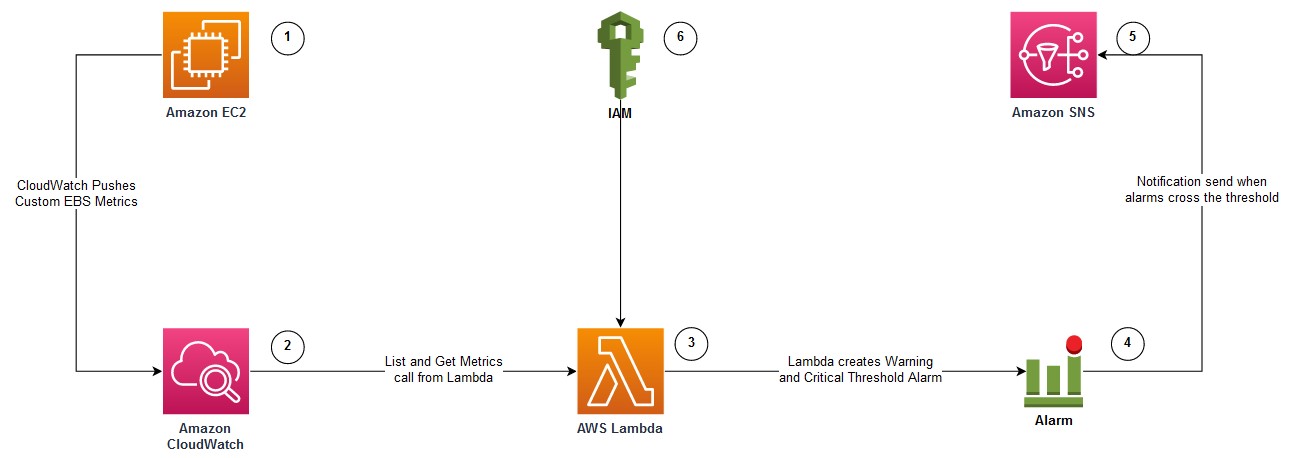
Post Syndicated from Chitradeep Barman original https://aws.amazon.com/blogs/big-data/amazon-migrates-financial-reporting-to-amazon-quicksight/
This is a guest post by from Chitradeep Barman and Yaniv Ackerman from Amazon Finance Technology (FinTech).
Amazon Finance Technology (FinTech) is responsible for financial reporting on Earth’s largest transaction dataset, as the central organization supporting accounting and tax operations across Amazon. Amazon FinTech’s accounting, tax, and business finance teams close books and file taxes in different regions.
Amazon FinTech had been using a legacy business intelligence (BI) tool for over 10 years, and with its dataset growing at 20% year over year, it was beginning to face operational and performance challenges.
In 2019, Amazon FinTech decided to migrate its data visualization and BI layer to AWS to improve data analysis capabilities, reduce costs, and improve its use of AWS Cloud–native services, which reduces risk and technical complexity. By the end of 2021, Amazon FinTech had migrated to Amazon QuickSight, which organizations use to understand data by asking questions in natural language, exploring through interactive dashboards, or automatically looking for patterns and outliers powered by machine learning (ML).
In this post, we share the challenges and benefits of this migration.
Improving reporting and BI capabilities on AWS
Amazon FinTech’s customers are in accounting, tax, and business finance teams across Amazon Finance and Global Business Services, AWS, and Amazon subsidiaries. It provides these teams with authoritative data to do financial reporting and close Amazon’s books, as well as file taxes in jurisdictions and countries around the world. Amazon FinTech also provides data and tools for analysis and BI.
“Over time, with data growth, we started facing operational and maintenance challenges with the legacy BI tool, resulting in a multifold increase in engineering overhead,” said Chitradeep Barman, a senior technical program manager with Amazon FinTech who drove the technical implementation of the migration to QuickSight.
To improve security, increase scalability, and reduce costs, Amazon FinTech decided to migrate to QuickSight on AWS. This transition aligned with the organization’s goal to rely on native AWS technology and reduce dependency on other third-party tools.
Amazon FinTech was already using Amazon Redshift, which can analyze exabytes of data and run complex analytical queries. It can run and scale analytics on data in seconds without the need to manage the data warehouse infrastructure for its cloud data warehouse. As an AWS-native data visualization and BI tool, QuickSight seamlessly connects with AWS services, including Amazon Redshift. The migration was sizable: after consolidating existing reports, there were about 2,000 financial reports in the legacy tool that were used by over 2,500 users. The reports pulled data from millions of records.
Innovating while migrating
Amazon FinTech migrated complex reports and simultaneously started multiple training sessions. Additional training modules were built to complement existing QuickSight trainings and calibrated to meet the specific needs of Amazon FinTech’s customers.
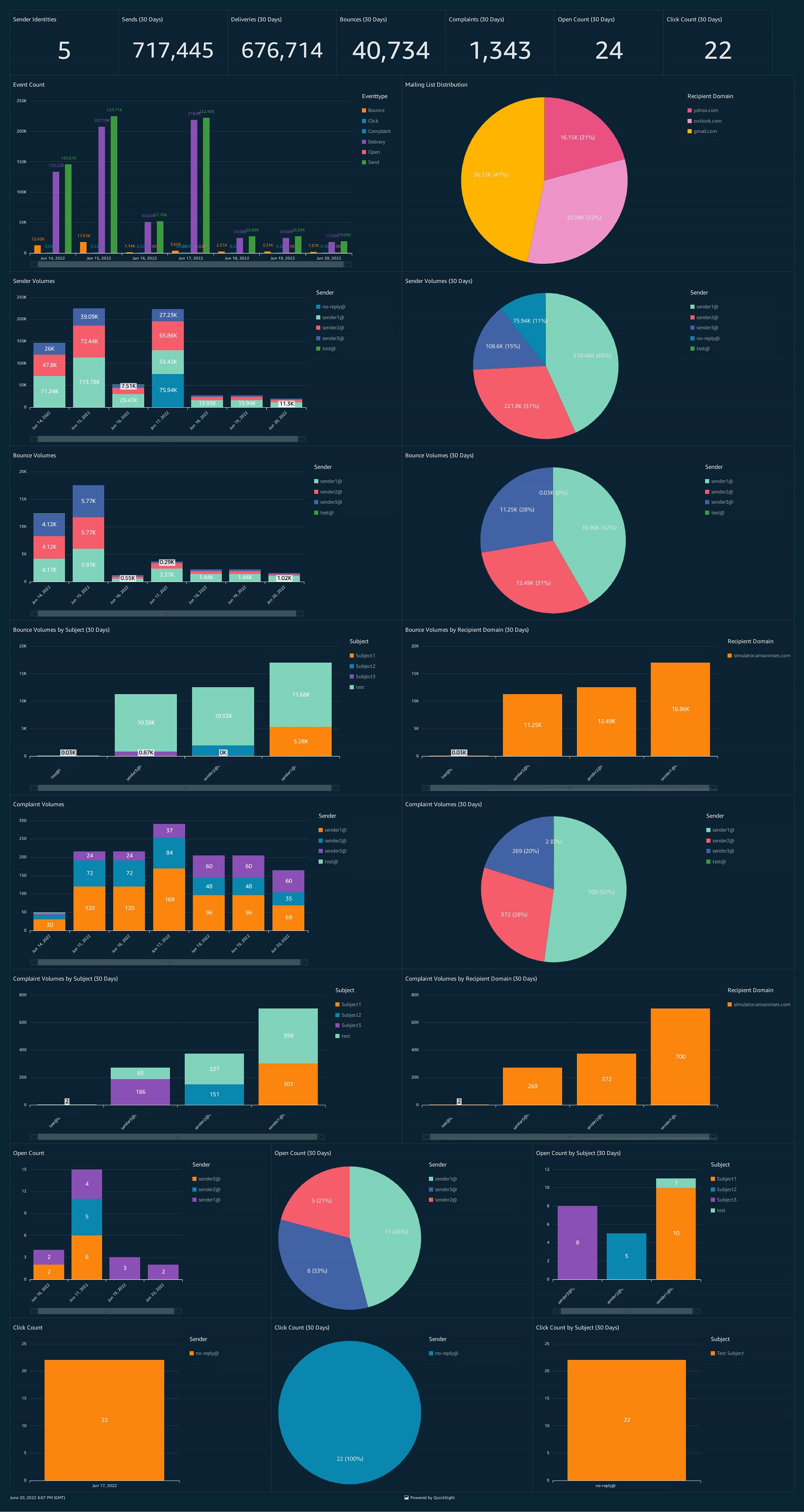
Amazon FinTech deals with petabytes of data and had built up a repository of 10,000 reports used by 2,500 employees across Amazon. Collaborating with the QuickSight team, they consolidated their reports to reduce redundancy and focus on what their finance customers needed. Amazon FinTech built 450 canned and over 1,800 ad hoc reports in QuickSight, developing a reusable solution with the QuickSight API. As shown in the following figure, on average per month, Amazon FinTech has over 1,300 unique QuickSight users run almost 2,500 unique QuickSight reports, with more than 4,600 total runs.

Amazon FinTech has been able to scale to meet customer requirements using QuickSight.
“AWS services come along with scalability. The whole point of migrating to AWS is that we do not need to think about scaling our infrastructure, and we can focus on the functional part of it,” says Barman.
QuickSight is cloud based, fully managed, and serverless, meaning you don’t have to build your own infrastructure to handle peak usage. It auto scales across tens of thousands of users who work independently and simultaneously.
As of May 2022, more than 2,500 Amazon Finance employees are using QuickSight for financial and operational reporting and to prepare Amazon’s tax statements.
“The advantage of Amazon QuickSight is that it empowers nontechnical users, including accountants and tax and financial analysts. It gives them more capability to run their reporting and build their own analyses,” says Keith Weiss, principal program manager at Amazon FinTech. According to Weiss, “QuickSight has much richer data visualization than competing BI tools.”
QuickSight is constantly innovating for customers, adding new features, and recently released the AI/ML service Amazon QuickSight Q, which lets users ask questions in natural language and receive accurate answers with relevant visualizations to help gain insights from the underlying data. Barman, Weiss, and the rest of the Amazon FinTech team are excited to implement Q in the near future.
By switching to QuickSight, which uses pay-as-you-go pricing, Amazon FinTech saved 40% without sacrificing the security, governance, and compliance requirements their account needed to comply with internal and external auditors. The AWS pricing structure makes QuickSight much more cost-effective than other BI tools on the market.
Overall, Amazon FinTech saw the following benefits:
- Performance improvements – Latency of consumer-facing reports was reduced by 30%
- Cost reduction – FinTech reduced licensing, database, and support costs by over 40%, and with the AWS pay-as-you-go model, it’s much more cost-effective to be on QuickSight
- Controllership – FinTech reports are global, and controlled accessibility to reporting data is a key aspect to ensure only relevant data is visible to specific teams
- Improved governance – QuickSight APIs to track and promote changes within different environments reduced manual overhead and improved change trackability
Seamless and reliable
At the end of each month, Amazon FinTech teams must close books in 5 days, and since implementing QuickSight for this purpose, Barman says that “reports have run seamlessly, and there have been no critical situations.”
Amazon FinTech’s account on QuickSight is now the source of truth for Amazon’s financial reporting, including tax filings and preparing financial statements. It enables Amazon’s own finance team to close its books and file taxes at the unparalleled scale at which Amazon operates, with all its complexity. Most importantly, despite initial skepticism, according to Weiss, “Our finance users love it.”
Learn more about Amazon QuickSight and get started diving deeper into your data today!
About the authors
 Chitradeep Barman is a Sr. Technical Program Manager at Amazon Finance Technology (FinTech). He led the Amazon wide migration of BI reporting from Oracle BI (OBIEE) to AWS QuickSight. Chitradeep started his career as a data engineer and over time grew as a data architect. Before joining Amazon, he lead the design and implementation to launch the BI analytics and reporting platform for Cisco Capital (a fully owned subsidiary of Cisco Systems).
Chitradeep Barman is a Sr. Technical Program Manager at Amazon Finance Technology (FinTech). He led the Amazon wide migration of BI reporting from Oracle BI (OBIEE) to AWS QuickSight. Chitradeep started his career as a data engineer and over time grew as a data architect. Before joining Amazon, he lead the design and implementation to launch the BI analytics and reporting platform for Cisco Capital (a fully owned subsidiary of Cisco Systems).
 Yaniv Ackerman is a senior software development manager in Fintech org. He has over 20 years of experience building business critical, scalable and high-performance software. Yaniv’s team build data lakes, analytics and automation solutions for financial usage.
Yaniv Ackerman is a senior software development manager in Fintech org. He has over 20 years of experience building business critical, scalable and high-performance software. Yaniv’s team build data lakes, analytics and automation solutions for financial usage.




























 Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.
Dylan Qu is a Specialist Solutions Architect focused on big data and analytics with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS.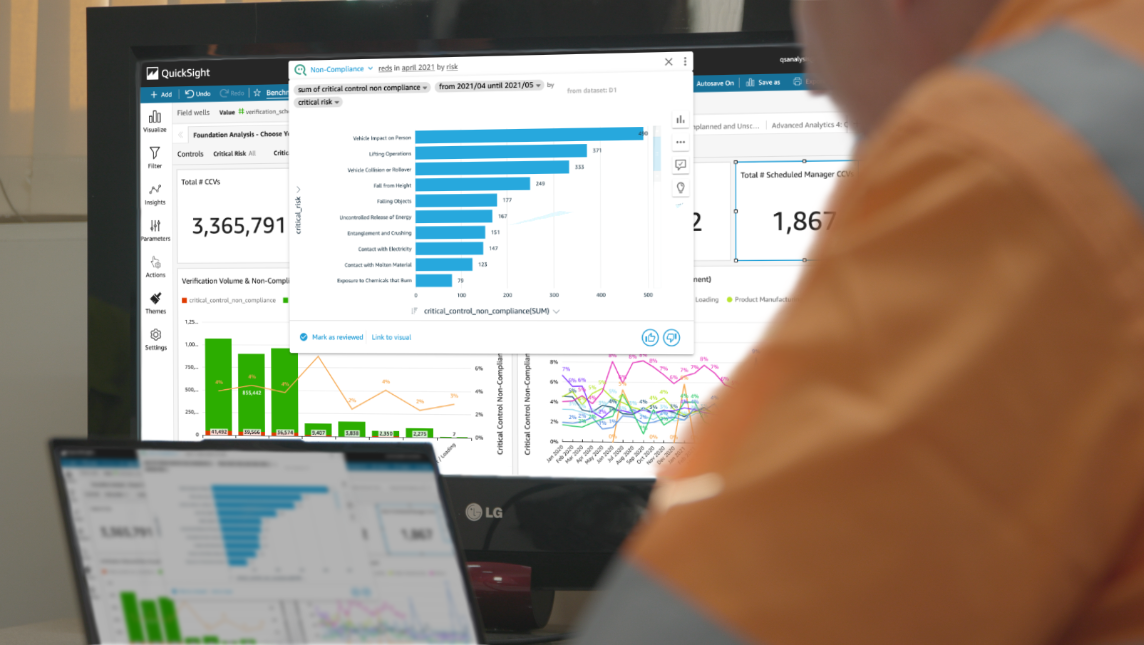






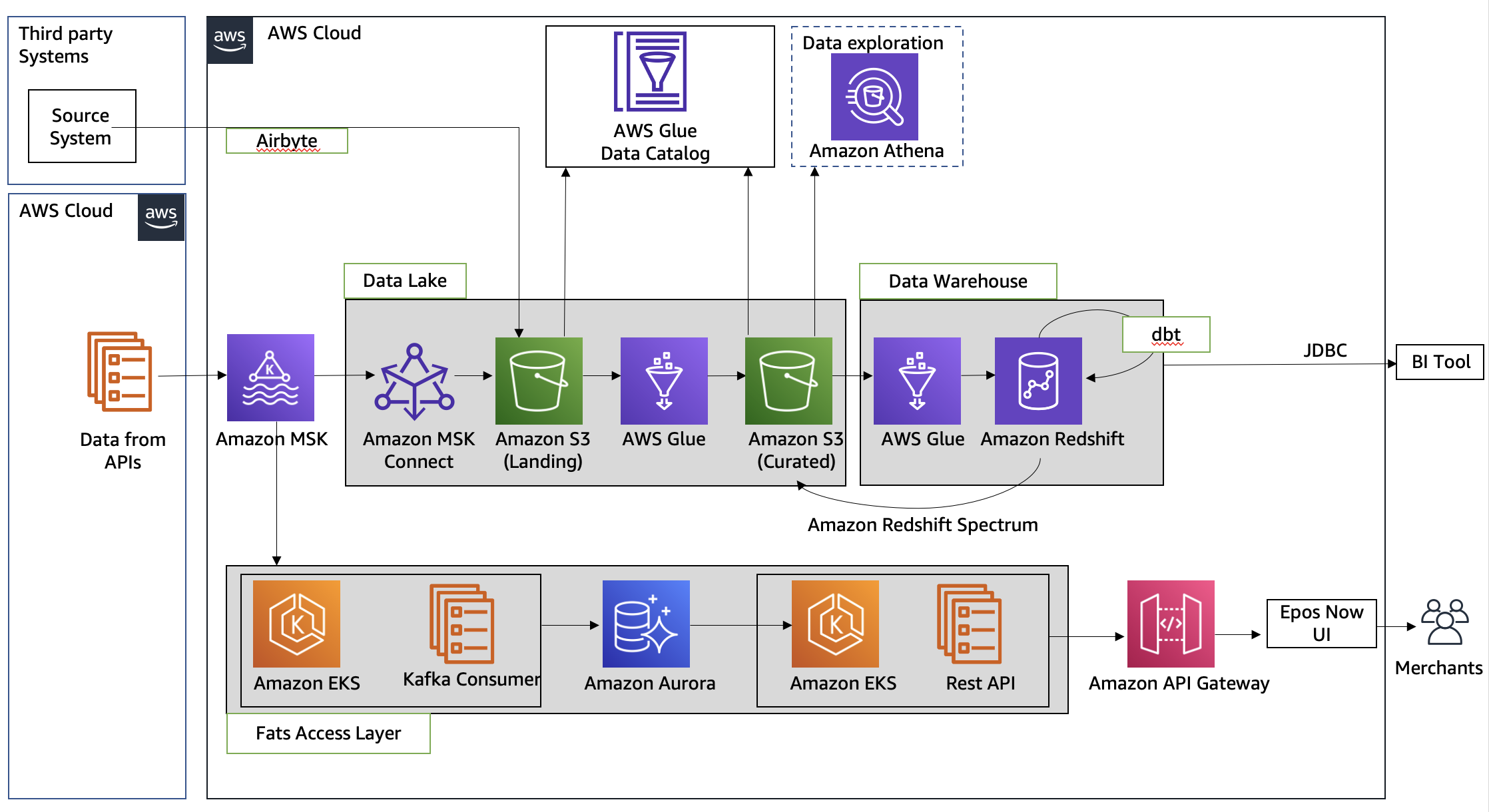



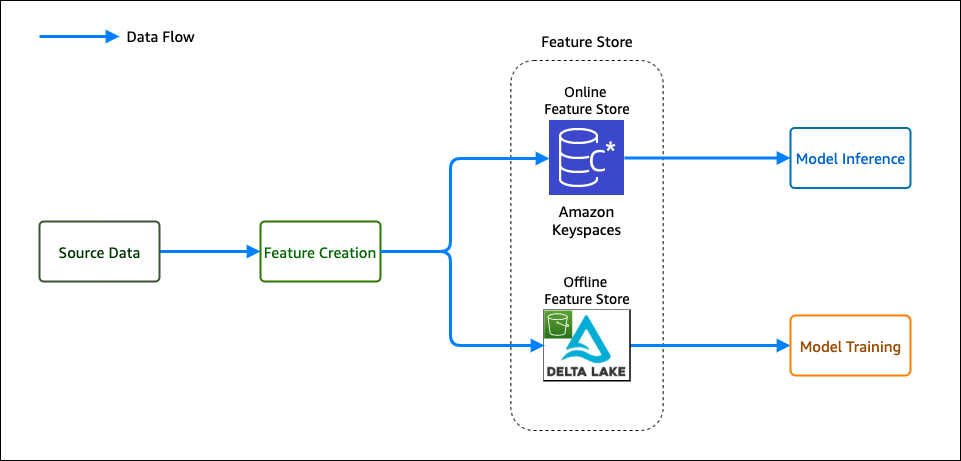
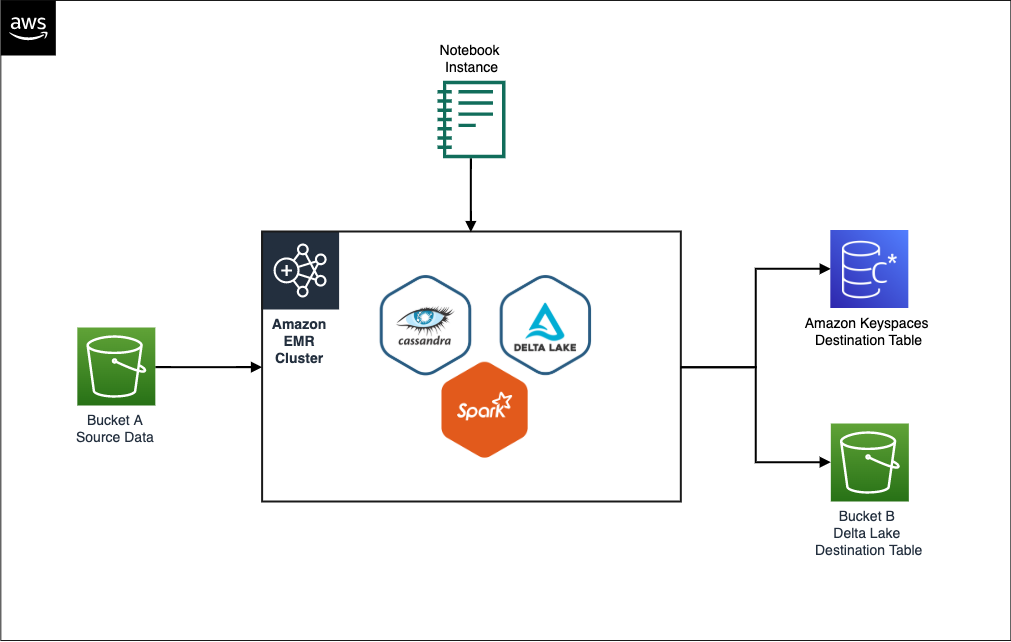
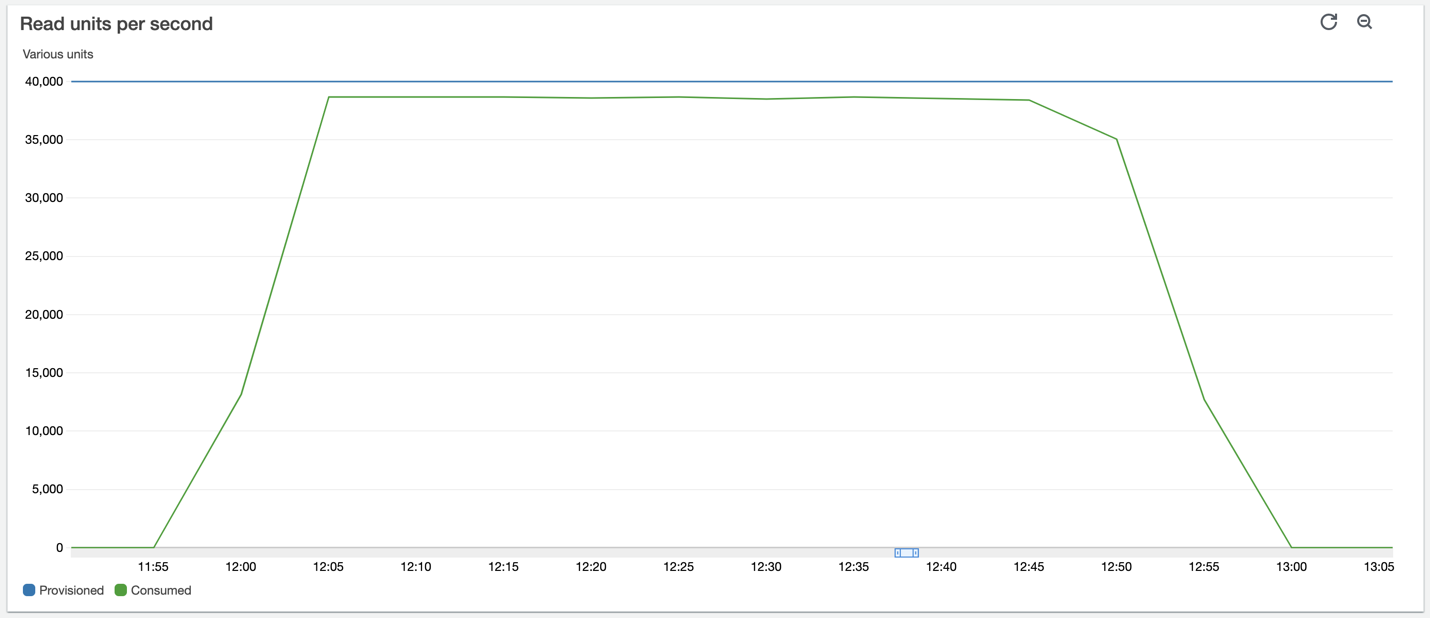
 Shaheer Mansoor is a Data Scientist at AWS. His focus is on building machine learning platforms that can host AI solutions at scale. His interest areas are ML Ops, Feature Stores, Model Hosting and Model Monitoring.
Shaheer Mansoor is a Data Scientist at AWS. His focus is on building machine learning platforms that can host AI solutions at scale. His interest areas are ML Ops, Feature Stores, Model Hosting and Model Monitoring. Vadym Dolinin is a Machine Learning Architect in SumUp. He works with several teams on crafting the ML platform, which enables data scientists to build, deploy, and operate machine learning solutions in SumUp. Vadym has 13 years of experience in the domains of data engineering, analytics, BI, and ML.
Vadym Dolinin is a Machine Learning Architect in SumUp. He works with several teams on crafting the ML platform, which enables data scientists to build, deploy, and operate machine learning solutions in SumUp. Vadym has 13 years of experience in the domains of data engineering, analytics, BI, and ML.