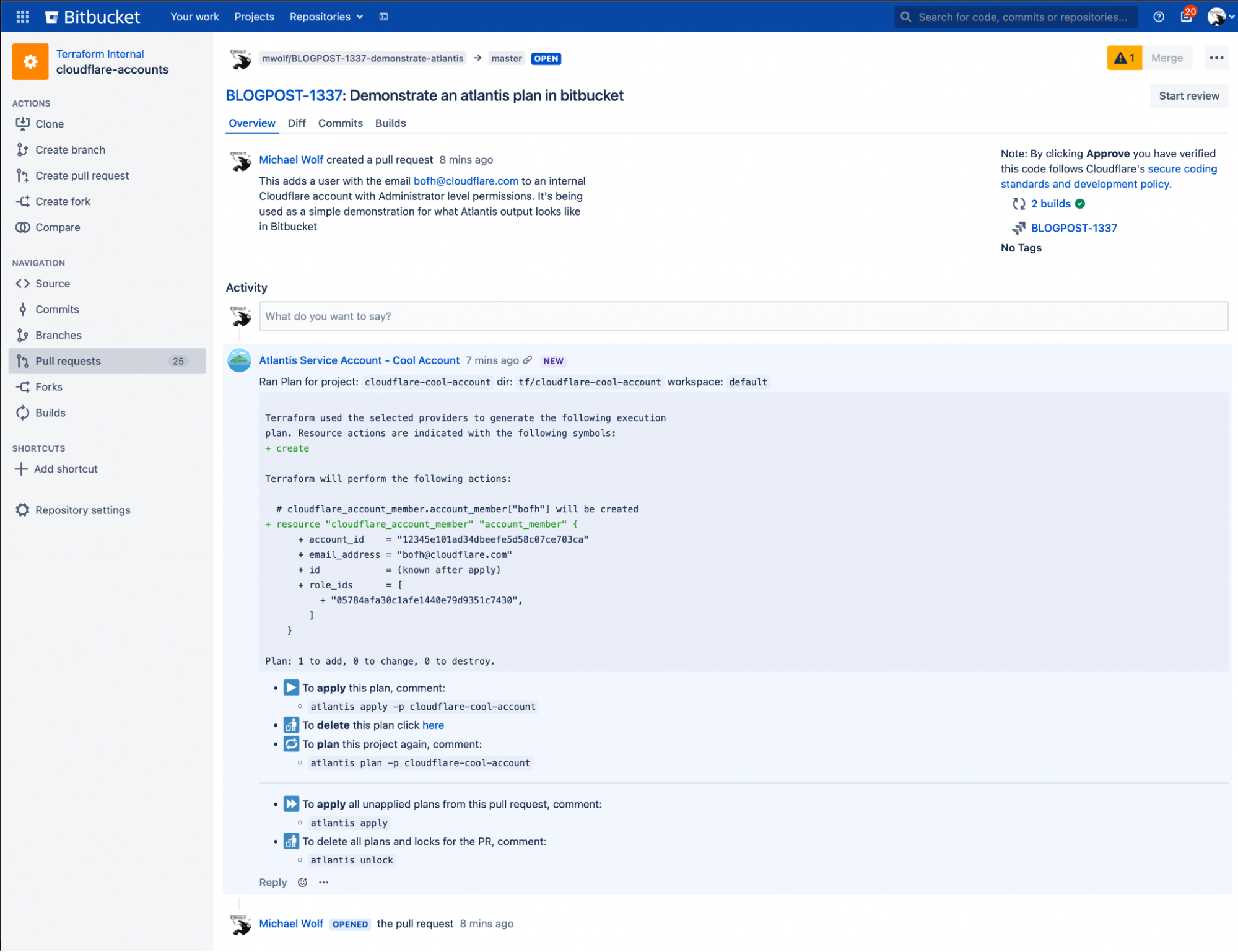
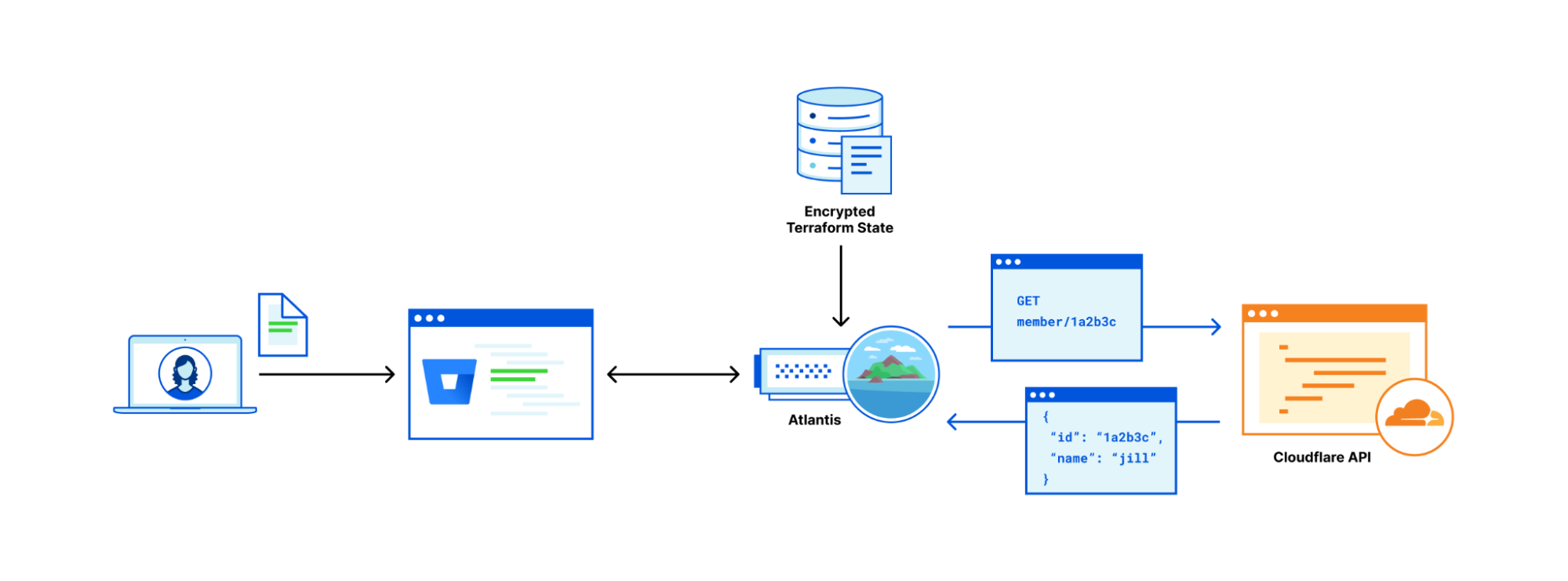
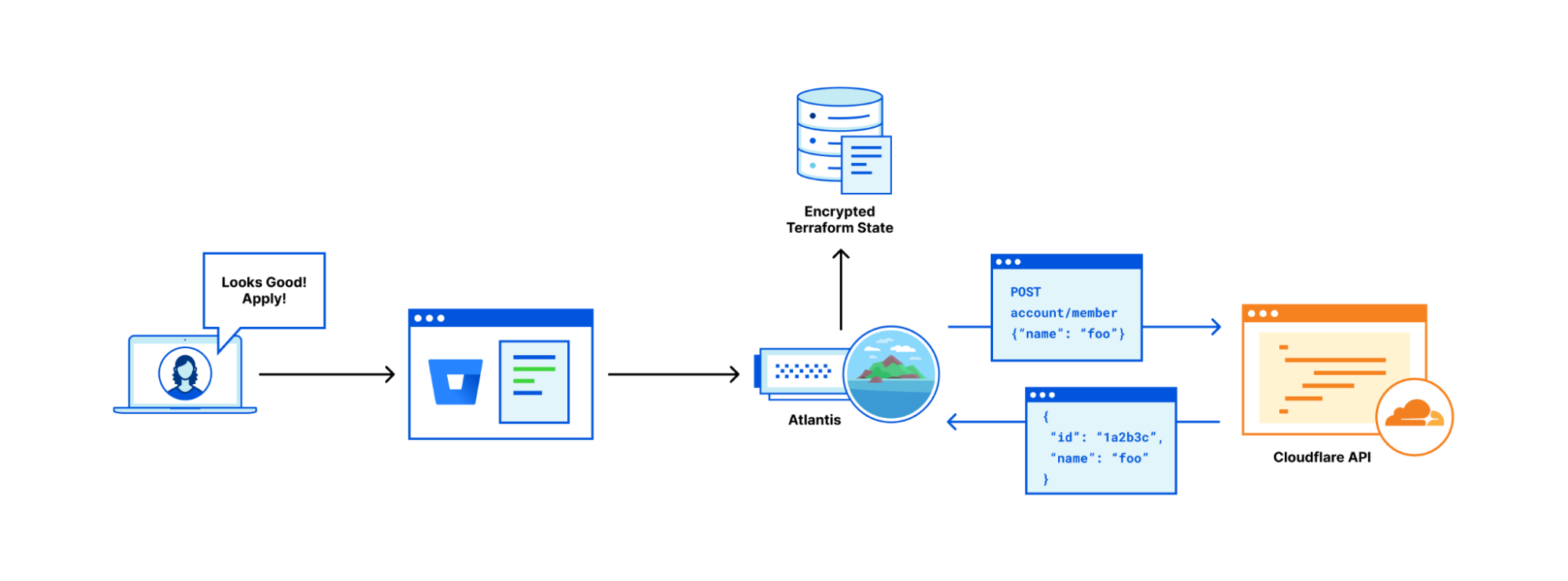
In today’s ever-evolving cybersecurity landscape, detecting and responding to cyber threats is paramount for organizations in cloud environments. At the same time, investigating cyber threat alerts can be arduous due to the time-consuming and complex process of data collection. To tackle this pain point, Rapid7 developed a new Cloud Resource Enrichment API that streamlines data retrieval from various cloud resources. The API empowers security analysts to swiftly respond to cyber threats and improve incident response time.
Identifying the Need for a Unified API
Protecting cloud resources from cyber attacks is a growing challenge. Security analysts must grapple with gathering relevant data spread across multiple systems and APIs, leading to incident response inefficiencies. Presented with this challenge, we recognized a pressing need for a unified API that collects all relevant data types related to a cloud resource during a cyber threat action. This API streamlines data access, enabling analysts to piece together a comprehensive view of incidents rapidly, enhancing cybersecurity operations.
Defining the Vision and Scope
Our development team worked closely with security analysts to tailor the API’s functionalities to meet real-world needs. Defining the API’s scope involved meticulous prioritization of features, striking the right balance between usability and data abundance. By involving analysts from the outset, we laid a solid foundation for the API’s success.
The Development Journey
Adopting agile methodologies, our team iteratively developed the API, adapting and fine-tuning as we progressed. The iterative development process played a vital role in ensuring the API’s success. By breaking down the project into smaller, manageable tasks, we could focus on specific features, implement them efficiently, and gather feedback from early prototypes. With a comprehensive design phase, we defined the API’s architecture and capabilities based on insights from security analysts. Regular meetings and feedback gathering facilitated continuous improvements, streamlining the data retrieval process.
The API utilizes RESTful API design principles for data integration and communication between cloud systems. It collects the following types of data:
Harvested cloud resource properties (image, IP, network interfaces, region, cloud organization and account, security groups, and much, much more)
Permissions data (permissions on the resource, permissions of the resource)
Application context (tagging made by the client in the cloud environment)
Each data type required collaboration with a different team which is responsible for collecting and processing the data. This resulted in a feature that involved developers from 6 different teams! Regular meetings and continuous communication with the development team and the product manager, allowed us to incorporate suggestions and make iterative improvements to the API’s design and functionality.
Conclusion
The development journey of our Cloud Resource Enrichment API has been both challenging and rewarding. With a user-centric approach, we have crafted a powerful tool that empowers security teams to respond effectively to cyber threats. As we continue to enhance the API, we remain committed to fortifying organizations’ cyber defenses and elevating incident response capabilities. Together, we can better equip security analysts to face the ever-changing cyber war with confidence.
Cloudflare has a unique vantage point on the Internet. From this position, we are able to see, explore, and identify trends that would otherwise go unnoticed. In this report we are doing just that and sharing our insights into Internet-wide application security trends.
Since the last report, our network is bigger and faster: we are now processing an average of 46 million HTTP requests/second and 63 million at peak. We consistently handle approximately 25 million DNS queries per second. That's around 2.1 trillion DNS queries per day, and 65 trillion queries a month. This is the sum of authoritative and resolver requests served by our infrastructure. Summing up both HTTP and DNS requests, we get to see a lot of malicious traffic. Focusing on HTTP requests only, in Q2 2023 Cloudflare blocked an average of 112 billion cyber threats each day, and this is the data that powers this report.
But as usual, before we dive in, we need to define our terms.
Definitions
Throughout this report, we will refer to the following terms:
Mitigated traffic: any eyeball HTTP* request that had a “terminating” action applied to it by the Cloudflare platform. These include the following actions: BLOCK, CHALLENGE, JS_CHALLENGE and MANAGED_CHALLENGE. This does not include requests that had the following actions applied: LOG, SKIP, ALLOW. In contrast to last year, we now exclude requests that had CONNECTION_CLOSE and FORCE_CONNECTION_CLOSE actions applied by our DDoS mitigation system, as these technically only slow down connection initiation. They also accounted for a relatively small percentage of requests. Additionally, we improved our calculation regarding the CHALLENGE type actions to ensure that only unsolved challenges are counted as mitigated. A detailed description of actions can be found in our developer documentation.
Bot traffic/automated traffic: any HTTP* request identified by Cloudflare’s Bot Management system as being generated by a bot. This includes requests with a bot score between 1 and 29 inclusive. This has not changed from last year’s report.
API traffic: any HTTP* request with a response content type of XML or JSON. Where the response content type is not available, such as for mitigated requests, the equivalent Accept content type (specified by the user agent) is used instead. In this latter case, API traffic won’t be fully accounted for, but it still provides a good representation for the purposes of gaining insights.
Unless otherwise stated, the time frame evaluated in this post is the 3 month period from April 2023 through June 2023 inclusive.
Finally, please note that the data is calculated based only on traffic observed across the Cloudflare network and does not necessarily represent overall HTTP traffic patterns across the Internet.
* When referring to HTTP traffic we mean both HTTP and HTTPS.
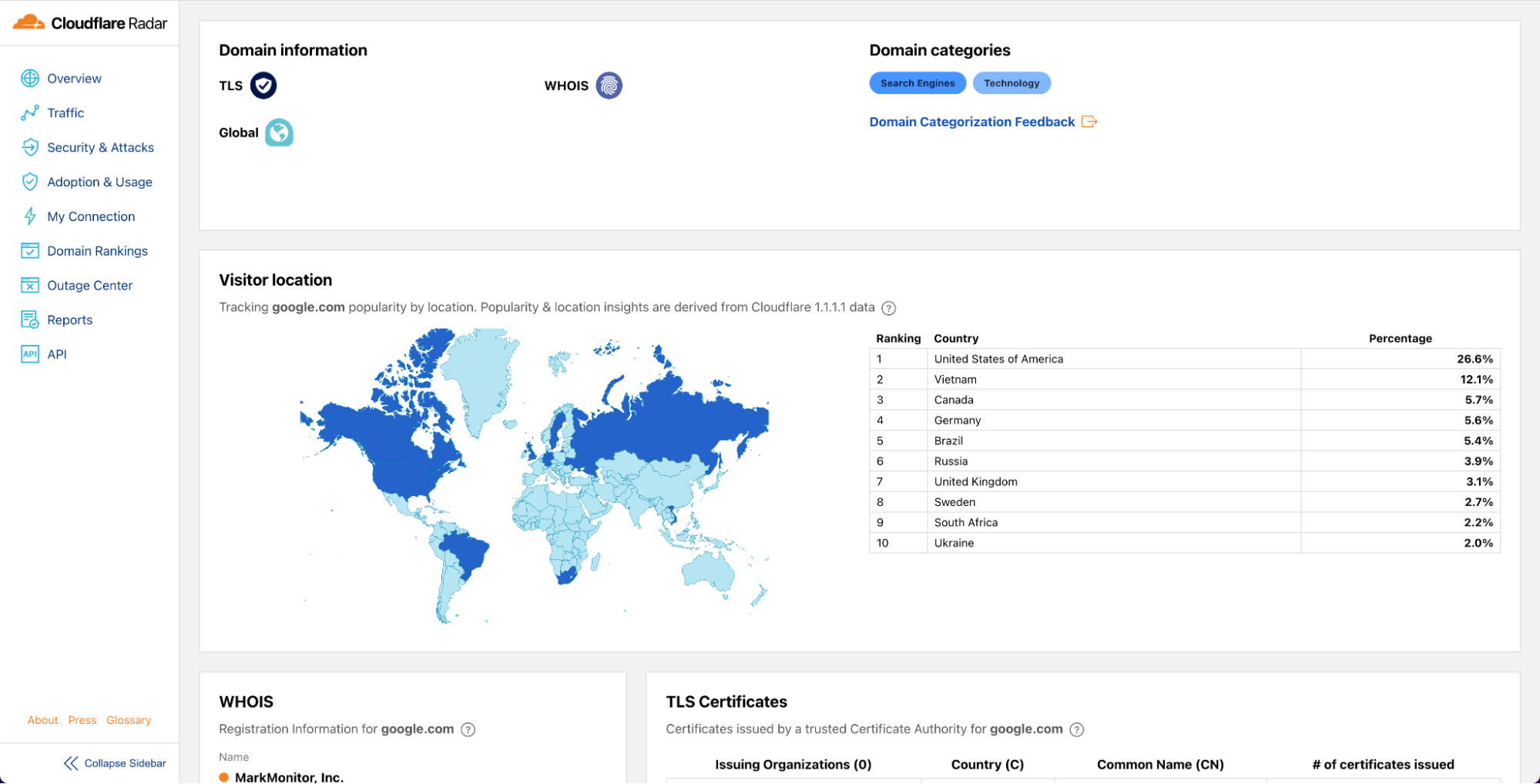
Global traffic insights
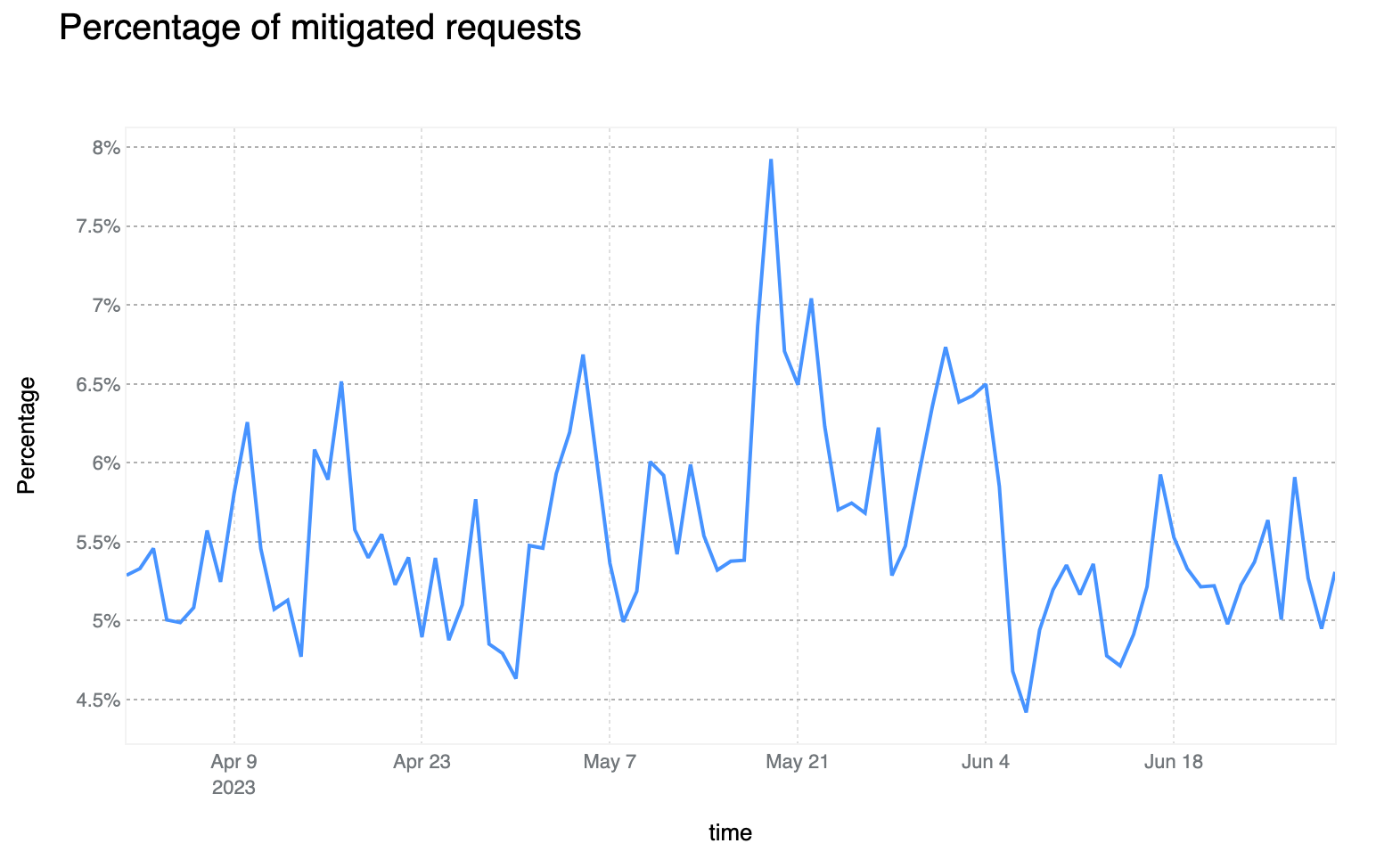
Mitigated daily traffic stable at 6%, spikes reach 8%
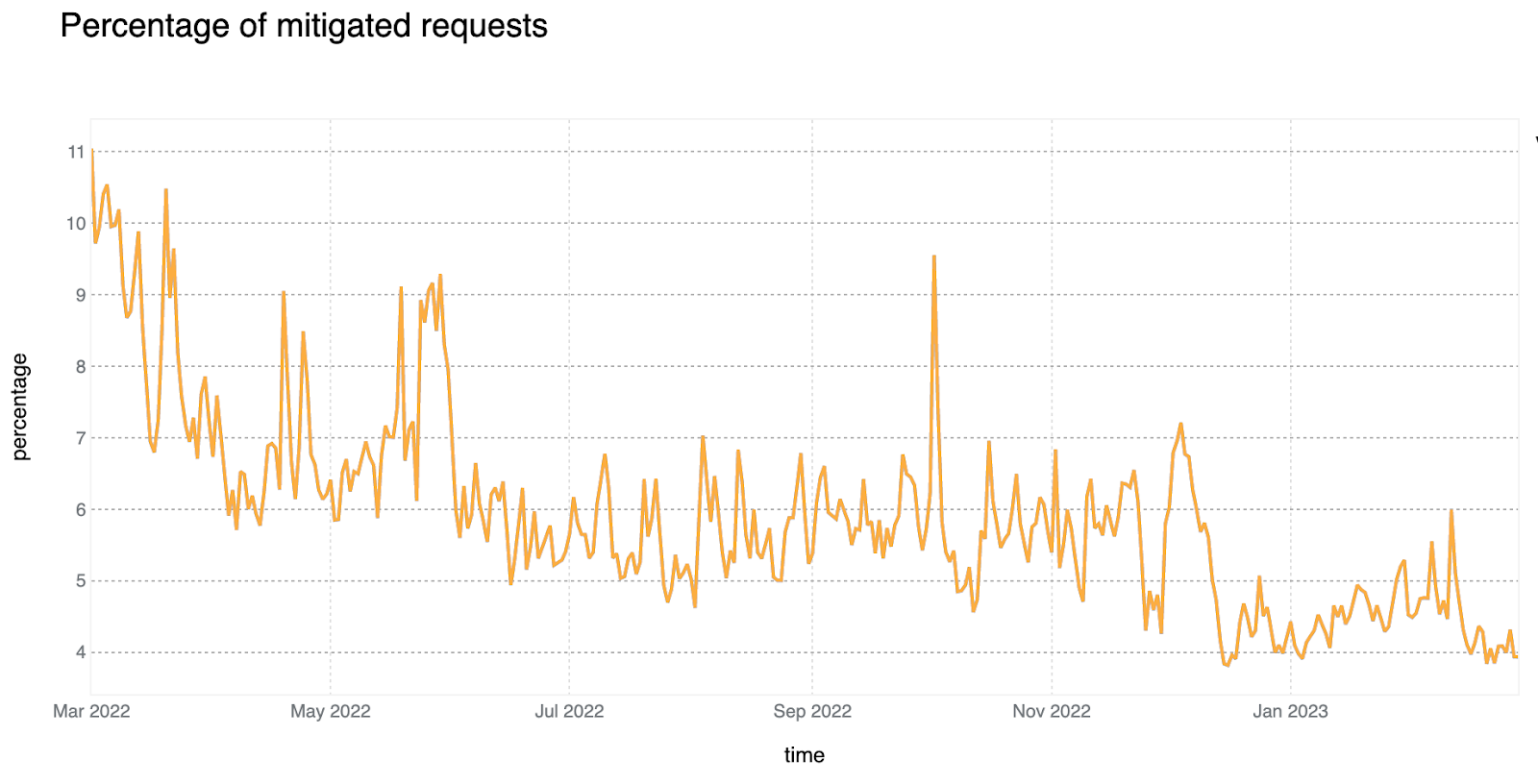
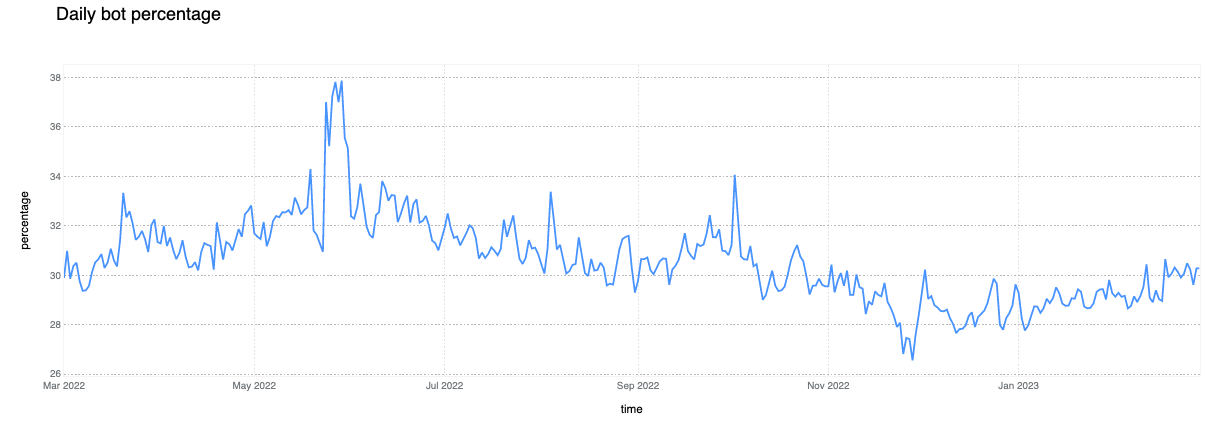
Although daily mitigated HTTP requests decreased by 2 percentage points to 6% on average from 2021 to 2022, days with larger than usual malicious activity can be clearly seen across the network. One clear example is shown in the graph below: towards the end of May 2023, a spike reaching nearly 8% can be seen. This is attributable to large DDoS events and other activity that does not follow standard daily or weekly cycles and is a constant reminder that large malicious events can still have a visible impact at a global level, even at Cloudflare scale.
75% of mitigated HTTP requests were outright BLOCKed. This is a 6 percentage point decrease compared to the previous report. The majority of other requests are mitigated with the various CHALLENGE type actions, with managed challenges leading with ~20% of this subset.
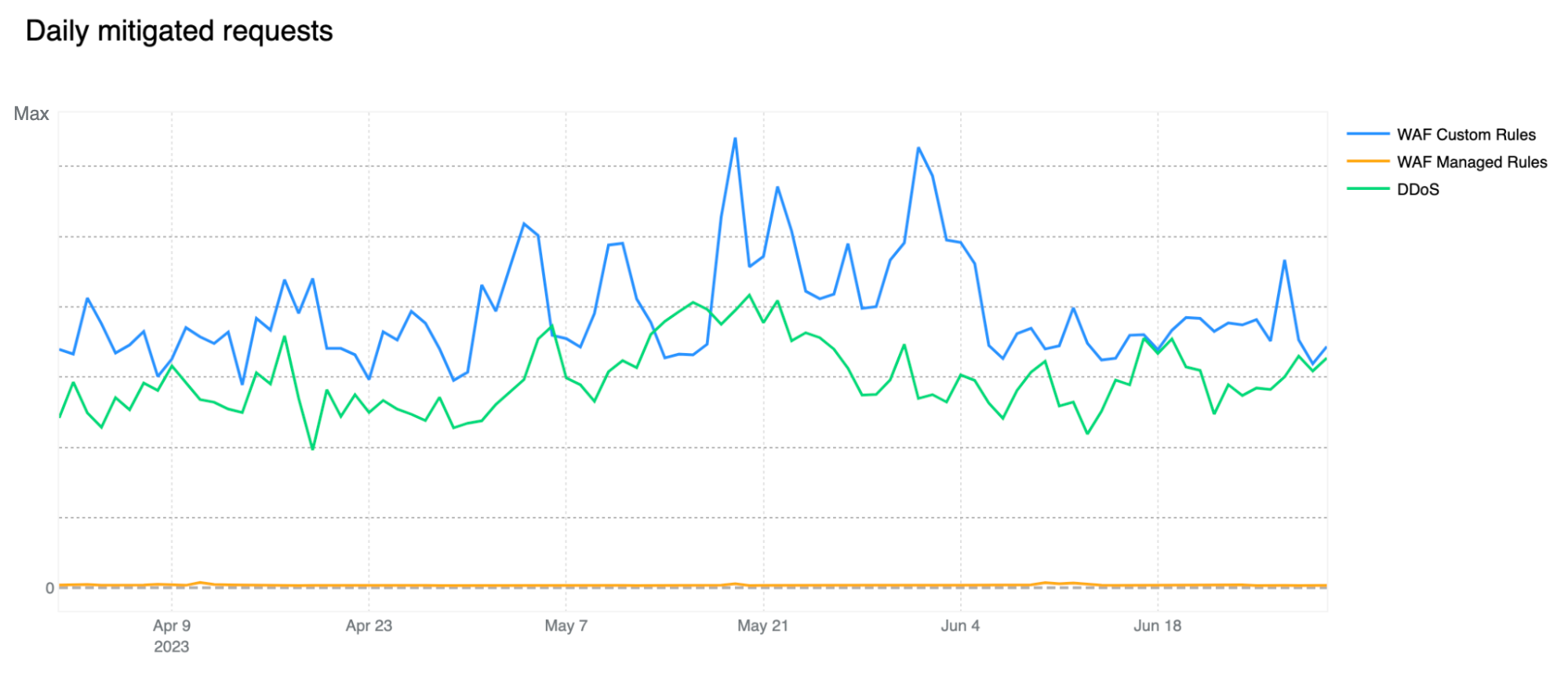
Shields up: customer configured rules now biggest contributor to mitigated traffic
In our previous report, our automated DDoS mitigation system accounted for, on average, more than 50% of mitigated traffic. Over the past two quarters, due to both increased WAF adoption, but most likely organizations better configuring and locking down their applications from unwanted traffic, we’ve seen a new trend emerge, with WAF mitigated traffic surpassing DDoS mitigation. Most of the increase has been driven by WAF Custom Rule BLOCKs rather than our WAF Managed Rules, indicating that these mitigations are generated by customer configured rules for business logic or related purposes. This can be clearly seen in the chart below.
Note that our WAF Managed Rules mitigations (yellow line) are negligible compared to overall WAF mitigated traffic also indicating that customers are adopting positive security models by allowing known good traffic as opposed to blocking only known bad traffic. Having said that, WAF Managed Rules mitigations reached as much as 1.5 billion/day during the quarter.
Our DDoS mitigation is, of course, volumetric and the amount of traffic matching our DDoS layer 7 rules should not be underestimated, especially given that we are observing a number of novel attacks and botnets being spun up across the web. You can read a deep dive on DDoS attack trends in our Q2 DDoS threat report.
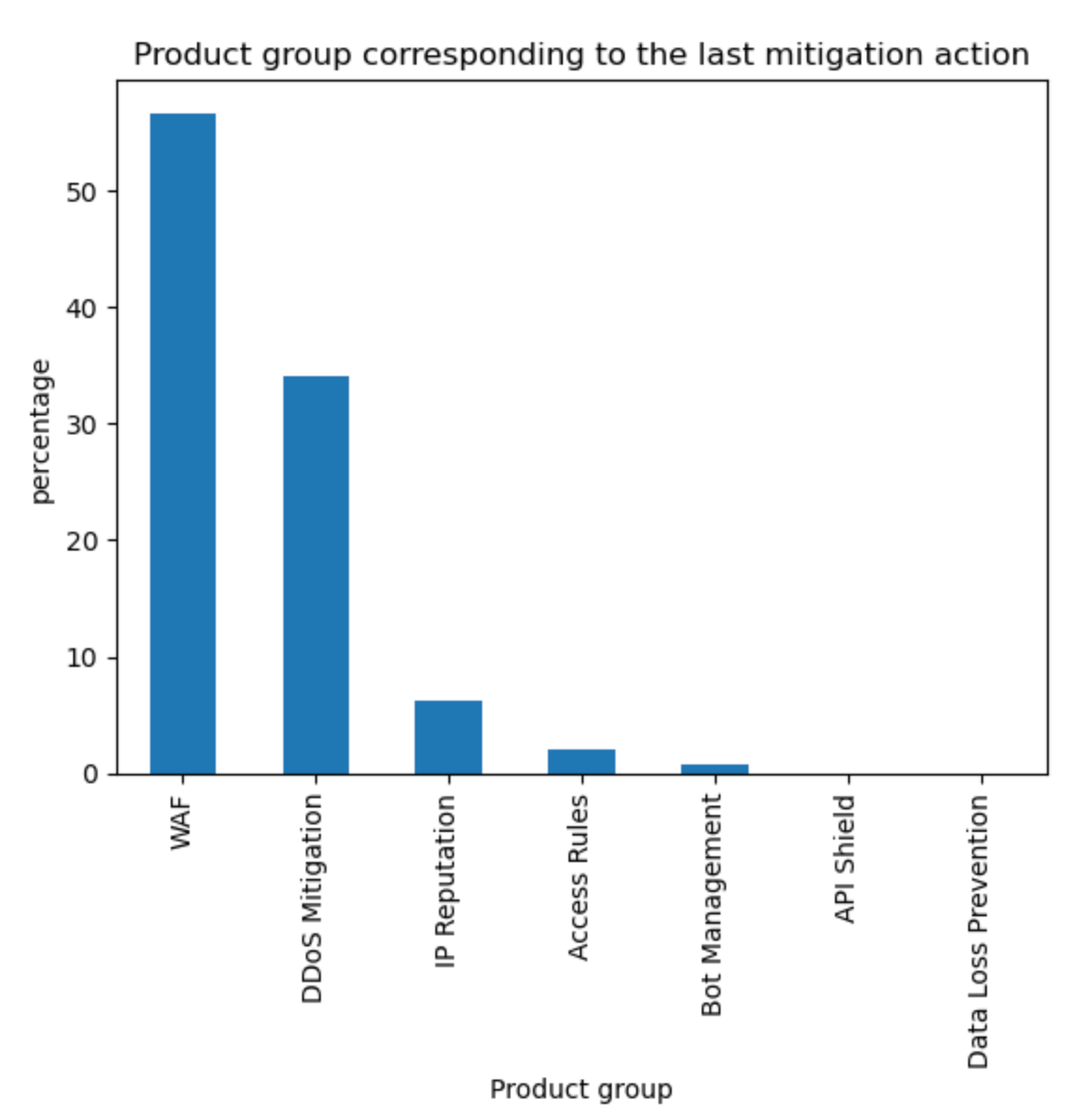
Aggregating the source of mitigated traffic, the WAF now accounts for approximately 57% of all mitigations. Tabular format below with other sources for reference.
Source
Percentage %
WAF
57%
DDoS Mitigation
34%
IP Reputation
6%
Access Rules
2%
Other
1%
Application owners are increasingly relying on geo location blocks
Given the increase in mitigated traffic from customer defined WAF rules, we thought it would be interesting to dive one level deeper and better understand what customers are blocking and how they are doing it. We can do this by reviewing rule field usage across our WAF Custom Rules to identify common themes. Of course, the data needs to be interpreted correctly, as not all customers have access to all fields as that varies by contract and plan level, but we can still make some inferences based on field “categories”. By reviewing all ~7M WAF Custom Rules deployed across the network and focusing on main groupings only, we get the following field usage distribution:
Field
Used in percentage % of rules
Geolocation fields
40%
HTTP URI
31%
IP address
21%
Other HTTP fields (excluding URI)
34%
Bot Management fields
11%
IP reputation score
4%
Notably, 40% of all deployed WAF Custom Rules use geolocation-related fields to make decisions on how to treat traffic. This is a common technique used to implement business logic or to exclude geographies from which no traffic is expected and helps reduce attack surface areas. While these are coarse controls which are unlikely to stop a sophisticated attacker, they are still efficient at reducing the attack surface.
Another notable observation is the usage of Bot Management related fields in 11% of WAF Custom Rules. This number has been steadily increasing over time as more customers adopt machine learning-based classification strategies to protect their applications.
Old CVEs are still exploited en masse
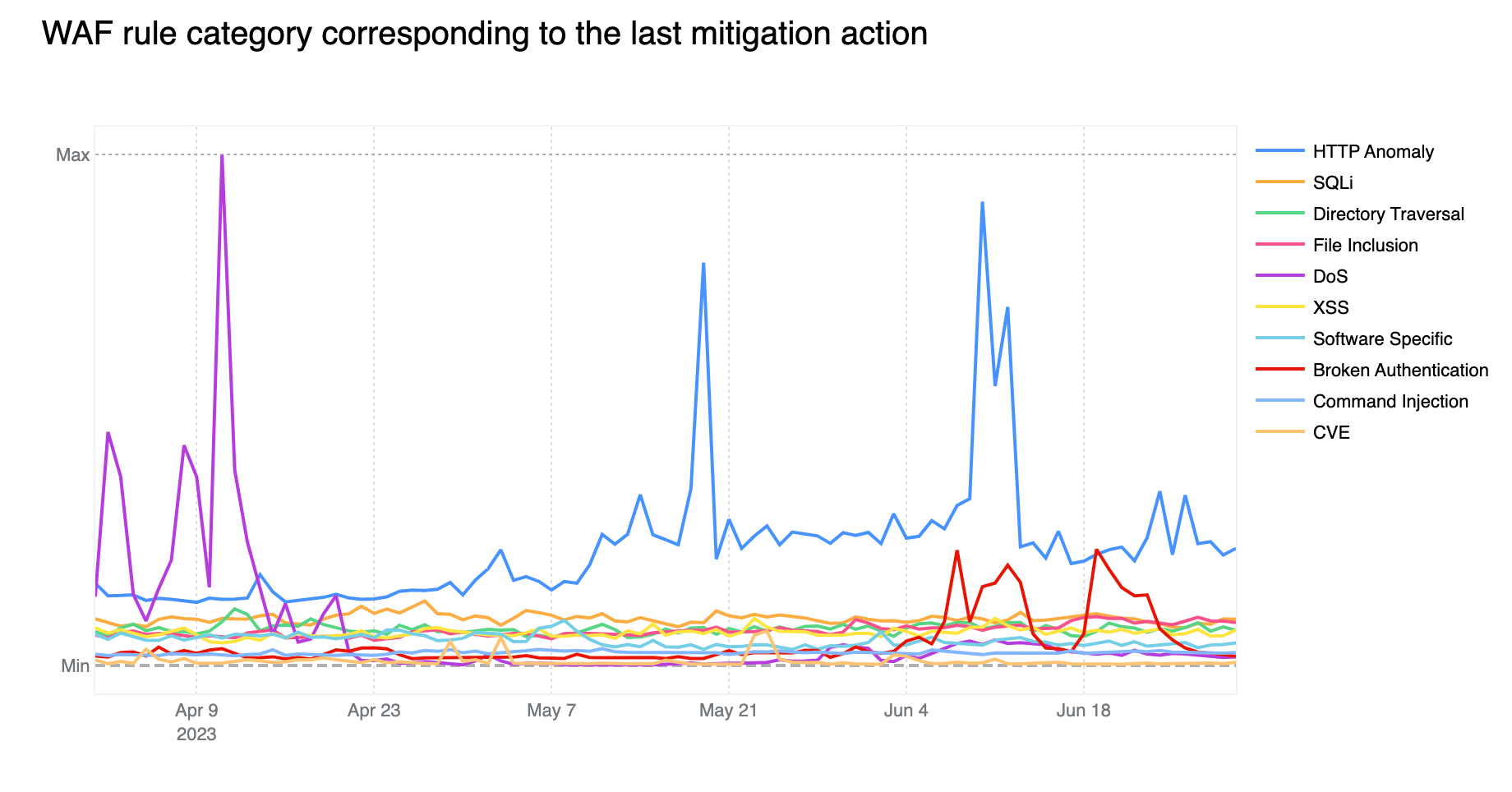
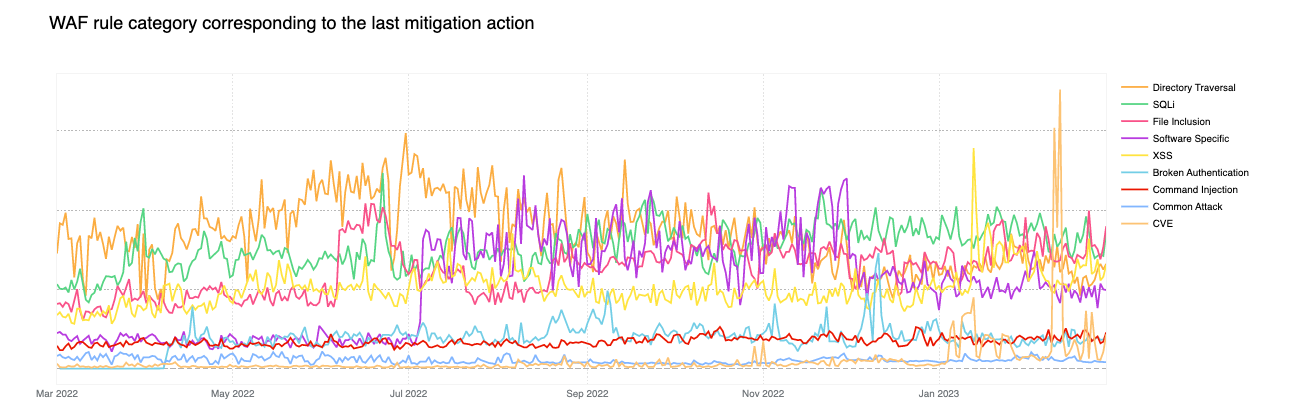
Contributing ~32% of WAF Managed Rules mitigated traffic overall, HTTP Anomaly is still the most common attack category blocked by the WAF Managed Rules. SQLi moved up to second position, surpassing Directory Traversal with 12.7% and 9.9% respectively.
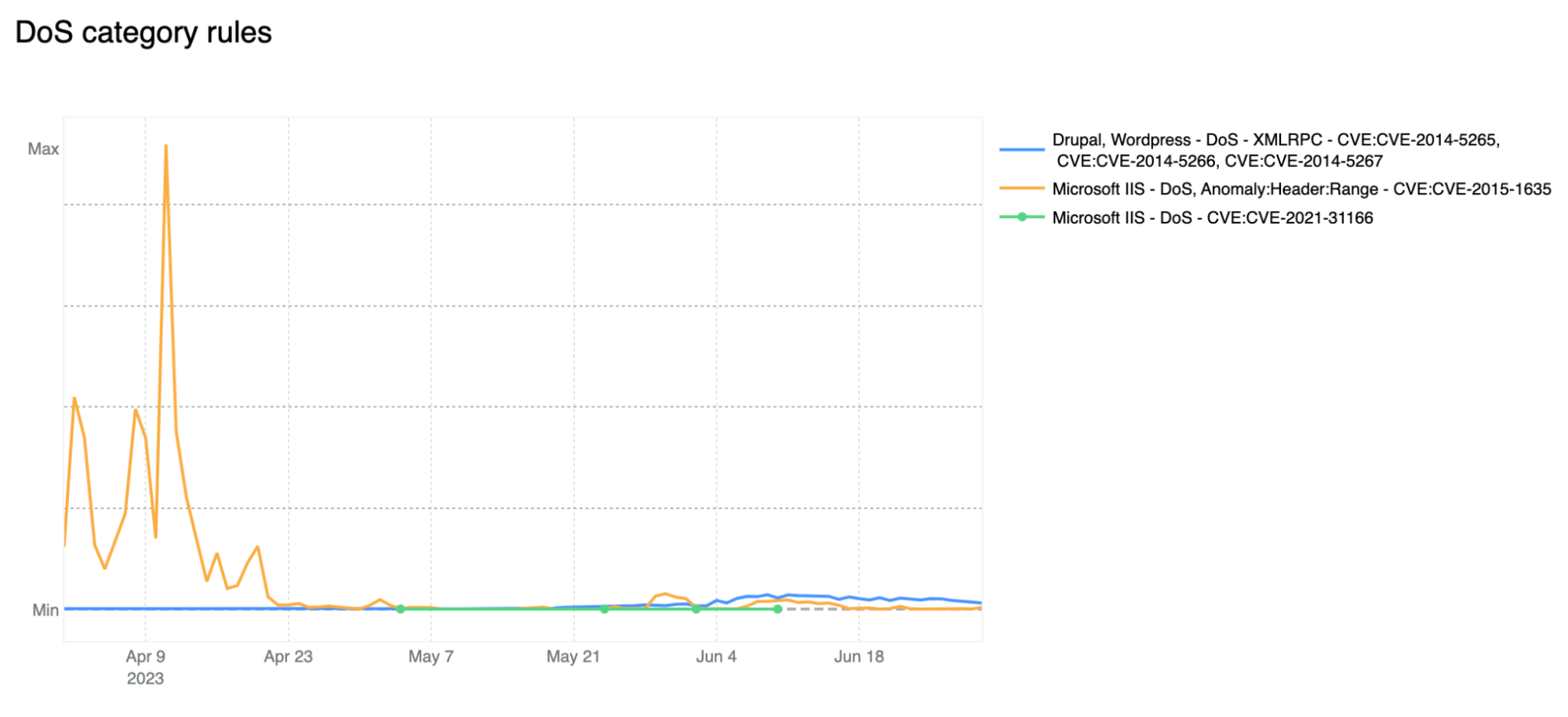
If we look at the start of April 2023, we notice the DoS category far exceeding the HTTP Anomaly category. Rules in the DoS category are WAF layer 7 HTTP signatures that are sufficiently specific to match (and block) single requests without looking at cross request behavior and that can be attributed to either specific botnets or payloads that cause denial of service (DoS). Normally, as is the case here, these requests are not part of “distributed” attacks, hence the lack of the first “D” for “distributed” in the category name.
Tabular format for reference (top 10 categories):
Source
Percentage %
HTTP Anomaly
32%
SQLi
13%
Directory Traversal
10%
File Inclusion
9%
DoS
9%
XSS
9%
Software Specific
7%
Broken Authentication
6%
Common Injection
3%
CVE
1%
Zooming in, and filtering on the DoS category only, we find that most of the mitigated traffic is attributable to one rule: 100031 / ce02fd… (old WAF and new WAF rule ID respectively). This rule, with a description of “Microsoft IIS – DoS, Anomaly:Header:Range – CVE:CVE-2015-1635” pertains to a CVE dating back to 2015 that affected a number of Microsoft Windows components resulting in remote code execution*. This is a good reminder that old CVEs, even those dating back more than 8 years, are still actively exploited to compromise machines that may be unpatched and still running vulnerable software.
* Due to rule categorisation, some CVE specific rules are still assigned to a broader category such as DoS in this example. Rules are assigned to a CVE category only when the attack payload does not clearly overlap with another more generic category.
Another interesting observation is the increase in Broken Authentication rule matches starting in June. This increase is also attributable to a single rule deployed across all our customers, including our FREE users: “WordPress – Broken Access Control, File Inclusion”. This rule is blocking attempts to access wp-config.php – the WordPress default configuration file which is normally found in the web server document root directory, but of course should never be accessed directly via HTTP.
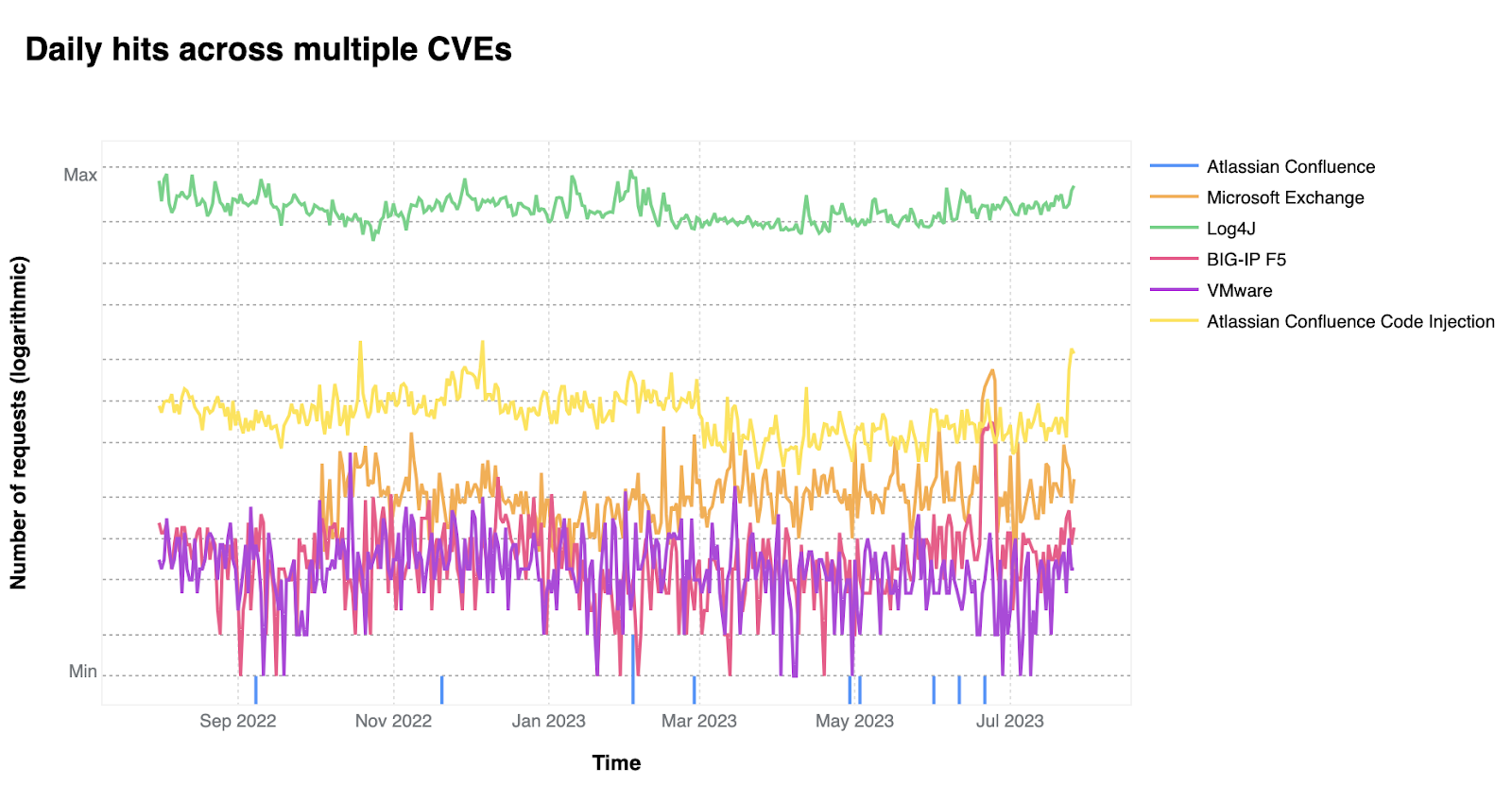
On a similar note, CISA/CSA recently published a report highlighting the 2022 Top Routinely Exploited Vulnerabilities. We took this opportunity to explore how each CVE mentioned in CISA’s report was reflected in Cloudflare’s own data. The CISA/CSA discuss 12 vulnerabilities that malicious cyber actors routinely exploited in 2022. However, based on our analysis, two CVEs mentioned in the CISA report are responsible for the vast majority of attack traffic we have seen in the wild: Log4J and Atlassian Confluence Code Injection. Our data clearly suggests a major difference in exploit volume between the top two and the rest of the list. The following chart compares the attack volume (in logarithmic scale) of the top 6 vulnerabilities of the CISA list according to our logs.
Bot traffic insights
Cloudflare’s Bot Management continues to see significant investment as the addition of JavaScript Verified URLs for greater protection against browser-based bots, Detection IDs are now available in Custom Rules for additional configurability, and an improved UI for easier onboarding. For self-serve customers, we’ve added the ability to “Skip” Super Bot Fight Mode rules and support for WordPress Loopback requests, to better integrate with our customers’ applications and give them the protection they need.
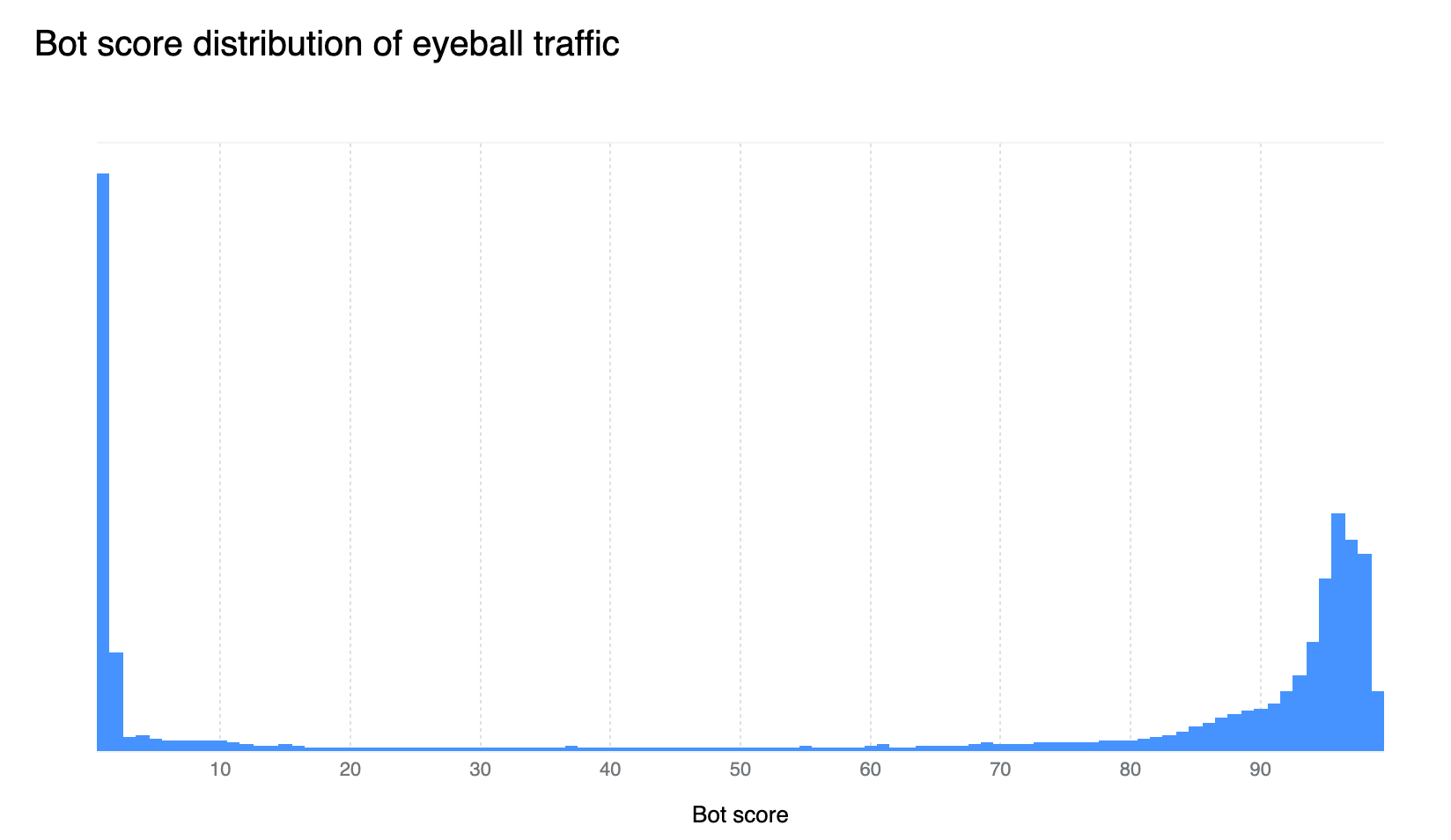
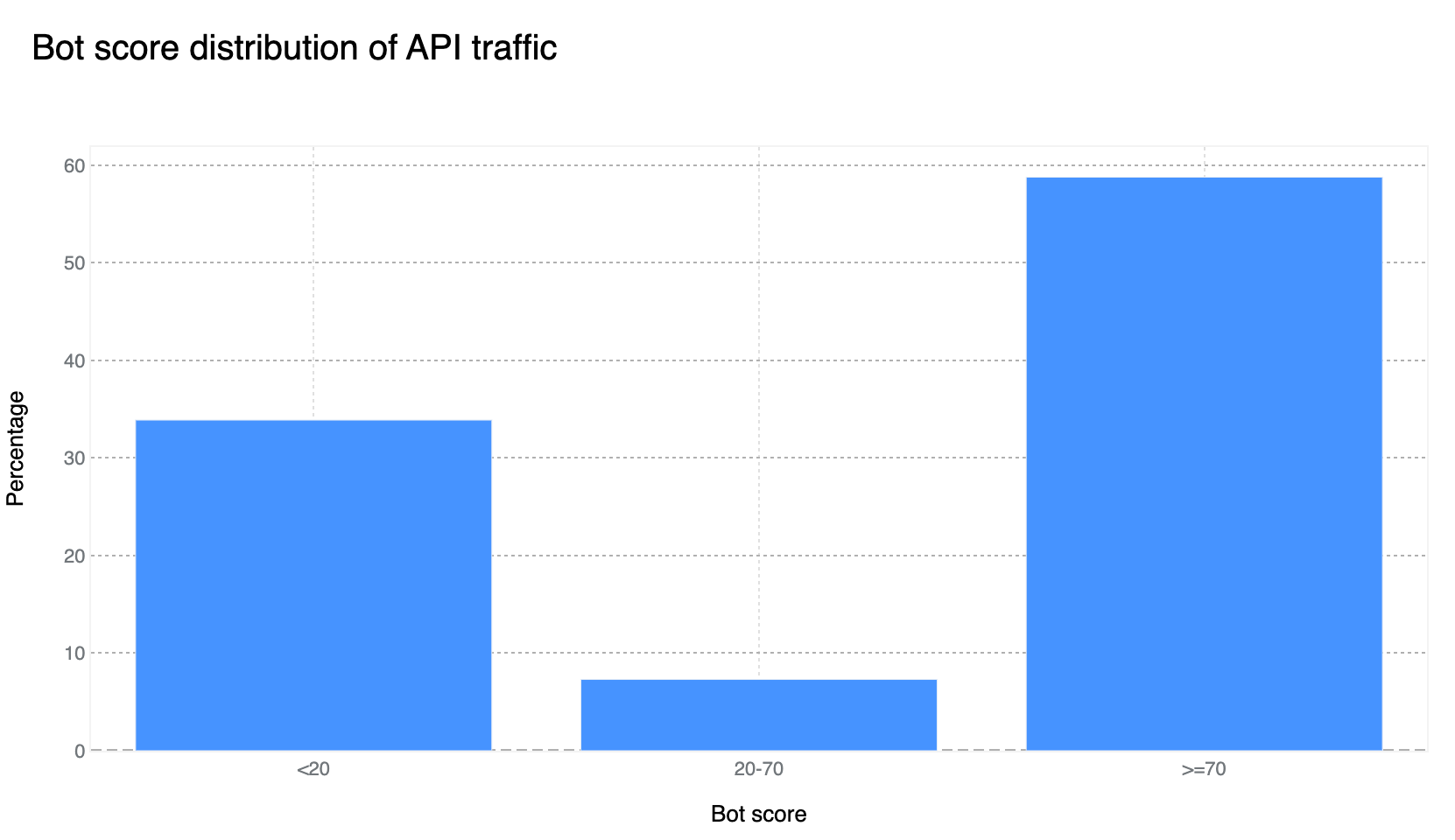
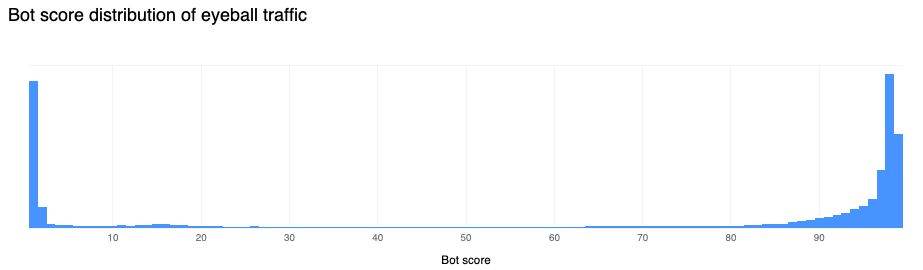
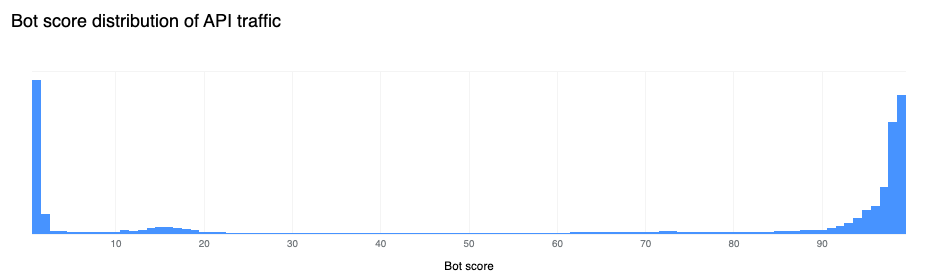
Our confidence in the Bot Management classification output remains very high. If we plot the bot scores across the analyzed time frame, we find a very clear distribution, with most requests either being classified as definitely bot (score below 30) or definitely human (score greater than 80), with most requests actually scoring less than 2 or greater than 95. This equates, over the same time period, to 33% of traffic being classified as automated (generated by a bot). Over longer time periods we do see the overall bot traffic percentage stable at 29%, and this reflects the data shown on Cloudflare Radar.
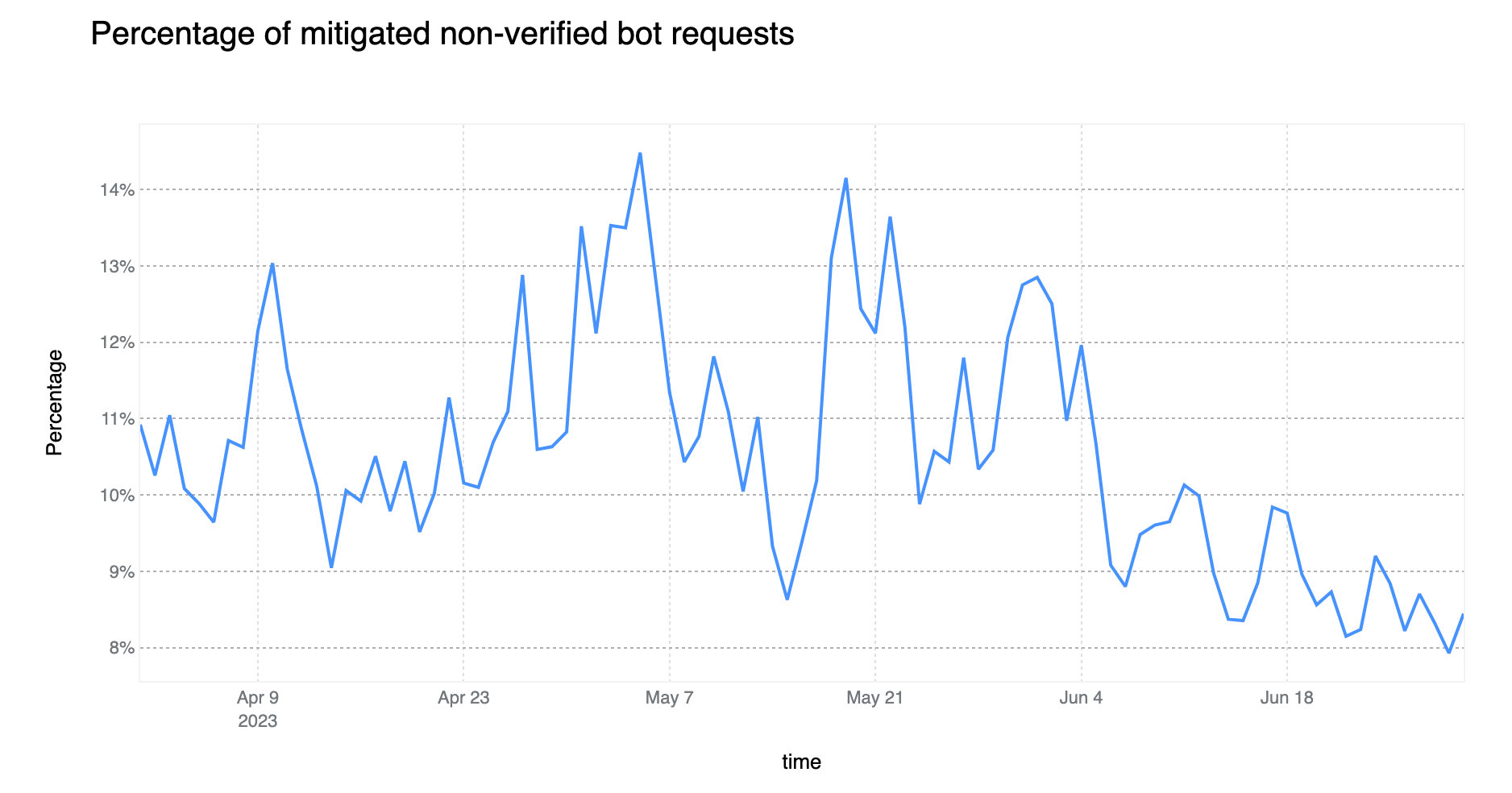
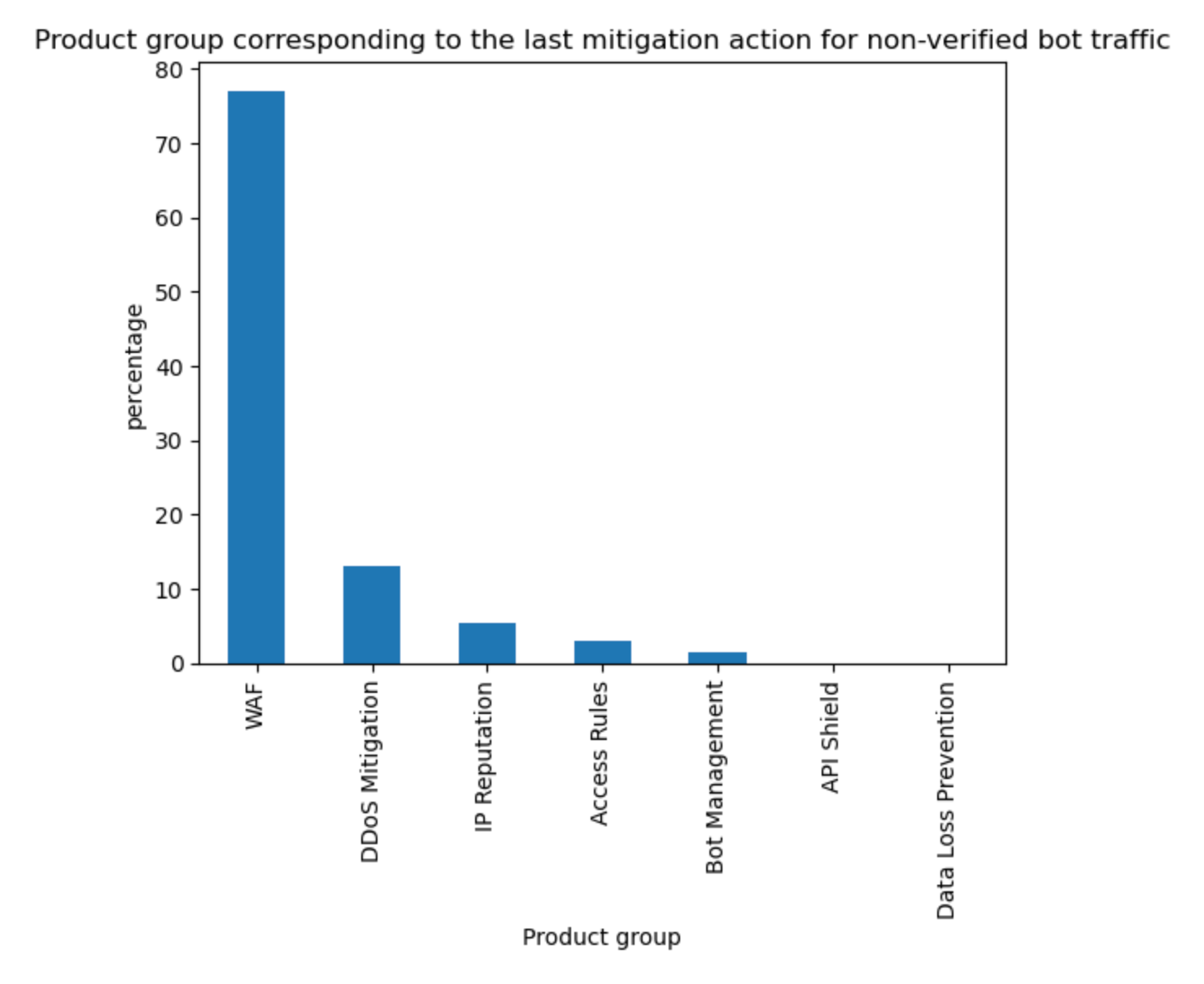
On average, more than 10% of non-verified bot traffic is mitigated
Compared to the last report, non-verified bot HTTP traffic mitigation is currently on a downward trend (down 6 percentage points). However, the Bot Management field usage within WAF Custom Rules is non negligible, standing at 11%. This means that there are more than 700k WAF Custom Rules deployed on Cloudflare that are relying on bot signals to perform some action. The most common field used is cf.client.bot, an alias to cf.bot_management.verified_bot which is powered by our list of verified bots and allows customers to make a distinction between “good” bots and potentially “malicious” non-verified ones.
Enterprise customers have access to the more powerful cf.bot_management.score which provides direct access to the score computed on each request, the same score used to generate the bot score distribution graph in the prior section.
The above data is also validated by looking at what Cloudflare service is mitigating unverified bot traffic. Although our DDoS mitigation system is automatically blocking HTTP traffic across all customers, this only accounts for 13% of non-verified bot mitigations. On the other hand, WAF, and mostly customer defined rules, account for 77% of such mitigations, much higher than mitigations across all traffic (57%) discussed at the start of the report. Note that Bot Management is specifically called out but refers to our “default” one-click rules, which are counted separately from the bot fields used in WAF Custom Rules.
Tabular format for reference:
Source
Percentage %
WAF
77%
DDoS Mitigation
13%
IP reputation
5%
Access Rules
3%
Other
1%
API traffic insights
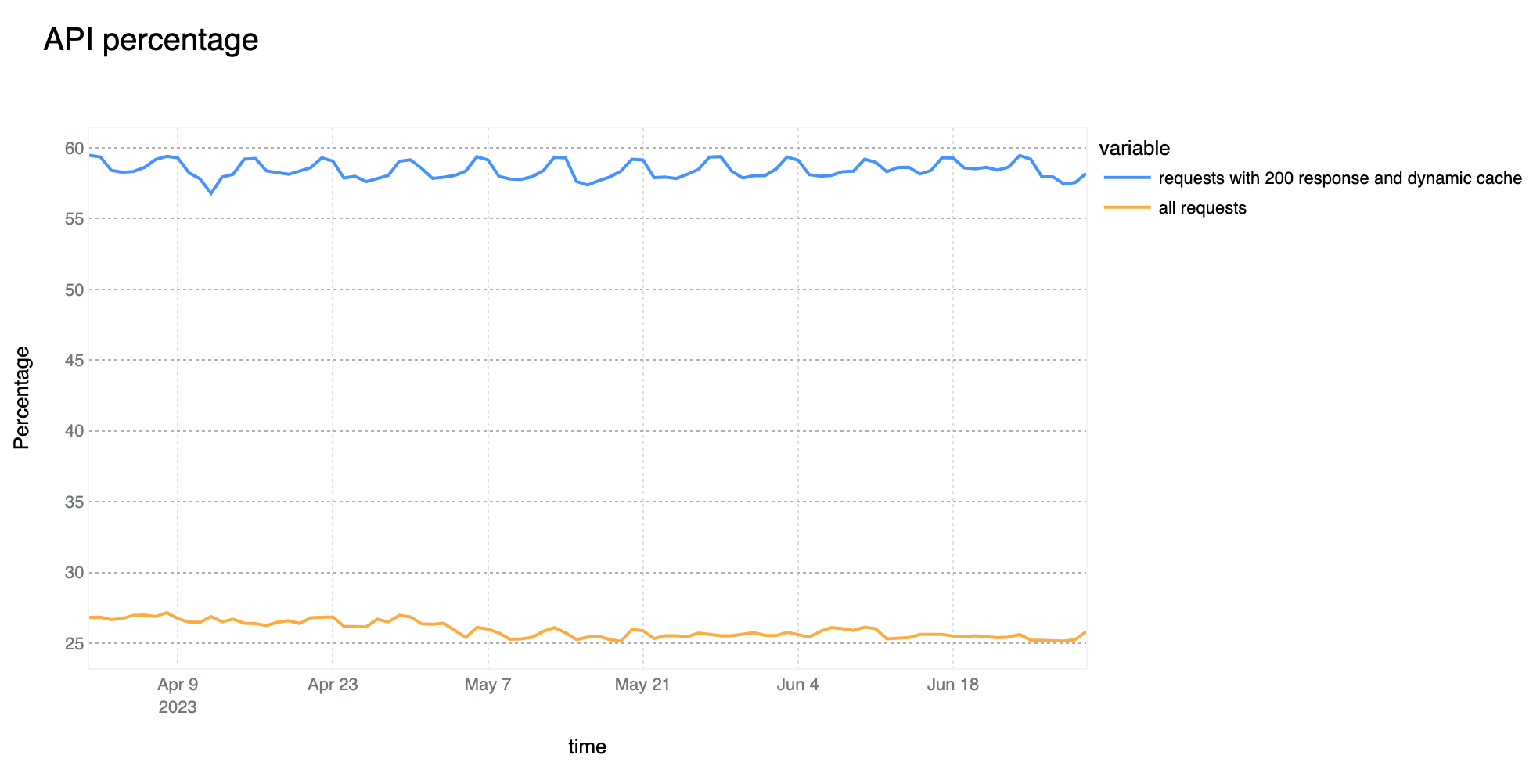
58% of dynamic (non cacheable) traffic is API related
The growth of overall API traffic observed by Cloudflare is not slowing down. Compared to last quarter, we are now seeing 58% of total dynamic traffic be classified as API related. This is a 3 percentage point increase as compared to Q1.
Our investment in API Gateway is also following a similar growth trend. Over the last quarter we have released several new API security features.
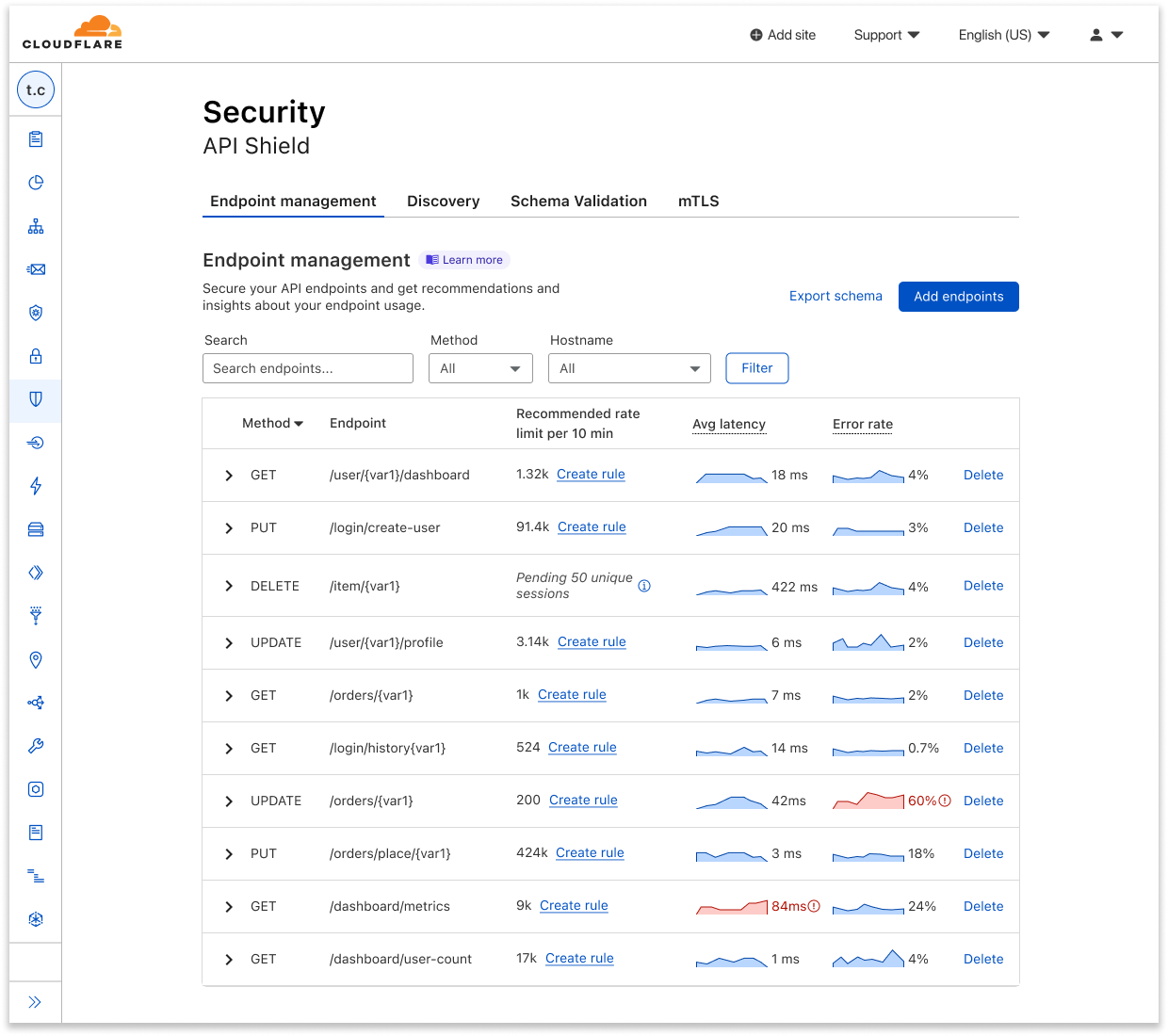
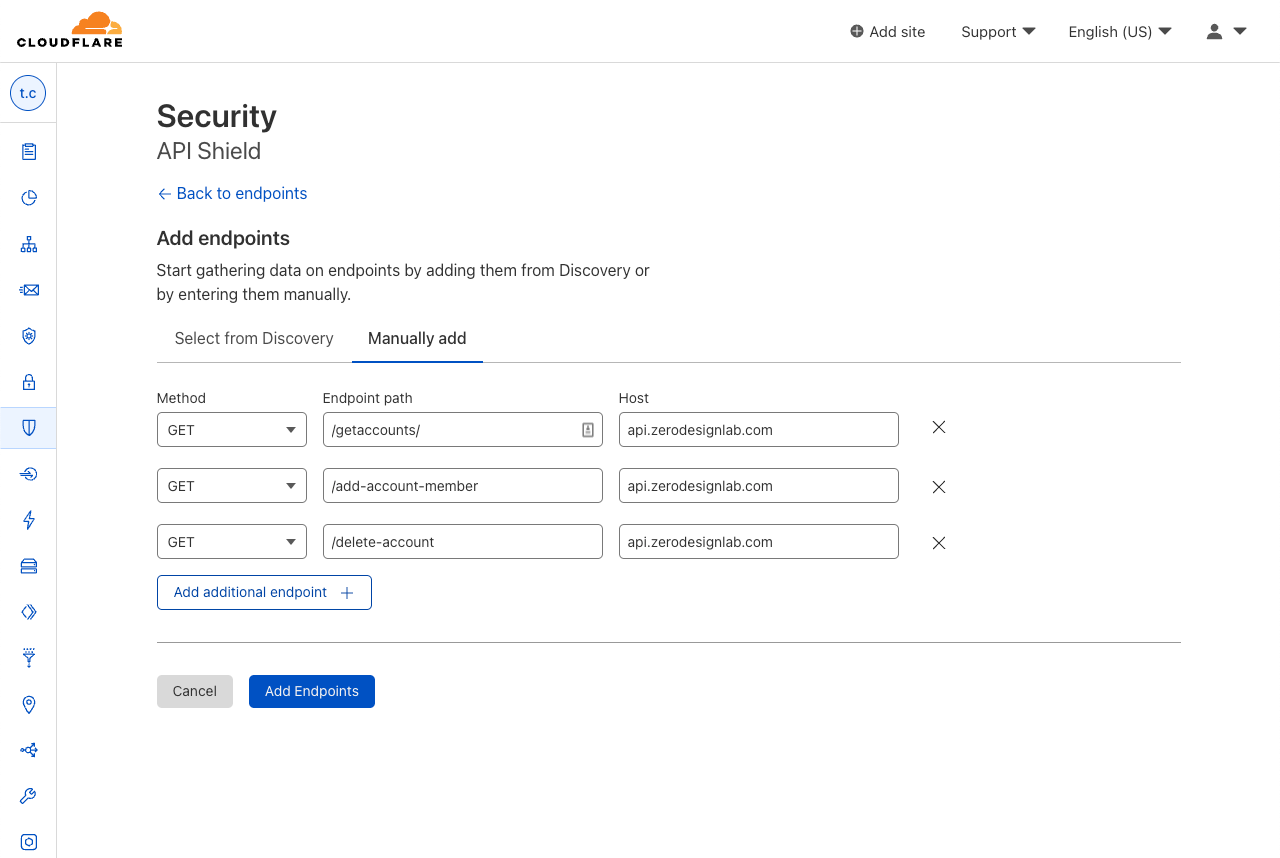
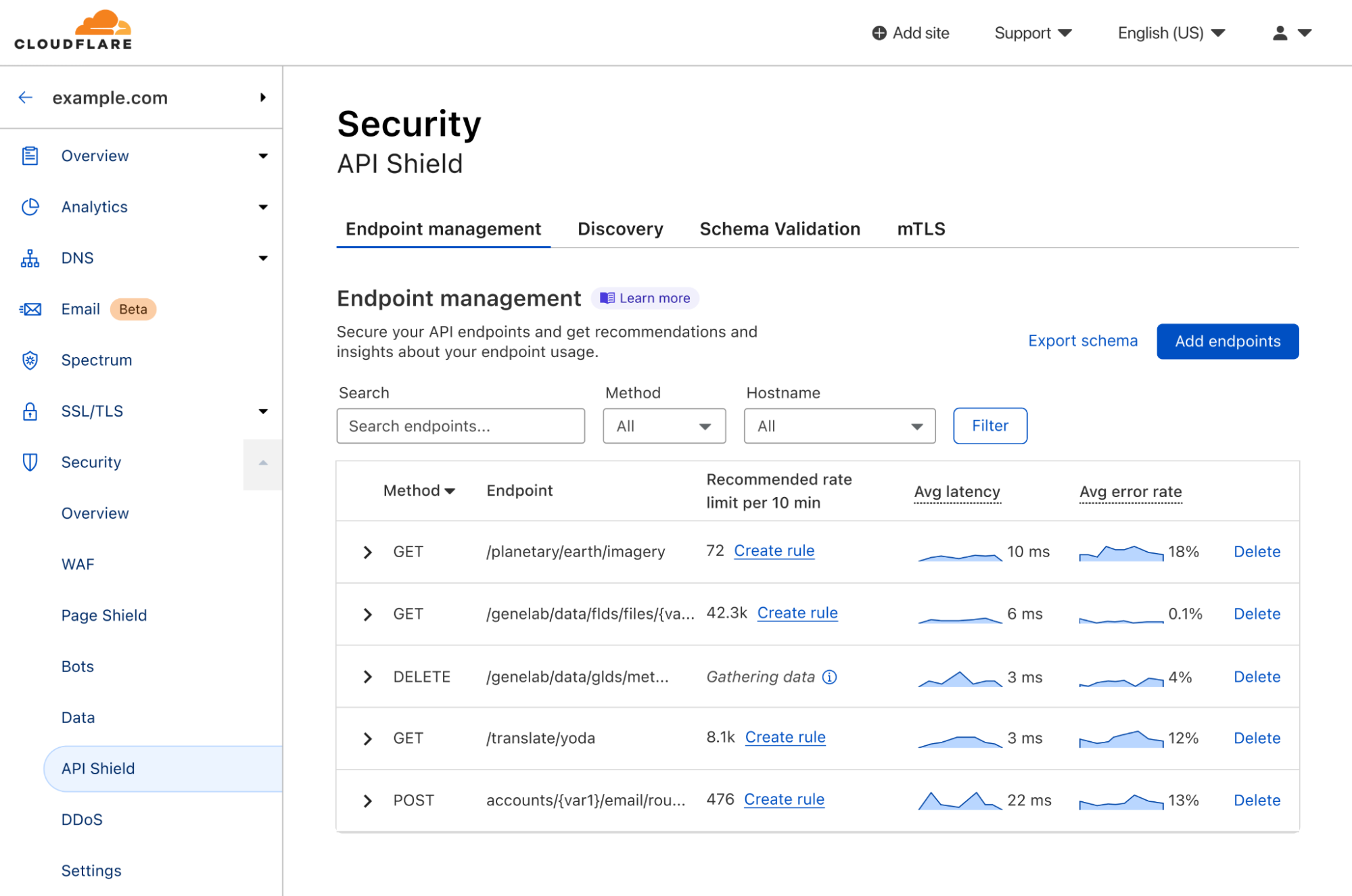
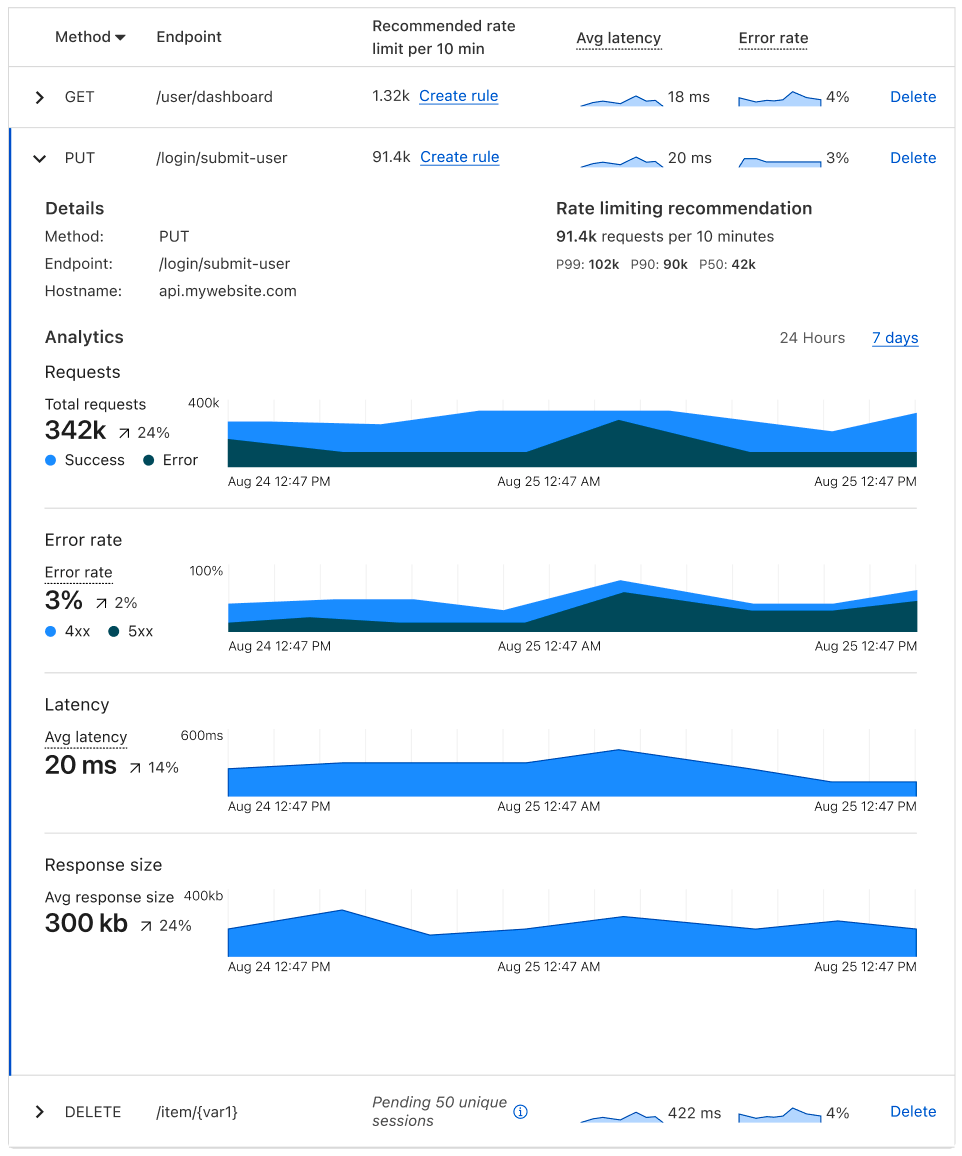
First, we’ve made API Discovery easier to use with a new inbox view. API Discovery inventories your APIs to prevent shadow IT and zombie APIs, and now customers can easily filter to show only new endpoints found by API Discovery. Saving endpoints from API Discovery places them into our Endpoint Management system.
Next, we’ve added a brand new API security feature offered only at Cloudflare: the ability to control API access by client behavior. We call it Sequence Mitigation. Customers can now create positive or negative security models based on the order of API paths accessed by clients. You can now ensure that your application’s users are the only ones accessing your API instead of brute-force attempts that ignore normal application functionality. For example, in a banking application you can now enforce that access to the funds transfer endpoint can only be accessed after a user has also accessed the account balance check endpoint.
We’re excited to continue releasing API security and API management features for the remainder of 2023 and beyond.
65% of global API traffic is generated by browsers
The percentage of API traffic generated by browsers has remained very stable over the past quarter. With this statistic, we are referring to HTTP requests that are not serving HTML based content that will be directly rendered by the browser without some preprocessing, such as those more commonly known as AJAX calls which would normally serve JSON based responses.
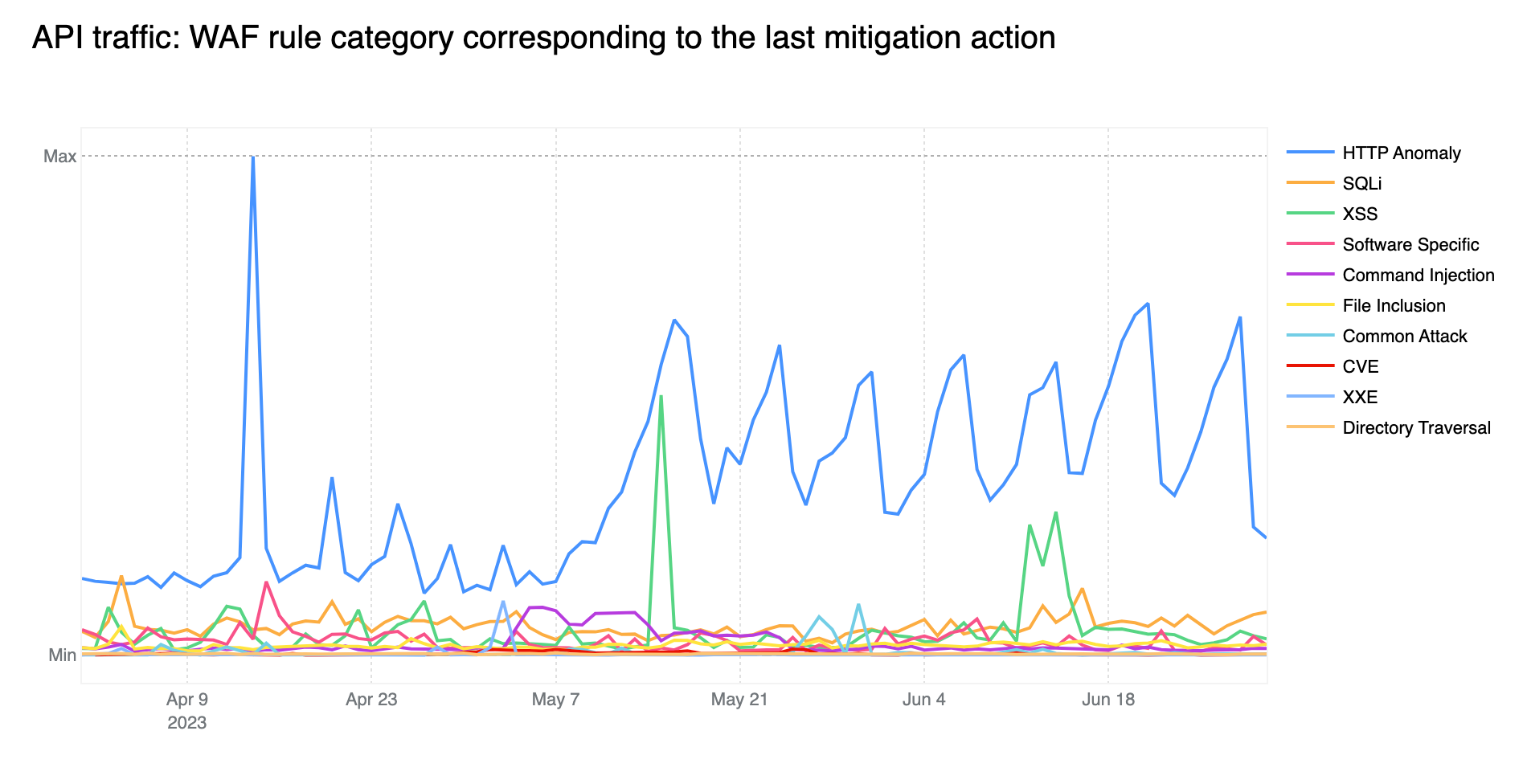
HTTP Anomalies are the most common attack vector on API endpoints
Just like last quarter, HTTP Anomalies remain the most common mitigated attack vector on API traffic. SQLi injection attacks, however, are non negligible, contributing approximately 11% towards the total mitigated traffic, closely followed by XSS attacks, at around 9%.
Tabular format for reference (top 5):
Source
Percentage %
HTTP Anomaly
64%
SQLi
11%
XSS
9%
Software Specific
5%
Command Injection
4%
Looking forward
As we move our application security report to a quarterly cadence, we plan to deepen some of the insights and to provide additional data from some of our newer products such as Page Shield, allowing us to look beyond HTTP traffic, and explore the state of third party dependencies online.
Stay tuned and keep an eye on Cloudflare Radar for more frequent application security reports and insights.
The OWASP Top 10 API Security Risks is a list of the highest priority API based threats in 2023. Let’s dig a little deeper into each item on the OWASP Top 10 API Security Risks list to outline the type of threats you may encounter and appropriate responses to curtail each threat.
1. Broken object level authorization
Object level authorization is a control method that restricts access to objects to minimize system exposures. All API endpoints that handle objects should perform authorization checks utilizing user group policies.
We recommend using this authorization mechanism in every function that receives client input to access objects from a data store. As an additional means for hardening, it is recommended to use cryptographically secure random GUID values for object reference IDs.
2. Broken authentication
Authentication relates to all endpoints and data flows that handle the identity of users or entities accessing an API. This includes credentials, keys, tokens, and even password reset functionality. Broken authentication can lead to many issues such as credential stuffing, brute force attacks, weak unsigned keys, and expired tokens.
Authentication covers a wide range of functionality and requires strict scrutiny and strong practices. Detailed threat modeling should be performed against all authentication functionality to understand data flows, entities, and risks involved in an API. Multi-factor authentication should be enforced where possible to mitigate the risk of compromised credentials.
To prevent brute force and other automated password attacks, rate-limitation should be implemented with a reasonable threshold. Weak and expired credentials should not be accepted, this includes JWTs, passwords, and keys. Integrity checks should be performed against all tokens as well, ensuring signature algorithms and values are valid to prevent tampering attacks.
3. Broken object property level authorization
Related to object level authorization, object property level authorization is another control method to restrict access to specific properties or fields of an object. This category combines aspects of 2019 OWASP API Security’s “excessive data exposure” and “mass assignment”. If an API endpoint is exposing sensitive object properties that should not be read or modified by an unauthorized user it is considered vulnerable.
The overall mitigation strategy for this is to validate user permissions in all API endpoints that handle object properties. Access to properties and fields should be kept to a bare minimum at an as-needed basis scoped to the functionality of a given endpoint.
4. Unrestricted resource consumption
API resource consumption pertains to CPU, memory, storage, network, and service provider usage for an API. Denial of service attacks result from overconsumption of these resources leading to downtime and racked up service charges.
Setting minimum and maximum limits relative to business functional needs is the overall strategy to mitigating resource consumption risks. API endpoints should limit the rate and maximum number of calls at a per-client basis. For API infrastructure, using containers and serverless code with defined resource limits will mitigate the risk of server resource consumption.
Coding practices that limit resource consumption need to be in place, as well. Limit the number of records returned in API responses with careful use of paging, as appropriate. File uploads should also have size limits enforced to prevent overuse of storage. Additionally, regular expressions and other data-processing means must be carefully evaluated for performance in order to avoid high CPU and memory consumption.
5. Broken function level authorization
Lack of authorization checks in controllers or functions behind API endpoints are covered under broken function level authorization. This vulnerability class allows attackers to access unauthorized functionality; whether they are changing an HTTP method from a `GET` to a `PUT` to modify data that is not expected to be modified, or changing a URL string from `user` to `admin`. Proper authorization checks can be difficult due to controller complexities and the numbers of user groups and roles.
Comprehensive threat modeling against an API architecture and design is paramount in preventing these vulnerabilities. Ensure that API functionality is carefully structured and corresponding controllers are performing authentication checks. For example, all functionality under an `/api/v1/admin` endpoint should be handled by an admin controller class that performs strict authentication checks. When in doubt, access should be denied by default and grants should be given on a as needed basis.
6. Unrestricted Access to Sensitive Business Flows
Automated threats are becoming increasingly more difficult to combat and must be addressed on a case-by-case basis. An API is vulnerable if sensitive functionality is exposed in such a way that harm could occur if excessive automated use occurs. There may not be a specific implementation bug, but rather an exposure of business flow that can be abused in an automated fashion.
Threat modeling exercises are important as an overall mitigation strategy. Business functionality and all dataflows must be carefully considered, and the excessive automated use threat scenario must be discussed. From an implementation perspective, device fingerprinting, human detection, irregular API flow and sequencing pattern detection, and IP blocking can be implemented on a case-by-case basis.
7. Server side request forgery
Server side request forgery (SSRF) vulnerabilities happen when a client provides a URL or other remote resource as data to an API. The result is a crafted outbound request to that URL on behalf of the API. These are common in redirect URL parameters, webhooks, file fetching functionality, and URL previews.
SSRF can be leveraged by attackers in many ways. Modern usage of cloud providers and containers exposes instance metadata URLs and internal management consoles that can be targeted to leak credentials and abuse privileged functionality. Internal network calls such as backend service-to-service requests, even when protected by service meshes and mTLS, can be exploited for unexpected results. Internal repositories, build tools, and other internal resources can all be targeted with SSRF attacks.
We recommend validating and sanitizing all client provided data to mitigate SSRF vulnerabilities. Strict allow-listing must be enforced when implementing resource-fetching functionality. Allow lists should be granular, restricting all but specified services, URLs, schemes, ports, and media types. If possible, isolate this functionality within a controlled network environment with careful monitoring to prevent probing of internal resources.
8. Security misconfiguration
Misconfigurations in any part of the API stack can result in weakened security. This can be the result of incomplete or inconsistent patching, enabling unnecessary features, or improperly configuring permissions. Attackers will enumerate the entire surface area of an API to discover these misconfigurations, which could be exploited to leak data, abuse extra functionality, or find additional vulnerabilities in out of date components.
Having a robust, fast, and repeatable hardening process is paramount to mitigating the risk of misconfiguration issues. Security updates must be regularly applied and tracked with a patch management process. Configurations across the entire API stack should be regularly reviewed. Asset Management and Vulnerability Management solutions should be considered to automate this hardening process.
9. Improper inventory management
Complex services with multiple interconnected APIs present a difficult inventory management problem and introduces more exposure to risk. Having multiple versions of APIs across various environments further increases the challenge. Improper inventory management can lead to running unpatched systems and exposing data to attackers. With modern microservices making it easier than ever to deploy many applications, it is important to have strong inventory management practices.
Documentation for all assets including hosts, applications, environments, and users should be carefully collected and managed in an asset management solution. All third-party integrations need to be vetted and documented, as well, to have visibility into any risk exposure. API documentation should be standardized and available to those authorized to use the API. Careful controls over access to and changes of environments, plus what’s shared externally vs. internally, and data protection measures must be in place to ensure that production data does not fall into other environments.
10. Unsafe consumption of APIs
Data consumed from other APIs must be handled with caution to prevent unexpected behavior. Third-party APIs could be compromised and leveraged to attack other API services. Attacks such as SQL injection, XML External Entity injection, deserialization attacks, and more, should be considered when handling data from other APIs.
Careful development practices must be in place to ensure all data is validated and properly sanitized. Evaluate third-party integrations and service providers’ security posture. Ensure all API communications occur over a secure channel such as TLS. Mutual authentication should also be enforced when connections between services are established.
What’s next?
The OWASP Top 10 API Security Risks template is now ready and available for use within InsightAppSec, mapping each of Rapid7’s API attack modules to their corresponding OWASP categories for ease of reference and enhanced API threat coverage.
Make sure to utilize the new template to ensure best in class coverage against API security threats today! And of course, as is always the case, ensure you are following Rapid7’s best practices for securing your APIs.
The Workers Browser Rendering API allows developers to programmatically control and interact with a headless browser instance and create automation flows for their applications and products.
Since the private beta announcement, based on the feedback we've been receiving and our own roadmap, the team has been working on the developer experience and improving the platform architecture for the best possible performance and reliability. Today we enter the open beta and will start onboarding the customers on the wait list.
Developer experience
Starting today, Wrangler, our command-line tool for configuring, building, and deploying applications with Cloudflare developer products, has support for the Browser Rendering API bindings.
Bindings allow your Workers to interact with resources on the Cloudflare developer platform. In this case, they will provide your Worker script with an authenticated endpoint to interact with a dedicated Chromium browser instance.
This is all you need in your wrangler.toml once this service is enabled for your account:
browser = { binding = "MYBROWSER", type = "browser" }
Now you can deploy any Worker script that requires Browser Rendering capabilities. You can spawn Chromium instances and interact with them programmatically in any way you typically do manually behind your browser.
Under the hood, the Browser Rendering API gives you access to a WebSocket endpoint that speaks the DevTools Protocol. DevTools is what allows us to instrument a Chromium instance running in our global network, and it's the same protocol that Chrome uses on your computer when you inspect a page.
With enough dedication, you can, in fact, implement your own DevTools client and talk the protocol directly. But that'd be crazy; almost no one does that.
So…
Puppeteer
Puppeteer is one of the most popular libraries that abstract the lower-level DevTools protocol from developers and provides a high-level API that you can use to easily instrument Chrome/Chromium and automate browsing sessions. It's widely used for things like creating screenshots, crawling pages, and testing web applications.
Puppeteer typically connects to a local Chrome or Chromium browser using the DevTools port.
We forked a version of Puppeteer and patched it to connect to the Workers Browser Rendering API instead. The changes are minimal; after connecting the developers can then use the full Puppeteer API as they would on a standard setup.
In the long term, we will update Puppeteer to keep matching the version of our Chromium instances infrastructure running in our network.
Developer documentation
Following the tradition with other Developer products, we created a dedicated section for the Browser Rendering APIs in our Developer's Documentation site.
You can access this page to learn more about how the service works, Wrangler support, APIs, and limits, and find examples of starter templates for common applications.
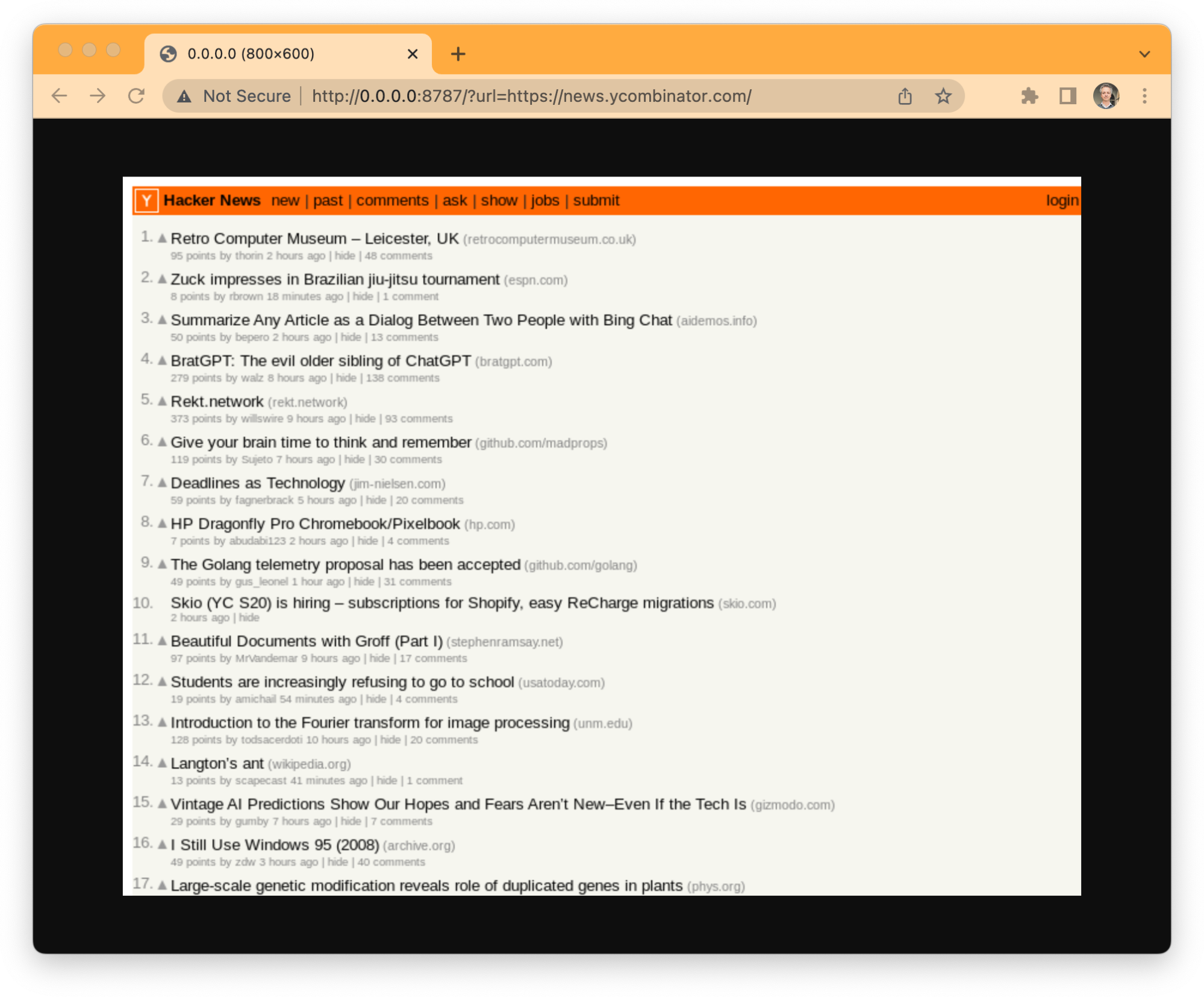
An example application: taking screenshots
Taking screenshots from web pages is one of the typical cases for browser automation.
Let's create a Worker that uses the Browser Rendering API to do just that. This is a perfect example of how to set up everything and get an application running in minutes, it will give you a good overview of the steps involved and the basics of the Puppeteer API, and then you can move from here to other more sophisticated use-cases.
Step one, start a project, install Wrangler and Cloudflare’s fork of Puppeteer:
Step two, let’s create the simplest possible wrangler.toml configuration file with the Browser Rendering API binding:
name = "browser-worker"
main = "src/index.ts"
compatibility_date = "2023-03-14"
node_compat = true
workers_dev = true
browser = { binding = "MYBROWSER", type = "browser" }
Step three, create src/index.ts with your Worker code:
import puppeteer from "@cloudflare/puppeteer";
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
let img: Buffer;
if (url) {
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
img = (await page.screenshot()) as Buffer;
await browser.close();
return new Response(img, {
headers: {
"content-type": "image/jpeg",
},
});
} else {
return new Response(
"Please add the ?url=https://example.com/ parameter"
);
}
},
};
That's it, no more steps. This Worker instantiates a browser using Puppeteer, opens a new page, navigates to whatever you put in the "url" parameter, takes a screenshot of the page, closes the browser, and responds with the JPEG image of the screenshot. It can't get any easier to get started with the Browser Rendering API.
Run npx wrangler dev –remote to test it and npx wrangler publish when you’re done.
You can explore the entire Puppeteer API and implement other functionality and logic from here. And, because it's Workers, you can add other developer products to your code. You might need a relational database, or a KV store to cache your screenshots, or an R2 bucket to archive your crawled pages and assets, or maybe use a Durable Object to keep your browser instance alive and share it with multiple requests, or queues to handle your jobs asynchronous, we have all of this and more.
You can also find this and other examples of how to use Browser Rendering in the Developer Documentation.
How do we use Browser Rendering
Dogfooding our products is one of the best ways to test and improve them, and in some cases, our internal needs dictate or influence our roadmap. Workers Browser Rendering is a good example of that; it was born out of our necessities before we realized it could be a product. We've been using it extensively for things like taking screenshots of pages for social sharing or dashboards, testing web software in CI, or gathering page load performance metrics of our applications.
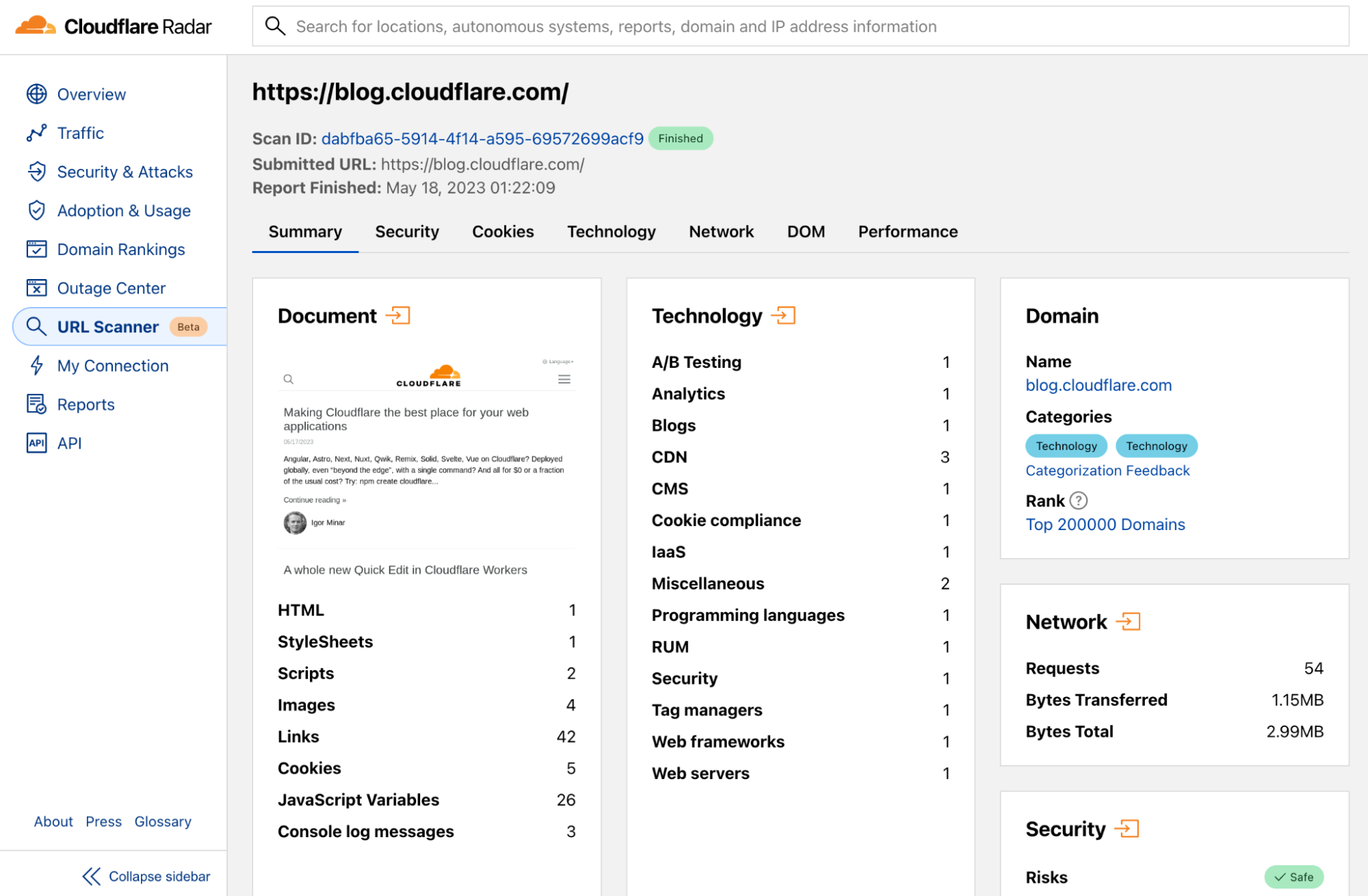
But there's one product we've been using to stress test and push the limits of the Browser Rendering API and drive the engineering sprints that brought us to open the beta to our customers today: The Cloudflare Radar URL Scanner.
The URL Scanner scans any URL and compiles a full report containing technical, performance, privacy, and security details about that page. It's processing thousands of scans per day currently. It was built on top of Workers and uses a combination of the Browser Rendering APIs with Puppeteer to create enriched HAR archives and page screenshots, Durable Objects to reuse browser instances, Queues to handle customers' load and execute jobs asynchronously, and R2 to store the final reports.
This tool will soon have its own "how we built it" blog. Still, we wanted to let you know about it now because it is a good example of how you can build sophisticated applications using Browser Rendering APIs at scale starting today.
Future plans
The team will keep improving the Browser Rendering API, but a few things are worth mentioning today.
First, we are looking into upstreaming the changes in our Puppeteer fork to the main project so that using the official library with the Cloudflare Workers Browser Rendering API becomes as easy as a configuration option.
Second, one of the reasons why we decided to expose the DevTools protocol bare naked in the Worker binding is so that it can support other browser instrumentalization libraries in the future. Playwright is a good example of another popular library that developers want to use.
And last, we are also keeping an eye on and testing WebDriver BiDi, a "new standard browser automation protocol that bridges the gap between the WebDriver Classic and CDP (DevTools) protocols." Click here to know more about the status of WebDriver BiDi.
Final words
The Workers Browser Rendering API enters open beta today. We will gradually be enabling the customers in the wait list in batches and sending them emails. We look forward to seeing what you will be building with it and want to hear from you.
One year ago we published our first Application Security Report. For Security Week 2023, we are providing updated insights and trends around mitigated traffic, bot and API traffic, and account takeover attacks.
Cloudflare has grown significantly over the last year. In February 2023, Netcraft noted that Cloudflare had become the most commonly used web server vendor within the top million sites at the start of 2023, and continues to grow, reaching a 21.71% market share, up from 19.4% in February 2022.
This continued growth now equates to Cloudflare handling over 45 million HTTP requests/second on average (up from 32 million last year), with more than 61 million HTTP requests/second at peak. DNS queries handled by the network are also growing and stand at approximately 24.6 million queries/second. All of this traffic flow gives us an unprecedented view into Internet trends.
Before we dive in, we need to define our terms.
Definitions
Throughout this report, we will refer to the following terms:
Mitigated traffic: any eyeball HTTP* request that had a “terminating” action applied to it by the Cloudflare platform. These include the following actions: BLOCK, CHALLENGE, JS_CHALLENGE and MANAGED_CHALLENGE. This does not include requests that had the following actions applied: LOG, SKIP, ALLOW. In contrast to last year, we now exclude requests that had CONNECTION_CLOSE and FORCE_CONNECTION_CLOSE actions applied by our DDoS mitigation system, as these technically only slow down connection initiation. They also accounted for a relatively small percentage of requests. Additionally, we improved our calculation regarding the CHALLENGE type actions to ensure that only unsolved challenges are counted as mitigated. A detailed description of actions can be found in our developer documentation.
Bot traffic/automated traffic: any HTTP* request identified by Cloudflare’s Bot Management system as being generated by a bot. This includes requests with a bot score between 1 and 29 inclusive. This has not changed from last year’s report.
API traffic: any HTTP* request with a response content type of XML or JSON. Where the response content type is not available, such as for mitigated requests, the equivalent Accept content type (specified by the user agent) is used instead. In this latter case, API traffic won’t be fully accounted for, but it still provides a good representation for the purposes of gaining insights.
Unless otherwise stated, the time frame evaluated in this post is the 12 month period from March 2022 through February 2023 inclusive.
Finally, please note that the data is calculated based only on traffic observed across the Cloudflare network and does not necessarily represent overall HTTP traffic patterns across the Internet.
*When referring to HTTP traffic we mean both HTTP and HTTPS.
Global traffic insights
6% of daily HTTP requests are mitigated on average
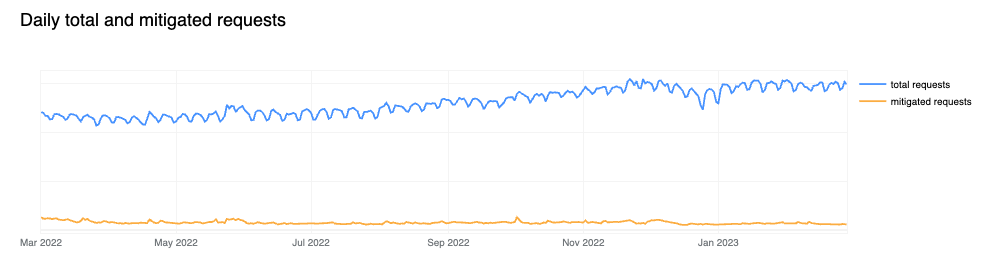
In looking at all HTTP requests proxied by the Cloudflare network, we find that the share of requests that are mitigated has dropped to 6%, down two percentage points compared to last year. Looking at 2023 to date, we see that mitigated request share has fallen even further, to between 4-5%. Large spikes visible in the chart below, such as those seen in June and October, often correlate with large DDoS attacks mitigated by Cloudflare. It is interesting to note that although the percentage of mitigated traffic has decreased over time, the total mitigated request volume has been relatively stable as shown in the second chart below, indicating an increase in overall clean traffic globally rather than an absolute decrease in malicious traffic.
81% of mitigated HTTP requests were outright BLOCKed, with mitigations for the remaining set split across the various CHALLENGE type actions.
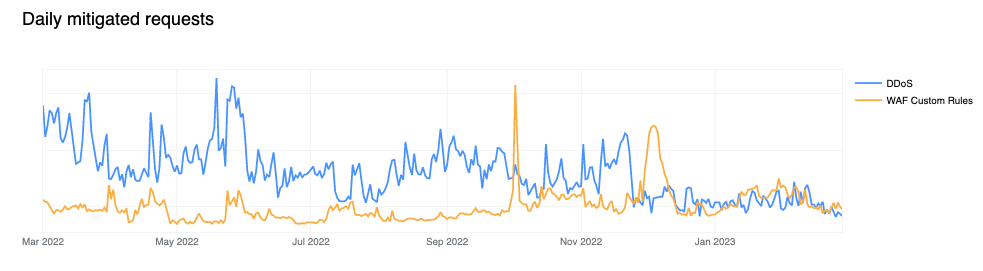
DDoS mitigation accounts for more than 50% of all mitigated traffic
Cloudflare provides various security features that customers can configure to keep their applications safe. Unsurprisingly, DDoS mitigation is still the largest contributor to mitigated layer 7 (application layer) HTTP requests. Just last month (February 2023), we reported the largest known mitigated DDoS attack by HTTP requests/second volume (This particular attack is not visible in the graphs above because they are aggregated at a daily level, and the attack only lasted for ~5 minutes).
Compared to last year, however, mitigation by the Cloudflare WAF has grown significantly, and now accounts for nearly 41% of mitigated requests. This can be partially attributed to advances in our WAF technology that enables it to detect and block a larger range of attacks.
Tabular format for reference:
Source
Percentage %
DDoS Mitigation
52%
WAF
41%
IP reputation
4%
Access Rules
2%
Other
1%
Please note that in the table above, in contrast to last year, we are now grouping our products to match our marketing materials and the groupings used in the 2022 Radar Year in Review. This mostly affects our WAF product that comprises the combination of WAF Custom Rules, WAF Rate Limiting Rules, and WAF Managed Rules. In last year’s report, these three features accounted for an aggregate 31% of mitigations.
To understand the growth in WAF mitigated requests over time, we can look one level deeper where it becomes clear that Cloudflare customers are increasingly relying on WAF Custom Rules (historically referred to as Firewall Rules) to mitigate malicious traffic or implement business logic blocks. Observe how the orange line (firewallrules) in the chart below shows a gradual increase over time while the blue line (l7ddos) clearly trends lower.
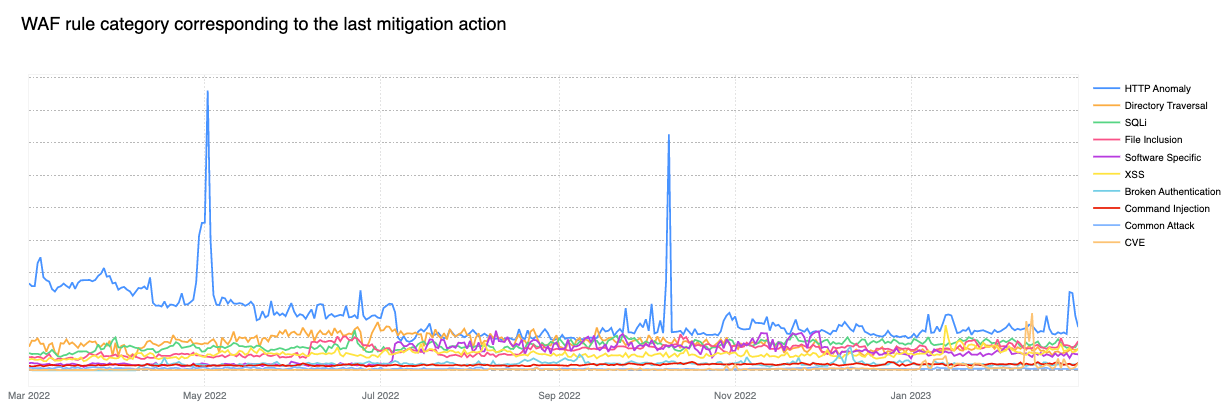
HTTP Anomaly is the most frequent layer 7 attack vector mitigated by the WAF
Contributing 30% of WAF Managed Rules mitigated traffic overall in March 2023, HTTP Anomaly’s share has decreased by nearly 25 percentage points as compared to the same time last year. Examples of HTTP anomalies include malformed method names, null byte characters in headers, non-standard ports or content length of zero with a POST request. This can be attributed to botnets matching HTTP anomaly signatures slowly changing their traffic patterns.
Removing the HTTP anomaly line from the graph, we can see that in early 2023, the attack vector distribution looks a lot more balanced.
Tabular format for reference (top 10 categories):
Source
Percentage % (last 12 months)
HTTP Anomaly
30%
Directory Traversal
16%
SQLi
14%
File Inclusion
12%
Software Specific
10%
XSS
9%
Broken Authentication
3%
Command Injection
3%
Common Attack
1%
CVE
1%
Of particular note is the orange line spike seen towards the end of February 2023 (CVE category). The spike relates to a sudden increase of two of our WAF Managed Rules:
These two rules are also tagged against CVE-2018-14774, indicating that even relatively old and known vulnerabilities are still often targeted in an effort to exploit potentially unpatched software.
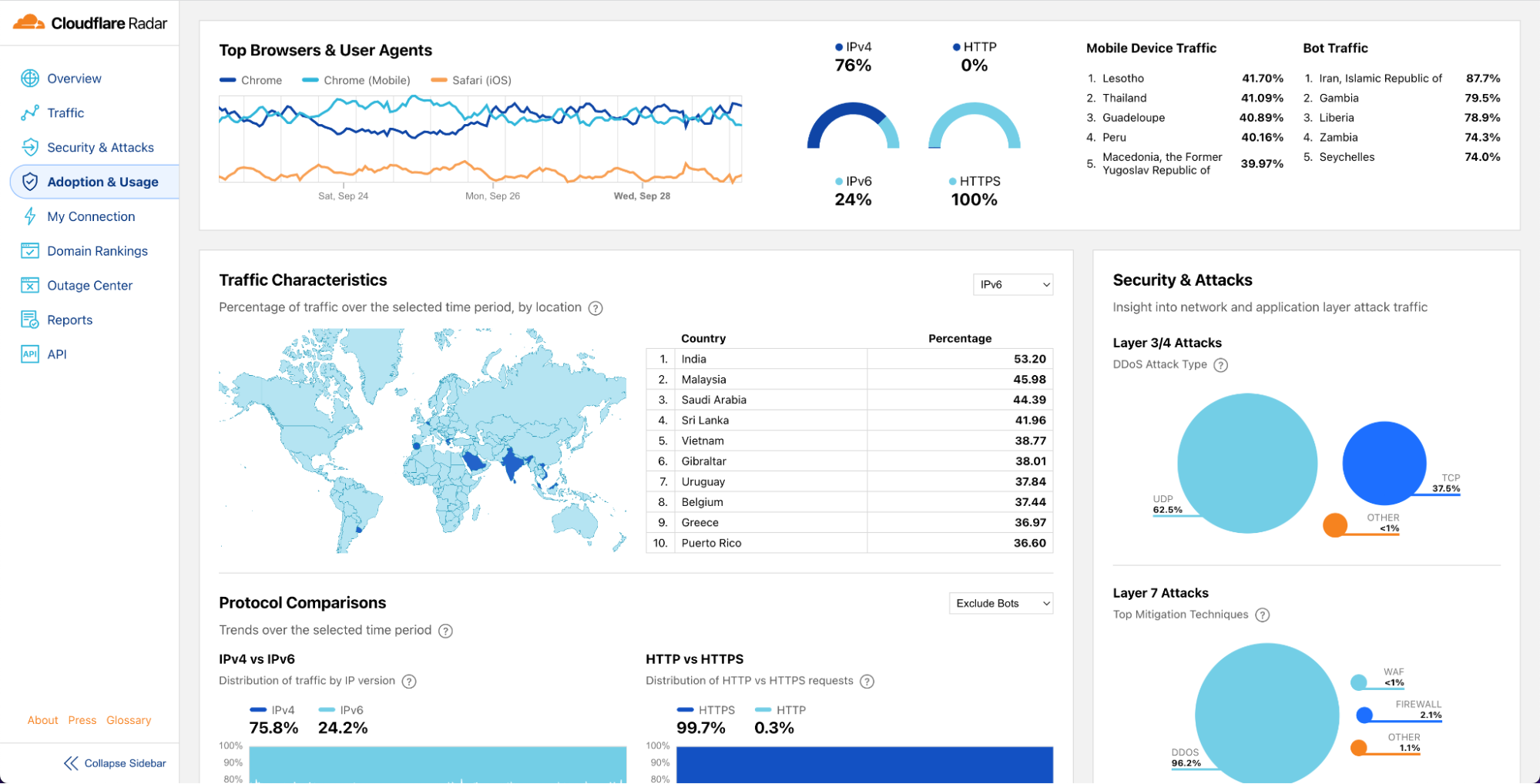
Bot traffic insights
Cloudflare’s Bot Management solution has seen significant investment over the last twelve months. New features such as configurable heuristics, hardened JavaScript detections, automatic machine learning model updates, and Turnstile, Cloudflare’s free CAPTCHA replacement, make our classification of human vs. bot traffic improve daily.
Our confidence in the classification output is very high. If we plot the bot scores across the traffic from the last week of February 2023, we find a very clear distribution, with most requests either being classified as definitely bot (less than 30) or definitely human (greater than 80) with most requests actually scoring less than 2 or greater than 95.
30% of HTTP traffic is automated
Over the last week of February 2023, 30% of Cloudflare HTTP traffic was classified as automated, equivalent to about 13 million HTTP requests/second on the Cloudflare network. This is 8 percentage points less than at the same time last year.
Looking at bot traffic only, we find that only 8% is generated by verified bots, comprising 2% of total traffic. Cloudflare maintains a list of known good (verified) bots to allow customers to easily distinguish between well-behaved bot providers like Google and Facebook and potentially lesser known or unwanted bots. There are currently 171 bots in the list.
16% of non-verified bot HTTP traffic is mitigated
Non-verified bot traffic often includes vulnerability scanners that are constantly looking for exploits on the web, and as a result, nearly one-sixth of this traffic is mitigated because some customers prefer to restrict the insights such tools can potentially gain.
Although verified bots like googlebot and bingbot are generally seen as beneficial and most customers want to allow them, we also see a small percentage (1.5%) of verified bot traffic being mitigated. This is because some site administrators don’t want portions of their site to be crawled, and customers often rely on WAF Custom Rules to enforce this business logic.
The most common action used by customers is to BLOCK these requests (13%), although we do have some customers configuring CHALLENGE actions (3%) to ensure any human false positives can still complete the request if necessary.
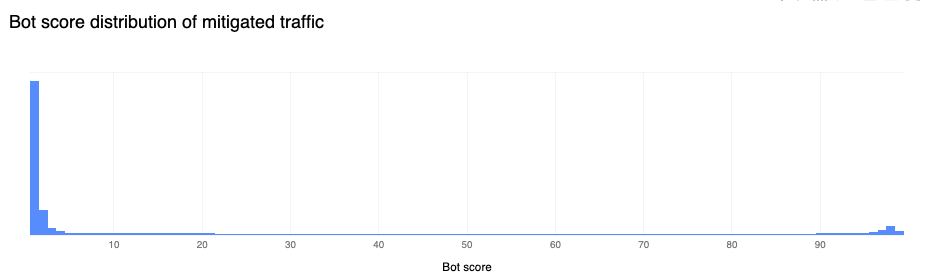
On a similar note, it is also interesting that nearly 80% of all mitigated traffic is classified as a bot, as illustrated in the figure below. Some may note that 20% of mitigated traffic being classified as human is still extremely high, but most mitigations of human traffic are generated by WAF Custom Rules, and are frequently due to customers implementing country-level or other related legal blocks on their applications. This is common, for example, in the context of US-based companies blocking access to European users for GDPR compliance reasons.
API traffic insights
55% of dynamic (non cacheable) traffic is API related
Just like our Bot Management solution, we are also investing heavily in tools to protect API endpoints. This is because a lot of HTTP traffic is API related. In fact, if you count only HTTP requests that reach the origin and are not cacheable, up to 55% of traffic is API related, as per the definition stated earlier. This is the same methodology used in last year’s report, and the 55% figure remains unchanged year-over-year.
If we look at cached HTTP requests only (those with a cache status of HIT, UPDATING, REVALIDATED and EXPIRED) we find that, maybe surprisingly, nearly 7% is API related. Modern API endpoint implementations and proxy systems, including our own API Gateway/caching feature set, in fact, allow for very flexible cache logic allowing both caching on custom keys as well as quick cache revalidation (as often as every second) allowing developers to reduce load on back end endpoints.
Including cacheable assets and other requests in the total count, such as redirects, the number goes down, but is still 25% of traffic. In the graph below we provide both perspectives on API traffic:
Yellow line: % of API traffic against all HTTP requests. This will include redirects, cached assets and all other HTTP requests in the total count;
Blue line: % of API traffic against dynamic traffic returning HTTP 200 OK response code only;
65% of global API traffic is generated by browsers
A growing number of web applications nowadays are built “API first”. This means that the initial HTML page load only provides the skeleton layout, and most dynamic components and data are loaded via separate API calls (for example, via AJAX). This is the case for Cloudflare’s own dashboard. This growing implementation paradigm is visible when analyzing the bot scores for API traffic. We can see in the figure below that a large amount of API traffic is generated by user-driven browsers classified as “human” by our system, with nearly two-thirds of it clustered at the high end of the “human” range.
Calculating mitigated API traffic is challenging, as we don’t forward the request to origin servers, and therefore cannot rely on the response content type. Applying the same calculation that was used last year, a little more than 2% of API traffic is mitigated, down from 10.2% last year.
HTTP Anomaly surpasses SQLi as most common attack vector on API endpoints
Compared to last year, HTTP anomalies now surpass SQLi as the most popular attack vector attempted against API endpoints (note the blue line being higher at the start of the graph just when last year’s report was published). Attack vectors on API traffic are not consistent throughout the year and show more variation as compared to global HTTP traffic. For example, note the spike in file inclusion attack attempts in early 2023.
Exploring account takeover attacks
Since March 2021, Cloudflare has provided a leaked credential check feature as part of its WAF. This allows customers to be notified (via an HTTP request header) whenever an authentication request is detected with a username/password pair that is known to be leaked. This tends to be an extremely effective signal at detecting botnets performing account takeover brute force attacks.
Customers also use this signal, on valid username/password pair login attempts, to issue two factor authentication, password reset, or in some cases, increased logging in the event the user is not the legitimate owner of the credentials.
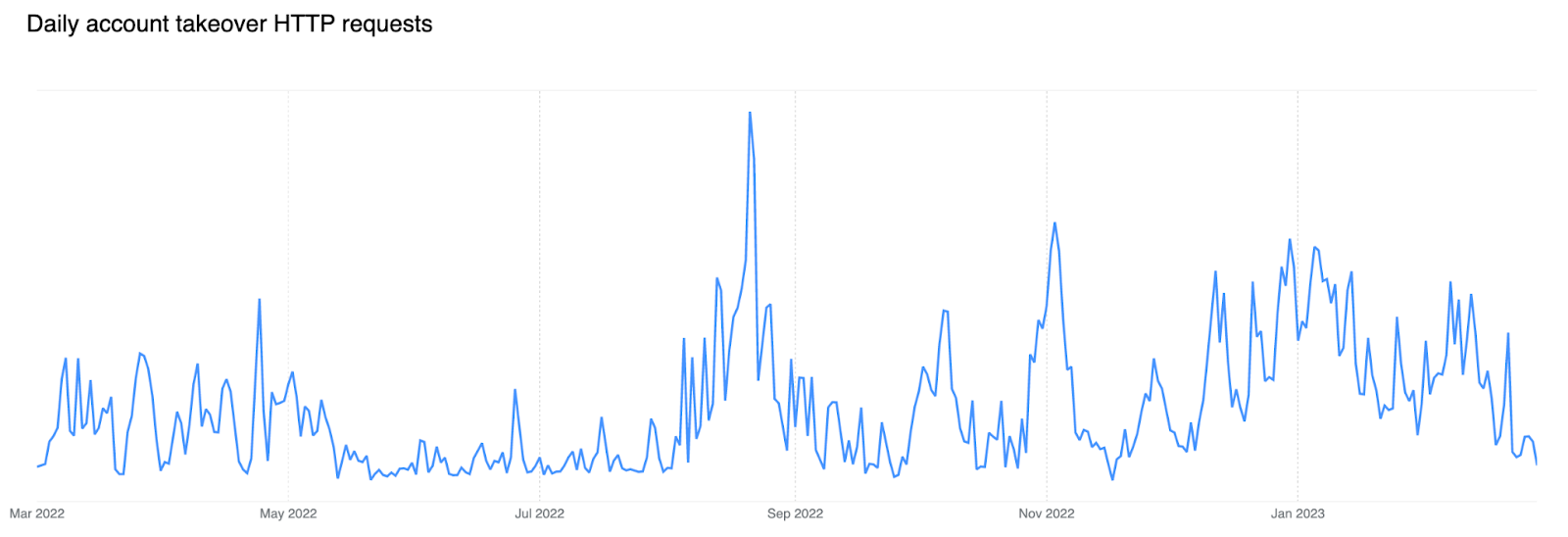
Brute force account takeover attacks are increasing
If we look at the trend of matched requests over the past 12 months, an increase is noticeable starting in the latter half of 2022, indicating growing fraudulent activity against login endpoints. During large brute force attacks we have observed matches against HTTP requests with leaked credentials at a rate higher than 12k per minute.
Our leaked credential check feature has rules matching authentication requests for the following systems:
Drupal
Ghost
Joomla
Magento
Plone
WordPress
Microsoft Exchange
Generic rules matching common authentication endpoint formats
This allows us to compare activity from malicious actors, normally in the form of botnets, attempting to “break into” potentially compromised accounts.
Microsoft Exchange is attacked more than WordPress
Mostly due to its popularity, you might expect WordPress to be the application most at risk and/or observing most brute force account takeover traffic. However, looking at rule matches from the supported systems listed above, we find that after our generic signatures, the Microsoft Exchange signature is the most frequent match.
Most applications experiencing brute force attacks tend to be high value assets, and Exchange accounts being the most likely targeted according to our data reflects this trend.
If we look at leaked credential match traffic by source country, the United States leads by a fair margin. Potentially notable is the absence of China in top contenders given network size. The only exception is Ukraine leading during the first half of 2022 towards the start of the war — the yellow line seen in the figure below.
Looking forward
Given the amount of web traffic carried by Cloudflare, we observe a broad spectrum of attacks. From HTTP anomalies, SQL injection attacks, and cross-site scripting (XSS) to account takeover attempts and malicious bots, the threat landscape is constantly changing. As such, it is critical that any business operating online is investing in visibility, detection, and mitigation technologies so that they can ensure their applications, and more importantly, their end user’s data, remains safe.
We hope that you found the findings in this report interesting, and at the very least, gave you an appreciation on the state of application security on the Internet. There are a lot of bad actors online, and there is no indication that Internet security is getting easier.
We are already planning an update to this report including additional data and insights across our product portfolio. Keep an eye on Cloudflare Radar for more frequent application security reports and insights.
At Cloudflare, we reuse existing core systems to power multiple products and testing of these core systems is essential. In particular, we require being able to have a wide and thorough visibility of our live APIs’ behaviors. We want to be able to detect regressions, prevent incidents and maintain healthy APIs. That is why we built Scout.
Scout is an automated system periodically running Python tests verifying the end to end behavior of our APIs. Scout allows us to evaluate APIs in production-like environments and thus ensures we can green light a production deployment while also monitoring the behavior of APIs in production.
Why Scout?
Before Scout, we were using an automated test system leveraging the Robot Framework. This older system was limiting our testing capabilities. In fact, we could not easily match json responses against keys we were looking for. We would abandon covering different behaviors of our APIs as it was impossible to decide on which resources a given test suite would run. Two different test suites would create false negatives as they were running on the same account.
Regarding schema validation, only API responses were validated against a json schema and tests would not fail if the response did not match the schema. Moreover, It was impossible to validate API requests.
Test suites were run in a queue, making the delay to a new feature assessment dependent on the number of test suites to run. The queue would as well potentially make newer test suites run the following day. Hence we often ended up with a mismatch between tests and APIs versions. Test steps could not be run in parallel either.
We could not split test suites between different environments. If a new API feature was being developed it was impossible to write a test without first needing the actual feature to be released to production.
We built Scout to overcome all these difficulties. We wanted the developer experience to be easy and we wanted Scout to be fast and reliable while spotting any live API issue.
A Scout test example
Scout is built in Python and leverages the functionalities of Pytest. Before diving into the exact capabilities of Scout and its architecture, let’s have a quick look at how to use it!
Following is an example of a Scout test on the Rulesets API (the docs are available here):
from scout import requires, validate, Account, Zone
@validate(schema="rulesets", ignorePaths=["accounts/[^/]+/rules/lists"])
@requires(
account=Account(
entitlements={"rulesets.max_rules_per_ruleset": 2),
zone=Zone(plan="ENT",
entitlements={"rulesets.firewall_custom_phase_allowed": True},
account_entitlements={"rulesets.max_rules_per_ruleset": 2 }))
class TestZone:
def test_create_custom_ruleset(self, cfapi):
response = cfapi.zone.request(
"POST",
"rulesets",
payload=f"""{{
"name": "My zone ruleset",
"description": "My ruleset description",
"phase": "http_request_firewall_custom",
"kind": "zone",
"rules": [
{{
"description": "My rule",
"action": "block",
"expression": "http.host eq \"fake.net\""
}}
]
}}""")
response.expect_json_success(
200,
result=f"""{{
"name": "My zone ruleset",
"version": "1",
"source": "firewall_custom",
"phase": "http_request_firewall_custom",
"kind": "zone",
"rules": [
{{
"description": "My rule",
"action": "block",
"expression": "http.host eq \"fake.net\"",
"enabled": true,
...
}}
],
...
}}""")
A Scout test is a succession of roundtrips of requests and responses against a given API. We use the functionalities of Pytest fixtures and marks to be able to target specific resources while validating the request and responses. Pytest marks in Scout allow to provide an extra set of information to test suites. Pytest fixtures are contexts with information and methods which can be used across tests to enhance their capabilities. Hence the conjunction of marks with fixtures allow Scout to build the whole harness required to run a test suite against APIs.
Being able to exactly describe the resources against which a given test will run provides us confidence the live API behaves as expected under various conditions.
The cfapi fixture provides the capability to target different resources such as a Cloudflare account or a zone. In the test above, we use a Pytest mark @requires to describe the characteristics of the resources we want, e.g. we need here an account with a flag allowing us to have 2 rules for a ruleset. This will allow the test to only be run against accounts with such entitlements.
The @validate mark provides the capability to validate requests and responses to a given OpenAPI schema (here the rulesets OpenAPI schema). Any validation failure will be reported and flagged as a test failure.
Regarding the actual requests and responses, their payloads are described as f-strings, in particular the response f-string can be written as a “semi-json”:
Among many test assertions possible, Scout can assert the validity of a partial json response and it will log the information. We added the handling of ellipsis … as an indication for Scout not to care about any further fields at a given json nesting level. Hence, we are able to do partial matching on JSON API responses, thus focusing only on what matters the most in each test.
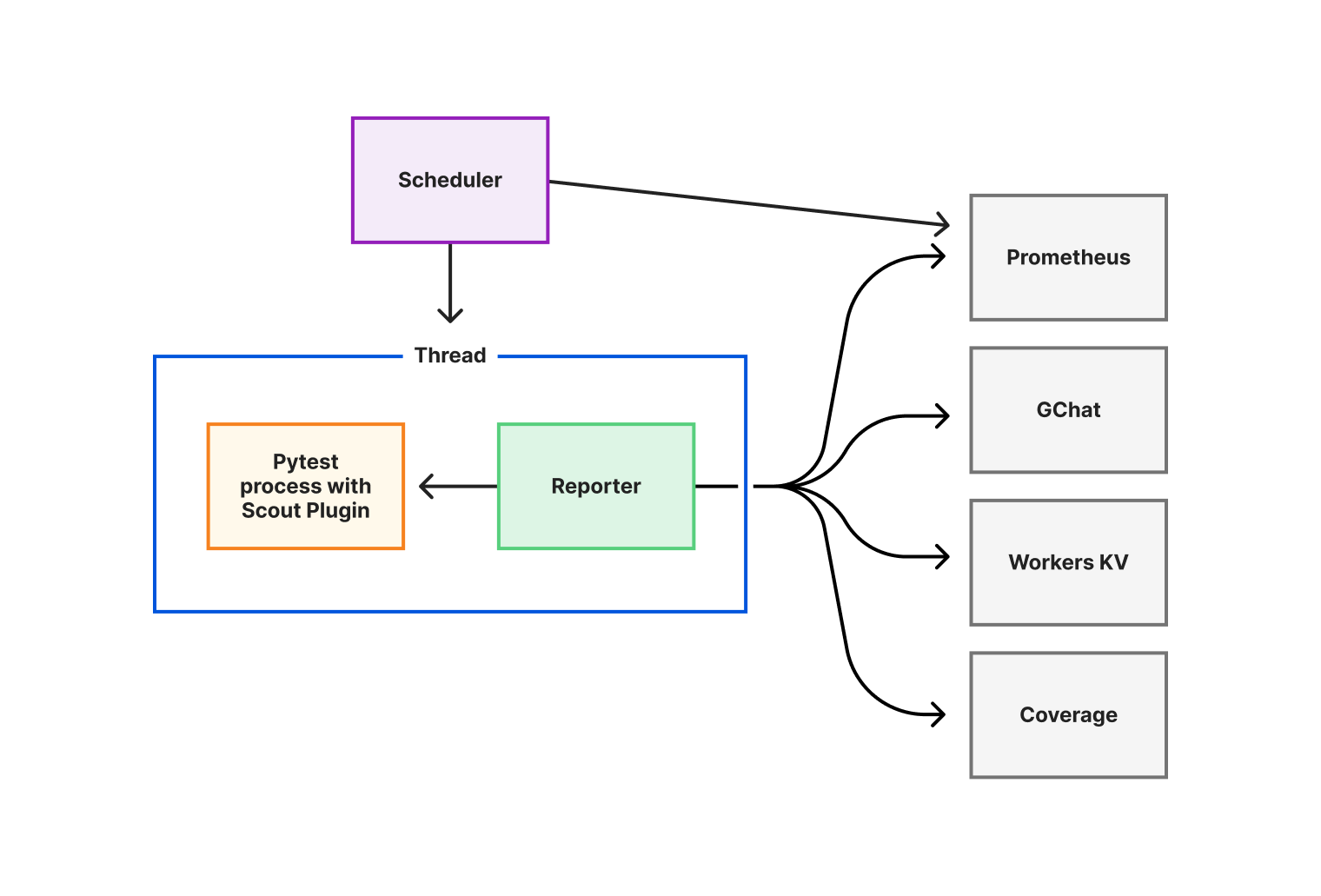
Once a test suite run is complete, the results are pushed by the service and stored using Cloudflare Workers KV. They are displayed via a Cloudflare Worker.
Scout is run in separate environments such as production-like and production environments. It is part of our deployment process to verify Scout is green in our production-like environment prior to deploying to production where Scout is also used for monitoring purposes.
How we built it
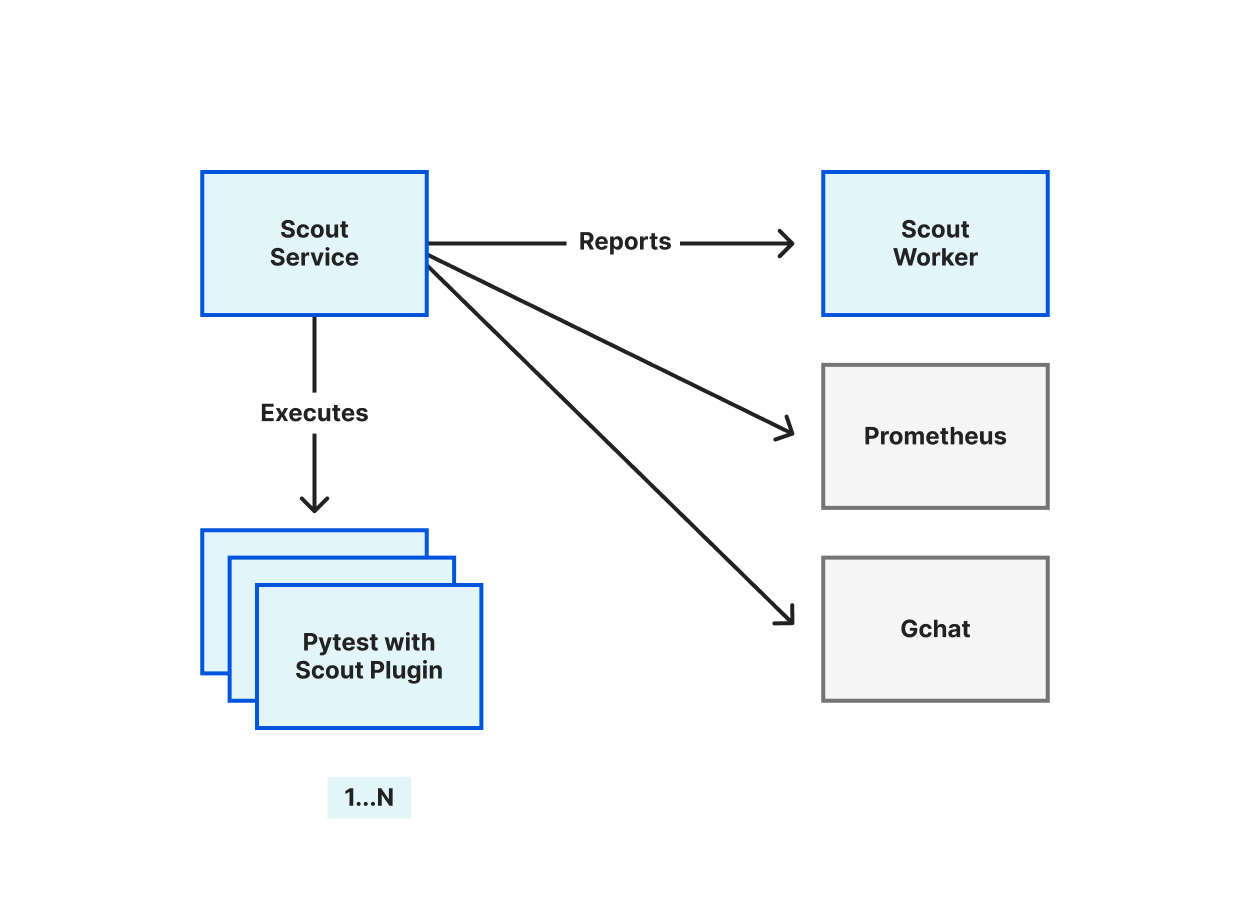
The core of Scout is written in Python and it is a combination of three components interacting together:
The Scout plugin: a Pytest plugin to write tests easily
The Scout service: a scheduler service to run the test suites periodically
The Scout Worker: a collector and presenter of test reports
The Scout plugin
This is the core component of the Scout system. It allows us to write self explanatory tests while ensuring a high level of compliance against OpenAPI schemas and verifying the APIs’ behaviors.
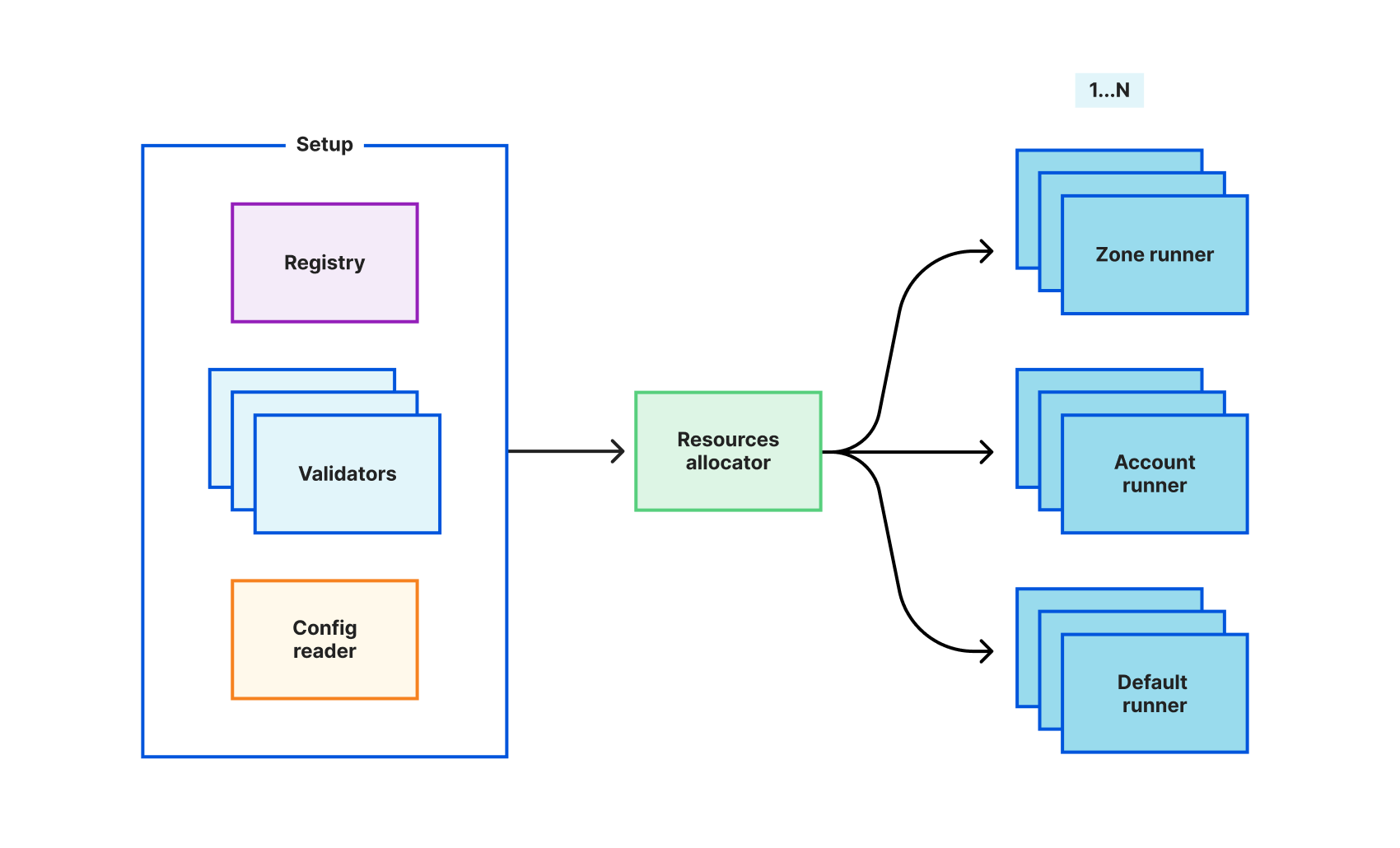
The Scout plugin architecture can be split into three components: setup, resource allocator, and runners. Setup is a conjunction of multiple sub components in charge of setting up the plugin.
The Registry contains all the information regarding a pool of accounts and zones we use for testing. As an example, entitlements are flags gating customers for using products features, the Registry provides the capability to describe entitlements per account and zone so that Scout can run a test against a specific setup.
As explained earlier, Scout can validate requests and responses against OpenAPI schemas. This is the responsibility of validators. A validator is built per OpenAPI schema and can be selected via the @validate mark we saw above.
As soon as a validator is selected, all the interaction of a given test with an API will be validated. If there is a validation failure, it will be marked as a test failure.
Last element of the setup, the config reader. It is the sub component in charge of providing all the URLs and authentication elements required for the Scout plugin to communicate with APIs.
Next in the chain, the resources allocator. This component is in charge of consuming the configuration and objects of the setup to build multiple runners. This is a factory which will make available the runners in the cfapi fixture.
When such a line of code is processed, it is the actual method request of the zone runner allocated for the test which is executed. Actually, the resources allocator is able to provide specialized runners (account, zone or default) which grant the possibility of targeting specific API endpoints for a given account or zone.
Runners are in charge of handling the execution of requests, managing the test expectations and using the validators for request/response schema validation.
Any failure on expectation or validation and any exceptions are recorded in the stash. The stash is shared across all runners. As such, when a test setup, run or cleanup is processed, the timeline of execution and potential retries are logged in the stash. The stash contents are later used for building the test suite reports.
Scout is able to run multiple test steps in parallel. Actually, each resource couple (Account Runner, Zone Runner) is associated with a Pytest-xdist worker which runs test steps independently. There can be as many workers as there are resource couples. An extra “default” runner is provided for reaching our different APIs and/or URLs with or without authentication.
Testing a test system was not the easiest part. We have been required to build a fake API and assert the Scout plugin would behave as it should in different situations. We reached and maintained a test coverage confidence which was considered good (close to 90%) for using the Scout plugin permanently.
The Scout service
The Scout service is meant to schedule test suites periodically. It is a configurable scheduler providing a reporting harness for the test suites as well as multiple metrics. It was a design decision to build a scheduler instead of using cron jobs.
We wanted to be aware of any scheduling issue as well as run issues. For this we used Prometheus metrics. The problem is that the Prometheus default configuration is to scrape metrics advertised by services. This scraping happens periodically and we were concerned about the eventuality of missing metrics if a cron job was to finish prior to the next Prometheus metrics scraping. As such we decided a small scheduler was better suited for overall observability of the test runs. Among the metrics the Scout service provides are network failures, general test failures, reporting failures, tests lagging and more.
The Scout service runs threads on configured periods. Each thread is a test suite run as a separate Pytest with Scout plugin process followed by a reporting execution consuming the results and publishing them to the relevant parties.
The reporting component provided to each thread publishes the report to Workers KV and notifies us on chat in case there is a failure. Reporting takes also care of publishing the information relevant for building API testing coverage. In fact it is mandatory for us to have coverage of all the API endpoints and their possible methods so that we can achieve a wide and thorough visibility of our live APIs.
As a fallback, if there are any thread failure, test failure or reporting failure we are alerted based on the Prometheus metrics being updated across the service execution. The logs of the Scout service as well as the logs of each Pytest-Scout plugin execution provide the last resort information if no metrics are available and reporting is failing.
The service can be deployed with a minimal YAML configuration and be set up for different environments. We can for example decide to run different test suites based on the environment, publish or not to Cloudflare Workers, set different periods and retry mechanisms and so on.
We keep the tests as part of our code base alongside the configuration of the Scout service, and that’s about it, the Scout service is a separate entity.
The Scout Worker
It is a Cloudflare worker in charge of fetching the most recent Worker KVs and displaying them in an eye pleasing manner. The Scout service publishes a test report as JSON, thus the Scout worker parses the report and displays its content based on the status of the test suite run.
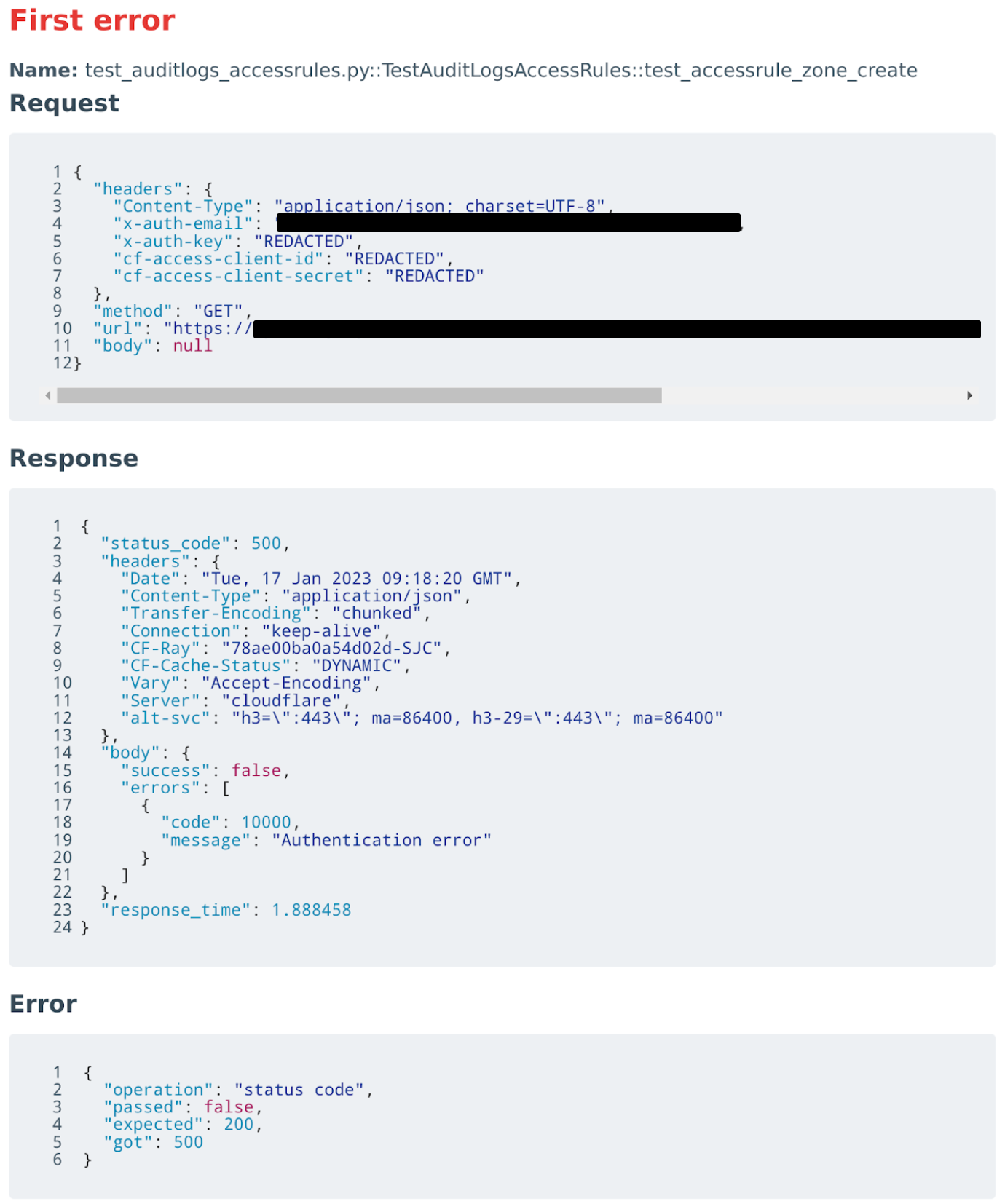
For example, we present below an authentication failure during a test which resulted in such a display in the worker:
What does Scout let us do
Through leveraging the capabilities of Pytest and Cloudflare Workers, we have been able to build a configurable, robust and reliable system which allows us to easily write self explanatory tests for our APIs.
We can validate requests and responses against OpenAPI schemas and test behaviors over specific resources while getting alerted through multiple means if something goes wrong.
For specific use cases, we can write a test verifying the API behaves as it should, the configuration to be pushed at the edge is valid and a given zone will react as it should to security threats. Thus going beyond an end-to-end API test.
Scout quickly became our permanent live tester and monitor of APIs. We wrote tests for all endpoints to maintain a wide coverage of all our APIs. Scout has since been used for verifying an API version prior to its deployment to production. In fact, after a deployment in a production-like environment we can know in a couple of minutes if a new feature is good to go to production and assess if it is behaving correctly.
We hope you enjoyed this deep dive description into one of our systems!
As you know, a picture is worth a thousand words. Therefore, I would like to share the process of creating a webhook from scratch. In this article, we will walk through the creation process step by step – starting with studying the target service with which Zabbix will integrate and finishing with tests for sending events from Zabbix. Although it may seem complicated, writing your own integrations is not so difficult.
Preparation
First, we need to decide what we want to see as a result of the webhook. In most cases, the services to which we will send events are divided into 2 types:
Messengers to which you can send messages. For example, Telegram, Slack, Discord, etc.
Service Desks where you can open, close, and update tickets. For example, Jira, Redmine, ServiceNow, etc.
In both cases, the principle of creating a webhook will not differ – the difference is only in the complexity of one type from the other.
In this article, I will describe the process of creating a webhook for messengers – and specifically for Line messenger.
After we have decided on the type, we need to find out whether this service supports the possibility of API requests and, if it does, what is required for this. Usually, all the services you want to integrate Zabbix with have somewhat detailed documentation about the API methods they support. By the way, Zabbix also has its own API, which is documented in detail.
After we are done studying the Line documentation, we find out that messages are sent using the POST method to the https://api.line.me/v2/bot/message/push endpoint, using the Line bot token in the request header for authorization and passing a specially formatted JSON in the request body with the content of the message. Confused? No problem. Let’s take a closer look.
HTTP requests
The operation of the API is based on HTTP requests, which are executed with parameters provided by the developers of this API.
Several types of HTTP requests are used more often than others:
GET – is perhaps the most common one that all of us encounter on a daily basis. This request only involves getting data. For example, the browser used a GET request from the web server to fetch the article you are currently reading.
POST – is a request that sends data to a resource. This is exactly the case when we want to pass something to the service using API requests.
PUT – is much less common than the previous 2, but no less important. This query replaces the values in a resource.
These are not all HTTP request methods, but these three will suffice for a general introduction.
We are done with methods. Let’s move on to the endpoint.
An endpoint is a permanent address of a resource via which we transfer, receive, or change data. In this case, https://api.line.me/v2/bot/message/push is the endpoint that accepts POST requests to send messages.
So, the method and the endpoint are defined. What’s next?
Generally, any HTTP request consists of:
URL
Method
Headers
Body
HTTP request structure
We have already dealt with the first two, but the headers and the request body remain.
Headers usually contain service information that allows you to process a request correctly. For example, the Content-Type: application/json header implies that our request body should be interpreted as a json object. Also, quite often, authorization information is passed in the headers. As in the case of Line, the Authorization: Bearer {channel access token} header contains the authorization token of the bot on behalf of which messages will be sent.
The request body usually contains the information we want to pass on to the service. In our case, this will be the subject and body of the event in Zabbix.
Checking the service API
The documentation is good, but it is necessary to check that everything we read works exactly how it is documented. It is not uncommon that a service can be developed faster than the documentation can keep up with it. So field testing never hurts. Excluding unexpected behavior will significantly reduce the time spent searching for problems.
I recommend using Postman to work with API requests – a handy tool that saves time. But for this article, we will use cURL due to its prevalence and ease of use.
I will not describe the process of creating the Line Bot API token because this is not directly related to the article. However, for those interested in this process, I will leave a link here.
As we have already found out, the request type will be POST, the access point URL is https://api.line.me/v2/bot/message/push, and additional headers must be passed: Content-Type: application/json which specifies the type of data to be sent (in our case it is JSON) and Authorization: Bearer {token value}. And the messages themselves are in JSON format. For example, I used 2 messages – “Hello, world1” and “Hello, world2”. As a result, I got the following query:
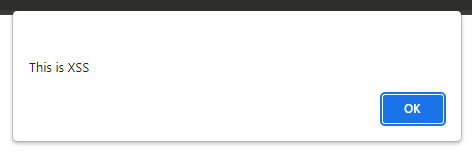
After executing the request, we got the expected result of 2 messages that came to the messenger, which were in the request body.
Excellent! So half of the work has already been done: there is a ready-made request that works in manual mode and successfully sends messages to Line. The only thing left is to put the necessary information in the right places and automate the process using JS and Zabbix.
Integration with Zabbix
After successfully completing the tests, go to Zabbix, create a new notification method in the Administration section, select the webhook type, and name it Line.
For webhook integrations with external services, Zabbix uses the built-in JavaScript engine on Duktape. Parameters are passed to the script, which is used to build the logic of the webhook. As a result of the script, tags can be returned that will be assigned to the event. This is usually necessary in case of integration with service desks in order to be able to update the status of tickets.
Let’s take a closer look at the webhook setup interface.
The Media type section contains the general settings for the new media type:
Name – Name of the media type.
Type – The type of media type. There are 4 types: email, SMS, webhook, and script.
Parameters – This is a list of variables passed to the code. All necessary data can be passed through parameters: event id, event type, trigger severity, event source, etc. You can specify macros and text values in parameters. The parameters are passed as a JSON string, accessible through the built-in variable value.
Script – JS script describing the logic of the webhook.
Timeout – The time after which the script will be terminated.
Process tags – If this option is enabled, the webhook will support generating tags for events sent using this hook.
Include event menu entry – This option makes the Menu Entry Name and Menu Entry URL fields available for use.
Menu entry name – The text displayed in the event dropdown menu for the Menu entry URL submitted using this hook.
Menu entry URL – A link to an external resource in the event menu.
Description – A text field that contains a description of the notification method.
Enabled – an Option that allows enabling or disabling the media type.
The Message templates section contains templates that are used by webhook to send alerts. Each template contains:
Message type – The event type to which the message will apply. For example, Problem – when the trigger fires and Problem recovery – when the problem is resolved.
Subject – The headline of the message.
Message – A message template that contains useful information about the event. For example, event time, date, event name, host name, etc.
The Options section contains additional options:
Concurrent sessions – The number of concurrent sessions to send an alert.
Attempts – The number of retries in case of send failure.
Attempt interval – The frequency of attempts to send an alert.
When writing your own webhook, you can take an existing one as a basis – Zabbix has more than thirty ready-made webhook solutions of varying complexity. All basic functions are usually repeated from hook to hook with little or no change at all, as are the parameters passed to them.
Let’s set the following parameters:
It is convenient to set parameter values with macros. A macro is a variable in Zabbix that contains a specific value. Macros allow you to optimize and automate your work. They can be used in various places, such as triggers, filters, alerts, and so on.
A little more about each macro separately in order to understand why each of them is needed:
{ALERT.SUBJECT} – The subject of the event message. This value is taken from the Subject field of the corresponding Message template type.
{ALERT.MESSAGE} – The event message body. This value is taken from the Message field of the corresponding Message template type.
{EVENT.ID} – The event id in Zabbix. Could be used for generating a link to an event
{EVENT.NSEVERITY} – The numerical definition of the event’s severity from 0-5. We will use this to change the message in case of different severity.
{EVENT.SOURCE} – The event source. Needed to handle events correctly. In most cases, we are interested in triggers; this corresponds to source value 0.
{EVENT.UPDATE.STATUS} – Returns 1 if it is an update event. For example, in case of acknowledge operations or a change in severity.
{EVENT.VALUE} – The event state. 0 for recovery and 1 for the problem.
{ALERT.SENDTO} – The field from the media type assigned to the user. It returns the ID of the user or group in the Line, where it will be necessary to send a message
{TRIGGER.DESCRIPTION} – A macro that will be expanded if the event source is a trigger. Returns the description of the trigger
{TRIGGER.ID} – The trigger ID. Required to generate a link to an event in Zabbix
Webhooks can use other macros if needed. A list of all macros can be viewed on the documentation page. Be careful – not all macros can be used in webhooks.
Writing the script
Before writing the script, let’s define the main points that the webhook will need to be able to perform:
the script should describe the logic for sending messages
handle possible errors
logging for debugging
I will not describe the entire code in order not to repeat the same type of blocks and concentrate only on important aspects.
To send messages, let’s write a function that will accept messages and params variables. We got the following function:
function sendMessage(messages, params) {
// Declaring variables
var response,
request = new HttpRequest();
// Adding the required headers to the request
request.addHeader('Content-Type: application/json');
request.addHeader('Authorization: Bearer ' + params.bot_token);
// Forming the request that will send the message
response = request.post('https://api.line.me/v2/bot/message/push', JSON.stringify({
"to": params.send_to,
"messages": messages
}));
// If the response is different from 200 (OK), return an error with the content of the response
if (request.getStatus() !== 200) {
throw "API request failed: " + response;
}
}
Of course, this is not a reference function, and depending on the requirements for the request may differ. There may be other required headers and a different request body. In some cases, it may be necessary to add an additional step to obtain authorization data through another API request.
In this case, the request to send a message returns an empty {} object, so it makes no sense to return it from the function. But for example, when sending a message to Telegram, an object with data about this message is returned. If you pass this data to tags, you can write logic that will change the already sent message – for example, in case of closing or updating the problem.
Now let’s describe a function that will accept webhook parameters and validate their values. In the example, we will not describe all the conditions because they are of the same type:
function validateParams(params) {
// Checking that the bot_token parameter is a string and not empty
if (typeof params.bot_token !== 'string' || params.bot_token.trim() === '') {
throw 'Field "bot_token" cannot be empty';
}
// Checking that the event_source parameter is only a number from 0-3
if ([0, 1, 2, 3].indexOf(parseInt(params.event_source)) === -1) {
throw 'Incorrect "event_source" parameter given: "' + params.event_source + '".nMust be 0-3.';
}
// If an event of type "Discovery" or "Autoregistration" set event_value 1,
// which means "Problem", and we will process these events same as problems
if (params.event_source === '1' || params.event_source === '2') {
params.event_value = '1';
}
...
// Checking that trigger_id is a number and not equal to zero
if (isNaN(params.trigger_id) && params.event_source === '0') {
throw 'field "trigger_id" is not a number';
}
}
As you can see from the code, in most cases these are simple checks that allow you to avoid errors associated with the input data. Validation is necessary because there is no guarantee that the expected value will be in the parameter.
The main block of code is placed inside the try…catch block in order to correctly handle errors:
try {
// Declaring the params variable and writing the webhook parameters to it
var params = JSON.parse(value);
// Calling the validation function and passing parameters to it for verification
validateParams(params);
// If the event is a trigger and it is in the problem status, compose the message body
if (params.event_source === '0' && params.event_value === '1') {
var line_message = [
{
"type": "text",
"text": params.alert_subject + 'nn' +
params.alert_message + 'n' + params.trigger_description
}
];
}
...
// Sending a composed message
sendMessage(line_message, params);
// Returning OK so that the webhook understands that the script has completed with OK status
return 'OK';
}
catch (err) {
// Adding a log function so in case of problems you can see the error in the Zabbix server console
Zabbix.log(4, '[ Line Webhook ] Line notification failed : ' + err);
// In case of an error, return it from the webhook
throw 'Line notification failed : ' + err;
}
Here we assign parameter values to the params variable, then validate them using the validateParams() function, describe the main conditions for generating a message, and send this message to the messenger. At the same time, the try…catch block allows you to catch all errors, log them to Zabbix and return them in a readable form to the user in the web interface.
For writing webhooks in Zabbix, there is a guideline dedicated to this topic. Please read this information because it will help you write better code and avoid common mistakes.
Testing
After we’ve finished with the webhook script, it’s time to test how our code works. To do this, Zabbix provides a function to send test messages. Go to the Administration → Media types, find Line, and click on the Test button opposite it. In the window that appears, fill in all the fields with the necessary data and press the Test button. Check the messenger and see that the message came with the data we specified in the test.
Ready-made Line integration can be found in the Zabbix git repository and in all recent Zabbix instance builds.
Troubleshooting
Of course, everything in the article looks like I did it on the first attempt and did not encounter a single error or problem. Naturally, this is not the case in practice. Work with each new product includes Research & Development. How can you catch errors and, most importantly, understand the problem?
Well, as I wrote earlier – read the documentation and test all requests before writing code. At this stage, it is easiest to catch all the problems. The response to the HTTP request will explicitly describe the error. For example, if you make a mistake in the request body and send an object with incorrect values, the service will return the body with an error description and the response status 400 (Bad request).
There are several options for debugging in case of errors that may occur when writing a webhook script:
Focus on the errors displayed when the notification method is executed. For example, if you mistyped or set the wrong name of the function and variable.
Include logging in the code for displaying service information. For example, while you are in the script development stage, the result of the function can be logged using the Zabbix.log() function. Zabbix supports 6 debug levels (0-5), which can be set in this function. Usually, webhooks use level 4, which contains information for debugging.
Use the zabbix_js utility. You can transfer a file with a script and parameters to it. You can read more about it here.
Conclusion
I hope this article has helped you better understand how webhooks work in Zabbix and highlighted the basic steps for creating, diagnosing, and preparing to write your integration. The Zabbix community is constantly adding custom templates and media types. I expect that after reading this article, more people will be interested in creating their own webhooks and sharing them with the community. We appreciate any contribution to the development and expansion of the base of integration solutions.
Questions
Q: I don’t know JS, but I know other languages. Is native support of other languages planned in Zabbix, such as Python?
A: For now, there are no such plans.
Q: Are there any restrictions with writing a JS script for a webhook?
A: Yes, there are. The built-in Duktape engine is used to execute the code, and it does not have all the functionality that is available in the latest JS releases. Therefore, I recommend that you read the documentation of this engine and the built-in objects to learn more about the available methods.
Internet shutdowns have long been a tool in government toolboxes when it comes to silencing opposition and cutting off access from the outside world. The KeepItOn campaign by Access Now, a group that defends the digital rights of global Internet users, documented at least 182 Internet shutdowns in 34 countries in 2021. Many of these shutdowns occurred during public protests, elections, and wars as an extreme form of censorship in places like Afghanistan, Democratic Republic of the Congo, Ukraine, India, and Iran.
There are a range of ways governments block or slow communications, including throttling, IP blocking, DNS interference, mobile data shutoffs, and deep packet inspection, all with similar goals: exerting control over information.
Although Internet shutdowns are largely public, it is difficult to document and track the ways in which governments implement them. The shutdowns not only impact people’s ability to participate in civil and political life and the economy but also have grave consequences for trust in democratic institutions.
We have reported on these shutdowns in the past, and for Cloudflare Impact Week, we want to tell you more about how we work with civil society organizations to provide tools to track and document the scope of these disruptions. We want to support their critical work and provide the tools they need so they can demand accountability and condemn the use of shutdowns to silence dissent.
Radar Internet shutdown alerts for civil society
We launched Radar in 2020 to shine light on the Internet’s patterns, insights, threats, and trends based on aggregated data from our network. Once we launched Radar, we found that many civil society organizations and those who work in democracy-building use Radar to track trends in countries to better understand the rise and fall of Internet usage.
Internally, we had an alert system for potential Internet disruptions that we use as an early warning regarding shifts in network patterns and incidents. When we engaged with these organizations that use Radar to track Internet trends, we learned more about how our internal tool to identify traffic distributions could be useful for organizations that work with human rights defenders on the ground that are impacted by these shutdowns.
To determine the best way to provide a tool to alert organizations when Cloudflare has seen these disruptions, we spoke with organizations such as Access Now, Internews, The Carter Center, National Democratic Institute, Internet Society, and the International Foundation for Electoral Systems. After our conversations, we launched Radar Internet shutdown alerts in 2021 to provide alerts on when Cloudflare has detected significant drops in traffic with the hope that the information is used to document, track, and hold institutions accountable for these human rights violations.
Since 2021, we have been providing these alerts to civil society partners to track these shutdowns. As we have collected feedback to improve the alerts, we have seen many partners looking for more ways to integrate Radar and the alerts into their existing tracking mechanisms. With this, we announced Radar 2.0 with API access for free so academics, data sleuths, civil society, human rights organizations, and other web enthusiasts can analyze, visualize, and investigate Internet usage across the globe, based on data from our global network. In addition, we launched Cloudflare Radar Outage Center to archive Internet outages and make it easier for civil society organizations, journalists/news media, and impacted parties to track past shutdowns.
Highlighting the work of our civil society partners to track Internet shutdowns
We believe our job at Cloudflare is to build tools that improve privacy and security for a range of players on the Internet. With this, we want to highlight the work of our civil society partners. These organizations are pushing back against targeted shutdowns that inflict lasting damage to democracies around the world. Here are their stories.
Access Now’s #KeepItOn coalition was launched in 2016 to help unite and organize the efforts of activists and organizations across the world to end Internet shutdowns. It now represents more than 280 organizations from 105 countries across the globe. The goal of STOP Project (Shutdown Tracker Optimization Project) is ultimately to document and report shutdowns accurately, which requires diligent verification. Access Now regularly uses multiple sources to identify and understand the shutdown, the choice and combination of which depends on where and how the shutdown occurred.
The tracker uses both quantitative and qualitative data to record the number of Internet shutdowns in the world in a given year and to characterize the nature of the shutdowns, including their magnitude, scope, and causes.
Zach Rosson, #KeepItOn Data Analyst, Access Now, details, “Sometimes, we confirm an Internet shutdown through means such as technical measurement, while at other times we rely upon contextual information, such as news reports or personal accounts. We also work hard to document how a particular shutdown was ordered and how it impacted society, including why and how it happened.”
On how Access Now’s #KeepItOn coalition uses Cloudflare Radar, Rosson says, “We use Radar Internet shutdown alerts in both email and tweet form, as a trusted source to help verify a shutdown occurrence. These alerts and their underlying measurements are used as primary sources in our dataset when compiling shutdowns for our annual report, so they are used in an archival sense as well. Cloudflare Radar is sometimes the first place that we hear about a shutdown, which is quite useful in a rapid response context, since we can quickly mobilize to verify the shutdown and have strong evidence when advocating against it.”
The recorded instances of shutdowns include events reported through local or international news sources that are included in the dataset, from local actors through Access Now’s Digital Security Helpline or the #KeepItOn Coalition email list, or directly from telecommunication and Internet companies.
Rosson notes, “When it comes to Radar 2.0 and API, we plan to use these resources to speed up our response, verification, and publication of shutdown data as compiled from different sources. Thus, the Cloudflare Radar Outage Center (CROC) and related API endpoint will be very useful for us to access timely information on shutdowns, either through visual inspection of the CROC in the short term or through using the API to pull data into a centralized database in the long term.”
On the Internet Society Pulse platform, Susannah Gray, Director, Communications, Internet Society, explains that they strive to curate meaningful information around a government-mandated Internet shutdown by using data from multiple trusted sources, and making it available to everyone, everywhere in an easy-to-understand manner. ISOC does this by monitoring Internet traffic using various tools, including Radar. When they see something that might indicate that an Internet shutdown is in progress, they check if the shutdown meets their criteria. For a shutdown to appear on the Pulse Shutdowns Tracker it needs to meet all the following requirements. It must:
Be artificially induced, as evident from reputable sources, including government statements and orders.
ISOC uses many resources to track shutdowns. Gray explains, “Radar Internet shutdown alerts are incredibly useful for bringing incidents to our attention as they are happening. The easy access to the data provided helps us assess the nature of an outage. If an outage is established as a government-mandated shutdown, we often use screenshots of Radar charts on the Pulse shutdowns tracker incident page to help illustrate how traffic stopped flowing in and out of a country during the shutdown. We provide a link back to the Radar platform so that people interested in getting more in-depth data can find out more.”
ISOC’s aim has never been to be the first to report a government-mandated shutdown: instead, their mission is to report accurate and meaningful information about the shutdown and explore its impact on the economy and society.
Gray adds, “For Radar 2.0 and the API, we plan to use it as part of the data aggregation tool we are developing. This internal tool will combine several outage alert and monitoring tools and sources into one single system so that we are able to track incidents more efficiently.”
OONI is a nonprofit that measures Internet censorship, including the blocking of websites, instant messaging apps, and circumvention tools. Cloudflare Radar is one of the main public data sources that they use when examining reported Internet connectivity shutdowns. For example, OONI relied on Radar data when reporting on shutdowns in Iran amid ongoing protests. In 2022, the team launched the Measurement Aggregation Toolkit (MAT), which enables the public to track censorship worldwide and create their own charts based on real-time OONI data. OONI also forms partnerships with multiple digital rights organizations that use OONI tools and data to monitor and respond to censorship events in their regions.
Maria Xynou, OONI Research and Partnerships Director, explains “Cloudflare Radar is one of the main public data sources that OONI has referred to when examining reported internet connectivity shutdowns. Specifically, OONI refers to Cloudflare Radar to check whether the platform provides signals of a reported internet connectivity shutdown; compare Cloudflare Radar signals with those visible in other, relevant public data sources (such as IODA, and Google traffic data).”
Tracking the shutdowns of tomorrow
As we work with more organizations in the human rights space and learn how our global network can be used for good, we are eager to improve and create new tools to protect human rights in the digital age.
Configuration management is far from a solved problem. As organizations scale beyond a handful of administrators, having a secure, auditable, and self-service way of updating system settings becomes invaluable. Managing a Cloudflare account is no different. With dozens of products and hundreds of API endpoints, keeping track of current configuration and making bulk updates across multiple zones can be a challenge. While the Cloudflare Dashboard is great for analytics and feature exploration, any changes that could potentially impact users really should get a code review before being applied!
This is where Cloudflare’s Terraform provider can come in handy. Built as a layer on top of the cloudflare-go library, the provider allows users to interface with the Cloudflare API using stateful Terraform resource declarations. Not only do we actively support this provider for customers, we make extensive use of it internally! In this post, we hope to provide some best practices we’ve learned about managing complex Cloudflare configurations in Terraform.
Why Terraform
Unsurprisingly, we find Cloudflare’s products to be pretty useful for securing and enhancing the performance of services we deploy internally. We use DNS, WAF, Zero Trust, Email Security, Workers, and all manner of experimental new features throughout the company. This dog-fooding allows us to battle-harden the services we provide to users and feed our desired features back to the product teams all while running the backend of Cloudflare. But, as Cloudflare grew, so did the complexity and importance of our configuration.
When we were a much smaller company, we only had a handful of accounts with designated administrators making changes on behalf of their colleagues. However, over time this handful of accounts grew into hundreds with each managed by separate teams. Independent accounts are useful in that they allow service-owners to make modifications that can’t impact others, but it comes with overhead.
We faced the challenge of ensuring consistent security policies, up-to-date account memberships, and change visibility. While our accounts were still administered by kind human stewards, we had numerous instances of account members not being removed after they transferred to a different team. While this never became a security incident, it demonstrated the shortcomings of manually provisioning account memberships. In the case of a production service migration, the administrator executing the change would often hop on a video call and ask for others to triple-check an IP address, ruleset, or access policy update. It was an era of looking through the audit logs to see what broke a service.
We wanted to make it easier for developers and users to make the changes they wanted without having to reach out to an administrator. Defining our configuration in code using Terraform has allowed us to keep tabs on the complexity of configuration while improving visibility and change management practices. By dogfooding the Cloudflare Terraform provider, we’ve been able to ensure:
Modifications to accounts are peer reviewed by the team that owns an account.
Each change is tied to a user, commit, and a ticket explaining the rationale for the change.
API Tokens are tied to service accounts rather than individual human users, meaning they survive team changes and offboarding.
Account configuration can be audited by anyone at the company for current state, accuracy, and security without needing to add everyone as a member of every account.
Large changes, such as enforcing hard keys can be done rapidly– even in a single pull request.
Configuration can be easily copied and reused across accounts to promote best practices and speed up development.
We can use and iterate on our awesome provider and provide a better experience to other users (shoutout in particular to Jacob!).
Terraform in CI/CD
Terraform has a fairly mature open source ecosystem, built from years of running-in-production experience. Thus, there are a number of ways to make interacting with the system feel as comfortable to developers as git. One of these tools is Atlantis.
Atlantis acts as continuous integration/continuous delivery (CI/CD) for Terraform; fitting neatly into version control workflows, and giving visibility into the changes being deployed in each code change. We use Atlantis to display Terraform plans (effectively a diff in configuration) within pull requests and apply the changes after the pull request has been approved. Having all the output from the terraform provider in the comments of a pull request means there’s no need to fiddle with the state locally or worry about where a state lock is coming from. Using Terraform CI/CD like this makes configuration management approachable to developers and non-technical folks alike.
In this example pull request, I’m adding a user to the cloudflare-cool-account (see the code in the next section). Once the PR is opened, Bitbucket posts a webhook to Atlantis, telling it to run a `terraform plan` using this branch. The resulting comment is placed in the pull request. Notice that this pull request can’t be applied or merged yet as it doesn’t have an approval! Once the pull request is approved, I would comment “atlantis apply”, wait for Atlantis to post a comment containing the output of the command, and merge the pull request if that output looks correct.
Our Terraforming Cloudflare architecture consists of a monorepo with one directory (and tfstate) for each internally-owned Cloudflare account. This keeps all of our Cloudflare configuration centralized for easier oversight while remaining neatly organized.
It will be possible in a future (as of this writing) release to manage multiple Cloudflare accounts in the same tfstate, but we’ve found that accounts in our use generally map fairly neatly onto teams. Teams can be configured as CODEOWNERS for a given directory and be tagged on any pull requests to that account. With teams owning separate accounts and each account having a separate tfstate, it’s rare for pull requests to get stuck waiting for a lock on the tfstate. Team-account-sized states remain relatively small, meaning that they also build quickly. Later on, we’ll share some of the other optimizations we’ve made to keep the repo user-friendly.
Each of our terraform states, given that they include secrets (including the API key!), is stored encrypted in an internal datastore. When a pull request is opened, Atlantis reaches out to a piece of middleware (that we may open source once it’s cleaned up a bit) that retrieves and decrypts the state for processing. Once the pull request is applied, the state is encrypted and put away again.
We execute a daily Terraform apply across all tfstates to capture any unintended config drift and rotate certificates when they approach expiration. This prevents unrelated changes from popping up in pull request diffs and causing confusion. While we could run more frequent state applies to ensure Terraform remains firmly up to date, once-a-day rectification strikes a balance between code enforcement and avoiding state locks while users are running Terraform plans in pull requests.
One of the problems that we encountered during our transition to Terraform is that folks were in the habit of making updates to configuration in the Dashboard and were still able to edit settings there. Thus, we didn’t always have a single source of truth for our configuration in code. It also meant the change would get mysteriously (to them) reverted the next day! So that’s why I’m excited to share a new Zero Trust Dashboard toggle that we’ve been turning on for our accounts internally: API/Terraform read-only mode.
Easily one of my favorite new features
With this button, we’re able to politely prevent manual changes to your Cloudflare account’s Zero Trust configuration without removing permissions from the set of users who can fix settings manually in a break-glass emergency scenario. Check out how you can enable this setting in your Zero Trust organization.
Slick Snippets and Terraforming Recommendations
As our Terraform repository has matured, we’ve refined how we define Cloudflare resources in code. By finding a sweet spot between code reuse and readability, we’ve been able to minimize operational overhead and generally let users get their work done. Here’s a couple of useful snippets that have been particularly valuable to us.
Account Membership
This allows for defining a fairly straightforward mapping of user emails to account privileges without code duplication or complex modules. We pull the list of human-friendly names of account roles from the API to show user permission assignments at a glance. Note: status is a new argument that allows for accounts to be added without sending an email to the user; perfect for when an organization is using SSO. (Thanks patrobinson for the feature request and mblackman for the PR!)
The GitHub issue and provider change that enabled automatic Access service token refreshes actually came from a need inside Cloudflare. Here’s how we ended up implementing it. We begin by defining a set of services that need to connect to our hostnames that are protected by Access. Each of these tokens are created and stored in a secret key value store. Next, we reference those access tokens by ID in the target Access policies. Once this has run, the service owner or the service itself can retrieve the credentials from the data store. (Note: we’re using Vault here, but any storage provider could be used in its place).
mTLS (Authenticated Origin Pulls) certificate creation and rotation
To further defense-in-depth objectives, we’ve been rolling out mTLS throughout our internal systems. One of the places where we can take advantage of our Terraform provider is in defining AOP (Authenticated Origin Pulls) certificates to lock down the Cloudflare-edge-to-origin connection. Anyone who has managed certificates of any kind can speak to the headaches they can cause. Having certificate configurations in Terraform takes out the manual work of rotation and expiration.
In this example we’re defining hostname-level AOP as opposed to zone-level AOP. We start by cutting a certificate for each hostname. Once again we’re using Vault for certificate creation, but other backends could be used just as well. This certificate is created with a (not-shown) 30 day expiration, but set to renew automatically. This means once the time-to-expiration is equal to min_seconds_remaining, the resource will be automatically tainted and replaced on the next Terraform run. We like to give this automation plenty of room before expiration to take into account holiday seasons and avoid sending alerts to humans when the alerts hit seven days to expiration. For the rest of this snippet, the certificate is uploaded to Cloudflare and the ID from that upload is then placed in the AOP configuration for the given hostname. The create_before_destroy meta-argument ensures that the replacement certificate is uploaded successfully before we remove the certificate that’s currently in place.
The comfortable automation that we’ve achieved thus far did not come without some hair-pulling. Below are a few of the learnings that have allowed us to maintain the repository as a side project run by two engineers (shoutout David).
Store your state somewhere safe
It feels worth repeating that the tfstate contains secrets including any API keys you’re using with providers and the default location of the tfstate is in the current working directory. It’s very easy to accidentally commit this to source control. By defining a backend, the state can be stored with a cloud storage provider, in a secure location on a filesystem, in a database, or even Cloudflare Workers! Wherever the state is stored, make sure it is encrypted.
Choose simplicity, avoid modules
Modules are intended to reduce code repetition for well-defined chunks of systems such as “I want three clusters of whizz-bangs in locations A, C, and F.” If cloud-computing was like Factorio, this would be amazing. However, financial, technical, and physical constraints mean subtle differences in systems develop over time such as “I want fewer whizz-bangs in C and the whizz-bangs in F should get a different network topology.” In Terraform, implementation logic of these requirements is moved to the module code. HCL is absolutely not the place to write decipherable conditionals. While module versioning prevents having to make every change backwards-compatible, keeping module usage up-to-date becomes another chore for repository maintainers.
An understandable code base is a user-friendly codebase. It’s rare that a deeply cryptic error will return from a misconfigured resource definition. Conversely, modules, especially custom ones, can lead users on a head-scratching adventure. This kind of system can’t scale with confused users.
A few well-designed for_each loops (we’re obviously fans) can achieve similar objectives as modules without the complexity. It’s fine to use plain old resources too! Especially when there are more than a handful of varying arguments, it’s more valuable for the configuration to be clear than to be eloquent. For example: an account_member resource makes sense to be in a for_loop, but a page_rule probably doesn’t.
Keep tfstates small
Maintaining quick pull-request-to-plan turnaround keeps Terraform from feeling like a burden on users’ time. Furthermore, if a plan is taking 30 minutes to run, a rollback in the case of an issue would also take 30 minutes! This post describes our single-account-to-tfstate model.
However, after noticing slow-downs coming from the large number of AOP certificate configurations in a big zone, we moved that code to a separate tfstate. We were able to make this change because AOP configuration is fairly self-contained. To ensure there would be no fighting between the states, we kept the API token permissions for each tfstate mutually exclusive of each other. Our Atlantis Terraform plans typically finish under five minutes. If it feels impossible to keep the size of a tfstate down to a reasonable amount of time, it may be worth considering a different tool for that bit of configuration management.
Know when to use a Different tool
Terraform isn’t a panacea. We generally don’t use Terraform to manage DNS records, for example. We use OctoDNS which integrates more neatly into our infrastructure automation. DNS records can quickly add up to long state-rendering times and are often dynamically generated from systems that Terraform doesn’t know about. To avoid conflicts, there should only ever be one system publishing changes to DNS records.
We also haven’t figured out a maintainable way of managing Workers scripts in Terraform. When a .js script in the Terraform directory changes, Terraform isn’t aware of it. This means a change needs to occur somewhere else in a .tf file before the plan diff is generated. It likely isn’t an unsolvable issue, but doesn’t seem particularly worth cramming into Terraform when there are better options for Worker management like Wrangler.
Looking forward
We’re continuing to invest in the Cloudflare Terraforming experience both for our own use and for the benefit of our users. With the provider, we hope to offer a comfortable and scalable method of interacting with Cloudflare products. Hopefully this post has presented some useful suggestions to anyone interested in adopting Cloudflare-configuration-as-code. Don’t hesitate to reach out on the GitHub project for troubleshooting, bug reports, or feature requests. For more in depth documentation on using Terraform to manage your Cloudflare account, read on here. And if you don’t have a Cloudflare account already, click here to get started.
Today, we are announcing the general availability of OpenAPI Schemas for the Cloudflare API. These are published via GitHub and will be updated regularly as Cloudflare adds and updates APIs. OpenAPI is the widely adopted standard for defining APIs in a machine-readable format. OpenAPI Schemas allow for the ability to plug our API into a wide breadth of tooling to accelerate development for ourselves and customers. Internally, it will make it easier for us to maintain and update our APIs. Before getting into those benefits, let’s start with the basics.
What is OpenAPI?
Much of the Internet is built upon APIs (Application Programming Interfaces) or provides them as services to clients all around the world. This allows computers to talk to each other in a standardized fashion. OpenAPI is a widely adopted standard for how to define APIs. This allows other machines to reliably parse those definitions and use them in interesting ways. Cloudflare’s own API Shield product uses OpenAPI schemas to provide schema validation to ensure only well-formed API requests are sent to your origin.
Cloudflare itself has an API that customers can use to interface with our security and performance products from other places on the Internet. How do we define our own APIs? In the past we used a standard called JSON Hyper-Schema. That had served us well, but as time went on we wanted to adopt more tooling that could both benefit ourselves internally and make our customer’s lives easier. The OpenAPI community has flourished over the past few years providing many capabilities as we will discuss that were unavailable while we used JSON Hyper-Schema. As of today we now use OpenAPI.
You can learn more about OpenAPI itself here. Having an open, well-understood standard for defining our APIs allows for shared tooling and infrastructure to be used that can read these standard definitions. Let’s take a look at a few examples.
Uses of Cloudflare’s OpenAPI schemas
Most customers won’t need to use the schemas themselves to see value. The first system leveraging OpenAPI schemas is our new API Docs that were announced today. Because we now have OpenAPI schemas, we leverage the open source tool Stoplight Elements to aid in generating this new doc site. This allowed us to retire our previously custom-built site that was hard to maintain. Additionally, many engineers at Cloudflare are familiar with OpenAPI, so we gain teams can write new schemas more quickly and are less likely to make mistakes by using a standard that teams understand when defining new APIs.
There are ways to leverage the schemas directly, however. The OpenAPI community has a huge number of tools that only require a set of schemas to be able to use. Two such examples are mocking APIs and library generation.
Mocking Cloudflare’s API
Say you have code that calls Cloudflare’s API and you want to be able to easily run unit tests locally or integration tests in your CI/CD pipeline. While you could just call Cloudflare’s API in each run, you may not want to for a few reasons. First, you may want to run tests frequently enough that managing the creation and tear down of resources becomes a pain. Also, in many of these tests you aren’t trying to validate logic in Cloudflare necessarily, but your own system’s behavior. In this case, mocking Cloudflare’s API would be ideal since you can gain confidence that you aren’t violating Cloudflare’s API contract, but without needing to worry about specifics of managing real resources. Additionally, mocking allows you to simulate different scenarios, like being rate limited or receiving 500 errors. This allows you to test your code for typically rare circumstances that can end up having a serious impact.
As an example, Spotlight Prism could be used to mock Cloudflare’s API for testing purposes. With a local copy of Cloudflare’s API Schemas you can run the following command to spin up a local mock server:
This means faster development and shorter test runs while still catching API contract issues early before they get merged or deployed.
Library generation
Cloudflare has libraries in many programming languages like Terraform and Go, but we don’t support every possible programming language. Fortunately, using a tool like openapi generator, you can feed in Cloudflare’s API schemas and generate a library in a wide range of languages to then use in your code to talk to Cloudflare’s API. For example, you could generate a Java library using the following commands:
And then start using that client in your Java code to talk to Cloudflare’s API.
How Cloudflare transitioned to OpenAPI
As mentioned earlier, we previously used JSON Hyper-Schema to define our APIs. We have roughly 600 endpoints that were already defined in the schemas. Here is a snippet of what one endpoint looks like in JSON Hyper-Schema:
/zones:
get:
description: List, search, sort, and filter your zones.
operationId: zone-list-zones
responses:
4xx:
content:
application/json:
schema:
allOf:
- $ref: '#/components/schemas/components-schemas-response_collection'
- $ref: '#/components/schemas/api-response-common-failure'
description: List Zones response failure
"200":
content:
application/json:
schema:
$ref: '#/components/schemas/components-schemas-response_collection'
description: List Zones response
security:
- api_email: []
api_key: []
summary: List Zones
tags:
- Zone
x-cfPermissionsRequired:
enum:
- '#zone:read'
x-cfPlanAvailability:
business: true
enterprise: true
free: true
pro: true
You can see that the two look fairly similar and for the most part the same information is contained in each including method type, a description, and request and response definitions (although those are linked in $refs). The value of migrating from one to the other isn’t the change in how we define the schemas themselves, but in what we can do with these schemas. Numerous tools can parse the latter, the OpenAPI, while much fewer can parse the former, the JSON Hyper-Schema.
If this one API was all that made up the Cloudflare API, it would be easy to just convert the JSON Hyper-Schema into the OpenAPI Schema by hand and call it a day. Doing this 600 times, however, was going to be a huge undertaking. When considering that teams are constantly adding new endpoints, it would be impossible to keep up. It was also the case that our existing API docs used the existing JSON Hyper-Schema, so that meant that we would need to keep both schemas up to date during any transition period. There had to be a better way.
Auto conversion
Given both JSON Hyper-Schema and OpenAPI are standards, it reasons that it should be possible to take a file in one format and convert to the other, right? Luckily the answer is yes! We built a tool that took all existing JSON Hyper-Schema and output fully compliant OpenAPI schemas. This of course didn’t happen overnight, but because of existing OpenAPI tooling, we could iteratively improve the auto convertor and run OpenAPI validation tooling over the output schemas to see what issues the conversion tool still had.
After many iterations and improvements to the conversion tool, we finally had fully compliant OpenAPI Spec schemas being auto-generated from our existing JSON Hyper-Schema. While we were building this tool, teams kept adding and updating the existing schemas and our Product Content team was also updating text in the schemas to make our API docs easier to use. The benefit of this process is we didn’t have to slow any of that work down since anything that changed in the old schemas was automatically reflected in the new schemas!
Once the tool was ready, the remaining step was to decide when and how we would stop making updates to the JSON Hyper-Schemas and move all teams to the OpenAPI Schemas. The (now old) API docs were the biggest concern, given they only understood JSON Hyper-Schema. Thanks to the help of our Developer Experience and Product Content teams, we were able to launch the new API docs today and can officially cut over to OpenAPI today as well!
What’s next?
Now that we have fully moved over to OpenAPI, more opportunities become available. Internally, we will be investigating what tooling we can adopt in order to help reduce the effort of individual teams and speed up API development. One idea we are exploring is automatically creating openAPI schemas from code notations. Externally, we now have the foundational tools necessary to begin exploring how to auto generate and support more programming language libraries for customers to use. We are also excited to see what you may do with the schemas yourself, so if you do something cool or have ideas, don’t hesitate to share them with us!
Earlier this year, we announced our participation in a new W3C Community Group for the advancement of Web-interoperable API standards. Since then, this new WinterCG has been hard at work identifying the common API standards around which all JavaScript runtimes can build. Today I just want to give a peek at some work the WinterCG has been doing; and show off some of the improvements we have been making in the Workers runtime to increase alignment with Web Platform standards around event handling, task cancellation using AbortController, text encoding and decoding, URL parsing and pattern matching, and streams support.
The WinterCG Minimum Common Web Platform API
Right at the start of the WinterCG activity, the group took some time to evaluate and compare the various non-browser JavaScript runtimes such as Node.js, Deno, Bun, and Workers with the purpose of identifying the Web Platform APIs they all had in common. Following a very simple criteria, we looked at the standard APIs that were already implemented and supported by at least two of these runtimes and compiled those into a list that the WinterCG calls the “Minimum Common Web Platform API“. This list will serve as the basis for what the community group defines as the minimum set of Web Platform APIs that should be implemented consistently across runtimes that claim to be “Web-interoperable”.
Today, we are happy to say that the Workers runtime has compliant or nearly compliant implementations of every one of these WinterCG Minimum Common Web Platform APIs. Some of these APIs intentionally diverge from the standards either due to backwards compatibility concerns, Workers-specific features, or performance optimizations. Other APIs diverge still because we are still in the process of updating them to align with the specifications.
Improving standards compliance in the Workers runtime
The Workers runtime has, from the beginning, had the mission to align its developer experience with JavaScript and Web Platform standards as much as possible. Over the past year we have worked hard to continue advancing that mission forward both by improving the standards-compliance of existing APIs such as Event, EventTarget, URL, and streams; and the introduction of new Web Platform APIs such as URLPattern, encoding streams, and compression streams.
Event and EventTarget
The Workers runtime has provided an implementation of the Event and EventTarget Web Platform APIs from the very beginning. These were, however, only limited implementations of what the WHATWG DOM specification defines. Specifically, Workers had only implemented the bare minimum of the Event API that it itself needed to operate.
Today, the Event and EventTarget implementations in Workers provide a more complete implementation.
Let’s look at the official definition of Event as defined by the WHATWG DOM standard:
Web Platform API specifications are always written in terms of a definition language called Web IDL. Every attribute defined in the interface is a property that is exposed on the object. Event objects, then, are supposed to have properties like type, target, srcElement, currentTarget, bubbles, cancelable, returnValue, defaultPrevented, composed, isTrusted, and timeStamp. They are also expected to have methods such as composedPath(), stopPropagation(), and stopImmediatePropagation(). Because most of these were not immediately needed by Workers, most were not provided originally.
Today, all standard, non-legacy properties and methods defined by the specification are available for use:
While we were at it, we also fixed a long standing bug in the implementation of Event that prevented user code from properly subclassing the Event object to create their own custom event types. This change is protected by a compatibility flag that is now enabled by default for all Workers using a compatibility date on or past 2022-01-31.
class MyEvent extends Event {
constructor() {
super('my-event')
}
get type() { return super.type.toUpperCase() }
}
const myEvent = new MyEvent();
// Previously, this would print "my-event" instead of "MY-EVENT" as expected.
console.log(myEvent.type);
The EventTarget implementation has also been updated to support once handlers (event handlers that are triggered at-most once then automatically unregistered), cancelable handlers (using AbortSignal), and event listener objects, all in line with the standard.
Once handlers are key for preventing memory leaks in your applications when you know that a particular event is only ever going to be emitted once, or whenever you only care about handling it once. The stored reference to the function or object that is handling the event is removed immediately upon the first invocation, allowing the memory to be garbage collected.
Using a cancelable event handler
const ac = new AbortController();
addEventListener('foo', (event) => {
console.log('not printed at all');
}, {
signal: ac.signal
});
ac.abort();
dispatchEvent(new Event('foo'));
Using an event listener object
While passing a function to addEventListener() is the most common case, the standard actually allows an event listener to be an object with a handleEvent() method as well.
As illustrated in the cancelable event example above, we have also introduced an implementation of the AbortController and AbortSignal APIs into Workers. These provide a standard, and interoperable way of signaling cancellation of several kinds of tasks.
The AbortController/AbortSignal pattern is straightforward: An AbortSignal is just a type of EventTarget that will emit a single “abort” event when it is triggered:
const ac = new AbortController();
ac.signal.addEventListener('abort', (event) => {
console.log(event.reason); // 'just because'
}, { once: true });
ac.abort('just because');
The AbortController is used to actually trigger the abort event, optionally with a reason argument that is passed on to the event. The reason is typically an Error object but can be any JavaScript value.
The AbortSignal can only be triggered once, so the “abort” event should only ever be emitted once.
It is also possible to create AbortSignals that timeout after a specified period of time:
const signal = AbortSignal.timeout(10);
Or an AbortSignal that is pre-emptively triggered immediately on creation (these will never actually emit the “abort” event):
const signal = AbortSignal.abort('for reasons');
Currently, within Workers, AbortSignal and AbortController has been integrated with the EventTarget, fetch(), and streams APIs in alignment with the relevant standard specifications for each.
Using AbortSignal to cancel a fetch()
const ac = new AbortController();
const res = fetch('https://example.org', {
signal: ac.signal
});
ac.abort(new Error('canceled'))
try {
await res;
} catch (err) {
console.log(err);
}
TextEncoderStream and TextDecoderStream
The Workers runtime has long provided basic implementations of the TextEncoder and TextDecoder APIs. Initially, these were limited to only supporting encoding and decoding of UTF-8 text. The standard definition of TextDecoder, however, defines a much broader range of text encodings that are now fully supported by the Workers implementation. Per the standard, TextEncoder currently only supports UTF-8.
In addition to supporting the full range of encodings defined by the standard, Workers also now provides implementations of the TextEncoderStream and TextDecoderStream, which provide TransformStream implementations that apply encoding and decoding to streaming data:
const ds = new DecompressionStream('gzip');
const decompressedStream = blob.stream().pipeThrough(ds);
const cs = new CompressionStream('gzip');
const compressedStream = blob.stream().pipeThrough(cs);
These are TransformStream implementations that fully conform to the standard definitions. Use of the compression streams does not require a compatibility flag to enable.
URL and URLPattern
Similar to Event, there has been an implementation of the Web Platform standard URL API available within Workers from nearly the beginning. But also like Event, the implementation was not entirely compatible with the standard.
The incompatibilities were subtle, for instance, in the original implementation, the URL string “https://a//b//c//” would be parsed incorrectly as “https://a/b/c” (note that the extra empty path segments are removed) whereas the standard parsing algorithm would produce “https://a//b//c/” as a result. Such inconsistent results were causing interoperability issues with JavaScript written to run across multiple JavaScript runtimes and needed to be fixed.
A new implementation of the URL parsing algorithm has been provided, and as of October 31, 2022 it has been enabled by default for all newly deployed Workers. Older Workers can begin using the new implementation by updating their compatibility dates to 2022-10-31 or by enabling the url_standard compatibility flag.
Along with the updated URL implementation, Workers now provides an implementation of the standard URLPattern API.
URLPattern provides a regular-expression-like syntax for matching a URL string against a pattern. For instance, consider this example taken from the MDN documentation for URLPattern:
// Matching a pathname
let pattern1 = new URLPattern('https://example.com/books/:id')
// same as
let pattern2 = new URLPattern(
'/books/:id',
'https://example.com',
);
// or
let pattern3 = new URLPattern({
protocol: 'https',
hostname: 'example.com',
pathname: '/books/:id',
});
// or
let pattern4 = new URLPattern({
pathname: '/books/:id',
baseURL: 'https://example.com',
});
ReadableStream, WritableStream, and TransformStream
Last, but absolutely not least, our most significant effort over the past year has been providing new standards compliant implementations of the ReadableStream, WritableStream, and TransformStream APIs.
The Workers runtime has always provided an implementation of these objects but they were never fully conformant to the standard. User code was not capable of creating custom ReadableStream and WritableStream instances, and TransformStreams were limited to simple identity pass-throughs of bytes. The implementations have been updated now to near complete compliance with the standard (near complete because we still have a few edge cases and features we are working on).
The new streams implementation will be enabled by default in all new Workers as of November 30, 2022, or can be enabled earlier using the streams_enable_constructors and transformstream_enable_standard_constructor compatibility flags.
Creating a custom ReadableStream
async function handleRequest(request) {
const enc = new TextEncoder();
const rs = new ReadableStream({
pull(controller) {
controller.enqueue(enc.encode('hello world'));
controller.close();
}
});
return new Response(rs);
}
The new implementation supports both “regular” and “bytes” ReadableStream types, supports BYOB readers, and includes performance optimizations for both tee() and pipeThrough().
It has always been possible in Workers to call new TransformStream() (with no arguments) to create a limited version of a TransformStream that only accepts bytes and only acts as a pass-through, passing the bytes written to the writer on to the reader without any modification.
That original implementation is now available within Workers using the IdentityTransformStream class.
const { readable, writable } = new IdentityTransformStream();
const writer = writable.getWriter();
const reader = readable.getReader();
const enc = new TextEncoder();
const dec = new TextDecoder();
writer.write(enc.encode("hello world"));
const res = await reader.read();
console.log(dec.decode(res.value)); // "hello world"
If your code is using new TransformStream() today as this kind of pass-through, the new implementation will continue to work except for one very important difference: the old, non-standard implementation of new TransformStream() supported BYOB reads on the readable side (i.e. readable.getReader({ mode: 'byob' })). The new implementation (enabled via a compatibility flag and becoming the default on November 30 ) does not support BYOB reads as required by the stream standard.
What’s next
It is clear that we have made a lot of progress in improving the standards compliance of the Workers runtime over the past year, but there is far more to do. Next we will be turning our attention to the implementation of the fetch() and WebSockets APIs, as well as actively seeking closer alignment with other runtimes through collaboration in the Web-interoperable Runtimes Community Group.
If you are interested in helping drive the implementation of Web Platform APIs forward, and advancing interoperability between JavaScript runtime environments, the Workers Runtime team at Cloudflare is hiring! Reach out, or see our open positions here.
Cloudflare Radar was launched two years ago to give everyone access to the Internet trends, patterns and insights Cloudflare uses to help improve our service and protect our customers.
Until then, these types of insights were only available internally at Cloudflare. However, true to our mission of helping build a better Internet, we felt everyone should be able to look behind the curtain and see the inner workings of the Internet. It’s hard to improve or understand something when you don’t have clear visibility over how it’s working.
On Cloudflare Radar you can find timely graphs and visualizations on Internet traffic, security and attacks, protocol adoption and usage, and outages that might be affecting the Internet. All of these can be narrowed down by timeframe, country, and Autonomous System (AS). You can also find interactive deep dive reports on important subjects such as DDoS and the Meris Botnet. It’s also possible to search for any domain name to see details such as SSL usage and which countries their visitors are coming from.
Since launch, Cloudflare Radar has been used by NGOs to confirm the Internet disruptions their observers see in the field, by journalists looking for Internet trends related to an event in a country of interest or at volume of cyberattacks as retaliation to political sanctions, by analysts looking at the prevalence of new protocols and technologies, and even by brand PR departments using Cloudflare Radar data to analyze the online impact of a major sports event.
Cloudflare Radar has clearly become an important tool for many and, most importantly, we find it has helped shed light on parts of the Internet that deserve more attention and investment.
Introducing Cloudflare Radar 2.0
What has made Cloudflare Radar so valuable is that the data and insights it contains are unique and trustworthy. Cloudflare Radar shows aggregate data from across the massive spectrum of Internet traffic we see every day, presenting you with datasets you won’t find elsewhere.
However, there were still gaps. Today, on the second anniversary of Cloudflare Radar, we are launching Cloudflare Radar 2.0 in beta. It will address three common pieces of feedback from users:
Ease of finding insights and data. The way information was structured on Cloudflare Radar made finding information daunting for some people. We are redesigning Cloudflare Radar so that it becomes a breeze.
Number of insights. We know many users have wanted to see insights about other important parts of the Internet, such as email. We have also completely redesigned the Cloudflare Radar backend so that we can quickly add new insights over the coming months (including insights into email).
Sharing insights.The options for sharing Cloudflare Radar insights were limited. We will now provide you the options you want, including downloadable and embeddable graphs, sharing to social media platforms, and an API.
Finding insights and data
On a first visit to the redesigned Cloudflare Radar homepage one will notice:
Prominent and intuitive filtering capabilities on the top bar. A global search bar is also coming soon.
Content navigation on the sidebar.
Content cards showing glanceable and timely information.
The content you find on the homepage are what we call “quick bytes”. Those link you to more in-depth content for that specific topic, which can also be found through the sidebar navigation.
At the top of the page you can search for a country, autonomous system number (ASN), domain, or report to navigate to a home page for that specific content. For example, the domain page for google.com:
The navigation sidebar allows you to find more detailed insights and data related to Traffic, Security & Attacks, Adoption & Usage, and Domains. (We will be adding additional topic areas in the future.) It also gives you quick access to the Cloudflare Radar Outage Center, a tool for tracking Internet disruptions around the world and to which we are dedicating a separate blog post, and to Radar Reports, which are interactive deep dive reports on important subjects such as DDoS and the Meris Botnet.
Within these topic pages (such as the one for Adoption & Usage shown above), you will find the quick bytes for the corresponding topic at the top, and quick bytes for related topics on the right. The quick bytes on the right allow you to quickly glance at and navigate to related sections.
In the middle of the page are the more detailed charts for the topic you’re exploring.
Sharing insights
Cloudflare Radar’s reason to exist is to make Internet insights available to everyone, but historically we haven’t been as flexible as our users would want. People could download a snapshot of the graph, but not much more.
With Cloudflare Radar 2.0 we will be introducing three major new ways of using Radar insights and data:
Social share. Cloudflare Radar 2.0 charts have a more modern and clean look and feel, and soon you’ll be able to share them directly on the social media platform of your choice. No more dealing with low quality screenshots.
Embeddable charts. The beautiful charts will also be able to be embedded directly into your webpage or blog – it will work just like a widget, always showing up-to-date information.
API. If you like the data on Cloudflare Radar but want to manipulate it further for analysis, visualization, or for posting your own charts, you’ll have the Cloudflare Radar API available to you starting today.
Note: The API is available today. To use the Cloudflare API you need an API token or key (more details here). Embedding charts and sharing directly to social are new features to be released later this year.
Technology changes
Cloudflare Radar 2.0 was built on a new technology stack; we will write a blog post about why and how we did it soon. A lot changed: we now have proper GraphQL data endpoints and a public API, the website runs on top of Cloudflare Pages and Workers, and we’re finally doing server-side rendering using Remix. We adopted SVG whenever possible, built our reusable data visualization components system, and are using Cosmos for visual TDD. These foundational changes will provide a better UX/UI to our users and give us speed when iterating and improving Cloudflare Radar in the future.
We hope you find this update valuable, and recommend you keep an eye on radar.cloudflare.com to see the new insights and topics we’ll be adding regularly. If you have any feedback, please send it to us through the Cloudflare Community.
In this blog post, you will learn how to set up backups for your Zabbix environment. There’s a wide variety of different options when it comes to taking backups of our Zabbix environment, for us, it will just be a matter of choosing the right fit.
Introduction
Monitoring is an important part of our IT infrastructure and often times when our monitoring isn’t working for a certain period, we feel like we are blind as to what is going on with our different IT components. As such, taking backups of our Zabbix environment is an important part of running a production Zabbix environment, as we do want to be prepared for a possible issue that might corrupt or even lose our data. It’s always a possibility and as such we should be prepared.
For Zabbix, there are a few different methods on how to take backups and it all starts at the database level. Both the Zabbix frontend as well as the Zabbix server write their data into the Zabbix database as we can see in the illustration below:
This means that both our configuration as well as all of our collected values are present in the same Zabbix database and if we take a database backup, we back up (almost) everything we need. So, let’s start there and have a look at how we can make a database backup.
How to
MySQL backups
Let’s start with the most used variant of Zabbix databases: MySQL and it’s forks like MariaDB and Percona. All of them can easily be backed up using built-in functionality like the MySQLDump command and we can then use other industry standards to get things going. First, we have to understand the tables in our database though. Most of the tables in your Zabbix environment contain configuration data and as such, they are all important to backup. There are a few tables that we need to consider, however, as they can contain Giga or even Terabytes of data. These are the History, Trends and Events tables:
It is possible to omit these tables from your backup and make smaller, more manageable backups. To make the backup we can then start using tools like MySQLDump:
Once we have taken a backup, we can easily import that back into our environment using the MySQLImport command or simply using the cat command:
Do not forget, taking and importing large backups can take a long time. This completely depends on your MySQL database performance tuning settings as well as the underlying resources like CPU, Memory and Disk I/O. Also, make sure to check out the MySQL documentation:
Alternatively, it’s also possible to create backups using tools like xtrabackup and mariadbbackup.
PostgreSQL backups
We can actually use the same kinds of methods for the PostgreSQL backups. Keep the required tables in mind and fire away with the built-in tools:
Then we can restore it by loading the file into postgres:
What about the configuration files?
Once we have a database backup, everything is backed up, right? Well, almost everything. With just a database backup we are quite safe, but (and this is oftentimes overlooked) there are a lot of configuration files and perhaps even custom scripts we need to take into account! There are three parts to this story – the Zabbix server, the Zabbix frontend, and also the Zabbix additional components. All of them have their own set of configuration files and locations that are used for storing custom scripts.
The Zabbix frontend location and configuration files can be different, depending on the environment, as we have a few choices to make. Are we running Apache or Nginx? On what Linux distribution? All of these have to be considered when making configuration backups. In general, the locations for the configuration would be:
/etc/nginx/
/etc/httpd/
/etc/apache2
There’s also a symlink to the Zabbix frontend configuration file located in /etc/zabbix/ but we will get to that one in a bit.
Then we have the Zabbix server itself, which keeps its configuration in /etc/zabbix/ and if we’re following best practices any script should be placed in /usr/lib/zabbix. So we need:
/etc/zabbix/
/usr/lib/zabbix
Let’s add them to the list and find a method to back up these files. Crontab is a built-in tool that we can use, but there are definitely other (perhaps better) solutions out there. Let’s add the following to cron:
I also added a find command here, which will serve as our roll-over or rotation toll. It will find files older than 180 days and delete them from /mnt/backup/config_files/. Make sure to pick a good (network) folder to store these files as it’s important to keep these safe. Feel free to change the number of days you’d like to store the files for.
What about the additional components like Zabbix proxy, Zabbix Java gateway and Zabbix web service (used for PDF reporting)?. Well, these have configuration files as well. Make sure to run a backup on the devices running these additional components. As for Zabbix proxies – they have the same file locations as Zabbix server:
For Zabbix Java gateway and Zabbix web service, we can omit the /usr/lib/zabbix/ folder.
Don’t forget the import/export files!
In general, database backups are slow to make, but also slow to import back unless we do not include the history/trends in the backup. But even then, restoring an entire database simply because someone made an error on a single template is a hassle. Zabbix ships with the built-in frontend export functionality, allowing us to export (and then import) entire parts of the configuration instantly! We can use these for a number of different parts of the configuration:
Hosts
Templates
Media types
Maps
images
Host groups (API ONLY)
Template groups (API ONLY)
All of these are available through the Zabbix API allowing us to choose whether we do a manual configuration backup from the frontend, as well as providing us with automation options using that API. You could even manage and update your Zabbix configuration from GIT entirely if you write the right scripts for this.
Frontend backups
To run an export from the frontend simply go to one of the supported sections like Configuration | Templates and select the export data format. When selecting multiple entities, keep in mind that they will all be exported to a single file.
We can then make our edits and import files from the frontend as well:
For Templates this will even result in a nice diff pop-up window, detailing all the changes, deletes and additions to the templates:
API backups
For the API things get a little more complicated as we need to select a mode of execution. Of course, it’s possible to do a curl command from the CLI or even use something like Postman:
Request body
The response will then look something like this:
But this feature really starts to shine once we combine it with our own automation scripts. Use it wisely!
High availability
So, what about high availability? Isn’t that some form of a backup?
Well yes and no. High availability is not an “IT backup” in the form of making sure we can recover something that is broken. But it is a backup in the way that if a Zabbix server instance fails, another one takes over for it. HA is somewhat out of scope for this blog post, but it’s still worth mentioning. There are several solutions to set up Zabbix as a full high availability cluster. For MySQL we can use a Primary/Primary setup, for the frontend we can use load balancing techniques like HAProxy and for the Zabbix server, we can use the built-in high availability method. Combine all of these together and you’ll definitely be able to serve your every (production ready!) need.
Conclusion
To conclude, there are many options to start taking backups of our Zabbix environment. It all starts at the database and these backups are definitely vital to keep things safe in case of disaster. When making the backups, do not forget about the configuration files and custom scripts as well as the frontend backup option. Combining all of these solutions will safeguard our environment, but if that isn’t enough – do not forget about industry standards like snapshots. Even further safeguarding our environment on multiple levels.
I hope you enjoyed reading this blog post. If you have any questions or need help configuring anything on your Zabbix setup feel free to contact me and the team at Opensource ICT Solutions. We build a ton of cool integrations like this and much more!
The Internet is an endless flow of conversations between computers. These conversations, the constant exchange of information from one computer to another, are what allow us to interact with the Internet as we know it. Application Programming Interfaces (APIs) are the vital channels that carry these conversations, and their usage is quickly growing: in fact, more than half of the traffic handled by Cloudflare is for APIs, and this is increasing twice as fast as traditional web traffic.
In March, we announced that we’re expanding our API Shield into a full API Gateway to make it easy for our customers to protect and manage those conversations. We already offer several features that allow you to secure your endpoints, but there’s more to endpoints than their security. It can be difficult to keep track of many endpoints over time and understand how they’re performing. Customers deserve to see what’s going on with their API-driven domains and have the ability to manage their endpoints.
Today, we’re excited to announce that the ability to save, update, and monitor the performance of all your API endpoints is now generally available to API Shield customers. This includes key performance metrics like latency, error rate, and response size that give you insights into the overall health of your API endpoints.
A Refresher on APIs
The bar for what we expect an application to do for us has risen tremendously over the past few years. When we open a browser, app, or IoT device, we expect to be able to connect to data instantly, compare dozens of flights within seconds, choose a menu item from a food delivery app, or see the weather for ten locations at once.
How are applications able to provide this kind of dynamic engagement for their users? They rely on APIs, which provide access to data and services—either from the application developer or from another company. APIs are fundamental in how computers (or services) talk to each other and exchange information.
You can think of an API as a waiter: say a customer orders a delicious bowl of Mac n Cheese. The waiter accepts this order from the customer, communicates the request to the chef in a format the chef can understand, and then delivers the Mac n Cheese back to the customer (assuming the chef has the ingredients in stock). The waiter is the crucial channel of communication, which is exactly what the API does.
Managing API Endpoints
The first step in managing APIs is to get a complete list of all the endpoints exposed to the internet. API Discovery automatically does this for any traffic flowing through Cloudflare. Undiscovered APIs can’t be monitored by security teams (since they don’t know about them) and they’re thus less likely to have proper security policies and best practices applied. However, customers have told us they also want the ability to manually add and manage APIs that are not yet deployed, or they want to ignore certain endpoints (for example those in the process of deprecation). Now, API Shield customers can choose to save endpoints found by Discovery or manually add endpoints to API Shield.
But security vulnerabilities aren’t the only risk or area of concern with APIs – they can be painfully slow or connections can be unsuccessful. We heard questions from our customers such as: what are my most popular endpoints? Is this endpoint significantly slower than it was yesterday? Are any endpoints returning errors that may indicate a problem with the application?
That’s why we built Performance Metrics into API Shield, which allows our customers to quickly answer these questions themselves with real-time data.
Prioritizing Performance
Once you’ve discovered, saved, or removed endpoints, you want to know what’s going well and what’s not. To end-users, a huge part of what defines the experience as “going well” is good performance. Poor performance can lead to a frustrating experience: when you’re shopping online and press a button to check out, you don’t want to wait around for minutes for the page to load. And you certainly never want to see a dreaded error symbol telling you that you can’t get what you came for.
Exposing performance metrics of API endpoints puts concrete numerical data into your developers’ hands to tell you how things are going. When things are going poorly, these dashboard metrics will point out exactly which aspect of performance is causing concern: maybe you expected to see a spike in requests, but find out that request count is normal and latency is just higher than usual.
Empowering our customers to make data-driven decisions to better manage their APIs ends up being a win for our customers and our customers’ customers, who expect to seamlessly engage with the domain’s APIs and get exactly what they came for.
Management and Performance Metrics in the Dashboard
So, what’s available today? Log onto your Cloudflare dashboard, go to the domain-level Security tab, and open up the API Shield page. Here, you’ll see the Endpoint Management tab, which shows you all the API endpoints that you’ve saved, alongside placeholders for metrics that will soon be gathered.
Here you can easily delete endpoints you no longer want to track, or click manually add additional endpoints. You can also export schemas for each host to share internally or externally.
Once you’ve saved the endpoints that you want to keep tabs on, Cloudflare will start collecting data on its performance and make it available to you as soon as possible.
In Endpoint Management, you can see a few summary metrics in the collapsed view of each endpoint, including recommended rate limits, average latency, and error rate. It can be difficult to tell whether things are going well or not just from seeing a value alone, so we added sparklines that show relative performance, comparing an endpoint’s current metrics with its usual or previous data.
If you want to view further details about a given endpoint, you can expand it for additional metrics such as response size and errors separated by 4xx and 5xx. The expanded view also allows you to view all metrics at a single timestamp by hovering over the charts.
For each saved endpoint, customers can see the following metrics:
Request count: total number of requests to the endpoint over time.
Rate limiting recommendation per 10 minutes, which is guided by the request count.
Latency: average origin response time, in milliseconds (ms). How long does it take from the moment a visitor makes a request to the moment the visitor gets a response back from the origin?
Error rate vs. overall traffic: grouped by 4xx, 5xx, and their sum.
Response size: average size of the response (in bytes) returned to the request.
You can toggle between viewing these metrics on a 24-hour period or a 7-day period, depending on the scale on which you’d like to view your data. And in the expanded view, we provide a percentage difference between the averages of the current vs. the previous period. For example, say I’m viewing my metrics on a 24-hour timeline. My average latency yesterday was 10 ms, and my average latency today is 30 ms, so the dashboard shows a 200% increase. We also use anomaly detection to bring attention to endpoints that have concerning performance changes.
Additional improvements to Discovery and Schema Validation
As part of making endpoint management GA, we’re also adding two additional enhancements to API Shield.
First, API Discovery now accepts cookies — in addition to authorization headers — to discover endpoints and suggest rate limiting thresholds. Previously, you could only identify an API session with HTTP headers, which didn’t allow customers to protect endpoints that use cookies as session identifiers. Now these endpoints can be protected as well. Simply go to the API Shield tab in the dashboard, choose edit session identifiers, and either change the type, or click Add additional identifier.
Second, we added the ability to validate the body of requests via Schema Validation for all customers. Schema Validation allows you to provide an OpenAPI schema (a template for your API traffic) and have Cloudflare block non-conformant requests as they arrive at our edge. Previously, you provided specific headers, cookies, and other features to validate. Now that we can validate the body of requests, you can use Schema Validation to confirm every element of a request matches what is expected. If a request contains strange information in the payload, we’ll notice. Note: customers who have already uploaded schemas will need to re-upload to take advantage of body validation.
Endpoint Management, performance metrics, schema exporting, discovery via cookies, and schema body validation are all available now for all API Shield customers. To use them, log into the Cloudflare dashboard, click on Security in the navigation bar, and choose API Shield. Once API Shield is enabled, you’ll be able to start discovering endpoints immediately. You can also use all features through our API.
If you aren’t yet protecting a website with Cloudflare, it only takes a few minutes to sign up.
Collect metrics from HTTP endpoints such as web application APIs by defining HTTP agent items.
Collecting metrics from web services and applications is a complex affair usually done by scripting around CLIs and APIs. Organizations require an efficient way to monitor such and endpoints and react to collected data.
Collect and react to data from web services and applications with Zabbix HTTP agent items:
Collect metrics agentlessly using HTTP/HTTPS protocols
Collect metrics in bulk to reduce the number of outgoing requests
Zabbix preprocessing can be utilized to extract the required metrics from the response
Select from multiple HTTP authentication types
Check out the video to learn how to define HTTP items and collect metrics from HTTP endpoints.
Define HTTP items and collect metrics from HTTP endpoints:
Navigate to Configuration → Hosts and find your host
Open the Items section and press the Create item button
Select Type – HTTP agent
Provide the item key, name and URL
For now, set the Type of information to Text
Optionally, provide the request body and required status codes
Press the Test button and then press Get value and test
Save the resulting value to help you define the preprocessing steps
Navigate to the Preprocessing tab
Define a JSONPath preprocessing step to extract a value from the previous test result
Navigate to the Item section
Change the Type of information to Numeric (float)
Perform the item test one more time
Press Add to add the item
Tips and best practices
HTTP item check is executed by Zabbix server or Zabbix proxy
Zabbix will follow redirects if the Follow redirects option is checked
HTTP items have their own Timeout parameter defined in the item configuration
Receiving a status code not listed in the Required status codes field will result in the item becoming unsupported
Learn how to automate your Zabbix configuration workflows and integrate Zabbix with external systems by signing up for the Automation and Integration with Zabbix API course. During the course, students will learn how to use the Zabbix API by implementing different use cases under the guidance of a Zabbix certified trainer.
API usage is skyrocketing. According to the latest State of the API Report, API requests increased by 56% last year to a total of 855 million, and Google says the growth isn’t expected to slow any time soon.
APIs – short for application programming interfaces – are a critical component of how applications are built. They control the type of requests that occur between programs, how requests are made, and the format of those requests.
The huge increase in usage stems from the important role APIs – and web applications more broadly – play in digital transformation. APIs have helped facilitate the transition from monolithic applications to microservices. They’ve enabled businesses to provide user-oriented API-based services for B2B use cases, including automation and integration. And they’re integral to modern web applications, which are no longer just HTML with links but rich user interfaces, built as single-page apps with REST API backends. Nearly every modern application utilizes – or is – an API.
Today, it’s almost impossible to do anything online without interacting with an API. That’s why cyberattacks are increasingly targeting APIs, and they’ve become a large part of the application attack surface.
Why securing APIs is important
APIs are a lucrative target that can allow hackers to gain access to an otherwise secure system and exploit vulnerabilities. Not only do APIs often suffer from the same vulnerabilities as web applications – like broken access controls, injections, security misconfigurations, and vulnerabilities inherited from other dependent code libraries – but they are also more susceptible to resource consumption and rate limiting issues due to the automated nature of their users.
Due to a lack of knowledge in the market, it’s also common that legacy issues from early APIs are carried forward. For example, not all APIs will be fronted by an API gateway, with older APIs sitting in the background with little or no protection simply due to a lack of awareness of them. Many unused APIs will also not have been decommissioned, as newer APIs are produced and replace them as a product evolves, due to a lack of standard process and bad practice. This can leave legacy APIs vulnerable to attacks.
How to secure an API
The first step in securing your APIs is to audit your environment and/or applications to take an inventory of what APIs you have and which ones you’re actually utilizing. Then, you must understand the purpose of each individual API to allow you to validate that it is working as expected. You must also understand the expected behavior of the API to allow identification of threats more readily by being able to capture abnormal activity. Once you have a firm understanding of what the API’s functionality is and what expected behavior is, you can then both manage and test your API more effectively and efficiently.
API management is a key element for API security. APIs not only require the same controls as web apps but also additional controls specific to the API’s unique function. Documentation and version control of APIs is of vital importance, as one product can have multiple APIs – even hundreds or thousands.
Poor management can lead to issues with legacy and defunct APIs, as you will often find that only a small portion of APIs pass through an API gateway. Meanwhile, older APIs – which haven’t been decommissioned, or which teams simply aren’t aware of – can sit in the background with no protection. The probability of known vulnerabilities with older APIs is also significantly higher, which amplifies the risk profile.
The same legacy issues can also lead to coverage gaps, and calls that are outside of an API gateway could leave a blind spot when it comes to intra-API calls. Publishing and clearly defining your API will simplify users’ understanding of the API, allowing them to connect in the most appropriate and effective way. Ensuring your API is appropriately monitored is a key management technique. Continuously undertaking performance checks will allow you to understand if the API is under stress from being overloaded. It can also provide an indication of traffic volumes to monitor usage, potentially gauge malicious activity (via audit logs), and judge whether you need to scale up your operation. Lastly, having a response plan in place for attacks is a vital control in API security, allowing for a rapid but controlled response to potential threats.
There have been many recent examples of API-based attacks, such as those experienced by WordPress – and even on the dating scene with Bumble’s recent vulnerability issues. Some simple but effective steps you can take to secure your API and reduce the risk of such exposures include:
Authentication: Do you have a control in place to understand who’s calling your API?
Authorization: Should the person calling be able to access this data?
Encryption: Have you encrypted your network traffic?
Traffic management: Have you set rate limits or thresholds to keep a customer from pulling too much data or running scripts to tie up an API?
Audit logging: Effective logging ensures you can understand what normal traffic looks like and allows you to identify abnormal activity.
How to test your API
API testing is still evolving to keep up with the increase in volume and complexity. While manual API security testing can be done with traditional testing tools, and fully automated API security testing is partially supported by most major DAST solutions, there are many open-source tools written for guided API security testing. API testing used in conjunction with proper API management will increase API security.
API testing is most effective when you have a full risk profile of your business – i.e. you are fully aware of all of your APIs (including legacy or defunct APIs) to ensure you have no blindspots that could be exposed or manipulated. Taking time to identify vulnerabilities in API frameworks, your network, configuration, and policy all enhance your API security.
Anticipating threats by understanding expected behavior and having adequate testing in place will allow for proactive coverage and enhanced protection and threat identification.
Finally, you must continuously test your endpoint to ensure protection is maintained at all times and optimum security is in place. The ability to identify and block security risks before they occur is vital in the fight to provide the best protection against threats to your API.
I recently wrote a blog post on injection-type vulnerabilities and how they were knocked down a few spots from 1 to 3 on the new OWASP Top 10 for 2022. The main focus of that article was to demonstrate how stack traces could be — and still are — used via injection attacks to gather information about an application to further an attacker’s goal. In that post, I skimmed over one of my all time favorite types of injections: cross-site scripting (XSS).
In this post, I’ll cover this gem of an exploit in much more depth, highlighting how it has managed to adapt to the newer environments of today’s modern web applications, specifically the API and Javascript Object Notation (JSON).
I know the term API is thrown around a lot when referencing web applications these days, but for this post, I will specifically be referencing requests made from the front end of a web application to the back end via ajax (Asynchronous JavaScript and XML) or more modern approaches like the fetch method in JavaScript.
Before we begin, I’d like to give a quick recap of what XSS is and how a legacy application might handle these types of requests that could trigger XSS, then dive into how XSS still thrives today in modern web applications via the methods mentioned so far.
What is cross-site scripting?
There are many types of XSS, but for this post, I’ll only be focusing on persistent XSS, which is sometimes referred to as stored XSS.
XSS is a type of injection attack, in which malicious scripts are injected into otherwise benign and trusted websites. XSS attacks occur when an attacker uses a web application to execute malicious code — generally in the form of a browser-side script like JavaScript, for example — against an unsuspecting end user. Flaws that allow these attacks to succeed are quite widespread and occur anywhere a web application accepts an input from a user without sanitizing, validating, escaping, or encoding it.
Because the end user’s browser has no way to know not to trust the malicious script, the browser will execute the script. Because of this broken trust, attackers typically leverage these vulnerabilities to steal victims’ cookies, session tokens, or other sensitive information retained by the browser. They could also redirect to other malicious sites, install keyloggers or crypto miners, or even change the content of the website.
Now for the “stored” part. As the name implies, stored XSS generally occurs when the malicious payload has been stored on the target server, usually in a database, from input that has been submitted in a message forum, visitor log, comment field, form, or any parameter that lacks proper input sanitization.
What makes this type of XSS so much more damaging is that, unlike reflected XSS – which only affects specific targets via cleverly crafted links – stored XSS affects any and everyone visiting the compromised site. This is because the XSS has been stored in the applications database, allowing for a much larger attack surface.
Old-school apps
Now that we’ve established a basic understanding of stored XSS, let’s go back in time a few decades to when web apps were much simpler in their communications between the front-end and back-end counterparts.
Let’s say you want to change some personal information on a website, like your email address on a contacts page. When you enter in your email address and click the update button, it triggers the POST method to send the form data to the back end to update that value in a database. The database updates the value in a table, then pushes a response back to the web applications front end, or UI, for you to see. This would usually result in the entire page having to reload to display only a very minimal amount of change in content, and while it’s very inefficient, nonetheless the information would be added and updated for the end user to consume.
In the example below, clicking the update button submits a POST form request to the back-end database where the application updates and stores all the values, then provides a response back to the webpage with the updated info.
Old-school XSS
As mentioned in my previous blog post on injection, I give an example where an attacker enters in a payload of <script>alert(“This is XSS”)</script> instead of their email address and clicks the update button. Again, this triggers the POST method to take our payload and send it to the back-end database to update the email table, then pushes a response back to the front end, which gets rendered back to the UI in HTML. However, this time the email value being stored and displayed is my XSS payload, <script>alert(“This is XSS”)</script>, not an actual email address.
As seen above, clicking the “update” button submits the POST form data to the back end where the database stores the values, then pushes back a response to update the UI as HTML.
However, because our payload is not being sanitized properly, our malicious JavaScript gets executed by the browser, which causes our alert box to pop up as seen below.
While the payload used in the above example is harmless, the point to drive home here is that we were able to get the web application to store and execute our JavaScript all through a simple contact form. Anyone visiting my contact page will see this alert pop up because my XSS payload has been stored in the database and gets executed every time the page loads. From this point on, the possible damage that could be done here is endless and only limited by the attacker’s imagination… well, and their coding skills.
New-school apps
In the first example I gave, when you updated the email address on the contact page and the request was fulfilled by the backend, the entire page would reload in order to display the newly created or updated information. You can see how inefficient this is, especially if the only thing changing on the page is a single line or a few lines of text. Here is where ajax and/or the fetch method comes in.
Ajax, or the fetch method, can be used to get data from or post data to a remote source, then update the front-end UI of that web application without having to refresh the page. Only the content from the specific request is updated, not the entire page, and that is the key difference between our first example and this one.
And a very popular format for said data being sent and received is JavaScript Object Notation, most commonly known as JSON. (Don’t worry, I’ll get back to those curly braces in just a bit.)
New-school XSS
(Well, not really, but it sounds cool.)
Now, let’s pretend we’ve traveled back to the future and our contact page has been rewritten to use ajax or the fetch method to send and receive data to and from the database. From the user’s point of view, nothing has changed — still the same ol’ form. But this time, when the email address is being updated, only the contact form refreshes. The entire page and all of its contents do not refresh like in the previous version, which is a major win for efficiency and user experience.
Below is an example of what a POST might look like formatted in JSON.
“What is JSON?” you might ask. Short for JavaScript Object Notation, it is a lightweight text format for storing and transferring data and is most commonly used when sending data to and from servers. Remember those curly braces I mentioned earlier? Well, one quick and easy way to spot JSON is the formatting and the use of curly braces.
In the example above, you can see what our new POST looks like using ajax or the fetch method in JavaScript. While the end result is no different than before, as seen in the example below, the method that was used to update the page is quite different. The key difference here is that the data we’re wanting to update is being treated as just that: data, but in the form of JSON as opposed to HTML.
Now, let’s inject the same XSS payload into the same email field and hit update. In the example below, you can see that our POST request has been wrapped in curly braces, using JSON, and is formatted a bit differently than previously before being sent to the back end to be processed.
In the example above, you can see that the application is allowing my email address to be the XSS payload in its entirety. However, the JavaScript here is only being displayed and not being executed as code by the browser, so the alert “pop” message never gets triggered as in the previous example. That again is the key difference from the original way we were fulfilling the requests versus our new, more modern way — or in short, using JSON instead of HTML.
Now you might be asking yourself, what’s wrong with allowing the XSS payload to be the email address if it’s only being displayed and not being executed as JavaScript by the browser. That is a valid question, but hear me out.
See, I’ve been working in this industry long enough to know that the two most common responses to a question or statement regarding cybersecurity begin with either “that depends…” or “what if…” I’m going to go with the latter here and throw a couple what-ifs at you.
Now that my XSS is stored in your database, it’s only a matter of time before this ticking time bomb goes off. Just because my XSS is being treated as JSON and not HTML now does not mean that will always be the case, and attackers are betting on this.
Here are a few scenarios.
Scenario 1
What if team B handles this data differently from team A? What if team B still uses more traditional methods of sending and receiving data to and from the back end and does leverage the use of HTML and not JSON?
In that case, the XSS would most likely eventually get executed. It might not affect the website that the XSS was originally injected into, but the stored data can be (and usually is) also used elsewhere. The XSS stored in that database is probably going to be shared and used by multiple other teams and applications at some point. The odds of all those different teams leveraging the exact same standards and best practices are slim to none, and attackers know this.
Scenario 2
What if, down the road, a developer using more modern techniques like ajax or the fetch method to send and receive data to and from the back end decides to use the .innerHTML property instead of .innerTEXT to load that JSON into the UI? All bets are off, and the stored XSS that was previously being protected by those lovely curly braces will now most likely get executed by the browser.
Scenario 3
Lastly, what if the current app had been developed to use server-side rendering, but a decision from higher up has been made that some costs need to be cut and that the company could actually save money by recoding some of their web apps to be client-side rather than server-side?
Previously, the back end was doing all the work, including sanitizing all user input, but now the shift will be for the browser to do all the heavy lifting. Good luck spotting all the XSS stored in the DB — in its previous state, it was “harmless,” but now it could get rendered to the UI as HTML, allowing the browser to execute said stored XSS. In this scenario, a decision that was made upstream will have an unexpected security impact downstream, both figuratively and literally — a situation that is all too well-known these days.
Final thoughts
Part of my job as a security advisor is to, well, advise. And it’s these types of situations that keep me up at night. I come across XSS in applications every day, and while I may not see as many fun and exciting “pops” as in years past, I see something a bit more troubling.
This type of XSS is what I like to call a “sleeper vuln” – laying dormant, waiting for the right opportunity to be woken up. If I didn’t know any better, I’d say XSS has evolved and is aware of its new surroundings. Of course, XSS hasn’t evolved, but the applications in which it lives have.
At the end of the day, we’re still talking about the same XSS from its conception, the same XSS that has been on the OWASP Top 10 for decades — what we’re really concerned about is the lack of sanitization or handling of user input. But now, with the massive adoption of JavaScript frameworks like Angular, libraries like React, the use of APIs, and the heavy reliance on them to handle the data properly, we’ve become complacent in our duties to harden applications the proper way.
There seems to be a division in camps around XSS in JSON. On the one hand, some feel that since the JavaScript isn’t being executed by the browser, everything is fine. Who cares if an email address (or any data for that matter) is potentially dangerous — as long as it’s not being executed by the browser. And on the other hand, you have the more fundamentalist, dare I say philosophical thought that all user input should never be trusted: It should always be sanitized, regardless of whether it’s treated as data or not — and not solely because of following best coding and security practices, but also because of the “that depends” and “what if” scenarios in the world.
I’d like to point out in my previous statement above, that “as long as” is vastly different from “cannot.” “As long as” implies situational awareness and that a certain set of criteria need to be met for it to be true or false, while “cannot” is definite and fixed, regardless of the situation or criteria. “As long as the XSS is wrapped in curly braces” means it does not pose a risk in its current state but could in other states. But if input is sanitized and escaped properly, the XSS would never exist in the first place, and thus it “cannot” or could not be executed by the browser, ever.
I guess I cannot really complain too much about these differences of opinions though. The fact that I’m even having these conversations with others is already a step in the right direction. But what does concern me is that it’s 2022, and we’re still seeing XSS rampant in applications, but because it’s wrapped in JSON somehow makes it acceptable. One of the core fundamentals of my job is to find and prioritize risk, then report. And while there is always room for discussion around the severity of these types of situations, lots of factors have to be taken into consideration, a spade isn’t always a spade in application security, or cybersecurity in general for that matter. But you can rest assured if I find XSS in JSON in your environment, I will be calling it out.
I hope there will be a future where I can look back and say, “Remember that one time when curly braces were all that prevented your website from getting hacked?” Until then, JSON or not, never trust user data, and sanitize all user input (and output for that matter). A mere { } should never be the difference between your site getting hacked or not.
In this post, we will show you how to deploy a solution into your Amazon Web Services (AWS) account that enables you to simply attach manual evidence to controls using AWS Audit Manager. Making evidence-collection as seamless as possible minimizes audit fatigue and helps you maintain a strong compliance posture.
As an AWS customer, you can use APIs to deliver high quality software at a rapid pace. If you have compliance-focused teams that rely on manual, ticket-based processes, you might find it difficult to document audit changes as those changes increase in velocity and volume.
As your organization works to meet audit and regulatory obligations, you can save time by incorporating audit compliance processes into a DevOps model. You can use modern services like Audit Manager to make this easier. Audit Manager automates evidence collection and generates reports, which helps reduce manual auditing efforts and enables you to scale your cloud auditing capabilities along with your business.
AWS Audit Manager uses services such as AWS Security Hub, AWS Config, and AWS CloudTrail to automatically collect and organize evidence, such as resource configuration snapshots, user activity, and compliance check results. However, for controls represented in your software or processes without an AWS service-specific metric to gather, you need to manually create and provide documentation as evidence to demonstrate that you have established organizational processes to maintain compliance. The solution in this blog post streamlines these types of activities.
Solution architecture
This solution creates an HTTPS API endpoint, which allows integration with other software development lifecycle (SDLC) solutions, IT service management (ITSM) products, and clinical trial management systems (CTMS) solutions that capture trial process change amendment documentation (in the case of pharmaceutical companies who use AWS to build robust pharmacovigilance solutions). The endpoint can also be a backend microservice to an application that allows contract research organizations (CRO) investigators to add their compliance supporting documentation.
In this solution’s current form, you can submit an evidence file payload along with the assessment and control details to the API and this solution will tie all the information together for the audit report. This post and solution is directed towards engineering teams who are looking for a way to accelerate evidence collection. To maximize the effectiveness of this solution, your engineering team will also need to collaborate with cross-functional groups, such as audit and business stakeholders, to design a process and service that constructs and sends the message(s) to the API and to scale out usage across the organization.
To download the code for this solution, and the configuration that enables you to set up auto-ingestion of manual evidence, see the aws-audit-manager-manual-evidence-automation GitHub repository.
Architecture overview
In this solution, you use AWS Serverless Application Model (AWS SAM) templates to build the solution and deploy to your AWS account. See Figure 1 for an illustration of the high-level architecture.
Figure 1. The architecture of the AWS Audit Manager automation solution
The SAM template creates resources that support the following workflow:
A client can call an Amazon API Gateway endpoint by sending a payload that includes assessment details and the evidence payload.
An AWS Lambda function implements the API to handle the request.
Within the Step Functions workflow, a Standard Workflow calls two Lambda functions. The first looks for a matching control within an assessment, and the second updates the control within the assessment with the evidence.
Code for the application’s Lambda implementation of the Step Functions workflow. It also includes a Step Functions definition file.
template.yml
A template that defines the application’s AWS resources.
Resources for this project are defined in the template.yml file. You can update the template to add AWS resources through the same deployment process that updates your application code.
The AWS SAM CLI is an extension of the AWS CLI that adds functionality for building and testing Lambda applications. The AWS SAM CLI uses Docker to run your functions in an Amazon Linux environment that matches Lambda. It can also emulate your application’s build environment and API.
To use the AWS SAM CLI, you need the following tools:
Open your terminal and use the following command to create a folder to clone the project into, then navigate to that folder. Be sure to replace <FolderName> with your own value.
mkdir Desktop/<FolderName>&& cd $_
Clone the project into the folder you just created by using the following command.
Navigate into the newly created project folder by using the following command.
cd aws-audit-manager-manual-evidence-automation
In the AWS SAM shell, use the following command to build the source of your application.
sam build
In the AWS SAM shell, use the following command to package and deploy your application to AWS. Be sure to replace <DOC-EXAMPLE-BUCKET> with your own unique S3 bucket name.
sam deploy –guided –parameter-overrides paramBucketName=<DOC-EXAMPLE-BUCKET>
When prompted, enter the AWS Region where AWS Audit Manager was configured. For the rest of the prompts, leave the default values.
To activate the IAM authentication feature for API gateway, override the default value by using the following command.
paramUseIAMwithGateway=AWS_IAM
To test the deployed solution
After you deploy the solution, run an invocation like the one below for an assessment (using curl). Be sure to replace <YOURAPIENDPOINT> and <AWS REGION> with your own values.
Check to see that your file is correctly attached to the control for your assessment.
Form-data interface parameters
The API implements a form-data interface that expects four parameters:
AssessmentName: The name for the assessment in Audit Manager. In this example, the AssessmentName is GxP21cfr11.
ControlSetName: The display name for a control set within an assessment. In this example, the ControlSetName is General requirements.
ControlIdName: this is a particular control within a control set. In this example, the ControlIdName is 11.100(a).
Payload: this is the file representing evidence to be uploaded.
As a refresher of Audit Manager concepts, evidence is collected for a particular control. Controls are grouped into control sets. Control sets can be grouped into a particular framework. The assessment is considered an implementation, or an instance, of the framework. For more information, see AWS Audit Manager concepts and terminology.
To clean up the deployed solution
To clean up the solution, use the following commands to delete the AWS CloudFormation stack and your S3 bucket. Be sure to replace <YourStackId> and <DOC-EXAMPLE-BUCKET> with your own values.
This solution provides a way to allow for better coordination between your software delivery organization and compliance professionals. This allows your organization to continuously deliver new updates without overwhelming your security professionals with manual audit review tasks.
Next steps
There are various ways to extend this solution.
Update the API Lambda implementation to be a webhook for your favorite software development lifecycle (SDLC) or IT service management (ITSM) solution.
Modify the steps within the Step Functions state machine to more closely match your unique compliance processes.
Use AWS CodePipeline to start Step Functions state machines natively, or integrate a variation of this solution with any continuous compliance workflow that you have.
Вицепремиерът и министър на регионалното развитие от квотата на „Има такъв народ“ Гроздан Караджов е назначил замесени в “инхаус” сделки за укрепване на свлачища и АМ “Хемус” в управителния съвет…
The importance of the Cloudflare Partner Network was on full display in 2021, with record level partner growth in 2021 and aiming even higher in 2022. We’ve been listening to our partners and working to constantly strengthen our ability to deliver value for businesses of all types. An area we identified we could do better, is a program to support “service partners” that want to wrap managed and professional services around Cloudflare products. Today, we are excited to announce the next evolution of the Cloudflare Channel and Alliances Partner Program to specifically enable partners that provide services around Cloudflare products with recurring revenue streams as they equip businesses of all sizes and types with Cloudflare’s leading Zero Trust and SASE solutions.
Core to enabling Services Partners are some exciting enhancements:
New Program Paths
New Managed Services Partner (MSP) Accreditation.
New Support & Go-To-Market Motions
New Program Paths
We have seen a 29% increase in ransom DDoS attacks over the past year and a 175% increase just last quarter. Partners continue to be on the front lines helping mitigate and prevent disruption from these events as they extend our services. Our goal for 2022 is to arm our partners with the tools to address these increased threats to their customers’ infrastructure and applications, like Office365. We know the painstaking efforts that Services Partners make to build compelling offerings and provide the best customer outcomes. To that end, we’ve enhanced the Cloudflare Channel and Alliances Partner Program to not only focus on extending security, performance, and reliability to more customers, but provide a services-first approach for partners. We are committing to the growth of MSP & MSSP partners who share Cloudflare’s mission of helping to build a better Internet.
We’ve been building out the Cloudflare Partner Network for years, working alongside businesses of all sizes and types including our world-wide system integrator partners like Rackspace, as well as partners across EMEA, APAC like Blazeclan, and Kingsoft in China, to name a few. Working with enthusiastic, targeted partners has given us the opportunity to build a program to deliver a robust yet tailored program to support our partners’ ever-evolving needs from network transformations and application modernization, to Zero Trust solutions and onwards.
“Rackspace offers expert consultative services and 24×7 managed support based on Cloudflare’s web application security, secure Internet access, gateway and browsing technologies. With Rackspace Elastic Engineering for Security and Cloudflare’s cutting-edge cloud solutions, we’ll be able to help our customers fast-forward to a modern, Zero Trust approach to securing their teams, applications and infrastructure.” – Gary Alterson, Vice President of Security Services at Rackspace Technology
“We are excited to participate in Cloudflare’s new Services Partner Program. Cloudflare provides the advanced cloud technology at the center of digital business models. As a Cloudflare MSP Elite partner, we are able to leverage their innovative cloud solutions with embedded, network edge security to give our customers single-pane-of-glass reporting and policy management across internet applications.” – Veeraj Thaploo, CTO, Blazeclan technologies
Advanced Managed Services Partners
The entry point for partners that are providing managed IT services for small to midsize organizations who are fanatical about providing the best customer experience by leveraging Cloudflare’s extensive platform. Advanced MSP Partners will have access to tools that will help embed Cloudflare into their services offerings to deliver unique, outcome-based SASE and Zero Trust solutions.
Elite Managed Services Partners
Reserved for global partners that possess resource-intense engagement in IT consulting, advisory, and large scale services in the Large Enterprise segment. Elite MSP Partners will have access to dedicated technical and sales resources as well as a named Partner Success Manager to guide growth and business development around their Cloudflare-based services practice. In addition, these partners will have access to executive leadership and marketing programs to develop joint go-to-market functions.
Services-Only Partnerships
Invite-only for partners to deliver general professional services, highly technical services such as Application Modernization via Cloudflare Workers development, Implementation and Migration Services, and Security Assessments.
New Managed Services Partner Accreditation (AMSP)
Helping build a better Internet isn’t simple. Providing managed services for a wide range of customer types and sizes requires a targeted but ever-evolving approach. To support the new Services Program, we’ve introduced a new Certification course that provides the foundational tools for creating the Cloudflare customer experience. Course highlights include best practices for services design, implementation, and providing ongoing technical and relationship management. Services Partners provide customers with a seamless experience from implementation to configuration to ongoing services; here are some of the highlights:
New Enablement path for MSP Partners – L1/ L2 Support + Account Management
New Customer Success Enablement path for Services Partners
New Specialist Accreditation for Cloudflare Zero Trust
New Support & Go-To-Market Motions
Technical Services Managers & Partner Success
Regional resources dedicated to helping partners develop, drive, and expand their Cloudflare-based services offerings, specifically centered around SASE and Zero Trust.
Tenant API Provisioning
Our Partner Platform was built to be extensible, and we’re excited to announce that all of our partners can support the provisioning and deployment of a leading Zero Trust suite of products.
MSP-only Licensing Plan
MSPs and MSSPs deliver finished goods and need cost-efficient ways to deliver customer outcomes. We’ve heard this from our partners, and we are developing a licensing plan that enables MSPs to sell their services powered by the Cloudflare One platform.
Transform your Customer’s Network
We’ve been working diligently to build the pilot program throughout this past year, and are eager to work with the next cohort of service partners that want to help build a better Internet for customers. We’re just getting started in providing a tailored and targeted foundation for the Cloudflare Partner Ecosystem.
Cloudflare Services Partner Offering Menu
Come join us!
During the initial launch phase, we are working with a select group of partners, and are looking forward to expanding and growing with even more partnerships. Our goal is to enable partners that are creating cloud-based security solutions and that want to join us, to further our mission to help build a better Internet. If you believe your organization would be a great fit for this program, we would love to chat with you.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.