tests. Amazon SES offers the mailbox simulator feature which enables a sender the ability to test different sending events to ensure your service is working as expected. Using the mailbox simulator you can test: delivery success, bounces, complaints, automated responses (like out of office messages), and when a recipient address is on the suppression list.
In this blog we will outline some information about the mailbox simulator and how to interact with the feature to test your email sending services.
What is the mailbox simulator?
The mailbox simulator is a feature offered to help Amazon SES senders test their sending services to verify normal operation. It provides mechanisms to test their monitoring and event notification services. This feature gives a sender the ability to test their service and email monitoring to verify that it is working as expected without the risk of negatively impacting their sending reputation. The mailbox simulator is an MTA operated by SES that is set to receive mail and to simulate different sending events based on the recipient address used.
Why use the mailbox simulator?
The mailbox simulator provides an easy-to-use mechanism to test your integration with Amazon SES. This gives senders the ability to test their sending environment without triggering actual bounces or complaints, which negatively impact their account sending reputation, as well as not counting against a sender’s email sending quotas. It is important to test these events to ensure that event monitoring is properly setup and function. A gap in monitoring these events could lead to a decrease in sender reputation from bounces or complaint events going unnoticed. The mailbox simulator gives a sender the ability to programmatically evaluate whether their event monitoring process has been set up properly without the negative impact to their sending reputation that would occur if sending test emails to differing mailbox providers or invalid email addresses.
How do I use the mailbox simulator?
Your first step is setting up a destination for your event notifications. This can be done using Amazon Simple Notification Service (SNS) or by using event publishing depending on your use-case. Once you have set up an event destination and configured it for your sending identity (either an email address or domain) you are ready to proceed to testing the configuration.
Using the Amazon SES mailbox simulator is simple. In practice, you will be sending an email to an Amazon SES owned mailbox. This mailbox will respond based on the event-type you want to test. Below is a map of the event types and the corresponding email addresses to test the events:
If you are using the Amazon SES console to test these events, SES has already included the addresses to simplify the testing experience and you can find these under the ‘Scenario’ dropdown.
After sending an email to one of the five destinations, you should soon receive a notification, or event, to your publishing destination. This is an example of a success event.
If you have not received confirmation of the event, it is likely there is a problem with your monitoring configuration. We recommend reviewing the documentation on SNS topic setup and/or event publishing to uncover if an error was made during initial setup.
Note: A sender may have verified an email address and a domain to use for testing. The domain may have the appropriate configuration while the email address does not. When sending an email from SES, SES will use the most specific identity (email address is used before the domain) and will use the configuration associated with that identity. This means that in this instance you can either remove the email address verification for that domain and re-test or set up the same configuration for that email address that is verified.
What next?
Now that your initial setup of event publishing is complete and you have tested your first event through the mailbox simulator, it is time to set up automated testing using the mailbox simulator. Testing email events after a successful update to your application is recommended to confirm that updates have not caused bugs in your event ingestion mechanisms.
Join us on Wednesday, May 17, for AWS Serverless Innovation Day, a free full-day virtual event. You will learn about AWS Serverless technologies and event-driven architectures from customers, experts, and leaders.
AWS Serverless Innovation Day is an event to empower builders and technical decision-makers with different AWS Serverless technologies, including AWS Lambda, Amazon Elastic Container Service (Amazon ECS) with AWS Fargate, Amazon EventBridge, and AWS Step Functions. The talks of the day will cover three key topics: event-driven architectures, serverless containers, and serverless functions, and how they can be utilized to build and modernize applications. Application modernization is a priority for organizations this year, and serverless helps to increase the software delivery speed and reduce the total cost of ownership.
Eric Johnson and Jessica Deen will be the hosts for the event. Holly Mesrobian, VP of Serverless Compute at AWS, will deliver the welcome keynote and share AWS’s vision for Serverless. The day ends with closing remarks from James Beswick and Usman Khalid, Events and Workflows Director at AWS.
The event is split into three groups of talks: event-driven architecture, serverless containers, and Lambda-based applications. Each group kicks off with a fireside chat between AWS customers and an AWS leader. You can learn how organizations, such as Capital One, PostNL, Pentasoft, Delta Air Lines, and Smartsheets, are using AWS Serverless technologies to solve their most challenging problems and continue to innovate.
During the day, all the sessions include demos and use cases, where you can learn the best practices and how to build applications. If you cannot attend all day, here are some of my favorite sessions to watch:
Building with serverless workflows at scale – Ben Smith will show you how to unleash the power of AWS Step Functions.
Event design and event-first development – In this session, David Boyne will show you a robust approach to event design with Amazon EventBridge.
Best practices for AWS Lambda – You will learn from Julian Wood how to get the most out of your functions.
Optimizing for cost using Amazon ECS – Scott Coulton will show you how to reduce operational overhead from the control plane with Amazon ECS.
There is no up-front registration required to join the AWS Serverless Innovation Day, but if you want to be notified before the event starts, get in-depth news, articles, and event updates, and get a notification when the on-demand videos are available, you can register on the event page. The event will be streamed on Twitch, LinkedIn Live, YouTube, and Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce 2023 is fast approaching, and this post can help you plan your agenda with a look at the sessions in the identity and access management track. AWS re:Inforce is a learning conference where you can learn more about cloud security, compliance, identity, and privacy. You have access to hundreds of technical and non-technical sessions, an AWS Partner expo featuring security partners with AWS Security Competencies, and keynote and leadership sessions featuring AWS Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, California, on June 13 and 14. re:Inforce 2023 features content in the following six areas:
The identity and access management track will share recommended practices and learnings for identity management and governance in AWS environments. You will hear from other AWS customers about how they are building customer identity and access management (CIAM) patterns for great customer experiences and new approaches for managing standard, elevated, and privileged workforce access. You will also hear from AWS leaders about accelerating the journey to least privilege with access insights and the role of identity within a Zero Trust architecture.
This post highlights some of the identity and access management sessions that you can sign up for, including breakout sessions, chalk talks, code talks, lightning talks, builders’ sessions, and workshops. For the full catalog, see the AWS re:Inforce catalog preview.
Breakout sessions
Lecture-style presentations that cover topics at all levels and delivered by AWS experts, builders, customers, and partners. Breakout sessions typically include 10–15 minutes of Q&A at the end.
IAM201: A first-principles approach: AWS Identity and Access Management (IAM) Learning how to build effectively and securely on AWS starts with a strong working knowledge of AWS Identity and Access Management (IAM). In this session aimed at engineers who build on AWS, explore a no-jargon, first-principles approach to IAM. Learn the fundamental concepts of IAM authentication and authorization policies as well as concrete techniques that you can immediately apply to the workloads you run on AWS.
IAM301: Establishing a data perimeter on AWS, featuring USAA In this session, dive deep into the data perimeter controls that help you manage your trusted identities and their access to trusted resources from expected networks. USAA shares how they use automation to embed security and AWS Identity and Access Management (IAM) baselines to empower a self-service mindset. Learn how they use data perimeters to support decentralization without compromising on security. Also, discover how USAA uses a threat-based approach to prioritize implementation of specific data perimeters.
IAM302: Create enterprise-wide preventive guardrails, featuring Inter & Co. In this session, learn how to establish permissions guardrails within your multi-account environment with AWS Organizations and service control policies (SCPs). Explore how effective use of SCPs can help your builders innovate on AWS while maintaining a high bar on security. Learn about the strategies to incorporate SCPs at different levels within your organization. In addition, Inter & Co. share their strategies for implementing enterprise-wide guardrails at scale within their multi-account environments. Discover how they use code repositories and CI/CD pipelines to manage approvals and deployments of SCPs.
IAM303: Balance least privilege & agile development, feat. Fidelity & Merck Finding a proper balance between securing multiple AWS accounts and enabling agile development to accelerate business innovation has been key to the cloud adoption journey for AWS customers. In this session, learn how Fidelity and Merck empowered their business stakeholders to quickly develop solutions while still conforming to security standards and operating within the guardrails at scale.
IAM304: Migrating to Amazon Cognito, featuring approaches from Fandango Digital transformation of customer-facing applications often involves changes to identity and access management to help improve security and user experience. This process can benefit from fast-growing technologies and open standards and may involve migration to a modern customer identity and access management solution, such as Amazon Cognito, that offers the security and scale your business requires. There are several ways to approach migrating users to Amazon Cognito. In this session, learn about options and best practices, as well as lessons learned from Fandango’s migration to Amazon Cognito.
IAM305: Scaling access with AWS IAM Identity Center, feat. Allegiant Airlines In this session, learn how to scale assignment of permission sets to users and groups by automating federated role-based access to any AWS accounts in your organization. As a highlight of this session, hear Allegiant Airlines’ success story of how this automation has benefited Allegiant by centralizing management of federated access for their organization of more than 5,000 employees. Additionally, explore how to build this automation in your environment using infrastructure as code tools like Terraform and AWS CloudFormation using a CI/CD pipeline.
IAM306: Managing hybrid workloads with IAM Roles Anywhere, featuring Hertz A key element of using AWS Identity and Access Management (IAM) Roles Anywhere is managing how identities are assigned to your workloads. In this session, learn how you can define and manage identities for your workloads, how to use those identities to control access to an AWS resource via attribute-based access control (ABAC), and how to monitor and audit activities performed by those identities. Discover key concepts, best practices, and troubleshooting tips. Hertz describes how they used IAM Roles Anywhere to secure access to AWS services from Salesforce and how it has improved their overall security posture.
IAM307: Steps towards a Zero Trust architecture on AWS Modern workplaces have evolved beyond traditional network boundaries as they have expanded to hybrid and multi-cloud environments. Identity has taken center stage for information security teams. The need for fine-grained, identity-based authorization, flexible identity-aware networks, and the removal of unneeded pathways to data has accelerated the adoption of Zero Trust principles and architecture. In this session, learn about different architecture patterns and security mechanisms available from AWS that you can apply to secure standard, sensitive, and privileged access to your critical data and workloads.
Builders’ sessions
Small-group sessions led by an AWS expert who guides you as you build the service or product on your own laptop. Use your laptop to experiment and build along with the AWS expert.
IAM351: Sharing resources across accounts with least-privilege permissions Are you looking to manage your resource access control permissions? Learn how you can author customer managed permissions to provide least-privilege access to your resources shared using AWS Resource Access Manager (AWS RAM). Explore how to use customer managed permissions with use cases ranging from managing incident response with AWS Systems Manager Incident Manager to enhancing your IP security posture with Amazon VPC IP Address Manager.
IAM352: Cedar policy language in action Cedar is a language for defining permissions as policies that describe who should have access to what. Amazon Verified Permissions and AWS Verified Access use Cedar to define fine-grained permissions for applications and end users. In this builders’ session, come learn by building Cedar policies for access control.
IAM355: Using passwordless authentication with Amazon Cognito and WebAuthn In recent years, passwordless authentication has been on the rise. The FIDO Alliance, a first-mover for enabling passwordless in 2009, is an open industry association whose stated mission is to develop and promote authentication standards that “help reduce the world’s over-reliance on passwords.” This builders’ session allows participants to learn about and follow the steps to implement a passwordless authentication experience on a web or mobile application using Amazon Cognito.
IAM356: AWS Identity and Access Management (IAM) policies troubleshooting In this builders’ session, walk through practical examples that can help you build, test, and troubleshoot AWS Identity and Access Management (IAM) policies. Utilize a workflow that can help you create fine-grained access policies with the help of the IAM API, the AWS Management Console, and AWS CloudTrail. Also review key concepts of IAM policy evaluation logic.
Chalk talks
Highly interactive sessions with a small audience. Experts lead you through problems and solutions on a digital whiteboard as the discussion unfolds.
IAM231: Lessons learned from AWS IAM Identity Center migrations In this chalk talk, discover best practices and tips to migrate your workforce users’ access from IAM users to AWS IAM Identity Center (successor to AWS Single Sign-On). Learn how to create preventive guardrails, gain visibility into the usage of IAM users across an organization, and apply authentication solutions for common use cases.
IAM331: Leaving IAM access keys behind: A modern path forward Static credentials have been used for a long time to secure multiple types of access, including access keys for AWS Identity and Access Management (IAM) users, command line tools, secure shell access, application API keys, and pre-shared keys for VPN access. However, best practice recommends replacing static credentials with short-term credentials. In this chalk talk, learn how to identify static access keys in your environment, quantify the risk, and then apply multiple available methods to replace them with short-term credentials. The talk also covers prescriptive guidance and best practice advice for improving your overall management of IAM access keys.
IAM332: Practical identity and access management: The basics of IAM on AWS Learn from prescriptive guidance on how to build an Identity and Access Management strategy on AWS. We provide guidance on human access versus machine access using services like IAM Identity Center. You will also learn about the different IAM policy types, where each policy type is useful, and how you should incorporate each policy type in your AWS environment. This session will walk you through what you need to know to build an effective identity and access management baseline.
IAM431: A tour of the world of IAM policy evaluation This session takes you beyond the basics of IAM policy evaluation and focuses on how policy evaluation works with advanced AWS features. Hear about how policies are evaluated alongside AWS Key Management Service (AWS KMS) key grants, Amazon Simple Storage Service (Amazon S3) and Amazon Elastic File System (Amazon EFS) access points, Amazon VPC Lattice, and more. You’ll leave this session with prescriptive guidance on what to do and what to avoid when designing authorization schemes.
Code talks
Engaging, code-focused sessions with a small audience. AWS experts lead an interactive discussion featuring live coding and/or code samples as they explain the “why” behind AWS solutions.
IAM341: Cedar: Fast, safe, and fine-grained access for your applications Cedar is a new policy language that helps you write fine-grained permissions in your applications. With Cedar, you can customize authorization and you can define and enforce who can access what. This code talk explains the design of Cedar, how it was built to a high standard of assurance, and its benefits. Learn what makes Cedar ergonomic, fast, and analyzable: simple syntax for expressing common authorization use cases, policy structure that allows for scalable real-time evaluation, and comprehensive auditing based on automated reasoning. Also find out how Cedar’s implementation was made safer through formal verification and differential testing.
IAM441: Enable new Amazon Cognito use cases with OAuth2.0 flows Delegated authorization without user interaction on a consumer device and reinforced passwordless authentication for higher identity assurance are advanced authentication flows achievable with Amazon Cognito. In this code talk, you can discover new OAuth2.0 flow diagrams, code snippets, and long and short demos that offer different approaches to these authentication use cases. Gain confidence using AWS Lambda triggers with Amazon Cognito, native APIs, and OAuth2.0 endpoints to help ensure greater success in customer identity and access management strategy.
Lightning talks
Short and focused theater presentations that are dedicated to either a specific customer story, service demo, or partner offering (sponsored).
IAM221: Accelerate your business with AWS Directory Service In this lightning talk, explore AWS Directory Service for Microsoft Active Directory and discover a number of use cases that provide flexibility, empower agile application development, and integrate securely with other identity stores. Join the talk to discover how you can take advantage of this managed service and focus on what really matters to your customers.
IAM321: Move toward least privilege with IAM Access Analyzer AWS Identity and Access Management (IAM) Access Analyzer provides tools that simplify permissions management by making it easy for organizations to set, verify, and refine permissions. In this lightning talk, dive into how you can detect resources shared with an external entity across one or multiple AWS accounts with IAM Access Analyzer. Find out how you can activate and use this feature and how it integrates with AWS Security Hub.
Workshops
Interactive learning sessions where you work in small teams to solve problems using AWS Cloud security services. Come prepared with your laptop and a willingness to learn!
IAM371: Building a Customer Identity and Access Management (CIAM) solution How do your customers access your application? Get a head start on customer identity and access management (CIAM) by using Amazon Cognito. Join this workshop to learn how to build CIAM solutions on AWS using Amazon Cognito, Amazon Verified Permissions, and several other AWS services. Start from the basic building blocks of CIAM and build up to advanced user identity and access management use cases in customer-facing applications.
IAM372: Consuming AWS Resources from everywhere with IAM Roles Anywhere If your workload already lives on AWS, then there is a high chance that some temporary AWS credentials have been securely distributed to perform needed tasks. But what happens when your workload is on premises? In this workshop, learn how to use AWS Identity and Access Management (IAM) Roles Anywhere. Start from the basics and create the necessary steps to learn how to use your applications outside of AWS in a safe way using IAM Roles Anywhere in practice.
IAM373: Building a data perimeter to allow access to authorized users In this workshop, learn how to create a data perimeter by building controls that allow access to data only from expected network locations and by trusted identities. The workshop consists of five modules, each designed to illustrate a different AWS Identity and Access Management (IAM) principle or network control. Learn where and how to implement the appropriate controls based on different risk scenarios.
If these sessions look interesting to you, join us in Anaheim by registering for AWS re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is fast approaching, and this post can help you plan your agenda. AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As a re:Inforce attendee, you have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, CA, on June 13 and 14. re:Inforce 2023 features content in the following six areas:
Data Protection
Governance, Risk, and Compliance
Identity and Access Management
Network and Infrastructure Security
Threat Detection and Incident Response
Application Security
The data protection track will showcase services and tools that you can use to help achieve your data protection goals in an efficient, cost-effective, and repeatable manner. You will hear from AWS customers and partners about how they protect data in transit, at rest, and in use. Learn how experts approach data management, key management, cryptography, data security, data privacy, and encryption. This post will highlight of some of the data protection offerings that you can add to your agenda. To learn about sessions from across the content tracks, see the AWS re:Inforce catalog preview.
“re:Inforce is a great opportunity for us to hear directly from our customers, understand their unique needs, and use customer input to define solutions that protect sensitive data. We also use this opportunity to deliver content focused on the latest security research and trends, and I am looking forward to seeing you all there. Security is everyone’s job, and at AWS, it is job zero.” — Ritesh Desai, General Manager, AWS Secrets Manager
Breakout sessions, chalk talks, and lightning talks
DAP301: Moody’s database secrets management at scale with AWS Secrets Manager Many organizations must rotate database passwords across fleets of on-premises and cloud databases to meet various regulatory standards and enforce security best practices. One-time solutions such as scripts and runbooks for password rotation can be cumbersome. Moody’s sought a custom solution that satisfies the goal of managing database passwords using well-established DevSecOps processes. In this session, Moody’s discusses how they successfully used AWS Secrets Manager and AWS Lambda, along with open-source CI/CD system Jenkins, to implement database password lifecycle management across their fleet of databases spanning nonproduction and production environments.
DAP401: Security design of the AWS Nitro System The AWS Nitro System is the underlying platform for all modern Amazon EC2 instances. In this session, learn about the inner workings of the Nitro System and discover how it is used to help secure your most sensitive workloads. Explore the unique design of the Nitro System’s purpose-built hardware and software components and how they operate together. Dive into specific elements of the Nitro System design, including eliminating the possibility of operator access and providing a hardware root of trust and cryptographic system integrity protections. Learn important aspects of the Amazon EC2 tenant isolation model that provide strong mitigation against potential side-channel issues.
DAP322: Integrating AWS Private CA with SPIRE and Ottr at Coinbase Coinbase is a secure online platform for buying, selling, transferring, and storing cryptocurrency. This lightning talk provides an overview of how Coinbase uses AWS services, including AWS Private CA, AWS Secrets Manager, and Amazon RDS, to build out a Zero Trust architecture with SPIRE for service-to-service authentication. Learn how short-lived certificates are issued safely at scale for X.509 client authentication (i.e., Amazon MSK) with Ottr.
DAP331: AWS Private CA: Building better resilience and revocation techniques In this chalk talk, explore the concept of PKI resiliency and certificate revocation for AWS Private CA, and discover the reasons behind multi-Region resilient private PKI. Dive deep into different revocation methods like certificate revocation list (CRL) and Online Certificate Status Protocol (OCSP) and compare their advantages and limitations. Leave this talk with the ability to better design resiliency and revocations.
DAP231: Securing your application data with AWS storage services Critical applications that enterprises have relied on for years were designed for the database block storage and unstructured file storage prevalent on premises. Now, organizations are growing with cloud services and want to bring their security best practices along. This chalk talk explores the features for securing application data using Amazon FSx, Amazon Elastic File System (Amazon EFS), and Amazon Elastic Block Store (Amazon EBS). Learn about the fundamentals of securing your data, including encryption, access control, monitoring, and backup and recovery. Dive into use cases for different types of workloads, such as databases, analytics, and content management systems.
Hands-on sessions (builders’ sessions and workshops)
DAP353: Privacy-enhancing data collaboration with AWS Clean Rooms Organizations increasingly want to protect sensitive information and reduce or eliminate raw data sharing. To help companies meet these requirements, AWS has built AWS Clean Rooms. This service allows organizations to query their collective data without needing to expose the underlying datasets. In this builders’ session, get hands-on with AWS Clean Rooms preventative and detective privacy-enhancing controls to mitigate the risk of exposing sensitive data.
DAP371: Post-quantum crypto with AWS KMS TLS endpoints, SDKs, and libraries This hands-on workshop demonstrates post-quantum cryptographic algorithms and compares their performance and size to classical ones. Learn how to use AWS Key Management Service (AWS KMS) with the AWS SDK for Java to establish a quantum-safe tunnel to transfer the most critical digital secrets and protect them from a theoretical computer targeting these communications in the future. Find out how the tunnels use classical and quantum-resistant key exchanges to offer the best of both worlds, and discover the performance implications.
DAP271: Data protection risk assessment for AWS workloads Join this workshop to learn how to simplify the process of selecting the right tools to mitigate your data protection risks while reducing costs. Follow the data protection lifecycle by conducting a risk assessment, selecting the effective controls to mitigate those risks, deploying and configuring AWS services to implement those controls, and performing continuous monitoring for audits. Leave knowing how to apply the right controls to mitigate your business risks using AWS advanced services for encryption, permissions, and multi-party processing.
If these sessions look interesting to you, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As a re:Inforce attendee, you have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. AWS re:Inforce 2023 will take place in-person in Anaheim, CA, on June 13 and 14.
In these sessions, you’ll hear directly from AWS leaders and get hands-on with the tools that help you ship securely. You’ll hear how organization and culture help security accelerate your business, and you’ll dive deep into the technology that helps you more swiftly get features to customers. You might even find some new tools that make it simpler to empower your builders to move quickly and ship securely.
Breakout sessions, chalk talks, and lightning talks
APS221: From code to insight: Amazon Inspector & AWS Lambda in action In this lightning talk, see a demo of Amazon Inspector support for AWS Lambda. Inspect a Java application running on Lambda for security vulnerabilities using Amazon Inspector for an automated and continual vulnerability assessment. In addition, explore how Amazon Inspector can help you identify package and code vulnerabilities in your serverless applications.
APS302: From IDE to code review, increasing quality and security Attend this session to discover how to improve the quality and security of your code early in the development cycle. Explore how you can integrate Amazon Code Whisperer, Amazon CodeGuru reviewer, and Amazon Inspector into your development workflow, which can help you identify potential issues and automate your code review process.
APS201: How AWS and MongoDB raise the security bar with distributed ownership In this session, explore how AWS and MongoDB have approached creating their Security Guardians and Security Champions programs. Learn practical advice on scoping, piloting, measuring, scaling, and managing a program with the goal of accelerating development with a high security bar, and discover tips on how to bridge the gap between your security and development teams. Learn how a guardians or champions program can improve security outside of your dev teams for your company as a whole when applied broadly across your organization.
APS202: AppSec tooling & culture tips from AWS & Toyota Motor North America In this session, AWS and Toyota Motor North America (TMNA) share how they scale AppSec tooling and culture across enterprise organizations. Discover practical advice and lessons learned from the AWS approach to threat modeling across hundreds of service teams. In addition, gain insight on how TMNA has embedded security engineers into business units working on everything from mainframes to serverless. Learn ways to support teams at varying levels of maturity, the importance of differentiating between risks and vulnerabilities, and how to balance the use of cloud-native, third-party, and open-source tools at scale.
APS331: Shift security left with the AWS integrated builder experience As organizations start building their applications on AWS, they use a wide range of highly capable builder services that address specific parts of the development and management of these applications. The AWS integrated builder experience (IBEX) brings those separate pieces together to create innovative solutions for both customers and AWS Partners building on AWS. In this chalk talk, discover how you can use IBEX to shift security left by designing applications with security best practices built in and by unlocking agile software to help prevent security issues and bottlenecks.
Hands-on sessions (builders’ sessions and workshops)
APS271: Threat modeling for builders Attend this facilitated workshop to get hands-on experience creating a threat model for a workload. Learn some of the background and reasoning behind threat modeling, and explore tools and techniques for modeling systems, identifying threats, and selecting mitigations. In addition, explore the process for creating a system model and corresponding threat model for a serverless workload. Learn how AWS performs threat modeling internally, and discover the principles to effectively perform threat modeling on your own workloads.
APS371: Integrating open-source security tools with the AWS code services AWS, open-source, and partner tooling works together to accelerate your software development lifecycle. In this workshop, learn how to use Automated Security Helper (ASH), a source-application security tool, to quickly integrate various security testing tools into your software build and deployment flows. AWS experts guide you through the process of security testing locally on your machines and within the AWS CodeCommit, AWS CodeBuild, and AWS CodePipeline services. In addition, discover how to identify potential security issues in your applications through static analysis, software composition analysis, and infrastructure-as-code testing.
APS352: Practical shift left for builders Providing early feedback in the development lifecycle maximizes developer productivity and enables engineering teams to deliver quality products. In this builders’ session, learn how to use AWS Developer Tools to empower developers to make good security decisions early in the development cycle. Tools such as Amazon CodeGuru, Amazon CodeWhisperer, and Amazon DevOps Guru can provide continuous real-time feedback upon each code commit into a source repository and supplement this with ML capabilities integrated into the code review stage.
APS351: Secure software factory on AWS through the DoD DevSecOps lens Modern information systems within regulated environments are driven by the need to develop software with security at the forefront. Increasingly, organizations are adopting DevSecOps and secure software factory patterns to improve the security of their software delivery lifecycle. In this builder’s session, we will explore the options available on AWS to create a secure software factory aligned with the DoD Enterprise DevSecOps initiative. We will focus on the security of the software supply chain as we deploy code from source to an Amazon Elastic Kubernetes Service (EKS) environment.
If these sessions look interesting to you, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Developer Innovation Day is a brand-new event designed specifically for developers and development teams. In the event, sessions throughout the day will show how you can improve productivity and collaboration, provide a first look at new product updates, and go deep on AWS tools for development and delivery. Topics to be addressed include how you can speed up web and mobile application development and how you can build and deliver faster by taking advantage of modern infrastructure, DevOps, and generative AI-enabled tools.
We’ll be starting the day with a keynote from Adam Seligman, Vice President of Developer Experience at AWS. And, to wrap up the event, there are closing sessions from Dr. Werner Vogels, CTO at Amazon, Harry Mower, Director, AWS Code Suite, and Doug Seven, Director of Software Development, Amazon CodeWhisperer. A panel of experts will join Werner to discuss the latest trends in generative AI and what it all means for developers. Harry and Doug will discuss trends in developer and team productivity. Of course, no event would be complete without our own Jeff Barr, VP of AWS Evangelism, who’ll be sharing a “Best practices and key takeaways” session with a recap of key stories, announcements, and moments from the day!
AWS staff will present the technical breakout sessions during the day, and AWS Heroes and Community Builders will also be involved, presenting community spotlights, which are an excellent chance to get involved with the global AWS community. During and after the event there’s also a chance to sign up for an AWS Amplify hackathon that will be held in May and also an Amazon CodeCatalyst immersion day. Other fun events are also in the works—watch the event details page for more information.
There’s no up-front registration required to join AWS Developer Innovation Day, which, I’ll remind you, is also free to attend. Simply head on over to the event page and select Add to calendar. I’m excited to be joined by colleagues from the AWS on Air team to host the event, and we all hope you’ll choose to join in the fun and learning opportunities at this brand-new event!
I could almost title this blog post the “AWS AI/ML Week in Review.” This past week, we announced several new innovations and tools for building with generative AI on AWS. Let’s dive right into it.
Last Week’s Launches Here are some launches that got my attention during the previous week:
Announcing Amazon Bedrock and Amazon Titan models – Amazon Bedrock is a new service to accelerate your development of generative AI applications using foundation models through an API without managing infrastructure. You can choose from a wide range of foundation models built by leading AI startups and Amazon. The new Amazon Titan foundation models are pre-trained on large datasets, making them powerful, general-purpose models. You can use them as-is or privately to customize them with your own data for a particular task without annotating large volumes of data. Amazon Bedrock is currently in limited preview. Sign up here to learn more.
Amazon EC2 Trn1n and Inf2 instances are now generally available – Trn1n instances, powered by AWS Trainium accelerators, double the network bandwidth (compared to Trn1 instances) to 1,600 Gbps of Elastic Fabric Adapter (EFAv2). The increased bandwidth delivers even higher performance for training network-intensive generative AI models such as large language models (LLMs) and mixture of experts (MoE). Inf2 instances, powered by AWS Inferentia2 accelerators, deliver high performance at the lowest cost in Amazon EC2 for generative AI models, including LLMs and vision transformers. They are the first inference-optimized instances in Amazon EC2 to support scale-out distributed inference with ultra-high-speed connectivity between accelerators. Compared to Inf1 instances, Inf2 instances deliver up to 4x higher throughput and up to 10x lower latency. Check out my blog posts on Trn1 instances and Inf2 instances for more details.
Amazon CodeWhisperer, free for individual use, is now generally available – Amazon CodeWhisperer is an AI coding companion that generates real-time single-line or full-function code suggestions in your IDE to help you build applications faster. With GA, we introduce two tiers: CodeWhisperer Individual and CodeWhisperer Professional. CodeWhisperer Individual is free to use for generating code. You can sign up with an AWS Builder ID based on your email address. The Individual Tier provides code recommendations, reference tracking, and security scans. CodeWhisperer Professional—priced at $19 per user, per month—offers additional enterprise administration capabilities. Steve’s blog post has all the details.
Amazon GameLift adds support for Unreal Engine 5 – Amazon GameLift is a fully managed solution that allows you to manage and scale dedicated game servers for session-based multiplayer games. The latest version of the Amazon GameLift Server SDK 5.0 lets you integrate your Unreal 5-based game servers with the Amazon GameLift service. In addition, the latest Amazon GameLift Server SDK with Unreal 5 plugin is built to work with Amazon GameLift Anywhere so that you can test and iterate Unreal game builds faster and manage game sessions across any server hosting infrastructure. Check out the release notes to learn more.
Amazon Rekognition launches Face Liveness to deter fraud in facial verification – Face Liveness verifies that only real users, not bad actors using spoofs, can access your services. Amazon Rekognition Face Liveness analyzes a short selfie video to detect spoofs presented to the camera, such as printed photos, digital photos, digital videos, or 3D masks, as well as spoofs that bypass the camera, such as pre-recorded or deepfake videos. This AWS Machine Learning Blog post walks you through the details and shows how you can add Face Liveness to your web and mobile applications.
Other AWS News Here are some additional news items and blog posts that you may find interesting:
Updates to the AWS Well-Architected Framework – The most recent content updates and improvements focus on providing expanded guidance across the AWS service portfolio to help you make more informed decisions when developing implementation plans. Services that were added or expanded in coverage include AWS Elastic Disaster Recovery, AWS Trusted Advisor, AWS Resilience Hub, AWS Config, AWS Security Hub, Amazon GuardDuty, AWS Organizations, AWS Control Tower, AWS Compute Optimizer, AWS Budgets, Amazon CodeWhisperer, and Amazon CodeGuru. This AWS Architecture Blog post has all the details.
Amazon releases largest dataset for training “pick and place” robots – In an effort to improve the performance of robots that pick, sort, and pack products in warehouses, Amazon has publicly released the largest dataset of images captured in an industrial product-sorting setting. Where the largest previous dataset of industrial images featured on the order of 100 objects, the Amazon dataset, called ARMBench, features more than 190,000 objects. Check out this Amazon Science Blog post to learn more.
AWS open-source news and updates – My colleague Ricardo writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community. Read edition #153 here.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
#BuildOn Generative AI – Join our weekly live Build On Generative AI Twitch show. Every Monday morning, 9:00 US PT, my colleagues Emily and Darko take a look at aspects of generative AI. They host developers, scientists, startup founders, and AI leaders and discuss how to build generative AI applications on AWS.
In today’s episode, Emily walks us through the latest AWS generative AI announcements. You can watch the video here.
.NET Developer Day – .NET Enterprise Developer Day EMEA 2023 (April 25) is a free, one-day virtual event providing enterprise developers with the most relevant information to swiftly and efficiently migrate and modernize their .NET applications and workloads on AWS.
AWS Developer Innovation Day – AWS Developer Innovation Day (April 26) is a new, free, one-day virtual event designed to help developers and teams be productive and collaborate from discovery to delivery, to running software and building applications. Get a first look at exciting product updates, technical deep dives, and keynotes.
The AWS Summit season has started. AWS Summits are free technical and business conferences happening in large cities across the planet. This week, we were happy to welcome our customers and partners in Sydney and Paris. In France, 9,973 customers and partners joined us for the day to meet and exchange ideas but also to attend one of the more than 145 technical breakout sessions and the keynote. This is the largest cloud computing event in France, and I can’t resist sharing a picture from the main room during the opening keynote.
There are AWS Summits on all continents ; you can find the list and the links for registration here https://aws.amazon.com/events/summits. The next on my agenda are listed at the end of this post.
AWS Lambda response streaming – Response streaming is a new invocation pattern that lets functions progressively stream response payloads back to clients. You can use Lambda response payload streaming to send response data to callers as it becomes available. Response streaming also allows you to build functions that return larger payloads and perform long-running operations while reporting incremental progress (within the 15 minutes execution period). My colleague Julian wrote an incredibly detailed blog post to help you to get started.
AWS Supply Chain Now Generally Available – AWS Supply Chain is a cloud application that mitigates risk and lowers costs with unified data and built-in contextual collaboration. It connects to your existing enterprise resource planning (ERP) and supply chain management systems to bring you ML-powered actionable insights into your supply chain.
AWS Service Catalog Supports Terraform Templates – With AWS Service Catalog, you can create, govern, and manage a catalog of infrastructure as code (IaC) templates that are approved for use on AWS. You can now define AWS Service Catalog products and their resources using either AWS CloudFormation or Hashicorp Terraform and choose the tool that better aligns with your processes and expertise.
Amazon S3 enforces two security best practices and brings new visibility into object replication status – As announced on December 13, 2022, Amazon S3 is now deploying two new default bucket security settings by automatically enabling S3 Block Public Access and disabling S3 access control lists (ACLs) for all new S3 buckets. Amazon S3 also adds a new Amazon CloudWatch metric that can be used to diagnose and correct S3 Replication configuration issues more quickly. The OperationFailedReplication metric, available in both the Amazon S3 console and in Amazon CloudWatch, gives you per-minute visibility into the number of objects that did not replicate to the destination bucket for each of your replication rules.
AWS Cloud Operation Competency Partners – AWS Cloud Operations covers five fundamental solution areas: Cloud Governance, Cloud Financial Management, Monitoring and Observability, Compliance and Auditing, and Operations Management. The new competency enables customers to select validated AWS Partners who offer comprehensive solutions with an integrated approach across multiple areas.
Amplify Library for Swift on macOS – Amplify is an open-source, client-side library making it easier to access a cloud backend from your front-end application code. It provides language-specific constructs to abstract low-level details of the cloud API. It helps you to integrate services such as analytics, object storage, REST or GraphQL APIs, user authentication, geolocation and mapping, and push notifications. You can now write beautiful macOS applications that connect to the same cloud backend as their iOS counterparts.
X in Y Jeff started this section a while ago to list the expansion of new services and capabilities to additional Regions. I noticed 11 Regional expansions this week:
Upcoming AWS Events And to finish this post, I recommend you check your calendars and sign up for these AWS-led events:
.Net Developer Day – .NET Enterprise Developer Day EMEA 2023 (April 25) is a free, one-day virtual conference providing enterprise developers with the most relevant information to swiftly and efficiently migrate and modernize their .NET applications and workloads on AWS.
AWS re:Inforce 2023 – Now register AWS re:Inforce, in Anaheim, California, June 13–14. AWS Chief Information Security Officer CJ Moses will share the latest innovations in cloud security and what AWS Security is focused on. The breakout sessions will provide real-world examples of how security is embedded into the way businesses operate. To learn more and get the limited discount code to register, see CJ’s blog post of Gain insights and knowledge at AWS re:Inforce 2023 in the AWS Security Blog.
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Seoul (May 3–4), Berlin and Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Amsterdam (June 1), London (June 7), Madrid (June 15), and Milano (June 22).
AWS Community Day – Join community-led conferences driven by AWS user group leaders close to your city: Lima (April 15), Helsinki (April 20), Chicago (June 15), Manila (June 29–30), and Munich (September 14). Recently, we have been bringing together AWS user groups from around the world into Meetup Pro accounts. Find your group and its meetups in your city!
The Official AWS Podcast – Listen each week for updates on the latest AWS news and deep dives into exciting use cases. There are also official AWS podcasts in your local languages. Check out the ones in French, German, Italian, and Spanish.
Three years before millions of viewers saw, arguably, one of the most thrilling World Cup Finals ever broadcast, TF1, the leading private TV channel in France, started a project to redefine the foundations of its broadcasting platform, including adopting a new cloud-based architecture.
They, and all other broadcasters, have been observing diminishing audiences for traditional over-the-air broadcasting and increasing popularity of digital platforms, such as smart TVs, and boxes like FireTV, ChromeCast, and AppleTV, as well as laptops, tablets, and mobile phones. According to Thierry Bonhomme, CTO of eTF1 (the group within TF1 in charge of digital platforms) whom I recently interviewed for the AWS French Podcast, digital broadcasting now accounts for 20–25 percent of TF1’s total audience.
This online and mobile usage drives very specific traffic patterns on IT systems: a huge peak of connections and authentications in the few minutes before the start of a game and millions of video streams that must be delivered reliably over a variety of changing network qualities. In addition to these technical challenges, there is also an economic challenge: to deliver advertisements at key moments, such as before a national anthem or during a 15-minute half-time. The digital platform sells its own set of commercials, which are different from the commercials broadcast over the air, and might also be different from region to region. All these video streams have to be delivered to millions of viewers on a wide range of devices and a variety of network conditions: from 1 Gbs fiber at home down to 3 G networks in remote areas.
TF1’s approach to readiness included redesigning its digital architecture, setting up metrics showing how the new system is performing, and defining processes, roles and responsibilities for people in the team. As part of this preparation, AWS helped TF1 prepare their system to meet their scalability, performance, and security requirements.
In my conversation with Thierry, he described the two main objectives the company had when designing its new technical architecture for the future of broadcasting: first, the scalability of the platform and second, meet the demand for performance. Scalability is key to absorbing the peaks of concurrent viewers. And performance is required to ensure that the video streams start quickly (in less than 3 seconds) and there is no interruption of the video player (known as re-buffering). After all, nobody wants to know their team just scored by hearing their neighbors yelling before seeing it happen on the screen they’re watching.
The Technology Starting in 2019, TF1 started to redesign its digital broadcasting architecture and to rewrite significant parts of the code, such as the back-end API or the front-end applications running on set-top boxes, on Android, or on iOS devices. They adopted a micro service architecture, deployed on Amazon Elastic Kubernetes Service (EKS) and written in the Go programming language for maximum performance. They designed a set of REST and GraphQL APIs to define the contracts between front and back-end applications, and an event-driven architecture with Apache Kafka for maximum scalability. They adopted multiple content delivery networks, including Amazon CloudFront, to reliably distribute the video streams to client devices. In August 2020, TF1 got a chance to test the new platform on a large-scale sporting event when Bayern Munich beat Paris Saint Germain 1-0 at the UEFA European Champion League.
Here’s a peek at what happens from the moment the action is shot on the field to the moment you see it on your mobile device: The high-quality video stream first lands in the TF1 tower, located in Paris, where hardware encoders create the necessary videos streams adapted to your device. AWS Elemental Live hardware encoders are able to generate up to eight different encodings: 4K for TVs, high-definition (1080), standard definition (720), and a variety of other formats suited to a wide range of mobile devices and network bandwidth. (This extra video encoding step is one of the reasons why you might sometimes observe a extra latency between the video you receive on your traditional TV and the feed you receive on your mobile device.) The system sends the encoded videos to AWS Elemental Media Package for packaging and, finally, to the CDNs where the player applications fetch the video segments. The player applications select the best video encoding depending on your device size and current network bandwidth available.
At the end of 2021, one year before millions watched French player Kylian Mbappé score a hat trick (three goals) for the first time in a World Cup final since 1966, TF1 started preparing for the big event by identifying risks based on previous experiences and areas needing improvement. Thierry described how they built hypotheses of the likely audience size based on different game scenarios: the longer the French national team might stay in the competition, the higher the expected traffic. They classified risks for each phase of the tournament (selection pools, quarter-final, semi-final, and final). Based on these scenarios, they figured that the platform must be able to sustain 4.5 million viewers connecting to the platform 15 minutes before the start of a game (that’s 5,000 new viewers every second).
This level of scalability requires preparation from TF1’s team but also all external systems in use, such as the AWS cloud services, the authentication and authorization service, and the CDN services.
A viewer arrival triggers multiple flows and API calls. The viewer must authenticate, and some must create a new account or reset their passwords. Once authenticated, the viewer sees the homepage that, in turn, triggers multiple API calls, one of them to the catalog service. When the viewer selects a live stream, other API calls are made to receive the video stream URL. Then the video part kicks in. The client-side player connects to the chosen CDN and starts to download video segments. Once the video is playing, the platform must ensure the stream is delivered smoothly, with high quality and no drop that would cause a re-buffering. All these elements are key to ensuring the best possible viewer experience.
The Preparation Six months before France made it to the final and squared off against Argentina, TF1 started to work closely with their vendors, including AWS, to define requirements, reserve capacity, and start to work on test and execution plans. At this point, TF1 engaged with AWS Infrastructure Event Management, a dedicated program of the AWS enterprise support plan. Our experts offer architecture and guidance and operational support during the preparation and execution of planned events, such as shopping holidays, product launches, migrations – and in this case, the largest football (soccer) event in the world. For these events, AWS helps customers assess operational readiness, identify and mitigate risks, and execute confidently with AWS experts by their side.
Special care was given to test the scalability of the API. The TF1 team developped a load-testing engine to simulate users connecting to the platform, authenticating, selecting a program, and starting a video stream. To closely simulate real traffic, TF1 used another hyperscale cloud provider to send requests to their AWS infrastructure. The testing allowed them to define the correct metrics to observe in their dashboards and the correct values to generate alarms. Thierry said the first time the load simulator ran full speed, simulating 5,000 new connections per second, it crashed the entire back end.
But like any world class team, TF1 used this to their advantage. They took 2–3 weeks to tune the system. They eliminated redundant API calls from client applications and applied aggressive caching strategies. They learned how to scale their back-end platform in response to such traffic. They also learned to identify the value of key metrics under load. After a couple of back-end deployments and new releases for their Android and iOS apps, the system successfully passed the load test. It was a month before the start of the event. At that moment, TF1 decided to freeze all new developments or deployments until the first kickoff in Qatar, unless critical bugs were found.
Monitoring and Planning The technological platform was only one piece of the project, Thierry told me. They also designed metric dashboards using Datadog and Grafana to monitor key performance indicators and detect anomalies during the event. Thierry noted that when observing average values, they often miss parts of the picture. For example, he said, observing a P95 percentile value instead of an average shows the experience for five percent of your users. When you have three million of them, five percent represents 150K customers, so it is important to know what their experience is. (Incidentally, this percentile technique is used routinely at Amazon and AWS across all service teams, and Amazon CloudWatch has built-in support to measure percentile values.)
TF1 also prepared for the worst, he said, including the specter of having three million people staring at a black screen during a game. TF1 involved community managers and social media owners early on, and they prepared press releases and social media messages for multiple scenarios. The team also planned to gather all key team members together in a “war room” during each game to reduce communication and reaction time if something needed immediate action. This team included the AWS technical account manager, their counterpart from the authentication service, and other CDN vendors. AWS also had on-call engineers from service teams and premium support team monitoring the health of our services and ready to react in case something went wrong.
The Attacks Weren’t Just on the Field Three key moments at the start of the tournament provided opportunities to test the platform for real: the opening ceremony, the first game, and particularly for TF1’s audience, the first game for the French team. As the tournament played out over the following weeks — with increased intensity, suspense, and load on IT systems as the French team progressed — the TF1 team would reevaluate its traffic estimates and conduct debriefs after each game. But while the intensity of the action was unfolding on the field, TF1’s team had some behind-the-scenes excitement of its own.
Starting in the quarter final, the team noticed unusual activity from a wide range of distributed IP addresses, and they determined that the system was under a large distributed denial of service (DDOS) attack from a network of compromised machines; someone was trying to take down the service and prevent millions of people from watching. TF1 is accustomed to these types of attacks, and their dashboard helped to identify the traffic patterns in real time. Services such as AWS Shield and AWS Web Application Firewall helped to mitigate the incident without impacting the viewer experience. The TF1 security team and AWS experts conducted further analysis to proactively block some patterns of traffic and IP addresses for the next game.
Still, the intensity of the attacks increased during the semi-finals and final game, when it peaked at 40 millions of requests for a ten-minute period. “These attacks are a cat-and-mouse game,” said Thierry: attackers try new strategies and apply new patterns, but the team in the war room detects them and dynamically updates the filtering rules to block them before viewers can even detect a change in the quality of the service. The long and detailed preparation served its purpose, and everybody knew what to do. Thierry reported that the attacks were successfully mitigated with no consequences.
The Thrilling Finale By the time France took to the pitch on Dec. 18, 2022, TF1 knew they would break records on the platform. Thierry said the traffic was higher than estimated, but the platform absorbed it. He also described that during the first part of the game, when Argentina was leading, the TF1 team observed a slow decline of connections… that is, until the first goal scored by MBappé 10 minutes before the end of the game. At that point, all dashboards showed a sudden return of viewers for the thrilling last moments of the game. At peak, more than 3.2 million digital players were connected at the same time, delivering 3.6 terabits per second of outgoing bandwidth through all four CDNs.
Across the globe, Amazon CloudFront also helped 18 broadcasters deliver video streams. In all, over 48 million unique client IPs connected to one of 450+ edge locations globally during the tournament, peaking at just under 23 terabits per second across these customer distributions during the final game of the tournament.
The Future While Argentina ultimately triumphed and Lionel Messi achieved his long-sought World Cup win, the 2022 FIFA World Cup proved to the team at TF1 that their processes, their architecture, and their implementation are able to deliver a high-quality viewing experience to millions. The team is now confident the platform is ready to absorb the next planned large-scale events: the World Cup of Rugby in September 2023 and the next French presidential election in 2027. Thierry concluded our conversation predicting digital broadcasting will eventually attain a larger audience than over-the-air, and having 3+ millions simultaneous viewers will become the new normal.
If your company is also looking to transform its business using the power of cloud computing, consult with one of our AWS Enterprise support advisors today.
In Finland, where I live, spring has arrived. The snow has melted, and the trees have grown their first buds. But I don’t get my hopes high, as usually around Easter we have what is called takatalvi. Takatalvi is a Finnish world that means that the winter returns unexpectedly in the spring.
Last Week’s Launches Here are some launches that got my attention during the previous week.
AWS Batch – AWS Batch now allows you to configure ephemeral storage up to 200GiB on AWS Fargate type jobs. With this launch, you no longer need to limit the size of your data sets or the size of the Docker images to run machine learning inference.
Application Load Balancer – Application Load Balancer (ALB) now supports Transport Layer Security (TLS) protocol version 1.3, enabling you to optimize the performance of your application while keeping it secure. TLS 1.3 on ALB works by offloading encryption and decryption of TLS traffic from your application server to the load balancer.
Other AWS News Some other updates and news that you may have missed:
I read the post Implementing an event-driven serverless story generation application with ChatGPT and DALL-E a few days ago, and since then I have been reading my child a lot of AI-generated stories. In this post, David Boyne, explains step by step how you can create an event-driven serverless story generation application. This application produces a brand-new story every day at bedtime with images, which can be played in audio format.
Podcast Charlas Técnicas de AWS – If you understand Spanish, this podcast is for you. Podcast Charlas Técnicas is one of the official AWS podcasts in Spanish, and every other week there is a new episode. The podcast is meant for builders, and it shares stories about how customers have implemented and learned AWS services, how to architect applications, and how to use new services. You can listen to all the episodes directly from your favorite podcast app or at AWS Podcasts en español.
AWS open-source news and updates – The open source newsletter is curated by my colleague Ricardo Sueiras to bring you the latest open-source projects, posts, events, and more.
Upcoming AWS Events Check your calendars and sign up for the AWS Summit closest to your city. AWS Summits are free events that bring the local community together, where you can learn about different AWS services.
On this day 17 years ago, we launched a very simple object storage service. It allowed developers to create, list, and delete private storage spaces (known as buckets), upload and download files, and manage their access permissions. The service was available only through a REST and SOAP API. It was designed to provide highly durable data storage with 99.999999999 percent data durability (that’s 11 nines!).
Fast forward to 2023, Amazon Simple Storage Service (Amazon S3) holds more than 280 trillion objects and averages over 100 million requests per second. To protect data integrity, Amazon S3 performs over four billion checksum computations per second. Over the years, we added many capabilities, such as a range of storage classes, to store your colder data cost effectively. Every day, you restore on average more than 1 petabyte from the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive storage classes. Since launch, you have saved $1 billion from using Amazon S3 Intelligent-Tiering. In 2015, we added the possibility of replicating your data across Regions. Every week, Amazon S3 Replication moves more than 100 petabytes of data. Amazon S3 is also at the core of hundreds of thousands of data lakes. It also has become a critical component of a growing ecosystem of serverless applications. Every day, Amazon S3 sends over 125 billion event notifications to serverless applications. Altogether, Amazon S3 is helping people around the world securely store and extract value from their data.
To celebrate Amazon S3‘s birthday AWS is hosting the AWS Pi Day event for the third consecutive year. This live online event starts at 13:00 PDT today (March 14, 2023) on the AWS On Air channel on Twitch and will feature four hours of fresh educational content from AWS experts. We will discuss not only Amazon S3 best practices, we will also dive into the latest innovations across AWS data services, from storage to analytics and AI/ML. Tune in to learn how to get the most out of your data by making it more secure, available, accessible, and connected, and to help you respond to rapid growth and changing demand. You will also learn how to optimize your data costs, automate your cost savings, eliminate operational complexity, and get new insights from your data. Have a look at the full agenda on the registration page.
But we are not stopping there, and today we take the occasion of this celebration to announce seven new capabilities across our data services.
Mountpoint for Amazon S3 (alpha release): an open-source file client for Amazon S3 Mountpoint for Amazon S3 is an open-source file client for Amazon S3 that you can install on your compute instance. It translates local file storage API calls to REST API calls on objects in Amazon S3. When using Mountpoint for Amazon S3, data lake applications that access objects using file APIs can achieve high single-instance transfer rates, saving on compute costs.
You can get started with Mountpoint for Amazon S3 by mounting an Amazon S3 bucket at a local mount point on your compute instance. Once mounted, applications read objects as files available locally. Mountpoint for Amazon S3 supports sequential and random read operations on existing S3 objects. It is available to download for Linux operating systems as an alpha release and is not yet intended for production workloads. Instead, we want to collect your feedback early and incorporate your input into the design and implementation. To get started, visit the Mountpoint for Amazon S3 GitHub repo, read the technical launch blog, and share your feedback.
Now Generally Available: AWS Data Exchange for Amazon S3 AWS Data Exchange for Amazon S3 enables you to easily find, subscribe to, and use third-party data files for faster time to insight, storage cost optimization, simplified data licensing management, and more. Data Exchange subscribers can directly use files from data providers’ Amazon S3 buckets for their analysis with AWS services without needing to create or manage copies to their account. Data providers can license in-place access to data hosted in their Amazon S3 buckets.
Amazon S3 Multi-Region Access Points now support replicated datasets that span multiple AWS accounts We launched Amazon S3 Multi-Region Access Points in September 2021. We added failover control in November 2022. Amazon S3 Multi-Region Access Points now support datasets that are replicated across multiple AWS accounts. Cross-account Multi-Region Access Points simplify object storage access for applications that span both AWS Regions and accounts, avoiding the need for complex request routing logic in your application. They provide a single global endpoint for your multi-Region applications and dynamically route S3 requests based on policies that you define. This helps you to easily implement multi-Region resilience, latency-based routing, and active/passive failover, even when your data is stored in multiple AWS accounts.
Aliases for S3 Object Lambda Access Points as CloudFront origin Amazon S3 Object Lambda, launched in March 2021, lets you add your own code to S3 GET, HEAD, and LIST API requests to modify data as it is returned to an application. With today’s launch of aliases for S3 Object Lambda Access Points any application that requires an S3 bucket name can easily present different views of data depending on the requester. You can now use an S3 Object Lambda Access Point alias as an origin for your Amazon CloudFront distribution to modify the data requested. For example, you can dynamically transform an image depending on the device that a user is visiting from, such as a desktop or a smartphone.
Simplify private connectivity from on-premises networks Amazon Virtual Private Cloud (Amazon VPC) interface endpoints for Amazon S3 now offer private DNS options that can help you more easily route Amazon S3 requests to the lowest-cost endpoint in your VPC. With private DNS for Amazon S3, your on-premises applications can use AWS PrivateLink to access Amazon S3 over an interface endpoint, while requests from your in-VPC applications access Amazon S3 using gateway endpoints. Routing requests like this helps you take advantage of the lowest-cost private network path without having to make code or configuration changes to your clients.
Local Amazon S3 Replication on Outposts Amazon S3 on Outposts now supports S3 replication on Outposts. This extends S3’s fully managed approach to replication to S3 on Outposts buckets. It helps you meet your data residency and data redundancy requirements. With local S3 Replication on Outposts, you can create and configure replication rules to automatically replicate your S3 objects to another Outpost or to another bucket on the same Outpost. During replication, your S3 on Outposts objects are always sent over your local gateway, and objects do not travel back to the AWS Region. S3 Replication on Outposts provides an easy and flexible way to automatically replicate data within a specific data perimeter to address your data redundancy and compliance requirements.
Amazon OpenSearch Security Analytics The new Amazon OpenSearch Service’s security analytics capability enables your Security Operations (SecOps) teams to detect potential threats quickly while having the tools to help with security investigations on historical data—all with lower data storage costs. Like many other advanced capabilities of Amazon OpenSearch Service, there is no additional charge for security analytics.
Join Us Online Today You will learn more about these launches and about AWS data services in general. We have also prepared some live demos. We designed the AWS Pi Day event for system administrators, engineers, developers, and architects. Our sessions will bring you the latest and greatest information on storage, security, backup, archiving, training and certification, and more.
And to dive deeper, get Pi Day started early by attending AWS Innovate: Data and AI/ML Edition to learn about cutting-edge machine learning tools, strategies for building future-proof applications, and making data-driven decisions for your organization. Don’t miss Swami Sivasubramanian‘s keynote, starting at 9:00 PDT.
Today, we celebrate Martin Luther King Jr. Day in the US to honor the late civil rights leader’s life, legacy, and achievements. In this article, Amazon employees share what MLK Day means to them and how diversity makes us stronger.
Coming back to our AWS Week in Review—it’s been a busy week!
Last Week’s Launches Here are some launches that got my attention during the previous week:
AWS Clean Rooms now available in preview – During AWS re:Invent this past November, we announced AWS Clean Rooms, a new analytics service that helps companies across industries easily and securely analyze and collaborate on their combined datasets—without sharing or revealing underlying data. You can now start using AWS Clean Rooms (Preview).
Amazon Kendra updates – Amazon Kendra is an intelligent search service powered by machine learning (ML) that helps you search across different content repositories with built-in connectors. With the newAmazon Kendra Intelligent Ranking for self-managed OpenSearch, you can now improve the quality of your OpenSearch search results using Amazon Kendra’s ML-powered semantic ranking technology.
Amazon Personalizeupdates – Amazon Personalize helps you improve customer engagement through personalized product and content recommendations. Using the new Trending-Now recipe, you can now generate recommendations for items that are rapidly becoming more popular with your users. Amazon Personalize now also supports tag-based resource authorization. Tags are labels in the form of key-value pairs that can be attached to individual Amazon Personalize resources to manage resources or allocate costs.
Amazon SageMaker Canvas now delivers up to 3x faster ML model training time– SageMaker Canvas is a visual interface that enables business analysts to generate accurate ML predictions on their own—without having to write a single line of code. The accelerated model training times help you prototype and experiment more rapidly, shortening the time to generate predictions and turn data into valuable insights.
Other AWS News Here are some additional news items and blog posts that you may find interesting:
AWS open-source news and updates – My colleague Ricardo writes this weekly open-source newsletter in which he highlights new open-source projects, tools, and demos from the AWS Community. Read edition #141 here.
ML model hosting best practices in Amazon SageMaker – This seven-part blog series discusses best practices for ML model hosting in SageMaker to help you identify which hosting design pattern meets your needs best. The blog series also covers advanced concepts such as multi-model endpoints (MME), multi-container endpoints (MCE), serial inference pipelines, and model ensembles. Read part one here.
I would also like to recommend this really interesting Amazon Science article about differential privacy for end-to-end speech recognition. The data used to train AI models is protected by differential privacy (DP), which adds noise during training. In this article, Amazon researchers show how ensembles of teacher models can meet DP constraints while reducing error by more than 26 percent relative to standard DP methods.
Upcoming AWS Events Check your calendars and sign up for these AWS events:
#BuildOnLive – Build On AWS Live events are a series of technical streams on twitch.tv/aws that focus on technology topics related to challenges hands-on practitioners face today.
Join the Build On Live Weekly show about the cloud, the community, the code, and everything in between, hosted by AWS Developer Advocates. The show streams every Thursday at 09:00 US PT on twitch.tv/aws.
Join the new The Big Dev Theory show, co-hosted with AWS partners, discussing various topics such as data and AI, AIOps, integration, and security. The show streams every Tuesday at 08:00 US PT on twitch.tv/aws.
AWS Community Days – AWS Community Day events are community-led conferences that deliver a peer-to-peer learning experience, providing developers with a venue to acquire AWS knowledge in their preferred way: from one another.
In January, the AWS community will host in-person events in Singapore (January 28) and in Tel Aviv, Israel (January 30).
AWS Innovate Data and AI/ML edition – AWS Innovate is a free online event to learn the latest from AWS experts and get step-by-step guidance on using AI/ML to drive fast, efficient, and measurable results.
AWS Innovate Data and AI/ML edition for Asia Pacific and Japan is taking place on February 22, 2023. Register here.
Registrations for AWS Innovate EMEA (March 9, 2023) and the Americas (March 14, 2023) will open soon. Check the AWS Innovate page for updates.
AWS re:Invent returned to Las Vegas, Nevada, November 28 to December 2, 2022. After a virtual event in 2020 and a hybrid 2021 edition, spirits were high as over 51,000 in-person attendees returned to network and learn about the latest AWS innovations.
Now in its 11th year, the conference featured 5 keynotes, 22 leadership sessions, and more than 2,200 breakout sessions and hands-on labs at 6 venues over 5 days.
With well over 100 service and feature announcements—and innumerable best practices shared by AWS executives, customers, and partners—distilling highlights is a challenge. From a security perspective, three key themes emerged.
Turn data into actionable insights
Security teams are always looking for ways to increase visibility into their security posture and uncover patterns to make more informed decisions. However, as AWS Vice President of Data and Machine Learning, Swami Sivasubramanian, pointed out during his keynote, data often exists in silos; it isn’t always easy to analyze or visualize, which can make it hard to identify correlations that spark new ideas.
“Data is the genesis for modern invention.” – Swami Sivasubramanian, AWS VP of Data and Machine Learning
At AWS re:Invent, we launched new features and services that make it simpler for security teams to store and act on data. One such service is Amazon Security Lake, which brings together security data from cloud, on-premises, and custom sources in a purpose-built data lake stored in your account. The service, which is now in preview, automates the sourcing, aggregation, normalization, enrichment, and management of security-related data across an entire organization for more efficient storage and query performance. It empowers you to use the security analytics solutions of your choice, while retaining control and ownership of your security data.
Amazon Security Lake has adopted the Open Cybersecurity Schema Framework (OCSF), which AWS cofounded with a number of organizations in the cybersecurity industry. The OCSF helps standardize and combine security data from a wide range of security products and services, so that it can be shared and ingested by analytics tools. More than 37 AWS security partners have announced integrations with Amazon Security Lake, enhancing its ability to transform security data into a powerful engine that helps drive business decisions and reduce risk. With Amazon Security Lake, analysts and engineers can gain actionable insights from a broad range of security data and improve threat detection, investigation, and incident response processes.
Strengthen security programs
According to Gartner, by 2026, at least 50% of C-Level executives will have performance requirements related to cybersecurity risk built into their employment contracts. Security is top of mind for organizations across the globe, and as AWS CISO CJ Moses emphasized during his leadership session, we are continuously building new capabilities to help our customers meet security, risk, and compliance goals.
In addition to Amazon Security Lake, several new AWS services announced during the conference are designed to make it simpler for builders and security teams to improve their security posture in multiple areas.
Identity and networking
Authorization is a key component of applications. Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for custom applications that simplifies policy-based access for developers and centralizes access governance. The new service gives developers a simple-to-use policy and schema management system to define and manage authorization models. The policy-based authorization system that Amazon Verified Permissions offers can shorten development cycles by months, provide a consistent user experience across applications, and facilitate integrated auditing to support stringent compliance and regulatory requirements.
Additional services that make it simpler to define authorization and service communication include Amazon VPC Lattice, an application-layer service that consistently connects, monitors, and secures communications between your services, and AWS Verified Access, which provides secure access to corporate applications without a virtual private network (VPN).
Threat detection and monitoring
Monitoring for malicious activity and anomalous behavior just got simpler. Amazon GuardDuty RDS Protection expands the threat detection capabilities of GuardDuty by using tailored machine learning (ML) models to detect suspicious logins to Amazon Aurora databases. You can enable the feature with a single click in the GuardDuty console, with no agents to manually deploy, no data sources to enable, and no permissions to configure. When RDS Protection detects a potentially suspicious or anomalous login attempt that indicates a threat to your database instance, GuardDuty generates a new finding with details about the potentially compromised database instance. You can view GuardDuty findings in AWS Security Hub, Amazon Detective (if enabled), and Amazon EventBridge, allowing for integration with existing security event management or workflow systems.
To bolster vulnerability management processes, Amazon Inspector now supports AWS Lambda functions, adding automated vulnerability assessments for serverless compute workloads. With this expanded capability, Amazon Inspector automatically discovers eligible Lambda functions and identifies software vulnerabilities in application package dependencies used in the Lambda function code. Actionable security findings are aggregated in the Amazon Inspector console, and pushed to Security Hub and EventBridge to automate workflows.
Data protection and privacy
The first step to protecting data is to find it. Amazon Macie now automatically discovers sensitive data, providing continual, cost-effective, organization-wide visibility into where sensitive data resides across your Amazon Simple Storage Service (Amazon S3) estate. With this new capability, Macie automatically and intelligently samples and analyzes objects across your S3 buckets, inspecting them for sensitive data such as personally identifiable information (PII), financial data, and AWS credentials. Macie then builds and maintains an interactive data map of your sensitive data in S3 across your accounts and Regions, and provides a sensitivity score for each bucket. This helps you identify and remediate data security risks without manual configuration and reduce monitoring and remediation costs.
Encryption is a critical tool for protecting data and building customer trust. The launch of the end-to-end encrypted enterprise communication service AWS Wickr offers advanced security and administrative controls that can help you protect sensitive messages and files from unauthorized access, while working to meet data retention requirements.
Management and governance
Maintaining compliance with regulatory, security, and operational best practices as you provision cloud resources is key. AWS Config rules, which evaluate the configuration of your resources, have now been extended to support proactive mode, so that they can be incorporated into infrastructure-as-code continuous integration and continuous delivery (CI/CD) pipelines to help identify noncompliant resources prior to provisioning. This can significantly reduce time spent on remediation.
Managing the controls needed to meet your security objectives and comply with frameworks and standards can be challenging. To make it simpler, we launched comprehensive controls management with AWS Control Tower. You can use it to apply managed preventative, detective, and proactive controls to accounts and organizational units (OUs) by service, control objective, or compliance framework. You can also use AWS Control Tower to turn on Security Hub detective controls across accounts in an OU. This new set of features reduces the time that it takes to define and manage the controls required to meet specific objectives, such as supporting the principle of least privilege, restricting network access, and enforcing data encryption.
Do more with less
As we work through macroeconomic conditions, security leaders are facing increased budgetary pressures. In his opening keynote, AWS CEO Adam Selipsky emphasized the effects of the pandemic, inflation, supply chain disruption, energy prices, and geopolitical events that continue to impact organizations.
Now more than ever, it is important to maintain your security posture despite resource constraints. Citing specific customer examples, Selipsky underscored how the AWS Cloud can help organizations move faster and more securely. By moving to the cloud, agricultural machinery manufacturer Agco reduced costs by 78% while increasing data retrieval speed, and multinational HVAC provider Carrier Global experienced a 40% reduction in the cost of running mission-critical ERP systems.
“If you’re looking to tighten your belt, the cloud is the place to do it.” – Adam Selipsky, AWS CEO
Security teams can do more with less by maximizing the value of existing controls, and bolstering security monitoring and analytics capabilities. Services and features announced during AWS re:Invent—including Amazon Security Lake, sensitive data discovery with Amazon Macie, support for Lambda functions in Amazon Inspector, Amazon GuardDuty RDS Protection, and more—can help you get more out of the cloud and address evolving challenges, no matter the economic climate.
Security is our top priority
AWS re:Invent featured many more highlights on a variety of topics, such as Amazon EventBridge Pipes and the pre-announcement of GuardDuty EKS Runtime protection, as well as Amazon CTO Dr. Werner Vogels’ keynote, and the security partnerships showcased on the Expo floor. It was a whirlwind week, but one thing is clear: AWS is working harder than ever to make our services better and to collaborate on solutions that ease the path to proactive security, so that you can focus on what matters most—your business.
AWS re:Invent returned to Las Vegas, NV, in November 2022. The conference featured over 2,200 sessions and hands-on labs and more than 51,000 attendees over 5 days. If you weren’t able to join us in person, or just want to revisit some of the security, identity, and compliance announcements and on-demand sessions, this blog post is for you.
Key announcements
Here are some of the security announcements that we made at AWS re:Invent 2022.
We announced the preview of a new service, Amazon Security Lake. Amazon Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in your AWS account. Security Lake makes it simpler to analyze security data so that you can get a more complete understanding of security across your entire organization. You can also improve the protection of your workloads, applications, and data. Security Lake automatically gathers and manages your security data across accounts and AWS Regions.
We introduced the AWS Digital Sovereignty Pledge—our commitment to offering the most advanced set of sovereignty controls and features available in the cloud. As part of this pledge, we launched a new feature of AWS Key Management Service, External Key Store (XKS), where you can use your own encryption keys stored outside of the AWS Cloud to protect data on AWS.
To help you with the building blocks for zero trust, we introduced two new services:
AWS Verified Access provides secure access to corporate applications without a VPN. Verified Access verifies each access request in real time and only connects users to the applications that they are allowed to access, removing broad access to corporate applications and reducing the associated risks.
Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for custom applications. Using the Cedar policy language, Amazon Verified Permissions centralizes fine-grained permissions for custom applications and helps developers authorize user actions in applications.
We announced Automated sensitive data discovery for Amazon Macie. This new capability helps you gain visibility into where your sensitive data resides on Amazon Simple Storage Service (Amazon S3) at a fraction of the cost of running a full data inspection across all your S3 buckets. Automated sensitive data discovery automates the continual discovery of sensitive data and potential data security risks across your S3 storage aggregated at the AWS Organizations level.
Amazon Inspector now supports AWS Lambda functions, adding continual, automated vulnerability assessments for serverless compute workloads. Amazon Inspector automatically discovers eligible AWS Lambda functions and identifies software vulnerabilities in application package dependencies used in the Lambda function code. The functions are initially assessed upon deployment to Lambda and continually monitored and reassessed, informed by updates to the function and newly published vulnerabilities. When vulnerabilities are identified, actionable security findings are generated, aggregated in Amazon Inspector, and pushed to Security Hub and Amazon EventBridge to automate workflows.
Amazon GuardDuty now offers threat detection for Amazon Aurora to identify potential threats to data stored in Aurora databases. Currently in preview, Amazon GuardDuty RDS Protection profiles and monitors access activity to existing and new databases in your account, and uses tailored machine learning models to detect suspicious logins to Aurora databases. When a potential threat is detected, GuardDuty generates a security finding that includes database details and contextual information on the suspicious activity. GuardDuty is integrated with Aurora for direct access to database events without requiring you to modify your databases.
AWS Security Hub is now integrated with AWS Control Tower, allowing you to pair Security Hub detective controls with AWS Control Tower proactive or preventive controls and manage them together using AWS Control Tower. Security Hub controls are mapped to related control objectives in the AWS Control Tower control library, providing you with a holistic view of the controls required to meet a specific control objective. This combination of over 160 detective controls from Security Hub, with the AWS Control Tower built-in automations for multi-account environments, gives you a strong baseline of governance and off-the-shelf controls to scale your business using new AWS workloads and services. This combination of controls also helps you monitor whether your multi-account AWS environment is secure and managed in accordance with best practices, such as the AWS Foundational Security Best Practices standard.
We launched our Cloud Audit Academy (CAA) course for Federal and DoD Workloads (FDW) on AWS. This new course is a 12-hour interactive training based on NIST SP 800-171, with mappings to NIST SP 800-53 and the Cybersecurity Maturity Model Certification (CMMC) and covers AWS services relevant to each NIST control family. This virtual instructor-led training is industry- and framework-specific for our U.S. Federal and DoD customers.
AWS Wickr allows businesses and public sector organizations to collaborate more securely, while retaining data to help meet requirements such as e-discovery and Freedom of Information Act (FOIA) requests. AWS Wickr is an end-to-end encrypted enterprise communications service that facilitates one-to-one chats, group messaging, voice and video calling, file sharing, screen sharing, and more.
We introduced the Post-Quantum Cryptography hub that aggregates resources and showcases AWS research and engineering efforts focused on providing cryptographic security for our customers, and how AWS interfaces with the global cryptographic community.
Watch on demand
Were you unable to join the event in person? See the following for on-demand sessions.
To learn about the latest innovations in cloud security from AWS and what you can do to foster a culture of security in your business, watch AWS Chief Information Security Officer CJ Moses’s leadership session with guest Deneen DeFiore, Chief Information Security Officer at United Airlines.
See how AWS, customers, and partners work together to raise their security posture with AWS infrastructure and services. Learn about trends in identity and access management, threat detection and incident response, network and infrastructure security, data protection and privacy, and governance, risk, and compliance.
Dive into our launches! Hear from security experts on recent announcements. Learn how new services and solutions can help you meet core security and compliance requirements.
Consider joining us for more in-person security learning opportunities by saving the date for AWS re:Inforce 2023, which will be held June 13-14 in Anaheim, California. We look forward to seeing you there!
If you’d like to discuss how these new announcements can help your organization improve its security posture, AWS is here to help. Contact your AWS account team today.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS offers the most scalable, highest performing data services to keep up with the growing volume and velocity of data to help organizations to be data-driven in real-time. We help customers unify diverse data sources by investing in a zero ETL future. We provide the industry’s most comprehensive set of capabilities for an end-to-end data strategy for all your workloads. And, our services help you enable end-to-end data governance so your teams are free to move faster with data.
This post walks you through all of the new analytics service launches. You’ll find links to blog posts, announcements, session recordings, and press releases so you can dive deeper into those launches.
For more 2022 re:Invent recaps and ongoing coverage of all the important AWS launches, be sure to stay in touch with us here:
This press release covers five new database and analytics capabilities that make it faster and easier for you to manage and analyze data at petabyte scale—Amazon DocumentDB Elastic Clusters, Amazon OpenSearch Serverless, Amazon Athena for Apache Spark, AWS Glue Data Quality, and Amazon Redshift Multi-AZ.
This press release covers five new capabilities for Amazon QuickSight, the most popular serverless BI service built for the cloud. These new capabilities will help customers streamline business intelligence operations.
This press release covers two new integrations that make it easier for customers to connect and analyze data across data stores without having to move data between services.
Amazon DataZone makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and on third-party sources. To learn more about Amazon DataZone, please visit the product page or watch the re:Invent session recording.
Adam Selipsky, Chief Executive Officer of Amazon Web Services, highlighted innovations in data, infrastructure, and more that are helping customers achieve their goals faster, take advantage of untapped potential, and create a better future with AWS. The analytics new launches Adam mentioned include Amazon OpenSearch Serverless, Amazon DataZone, and Amazon Aurora zero-ETL integration with Amazon Redshift.
Swami Sivasubramanian, Vice President of AWS Data and Machine Learning, revealed the latest AWS innovations that can help you transform your company’s data into meaningful insights and actions for your business. In this keynote, Swami launched Amazon Athena for Apache Spark, Amazon Redshift integration for Apache Spark, Amazon Redshift Multi-AZ, AWS Glue Data Quality, and other new AWS capabilities.
G2 Krishnamoorthy, VP of AWS Analytics, covered the latest service innovations around data and also highlighted customer successes with AWS analytics. New analytics capabilities he covered include AWS Glue for Ray, Amazon Redshift Streaming Ingestion, Amazon Aurora zero-ETL to Amazon Redshift, Amazon Redshift integration for Apache Spark, Amazon DataZone, Amazon Athena for Apache Spark, Amazon OpenSearch Serverless, Amazon QuickSight API, and more.
Mai-Lan Tomsen Bukovec, Vice President of AWS Foundational Data Services, and Andy Warfield, AWS Distinguished Engineer, shared the latest AWS storage innovations and an inside look at how customers drive modern business on data lakes and with high-performance data. They also dived deep into technical and organizational strategies that protect with resilience, respond with agility, and fuel innovations with data-driven insights on AWS storage.
Amazon DataZone
To gain value from your data, it needs to be accessible by people and systems that need it for analytics. This session introduces you to Amazon DataZone, a new AWS business data catalog that allows you to unlock data across organizational boundaries with built-in governance.
Blog – New – Amazon Redshift Integration with Apache Spark This new release makes it easy to build and run Spark applications on Amazon Redshift and Redshift Serverless, enabling you to open up the data warehouse for a broader set of AWS analytics and machine learning (ML) solutions.
Blog – Simplify data ingestion from Amazon S3 to Amazon Redshift using auto-copy This feature simplifies data loading from Amazon S3 into Amazon Redshift. You can now set up continuous file ingestion rules to track your Amazon S3 paths and automatically load new files without needing additional tools or custom solutions.
Blog – Simplify data loading on the Amazon Redshift console with Informatica Data Loader You need to bring data quickly and at scale from various data stores. You also need a simple, easy, and cloud-native solution to quickly onboard new data sources or to analyze recent data for actionable insights. With this feature, you can securely connect and load data to Amazon Redshift at scale via a simple and guided interface.
Watch the recording to learn about important new features of Amazon Redshift. Learn how Amazon Redshift reinvented data warehousing to help you analyze all your data across data lakes, data warehouses, and databases with the best price performance. In this session, Goldman Sachs shared their Amazon Redshift use case.
Blog – New — Amazon Athena for Apache Spark With this feature, we can run Apache Spark workloads, use Jupyter Notebook as the interface to perform data processing on Athena, and programmatically interact with Spark applications using Athena APIs.
Blog – Announcing Automated Data Preparation for Amazon QuickSight Q Automated data preparation uses machine learning to infer semantic information about data and adds it to datasets as metadata about the columns (fields), making it faster for you to prepare data in order to support natural language questions.
Thanks for reading! re:Invent is certainly not just about new launches. The Analytics and Business Intelligence tracks dived deep into each one of the analytics services through sessions (86 in total!), covering a wide range of topics and use cases.
Gwen Chen is Senior Product Marketing Manager for Amazon Redshift and re:Invent Analytics Track Lead. She believes in the power of communication, and likes data, analytics, and AI/ML.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.

 AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Hong Kong (July 20), New York City (July 26), Taiwan (August 2-3), São Paulo (August 3), and Mexico City (August 30).
AWS Global Summits – Check your calendars and sign up for the AWS Summit close to where you live or work: Hong Kong (July 20), New York City (July 26), Taiwan (August 2-3), São Paulo (August 3), and Mexico City (August 30).






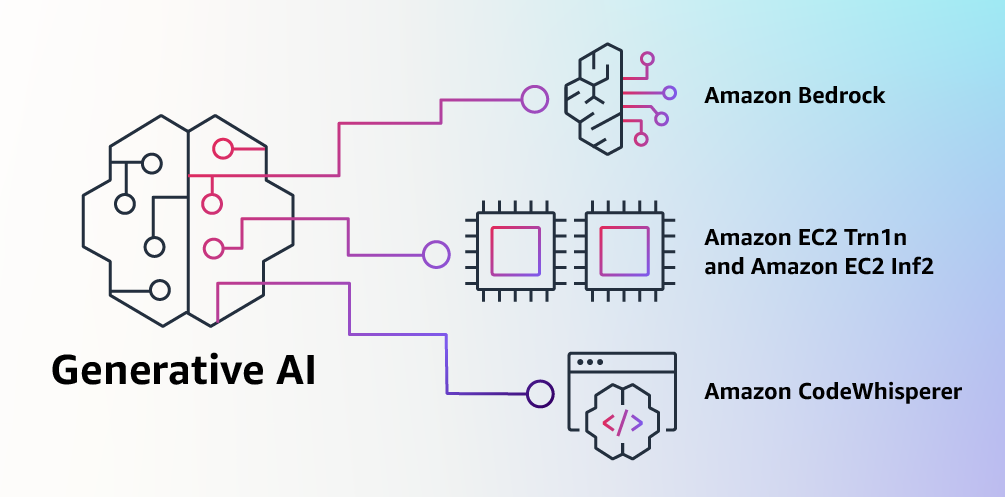

 .NET Developer Day –
.NET Developer Day – 

 This online and mobile usage drives very specific traffic patterns on IT systems: a huge peak of connections and authentications in the few minutes before the start of a game and millions of video streams that must be delivered reliably over a variety of changing network qualities. In addition to these technical challenges, there is also an economic challenge: to deliver advertisements at key moments, such as before a national anthem or during a 15-minute half-time. The digital platform sells its own set of commercials, which are different from the commercials broadcast over the air, and might also be different from region to region. All these video streams have to be delivered to millions of viewers on a wide range of devices and a variety of network conditions: from 1 Gbs fiber at home down to 3 G networks in remote areas.
This online and mobile usage drives very specific traffic patterns on IT systems: a huge peak of connections and authentications in the few minutes before the start of a game and millions of video streams that must be delivered reliably over a variety of changing network qualities. In addition to these technical challenges, there is also an economic challenge: to deliver advertisements at key moments, such as before a national anthem or during a 15-minute half-time. The digital platform sells its own set of commercials, which are different from the commercials broadcast over the air, and might also be different from region to region. All these video streams have to be delivered to millions of viewers on a wide range of devices and a variety of network conditions: from 1 Gbs fiber at home down to 3 G networks in remote areas.
 By the time France took to the pitch on Dec. 18, 2022, TF1 knew they would break records on the platform. Thierry said the traffic was higher than estimated, but the platform absorbed it. He also described that during the first part of the game, when Argentina was leading, the TF1 team observed a slow decline of connections… that is, until
By the time France took to the pitch on Dec. 18, 2022, TF1 knew they would break records on the platform. Thierry said the traffic was higher than estimated, but the platform absorbed it. He also described that during the first part of the game, when Argentina was leading, the TF1 team observed a slow decline of connections… that is, until