Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/modernize-your-mainframe-applications-deploy-them-in-the-cloud/
Today, we are launching AWS Mainframe Modernization service to help you modernize your mainframe applications and deploy them to AWS fully-managed runtime environments. This new service also provides tools and resources to help you plan and implement migration and modernization.
Since the introduction of System/360 on April 7 1964, mainframe computers have enabled many industries to transform themselves. The mainframe has revolutionized the way people buy things, how people book and purchase travel, and how governments manage taxes or deliver social services. Two thirds of the Fortune 100 companies have their core businesses located on a mainframe. And according to a 2018 estimate, $3 trillion ($3 x 10^12) in daily commerce flows through mainframes.
Mainframes are using their very own set of technologies: programming languages such as COBOL, PL/1, and Natural, to name a few, or databases and data files such as VSAM, DB2, IMS DB, or Adabas. They also run “application servers” (or transaction managers as we call them) such as CICS or IMS TM. Recent IBM mainframes also run applications developed in the Java programming language deployed on WebSphere Application Server.
Many of our customers running mainframes told us they want to modernize their mainframe-based applications to take advantage of the AWS cloud. They want to increase their agility and their capacity to innovate, gain access to a growing pool of talents with experience running workloads on AWS, and benefit from the continual AWS trend of improving cost/performance ratio.
Application modernization is a journey composed of four phases:
- First, you assess the situation. Are you ready to migrate? You define the business case and educate the migration team.
- Second, you mobilize. You kick off the project, identify applications for a proof of concept, and refine your migration plan and business cases.
- Third, you migrate and modernize. For each application, you run in-depth discovery, decide on the right application architecture and migration journey, replatform or refactor the code base, and test and deploy to production.
- Last, you operate and optimize. You monitor deployed applications, manage resources, and ensure that security and compliance are up to date.
AWS Mainframe Modernization helps you during each phase of your journey.
Assess and Mobilize
During the assessment and mobilization phase, you have access to analysis and development tools to discover the scope of your application portfolio and to transform source code as needed. Typically, the service helps you discover the assets of your mainframe applications and identify all the data and other dependencies. We provide you with integrated development environments where you can adapt or refactor your source code, depending on whether you are replatforming or refactoring your applications.
Application Automated Refactoring
You may choose to use the automated refactoring pattern, where mainframe application assets are automatically converted into a modern language and ecosystem. With automated refactoring, AWS Mainframe Modernization uses Blu Age tools to convert your COBOL, PL/1, or JCL code to Java services and scripts. It generates modern code, data access, and data format by implementing patterns and rules to transform screens, indexed files, and batch applications to a modern application stack.

Application Replatforming
You may also choose to replatform your applications, meaning move them to AWS with minimal changes to the source code. When replatforming, the fully-managed runtime comes preinstalled with the Micro Focus mainframe-compatible components, such as transaction managers, data mapping tools, screen and maps readers, and batch execution environments, allowing you to run your application with minimum changes.

This blog post can help you learn more about nuances between replatforming and refactoring.
DevOps For Your Mainframe Applications
AWS Mainframe Modernization service provides you with AWS CloudFormation templates to easily create continuous integration and continuous deployment pipelines. It also deploys and configures monitoring services to monitor the managed runtime. This allows you to maintain or continue to evolve your applications once migrated, using best practices from Agile and DevOps methodologies.
Managed Services
AWS Mainframe Modernization takes care of the undifferentiated heavy lifting and provides you with fully managed runtime environments based on 15 years of cloud architecture best practices in terms of security, high availability, scalability, system management, and using infrastructure as code. These are all important for the business-critical applications running on mainframes.
The analysis tools, development tools, and the replatforming or refactoring runtimes come preinstalled and ready to use. But there is much more than preinstalled environments. The service deploys and manages the whole infrastructure for you. It deploys the required network, load balancer, and configure log collection with Amazon CloudWatch, among others. It manages application versioning, deployments, and high availability dependencies. This saves you days of designing, testing, automating, and deploying your own infrastructure.
The fully managed runtime includes extensive automation and managed infrastructure resources that you can operate via the AWS console, the AWS Command Line Interface (CLI), and application programming interfaces (APIs). This removes the burden and undifferentiated heavy lifting of managing a complex infrastructure. It allows you to spend time and focus on innovating and building new capabilities.
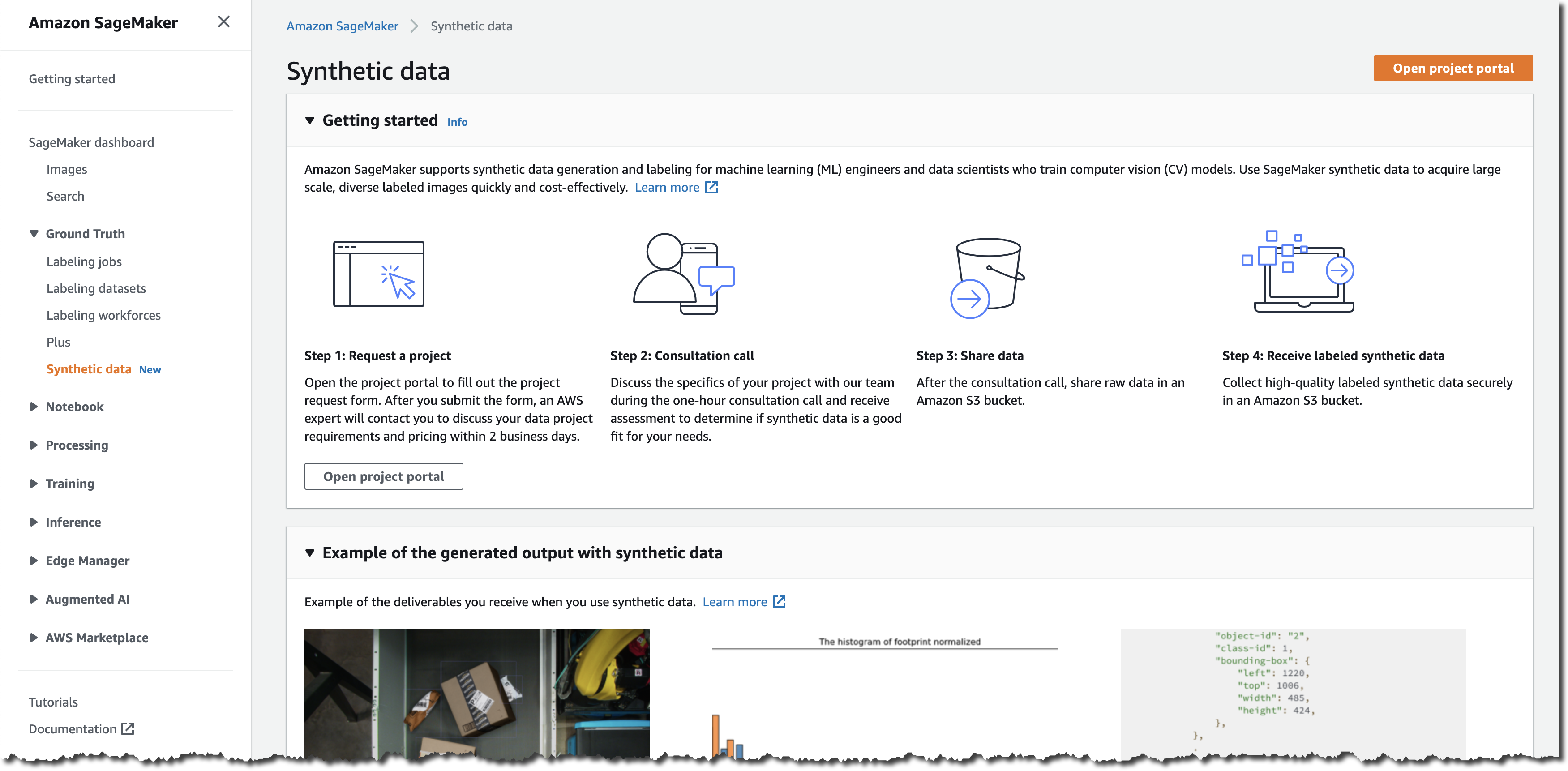
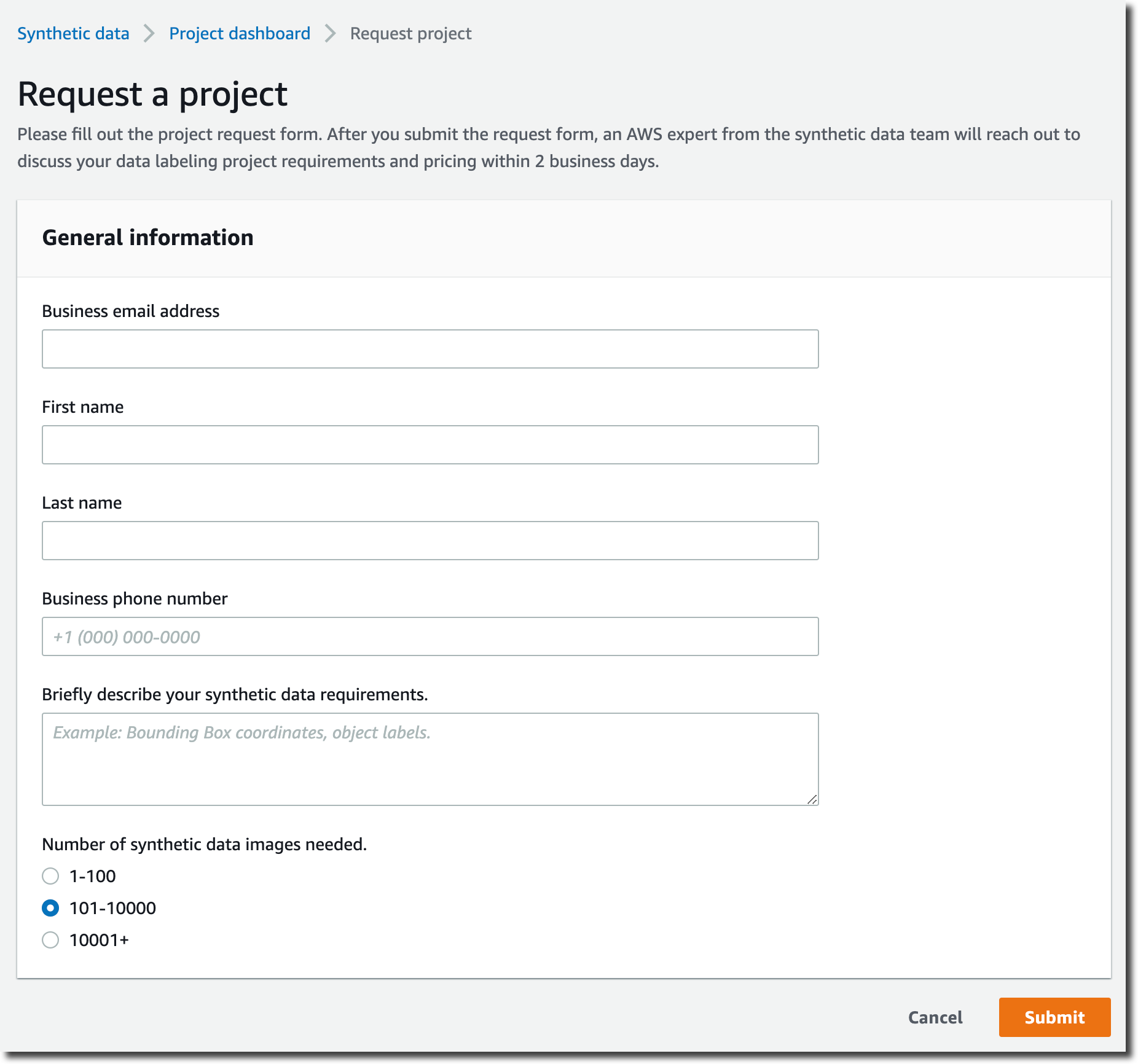
Let’s Deploy an App
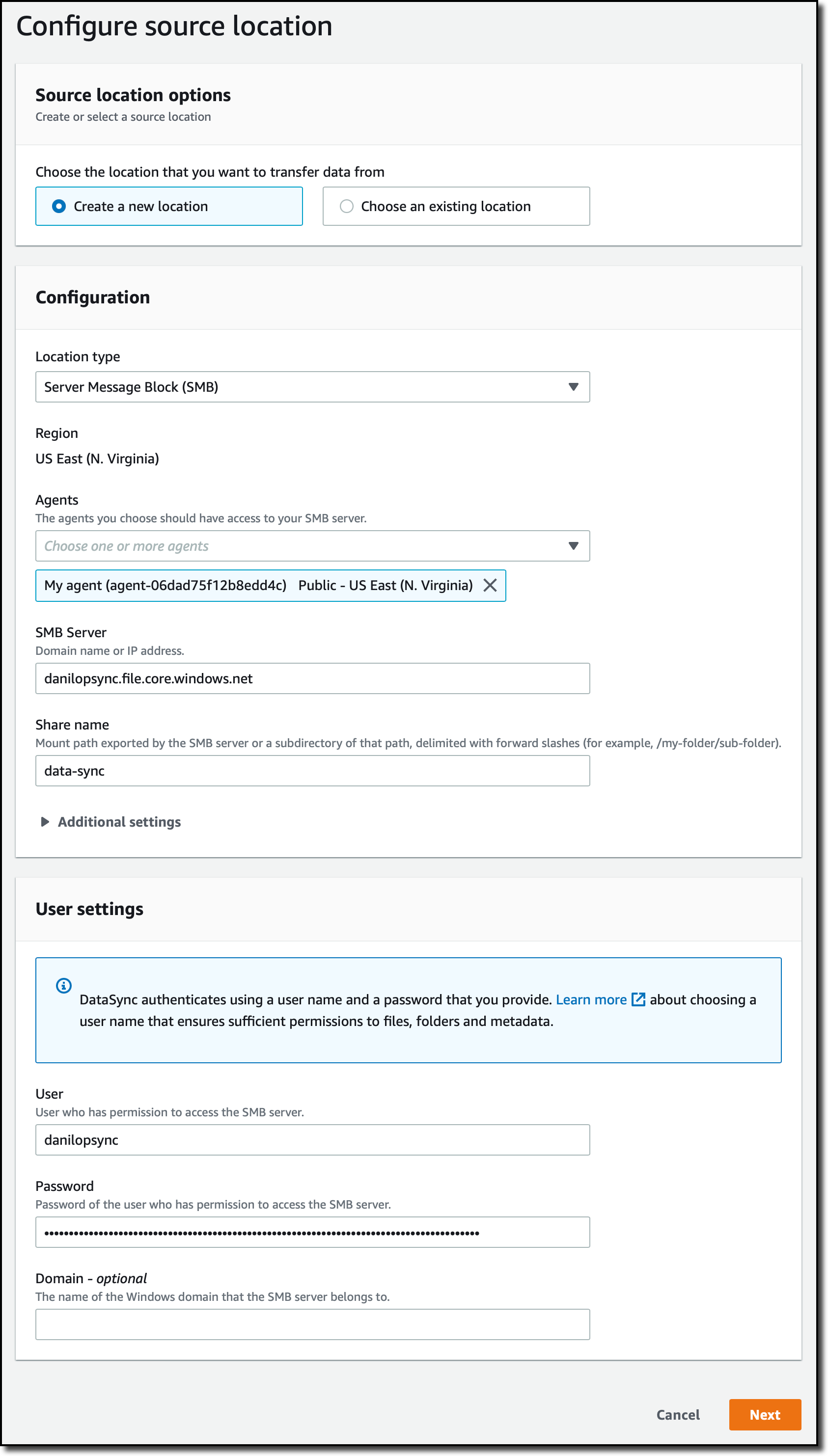
As usual, I like to show you how it works. I am using a demo banking application. The application has been replatformed and is available as two .zip files. The first one contains the application binaries, and the second one the data files. I uploaded the content of these zipped files to an Amazon Simple Storage Service (Amazon S3) bucket. As part of the prerequisites, I also created a PostgreSQL Aurora database, stored its username and password in AWS Secrets Manager, and I created an encryption key in AWS Key Management Service (KMS).

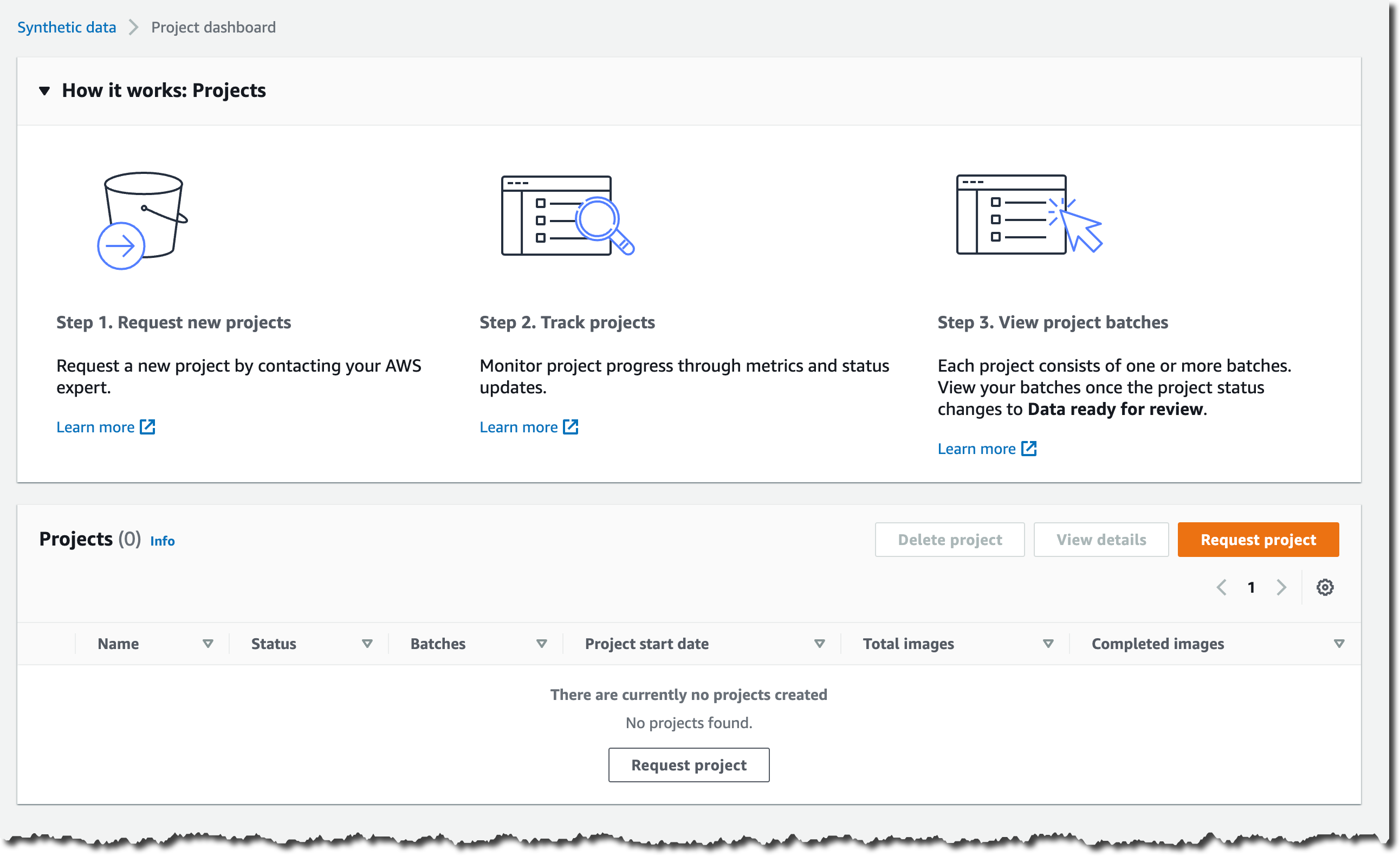
Create an Environment
Let’s deploy and run the BankDemo sample application in an AWS Mainframe Modernization managed runtime environment with the Micro Focus runtime engine. For brevity, I highlight only the main steps. The full tutorial is available as part of the service documentation.
I open the AWS Management Console and navigate to AWS Mainframe Modernization. I navigate to Environments and select Create environment.
 I give the environment a name and select Micro Focus runtime since we are deploying a replatformed application. Then I select Next.
I give the environment a name and select Micro Focus runtime since we are deploying a replatformed application. Then I select Next.
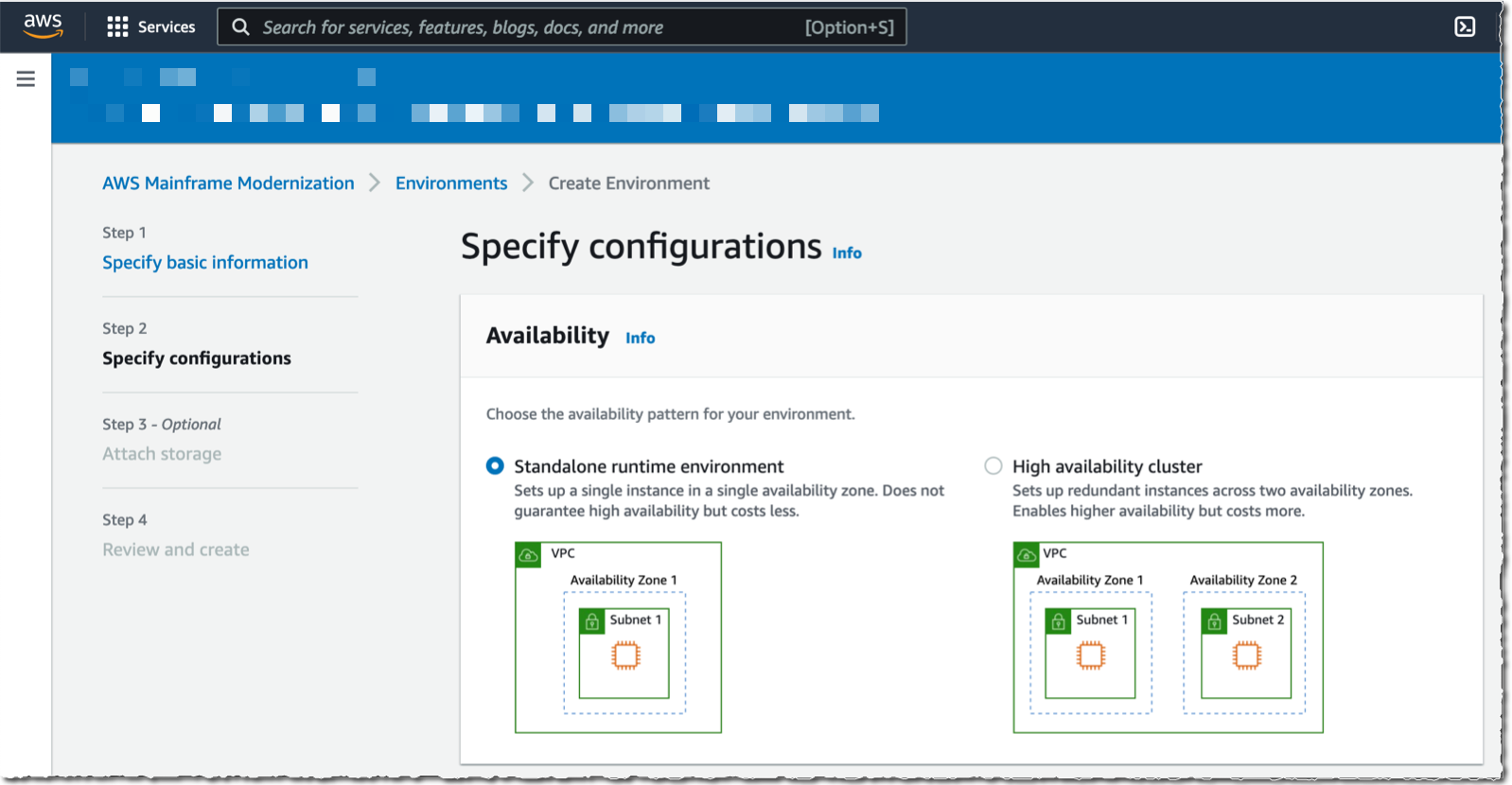
 In the Specify Configurations section, I leave all the default values: a Standalone runtime environment, the
In the Specify Configurations section, I leave all the default values: a Standalone runtime environment, the M2.m5.large EC2 instance type, and the default VPC and subnets. Then I select Next.

On the Attach Storage section, I mount an EFS endpoint as /m2/mount/demo. Then I select Next.
 In the Review and create section, I review my configuration and select Create environment. After a while, the environment status switches to Available.
In the Review and create section, I review my configuration and select Create environment. After a while, the environment status switches to Available.

Create an Application
Now that I have an environment, let’s deploy the sample banking application on it. I select the Applications section and select Create application.
 I give my application a name, and under Engine type, I select Micro Focus.
I give my application a name, and under Engine type, I select Micro Focus.
 In the Specify resources and configurations section, I enter a JSON definition of my application. The JSON tells the runtime environment where my application’s various files are located and how to access Secrets Manager. You can find a sample JSON file in the tutorial section of the documentation.
In the Specify resources and configurations section, I enter a JSON definition of my application. The JSON tells the runtime environment where my application’s various files are located and how to access Secrets Manager. You can find a sample JSON file in the tutorial section of the documentation.
 In the last section, I Review and create the application. I select Create application. After a moment, the application becomes available.
In the last section, I Review and create the application. I select Create application. After a moment, the application becomes available.
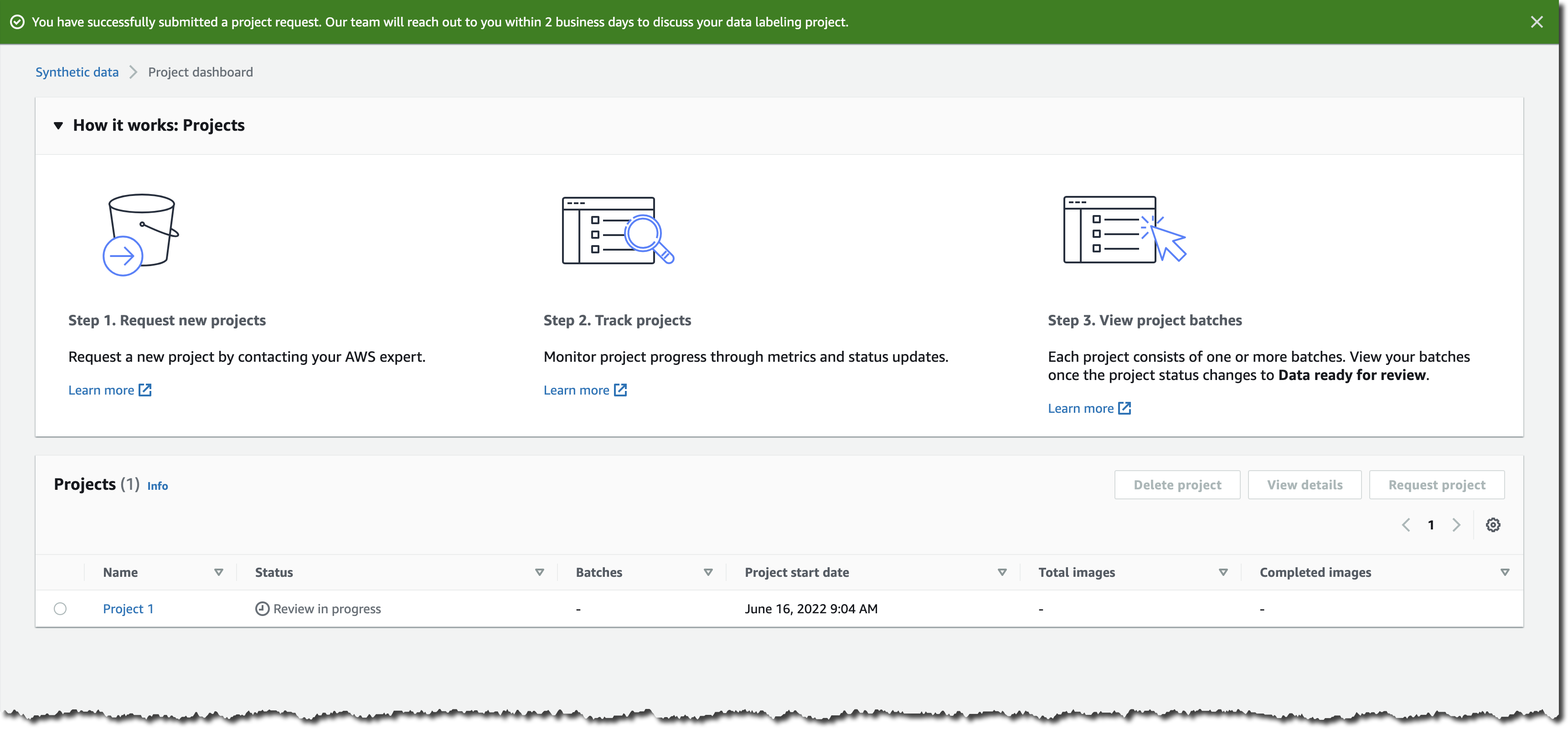
 Once available, I deploy the application to the environment. I select the AWSNewsBlog-SampleBanking app, then I select the Actions dropdown menu, and I select Deploy application.
Once available, I deploy the application to the environment. I select the AWSNewsBlog-SampleBanking app, then I select the Actions dropdown menu, and I select Deploy application.
 After a while, the application status changes to Ready.
After a while, the application status changes to Ready.
Import Data sets
The last step before starting the application is to import its data sets. In the navigation pane, I select Applications, then choose AWSNewsBlog-SampleBank. I then select the Data sets tab and select Import. I may either specify the data set configuration values individually using the console or provide the location of an S3 bucket that contains a data set configuration JSON file.
 I use the JSON file provided by the tutorial in the documentation. Before uploading the JSON file to S3, I replace the
I use the JSON file provided by the tutorial in the documentation. Before uploading the JSON file to S3, I replace the $S3_DATASET_PREFIX variable with the actual value of my S3 bucket and prefix. For this example, I use awsnewsblog-samplebank/catalog.
 After a while, the data set status changes to Completed.
After a while, the data set status changes to Completed.
My application and its data set are now deployed into the cloud.
Start the Application
The last step is to start the application. I navigate to the Applications section. I then select AWSNewsBlog-SampleBank. In the Actions dropdown menu, I select Start application. After a moment, the application status changes to Running.

Access the Application
To access the application, I need a 3270 terminal emulator. Depending on your platform, a couple of options are available. I choose to use a web-based TN3270 web-based client provided by Micro Focus and available on the AWS Marketplace. I configure the terminal emulator to point it to the AWS Mainframe Modernization environment endpoint, and I use port 6000.

Once the session starts, I receive the CICS welcome prompt. I type BANK and press ENTER to start the app. I authenticate with user BA0001 and password A. The main application menu is displayed. I select the first option of the menu and press ENTER.

Congrats, your replatformed application has been deployed in the cloud and is available through a standard IBM 3270 terminal emulator.
Pricing and Availability
AWS Mainframe Modernization service is available in the following AWS Regions: US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), Canada (Central), Europe (Frankfurt), Europe (Ireland), and South America (São Paulo).
You only pay for what you use. There are no upfront costs. Third-party license costs are included in the hourly price. Runtime environments for refactored applications, based on Blu Age, start at $2.50/hour. Runtime environments for replatformed applications, based on Micro Focus, start at $5.55/hour. This includes the software licenses (Blu Age or Micro Focus). As usual, AWS Support plans are available. They also cover Blu Age and Micro Focus software.
Committed plans are available for pricing discounts. The pricing details are available on the service pricing page.
And now, go build 😉
— seb


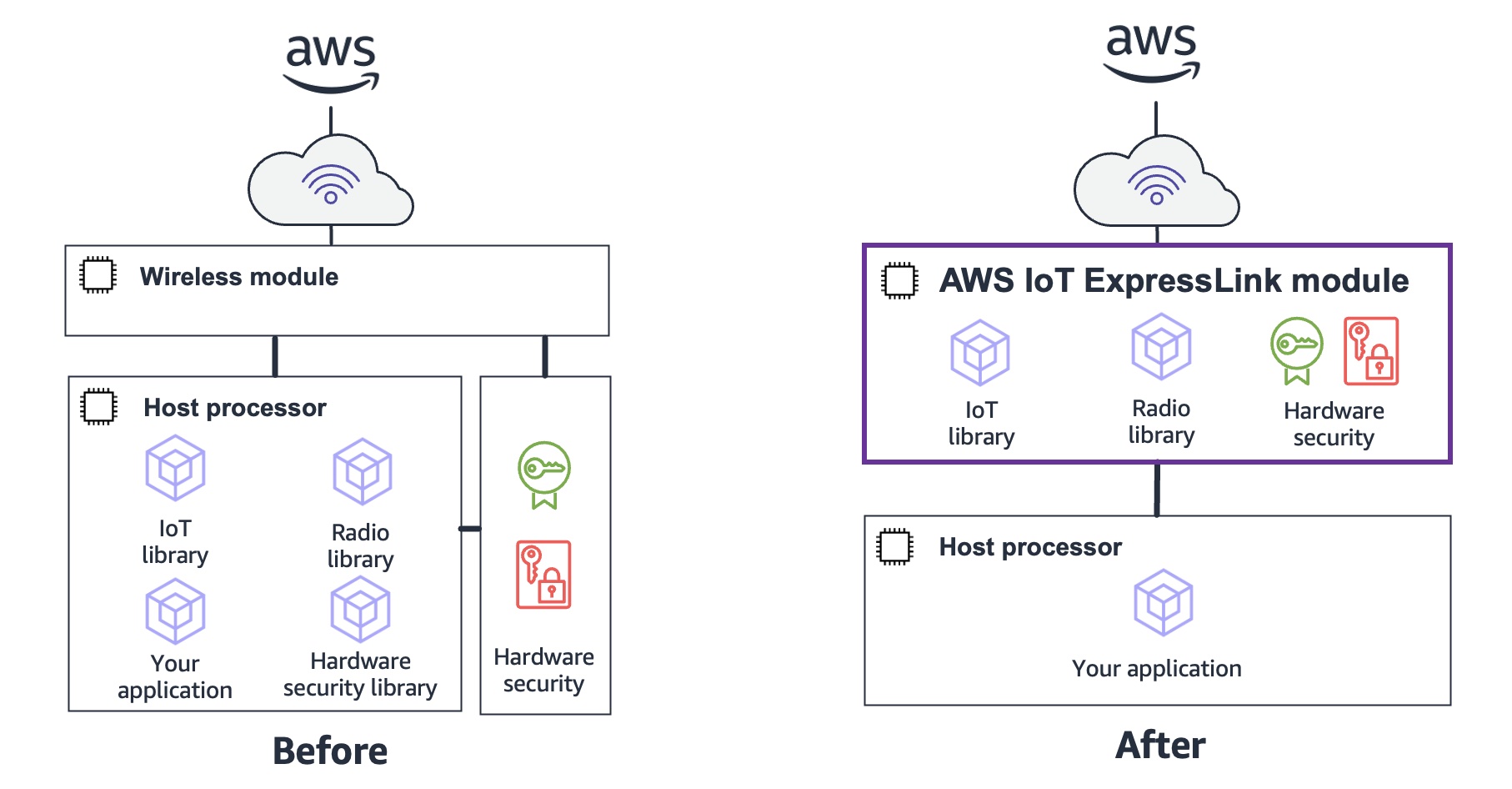




 Infineon Technologies AG specializes in semiconductor solutions the goal of which is to make life easier, safer, and greener. Sivaram Trikutam, Vice President, Wi-Fi Product Line at Infineon Technologies, said:
Infineon Technologies AG specializes in semiconductor solutions the goal of which is to make life easier, safer, and greener. Sivaram Trikutam, Vice President, Wi-Fi Product Line at Infineon Technologies, said: IFW56810 Cloud Connectivity Manager
IFW56810 Cloud Connectivity Manager Espressif Systems is a multinational, fabless semiconductor company with a strong focus on providing connectivity solutions to internet-connected devices. Amey Inamdar, Director of Technical Marketing, Espressif Systems, said:
Espressif Systems is a multinational, fabless semiconductor company with a strong focus on providing connectivity solutions to internet-connected devices. Amey Inamdar, Director of Technical Marketing, Espressif Systems, said:



















 We also have more
We also have more 










 Please join
Please join  You can now register for
You can now register for 














{kind=link}