Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/aws-week-in-review-public-preview-of-amazon-datazone-and-aws-datasync-updates-april-3-2023/
 Last weekend, I enjoyed the spring vibes at Seoul Forest, a large park in the middle of Seoul city, where cherry blossoms are in full bloom.
Last weekend, I enjoyed the spring vibes at Seoul Forest, a large park in the middle of Seoul city, where cherry blossoms are in full bloom.
Compared to last year, there were crowds of people, so I realized that it was really back to normal after the pandemic. I hope you all enjoy the season of spring or fall with your family.
Last Week’s Launches
Like an April Fool’s Day joke, there were 65 launches last week, far more than usual. AWS product teams are working hard with a customer obsession.
So, I had a lot of trouble choosing the important ones. Other than the ones I’ve picked out, there may be important feature releases that fit your needs. Be sure to take a look at the full launches list in the last week.
First, here is a list of the general availability of AWS services and features treated by AWS News Blog:
- Amazon VPC Lattice Simplifies Service-to-Service Connectivity, Security, and Monitoring
- Amazon SageMaker Canvas Supports Custom Text and Image Classification Models
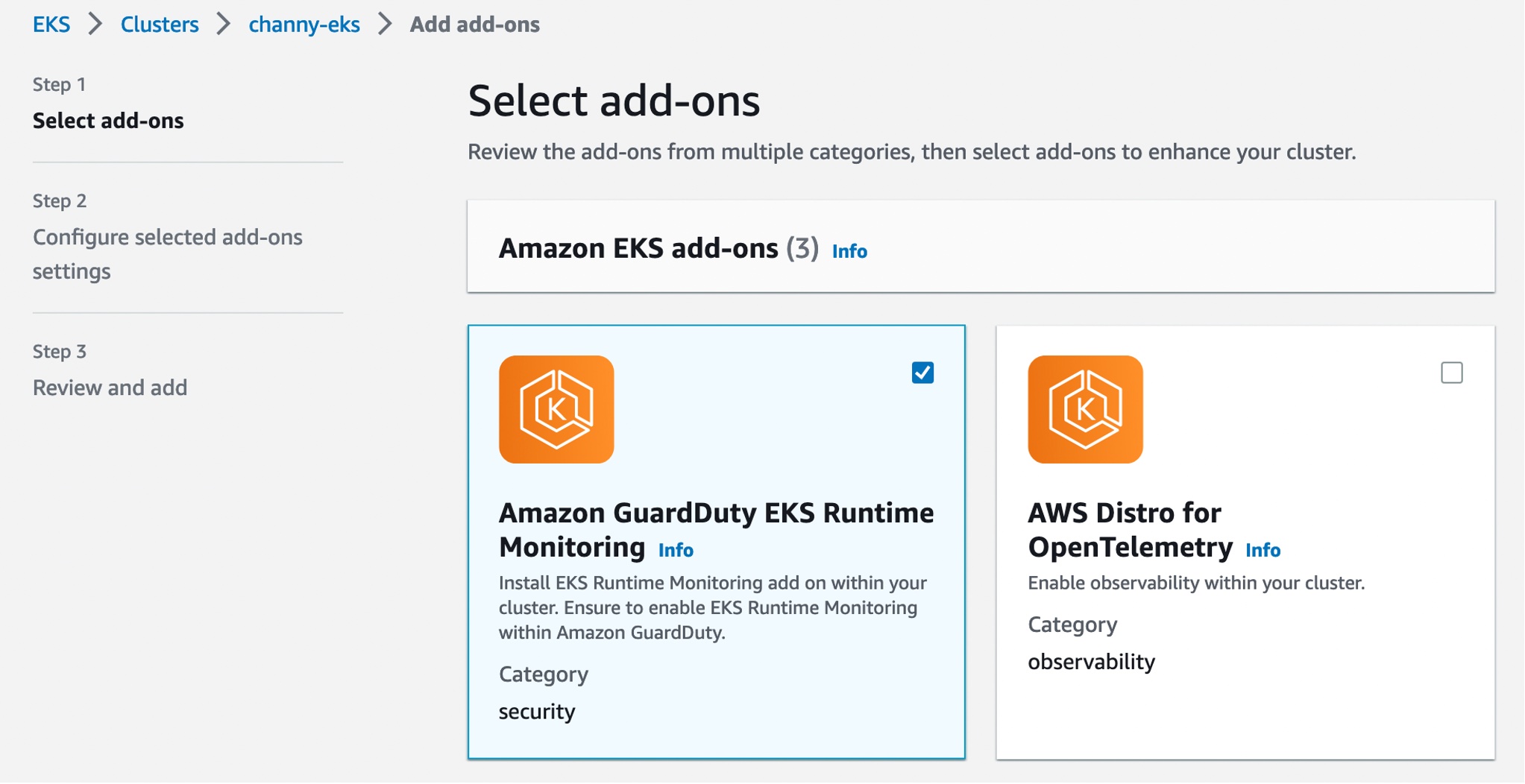
- Amazon GuardDuty Now Supports Amazon EKS Runtime Monitoring
- Amazon Connect Agent Workspace Step-by-Step Guides
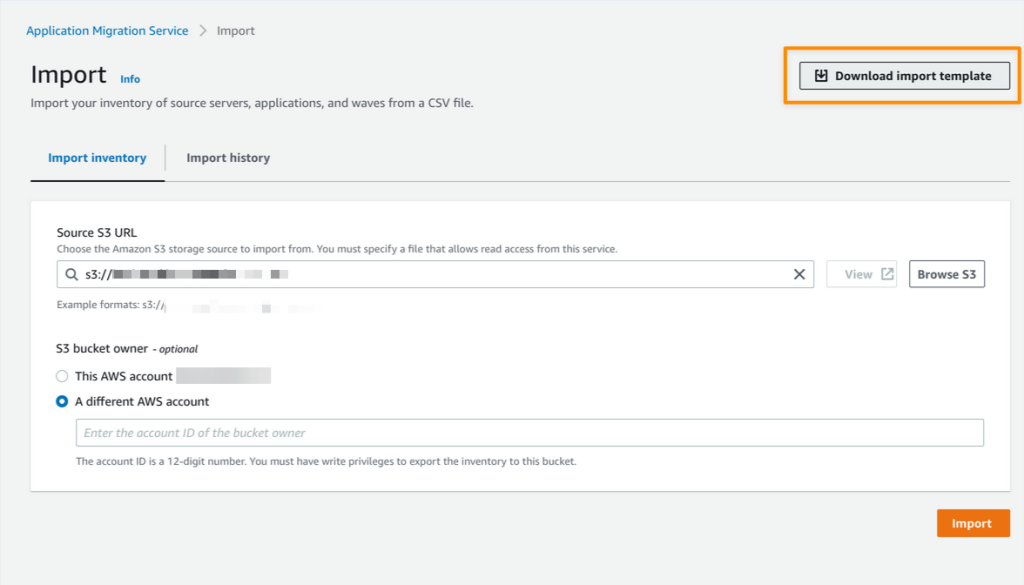
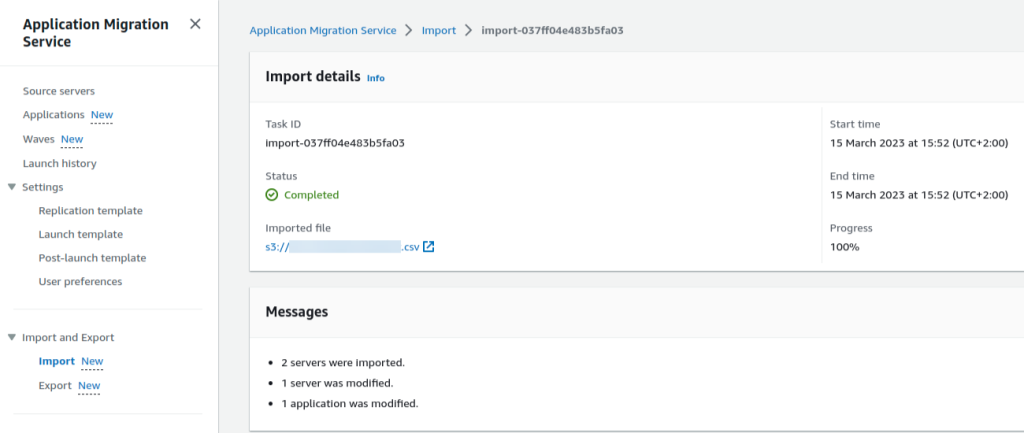
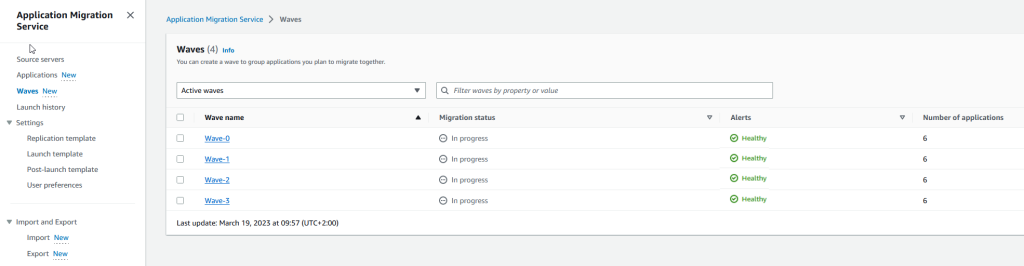
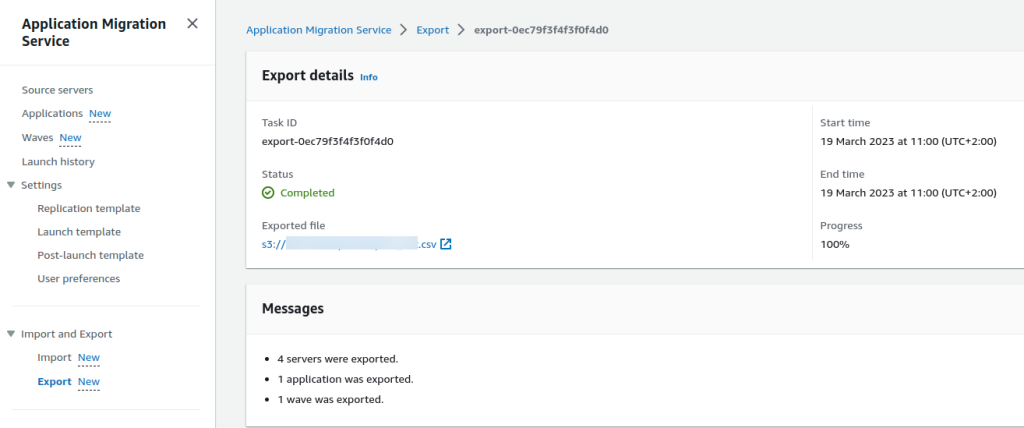
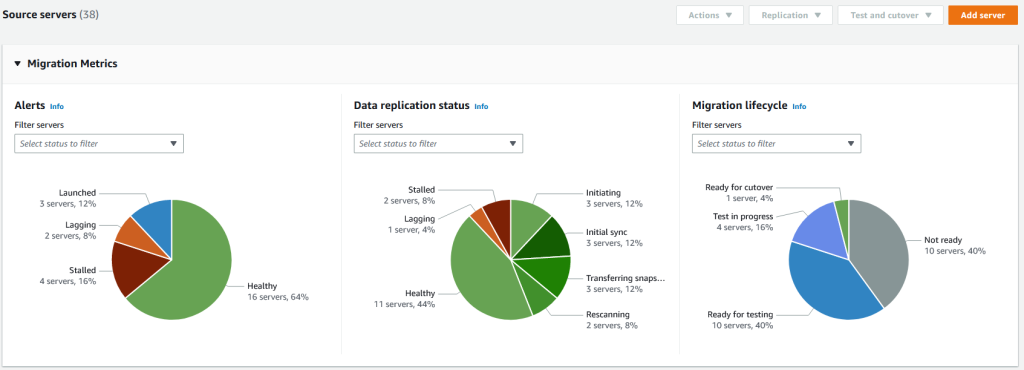
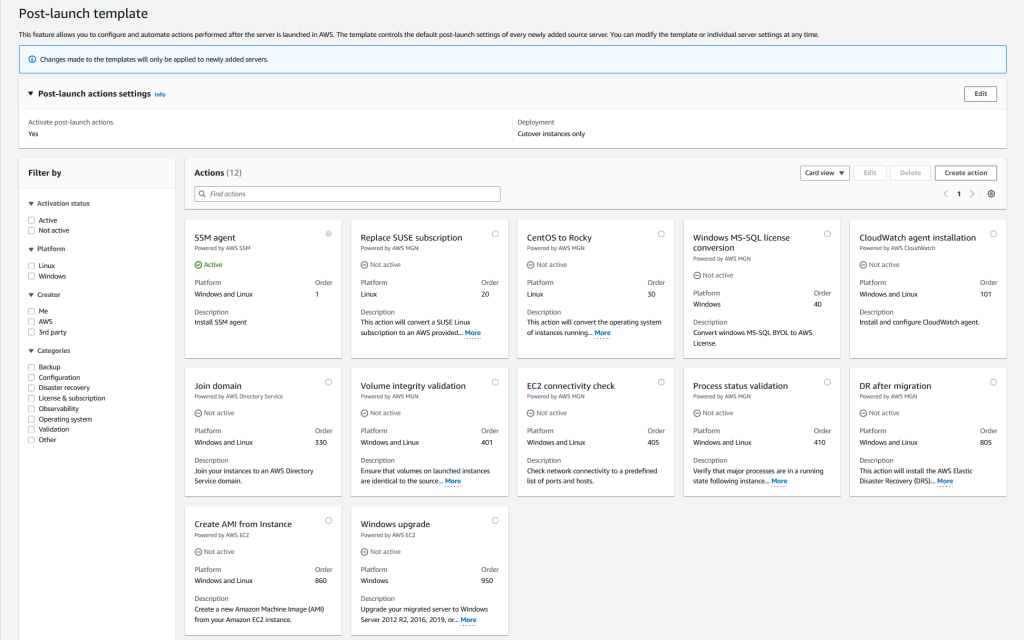
- AWS Application Migration Service Major Updates: Import and Export Feature, Source Server Migration Metrics Dashboard, and Additional Post-Launch Actions
- Amazon Chime SDK Call Analytics: Real-Time Voice Tone Analysis and Speaker Search
Let’s take a look at some launches from the last week that I want to remind you of:
The Preview of Amazon DataZone – At AWS re:Invent 2022, we preannounced Amazon DataZone, a new data management service to catalog, discover, analyze, share, and govern data between data producers and consumers in the organization. You can now try out the public preview of Amazon DataZone.
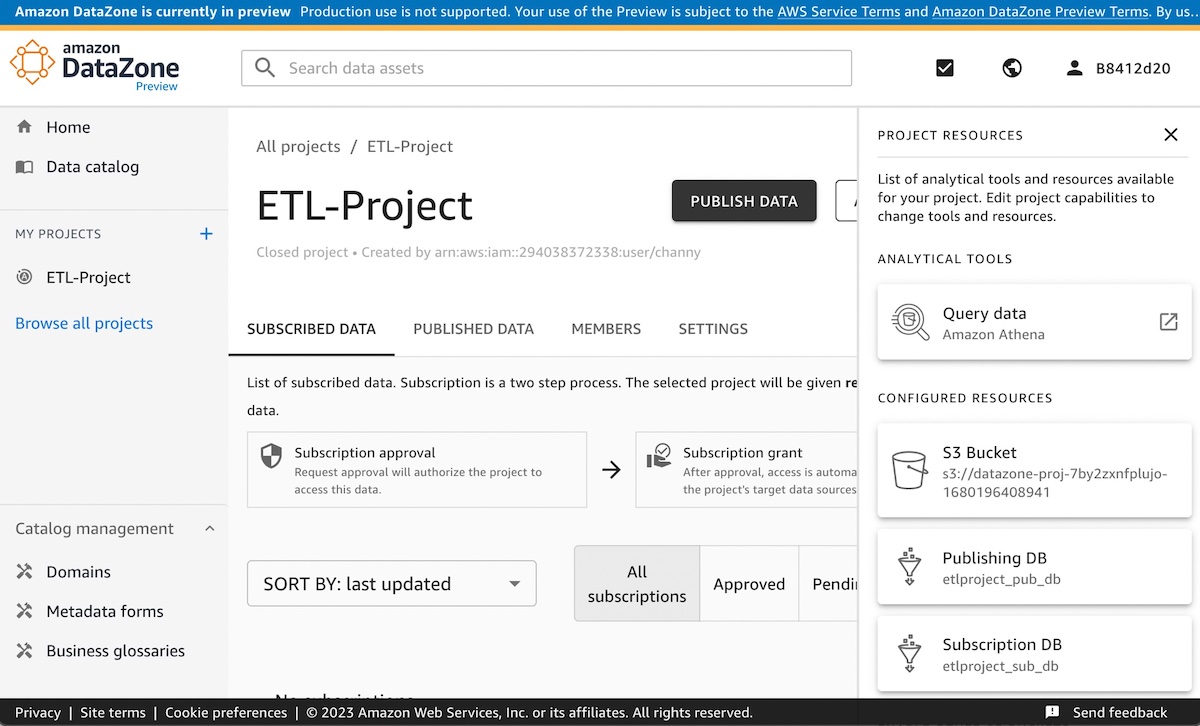
Data producers populate the business data catalog from AWS Glue Data Catalog and Amazon Redshift tables. Data consumers search for and subscribe to data assets in the data catalog and analyze with tools such as Amazon Athena query editors in the Amazon DataZone portal. To get started with Amazon DataZone, see our Quick Start Guide to include sample datasets to implement a complete use case.
AWS DataSync Supports Azure Blob Storage in Preview – AWS DataSync supports copying your object data at scale from Azure Blob Storage to AWS storage services such as Amazon S3. AWS DataSync supports all blob types within Azure Blob Storage and can also be used with Azure Data Lake Storage (ADLS) Gen 2.

In addition to Azure Blob Storage, DataSync supports Google Cloud Storage and Azure Files storage locations as well as various general storage systems and AWS storage services. To learn more, see Migrating Azure Blob Storage to Amazon S3 using AWS DataSync in the AWS Storage Blog.
On-call schedules with AWS Systems Manager Incident Manager – You can now configure or change on-call rotation schedules with a group of contacts and have 24/7 coverage and responsiveness for critical issues in the Incident Manager console.
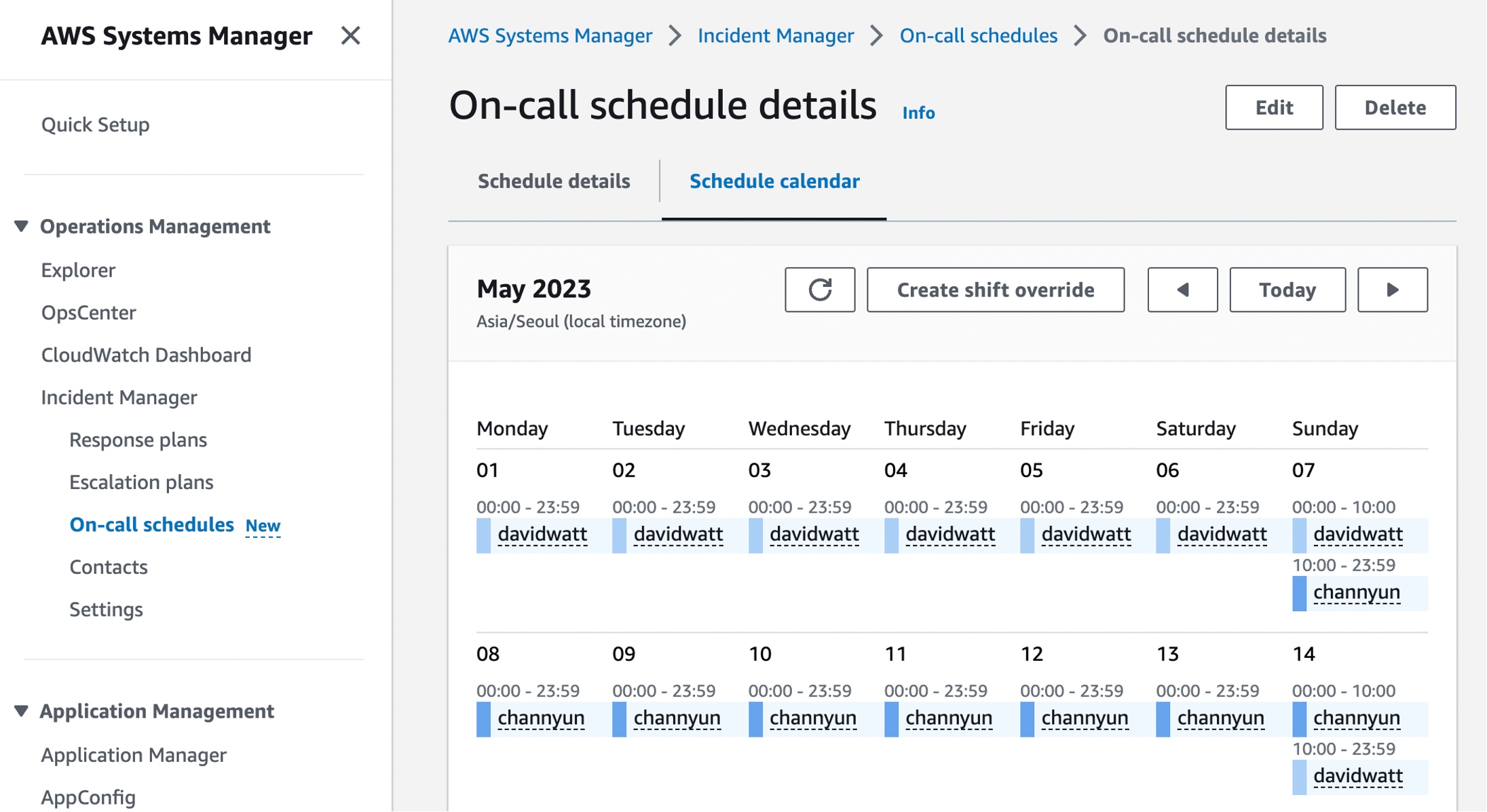
AWS Incident Manager helps you bring the right people and information together when a critical issue is detected, activating preconfigured response plans to engage responders using SMS, phone calls, and chat channels, as well as to run AWS Systems Manager Automation runbooks. To learn how to get started with an-call schedules in Incident Manager, see our Working with on-call schedules in Incident Manager in the AWS documentation.
AWS CloudShell Colsone Toolbar – You can now use AWS Cloudshell Console Toolbar with AWS Management Console in a single view. The Console Toolbar maintains its state (e.g., open, closed) and commands will continue to run in CloudShell as you navigate between services in the Console. For example, it allows you to run a command in CloudShell and view a CloudWatch alarm in the Console at the same time.
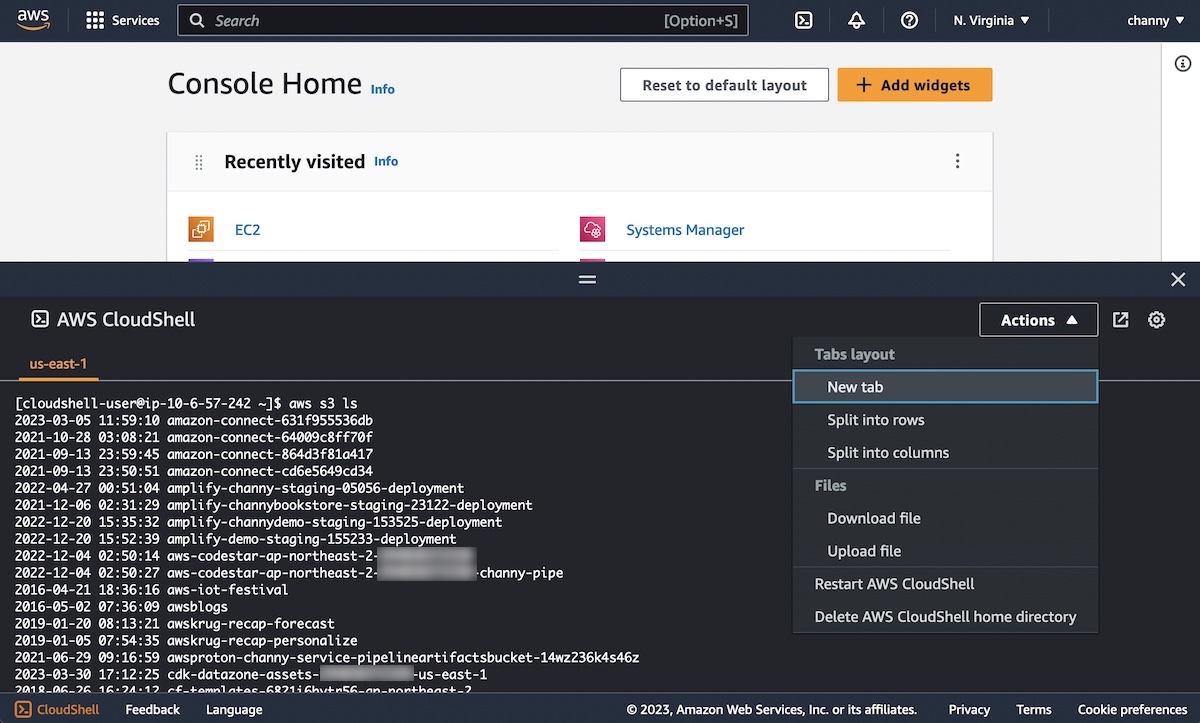
After signing into the Console, you can access CloudShell in the lower left of the Console by selecting the CloudShell icon in the Console Toolbar.
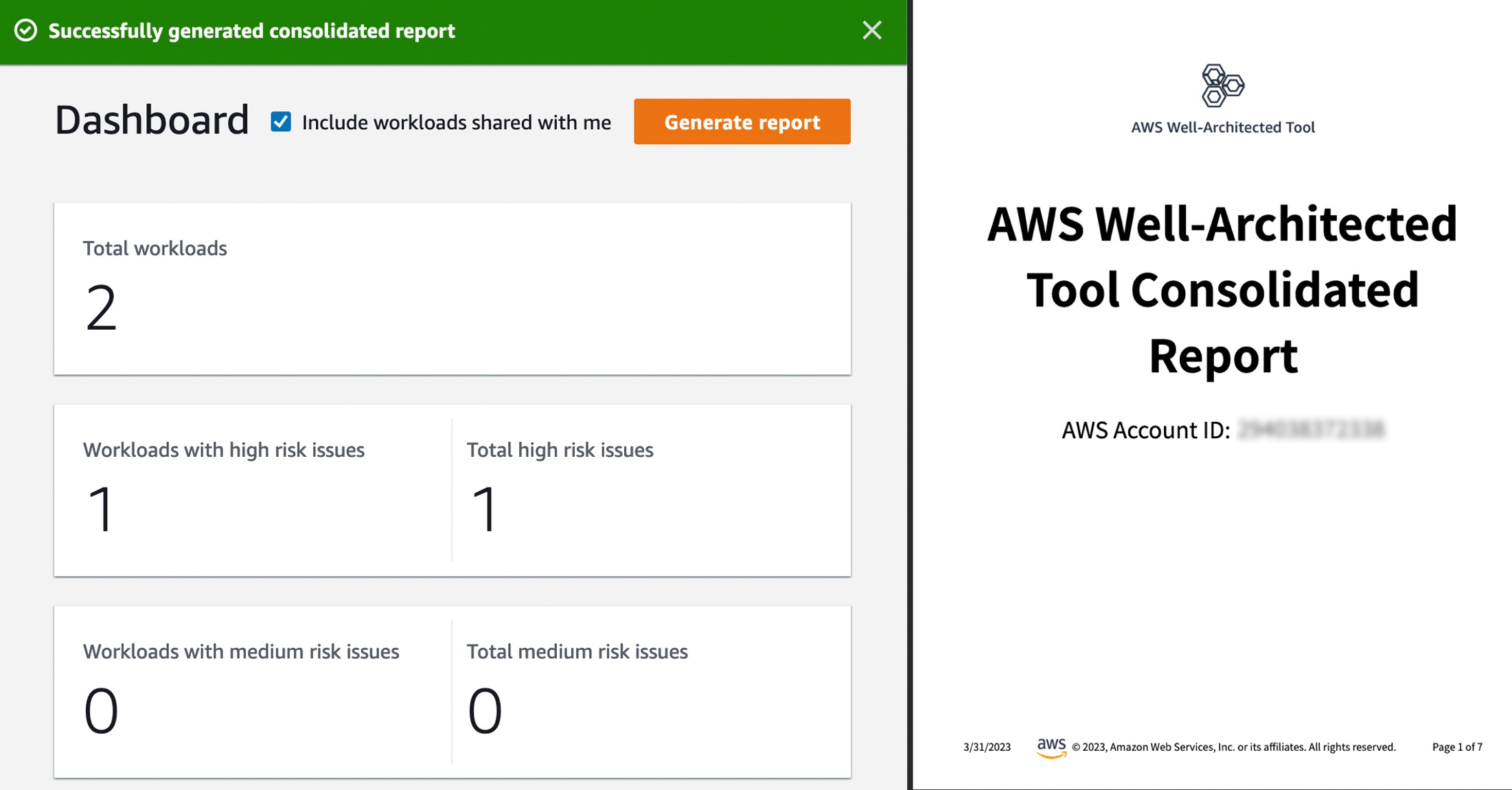
New Features of AWS Well-Architected Tool – The Consolidated Report and Enhanced Search enable customers to quickly identify risk themes across their workloads and scale improvements across their organization. This macro-level view helps executive stakeholders understand where common issues lie and prioritize team resources to drive widespread improvement. To learn more, see AWS Well-Architected Tool Dashboard in the AWS documentation.
For a full list of AWS announcements, be sure to keep an eye on the What’s New at AWS page.
Other AWS News
Here are some other news items that you may find interesting from the last week:
Welcome to the .NET on AWS Blog – We launched a new blog channel for millions of .NET developers across the world. Blog posts will also cover built-for-the-cloud development, modernizing .NET Framework applications, and how to deploy .NET workloads on different AWS services. We will use this channel to share news on the work we’ve done with the .NET open-source community, post follow-ups from important events, and post announcements about upcoming presentations from our .NET developer advocates. To learn more, visit our .NET on AWS website and follow us on Twitter at @dotnetonAWS.
AWS Knowledge Center in AWS re:Post – You can now access trusted, authoritative articles and videos of AWS Knowledge Center on AWS re:Post to get answers to technical questions. Knowledge Center content is produced by an AWS team and covers the most frequent questions and requests from AWS customers. These articles are available in 10 localized languages: English, French, German, Italian, Japanese, Korean, Portuguese, Simplified Chinese, Spanish, and Traditional Chinese.
TF1’s FIFA Worldcup Digital Broadcasting Story – Sébastien shared an awesome story about how the French broadcaster TF1 use AWS Cloud technology and expertise to bring the FIFA World Cup to millions of people. He shared the history of redesigning its digital broadcasting architecture on AWS, testing the new platform on large-scale sporting events. For the preparation of the FIFA Worldcup event, TF1 enhanced monitoring to detect anomalies during the event and established the backup plan in a “war room” for the worst scenario. Even if you’re not a fan of football, I recommend reading the behind-the-scenes of the FIFA Worldcup Finals. It’s long but really fun!
Upcoming AWS Events
Check your calendars and sign up for these AWS-led events:
![]() AWS re:Inforce 2023 – Now register AWS re:Inforce, in Anaheim, California, June 13–14. AWS Chief Information Security Officer CJ Moses will share the latest innovations in cloud security and what AWS Security is focused on. The breakout sessions will provide real-world examples of how security is embedded into the way businesses operate. To learn more and get the limited discount code to register, see CJ’s blog post of Gain insights and knowledge at AWS re:Inforce 2023 in the AWS Security Blog.
AWS re:Inforce 2023 – Now register AWS re:Inforce, in Anaheim, California, June 13–14. AWS Chief Information Security Officer CJ Moses will share the latest innovations in cloud security and what AWS Security is focused on. The breakout sessions will provide real-world examples of how security is embedded into the way businesses operate. To learn more and get the limited discount code to register, see CJ’s blog post of Gain insights and knowledge at AWS re:Inforce 2023 in the AWS Security Blog.
 AWS Global Summits – Check your calendars and sign up for the AWS Summit closest to your city: Paris and Sydney (April 4), Seoul (May 3-4), Berlin and Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Amsterdam (June 1), London (June 7), Madrid (June 15), and Milano (June 22).
AWS Global Summits – Check your calendars and sign up for the AWS Summit closest to your city: Paris and Sydney (April 4), Seoul (May 3-4), Berlin and Singapore (May 4), Stockholm (May 11), Hong Kong (May 23), Amsterdam (June 1), London (June 7), Madrid (June 15), and Milano (June 22).
![]() AWS Community Day – Join community-led conferences driven by AWS user group leaders closest to your city: Peru (April 15), Helsinki (April 20), Chicago (June 15), Philippines (June 29–30), and Munich (September 14). Recently, we are bringing together AWS user groups from around the world into Meetup Pro accounts. Find your group and its meetups in your city!
AWS Community Day – Join community-led conferences driven by AWS user group leaders closest to your city: Peru (April 15), Helsinki (April 20), Chicago (June 15), Philippines (June 29–30), and Munich (September 14). Recently, we are bringing together AWS user groups from around the world into Meetup Pro accounts. Find your group and its meetups in your city!
You can browse all upcoming AWS-led in-person and virtual events, and developer-focused events such as AWS DevDay.
That’s all for this week. Check back next Monday for another Week in Review!
— Channy
This post is part of our Week in Review series. Check back each week for a quick roundup of interesting news and announcements from AWS!
























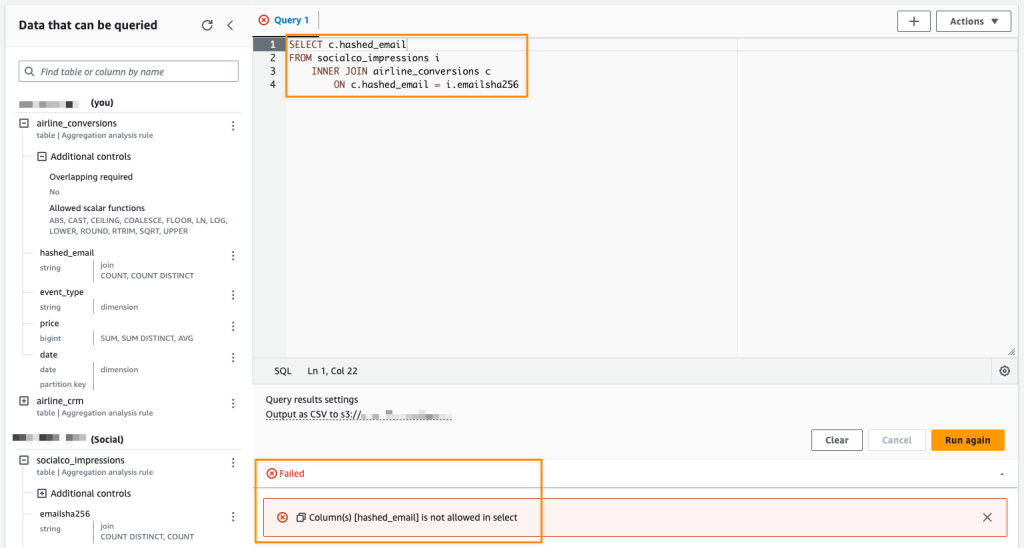
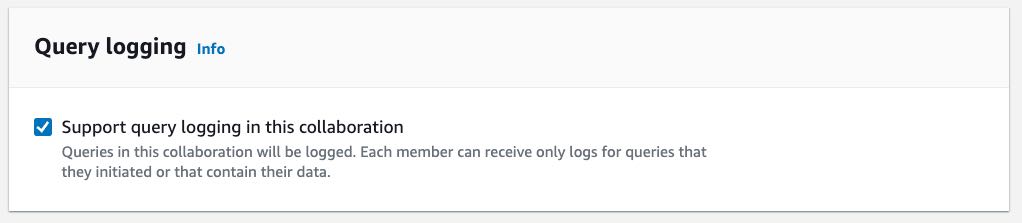
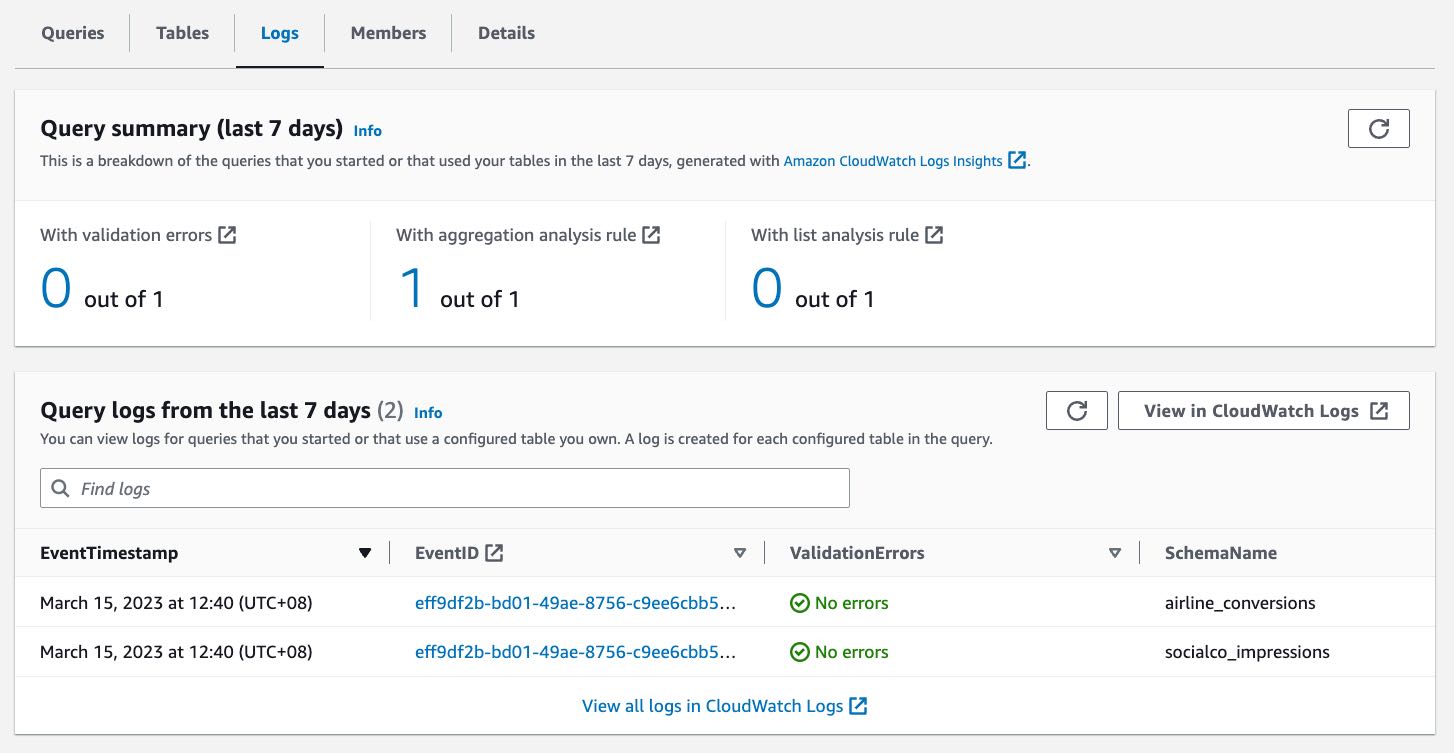
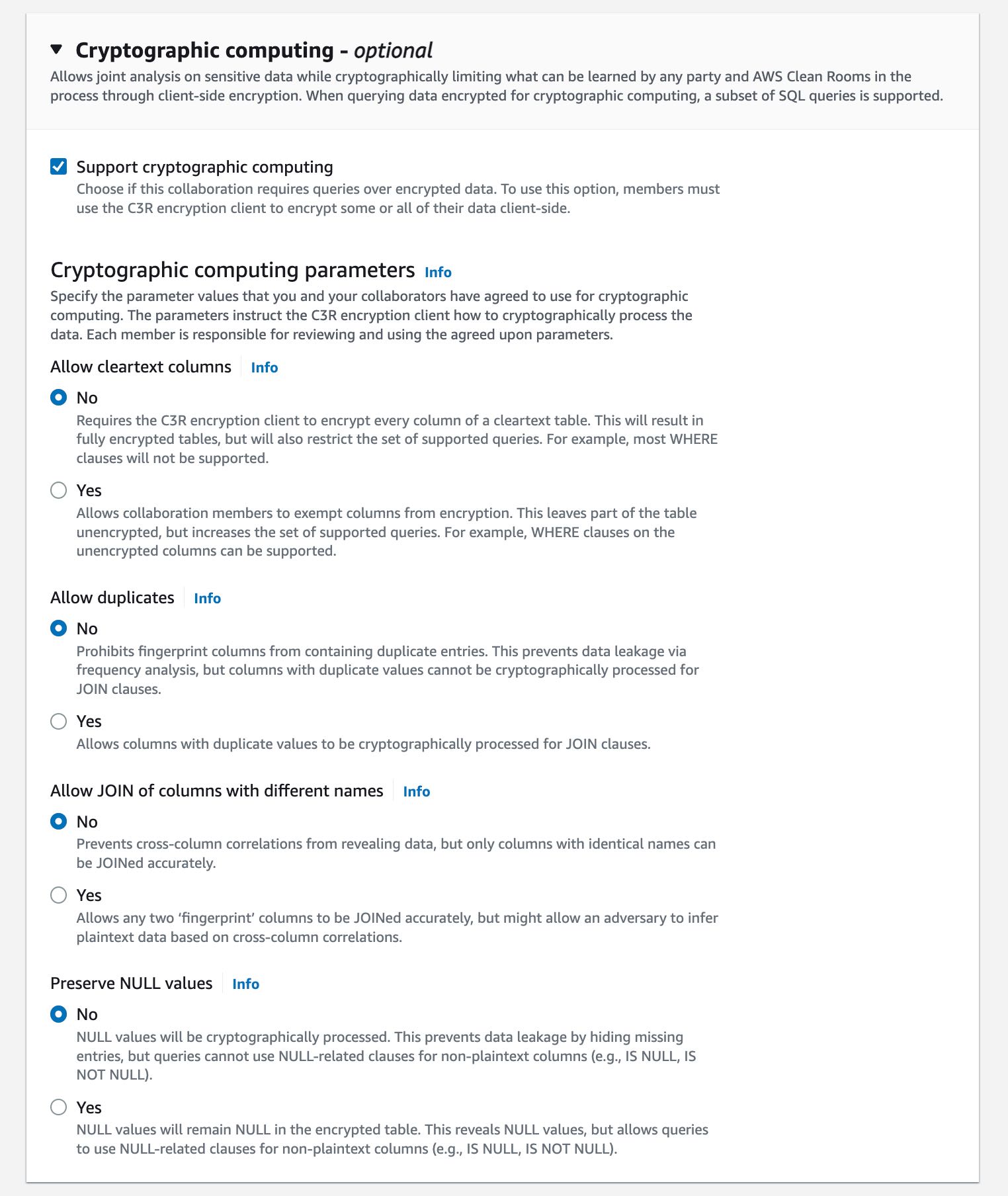


 “Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.
“Providing marketers with greater control over their own signals while being able to analyze them in conjunction with signals from Amazon Ads is crucial in today’s marketing landscape. By migrating AMC’s compute infrastructure to AWS Clean Rooms under the hood, marketers can use their own signals in AMC without storing or maintaining data outside of their AWS environment. This simplifies how marketers can manage their signals and enables AMC teams to focus on building new capabilities for brands,” said Paula Despins, Vice President of Ads Measurement at Amazon Ads.