Post Syndicated from Avijit Goswami original https://aws.amazon.com/blogs/big-data/improve-operational-efficiencies-of-apache-iceberg-tables-built-on-amazon-s3-data-lakes/
Apache Iceberg is an open table format for large datasets in Amazon Simple Storage Service (Amazon S3) and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. When you build your transactional data lake using Apache Iceberg to solve your functional use cases, you need to focus on operational use cases for your S3 data lake to optimize the production environment. Some of the important non-functional use cases for an S3 data lake that organizations are focusing on include storage cost optimizations, capabilities for disaster recovery and business continuity, cross-account and multi-Region access to the data lake, and handling increased Amazon S3 request rates.
In this post, we show you how to improve operational efficiencies of your Apache Iceberg tables built on Amazon S3 data lake and Amazon EMR big data platform.
Optimize data lake storage
One of the major advantages of building modern data lakes on Amazon S3 is it offers lower cost without compromising on performance. You can use Amazon S3 Lifecycle configurations and Amazon S3 object tagging with Apache Iceberg tables to optimize the cost of your overall data lake storage. An Amazon S3 Lifecycle configuration is a set of rules that define actions that Amazon S3 applies to a group of objects. There are two types of actions:
- Transition actions – These actions define when objects transition to another storage class; for example, Amazon S3 Standard to Amazon S3 Glacier.
- Expiration actions – These actions define when objects expire. Amazon S3 deletes expired objects on your behalf.
Amazon S3 uses object tagging to categorize storage where each tag is a key-value pair. From an Apache Iceberg perspective, it supports custom Amazon S3 object tags that can be added to S3 objects while writing and deleting into the table. Iceberg also let you configure a tag-based object lifecycle policy at the bucket level to transition objects to different Amazon S3 tiers. With the s3.delete.tags config property in Iceberg, objects are tagged with the configured key-value pairs before deletion. When the catalog property s3.delete-enabled is set to false, the objects are not hard-deleted from Amazon S3. This is expected to be used in combination with Amazon S3 delete tagging, so objects are tagged and removed using an Amazon S3 lifecycle policy. This property is set to true by default.
The example notebook in this post shows an example implementation of S3 object tagging and lifecycle rules for Apache Iceberg tables to optimize storage cost.
Implement business continuity
Amazon S3 gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. Amazon S3 is designed for 99.999999999% (11 9’s) of durability, S3 Standard is designed for 99.99% availability, and Standard – IA is designed for 99.9% availability. Still, to make your data lake workloads highly available in an unlikely outage situation, you can replicate your S3 data to another AWS Region as a backup. With S3 data residing in multiple Regions, you can use an S3 multi-Region access point as a solution to access the data from the backup Region. With Amazon S3 multi-Region access point failover controls, you can route all S3 data request traffic through a single global endpoint and directly control the shift of S3 data request traffic between Regions at any time. During a planned or unplanned regional traffic disruption, failover controls let you control failover between buckets in different Regions and accounts within minutes. Apache Iceberg supports access points to perform S3 operations by specifying a mapping of bucket to access points. We include an example implementation of an S3 access point with Apache Iceberg later in this post.
Increase Amazon S3 performance and throughput
Amazon S3 supports a request rate of 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in a bucket. The resources for this request rate aren’t automatically assigned when a prefix is created. Instead, as the request rate for a prefix increases gradually, Amazon S3 automatically scales to handle the increased request rate. For certain workloads that need a sudden increase in the request rate for objects in a prefix, Amazon S3 might return 503 Slow Down errors, also known as S3 throttling. It does this while it scales in the background to handle the increased request rate. Also, if supported request rates are exceeded, it’s a best practice to distribute objects and requests across multiple prefixes. Implementing this solution to distribute objects and requests across multiple prefixes involves changes to your data ingress or data egress applications. Using Apache Iceberg file format for your S3 data lake can significantly reduce the engineering effort through enabling the ObjectStoreLocationProvider feature, which adds an S3 hash [0*7FFFFF] prefix in your specified S3 object path.
Iceberg by default uses the Hive storage layout, but you can switch it to use the ObjectStoreLocationProvider. This option is not enabled by default to provide flexibility to choose the location where you want to add the hash prefix. With ObjectStoreLocationProvider, a deterministic hash is generated for each stored file and a subfolder is appended right after the S3 folder specified using the parameter write.data.path (write.object-storage-path for Iceberg version 0.12 and below). This ensures that files written to Amazon S3 are equally distributed across multiple prefixes in your S3 bucket, thereby minimizing the throttling errors. In the following example, we set the write.data.path value as s3://my-table-data-bucket, and Iceberg-generated S3 hash prefixes will be appended after this location:
Your S3 files will be arranged under MURMUR3 S3 hash prefixes like the following:
Using Iceberg ObjectStoreLocationProvider is not a foolproof mechanism to avoid S3 503 errors. You still need to set appropriate EMRFS retries to provide additional resiliency. You can adjust your retry strategy by increasing the maximum retry limit for the default exponential backoff retry strategy or enabling and configuring the additive-increase/multiplicative-decrease (AIMD) retry strategy. AIMD is supported for Amazon EMR releases 6.4.0 and later. For more information, refer to Retry Amazon S3 requests with EMRFS.
In the following sections, we provide examples for these use cases.
Storage cost optimizations
In this example, we use Iceberg’s S3 tags feature with the write tag as write-tag-name=created and delete tag as delete-tag-name=deleted. This example is demonstrated on an EMR version emr-6.10.0 cluster with installed applications Hadoop 3.3.3, Jupyter Enterprise Gateway 2.6.0, and Spark 3.3.1. The examples are run on a Jupyter Notebook environment attached to the EMR cluster. To learn more about how to create an EMR cluster with Iceberg and use Amazon EMR Studio, refer to Use an Iceberg cluster with Spark and the Amazon EMR Studio Management Guide, respectively.
The following examples are also available in the sample notebook in the aws-samples GitHub repo for quick experimentation.
Configure Iceberg on a Spark session
Configure your Spark session using the %%configure magic command. You can use either the AWS Glue Data Catalog (recommended) or a Hive catalog for Iceberg tables. In this example, we use a Hive catalog, but we can change to the Data Catalog with the following configuration:
Before you run this step, create a S3 bucket and an iceberg folder in your AWS account with the naming convention <your-iceberg-storage-blog>/iceberg/.
Update your-iceberg-storage-blog in the following configuration with the bucket that you created to test this example. Note the configuration parameters s3.write.tags.write-tag-name and s3.delete.tags.delete-tag-name, which will tag the new S3 objects and deleted objects with corresponding tag values. We use these tags in later steps to implement S3 lifecycle policies to transition the objects to a lower-cost storage tier or expire them based on the use case.
Create an Apache Iceberg table using Spark-SQL
Now we create an Iceberg table for the Amazon Product Reviews Dataset:
In the next step, we load the table with the dataset using Spark actions.
Load data into the Iceberg table
While inserting the data, we partition the data by review_date as per the table definition. Run the following Spark commands in your PySpark notebook:
Insert a single record into the same Iceberg table so that it creates a partition with the current review_date:
You can check the new snapshot is created after this append operation by querying the Iceberg snapshot:
You will see an output similar to the following showing the operations performed on the table.

Check the S3 tag population
You can use the AWS Command Line Interface (AWS CLI) or the AWS Management Console to check the tags populated for the new writes. Let’s check the tag corresponding to the object created by a single row insert.
On the Amazon S3 console, check the S3 folder s3://your-iceberg-storage-blog/iceberg/db/amazon_reviews_iceberg/data/ and point to the partition review_date_year=2023/. Then check the Parquet file under this folder to check the tags associated with the data file in Parquet format.
From the AWS CLI, run the following command to see that the tag is created based on the Spark configuration spark.sql.catalog.dev.s3.write.tags.write-tag-name":"created":
In this step, we delete a record from the Iceberg table and expire the snapshot corresponding to the deleted record. We delete the new single record that we inserted with the current review_date:
We can now check that a new snapshot was created with the operation flagged as delete:

This is useful if we want to time travel and check the deleted row in the future. In that case, we have to query the table with the snapshot-id corresponding to the deleted row. However, we don’t discuss time travel as part of this post.
We expire the old snapshots from the table and keep only the last two. You can modify the query based on your specific requirements to retain the snapshots:
If we run the same query on the snapshots, we can see that we have only two snapshots available:

From the AWS CLI, you can run the following command to see that the tag is created based on the Spark configuration spark.sql.catalog.dev.s3. delete.tags.delete-tag-name":"deleted":
The snapshots that have expired show the latest snapshot ID as null.

Create S3 lifecycle rules to transition the buckets to a different storage tier
Create a lifecycle configuration for the bucket to transition objects with the delete-tag-name=deleted S3 tag to the Glacier Instant Retrieval class. Amazon S3 runs lifecycle rules one time every day at midnight Universal Coordinated Time (UTC), and new lifecycle rules can take up to 48 hours to complete the first run. Amazon S3 Glacier is well suited to archive data that needs immediate access (with milliseconds retrieval). With S3 Glacier Instant Retrieval, you can save up to 68% on storage costs compared to using the S3 Standard-Infrequent Access (S3 Standard-IA) storage class, when the data is accessed once per quarter.

When you want to access the data back, you can bulk restore the archived objects. After you restore the objects back in S3 Standard class, you can register the metadata and data as an archival table for query purposes. The metadata file location can be fetched from the metadata log entries metatable as illustrated earlier. As mentioned before, the latest snapshot ID with Null values indicates expired snapshots. We can take one of the expired snapshots and do the bulk restore:
Capabilities for disaster recovery and business continuity, cross-account and multi-Region access to the data lake
Because Iceberg doesn’t support relative paths, you can use access points to perform Amazon S3 operations by specifying a mapping of buckets to access points. This is useful for multi-Region access, cross-Region access, disaster recovery, and more.
For cross-Region access points, we need to additionally set the use-arn-region-enabled catalog property to true to enable S3FileIO to make cross-Region calls. If an Amazon S3 resource ARN is passed in as the target of an Amazon S3 operation that has a different Region than the one the client was configured with, this flag must be set to ‘true‘ to permit the client to make a cross-Region call to the Region specified in the ARN, otherwise an exception will be thrown. However, for the same or multi-Region access points, the use-arn-region-enabled flag should be set to ‘false’.
For example, to use an S3 access point with multi-Region access in Spark 3.3, you can start the Spark SQL shell with the following code:
In this example, the objects in Amazon S3 on my-bucket1 and my-bucket2 buckets use the arn:aws:s3::123456789012:accesspoint:mfzwi23gnjvgw.mrap access point for all Amazon S3 operations.
For more details on using access points, refer to Using access points with compatible Amazon S3 operations.
Let’s say your table path is under mybucket1, so both mybucket1 in Region 1 and mybucket2 in Region have paths of mybucket1 inside the metadata files. At the time of the S3 (GET/PUT) call, we replace the mybucket1 reference with a multi-Region access point.
Handling increased S3 request rates
When using ObjectStoreLocationProvider (for more details, see Object Store File Layout), a deterministic hash is generated for each stored file, with the hash appended directly after the write.data.path. The problem with this is that the default hashing algorithm generates hash values up to Integer MAX_VALUE, which in Java is (2^31)-1. When this is converted to hex, it produces 0x7FFFFFFF, so the first character variance is restricted to only [0-8]. As per Amazon S3 recommendations, we should have the maximum variance here to mitigate this.
Starting from Amazon EMR 6.10, Amazon EMR added an optimized location provider that makes sure the generated prefix hash has uniform distribution in the first two characters using the character set from [0-9][A-Z][a-z].
This location provider has been recently open sourced by Amazon EMR via Core: Improve bit density in object storage layout and should be available starting from Iceberg 1.3.0.
To use, make sure the iceberg.enabled classification is set to true, and write.location-provider.impl is set to org.apache.iceberg.emr.OptimizedS3LocationProvider.
The following is a sample Spark shell command:
The following example shows that when you enable the object storage in your Iceberg table, it adds the hash prefix in your S3 path directly after the location you provide in your DDL.
Define the table write.object-storage.enabled parameter and provide the S3 path, after which you want to add the hash prefix using write.data.path (for Iceberg Version 0.13 and above) or write.object-storage.path (for Iceberg Version 0.12 and below) parameters.

Insert data into the table you created.

The hash prefix is added right after the /current/ prefix in the S3 path as defined in the DDL.

Clean up
After you complete the test, clean up your resources to avoid any recurring costs:
- Delete the S3 buckets that you created for this test.
- Delete the EMR cluster.
- Stop and delete the EMR notebook instance.
Conclusion
As companies continue to build newer transactional data lake use cases using Apache Iceberg open table format on very large datasets on S3 data lakes, there will be an increased focus on optimizing those petabyte-scale production environments to reduce cost, improve efficiency, and implement high availability. This post demonstrated mechanisms to implement the operational efficiencies for Apache Iceberg open table formats running on AWS.
To learn more about Apache Iceberg and implement this open table format for your transactional data lake use cases, refer to the following resources:
- Apache Iceberg table specifications
- Apache Iceberg support on Amazon EMR
- Use a cluster with Iceberg installed
About the Authors
 Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open-source solutions. Outside of his work, Avijit likes to travel, hike in the San Francisco Bay Area trails, watch sports, and listen to music.
 Rajarshi Sarkar is a Software Development Engineer at Amazon EMR/Athena. He works on cutting-edge features of Amazon EMR/Athena and is also involved in open-source projects such as Apache Iceberg and Trino. In his spare time, he likes to travel, watch movies, and hang out with friends.
Rajarshi Sarkar is a Software Development Engineer at Amazon EMR/Athena. He works on cutting-edge features of Amazon EMR/Athena and is also involved in open-source projects such as Apache Iceberg and Trino. In his spare time, he likes to travel, watch movies, and hang out with friends.
 Prashant Singh is a Software Development Engineer at AWS. He is interested in Databases and Data Warehouse engines and has worked on Optimizing Apache Spark performance on EMR. He is an active contributor in open source projects like Apache Spark and Apache Iceberg. During his free time, he enjoys exploring new places, food and hiking.
Prashant Singh is a Software Development Engineer at AWS. He is interested in Databases and Data Warehouse engines and has worked on Optimizing Apache Spark performance on EMR. He is an active contributor in open source projects like Apache Spark and Apache Iceberg. During his free time, he enjoys exploring new places, food and hiking.




















 Rushabh Lokhande is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and golf.
Rushabh Lokhande is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He helps customers implement big data, machine learning, and analytics solutions. Outside of work, he enjoys spending time with family, reading, running, and golf. Ryan Gomes is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics and machine learning solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family.
Ryan Gomes is a Data & ML Engineer with the AWS Professional Services Analytics Practice. He is passionate about helping customers achieve better outcomes through analytics and machine learning solutions in the cloud. Outside of work, he enjoys fitness, cooking, and spending quality time with friends and family. Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
Vishwa Gupta is a Senior Data Architect with the AWS Professional Services Analytics Practice. He helps customers implement big data and analytics solutions. Outside of work, he enjoys spending time with family, traveling, and trying new food.
 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects focused on underprivileged Children’s education. Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment.
Chandra Dhandapani is a Senior Solutions Architect at AWS, where he specializes in creating solutions for customers in Analytics, AI/ML, and Databases. He has a lot of experience in building and scaling applications across different industries including Healthcare and Fintech. Outside of work, he is an avid traveler and enjoys sports, reading, and entertainment. Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family.
Amit Kumar Agrawal is a Senior Solutions Architect at AWS, based out of San Francisco Bay Area. He works with large strategic ISV customers to architect cloud solutions that address their business challenges. During his free time he enjoys exploring the outdoors with his family. Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.
Viral Shah is a Analytics Sales Specialist working with AWS for 5 years helping customers to be successful in their data journey. He has over 20+ years of experience working with enterprise customers and startups, primarily in the data and database space. He loves to travel and spend quality time with his family.








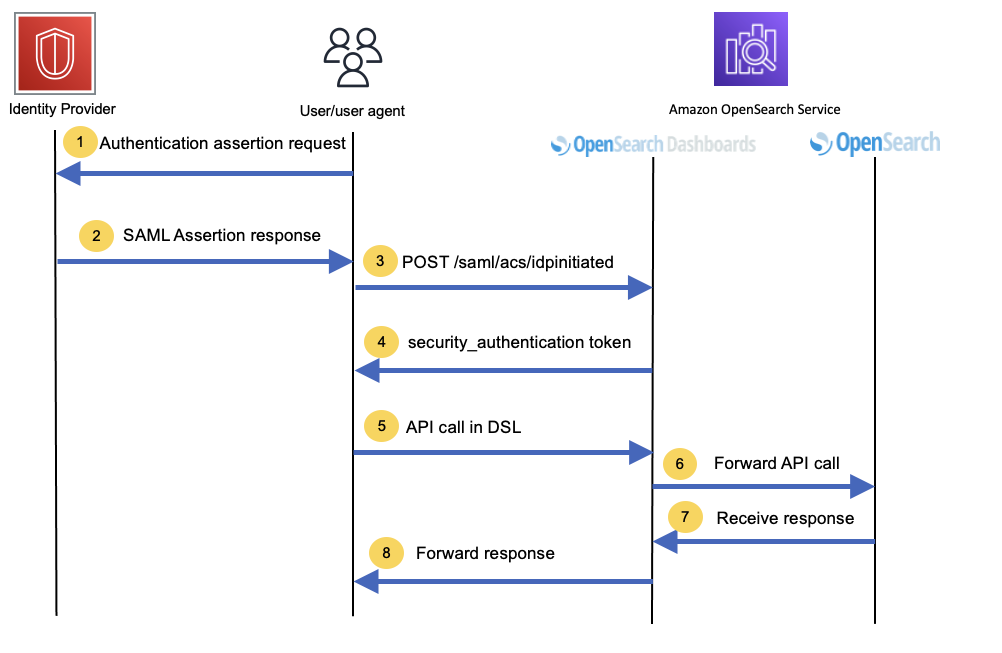
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.














 Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain. Shu Sia Lukito is a Partner Solutions Architect at AWS. She is on a mission to help AWS partners build successful AWS practices and help their customers accelerate their journey to the cloud. In her spare time, she enjoys spending time with her family and making spicy food.
Shu Sia Lukito is a Partner Solutions Architect at AWS. She is on a mission to help AWS partners build successful AWS practices and help their customers accelerate their journey to the cloud. In her spare time, she enjoys spending time with her family and making spicy food.






 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.


 Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.
Arun Lakshmanan is a Search Specialist with Amazon OpenSearch Service based out of Chicago, IL. He has over 20 years of experience working with enterprise customers and startups. He loves to travel and spend quality time with his family.