Post Syndicated from Girish Kumar Chidananda original https://aws.amazon.com/blogs/big-data/a-dive-into-redbuss-data-platform-and-how-they-used-amazon-quicksight-to-accelerate-business-insights/
This post is co-authored with Girish Kumar Chidananda from redBus.
redBus is one of the earliest adopters of AWS in India, and most of its services and applications are hosted on the AWS Cloud. AWS provided redBus the flexibility to scale their infrastructure rapidly while keeping costs extremely low. AWS has a comprehensive suite of services to cater to most of their needs, including providing customer support that redBus can vouch for.
In this post, we share redBus’s data platform architecture, and how various components are connected to form their data highway. We also discuss the challenges redBus faced in building dashboards for their real-time business intelligence (BI) use cases, and how they used Amazon QuickSight, a fast, easy-to-use, cloud-powered business analytics service that makes it easy for all employees within redBus to build visualizations and perform ad hoc analysis to gain business insights from their data, any time, and on any device.
About redBus
redBus is the world’s largest online bus ticketing platform built in India and serving more than 36 million happy customers around the world. Along with its bus ticketing vertical, redBus also runs a rail ticketing service called redRails and a bus and car rental service called rYde. It is part of the GO-MMT group, which is India’s leading online travel company, with an extensive brand portfolio that includes other prominent online travel brands like MakeMyTrip and Goibibo.
redBus’s data highway 1.0
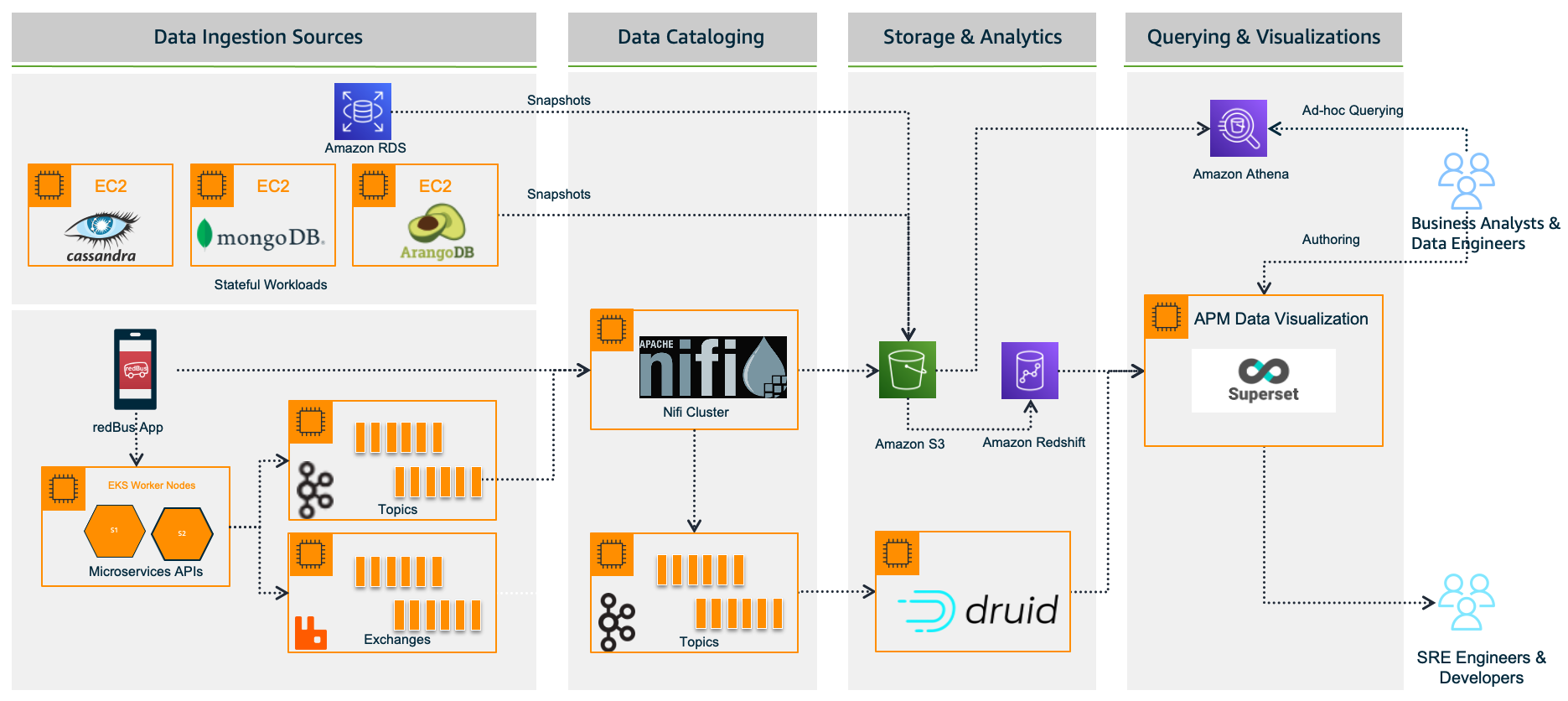
redBus relies heavily on making data-driven decisions at every level, from its traveler journey tracking, forecasting demand during high traffic, identifying and addressing bottlenecks in their bus operators signup process, and more. As redBus’s business started growing in terms of the number of cities and countries they operated in and the number of bus operators and travelers using the service in each city, the amount of incoming data also increased. The need to access and analyze the data in one place required them to build their own data platform, as shown in the following diagram.

In the following sections, we look at each component in more detail.
Data ingestion sources
With the data platform 1.0, the data is ingested from various sources:
- Real time – The real-time data flows from redBus mobile apps, the backend microservices, and when a passenger, bus operator, or application does any operation like booking bus tickets, searching the bus inventory, uploading a KYC document, and more
- Batch mode – Scheduled jobs fetch data from multiple persistent data stores like Amazon Relational Database Service (Amazon RDS), where the OLTP data from all its applications are stored, Apache Cassandra clusters, where the bus inventory from various operators is stored, Arango DB, where the user identity graphs are stored, and more
Data cataloging
The real-time data is ingested into their self-managed Apache Nifi clusters, an open-source data platform that is used to clean, analyze, and catalog the data with its routing capabilities before sending the data to its destination.
Storage and analytics
redBus uses the following services for its storage and analytical needs:
- Amazon Simple Storage Service (Amazon S3), an object storage service that provides the foundation for their data lake because of its virtually unlimited scalability and higher durability. Real-time data flows from Apache Druid and data from the data stores flow at regular intervals based on the schedules.
- Apache Druid, an OLAP-style data store (data flows via Kafka Druid data loader), which computes facts and metrics against various dimensions during the data loading process.
- Amazon Redshift, a cloud data warehouse service that helps you analyze exabytes of data and run complex analytical queries. redBus uses Amazon Redshift to store the processed data from Amazon S3 and the aggregated data from Apache Druid.
Querying and visualization
To make redBus as data-driven as possible, they ensured that the data is accessible to their SRE engineers, data engineers, and business analysts via a visualization layer. This layer features dashboards being served using Apache SuperSet, an open-source data visualization application, and Amazon Athena, an interactive query service to analyze data in Amazon S3 using standard SQL for ad hoc querying requirements.
The challenges
Initially, redBus handled data that was being ingested at the rate of 10 million events per day. Over time, as its business started growing, so did the data volume (from gigabytes to terabytes to petabytes), data ingestion per day (from 10 million to 320 million events), and its business intelligence dashboard needs. Soon after, they started facing challenges with their self-managed Superset’s BI capabilities, and the increased operational complexities.
Limited BI capabilities
redBus encountered the following BI limitations:
- Inability to create visualizations from multiple data sources – Superset doesn’t allow creating visualizations from multiple tables within its data exploration layer. redBus data engineers had to have the tables joined beforehand at the data source level itself. In order to create a 360-degree view for redBus’s business stakeholders, it became inconvenient for data engineers to maintain multiple tables supporting the visualization layer.
- No global filter for visuals in a dashboard – A global or primary filter across visuals in a dashboard is not supported in Superset. For example, consider there are visuals like Sales Wins by Region, YTD Revenue Realized by Region, Sales Pipeline by Region, and more in a dashboard, and a filter Region is added to the dashboard with values like EMEA, APAC, and US. The filter Region will only apply to one of the visuals, not the entire dashboard. However, dashboard users expected filtering across the dashboard.
- Not a business-user friendly tool – Superset is highly developer centric when it comes to customization. For example, if a redBus business analyst had to customize a timed refresh that automatically re-queries every slice on a dashboard according to a pre-set value, then the analyst has to update the dashboard’s JSON metadata field. Therefore, having knowledge of JSON and its syntax is mandatory for doing any customization on the visuals or dashboard.
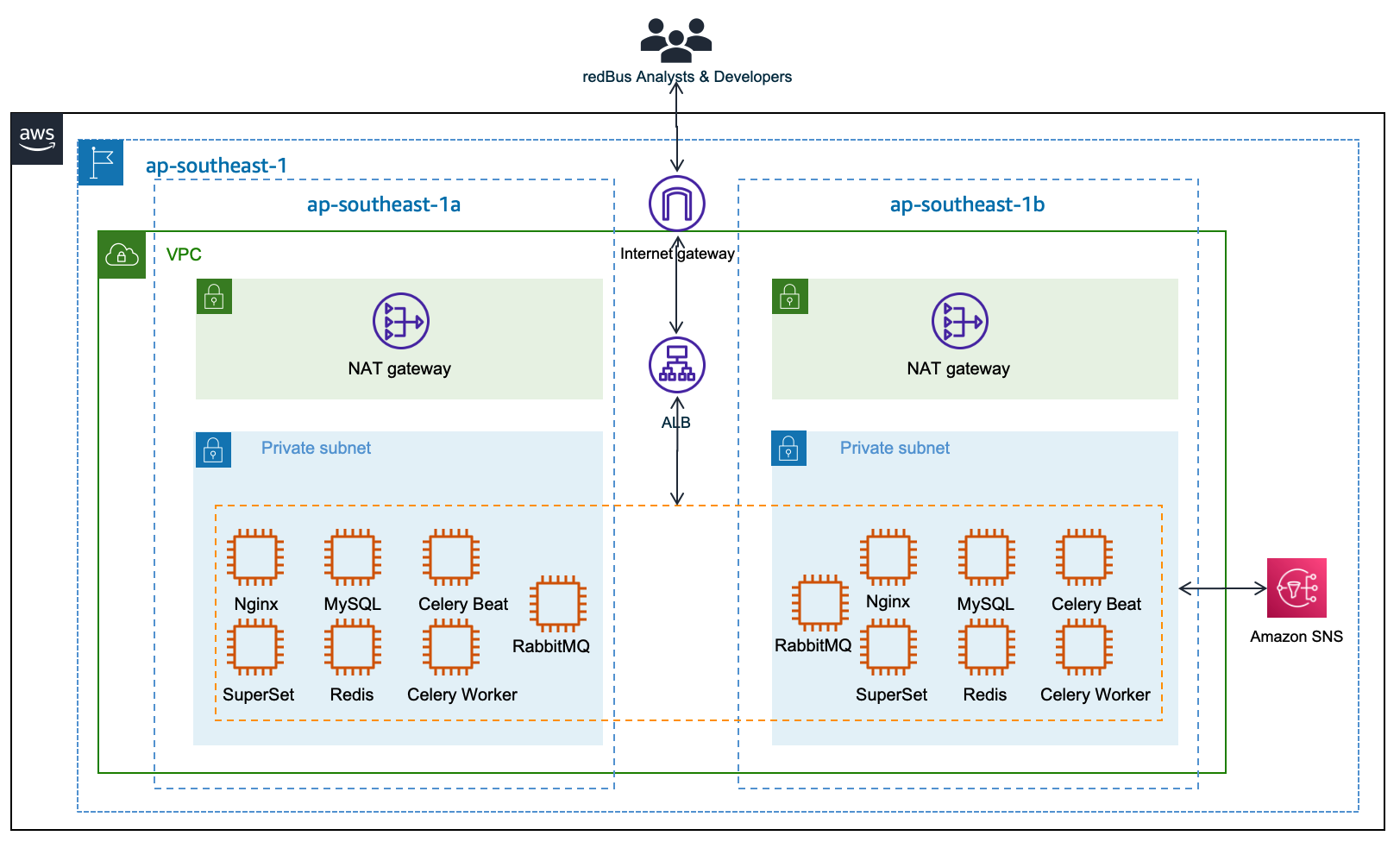
Increased operational cost
Although Superset is open source, which means there are no licensing costs, it also means there is more effort in maintaining all the components required for it to function as an enterprise-grade BI tool. redBus has deployed and maintained a web server (Nginx) fronted by an Application Load Balancer to do the load balancing; a metadata database server (MySQL) where Superset stores its internal information like users, slices, and dashboard definitions; an asynchronous task queue (Celery) for supporting long-running queries; a message broker (RabbitMQ); and a distributed caching server (Redis) for caching the results, charting data, and more on Amazon Elastic Compute Cloud (Amazon EC2) instances. The following diagram illustrates this architecture.

redBus’s DevOps team had to do the heavy lifting of provisioning the infrastructure, taking backups, scaling the components manually as needed, upgrading the components individually, and more. It also required a Python web developer to be around for making the configurational changes so all the components work together seamlessly. All these manual operations increased the total cost of ownership for redBus.
Journey towards QuickSight
redBus started exploring BI solutions primarily around a couple of its dashboarding requirements:
- BI dashboards for business stakeholders and analysts, where the data is sourced via Amazon S3 and Amazon Redshift.
- A real-time application performance monitoring (APM) dashboard to help their SRE engineers and developers identify the root cause of an issue in their microservices deployment so they can fix the issues before they affect their customer’s experience. In this case, the data is sourced via Druid.
QuickSight fit into most of redBus’s BI dashboard requirements, and in no time their data platform team started with a proof of concept (POC) for a couple of their complex dashboards. At the end of the POC, which spanned a month’s time, the team shared their findings.
First, QuickSight is rich in BI capabilities, including the following:
- It’s a self-service BI solution with drag-and-drop features that could help redBus analysts comfortably use it without any coding efforts.
- Visualizations from multiple data sources in a single dashboard could help redBus business stakeholders get a 360-degree view of sales, forecasting, and insights in a single pane of glass.
- Cascading filters across visuals and across sheets in a dashboard are much-needed features for redBus’s BI requirements.
- QuickSight offers Excel-like visuals—tables with calculations, pivot tables with cell grouping, and styling are attractive for the viewers.
- The Super-fast, Parallel, In-memory Calculation Engine (SPICE) in QuickSight could help redBus scale to hundreds of thousands of users, who can all simultaneously perform fast interactive analysis across a wide variety of AWS data sources.
- Off-the-shelf ML insights and forecasting at no additional cost would allow redBus’s data science team to focus on ML models besides sales forecasting and similar models.
- Built-in row-level security (RLS) could allow redBus to grant filtered access for their viewers. For example, redBus has many business analysts who manage different countries. With RLS, each business analyst only sees data related to their assigned country within a single dashboard.
- redBus uses OneLogin as its identity provider, which supports Security Assertion Markup Language 2.0 (SAML 2.0). With the help of identity federation and single sign-on support from QuickSight, redBus could provide a simple onboarding flow for their QuickSight users.
- QuickSight offers built-in alerts and email notification capabilities.
Secondly, QuickSight is a fully managed, cloud-native, serverless BI service offering from AWS, with the following features:
- redBus engineers don’t need to focus on the heavy lifting of provisioning, scaling, and maintaining their BI solution on EC2 instances.
- QuickSight offers native integration with AWS services like Amazon Redshift, Amazon S3, and Athena, and other popular frameworks like Presto, Snowflake, Teradata, and more. QuickSight connects to most of the data sources that redBus already has except Apache Druid, because native integration with Druid was not available as of December 2022. For a complete list of the supported data sources, see Supported data sources.
The outcome
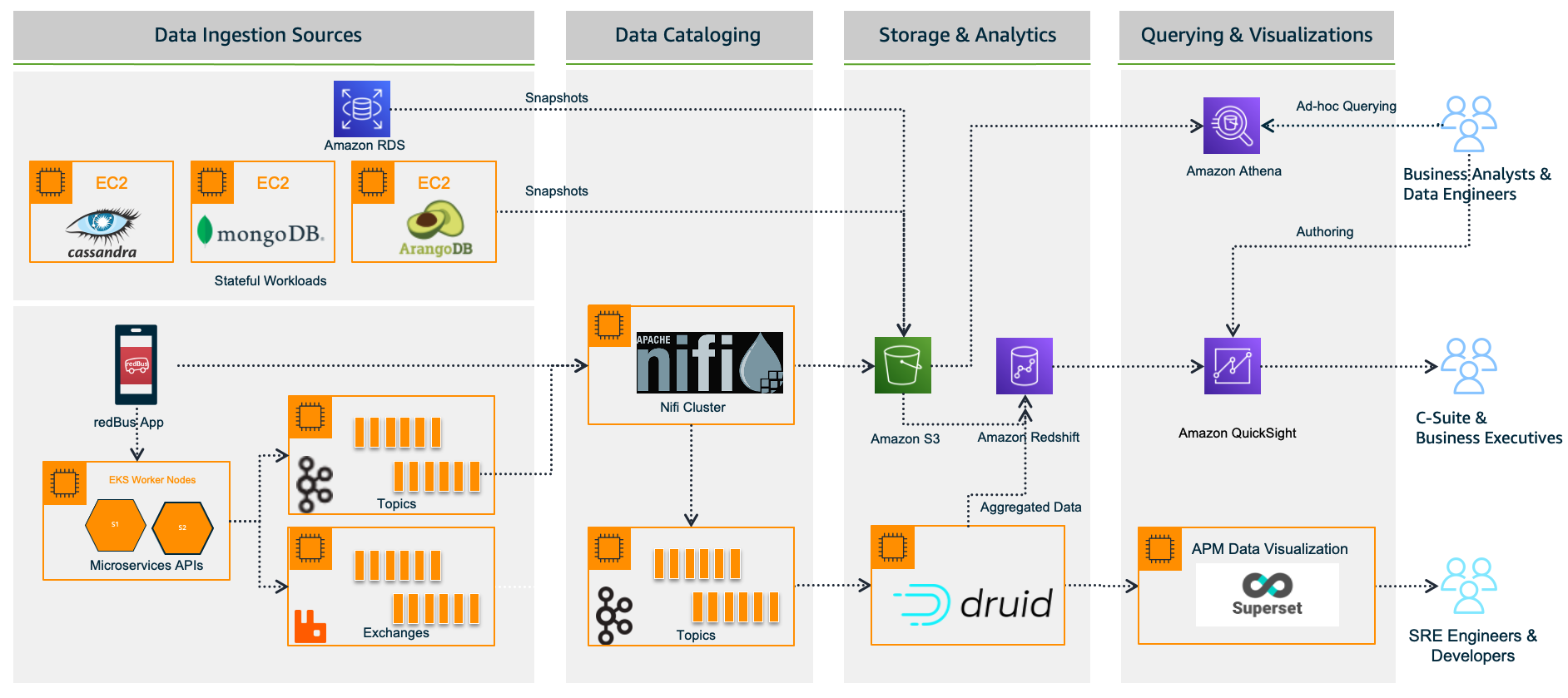
Considering all the rich features and lower total cost of ownership, redBus chose QuickSight for their BI dashboard requirements. With QuickSight, redBus’s data engineers have built a number of dashboards in no time to give insights from petabytes of data to business stakeholders and analysts. The redBus data highway evolved to bring business intelligence to a much wider audience in their organization, with better performance and faster time-to-value. As of November 2022, it combines QuickSight for business users and Superset for real-time APM dashboards (at the time of writing, QuickSight doesn’t offer a native connector to Druid), as shown in the following diagram.

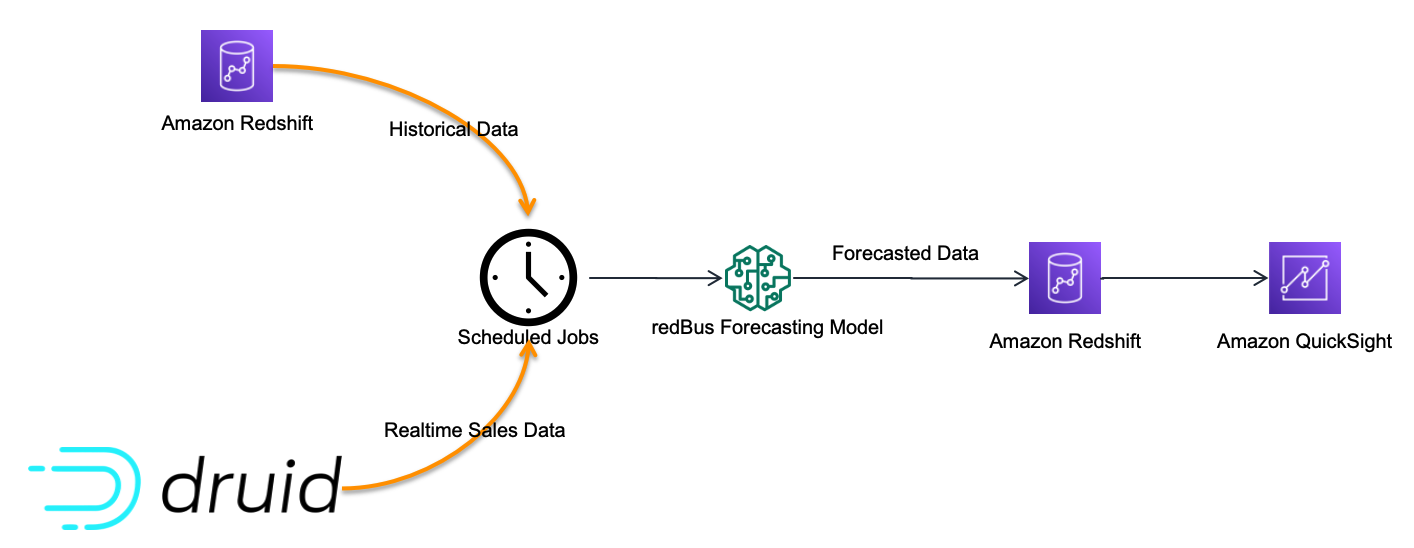
Sales anomaly detection dashboard
Although there are many dashboards that redBus deployed to production, sales anomaly detection is one of the interesting dashboards that redBus built. It uses redBus’s proprietary sales forecasting model, which in turn is sourced by historical sales data from Amazon Redshift tables and real-time sales data from Druid tables, as shown in the following figure.

At regular intervals, the scheduled jobs feed the redBus forecasting model with real-time and historical sales data, and then the forecasted data is pushed into an Amazon Redshift table. The sales anomaly detection dashboard in QuickSight is served by the resultant Amazon Redshift table.
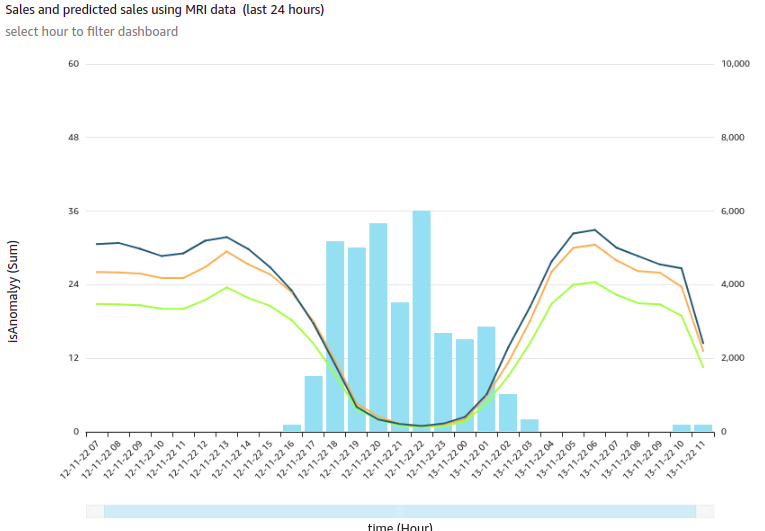
The following is one of the visuals from the sales anomaly detection dashboard. It’s built using a line chart representing hourly actual sales, predicted sales, and an alert threshold for a time series for a particular business cohort in redBus.

In this visual, each bar represents the number of sales anomalies triggered at a particular point in the time series.
redBus’s analysts could further drill down to the sales details and anomalies at the minute level, as shown in the following diagram. This drill-down feature comes out of the box with QuickSight.
For more details on adding drill-downs to QuickSight dashboard visuals, see Adding drill-downs to visual data in Amazon QuickSight.
Apart from the visuals, it has become one of viewers’ favorite dashboards at redBus due to the following notable features:
- Because filtering across visuals is an out-of-the-box feature in QuickSight, a timestamp-based filter is added to the dashboard. This helps in filtering multiple visuals in the dashboard in a single click.
- URL actions configured on the visuals help the viewers navigate to the context-sensitive in-house applications.
- Email alerts configured on KPIs and Gauge visuals help the viewers get notifications on time.
Next steps
Apart from building new dashboards for their BI dashboard needs, redBus is taking the following next steps:
- Exploring QuickSight Embedded Analytics for a couple of their application requirements to accelerate time to insights for users with in-context data visuals, interactive dashboards, and more directly within applications
- Exploring QuickSight Q, which could enable their business stakeholders to ask questions in natural language and receive accurate answers with relevant visualizations that can help them gain insights from the data
- Building a unified dashboarding solution using QuickSight covering all their data sources as integrations become available
Conclusion
In this post, we showed you how redBus built its data platform using various AWS services and Apache frameworks, the challenges the platform went through (especially in their BI dashboard requirements and challenges while scaling), and how they used QuickSight and lowered the total cost of ownership.
To know more about engineering at redBus, check out their medium blog posts. To learn more about what is happening in QuickSight or if you have any questions, reach out to the QuickSight Community, which is very active and offers several resources.
About the Authors
 Girish Kumar Chidananda works as a Senior Engineering Manager – Data Engineering at redBus, where he has been building various data engineering applications and components for redBus for the last 5 years. Prior to starting his journey in the IT industry, he worked as a Mechanical and Control systems engineer in various organizations, and he holds an MS degree in Fluid Power Engineering from University of Bath.
Girish Kumar Chidananda works as a Senior Engineering Manager – Data Engineering at redBus, where he has been building various data engineering applications and components for redBus for the last 5 years. Prior to starting his journey in the IT industry, he worked as a Mechanical and Control systems engineer in various organizations, and he holds an MS degree in Fluid Power Engineering from University of Bath.
 Kayalvizhi Kandasamy works with digital-native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services, she uses her experience to help people bring their ideas to life, focusing primarily on microservice architectures and cloud-native solutions using AWS services. Outside of work, she likes playing chess and is a FIDE rated chess player. She also coaches her daughters the art of playing chess, and prepares them for various chess tournaments.
Kayalvizhi Kandasamy works with digital-native companies to support their innovation. As a Senior Solutions Architect (APAC) at Amazon Web Services, she uses her experience to help people bring their ideas to life, focusing primarily on microservice architectures and cloud-native solutions using AWS services. Outside of work, she likes playing chess and is a FIDE rated chess player. She also coaches her daughters the art of playing chess, and prepares them for various chess tournaments.