Post Syndicated from Aaron McAllister original https://blog.cloudflare.com/nist-sp-1300-85/
For decades, the United States National Institute of Standards and Technology (NIST) has been guiding industry efforts through the many publications in its Computer Security Resource Center. NIST has played an especially important role in the adoption of Zero Trust architecture, through its series of publications that began with NIST SP 800-207: Zero Trust Architecture, released in 2020.
NIST has released another Special Publication in this series, SP 1800-35, titled “Implementing a Zero Trust Architecture (ZTA)” which aims to provide practical steps and best practices for deploying ZTA across various environments. NIST’s publications about ZTA have been extremely influential across the industry, but are often lengthy and highly detailed, so this blog provides a short and easier-to-read summary of NIST’s latest guidance on ZTA.
And so, in this blog post:
-
We summarize the key items you need to know about this new NIST publication, which presents a reference architecture for Zero Trust Architecture (ZTA) along with a series of “Builds” that demonstrate how different products from various vendors can be combined to construct a ZTA that complies with the reference architecture.
-
We show how Cloudflare’s Zero Trust product suite can be integrated with offerings from other vendors to support a Zero Trust Architecture that maps to the NIST’s reference architecture.
-
We highlight a few key features of Cloudflare’s Zero Trust platform that are especially valuable to customers seeking compliance with NIST’s ZTA reference architecture, including compliance with FedRAMP and new post-quantum cryptography standards.
Let’s dive into NIST’s special publication!
In SP 1800-35, NIST reminds us that:
A zero-trust architecture (ZTA) enables secure authorized access to assets — machines, applications and services running on them, and associated data and resources — whether located on-premises or in the cloud, for a hybrid workforce and partners based on an organization’s defined access policy.
NIST uses the term Subject to refer to entities (i.e. employees, developers, devices) that require access to Resources (i.e. computers, databases, servers, applications). SP 1800-35 focuses on developing and demonstrating various ZTA implementations that allow Subjects to access Resources. Specifically, the reference architecture in SP 1800-35 focuses mainly on EIG or “Enhanced Identity Governance”, a specific approach to Zero Trust Architecture, which is defined by NIST in SP 800-207 as follows:
For [the EIG] approach, enterprise resource access policies are based on identity and assigned attributes.
The primary requirement for [R]esource access is based on the access privileges granted to the given [S]ubject. Other factors such as device used, asset status, and environmental factors may alter the final confidence level calculation … or tailor the result in some way, such as granting only partial access to a given [Resource] based on network location.
Individual [R]esources or [policy enforcement points (PEP)] must have a way to forward requests to a policy engine service or authenticate the [S]ubject and approve the request before granting access.
While there are other approaches to ZTA mentioned in the original NIST SP 800-207, we omit those here because SP 1800-35 focuses mostly on EIG.
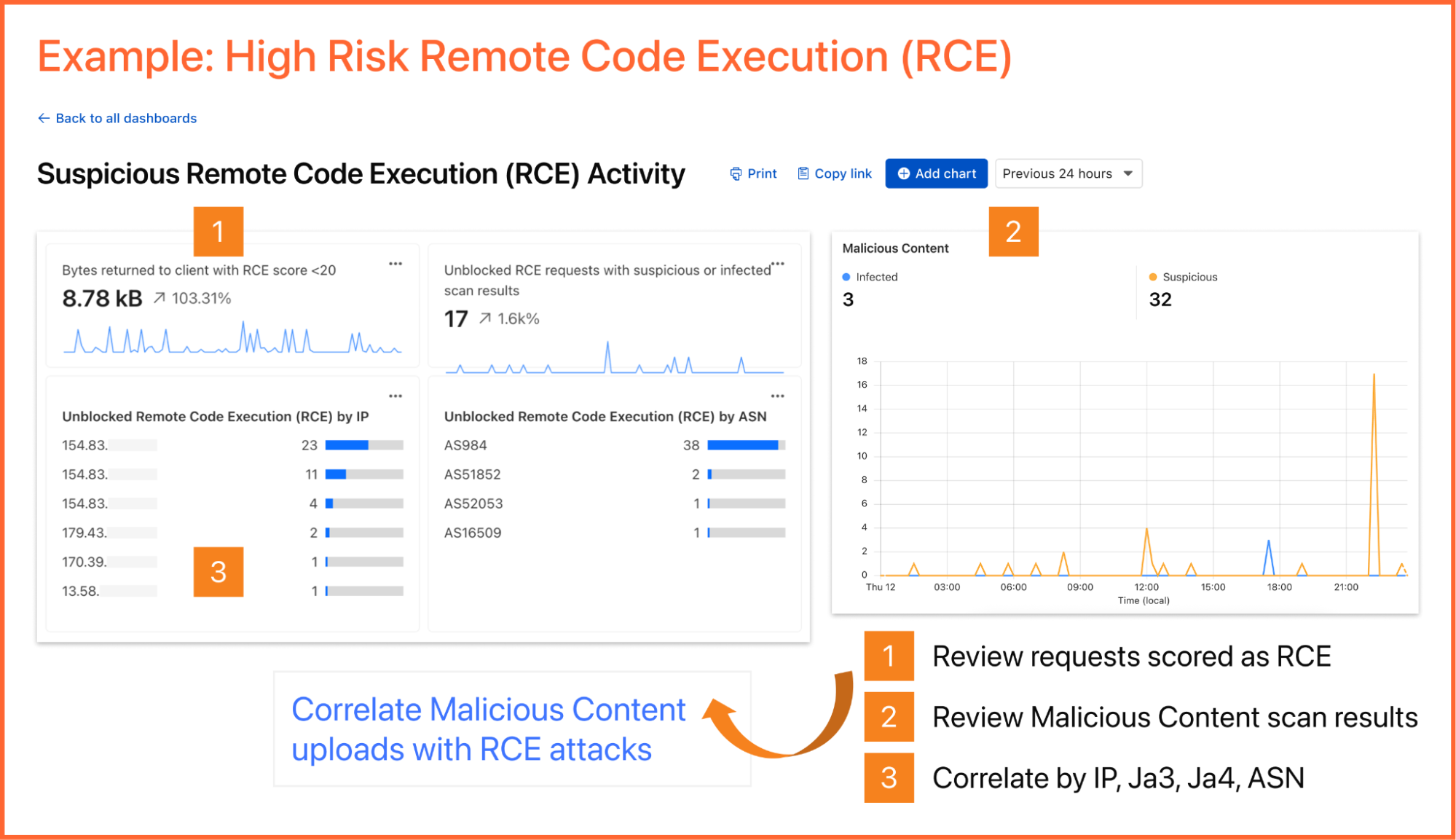
The ZTA reference architecture from SP 1800-35 focuses on EIG approaches as a set of logical components as shown in the figure below. Each component in the reference architecture does not necessarily correspond directly to physical (hardware or software) components, or products sold by a single vendor, but rather to the logical functionality of the component.
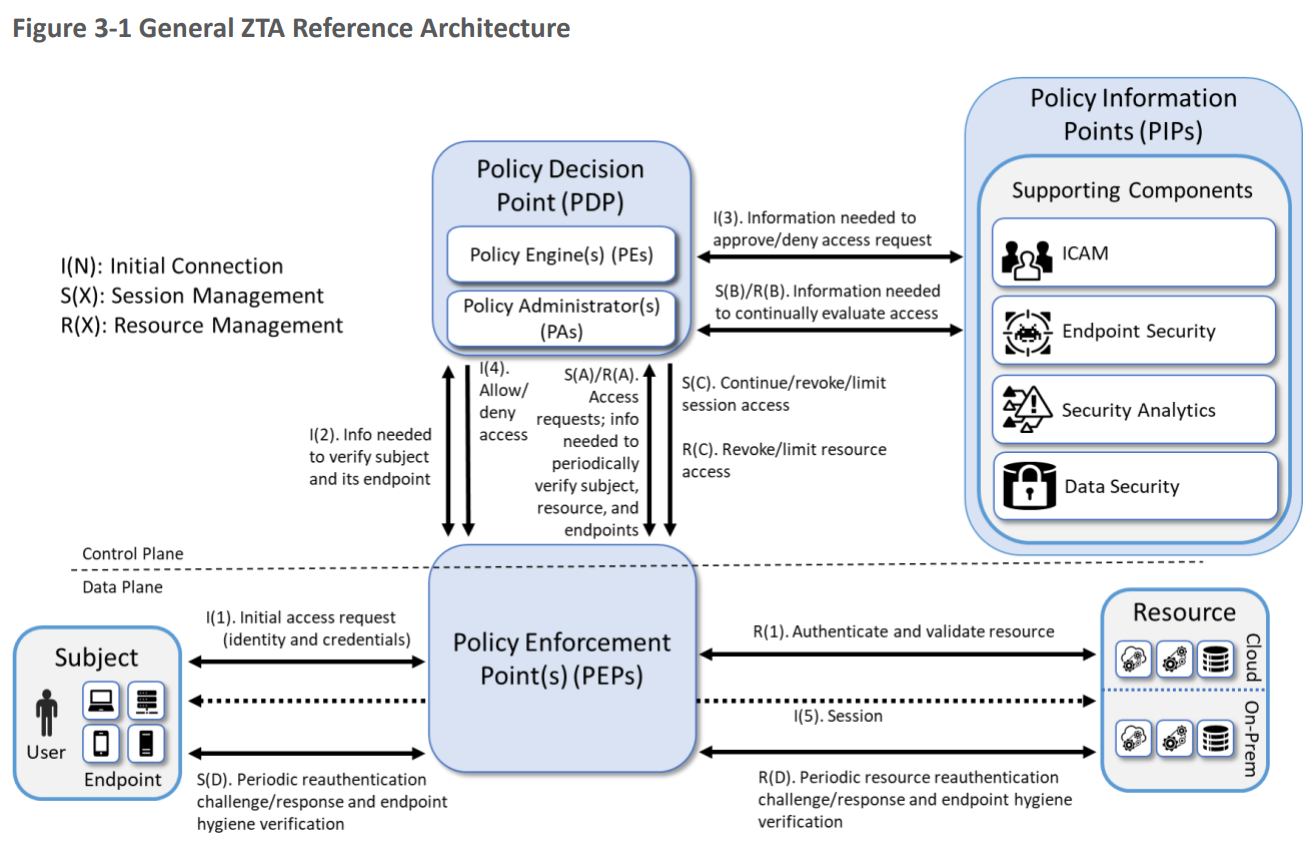
Figure 1: General ZTA Reference Architecture. Source: NIST, Special Publication 1800-35, “Implementing a Zero Trust Architecture (ZTA)”, 2025.
The logical components in the reference architecture are all related to the implementation of policy. Policy is crucial for ZTA because the whole point of a ZTA is to apply policies that determine who has access to what, when and under what conditions.
The core components of the reference architecture are as follows:
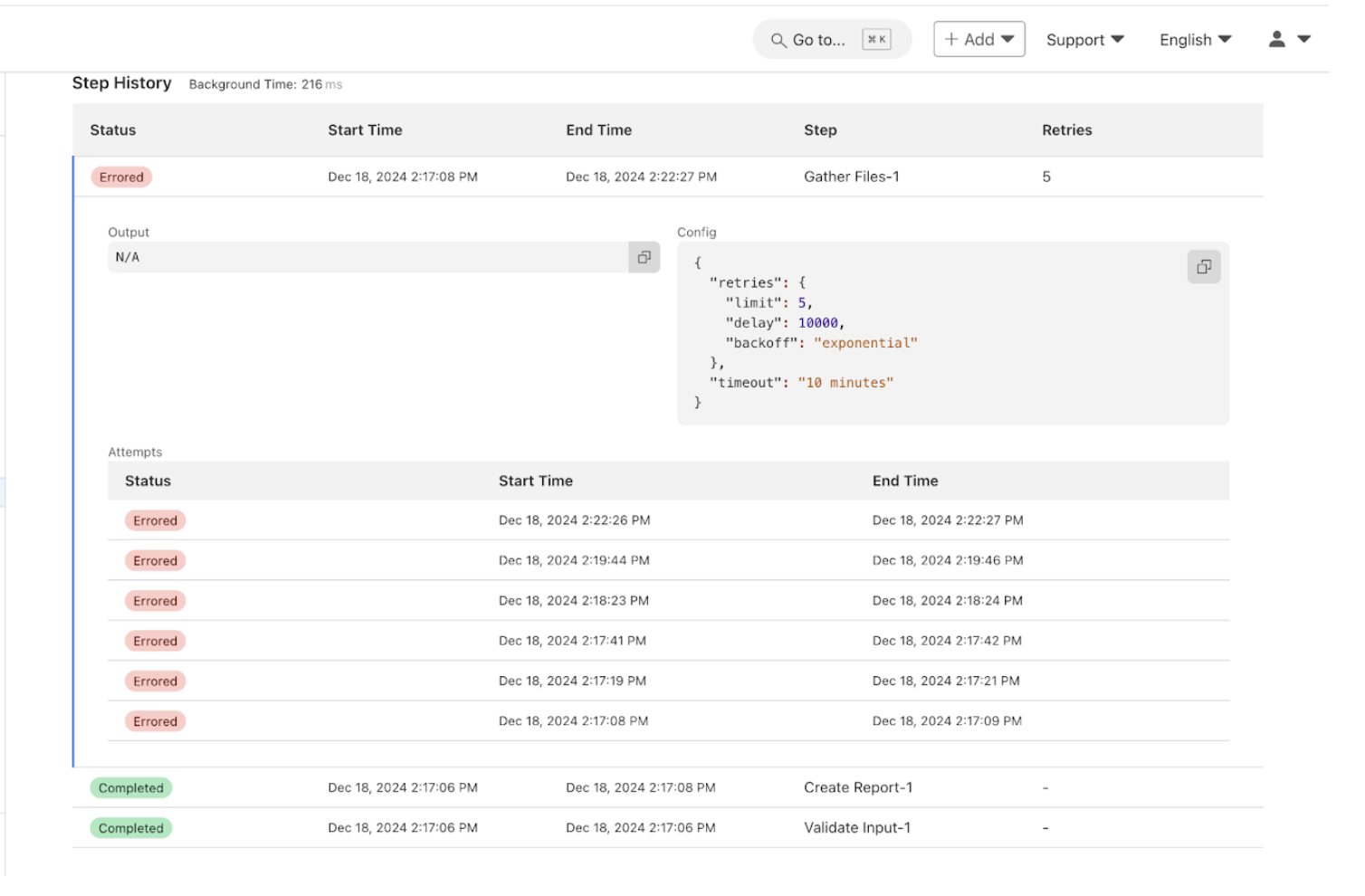
| Policy Enforcement Point(PEP) | The PEP protects the “trust zones” that host enterprise Resources, and handles enabling, monitoring, and eventually terminating connections between Subjects and Resources. You can think of the PEP as the dataplane that supports the Subject’s access to the Resources.
|
Policy Enforcement Point |
The PEP protects the “trust zones” that host enterprise Resources, and handles enabling, monitoring, and eventually terminating connections between Subjects and Resources. You can think of the PEP as the dataplane that supports the Subject’s access to the Resources. |
|
Policy Engine (PE) |
The PE handles the ultimate decision to grant, deny, or revoke access to a Resource for a given Subject, and calculates the trust scores/confidence levels and ultimate access decisions based on enterprise policy and information from supporting components. |
|
Policy Administrator (PA) |
The PA executes the PE’s policy decision by sending commands to the PEP to establish and terminate the communications path between the Subject and the Resource. |
|
Policy Decision Point (PDP) |
The PDP is where the decision as to whether or not to permit a Subject to access a Resource is made. The PIP included the Policy Engine (PE) and the Policy Administrator (PA). You can think of the PDP as the control plane that controls the Subject’s access to the Resources. |
The PDP operates on inputs from Policy Information Points (PIPs) which are supporting components that provide critical data and policy rules to the Policy Decision Point (PDP).
|
Policy Information Point (PIP) |
The PIPs provide various types of telemetry and other information needed for the PDP to make informed access decisions. Some PIPs include:
NIST’s figure might suggest that supporting components in the PIP are mere plug-ins responding in real-time to the PDP. However, for many vendors, the ICAM, EDR/EPP, security analytics, and data security PIPs often represent complex and distributed infrastructures. |
Next, the SP 1800-35 introduces two more detailed reference architectures, the “Crawl Phase” and the “Run Phase”. The “Run Phase” corresponds to the reference architecture that is shown in the figure above. The “Crawl Phase” is a simplified version of this reference architecture that only deals with protecting on-premise Resources, and omits cloud Resources. Both of these phases focused on Enhanced Identity Governance approaches to ZTA, as we defined above. NIST stated, “We are skipping the EIG walk phase and have proceeded directly to the run phase“.
The SP 1800-35 then provides a sequence of detailed instructions, called “Builds”, that show how to implement “Crawl Phase” and “Run Phase” reference architectures using products sold by various vendors.
Since Cloudflare’s Zero Trust platform natively supports access to both cloud and on-premise resources, we will skip over the “Crawl Phase” and move directly to showing how Cloudflare’s Zero Trust platform can be used to support “Run Phase” of the reference architecture.
Nothing in NIST SP 1800-35 represents an endorsement of specific vendor technologies. Instead, the intent of the publication is to offer a general architecture that applies regardless of the technologies or vendors an organization chooses to deploy. It also includes a series of “Builds” using a variety of technologies from different vendors, that allow organizations to achieve a ZTA. This section describes how Cloudflare fits in with a ZTA, enabling you to accelerate your ZTA deployment from Crawl directly to Run.
Regarding the “Builds” in SP 1800-35, this section can be viewed as an aggregation of the following three specific builds:
-
Enterprise 1 Build 3 (E1B3): Software-Defined Perimeter (SDP) with Cloudflare as the Policy Engine (PE).
-
Enterprise 2 Build 4 (E2B4): SDP and Secure Access Service Edge (SASE) with Cloudflare Secure Web Gateway, Cloudflare Zero Trust Network Access (ZTNA), and Cloudflare Cloud Access Security Broker as PEs.
-
Enterprise 3 Build 5 (E3B5): SDP and SASE with Microsoft Entra Conditional Access (formerly known as Azure AD Conditional Access) and Cloudflare Zero Trust as PEs.
Now let’s see how we can map Cloudflare’s Zero Trust platform to the ZTA reference architecture:
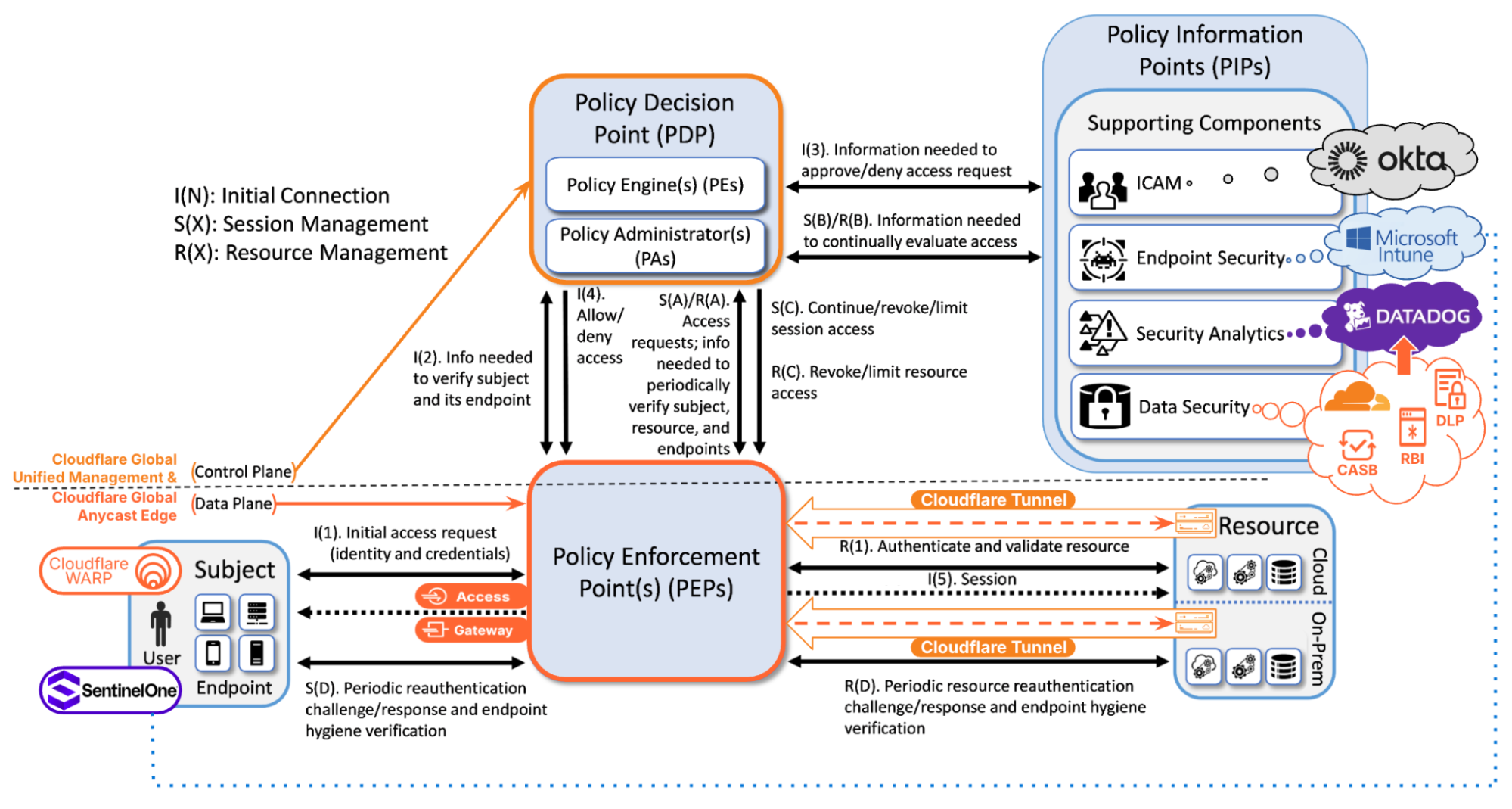
Figure 2: General ZTA Reference Architecture Mapped to Cloudflare Zero Trust & Key Integrations. Source: NIST, Special Publication 1800-35, “Implementing a Zero Trust Architecture (ZTA)”, 2025, with modification by Cloudflare.
Cloudflare’s platform simplifies complexity by delivering the PEP via our global anycast network and the PDP via our Software-as-a-Service (SaaS) management console, which also serves as a global unified control plane. A complete ZTA involves integrating Cloudflare with PIPs provided by other vendors, as shown in the figure above.
Now let’s look at several key points in the figure.
In the bottom right corner of the figure are Resources, which may reside on-premise, in private data centers, or across multiple cloud environments. Resources are made securely accessible through Cloudflare’s global anycast network via Cloudflare Tunnel (as shown in the figure) or Magic WAN (not shown). Resources are shielded from direct exposure to the public Internet by placing them behind Cloudflare Access and Cloudflare Gateway, which are PEPs that enforce zero-trust principles by granting access to Subjects that conform to policy requirements.
In the bottom left corner of the figure are Subjects, both human and non-human, that need access to Resources. With Cloudflare’s platform, there are multiple ways that Subjects can again access to Resources, including:
-
Agentless approaches that allow end users to access Resources directly from their web browsers. Alternatively, Cloudflare’s Magic WAN can be used to support connections from enterprise networks directly to Cloudflare’s global anycast network via IPsec tunnels, GRE tunnels or Cloudflare Network Interconnect (CNI).
-
Agent-based approaches use Cloudflare’s lightweight WARP client, which protects corporate devices by securely and privately sending traffic to Cloudflare’s global network.
Now we move onto the PEP (the Policy Enforcement Point), which is the dataplane of our ZTA. Cloudflare Access is a modern Zero Trust Network Access solution that serves as a dynamic PEP, enforcing user-specific application access policies based on identity, device posture, context, and other factors. Cloudflare Gateway is a Secure Web Gateway for filtering and inspecting traffic sent to the public Internet, serving as a dynamic PEP that provides DNS, HTTP and network traffic filtering, DNS resolver policies, and egress IP policies.
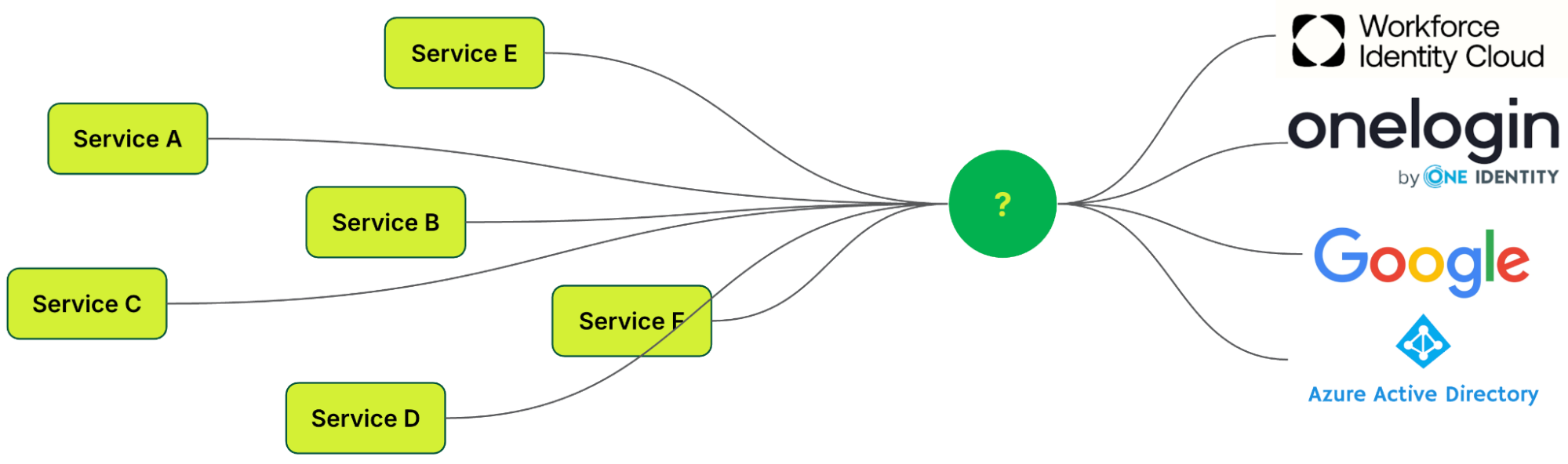
Both Cloudflare Access and Cloudflare Gateway rely on Cloudflare’s control plane, which acts as a PDP offering a policy engine (PE) and policy administrator (PA). This PDP takes in inputs from PIPs provided by integrations with other vendors for ICAM, endpoint security, and security analytics. Let’s dig into some of these integrations.
-
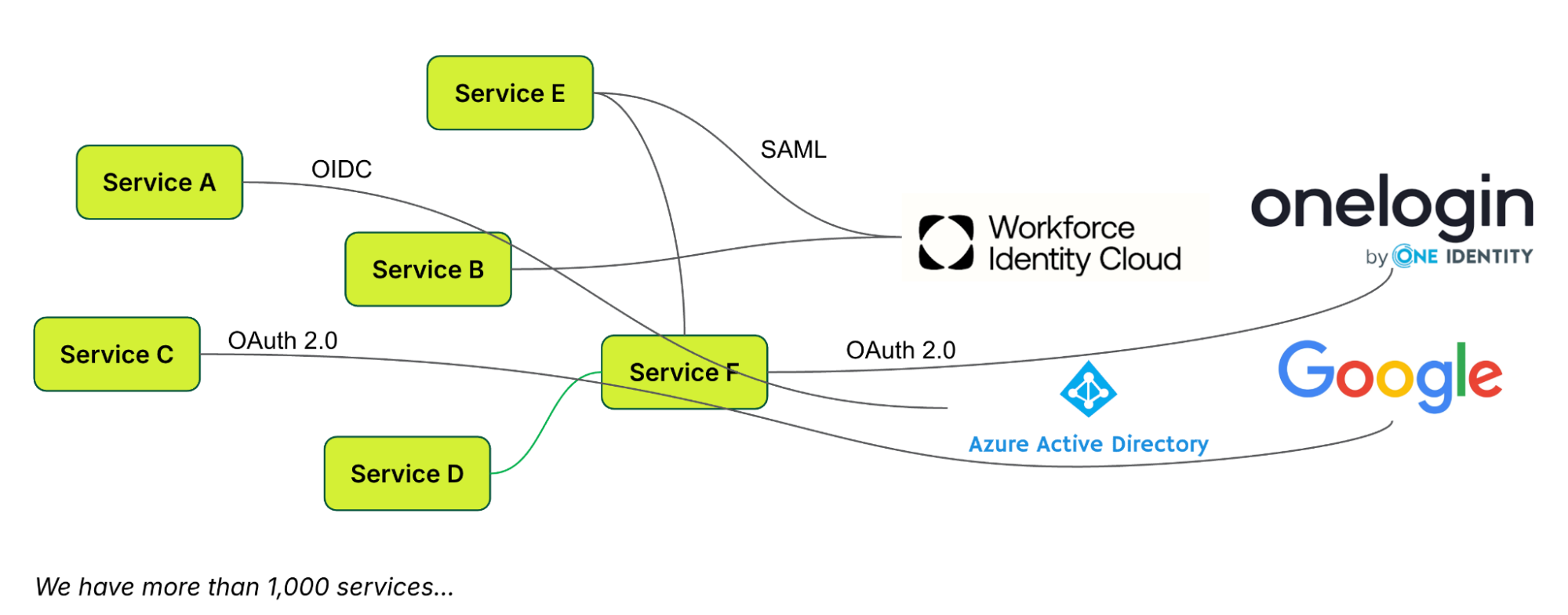
ICAM: Cloudflare’s control plane integrates with many ICAM providers that provide Single Sign On (SSO) and Multi-Factor Authentication (MFA). The ICAM provider authenticates human Subjects and passes information about authenticated users and groups back to Cloudflare’s control plane using Security Assertion Markup Language (SAML) or OpenID Connect (OIDC) integrations. Cloudflare’s ICAM integration also supports AI/ML powered behavior-based user risk scoring, exchange, and re-evaluation.
In the figure above, we depicted Okta as the ICAM provider, but Cloudflare supports many other ICAM vendors (e.g. Microsoft Entra, Jumpcloud, GitHub SSO, PingOne). For non-human Subjects — such as service accounts, Internet of Things (IoT) devices, or machine identities — authentication can be performed through certificates, service tokens, or other cryptographic methods.
-
Endpoint security: Cloudflare’s control plane integrates with many endpoint security providers to exchange signals, such as device posture checks and user risk levels. Cloudflare facilitates this through integrations with endpoint detection and response EDR/EPP solutions, such as CrowdStrike, Microsoft, SentinelOne, and more. When posture checks are enabled with one of these vendors such as Microsoft, device state changes, ‘noncompliant’, can be sent to Cloudflare Zero Trust, automatically restricting access to Resources. Additionally, Cloudflare Zero Trust enables the ability to synchronize the Microsoft Entra ID risky users list and apply more stringent Zero Trust policies to users at higher risk.
-
Security Analytics: Cloudflare’s control plane integrates with real-time logging and analytics for persistent monitoring. Cloudflare’s own analytics and logging features monitor access requests and security events. Optionally, these events can be sent to a Security Information and Event Management (SIEM) solution such as, CrowdStrike, Datadog, IBM QRadar, Microsoft Sentinel, New Relic, Splunk, and more using Cloudflare’s logpush integration.
Cloudflare’s user risk scoring system is built on the OpenID Shared Signals Framework (SSF) Specification, which allows integration with existing and future providers that support this standard. SSF focuses on the exchange of Security Event Tokens (SETs), a specialized type of JSON Web Token (JWT). By using SETs, providers can share user risk information, creating a network of real-time, shared security intelligence. In the context of NIST’s Zero Trust Architecture, this system functions as a PIP, which is responsible for gathering information about the Subject and their context, such as risk scores, device posture, or threat intelligence. This information is then provided to the PDP, which evaluates access requests and determines the appropriate policy actions. The PEP uses these decisions to allow or deny access, completing the cycle of secure, dynamic access control.
-
Data security: Cloudflare’s Zero Trust offering provides robust data security capabilities across data-in-transit, data-in-use, and data-at-rest. Its Data Loss Prevention (DLP) safeguards sensitive information in transit by inspecting and blocking unauthorized data movement. Remote Browser Isolation (RBI) protects data-in-use by preventing malware, phishing, and unauthorized exfiltration while enabling secure web access. Meanwhile, Cloud Access Security Broker (CASB) ensures data-at-rest security by enforcing granular controls over SaaS applications, preventing unauthorized access and data leakage. Together, these capabilities provide comprehensive protection for modern enterprises operating in a cloud-first environment.
By leveraging Cloudflare’s Zero Trust platform, enterprises can simplify and enhance their ZTA implementation, securing diverse environments and endpoints while ensuring scalability and ease of deployment. This approach ensures that all access requests—regardless of where the Subjects or Resources are located—adhere to robust security policies, reducing risks and improving compliance with modern security standards.
Cloudflare works with multiple enterprises, and federal and state agencies that rely on NIST guidelines to secure their networks. So we take a brief detour to describe some unique features of Cloudflare’s Zero Trust platform that we’ve found to be valuable to these enterprises.
-
FedRAMP data centers. Many government agencies and commercial enterprises have FedRAMP requirements, and Cloudflare is well-equipped to support them. FedRAMPs requirements sometimes require organizations to self-host software and services inside their own network perimeter, which can result in higher latency, degraded performance and increased cost. At Cloudflare, we take a different approach. Organizations can still benefit from Cloudflare’s global network and unparalleled performance while remaining Fedramp compliant. To support FedRAMP customers, Cloudflare’s dataplane (aka our PEP, or Policy Enforcement Point) consists of data centers in over 330 cities where customers can send their encrypted traffic, and 32 FedRAMP datacenters where traffic is sent to when sensitive dataplane operations are required (e.g. TLS inspection). This architecture means that our customers do not need to self-host a PEP and incur the associated cost, latency, and performance degradation.
-
Post-quantum cryptography. NIST has announced that by 2030 all conventional cryptography (RSA and ECDSA) must be deprecated and upgraded to post-quantum cryptography. But upgrading cryptography is hard and takes time, so Cloudflare aims to take on the burden of managing cryptography upgrades for our customers. That’s why organizations can tunnel their corporate network traffic though Cloudflare’s Zero Trust platform, protecting it against quantum adversaries without the hassle of individually upgrading each and every corporate application, system, or network connection. End-to-end quantum safety is available for communications from end-user devices, via web browser (today) or Cloudflare’s WARP device client (mid-2025), to secure applications connected with Cloudflare Tunnel.
NIST’s latest publication, SP 1800-35, provides a structured approach to implementing Zero Trust, emphasizing the importance of policy enforcement, continuous authentication, and secure access management. Cloudflare’s Zero Trust platform simplifies this complex framework by delivering a scalable, globally distributed solution that is FedRAMP-compliant and integrates with industry-leading providers like Okta, Microsoft, Ping, CrowdStrike, and SentinelOne to ensure comprehensive protection.
A key differentiator of Cloudflare’s Zero Trust solution is our global anycast network, one of the world’s largest and most interconnected networks. Spanning 330+ cities across 120+ countries, this network provides unparalleled performance, resilience, and scalability for enforcing Zero Trust policies without negatively impacting the end user experience. By leveraging Cloudflare’s network-level enforcement of security controls, organizations can ensure that access control, data protection, and security analytics operate at the speed of the Internet — without backhauling traffic through centralized choke points. This architecture enables low-latency, highly available enforcement of security policies, allowing enterprises to seamlessly protect users, devices, and applications across on-prem, cloud, and hybrid environments.
Now is the time to take action. You can start implementing Zero Trust today by leveraging Cloudflare’s platform in alignment with NIST’s reference architecture. Whether you are beginning your Zero Trust journey or enhancing an existing framework, Cloudflare provides the tools, network, and integrations to help you succeed. Sign up for Cloudflare Zero Trust, explore our integrations, and secure your organization with a modern, globally distributed approach to cybersecurity.