Post Syndicated from Rita Kozlov original https://blog.cloudflare.com/cloudflare-pages/


Across multiple cultures around the world, this time of year is a time of celebration and sharing of gifts with the people we care the most about. In that spirit, we thought we’d take this time to give back to the developer community that has been so supportive of Cloudflare for the last 10 years.
Today, we’re excited to announce Cloudflare Pages: a fast, secure and free way to build and host your JAMstack sites.
Today, the path from an idea to a website is paved with good intentions
Websites are the way we express ourselves on the web. It doesn’t matter if you’re a hobbyist with a blog, or the largest of corporations with millions of customers — if you want to reach people outside the confines of 140 280 characters, the web is the place to be.
As a frontend developer, it’s your responsibility to bring this expression to life. And make no mistake — with so many frontend frameworks, tooling, and static site generators at your disposal — it’s a great time to be in your line of work.
That is, of course, right up until the point when you’re ready to show your work off to the world. That’s when things can start to get a little hairy.
At this point, continuing to keep things local rather than committing to source starts to become… irresponsible. But then: how do you quickly iterate and maintain momentum? As you change things, you need to make sure those changes don’t get lost — saving them to source control — while keeping in sync with what’s currently deployed to production.
There are no great solutions.
If you’re in a larger organization, you might have a DevOps organization devoted to exactly that: automating deployments using Continuous Integration (CI) tooling.
Most CI tooling, however, is quite cumbersome, and for good reason — to allow organizations to customize their automation, regardless of their stack and setup. But for the purpose of developing a website, it can still feel like an unnecessary and frustrating diversion on the road to delivering your web project. Configuring a .yaml file, adding and removing commands, waiting minutes for each build to run, and praying to the CI gods at each one that these are the right commands. Hopelessly rerunning the same build over and over, and expecting a different result.
Often, hours are lost. The process stands in the way of you and doing your best work.
Cloudflare Pages: letting frontend devs do what they do best
We think there’s a better way.
With Cloudflare Pages, we set out to simplify every step along the journey by tying deployment to your existing development workflow.
Seamless Git integration, with builds built-in
With Cloudflare Pages, all you have to do is select your repo, and tell us which framework you’re using. We’ll take care of chanting CI incantations on your behalf, while you keep doing what you were already doing: git commit and git push your changes — we’ll build and deploy them for you.
As the project grows, so do the stakes, and the number of collaborators.
For a site in production, changes need to be reviewed thoroughly. As the reviewer, looking at the code, and skimming for red flags only gets you so far. To thoroughly review, you have to commit or git stash your changes, pull down locally, get it running to make sure it actually works — looking at code alone won’t catch everything!
The other developers on the team are not the only stakeholders. There are designers, marketers, PMs who want to provide feedback before the changes go out.
Unique preview URLs
With Cloudflare Pages, each commit gets its own unique URL. Preview URLs make it easier to get meaningful code reviews without the overhead of pulling down the branch. They also make it easier to get feedback from PMs, designers and marketers on the latest iteration, bridging the gap between mocks and code.
Infinite staging
“Does anyone mind if I take over staging?” might also sound like a familiar question. With Cloudflare Pages, each feature branch will have its own dedicated consistent alias, allowing you to have a consistent URL for the latest changes.
With Preview and Production environments, all feature branches and preview links will be built with preview variables, so you can experiment without impacting production data.
When you’re ready to deploy to production, we’ll redeploy to production for you with the updated production environment variables.
Collaboration for all
Collaboration is the key to building amazing websites and products — the more the merrier! As a security company, we definitely don’t want you sharing password and credentials. Which is why we provide multi user access for free for unlimited users — invite all your friends, on us!
Modern sites with modern standards
We all know premature optimization is a cardinal sin, but once your project is in front of customers you want to have the best performance possible. If it’s successful, you also want it to be available!
Today, this is time you have to spend optimizing performance (chasing those 100 lighthouse scores), and scaling, from a few to millions of users.
Luckily, we happen to know a thing or two about running a global network of 200 data centers though, so we’ve got you covered.
With Pages, your site is deployed directly to our edge, milliseconds away from customers, and at global scale.
The latest web standards are fun to read about on Hacker News but not fun to implement yourself. With Cloudflare Pages, we’ll do the heavy lifting to keep you ahead of the curve: IPv6, HTTP/3, TLS 1.3, all the latest image formats.
Oh, and one more thing
We’re really excited for developers and their teams to use Cloudflare Pages to collaborate on the best static sites together. There’s just one thing that didn’t sit quite right with us: why stop at static sites?
What if we could make building full-blown, dynamic applications just as easy?
Although APIs are a core part of the JAMstack, today that refers primarily to the robust API economy developers have access to. And while that’s great, it’s not always enough. If you want to build your own APIs, and store user or application data, you need more than third party APIs. What to do, though?
Well, this is the point at which it’s mighty helpful we’ve already built a global serverless platform: Cloudflare Workers. Workers allows frontend developers to easily write scalable backends to their applications in the same language as the frontend, JavaScript.
Over the coming months, we’ll be working on integrating Workers and Pages into a seamless experience. It’ll work the exact same way Pages does: just write your code, git push, and we’ll deploy it for you. The only difference is, it won’t just be your frontend, it’ll be your backend, too. And just to be clear: this is not just for stateless functions. With Workers KV and Durable Objects, we see a huge opportunity to really enable any web application to be built on this platform.
We’re super excited about the future of Pages, and how with the power of Cloudflare Workers behind it, it represents a bold vision for how new applications are going to be built on the web.
But you know the thing about gifts? They’re no good without someone to receive them. We’d love for you to sign up for our beta and try out Cloudflare Pages!
PS: we’re hiring!
Want to help us shape the future of development on the web? Join our team.








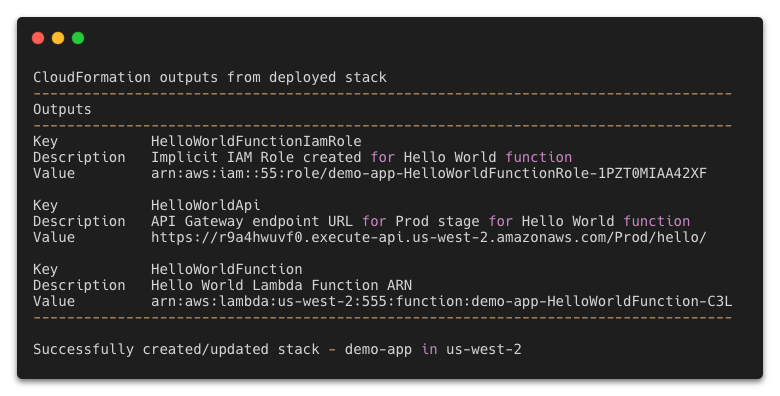




























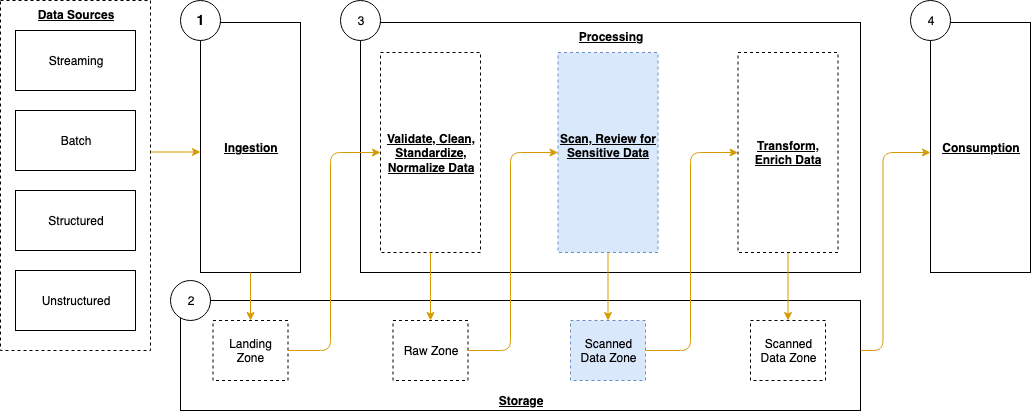
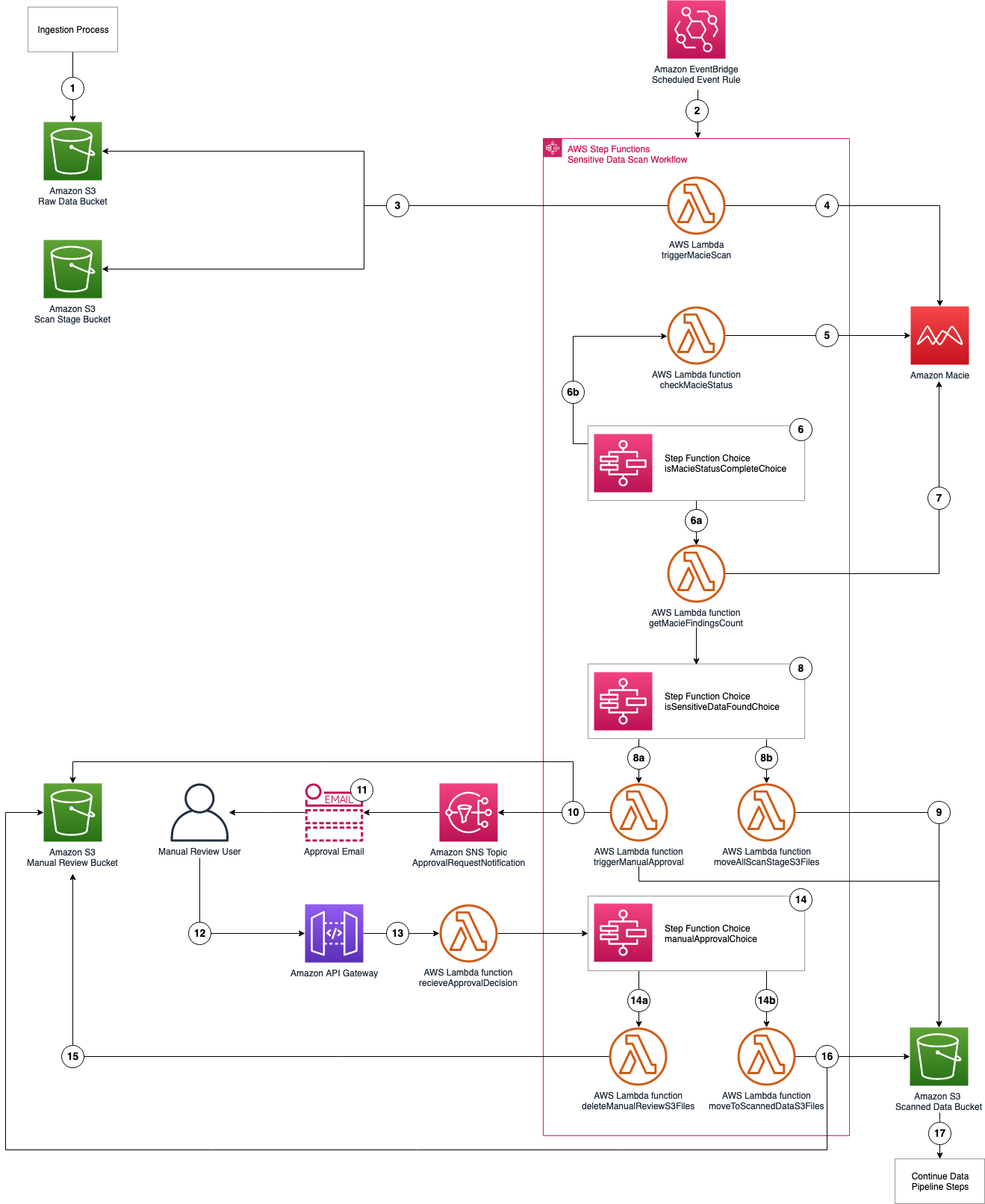



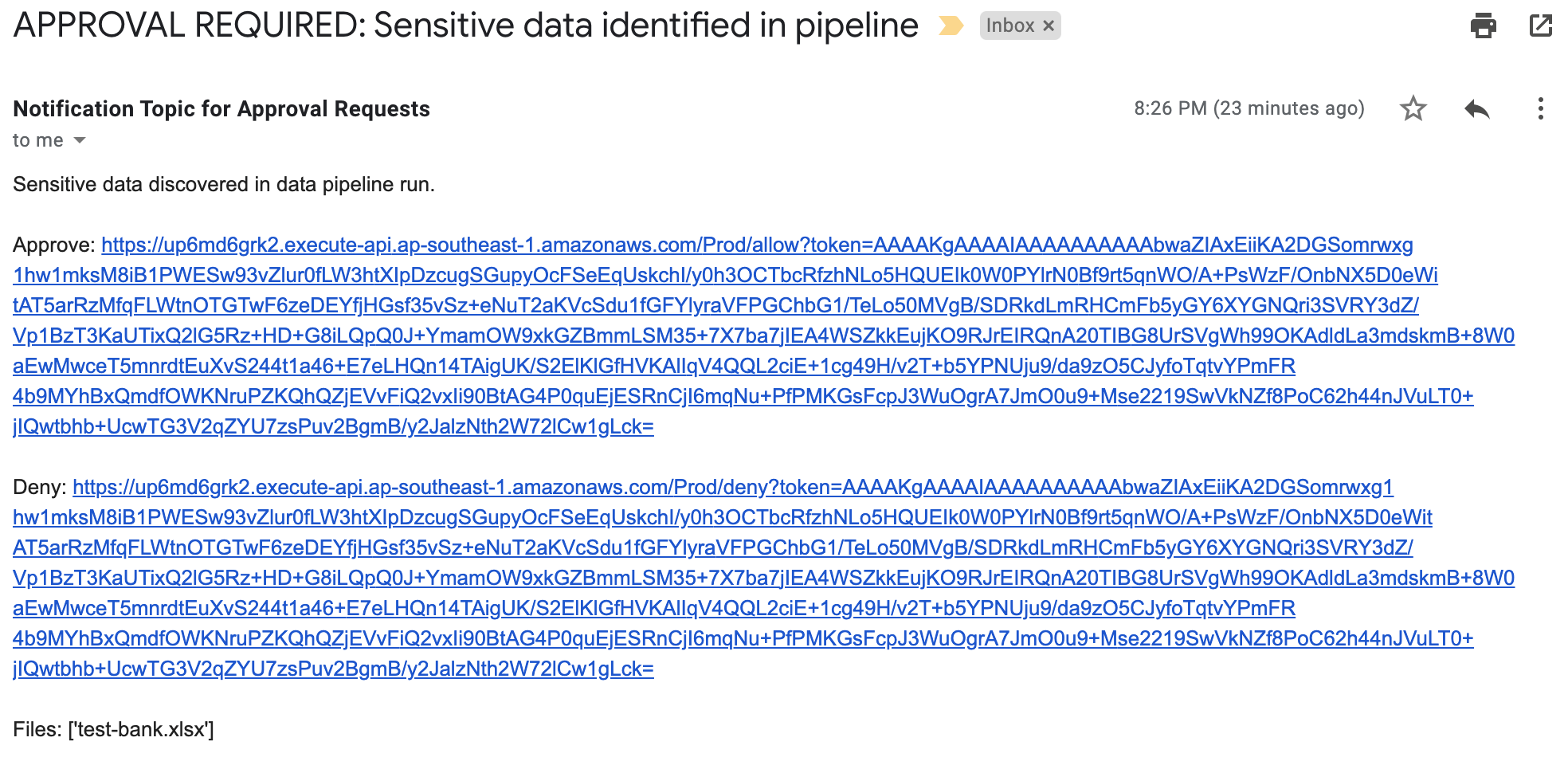
















 This generates a sample workflow definition that you can change once the workflow is created.
This generates a sample workflow definition that you can change once the workflow is created.












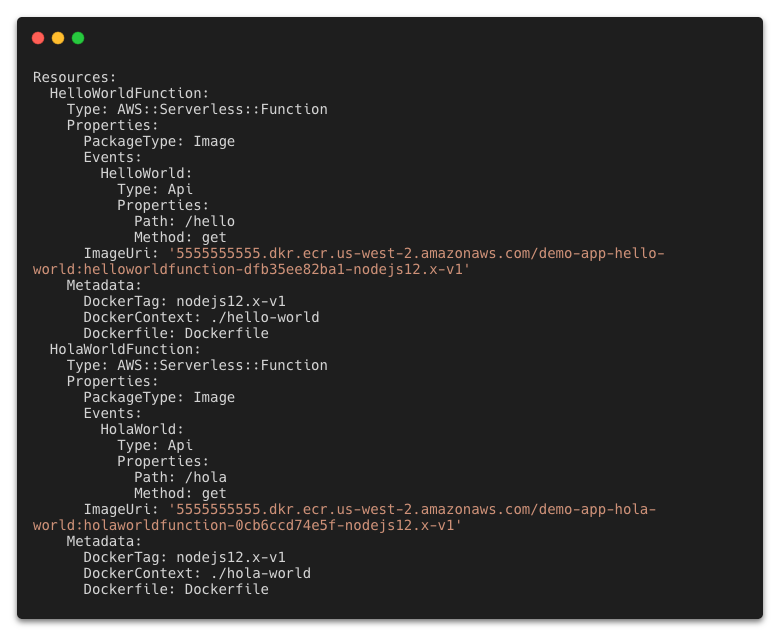
 The Definition section shows the ASL that makes up the example workflow. The following example shows the new API Gateway resource and its parameters:
The Definition section shows the ASL that makes up the example workflow. The following example shows the new API Gateway resource and its parameters:





