Post Syndicated from Emmanuel Isimah original https://aws.amazon.com/blogs/security/consolidating-controls-in-security-hub-the-new-controls-view-and-consolidated-findings/
In this blog post, we focus on two recently released features of AWS Security Hub: the consolidated controls view and consolidated control findings. You can use these features to manage controls across standards and to consolidate findings, which can help you significantly reduce finding noise and administrative overhead.
Security Hub is a cloud security posture management service that you can use to apply security best practice controls, such as “EC2 instances should not have a public IP address.” With Security Hub, you can check that your environment is properly configured and that your existing configurations don’t pose a security risk. Security Hub has more than 200 controls that cover more than 30 AWS services, such as Amazon Elastic Compute Cloud (Amazon EC2), Amazon Simple Storage Service (Amazon S3), and AWS Lambda. In addition, Security Hub has integrations with more than 85 partner products. Security Hub can centralize findings across your AWS accounts and AWS Regions into a single delegated administrator account in your aggregation Region of choice, creating a single pane of glass to view findings. This can help you to triage, investigate, and respond to findings in a simpler way and improve your security posture.
The Security Hub controls are grouped into the following security standards:
- AWS Foundational Security Best Practices (FSBP) standard, which has been curated by AWS security specialists
- Payment Card Industry Data Security Standard (PCI DSS) version 3.2.1
- Center for Internet Security (CIS) AWS Foundations Benchmark versions 1.2.0 and 1.4.0
- National Institute of Standards and Technology (NIST) Special Publication 800-53 Rev. 5
- Service Managed Standard for AWS Control Tower
With the new features — consolidated controls view and consolidated control findings—you can now do the following:
- Enable or disable controls across standards in a single action. Previously, if you wanted to maintain the same enablement status of controls between standards, you had to take the same action across multiple standards (up to six times!).
- If you choose to turn on consolidated control findings, you will receive only a single finding for a security check, even if the security check is enabled across several standards. This reduces the number of findings and helps you focus on the most important misconfigured resources in your AWS environment. It allows you to apply actions and updates (such as suppressing the finding or changing its severity) one time rather than having to do so multiple times across non-consolidated findings.
Overview of new features
Now we’ll discuss some of the details of how you can use the two new features to streamline the management of controls.
The new consolidated controls view
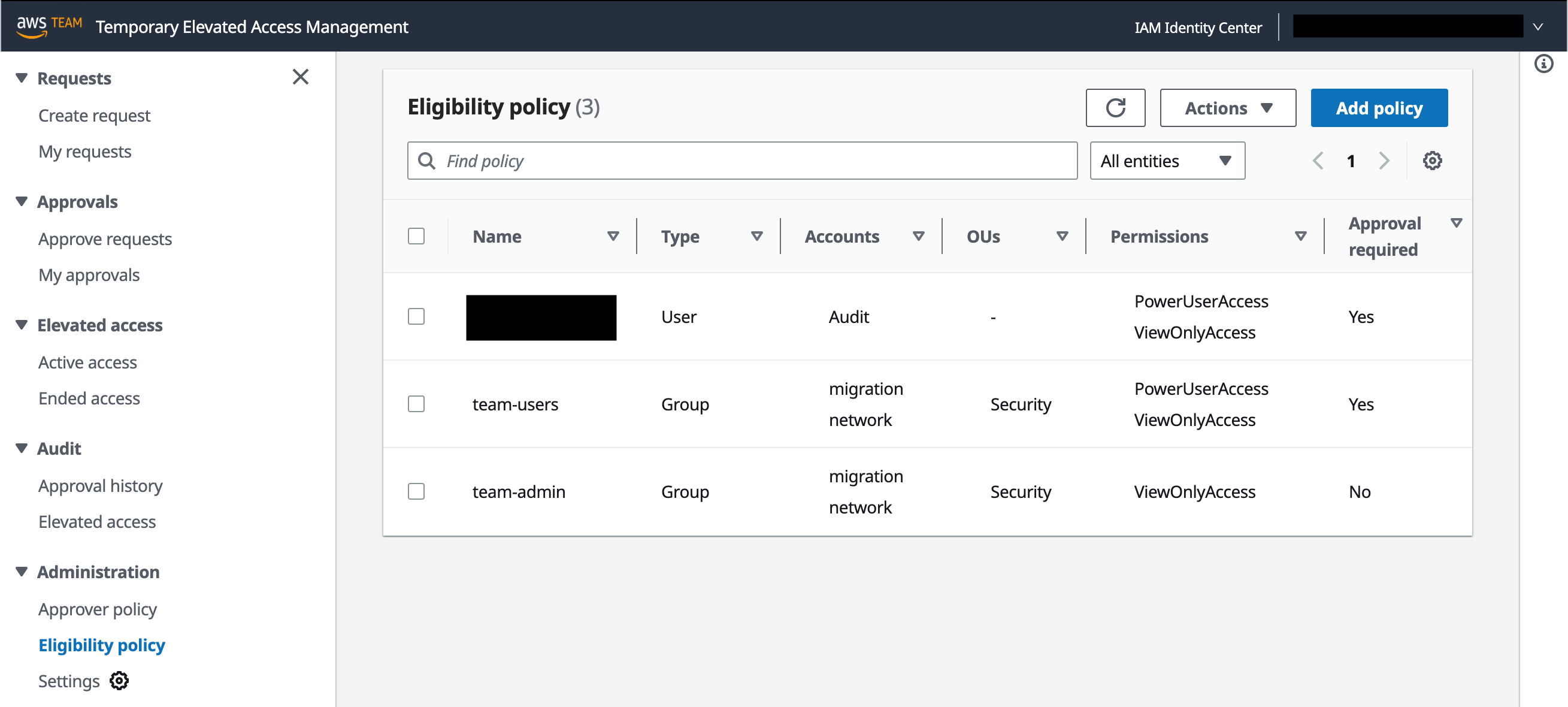
On the new Controls page, now available in the Security Hub console as shown in Figure 1, you can view and configure security controls across standards from one central location.

Figure 1: Security Hub Controls page
Before this release, controls had to be managed within the context of individual security standards. Even if the same control was part of multiple standards, the control had different IDs in each of them. With this recent release, Security Hub now assigns controls a unique security control ID across standards, so that it’s simpler for you to reference the controls and view their findings. Following the current naming convention of the AWS FSBP standard, the consolidated control IDs start with the relevant service in scope for the control. In fact, whenever possible, the new consolidated control ID is the same as the previous FSBP control ID.
For example, before this release, control IAM.6 in FSBP was also referenced as 1.14 in CIS 1.2, and 1.6 in CIS 1.4, PCI.IAM.4, and CT.IAM.6. After the release, the control is now referenced as IAM.6 in the Security Hub standards. This change does not affect the pre-existing API calls for Security Hub, such as UpdateStandardsControl, where you can still provide the previous StandardControlARN in order to make the call.
By using the new Controls view, you can understand the status of controls across your system, view control findings, and prioritize next steps without context switching. The following information is available on the Controls page of the Security Hub console:
- An overall security score, which is based on the proportion of passed controls to the total number of enabled controls.
- A breakdown of security checks across controls, with the percentage of failed security checks highlighted. Because many controls can contain multiple security checks and multiple findings, this value might be different from the security score, which considers controls as a single object. You can use this metric, as well as your security score, to monitor your progress as you work to remediate findings.
- A list of controls that are categorized into different tabs based on enablement and compliance status. If you are an administrator of an organization within Security Hub, the enablement and compliance status will reflect the aggregate status of the entire organization. In your finding aggregation Region, the status will also be aggregated across linked Regions.
From the controls page, you can select a control to view its details (including its title and the standards it belongs to), and view and act on the findings generated by the control.
Security Hub also offers new API operations that match the capabilities of the controls page. Unlike the pre-existing API operations, these new API operations use the consolidated control IDs (also known as security control IDs) to provide a way to know and manage the relationship between controls and standards. You can use these API operations to manage each Security Hub control across standards, to make sure that the status of controls in the standards is aligned. The new API operations include the following:
- BatchGetSecurityControls — Given a list of security control IDs, returns the full definition of those controls.
- BatchGetStandardsControlAssociations — Given a list of security control IDs and standards, returns whether each control is turned on in the relevant standard or not.
- BatchUpdateStandardsControlAssociations — Allows you to update the enablement status of controls across standards. You can use this API operation to align the status of a security control across standards. For more information, see Enabling and disabling controls in all standards.
- ListSecurityControlDefinitions — Returns the list of security controls that are a part of a specific standard.
- ListStandardsControlAssociations –— Given a security control ID, returns the standards that the control is a part of.
We also provide an example script that makes use of these API calls and applies them across accounts and Regions so that your configuration is consistent. You can use our script to enable or disable Security Hub controls across your various accounts or Regions.
Consolidating control findings between standards
Before we released the consolidated control findings feature, Security Hub generated separate findings per standard for each related control. Now, you can turn on consolidated control findings, and after doing so, Security Hub will produce a single finding per security check, even when the underlying control is shared across multiple standards. Having a single finding per check across standards will help you investigate, update, and remediate failed findings more quickly, while also reducing finding noise.
As an example, we can look at control CloudTrail.2, which is shared between standards supported by Security Hub. Before you turn on this capability, you might potentially receive up to six findings for each security check generated by this control—with one finding for each security standard. After you turn on consolidated control findings, these older findings will be archived and Security Hub will generate one finding per security check in this control, regardless of how many security standards you have enabled. For an example of how the standard-specific findings compare to the new consolidated finding, see Sample control findings. The following is an example of a consolidated finding for the CloudTrial.2 control; we’ve highlighted the part that shows this finding is shared across standards.
To turn on consolidated control findings
- Open the Security Hub console.
- In the left navigation pane, choose Settings, and then choose the General tab.
- Under Controls, turn on Consolidated control findings, and then choose Save.

Figure 2: Turn on consolidated control findings
If you are using the Security Hub integration with AWS Organizations or have invited member accounts through a manual invitation process, consolidated control findings can only be turned on by the administrator account. When this action is taken in the administrator account, the action will also be reflected in each member account in the current Region. It can take up to 18 hours for Security Hub to archive existing standard-specific findings and generate the new, standard-agnostic, findings.
You can also enable consolidated control findings by using the API (calling the UpdateSecurityHubConfiguration API with the ControlFindingGenerator parameter equal to SECURITY_CONTROL), or by using the AWS CLI (running the update-security-hub-configuration command with control-finding-generator equal to SECURITY_CONTROL), as in the following example.
Much like the console behavior, if you have an organizational setup in Security Hub, this API action can only be taken by the administrator, and it will be reflected in each member account in the same Region.
What to expect when you enable consolidated control findings
To allow for these new capabilities to be launched, changes to the AWS Security Finding Format (ASFF) are required. This format is used by Security Hub for findings it generates from its controls or ingests from external providers. When you turn on finding consolidation, Security Hub will archive old standard-specific findings and generate standard-agnostic findings instead. This action will only affect control findings that Security Hub generates, and it will not affect findings ingested from partner products. However, in Security Hub findings, turning on consolidated control findings might cause some updates that you previously made to findings to be archived. Despite this one-time change, after the migration is complete (it can take up to 18 hours), you will be able to update finding fields in a single action and the updates will apply across standards, without the need to make multiple updates.
One field affected by the new capabilities is the Workflow field, which provides information about the status of the investigation into a finding. Manipulating this field can also update the overall compliance status of the control that the finding is related to. For example, if you have a control with one failed finding (and the rest have passed), and the failed finding comes from a resource for which you’d like to make an exception, you can decide to suppress that failed finding by updating the Workflow field. If you suppress failed findings in a control, its compliance status can change to pass.
Before turning on consolidated control findings, if you want to maintain an aligned compliance status in controls that belong to multiple standards, you have to update the Workflow status of findings in each standard. After turning on finding consolidation, you will only have to update the Workflow status once, and the suppression will be applied across standards, helping you to reduce the number of steps needed to suppress the same findings across standards.
As mentioned earlier, when you turn on this new capability, some updates made to the previous, standard-specific findings will be archived and will not be included in the new consolidated control findings generated by Security Hub. In the case of the Workflow status, the new consolidated findings will be created with a value of NEW (for failed findings) or RESOLVED (for new findings) in the Workflow field. However, after you have onboarded to the new finding format, you can update the value of the Workflow field, as well as other fields, and this value will be maintained without requiring you to make continuous updates. For the full list of fields that can be affected by the migration to the consolidated finding format, see Consolidated control findings – ASFF changes. Before you turn on finding consolidation, we suggest that you check if your custom automations refer to those affected fields. If they do, you can update your automations and test them by using the Sample control findings in the documentation.
Conclusion
This blog post covers new Security Hub features that make it simpler for you to manage controls across standards. With the new consolidated control findings feature, you can focus on the most relevant findings and reduce noise, which is why we recommend that you review the new feature and its associated changes and turn it on at your earliest convenience.
If you have feedback about this blog post, submit comments in the Comments section below. If you have questions about this blog post, start a new thread on the Security Hub forum or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.