Post Syndicated from Danilo Poccia original https://aws.amazon.com/blogs/aws/new-for-amazon-transcribe-real-time-analytics-during-live-calls/
The experience customers have when interacting with a contact center can have a profound impact on them. For this reason, we launched Amazon Transcribe Call Analytics last year to help you analyze customer call recordings and get insights into issues and trends related to customer satisfaction and agent performance.
To assist agents in resolving live calls faster, we are introducing today real-time call analytics in Amazon Transcribe Call Analytics. Real-time call analytics provides APIs for developers to accurately transcribe live calls and at the same time identify customer experience issues and sentiment in real time. Transcribe Call Analytics uses state-of-the-art machine learning capabilities to automatically assess thousands of in-progress calls and detect customer experience issues, such as repeated requests to speak to a manager or cancel a subscription.
With a few clicks, supervisors and analysts can create categories in the AWS console to identify customer experience issues using criteria such as specific terms such as “not happy,” “poor quality,” and “cancel my subscription.” Transcribe Call Analytics analyzes in-progress calls in real time to detect when a category is met. Developers can use those signals, along with sentiment trends from the API, to build a proactive system that alerts supervisors about emerging issues or assists agents with relevant information to solve customer issues.
Transcribe Call Analytics also provides a real-time transcript of the live conversation that supervisors can use to quickly get up to speed on the customer interaction and assess the appropriate action. The in-call transcript also eliminates the need for customers to repeat themselves if the call is transferred to another agent. Agents can focus all their attention on the customer during the call instead of taking notes for entry in a CRM system because Transcribe Call Analytics includes an automated call summarization capability, which identifies the issue, outcome, and action item associated with a call.
Transcribe Call Analytics is a foundational API for AWS Contact Center Intelligence solutions such as post-call analytics and the updated real-time call analytics with agent assist solution using the new real-time capabilities.
Let’s see how this works in practice.
Exploring Real-Time Call Analytics in the Console
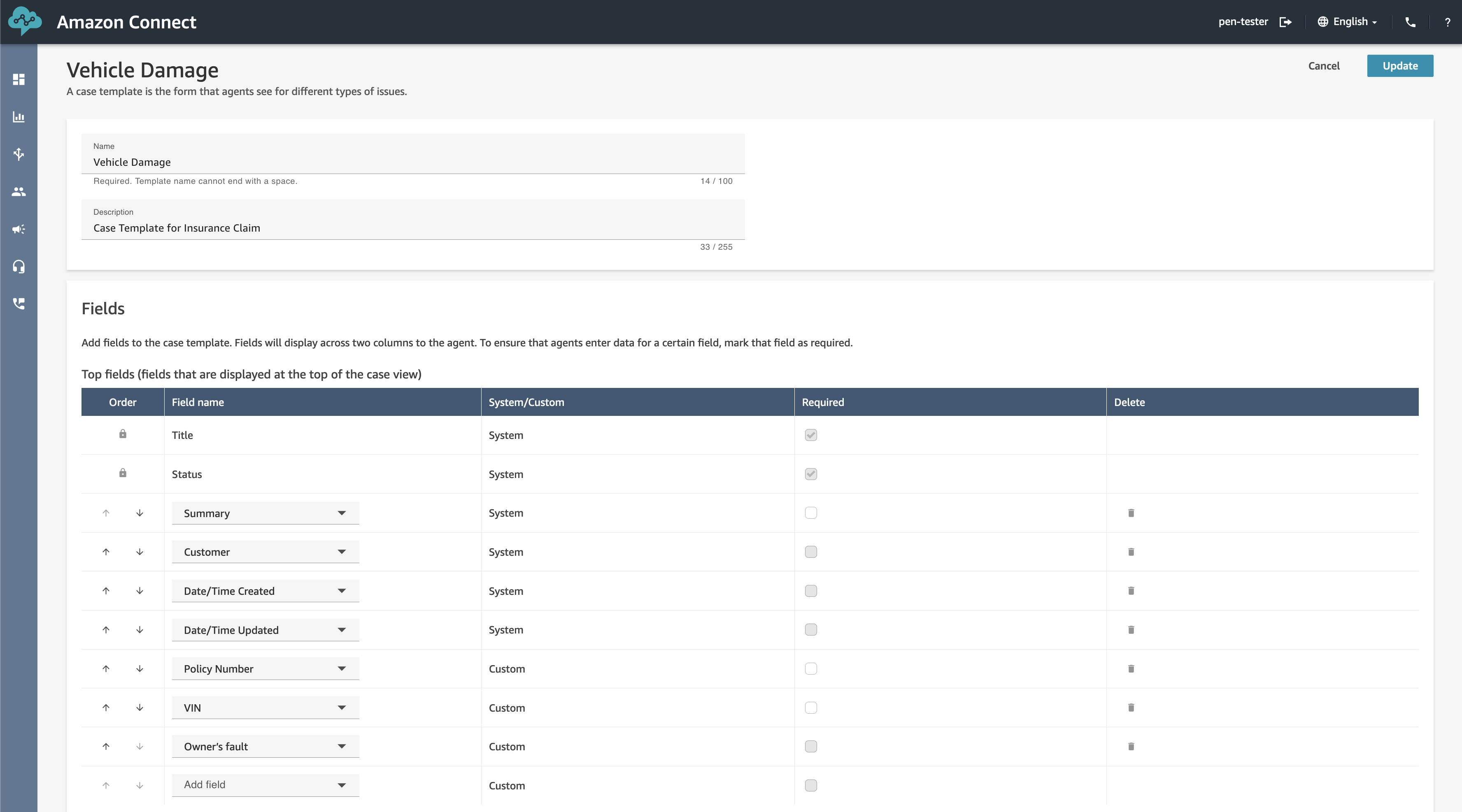
To see how this works visually, I use the Amazon Transcribe console. First, I create a category to be notified if some terms are used in the call that would require an escalation. I choose Category Management from the navigation pane and then Create category.
I enter Escalation as the name for the category. I select REAL_TIME in the Category type dropdown. Then, I choose Create from scratch.

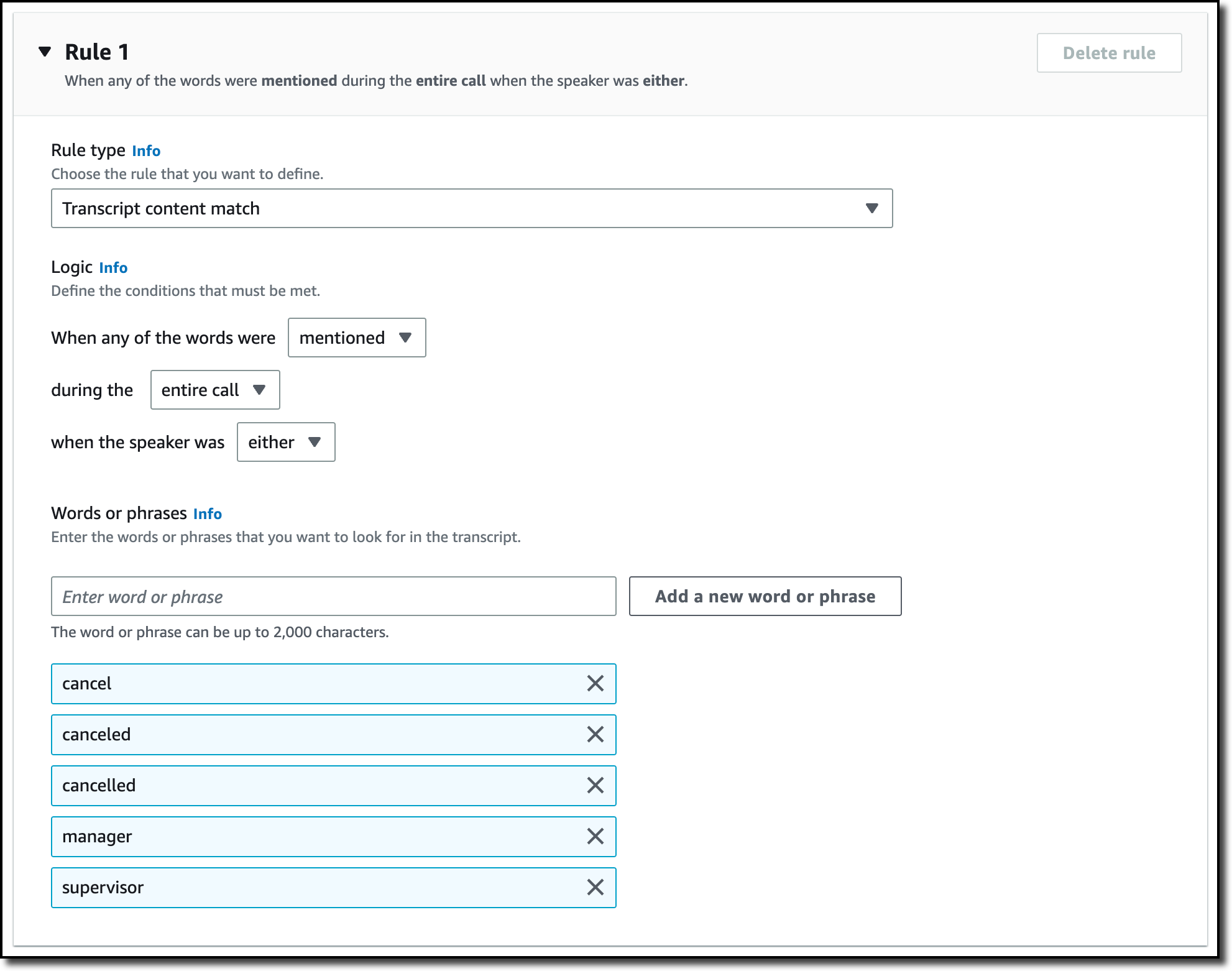
I only need one rule for this category. In the Rule type dropdown, I select Transcript content match. In the next three options, I choose to trigger the rule when any of the words are mentioned during the entire call, and the speaker is either the customer or the agent. Now, I can enter the words or phrases to look for in the transcript. In this case, I enter cancel, canceled, cancelled, manager, and supervisor. In your case, you might be more specific depending on your business. For example, if subscriptions are your business, you can look for the phrase cancel my subscription.
Now that the category has been created, I use one of the sample calls in the console to test it. I choose Real-Time Analytics in the navigation pane. By choosing Configure advanced settings, I can configure the personally identifiable information (PII) identification and redaction settings. For example, I can choose to identify personal data such as email addresses or redact financial data like bank account numbers.
With no additional charge, I can enable Post-call Analytics so that, at the end of the call, I receive the output of the transcription job in an Amazon Simple Storage Service (Amazon S3) bucket. This output is in a similar format to what I’d receive if I were analyzing a call recording with Transcribe Call Analytics. In this way, I can use the post-call analytics output derived from the audio stream in any process I already have in place for output of analytics generated from call recordings, for example, to update dashboards or generate periodic reports.
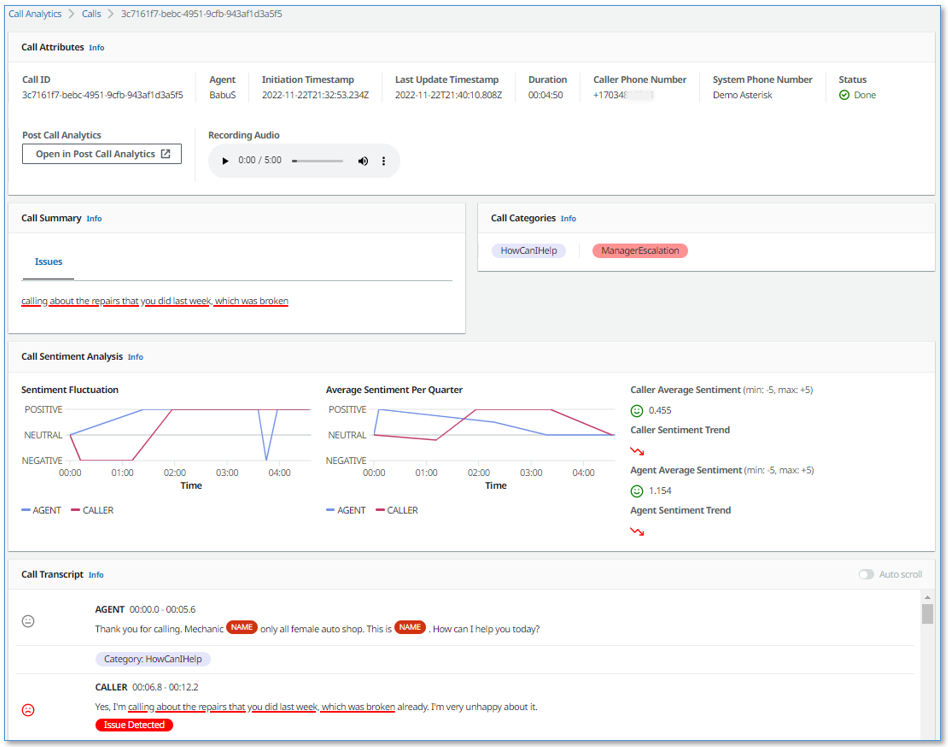
With Insurance complaints in Step 1: Specify input audio selected, I choose Start streaming. In the Transcription output section of the console, I receive in real-time the transcription of the call. The words of the customer and agent appear as they are pronounced. Each sentence is flagged with its recognized sentiment (positive, neutral, or negative). The Escalation category that I just configured is found in two sentences, first, when the customer mentions that their insurance has been canceled, and then when the agent mentions their manager. Also, part of a sentence is underlined because an issue has been detected.

Using the Download dropdown, I download the full JSON transcript. If I am only interested in the transcription, I can download the text transcript. The JSON transcript contains an array where each item is similar to what I’d get in real time when using the real-time call analytics API.
Using the Live Call Analytics With Agent Assist (LCA) Solution
You can use the open-source real-time call analytics with agent assist solution for your contact center or as an inspiration of what Amazon Transcribe enables for developers. Let’s look at a couple of screenshots to understand how it works.
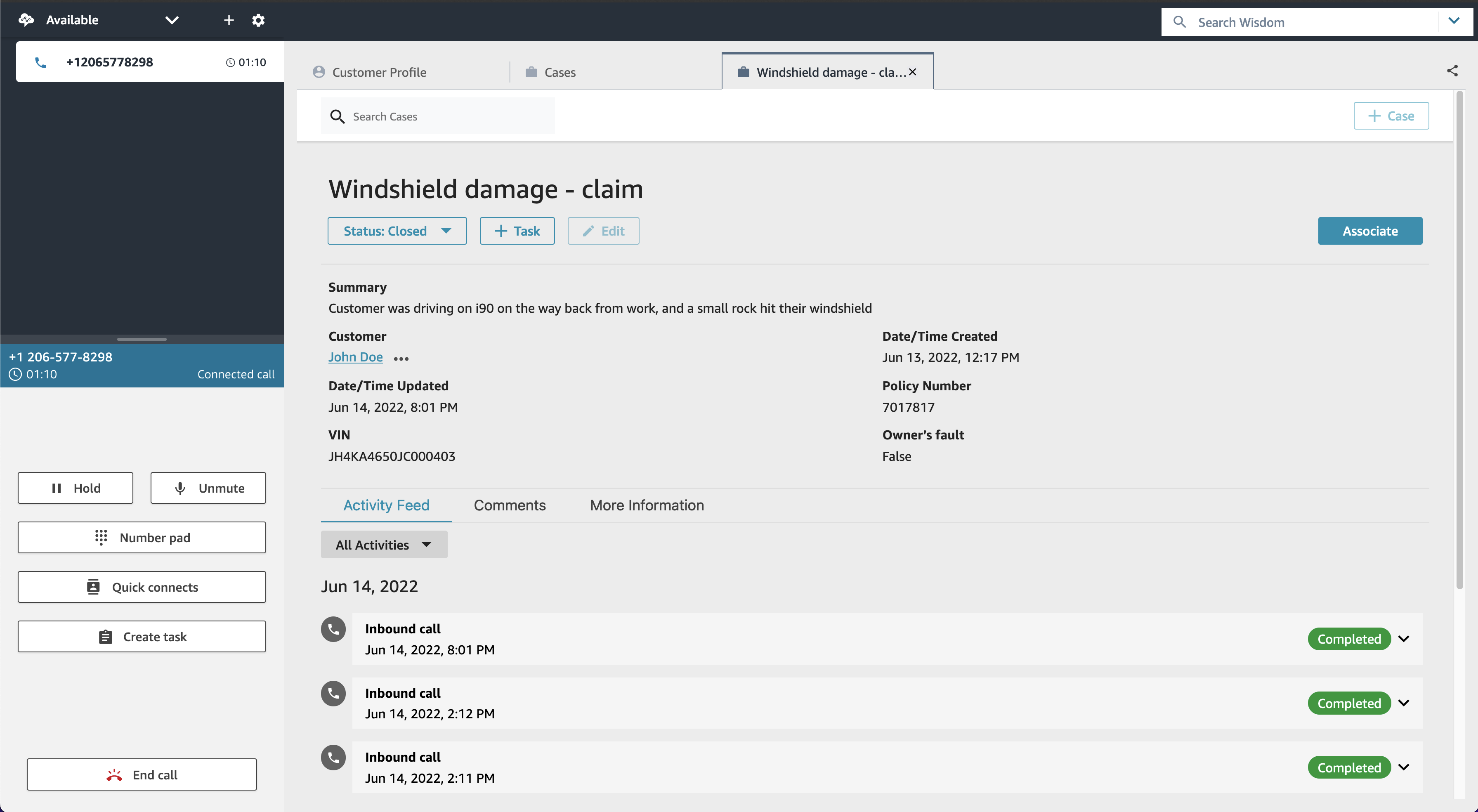
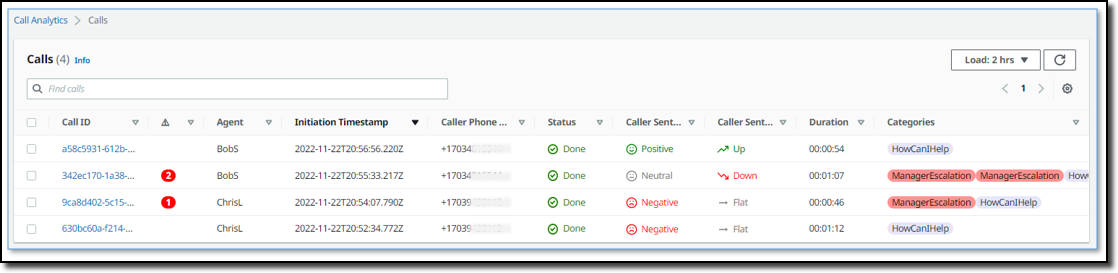
Here there is a list of on-going calls with the overall sentiment, the sentiment trend (is it improving or not?), and the categories found in real-time during the call that can be used for specific activities.
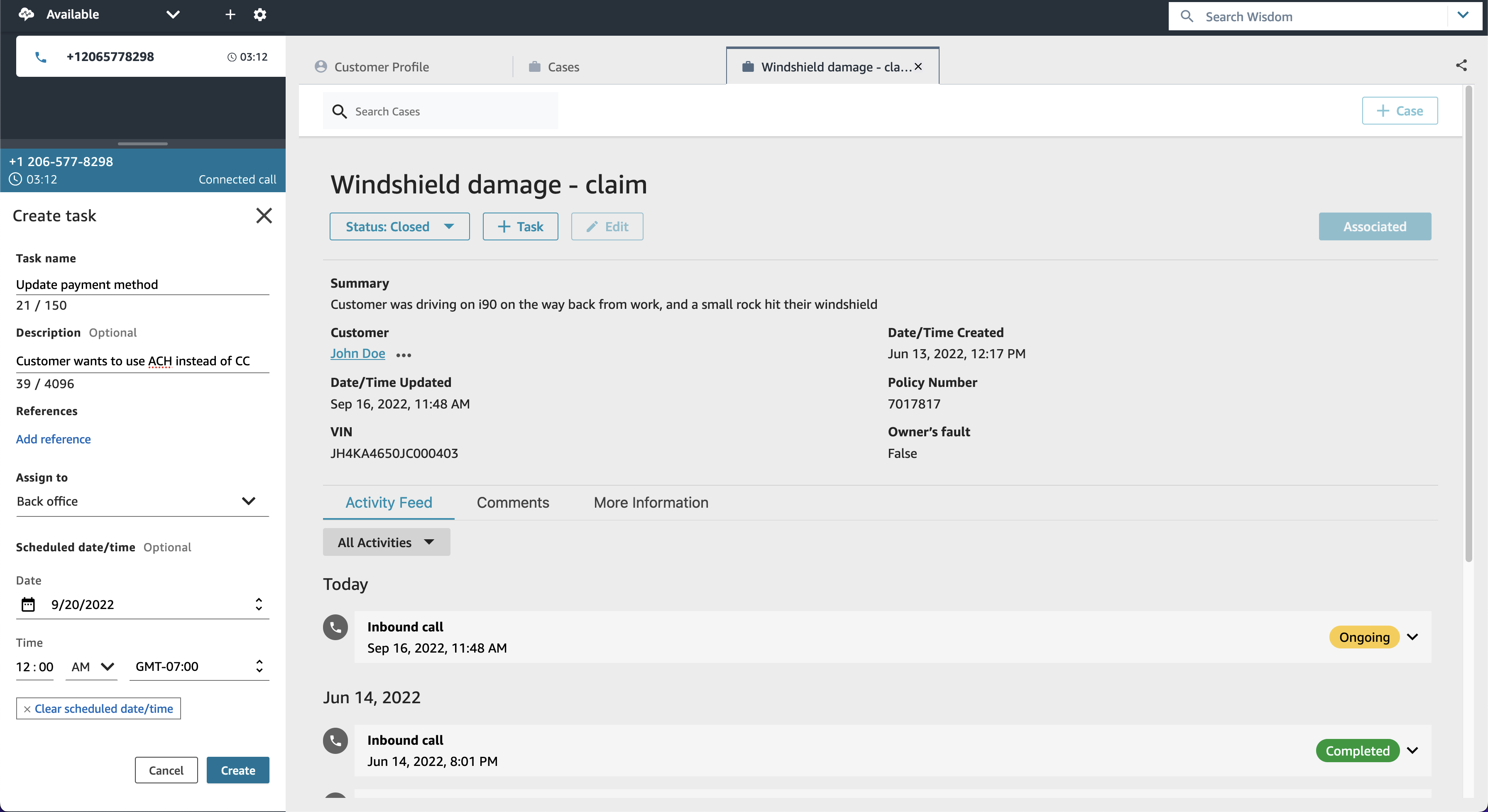
When selecting a call from the list, you have access to more in-depth information, including the call transcript and the issues found during the on-going call. This allows to take action quickly to help resolve the call.
Availability and Pricing
Amazon Transcribe Call Analytics with real-time capabilities is available today in US (N. Virginia, Oregon), Canada (Central), Europe (Frankfurt, London), and Asia Pacific (Seoul, Sydney, Tokyo) and supports US English, British English, Australian English, US Spanish, Canadian French, French, German, Italian, and Brazilian Portuguese.
With Amazon Transcribe Call Analytics, you pay as you go and are billed monthly based on tiered pricing. For more information, see Amazon Transcribe pricing.
As part of the AWS Free Tier, you can get started with Amazon Transcribe Call Analytics for free, including the new real-time call analytics API. You can analyze up to 60 minutes of call audio monthly for free for the first 12 months. For more information, see the AWS Free Tier page.
If you’re at re:Invent, you can learn more about this new capability in session AIM307 – JPMorganChase real-time agent assist for contact center productivity. I will update this post when the recording of the session is publicly available.
Start analyzing contact center conversations in real-time to improve your customers’ experience.
— Danilo







 In November 2020, Jeff
In November 2020, Jeff