Post Syndicated from Erick Leon original https://aws.amazon.com/blogs/big-data/analyze-logs-with-dynatrace-davis-ai-engine-using-amazon-kinesis-data-firehose-http-endpoint-delivery/
This blog post is co-authored with Erick Leon, Sr. Technical Alliance Manager from Dynatrace.
Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. With just a few clicks, you can create fully-managed delivery streams that auto scale on demand to match the throughput of your data. Customers already use Kinesis Data Firehose to ingest raw data from various data sources, including logs from AWS services. Kinesis Data Firehose now supports delivering streaming data to Dynatrace. Dynatrace begins analyzing incoming data within minutes of Amazon CloudWatch data generation.
Starting today, you can use Kinesis Data Firehose to send CloudWatch Metrics and Logs directly to the Dynatrace observability platform to perform your explorations and analysis. Dynatrace, an AWS Partner Network (APN) has provided full observability into AWS Services by ingesting CloudWatch metrics that are published by AWS services. Dynatrace ingests this data to perform root-cause analysis using the Dynatrace Davis AI engine.
In this post, we describe the Kinesis Data Firehose and related Dynatrace integration.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- AWS account.
- Access to the CloudWatch and Kinesis Data Firehose with permissions to manage HTTP endpoints.
- Dynatrace Intelligent Observability Platform account, or get a free 15 day trial here.
- Dynatrace version 1.182+.
- An updated AWS monitoring policy to include the additional AWS services.
To update the AWS Identity and Access Management (IAM) policy, use the JSON in the link above, containing the monitoring policy (permissions) for all supporting services. - Dynatrace API token: create token with the following permission and keep readily available in a notepad.

Figure 1 – Dynatrace API Token
How it works
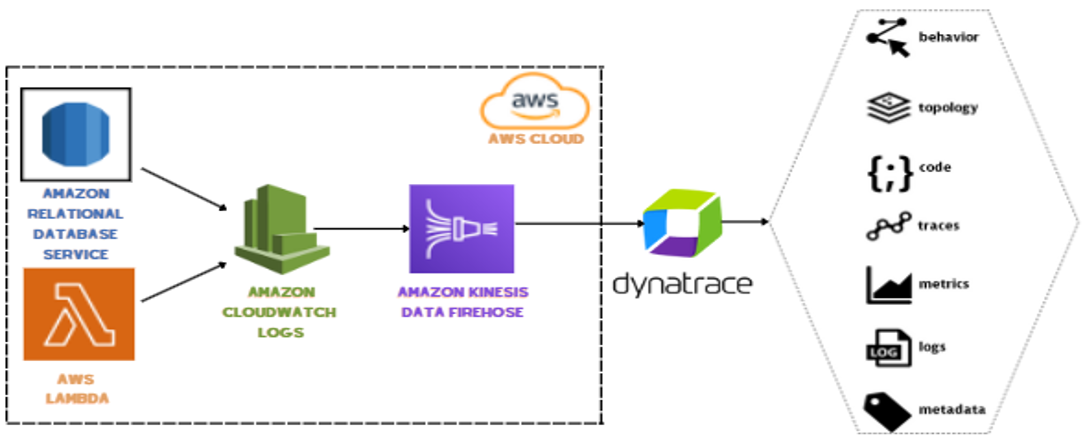
Figure 2 – Amazon Kinesis Data Firehose HTTP endpoint delivery
Simply create a log stream for your Amazon services to deliver your context rich logs to the Amazon CloudWatch Logs service. Next, select your Dynatrace HTTP endpoint to enhance your logs streams with the power of the Dynatrace Intelligence Platform. Finally, you can also back up your logs to an Amazon Simple Storage Service (Amazon S3) bucket.
Setup instructions
To add a service to monitoring, follow these steps:
- In the Dynatrace menu, go to Settings > Cloud and virtualization, and select AWS.
- On the AWS overview page, scroll down and select the desired AWS instance. Select the Edit button.
- Scroll down and select Add service. Choose the service name from the drop-down, and select Add service.
- Select Save changes.
To process and deliver AWS CloudWatch Metrics to Dynatrace, follow these steps.
- Log in to the AWS console and type “Kinesis” in the text search bar. Select Kinesis
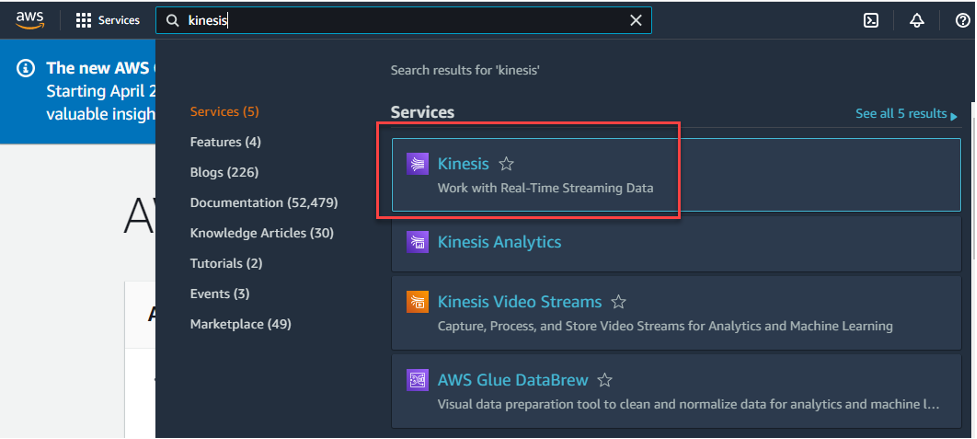
Figure 3 – AWS Console
- On the Amazon Kinesis services page, select the radio button for Kinesis Data Firehose and select the Create delivery stream button.

Figure 4 – Amazon Kinesis
- Choose the “Direct PUT” from the drop down, and from Destination drop down, choose “Dynatrace”.
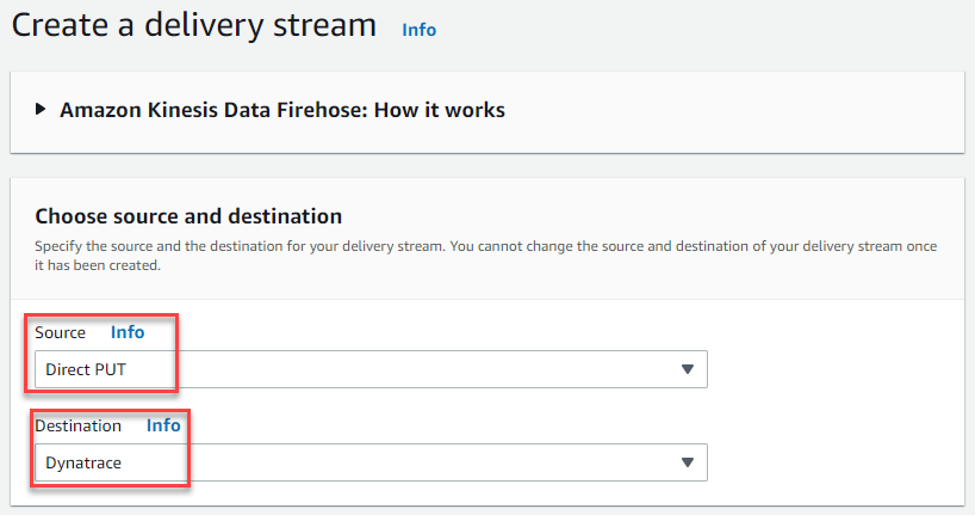
Figure 5 – Amazon Kinesis Data Firehose
- Delivery stream name – Give your stream a new name, for example: – “KFH-StreamToDynatrace”
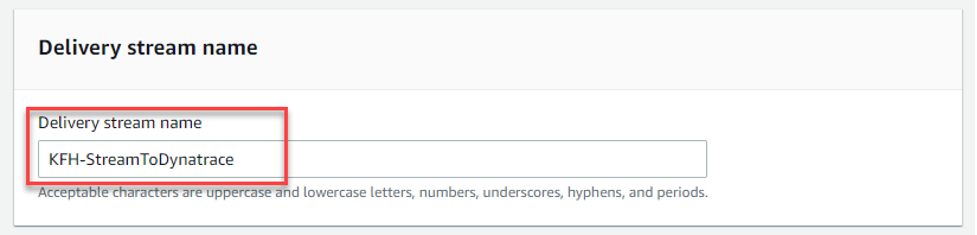
Figure 6 – Delivery stream name
- In the section “Destination settings”:
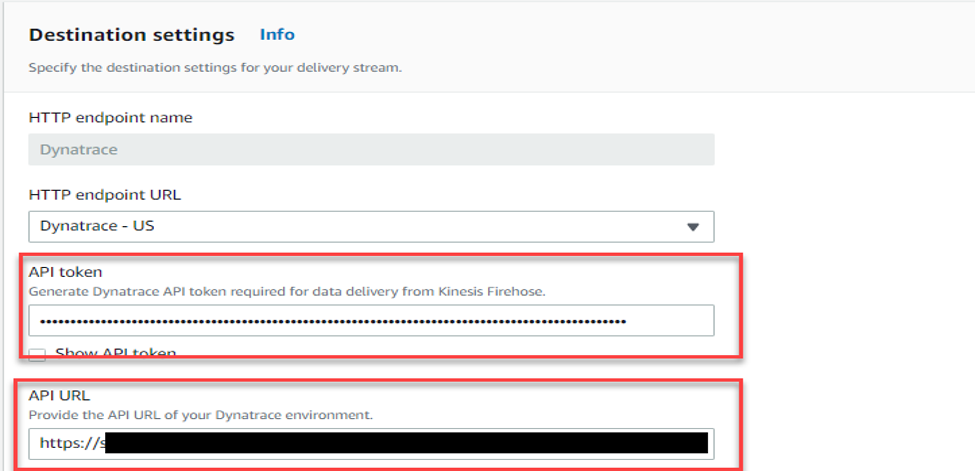
Figure 7 – Destination settings
- HTTP endpoint name – “Dynatrace”.
- HTTP endpoint URL – From the drop down, select “Dynatrace – US”.
- API token – Enter Dynatrace API TOKEN created in the prerequisite section.
- API URL – enter the Dynatrace URL for your tenant, for example: https://xxxxx.live.dynatrace.com
- Back Up Settings – Either select an existing S3 bucket or create a new one and add details and select the Create delivery stream button.
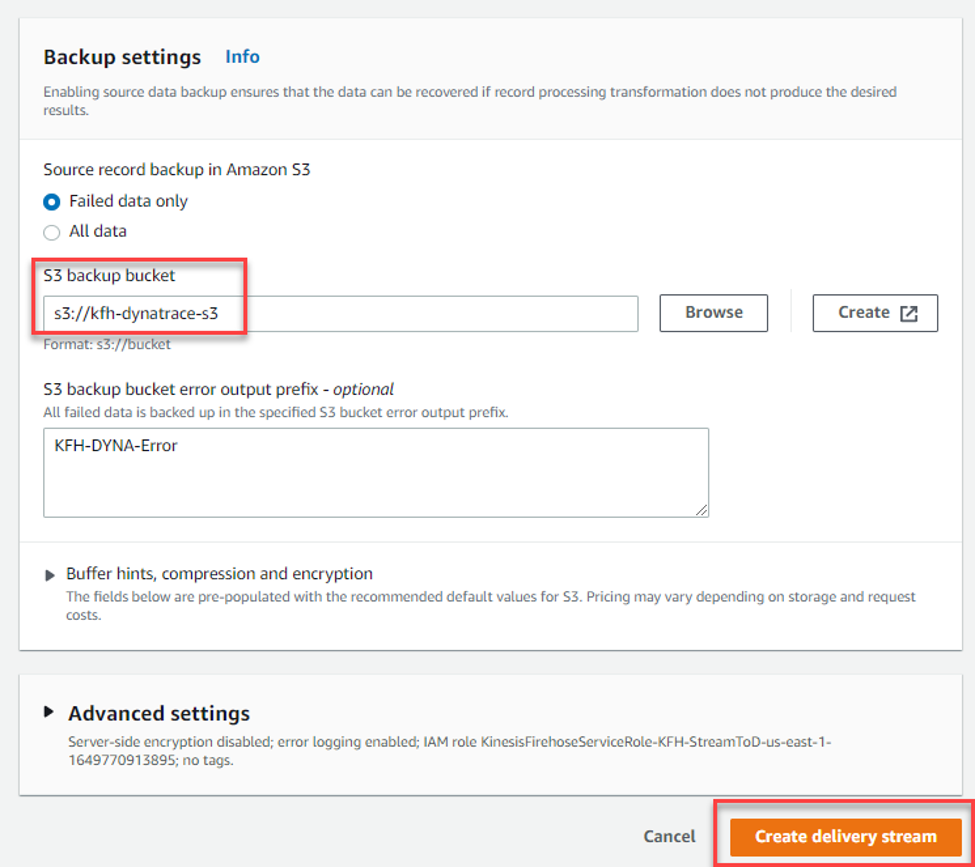
Figure 8 – Backup settings
Once successful, your AWS Console will look like the following:
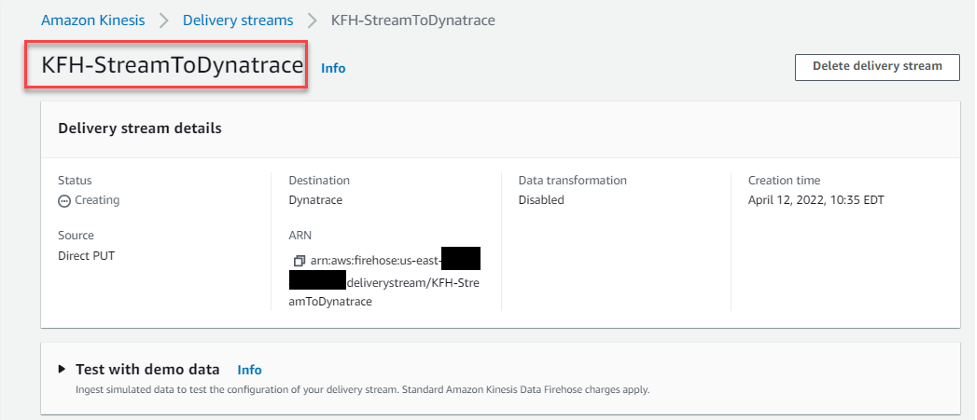
Figure 9 – Amazon Kinesis Data Firehose
The Dynatrace Experience
Once the initial setups are completed in both Dynatrace and the AWS Console, follow these steps to visualize your new KHF stream data in the Dynatrace console.
- Log in to the Dynatrace Console, and on the left side menu expand the “infrastructure” section, and select “AWS”
- From the screen, select the AWS account that you want to add the KFH stream to.
- Next, you’ll see a virtualization of your AWS assets for the account selected. Select the box marked “Supporting Services”.
- Next, press the “Configure services” button.
- Next, select “Add service”.
- From the drop down, select “Kinesis Data Firehose”.
- Next, select the “Add metric” button, and select the metrics that you want to see for this stream. Dynatrace has a comprehensive list of metrics that can be selected from the UI. The list can be found in this link.
Troubleshooting
- After configuration, load to the new KFH stream no data in the Dynatrace Console.
- Check the Error Logs tab check to make sure that the Destination URL is correct for the Dynatrace Tenant.
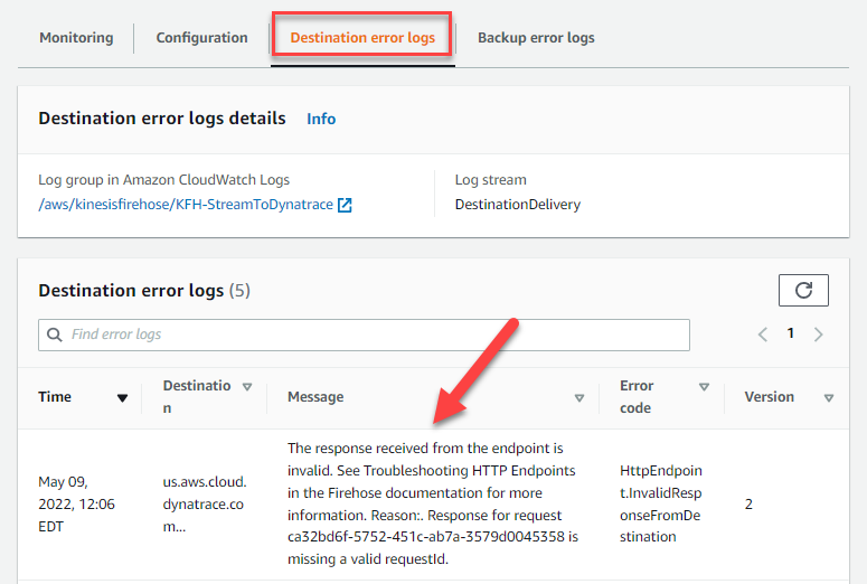
Figure 10 – Destination error logs
- Invalid or misconfigured Dynatrace API token or scope isn’t properly set.
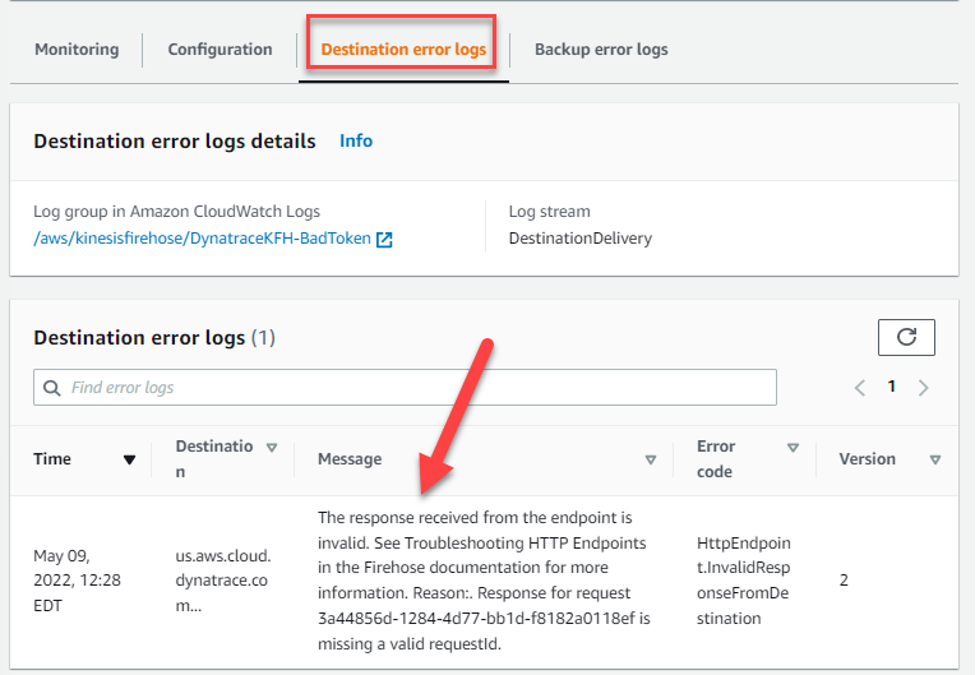
Figure 11 – Destination error logs
Conclusion
In this post, we demonstrate the Kinesis Data Firehose and related Dynatrace integration. In addition, engineers can use CloudWatch Metrics to explore their production systems alongside events in Dynatrace. This provides a seamless, current view of your system (from logs to events and traces) in a single data store.
To learn more about CloudWatch Service, see the Amazon CloudWatch home page. If you have any questions, post them on the AWS CloudWatch service forum.
If you haven’t yet signed up for Dynatrace, then you can try out Kinesis Data Firehose with Dynatrace with a free Dynatrace trial.
About the Authors
 Erick Leon is a Technical Alliances Sr. Manager at Dynatrace, Observability Practice Architect, and Customer Advocate. He promotes strong technical integrations with a focus on AWS. With over 15 years as a Dynatrace customer, his real-world experiences and lessons learned bring valuable insights into the Dynatrace Intelligent Observability Platform.
Erick Leon is a Technical Alliances Sr. Manager at Dynatrace, Observability Practice Architect, and Customer Advocate. He promotes strong technical integrations with a focus on AWS. With over 15 years as a Dynatrace customer, his real-world experiences and lessons learned bring valuable insights into the Dynatrace Intelligent Observability Platform.
 Shashiraj Jeripotula (Raj) is a San Francisco-based Sr. Partner Solutions Architect at AWS. He works with various independent software vendors (ISVs), and partners who specialize in cloud management tools and DevOps to develop joint solutions and accelerate cloud adoption on AWS.
Shashiraj Jeripotula (Raj) is a San Francisco-based Sr. Partner Solutions Architect at AWS. He works with various independent software vendors (ISVs), and partners who specialize in cloud management tools and DevOps to develop joint solutions and accelerate cloud adoption on AWS.
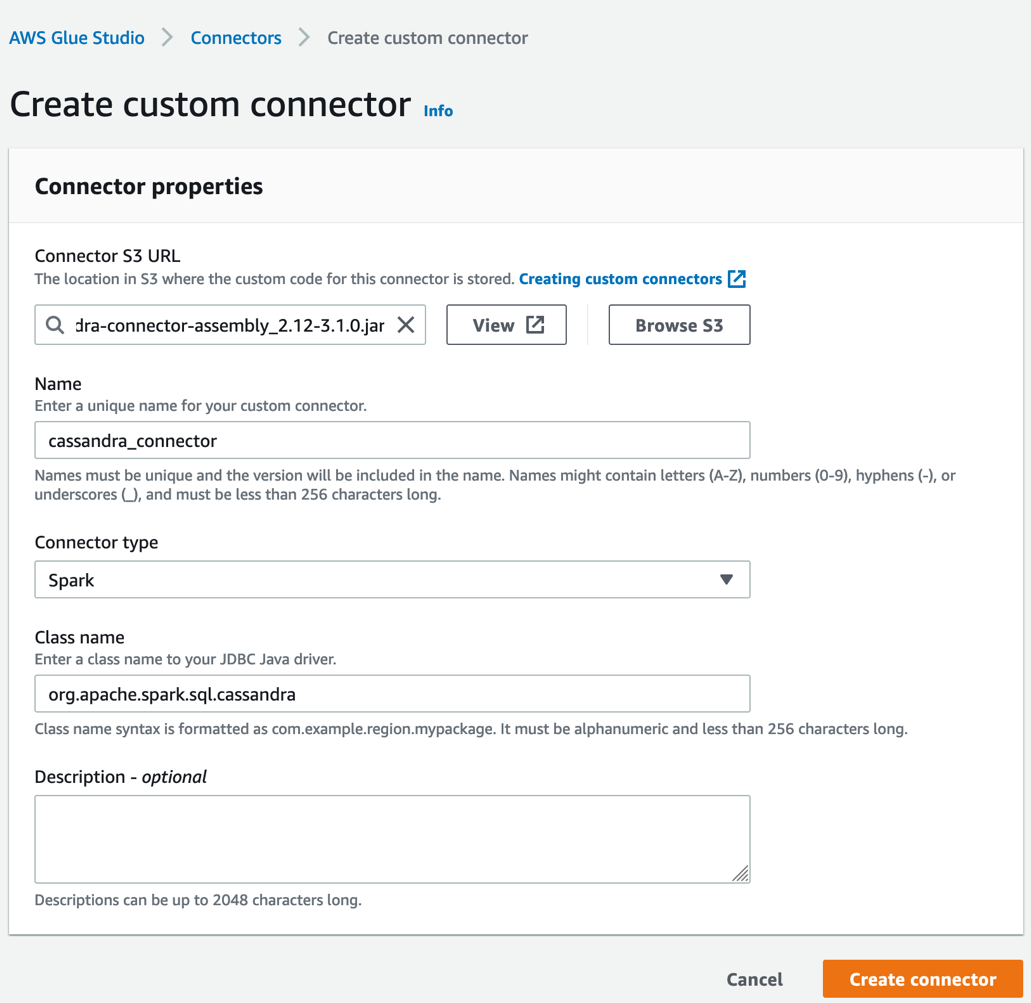












 Fig 5. Terraform state file buckets and state lock tables per environment in the central tooling account.
Fig 5. Terraform state file buckets and state lock tables per environment in the central tooling account.
 Fig 6. Terraform state files per account and Region for each environment in the central tooling account
Fig 6. Terraform state files per account and Region for each environment in the central tooling account
 Fig 7. Git tags and the respective Terraform state files.
Fig 7. Git tags and the respective Terraform state files.
 Fig 8. Multi-Region CI/CD with Terraform state resources stored in the same Region as the workload account resources for the respective Region
Fig 8. Multi-Region CI/CD with Terraform state resources stored in the same Region as the workload account resources for the respective Region