Cryptography is everywhere in our daily lives. If you’re reading this blog, you’re using HTTPS, an extension of HTTP that uses encryption to secure communications. On AWS, multiple services and capabilities help you manage keys and encryption, such as:
AWS CloudHSM, which you can use to manage single-tenant hardware security modules (HSMs).
HSMs are physical devices that securely protect cryptographic operations and the keys used by these operations. HSMs can help you meet your corporate, contractual, and regulatory compliance requirements. With CloudHSM, you have access to general-purpose HSMs. When payments are involved, there are specific payment HSMs that offer capabilities such as generating and validating the personal identification number (PIN) and the security code of a credit or debit card.
Today, I am happy to share the availability of AWS Payment Cryptography, an elastic service that manages payment HSMs and keys for payment processing applications in the cloud.
Applications using payments HSMs have challenging requirements because payment processing is complex, time sensitive, and highly regulated and requires the interaction of multiple financial service providers and payment networks. Every time you make a payment, data is exchanged between two or more financial service providers and must be decrypted, transformed, and encrypted again with a unique key at each step.
This process requires highly performant cryptography capabilities and key management procedures between each payment service provider. These providers might have thousands of keys to protect, manage, rotate, and audit, making the overall process expensive and difficult to scale. To add to that, payment HSMs historically employ complex and error-prone processes, such as exchanging keys in a secure room using multiple hand-carried paper forms, each with separate key components printed on them.
Introducing AWS Payment Cryptography AWS Payment Cryptography simplifies your implementation of cryptographic functions and key management used to secure data in payment processing in accordance with various payment card industry (PCI) standards.
With AWS Payment Cryptography, you can eliminate the need to provision and manage on-premises payment HSMs and use the provided tools to avoid error-prone key exchange processes. For example, with AWS Payment Cryptography, payment and financial service providers can begin development within minutes and plan to exchange keys electronically, eliminating manual processes.
To provide its elastic cryptographic capabilities in a compliant manner, AWS Payment Cryptography uses HSMs with PCI PTS HSM device approval. These capabilities include encryption and decryption of card data, key creation, and pin translation. AWS Payment Cryptography is also designed in accordance with PCI security standards such as PCI DSS, PCI PIN, and PCI P2PE, and it provides evidence and reporting to help meet your compliance needs.
You can import and export symmetric keys between AWS Payment Cryptography and on-premises HSMs under key encryption key (KEKs) using the ANSI X9 TR-31 protocol. You can also import and export symmetric KEKs with other systems and devices using the ANSI X9 TR-34 protocol, which allows the service to exchange symmetric keys using asymmetric techniques.
To simplify moving consumer payment processing to the cloud, existing card payment applications can use AWS Payment Cryptography through the AWS SDKs. In this way, you can use your favorite programming language, such as Java or Python, instead of vendor-specific ASCII interfaces over TCP sockets, as is common with payment HSMs.
Access can be authorized using AWS Identity and Access Management (IAM) identity-based policies, where you can specify which actions and resources are allowed or denied and under which conditions.
Monitoring is important to maintain the reliability, availability, and performance needed by payment processing. With AWS Payment Cryptography, you can use Amazon CloudWatch, AWS CloudTrail, and Amazon EventBridge to understand what is happening, report when something is wrong, and take automatic actions when appropriate.
Let’s see how this works in practice.
Using AWS Payment Cryptography Using the AWS Command Line Interface (AWS CLI), I create a double-length 3DES key to be used as a card verification key (CVK). A CVK is a key used for generating and verifying card security codes such as CVV, CVV2, and similar values.
Note that there are two commands for the CLI (and similarly two endpoints for API and SDKs):
payment-cryptography for control plane operation such as listing and creating keys and aliases.
payment-cryptography-data for cryptographic operations that use keys, for example, to generate PIN or card validation data.
To reference this key in the next steps, I can use the Amazon Resource Name (ARN) as found in the KeyARN property, or I can create an alias. An alias is a friendly name that lets me refer to a key without having to use the full ARN. I can update an alias to refer to a different key. When I need to replace a key, I can just update the alias without having to change the configuration or the code of your applications. To be recognized easily, alias names start with alias/. For example, the following command creates the alias alias/my-key for the key I just created:
As you can see, there is another key I created before, which has since been deleted. When a key is deleted, it is marked for deletion (DELETE_PENDING). The actual deletion happens after a configurable period (by default, 7 days). This is a safety mechanism to prevent the accidental or malicious deletion of a key. Keys marked for deletion are not available for use but can be restored.
In a similar way, I list all my aliases to see to which keys they are they referring:
Now, I use the key to generate a card security code with the CVV2 authentication system. You might be familiar with CVV2 numbers that are usually written on the back of a credit card. This is the way they are computed. I provide as input the primary account number of the credit card, the card expiration date, and the key from the previous step. To specify the key, I use its alias. This is a data plane operation:
Optionally, I can enable more columns, for example, to see the key type (symmetric/asymmetric) and the algorithm used.
I choose the key I used in the previous example to get more details. Here, I see the cryptographic configuration, the tags assigned to the key, and the aliases that refer to this key.
AWS Payment Cryptography supports many more operations than the ones I showed here. For this walkthrough, I used the AWS CLI. In your applications, you can use AWS Payment Cryptography through any of the AWS SDKs.
Availability and Pricing AWS Payment Cryptography is available today in the following AWS Regions: US East (N. Virginia) and US West (Oregon).
With AWS Payment Cryptography, you only pay for what you use based on the number of active keys and API calls with no up-front commitment or minimum fee.For more information, see AWS Payment Cryptography pricing.
AWS Payment Cryptography removes your dependencies on dedicated payment HSMs and legacy key management systems, simplifying your integration with AWS native APIs. In addition, by operating the entire payment application in the cloud, you can minimize round-trip communications and latency.
October 8, 2025: This blog post has been updated to include the Amazon Cognito managed login experience. The managed login experience has an updated look, additional features, and enhanced customization options.
September 8, 2023: It’s important to know that if you activate user sign-up in your user pool, anyone on the internet can sign up for an account and sign in to your apps. Don’t enable self-registration in your user pool unless you want to open your app to allow users to sign up.
June 9, 2023: Original publication date.
Amazon Cognito is an authentication, authorization, and user management service for your web and mobile applications. Your users can sign in directly through many different authentication methods, such as user accounts within Amazon Cognito or through social providers such as Facebook, Amazon, Apple, or Google. You can also configure federation through a third-party OpenID Connect (OIDC) or SAML 2.0 identity provider (IdP).
Amazon Cognito user pools are user directories that provide sign-up and sign-in functions for your application users, including federated authentication capabilities. A Cognito user pool has two primary UI options:
Managed login: AWS hosts, preconfigures, maintains, and scales the UI—including managed login branding and classic Hosted UI branding—with a set of options that you can customize or configure for sign-up and sign-in for app users.
Custom UI: You can configure an Amazon Cognito user pool with a completely custom UI by using the SDK. You’re accountable for hosting, configuring, maintaining, and scaling your custom UI as a part of your responsibility in the AWS Shared Responsibility Model.
In this blog post, we review the benefits of using the managed login or creating a custom UI with the SDK and things to consider in determining which to choose for your application.
Managed login
Managed login provides web interfaces for sign-up, sign-in, multi-factor authentication (MFA), password management, and passwordless and passkey sign-in capabilities in your user pool. The managed login provides an authorization server based on the OAuth 2.0 specification, and has a default implementation of user flows for sign-up and sign-in. Your application can redirect to the managed login, which will handle the user flows through the authorization code grant flow. The managed login also supports sign-in through social providers and federation from OIDC-compliant and SAML 2.0 providers. Amazon Cognito offers two visual modes and branding and customization experiences: managed login branding with branding editor and hosted UI (classic) branding.
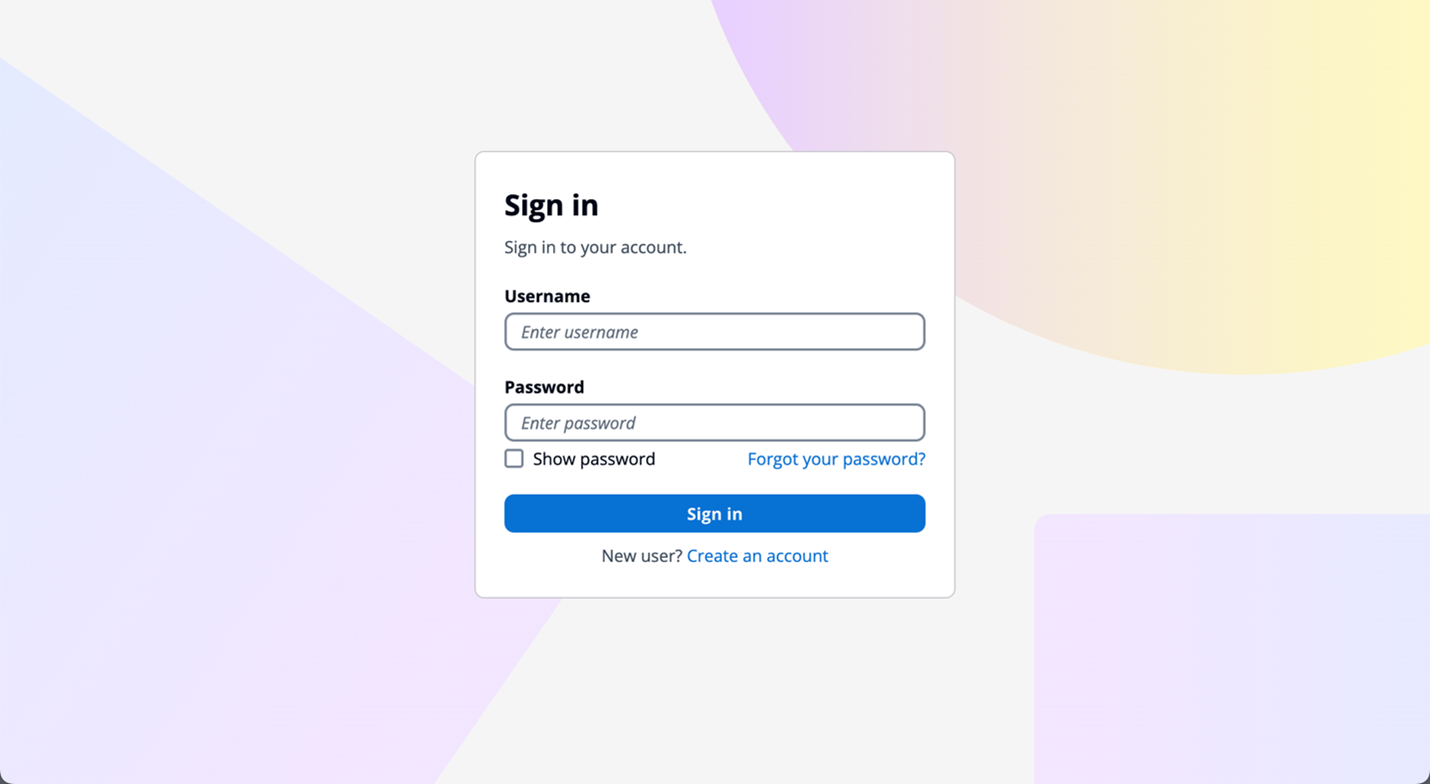
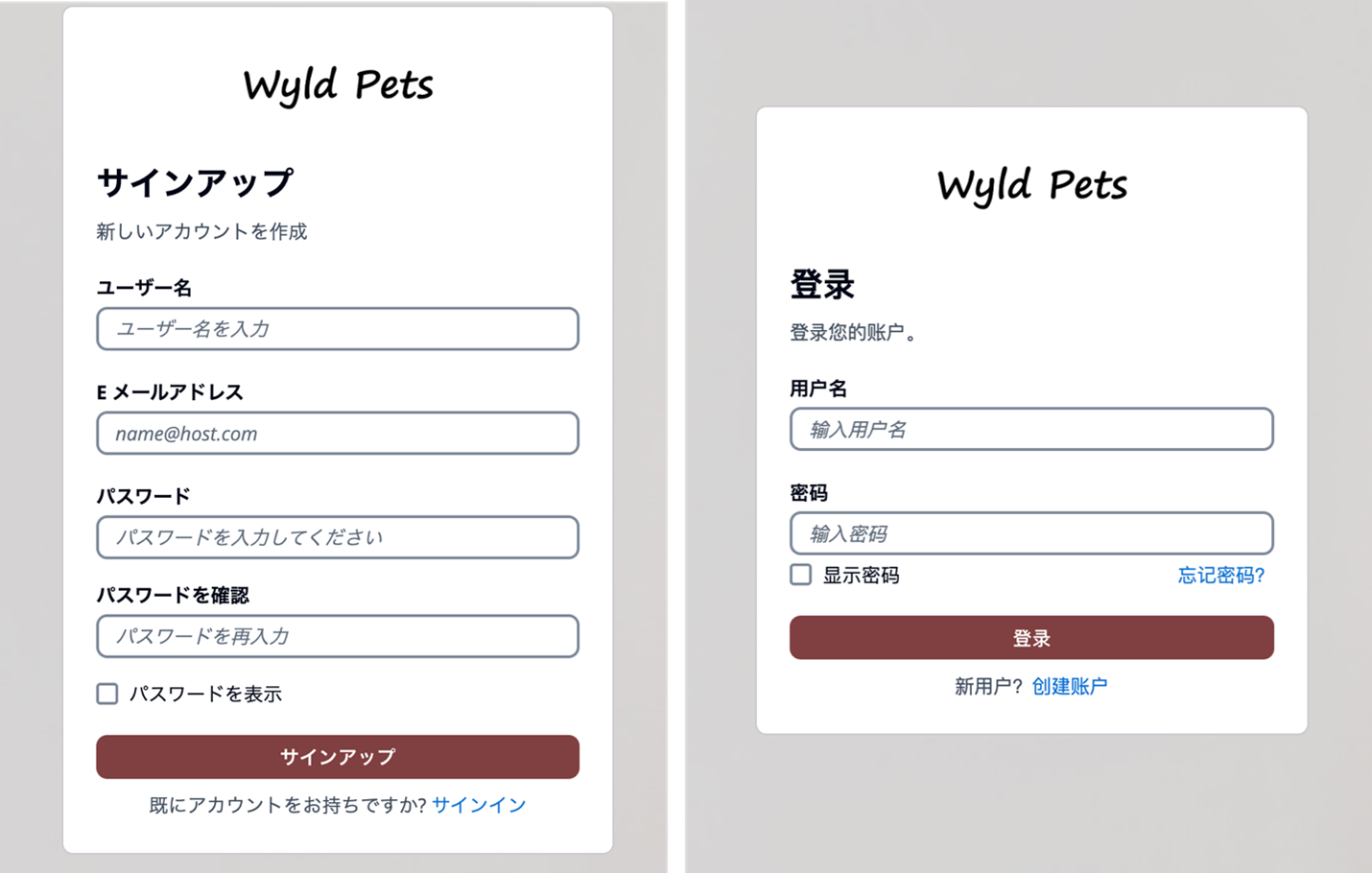
Managed login branding with branding editor Managed login branding provides an improved user experience with the most up-to-date authentication options for the user pool UI experience. Figure 1 shows managed login using the default branding settings.
Figure 1: Managed login default branding settings
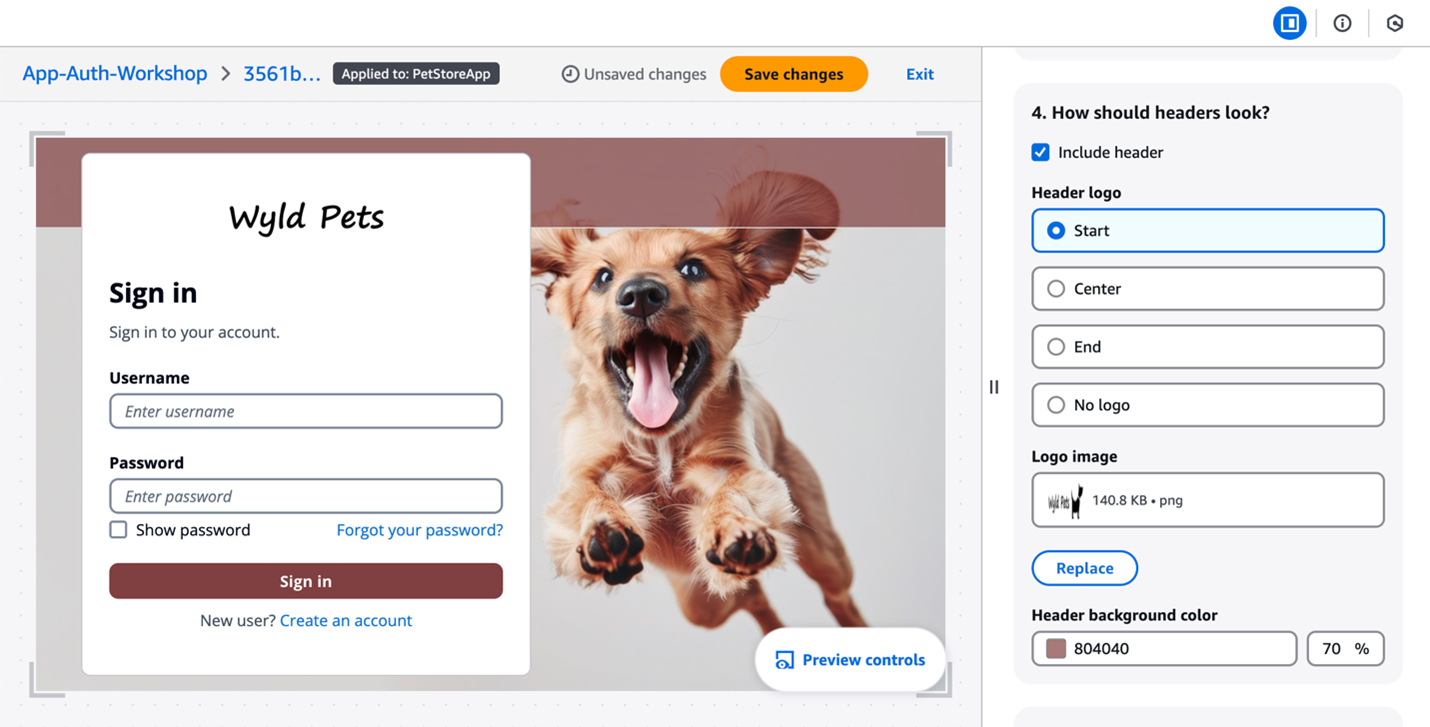
The branding editor is a no-code visual editor that you can use to customize the look and feel of the entire user journey. You can customize each user pool application client individually, and preview screens in real-time with different screen sizes, as shown in Figure 2.
Figure 2: Customization in the Amazon Cognito branding editor (Image credits)
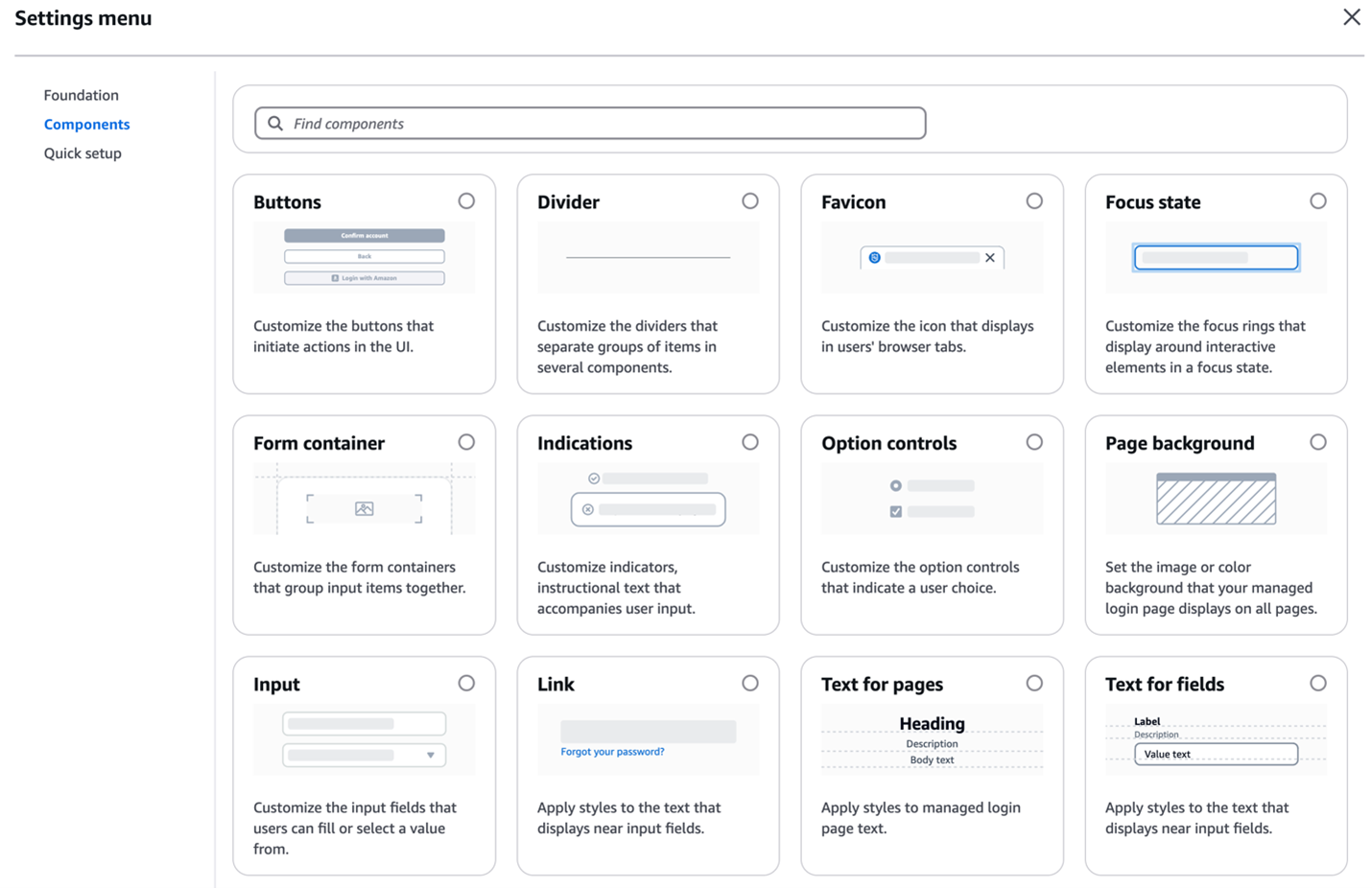
As shown in Figure 3, You can customize various components using the branding editor, including background, header and footer, buttons, focus state, icons, and more.
Figure 3: Various components customization options
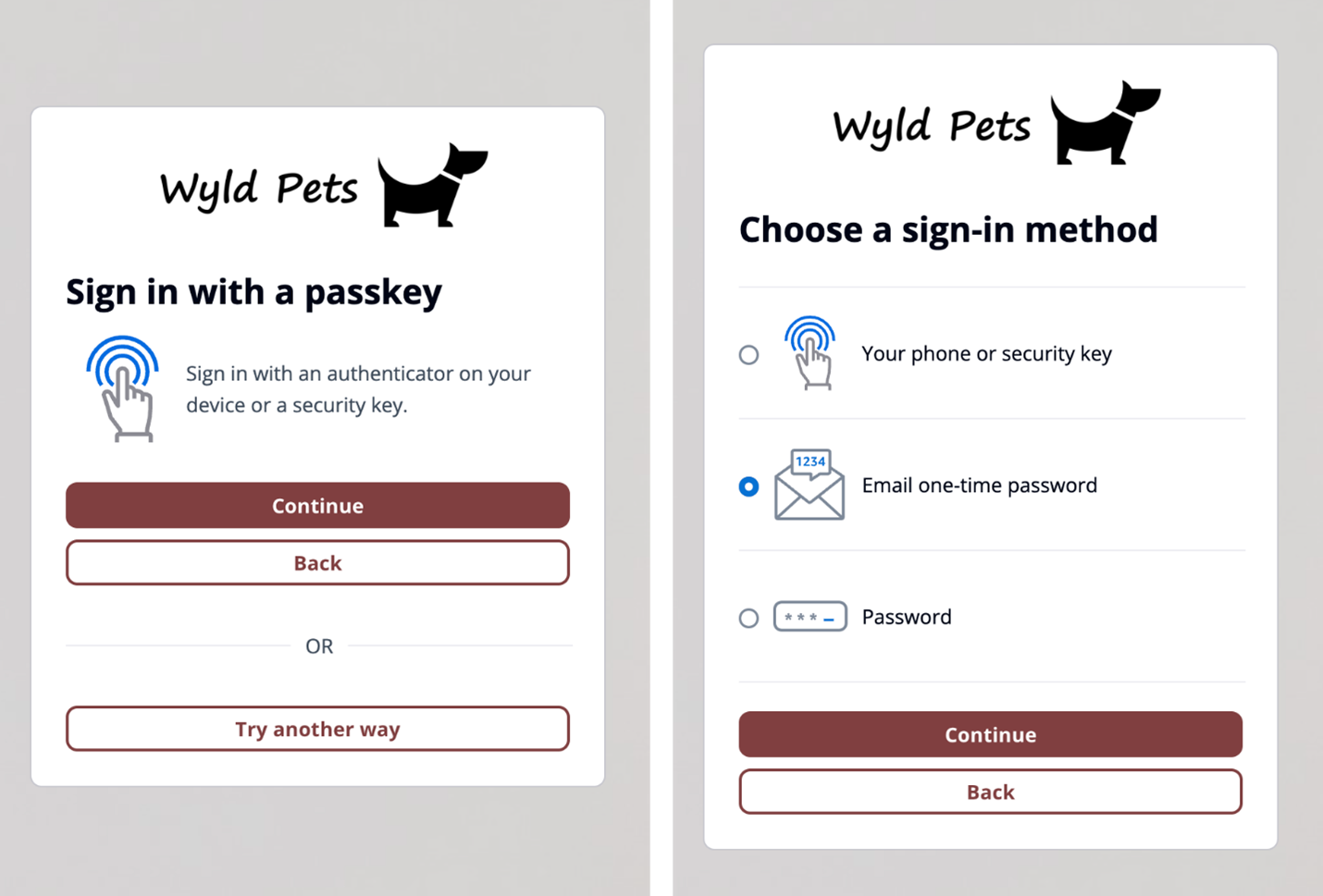
Additionally, managed login branding adds support for passwordless sign-in with passkeys, email one-time-passwords (OTP) and SMS OTPs, as shown in Figure 4. After you enable passwordless login in your user pool, managed login branding adapts to curated user flows with users’ preferred authentication methods.
Figure 4: Sign in with passkey flow (left) and user-selected sign-in method flow (right)
Managed login branding also offers localization options in several languages (two are shown in Figure 5). You can add a lang query parameter in the link you distribute to users, and Amazon Cognito will set a cookie in users’ browsers with their language preference after the initial request.
Figure 5: Cognito user sign up page in Japanese (left) and user sign in page in Simplified Chinese (right)
Hosted UI (classic) branding For customers who prefer a traditional approach, Amazon Cognito continues to support the Hosted UI (classic) branding (shown in Figure 6) with basic customization where you can upload a CSS file to design the UI styling and upload a brand-specific logo. Hosted UI (classic) supports standard authentication flows with MFA and self-service sign up.
Figure 6: Hosted UI (classic) branding
The managed login branding with branding editor is available to Amazon Cognito user pools with Essentials and Plus feature tiers, and Hosted UI (classic) branding is available to most Cognito user pools including Lite tier. To learn more about Cognito feature tiers, visit Amazon Cognito pricing.
Security and compliance capabilities
Both managed login branding and Hosted UI (classic) branding are designed to help you meet your compliance and security requirements and your users’ needs. Managed login supports custom OAuth scopes and OAuth 2.0 flows. If you want single sign-on (SSO), you can use managed login to support a single login across many application clients, with browser session cookies for the same domain. Actions are logged in AWS CloudTrail, and you can use the logs for audit and reactionary automation. The managed login experience also supports the full suite of threat protection features for Amazon Cognito. For additional protection, managed login has support for AWS WAF web ACLs and for AWS WAF CAPTCHA, which can help protect your Cognito user pools from web-based exploits and unwanted bots.
Figure 7: Example default managed login with several login providers enabled
For federation, managed loginsupports federation with third-party IdPs that support OIDC and SAML 2.0, as well as social IdPs, as shown in Figure 7. Identity providers are connected to your Amazon Cognito user pool. In managed login, users use a button to select the federation source, and redirection is automatic. With SAML and OIDC IdPs, you can also configure mapping by using the domain in the user’s email address. In this case, a single text field is visible to your application users to enter an email address, as shown in Figure 8, and the lookup and redirect to the appropriate SAML IdP is automatic, as described in Choosing SAML identity provider names.
Figure 8: Managed login that links to corporate IdP through an email domain
Managed login integrates with Application Load Balancer (ALB) for web applications and works with AWS Amplify to enable social identity provider and enterprise federation (SAML and OIDC) capabilities. Beyond these integrations, Amazon Cognito user pools integrate with various AWS services (such as AWS AppSync), that require user authentication and authorization, and Amazon API Gateway through Cognito authorizers to secure your REST and HTTP endpoints.
You might choose to use managed login for many reasons. AWS fully manages the hosting, maintenance, and scaling of the managed login, which can contribute to the speed of go-to-market for customers. If your app requires OAuth 2.0 custom scopes, federation, social login, or native users with basic but customized branding and potentially numerous Amazon Cognito user pools, you might benefit from using managed login.
Creating a custom UI using the SDK for Amazon Cognito provides a host of benefits and features that can help you completely customize the UI for your application users. With a custom UI, you have complete control over the look and feel of the UI that your application users will land on, including designing your app to support multiple languages, and you can build and design custom authentication flows.
There are numerous features that are supported when you build a custom UI. As with the managed login, the APIs invoked from a custom UI using the SDK will create log entries in CloudTrail, and you can use the logs for audit and automation. You can also create a custom authentication flow for your users with a fully custom authentication experience beyond the those available in managed login.
In a custom UI, you can build custom session management and integrate with AWS WAF. A custom UI also works with the threat protection features of Amazon Cognito.
Figure 9: Example of a custom user interface
With a custom UI, such as the one shown in Figure 10, you can orchestrate a suite of sign-in options and sign-in flows for your users. For example, you can collect a user or tenant identifier at the beginning of the authentication flow and apply your own logic for user authentication flow, such as redirecting federated users to external IdPs, displaying a password prompt for local users, or directing users to create a new account if they don’t exist. You can also build flows to let a user choose alternative MFA methods if their preferred choices aren’t available.
Figure 10: Custom UI example
When you build a custom UI, there is support for custom endpoints and proxies so that you have a wider range of options for management and consistency across application development as it relates to authentication. Custom authentication flows are only available in applications with a custom UI, which gives you the ability to make customized challenge prompts and answers to help you meet custom security requirements by using AWS Lambda triggers. For example, you could use it to implement OAuth 2.0 device grant flows. Lastly, a custom UI supports a remember device feature where you can add low-effort sign-in from trusted devices.
You might choose to build a custom UI with an SDK when full customization is a requirement or where you want to incorporate customized authentication flows using the custom authentication challenge Lambda triggers. A custom UI is a great choice if you aren’t required to use OAuth 2.0 flows and you have the resources to develop and implement a unique UI for your application users.
When deciding between Amazon Cognito managed login branding options and a custom UI, there are some unique differences that can help you determine which UI is best for your application needs. Managed login offers a modern, customizable authentication experience with advanced features like no-code visual customization, dark mode themes, and support for passwordless options. It supports OAuth 2.0 flows, custom OAuth scopes, the ability to sign in one time and access many Cognito application clients (using SSO), and full use of the Cognito threat protection features. For applications requiring complete control over the authentication experience and UX—including custom authentication flows, device fingerprinting, and reduced token expiration—a custom UI is the better choice. This option allows for full UI customization, implementation of custom authentication flows, and integration with specific frameworks or libraries not supported by managed login.
When making your decision, consider factors such as the level of customization required, specific authentication features needed, development resources available, integration requirements with other AWS services, security and compliance needs, and user experience priorities. Remember that your application authentication requirements and customer experience should take precedence over other considerations. You can use the following table to help select the best UI for your requirements.
Requirements
Managed login
Hosted UI (classic)
Custom UI (SDK)
OAuth 2.0 flows
Supported
Supported
Not available
Custom OAuth scopes
Supported
Supported
Supported
Customization of UI
No-code branding designer
Limited CSS customization
Full custom control
Custom user input forms
Not available
Not available
Supported
Custom authentication flow
Not available
Not available
Supported
Passwordless authentication flow
Supported
Not available
Custom implementation available
Localization with multiple languages
Supported
Not available
Supported
Login once across many app clients
Supported
Supported
Not available
Session expiration configurable under 1 hour
Not available
Not available
Supported
Trusted-device authentication
Not available
Not available
Supported
AWS WAF integration
Supported
Supported
Supported
Support for AWS WAF CAPTCHA
Supported
Supported
Not available
Ability to use a custom endpoint or proxy
Not available
Not available
Supported
AWS Application Load Balancer integration
Supported
Supported
Not available
Figure 11: Decision criteria matrix
Conclusion
In this post, you learned about using managed login, including its two branding options and creating a custom UI in Amazon Cognito and the many supported features and benefits of each. Each UI option targets a specific need. Choose from available options based on your list of requirements for authentication and the user sign-up and sign-in experience. You can use the information in this post as a reference as you add Amazon Cognito to your mobile and web applications for authentication.
Have a question? Contact us for general support services.
AWS recommends using automation where possible to keep people away from systems—yet not every action can be automated in practice, and some operations might require access by human users. Depending on their scope and potential impact, some human operations might require special treatment.
One such treatment is temporary elevated access, also known as just-in-time access. This is a way to request access for a specified time period, validate whether there is a legitimate need, and grant time-bound access. It also allows you to monitor activities performed, and revoke access if conditions change. Temporary elevated access can help you to reduce risks associated with human access without hindering operational capabilities.
In this post, we introduce a temporary elevated access management solution (TEAM) that integrates with AWS IAM Identity Center (successor to AWS Single Sign-On) and allows you to manage temporary elevated access to your multi-account AWS environment. You can download the TEAM solution from AWS Samples, deploy it to your AWS environment, and customize it to meet your needs.
The TEAM solution provides the following features:
Workflow and approval — TEAM provides a workflow that allows authorized users to request, review, and approve or reject temporary access. If a request is approved, TEAM activates access for the requester with the scope and duration specified in the request.
View request details and session activity — Authorized users can view request details and session activity related to current and historical requests from within the application’s web interface.
Ability to use managed identities and group memberships — You can either sync your existing managed identities and group memberships from an external identity provider into IAM Identity Center, or manage them directly in IAM Identity Center, in order to control user authorization in TEAM. Similarly, users can authenticate directly in IAM Identity Center, or they can federate from an external identity provider into IAM Identity Center, to access TEAM.
A rich authorization model — TEAM uses group memberships to manage eligibility (authorization to request temporary elevated access with a given scope) and approval (authorization to approve temporary elevated access with a given scope). It also uses group memberships to determine whether users can view historical and current requests and session activity, and whether they can administer the solution. You can manage both eligibility and approval policies at different levels of granularity within your organization in AWS Organizations.
TEAM overview
You can download the TEAM solution and deploy it into the same organization where you enable IAM Identity Center. TEAM consists of a web interface that you access from the IAM Identity Center access portal, a workflow component that manages requests and approvals, an orchestration component that activates temporary elevated access, and additional components involved in security and monitoring.
Figure 1 shows an organization with TEAM deployed alongside IAM Identity Center.
Figure 1: An organization using TEAM alongside IAM Identity Center
Figure 1 shows three main components:
TEAM — a self-hosted solution that allows users to create, approve, monitor and manage temporary elevated access with a few clicks in a web interface.
IAM Identity Center — an AWS service which helps you to securely connect your workforce identities and manage their access centrally across accounts.
AWS target environment — the accounts where you run your workloads, and for which you want to securely manage both persistent access and temporary elevated access.
There are four personas who can use TEAM:
Requesters — users who request temporary elevated access to perform operational tasks within your AWS target environment.
Approvers — users who review and approve or reject requests for temporary elevated access.
Auditors — users with read-only access who can view request details and session activity relating to current and historical requests.
Admins — users who can manage global settings and define policies for eligibility and approval.
TEAM determines a user’s persona from their group memberships, which can either be managed directly in IAM Identity Center or synced from an external identity provider into IAM Identity Center. This allows you to use your existing access governance processes and tools to manage the groups and thereby control which actions users can perform within TEAM.
The following steps describe how you use TEAM during normal operations to request, approve, and invoke temporary elevated access. The steps correspond to the numbered items in Figure 1:
Access the AWS access portal in IAM Identity Center (all personas)
Access the TEAM application (all personas)
Request elevated access (requester persona)
Approve elevated access (approver persona)
Activate elevated access (automatic)
Invoke elevated access (requester persona)
Log session activity (automatic)
End elevated access (automatic; or requester or approver persona)
View request details and session activity (requester, approver, or auditor persona)
In the TEAM walkthrough section later in this post, we provide details on each of these steps.
Deploy and set up TEAM
Before you can use TEAM, you need to deploy and set up the solution.
Prerequisites
To use TEAM, you first need to have an organization set up in AWS Organizations with IAM Identity Center enabled. If you haven’t done so already, create an organization, and then follow the Getting started steps in the IAM Identity Center User Guide.
Before you deploy TEAM, you need to nominate a member account for delegated administration in IAM Identity Center. This has the additional benefit of reducing the need to use your organization’s management account. We strongly recommend that you use this account only for IAM Identity Center delegated administration, TEAM, and associated services; that you do not deploy any other workloads into this account, and that you carefully manage access to this account using the principle of least privilege.
We recommend that you enforce multi-factor authentication (MFA) for users, either in IAM Identity Center or in your external identity provider. If you want to statically assign access to users or groups (persistent access), you can do that in IAM Identity Center, independently of TEAM, as described in Multi-account permissions.
Deploy TEAM
To deploy TEAM, follow the solution deployment steps in the TEAM documentation. You need to deploy TEAM in the same account that you nominate for IAM Identity Center delegated administration.
Access TEAM
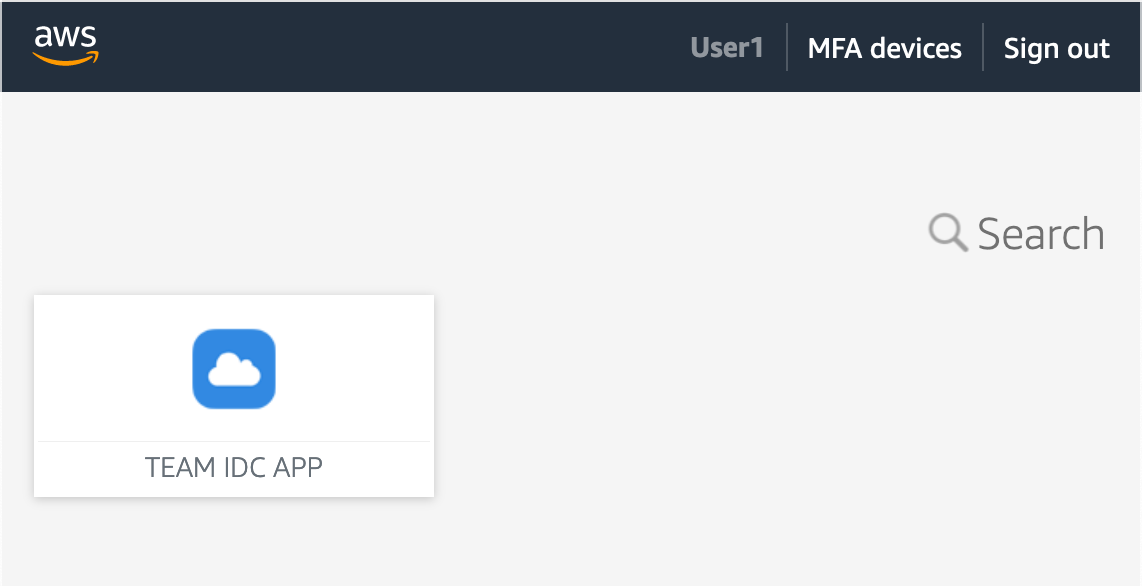
After you deploy TEAM, you can access it through the IAM Identity Center web interface, known as the AWS access portal. You do this using the AWS access portal URL, which is configured when you enable IAM Identity Center. Depending on how you set up IAM Identity Center, you are either prompted to authenticate directly in IAM Identity Center, or you are redirected to an external identity provider to authenticate. After you authenticate, the AWS access portal appears, as shown in Figure 2.
Figure 2: TEAM application icon in the AWS access portal of IAM Identity Center
You configure TEAM as an IAM Identity Center Custom SAML 2.0 application, which means it appears as an icon in the AWS access portal. To access TEAM, choose TEAM IDC APP.
When you first access TEAM, it automatically retrieves your identity and group membership information from IAM Identity Center. It uses this information to determine what actions you can perform and which navigation links are visible.
Set up TEAM
Before users can request temporary elevated access in TEAM, a user with the admin persona needs to set up the application. This includes defining policies for eligibility and approval. A user takes on the admin persona if they are a member of a named IAM Identity Center group that is specified during TEAM deployment.
Manage eligibility policies
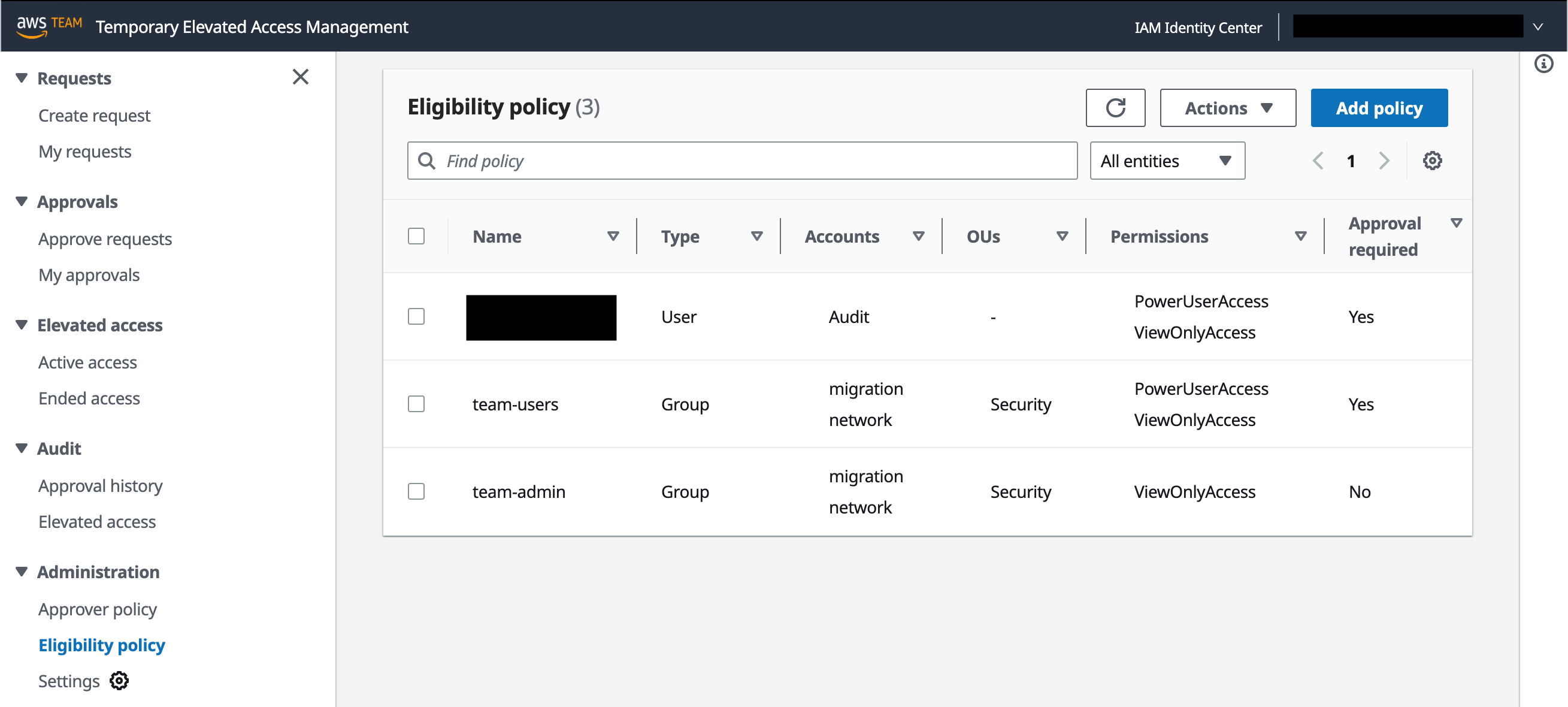
Eligibility policies determine who can request temporary elevated access with a given scope. You can define eligibility policies to ensure that people in specific teams can only request the access that you anticipate they’ll need as part of their job function.
To manage eligibility policies, in the left navigation pane, under Administration, select Eligibility policy. Figure 3 shows this view with three eligibility policies already defined.
Figure 3: Manage eligibility policies
An eligibility policy has four main parts:
Name and Type — An IAM Identity Center user or group
Accounts or OUs — One or more accounts, organizational units (OUs), or both, which belong to your organization
Each eligibility policy allows the specified IAM Identity Center user, or a member of the specified group, to log in to TEAM and request temporary elevated access using the specified permission sets in the specified accounts. When you choose a permission set, you can either use a predefined permission set provided by IAM Identity Center, or you can create your own permission set using custom permissions to provide least-privilege access for particular tasks.
Note: If you specify an OU in an eligibility or approval policy, TEAM includes the accounts directly under that OU, but not those under its child OUs.
Manage approval policies
Approval policies work in a similar way as eligibility policies, except that they authorize users to approve temporary elevated access requests, rather than create them. If a specific account is referenced in an eligibility policy that is configured to require approval, then you need to create a corresponding approval policy for the same account. If there is no corresponding approval policy—or if one exists but its groups have no members — then TEAM won’t allow users to create temporary elevated access requests for that account, because no one would be able to approve them.
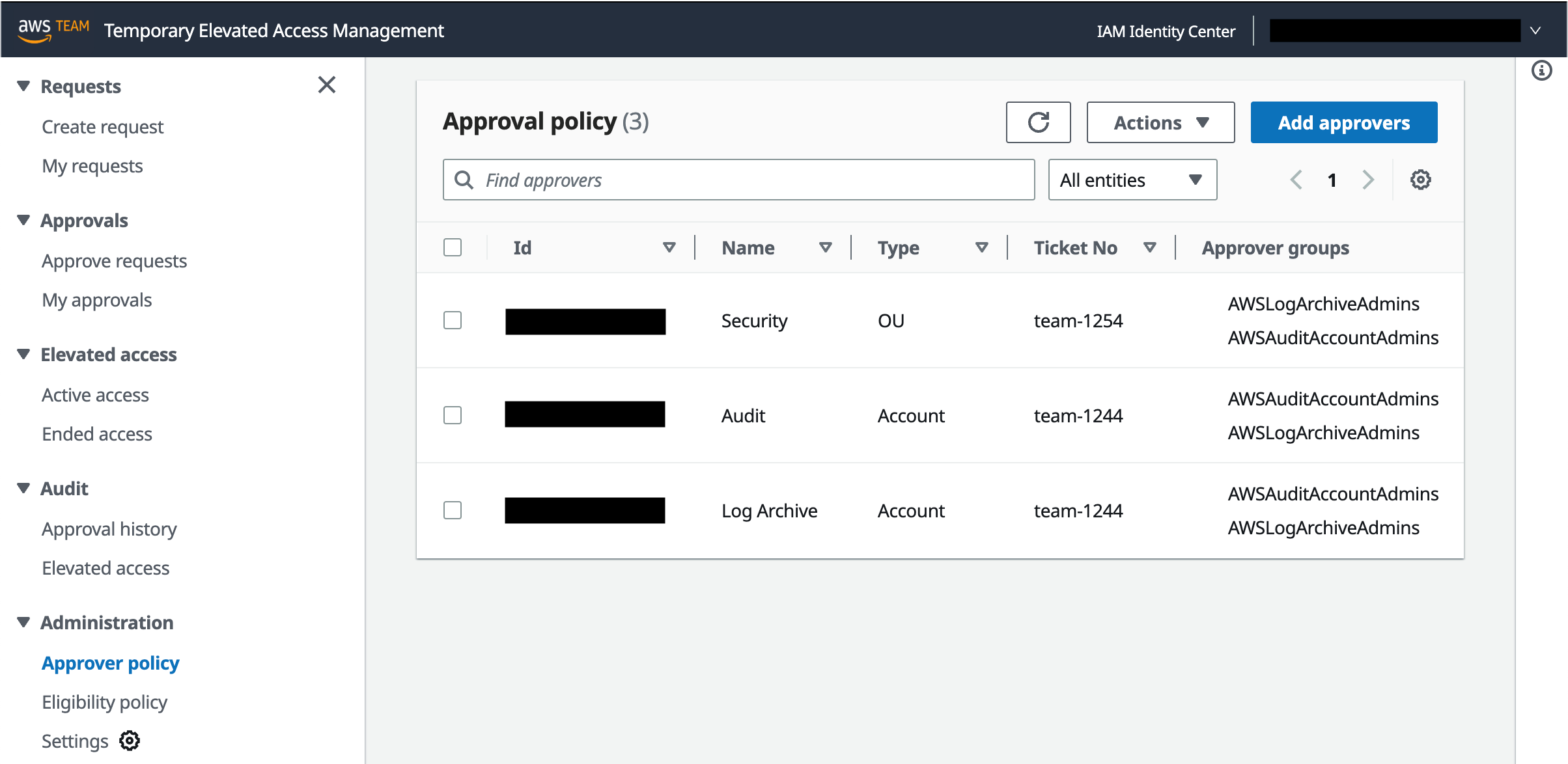
To manage approval policies, in the left navigation pane, under Administration, select Approval policy. Figure 4 shows this view with three approval policies already defined.
Approver groups — One or more IAM Identity Center groups
Each approval policy allows a member of a specified group to log in to TEAM and approve temporary elevated access requests for the specified account, or all accounts under the specified OU, regardless of permission set.
Note: If you specify the same group for both eligibility and approval in the same account, this means approvers can be in the same team as requesters for that account. This is a valid approach, sometimes known as peer approval. Nevertheless, TEAM does not allow an individual to approve their own request. If you prefer requesters and approvers to be in different teams, specify different groups for eligibility and approval.
TEAM walkthrough
Now that the admin persona has defined eligibility and approval policies, you are ready to use TEAM.
To begin this walkthrough, imagine that you are a requester, and you need to perform an operational task that requires temporary elevated access to your AWS target environment. For example, you might need to fix a broken deployment pipeline or make some changes as part of a deployment. As a requester, you must belong to a group specified in at least one eligibility policy that was defined by the admin persona.
Step 1: Access the AWS access portal in IAM Identity Center
To access the AWS access portal in IAM Identity Center, use the AWS access portal URL, as described in the Access TEAM section earlier in this post.
Step 2: Access the TEAM application
To access the TEAM application, select the TEAM IDC APP icon, as described in the Access TEAM section earlier.
Step 3: Request elevated access
The next step is to create a new elevated access request as follows:
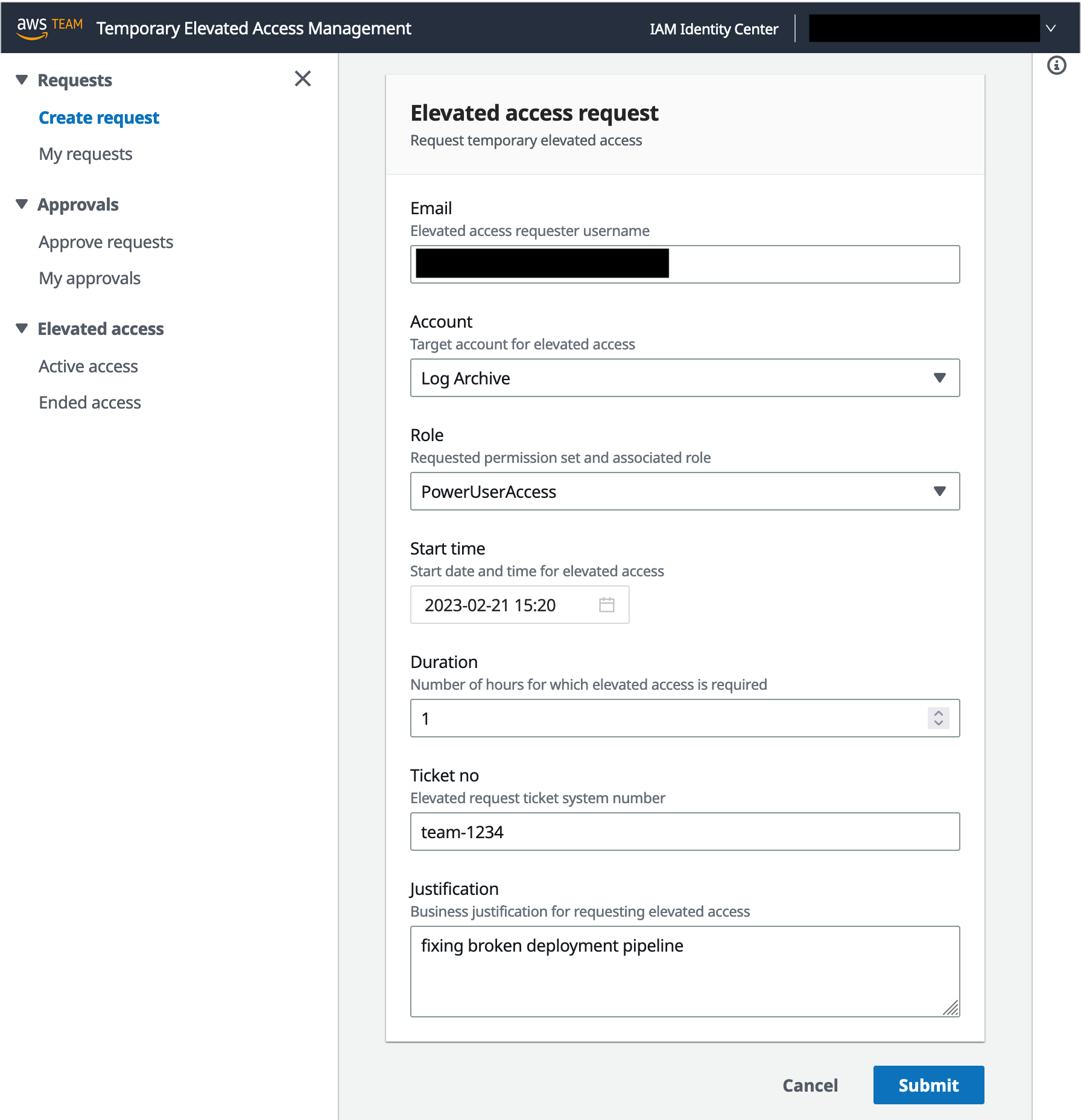
Under Requests, in the left navigation pane, choose Create request.
In the Elevated access request section, do the following, as shown in Figure 5:
Select the account where you need to perform your task.
For Role, select a permission set that will give you sufficient permissions to perform the task.
Enter a start date and time, duration, ticket ID (typically representing a change ticket or incident ticket related to your task), and business justification.
Choose Submit.
Figure 5: Create a new request
When creating a request, consider the following:
In each request, you can specify exactly one account and one permission set.
You can only select an account and permission set combination for which you are eligible based on the eligibility policies defined by the admin persona.
As a requester, you should apply the principle of least privilege by selecting a permission set with the least privilege, and a time window with the least duration, that will allow you to complete your task safely.
TEAM captures a ticket identifier for audit purposes only; it does not try to validate it.
The duration specified in a request determines the time window for which elevated access is active, if your request is approved. During this time window, you can invoke sessions to access the AWS target environment. It doesn’t affect the duration of each session.
Session duration is configured independently for each permission set by an IAM Identity Center administrator, and determines the time period for which IAM temporary credentials are valid for sessions using that permission set.
Sessions invoked just before elevated access ends might remain valid beyond the end of the approved elevated access period. If this is a concern, consider minimizing the session duration configured in your permission sets, for example by setting them to 1 hour.
Step 4: Approve elevated access
After you submit your request, approvers are notified by email. Approvers are notified when there are new requests that fall within the scope of what they are authorized to approve, based on the approval policies defined earlier.
For this walkthrough, imagine that you are now the approver. You will perform the following steps to approve the request. As an approver, you must belong to a group specified in an approval policy that the admin persona configured.
Access the TEAM application in exactly the same way as for the other personas.
In the left navigation pane, under Approvals, choose Approve requests. TEAM displays requests awaiting your review, as shown in Figure 6.
To view the information provided by the requester, select a request and then choose View details.
Figure 6: Requests awaiting review
Select a pending request, and then do one of the following:
To approve the request, select Actions and then choose Approve.
To reject the request, select Actions and then choose Reject.
Figure 7 shows what TEAM displays when you approve a request.
Figure 7: Approve a request
After you approve or reject a request, the original requester is notified by email.
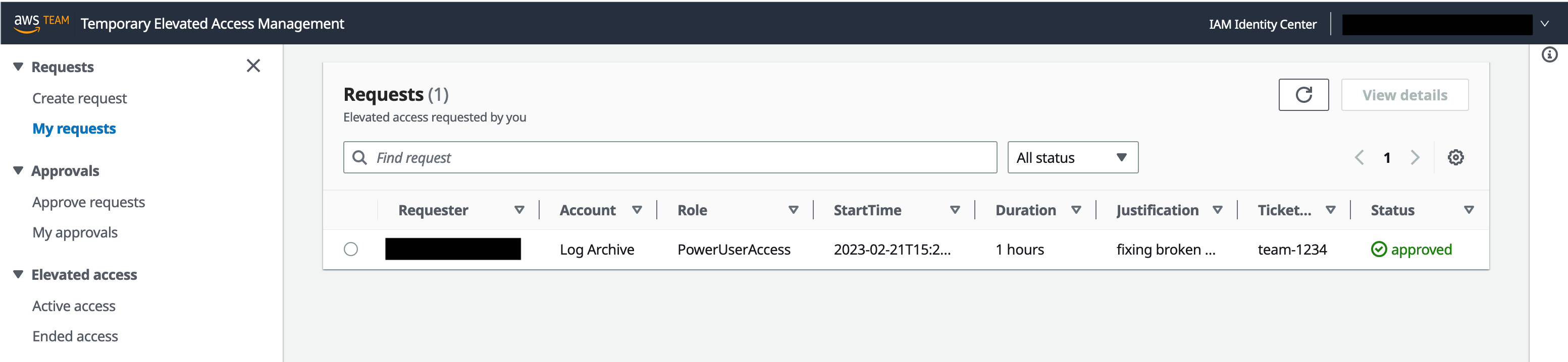
A requester can view the status of their requests in the TEAM application.
To see the status of your open requests in the TEAM application, in the left navigation pane, under Requests, select My requests. Figure 8 shows this view with one approved request.
Figure 8: Approved request
Step 5: Automatic activation of elevated access
After a request is approved, the TEAM application waits until the start date and time specified in the request and then automatically activates elevated access. To activate access, a TEAM orchestration workflow creates a temporary account assignment, which links the requester’s user identity in IAM Identity Center with the permission set and account in their request. Then TEAM notifies the requester by email that their request is active.
A requester can now view their active request in the TEAM application.
To see active requests, in the left navigation pane under Elevated access, choose Active access. Figure 9 shows this view with one active request.
Figure 9: Active request
To see further details for an active request, select a request and then choose View details. Figure 10 shows an example of these details.
Figure 10: Details of an active request
Step 6: Invoke elevated access
During the time period in which elevated access is active, the requester can invoke sessions to access the AWS target environment to complete their task. Each session has the scope (permission set and account) approved in their request. There are three ways to invoke access.
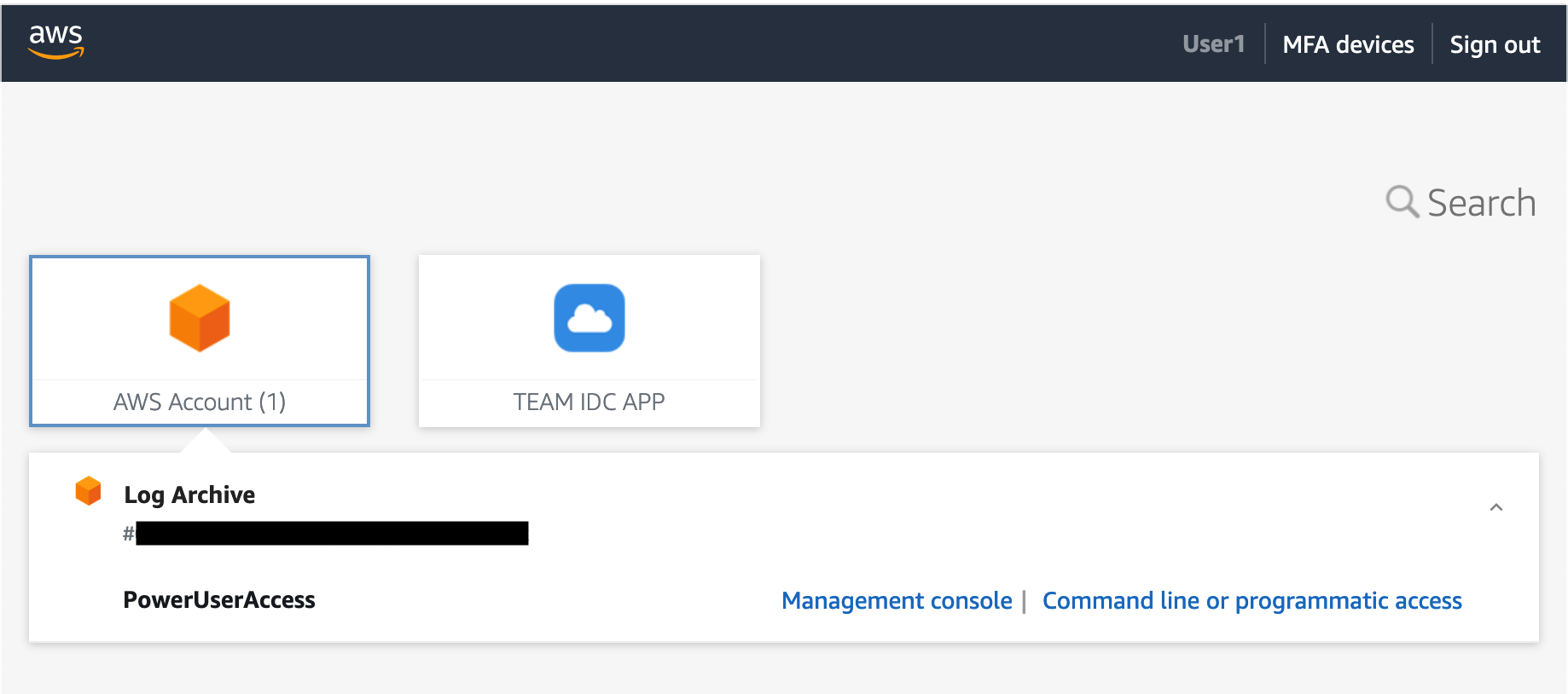
The first two methods involve accessing IAM Identity Center using the AWS access portal URL. Figure 11 shows the AWS access portal while a request is active.
Figure 11: Invoke access from the AWS access portal
From the AWS access portal, you can select an account and permission set that is currently active. You’ll also see the accounts and permission sets that have been statically assigned to you using IAM Identity Center, independently of TEAM. From here, you can do one of the following:
Choose Command line or programmatic access to copy and paste temporary credentials.
The third method is to initiate access directly from the command line using AWS CLI. To use this method, you first need to configure AWS CLI to integrate with IAM Identity Center. This method provides a smooth user experience for AWS CLI users, since you don’t need to copy and paste temporary credentials to your command line.
Regardless of how you invoke access, IAM Identity Center provides temporary credentials for the IAM role and account specified in your request, which allow you to assume that role in that account. The temporary credentials are valid for the duration specified in the role’s permission set, defined by an IAM Identity Center administrator.
When you invoke access, you can now complete the operational tasks that you need to perform in the AWS target environment. During the period in which your elevated access is active, you can invoke multiple sessions if necessary.
Step 7: Log session activity
When you access the AWS target environment, your activity is logged to AWS CloudTrail. Actions you perform in the AWS control plane are recorded as CloudTrail events.
Note: Each CloudTrail event contains the unique identifier of the user who performed the action, which gives you traceability back to the human individual who requested and invoked temporary elevated access.
Step 8: End elevated access
Elevated access ends when either the requested duration elapses or it is explicitly revoked in the TEAM application. The requester or an approver can revoke elevated access whenever they choose.
When elevated access ends, or is revoked, the TEAM orchestration workflow automatically deletes the temporary account assignment for this request. This unlinks the permission set, the account, and the user in IAM Identity Center. The requester is then notified by email that their elevated access has ended.
Step 9: View request details and session activity
You can view request details and session activity for current and historical requests from within the TEAM application. Each persona can see the following information:
Requesters can inspect elevated access requested by them.
Approvers can inspect elevated access that falls within the scope of what they are authorized to approve.
Auditors can inspect elevated access for all TEAM requests.
Session activity is recorded based on the log delivery times provided by AWS CloudTrail, and you can view session activity while elevated access is in progress or after it has ended. Figure 12 shows activity logs for a session displayed in the TEAM application.
Figure 12: Session activity logs
Security and resiliency considerations
The TEAM application controls access to your AWS environment, and you must manage it with great care to prevent unauthorized access. This solution is built using AWS Amplify to ease the reference deployment. Before operationalizing this solution, consider how to align it with your existing development and security practices.
AWS Security Partners provide temporary elevated access solutions that integrate with IAM Identity Center, and AWS has validated the integration of these partner offerings and assessed their capabilities against a common set of customer requirements. For further information, see temporary elevated access in the IAM Identity Center User Guide.
The blog post Managing temporary elevated access to your AWS environment describes an alternative self-hosted solution for temporary elevated access which integrates directly with an external identity provider using OpenID Connect, and federates users directly into AWS Identity and Access Management (IAM) roles in your accounts. The TEAM solution described in this blog post, on the other hand, integrates with IAM Identity Center, which provides a way to centrally manage user access to accounts across your organization and optionally integrates with an external identity provider.
Conclusion
In this blog post, you learned that your first priority should be to use automation to avoid the need to give human users persistent access to your accounts. You also learned that in the rare cases in which people need access to your accounts, not all access is equal; there are times when you need a process to verify that access is needed, and to provide temporary elevated access.
We introduced you to a temporary elevated access management solution (TEAM) that you can download from AWS Samples and use alongside IAM Identity Center to give your users temporary elevated access. We showed you the TEAM workflow, described the TEAM architecture, and provided links where you can get started by downloading and deploying TEAM.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on AWS IAM Identity Center re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the AWS Security Profile series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Matt Campagna, Senior Principal, Security Engineering, AWS Cryptography, and re:Inforce 2023 session speaker, who shares thoughts on data protection, cloud security, post-quantum cryptography, and more. Matthew was first profiled on the AWS Security Blog in 2019. This is part 1 of 3 in a series of interviews with our AWS Cryptography team.
What do you do in your current role and how long have you been at AWS?
I started at Amazon in 2013 as the first cryptographer at AWS. Today, my focus is on the cryptographic security of our customers’ data. I work across AWS to make sure that our cryptographic engineering meets our most sensitive customer needs. I lead our migration to quantum-resistant cryptography, and help make privacy-preserving cryptography techniques part of our security model.
How did you get started in the data protection and cryptography space? What about it piqued your interest?
I first learned about public-key cryptography (for example, RSA) during a math lesson about group theory. I found the mathematics intriguing and the idea of sending secret messages using only a public value astounding. My undergraduate and graduate education focused on group theory, and I started my career at the National Security Agency (NSA) designing and analyzing cryptologics. But what interests me most about cryptography is its ability to enable business by reducing risks. I look at cryptography as a financial instrument that affords new business cases, like e-commerce, digital currency, and secure collaboration. What enables Amazon to deliver for our customers is rooted in cryptography; our business exists because cryptography enables trust and confidentiality across the internet. I find this the most intriguing aspect of cryptography.
AWS has invested in the migration to post-quantum cryptography by contributing to post-quantum key agreement and post-quantum signature schemes to protect the confidentiality, integrity, and authenticity of customer data. What should customers do to prepare for post-quantum cryptography?
Our focus at AWS is to help ensure that customers can migrate to post-quantum cryptography as fast as prudently possible. This work started with inventorying our dependencies on algorithms that aren’t known to be quantum-resistant, like integer-factorization-based cryptography, and discrete-log-based cryptography, like ECC. Customers can rely on AWS to assist with transitioning to post-quantum cryptography for their cloud computing needs.
We recommend customers begin inventorying their dependencies on algorithms that aren’t quantum-resistant, and consider developing a migration plan, to understand if they can migrate directly to new post-quantum algorithms or if they should re-architect them. For the systems that are provided by a technology provider, customers should ask what their strategy is for post-quantum cryptography migration.
AWS offers post-quantum TLS endpoints in some security services. Can you tell us about these endpoints and how customers can use them?
Our open source TLS implementation, s2n-TLS, includes post-quantum hybrid key exchange (PQHKEX) in its mainline. It’s deployed everywhere that s2n is deployed. AWS Key Management Service, AWS Secrets Manager, and AWS Certificate Manager have enabled PQHKEX cipher suites in our commercial AWS Regions. Today customers can use the AWS SDK for Java 2.0 to enable PQHKEX on their connection to AWS, and on the services that also have it enabled, they will negotiate a post-quantum key exchange method. As we enable these cipher suites on additional services, customers will also be able to connect to these services using PQHKEX.
You are a frequent contributor to the Amazon Science Blog. What were some of your recent posts about?
In 2022, we published a post on preparing for post-quantum cryptography, which provides general information on the broader industry development and deployment of post-quantum cryptography. The post links to a number of additional resources to help customers understand post-quantum cryptography. The AWS Post-Quantum Cryptography page and the Science Blog are great places to start learning about post-quantum cryptography.
We also published a post highlighting the security of post-quantum hybrid key exchange. Amazon believes in evidencing the cryptographic security of the solutions that we vend. We are actively participating in cryptographic research to validate the security that we provide in our services and tools.
What’s been the most dramatic change you’ve seen in the data protection and post-quantum cryptography landscape since we talked to you in 2019?
Since 2019, there have been two significant advances in the development of post-quantum cryptography.
First, the National Institute of Standards and Technology (NIST) announced their selection of PQC algorithms for standardization. NIST expects to finish the standardization of a post-quantum key encapsulation mechanism (Kyber) and digital signature scheme (Dilithium) by 2024 as part of the Federal Information Processing Standard (FIPS). NIST will also work on standardization of two additional signature standards (FALCON and SPHINCS+), and continue to consider future standardization of the key encapsulation mechanisms BIKE, HQC, and Classical McEliece.
Second, the NSA announced their Commercial National Security Algorithm (CNSA) Suite 2.0, which includes their timelines for National Security Systems (NSS) to migrate to post-quantum algorithms. The NSA will begin preferring post-quantum solutions in 2025 and expect that systems will have completed migration by 2033. Although this timeline might seem far away, it’s an aggressive strategy. Experience shows that it can take 20 years to develop and deploy new high-assurance cryptographic algorithms. If technology providers are not already planning to migrate their systems and services, they will be challenged to meet this timeline.
What makes cryptography exciting to you?
Cryptography is a dynamic area of research. In addition to the business applications, I enjoy the mathematics of cryptography. The state-of-the-art is constantly progressing in terms of new capabilities that cryptography can enable, and the potential risks to existing cryptographic primitives. This plays out in the public sphere of cryptographic research across the globe. These advancements are made public and are accessible for companies like AWS to innovate on behalf of our customers, and protect our systems in advance of the development of new challenges to our existing crypto algorithms. This is happening now as we monitor the advancements of quantum computing against our ability to define and deploy new high-assurance quantum-resistant algorithms. For me, it doesn’t get more exciting than this.
Where do you see the cryptography and post-quantum cryptography space heading to in the future?
While NIST transitions from their selection process to standardization, the broader cryptographic community will be more focused on validating the cryptographic assurances of these proposed schemes for standardization. This is a critical part of the process. I’m optimistic that we will enter 2025 with new cryptographic standards to deploy.
There is a lot of additional cryptographic research and engineering ahead of us. Applying these new primitives to the cryptographic applications that use classical asymmetric schemes still needs to be done. Some of this work is happening in parallel, like in the IETF TLS working group, and in the ETSI Quantum-Safe Cryptography Technical Committee. The next five years should see the adoption of PQHKEX in protocols like TLS, SSH, and IKEv2 and certification of new FIPS hardware security modules (HSMs) for establishing new post-quantum, long-lived roots of trust for code-signing and entity authentication.
I expect that the selected primitives for standardization will also be used to develop novel uses in fields like secure multi-party communication, privacy preserving machine learning, and cryptographic computing.
With AWS re:Inforce 2023 around the corner, what will your session focus on? What do you hope attendees will take away from your session?
Session DAP302 – “Post-quantum cryptography migration strategy for cloud services” is about the challenge quantum computers pose to currently used public-key cryptographic algorithms and how the industry is responding. Post-quantum cryptography (PQC) offers a solution to this challenge, providing security to help protect against quantum computer cybersecurity events. We outline current efforts in PQC standardization and migration strategies. We want our customers to leave with a better understanding of the importance of PQC and the steps required to migrate to it in a cloud environment.
Is there something you wish customers would ask you about more often?
The question I am most interested in hearing from our customers is, “when will you have a solution to my problem?” If customers have a need for a novel cryptographic solution, I’m eager to try to solve that with them.
How about outside of work, any hobbies?
My main hobbies outside of work are biking and running. I wish I was as consistent attending to my hobbies as I am to my work desk. I am happier being able to run every day for a constant speed and distance as opposed to running faster or further tomorrow or next week. Last year I was fortunate enough to do the Cycle Oregon ride. I had registered for it twice before without being able to find the time to do it.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Web Services (AWS) successfully completed a special onboarding audit with no findings for ISO 9001, 27001, 27017, 27018, 27701, and 22301, and Cloud Security Alliance (CSA) STAR CCM v4.0. Ernst and Young Certify Point auditors conducted the audit and reissued the certificates on May 23, 2023. The objective of the audit was to assess the level of compliance with the requirements of the applicable international standards.
We added eight additional AWS services and one additional AWS Region to the scope of this special onboarding audit. The following are the eight additional services:
The additional Region is Asia Pacific (Melbourne).
For a full list of AWS services that are certified under ISO and CSA Star, see the AWS ISO and CSA STAR Certified page. Customers can also access the certifications in the console through AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
In the AWS Security Profile series, we interview Amazon Web Services (AWS) experts who help keep our customers safe and secure. This interview features Valerie Lambert, Senior Software Development Engineer, Crypto Tools, and upcoming AWS re:Inforce 2023 speaker, who shares thoughts on data protection, cloud security, cryptography tools, and more.
What do you do in your current role and how long have you been at AWS? I’m a Senior Software Development Engineer on the AWS Crypto Tools team in AWS Cryptography. My team focuses on building open source, client-side encryption solutions, such as the AWS Encryption SDK. I’ve been working in this space for the past four years.
How did you get started in cryptography? What about it piqued your interest? When I started on this team back in 2019, I knew very little about the specifics of cryptography. I only knew its importance for securing our customers’ data and that security was our top priority at AWS. As a developer, I’ve always taken security and data protection very seriously, so when I learned about this particular team from one of my colleagues, I was immediately interested and wanted to learn more. It also helped that I’m a very math-oriented person. I find this domain endlessly interesting, and love that I have the opportunity to work with some truly amazing cryptography experts.
Why do cryptography tools matter today? Customers need their data to be secured, and builders need to have tools they can rely on to help provide that security. It’s well known that no one should cobble together their own encryption scheme. However, even if you use well-vetted, industry-standard cryptographic primitives, there are still many considerations when applying those primitives correctly. By using tools that are simple to use and hard to misuse, builders can be confident in protecting their customers’ most sensitive data, without cryptographic expertise required.
What’s been the most dramatic change you’ve seen in the data protection and cryptography space? In the past few years, I’ve seen more and more formal verification used to help prove various properties about complex systems, as well as build confidence in the correctness of our libraries. In particular, the AWS Crypto Tools team is using Dafny, a formal verification-aware programming language, to implement the business logic for some of our libraries. Given the high bar for correctness of cryptographic libraries, having formal verification as an additional tool in the toolbox has been invaluable. I look forward to how these tools mature in the next couple years.
You are speaking in Anaheim June 13-14 at AWS re:Inforce 2023 — what will your session focus on? Our team has put together a workshop (DAP373) that will focus on strategies to use client-side encryption with Amazon DynamoDB, specifically focusing on solutions for effectively searching on data that has been encrypted on the client side. I hope that attendees will see that, with a bit of forethought put into their data access patterns, they can still protect their data on the client side.
Where do you see the cryptography tools space heading in the future? More and more customers have been coming to us with use cases that involve client-side encryption with different database technologies. Although my team currently vends an out-of-the-box solution for DynamoDB, customers working with other database technologies have to build their own solutions to help keep their data safe. There are many, many considerations that come with encrypting data on the client side for use in a database, and it’s very expensive for customers to design, build, and maintain these solutions. The AWS Crypto Tools team is actively investigating this space—both how we can expand the usability of client-side encrypted data in DynamoDB, and how to bring our tools to more database technologies.
Is there something you wish customers would ask you about more often? Customers shouldn’t need to understand the cryptographic details that underpin the security properties that our tools provide to protect their end users’ data. However, I love when our customers are curious and ask questions and are themselves interested in the nitty-gritty details of our solutions.
How about outside of work, any hobbies? A couple years ago, I picked up aerial circus arts as a hobby. I’m still not very good, but it’s a lot of fun to play around on silks and trapeze. And it’s great exercise!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
The United States Government recently launched its National Cybersecurity Strategy. The Strategy outlines the administration’s ambitious vision for building a more resilient future, both in the United States and around the world, and it affirms the key role cloud computing plays in realizing this vision.
Amazon Web Services (AWS) is broadly committed to working with customers, partners, and governments such as the United States to improve cybersecurity. That longstanding commitment aligns with the goals of the National Cybersecurity Strategy. In this blog post, we will summarize the Strategy and explain how AWS will help to realize its vision.
The Strategy identifies two fundamental shifts in how the United States allocates cybersecurity roles, responsibilities, and resources. First, the Strategy calls for a shift in cybersecurity responsibility away from individuals and organizations with fewer resources, toward larger technology providers that are the most capable and best-positioned to be successful. At AWS, we recognize that our success and scale bring broad responsibility. We are committed to improving cybersecurity outcomes for our customers, our partners, and the world at large.
Second, the Strategy calls for realigning incentives to favor long-term investments in a resilient future. As part of our culture of ownership, we are long-term thinkers, and we don’t sacrifice long-term value for short-term results. For more than fifteen years, AWS has delivered security, identity, and compliance services for millions of active customers around the world. We recognize that we operate in a complicated global landscape and dynamic threat environment that necessitates a dynamic approach to security. Innovation and long-term investments have been and will continue to be at the core of our approach, and we continue to innovate to build and improve on our security and the services we offer customers.
AWS is working to enhance cybersecurity outcomes in ways that align with each of the Strategy’s five pillars:
Defend Critical Infrastructure — Customers, partners, and governments need confidence that they are migrating to and building on a secure cloud foundation. AWS is architected to have the most flexible and secure cloud infrastructure available today, and our customers benefit from the data centers, networks, custom hardware, and secure software layers that we have built to satisfy the requirements of the most security-sensitive organizations. Our cloud infrastructure is secure by design and secure by default, and our infrastructure and services meet the high bar that the United States Government and other customers set for security.
Disrupt and Dismantle Threat Actors — At AWS, our paramount focus on security leads us to implement important measures to prevent abuse of our services and products. Some of the measures we undertake to deter, detect, mitigate, and prevent abuse of AWS products include examining new registrations for potential fraud or identity falsification, employing service-level containment strategies when we detect unusual behavior, and helping protect critical systems and sensitive data against ransomware. Amazon is also working with government to address these threats, including by serving as one of the first members of the Joint Cyber Defense Collaborative (JCDC). Amazon is also co-leading a study with the President’s National Security Telecommunications Advisory Committee on addressing the abuse of domestic infrastructure by foreign malicious actors.
Shape Market Forces to Drive Security and Resilience — At AWS, security is our top priority. We continuously innovate based on customer feedback, which helps customer organizations to accelerate their pace of innovation while integrating top-tier security architecture into the core of their business and operations. For example, AWS co-founded the Open Cybersecurity Schema Framework (OCSF) project, which facilitates interoperability and data normalization between security products. We are contributing to the quality and safety of open-source software both by direct contributions to open-source projects and also by an initial commitment of $10 million in a variety of open-source security improvement projects in and through the Open Source Security Foundation (OpenSSF).
Invest in a Resilient Future — Cybersecurity skills training, workforce development, and education on next-generation technologies are essential to addressing cybersecurity challenges. That’s why we are making significant investments to help make it simpler for people to gain the skills they need to grow their careers, including in cybersecurity. Amazon is committing more than $1.2 billion to provide no-cost education and skills training opportunities to more than 300,000 of our own employees in the United States, to help them secure new, high-growth jobs. Amazon is also investing hundreds of millions of dollars to provide no-cost cloud computing skills training to 29 million people around the world. We will continue to partner with the Cybersecurity and Infrastructure Security Agency (CISA) and others in government to develop the cybersecurity workforce.
Forge International Partnerships to Pursue Shared Goals — AWS is working with governments around the world to provide innovative solutions that advance shared goals such as bolstering cyberdefenses and combating security risks. For example, we are supporting international forums such as the Organization of American States to build security capacity across the hemisphere. We encourage the administration to look toward internationally recognized, risk-based cybersecurity frameworks and standards to strengthen consistency and continuity of security among interconnected sectors and throughout global supply chains. Increased adoption of these standards and frameworks, both domestically and internationally, will mitigate cyber risk while facilitating economic growth.
AWS shares the Biden administration’s cybersecurity goals and is committed to partnering with regulators and customers to achieve them. Collaboration between the public sector and industry has been central to US cybersecurity efforts, fueled by the recognition that the owners and operators of technology must play a key role. As the United States Government moves forward with implementation of the National Cybersecurity Strategy, we look forward to redoubling our efforts and welcome continued engagement with all stakeholders—including the United States Government, our international partners, and industry collaborators. Together, we can address the most difficult cybersecurity challenges, enhance security outcomes, and build toward a more secure and resilient future.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
To support our customers in securing their Amazon Web Services (AWS) environment, AWS offers digital training, whitepapers, blog posts, videos, workshops, and documentation to learn about security in the cloud.
The AWS Ramp-Up Guide: Security is designed to help you quickly learn what is most important to you when it comes to security, identity, and compliance. The Ramp-Up Guide helps you get started with learning cloud foundations and then provides you with options for building skills in various security domains.
Recently, we have updated the AWS Ramp-Up Guide: Security. In this post, we will highlight some of the changes and discuss how to use the new guide.
Update highlights
Based on customer feedback, new service and feature releases, and our experience helping customers, we’ve updated the majority of the guide with new content. Some highlights of the new version include:
Focus on AWS security digital trainings — The new Ramp-Up Guide for security focuses on digital trainings provided by AWS Skill Builder. AWS Skill Builder is a learning center for AWS customers and partners to build cloud skills through digital trainings, self-paced labs, and other course types. AWS Skill Builder has a variety of AWS security content to help customers understand concepts and gain hands-on experience with AWS security.
Security focus areas — Because there are different roles and focuses within cybersecurity, we created sections for different focus areas of AWS security, including threat detection and incident response (TD/IR), compliance, data protection, and more. A Security Operations Center (SOC) analyst, for example, can choose to focus on TD/IR training, which is most relevant for that role.
Extensive additional resources — For each focus area, we added new resources, including whitepapers, blogs, re:Invent videos, and workshops. Customers can use these additional resources to supplement the AWS Skill Builder courses and labs.
How to use the new guide
The AWS Ramp-Up Guide: Security is designed to take you all the way from cloud foundations to the AWS Certified Security – Specialty certification. The guide takes the latest in digital training available from AWS Skill Builder and augments that with the latest resources aligned to foundational concepts and specialized areas within cloud security. Although you are free to use the learnings in any order, if you are new to the cloud, we recommend the following steps:
Sign up for your free AWS Skill Builder account, which provides you with more than 600 digital courses.
Note: You can optionally buy an AWS Skill Builder subscription if you’d like to complete the self-paced labs. See Pricing options for AWS Skill Builder for more details.
Review the “Learn the fundamentals of the AWS Cloud” section of the Ramp-Up Guide, choose a course name under Learning Resource, and search for that course in Skill Builder. If you are unsure of which course to start with, we recommend that you begin with “AWS Cloud Practitioner Essentials.”
After you’ve completed the “Learn the fundamentals of the AWS Cloud” section, proceed to the “AWS Cloud Security Fundamentals” section begin your security training.
After you complete the Security Fundamentals section, review the specialized security focus areas in the Ramp-Up Guide, choose a focus area, and complete the training items within that focus area.
After you’ve completed the training specific to your focus area, explore other focus areas beyond the scope of your immediate role. Security often requires knowledge across domains and focus areas, so we encourage you to explore the security focus areas beyond the immediate scope of your role.
Review the “Putting it all together” section to prepare for the AWS Certified Security – Specialization certification.
We greatly value feedback and contributions from our community. To share your thoughts and insights about the AWS Ramp-Up Guide: Security and your experience using it, and what you want to see in future versions, please contact [email protected].
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
AWS is excited to announce a new eBook, 5 Keys to Secure Enterprise Messaging. The new eBook includes best practices for addressing the security and compliance risks associated with messaging apps.
An estimated 3.09 billion mobile phone users access messaging apps to communicate, and this figure is projected to grow to 3.51 billion users in 2025.
Legal and regulatory requirements for data protection, privacy, and data retention have made protecting business communications a priority for organizations across the globe. Although consumer messaging apps are convenient and support real-time communication with colleagues, customers, and partners, they often lack the robust security and administrative controls many businesses require.
The eBook details five keys to secure enterprise messaging that balance people, process, and technology.
We encourage you to read the eBook, and learn about:
Establishing messaging policies and guidelines that are effective for your workforce
Training employees to use messaging apps in a way that doesn’t increase organizational risk
Building a security-first culture
Using true end-to-end encryption (E2EE) to secure communications
Retaining data to help meet requirements, without exposing it to outside parties
The following is background on ransomware, CIS, and the initiatives that led to the publication of this new blueprint.
The Ransomware Task Force
In April of 2021, the U.S. government launched the Ransomware Task Force (RTF), which has the mission of uniting key stakeholders across industry, government, and civil society to create new solutions, break down silos, and find effective new methods of countering the ransomware threat. The RTF has since launched several progress reports with specific recommendations, including the development of the RTF Blueprint for Ransomware Defense, which provides a framework with practical steps to mitigate, respond to, and recover from ransomware. AWS is a member of the RTF, and we have taken action to create our own AWS Blueprint for Ransomware Defense that maps actionable and foundational security controls to AWS services and features that customers can use to implement those controls. The AWS Blueprint for Ransomware Defense is based on the CIS Controls framework.
Center for Internet Security
The Center for Internet Security (CIS) is a community-driven nonprofit, globally recognized for establishing best practices for securing IT systems and data. To help establish foundational defense mechanisms, a subset of the CIS Critical Security Controls (CIS Controls) have been identified as important first steps in the implementation of a robust program to prevent, respond to, and recover from ransomware events. This list of controls was established to provide safeguards against the most impactful and well-known internet security issues. The controls have been further prioritized into three implementation groups (IGs), to help guide their implementation. IG1, considered “essential cyber hygiene,” provides foundational safeguards. IG2 builds on IG1 by including the controls in IG1 plus a number of additional considerations. Finally, IG3 includes the controls in IG1 and IG2, with an additional layer of controls that protect against more sophisticated security issues.
CIS recommends that organizations use the CIS IG1 controls as basic preventative steps against ransomware events. We’ve produced a mapping of AWS services that can help you implement aspects of these controls in your AWS environment. Ransomware is a complex event, and the best course of action to mitigate risk is to apply a thoughtful strategy of defense in depth. The mitigations and controls outlined in this mapping document are general security best practices, but are a non-exhaustive list.
Because data is often vital to the operation of mission-critical services, ransomware can severely disrupt business processes and applications that depend on this data. For this reason, many organizations are looking for effective security controls that will improve their security posture against these types of events. We hope you find the information in the AWS Blueprint for Ransomware Defense helpful and incorporate it as a tool to provide additional layers of security to help keep your data safe.
Let us know if you have any feedback through the AWS Security Contact Us page. Please reach out if there is anything we can do to add to the usefulness of the blueprint or if you have any additional questions on security and compliance. You can find more information from the IST (Institute for Security and Technology) describing ransomware and how to protect yourself on the IST website.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Web Services (AWS) has re-published the whitepaper Architecting for PCI DSS Scoping and Segmentation on AWS to provide guidance on how to properly define the scope of your Payment Card Industry (PCI) Data Security Standard (DSS) workloads that are running in the AWS Cloud. The whitepaper has been refreshed to include updated AWS best practices and technologies, and updates that are applicable to the new PCI DSS v4.0 requirements. The whitepaper looks at how to define segmentation boundaries between your in-scope and out-of-scope resources by using cloud-based AWS services.
The whitepaper is intended for engineers and solution builders, but it also serves as a guide for Qualified Security Assessors (QSAs) and internal security assessors (ISAs) to better understand the different segmentation controls that are available within AWS products and services, along with associated scoping considerations.
Compared to on-premises environments, software-defined networking on AWS transforms the scoping process for applications by providing additional segmentation controls beyond network segmentation. Thoughtful design of your applications and selection of security-impacting services for implementing your required controls can reduce the number of systems and services in your cardholder data environment (CDE).
In the AWS Security Profile series, we interview Amazon Web Services (AWS) thought leaders who help keep our customers safe and secure. This interview features Ritesh Desai, General Manager, AWS Secrets Manager, and re:Inforce 2023 session speaker, who shares thoughts on data protection, cloud security, secrets management, and more.
What do you do in your current role and how long have you been at AWS?
I’ve been in the tech industry for more than 20 years and joined AWS about three years ago. Currently, I lead our Secrets Management organization, which includes the AWS Secrets Manager service.
How did you get started in the data protection and secrets management space? What about it piqued your interest?
I’ve always been excited at the prospect of solving complex customer problems with simple technical solutions. Working across multiple small to large organizations in the past, I’ve seen similar challenges with secret sprawl and lack of auditing and monitoring tools. Centralized secrets management is a challenge for customers. As organizations evolve from start-up to enterprise level, they can end up with multiple solutions across organizational units to manage their secrets.
Being part of the Secrets Manager team gives me the opportunity to learn about our customers’ unique needs and help them protect access to their most sensitive digital assets in the cloud, at scale.
Why does secrets management matter to customers today?
Customers use secrets like database passwords and API keys to protect their most sensitive data, so it’s extremely important for them to invest in a centralized secrets management solution. Through secrets management, customers can securely store, retrieve, rotate, and audit secrets.
What’s been the most dramatic change you’ve seen in the data protection and secrets management space?
Secrets management is becoming increasingly important for customers, but customers now have to deal with complex environments that include single cloud providers like AWS, multi-cloud setups, hybrid (cloud and on-premises) environments, and only on-premises instances.
Customers tell us that they want centralized secrets management solutions that meet their expectations across these environments. They have two distinct goals here. First, they want a central secrets management tool or service to manage their secrets. Second, they want their secrets to be available closer to the applications where they’re run. IAM Roles Anywhere provides a secure way for on-premises servers to obtain temporary AWS credentials and removes the need to create and manage long-term AWS credentials. Now, customers can use IAM Roles Anywhere to access their Secrets Manager secrets from workloads running outside of AWS. Secrets Manager also launched a program in which customers can manage secrets in third-party secrets management solutions to replicate secrets to Secrets Manager for their AWS workloads. We’re continuing to invest in these areas to make it simpler for customers to manage their secrets in their tools of choice, while providing access to their secrets closer to where their applications are run.
With AWS re:Inforce 2023 around the corner, what will your session focus on? What do you hope attendees will take away from your session?
I’m speaking in a session called “Using AWS data protection services for innovation and automation” (DAP305) alongside one of our senior security specialist solutions architects on the topic of secrets management at scale. In the session, we’ll walk through a sample customer use case that highlights how to use data protection services like AWS Key Management Service (AWS KMS), AWS Private Certificate Authority (AWS Private CA), and Secrets Manager to help build securely and help meet organizational security and compliance expectations. Attendees will walk away with a clear picture of the services that AWS offers to protect sensitive data, and how they can use these services together to protect secrets at scale.
Where do you see the secrets management space heading in the future?
Traditionally, secrets management was addressed after development, rather than being part of the design and development process. This placement created an inherent clash between development teams who wanted to put the application in the hands of end users, and the security admins who wanted to verify that the application met security expectations. This resulted in longer timelines to get to market. Involving security in the mix only after development is complete, is simply too late. Security should enable business, not restrict it.
Organizations are slowly adopting the culture that “Security is everyone’s responsibility.” I expect more and more organizations will take the step to “shift-left” and embed security early in the development lifecycle. In the near future, I expect to see organizations prioritize the automation of security capabilities in the development process to help detect, remediate, and eliminate potential risks by taking security out of human hands.
Is there something you wish customers would ask you about more often?
I’m always happy to talk to customers to help them think through how to incorporate secure-by-design in their planning process. There are many situations where decisions could end up being expensive to reverse. AWS has a lot of experience working across a multitude of use cases for customers as they adopt secrets management solutions. I’d love to talk more to customers early in their cloud adoption journey, about the best practices that they should adopt and potential pitfalls to avoid, when they make decisions about secrets management and data protection.
How about outside of work—any hobbies?
I’m an avid outdoors person, and living in Seattle has given me and my family the opportunity to trek and hike through the beautiful landscapes of the Pacific Northwest. I’ve also been a consistent Tough Mudder-er for the last 5 years. The other thing that I spend my time on is working as an amateur actor for a friend’s nonprofit theater production, helping in any way I can.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Amazon Security Lake automatically centralizes security data from both cloud and on-premises sources into a purpose-built data lake stored on a particular AWS delegated administrator account for Amazon Security Lake.
When you turn on Amazon Security Lake, it begins to collect actionable security data from various AWS sources. However, many enterprises today have complex environments that include a mix of different cloud resources in addition to on-premises data centers.
Although the AWS data sources in Amazon Security Lake encompass a large amount of the necessary security data needed for analysis, you may miss the full picture if your infrastructure operates across multiple cloud venders (for example, AWS, Azure, and Google Cloud Platform) and on-premises at the same time. By querying data from across your entire infrastructure, you can increase the number of indicators of compromise (IOC) that you identify, and thus increase the likelihood that those indicators will lead to actionable outputs.
Solution architecture
Figure 1 shows how to configure data to travel from an Azure event hub to Amazon Security Lake.
Figure 1: Solution architecture
As shown in Figure 1, the solution involves the following steps:
An AWS user instantiates the required AWS services and features that enable the process to function, including AWS Identity and Access Management (IAM) permissions, Kinesis data streams, AWS Glue jobs, and Amazon Simple Storage Service (Amazon S3) buckets, either manually or through an AWS CloudFormation template, such as the one we will use in this post.
In response to the custom source created from the CloudFormation template, a Security Lake table is generated in AWS Glue.
From this point on, Azure activity logs in their native format are stored within an Azure cloud event hub within an Azure account. An Azure function is deployed to respond to new events within the Azure event hub and forward these logs over the internet to the Kinesis data stream that was created in the preceding step.
The Kinesis data stream forwards the data to an AWS Glue streaming job fronted by the Kinesis data.
The AWS Glue job then performs the extract, transfer, and load (ETL) mapping to the appropriate Open Cybersecurity Schema Framework (OCSF) (specified for API Activity events at OCSF API Activity Mappings).
The Azure events are partitioned with respect to the required partitioning requirements in Amazon Security Lake tables and stored in S3.
The user can query these tables by using Amazon Athena alongside the rest of their data inside Amazon Security Lake.
Prerequisites
Before you implement the solution, complete the following prerequisites:
Verify that you have enabled Amazon Security Lake in the AWS Regions that correspond to the Azure Activity logs that you will forward. For more information, see What is Amazon Security Lake?
Preconfigure the custom source logging for the source AZURE_ACTIVITY in your Region. To configure this custom source in Amazon Security Lake, open the Amazon Security Lake console, navigate to Create custom data source, and do the following, as shown in Figure 2:
For Data source name, enter AZURE_ACTIVITY.
For Event class, select API_ACTIVITY.
For Account Id, enter the ID of the account which is authorized to write data to your data lake.
For External Id, enter “AZURE_ACTIVITY-<YYYYMMDD>“
Step 1: Configure AWS services for Azure activity logging
The first step is to configure the AWS services for Azure activity logging.
To configure Azure activity logging in Amazon Security Lake, first prepare the assets required in the target AWS account. You can automate this process by using the provided CloudFormation template — Security Lake CloudFormation — which will do the heavy lifting for this portion of the setup.
Note: I have predefined these scripts to create the AWS assets required to ingest Azure activity logs, but you can generalize this process for other external log sources, as well.
The CloudFormation template has the following components:
securitylakeGlueStreamingRole — includes the following managed policies:
AWSLambdaKinesisExecutionRole
AWSGlueServiceRole
securitylakeGlueStreamingPolicy — includes the following attributes:
“s3:GetObject”
“s3:PutObject”
securitylakeAzureActivityStream — This Kinesis data stream is the endpoint that acts as the connection point between Azure and AWS and the frontend of the AWS Glue stream that feeds Azure activity logs to Amazon Security Lake.
securitylakeAzureActivityJob — This is an AWS Glue streaming job that is used to take in feeds from the Kinesis data stream and map the Azure activity logs within that stream to OCSF.
securitylake-glue-assets S3 bucket — This is the S3 bucket that is used to store the ETL scripts used in the AWS Glue job to map Azure activity logs.
Running the CloudFormation template will instantiate the aforementioned assets in your AWS delegated administrator account for Amazon Security Lake.
The CloudFormation template creates a new S3 bucket with the following syntax: securityLake-glue-assets-<ACCOUNT-ID>–<REGION>. After the CloudFormation run is complete, navigate to this bucket within the S3 console.
Within the S3 bucket, create a scripts and temporary folder in the S3 bucket, as shown in Figure 4.
Figure 4: Glue assets bucket
Update the Azure AWS Glue Pyspark script by replacing the following values in the file. You will attach this script to your AWS Glue job and use it to generate the AWS assets required for the implementation.
Replace <AWS_REGION_NAME> with the Region that you are operating in — for example, us-east-2.
Replace <AWS_ACCOUNT_ID> with the account ID of your delegated administrator account for Amazon Security Lake — for example, 111122223333.
Replace <SECURITYLAKE-AZURE-STREAM-ARN> with the Kinesis stream name created through the CloudFormation template. To find the stream name, open the Kinesis console, navigate to the Kinesis stream with the name securityLakeAzureActivityStream — <STREAM-UID>, and copy the Amazon Resource Name (ARN), as shown in the following figure.
Figure 5: Kinesis stream ARN
Replace <SECURITYLAKE-BUCKET-NAME> with the name of your data lake S3 bucket root name — for example, s3://aws-security-data-lake-DOC-EXAMPLE-BUCKET.
After you replace these values, navigate within the scripts folder and upload the AWS Glue PySpark Python script named azure-activity-pyspark.py, as shown in Figure 6.
Figure 6: AWS Glue script
Within your AWS Glue job, choose Job details and configure the job as follows:
For Type, select Spark Streaming.
For Language, select Python 3.
For Script path, select the S3 path that you created in the preceding step.
For Temporary path, select the S3 path that you created in the preceding step.
Save the changes, and run the AWS Glue job by selecting Save and then Run.
Choose the Runs tab, and make sure that the Run status of the job is Running.
Figure 7: AWS Glue job status
At this point, you have finished the configurations from AWS.
Step 2: Configure Azure services for Azure activity log forwarding
You will complete the next steps in the Azure Cloud console. You need to configure Azure to export activity logs to an Azure cloud event hub within your desired Azure account or organization. Additionally, you need to create an Azure function to respond to new events within the Azure event hub and forward those logs over the internet to the Kinesis data stream that the CloudFormation template created in the initial steps of this post.
Configure the following Python script — Azure Event Hub Function — in an Azure function app. This function is designed to respond to event hub events, create a connection to AWS, and forward those events to Kinesis as deserialized JSON blobs.
In the script, replace the following variables with your own information:
For <SECURITYLAKE-AZURE-STREAM-ARN>, enter the Kinesis data stream ARN.
For <SECURITYLAKE-AZURE-STREAM-NAME>, enter the Kinesis data stream name.
The <SECURITYLAKE-AZURE-STREAM-ARN> and securityLakeAzureActivityStream—<STREAM-UID> are the same variables that you obtained earlier in this post (see Figure 5).
You can find the AWS KMS key ID within the AWS KMS managed key policy associated with securityLakeAzureActivityStream. For example, in the key policy shown in Figure 8, the <SECURITYLAKE-AZURE-STREAM-KEYID> is shown in line 3.
Figure 8: Kinesis data stream inputs
Important: When you are working with KMS keys retrieved from the AWS console or AWS API keys within Azure, you should be extremely mindful of how you approach key management. Improper or poor handling of keys could result in the interception of data from the Kinesis stream or Azure function.
It’s a best security practice to use a trusted key management architecture that uses sufficient encryption and security protocols when working with keys that safeguard sensitive security information. Within Azure, consider using services such as the AWS Azure AD integration for seamless and ephemeral credential usage inside of the azure function. See – Azure AD Integration – for more information on how the Azure AD Integration works to safeguard and manage stored security keys and help make sure that no keys are accessible to unauthorized parties or stored as unencrypted text outside the AWS console.
Step 3: Validate the workflow and query Athena
After you complete the preceding steps, your logs should be flowing. To make sure that the process is working correctly, complete the following steps.
In the Kinesis Data Streams console, verify that the logs are flowing to your data stream. Open the Kinesis stream that you created previously, choose the Data viewer tab, and then choose Get records, as shown in Figure 9.
Figure 9: Kinesis data stream inputs
Verify that the logs are partitioned and stored within the correct Security Lake bucket associated with the configured Region. The log partitions within the Security Lake bucket should have the following syntax — “region=<region>/account_id=<account_id>/eventDay=<YYYYMMDD>/”, and they should be stored with the expected parquet compression.
Figure 10: S3 bucket with object
Assuming that CloudTrail logs exist within your Amazon Security Lake instance as well, you can now create a query in Athena that pulls data from the newly created Azure activity table and examine it alongside your existing CloudTrail logs by running queries such as the following:
SELECT
api.operation,
actor.user.uid,
actor.user.name,
src_endpoint.ip,
time,
severity,
metadata.version,
metadata.product.name,
metadata.product.vendor_name,
category_name,
activity_name,
type_uid,
FROM {SECURITY-LAKE-DB}.{SECURITY-LAKE-AZURE-TABLE}
UNION ALL
SELECT
api.operation,
actor.user.uid,
actor.user.name,
src_endpoint.ip,
time,
severity,
metadata.version,
metadata.product.name,
metadata.product.vendor_name,
category_name,
activity_name,
type_uid,
FROM {SECURITY-LAKE-DB}.{SECURITY-LAKE-CLOUDTRAIL-TABLE}
Figure 11: Query Azure activity and CloudTrail together in Athena
For additional guidance on how to configure access and query Amazon Security Lake in Athena, see the following resources:
In this blog post, you learned how to create and deploy the AWS and Microsoft Azure assets needed to bring your own data to Amazon Security Lake. By creating an AWS Glue streaming job that can transform Azure activity data streams and by fronting that AWS Glue job with a Kinesis stream, you can open Amazon Security Lake to intake from external Azure activity data streams.
You also learned how to configure Azure assets so that your Azure activity logs can stream to your Kinesis endpoint. The combination of these two creates a working, custom source solution for Azure activity logging.
To get started with Amazon Security Lake, see the Getting Started page, or if you already use Amazon Security Lake and want to read additional blog posts and articles about this service, see Blog posts and articles.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on Amazon Security Lake re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
Today we are thrilled to announce the general availability of Amazon Security Lake, first announced in a preview release at 2022 re:Invent. Security Lake centralizes security data from Amazon Web Services (AWS) environments, software as a service (SaaS) providers, on-premises, and cloud sources into a purpose-built data lake that is stored in your AWS account. With Open Cybersecurity Schema Framework (OCSF) support, the service normalizes and combines security data from AWS and a broad range of security data sources. This helps provide your team of analysts and security engineers with broad visibility to investigate and respond to security events, which can facilitate timely responses and helps to improve your security across multicloud and hybrid environments.
Figure 1 shows how Security Lake works, step by step. In this post, we discuss these steps, highlight some of the most popular use cases for Security Lake, and share the latest enhancements and updates that we have made since the preview launch.
Figure 1: How Security Lake works
Target use cases
In this section, we showcase some of the use cases that customers have found to be most valuable while the service was in preview.
Facilitate your security investigations with elevated visibility
Amazon Security Lake helps to streamline security investigations by aggregating, normalizing, and optimizing data storage in a single security data lake. Security Lake automatically normalizes AWS logs and security findings to the OCSF schema. This includes AWS CloudTrail management events, Amazon Virtual Private Cloud (Amazon VPC) Flow Logs, Amazon Route 53 Resolver query logs, and AWS Security Hub security findings from Amazon security services, including Amazon GuardDuty, Amazon Inspector, and AWS IAM Access Analyzer, as well as security findings from over 50 partner solutions. By having security-related logs and findings in a centralized location, and in the same format, Security Operations teams can streamline their process and devote more time to investigating security issues. This centralization reduces the need to spend valuable time collecting and normalizing logs into a specific format.
Figure 2 shows the Security Lake activation page, which presents users with options to enable log sources, AWS Regions, and accounts.
Figure 2: Security Lake activation page with options to enable log sources, Regions, and accounts
Figure 3 shows another section of the Security Lake activation page, which presents users with options to set rollup Regions and storage classes.
Figure 3: Security Lake activation page with options to select a rollup Region and set storage classes
Simplify your compliance monitoring and reporting
With Security Lake, customers can centralize security data into one or more rollup Regions, which can help teams to simplify their regional compliance and reporting obligations. Teams often face challenges when monitoring for compliance across multiple log sources, Regions, and accounts. By using Security Lake to collect and centralize this evidence, security teams can significantly reduce the time spent on log discovery and allocate more time towards compliance monitoring and reporting.
Analyze multiple years of security data quickly
Security Lake offers integration with third-party security services such as security information and event management (SIEM) and extended detection and response (XDR) tools, as well as popular data analytics services like Amazon Athena and Amazon OpenSearch Service to quickly analyze petabytes of data. This enables security teams to gain deep insights into their security data and take nimble measures to help protect their organization. Security Lake helps enforce least-privilege controls for teams across organizations by centralizing data and implementing robust access controls, automatically applying policies that are scoped to the required subscribers and sources. Data custodians can use the built-in features to create and enforce granular access controls, such as to restrict access to the data in the security lake to only those who require it.
Figure 4 depicts the process of creating a data access subscriber within Security Lake.
Figure 4: Creating a data access subscriber in Security Lake
Unify security data management across hybrid environments
The centralized data repository in Security Lake provides a comprehensive view of security data across hybrid and multicloud environments, helping security teams to better understand and respond to threats. You can use Security Lake to store security-related logs and data from various sources, including cloud-based and on-premises systems, making it simpler to collect and analyze security data. Additionally, by using automation and machine learning solutions, security teams can help identify anomalies and potential security risks more efficiently. This can ultimately lead to better risk management and enhance the overall security posture for the organization. Figure 5 illustrates the process of querying AWS CloudTrail and Microsoft Azure audit logs simultaneously by using Amazon Athena.
Figure 5: Querying AWS CloudTrail and Microsoft Azure audit logs together in Amazon Athena
Updates since preview launch
Security Lake automatically normalizes logs and events from natively supported AWS services to the OCSF schema. With the general availability release, Security Lake now supports the latest version of OCSF, which is version 1 rc2. CloudTrail management events are now normalized into three distinct OCSF event classes: Authentication, Account Change, and API Activity.
We made various improvements to resource names and schema mapping to enhance the usability of logs. Onboarding is made simpler with automated AWS Identity and Access Management (IAM) role creation from the console. Additionally, you have the flexibility to collect CloudTrail sources independently including management events, Amazon Simple Storage Service (Amazon S3) data events, and AWS Lambda events.
To enhance query performance, we made a transition from hourly to daily time partitioning in Amazon S3, resulting in faster and more efficient data retrieval. Also, we added Amazon CloudWatch metrics to enable proactive monitoring of your log ingestion process to facilitate the identification of collection gaps or surges.
New Security Lake account holders are eligible for a 15-day free trial in supported Regions. Security Lake is now generally available in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), Europe (London), and South America (São Paolo).
The AWS Professional Services organization is a global team of experts that can help customers realize their desired business outcomes when using AWS. Our teams of data architects and security engineers engage with customer Security, IT, and business leaders to develop enterprise solutions. We follow current recommendations to support customers in their journey to integrate data into Security Lake. We integrate ready-built data transformations, visualizations, and AI/machine learning (ML) workflows that help Security Operations teams rapidly realize value. If you are interested in learning more, reach out to your AWS Professional Services account representative.
Summary
We invite you to explore the benefits of using Amazon Security Lake by taking advantage of our 15-day free trial and providing your feedback on your experiences, use cases, and solutions. We have several resources to help you get started and build your first data lake, including comprehensive documentation, demo videos, and webinars. By giving Security Lake a try, you can experience firsthand how it helps you centralize, normalize, and optimize your security data, and ultimately streamline your organization’s security incident detection and response across multicloud and hybrid environments.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In this blog post, we will show you how to use Amazon Elastic Load Balancing (ELB)—specifically a Network Load Balancer—to apply a more granular control on the cipher suites that are used between clients and servers when establishing an SSL/TLS connection with Amazon API Gateway. The solution uses virtual private cloud (VPC) endpoints (powered by AWS PrivateLink) and ELB policies. By using this solution, highly regulated industries like financial services and healthcare and life sciences can exercise more control over cipher suite selection for TLS negotiation.
Configure the minimum TLS version on API Gateway
The TLS protocol is a mechanism to encrypt data in transit — data that is moving from one location to another such as across the internet or through a network. TLS requires that the client and server agree on the family of encryption algorithms — otherwise known as the cipher suite — to use to protect the communication between the client and server. The two parties agree on the cipher suite during the phase known as the TLS handshake, in which the client first provides a lists of preferred cipher suites, and the server then selects the one that it deems most appropriate.
API Gateway supports a wide range of protocols and ciphers and allows you to choose a minimum TLS version to be enforced by selecting a specific security policy. A security policy is a predefined combination of the minimum TLS version and cipher suite offered by API Gateway. Currently, you can choose either a TLS version 1.2 or TLS version 1.0 security policy. Although the usage of TLS v1.0 or TLSv1.2 covers a wide range of network security use cases, it doesn’t address the situation where you need to exclude specific ciphers that don’t meet your security requirements.
Options for granular control on TLS cipher suites
If you want to exclude specific ciphers, you can use the following solutions to offload and control the TLS connection termination with a customized cipher suite:
Amazon CloudFront distribution — Amazon CloudFront provides the TLS version and cipher suite in the CloudFront-Viewer-TLS-header, and you can configure it by using a CloudFront function on the Viewer request to then forward the appropriate traffic to an API Gateway. CloudFront is a global service that transfers customer data as an essential function of the service, so you should carefully consider its usage according to your specific use case.
Self-managed reverse proxy — Using a containerized reverse proxy (for example, an NGINX Docker image) that manages the TLS sessions and forwards traffic to an API Gateway is another approach for more granular control on the cipher suites. You can deploy and manage this solution with Amazon Elastic Container Service (Amazon ECS). You can also run Amazon ECS on AWS Fargate so that you don’t have to manage servers or clusters of Amazon Elastic Compute Cloud (Amazon EC2) instances. The self-managed reverse proxy approach entails an operational overhead associated with the configuration and management of the reverse proxy application.
Network Load Balancer — By placing a Network Load Balancer in front of an API Gateway, you can use the load balancer to terminate the TLS session on the client side, and reinitiate a new TLS session with the backend API gateway. This approach, in conjunction with the use of ELB policies, provides you with much more granular control on the cipher suite used for the communication. Network Load Balancer is a fully-managed service, meaning that it handles scalability and elasticity automatically. This represents the main advantage in comparison to a self-managed reverse proxy solution that would add operational overhead due to the need to manage the reverse proxy application and the ECS cluster.
Network Load Balancer is the solution with the most suitable set of trade-offs: it minimizes operational overhead while providing the necessary flexibility to control and secure the connection between client and server. Therefore, we focus on using Network Load Balancer in this post.
Prerequisites
To show how a Network Load Balancer can front-end an API gateway in practice, we will walk you through a real-world example. To follow along, make sure that you have the following prerequisites in place:
The application’s backend APIs consist of an API gateway with AWS Lambda function integration. The Lambda function holds the business logic.
A VPC spanning multiple Availability Zones, and private subnets already in place.
Figure 1: Sample architecture of API Gateway with Lambda backend
Use Network Load Balancer for cipher suite selection
We start with a scenario where a client interacts with the API gateway domain (for example, api.example.com) over a set of TLS/cipher combinations that are not acceptable for security reasons. In the subsequent steps, we will introduce a Network Load Balancer layer to frontend the API gateway domain without impacting the end-user interaction with the API gateway domain. In this section, we will walk you through how to make the application accessible through a Network Load Balancer and use ELB policies to exclude the TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 cipher suite. In doing so, we will limit the operational overhead as much as possible, while keeping the application scalable, elastic, and highly available.
Figure 2 shows the solution that you will build.
Figure 2: Target architecture, with a load balancer for cipher suite selection
The preceding diagram shows a workflow of the user interaction with the API gateway domain abstracted by the Network Load Balancer layer. For the first interaction, the user retrieves the API gateway domain from the Route 53 hosted zone. This API gateway domain aliases to the Network Load Balancer endpoint. In the next interaction, the user makes an HTTPS request to the domain endpoint with a TLS/cipher combination from the client side. The TLS connection is accepted or denied based on the security policy configured at the Network Load Balancer. In the rest of this post, we will walk you through how to set up this architecture.
Step 1: Create a VPC endpoint
The first step is to create a private VPC endpoint for API Gateway.
In the left navigation pane, choose Endpoints, and select Create endpoint.
For Name tag, enter a name for your endpoint. For this walkthrough, we will enter MyEndPoint as the name for the endpoint.
For Services, search for execute-api and select the service name, which will look similar to the following: com.amazonaws.<region-name>.execute-api.
For VPC, select the VPC where you want to deploy the endpoint. For this walkthrough, we will use MyVPC as the VPC.
For Subnets, select the private subnets where you want the private endpoint to be accessible. To help ensure high availability and resiliency, make sure that you select at least two subnets.
For Security Groups, select (or create) a security group for the API Gateway VPC endpoint. This security group will allow or deny traffic to the VPC endpoint. You can choose the ports and protocols along with the source and destination IP address range to allow for inbound and outbound traffic. In this example, you want the VPC endpoint to be accessed only from the Network Load Balancer, so make sure that you allow incoming traffic from the VPC’s Classless Inter-Domain Routing (CIDR) on port 443.
Leave the other configuration options as they are, and then choose Create Endpoint. Wait until the VPC endpoint is deployed.
When the VPC endpoint completes provisioning, take note of the endpoint ID and the IP addresses associated with it because you will need this information in the following steps. You will find one address for each subnet where you chose to deploy the VPC endpoint. After you select the newly created endpoint, you can find the assigned IP addresses in the Subnets tab.
Step 2: Associate API Gateway with the VPC endpoint and custom domain
The next step is to instruct the API Gateway to only accept invocations coming from the VPC endpoint, and then map your APIs with the custom domain name.
To associate API Gateway with the VPC endpoint and custom domain
In the left navigation pane, under API:<MyAPI>, choose Settings.
In the Endpoint Configuration section, for VPC Endpoint IDs, enter your VPC endpoint ID.
Leave the other configuration options as they are and choose Save Changes.
In the left navigation pane, under API:<MyAPI>, choose Resources.
Choose Actions and select Deploy API.
Select an existing stage, or if you haven’t created one yet, select [New Stage] and enter a name for the stage (for example, prod). Then choose Deploy.
Navigate back to the Amazon API Gateway console, and in the left navigation pane, choose Custom domain names.
Choose Create.
For Domain name, enter the full domain name that you plan to associate with your API Gateway (for example, api.example.com).
For ACM certificate, select the certificate for the domain that you own (for example, *.example.com).
Leave the rest as it is and choose Create domain name.
Select the domain name that you just associated with API Gateway and select API mappings.
Choose Configure API Mapping.
For API, select your API, and for Stage, select your preferred stage.
Leave the other configuration options as they are, and choose Save.
Step 3: Create a new target group for Network Load Balancer
Before creating a Network Load Balancer, you need to create a target group that it will redirect the requests to. You will configure the target group to redirect requests to the VPC endpoint.
To create a new target group for Network Load Balancer
In the left navigation pane, choose Target groups, and then choose Create target group.
For Choose a target type, select IP addresses.
For Target group name, enter your desired target group name. For this walkthrough, we will enter MyGroup as the target group name.
For Protocol, select TLS.
For Port, enter 443.
Select MyVPC.
Under Heath check protocol, select HTTPS, and under Health check path, enter /ping.
Leave the rest as it is and choose Next.
For Network, select MyVPC.
Choose Add IPv4 address and add the IP addresses associated with the VPC endpoint one by one (these are the IP address associated with the VPC endpoint and detailed in step 10 of the section Step 1: Create a VPC endpoint).
For Ports, enter 443, and then choose Include as pending below.
Choose Create target group, and then wait for the target group to complete creation.
Step 4: Create a Network Load Balancer
Now you can create the Network Load Balancer. You will configure it to redirect traffic to the target group that you defined in Step 3.
In the left navigation pane, choose Load Balancers, and then choose Create load balancer.
In the Network Load Balancer section, choose Create.
For Load balancer name, enter a name for your load balancer. For this walkthrough, we will use the name MyNLB.
For Scheme, select Internal.
For VPC, select MyVPC.
For Mappings, select the same subnets that you selected when you created the VPC endpoint in Step 1: Create a VPC endpoint.
In the Listeners and routing section, for Port, enter 443.
Forward the traffic to MyGroup.
Select a security policy that excludes the cipher suites that you don’t want to allow. To learn more about the available policies, see Security policies. In this example, we will select ELBSecurityPolicy-TLS13-1-2-Res-2021-06, which excludes the TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384 cipher.
For Default SSL cert, choose Select a certificate and then select your certificate (for example, *.example.com).
Leave the rest as it is and choose Create load balancer. Wait for the load balancer to complete deployment.
Step 5: Set up DNS forwarding
The final step is to configure the Domain Name System (DNS) to associate the custom domain name with our APIs.
To set up DNS forwarding
Open the Route53 console.
In the left navigation pane, choose Hosted zones.
Select the private hosted zone that manages your domain.
For Record type, leave the default A – Routes traffic to an IPV4 address and some AWS resources.
Turn on Alias.
For Route traffic to, select Alias to Network Load Balancer. Select the AWS Region where you deployed your resources and then select your load balancer.
Choose Create records.
Step 6: Validate your solution
At this point, you have deployed the resources that you need to implement the solution. You now need to validate that it works as expected.
Your resources are deployed in private subnets, so you need to test them by sending requests from within the private subnet itself. For example, you can do that by connecting to a Linux instance that you have running inside the private subnet.
After you have logged in to your private EC2 instance, you can validate your solution by sending requests to your endpoint.
From your terminal of choice, run the following commands. Replace <endpoint> with your chosen domain name—for example, api.example.com/<your-path>.
This command sends a GET request to API Gateway by selecting a cipher suite that’s allowed by the ELB policy. As a result, the Network Load Balancer allows the connection and returns success.
This command sends a GET request to the API Gateway by selecting a cipher suite that is excluded by the ELB policy. As a result, the Network Load Balancer denies the connection and returns an error response.
Figure 3 shows the expected behavior.
Figure 3: Target behavior: accept only connections with selected cipher suites
Conclusion
In this blog post, you learned how to use a Network Load Balancer as a reverse proxy for your private APIs managed by Amazon API Gateway. With this solution, the Network Load Balancer allows you to exclude specific cipher suites by selecting the ELB policy that’s most appropriate for your use case.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
At Amazon Web Services (AWS), we strive to continuously improve customer experience by delivering a cloud computing environment that supports the most modern security technologies. To improve the overall performance of your connections, we have already started to enable TLS version 1.3 globally across our AWS service API endpoints, and will complete this process by December 31, 2023. By using TLS 1.3, you can decrease your connection time by removing one network round trip for every connection request, and can benefit from some of the most modern and secure cryptographic cipher suites available today.
If you are using current software tools (2014 or later) including our AWS SDKs or AWS Command Line Interface (AWS CLI), you will automatically receive the benefits of TLS 1.3 with no action required on your part. This is because AWS services will negotiate the highest TLS protocol version that your client software supports. If you want to continue using TLS 1.2, you will still have full control through your client configurations. AWS will retain support for TLS 1.2, in addition to TLS 1.3, into the foreseeable future. Meanwhile, here’s the latest information on the on-going deprecation of TLS 1.0/1.1.
If you have any questions, start a new thread on AWS re:Post, or contact AWS Support or your technical account manager. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.
RSA Conference 2023 brought thousands of cybersecurity professionals to the Moscone Center in San Francisco, California from April 24 through 27.
The keynote lineup was eclectic, with more than 30 presentations across two stages featuring speakers ranging from renowned theoretical physicist and futurist Dr. Michio Kaku to Grammy-winning musician Chris Stapleton. Topics aligned with this year’s conference theme, “Stronger Together,” and focused on actions that can be taken by everyone, from the C-suite to those of us on the front lines of security, to strengthen collaboration, establish new best practices, and make our defenses more diverse and effective.
With over 400 sessions and 500 exhibitors discussing the latest trends and technologies, it’s impossible to recap every highlight. Now that the dust has settled and we’ve had time to reflect, here’s a glimpse of what caught our attention.
We announced three new capabilities for our Amazon GuardDuty threat detection service to help customers secure container, database, and serverless workloads. These include GuardDuty Elastic Kubernetes Service (EKS) Runtime Monitoring, GuardDuty RDS Protection for data stored in Amazon Aurora, and GuardDuty Lambda Protection for serverless applications. The new capabilities are designed to provide actionable, contextual, and timely security findings with resource-specific details.
Artificial intelligence
It was hard to find a single keynote, session, or conversation that didn’t touch on the impact of artificial intelligence (AI).
In “AI: Law, Policy and Common Sense Suggestions on How to Stay Out of Trouble,” privacy and gaming attorney Behnam Dayanim highlighted ambiguity around the definition of AI. Referencing a quote from University of Washington School of Law’s Ryan Calo, Dayanim pointed out that AI may be best described as “…a set of techniques aimed at approximating some aspect of cognition,” and should therefore be thought of differently than a discrete “thing” or industry sector.
Dayanim noted examples of skepticism around the benefits of AI. A recent Monmouth University poll, for example, found that 73% of Americans believe AI will make jobs less available and harm the economy, and a surprising 55% believe AI may one day threaten humanity’s existence.
Equally skeptical, he noted, is a joint statement made by the Federal Trade Commission (FTC) and three other federal agencies during the conference reminding the public that enforcement authority applies to AI. The statement takes a pessimistic view, saying that AI is “…oftenadvertised as providing insights and breakthroughs, increasing efficiencies and cost-savings, and modernizing existing practices,” but has the potential to produce negative outcomes.
Dayanim covered existing and upcoming legal frameworks around the world that are aimed at addressing AI-related risks related to intellectual property (IP), misinformation, and bias, and how organizations can design AI governance mechanisms to promote fairness, competence, transparency, and accountability.
Many other discussions focused on the immense potential of AI to automate and improve security practices. RSA Security CEO Rohit Ghai explored the intersection of progress in AI with human identity in his keynote. “Access management and identity management are now table stakes features”, he said. In the AI era, we need an identity security solution that will secure the entire identity lifecycle—not just access. To be successful, he believes, the next generation of identity technology needs to be powered by AI, open and integrated at the data layer, and pursue a security-first approach. “Without good AI,” he said, “zero trust has zero chance.”
Mark Ryland, director at the Office of the CISO at AWS, spoke with Infosecurity about improving threat detection with generative AI.
“We’re very focused on meaningful data and minimizing false positives. And the only way to do that effectively is with machine learning (ML), so that’s been a core part of our security services,” he noted.
“Machine learning and artificial intelligence will add a critical layer of automation to cloud security. AI/ML will help augment developers’ workstreams, helping them create more reliable code and drive continuous security improvement. — CJ Moses, CISO and VP of security engineering at AWS
The human element
Dozens of sessions focused on the human element of security, with topics ranging from the psychology of DevSecOps to the NIST Phish Scale. In “How to Create a Breach-Deterrent Culture of Cybersecurity, from Board Down,” Andrzej Cetnarski, founder, chairman, and CEO of Cyber Nation Central and Marcus Sachs, deputy director for research at Auburn University, made a data-driven case for CEOs, boards, and business leaders to set a tone of security in their organizations, so they can address “cyber insecure behaviors that lead to social engineering” and keep up with the pace of cybercrime.
Lisa Plaggemier, executive director of the National Cybersecurity Alliance, and Jenny Brinkley, director of Amazon Security, stressed the importance of compelling security awareness training in “Engagement Through Entertainment: How To Make Security Behaviors Stick.” Education is critical to building a strong security posture, but as Plaggemier and Brinkley pointed out, we’re “living through an epidemic of boringness” in cybersecurity training.
According to a recent report, just 28% of employees say security awareness training is engaging, and only 36% say they pay full attention during such training.
Citing a United Airlines preflight safety video and Amazon’s Protect and Connect public service announcement (PSA) as examples, they emphasized the need to make emotional connections with users through humor and unexpected elements in order to create memorable training that drives behavioral change.
Plaggemeier and Brinkley detailed five actionable steps for security teams to improve their awareness training:
Brainstorm with staff throughout the company (not just the security people)
Find ideas and inspiration from everywhere else (TV episodes, movies… anywhere but existing security training)
Be relatable, and include insights that are relevant to your company and teams
Start small; you don’t need a large budget to add interest to your training
Don’t let naysayers deter you — change often prompts resistance
“You’ve got to make people care. And so you’ve got to find out what their personal motivators are, and how to develop the type of content that can make them care to click through the training and…remember things as they’re walking through an office.” — Jenny Brinkley, director of Amazon Security
Cloud security
Cloud security was another popular topic. In “Architecting Security for Regulated Workloads in Hybrid Cloud,” Mark Buckwell, cloud security architect at IBM, discussed the architectural thinking practices—including zero trust—required to integrate security and compliance into regulated workloads in a hybrid cloud environment.
Maor highlighted common tactics focused on identity theft, including MFA push fatigue, phishing, business email compromise, and adversary-in-the middle attacks. After detailing techniques that are used to establish persistence in SaaS environments and deliver ransomware, Maor emphasized the importance of forensic investigation and threat hunting to gaining the knowledge needed to reduce the impact of SaaS security incidents.
Sarah Currey, security practice manager, and Anna McAbee, senior solutions architect at AWS, provided complementary guidance in “Top 10 Ways to Evolve Cloud Native Incident Response Maturity.” Currey and McAbee highlighted best practices for addressing incident response (IR) challenges in the cloud — no matter who your provider is:
Define roles and responsibilities in your IR plan
Train staff on AWS (or your provider)
Develop cloud incident response playbooks
Develop account structure and tagging strategy
Run simulations (red team, purple team, tabletop)
Prepare access
Select and set up logs
Enable managed detection services in all available AWS Regions
Determine containment strategy for resource types
Develop cloud forensics capabilities
Speaking to BizTech, Clarke Rodgers, director of enterprise strategy at AWS, noted that tools and services such as Amazon GuardDuty and AWS Key Management Service (AWS KMS) are available to help advance security in the cloud. When organizations take advantage of these services and use partners to augment security programs, they can gain the confidence they need to take more risks, and accelerate digital transformation and product development.
Security takes a village
There are more highlights than we can mention on a variety of other topics, including post-quantum cryptography, data privacy, and diversity, equity, and inclusion. We’ve barely scratched the surface of RSA Conference 2023. If there is one key takeaway, it is that no single organization or individual can address cybersecurity challenges alone. By working together and sharing best practices as an industry, we can develop more effective security solutions and stay ahead of emerging threats.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
With Amazon Detective, you can analyze and visualize security data to investigate potential security issues. Detective collects and analyzes events that describe IP traffic, AWS management operations, and malicious or unauthorized activity from AWS CloudTrail logs, Amazon Virtual Private Cloud (Amazon VPC)Flow Logs, Amazon GuardDuty findings, and, since last year, Amazon Elastic Kubernetes Service (EKS) audit logs. Using this data, Detective constructs a graph model that distills log data using machine learning, statistical analysis, and graph theory to build a linked set of data for your security investigations.
Starting today, Detective offers investigation support for findings in AWS Security Hub in addition to those detected by GuardDuty. Security Hub is a service that provides you with a view of your security state in AWS and helps you check your environment against security industry standards and best practices. If you’ve turned on Security Hub and another integrated AWS security services, those services will begin sending findings to Security Hub.
Enabling AWS Security Findings in the Amazon Detective Console When you enable Detective for the first time, Detective now identifies findings coming from both GuardDuty and Security Hub, and automatically starts ingesting them along with other data sources. Note that you don’t need to enable or publish these log sources for Detective to start its analysis because this is managed directly by Detective.
If you are an existing Detective customer, you can enable investigation of AWS Security Findings as a data source with one click in the Detective Management Console. I already have Detective enabled, so I add the source package.
In the Detective console, in the Settings section of the navigation pane, I choose General. There, I choose Edit in the Optional source packages section to enable Detective for AWS Security Findings.
Once enabled, Detective starts analyzing all the relevant data to identify connections between disparate events and activities. To start your investigation process, you can get a visualization of these connections, including resource behavior and activities. Historical baselines, which you can use to provide comparisons against recent activity, are established after two weeks.
Investigating AWS Security Findings in the Amazon Detective Console I start in the Security Hub console and choose Findings in the navigation pane. There, I filter findings to only see those where the Product name is Inspector and Severity label is HIGH.
The first one looks suspicious, so I choose its Title (CVE-2020-36223 – openldap). The Security Hub console provides me with information about the corresponding Common Vulnerabilities and Exposures (CVE) ID and where and how it was found. At the bottom, I have the option to Investigate in Amazon Detective. I follow the Investigate finding link, and the Detective console opens in another browser tab.
Here, I see the entities related to this Inspector finding. First, I open the profile of the AWS account to see all the findings associated with this resource, the overall API call volume issued by this resource, and the container clusters in this account.
For example, I look at the successful and failed API calls to have a better understanding of the impact of this finding.
Then, I open the profile for the container image. There, I see the images that are related to this image (because they have the same repository or registry as this image), the containers running from this image during the scope time (managed by Amazon EKS), and the findings associated with this resource.
Depending on the finding, Detective helps me correlate information from different sources such as CloudTrail logs, VPC Flow Logs, and EKS audit logs. This information makes it easier to understand the impact of the finding and if the risk has become an incident. For Security Hub, Detective only ingests findings for configuration checks that failed. Because configuration checks that passed have little security value, we’re filtering these outs.
Availability and Pricing Amazon Detective investigation support for AWS Security Findings is available today for all existing and new Detective customers in all AWS Regions where Detective is available, including the AWS GovCloud (US) Regions. For more information, see the AWS Regional Services List.
Amazon Detective is priced based on the volume of data ingested. By enabling investigation of AWS Security Findings, you can increase the volume of ingested data. For more information, see Amazon Detective pricing.
When GuardDuty and Security Hub provide a finding, they also suggest the remediation. On top of that, Detective helps me investigate if the vulnerability has been exploited, for example, using logs and network traffic as proof.
Currently, findings coming from Security Hub are not included in the Finding groups section of the Detective console. Our plan is to expand Finding groups to cover the newly integrated AWS security services. Stay tuned!
A full conference pass is $1,099. Register today with the code secure150off to receive a limited time $150 discount, while supplies last.
AWS re:Inforce is back, and we can’t wait to welcome security builders to Anaheim, CA, on June 13 and 14. AWS re:Inforce is a security learning conference where you can gain skills and confidence in cloud security, compliance, identity, and privacy. As an attendee, you will have access to hundreds of technical and non-technical sessions, an Expo featuring AWS experts and security partners with AWS Security Competencies, and keynote and leadership sessions featuring Security leadership. re:Inforce 2023 features content across the following six areas:
Data protection
Governance, risk, and compliance
Identity and access management
Network and infrastructure security
Threat detection and incident response
Application security
The threat detection and incident response track is designed to showcase how AWS, customers, and partners can intelligently detect potential security risks, centralize and streamline security management at scale, investigate and respond quickly to security incidents across their environment, and unlock security innovation across hybrid cloud environments.
Breakout sessions, chalk talks, and lightning talks
TDR201 | Breakout session | How Citi advanced their containment capabilities through automation Incident response is critical for maintaining the reliability and security of AWS environments. To support the 28 AWS services in their cloud environment, Citi implemented a highly scalable cloud incident response framework specifically designed for their workloads on AWS. Using AWS Step Functions and AWS Lambda, Citi’s automated and orchestrated incident response plan follows NIST guidelines and has significantly improved its response time to security events. In this session, learn from real-world scenarios and examples on how to use AWS Step Functions and other core AWS services to effectively build and design scalable incident response solutions.
TDR202 | Breakout session | Wix’s layered security strategy to discover and protect sensitive data Wix is a leading cloud-based development platform that empowers users to get online with a personalized, professional web presence. In this session, learn how the Wix security team layers AWS security services including Amazon Macie, AWS Security Hub, and AWS Identity and Access Management Access Analyzer to maintain continuous visibility into proper handling and usage of sensitive data. Using AWS security services, Wix can discover, classify, and protect sensitive information across terabytes of data stored on AWS and in public clouds as well as SaaS applications, while empowering hundreds of internal developers to drive innovation on the Wix platform.
TDR203 | Breakout session | Vulnerability management at scale drives enterprise transformation Automating vulnerability management at scale can help speed up mean time to remediation and identify potential business-impacting issues sooner. In this session, explore key challenges that organizations face when approaching vulnerability management across large and complex environments, and consider the innovative solutions that AWS provides to help overcome them. Learn how customers use AWS services such as Amazon Inspector to automate vulnerability detection, streamline remediation efforts, and improve compliance posture. Whether you’re just getting started with vulnerability management or looking to optimize your existing approach, gain valuable insights and inspiration to help you drive innovation and enhance your security posture with AWS.
TDR204 | Breakout session | Continuous innovation in AWS detection and response services Join this session to learn about the latest advancements and most recent AWS launches in detection and response. This session focuses on use cases such as automated threat detection, continual vulnerability management, continuous cloud security posture management, and unified security data management. Through these examples, gain a deeper understanding of how you can seamlessly integrate AWS services into your existing security framework to gain greater control and insight, quickly address security risks, and maintain the security of your AWS environment.
TDR205 | Breakout session | Build your security data lake with Amazon Security Lake, featuring Interpublic Group Security teams want greater visibility into security activity across their entire organizations to proactively identify potential threats and vulnerabilities. Amazon Security Lake automatically centralizes security data from cloud, on-premises, and custom sources into a purpose-built data lake stored in your account and allows you to use industry-leading AWS and third-party analytics and ML tools to gain insights from your data and identify security risks that require immediate attention. Discover how Security Lake can help you consolidate and streamline security logging at scale and speed, and hear from an AWS customer, Interpublic Group (IPG), on their experience.
TDR209 | Breakout session | Centralizing security at scale with Security Hub & Intuit’s experience As organizations move their workloads to the cloud, it becomes increasingly important to have a centralized view of security across their cloud resources. AWS Security Hub is a powerful tool that allows organizations to gain visibility into their security posture and compliance status across their AWS accounts and Regions. In this session, learn about Security Hub’s new capabilities that help simplify centralizing and operationalizing security. Then, hear from Intuit, a leading financial software company, as they share their experience and best practices for setting up and using Security Hub to centralize security management.
TDR210 | Breakout session | Streamline security analysis with Amazon Detective Join us to discover how to streamline security investigations and perform root-cause analysis with Amazon Detective. Learn how to leverage the graph analysis techniques in Detective to identify related findings and resources and investigate them together to accelerate incident analysis. Also hear a customer story about their experience using Detective to analyze findings automatically ingested from Amazon GuardDuty, and walk through a sample security investigation.
TDR310 | Breakout session | Developing new findings using machine learning in Amazon GuardDuty Amazon GuardDuty provides threat detection at scale, helping you quickly identify and remediate security issues with actionable insights and context. In this session, learn how GuardDuty continuously enhances its intelligent threat detection capabilities using purpose-built machine learning models. Discover how new findings are developed for new data sources using novel machine learning techniques and how they are rigorously evaluated. Get a behind-the-scenes look at GuardDuty findings from ideation to production, and learn how this service can help you strengthen your security posture.
TDR311 | Breakout session | Securing data and democratizing the alert landscape with an event-driven architecture Security event monitoring is a unique challenge for businesses operating at scale and seeking to integrate detections into their existing security monitoring systems while using multiple detection tools. Learn how organizations can triage and raise relevant cloud security findings across a breadth of detection tools and provide results to downstream security teams in a serverless manner at scale. We discuss how to apply a layered security approach to evaluate the security posture of your data, protect your data from potential threats, and automate response and remediation to help with compliance requirements.
TDR231 | Chalk talk | Operationalizing security findings at scale You enabled AWS Security Hub standards and checks across your AWS organization and in all AWS Regions. What should you do next? Should you expect zero critical and high findings? What is your ideal state? Is achieving zero findings possible? In this chalk talk, learn about a framework you can implement to triage Security Hub findings. Explore how this framework can be applied to several common critical and high findings, and take away mechanisms to prioritize and respond to security findings at scale.
TDR232 | Chalk talk | Act on security findings using Security Hub’s automation capabilities Alert fatigue, a shortage of skilled staff, and keeping up with dynamic cloud resources are all challenges that exist when it comes to customers successfully achieving their security goals in AWS. In order to achieve their goals, customers need to act on security findings associated with cloud-based resources. In this session, learn how to automatically, or semi-automatically, act on security findings aggregated in AWS Security Hub to help you secure your organization’s cloud assets across a diverse set of accounts and Regions.
TDR233 | Chalk talk | How LLA reduces incident response time with AWS Systems Manager Liberty Latin America (LLA) is a leading telecommunications company operating in over 20 countries across Latin America and the Caribbean. LLA offers communications and entertainment services, including video, broadband internet, telephony, and mobile services. In this chalk talk, discover how LLA implemented a security framework to detect security issues and automate incident response in more than 180 AWS accounts accessed by internal stakeholders and third-party partners using AWS Systems Manager Incident Manager, AWS Organizations, Amazon GuardDuty, and AWS Security Hub.
TDR432 | Chalk talk | Deep dive into exposed credentials and how to investigate them In this chalk talk, sharpen your detection and investigation skills to spot and explore common security events like unauthorized access with exposed credentials. Learn how to recognize the indicators of such events, as well as logs and techniques that unauthorized users use to evade detection. The talk provides knowledge and resources to help you immediately prepare for your own security investigations.
TDR332 | Chalk talk | Speed up zero-day vulnerability response In this chalk talk, learn how to scale vulnerability management for Amazon EC2 across multiple accounts and AWS Regions. Explore how to use Amazon Inspector, AWS Systems Manager, and AWS Security Hub to respond to zero-day vulnerabilities, and leave knowing how to plan, perform, and report on proactive and reactive remediations.
TDR333 | Chalk talk | Gaining insights from Amazon Security Lake You’ve created a security data lake, and you’re ingesting data. Now what? How do you use that data to gain insights into what is happening within your organization or assist with investigations and incident response? Join this chalk talk to learn how analytics services and security information and event management (SIEM) solutions can connect to and use data stored within Amazon Security Lake to investigate security events and identify trends across your organization. Leave with a better understanding of how you can integrate Amazon Security Lake with other business intelligence and analytics tools to gain valuable insights from your security data and respond more effectively to security events.
TDR431 | Chalk talk | The anatomy of a ransomware event Ransomware events can cost governments, nonprofits, and businesses billions of dollars and interrupt operations. Early detection and automated responses are important steps that can limit your organization’s exposure. In this chalk talk, examine the anatomy of a ransomware event that targets data residing in Amazon RDS and get detailed best practices for detection, response, recovery, and protection.
TDR221 | Lightning talk | Streamline security operations and improve threat detection with OCSF Security operations centers (SOCs) face significant challenges in monitoring and analyzing security telemetry data from a diverse set of sources. This can result in a fragmented and siloed approach to security operations that makes it difficult to identify and investigate incidents. In this lightning talk, get an introduction to the Open Cybersecurity Schema Framework (OCSF) and its taxonomy constructs, and see a quick demo on how this normalized framework can help SOCs improve the efficiency and effectiveness of their security operations.
TDR222 | Lightning talk | Security monitoring for connected devices across OT, IoT, edge & cloud With the responsibility to stay ahead of cybersecurity threats, CIOs and CISOs are increasingly tasked with managing cybersecurity risks for their connected devices including devices on the operational technology (OT) side of the company. In this lightning talk, learn how AWS makes it simpler to monitor, detect, and respond to threats across the entire threat surface, which includes OT, IoT, edge, and cloud, while protecting your security investments in existing third-party security tools.
TDR223 | Lightning talk | Bolstering incident response with AWS Wickr enterprise integrations Every second counts during a security event. AWS Wickr provides end-to-end encrypted communications to help incident responders collaborate safely during a security event, even on a compromised network. Join this lightning talk to learn how to integrate AWS Wickr with AWS security services such as Amazon GuardDuty and AWS WAF. Learn how you can strengthen your incident response capabilities by creating an integrated workflow that incorporates GuardDuty findings into a secure, out-of-band communication channel for dedicated teams.
TDR224 | Lightning talk | Securing the future of mobility: Automotive threat modeling Many existing automotive industry cybersecurity threat intelligence offerings lack the connected mobility insights required for today’s automotive cybersecurity threat landscape. Join this lightning talk to learn about AWS’s approach to developing an automotive industry in-vehicle, domain-specific threat intelligence solution using AWS AI/ML services that proactively collect, analyze, and deduce threat intelligence insights for use and adoption across automotive value chains.
Hands-on sessions (builders’ sessions and workshops)
TDR251 | Builders’ session | Streamline and centralize security operations with AWS Security Hub AWS Security Hub provides you with a comprehensive view of the security state of your AWS resources by collecting security data from across AWS accounts, Regions, and services. In this builders’ session, explore best practices for using Security Hub to manage security posture, prioritize security alerts, generate insights, automate response, and enrich findings. Come away with a better understanding of how to use Security Hub features and practical tips for getting the most out of this powerful service.
TDR351 | Builders’ session | Broaden your scope: Analyze and investigate potential security issues In this builders’ session, learn how you can more efficiently triage potential security issues with a dynamic visual representation of the relationship between security findings and associated entities such as accounts, IAM principals, IP addresses, Amazon S3 buckets, and Amazon EC2 instances. With Amazon Detective finding groups, you can group related Amazon GuardDuty findings to help reduce time spent in security investigations and in understanding the scope of a potential issue. Leave this hands-on session knowing how to quickly investigate and discover the root cause of an incident.
TDR352 | Builders’ session | How to automate containment and forensics for Amazon EC2 In this builders’ session, learn how to deploy and scale the self-service Automated Forensics Orchestrator for Amazon EC2 solution, which gives you a standardized and automated forensics orchestration workflow capability to help you respond to Amazon EC2 security events. Explore the prerequisites and ways to customize the solution to your environment.
TDR353 | Builders’ session | Detecting suspicious activity in Amazon S3 Have you ever wondered how to uncover evidence of unauthorized activity in your AWS account? In this builders’ session, join the AWS Customer Incident Response Team (CIRT) for a guided simulation of suspicious activity within an AWS account involving unauthorized data exfiltration and Amazon S3 bucket and object data deletion. Learn how to detect and respond to this malicious activity using AWS services like AWS CloudTrail, Amazon Athena, Amazon GuardDuty, Amazon CloudWatch, and nontraditional threat detection services like AWS Billing to uncover evidence of unauthorized use.
TDR354 | Builders’ session | Simulate and detect unwanted IMDS access due to SSRF Using appropriate security controls can greatly reduce the risk of unauthorized use of web applications. In this builders’ session, find out how the server-side request forgery (SSRF) vulnerability works, how unauthorized users may try to use it, and most importantly, how to detect it and prevent it from being used to access the instance metadata service (IMDS). Also, learn some of the detection activities that the AWS Customer Incident Response Team (CIRT) performs when responding to security events of this nature.
TDR341 | Code talk | Investigating incidents with Amazon Security Lake & Jupyter notebooks In this code talk, watch as experts live code and build an incident response playbook for your AWS environment using Jupyter notebooks, Amazon Security Lake, and Python code. Leave with a better understanding of how to investigate and respond to a security event and how to use these technologies to more effectively and quickly respond to disruptions.
TDR441 | Code talk | How to run security incident response in your Amazon EKS environment Join this Code Talk to get both an adversary’s and a defender’s point of view as AWS experts perform live exploitation of an application running on multiple Amazon EKS clusters, invoking an alert in Amazon GuardDuty. Experts then walk through incident response procedures to detect, contain, and recover from the incident in near real-time. Gain an understanding of how to respond and recover to Amazon EKS-specific incidents as you watch the events unfold.
TDR271-R | Workshop | Chaos Kitty: Gamifying incident response with chaos engineering When was the last time you simulated an incident? In this workshop, learn to build a sandbox environment to gamify incident response with chaos engineering. You can use this sandbox to test out detection capabilities, play with incident response runbooks, and illustrate how to integrate AWS resources with physical devices. Walk away understanding how to get started with incident response and how you can use chaos engineering principles to create mechanisms that can improve your incident response processes.
TDR371-R | Workshop | Threat detection and response on AWS Join AWS experts for a hands-on threat detection and response workshop using Amazon GuardDuty, AWS Security Hub, and Amazon Detective. This workshop simulates security events for different types of resources and behaviors and illustrates both manual and automated responses with AWS Lambda. Dive in and learn how to improve your security posture by operationalizing threat detection and response on AWS.
TDR372-R | Workshop | Container threat detection with AWS security services Join AWS experts for a hands-on container security workshop using AWS threat detection and response services. This workshop simulates scenarios and security events while using Amazon EKS and demonstrates how to use different AWS security services to detect and respond to events and improve your security practices. Dive in and learn how to improve your security posture when running workloads on Amazon EKS.
Browse the full re:Inforce catalog to get details on additional sessions and content at the event, including gamified learning, leadership sessions, partner sessions, and labs.
If you want to learn the latest threat detection and incident response best practices and updates, join us in California by registering for re:Inforce 2023. We look forward to seeing you there!
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
At Amazon Web Services (AWS), we’re committed to providing our customers with continued assurance over the security, availability, confidentiality, and privacy of the AWS control environment.
We’re proud to deliver the Spring 2023 System and Organization Controls (SOC) 1, 2 and 3 reports, which cover October 1, 2022, to March 31, 2023, to support your confidence in AWS services. SOC reports are independent third-party examination reports that demonstrate how AWS achieves key compliance controls and objectives.
In the past, the Privacy SOC 2 report was issued separately from the other reports. However, starting with this Spring 2023 reporting cycle, the SOC 2 report is now consolidated and covers the Security, Availability, Confidentiality, and Privacy Trust Service Criteria.
The Spring 2023 SOC reports include four additional services in scope, for a total of 158 services. See the full list on our Services in Scope by Compliance Program page.
The following are the four additional services now in scope for the Spring 2023 SOC reports:
Five additional AWS Regions have been added to the scope, for a total of 29 Regions. The following are the five additional Regions now in scope for the Spring 2023 SOC reports:
Australia: Asia Pacific (Melbourne) (ap-southeast-4)
India: Asia Pacific (Hyderabad) (ap-south-2)
Spain: Europe (Spain) (eu-south-2)
Switzerland: Europe (Zurich) (eu-central-2)
United Arab Emirates: Middle East (UAE) (me-central-1)
AWS strives to bring services into the scope of its compliance programs to help you meet your architectural and regulatory needs. If there are additional AWS services you would like to see added to the scope of our SOC reports (or other compliance programs), reach out to your AWS representatives.
As always, we value your feedback and questions. Feel free to reach out to the team through the Contact Us page. If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security how-to-content, news, and feature announcements? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.